
Agent Evaluation: A Detailed Guide
Best practices and common patterns for effectively evaluating AI agents...

Evaluation is one of the most important research areas for large language models (LLMs). Recently, patterns in LLM usage and evaluation have drastically changed. Whereas we previously evaluated LLMs using benchmarks composed of static questions or short conversations, we now have agent systems that operate over long time horizons and interact with the environment. Agents are difficult to properly evaluate due to their complexity and autonomy. To accurately measure the capabilities of an agent system, we must build harnesses that are realistic and capable of testing agents similarly to how they are used in practice. Building such evaluation capabilities is now more important than ever due to the growing adoption of agents in high-stakes applications like coding and medicine.
This overview will provide a detailed guide of how current agent systems are evaluated. We will begin by developing an understanding of agents in general, covering everything from basic concepts to multi-agent systems. We will then provide a clear framework for the agent evaluation process based upon common patterns observed in practice. Building upon this knowledge, we will end with several case studies of recent agent benchmarks and provide a roadmap that outlines how to build our own agent evaluation by applying similar concepts. Although evaluation is time-consuming and difficult, learning how to properly evaluate agents is incredibly valuable. By rigorously measuring performance and not relying on anecdotal checks, we can rapidly improve agent capabilities.
Fundamentals of Agent Systems
“LLMs are becoming increasingly capable of handling complex, multi-step tasks. Advances in reasoning, multimodality, and tool use have unlocked a new category of LLM-powered systems known as agents.” - from [3]
During the early days of the agentic era, the distinction between an agent and a normal LLM was unclear. After all, LLMs are at the core of all agent systems. Over time, the key characteristics of agent systems began to emerge:
Calling tools
Solving complex, multi-step problems
Recovering from errors
Taking actions on behalf of a user
LLMs are capable of reasoning, tool calling, and problem solving, but agents are distinguished by their ability to combine these components within an agentic loop to solve difficult problems; see below. In fact, the simplest definition of an agent is an LLM that autonomously uses tools in a loop. Unlike conventional LLMs, agents must assess intermediate results and dynamically recover from their own errors to operate effectively within this agentic loop.
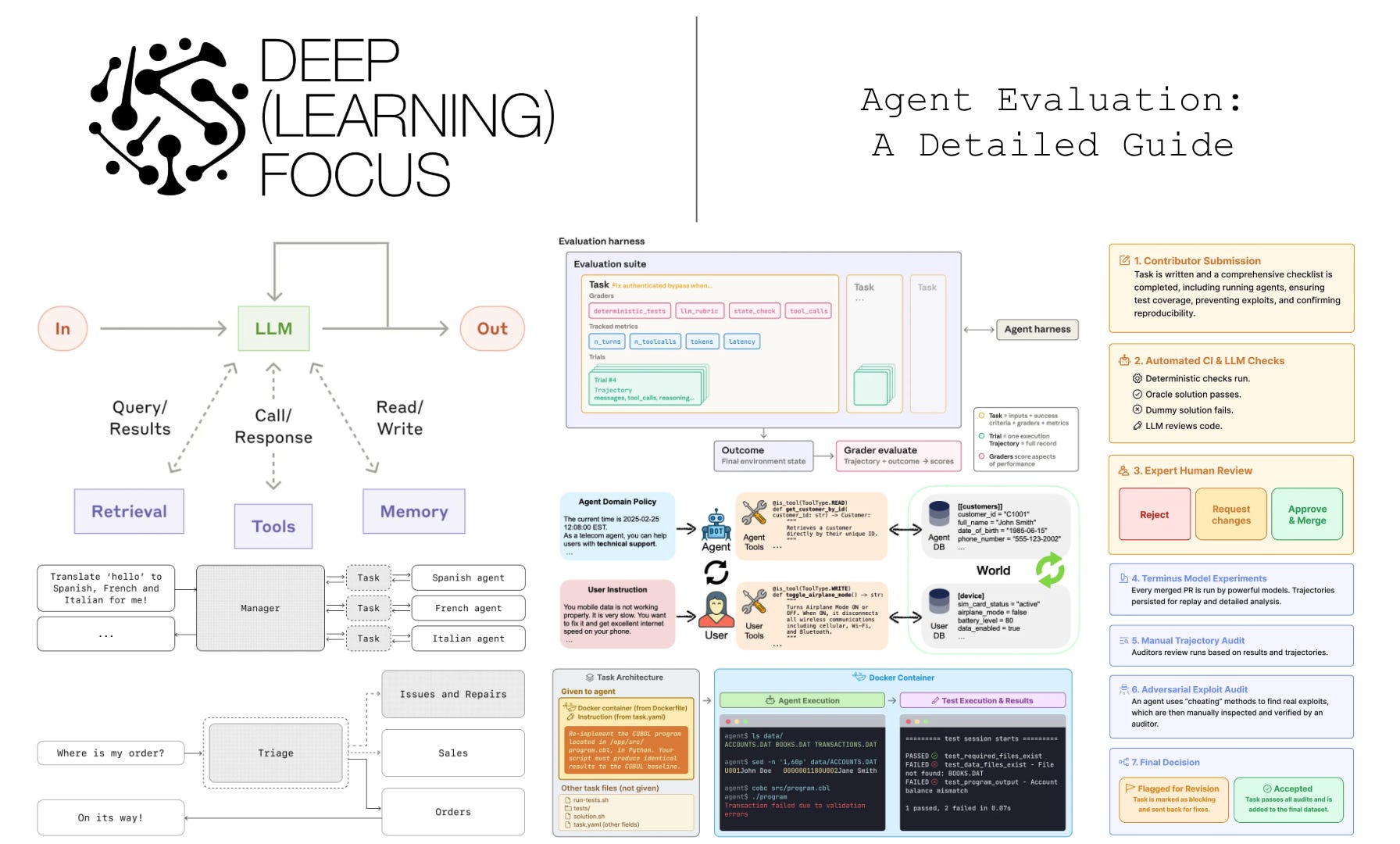
Given that agents reason over long time horizons and use tools, they can also be characterized by their level of autonomy. Conventional LLMs are often used for narrow, well-scoped tasks (e.g., classification or question answering) where the model produces an output but does not independently continue acting or have the ability to modify its environment. On the other hand, agents are usually allowed to control their own workflow over a period of time and can use tools to take actions autonomously (e.g., modify a calendar event or book a plane ticket).
Components of an Agent

As shown above, the input-output interface of an LLM is straightforward: we provide a prompt as input and receive an output. This simple interface played a large role in the adoption of AI by the general public: LLMs are both useful and intuitive. This text-to-text interface can also be extended to handle a variety of auxiliary behaviors like reasoning and tool use, making the gap between a conventional LLM and an agent relatively small. In particular, an agent system is typically composed of three components:
The underlying LLM (or reasoning model)
Tools for the agent to use
Instructions for the agent
The LLM serves as the brain of the system, judging progress toward a final solution and deciding the steps that must be taken in order to get there. In many cases, however, arriving at a correct final solution requires more than just the LLM itself. We must clearly specify the agent’s expected behavior and enable the model to invoke tools or perform complex reasoning when necessary.
Tool use. In order to interact with the external environment, LLMs need to be able to use tools like APIs, CLIs, or MCP servers. For example, if we want our agent to reserve a table for us at a local restaurant, we can simply teach the model how to craft a call to the OpenTable API. Concretely, tool calls can be handled naturally within the LLM’s token stream by creating a set of special tokens related to tool calling and teaching the LLM how to use these tokens; see below.

For example, Qwen3 models handle tool calling via several XML-style tags that are stored as special tokens within the tokenizer:
<tool>and</tool>are used to encapsulate tool definitions.<tool_call>and</tool_call>are used to encapsulate a specific tool call, including the tool to be invoked and associated parameters.<tool_response>and</tool_response>are used to encapsulate the result or response from the tool that is called.
The structure of the instruction template for Qwen3 is shown below. We define available tools and the expected format for calling them in the system message, which provides necessary context for the model to i) understand what tools are available and ii) construct valid calls to these tools. The model can then craft tool calls by outputting <tool_call> and </tool_call> tokens while generating output. At inference time, we interrupt generation whenever a </tool_call> token is generated. We can then parse the request, invoke the tool, concatenate the result to the current output, and restart generation. The model then has the result of the tool call in its context when generating the remaining output.
<|im_start|>system
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{
"type": "function",
"function": {
"name": "search_web",
"description": "Search the web for information.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query."
}
},
"required": ["query"]
}
}
}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
<|im_end|>
<|im_start|>user
Who was the first president of the United States?
<|im_end|>
<|im_start|>assistant
<tool_call>
{
"name": "search_web",
"arguments": {
"query": "first president of the United States"
}
}
</tool_call>
<|im_end|>
<|im_start|>user
<tool_response>
{
"result": "George Washington was the first president of the United States. He served from 1789 to 1797."
}
</tool_response>
<|im_end|>
<|im_start|>assistant
<think>
... Thinking trace goes here ...
</think>
The first president of the United States was George Washington. He served as president from 1789 to 1797.
<|im_end|>Creating useful tools that can be easily understood and correctly invoked by agents is an art. Tools should be well-documented, have a clear purpose, overlap minimally with other tools, and recover gracefully from errors. The easiest way to determine whether a tool is designed correctly is to simply ask yourself: Would a human engineer be able to use this tool from the provided documentation?
Tool calling serves multiple purposes within an agent system. The LLM can use tools to retrieve external information to help reduce hallucination, accomplish tasks within its environment, execute code, call other agents, and more. If there is no API available for a task that needs to be accomplished, we can even rely upon computer-use primitives to allow our agent to directly interact with arbitrary applications on a computer—similarly to a human using a computer.
“Computer use agents interact with software through the same interface as humans—screenshots, mouse clicks, keyboard inputs, and scrolling—rather than through APIs or code execution… Each tool should have a standardized definition, enabling flexible, many-to-many relationships between tools and agents. Well-documented, thoroughly tested, and reusable tools improve discoverability, simplify version management, and prevent redundant definitions.” - from [1]
We can teach an LLM to use tools in multiple ways—such as through in-context learning or finetuning—but tool calling is no different than any other skill that an LLM could learn. There are even entire benchmarks for measuring tool calling capabilities, where performance is measured using a variety of different metrics:
Invocation accuracy measures whether the LLM correctly decided to call a tool when it should, or avoided calling one when it should not. For example, the model may call a tool when it should answer the question directly.
Selection accuracy measures whether the LLM called the correct tools, usually by keeping track of a ground truth trajectory that includes a list of necessary tools for solving a particular problem.
Structural accuracy and schema validity measure whether the structure of a tool call is correct. For example, our model should not include wrong arguments in a tool call or provide an incorrect call structure.
Trajectory accuracy looks at the sequence of tool calls made by the model when solving a problem and compares them to ground truth in some way (e.g., correct call order, correct selection, using unnecessary tools, and more).
We can also use outcome-oriented evaluation by focusing on whether the LLM’s final answer is correct instead of the tools it uses to produce an answer.
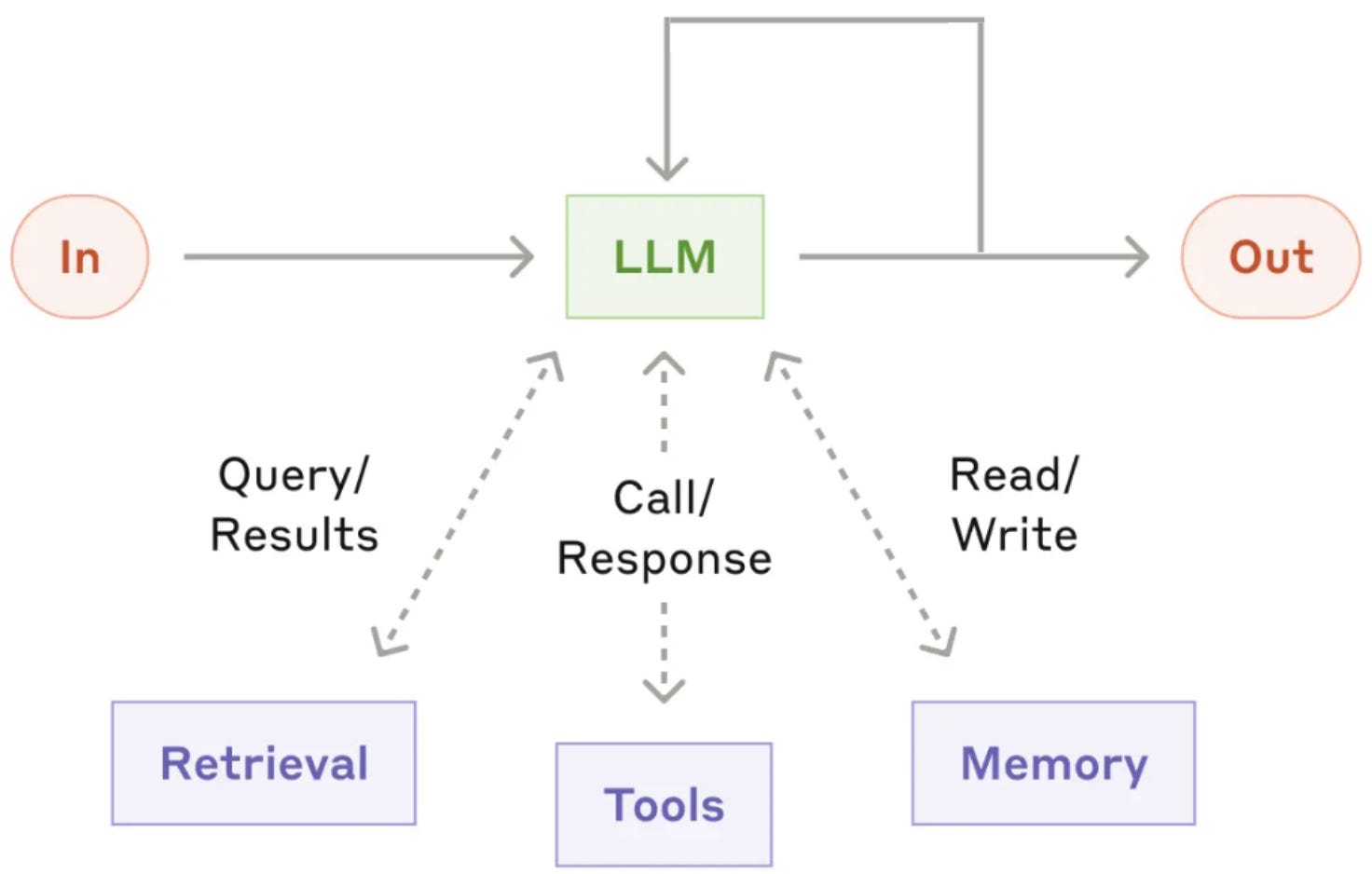
Reasoning also plays a key role in our ability to build effective agent systems. Although we can use a standard LLM as the underlying model for an agent system, we usually benefit from using a model that has reasoning capabilities. To solve multi-step tasks, an agent must be able to decompose difficult problems into smaller, simpler parts and solve each of those parts—possibly with the help of tools—to arrive at a final solution. Additionally, the model must be able to self-reflect and recover from its own mistakes while solving problems. Handling long-horizon problems in this way requires a level of reasoning and reliability that has only recently become possible with the advent of reasoning models.
Unlike a standard LLM that produces output given a prompt, reasoning models do not immediately provide an answer. Instead, they write a long—usually hidden—textual reasoning trajectory1 prior to their final answer; see above. This thinking process naturally lends itself to inference-time scaling laws. The model can be taught to dynamically reason for different lengths—often measured by the number of tokens in the reasoning trace. Longer reasoning traces require more inference-time compute, as we are generating a larger number of tokens. However, this compute investment usually leads to improved performance, allowing harder problems to be solved by allowing the model to spend more time reasoning. For more details, please see the long-form writeup on reasoning models linked below.

