
The History of Open-Source LLMs: Early Days (Part One)
Understanding GPT-Neo, GPT-J, GLM, OPT, BLOOM, and more...

This newsletter is presented by Rebuy, the commerce AI company.
Sponsor the newsletter | Follow me on Twitter | Get in touch | Suggest a topic

Research on language modeling has a long history that dates back to models like GTP and GPT-2 or even RNN-based techniques (e.g., ULMFit) that predate modern, transformer-based language models. Despite this long history, however, language models have only become popular relatively recently. The first rise in popularity came with the proposal of GPT-3 [1], which showed that impressive few-shot learning performance could be achieved across many tasks via a combination of self-supervised pre-training and in-context learning; see below.

After this, the recognition garnered by GPT-3 led to the proposal of a swath of large language models (LLMs). Shortly after, research on language model alignment led to the creation of even more impressive models like InstructGPT [19] and, most notably, its sister model ChatGPT. The impressive performance of these models led to a flood of interest in language modeling and generative AI.
Despite being incredibly powerful, many early developments in LLM research have one common property—they are closed source. When language models first began to gain widespread recognition, many of the most powerful LLMs were only accessible via paid APIs (e.g., the OpenAI API) and the ability to research and develop such models was restricted to select individuals or labs. Such an approach is markedly different from typical AI research practices, where openness and idea sharing is usually encouraged to promote forward progress.
“This restricted access has limited researchers’ ability to understand how and why these large language models work, hindering progress on efforts to improve their robustness and mitigate known issues such as bias and toxicity.” - from [4]
This overview. Despite the initial emphasis upon proprietary technology, the LLM research community slowly began to create open-source variants of popular language models like GPT-3. Although the first open-source language models lagged behind the best proprietary models, they laid the foundation for improved transparency within LLM research and catalyzed the development of many subsequent models that were more powerful (e.g., Falcon [10] and LLaMA-21).
