
T5: Text-to-Text Transformers (Part One)
Creating a unified framework for language modeling...


This newsletter is sponsored by Rebuy, the Commerce AI company. If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!
The transfer learning paradigm is comprised of two main stages. First, we pre-train a deep neural network over a bunch of data. Then, we fine-tune this model (i.e., train it some more) over a more specific, downstream dataset. The exact implementation of these stages may take many different forms. In computer vision, for example, we often pre-train models on the ImageNet dataset using a supervised learning objective. Then, these models perform supervised fine-tuning on the downstream dataset (i.e., the task that we are actually trying to solve). Alternatively, in natural language processing (NLP), we often perform self-supervised pre-training over an unlabeled textual corpus.
Combining large, deep neural networks with massive (pre-)training datasets often leads to impressive results. This finding was found to be especially true for NLP. Given that raw textual data is freely available on the internet, we can simply download a massive textual corpus, pre-train a large neural net on this data, then fine-tune the model on a variety of downstream tasks (or just use zero/few-shot learning techniques). This large-scale transfer learning approach was initially explored by BERT [2], which pre-trained a transformer encoder over unlabeled data using a masking objective, then fine-tuned on downstream language tasks.
The success of BERT [2] cannot be overstated (i.e., new state-of-the-art performance on nearly all language benchmarks). As a result, the NLP community began to heavily investigate the topic of transfer learning, leading to the proposal of many new extensions and improvements. Due to the rapid development in this field, comparison between alternatives was difficult. The text-to-text transformer (T5) model [1] proposed a unified framework for studying transfer learning approaches in NLP, allowing us to analyze different settings and derive a set of best practices. This set of best practices comprise T5, a state-of-the-art model and training framework for language understanding tasks.
Relevant History and Context
T5 reformulates existing transfer learning techniques into a unified format, compares them, and determines best practices to arrive at a high-performing result. But what does this mean? What is transfer learning and why should we care about it? To answer these questions, we will first overview a couple of important ideas, including transfer learning and different variants of the transformer architecture, that will be pivotal to understanding the analysis in [1]. From here, we will provide some historical context by explaining the BERT [2] architecture, which popularized transfer learning for natural language processing (NLP) tasks.