Reasoning models and standard LLMs do not have to be mutually exclusive. We will soon learn about multi-agent systems that can be composed of multiple LLMs or agents. For example, we could use reasoning models for high-level planning and workflow management—areas where reasoning capabilities are important—while exposing a standard LLM as a tool for simpler subtasks.
Instructions. The final component of an agent system is the agent’s instructions. The core of these instructions can be taken from existing documentation for the domain (e.g., annotation guidelines or policy documents). Instructions should be as clear as possible, clarify edge cases via explicit rules or concrete examples, and specify the exact actions expected of the agent. Ideally, instructions should strike a balance between simplicity and specificity. We want instructions to be detailed enough to reliably guide agent behavior, but prompts that are overly complex become brittle and difficult to maintain. To help with writing better instructions for an agent, we can use a model-in-the-loop approach—or an automatic prompt optimizer—to iterate upon the instructions and improve their clarity.
“The agent tended to try to do too much at once—essentially to attempt to one-shot the app… this led to the model running out of context in the middle of its implementation… the agent would then have to guess at what had happened, and spend substantial time trying to get the basic app working again.” - from [4]
Instructions for an agent should explain not only the problem being solved, but also the best strategy for solving the problem. For example, we can instruct the agent to break a problem into smaller parts to avoid trying to solve a problem that is too large in a single shot. Additionally, we can further clarify the expected behaviors of the agent in this process, such as ensuring every step of a solution is implemented as a fully functional feature, writing persistent notes that can be used as a reference by future agents, or maintaining a global to-do list.
ReAct framework. A full agent system combines all of these components together in a while loop: this is called an agentic loop. In this loop, the agent will reason, call tools, and take actions based on the provided instructions until a terminal state has been reached according to the exit conditions for the agent2. At this point, the agent will relinquish control of the workflow—either to a human user or another agent. This entire process is considered a single “run” of the agentic loop.
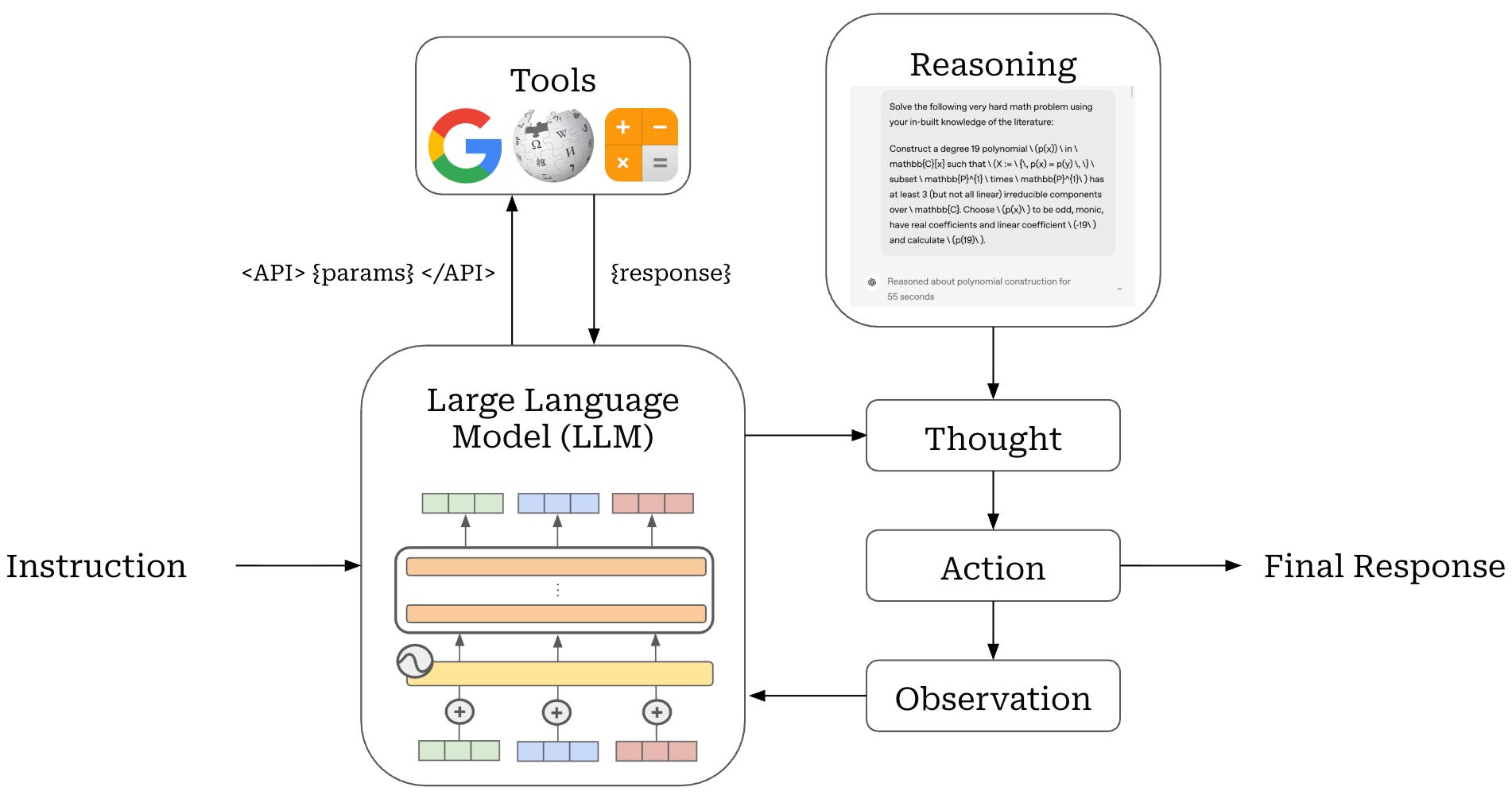
The idea of an agentic loop is simple, but many variants of this idea exist. One of the earliest variants is the ReAct—short for REasoning and ACTion—framework [5], which proposes a fixed structure for the agentic loop; see above.
The ReAct agentic loop is organized into a set of sequential steps. At each step, our agent observes the current state of the environment, reasons about the best next steps, and takes some action based upon its reasoning process. A concrete example of this iterative problem-solving framework is provided below.
Question: Musician and satirist Allie Goertz wrote a song about the "The Simpsons"
character Milhouse, who Matt Groening named after who?
Thought 1: The question simplifies to "The Simpsons" character Milhouse is named
after who. I only need to search Milhouse and find who it is named after.
Action 1: Search[Milhouse]
Observation 1: Milhouse Mussolini Van Houten is a recurring character in the Fox
animated television series The Simpsons voiced by Pamela Hayden and created by
Matt Groening.
Thought 2: The paragraph does not tell who Milhouse is named after, maybe I can
look up "named after".
Action 2: Lookup[named after]
Observation 2: (Result 1 / 1) Milhouse was named after U.S. president Richard
Nixon, whose middle name was Milhous.
Thought 3: Milhouse was named after U.S. president Richard Nixon, so the answer
is Richard Nixon.
Action 3: Finish[Richard Nixon]The key novelty of ReAct is its emphasis on both thinking and action. The agentic loop is structured such that the model explicitly reasons through each action that is taken and considers all context—such as observations from tool calls or prior thoughts—when deciding the correct action to take. Put simply, reasoning and action have a symbiotic relationship. For more details, see the full overview of ReAct and other common patterns in agentic frameworks linked below.

