


The Story of RLHF: Origins, Motivations, Techniques, and Modern Applications
How learning from human feedback revolutionized generative language models...


For a long time, the AI community has leveraged different styles of language models (e.g., n-gram models, RNNs, transformers, etc.) to automate generative and discriminative1 natural language tasks. This area of research experienced a surge of interest in 2018 with the proposal of BERT [10], which demonstrated that the transformer architecture, self-supervised pretraining, and supervised transfer learning form a powerful combination. In fact, BERT set new state-of-the-art performance on every benchmark on which it was applied at the time. Although BERT could not be used for generative tasks, we saw with the proposal of T5 [11] that supervised transfer learning was effective in this domain as well. Despite these accomplishments, however, such models pale in comparison to the generative capabilities of LLMs like GPT-4 that we have today. To create a model like this, we need training techniques that go far beyond supervised learning.
“Our goal is to advance digital intelligence in the way that is most likely to benefit humanity as a whole.” - OpenAI Founding Statement (Dec. 2015)
Modern generative language models are the combined result of numerous notable advancements in AI research, including the decoder-only transformer, next token prediction, prompting, neural scaling laws, and more. However, one of the biggest factors in creating the recent generative AI boom was our ability to align these models to the desires of human users. Primarily, alignment was made possible by directly training LLMs based on human feedback via reinforcement learning from human feedback (RLHF). Using this approach, we can teach LLMs to surpass human writing capabilities, follow complex instructions, avoid harmful outputs, cite their sources, and much more. Fundamentally, RLHF enables the creation of AI systems that are more safe, capable, and useful. Within this overview, we will develop a deep understanding of RLHF, its origins/motivations, the role that it plays in creating powerful LLMs, the key factors that make it so impactful, and how recent research aims to make LLM alignment even more effective.
Where did RLHF come from?
Prior to learning about RLHF and the role that is plays in creating powerful language models, we need to understand some basic ideas that preceded and motivated the development of RLHF, such as:
Supervised learning (and how RLHF is different)
The LLM alignment process
Evaluation metrics for LLMs (and the ROUGE score in particular)
By building a deeper understanding of these ideas, we will gain important context that makes the motivation for developing a training technique like RLHF more clear. In particular, we will see that RLHF solves major problems with supervised learning techniques that prevent language models from performing their best. By learning directly from human feedback, we can easily optimize LLMs to produce high-quality outputs that align with the motives of human users.
General background. Beyond these concepts, this overview will require a basic understanding of reinforcement learning (RL) and how it is used in the language modeling domain. We have covered these ideas extensively in prior posts.
Additionally, a base-level understanding of (generative) LLMs will be helpful and necessary. For more details, check out the link below.
Supervised Learning for LLMs

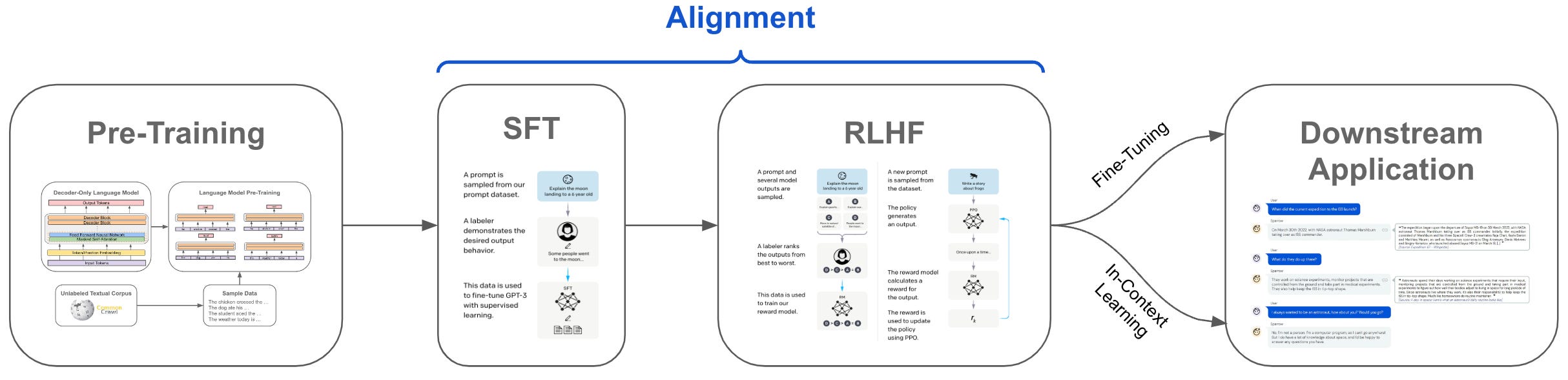
Most generative LLMs are trained via a pipeline that includes pretraining, supervised finetuning (SFT), reinforcement learning from human feedback (RLHF), and (maybe) some additional finetuning depending on our application; see above. Within this overview, we will focus heavily upon the RLHF component of the LLM training pipeline. However, it is important to have a working understanding of pretraining and SFT as well. Read more on these topics below.
Language Model Pretraining and Next Token Prediction [link]
Understanding Supervised Finetuning [link]
Before RLHF. When we contextualize modern generative LLMs with the language models that preceded them, RLHF is actually a recent addition to the training process. Previously, language models were trained to accomplish natural language tasks (e.g., summarization or classification) via a simplified transfer learning2 procedure that includes just pretraining and finetuning; see below.

