
Understanding and Using Supervised Fine-Tuning (SFT) for Language Models
Understanding how SFT works from the idea to a working implementation...


Large language models (LLMs) are typically trained in several stages, including pretraining and several fine-tuning stages; see below. Although pretraining is expensive (i.e., several hundred thousand dollars in compute), fine-tuning an LLM (or performing in-context learning) is cheap in comparison (i.e., several hundred dollars, or less). Given that high-quality, pretrained LLMs (e.g., MPT, Falcon, or LLAMA-2) are widely available and free to use (even commercially), we can build a variety of powerful applications by fine-tuning LLMs on relevant tasks.

One of the most widely-used forms of fine-tuning for LLMs within recent AI research is supervised fine-tuning (SFT). This approach curates a dataset of high-quality LLM outputs over which the model is directly fine-tuned using a standard language modeling objective. SFT is simple/cheap to use and a useful tool for aligning language models, which has made is popular within the open-source LLM research community and beyond. Within this overview, we will outline the idea behind SFT, look at relevant research on this topic, and provide examples of how practitioners can easily use SFT with only a few lines of Python code.
Useful Background Information
To gain a deep understanding of SFT, we need to have a baseline understanding of language models (and deep learning in general). Let’s cover some relevant background information and briefly refresh a few ideas that will be important.
AI Basics. In my opinion, the best resource for learning about AI and deep learning fundamentals is the Practical Deep Learning for Coders course from fast.ai. This course is extremely practical and oriented in a top-down manner, meaning that you learn how to implement ideas in code and use all the relevant tools first, then dig deeper into the details afterwards to understand how everything works. If you’re new to the space and want to quickly get a working understanding of AI-related tools, how to use them, and how they work, start with these videos.
Language models. SFT is a popular fine-tuning technique for LLMs. As such, we need to have a baseline understanding of language models. The resources below can be used to gain a quick understanding of how these models work:
Transformer Architecture [link]: Nearly all modern language models—and many other deep learning models—are based upon this architecture.
Decoder-only Transformers [link]: This is the specific variant of the transformer architecture that is used by most generative LLMs.
Brief History of LLMs [link]: LLMs have gone through several phases from the creation of GPT [1] to the release of ChatGPT.
Next token prediction [link]: this self-supervised training objective underlies nearly all LLM functionality and is used by SFT!
Language Model Pretraining [link]: language models are pretrained over a massive, unlabeled textual corpus.
Language Model Inference [link]: language models can be used to generate coherent sequences of text via autoregressive next token prediction.
Transformers library. The code in this overview relies upon the transformers library, which is one of the most powerful deep learning libraries out there. Plus, the library has a ton of tutorials and documentation that serve as a practical learning resource for any deep learning or LLM-related project.

Training LLMs. The training process for language models typically proceeds in three phases; see above. First, we pretrain the language model, which is (by far) the most computationally-expensive step of training. From here, we perform alignment, typically via the three-step framework (see below) with supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF)1.

The steps outlined above form the standardized training pipeline that is used for most state-of-the-art LLMs (e.g., ChatGPT or LLaMA-2 [3]). SFT and RLHF are computationally cheap compared to pretraining, but they require the curation of a dataset—either of high-quality LLM outputs or human feedback on LLM outputs—which can be difficult and time consuming.
Sometimes we have to do a bit more when applying an LLM to solve a downstream task. In particular, we can further specialize a language model (if needed) either via domain-specific fine-tuning or in-context learning; see below. Domain-specific fine-tuning simply trains the model further—usually via a language modeling objective, similarly to pretraining/SFT—on data that is relevant to the downstream task, while in-context learning adds extra context or examples into the language model’s prompt to be used as context for solving a problem.