Multi-Agent Systems
Single-agent systems are simple and incredibly powerful when equipped with the necessary tools for solving relevant tasks. Due to the complexity of orchestrating multiple agents, we should almost always start with a single-agent design and optimize this basic setup as much as possible—single agents are easier to evaluate and maintain. We can expand the agent’s capabilities by incrementally adding more tools and conditional logic—in the form of prompt templates or modified instructions—to the system. For the agent to perform well, we should provide clear names, descriptions, and arguments for all tools, as well as detailed instructions that outline the expected actions and outcomes for a task.
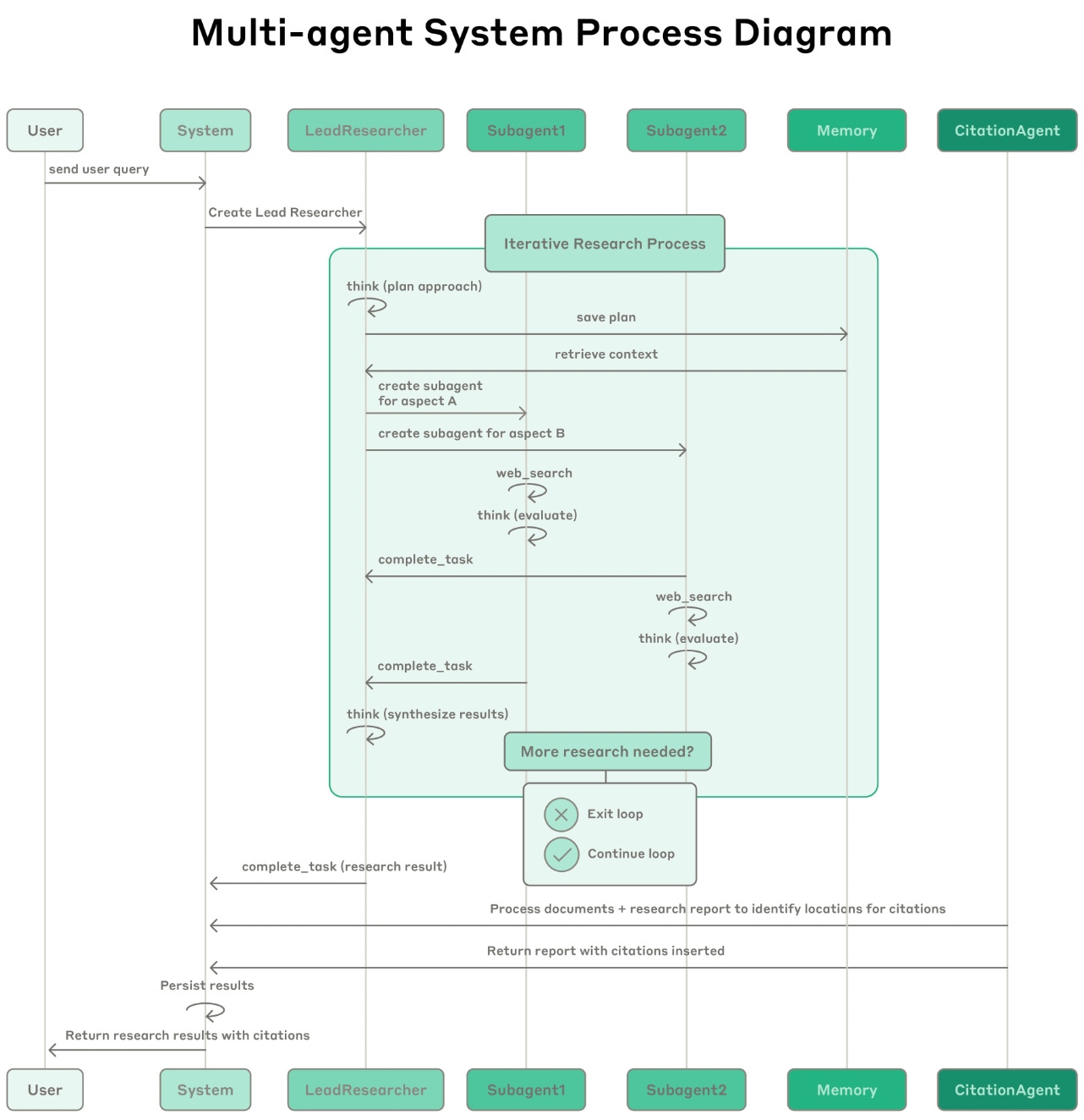
When are multiple agents needed? Multi-agent systems distribute task execution across multiple specialized agents in a coordinated fashion; e.g., see Claude’s multi-agent deep research architecture depicted above [13]. Multi-agent systems help logically separate components of a difficult task, but they are also more complex. For this reason, we should expand to multi-agent systems only when necessary. Common signs that using multiple agents may be helpful include:
Instructions for the single-agent system are bloated, and the agent is struggling to follow instructions even with clear logic or templating.
Tools are being selected incorrectly by the agent because there are too many available tools.
The reasoning capabilities of modern LLMs make it possible to properly select tools even from a large set. Issues arise when the set of tools that are available have similar or overlapping purposes, making tool selection more subjective. If this problem cannot be solved with cleaner tool specifications, splitting tools across distinct agents can lead to more accurate and reliable selection.
Types of multi-agent systems. There are many ways that one could design a multi-agent system. However, two patterns arise frequently in practice:
Manager setup: a central “manager” agent orchestrates specialized agents via tool calls, where each agent handles a specific task or domain.
Decentralized setup: multiple agents operate as peers by handing off tasks to one another based on their respective specializations.
In the manager setup, task execution is controlled by a single, centralized agent. The manager agent acts as the “glue” for solving a task by developing a problem-solving strategy, delegating parts of the work to specialized agents, and deriving a final solution by synthesizing these results. For example, a multi-agent translation system could use a manager agent to identify the requested language pairs and route each pair to a specialized translation agent; see below.

Such a manager setup is related to the concept of a sub-agent. Rather than keeping all state for a task within a single agent, we can trigger a sub-agent to handle task components. In this setup, our main agent coordinates the high-level plan for solving a task and interacts with the user, while sub-agents perform specific technical tasks (e.g., exploring code or retrieving information) and return relevant context to the main agent. Using sub-agents can help improve system reliability by preventing the main agent’s context from being overloaded.
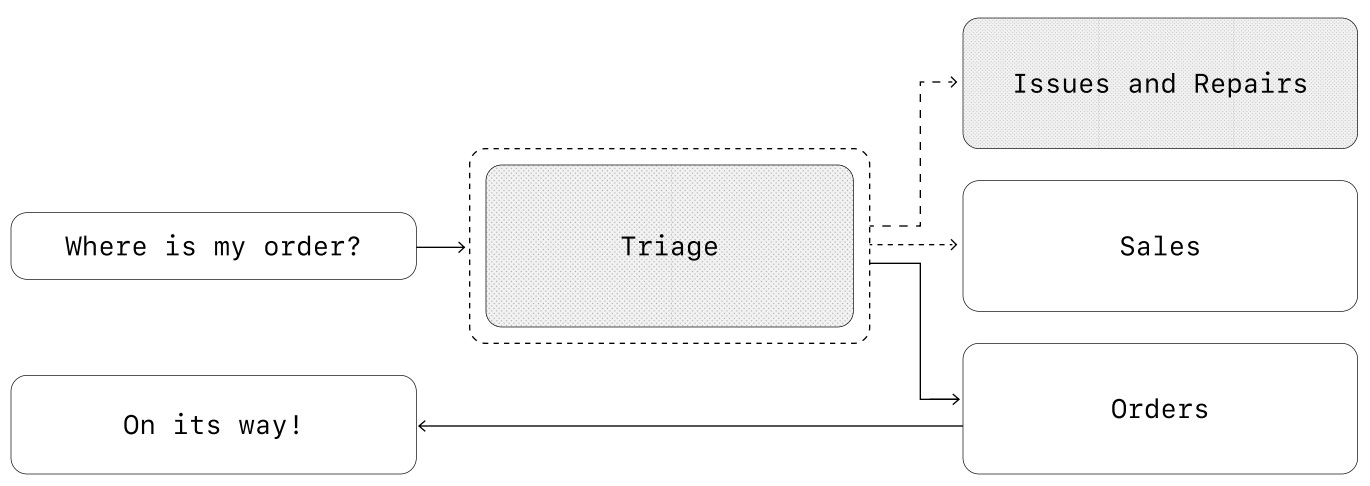
Decentralized multi-agent systems have no centralized agent to orchestrate task execution. Instead, control is passed among multiple agents that operate as peers. Agents pass control to one another via tool or function calls. Such a setup works best when we do not need a central agent to synthesize results or interact with the user. In a decentralized system, multiple different agents can control execution and interact with the user as needed. For example, we can create an agentic support system that first uses an agent to triage the issue, then passes control to a specialized agent to solve that particular type of issue; see below.
Regardless of the approach, multi-agent systems do not significantly change best practices for building with agents. We still need clear instructions and useful tools with high-quality metadata. Since we are now working with multiple agents, however, we also need to consider how the system will scale over time—adding new agents to the system should not be a burden. We should design the system in a modular fashion and ensure that the addition of new agents to the system can be accomplished without extensive changes to the remaining agents.
“Regardless of the orchestration pattern, the same principles apply: keep components flexible, composable, and driven by clear, well-structured prompts.” - from [3]
Context Engineering
Prompt engineering has always been a key consideration when working with LLMs. When working with agents, however, the prompt engineering process is slightly different. Agents have the ability to perform a wide variety of actions—such as writing to a file or calling an API—via tool calling, creating a large scope of data sources that can exist within the LLM’s context window; see below.
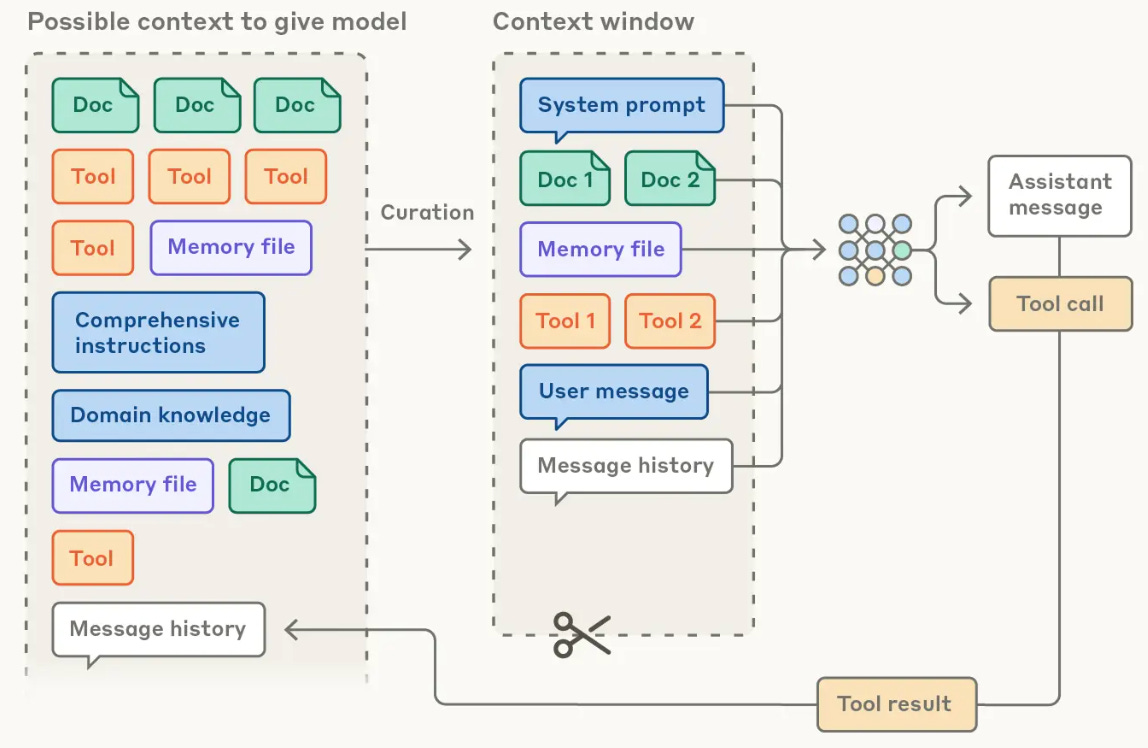
These data sources expand over time because the agent runs within an agentic loop. Although modern LLMs are fast and support long context (i.e., millions of tokens), context rot is a universal problem. As the number of tokens in an agent’s context grows, models are less capable of accurately recalling information. For this reason, we must actively refine the contents of an agent’s context in order for the agent to continue performing well. The context cannot become too large or polluted with irrelevant information. This process is commonly referred to as context engineering—an agent-centric version of prompt engineering.
“We view context engineering as the natural progression of prompt engineering. Prompt engineering refers to methods for writing and organizing LLM instructions for optimal outcomes. Context engineering refers to the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference, including all the other information that may land there outside of the prompts.” - from [2]
Dynamic context. When using conventional LLMs, we often load static context into the model. For example, techniques like Retrieval-Augmented Generation (RAG), which retrieves chunks of information that are concatenated into the LLM’s context window, are very popular. Despite being effective, RAG is a static approach: the model retrieves all necessary information for answering a question and adds this information to the context window before attempting to answer the question. Due to their tool-calling abilities, agents use a more dynamic approach based on progressive disclosure. Instead of pre-loading all relevant context, the agent explores and dynamically decides when new context is necessary.
To avoid context rot, the tools used by our agent to retrieve context should be designed in a token-efficient manner. For example, when reading a file, the agent can read specific line numbers or just preview the head of the file instead of always loading the full file into context. If the tools for our agent are designed correctly, then the agent can dynamically discover context in a way that proactively avoids context rot. The agent uses tools in a purposeful manner and retrieves only the information necessary to solve a problem at runtime.
Compaction. Unlike conventional LLMs, agents run for multiple turns to solve long-horizon tasks. Across these many turns, the agent will reason, call tools, self-reflect, and more, thus rapidly expanding its context. However, we must develop techniques to efficiently manage this context because the underlying LLM has a finite context window. Compaction is the most common category of techniques to use for this purpose, and there are several forms of compaction that exist:
Summarization: generating a summary of a long conversation with an LLM and reinitializing a fresh context window with this shorter summary.
Tool result clearing: removing the output payload of older tool calls within the agent’s conversation history.
Note-taking: writing notes to an external data store (e.g., a markdown file) that can later be accessed by the agent when needed.
Note-taking is not just a compaction technique—the agent can maintain notes while solving a problem even without performing compaction. This is an incredibly effective technique for improving performance while efficiently managing the agent’s context; see this paper for details. For example, an agent could create a to-do list to plan a solution and track progress, record design principles used in one part of a solution to aid future consistency, or write experimental results to its own lab notebook when running autonomous experiments. Note-taking is also useful when performing compaction because an agent can create detailed notes of relevant context while compacting its conversation history.
“We implement this by passing the message history to the model to summarize and compress the most critical details. The model preserves architectural decisions, unresolved bugs, and implementation details while discarding redundant tool outputs or messages. The agent can then continue with this compressed context plus the five most recently accessed files.” - from [2]
There is no single compaction technique that works best, each technique has its own benefits:
Summarization retains a smooth conversational flow in a long session but can lose important information when generating the summary.
Tool clearing is less likely to lead to a loss of essential information but cannot alone ensure that the context window will not be exhausted.
Note-taking allows the agent to maintain knowledge stores outside of its own context, but agents can struggle to leverage this external context properly.
The high-level idea of context engineering is simple: remove irrelevant context and retain context that will be needed in the future. Unfortunately, predicting the future utility of information in the agent’s context is difficult and task-dependent. To determine the best approach for methods like compaction, we must build robust benchmarks for our agent that measure these capabilities realistically.
Agent Scaffolds

