
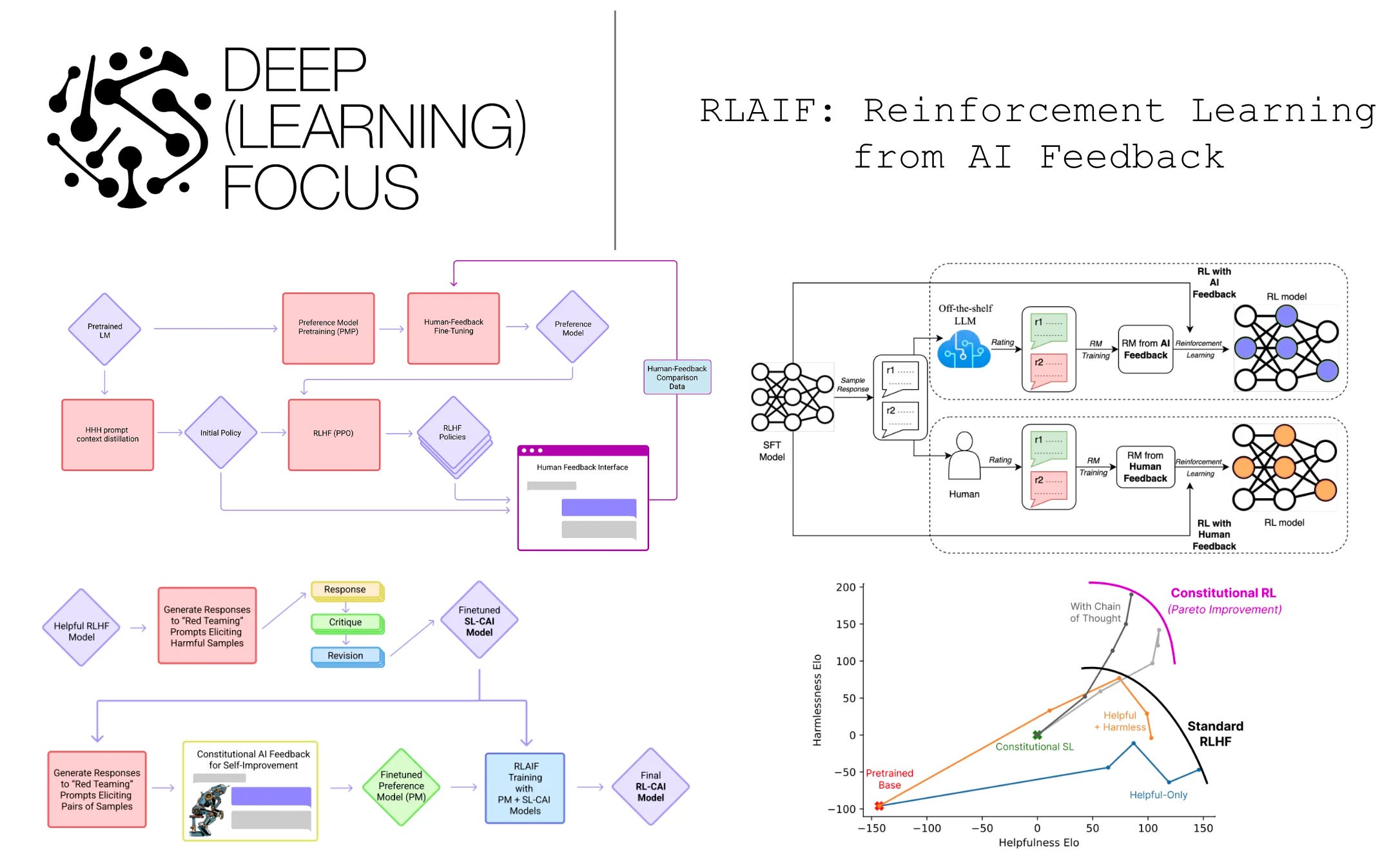
RLAIF: Reinforcement Learning from AI Feedback
Making alignment via RLHF more scalable by automating human feedback...