What is alignment? Finally, there is a term we have used several times in the above discussion that is important to understand: alignment. A pretrained language model is usually not useful. If we generate output with this model, the results will probably be repetitive and not very helpful. To create a more useful language model, we have to align this model to the desires of the human user. In other words, instead of generating the most likely textual sequence, our language model learns to generate the textual sequence that is desired by a user.
“For our collection of preference annotations, we focus on helpfulness and safety. Helpfulness refers to how well Llama 2-Chat responses fulfill users’ requests and provide requested information; safety refers to whether Llama 2-Chat’s responses are unsafe.” - from [5]
Such alignment, which is accomplished via the three-step framework with SFT and RLHF outlined above, can be used to encourage a variety of behaviors and properties within an LLM. Typically, those training the model select a set of one or a few criteria that are emphasized throughout the alignment process. Common alignment criteria include: improving instruction following capabilities, discouraging harmful output, making the LLM more helpful, and many more. For example, LLaMA-2 [5] is aligned to be i) helpful and ii) harmless/safe; see above.
What is SFT?
Supervised fine-tuning (SFT) is the first training step within the alignment process for LLMs, and it is actually quite simple. First, we need to curate a dataset of high-quality LLM outputs—these are basically just examples of the LLM behaving correctly; see below. Then, we directly fine-tune the model over these examples. Here, the “supervised” aspect of fine-tuning comes from the fact that we are collecting a dataset of examples that the model should emulate. Then, the model learns to replicate the style2 of these examples during fine-tuning.

Relation to next token prediction. Interestingly, SFT is not much different from language model pretraining—both pretraining and SFT use next token prediction as their underlying training objective! The main difference arises in the data that is used. During pretraining, we use a massive corpus of raw textual data to train the model. In contrast, SFT uses a supervised dataset of high-quality LLM outputs. During each training iteration, we sample several examples, then fine-tune the model on this data using a next token prediction objective. Typically, the next token prediction objective is only applied to the portion of each example that corresponds to the LLM’s output (e.g., the response in the figure above).