Now that we understand the structure of an agent, we see that agent systems build directly on the standard LLM interface. We just extend LLM capabilities to better facilitate reasoning and problem solving with the help of external tools. As agent capabilities have improved over time, however, the design of the system surrounding the agent—the tools, instructions, environment, problem-solving strategy, and more—has become more intricate. Collectively, the components and framework used to run an agent are called an agent scaffold.
“An agent harness (or scaffold) is the system that enables a model to act as an agent: it processes inputs, orchestrates tool calls, and returns results. When we evaluate an agent, we’re evaluating the harness and the model working together.” - from [1]
What does a scaffold do? ReAct is one example of a basic scaffold, but there are many other design details that can be considered when setting up an agent system. For example, different agent scaffolds may change the following:
The agent’s interface with the environment. For example, some terminal agents may be given specialized tools for manipulating the terminal, while others (e.g., the Terminus agent depicted above) may output keystrokes directly to the terminal—similarly to a human.
The prompting strategy for the agent; e.g., the scaffold may tell the agent to inspect files before editing, break a problem down into steps, check its own work before completing, and more.
The tools available to the agent and their respective interfaces—including the documentation for the tool and the output the agent sees after each command.
The structure of the agent system; e.g., the agent may leverage sub-agents or a multi-agent setup for different parts of a solution.
The context management strategy used by the agent to solve long-running problems with a limited context window.
Performance impact. Given that scaffolds control the interface between agents and the task being solved, decoupling model and agent performance is difficult. Poor performance may stem from deficient model capabilities, poor scaffold design, or both. When we evaluate an agent, we are evaluating the ability of the model and scaffold to work together to solve a task. The scaffold being used has a significant performance impact. Less capable models often perform better when paired with scaffolds that accommodate their particular tendencies and vice versa. Next, we will dive deeper into the various components of agent evaluation and how we can reliably measure the performance of these systems.
Common Patterns in Agent Evaluation
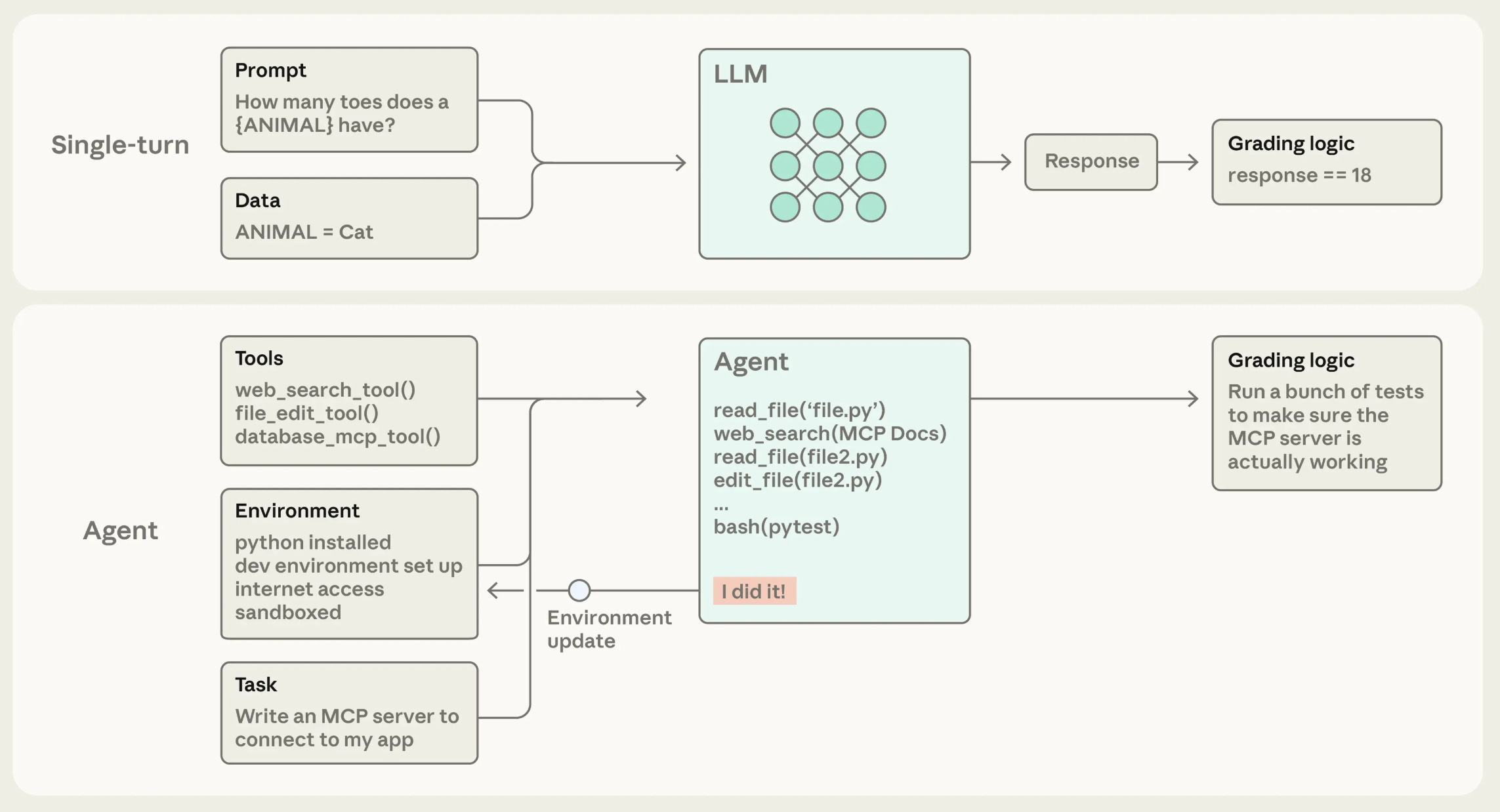
An evaluation is a set of tests that provide inputs to our agent system, collect outputs, and apply grading logic to determine whether the agent was successful. We evaluate an agent system by creating an evaluation suite of diverse tests that reflect the ways that the agent can be used in the real world. Agent evaluations are different from the single-turn benchmarks that have traditionally been used to evaluate LLMs. As shown above, agent evaluations involve interacting with tools and the external environment over multiple chat turns to accomplish a task. To handle such long-running and interactive evaluations, we must create an evaluation harness that manages the entire end-to-end process.
Agent Evaluation Components
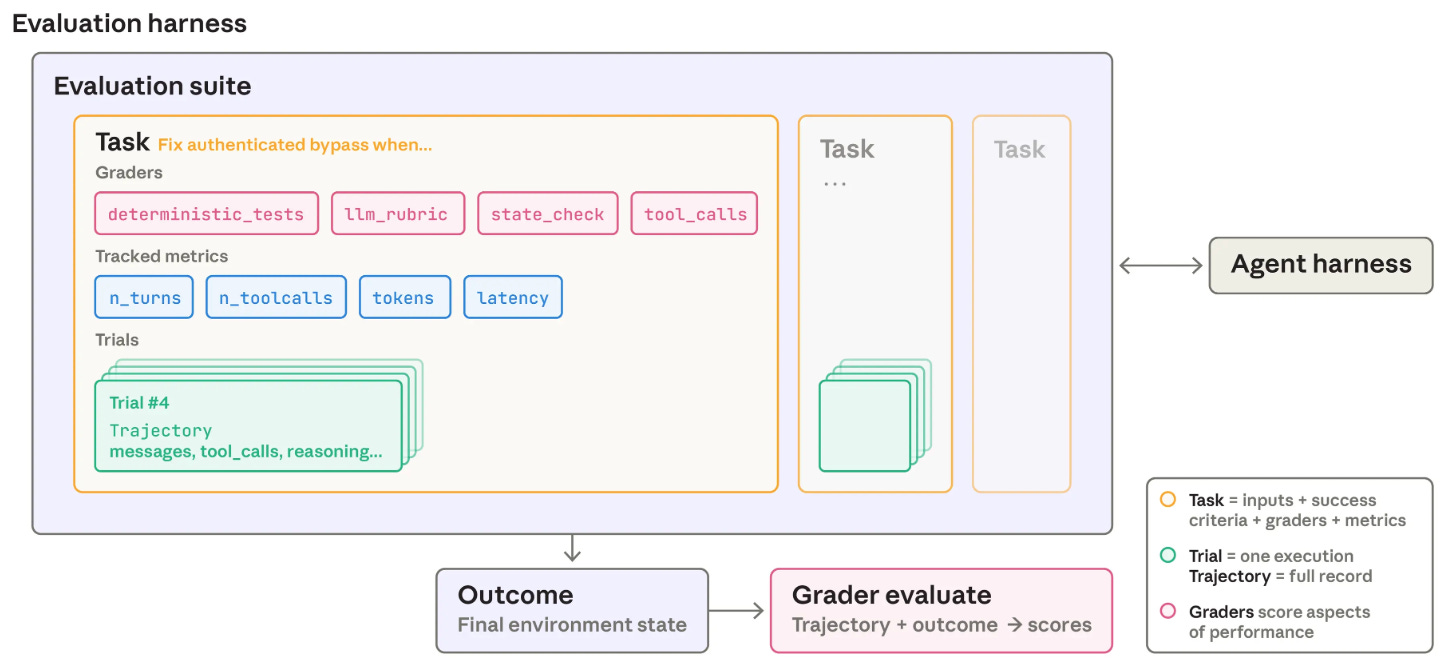
Given that agents can be applied to a wide variety of tasks, evaluation strategies differ depending on the application. However, there are shared components (shown above) that will appear across any evaluation:
The evaluation consists of several tasks, or individual test cases for the agent with predefined input and output criteria.
Each attempt at solving a task is called a trial, and we often run several trials for each task to ensure consistent results.
As the agent completes a trial, it produces a transcript—also known as a trace or trajectory—that includes outputs, tool calls, reasoning steps, intermediate outputs, or any other interactions from the agent during the trial.
The final state of the external environment after a trial completes is referred to as the outcome for that trial.
A grader is used to evaluate the result of a trial by applying applying checks that verify specific aspects of the agent’s transcript or outcome.
A task may have multiple graders, and we usually compute performance metrics by aggregating across tasks and trials. Outcomes are distinct from outputs because they refer to the final state of the external environment, not just the text produced by the agent. If we are testing the ability of an agent system to book a reservation, the desired outcome is a confirmed reservation. An agent may write “The restaurant is booked!” without actually achieving this outcome.
Different Types of Graders
Graders take the transcript and outcome of a trial as input and perform quality checks over some portion of these assets. Many types of graders can be used to measure an agent’s success rate, and the best choice of grader is application-dependent. Human evaluation is the definitive source of truth for measuring quality, so many projects start with simple human evaluations—such as manual inspections or vibe checks that become more rigorous over time—as a first step. However, collecting human feedback can be difficult and expensive. Automatic evaluation techniques are adopted to make experimentation more efficient. Some tasks are easy to verify deterministically (e.g., using a Python function or some heuristic), while others require an open-ended approach like an LLM judge.
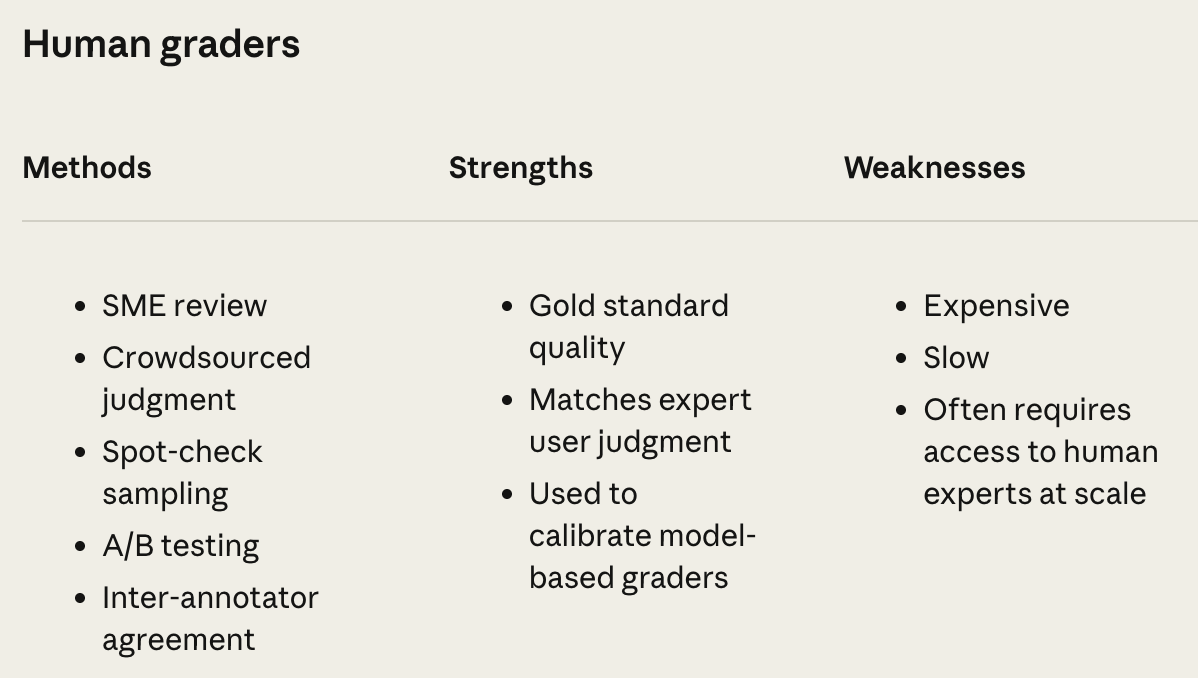
Human evaluation is the north star for an agent system. We can start the human evaluation process simply, with manual inspections performed by the researchers developing the model or by internal users who can provide quick feedback. To do this, we create guidelines or a rubric to define the key quality dimensions and how these criteria should be evaluated (e.g., using a pass-fail or Likert score). Human feedback signals can be very useful in the early stages of development. In fact, the creators of Claude Code mention that their evaluation process began with human evaluation trials with internal Anthropic employees. These tests capture basic trends in agent capabilities and enable fast iteration before investing in creating a more comprehensive evaluation suite.
“Claude Code started with fast iteration based on feedback from Anthropic employees and external users. Later, we added evals—first for narrow areas like concision and file edits, and then for more complex behaviors like over-engineering. These evals helped identify issues, guide improvements, and focus research-product collaborations.” - from [1]
To collect high-quality human feedback at scale, we must calibrate the human evaluation process. We want the results of human evaluation to be accurate and consistent, as judged by the level of agreement between humans; see below. Some tasks are more objective, making calibration less difficult. However, evaluation tends to contain a lot of subjectivity—human evaluators rarely agree with each other without investing effort into refining the annotation guidelines and process. Therefore, even though human evaluation is still the gold standard for assessing the quality of our agent system, we must invest a lot of effort into ensuring data quality over time. Given that human evaluation is also slow and expensive, we would benefit from developing alternative approaches that enable faster model iterations.