Beyond using larger models and datasets for pretraining, the drastic increase in large language model (LLM) quality has been due to advancements in the alignment process, which is largely been fueled by finetuning techniques like supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). RLHF in particular is an interesting technique, as it allows us to directly finetune a language model based on human-provided preferences. Put simply, we can just teach the model to produce outputs that humans prefer, which is a flexible and powerful framework. However, it requires that a large amount of human preference labels be collected, which can be expensive and time consuming. Within this overview, we will explore recent research that aims to automate the collection of human preferences for RLHF using AI, forming a new technique known as reinforcement learning from AI feedback (RLAIF).
Background Information
This overview will study the alignment of language models via SFT, RLHF, and RLAIF. To understand these concepts, we need a working understanding of some relevant background concepts related to both LLMs and deep learning in general. We will briefly overview these concepts below and provide links for further reading so that those who are less familiar can go more in depth.
The fundamentals. In my opinion, the best resource for learning about deep learning fundamentals is the Practical Deep Learning for Coders course from fast.ai. This course is extremely practical and oriented in a top-down manner, meaning that you learn how to implement ideas in code and use all the relevant tools first, then dig deeper into the details afterwards to understand how everything works. If you are new to AI and don’t know what to learn first, start with these videos.
Language models. Beyond a basic understanding of deep learning, this overview will require some familiarity with language models. First, we need to learn about the transformer architecture—more specifically the decoder-only transformer architecture—that is used by nearly all generative language models; see below.
Transformer Architecture [link]: Nearly all modern language models—and many other deep learning models—are based upon this architecture.
Decoder-only Transformers [link]: This is the specific variant of the transformer architecture that is used by most generative LLMs.
To learn more about the history of LLMs and how research in this area has progressed, we can also take a look at a few prior overviews listed below.
GPT and GPT-2 [link]: these were some of the first language models proposed that match the style of models that we use today.
GPT-3 and Scaling Laws [link]: these papers discovered that using large language models (LLMs) yields drastic performance improvements.
Modern LLMs [link]: a variety of models were explored post GPT-3, but the best models were both i) large and ii) trained over tons of data.
Specialized LLMs [link]: advancements in LLM research led to these powerful models being applied to a variety of domains and use cases.
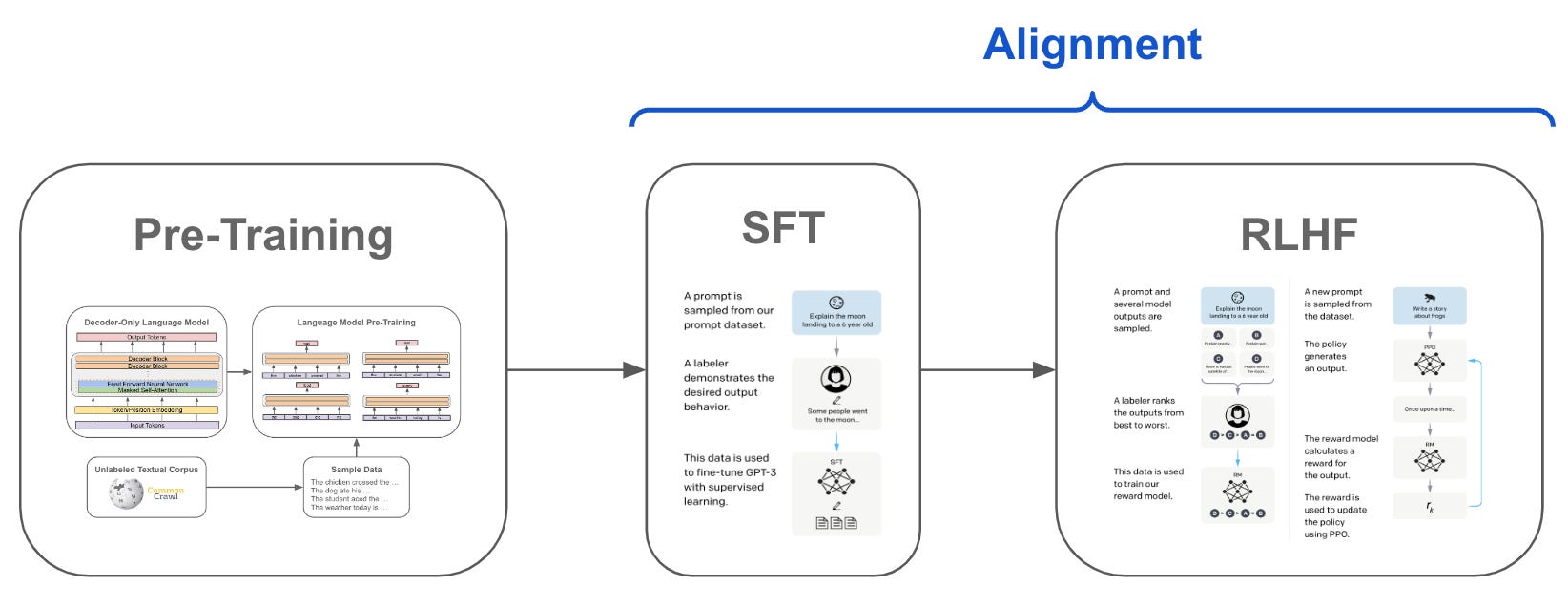
Training a language model. The language model training process progresses in several phases; see above. First, we pretrain the model over a large corpus of unlabeled textual data, which is the most expensive part of training. After pretraining, we perform a three-part1 alignment process, including both supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF); see below. Alignment via SFT/RLHF was used in [15] for summarizing text with LLMs and explored for improving instruction following capabilities in generic LLMs by InstructGPT [11], the sister model to ChatGPT. This approach has since become standardized and is used by a variety of powerful models.

More on RLHF. Within this overview, we will primarily focus upon the RLHF phase of alignment, which finetunes the LLM directly on human feedback. Put simply, humans identify outputs that they prefer, and the LLM learns to produce more outputs like this. More specifically, we i) obtain a set of prompts to use for RLHF, ii) generate two or more responses to each prompt with our language model, and iii) allow human annotators to rank responses based on their preferences. Using this dataset of human preferences, we can train a reward model, which is usually just a finetuned (potentially smaller) version of the LLM with an added regression head for predicting preference scores; see below.