Notable examples of models that follow this approach include BERT [10] and T5 [11]. These models are first pretrained (using a self-supervised learning objective) over a large corpus of unlabeled textual data, then finetuned on a downstream dataset. This finetuning process is supervised, meaning that we learn directly from human-annotated examples of correct solutions to a task. We should note, however, that the term “SFT” refers to a particular type of supervised finetuning for generative LLMs, where we finetune the model with a next token prediction objective over a dataset of reference generations that we want to imitate. The idea of finetuning via supervised learning (i.e., transfer learning), as is used by BERT and T5, is more generic and encompasses more than just generative-style tasks.
Is supervised learning enough? (Supervised) finetuning works well for closed-ended/discriminative tasks like classification, regression, question answering, retrieval, and more. Generative tasks, however, are slightly less compatible with supervised learning. Training language models to generate text in a supervised manner requires us to manually write examples of desirable outputs3. Then, we can train the underlying model to maximize the probability of generating these provided examples. Even before the popularization of generative LLMs, such an approach was heavily utilized for tasks like summarization, where we could teach a pretrained language model to write high-quality summaries by simply training on example summaries written by humans.
“While this strategy has led to markedly improved performance, there is still a misalignment between this fine-tuning objective—maximizing the likelihood of human-written text—and what we care about—generating high-quality outputs as determined by humans.” - from [1]
This approach works well in certain domains. Even today, SFT is widely and successfully used within generative LLM research (especially in the open-source community). However, supervised training techniques have a fundamental limitation when it comes to learning how to generate text—there is a misalignment between the supervised training objective and what we actually want! Namely, we train the model to maximize the probability of human written generations, but what we want is a model that produces high-quality outputs. These two objectives are not always aligned, which may lead us to wonder if a better finetuning approach exists.
Language Model Alignment
If we examine the outputs of a generative LLM immediately after pretraining, we will see that, despite possessing a vast amount of knowledge, the model generates repetitive and uninteresting results. Even if this model can accurately predict the next token, this does not imply the ability to generate coherent and interesting text. Again, we have a misalignment between the objective used for pretraining—next token prediction—and what we actually want—a model that generates high-quality outputs. For this, we need something more. We need to align the LLM.
What is alignment? Alignment refers to the idea of teaching an LLM to produce output that aligns with human desires. When performing alignment, we typically start by defining a set of “criteria” that we want to instill within the LLM. For example, common alignment criteria might include:
Helpfulness: the model fulfills user requests, follows detailed instructions, and provides information requested by the user.
Safety: the model avoids responses that are “unsafe”.
Factuality: the model does not “hallucinate” or generate factually incorrect information within its output.
To align an LLM, we can finetune the model using SFT and RLHF in sequence; see above. As discussed previously, however, SFT is a supervised learning technique that directly finetunes the LLM on human-written responses. As such, this approach is subject to the aforementioned limitations of supervised learning.

The role of RLHF. Unlike pretraining and SFT, RLHF is not a supervised learning technique. Rather, it leverages reinforcement learning (RL) to directly finetune an LLM based on feedback that is provided from humans; see above. Put simply, humans can just identify which outputs from the LLM that they prefer, and RLHF will finetune the model based on this feedback. Such an approach is fundamentally different from supervised learning techniques due to the fact that we can directly train the LLM to produce high-quality outputs. We just identify outputs that we like, and the LLM will learn to produce more outputs like this!
Evaluating Language Models (and the ROUGE Score)
Before learning more about RLHF, we need to understand how LLMs are evaluated, including the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) [12] score in particular. To start this discussion, we should note that there are many ways that we could evaluate the output of a generative language model. For example, we could prompt a powerful language model like GPT-4 to evaluate the quality of a model’s output, or even leverage the reward model from RLHF (more info to come soon) to predict a preference/quality score. A full exploration of evaluation strategies for LLMs is out of scope for this overview, but those who are interested can see the article below for an in-depth discussion.
Traditional metrics. Prior to the LLM revolution, several popular evaluation metrics existed for language models that operated by comparing the model’s generated output to a reference output. Usually, these reference outputs are manually written by humans. ROUGE score, which is most commonly used to evaluate summarization tasks, is one of these classical metrics, and it works by simply counting the number of words—or the number of n-grams for ROUGE-N—in the reference output that also occur in the model’s generated output; see below.

Going further, ROUGE is not the only such metric that operates by comparing a model’s output to a known reference output. We also have:
Bilingual Evaluation Understudy (BLEU) score [13]: commonly used to evaluate translation tasks by counting the number of matching n-grams between the generated output and the reference, then dividing this number by the total number of n-grams within the generated output.
BERTScore [14]: generates an embedding4 for each n-gram in the generated output and reference output, then uses cosine similarity to compare n-grams from the two textual sequences.
MoverScore [15]: generalizes BERTScore from requiring a one-to-one matching between n-grams to allow many-to-one matches, thus making the evaluation framework more flexible.
Do we need something else? Although these fixed metrics work reasonably well for tasks like summarization or translation, they don’t work well for tasks that are more open-ended, including generative tasks like information-seeking dialogue. Why is this the case? There tends to be a poor correlation between these metrics and human judgements of a model’s output [16]. ROUGE and BLEU quantify the extent to which a model’s output matches some reference output. For many problems, however, there are numerous outputs a model could produce that are equally viable—fixed metrics like ROUGE cannot account for this; see below.