This overview is part of a three part series exploring the history of open-source language models. Here, we will learn about the beginning of this history, including several initial attempts at creating open-source language models. Although these models left something to be desired in terms of performance, they are incredibly important to understand, as the revolution of open-source LLMs that ensued was entirely based upon these models. In the following two parts of the series, we will learn more about recent open-source LLMs, as well as how imitation and alignment techniques have been used to improve their performance.
The Mechanics of a Language Model
Open-source LLM research catalyzed transparency and idea sharing, creating an environment in which researchers could collaborate and innovate more quickly. Put simply, the beauty of open-source LLM research is that it gives us the potential to study these incredible models and develop a deeper understanding of how they work. There are no unknown tricks hidden behind a paid API or black box. Open-source LLMs allow us to look at the code, run experiments, and even try out our own ideas and modifications—we have full access to the underlying model!
“A much broader segment of the AI community needs access to these models in order to conduct reproducible research and collectively drive the field forward.” - from [4]
But, to build a deep understanding of such models, we first need to understand the basics behind how they work. Within this section, we will overview these ideas, attempting to provide a (relatively) comprehensive understanding of LLMs.
The Language Modeling Objective
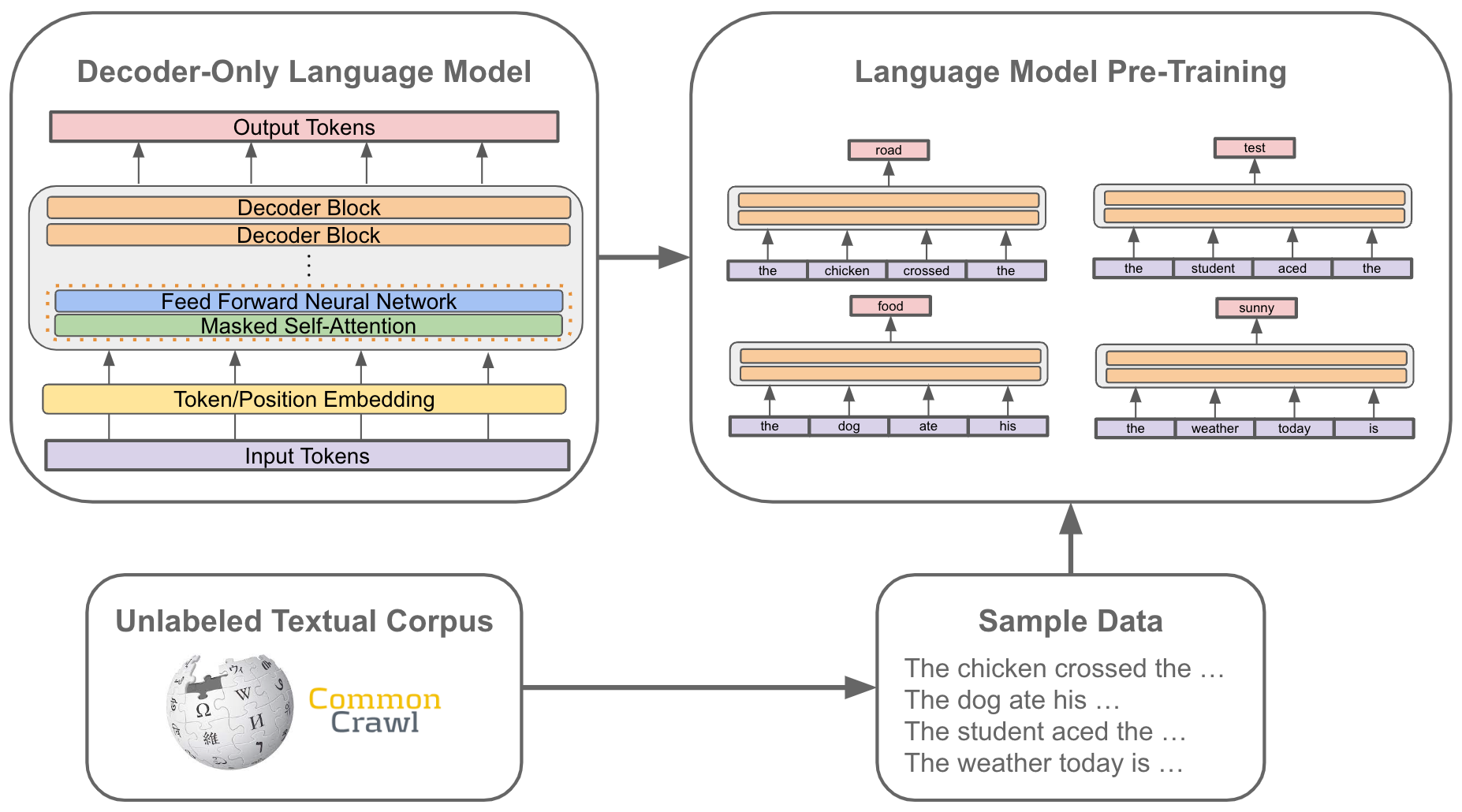
At the core of language modeling is next token prediction (also called the standard language modeling objective), which is used to train nearly all language models. To train a language model using next token prediction, we need a large corpus of raw text. Using this corpus, we train the model by i) sampling some text from the dataset and ii) training the model to predict the next word; see above. Because the ground truth next token can always be deduced from the raw text, next token prediction is a form of self-supervised learning.
What is a token? One can roughly consider next token prediction to be predicting the next word in a sequence, given a few preceding words as context. However, this analogy is not perfect, as tokens and words are not exactly equal. When a language model receives text as input, the raw text is first tokenized2 (i.e., converted into a sequence of discrete words or sub-words); see below.