We train this model over pairs of model responses where one response is preferred over the other. Using a ranking loss, we can train the model to predict accurate preference scores by just teaching it to rate preferred responses more highly than non-preferred responses. Once this model has been trained, RLHF finetunes the underlying LLM to generate outputs with higher preference scores using a reinforcement learning algorithm like PPO, where the reward model is used to automate preference judgements in this process.
Recent research has shown us that both SFT and RLHF are necessary for performing high-quality alignment. However, the exact implementation of these components varies a lot between publications. For a more detailed overview of RLHF and the many variants that exist, check out the article below!

Automating RLHF with AI Feedback
“As AI systems become more capable, we would like to enlist their help to supervise other AIs.” - from [1]
Despite its effectiveness, RLHF requires a lot of human preference annotations to work well. For example, LLaMA-2 [12] is trained using >1M human preference annotations! We will now explore a method that mitigates this issue by using AI to automate preference annotations. More specifically, recent research has found that LLMs can generate accurate preference labels if prompted correctly. A variety of papers have explored this topic. First, we will explore a background paper that studies RLHF, followed by a few papers that propose alternative approaches for reinforcement learning from AI feedback (RLAIF).
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback [8]

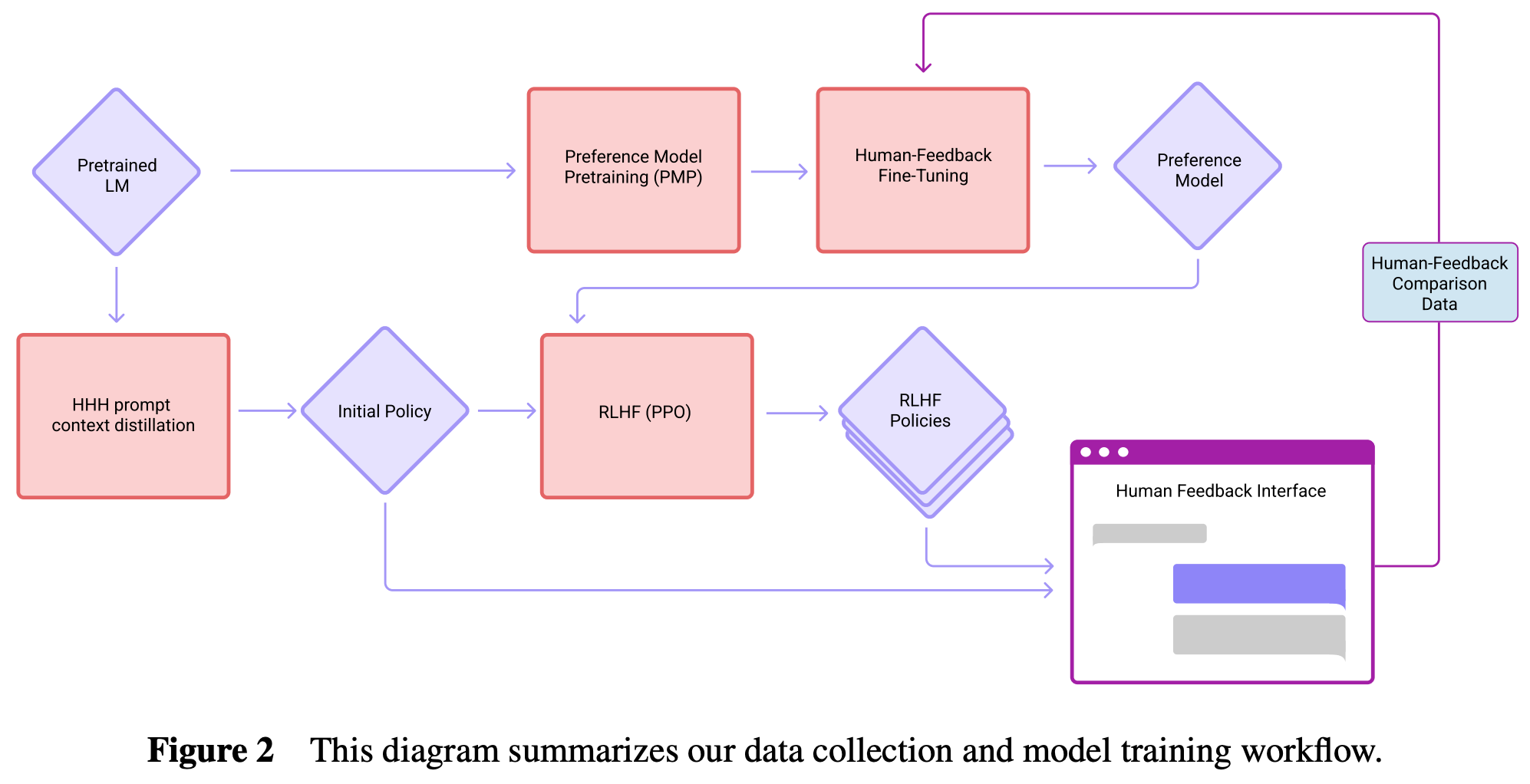
In [8], authors train a language model to be helpful and harmless using RLHF. By following an iterative feedback approach that performs RLHF on a weekly basis with fresh data, authors in [8] find that they can train an LLM to be both helpful and harmless without comprising performance on any benchmarks and even improving performance on specialized tasks like coding or summarization; see above. Although human feedback is used to fine-tune the LLM in [8], this paper is the precursor to an AI-based feedback approach explored in [1] and, as such, provides necessary context for this overview. Interestingly, the human feedback dataset that is curated in [8] is freely available online and is extensively used in [1].
Collecting data. Feedback data is collected based on a model’s helpfulness and harmlessness, as judged by human annotators, on a prompt given to the model. Interestingly, we see in [8] that authors allow human annotators to interpret these terms loosely—there are no detailed, itemized requirements written to further explain the meaning of helpful or harmless, allowing a large and diverse preference dataset to be collected. Annotations for helpfulness and harmlessness are collected separately and with a different prompting approach:
Helpful data is collected by asking humans to solicit help from the model with a text-based task (e.g., question answering, writing, discussion, etc.).
Harmless data is collected by asking humans to adversarially probe2 a model to get help with a harmful goal or use toxic language.
In all cases, two model responses are generated for each prompt, and the human annotator identifies the preferable response (i.e., a binary preference label) and a strength of preference based upon which response is more helpful or more harmless; see below. Authors spot check annotations to ensure that annotators that produce low-quality preference labels are removed from the dataset.

