
The History of Open-Source LLMs: Imitation and Alignment (Part Three)
Open-source LLMs need alignment to become truly remarkable...


A majority of prior research on open-source large language models (LLMs) focused heavily upon creating pre-trained base models. However, these models have not undergone any fine-tuning, so they fail to match the quality of top closed-source LLMs (e.g., ChatGPT or Claude) due to their lack of alignment. Paid models are aligned extensively using techniques like SFT and RLHF, which greatly enhances their usability. In comparison, open-source models are typically fine-tuned to a lesser extent using smaller, public datasets. Within this overview, however, we will take a look at recent research that aims to improve the quality of open-source LLMs via more extensive fine-tuning and alignment.
This overview is the third (and final1) part of my series on the history of open-source LLMs. In the first part of the series, we looked at initial attempts at creating open-source language models. Although these initial pre-trained LLMs performed poorly, they were quickly followed up by much better open-source base models, which we covered in part two of this series. Now, we will cover how these better open-source models can be fine-tuned/aligned to improve their quality and close the gap in performance between open-source and proprietary LLMs, completing the journey from initial models like OPT to the incredibly high-performing open-source LLMs that we have today (e.g., LLaMA-2-Chat).

The alignment process. This overview will study the fine-tuning and alignment process for open-source LLMs. Prior to studying research in this area, however, we need to understand what alignment is and how it is accomplished. We should recall that the training process for language models proceeds in several parts. As shown above, we begin with pre-training, which is followed by several fine-tuning steps. After pre-training, the LLM can accurately perform next token prediction, but its output may be repetitive and uninteresting. Thus, the model needs to be fine-tuned to improve its alignment, or its ability to generate text that aligns with the desires of a human user (e.g., follow instructions, avoid harmful output, avoid lying, produce interesting or creative output, etc.).

SFT. Alignment is accomplished via two fine-tuning techniques: supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF); see above for a depiction and here for more details. SFT simply fine-tunes the model, using a standard language modeling objective, over examples of high-quality prompt and response pairs. The LLM is allowed to see examples of how it should respond and learn from these responses! SFT is incredibly simple and effective, but it requires carefully curating a dataset that captures “correct” behavior.
RLHF trains the LLM directly on feedback from human annotators—humans identify outputs that they like, and the LLM learns how to produce more outputs like this. To do this, we first obtain a set of prompts and generate several different outputs from the LLM on each prompt. Using a group of human annotators, we score each of these responses based on their quality. These scores can then be used to train a reward model (i.e., just a fine-tuned version of our LLM with an added regression head) to predict the score of a response. From here, RLHF fine-tunes the model to maximize this score using a reinforcement learning algorithm called PPO. Typically, the highest-performing LLMs are aligned by performing both SFT and RLHF2 (with lots of human feedback) in sequence.
Imitation Learning

With the release of LLaMA [3], the open-source research community finally had access to powerful base LLMs that could be fine-tuned or aligned for a variety of different applications. As such, LLaMa catalyzed an explosion of open-source LLM research, as practitioners rushed to fine-tune LLaMA models on their task of choice. Interestingly, one of the most common directions of research during this time was imitation learning. Imitation learning, which is (arguably) a form of alignment3, fine-tunes an LLM over outputs from another, more powerful LLM. Such an approach is inspired by the idea of knowledge distillation; see above.
“The premise of model imitation is that once a proprietary LM is made available via API, one can collect a dataset of API outputs and use it to fine-tune an open-source LM.” - from [6]
The question posed by open-source imitation learning research was simple: can we create a model that is as powerful as ChatGPT or GPT-4 by just fine-tuning on responses from these models? To test this out, we can follow a simple approach:
Collect dialogue examples from these models (e.g., using the OpenAI API).
Perform (supervised) fine-tuning on this data (i.e., using a normal language modeling objective).
As we will see, the research community hotly debated whether imitation learning was a valuable approach for quite some time! In the end, we found out that the approach is practically useful, but it only works well under certain conditions.
Initial Efforts in Imitation Learning

