


Self-Critique, Self-RAG, NEFTune, Safe RLHF and More
Notable advances in LLM research prior to the week of October 30th, 2023...

This newsletter is presented by Rebuy, the commerce AI company.
If you like the newsletter, feel free to get in touch with me or follow me on Medium, X, and LinkedIn. I try my best to produce useful/informative content.
Recent AI research has focused heavily on analyzing the capabilities of large language models (LLMs), improving the alignment (and finetuning) process, and making practical tools for LLMs (e.g., retrieval augmented generation) more effective. In this overview, we will take a look at several papers that propose advancements along these lines, including:
Can LLMs Really Improve by Self-critiquing Their Own Plans? [2]
NEFTune: Noisy Embeddings Improve Instruction Finetuning [7]
Safe RLHF: Safe Reinforcement Learning from Human Feedback [9]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection [12]
These papers contain a variety of practical takeaways and interesting learnings that help us to better understand LLMs. Most notably, we learn that:
Simple practical tricks (e.g., adding noise to word embeddings) are still being discovered that improve LLM training.
LLMs are not very good at evaluating their outputs in certain applications.
Explicitly considering (and addressing) the tension between alignment criteria during RLHF can improve the alignment process.
RAG—a simple technique that is used constantly in LLM applications—can be improved via a more thoughtful approach to retrieval.
Can language models really self-critique? [1, 2]
“There is still the wide spread belief that LLMs can self-critique and improve their own solutions in an iterative fashion. This belief seemingly rests on the assumption that verification of correctness should be easier than generation.” - from [1]
A variety of recent techniques in AI research rely upon large, foundation language models to critique and refine their own output. Examples of such an approach being used practically include:
Self-Instruct [3]: uses an LLM to iteratively generate and filter instructions to automatically generate an instruction tuning dataset.
Constitutional AI [4]: asks the LLM to critique and revise its own responses to prompts based on a set of alignment criteria.
Graph of Thoughts Prompting [5]: uses the LLM to score intermediate solutions to a problem while searching for a final solution1.
Reasoning with Self-Verification [6]: uses an LLM to verify/score its own solutions to determine the best possible answer to a reasoning problem.
More generally, powerful LLMs like GPT-4 are now commonly used to evaluate other language models, as they provide an automatic (and relatively reliable) approach for evaluating the quality of arbitrary responses to prompts. Traditional metrics like ROUGE or BLEU score struggle to holistically capture overall response quality in a manner comparable to GPT-4.
Given that using LLMs to critique and score their own output (or the output of other models) is becoming so common, we might begin to wonder: Are LLMs truly capable of critiquing their own responses? Do these critiques have biases or limitations that we should consider?
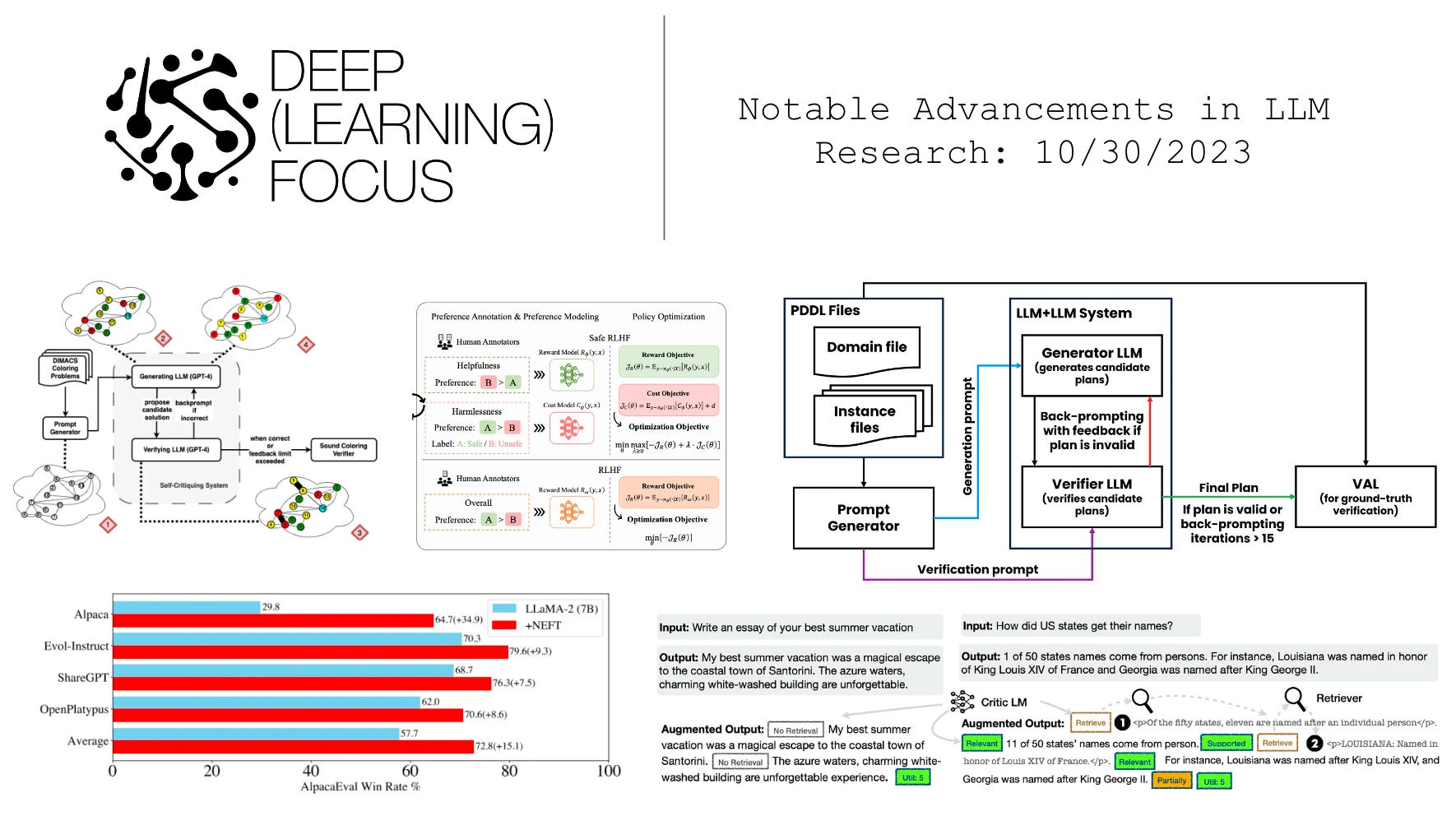
These questions were recently explored by a pair of papers [1, 2] that call into question the ability of LLMs to self-critique. In the first paper, authors study the ability of GPT-4 to solve (or verify solutions to) graph coloring problems via direct or iterative prompting2. Immediately, the authors discover that LLMs struggle with both solving and verifying solutions to graph coloring problems via a direct prompting approach. Such a finding has implications for self-critiquing—how can an LLM iteratively critique and solve a problem if it struggles to verify solutions?