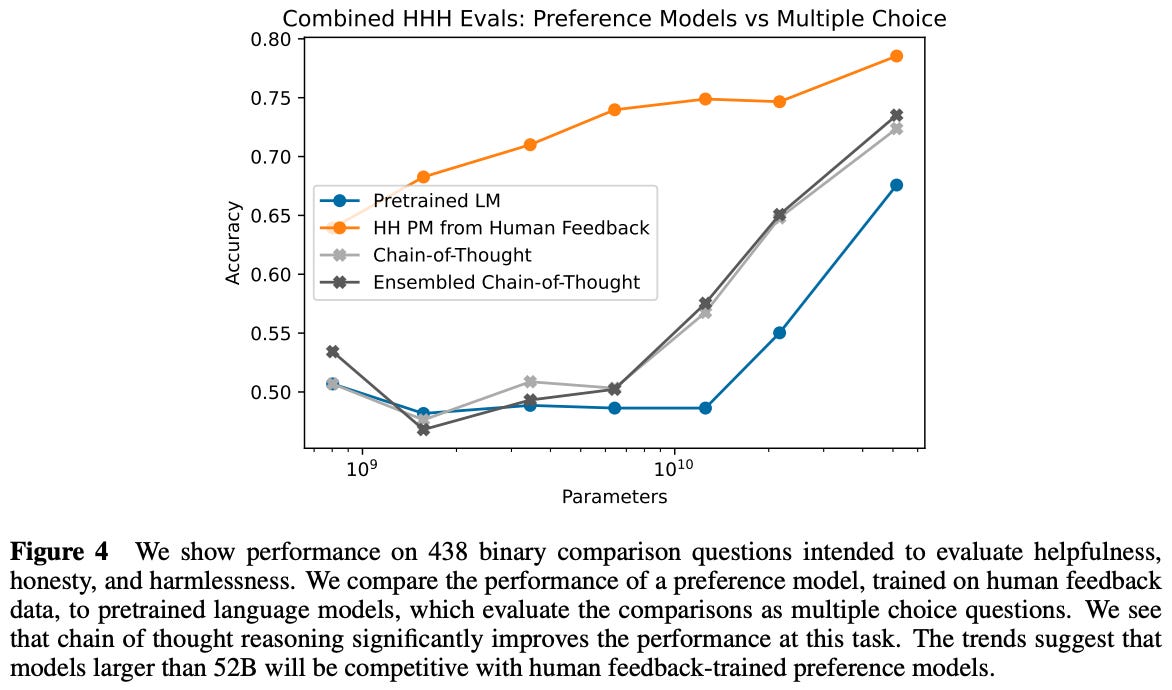
Training setup. The LLMs used in [8] have between 13M and 52B parameters and reflect those described in [9]. Experiments are performed with criteria-specific preference models (i.e., separate models for helpfulness and harmlessness)3, as well as preference models that are trained over a mixture of helpful and harmless data. Given that helpfulness and harmfulness are often a tradeoff, we see in [8] that preference models trained on one criteria often perform poorly on the other.
“That is, helpfulness tends to increase harmfulness, since models are willing to obey pernicious requests, and conversely models trained to be harmless tend to be more evasive and generally less helpful.” - from [1]
Authors in [8] indicate that training preference models over a mixture of data that captures both alignment criteria can also achieve competitive performance. However, these models must be scaled to a certain size to achieve sufficient accuracy on their preference scores; see below.