After the release of LLaMA, researchers quickly began to release a variety of imitation models using dialogue derived from ChatGPT. Typically, the data used for training—which prohibits the resulting model from being used commercially—is obtained either from the OpenAI API or sources like ShareGPT. A few of the most widely-known imitation models are outlined below (in chronological order).
Alpaca [7] fine-tunes LLaMA-7B by using the self-instruct [11] framework to automatically collect a fine-tuning dataset from GPT-3.5 (i.e., text-davinci-003). Collecting data and fine-tuning Alpaca costs only $600; see here.
Vicuna [8] fine-tunes LLaMA-13B over 70K dialogue examples from ChatGPT (i.e., derived from ShareGPT). Interestingly, the entire fine-tuning process for Vicuna costs only $300; more details are available here.
Koala [9] fine-tunes LLaMA-13B on a large dataset of dialogue examples from both the Alpaca fine-tuning set and a variety of other sources like ShareGPT, HC3, OIG, Anthropic HH, and OpenAI WebGPT/Summarization. Compared to prior imitation models, Koala is fine-tuned over a larger dataset and evaluated more extensively; read more about the model here.
GPT4ALL [16] fine-tunes LLaMA-7B on over 800K chat completions from GPT-3.5-turbo. Along with the model, authors release both training/inference code and quantized model weights that can be used to perform inference with minimal compute resources (e.g., a laptop); see here for more details.

The impact of imitation. These models were published in close succession and claimed to achieve comparably quality to top proprietary models like ChatGPT and GPT-4. For example, Vicuna is found to maintain 92% of the quality of GPT-44, while Koala is found to match or exceed the quality of ChatGPT in many cases; see above. Such findings seemed to indicate that model imitation could be used to distill the capabilities of any proprietary model into a smaller, open-source LLM. If this were true, the quality of even the best proprietary LLMs could be easily replicated and these models would be left with no true advantage.
“Open-source models are faster, more customizable, more private, and … more capable. They are doing things with $100 and 13B params that [Google] struggles with at $10M and 540B. And they are doing so in weeks, not months.” - from [9]
The explosion of imitation models was one of the first instances in which open-source models were truly seen as a potential alternative to the closed-source LLMs that had dominated the LLM landscape since the proposal of GPT-3. Despite the use of paid APIs becoming standard, the impressive performance of imitation models fostered a feeling of promise for open-source LLMs.
Are imitation models a false promise?

Despite the promise of imitation models’ impressive performance, we see in [6] that we are missing something important. Namely, more targeted evaluations of these models reveal that they do not perform nearly as well as top proprietary LLMs like ChatGPT and GPT-4. In fact, we see that fine-tuning a base model via imitation actually does very little to close the gap in performance between open-source and proprietary models in most cases. Rather, the resulting model tends to only improve in performance on tasks that are heavily represented in the fine-tuning set and may even have a more pronounced tendency for hallucination.

Experimental setup. To determine the utility of imitation learning, authors in [6] curate a dataset of ~130K diverse dialogue examples from ChatGPT. Then, several different sizes of language models are fine-tuned over various amounts of imitation data before having their performance measured. As shown above, there are a few interesting observations that we can make from these experiments:
The amount of imitation data used for fine-tuning does not improve model quality in human evaluation trials.
Imitation models’ performance on standardized benchmarks is often worse than that of the base model (and deteriorates as more imitation data is used).
Increasing the size of the base model consistently improves the quality of the resulting imitation models.
What is going on here? When imitation models are evaluated across a wider variety of natural language benchmarks, we see that their performance is comparable to or below that of the corresponding base LLM. In other words, imitation models do not actually match the quality of models like ChatGPT. Compared to proprietary LLMs, these models have a less extensive knowledge base, as revealed by the performance improvement observed with larger base models.
“We argue that the highest leverage action for improving open-source models is to tackle the difficult challenge of developing better base LMs, rather than taking the shortcut of imitating proprietary systems.” - from [6]
With this in mind, the first question we might have is: why did it seem like these models performed so well? We see in [6] that imitation models learn to mimic the style of a model like ChatGPT. As such, human workers can be tricked into perceiving the model as high-quality even if it generates factually incorrect information more frequently (i.e., this is harder to easily check or verify).
Is imitation learning actually useful?
“Our research indicates that learning from step-by-step explanations, whether these are generated by humans or more advanced AI models, is a promising direction to improve model capabilities and skills.” - from [1]
After work in [6] revealed that imitation models did not perform nearly as well as initially thought, the research community was unclear whether imitation models actually had any value. Notably, analysis in [6] indicates that local imitation—or learning to imitate a model’s behavior on a specific task, instead of imitating its behavior as a whole—is quite effective. However, this does not mean the imitation model matches the quality of proprietary models more generally. To make imitation models better in general, authors in [6] pose two paths forward:
Generating a much bigger and more comprehensive imitation dataset
Creating a better base model to use for imitation learning
Interestingly, both of these recommendations were explored extensively by subsequent research and found to yield positive results.