Again, we have a misalignment between what is being measured—the overlap between two textual sequences—and what we actually want to measure—output quality. Although such fixed metrics were heavily leveraged in the early days of NLP, model quality improved drastically as more effective training techniques like RLHF were introduced. As a result, the research community was forced to find more flexible metrics and address the poor correlation between traditional metrics like ROUGE and BLEU with the true quality of a model’s output.
Learning from Human Feedback
“While [next-token prediction] has led to markedly improved performance, there is still a misalignment between this fine-tuning objective—maximizing the likelihood of human-written text—and what we care about—generating high-quality outputs as determined by humans.” - from [1]
Next token prediction is a training objective that is used almost universally for LLMs (i.e., during pretraining and supervised funetuning); see below. By learning to maximize the log-probabilities of (human-written) sequences of text within a dataset, this technique provides us with the ability to train language models over large corpora of unsupervised text. Despite the massive impact and general utility of next token prediction, however, the resulting LLM’s performance is highly dependent upon data quality and the model only learns to produce output that is comparable to its training set. In contrast, RLHF provides us with the ability to directly optimize an LLM based on human feedback, thus avoiding misalignment between the LLM’s training objective and the true goal of training—producing high quality output as evaluated by human users.
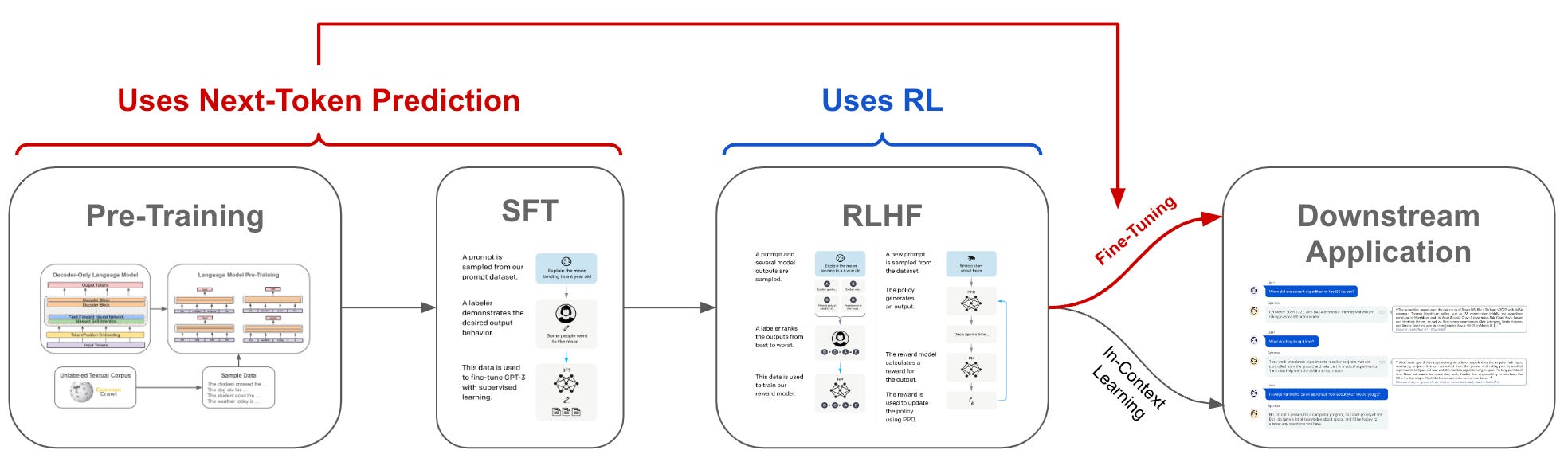
Within this section, we dive deeper into the ideas behind RLHF so that we can better understand:
The role of RLHF in the LLM training process.
The benefits of RLHF compared to supervised learning.
First, we will outline the details of RLHF as proposed by early works [1, 2] in LLM alignment. Then, we will cover notable research papers that have leveraged RLHF for LLM finetuning, including both the original/foundational papers in this space and new extensions of these techniques that have been explored more recently.
How does RLHF work?
“Reward learning enables the application of reinforcement learning (RL) to tasks where reward is defined by human judgment” - from [5]
As credited by most AI researchers, RLHF was first applied to LLMs in [1] and [2], which study the problems of abstractive summarization and language model alignment, respectively. However, the methodologies proposed in these works draw heavily from previously-explored techniques:
Better Rewards Yield Better Summaries [4]: extends RL-based systems that directly use ROUGE score as the reward for training summarization models (i.e., this can lead to low human judgement scores) to instead obtain the reward from a reward model that is trained over human ratings of summaries.
Fine-Tuning Language Models from Human Preferences [5]: learns a reward model from human comparisons of model outputs and uses this reward model to finetune language models on a variety of different natural language tasks.
However, work in [1, 2] does not copy these techniques directly. As we will see, the modern approach to RLHF has been adapted to improve the efficiency of both human annotation and LLM finetuning. Going further, recent research explores the application of RLHF to much larger language models (i.e., GPT-style LLMs).

Understanding RLHF. We will now look at the implementation of RLHF that is used in [1] and [2]; see above. Typically, RLHF is applied in tandem with SFT—the model obtained after pretraining and SFT serves as a starting point for RLHF5. Although there are slight differences between the methodologies of [1] and [2], the RLHF framework is comprised of three standard steps:
Collect human comparisons: human feedback is collected offline in large batches prior to each round of RLHF. A dataset of human feedback is comprised of prompts, several (LLM-generated) responses to each prompt, and a ranking of these responses based on human preference.
Train a reward model: a reward model is trained over the dataset of human comparisons to accurately predict a human preference score when given an output generated by an LLM as input.
Optimize a policy according to the reward model: the policy (i.e., the LLM) is finetuned using reinforcement learning—PPO in particular—to maximize reward based upon human preferences scores generated by the reward model.
Data collection. Notably, the approach outlined above is heavily dependent upon the quality of feedback provided by human annotators. As such, a key aspect of successfully applying RLHF—as is explicitly mentioned in both [1] and [2]—is to maintain a close correspondence between annotators and AI researchers or practitioners (i.e., those training the model) via extensive onboarding, a shared communication channel, and close monitoring of agreement rates between annotators and researchers. Put simply, the rate of agreement between researchers and human annotators should be maximized to ensure that human preference data accurately reflect the desired alignment criteria.
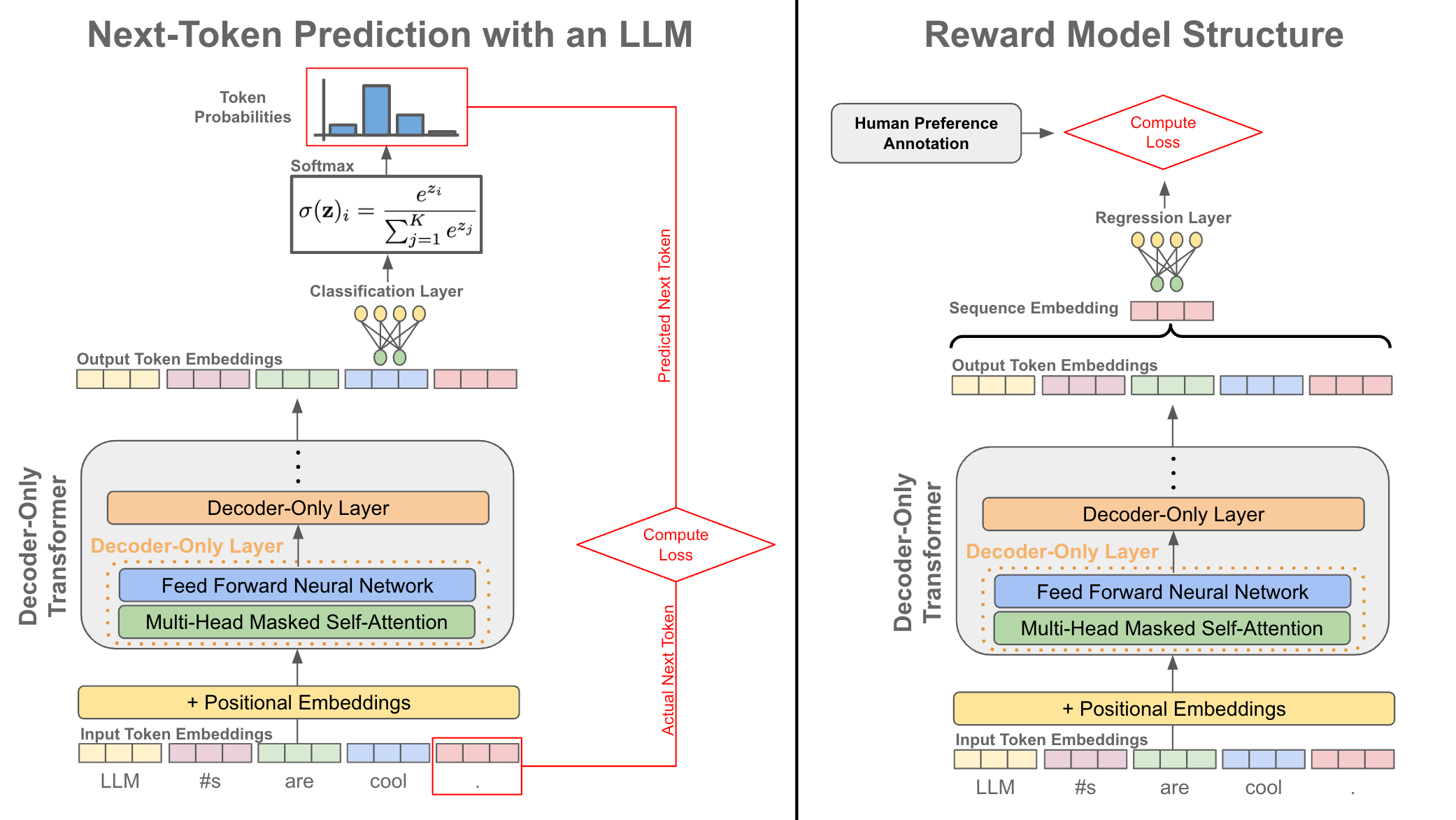
Training the reward model. The reward model shares the same underlying architecture as the LLM itself. However, the classification head6 that is used for next-token prediction is removed and replaced with a regression head that predicts a preference score; see above. Interestingly, the reward model is typically initialized with the same weights as the LLM (either the pretrained model or the model trained via SFT), thus ensuring that the reward model shares the same knowledge base as the underlying LLM.