From here, authors attempt to solve the same graph coloring problems using GPT-4 with an approach that iteratively i) generates a solution, ii) critiques the solution, and iii) outputs a revised solution. Several different approaches are tested within these experiments. First, GPT-4 is directly used to critique and revise its own solutions. However, we see no improvement in performance over baseline techniques in these experiments. In fact, performance oftentimes deteriorates. Why is this the case? Well, we have already learned from the experiments described above that GPT-4 cannot verify solutions to graph coloring problems. As such, the model cannot recognize correct solutions and may even reject a correct answer to arrive at an incorrect final solution!

Given that LLMs cannot critique their own solutions, we might wonder whether better performance can be achieved by using a more reliable, external verifier. Authors in [1] craft three different techniques for studying this approach that use an external module to i) verify the LLM’s solution and ii) pass different amounts of information about failed solutions back to the LLM to help with iteratively revising its output. The different feedback approaches include:
A simple pass/fail result
A fail along with the first error in the solution
A fail along with all errors in the solution
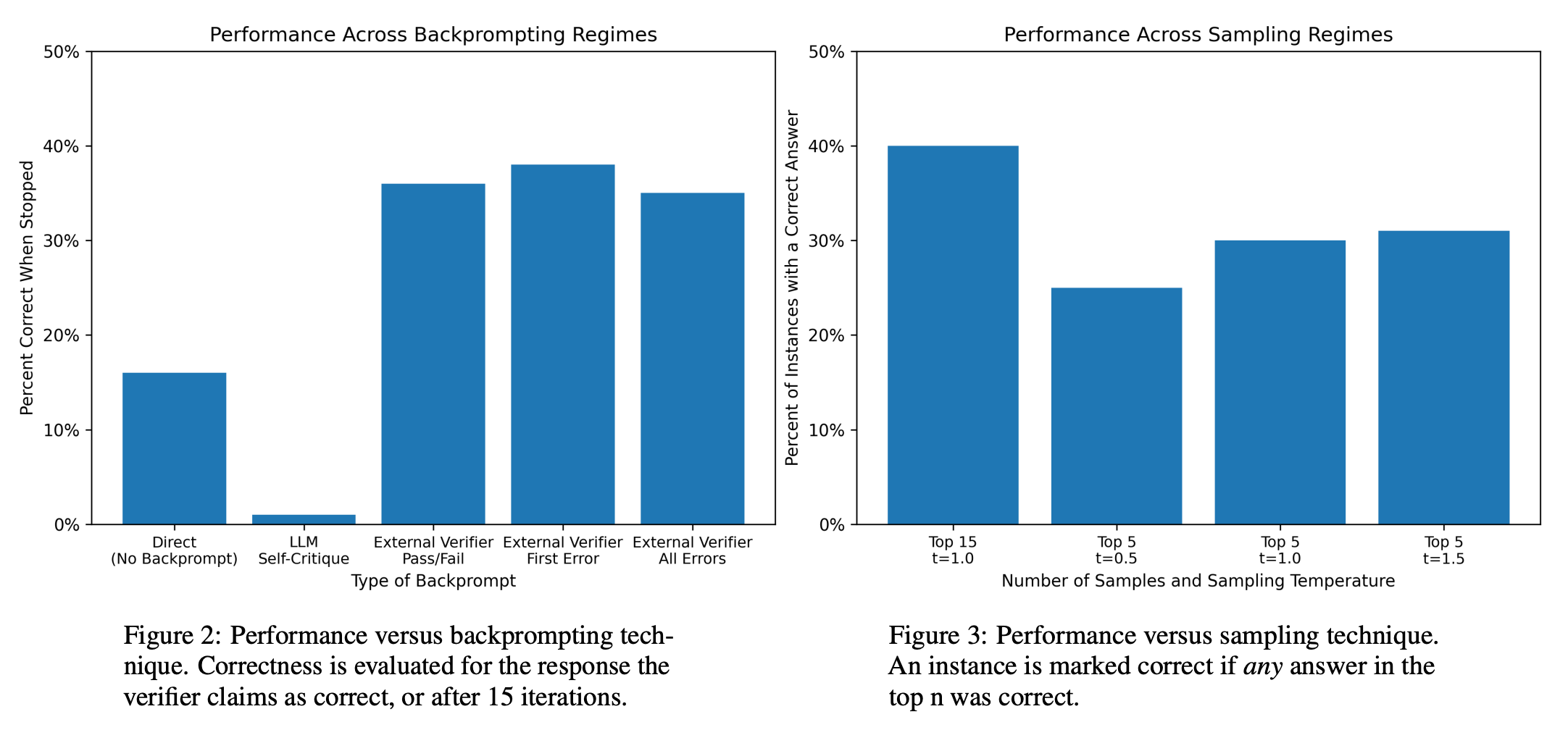
We see in these experiments that using an external verifier does modestly improve performance. However, the style and amount of feedback provided to the LLM by the verifier has no impact on performance—providing a simple indication of pass/fail is just as good as pointing out all of the errors in the solution!
“Our investigation thus raises significant grounds to be skeptical about the effectiveness of iterative prompting techniques in general, and those relying on the self-critiquing capabilities of LLMs in particular.” - from [1]
Such a finding leads authors in [1] to conclude that LLMs lack the ability to meaningfully self-critique and revise their responses. Rather, the ability of such models to iteratively solve problems is reliant upon the correct answer being present in the top-K responses from the language model. To verify this claim, authors test the approach of i) randomly generating several solutions with the LLM and ii) using an external verifier to determine if one of the solutions is correct. This approach is found to yield competitive performance; see below.