Orca [12] is an imitation model based upon LLaMA-13B; see here for more details. Compared to prior work on imitation learning, however, Orca is trained over a higher-quality, more detailed, and more comprehensive dataset collected from ChatGPT and GPT-4. In particular, prior datasets collected for imitation learning can be considered “shallow”—they are simply examples of prompt and response pairs generated by a model like ChatGPT; see above.
“We conclude that broadly matching ChatGPT using purely imitation would require a concerted effort to collect enormous imitation datasets and far more diverse and higher quality imitation data than is currently available.” - from [6]
Improving upon shallow imitation, Orca attempts to augment imitation datasets generated by models like ChatGPT or GPT-4 with:
Explanation traces
Step-by-step thought processes
Complex instructions
To do this, the model being imitated is prompted to provide detailed explanations of its response via an instruction or system message. Such an approach goes beyond simple prompt-response pairs by adding extra, useful information to the data seen by an imitation model. When learning from powerful LLMs like ChatGPT, Orca sees more than just the model’s response. Namely, it can learn from detailed explanations and thought processes generated along with the model’s response on complex prompts! See below for an illustration.

After being fine-tuned over a massive dataset of such detailed imitation data (i.e., 5M examples from ChatGPT and 1M examples from GPT-45), we see that Orca performs incredibly well compared to prior imitation models; see below.

Although Orca significantly narrows the gap between open-source imitation models and proprietary LLMs, we still see in the table below that the model is outperformed consistently by GPT-4. Unfortunately, even an improved imitation approach is not enough to fully match the quality of top proprietary models.

Nonetheless, Orca’s impressive performance reveals that imitation learning is a valuable fine-tuning strategy that can drastically improve the performance of any high-quality base LLM. Going further, we learn in [12] that leveraging imitation learning successfully has two main requirements:
A large, comprehensive imitation dataset
Detailed explanation traces within each response
Better base LLMs. Although authors in [6] argue that collecting a sufficiently large and diverse imitation learning dataset is incredibly difficult, we see with Orca that such a feat is at least possible. Additionally, later work extensively explores the alternative suggestion in [6]: creating more powerful (open-source) base models. Although open-source pre-trained LLMs performed poorly at first, we have recently seen the proposal of a variety of powerful pre-trained LLMs; e.g., LLaMA [3], MPT [14, 15], and Falcon [13]. Given that model pre-training is a starting point for any fine-tuning that follows (e.g., imitation learning, SFT, RLHF, etc.), starting with a better base model improves the downstream imitation model as well! Luckily, we covered all of the best open-source, pre-trained language models in part two of this series. See below for more details.
Aligning Open-Source LLMs