What is transfer learning?
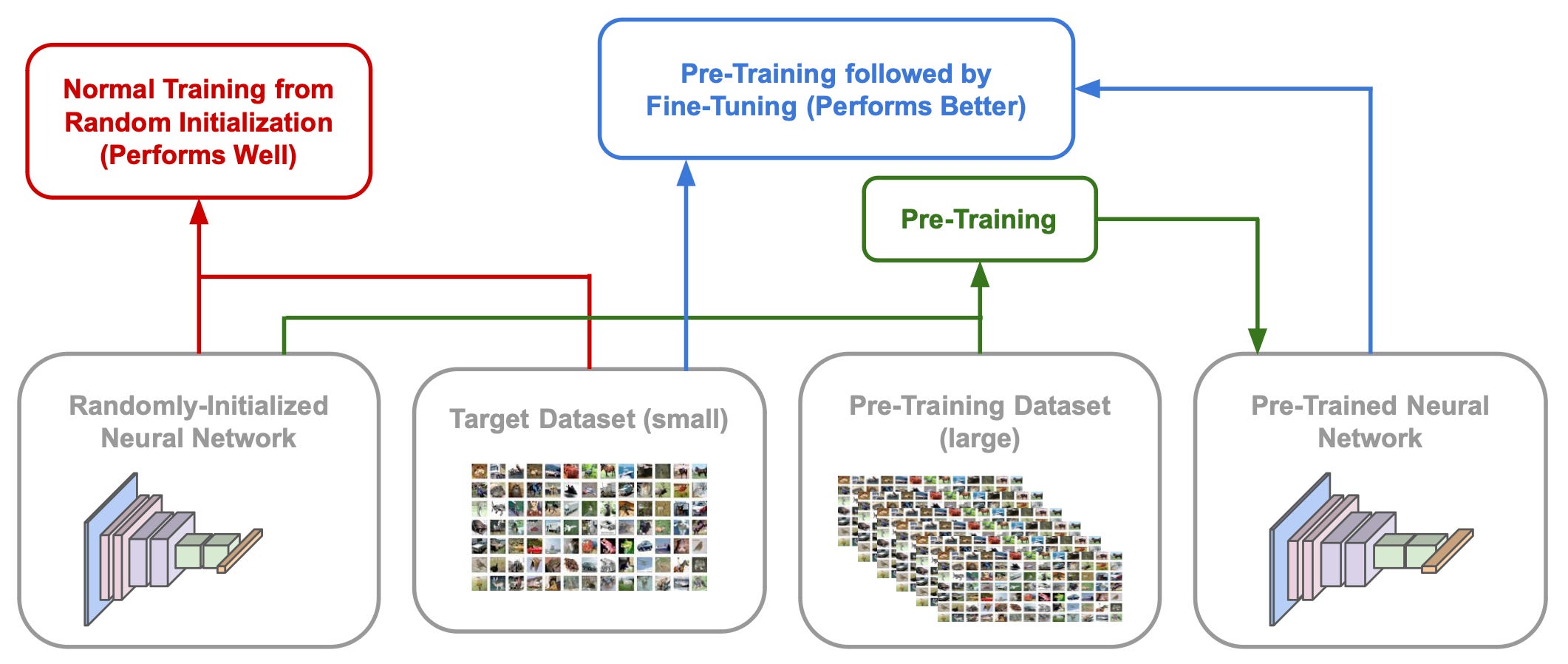
If we want to train a neural network to solve some task, we have two basic options.
Training from scratch: randomly initialize your neural network and train it (in a supervised manner) on your target task.
Transfer learning: pre-train the network on a separate dataset, then fine-tune it (i.e., train it more) on the target task.
Typically, pre-training is performed over a dataset that is much larger than the downstream, target dataset. In general, pre-training drastically improves data efficiency. The model learns faster during fine-tuning and may even perform better. The transfer learning process can take many different forms. In computer vision, for example, we might pre-train a model over ImageNet (using supervised learning), then fine-tune on a smaller dataset like CIFAR-10/100. For natural language processing (NLP) tasks, the story is a bit different. Typically, we use self-supervised pre-training objectives (e.g., masked language modeling or causal language modeling) with unlabeled text.
Different Transformer Architectures

The transformer, as originally proposed in [1], uses an encoder-decoder architecture, as shown above. For a more in-depth overview of this architecture, check out the link below.
However, the encoder-decoder transformer architecture is not our only option! BERT uses an encoder-only architecture, while most modern large language models (LLMs) are based upon decoder-only transformers. Let’s take a minute to understand the differences between each of these architectural variants.

a primer on self-attention. The self-attention operation takes a sequence of token vectors as input and produces a new sequence of transformed token vectors with the same length as output; see above. Each entry of this new sequence is a weighted average of vectors in the input sequence. Specifically, we compute each token vector in the output sequence as follows, where y_i and x_j are elements of the output and input sequences, respectively.
The weight w_{i, j} above is an attention score that is produced as a function of x_i and x_j. Put simply, this score captures how much the current token should “pay attention to” another token in the sequence while computing its new representation.