The tokenizer associated with a language model typically has a fixed-size vocabulary, or set of viable tokens that can be created from a textual sequence.
Predicting next tokens. Once a sequence of tokens has been created, the language model has an embedding layer that stores a unique and learnable vector embedding for every token within the tokenizer’s vocabulary. Using this embedding layer, we can convert each token within the input sequence into a corresponding vector embedding, forming a sequence of token vectors; see below.

After adding positional embeddings to each token, we can pass this sequence of token vectors into a decoder-only transformer (more explanation will follow), which transforms (no pun intended) each of these token vectors and produces a corresponding output vector for each token. Notably, the number of output vectors is the same as the number of input vectors; see below.
Now that we have an output representation for each token, we are ready to perform next-token prediction! For each token in the sequence, we simply take its output token vector and use this to predict the token that comes next in the sequence! An illustration of this process is shown below. In practice, this next token prediction objective is simultaneously computed over all tokens in the sequence (and over all sequences in a mini-batch!) to maximize efficiency.

Due to the use of causal (or masked) self-attention, each output token vector only considers the current token and those that is come before it in the sequence when computing its representation. If we were to use bidirectional self-attention, each output token vector would be computed by looking at the entire sequence of vectors, which would allow the model to cheat and solve next token prediction by just copying the token that comes next in the sequence. As such, masked self-attention is needed for next-token prediction. But, what is self-attention and—more fundamentally—what is a transformer? Let’s dive into this next.
A quick note. The phrase “language model” may sometimes be used to refer to models beyond those that specialize in performing next token prediction. For example, BERT [18] is considered by some to be a “language model”, but it is trained using a Cloze-style objective and is not a generative model. As such, language models that specialize in next token prediction are oftentimes distinguished as “causal” language models. Here, we will use both of these terms interchangeably to refer to models that specialize in next token prediction.
The Transformer Architecture and its Variants
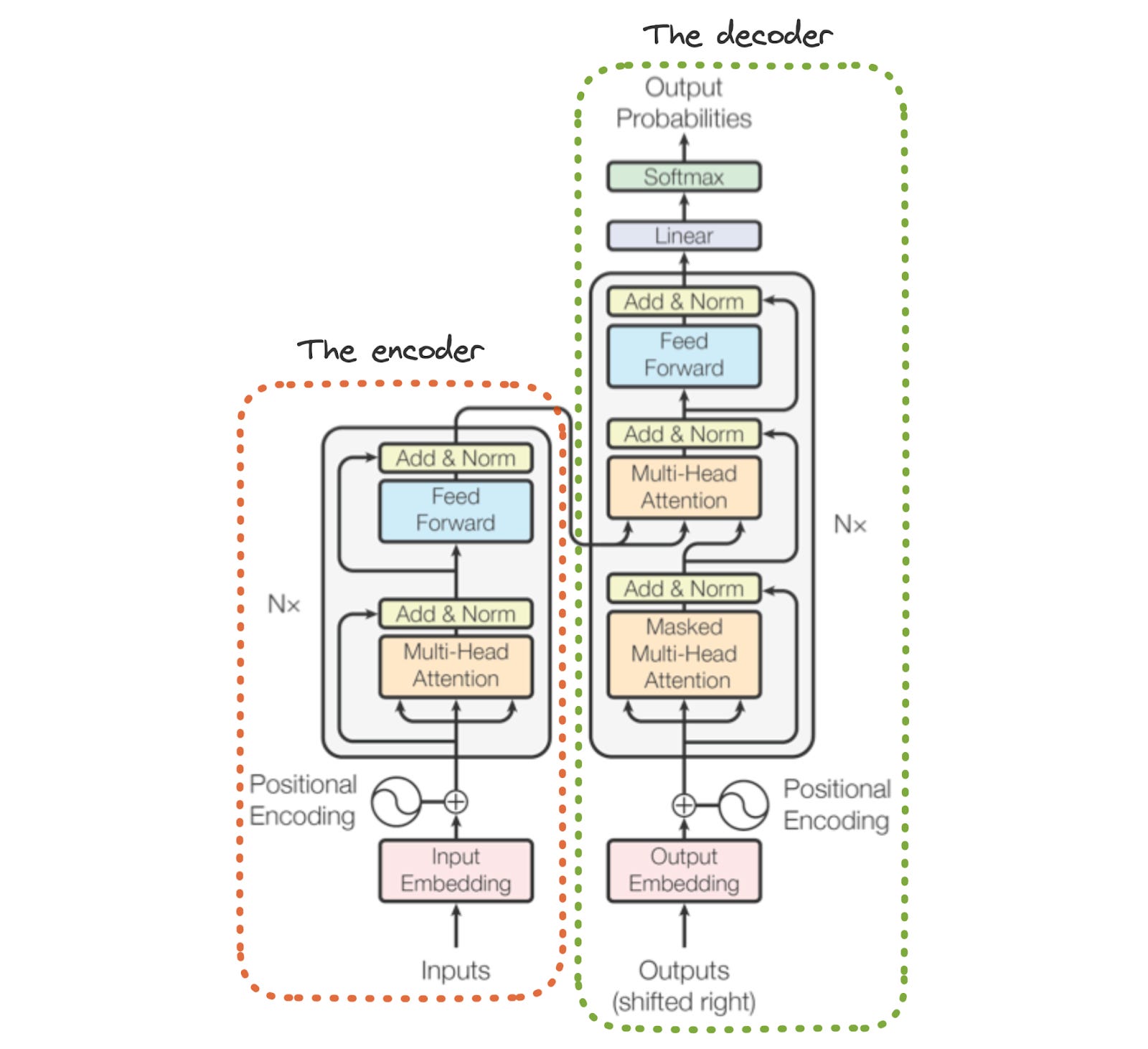
All language models use some variant of the transformer architecture. This architecture (shown above) was originally proposed in [17] for solving sequence-to-sequence tasks3. However, it was subsequently extended to solve a variety of different problems, from assessing the semantic similarity of text to classifying images. In its original form, the transformer architecture has two components:
Encoder: each block performs bidirectional self-attention and a pointwise feed-forward transformation4, which are separated with a residual connection5 and LayerNorm.
Decoder: each block performs causal self-attention, cross attention (i.e., self-attention across encoder and decoder tokens), and a pointwise feed-forward transformation, each separated by a residual connection and LayerNorm.
When both components of the architecture are present, the encoder processes the input sequence and produces an output sequence. Then, the decoder generates its own output sequence, given the encoder’s output sequence as input. In other words, the encoder processes the entire input sequence to form a representation that the decoder uses as context when generating output. As a whole, the transformer takes a sequence as input and produces a new sequence as output.