Imitation learning attempted to improve the quality of open-source base models by training over the responses (and explanation traces) of proprietary LLMs. Although this approach is successful in some cases, this is (obviously) not the manner in which the top proprietary models are trained—imitation is a short cut for creating powerful open-source models. If we want open-source LLMs that rival the quality of proprietary models, we need to invest significantly into alignment.
“These closed product LLMs are heavily fine-tuned to align with human preferences, which greatly enhances their usability and safety. This step can require significant costs in compute and human annotation, and is often not transparent or easily reproducible.” - from [1]
What’s the hold up? The idea of aligning open-source imitation models seems easy enough. We have really great base models, why not just replicate the alignment process used by models like GPT-4? The alignment process requires extensive compute and human annotation resources. Plus, it is heavily dependent upon proprietary data, which limits transparency and makes reproducing results quite difficult. As such, open-source models have lagged behind their proprietary counterparts in alignment research for quite some time. Within this section, however, we will explore two recent works—LIMA [2] and LLaMA-2 [1]—that drastically improve the quality of open-source LLMs via better alignment.
Prior Work on Open-Source Alignment
Before covering LIMA and LLaMA-2, it is important to note that the open-source research community has not avoided aligning pre-trained models altogether. For example, Falcon-40B-Instruct [13] undergoes SFT over 150M token of data from Baize. Similarly, numerous fine-tuned variants of MPT-7B [14] and MPT-30B [15] have been released, including both chat/instruct variants that undergo SFT on public datasets and a StoryWriter variant that is fine-tuned over data with a much longer context length.

Plus, if we take a simple look at the Open LLM Leaderboard (see above), we see a variety of different models that have underwent fine-tuning via SFT on all types of different datasets. Open-source LLMs have not avoided alignment altogether. However, top proprietary models undergo both SFT and RLHF over massive datasets of high-quality dialogue and human feedback. In comparison, most open-source models have been aligned using solely SFT over public datasets that lack in quality and diversity. To truly match the quality of proprietary models, open-source LLMs needed to make an attempt at replicating their alignment process.
LIMA: Data-Efficient Alignment [2]
“A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.” - from [2]
As mentioned above, open-source LLMs—for quite some time—mostly performed alignment via SFT on public datasets. Given this heavy emphasis upon SFT, authors in [2] studied extensively the impact impact of SFT on pre-trained LLMs. The goal of this analysis was to uncover the relative importance of pre-training and alignment via SFT in creating a high-performing LLM, as well as to reveal best practices for maximizing a model’s performance after undergoing SFT.
The dataset. To do this, authors in [2] construct a small dataset of 1,000 dialogue examples to use for SFT. Although this might not seem like enough data, the examples included in this dataset are carefully curated to ensure quality by using diverse prompts and a uniform output style or tone; see below.

The SFT dataset used to train LIMA is small but of incredibly high quality. Interestingly, we see in [2] that LIMA performs surprisingly well when fine-tuned over this dataset, even approaching the performance of state-of-the-art LLMs like GPT-4 or Claude; see below.