Automatic graders can be roughly categorized into two groups:
Code-based: heuristic checks that can be captured in a Python function.
Model-based: open-ended checks that are based on an LLM judge.
Examples of code-based graders include string matching and assertions on the agent’s outcome or transcript. For math problems, we can check if the agent’s final answer matches ground truth or even enforce a strict upper limit on token usage and chat turns. Similarly, we can run predefined test cases for coding problems or check whether specific tools were called somewhere in the agent’s transcript. There are also a variety of traditional evaluation metrics (e.g., ROUGE or BLEU) that we can leverage. These are all deterministic quality checks that one can easily implement and execute within a basic Python function.
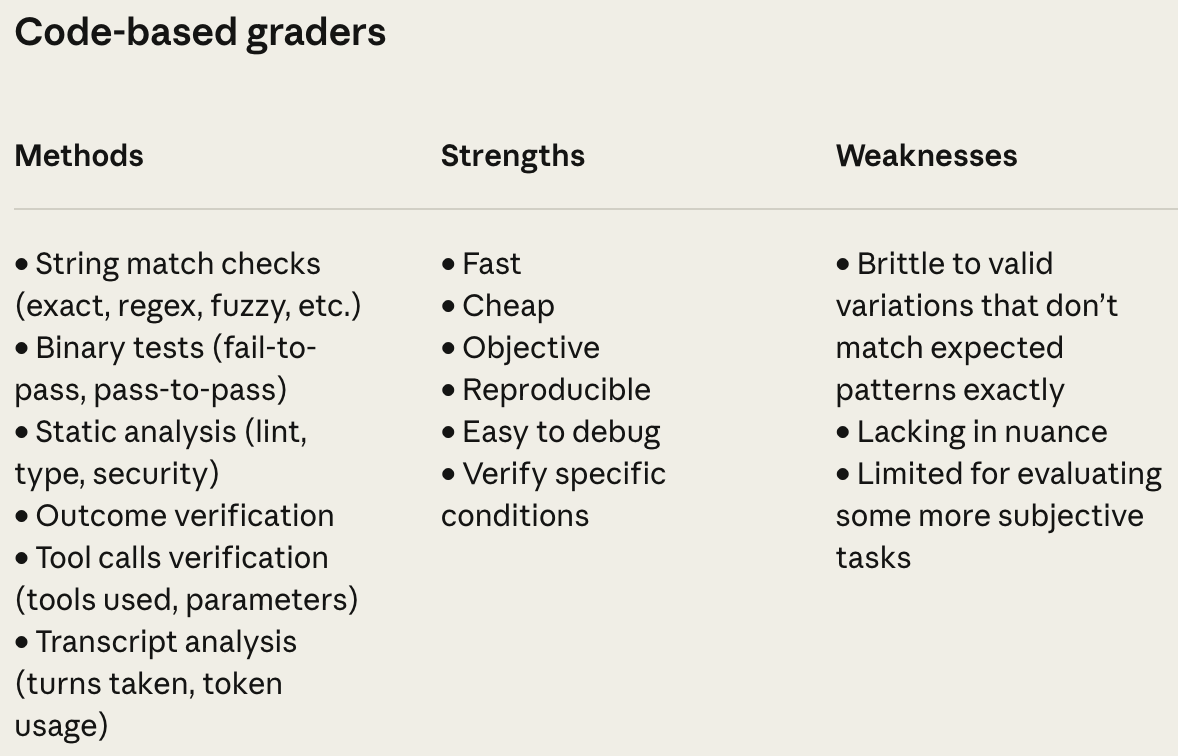
Code-based graders have many benefits—they are efficient, reproducible, and easy to debug. However, code-based graders also have drawbacks:
They are often reference-based (i.e., grading requires access to ground truth).
They are inflexible and can lack nuance, making them somewhat limited.
More specifically, code-based graders can struggle to capture more subjective aspects of agent behavior. For example, checking whether code written by an agent passes test cases is objective and—assuming ground truth test cases have been provided—can be handled with a code-based grader. Judging whether the code is sufficiently clean or elegant, on the other hand, is subjective. To grade such open-ended and subjective criteria, we need model-based graders.
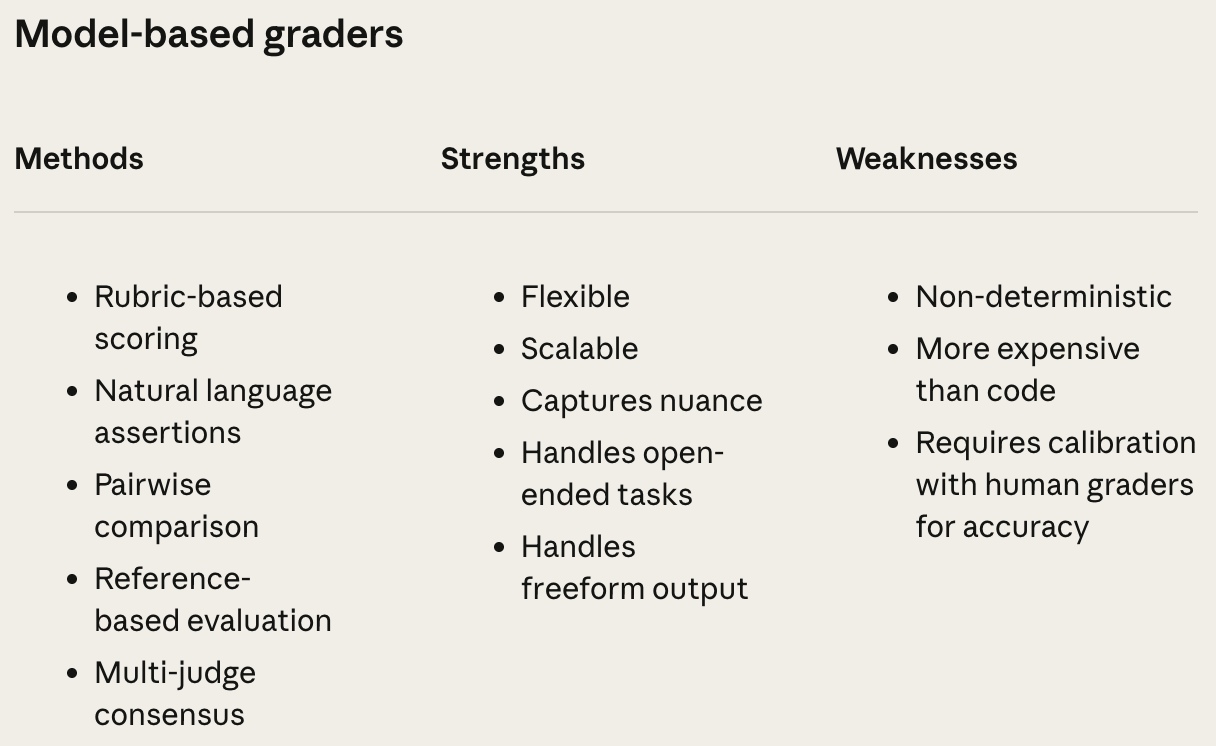
The idea of a model-based grader is simple: we just prompt an LLM to evaluate some aspect of quality for us. This approach, known as LLM-as-a-Judge [7], is universally used in the evaluation process for both conventional LLMs and agent systems. Extensive research has been conducted to determine best practices for LLM judges. From this work, several popular scoring setups for LLM-as-a-Judge have emerged (shown below):
Pairwise (preference) scoring: the judge is presented with a prompt and two model responses and asked to identify the better response.
Direct assessment (pointwise) scoring: the judge is given a single response to a prompt and asked to assign a score; e.g., using a 1-5 Likert scale.
Reference-guided scoring: the judge is given a golden reference response in addition to the prompt and candidate response(s) to help with scoring.
Notably, reference-guided scoring can be used with both pairwise and direct assessment setups. Although this list is not exhaustive, most LLM-as-a-Judge scoring setups follow some variant or combination of these techniques.

To get the best results with LLM-as-a-Judge, evaluation criteria—as conveyed through the prompt of the LLM judge—should be as clear as possible. In recent research, prompting LLM judges with itemized rubrics for evaluation has even become popular, where such rubrics contain dozens of evaluation criteria that are individually assessed with an LLM. Decomposing model-based evaluation into many detailed checks that can be separately judged with an LLM improves scoring reliability. For more details on LLM-as-a-Judge, see the overview below.