The tension between helpfulness and harmfulness for training preference models is more pronounced with smaller models—larger preference models are better able to simultaneously capture both preferences. Despite collecting the strength of each preference score, however, preference models in [8] are trained to just assign a better score to the preferable output via a ranking loss. After the preference model is trained, the LLM is optimized using PPO—the most commonly-used RL algorithm for RLHF [10, 11]. Fresh data is collected iteratively, and the underlying LLM is finetuned over new data each week, as shown within the diagram below.
Does alignment degrade model quality? Recently, there has been a lot of discussion about whether the alignment procedure degrades the overall accuracy of the underlying LLM. This question is deeply related to the tension between helpfulness and harmlessness—avoiding harmful output may cause the model to be less helpful on certain problems (e.g., by avoiding the answer).
“A question that’s often raised about alignment training is whether it will compromise AI capabilities. We find that when RLHF is applied to large language models, the answer seems to be an almost-categorical no.” - from [8]
In [8], however, we see that finetuning with RLHF does not necessarily deteriorate performance across more generic natural language benchmarks; see below. While smaller models may see a slight deterioration, aligned models still perform quite well across other benchmarks. As such, we learn that alignment does not always come at the cost of deteriorated performance on a broader set of tasks.

Takeaways and analysis. Although RLHF is not the focus of this overview, it is worthwhile to understand some of the major takeaways from [8], as they provide insight into the properties of RLHF and how it can be automated with AI (i.e., RLAIF). In particular, we learn a few useful lessons from this analysis:
Smaller LLMs have an “alignment tax”—their performance deteriorates on other benchmarks after alignment with RLHF. However, larger models (13B and 52B parameters) have an opposite effect (i.e., an “alignment bonus”)!
Alignment with RLHF is compatible with specialized language models. We can apply RLHF to models finetuned on code and it actually improves their coding abilities!
Larger preference models are better for making alignment more robust; see below.
The iterative application of RLHF is effective4. We can i) collect new data, ii) finetune the LLM with RLHF and iii) redeploy this model to human annotators to collect more preference data on a weekly cadence.

Constitutional AI: Harmlessness from AI Feedback [1]
Research presented in [8] is quite interesting. RLHF is a powerful tool for aligning language models based on human feedback, but it is difficult to scale up! Aligning a language model with RLHF requires a lot of human preferences labels, usually 10X more labels compared to a technique like SFT. For example, LLaMA-2 [3] uses 100,000 data points for SFT, but over 1,000,000 annotated examples are curated for RLHF; see below.

With this in mind, we might wonder—is there anyway to automate creation of human preference labels for RLHF? Arguably, training a reward model is a form of automation! This reward model is trained over human preference data, then used to generate preference labels during the reinforcement learning phase of RLHF. However, this process still requires the creation of human preference labels, which is expensive and time consuming.
“Results suggest that large language models may already be approaching the performance of crowdworkers in identifying and assessing harmful behavior, and so motivate using AI feedback.” - from [1]
In [1], authors set out with a goal of training a model that is helpful and harmless—similarly to the model in [8]—but their approach, called Constitutional AI, leverages AI-provided feedback for collecting harmful preference data5 instead of humans. In other words, we completely remove human feedback for identifying harmful outputs in an attempt to make obtaining preferences or feedback for alignment with RLHF both more scalable and explainable.
Writing the LLM constitution. In [1], human input for harmfulness is reduced to an extreme. In particular, 16 text-based principles are written (the constitution), which are then leveraged—along with a some manually-curated examples for few-shot learning—to automate the collection of preference data for harmfulness. An example of a single principle from the constitution in [1] is shown below.

Not only does this approach allow high-quality preference data to be collected, but the principles used to guide the creation of those preferences are easy to read, explain, and understand. In this way, constitutional AI actually makes the alignment process more explainable, intuitive, and simple.

The approach. Constitutional AI uses both SFT and reinforcement learning for language model alignment. Starting with an LLM that is purely helpful (i.e., it has no ability to avoid harmful output), we generate responses, which may be harmful, to a set of prompts, then repeat the following steps:
Randomly sample a single principle from the constitution.
Ask the model to critique its response based on this principle.
Ask the model to revise its response in light of this critique.
After this constitution-based refinement process (shown below) has been repeated multiple times for each prompt and response, we can finetune the LLM (using SFT) over the set of resulting responses to make its output much less harmful. The purpose of this initial supervised learning phase is to get the model “on distribution”, meaning that the model already performs relatively well and requires less exploration or training during the second phase of alignment.

After SFT has been performed, the LLM is further finetuned with reinforcement learning. This process is identical to RLHF, but we replace human preferences for harmlessness—but not helpfulness, human annotations are still used for this criteria—with feedback provided by a generic LLM. For each prompt in a dataset of harmful prompts, the underlying LLM, which has already undergone SFT, is used to generate two responses. Then, we generate a preference score using a generic language model (i.e., not the language model that has undergone SFT!) and the prompt template below.