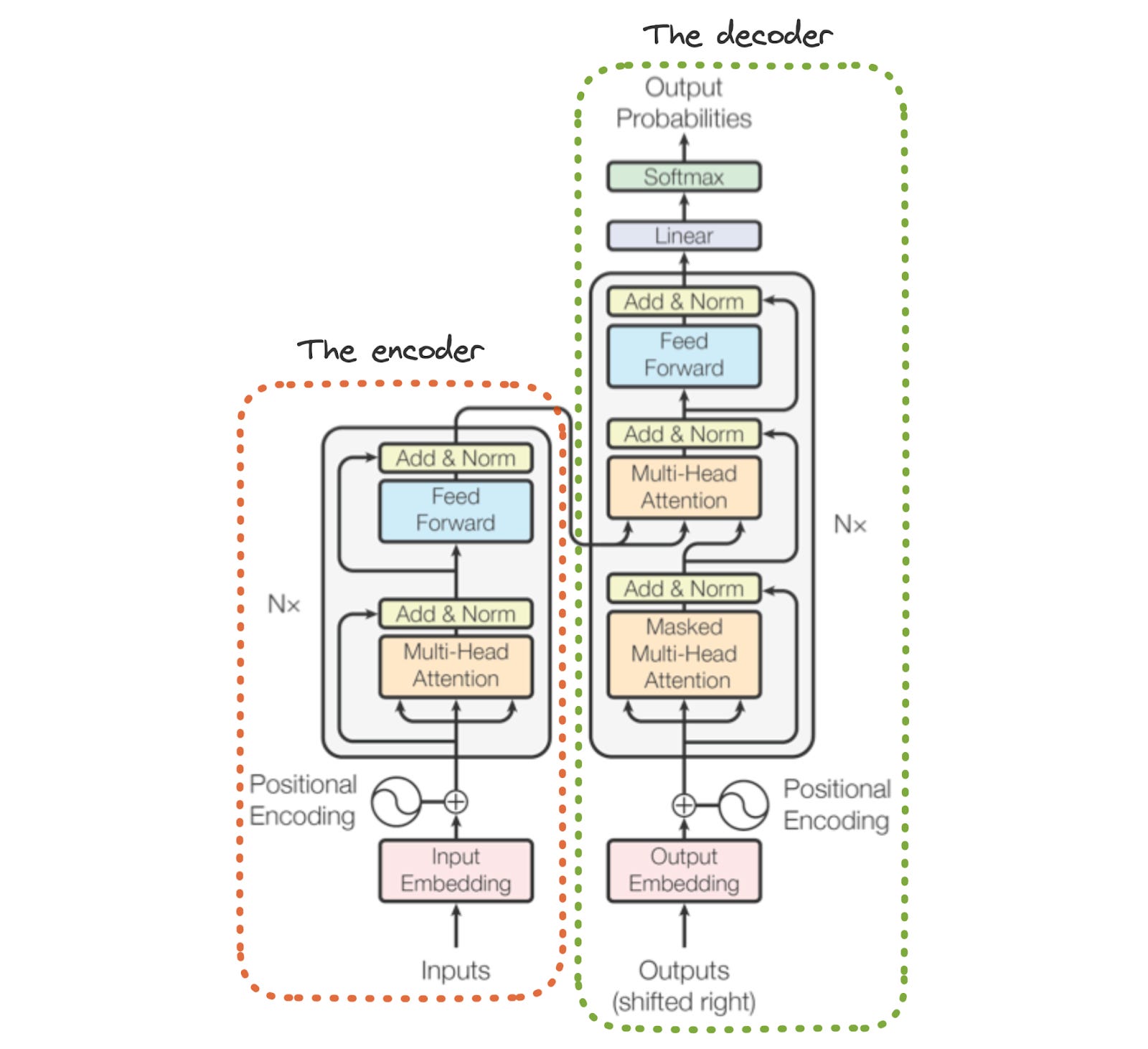
single stack or double stack? The original transformer architecture uses two “stacks” of transformer layers; see above. The first stack (the encoder module) is comprised of several blocks that contain bidirectional self-attention and a feed-forward neural network. The second stack (the decoder module) is pretty similar, but it uses masked self attention and has an added “cross attention” mechanism that considers activations within the corresponding encoder layer while performing self-attention. The transformer was originally used for sequence-to-sequence tasks (e.g., language translation). For other tasks, single stack transformer models have become popular:
Language models use a decoder-only architecture
BERT-style models use an encoder-only architecture
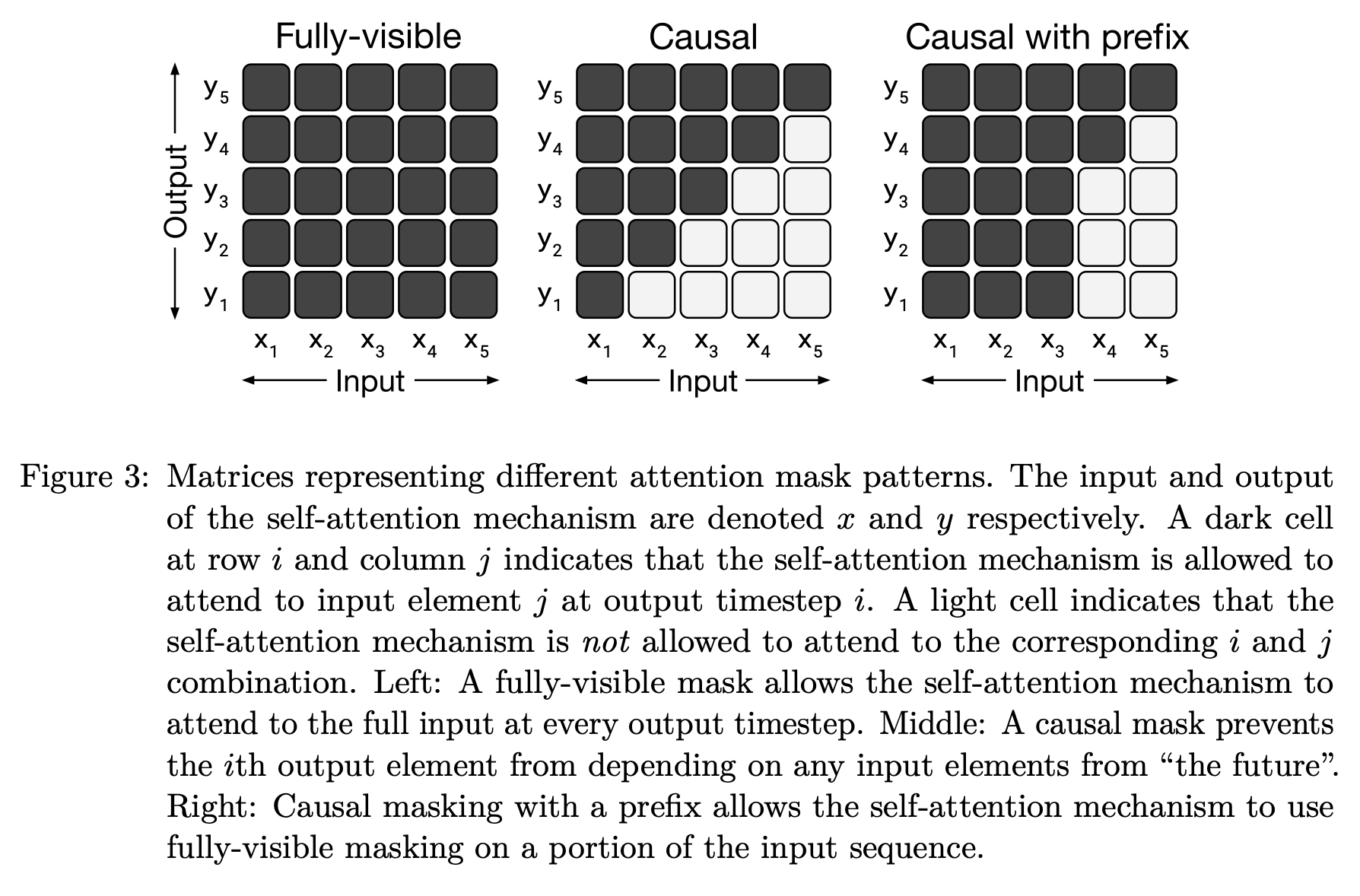
attention masks. Variants of the transformer architecture have one major distinction: the type of masking used in their attention layers. Here, when we say “masking”, we are referring to certain tokens being masked (or ignored) during the computation of self-attention. Put simply, certain tokens may look only at a select portion of other tokens in the full input sequence. The figure above depicts different masking options for self-attention.
Encoder-only models leverage bidirectional (or fully-visible) self-attention, which considers all tokens within the entire sequence during self-attention. Each token representation in self-attention is computed as a weighted average of all other tokens in the sequence. In contrast, decoder-only models use causal self-attention, where each token only considers tokens that come before it in the sequence.

We can also adopt a hybrid approach by defining a “prefix”. More specifically, we can perform bidirectional self-attention for a group of tokens at the beginning of the sequence (i.e., a prefix), then perform causal self-attention for the rest of the tokens in the sequence; see above. Fully-visible (or bi-directional) self-attention is useful for attending over a prefix or performing classification tasks. However, certain applications (e.g., language modeling) require causal self-attention during training to prevent the transformer from “looking into the future” (i.e., just copying the correct token when generating output).
what does T5 use? Although the analysis in [1] considers many transformer architectures, the primary model used for T5 is a standard encoder-decoder architecture. Aside from a few small modifications, this model is quite similar to the transformer as it was originally proposed [6]. Encoder-only architectures are not explored in [1] because they are designed for token or sequence level classification and not generative tasks like translation or summarization. T5 aims to find a unified approach (based on transfer learning) to solve many language understanding tasks.