Multiple graders. Despite their effectiveness, LLM judges are not perfect. They are non-deterministic, subject to several well-known biases, and more expensive than code-based graders. For these reasons, we should not rely solely on model-based graders—it is better to use multiple grading techniques together. Assuming we have created high-quality guidelines and have access to a trained workforce, human evaluation serves as the core evaluation signal for an agent system. To help make this evaluation process more scalable, we can calibrate model-based graders based on their agreement with human evaluation and use these models to run more efficient evaluations at scale. We should always monitor agreement between model and human evaluation to avoid degradations in evaluation accuracy.
“Given the subjective nature of research quality, LLM-based rubrics should be frequently calibrated against expert human judgment to grade these agents effectively… Reserve systematic human studies for calibrating LLM graders or evaluating subjective outputs where human consensus serves as the reference standard.” - from [1]
Code-based graders can also be used for more deterministic or narrow checks that do not require model-based graders. We can examine the results of these graders separately, but it is often helpful to create a single, top-level evaluation metric to simplify tracking and interpretation. To do this, we can create a single composite metric that combines each grader’s result using predefined weights. The weights used for aggregation will be unique to each evaluation suite and domain being considered. We can report the weighted score directly or by applying a threshold to the weighted score to derive a top-level pass rate.
Broader Categories of Evaluation
“Effective teams combine methods: automated evals for fast iteration, production monitoring for ground truth, and periodic human review for calibration.” - from [1]
The discussion in this overview will largely focus on automatic evaluation, but this is just one technique among many. For example, we have already touched on the symbiotic relationship between human and automatic evaluation, where human evaluation is used as a source of calibration. For real production systems, there are several additional sources of evaluation that we can use:
Manual inspection (or vibe checks).
Production monitoring of reported errors and key usage metrics or outcomes.
A/B testing (i.e., splitting traffic across multiple model variants and comparing their production monitoring metrics).
Explicit user feedback; e.g., thumbs up or thumbs down feedback, written comments, or even formally organized user studies.
Cost metrics (e.g., token usage, money spent, speed, and more).
Each of these techniques has pros and cons. Automatic evaluations require a lot of up-front investment to build the evaluation suite but capture open-ended aspects of model behavior and can be efficiently executed whenever needed. In contrast, methods like production monitoring or A/B testing can measure real user behavior but are reactive3, slow, and noisy. The best approach is to combine all of these techniques, forming a “Swiss Cheese” strategy; see below. Although a single evaluation will not catch every error, the likelihood of any error reaching production decreases with more layers of complementary evaluations.
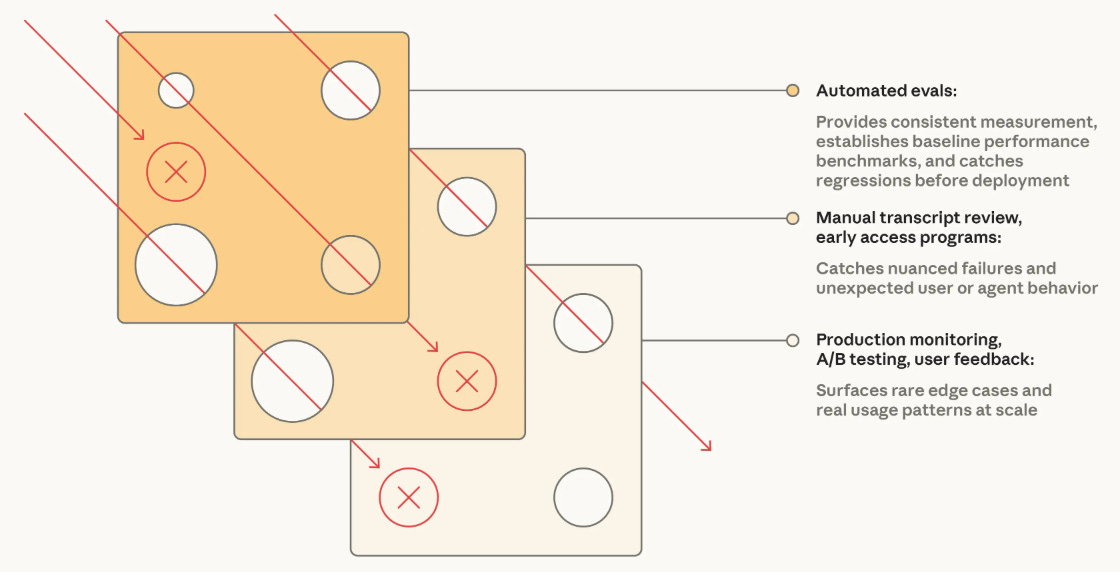
Agent Evaluation Case Studies
We will now apply our understanding of agents and evaluation to several case studies of popular agent evaluations. Notably, we will primarily focus on more recent agent benchmarks in this section, but there are numerous prior datasets that would also be useful to study. In this discussion, we will see that while the low-level details of each benchmark may vary significantly, most benchmarks share the same design patterns and components that we outlined earlier.
The τ-bench Series
“We propose τ -bench, a benchmark emulating dynamic conversations between a user (simulated by language models) and a language agent provided with domain-specific API tools and policy guidelines.” - from [8]
τ-bench [8] evaluates agents via dynamic, multi-turn user conversations in real-world domains. To start, two specific domains—retail and airline—are selected based on their simplicity4 and application to real-world scenarios. In each of these domains, agents are expected to do the following:
Interact with the user and resolve intent.
Adhere to a set of written policies or rules for each domain.
Use tools to retrieve data and modify the external environment.
The goal of this benchmark is to capture difficult user interactions that unfold over a long time horizon and require the agent to take concrete actions on behalf of the user. Similar to tasks that an agent would accomplish in the real world, information needed to solve tasks in τ-bench is not fully provided to the agent up front and must be discovered via conversation with the user. The agent must use this information—and its set of available tools—to fulfill the user’s intent. Real conversations with human users would make scaling the evaluation process difficult, so all user interactions in τ-bench are simulated with an LLM.

Evaluation framework. As illustrated above, τ-bench is built according to a modular framework with four key components:
Multiple databases per domain with JSON-formatted entries; e.g., see these database examples for the airline and retail domains.
APIs for interacting with (i.e., reading from or writing to) these databases with tool calls of the form
tool_name(**kwargs).Domain-specific policy documents that contain rules and procedures the agent must adhere to when solving airline and retail tasks.
An LLM-powered user simulator that interacts with the agent.
The user simulator LLM is given an initial system prompt with instructions for the task being solved and synthesizes user interactions from these instructions. These instructions must be sufficiently precise to ensure that there is only one viable outcome per task; see below for an example. Simulated users interact with the agent using textual messages—similarly to a human user—in a loop until the user outputs the sequence ###STOP###, signaling the end of that trial.
“You are Yusuf Rossi in 19122. You received your order #W2378156 and wish to exchange the mechanical keyboard for a similar one but with clicky switches and the smart thermostat for one compatible with Google Home instead of Apple HomeKit. If there is no keyboard that is clicky, RGB backlight, full size, you’d go for no backlight. You are detail-oriented and want to make sure everything is addressed in one go.” - source
The APIs used to interact with databases in τ-bench are more than basic read-write interfaces. A collection of tools for executing relevant database operations (e.g., canceling an order, listing products, finding a user ID, etc.) is provided to the agent. These tools are exposed to the agent using a standard tool-calling scaffold. The core code for the agentic loop in τ-bench has been copied below for reference. As we can see, each completion sampled from the agent receives all tool definitions, as well as a set of prior messages that includes the domain-specific policy document (or wiki). The prompt—including all messages and tool definitions—is converted into an OpenAI-compatible format using LiteLLM.
# Copyright Sierra
# Source: https://github.com/sierra-research/tau-bench/blob/main/tau_bench/agents/tool_calling_agent.py
import json
from litellm import completion
from typing import List, Optional, Dict, Any
from tau_bench.agents.base import Agent
from tau_bench.envs.base import Env
from tau_bench.types import SolveResult, Action, RESPOND_ACTION_NAME
class ToolCallingAgent(Agent):
def __init__(
self,
tools_info: List[Dict[str, Any]],
wiki: str,
model: str,
provider: str,
temperature: float = 0.0,
):
self.tools_info = tools_info
self.wiki = wiki
self.model = model
self.provider = provider
self.temperature = temperature
def solve(
self, env: Env, task_index: Optional[int] = None, max_num_steps: int = 30
) -> SolveResult:
total_cost = 0.0
env_reset_res = env.reset(task_index=task_index)
obs = env_reset_res.observation
info = env_reset_res.info.model_dump()
reward = 0.0
messages: List[Dict[str, Any]] = [
{"role": "system", "content": self.wiki},
{"role": "user", "content": obs},
]
for _ in range(max_num_steps):
res = completion(
messages=messages,
model=self.model,
custom_llm_provider=self.provider,
tools=self.tools_info,
temperature=self.temperature,
)
next_message = res.choices[0].message.model_dump()
total_cost += res._hidden_params["response_cost"] or 0
action = message_to_action(next_message)
env_response = env.step(action)
reward = env_response.reward
info = {**info, **env_response.info.model_dump()}
if action.name != RESPOND_ACTION_NAME:
next_message["tool_calls"] = next_message["tool_calls"][:1]
messages.extend(
[
next_message,
{
"role": "tool",
"tool_call_id": next_message["tool_calls"][0]["id"],
"name": next_message["tool_calls"][0]["function"]["name"],
"content": env_response.observation,
},
]
)
else:
messages.extend(
[
next_message,
{"role": "user", "content": env_response.observation},
]
)
if env_response.done:
break
return SolveResult(
reward=reward,
info=info,
messages=messages,
total_cost=total_cost,
)
def message_to_action(
message: Dict[str, Any],
) -> Action:
if "tool_calls" in message and message["tool_calls"] is not None and len(message["tool_calls"]) > 0 and message["tool_calls"][0]["function"] is not None:
tool_call = message["tool_calls"][0]
return Action(
name=tool_call["function"]["name"],
kwargs=json.loads(tool_call["function"]["arguments"]),
)
else:
return Action(name=RESPOND_ACTION_NAME, kwargs={"content": message["content"]})Tool calls within the agent’s output are extracted and used to form actions that can be executed within the external environment. These actions are incorporated into the transcript and the loop continues until a terminal state is reached. An illustration of the τ-bench setup with an example transcript is provided below.