Such a result reveals that language models can be effectively aligned via a small number of carefully chosen examples. Although LIMA still falls short of GPT-4’s performance, the ability to perform such high-quality alignment with such little data is both unexpected and impressive. Such a result shows us that data quality is seemingly the most important factor in performing alignment via SFT.
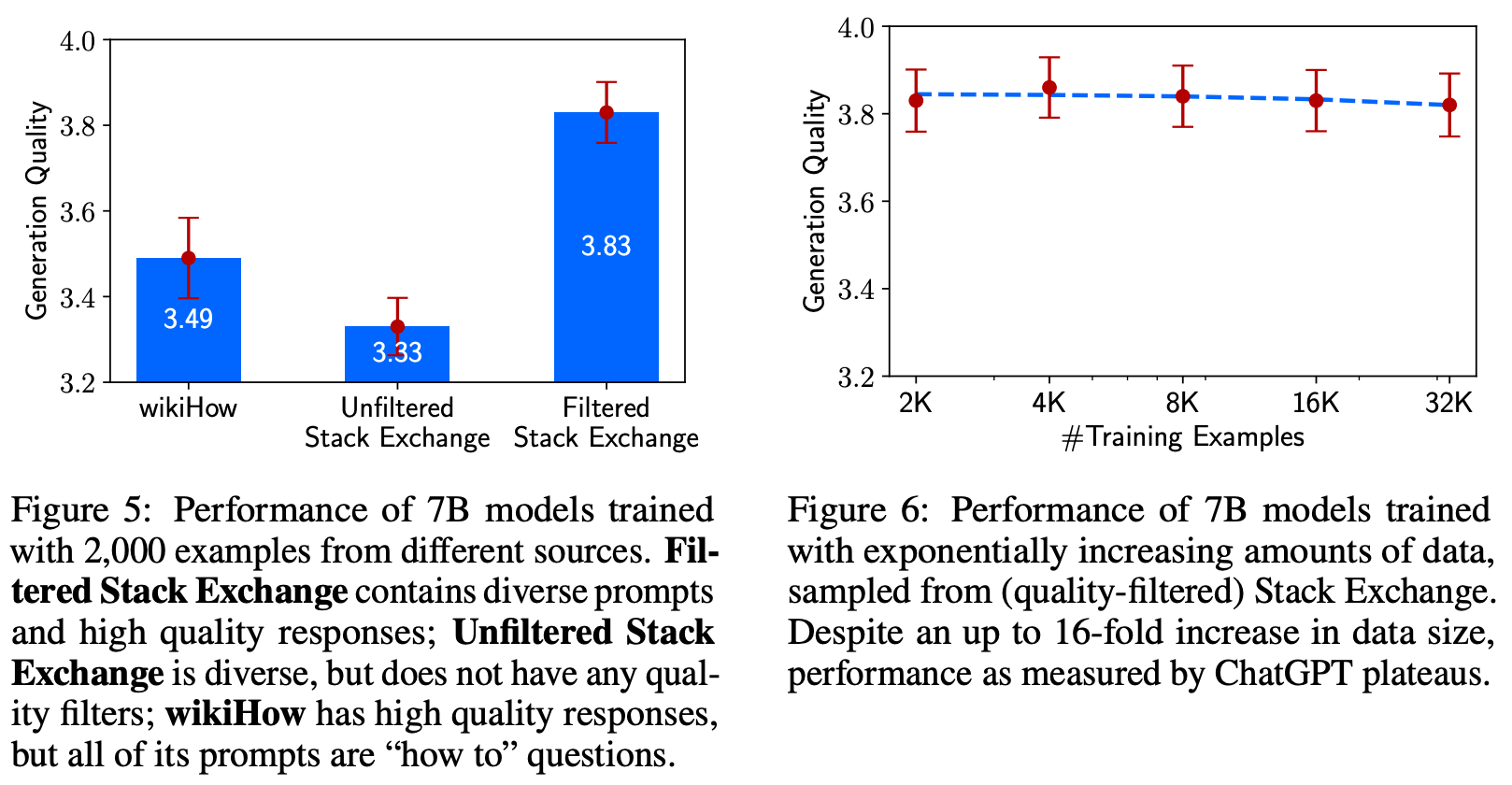
What do we learn? We learn a variety of useful lessons from LIMA. First, the quality of data is incredibly important for SFT. Just using more data is not enough—the data also needs to be of high quality; see above. Additionally, the results in [2] lead to the proposal of the “Superficial Alignment Hypothesis”, which offers a new and unique perspective of alignment. Put simply, this hypothesis posits that most of an LLM’s core knowledge is learned during pre-training, while alignment searches for the proper format or style for surfacing this knowledge. As such, alignment can be learned in a data efficient manner.
LLaMA-2: Improving Transparency in Alignment Research [1]
“Llama 2-Chat is the result of several months of research and iterative applications of alignment techniques, including both instruction tuning and RLHF, requiring significant computational and annotation resources.” - from [1]
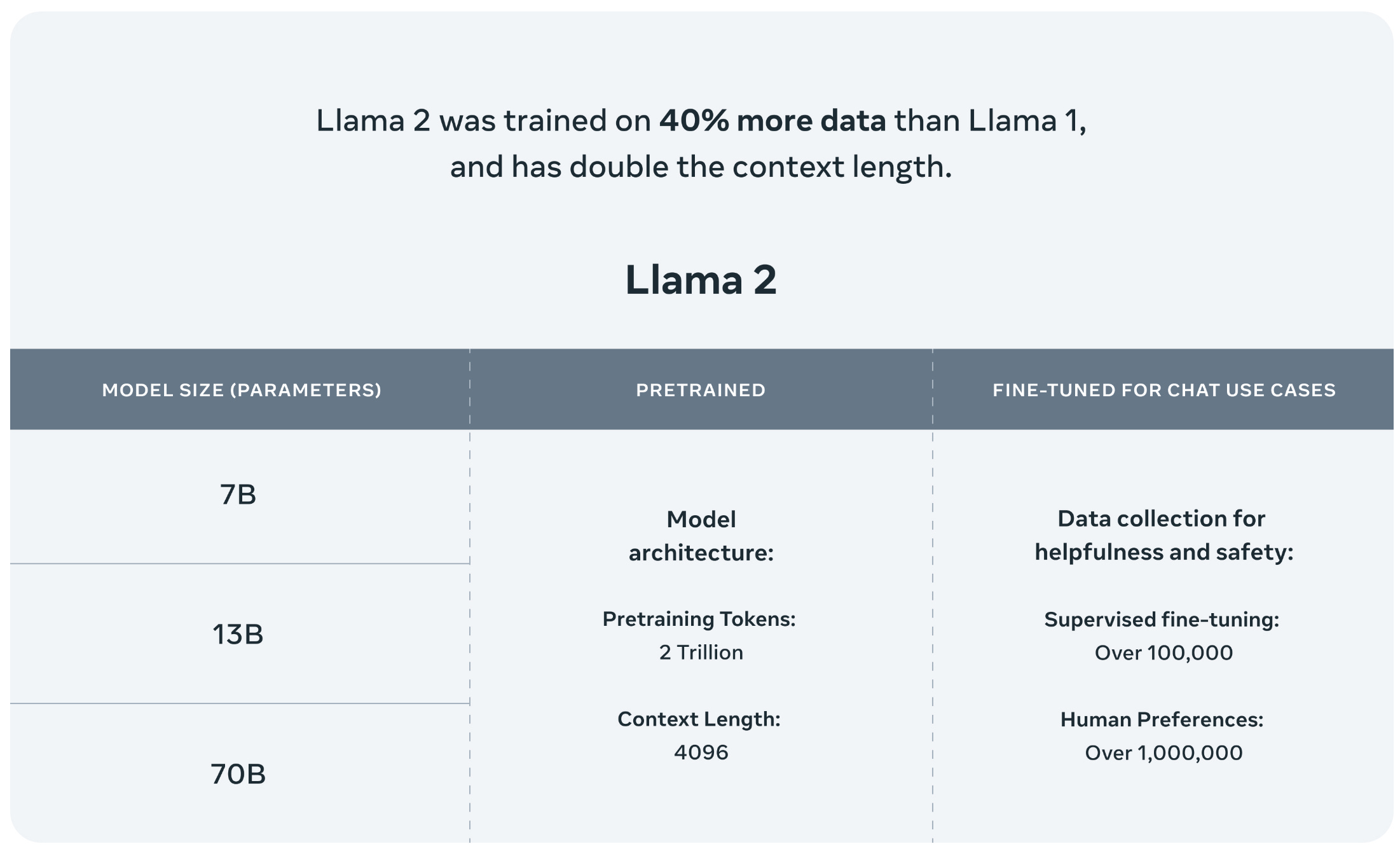
The recently-released LLaMA-2 [1] suite of LLMs is comprised of several open-source models with sizes ranging from 7-70 billion parameters. Compared to their predecessors (i.e., LLaMA-1 [3]), LLaMA-2 models differentiate themselves by pre-training over 40% more data (i.e., 2 trillion tokens instead of 1.4 trillion), having a longer context length, and using an architecture that is optimized for fast inference (i.e., by using grouped query attention [4]). LLaMA-2 achieves state-of-the-art performance among open-source models; read more below.
However, the LLaMA-2 suite contains more than just pre-trained LLMs. Authors invest heavily into the alignment process by fine-tuning each model—using both SFT and RLHF—over a massive amount of dialogue data and human feedback; see below. The resulting models are referred to as the LLaMA-2-Chat models.
These refined versions of LLaMA-2 perform incredibly well and take a major step towards closing the gap in alignment between open-source and proprietary LLMs. LLaMA-2’s alignment process emphasizes two key behavioral properties:
Helpfulness: the model fulfills users’ requests and provides requested information.
Safety: the model avoids responses that are “unsafe”
To ensure that the aligned model is both helpful and safe, data curated for both SFT and RLHF is filtered, collected, and annotated according to these principles.