BERT: Transfer Learning for NLP
In the early days, transfer learning in NLP typically used recurrent neural networks pre-trained with a causal language modeling objective. However, everything changed with the proposal of BERT [2], a transformer-based model [6] that is pre-trained using a self-supervised objective. BERT can be pre-trained over large amounts of unlabeled text, then fine-tuned to classify sentences (and even individual tokens in a sentence) with incredibly-high accuracy. At the time of its proposal, BERT set a new state-of-the-art on nearly all NLP tasks that were considered, solidifying transfer learning as the go-to approach within NLP.

To make this a bit more specific, BERT relies upon a “denoising” objective, called masked language modeling (MLM), during pre-training; see above. Although this might sound a bit complicated, the idea is simple, we just:
Mask some tokens in the input sequence by replacing them with a special
[MASK]tokenProcess the corrupted/modified sequence with BERT
Train BERT to accurately predict the masked tokens
The exact implementation is a bit more complicated. We select 15% of tokens at random, then either replace them with the [MASK] token (90% probability) or a random token (10% probability). By using this objective over a sufficiently-large pre-training corpus, BERT can learn a lot of general linguistic knowledge that makes it a highly-effective model for transfer learning.
how is T5 related to BERT? The proposal of BERT showed that transfer learning is a useful approach for solving NLP problems. Many people quickly began using BERT, trying new techniques, and proposing improvements. As a result, the field was overwhelmed with different options for performing transfer learning with BERT-like models. T5 [1] continues in this line of research, but tries to analyze all of these different proposals using a unified framework, giving us a much clearer picture of best practices for transfer learning in NLP. The final T5 model is trained using all of these best practices to reach state-of-the-art performance.
how does T5 related to LLMs? Currently, we are seeing a massive revolution in the generative AI space, in which LLMs (based on decoder-only transformer architectures) are being used to solve linguistic tasks via language model pre-training followed by zero/few-shot learning. LLMs are great, but T5 exists in a relatively distinct area of tools and research. Namely, T5 focuses mostly on models that explicitly process input with an encoder before generating output with a separate decoder. Plus, T5 adopts a transfer learning approach (i.e., pre-training followed by fine-tuning on each target task) instead of zero/few-shot learning.
Other Useful Links
The transformer architecture [link]
Self-attention [link]
The BERT model [link]
The basics of language models [link]
T5: The Unified Text-to-Text Transformer
The contribution of T5 is not a novel architecture or training methodology. Rather, the study performed in [1] is based entirely upon existing techniques. T5 considers all aspects of the transfer learning pipeline in NLP, such as different (unlabeled) datasets, pre-training objectives, benchmarks and fine-tuning methods. However, all of these aspects are studied via a unified text-to-text format. The goal of T5 is to i) analyze transfer learning setups and ii) determine the most effective approaches.