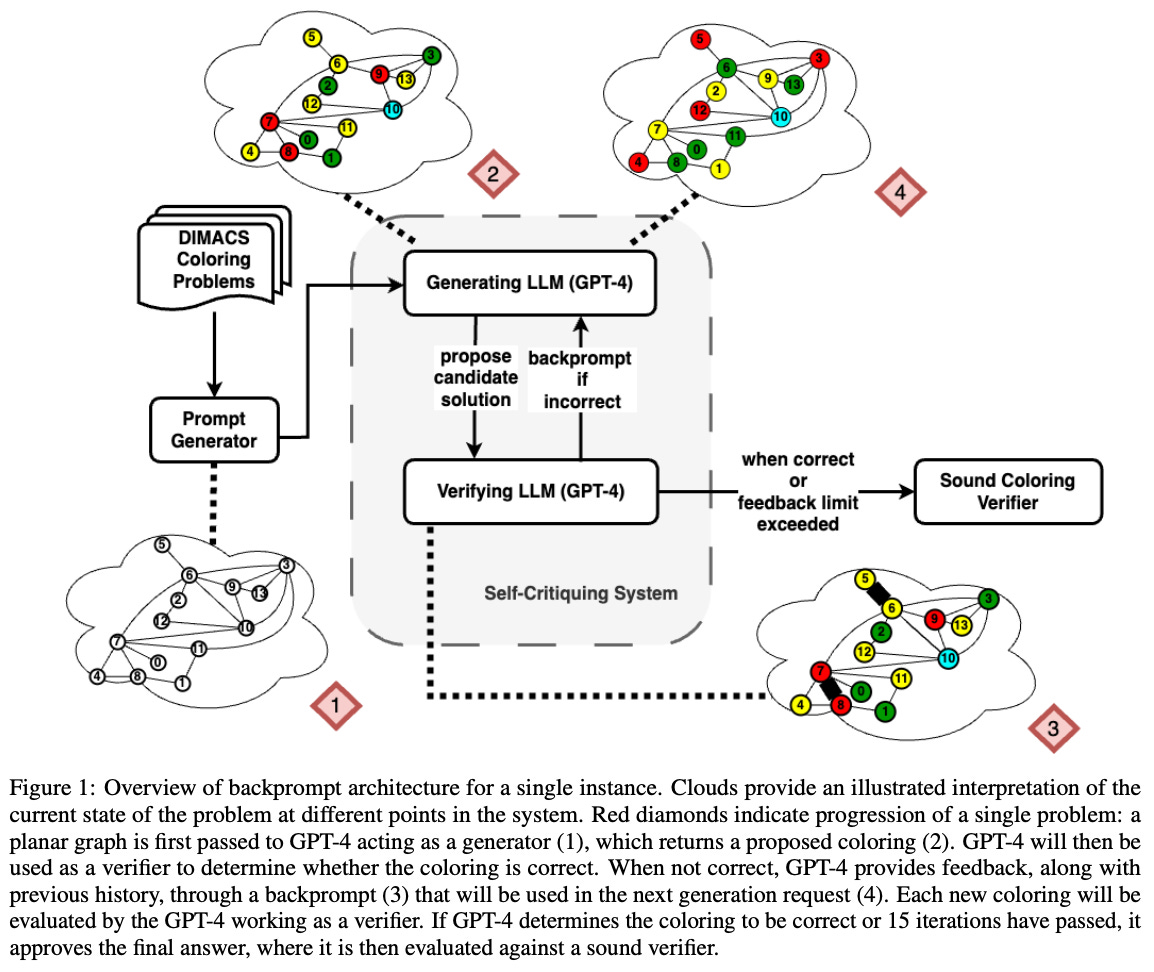
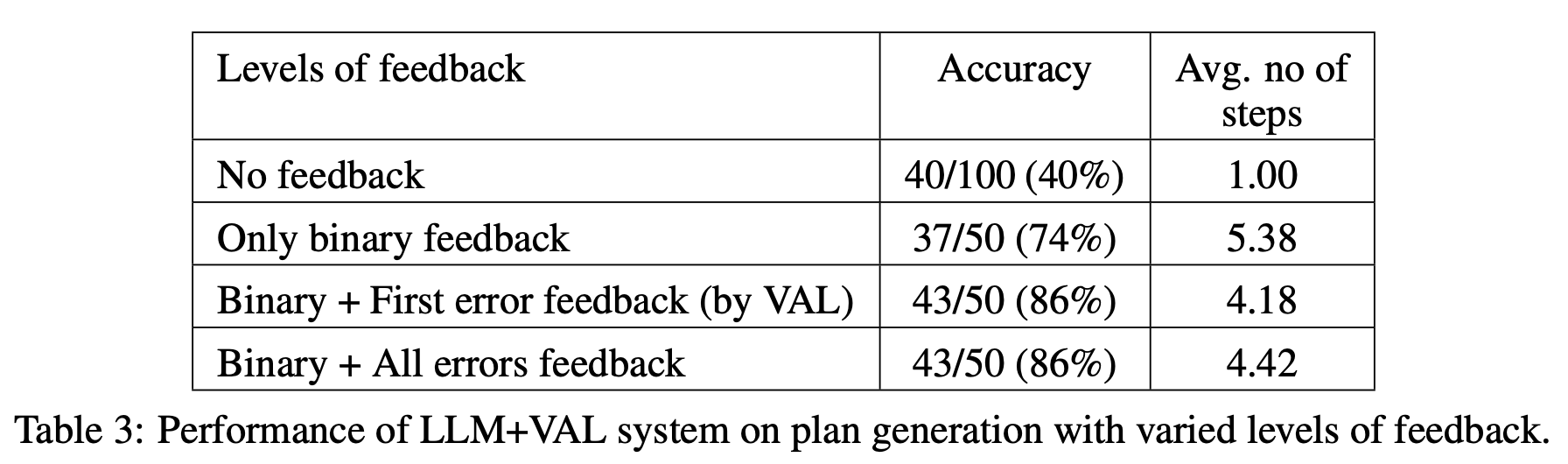
In the next work [2], authors3 similarly study the ability of GPT-4 to self-critique. However, this study is conducted in the context of classical planning problems. For more details on classical planning problems and how they are solved, see here or Section 3 of [2]. The LLM is used for both plan generation and verification. Additionally, the LLM receives feedback about its generated solution after verification—authors refer to this technique as “back-prompting”. To solve a planning problem, the LLM continuously generates a candidate solution and generates feedback based on its response4 until either i) the solution is approved as correct or ii) a predefined number of iterations are met; see below.

We see in [2] that self-critiquing appears to diminish the performance of LLMs in the planning domain. Compared to replacing LLM-based verification with an external verifier, the LLM-based approach suffers from false positives during verification, which leads resulting solutions to be less reliable; see below.