To train the reward model, we take pairs of ranked responses as input, predict the preference score of each response, and apply a ranking loss; see above. The purpose of this ranking loss is to train the reward model to output a higher preference score for the preferred output and vice versa. In this way, the reward model’s training procedure aims to teach the model to accurately predict a human preference score given a prompt and response pair as input7.
Finetuning via RL. To finetune the language model, we can formulate generating text via the LLM as an RL problem. In this domain, our policy is the LLM and its corresponding parameters. Each token generated by the LLM corresponds to a single time step within the environment, and an entire episode is completed when the LLM outputs the [EOS] token (i.e., finishes generating a sequence). The state is given by the sequence being outputted by the LLM, and there is no explicit transition function, as we simply add each outputted token to the generated sequence. At the end of each episode, we receive a single reward—generated by the reward model—based upon the overall quality of the full sequence; see below.
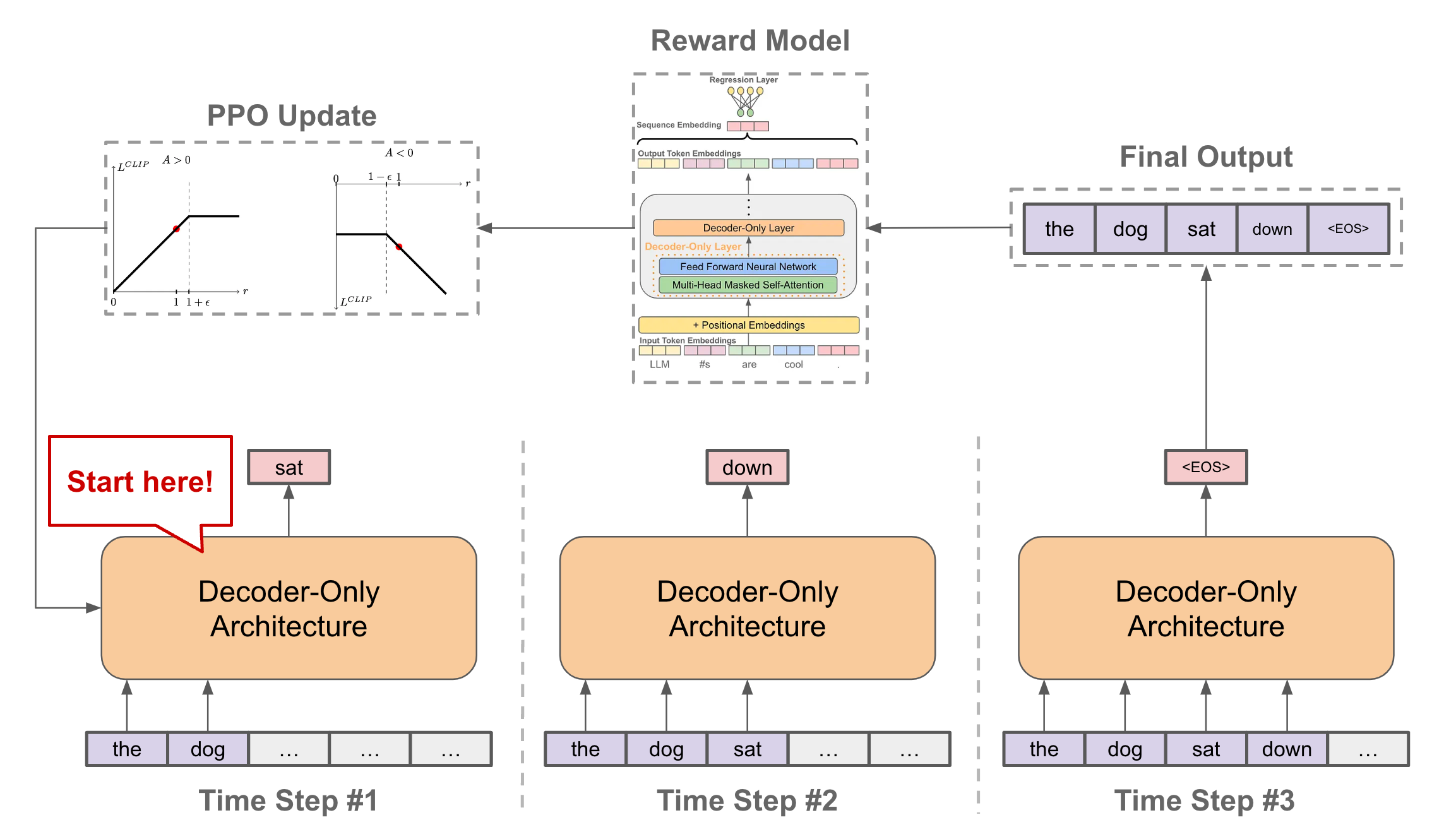
Using the setup described above, we can use (almost) any RL algorithm to finetune an LLM based upon feedback provided by the reward model. Early works in this space adopted PPO as the go-to algorithm for RLHF due to its simplicity, robustness, and efficiency. As we will see, however, a variety of different algorithms have been explored and adopted in recent months.