Where did this come from?
The three-step alignment process—including both SFT and RLHF—was originally proposed by InstructGPT [2] (though it was previously explored for summarization models in [21]), the precursor and sister model to ChatGPT. Due to the success of both InstructGPT and ChatGPT, this three-step framework has become standardized and quite popular, leading to its use in a variety of subsequent language models (e.g., Sparrow [4] and LLaMA-2 [6]). Alignment via SFT and RLHF is now used heavily in both research and practical applications.
Fine-tuning before SFT. Despite recent popularity of SFT, language model fine-tuning has long been a popular approach. For example, GPT [7] is fine-tuned directly on each task on which it is evaluated (see below), and encoder-only language models (e.g., BERT [8])—due to the fact that they are not commonly-used for generative tasks—almost exclusively use a fine-tuning approach for solving downstream tasks. Furthermore, several LLMs have adopted fine-tuning approaches that are slightly different than SFT; e.g., LaMDA [9] fine-tunes on a variety of auxiliary tasks and Codex [10] performs domain-specific fine-tuning (i.e., basically more pretraining on different data) on a code corpus.
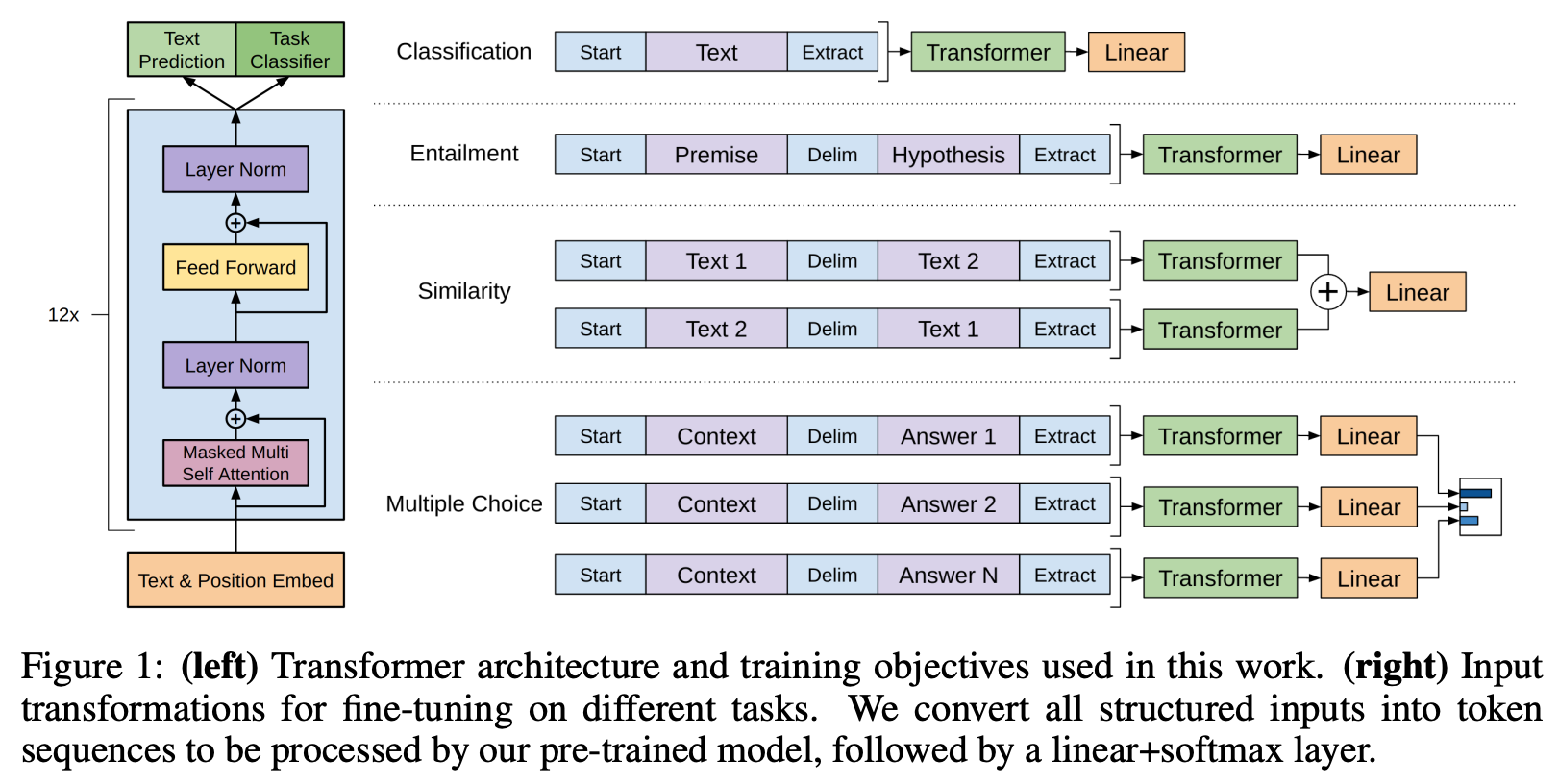
Notably, SFT is slightly different than generic fine-tuning. Typically, fine-tuning a deep learning model is done to teach the model how to solve a specific task, but it makes the model more specialized and less generic—the model becomes a “narrow expert”. The model will likely solve the task on which it is fine-tuned more accurately compared to a generic model (e.g., see GOAT [11]), but it may lose its ability to solve other tasks. In contrast, SFT is a core component of aligning language models, including generic foundation models. Because we are fine-tuning the model to emulate a correct style or behavior, rather than to solve a particular task, it does not lose its generic problem solving abilities.
Pros and Cons of SFT