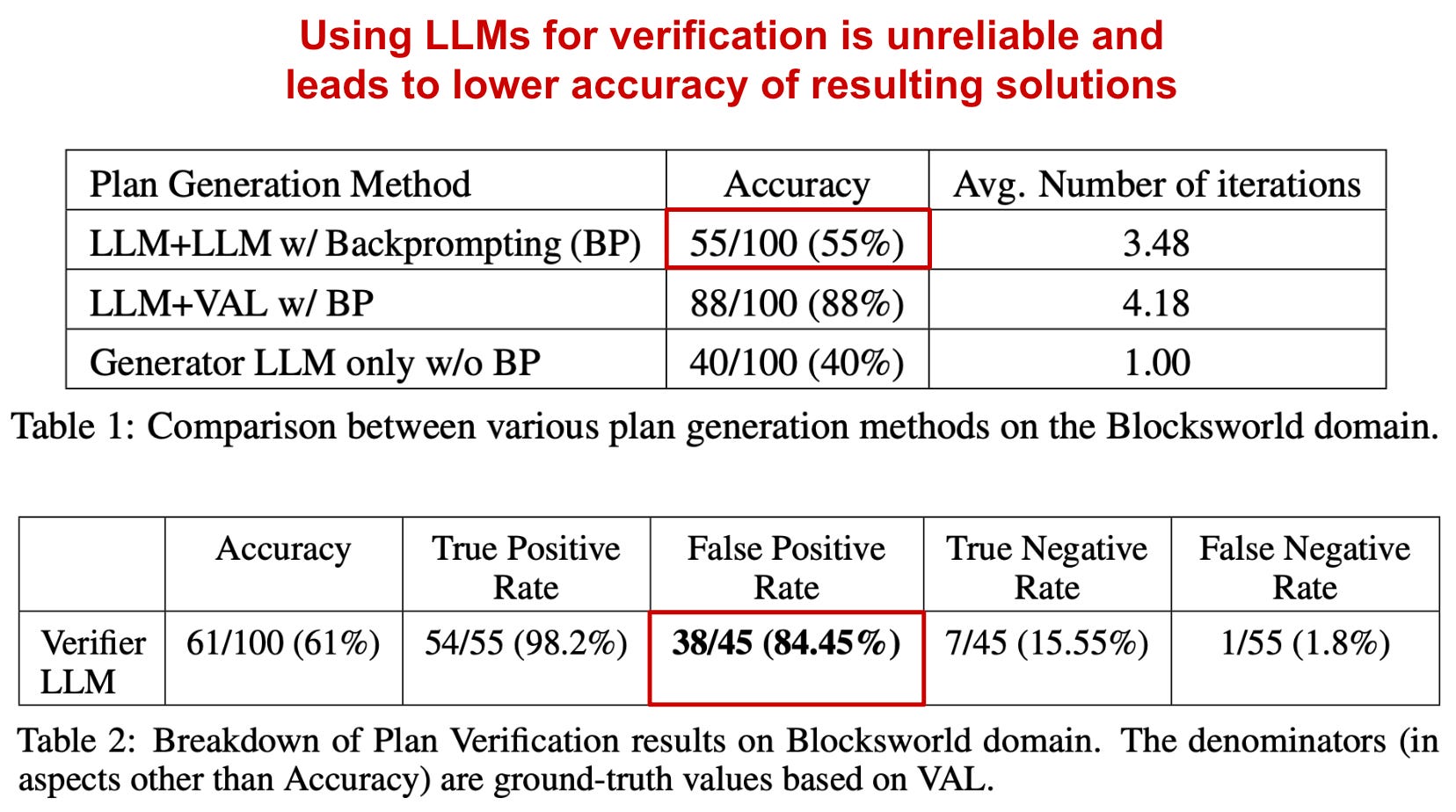
Additionally, we see in [2]—similarly to results in [1]—that feedback provided by the LLM has minimal impact on generated plans. After testing multiple different levels of granularity in feedback provided to the LLM when revising its solution, there seems to be no correlation between the amount of information provided to the LLM and the accuracy of the final result; see below.
What do we learn? In both [1] and [2], the poor performance of LLMs on iterative reasoning applications is due to GPT-4’s inability to verify correct solutions to the problem. Put simply, the LLM (understandably) cannot accurately revise its solution to a problem if it is incapable of verifying whether the solution is correct in the first place. Such a finding calls the ability of LLMs to self-critique their own solutions—an approach used quite frequently for complex reasoning problems—into question. However, we should keep in mind that these results were solely demonstrated on graph coloring and classical reasoning problems. As such, they may not be representative of the capabilities of LLMs in general.
“Our findings suggest that self-critiquing degrades the plan generation performance compared to when an external, sound verifier is utilized. This decline in performance can be directly attributed to the verifier LLM’s subpar results.” - from [2]
NEFTune: Noisy Embeddings Improve Instruction Finetuning [7]
“Each step of NEFTune begins by sampling an instruction from the dataset, and converting its tokens to embedding vectors. NEFTune then departs from standard training by adding a random noise vector to the embeddings.” - from [7]
NEFTune is a simple trick for finetuning language models that can significantly boost the resulting model’s performance. In [7], this trick is studied in the context of supervised finetuning (SFT) or general instruction tuning. To use NEFTune, we add uniform random noise to the language model’s input word embeddings—that’s it! Such an approach is found to consistently improve performance across a variety of models and finetuning datasets; see below.

To generate the random noise that is added to word embeddings, we can independently sample values in the range [-1, 1], then scale these values according to the sequence length L, embedding dimension d, and two tunable parameters—α and ɛ. Such a scaling approach (as shown in the algorithm below) was inspired by work in adversarial ML [8].

When uniform generation of noise is compared to other strategies (e.g., Gaussian noise), we see that the proposed approach performs the best; see below.

NEFTune is a simple trick that is easy to use and adds a slight (but consistent!) boost to LLM performance. For those who frequently finetune open-source LLMs and want to adopt NEFTune as a practical tool, the technique has already been added to the TRL package by HuggingFace and can be quickly integrated into existing finetuning pipelines with minimal effort (see below)!

Safe RLHF: Safe Reinforcement Learning from Human Feedback [9]
Due to the (potentially) massive societal impact of LLMs, AI researchers have invested significant effort into minimizing the number of harmful responses—such as those that facilitate discrimination, bias, or misinformation—generated by these models. Currently, reinforcement learning from human feedback (RLHF) is the go-to approach for aligning LLMs with human-defined criteria such as harmlessness and helpfulness. In most cases, the LLM is first pretrained, then aligned via both SFT and RLHF; see below.