Iterative RLHF. Before moving on, we should note that RLHF is typically not only applied once. Rather, most works tend to collect data in large batches and finetune the model via RLHF in an offline fashion. This process is repeated several times as more data is collected over time, allowing several “rounds” of the RLHF process to be performed. For example, LLaMA-2 [6] performs 5 successive rounds of RLHF (see above), while the HH LLM from Anthropic [7] is finetuned via RLHF on a weekly cadence as new batches of preference data are collected. Such an approach is in contrast to more traditional RL setups, where data is collected and used to train the policy in an online fashion.
Learning to Summarize from Human Feedback [1]
The problem of abstractive summarization—or using a language model to understand important aspects of a text and produce a human-readable summary—has been studied for a long time. Prior to the popularization of RLHF, however, most approaches to this problem trained the language model in a supervised manner based on human-written reference summaries and performed evaluation via the ROUGE score. Although such an approach works relatively well, both supervised learning and the ROUGE score are a proxy for what is actually desired—a model that writes high-quality summaries. In [1], authors explore replacing supervised learning with RLHF, allowing a pretrained language model to be finetuned to produce high-quality summaries directly based on human feedback.

The approach proposed in [1], which is one of the foundational works exploring RLHF, allows us to optimize an LLM based on the quality of its responses, as assessed by human annotators. Beginning with a pretrained LLM, we can iteratively i) collect human comparison data, ii) train a reward model to predict human-preferred summaries and iii) use the model as a reward function for finetuning via RL. With this approach, we can train an LLM to produce summaries that surpass the quality of human summaries and are even better than those produced by larger LLMs trained via supervised learning; see above.
The methodology. In [1], the LLM is first trained using supervised finetuning over human reference summaries, producing a supervised baseline that is later finetuned via RLHF. The methodology for RLHF proposed in [1] closely follows the general framework that we outlined in the previous section. However, authors in [1] study the problem of summarization in particular. As such, the methodology used for RLHF in [1] is specialized to this problem domain; see below.

The RLHF process is comprised of three steps. First, a dataset of human feedback is collected by:
Grabbing a textual input to summarize from the training dataset.
Using several policies8 to sample a variety of summaries for the input.
Grabbing two summaries from the set of sampled responses.
Asking a human annotator to identify the better of the two summaries.
Human comparison data is collected in large batches and used to finetune the LLM via RLHF in an offline fashion. Once the data has been collected, we use this comparison data to train a reward model that accurately predicts a human preference score given a summary produced by the LLM. From here, we use RL to finetune the model—authors in [1] use the PPO algorithm—based on preference scores outputted by the reward model.

Going beyond the basic RLHF framework we have seen so far, we see in [1] that the authors add a KL divergence term to the objective optimized by RL, which penalizes the policy from becoming too different from the supervised baseline policy during RLHF; see above. Such an approach, which is frequently used and adopted from prior work, encourages exploration without mode collapse and prevents summaries written by the LLM from becoming too different from those that are seen during training. Furthermore, authors in [1] note that—despite the ability of PPO to train an LLM that jointly models the policy and value function—they use separate models for the value function and policy.

Experimental results. In [1], large pretrained models—matching the style of GPT-3 [8]—with 1.3 billion to 6.7 billion parameters are finetuned over the TL;DR dataset to summarize text. This dataset, which contains over three million posts from Reddit along with author-written summaries, is filtered to contain only 120K high-quality examples; see above. Models are first trained using SFT (i.e., the results of SFT are treated as a baseline across experiments), then afterwards with RLHF. Given that the lengths of summaries can have a drastic impact on the resulting quality score, authors in [1] constrain generated summaries to 48 tokens and finetune the model to produce summaries of this length.
Finetuning language models with human feedback outperforms a variety of strong English summarization baselines. Notably, the 1.3B summarization model outperforms a 10X larger model trained with SFT, and the 6.7B summarization model performs even better than the 1.3B model, revealing that summarization quality benefits from model scale. Furthermore, we see that summarization models trained via RLHF generalize better to new domains. In particular, the models in [1] are applied to summarizing news articles (i.e., these are not in the training data) and found to perform well without further finetuning; see below.

From here, summarization models are evaluated in terms of:
Coverage: the summary covers all information from the original post.
Accuracy: statements in the summary are accurate.
Coherence: the summary is easy to read on its own.
Quality: the overall quality of the summary is good.
When evaluated in this manner, we see that summarization models trained via RLHF benefit the most in terms of coverage, while coherence and accuracy are only slightly improved compared to supervised baseline models; see below.

Looking forward. Although RLHF was explored only in the context of summarization in [1], the authors of this paper had an incredible amount of foresight about what was to come. The approach proposed in [1] later became a standard methodology for aligning LLMs, as we will soon see with InstructGPT. Additionally, authors in [1] explicitly state their intent to leverage the proposed methodology to better align AI to human desires in the long term. This statement was made over two years prior to the proposal of ChatGPT, making the work in [1] a building block to major advancements in AI that were yet to come.
“The methods we present in this paper are motivated in part by longer-term concerns about the misalignment of AI systems with what humans want them to do. When misaligned summarization models make up facts, their mistakes are fairly low-risk and easy to spot. However, as AI systems become more powerful and are given increasingly important tasks, the mistakes they make will likely become more subtle and safety-critical, making this an important area for further research.” - from [1]
Training language models to follow instructions with human feedback [2]
Going beyond the summarization domain, authors in [2] explore the use of RLHF for language model alignment by directly learning from human feedback. The resulting model, called InstructGPT [2], is the sister model and predecessor to ChatGPT. Given that this model is outlined and explained in detail within [2], this work grants us significant insight into how LLMs from OpenAI are trained.

Following an approach similar to [1], we start with a set of prompts that are either written by human annotators or collected from OpenAI’s API. We can then have annotators write responses to these prompts and finetune a pretrained LLM—GPT-3 in particular [8]—over these examples using SFT. Using this model, we can then collect comparison data by asking humans to select preferred outputs from the LLM and apply the same RLHF process that is outlined in [1] for finetuning. The resulting model is heavily preferred by humans (see above) and much better at following detailed instructions provided within each prompt.
“Making language models bigger does not inherently make them better at following a user’s intent.” - from [2]
The alignment process. Pretrained LLMs have a number of undesirable properties that we would want to fix during the alignment process, such as hallucinations, biased/toxic generations, or an inability to follow detailed instructions. To fix this, we need an alignment process that will train the LLM to satisfy human-desired criteria. In [2], the following alignment criteria are defined:
Helpful: follows the user’s instructions and infers intention from few-shot prompts or other patterns.
Honest: makes correct factual statements about the world.
Harmless: avoids harmful outputs, such as those that denigrate a protected class or contain sexual/violent content.
Using RLHF, we can teach an LLM to reflect each of these qualities within its output. Then, we can evaluate whether each of these qualities are satisfied via human evaluations or by using closed-domain evaluation tasks.