Again, we randomly sample a single principle from the constitution for each preference label that is created. All harmlessness preference labels in [1] are derived using a generic LLM via this multiple choice format. By taking and normalizing the log probabilities of each potential response, we can create a dataset of soft preference labels. In particular, ~182K harmlessness preference examples are collected. Then, these are mixed with a dataset of ~135K helpfulness preference examples. From here, we can perform a procedure that is nearly identical to RLHF in [8], but human-provided harmlessness data is replaced with preference labels from an LLM—reinforcement learning from AI feedback (RLAIF)!
Better prompt engineering. To improve the automated feedback provided via the approach described above, authors in [1] test some more advanced prompting techniques. First, utilizing few-shot examples within the critique and revision prompts used to generate examples for supervised learning is found to improve the quality of revised examples. Additionally, chain of thought prompting [13] is found to improve the the quality of revised responses. Finally, following a self-consistency [14] approach that generates five responses via chain of thought prompting and averages the resulting preference labels yields a final, small performance boost; see above. Interestingly, however, chain of thought prompting seems to be less helpful during the reinforcement learning phase. For examples of prompts used in [1], check out the paper’s repository below.
Experimental setup. In [1], we begin the alignment process with LLMs that are purely helpful—these models are trained using RLHF over a dataset of human feedback that solely measures helpfulness. Given these models as a starting point, our goal is to train a model that is both helpful and harmless. From [8], we know that such a model can be obtained via RLHF, but we are now trying to determine if a portion of the feedback can be automated via AI.
A dataset of ~182K red teaming prompts are collected, including 42K human written prompts and 140K prompts written by an LLM. All red team prompts are critiqued and revised four times prior to supervised learning, which uses both (AI-generated) harmless and (human written) helpful prompt and response pairs. Similarly, the reinforcement learning phase utilizes both AI-generated and human-generated preference feedback.
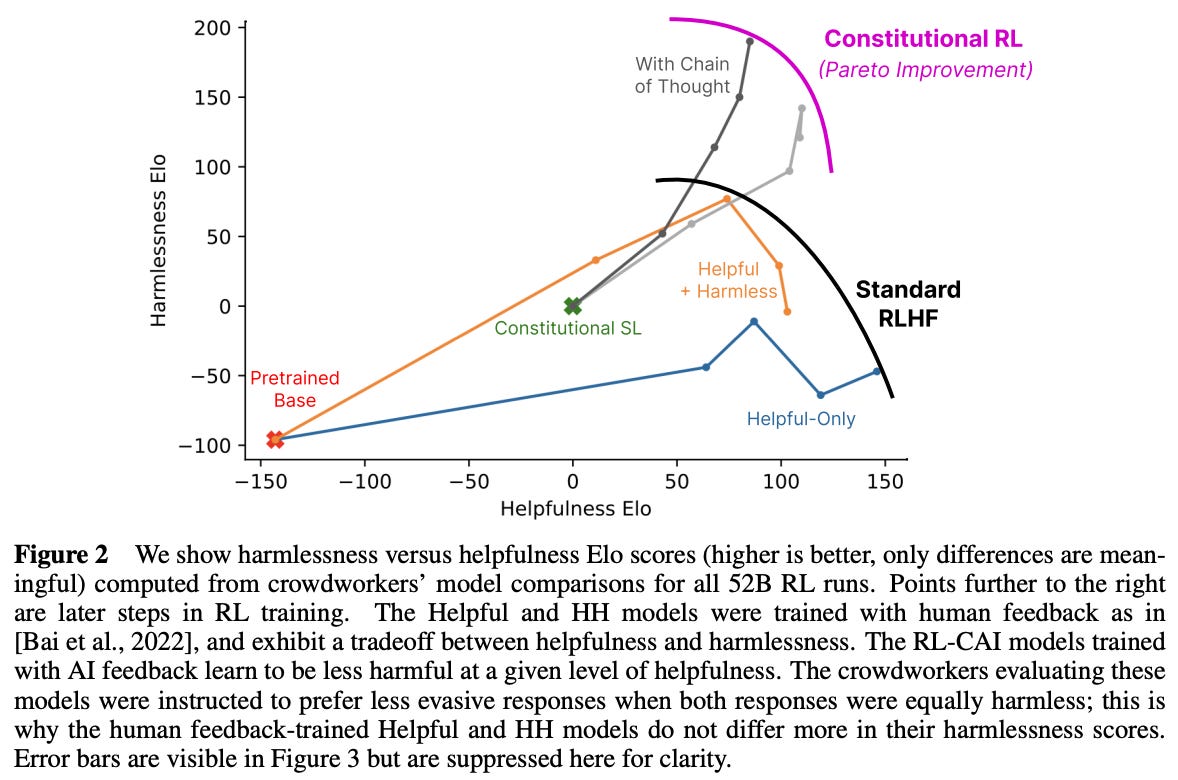
Results and analysis. We see in [1] that RLHF can be partially automated via AI-provided feedback with minimal performance degradation. Using AI-generated labels for harmlessness can still yield improvements in the underlying LLM’s harmlessness! As shown by the Pareto frontier in the above figure, constitutional AI can be used to finetune LLMs that achieve quite impressive levels of helpfulness and harmlessness. Plus, models trained in [1] are found to be less evasive, despite their harmlessness. Some other interesting takeaways include:
Soft preference labels yield better results for reinforcement learning than hard (binary) preference labels.
Performing two-part revisions (i.e., critique, then revise) for the supervised learning phase is less necessary for larger models, but drastically improves the quality of prompt and response pairs generated with smaller models.
Increasing the number of principles in the constitution does not improve preference accuracy, but it does improve the diversity of responses (see below).

RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback [2]
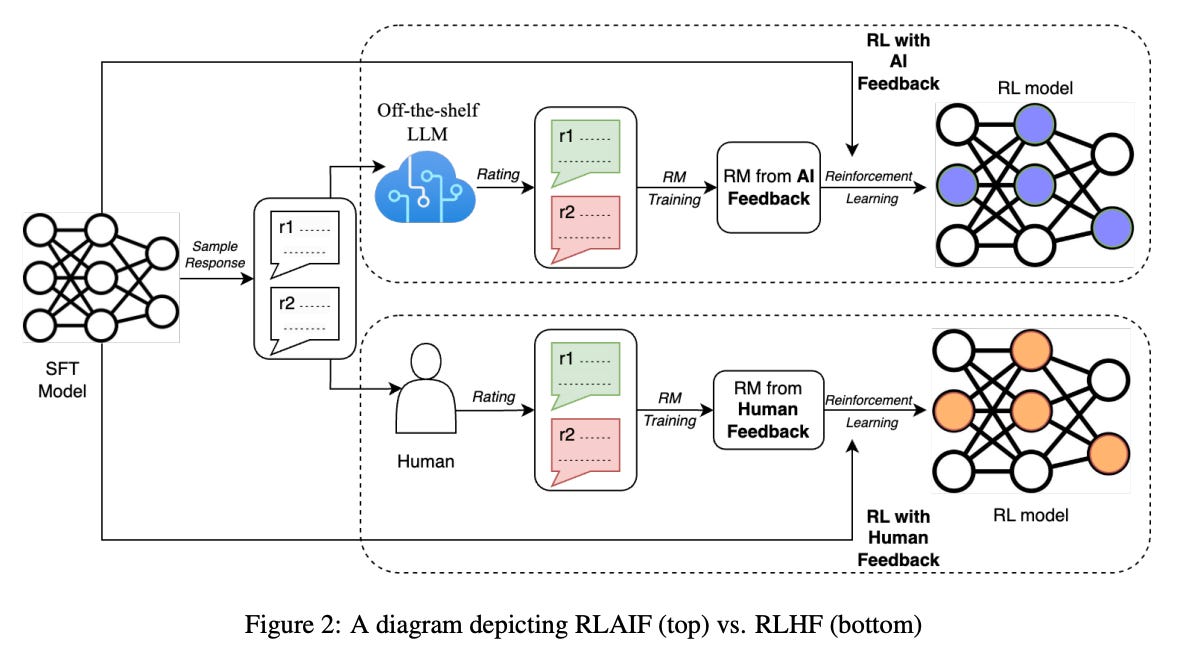
In [1], we see that the collection of human preference labels can at least be partially automated by using hybrid feedback from both humans and AI. However, full automation of feedback for RLHF was not explored until [2], where authors propose reinforcement learning from AI feedback (RLAIF). This technique is identical to RLHF, but it automates the creation of human preference labels with an off-the-shelf LLM6. Although RLAIF in [2] is explored specifically for text summarization tasks, we see that the technique yields similar results compared to RLHF, indicating that the alignment process can be automated via feedback provided by a generic language model.

Automating preference labels. To generate preference labels with an off-the-shelf LLM, authors just use the prompt template shown above. This template contains several components, as enumerated below:
Preamble: instructions that describe the task.
Few-shot examples: (optional) examples of text with correct preference scores.
Sample to annotate: input text and pair of summaries to be labeled with preference scores.
Ending: ending string that prompts the model to generate preference scores (e.g., “Preferred Summary =”).
Although a few different styles of preambles are tested in [2], the standard approach for creating AI-generated preference labels follows the structure described above. Instead of creating binary preference labels, however, authors in [2] collect the log probability of tokens corresponding to each of the potential preference outputs (i.e., whether summary one or summary two is preferred), apply a softmax, and use this as a “soft” preference distribution.

To generate all preference labels, authors use the PaLM-2 [4, 5] model from Google. Although multiple sizes of PaLM-2 exist, we learn in [2] that the quality of preference annotations improves as larger models are used; see above. As such, using a larger, generic PaLM-2 model for generating preference labels is best. The process of creating AI-generated preference labels is depicted below.

Advanced prompting techniques. Beyond the prompting framework outlined above, experiments are performed using more advanced prompting techniques, including few-shot prompting, chain of thought (CoT) prompting [6], and self-consistency [7]. Interestingly, CoT prompting is found to be beneficial in producing accurate preference labels when a two-stage approach—where we first generate a rationale, then concatenate this rationale with our input to generate a final preference label—is adopted. However, few-shot exemplars and self-consistency are not found to benefit the quality of preference labels. The results of analysis with different prompting techniques is provided in the tables above.