SFT is simple to use—the training process and objective are very similar to pretraining. Plus, the approach is highly effective at performing alignment and—relative to pretraining—is computationally cheap (i.e, 100X less expensive, if not more). As shown in the figure above, using SFT alone (i.e., without any RLHF) yields a clear benefit in terms of the model’s instruction following capabilities, correctness, coherence, and overall performance3. In other words, SFT is a highly effective technique for improving the quality of a language model. However, we should keep in mind that it is not perfect! Here are a few downsides we should consider.
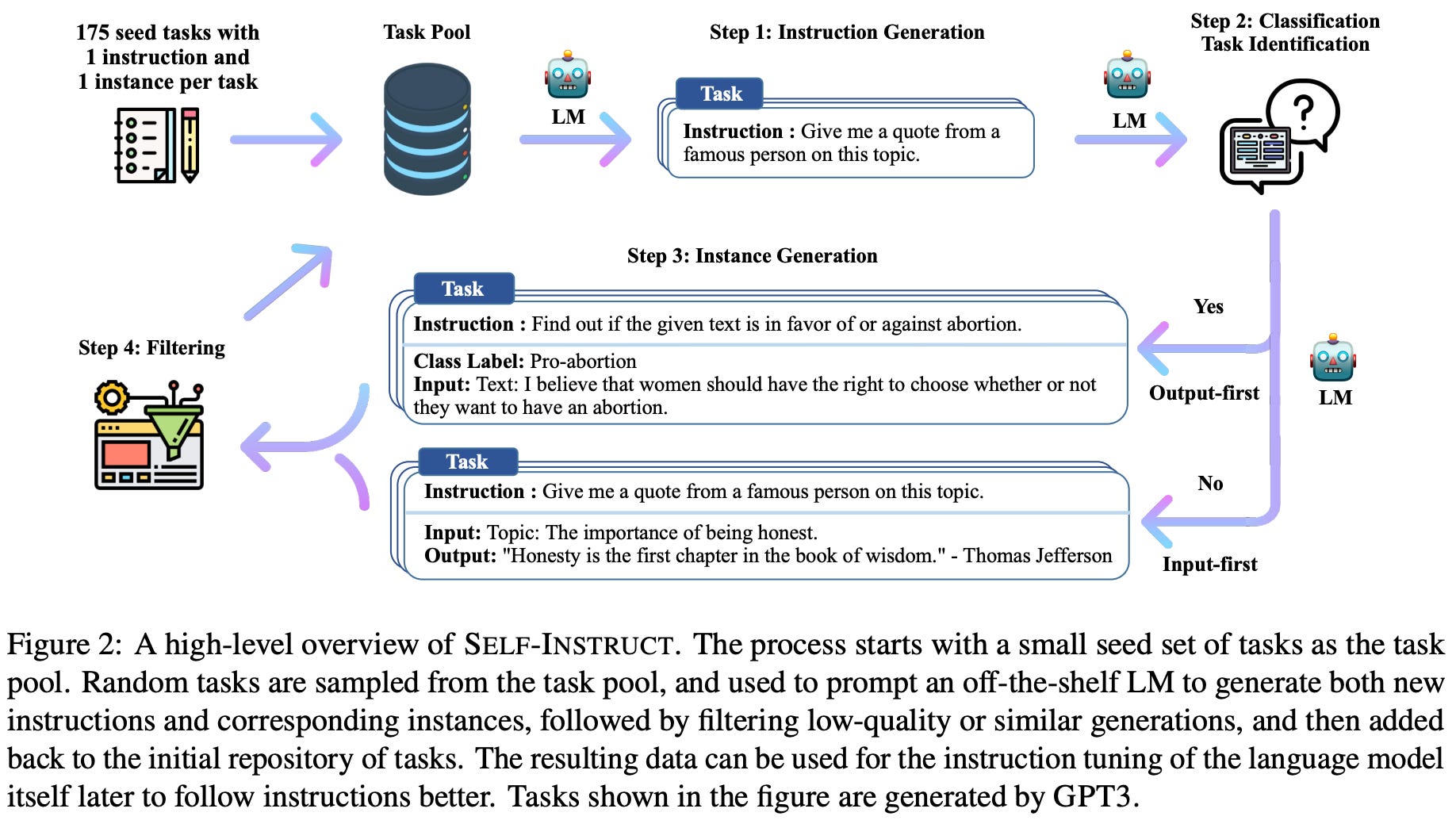
Creating a dataset. The results of SFT are heavily dependent upon the dataset that we curate. If this dataset contains a diverse set of examples that accurately capture all relevant alignment criteria and characterize the language model’s expected output, then SFT is a great approach. However, how can we guarantee that the dataset used for SFT comprehensively captures all of the behaviors that we want to encourage during the alignment process? This can only be guaranteed through careful manual inspection of data, which is i) not scalable and ii) usually expensive. As an alternative, recent research has explored automated frameworks of generating datasets for SFT (e.g., self instruct [12]; see above), but there is no guarantee on the quality of data. As such, SFT, despite its simplicity, requires the curation of a high-quality dataset, which can be difficult.