Text-to-Text Framework
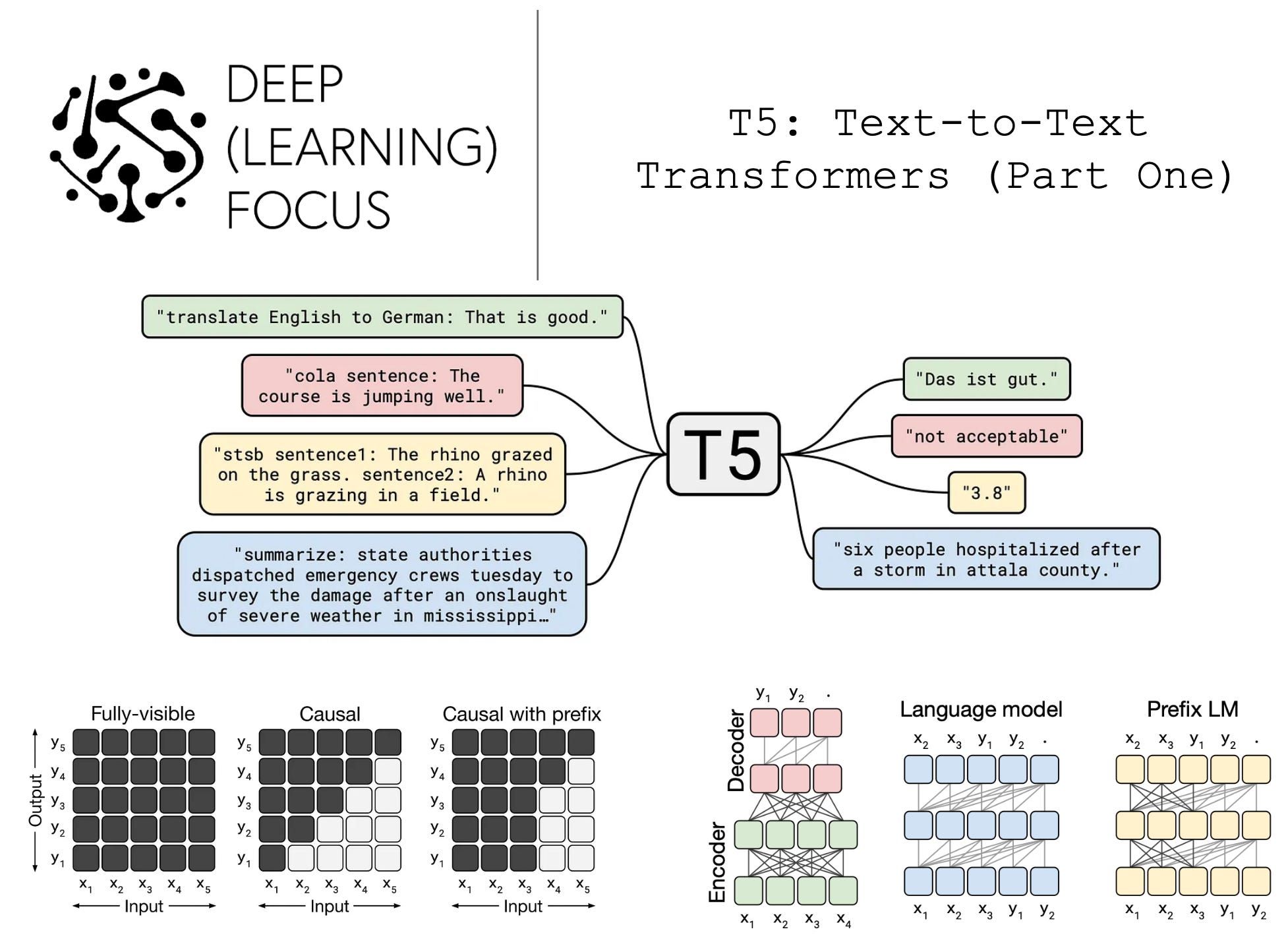
T5 converts all text processing problems into a “text-to-text” format (i.e., take text as input and produce text as output). This generic structure, which is also exploited by LLMs with zero/few-shot learning, allows us to model and solve a variety of different tasks with a shared approach. We can apply the same model, objective, training procedure and decoding process to every task that we consider! We just adopt a prompting approach and ask our language model to generate the answer in a textual format.

To make this a bit more concrete, all tasks being solved by T5 can be converted into text-to-text format as follows:
Add a task-specific prefix to the original input sequence
Feed this sequence to the transformer
Formulate the model’s target as a textual sequence
Using this format, we can easily perform tasks like summarization or translation (i.e., the target is naturally a sequence). Plus, we can perform classification by just training the model to generate text associated with the correct class. This process gets a bit complicated for problems like regression (i.e., we have to round real-valued outputs to the nearest decimal and treat it as a classification problem), but it tends to work well for a majority of linguistic tasks. Examples are shown in the figure above.
"An issue arises if our model outputs text on a text classification task that does not correspond to any of the possible labels… In this case, we always count the model’s output as wrong, though we never observed this behavior in any of our trained models.” - from [1]
T5 is fine-tuned on each task that it solves. This is in contrast to both LLMs, which use few-show learning, and the NLP decathlon [3], which uses multi-task learning to solve many tasks at once.
How is T5 studied?