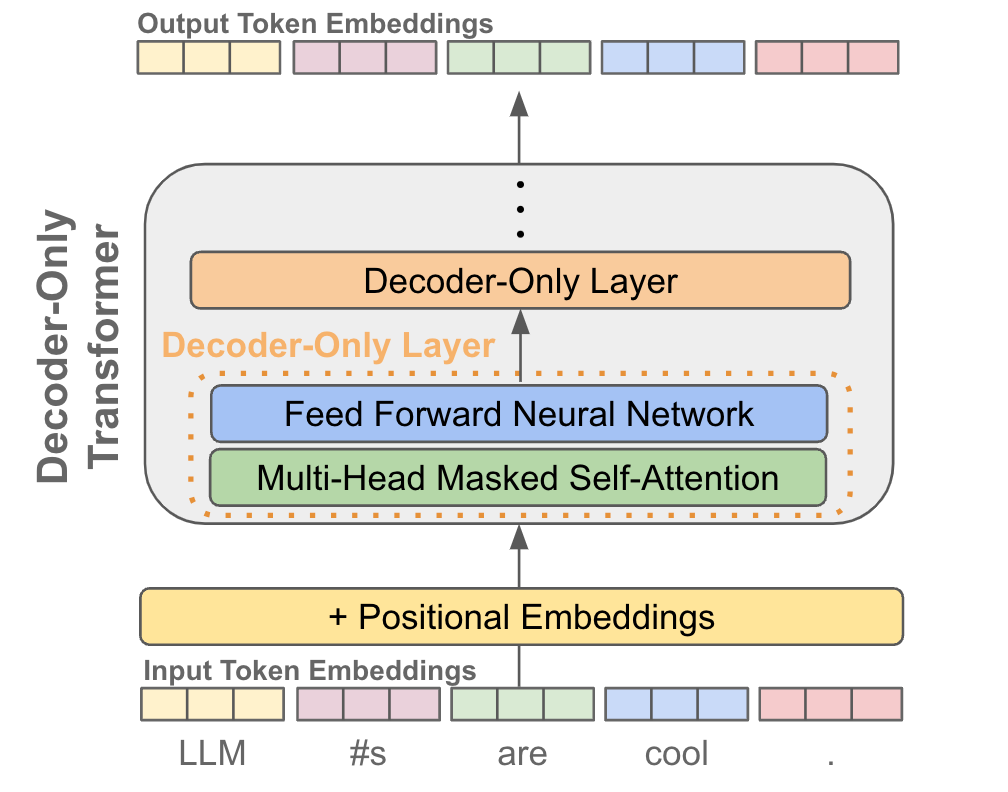
Decoder-only and encoder-only transformers. Nearly all causal language models use a decoder-only transformer as their underlying architecture, which is just a normal transformer with the encoder-portion of the architecture removed; see above. Additionally, the cross attention portion of each decoder block is removed due to the lack of an encoder (i.e., we can’t attend to an encoder that doesn’t exist)! Alternatively, one could form an encoder-only architecture by just using the encoder portion of the architecture. Encoder-only architectures (e.g., BERT [18]) excel at solving a variety of discriminative natural language tasks, but they are not used for generating text. To learn more, check out the link below.
Why the decoder? The choice of using the decoder-only architecture (as opposed to encoder-only or the full encoder-decoder transformer) for LLMs is not arbitrary. Rather, this choice is driven by the use of next-token prediction for training language models. The use of masked self-attention within the decoder ensures that the model cannot look forward in the sequence when predicting the next token. Otherwise, next-token prediction would be trivial, as the model could simply copy the next token; see below.

To perform next token prediction without cheating, both encoder-only and encoder-decoder transformers would have to avoid including any ground truth next token in their input sequence. To do this, we could i) ingest a prefix and ii) predict the token that follows this prefix. However, this approach is a bit inefficient because we can only predict a single next token at a time. In contrast, decoder-only models, due to their use of masked self-attention, can ingest an entire sequence of tokens and apply a language modeling objective to every token within the sequence. Plus, several papers [12] have shown practically that decoder-only architectures yield the best performance for next token prediction.
How do we generate text? Given the decoder-only architecture outlined above, generating text follows a simple autoregressive6 process. We just continually predict the next token, add this token to our input, and repeat; see below.