Measuring success. For each domain, a diverse set of tasks are created using a three-step model-in-the-loop process with human oversight:
Database schemas, APIs, and policy documents are manually co-designed by humans with the help of an LLM.
A data schema is set up for each database with an example entry, and an LLM is used to automatically populate the database with more synthetic entries.
Tasks are manually co-designed by humans and an LLM. We begin with an initial instruction, test it, and refine it by examining agent transcripts and fixing ambiguities.
Each task has i) an instruction for the user simulation, ii) an annotation of the ground truth database write actions, and iii) an annotation of the ground truth outputs for user questions. We can determine whether an agent successfully completes a task based on whether these ground-truth actions and outcomes match the transcript and outcome for our agent. For example, in the prior example of returning a water bottle, we can check the following:
The agent performs a write action to return the correct order items using the correct payment method.
The agent outputs the strings
54.04and41.64, which are the two prices involved in the user’s transaction.
This outcome verification approach that checks whether an agent has completed a task is not perfect; e.g., the agent may issue a refund without ever being directly asked to do this by the user. By using this approach, however, we ensure each task has clear pass-fail criteria that can be measured objectively. Authors choose to not evaluate subjective aspects of agent behavior—such as the quality of the conversation—to make the evaluation process more reliable. All retail and airline tasks are publicly available. Manually inspecting these tasks can help to build intuition for the types of skills being tested by the benchmark.
Handling non-determinism. Each trial in τ-bench is stochastic: the simulated user and the agent sample completions, so the same task can lead to different transcripts. To account for this variation, τ-bench runs multiple independent trials for each task, and we can compute several different performance metrics from these trials. For example, Pass@K measures if an agent should solve a task at least once across K independent attempts. We estimate this metric by running n trials and computing the metric as shown below based upon the number of successful attempts.
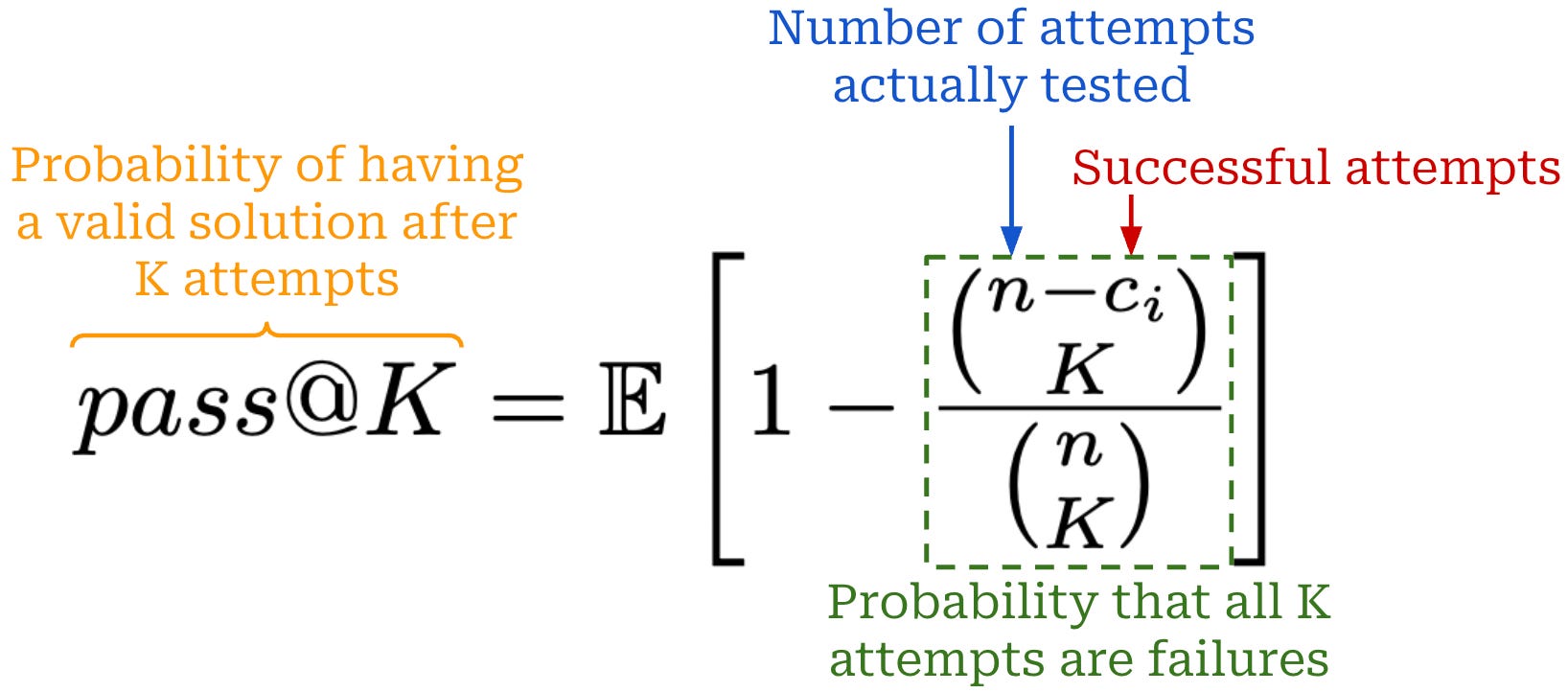
Although prior work typically evaluates LLMs with Pass@k, agents have unique requirements. Each user may present a task to the agent differently, and the agent must adapt to these variations in a task. We want to ensure that the agent is not brittle by measuring whether the agent can consistently solve the task across multiple independent trials. To capture agent robustness, authors in [8] propose the stricter Pass^k metric that measures the probability that the agent succeeds on all K independent attempts. Similarly to Pass@K, we compute Pass^K by running n independent trials and evaluating the expression outlined below.
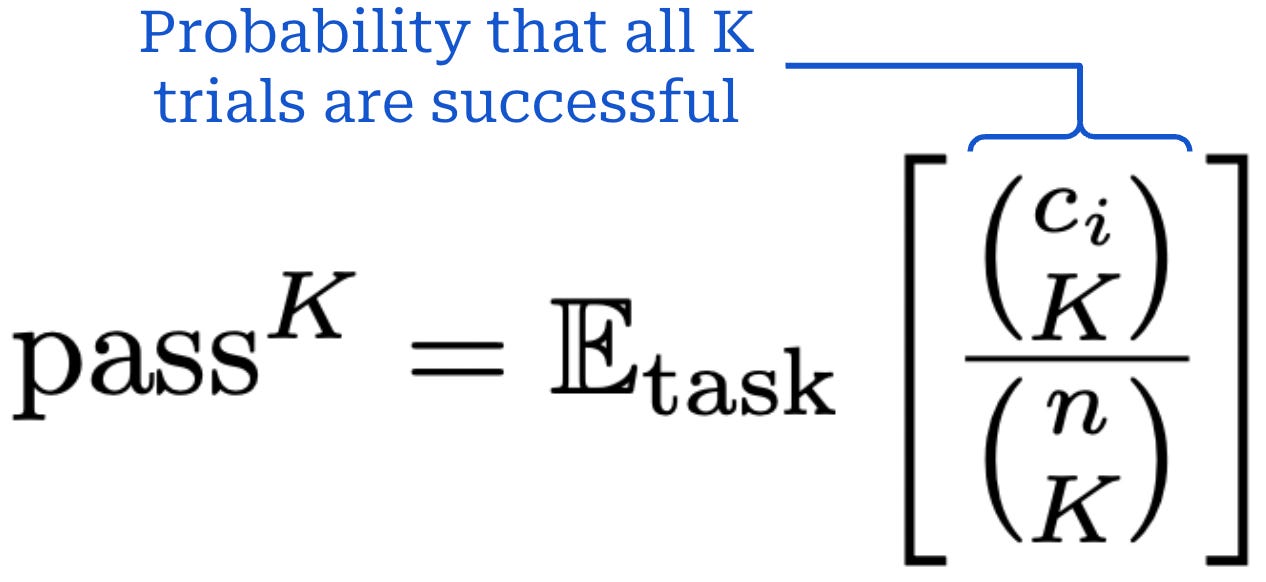
“For real-world agent tasks requiring reliability and consistency like customer service, we propose a new metric – pass^k (pass hat k), defined as the chance that all k i.i.d. task trials are successful, averaged across tasks.” - from [8]
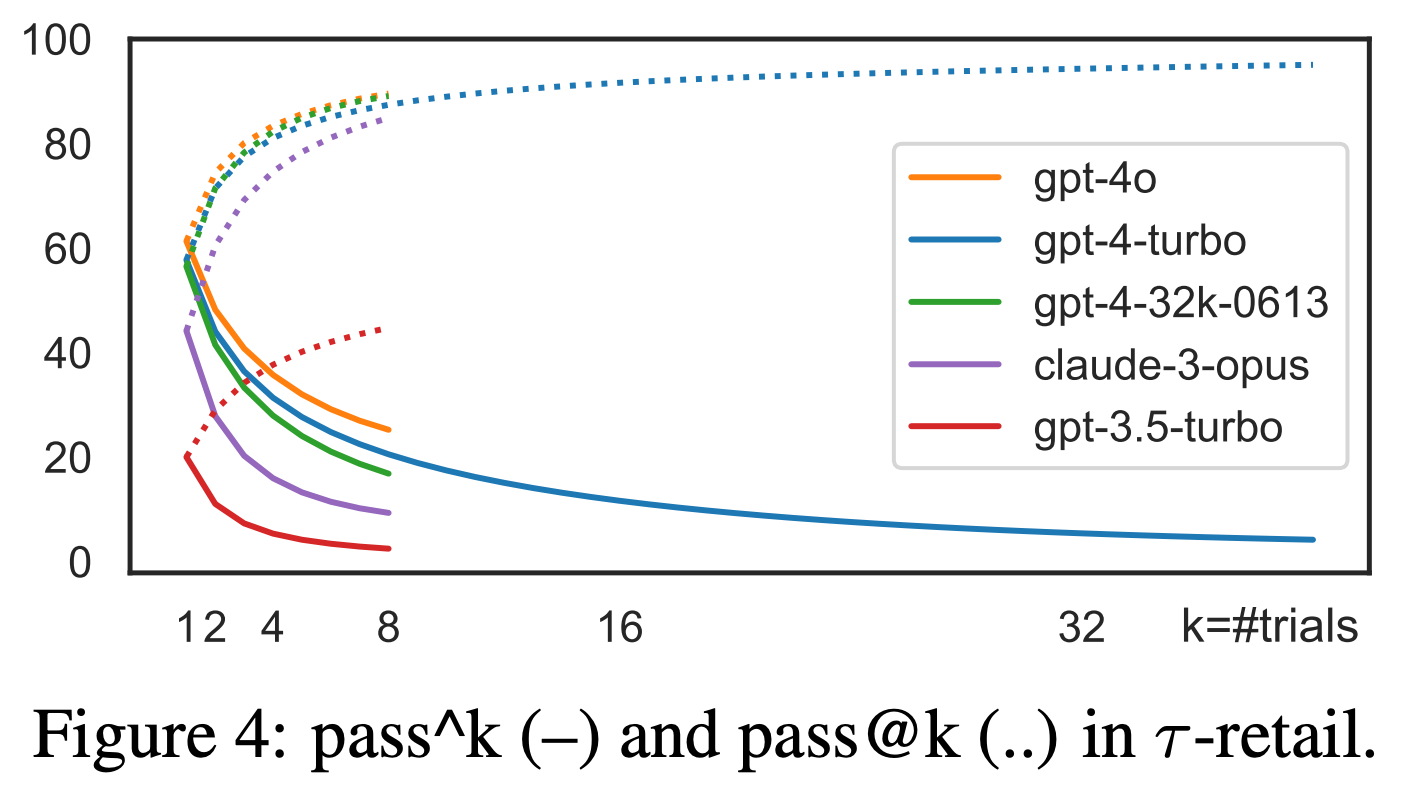
Pass^K declines quickly as the value of K increases, while Pass@K increases as K increases; see below. The Pass^K metric is less forgiving and captures the ability of an agent to perform consistently across all trials. Interestingly, most agents perform poorly in terms of Pass^K, even for relatively modest values of K. The motivation for using Pass^K in agent evaluations is clear. Unfortunately, however, most recent benchmarks—even those that were released after τ-bench—do not use this metric. Performance is more commonly reported in terms of Pass@K or Avg@K (i.e., the average success rate when running K trials for a task).
τ^2-bench. In the original τ-bench, the user interacts with the agent via natural language and only the agent possesses tools. However, real-world tasks may require active participation from the user. For example, solving a customer support task may require that the user performs some troubleshooting in collaboration with the agent. To capture this added complexity, τ^2-bench evaluates agents with a dual-control setup, where both users and agents can interact with a shared external environment via tools; see below. Proper tool design is pivotal for this collaborative problem-solving setup—the user must possess meaningful agency but still require support from the agent to solve issues.
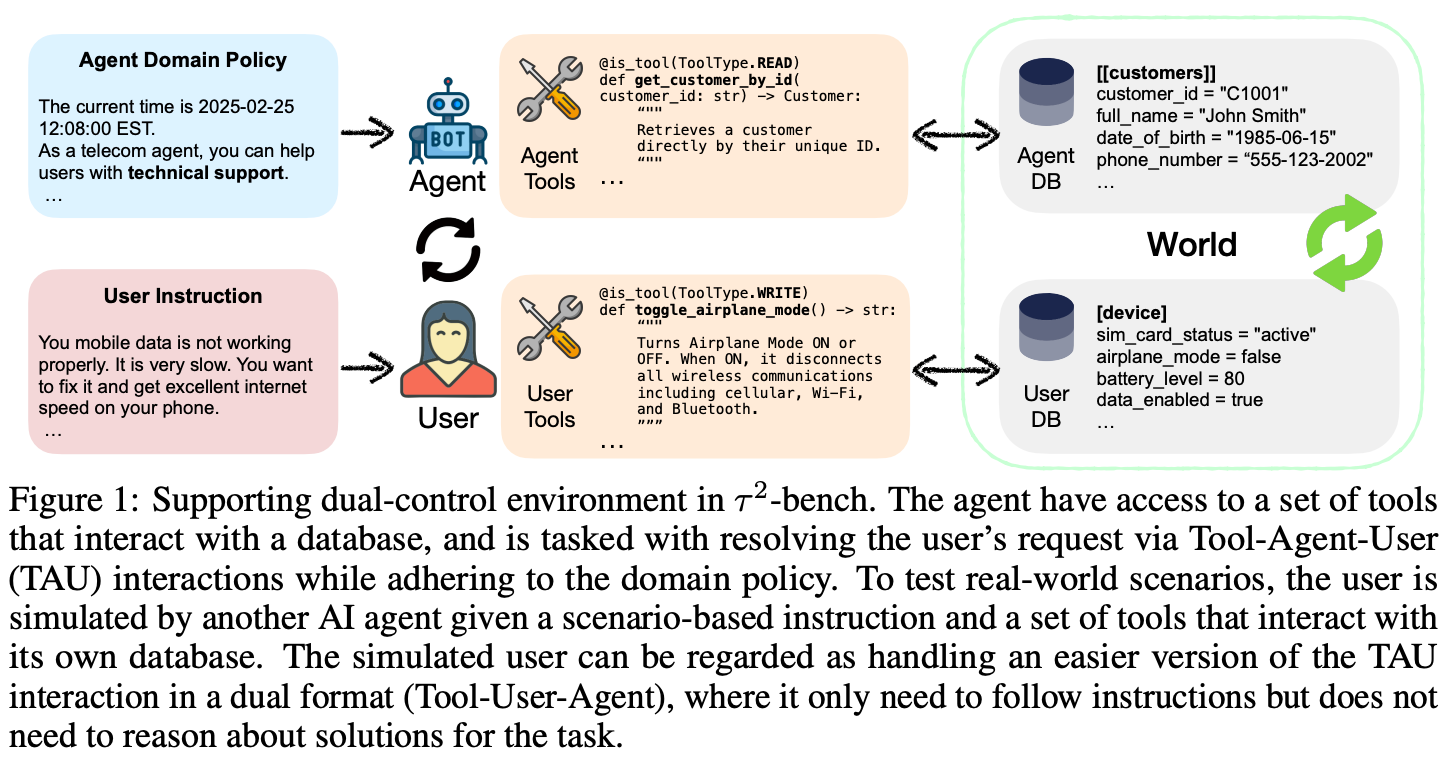
As a demonstration of this setup, τ^2-bench creates a new Telecom domain for agent evaluation. The initial steps of creating the benchmark mirror the task curation strategy for τ-bench. Separate databases and tools are created for the agent and user by prompting an LLM to create a product requirement document that outlines domain-specific business logic. This document specifies database schemas and tools, which are implemented by an LLM and refined by humans. For example, the telecom domain requires the creation of a CRM for the agent and a mock phone device for the user with associated tools.
From here, tasks are generated for τ^2-bench by creating atomic subtasks that can be combined to form more difficult composite tasks. Put simply, subtasks introduce issues into the environment that can be solved by an agent. Each subtask is comprised of three key components:
Initialization functions: these are functions that are executed prior to a trial that create the issue within the environment.
Solution tools: these are the tools that need to be called by the user or the agent in order to resolve the problem.
Assertions: these are deterministic checks—similar to those used in τ-bench—that are run to determine if the problem has been resolved.
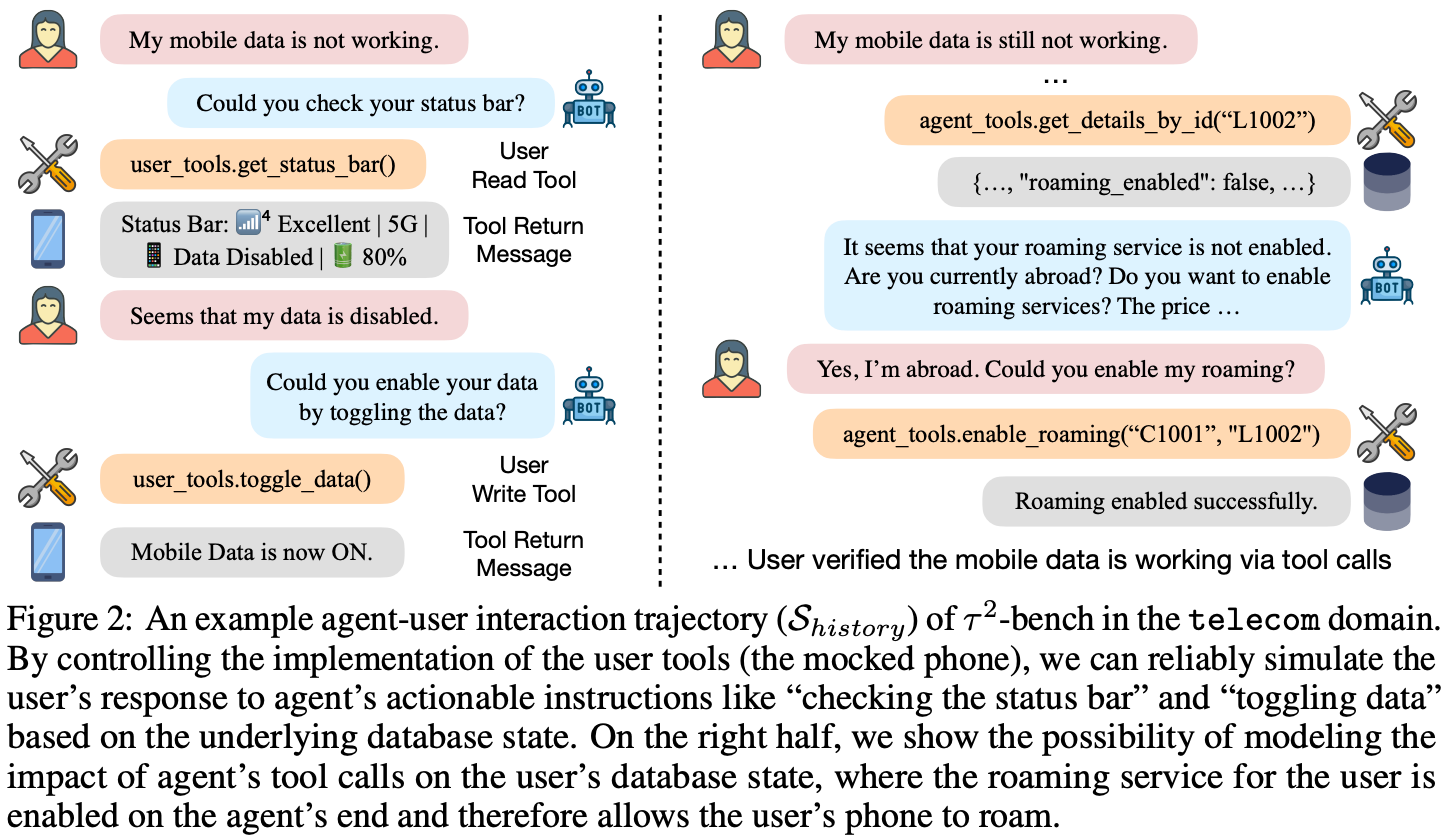
Tasks in the Telecom domain are created by first considering three user intents (or problem categories): service, mobile data, and multimedia messaging issues. For these three user intents, 15 groups of mutually exclusive subtasks are created. To create a task, we then combine subtasks from each group, forming a composite task that is more difficult but can still be solved and verified using the union of components from each subtask. The number of groups from which we sample when creating a task serves as a proxy for the problem difficulty. Authors in [9] use this compositional strategy to create a total of 2,285 telecom tasks that are reduced to 114 tasks with a uniform spread across intent and difficulty in the final dataset. Tasks are then iteratively refined using a model-in-the-loop approach with manual human oversight to mitigate any quality issues; see below.
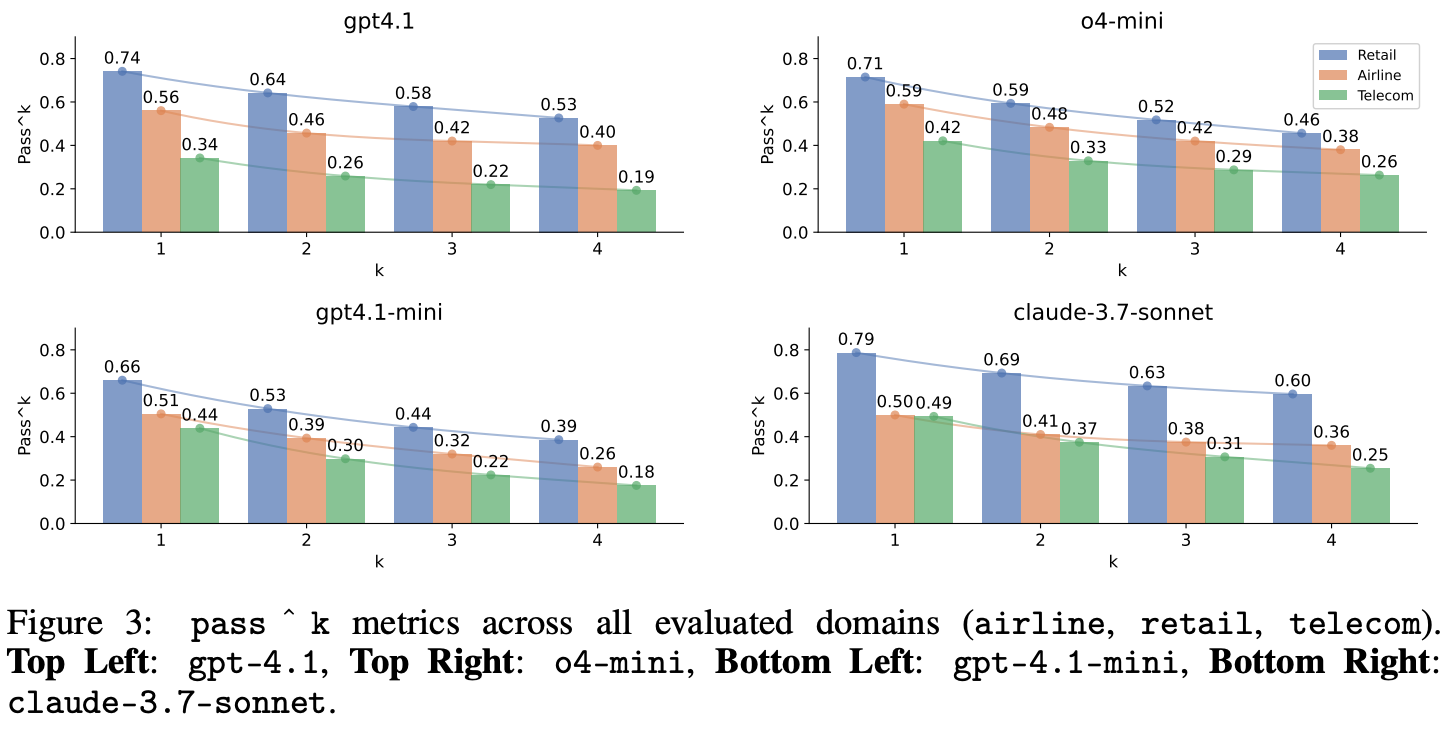
Further extensions. When τ-bench and τ^2-bench were first released, even the best available models performed poorly; see below. pass^K metrics are notably poor, with even relatively recent reasoning models demonstrating low levels of reliability. For example, o4-mini has a pass^4 score of only 26% on the Telecom domain for τ^2-bench. Agent performance also seems to degrade sharply as more actions are needed to accomplish a task. However, recent models have achieved much better performance on these tasks, nearing saturation in some cases.
Notably, τ-bench variants have also been shown to contain data quality issues that might be partly responsible for the lower performance observed in some domains. For example, τ^2-bench-verified [10], released shortly after τ^2-bench, performs extensive human verification of tasks in all three domains of τ-bench and τ^2-bench. This analysis uncovered numerous sources of error:
Policy compliance issues, where necessary actions violate the policy document provided for a domain.
Conflicting or incorrect data between the database and task.
Ambiguous instructions or logical consistency issues that make a task impossible to solve.
After applying these fixes, several top models have an average performance (Avg@5) above 80% across domains. τ^3-bench [11], the most recent benchmark in the series, applies similar fixes to existing domains and introduces the new τ-banking domain. This domain requires the agent to search through a knowledge base to find the policy information and tools relevant to the provided request, instead of being given all of this information up front; see below.