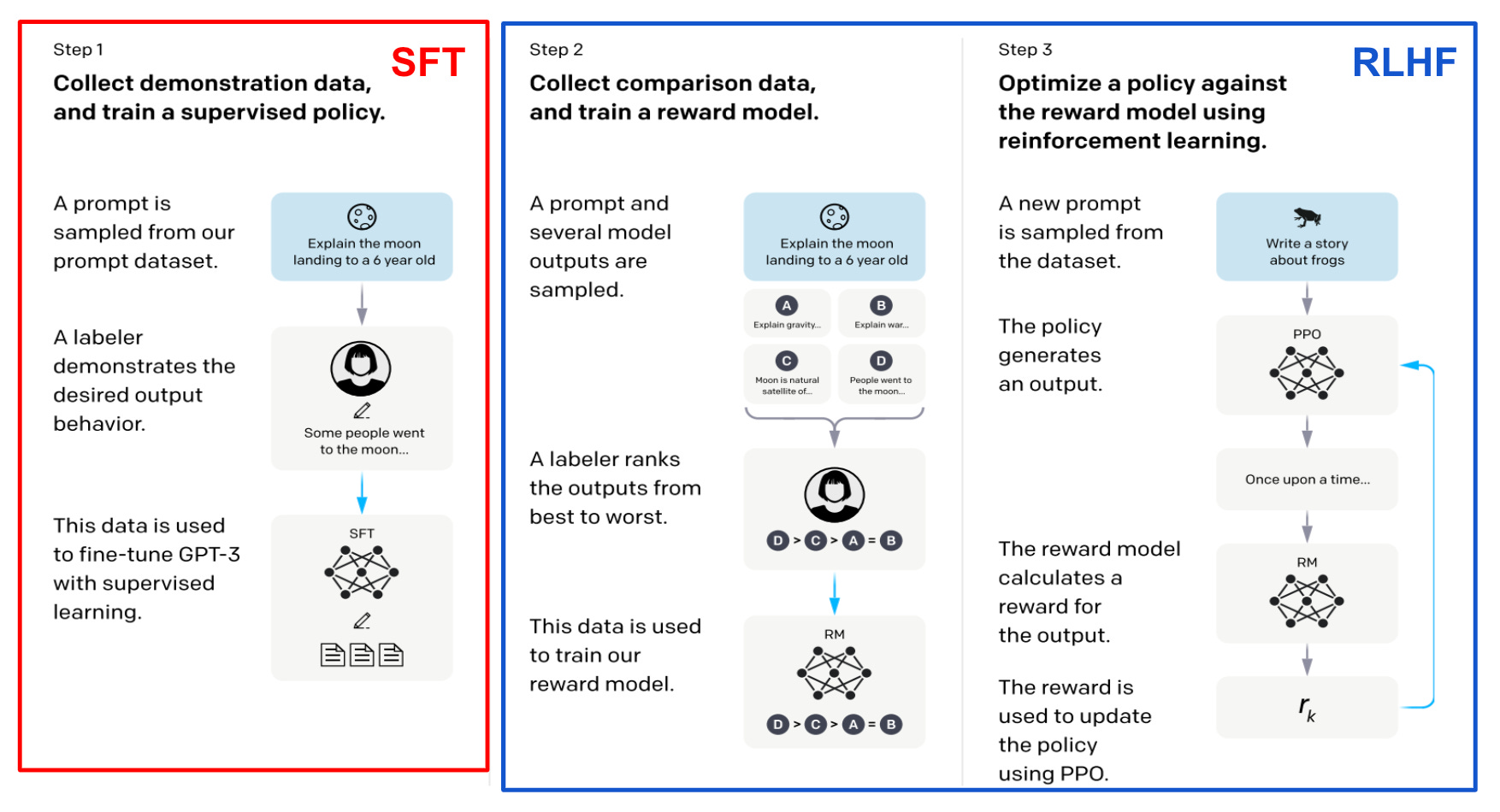
For example, top proprietary models (e.g., GPT-4 or Claude) are known to be aligned to minimize harmfulness. More specifically, these models are subjected to a red teaming process in which human annotators adversarially prompt the model to produce harmful responses. Then, finetuning is conducted via RLHF to reduce the prevalence of such harmful responses in the model’s future output.
“That is, helpfulness tends to increase harmfulness, since models are willing to obey pernicious requests, and conversely models trained to be harmless tend to be more evasive and generally less helpful.” - from [4]
Underlying tension. Although we want to encourage harmlessness within LLMs, making the model more harmless may make it less helpful (i.e., by avoiding responses to certain questions or becoming less helpful in general). For this reason, the two most commonly-used alignment criteria within LLM research are helpfulness and harmlessness (HH). These objectives have an underlying tension, as making a model more helpful may make it less harmless and vice versa. Navigating this tension and finding the correct balance between helpfulness and harmlessness during alignment is an important (and open) research problem.
In prior work [4, 10], we have seen that this HH tension is measurable—reward models that perform well on harmlessness perform poorly on helpfulness and vice versa. Usually, we mitigate this tension by training separate reward models for each alignment criterion. Then, we can optimize the LLM during RLHF based on two reward models that capture helpfulness and harmlessness separately. Going further, helpfulness and harmlessness are separated during annotation by having humans provide preference labels for a single alignment principle at a time—each preference label focuses on helpfulness or harmlessness, but not both.

Safe RLHF. In [9], authors propose a more rigorous approach for balancing helpfulness and harmlessness during alignment, called Safe RLHF. Similar to prior work, a two part (SFT and RLHF) framework is leveraged for alignment and human preference data is collected separately for helpfulness and harmlessness.
During RLHF, two kinds of models are trained—a reward model and a cost model. The reward model is a standard reward model for RLHF that produces a helpfulness score for any given response, while the cost model produces a similar score that captures the response’s harmlessness. Instead of using these models as separate reward models, however, we see in [9] the cost can alternatively be used as a constraint during the optimization process.

More specifically, the alignment process is reformulated to maximize the reward—measured by the reward model (i.e., helpfulness)—while satisfying a constraint on the cost—measured by the cost model (i.e., harmlessness). The resulting objective is shown above. Using this approach, we can both ensure that the model is helpful and minimize the number of harmful responses that it produces. To solve this objective, we leverage the Lagrangian method5—an optimization technique for solving problems with constraints. This approach has a lot of similarities to trust region policy optimization (TRPO), a reinforcement learning (RL) algorithm that preceded PPO (i.e., the most commonly-used RL algorithm for RLHF).
“We formalize the safety concern of LLMs as an optimization task of maximizing the reward function while satisfying specified cost constraints.” - from [9]
Why should we do this? Although the HH tension can be addressed via two separate reward models, we see in [9] that Safe RLHF may be superior due to its ability to adaptively balance the tradeoff between alignment criteria. Plus, LLMs aligned via Safe RLHF seem to perform better in experiments; see below.