Experimental setup. The models trained in [2] follow a standard, three-stage approach that includes SFT7 and RLHF. However, the RLHF component is replaced with RLAIF. In other words, we just generate preference feedback using the generic PaLM-2 model rather than a human, and everything else is exactly the same. Again, analysis in [2] solely considers a text summarization task, which is based on the TL;DR dataset (i.e., a dataset of Reddit posts from different communities that are paired with summaries written by the same author), as well as a corresponding human preference dataset—curated by OpenAI—that is created using data from TL;DR. To evaluate different summarization models, we use the following metrics:
AI labeler alignment: measures how well AI-provided preferences labels align with human-provided preference labels.
Pairwise accuracy: measures how accurate a trained reward model is with respect to a held-out set of human preferences.
Win rate: measures how often one model is preferred by humans over another.
Beginning with a pretrained base model, we first train this model via SFT on a high-quality dataset of summarization examples from TL;DR. From here, two separate models are trained—using either RLHF or RLAIF—based on the human preference dataset created on top of TL;DR. The analysis in [2] compares the quality of the three resulting models (SFT, SFT+RLHF, and SFT+RLAIF), as well as the quality of preference labels produced by humans versus LLMs.

Does RLAIF perform well? When we compare the quality of models trained via SFT, SFT+RLHF, and SFT+RLAIF, we immediately learn that both RLHF and RLAIF-based models consistently outperform models trained solely via SFT; see above. In other words, further fine-tuning via either RLHF or RLAIF yields a clear—and seemingly equal—benefit in terms of performance. When we directly compare models fine-tuned via RLHF and RLAIF, we see that the win rate is (roughly) 50%, meaning that both models are equal in performance.

Going further, RLHF and RLAIF-based summaries are preferred over human written references summaries in 80% of cases. A qualitative comparison of outputs generated by each of the three different models is provided above. Overall, we see in [2] that—on the task of text summarization—finetuning language models with AI-generated feedback is highly effective. In fact, RLAIF seems to yield models that roughly match the performance of models trained via RLHF, indicating that RLAIF is an alternative to RLHF with appealing scaling properties in terms of required human annotation costs.
“We show that RLAIF can produce comparable improvements to RLHF without depending on human annotators.” - from [2]
Takeaways
In many ways, alignment is the bedrock of modern advancements in language models. Creating a truly remarkable language model requires aligning this model’s output to the desires of a human user—accurately predicting the most probable next token is simply not enough. Going further, RLHF is a standardized, incredibly important component of the alignment process. Notably, RLHF has a major limitation—it requires a ton of human preference data to be collected for it to work well. This weakness is (arguably) the main reason that RLHF has not been as heavily explored within areas like open-source LLM research. RLHF requires human and monetary resources that are not always readily available.
Within this overview, we have learned about active directions of research that are aiming to mitigate this weakness by automating preference labeling with generic language models. We have seen that leveraging foundation models for such applications is quite effective and allows us to create aligned language models that have comparable quality relative to RLHF and require minimal (or no) human supervision. Applying RLAIF successfully is largely a prompt engineering problem—we need to write prompts that can generate accurate preference labels. However, we see in works like [1] and [2] that automating data cleaning and annotation tasks with LLMs is incredibly effective. Seemingly, AI-provided feedback is an extremely promising direction for improving the accessibility and effectiveness of alignment research for language models.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Bai, Yuntao, et al. "Constitutional ai: Harmlessness from ai feedback." arXiv preprint arXiv:2212.08073 (2022).
[2] Lee, Harrison, et al. “RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback.” arXiv preprint arXiv:2309.00267 (2023).
[3] “Introducing Llama2: The next generation of our open source large language model”, Meta, https://ai.meta.com/llama/.
[4] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[5] Anil, Rohan, et al. "Palm 2 technical report." arXiv preprint arXiv:2305.10403 (2023).
[6] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[7] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. 2022a. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
[8] Bai, Yuntao, et al. "Training a helpful and harmless assistant with reinforcement learning from human feedback." arXiv preprint arXiv:2204.05862 (2022).
[9] Askell, Amanda, et al. "A general language assistant as a laboratory for alignment." arXiv preprint arXiv:2112.00861 (2021).
[10] Stiennon, Nisan, et al. "Learning to summarize with human feedback." Advances in Neural Information Processing Systems 33 (2020): 3008-3021.
[11] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[12] Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288 (2023).
[13] Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models." Advances in Neural Information Processing Systems 35 (2022): 24824-24837.
[14] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. 2022a. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
[15] Stiennon, Nisan, et al. "Learning to summarize with human feedback." Advances in Neural Information Processing Systems 33 (2020): 3008-3021.
It may be a bit confusing that the three-part alignment only contains SFT and RLHF. However, RLHF has two internal phases (i.e., training the reward model and optimizing the LLM via RL), which makes three phases in total.
This is also commonly referred to as “red teaming” in AI literature.
This approach is similar to LLaMA-2 [12], which uses separate reward models for each of their alignment criteria to avoid issues with conflicting objectives.
Several notable LLMs have since adopted a similar approach; e.g., LLaMA-2 [12] is finetuned with several rounds of RLHF with fresh data.
Notably, human labeling is still used to collect helpful-based preference data. The same HH-RLHF dataset from [8] is used for this.
An off-the-shelf LLM is defined in [2] as a model that is “pre-trained or instruction-tuned for general usage but not fine-tuned for a specific downstream task”.
Unlike [1], examples for SFT are not generated using an AI-based critique and refine framework in [2].
Small typo
"harmless without comprising performance" to "harmless without compromising performance"
Great article, thanks!