The methodology. Authors in [2] curate a team of 40 human annotators, who are screened with a test to judge their annotation quality, to collect finetuning data for the LLM. The approach for RLHF used in [2] matches the approach used in [1] almost completely. Using a pretrained LLM and a set of prompts for finetuning, the alignment process proceeds according to the following steps (shown above):
Collect human demonstrations of responses for each prompt.
Train the model in a supervised fashion over human demonstrations.
Collect comparison data.
Train a reward model.
Optimize the underlying LLM/policy with PPO.
Repeat steps 3-5
The distribution of prompts used for finetuning in [2] is outlined in the table below. For SFT, a dataset of over 13K prompt and response pairs is constructed. The reward model9 is trained over 33K prompts, while a dataset of size 31K is used for finetuning with PPO. Unlike [1], human annotators are shown 4-9 responses to a prompt (i.e., instead of two) when collecting comparison data, allowing them to quickly rank these responses and generate a larger amount of comparison data more efficiently. Notably, the dataset used in [2] is 96% English.

Beyond the basic RLHF methodology used in [2], we see a few interesting tricks that are used to improve the finetuning process. First, a KL divergence term is added to the training objective used for RL (i.e., this is also done in [1]), which keeps the resulting model from diverging too much from the SFT model. Additionally, more pretraining updates are “mixed in” to the optimization process during RLHF, which mitigates the alignment tax and maintains the model’s performance across a wide set of natural language benchmarks.
“We were able to mitigate most of the performance degradations introduced by our fine-tuning. If this was not the case, these performance degradations would constitute an alignment tax—an additional cost for aligning the model.” - from [2]
The final finetuning objective used for RLHF in [2], including both added pretraining updates and the KL divergence term, is shown below.

Experimental findings. In [2], authors train three models with 1.3 billion parameters, 6 billion parameters, and 175 billion parameters (i.e., this model matches the architecture of GPT-3 [8]). From these experiments, we learn that human annotators prefer InstructGPT outputs over those of GPT-3, even for models with 10X fewer parameters; see below. Such a result has similarities to observations in [1], where we also see that finetuning via RLHF enables much smaller models to outperform larger models trained in a supervised manner.

Notably, outputs from InstructGPT-1.3B are preferred to those of GPT-3, which has 100X more parameters. Additionally, we see that InstructGPT-175B produces outputs that are preferred to GPT-3 85% of the time10. Going further, InstructGPT models are found to more reliably follow explicit constraints and instructions provided by a human user; see below.

Compared to pretrained and supervised models, InstructGPT is also found to be i) more truthful, ii) slightly less toxic, and iii) capable of generalizing the ability to follow instructions across different domains. For example, InstructGPT is able to follow instructions for summarizing or answering questions about code and handle prompts written in different languages, despite the finetuning dataset—which is 96% English!—lacking sufficient data within this distribution. Although the model did not get recognized as widely as ChatGPT, InstructGPT was a major step forward in AI and alignment research that proposed a lot of the foundational concepts used today for creating high-quality foundation language models.
Modern Variants of RLHF
RLHF was shown to be highly effective in [1] and [2], but these were early works in the space of LLM alignment. Over the last year, numerous modifications to the RLHF methodology have been proposed, including completely new algorithms for aligning LLMs. Here, we will quickly review some recent advancements in RLHF to gain a better understanding of how these techniques are used today.

LLaMA-2 [6] was one of the first open-source LLMs to invest extensively into alignment via RLHF (i.e., other open-source LLMs relied mostly upon SFT; see here). The RLHF process in [6] is comparable to [1, 2] with a few modifications:
Human annotators only compare two responses to a prompt at once, instead of 4-9 in the case of InstructGPT.
Instead of collecting binary preference data, human annotators are instructed to identify responses that are significantly or moderately better than others (i.e., more granular degrees of comparison).
Comparisons are collected with respect to a single alignment criteria at a time (e.g., a human annotator may receive a prompt and response pair focused upon minimizing harmfulness in particular).
The approach outlined above slightly modifies the RLHF annotation process to i) make it easier for human annotators, ii) yield more accurate comparisons, and iii) collect more granular feedback data on a model’s outputs. To incorporate non-binary human feedback into RLHF, we can simply add a margin into the training objective for a reward model, which encourages responses with a large difference in quality to be pushed further apart in their preference scores; see below.

Going further, authors in [6] explore two different reinforcement algorithms for finetuning via RLHF: PPO and Rejection Sampling. After performing multiple rounds of RLHF, we see that the combination of these two learning algorithms in tandem can drastically improve learning efficiency. See here for more details.

Safe RLHF [17] is a recently-proposed modification to the basic RLHF algorithm. As previously discussed, the alignment process for LLMs requires the definition of several alignment criteria. However, the alignment criteria that we define might conflict with each other sometimes. For example, harmlessness and helpfulness are two commonly-used alignment criteria that tend to conflict with each other. Typically, these cases are addressed by training a separate reward model to capture each alignment criteria, thus avoiding any conflict in modeling human preferences. However, Safe RLHF proposes a new learning algorithm that better balances conflicting alignment criteria via the definition of rewards and costs within the alignment process; see above and read more here.