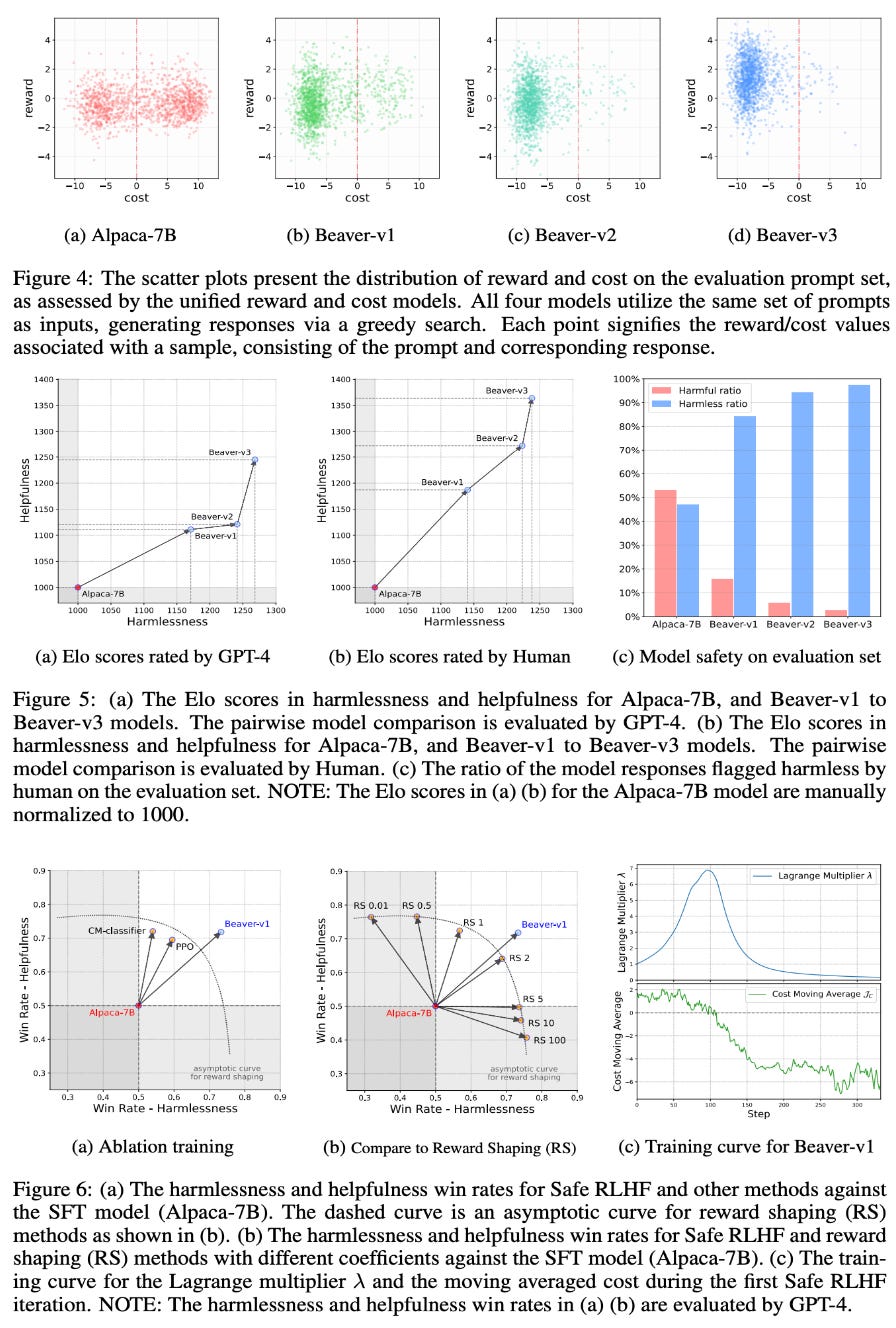
Using three successive rounds of Safe RLHF, Alpaca-7B is finetuned in [9] to produce the Beaver-7B model. Compared to the original Alpaca-7B and an SFT model, Beaver is both more helpful and less harmful, where the improvement in alignment becomes more evident after each round of Safe RLHF; see above.
Takeaways. Safe RLHF is a novel alignment approach that explicitly decouples conflicting alignment criteria within RLHF by modeling them as either rewards or costs. We can incorporate both rewards and costs into alignment by adding constraints based on the cost to the reward function during optimization via reinforcement learning. This approach, which has many similarities to trust region policy optimization, is shown to effectively balance conflicting alignment criteria such as helpfulness and harmlessness, which is a known issue in LLM research. However, the implementation of Safe RLHF is more complex than PPO-based RLHF due to the introduction of a constrained objective.
For those interested in learning more about RL and the inner-workings of RLHF, check out the recent series (from this newsletter) that outlines the use of RL for LLMs within AI research:
Basics of RL for LLMs [link]
Policy Gradients [link]
TRPO and PPO [link]
Reinforcement Learning from AI Feedback [link]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection [12]
“Large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad hoc approach that augments LMs with retrieval of relevant knowledge, decreases such issues.” - from [12]
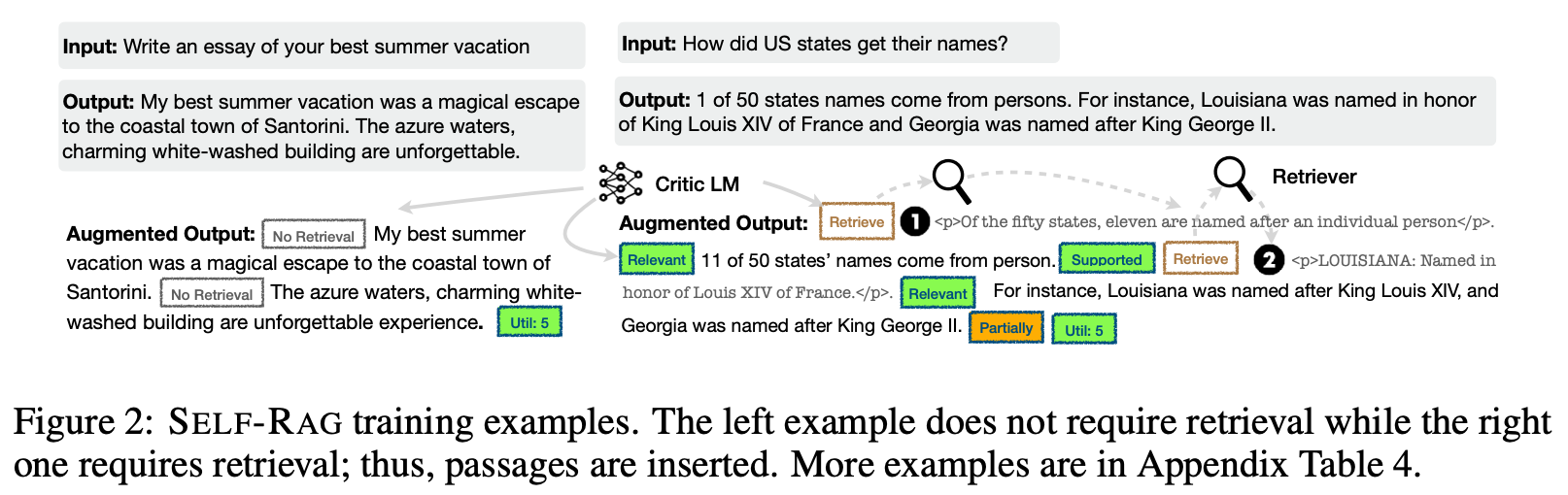
Retrieval Augmented Generation (RAG) is one of the most commonly-used practical tools for informing an LLM with up-to-date or domain-specialized information. RAG uses retrieval techniques to find relevant information that can be included as context within the LLM’s prompt. In [12], authors attempt to improve the quality of RAG by augmenting it with a self-reflection process. Using this approach (called Self-RAG), the LLM can decide:
Whether retrieval is necessary or not
If retrieved passages are actually relevant to the prompt
Instead of the typical RAG approach that always retrieves a fixed number of passages to include in the model’s prompt, Self-RAG can dynamically ensure that information within the prompt is both necessary and relevant. Then, by allowing the model to reflect upon its output, Self-RAG makes LLM responses both more factual and higher quality. The generation and self-reflection components within Self-RAG are handled by a single LLM that is trained end-to-end.