All analysis performed in [1] uses the unified, text-to-text framework described above, as it allows a variety of different language understanding tasks to be converted into a shared format. Additionally, analysis of T5 uses the same underlying transformer architecture and pre-training dataset.
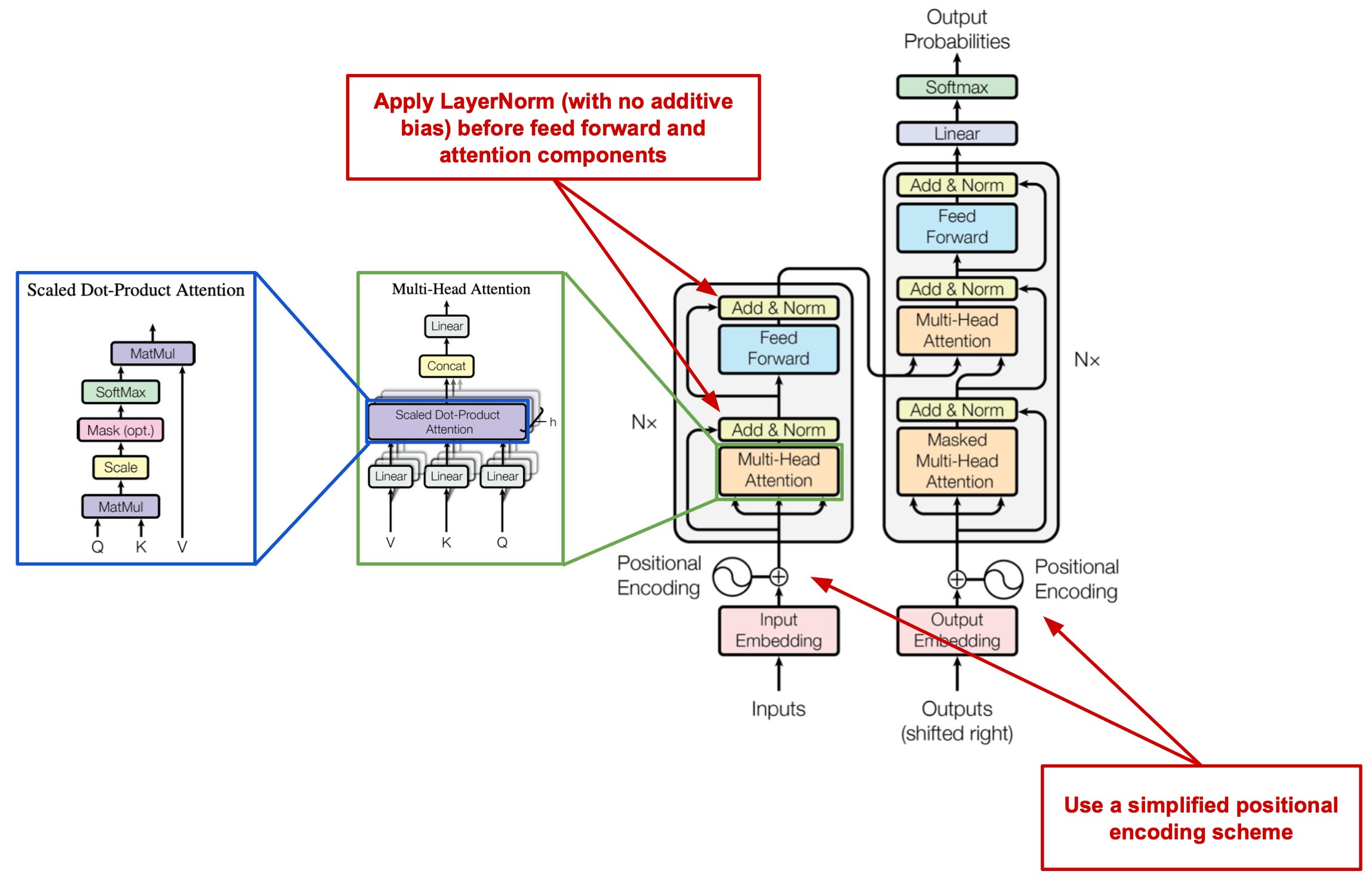
the model. As discussed previously, the transformer architecture, as it was originally proposed in [6], contains both an encoder and a decoder module. Recent work on language modeling has explored architectural variants that are encoder or decoder-only; e.g., BERT only uses the encoder [2], while most (large) language models only use the decoder. T5 uses an encoder-decoder architecture that closely resembles the original transformer. The differences are:
LayerNorm is applied immediately before each attention and feed forward transformation (i.e., outside of the residual path)
No additive bias is used for LayerNorm (i.e., see here; we only use scale and eliminate the additive bias)
A simple position embedding scheme is used that adds a scalar to the corresponding logit used to compute attention weights
Dropout is applied throughout the network (e.g., attention weights, feed forward network, skip connection, etc.)