Adding RLHF is beneficial. Even after curating a high-quality dataset for SFT, recent research indicates that further benefit can be gained by performing RLHF. In other words, fine-tuning a language model via SFT alone is not enough. This finding was especially evident in the recent LLaMA-2 [5] publication, which performs alignment via both SFT and RLHF; see above. For SFT, LLaMA-2 uses a large (27,540 examples in total) dataset of dialogue sessions that were manually curated to ensure quality and diversity. Despite using a large and high-quality source of data for SFT, performing further RLHF yields massive benefits in terms of helpfulness and safety (i.e., the alignment criteria for LLaMA-2); see below.

Furthermore, the authors note that, after SFT has been performed, the language model is capable of generating dialogue sessions of similar quality to those written by humans. As such, creating more data for SFT yields less of a benefit, as we can just automatically generate more data for SFT using the model itself.
“We found that the outputs sampled from the resulting SFT model were often competitive with SFT data handwritten by human annotators, suggesting that we could reprioritize and devote more annotation effort to preference-based annotation for RLHF.” - from [5]
Put simply, the current consensus within the research community seems to be that the optimal approach to alignment is to i) perform SFT over a moderately-sized dataset of examples with very high quality and ii) invest remaining efforts into curating human preference data for fine-tuning via RLHF.
Using SFT in Practice
Now that we understand the concept of SFT, let’s explore how this concept can be and has been used in both practical and research applications. First, we will look at an example of how we can perform SFT in Python. Then, we will overview several recent papers that have been published on the topic of SFT.
Implementation of SFT
As mentioned previously, the implementation of SFT is quite similar to language model pretraining. Under the hood, any implementation of SFT will use a next token prediction (also known as standard language modeling) objective, which we have already learned about extensively. In practice, one of the best tools that we can use for training an LLM with SFT is the transformer reinforcement learning (TRL) Python library, which contains an implementation of SFT that can be used to fine-tune an existing language model with only a few lines of code.

Performing SFT. Built on top of the HuggingFace transformers library, TRL can train a language model (in this case, Meta’s OPT model) via SFT using the code shown above. This simple example demonstrates how easy training a model via SFT can be! Due to the simplicity, fine-tuning models via SFT has been incredibly popular within the open-source LLM research community. A quick visit to the Open LLM Leaderboard will show us a swath of interesting examples. Fine-tuning a pretrained LLM using SFT is currently one of the easiest and most effective ways to get your hands dirty with training open-source LLMs.
Beyond this basic definition of SFT, there are a few useful (and more advanced) techniques that we might want to use, such as applying supervision only on model responses (as opposed to the full dialogue or example), augmenting all response examples with shared prompt template, or even adopting a parameter efficient fine-tuning (PEFT) approach (e.g., LoRA [13]). Interestingly, the SFTTrainer class defined by TRL is adaptable and extensible enough to handle each of these cases. See the link below for more details on the implementation.
SFT use cases in AI Research
Given that SFT is a standard component of the alignment process, it has been explored heavily within AI literature. We will overview several publications that have provided valuable insights on SFT. As always, the publications outlined below are not exhaustive. There are a massive number of papers on the topic of SFT (and AI in general). However, I’ve done my best to highlight some of the most valuable insights from the research community. If anything is missing, please feel free to share it in the comments for myself and others!
InstructGPT. The three part alignment process—including SFT and RLHF—used by most language models was first used by InstructGPT [2], though it was previously explored for text summarization models in [21]. This publication laid the foundation for a lot of recent LLM advancements and contains many valuable insights into the alignment process. Unlike recent models proposed by OpenAI, the details of InstructGPT’s training process and architecture are fully-disclosed within the publication. As such, this model offers massive insight into the creation of powerful language models, and reading the blog posts for ChatGPT and GPT-44 with this added context is much more informative.

Imitation models. During the recent explosion of open-source language models that followed the release of LLaMA, SFT was utilized heavily within the imitation learning context. Namely, we could:
Start with an open-source base model.
Collect a dataset of dialogue sessions from a proprietary language model (e.g., ChatGPT or GPT-4).
Train the model (using SFT) over the resulting dataset.
These models (e.g., Alpaca, Koala, and Vicuna) were cheap to train and performed quite well, highlighting that impressive results can be obtained with SFT using relatively minimal compute. Although early imitation models were later revealed to perform poorly compared to proprietary models, recent variants that are trained over larger imitation datasets (e.g., Orca [15]) perform well. Combining SFT with imitation learning is an cheap and easy way to make a decent LLM.