Pairwise PPO [18]. One interesting aspect of RLHF is the manner in which the reward model is trained and used. Namely, the reward model is trained based on relative scores—we want the preferred response to be scored higher than the other response. During optimization with PPO, however, we directly use the scalar output of the reward model as a training signal—we are not using the reward model’s output in a comparative manner. To address this, authors in [18] propose a variant of PPO (shown above) that is modified and optimized to work better with the comparative human preference data that is collected for RLHF. Learn more here.
Reinforcement Learning from AI Feedback (RLAIF). Although RLHF is useful, one major downside of this technique is that it requires a lot of human preference data to be collected. For example, LLaMA-2 uses over 1M human preference examples for alignment via RLHF. To mitigate this requirement upon human annotation, a recent line of work has explored automating human preference annotations with the use of a generic LLM. In other words, we perform RLHF with feedback provided by AI instead of humans. See here for more details.
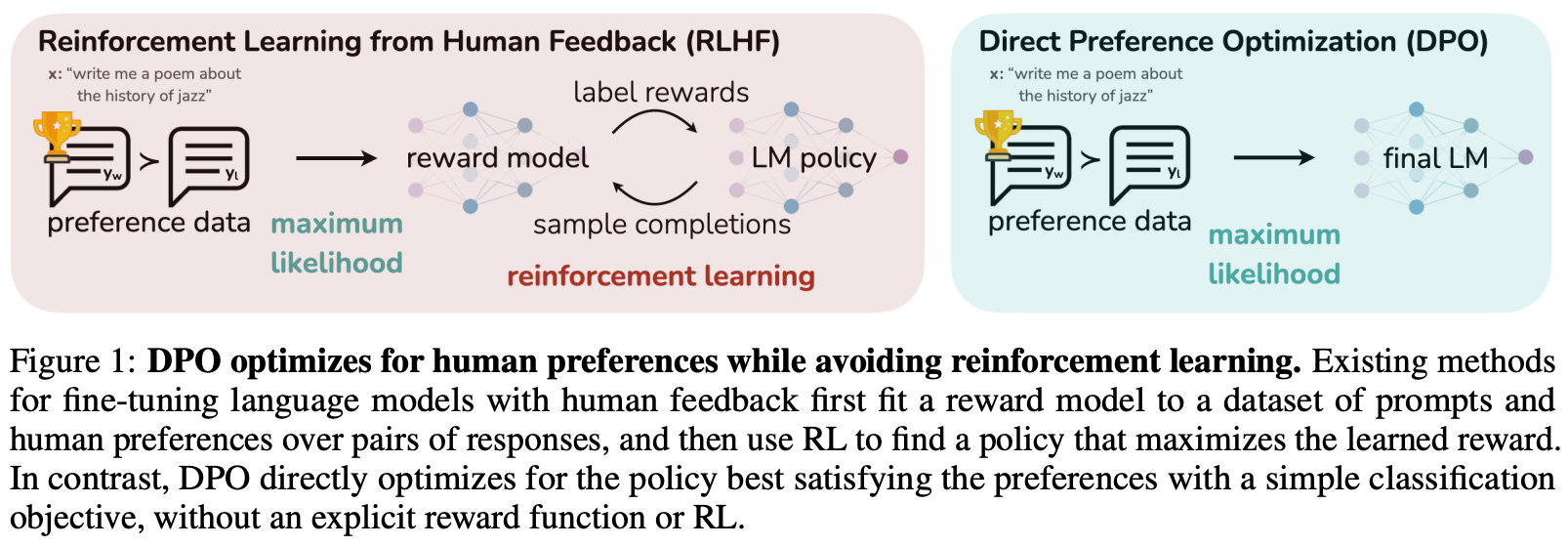
Direct Preference Optimization (DPO) [19]. Another downside of RLHF is that it is an (arguably) complicated training procedure that is oftentimes unstable, relies upon reinforcement learning, and trains an entirely separate reward model to automate human preference scores. As a solution, authors in [19] propose DPO. This approach, depicted in the figure above, is a simpler, but equally performant, alternative to RLHF that is more stable and eliminates the need for a reward model by finetuning the LLM using human preferences directly. Learn more here.
Did I miss something? A ton of research on LLM alignment and RLHF has been explored recently. If you are aware of any other important works that should be covered here, feel free to let me know in the comments! You can also learn more about RLHF variants by reading the overview below.

What makes RLHF so impactful?

We have now seen RLHF successfully used in several domains, providing clear empirical evidence that RLHF is an effective finetuning technique. However, we might wonder: Why does RLHF work so much better than supervised learning? To answer this question, we will quickly overview the primary benefits of RLHF and highlight the key aspects of this methodology that make it so impactful.
Human annotation process. The first notable difference between supervised learning and RLHF is the manner in which data is annotated. For supervised learning, we train the LLM using human-provided demonstrations of high-quality output. This means that, for every training example, a human must manually write a full, high-quality response to the given prompt. In contrast, RLHF generates responses to prompts automatically via an LLM and simply asks the human annotator to rank several responses to the same prompt; see below.

Because ranking outputs is a much easier task compared to writing outputs from scratch, the annotation strategy for RLHF lessens the cognitive load of human annotators, which leads to several notable benefits:
Annotations are higher quality (i.e., more accurate).
Collecting annotations is faster and more efficient.
Individual annotations can be focused upon a particular alignment principle.
Given that reinforcement learning generally requires more data (compared to supervised learning) to perform well, the annotation style of RLHF is a crucial aspect of its effectiveness. By defining alignment criteria and focusing human comparisons on specific aspects of the alignment process, we can quickly collect a large volume of accurate comparison data for finetuning with RLHF.
Beyond human quality. The annotation strategy used for RLHF also has benefits beyond annotation efficiency. Namely, we should notice that all responses used for collecting comparison data within RLHF are generated automatically by an LLM. This means that RLHF can train an LLM over responses that go beyond the writing capabilities of human annotators and, therefore, has the potential to surpass human performance. In comparison, supervised learning is constrained to the quality of responses that are manually written by human annotators.
“During annotation, the model has the potential to venture into writing trajectories that even the best annotators may not chart. Nonetheless, humans can still provide valuable feedback when comparing two answers, beyond their own writing competencies.” - from [6]
Writing high-quality responses from scratch is incredibly difficult. As such, the quality of human annotations used for supervised finetuning can vary drastically, which introduces noise into the learning process. Remember, the model learns from all responses shown to it during training, including both high-quality and lower quality data. Plus, a human annotator (obviously) is not capable of writing a response that goes beyond their personal writing ability. However, this same annotator will usually be capable of recognizing when one response is better than another, even when they cannot personally write a response of comparable quality from scratch.
Accurately capturing response quality. Finally, we see in [1] and [2] that the reward model that is created for RLHF is surprisingly accurate at capturing the quality of model responses11. Compared to automatic metrics like ROUGE, reward models provide a more consistent and accurate evaluation of model output quality, as judged by the agreement rate with human annotators. As such, optimizing the LLM based on the preference scores from this reward model tends to produce a model that performs quite well. We directly train the model to produce outputs that the reward model deems as preferable!
Given that reward models can so accurately evaluate response quality, the reward model from RLHF actually has two useful purposes: i) finetuning the underlying policy and ii) evaluating the quality of LLM outputs. Although this second purpose is somewhat of a side effect, it is nonetheless beneficial.