Training and Using Language Models
To complete our understanding of language models, we need to quickly explore how these models are typically trained and used in practice. Although a lot of research has been done in this area, most language models are trained according to a few standard techniques, as proposed in [19]; see below.
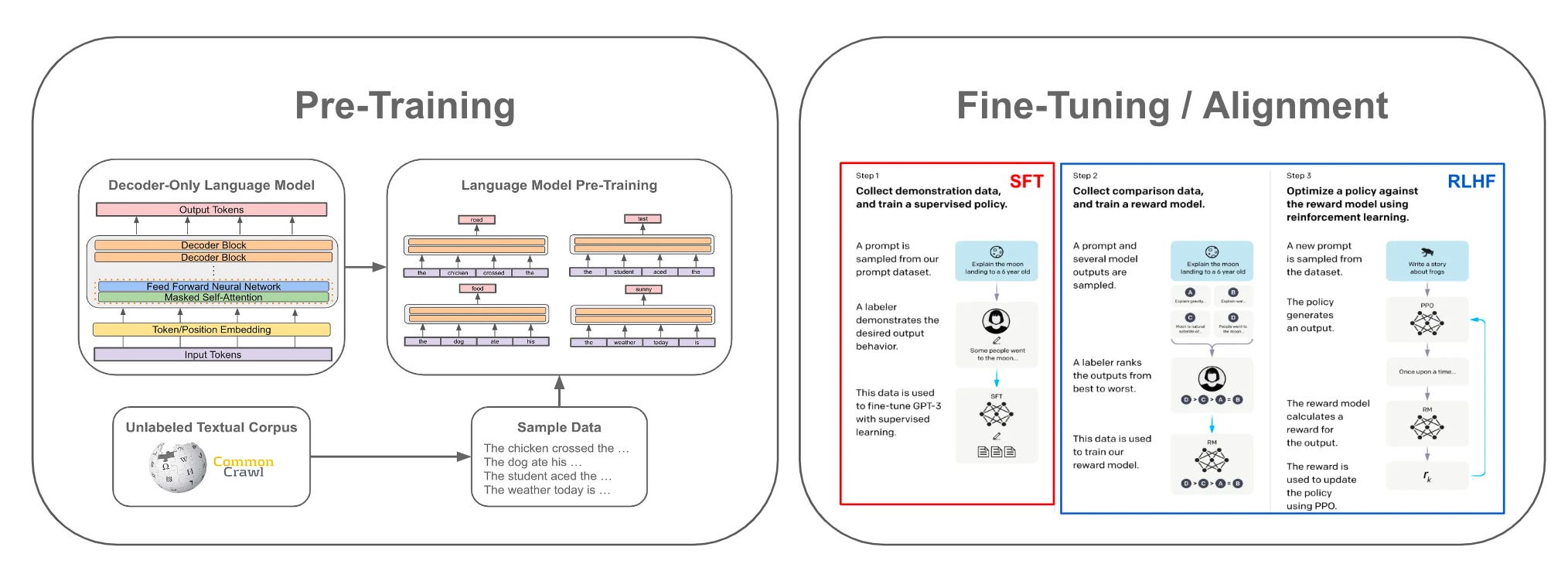
Language models can learn in a variety of different ways. Here, we will focus on pre-training, alignment, and in-context learning, which collectively encompass most of what’s required to train an LLM and use it in a practical application.
Pre-training. The pre-training process is the initial and most computationally expensive step of creating an LLM. Beginning with a randomly-initialized LLM, we must train this model—using a language modeling objective—over a massive corpus of raw text that is curated from a variety of different sources. Prior research [1] has shown us that by pre-training a very large model (i.e., lots of parameters) over a large dataset, we can obtain a foundation model that can accurately solve a variety of different tasks by performing next token prediction. To get the best results, we need scale in terms of both data and model size.
What else do we need? Language models that solely undergo pre-training can be powerful. Look at GPT-3 [1] and Chinchilla [15] for a few examples. However, there is a reason that LLMs did not explode in popularity until the proposal of models like ChatGPT—just performing next token prediction is not very interesting. Oftentimes, predicting the statistically-correct next token, although it leads to reasonable text being generated, produces output that is repetitive, simple, and generally not helpful. We needed some way to make LLMs craft outputs that are more helpful and interesting to us as humans!

Alignment refers to the process of fine-tuning an LLM to better align with the desires of human users. This is accomplished primarily via two techniques: supervised fine-tuning (SFT) and/or reinforcement learning from human feedback (RLHF). The desired behavior of an LLM depends a lot on the context or application in which it is deployed. However, alignment is a generic tool that can be used to arbitrarily fine-tune an LLM to behave in a certain way; see above. Recent research indicates that models do not learn new information during alignment. Rather, this process simply teaches the model how to properly format or present the knowledge that it has already gained from the pre-training process.
Using LLMs in practice. After we have pre-trained and fine-tuned (or aligned) our language model, the final step is to specialize the model to our desired application. This process may require extra fine-tuning over domain-specific data. More training is not always necessary, however, as we can accomplish a lot by just using in-context learning; see below.

Put simply, in-context learning refers to the idea of solving a variety of different problems using a single, general-purpose foundation model (e.g., a pre-trained LLM). Given the generic text-to-text structure of a language model, this can actually be done quite easily. We just need to construct a textual problem-solving prompt that can be provided as input to the LLM; see below.

Then, the LLM should generate the answer to our problem as output. As such, we can solve many different problems by just modifying the input prompt! The process of constructing good prompts for solving problems is referred to as prompt engineering, and we have explored this idea extensively in previous posts:
Initial Attempts at Open-Source LLMs
Given the expense of pre-training, it took some time for the research community to pursue the creation of an open-source LLM, causing proprietary models like GPT-3 to become the standard. However, once the first few models were proposed, the floodgates opened and research on open-source LLM progressed rapidly (almost too rapidly). We will learn about a few of the early models here, while more recent open-source LLMs will be covered in future parts of the series.
GPT-NeoX-20B [6]
One of the first open-source LLMs—a 20 billion parameter model called GPT-NeoX-20B [6]—was created by EleutherAI. GPT-NeoX-20B was created after the initial GPT-Neo model (2.7 billion parameters) [22], was pre-trained over the Pile, and achieves impressive few-show learning performance (comparable to GPT-3) on a variety of natural language benchmarks. Although this model is somewhat small compared to GPT-3 (i.e., 20 billion parameters vs. 175 billion parameters), it was the largest open-source language model to be released at the time. Plus, all of code for training and evaluating the model was released alongside its weights under an Apache 2.0 license, which permits commercial use.