SFT. The first step in LLaMA-2’s alignment process is fine-tuning with SFT. Similar to other open-source LLMs, LLaMA-2 is first fine-tuned over publicly-available instruction tuning data. However, such data tends to lack in diversity and quality, which—as demonstrated by LIMA [2]—massively impacts performance. As such, authors in [1] focus upon collecting a smaller set of high-quality data for SFT. This data comes from a variety of sources, including both manually created or annotated examples and data from public sources that is filtered for quality. Ultimately, LLaMA-2 undergoes a second stage of fine-tuning with 27,540 high-quality dialogue examples; see above for samples.
“Surprisingly, we found that the outputs sampled from the resulting SFT model were often competitive with SFT data handwritten by human annotators, suggesting that we could reprioritize and devote more annotation effort to preference-based annotation for RLHF.” - from [1]
Interestingly, authors in [1] observe that collecting more data (i.e., beyond the 27K high-quality examples) for SFT provides diminishing benefits. These findings align with the empirical analysis from LIMA [2]. We don’t need a ton of data for SFT, but the data should be of high-quality! Interestingly, authors in [1] also note that LLaMA-2 models that have underwent SFT seem to be capable of generating their own data for SFT anyways.
RLHF. LLaMA-2 is further fine-tuned using RLHF6 over a dataset of >1M examples of human feedback. To collect this feedback, a binary protocol is adopted, in which human annotators are asked to write a prompt and choose the better of two generated responses from the LLM. Here, human preference data is collected according to both helpfulness and safety standards. For example, human preference annotations focused upon safety may encourage the annotator to craft an adversarial prompt that is likely to elicit an unsafe response. Then, the human annotator can label which of the responses—if any—is preferable and safe.
“Everything else being equal, an improvement of the reward model can be directly translated into an improvement for Llama 2-Chat.” - from [1]
Human feedback data is collected in batches, and LLaMA-2 is fine-tuned via RLHF between each batch. As such, several versions of each LLaMA-2-Chat model—five in total—are iteratively created after each trial of RLHF. In [1], we see that a new reward model is trained for use in RLHF each time fresh human preference data is collected, ensuring the reward model accurately captures human preferences of the latest model. Additionally, we see that the quality of the resulting reward model is surprisingly predictive of LLaMA-2-Chat model quality overall. In total, LLaMA-2 is fine-tuned on over 1M instances of human feedback throughout the entirety of the iterative RLHF process.