How do we do this? To teach an LLM how to self-reflect, authors in [12] introduce special tokens, called reflection tokens, to the model’s vocabulary. These reflection tokens, including retrieval and critique tokens, are predicted similarly to any other token (i.e., using next-token prediction). Retrieval tokens are used to determine whether retrieval is necessary for responding to a prompt, while critique tokens are used to critique the quality of the model’s generations. This might sound vague, but let’s take a look at how Self-RAG is implemented.
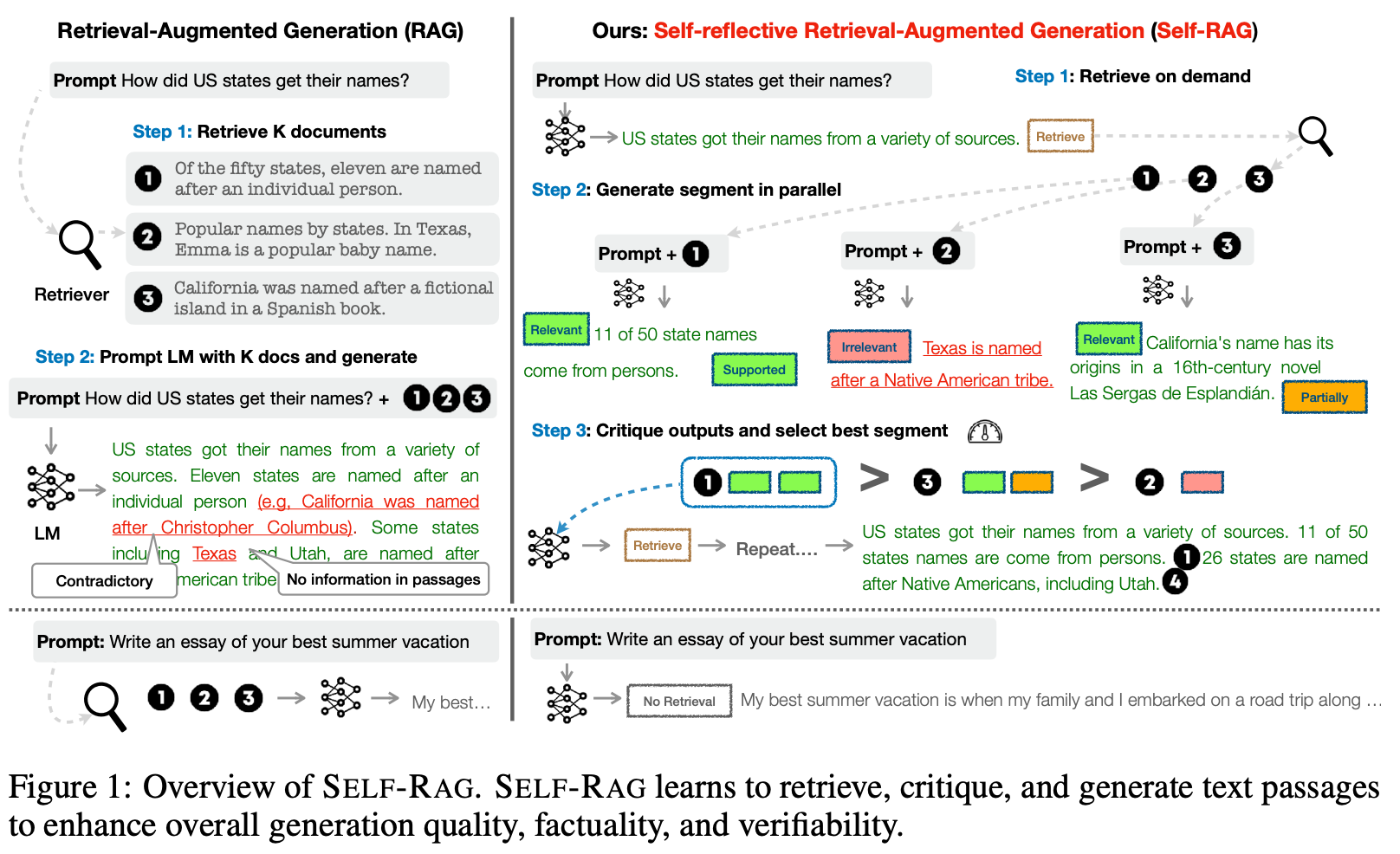
Given some prompt as input, the implementation of Self-RAG (shown above) follows the steps below to generate an output:
To determine if retrieval is necessary, the LLM first outputs a retrieval token.
If retrieval is not necessary, the LLM generates a response and critiques this response (using a critique token) to determine if it is useful.
If retrieval is deemed necessary, a retrieval module is called to retrieve the top-K passages based on the prompt.
The LLM then uses critique tokens to predict whether each passage that is retrieved is relevant to the prompt or not.
For each passage, the LLM generates a response and uses critique tokens to determine if it is i) factually supported by the passage and ii) useful.
All responses are then ranked according to relevance, quality, and whether their information is supported by the retrieved passage.
The inference process for Self-RAG is formulated in more detail within the algorithm below.

Determining whether each LLM response is factually supported by its corresponding passage makes fact verification easy within Self-RAG. For each generation, we can provide citations to relevant info that was used along with a corresponding self-assessment from the LLM.
Training process. To teach the LLM how to generate reflection tokens, authors in [12] collect a synthetic training dataset by prompting GPT-4. This dataset is initially used to train a critic model that can predict when reflection tokens should be used within a textual sequence. From here, the critic model is used to update a large corpus of training data in an offline fashion to contain reflection tokens. This dataset of textual sequences augmented with reflection tokens is used to train an LLM to use Self-RAG in an end-to-end fashion; see below.
We see in [12] that self-reflection can be learned with a language modeling objective—the model just learns how/when to predict necessary reflection tokens. Following an end-to-end approach with pure supervised learning, Self-RAG is capable of learning how to perform the entire inference process.