The model. GPT-NeoX-20B [6] uses a standard decoder-only transformer architecture, but makes the following two changes:
RoPE Embeddings
Parallel Attention and Feed Forward Layers
Improving upon standard position embeddings, RoPE embeddings (shown above) provide a new methodology for injecting positional information into the self-attention operation. This approach finds a better balance between absolute and relative position information and is used in a variety of other models (e.g., PaLM [9] and Falcon-40B [10]) due to its ability to improve performance on tasks with long sequence lengths. Additionally, the use of parallel attention and feed forward layers (see below) leads to a 15% improvement in training throughput with minimal performance degradation.

Interestingly, a custom tokenizer is created for GPT-NeoX-20B. This tokenizer is comparable to that of GPT-2 [11], but it is trained from scratch on the Pile—a large and diverse corpus of text—and is modified to more consistently tokenize whitespace characters. As such, the resulting tokenizer, in addition to being trained on a high-quality corpus, is especially effective at tokenizing code (i.e., there are a lot of whitespace characters in code!). As a result, several open-source models (e.g., MPT-7B [5]) adopt this tokenizer even today.

The performance. GPT-NeoX-20B was compared to both GPT-3 and other open-source models, such as GPT-J. In these evaluations, we see that GPT-NeoX-20B performs quite well (even when compared to proprietary models) on common language modeling tasks; see above. Notably, GPT-3 tends to achieve the best performance. However, GPT-NeoX-20B performs quite well relative to its size and even outperforms proprietary models with a similar number of parameters.

The performance of GPT-NeoX-20B is not quite state-of-the-art, but the model performs surprisingly well for its size, even when compared to recent models!
Open Pre-Trained Transformers (OPT) Language Models [4]

In a previous overview, we have discussed the details of the Open Pre-trained Transformers (OPT) library in depth. See below for a link.
OPT, which was proposed by Meta AI7, was created as an initiative to democratize access of powerful LLMs to the public and is comprised of several different LLMs with sizes ranging from 125 million to 175 billion parameters. These models are pre-trained over a curated dataset compiled from sources like Reddit, the Pile, and BooksCorpus, and the largest model in this suite—OPT-175B—was one of the first truly large language models to be open-sourced. Going further, the models are accompanied by a code repository and even a logbook that details the pre-training process of all models. Although OPT models are not commercially-usable, they are an incredibly resource that heavily influenced the open availability of LLMs for research.
The impact. The OPT language models were the first large-scale effort to make massive language models accessible to the research community—LLMs were now fully-available to anyone, rather than being hidden behind an API. Additionally, OPT’s open-source training code makes a highly efficient training framework, using common techniques like FSDP and tensor parallelism, readily available. This code achieves resource utilization that is 17% better than research published directly by NVIDIA [3], making it a great resource for training LLMs.