LIMA. Research in imitation learning revealed that using proprietary language models to generate large datasets for SFT is a useful approach. In contrast, parallel research explored whether alignment could be achieved via smaller, carefully curated datasets. In LIMA [16], authors curate a dataset of only 1K examples for SFT, and the resulting model is quite competitive with top open-source and proprietary LLMs; see above. In this case, the key to success is manual inspection of data to ensure both quality and diversity, which are found to be more important than the raw size of dataset used for SFT. These results are corroborated by LLaMA-2, where authors find that a moderately-sized dataset with high quality and diversity standards yields the best results for SFT.
Open-source alignment. Until the recent proposal of LLaMA-2 (and even afterwards), open-source LLMs were aligned using primarily SFT with minimal RLHF (if any). For example, several variants of the MPT models, as well as the Instruct versions of Falcon and LLaMA are created using SFT over a variety of different datasets (many of which are publicly available5 on HuggingFace!). Plus, if we take a quick look at the Open LLM Leaderboard, we will see that a variety of the top models are versions of popular base models (e.g., LLaMA-2 or Falcon) that have been fine-tuned via SFT on a mix of different data. Notable examples of this include Platypus, WizardLM, Airoboros, Guanaco, and more.
Concluding Remarks
Within this overview, we have learned about SFT, how it can be used in practice, and what has been learned about it within current research. SFT is a powerful tool for AI practitioners, as it can be used to align a language model to certain human-defined objectives in a data-efficient manner. Although further benefit can be achieved via RLHF, SFT is simple to use (i.e., very similar to pretraining), computationally inexpensive, and highly effective. Such properties have led SFT to be adopted heavily within the open-source LLM research community, where a variety of new models are trained (using SFT) and released nearly every day. Given access to a high-quality base model (e.g., LLaMA-2), we can efficiently and easily fine-tune these models via SFT to handle a variety of different use cases.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[2] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[3] Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288 (2023).
[4] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[5] Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288 (2023).
[6] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
[7] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[8] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[9] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
[10] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[11] Liu, Tiedong, and Bryan Kian Hsiang Low. "Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks." arXiv preprint arXiv:2305.14201 (2023).
[12] Wang, Yizhong, et al. "Self-instruct: Aligning language model with self generated instructions." arXiv preprint arXiv:2212.10560 (2022).
[13] Hu, Edward J., et al. "Lora: Low-rank adaptation of large language models." arXiv preprint arXiv:2106.09685 (2021).
[14] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[15] Mukherjee, Subhabrata, et al. "Orca: Progressive Learning from Complex Explanation Traces of GPT-4." arXiv preprint arXiv:2306.02707 (2023).
[16] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
[17] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[18] Chiang, Wei-Lin et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” (2023).
[19] Geng, Xinyang et al. “Koala: A Dialogue Model for Academic Research.” (2023).
[20] Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. GPT4All: Training an assistant-style chatbot with large scale data distillation from GPT-3.5-Turbo, 2023.
[21] Stiennon, Nisan, et al. "Learning to summarize with human feedback." Advances in Neural Information Processing Systems 33 (2020): 3008-3021.
Interestingly, the feedback doesn’t need to be from humans for this step. Recent research is exploring reinforcement learning from AI feedback (RLAIF)!
Recent research on LIMA [6] has revealed that most of a language model’s knowledge is learned during pretraining, while the alignment process teaches the language model the correct style, behavior, or method of surfacing knowledge that it already has.
Obviously, this depends a lot on the quality of data that is used, as well as the alignment criteria that are defined for collecting this data.
GPT-4 also has a technical report with more details than the blog post, but it still does not fully disclose the details of the model architecture or training process. GPT-4 is, however, disclosed in detail within a recent SemiAnalysis publication.
Awesome article as always, Cameron!
I hope you don't mind my minor nit & correction: in your article, you mentioned in some places that InstructGPT originally proposed the three step process Pretraining -> SFT -> RLHF. As far as I know, that's not correct and the procedure was proposed 2 years earlier via the "Learning to summarize from human feedback" paper (https://arxiv.org/abs/2009.01325).
(PS: I have a list of a few additional PPO resources here: https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives)
I need an answer but can't really find it in here. Can a LLM learn new things buy fine-tuning? For example i need add some historical personas with their some informations that i know that the model hasn't seen these data during pre-training?