As shown in the figure above, the quality of LLaMA-2-Chat—in terms of both helpfulness and safety—improves smoothly throughout the several iterations of alignment with both SFT and RLHF. This visualization clearly depicts the level of impact of each technique on the resulting model’s quality. Namely, performing SFT alone only gets us so far! The model’s alignment improves drastically with each phase of RLHF that is performed even after SFT is applied.

Performance. The LLaMA-2-Chat models are currently state-of-the-art for open-source LLMs, as shown by the Open LLM leaderboard above. When LLaMA-2-Chat models are compared to other popular LLMs in [1], we see that they far exceed other open-source models in terms of helpfulness and safety; see below.

Furthermore, LLaMA-2 is even found to perform comparably to top proprietary models like ChatGPT when evaluated in terms of helpfulness and safety. Put simply, these results heavily indicate that the quality of alignment performed for the LLaMA-2-Chat models is high. The resulting models tend to accurately capture and adhere to desired helpfulness and safety standards.
“[Alignment] can require significant costs in compute and human annotation, and is often not transparent or easily reproducible, limiting progress within the community to advance AI alignment research.” - from [1]
The importance of LLaMA-2. The impact of LLaMA-2 on open-source LLM research goes beyond simply setting a new state-of-the-art in terms of performance. Why? We see in [2] that LLaMA-2 adopts a fundamentally different approached compared to prior work. Due to the fact that closed-source LLMs are typically aligned with extensive amount of proprietary, human-annotated data, this process has been more difficult to replicate within open-source research. Although prior open-source models mostly leverage SFT and public sources of dialogue data7, LLaMA-2 is one of the first open-source LLMs to invest extensively into the alignment process, curating a great deal of high-quality dialogues and human preferences for both SFT and RLHF.
Closing Remarks
We have now studied the entire journey of open-source language models from OPT to LLAMA-2. Despite the incredible amount of research that occurred between these two models, their proposal was only a year apart! The open-source AI research community moves very quickly, and keeping up with research in this area is incredibly exciting, interesting, and rewarding. Having access to powerful models like LLaMA-2-Chat is humbling. As both practitioners and researchers, we have the ability to use these models, learn from them, and truly gain a deeper understanding of how they work. Such an opportunity is unique and should not be taken for granted. Especially for LLMs, open-source is pretty cool!
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews that explain relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on twitter or LinkedIn!
Bibliography
[1] Touvron, Hugo, et al. "Llama 2: Open Foundation and Fine-Tuned Chat Models." arXiv preprint arXiv:2307.09288 (2023).
[2] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
[3] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[4] Ainslie, Joshua, et al. "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints." arXiv preprint arXiv:2305.13245 (2023).
[5] “Introducing Llama2: The next generation of our open source large language model”, Meta, https://ai.meta.com/llama/.
[6] Gudibande, Arnav, et al. "The false promise of imitating proprietary llms." arXiv preprint arXiv:2305.15717 (2023).
[7] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[8] Chiang, Wei-Lin et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” (2023).
[9] Geng, Xinyang et al. “Koala: A Dialogue Model for Academic Research.” (2023).
[10] Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. GPT4All: Training an assistant-style chatbot with large scale data distillation from GPT-3.5-Turbo, 2023.
[11] Wang, Yizhong, et al. "Self-instruct: Aligning language model with self generated instructions." arXiv preprint arXiv:2212.10560 (2022).
[12] Mukherjee, Subhabrata, et al. "Orca: Progressive Learning from Complex Explanation Traces of GPT-4." arXiv preprint arXiv:2306.02707 (2023).
[13] “Introducing Falcon LLM”, Technology Innovation Institute, https://falconllm.tii.ae/.
[14] “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable Llms.” MosaicML, www.mosaicml.com/blog/mpt-7b.
[15] “MPT-30B: Raising the Bar for Open-Source Foundation Models.” MosaicML, www.mosaicml.com/blog/mpt-30b.
[16] Gou, Jianping, et al. "Knowledge distillation: A survey." International Journal of Computer Vision 129 (2021): 1789-1819.
[17] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[18] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
For now! I’m sure that I will write another post in this series after research on open-source LLMs continues to develop.
This “recipe”—commonly called the three-step technique—was proposed by InstructGPT (the sister model to ChatGPT) and has been heavily used by a variety of powerful LLMs ever since!
I’m not 100% sure whether imitation learning would be considered alignment. It is quite similar to SFT, where we choose dialogue examples for SFT from existing powerful LLMs (e.g., GPT-4). One could also consider imitation learning a form of generic fine-tuning or even an instruction tuning variant.
This metric is obtained via automatic evaluations that use GPT-4 as a judge.
Orca uses prompts from the FLAN collection to generate its imitation dataset, which takes several weeks to collect due to rate/token limits on the OpenAI API.
Interestingly, authors in [1] adopt two different approaches for RLHF, including the typical PPO variant of RLHF and a rejection sampling fine-tuning variant that i) samples K outputs from the model, ii) selects the best one, and iii) fine-tunes on this example. Notably, both methods are based upon reinforcement learning.
Cameron, great article! I’m wondering if we can translate your blog into Chinese and post it on AI community in China. We will highlight your name and keep the original link on the top of the translation version. Thank you.