The training notes and logbook associated with OPT provide a massive amount of (previously unknown) insight into the LLM training process. From these resources, we can better understand the full cost of training an LLM and the many struggles that may occur in this process (e.g., loss spikes, hardware failures, and other “mid flight” training adjustments that are required). Such difficulties with training LLMs became a topic of conversation and have since been (mostly) resolved by subsequent work on open-source LLMs; see above.
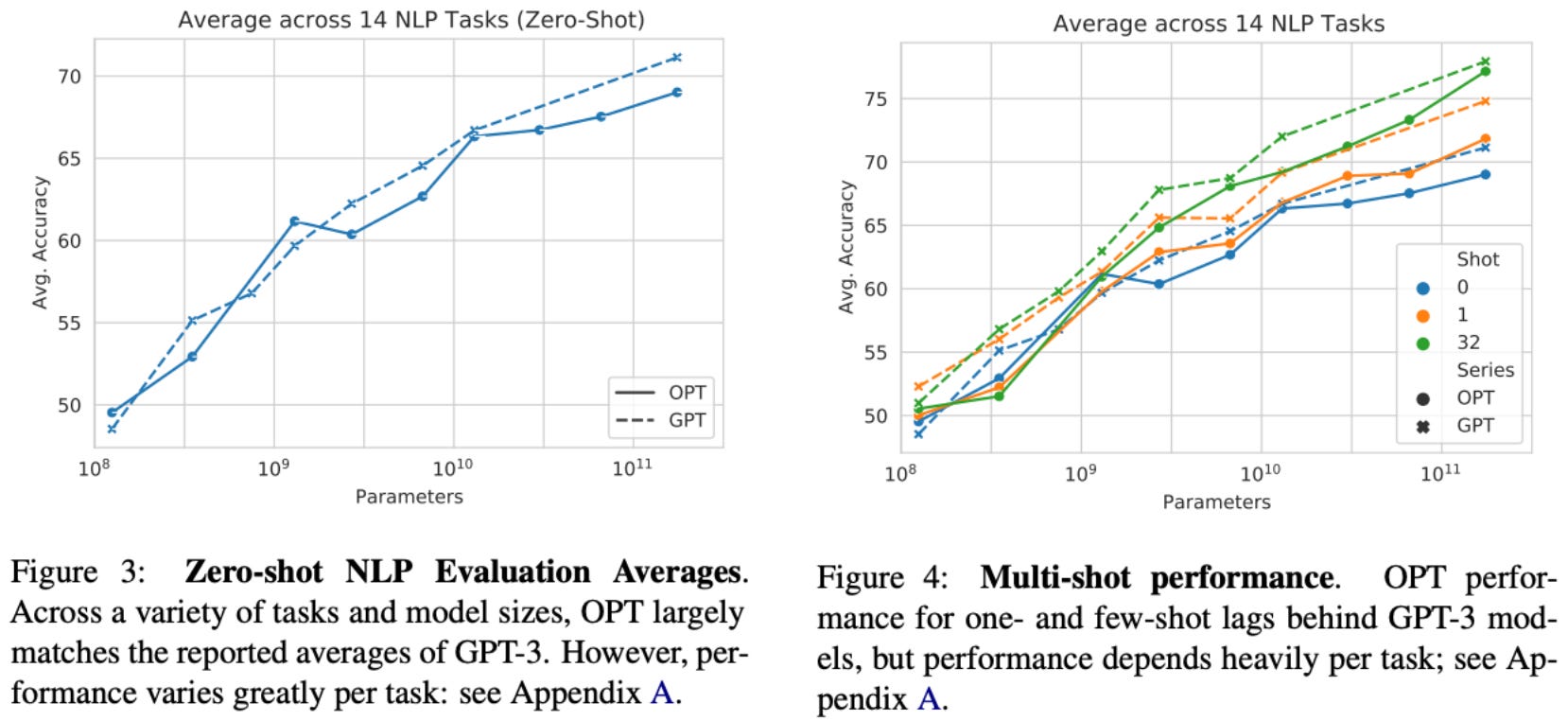
Does it perform well? OPT-175B was extensively compared to popular models at the time of its proposal and found to achieve comparable performance to GPT-3 in zero and few-shot learning settings; see above. Overall, OPT’s performance is not notable—the model is widely considered to lag behind proprietary models in terms of quality. Despite its lackluster performance, however, OPT was a massive step forward for AI research and significantly boosted the level of interest in open-source LLMs. This impact should not be understated, as it came at a time when the dominance of proprietary models had been accepted as a new standard.
BLOOM: An Open, Multilingual Language Model [12]
“Academia, nonprofits and smaller companies' research labs find it difficult to create, study, or even use LLMs as only a few industrial labs with the necessary resources and exclusive rights can fully access them.” - from [12]
Proposed in [12], BLOOM is an 176 billion parameter LLM that was trained as part of a massive, open collaboration of AI researchers (i.e., over 1000 researchers participated!), called the Big Science Research Workshop. Running over the timespan of one year (May 2021 to May 2022), the goal of this workshop was to create i) a massive multilingual text dataset and ii) a large multilingual language model that is trained on this dataset. The resulting model, which is slightly larger than GPT-3 and is open-sourced under the Responsible AI License (RAIL), can generate text in 46 different languages8 and 13 programming languages.
The dataset developed for training BLOOM, called the ROOTS corpus, is comprised of 498 HuggingFace datasets and contains over 1.6 terabytes of text that spans 46 natural languages and 13 programming languages. The distribution of this dataset across the different languages is shown in the figure below.

After obtaining the raw data, the authors apply a pipeline of different quality filters to remove text that is not natural language. The exact filtering components that are used, which are further outlined in Section 3.1.3 of [12], change depending on the source of the data. However, the overall pipeline shares a common goal of filtering out as much low-quality text as possible.

The architecture used by BLOOM is a standard decoder-only transformer. As shown above, however, a few modifications are made to this architecture, such as:
ALiBi [13]: This aids the model in generalizing to longer context lengths than those seen during training. [link]
Embedding Layer Norm: An extra layer norm is placed after the model’s embedding layer, which is empirically found to improve training stability.
Overall, this model is not much different than most LLMs. Interestingly, authors in [12] perform an extensive analysis between different types of transformer architectures (e.g., encoder-only models, encoder-decoder models, and decoder-only models), finding that the decoder-only model (used by nearly all causal language models) achieves the best performance after pre-training.
“Our results show that immediately after pre-training, causal decoder-only models performed best – validating the choice of state-of-the-art LLMs.” - from [12]
Does it perform well? Compared to other open-source LLMs, BLOOM performs relatively well. It achieves comparable, or improved, results relative to OPT in natural language benchmarks and tends to excel at machine translation tasks given that it was trained on a multilingual corpus; see below.

However, BLOOM’s performance falls below that of top proprietary models. For example, we see in results on the HumanEval benchmark (shown below) that the model’s coding abilities fall far short of alternatives like Codex [14]. Additionally, when we compare the performance of BLOOM to models like Chinchilla [15] and PaLM [9], we quickly see that the performance of open-source models falls short of their proprietary counterparts. In other words, research in open-source LLMs was still lagging at the time when BLOOM was proposed.