Going further, we see in [1] that reward models tend to obey scaling laws that are somewhat similar to those of LLMs. In particular, the quality of the reward model improves as we increase the size of the model and the amount of comparison data used for training; see above. In [2], authors note that using a much larger reward model—175 billion parameters, as opposed to 6 billion—can lead to instability. However, reward model scaling trends are also observed in more recent works like LLaMA-2 [6], where we see that reward model quality continues to improve as larger models and more data are used; see below.

Closing Thoughts
We should now have a deep understanding of RLHF and its impactful role in the training of generative language models. RLHF is a key innovation—along with several others (e.g., transformers, self-supervised learning, etc.)—that catalyzed the recent generative AI boom. Despite being widely used across many applications even today, supervised learning techniques fall short when it comes to training useful and aligned language models. By enabling us to train generative LLMs directly from human feedback, RLHF empowered AI researchers to create generative models that were shockingly informative/useful and could even exceed the writing capabilities of humans. Some key takeaways are outlined below.
Limitations of supervised learning. To train a generative language model with supervised learning, we collect a dataset of human-written responses to prompts and finetune the model to mimic these responses. Such an approach, despite being widely used, has a few notable problems. First, collecting training data is hard, as it requires humans write high-quality reference responses from scratch. Furthermore, there is a notable misalignment between the training objective used for supervised learning and what we actually want. Namely, we train the model to produce outputs similar to its training data, but what we actually want is a model that generates useful outputs—these two objectives are not always the same!
RLHF provides a solution. To solve this misalignment, why not just directly train the language model to produce outputs that we (the user) like? This is exactly the idea that inspired RLHF! To apply RLHF, we collect human preference data by having humans identify preferable responses, train a reward model to learn patterns in human preferences, then finetune the LLM with reinforcement learning to produce outputs that are more preferable to humans. RLHF is a flexible and effective alignment approach that allows us to create models that accomplish a variety of complex tasks in the exact manner desired by its human users.
Continued evolution. Despite the massive impact that RLHF has had on LLM alignment, it has notable limitations! For example, it requires a lot of human preference data to be curated (which can be expensive!), can struggle to handle conflicts between several alignment criteria, suffers from instability, and is more complicated compared to supervised learning. For this reason, AI researchers are actively iterating upon and improving RLHF, leading to the development of many RLHF variants such RLAIF, Safe RLHF, Pairwise DPO, and more.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Stiennon, Nisan, et al. "Learning to summarize with human feedback." Advances in Neural Information Processing Systems 33 (2020): 3008-3021.
[2] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[3] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[4] Böhm, Florian, et al. "Better rewards yield better summaries: Learning to summarise without references." arXiv preprint arXiv:1909.01214 (2019).
[5] Ziegler, Daniel M., et al. "Fine-tuning language models from human preferences." arXiv preprint arXiv:1909.08593 (2019).
[6] Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288 (2023).
[7] Bai, Yuntao, et al. "Training a helpful and harmless assistant with reinforcement learning from human feedback." arXiv preprint arXiv:2204.05862 (2022).
[8] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[9] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[10] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[11] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[12] Chin-Yew, Lin. "Rouge: A package for automatic evaluation of summaries." Proceedings of the Workshop on Text Summarization Branches Out, 2004. 2004.
[13] Papineni, Kishore, et al. "Bleu: a method for automatic evaluation of machine translation." Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 2002.
[14] Zhang, Tianyi, et al. "Bertscore: Evaluating text generation with bert." arXiv preprint arXiv:1904.09675 (2019).
[15] Zhao, Wei, et al. "MoverScore: Text generation evaluating with contextualized embeddings and earth mover distance." arXiv preprint arXiv:1909.02622 (2019).
[16] Sai, Ananya B., Akash Kumar Mohankumar, and Mitesh M. Khapra. "A survey of evaluation metrics used for NLG systems." ACM Computing Surveys (CSUR) 55.2 (2022): 1-39.
[17] Dai, Josef, et al. "Safe RLHF: Safe Reinforcement Learning from Human Feedback." arXiv preprint arXiv:2310.12773 (2023).
[18] Wu, Tianhao, et al. "Pairwise Proximal Policy Optimization: Harnessing Relative Feedback for LLM Alignment." arXiv preprint arXiv:2310.00212 (2023).
[19] Rafailov, Rafael, et al. "Direct preference optimization: Your language model is secretly a reward model." arXiv preprint arXiv:2305.18290 (2023).
Examples of generative tasks include dialogue/chat and summarization, while discriminative tasks are those that predict something other than free-form text (e.g., classification or multiple choice question answering).
Transfer learning is a commonly-used term in AI research that refers taking a pretrained model and finetuning it to accomplish a particular task.
Alternatively, we could automatically generate training examples using a framework like self-instruct.
Embedding-based metrics like BERTScore are nice because they can account for synonyms being present in the generated output and reference summary, while metrics like ROUGE and BLEU require and exact match between n-grams.
This is not always the case. However, initializing RLHF with a model trained via SFT tends to provide a much better starting point for the optimization process that enables faster learning, whereas starting with a model that has only underwent pretraining may require more exploration to find a high-quality policy.
The term “head” is commonly used in the AI community to refer to a single (usually feed-forward) layer at the end of the neural network that takes the network’s output as input and performs classification or regression.
Given that the reward model is trained based on relative preferences score via the ranking loss, we typically have to normalize preference values outputted by the reward model after training. For example, authors in [1] note that they normalize reward model outputs such that the rewards predicted over the training dataset have a mean score of 0. Later in the overview, we will see recent variants of RLHF that avoid this issue.
Responses to prompts are sampled from several different sources, including the current policy, the initial policy, human-written reference summaries, summaries from baseline models, summaries from models trained via supervised learning, and more.
Authors in [2] always use a 6B parameter LLM as the reward model. The largest model (i.e., 175B parameters) is found to be unstable during training in certain cases. Later work has shown that reward models follow strict scaling laws, meaning that larger models can achieve better reward accuracy. However, using smaller LLM architectures for the reward model is relatively common nonetheless.
When few-shot prompting is used, InstructGPT is only preferred 71% of the time. But, this is still an impressive win rate!
Given that the RLHF optimization process is guided by the output of our reward model, it is incredibly important for this model’s output to be accurate! Post-RLHF model quality is heavily dependent upon the accuracy of the reward model.
This is phenomenally detailed. Going to come back to this in a while to absorb all the information. Great work, Cameron. This must have taken a lot of effort to put together
Thanks Cameron!