“Our end-to-end training lets an LLM generate text informed by retrieved passages and criticize the output by learning to generate special tokens.” - from [12]
Authors in [12] train 7B and 13B parameter LLMs—based upon LLaMA—with the Self-RAG approach. From these experiments, we see that Self-RAG outperforms a variety of retrieval-augmented LLMs; see below.

A note on practicality. Self-RAG is an interesting approach that can make the RAG process more dynamic/adaptive. However, the technique proposed in [12] introduces a significant amount of added complexity to the inference process! One of the primary benefits of RAG is its simplicity and efficiency—it is a basic, practical approach for improving LLM output quality. Self-RAG is based upon the fundamental idea of making retrieval within RAG more dynamic. Although this idea is both useful and important, the added complexity of Self-RAG makes the approach not practical. We need a more realistic approach to use this in practice.
Honorable Mentions
Prometheus [14]: Proprietary LLMs like GPT-4 are commonly used to evaluate other LLMs, but this approach can be costly and unreliable. Authors in [14] construct a large dataset for evaluating LLM outputs and providing relevant feedback, then train a specialized LLM—called Prometheus—to perform accurate evaluations based on this dataset.
Large Multimodal Models (LMMs): this blog, written by Chip Huyen, does a great job of comprehensively outlining relevant knowledge and techniques in the hottest area of AI research—multimodal models6.
Survey on Factuality in LLMs [14]: This survey studies and analyzes important considerations related to hallucinations within LLMs. Authors define the concept of factuality for LLMs, consider societal implications of incorrect information produced by these models, and analyze different causes of hallucinations within LLMs.
GrowLength [15]: This paper proposes a simple approach for accelerating the LLM pretraining process—meaning that the model converges faster—by progressively increasing the length of textual sequences used during training.
FlashDecoding: This technique is an extension of FlashAttention that accelerates inference with LLMs by up to 8X on longer sequences.
Pairwise PPO [16]: This paper proposes an improvement to RLHF with PPO that works much better with relative/comparative feedback. Such an approach is useful because RLHF with PPO leverages human feedback in the form of relative preferences, but the reward model just produces a preference score, which requires post-processing and normalization to ensure the absolute value of rewards is within a reasonable scale. Pairwise PPO simply adapts this process to be more compatible with relative feedback.
Takeaways
Given that we have studied several papers across a variety of topics within this overview, we need to quickly recap the primary takeaways from each of these works. The primary learnings from each paper are outlined below.
Is self-critique useful? LLMs are commonly used to critique their own outputs (and those of other LLMs). In [1, 2], however, we see that LLMs struggle with critiquing their solutions on certain types of problems. Although it is unclear whether these results are representative of LLM capabilities in general, we learn that LLMs are not always capable of critiquing and revising their own responses.
Simple training trick. NEFTune shows us that adding random noise to input token embeddings during training and finetuning makes LLMs perform better. This simple practical trick is easy to implement and already available in TRL!
Multiple alignment criteria. Tension between alignment criteria—such as helpfulness and harmlessness—is an important practical consideration for LLMs. Prior work solves this tension via separate reward models, but new approaches (e.g., Safe RLHF) can better balance the tradeoff between alignment criteria.
Better RAG. Although RAG is extremely effective, it is a fixed approach that does not dynamically adapt the retrieval process based on the problem being solved. Self-RAG aims to make the retrieval process more dynamic, but introduces too much complexity to be used in practice. Nonetheless, exploring “smarter” retrieval techniques for RAG could be a fruitful area of future research.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Stechly, Kaya, Matthew Marquez, and Subbarao Kambhampati. "GPT-4 Doesn't Know It's Wrong: An Analysis of Iterative Prompting for Reasoning Problems." arXiv preprint arXiv:2310.12397 (2023).
[2] Valmeekam, Karthik, Matthew Marquez, and Subbarao Kambhampati. "Can Large Language Models Really Improve by Self-critiquing Their Own Plans?." arXiv preprint arXiv:2310.08118 (2023).
[3] Valmeekam, Karthik, Matthew Marquez, and Subbarao Kambhampati. "Can Large Language Models Really Improve by Self-critiquing Their Own Plans?." arXiv preprint arXiv:2310.08118 (2023).
[4] Bai, Yuntao, et al. "Constitutional ai: Harmlessness from ai feedback." arXiv preprint arXiv:2212.08073 (2022).
[5] Besta, Maciej, et al. "Graph of Thoughts: Solving Elaborate Problems with Large Language Models." arXiv preprint arXiv:2308.09687 (2023).
[6] Weng, Yixuan, et al. "Large language models are better reasoners with self-verification." CoRR, abs/2212.09561 (2023).
[7] Jain, Neel, et al. "NEFTune: Noisy Embeddings Improve Instruction Finetuning." arXiv preprint arXiv:2310.05914 (2023).
[8] Kong, Kezhi, et al. "Robust optimization as data augmentation for large-scale graphs." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[9] Dai, Josef, et al. "Safe RLHF: Safe Reinforcement Learning from Human Feedback." arXiv preprint arXiv:2310.12773 (2023).
[10] Bai, Yuntao, et al. "Training a helpful and harmless assistant with reinforcement learning from human feedback." arXiv preprint arXiv:2204.05862 (2022).
[11] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[12] Asai, Akari, et al. "Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection." arXiv preprint arXiv:2310.11511 (2023).
[13] Kim, Seungone, et al. "Prometheus: Inducing Fine-grained Evaluation Capability in Language Models." arXiv preprint arXiv:2310.08491 (2023).
[14] Wang, Cunxiang, et al. "Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity." arXiv preprint arXiv:2310.07521 (2023).
[15] Jin, Hongye, et al. "GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length." arXiv preprint arXiv:2310.00576 (2023).
[16] Wu, Tianhao, et al. "Pairwise Proximal Policy Optimization: Harnessing Relative Feedback for LLM Alignment." arXiv preprint arXiv:2310.00212 (2023).
Tree of Thoughts (ToT) prompting uses a similar self-verification approach as an intermediate step in solving complex reasoning problems.
Direct prompting refers to prompting the LLM once and generating a full solution to a problem in a single go. Iterative prompting, on the other hand, allows the LLM to iterate and critique its output via multiple prompts before outputting a final solution.
The authors of [1] and [2] are (mostly) different, but they come from the same research lab!
The generation and verification steps of iteratively solving planning problems provide different prompts to the same underlying LLM.
The idea of Lagrangians is to simply take your constraints and work them into your objective function as an additional (additive) term. This way, we can solve the problem normally, as if there are no constraints.
Multimodal means that the model has input/output data with multiple different modalities (e.g., text, image, audio, etc.).