Other Notable Models
We tried to cover several notable models that were proposed during the early days of open-source LLM research. But, there are still a few models not covered in this overview that are worth mentioning. Let’s take a quick look at a few of them.
GPT-J [21] is a 6 billion parameter, English-only causal language model that was proposed prior to GPT-NeoX-20B [6]. Similar to GPT-NeoX-20B, this model was pre-trained on the Pile. At the time of its release, GPT-J-6B was the largest publicly-available GPT-3-style language model.

GLM [20] is more of a pre-training objective rather than a language model. This work explores the idea of unifying different pre-training techniques (e.g., from BERT, T5, and GPT) by proposing a autoregressive blank infilling objective. In other words, we predict masked words in a sentence in an autoregressive manner, similar to a language model; see above. The resulting model, which is quite small (<1 billion parameters), is found to outperform BERT, T5 and GPT on several popular natural language processing benchmarks.
Where do we go from here?

Given that initial attempts at open-source LLMs yielded models that did not perform nearly as well as proprietary counterparts, we might reasonably wonder: What should we do to make these models better? As this research area has evolved, we have seen effort invested into two primary areas:
Creating better base LLMs9
Fine-tuning open-source LLMs (i.e., alignment and imitation)
Given that open-source LLMs are accessible to everyone, research in these areas progressed at a shocking pace—we went from OPT to near state-of-the-art models (e.g., LLaMA-2 or Falcon-40B [10]) in less than a year!
“We argue that the highest leverage action for improving open-source models is to tackle the difficult challenge of developing better base LMs” - from [16]
Both of the research directions outlined above were explored in parallel during this time, and each resulted in the development of useful techniques for AI practitioners. Within the next two parts of this survey, we will overview each of these areas and the key contributions of each, exploring how initial attempts at open-source LLMs evolved into incredibly-capable models such as LLaMA-2.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews that explain relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on twitter or LinkedIn!
Bibliography
[1] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[2] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[3] Smith, Shaden, et al. "Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model." arXiv preprint arXiv:2201.11990 (2022).
[4] Zhang, Susan, et al. “OPT: Open Pre-trained Transformer Language Models.” arXiv preprint arXiv:2205.01068 (2022).
[5] “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable Llms.” MosaicML, 5 May 2023, www.mosaicml.com/blog/mpt-7b.
[6] Black, Sid, et al. "Gpt-neox-20b: An open-source autoregressive language model." arXiv preprint arXiv:2204.06745 (2022).
[7] Gao, Leo, et al. "The pile: An 800gb dataset of diverse text for language modeling." arXiv preprint arXiv:2101.00027 (2020).
[8] Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." arXiv preprint arXiv:2104.09864 (2021).
[9] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[10] “Introducing Falcon LLM”, Technology Innovation Institute, 7 June 2023, https://falconllm.tii.ae/.
[11] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[12] Scao, Teven Le, et al. "Bloom: A 176b-parameter open-access multilingual language model." arXiv preprint arXiv:2211.05100 (2022).
[13] Press, Ofir, Noah A. Smith, and Mike Lewis. "Train short, test long: Attention with linear biases enables input length extrapolation." arXiv preprint arXiv:2108.12409 (2021).
[14] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[15] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[16] Gudibande, Arnav, et al. "The false promise of imitating proprietary llms." arXiv preprint arXiv:2305.15717 (2023).
[17] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[18] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[19] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[20] Du, Zhengxiao, et al. "Glm: General language model pretraining with autoregressive blank infilling." arXiv preprint arXiv:2103.10360 (2021).
[21] Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 billion parameter autoregressive language model, 2021.
[22] Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. 2021. GPT-Neo: Large scale autoregressive language modeling with MeshTensorflow.
LLaMA-2 was proposed just last week, and it has officially dethroned Falcon-40B as the state-of-the-art for open-source LLMs. More to come in part two of this series!
The most common tokenization technique used for LLMs currently is Byte-Pair Encoding tokenization. Read more about how it works here.
These are tasks that take a sequence as input and produce a sequence as output, such as language translation or text summarization.
This just means that the same feed-forward transformation is separately applied to the embedding of every token vector within the input sequence.
A residual connection just means that we add a module’s input value to its output. In other words, if a module performs an operation given by the function f(x), this same operation with a residual connection would have the form g(x) = f(x) + x.
This words just means that, given a starting input sequence, we sequentially i) generate an output, ii) add this output to our input sequence, and iii) repeat.
For nearly all of these languages (e.g., Spanish, French and Arabic), BLOOM is the first language model with >100B parameters to be trained on the language.
Even work on fine-tuning open-source LLMs heavily emphasizes the value of creating better base LLMs. Improvements to the base LLM yield benefits after fine-tuning too!
I've been absolutely devouring your articles for the last week -- you're doing a great job! Thank you very much for writing, please continue 💪
Galactica?