These modifications are illustrated in the above figure. Using this model (and a few others), T5 can test many different transfer learning settings to derive a set of best practices.
pre-training dataset. T5 is pre-trained over the Colossal Clean Crawled Corpus (C4), a 750Gb corpus of “relatively clean” English text that is created in [1]. While a variety of pre-training datasets have been proposed in prior work, authors in [1] choose to construct their own due to prior datasets not being publicly available, using a limited set of filtering rules, having limited scope (e.g., solely from Creative Commons), or focusing only on parallel data for machine translation (i.e., versions of the same exact sentence in multiple, different languages).

Notably, C4 was later used as a subset of the MassiveText dataset used to pre-train Gopher and Chinchilla [4, 5]. See the table above for size metrics of this dataset, which provides a better understanding of C4’s size relative to pre-training datasets used to train modern LLMs. With LLMs, we have seen that pre-training decoder-only models over sufficiently large datasets is crucial for their success. The same is true of transformers with different architectures, such as T5. Extensive pre-training over a large, unlabeled dataset is conducive to better downstream performance.
experimental setup. T5 is pre-trained over C4 then fine-tuned to solve a variety of downstream tasks. However, the exact settings used within this framework are variable. Namely, we can change the:
Transformer architecture
Pre-training setup (i.e., task or amount of data)
Fine-tuning setup
Size/Scale of the model
By changing each of these settings one-at-a-time and evaluating the results, we can develop a set of best practices for transfer learning in NLP, thus distilling the many proposals after BERT into a single, effective pipeline for creating effective language understanding models.
Takeaways
This post has covered all preliminary information related to the T5 model, including important background information and the basic experimental framework that is used. In the next post, we will cover details of the extensive analysis performed in [1], which uncovers best practices for transfer learning in NLP. For now, the major takeaways related to T5 are outlined below.
transfer learning is powerful. Transfer learning refers to the process of pre-training a deep learning model over some separate dataset, then fine-tuning (or further training) this model on a downstream, target dataset (i.e., the task we are actually trying to solve). If performed over a sufficiently large and aligned (i.e., similar to the downstream task) dataset, pre-training is incredibly effective. The model can learn much faster during fine-tuning and even reach a higher accuracy. This technique is effective across domains (e.g., computer vision and NLP), but the exact approach used for pre-training or fine-tuning might differ.
“While we do not explicitly measure improvements in data efficiency in this paper, we emphasize that this is one of the primary benefits of the transfer learning paradigm.” - from [1]
what comes after BERT? The proposal of BERT [2] was a massive breakthrough that popularized the use of transfer learning for NLP tasks. In fact, BERT set a new state-of-the-art performance on nearly every task that it considered. Due to its success, the research community adopted and iterated upon BERT’s approach. T5 attempts to unify all of this follow-up work and analysis that came after the proposal of BERT, providing a clearer view of the most effective transfer learning approaches.
generic task formulation. In order to create a unified framework according to which many different transfer learning approaches can be studied, T5 proposed a generic text-to-text framework. Similar to prompting and few-shot learning techniques used for LLMs, this text-to-text framework can restructure any language task into textual input and output. Specifically, this is done by appending a task-specific prefix to the textual input (i.e., so that T5 knows what task it is trying to solve) and using the decoder module of T5 to generate text corresponding to the desired target (e.g., a label, regression value, or sequence of text).
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Bibliography
[1] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[2] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[3] McCann, Bryan, et al. "The natural language decathlon: Multitask learning as question answering." arXiv preprint arXiv:1806.08730 (2018).
[4] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[5] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[6] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).