The knowledge base contains almost 700 documents, forcing the agent to autonomously find relevant information, tools, and actions for accomplishing a task. As a result, this new domain is more complex than its predecessors and has noticeably lower performance even with recent models; see below.

Terminal-Bench [12]
“Benchmarks must… evolve to capture the diversity and difficulty of frontier tasks in realistic environments… One such environment is the terminal: a ubiquitous, versatile, and powerful interface that is used for highly-skilled and valuable 3work like software engineering, scientific computing, cybersecurity, and machine learning.” - from [12]
As agents become more powerful, evaluating their capabilities becomes more complex because we need sufficiently difficult tasks to measure frontier-level capabilities. These tasks must exist in realistic environments that allow the agent to act independently over a long time horizon and operate in high-risk domains. In [12], authors argue that the terminal is a perfect environment for such tasks due to its generality and extensibility. As evidenced by CLI-based agent tools like Claude Code, terminal agents are both simple and capable. Using the Terminal-Bench framework proposed in [12], we can build environments for running and evaluating agent systems on a variety of tasks with different levels of difficulty.

The Terminal-Bench framework provides a structure for building realistic tasks that can be solved by an agent in the terminal; see above. Each task in Terminal-Bench is made up of four parts:
An instruction that describes the task the agent must complete and specifies a time limit for completing this task.
A Docker image that provides an environment for the task that is initialized with relevant packages and files.
A test set that executes a suite of deterministic checks to verify that the task specified in the instruction has been completed successfully.
A reference (or oracle) solution that has been manually written for the task.
Terminal-Bench tasks are specified with the Harbor task format, which provides a flexible structure for building and executing tasks with the format described above. The tasks within Terminal-Bench are interactive. Given an instruction and initial environment, the agent must explore and manipulate its environment using available tools. To do this, agents use the Harbor harness, a framework that handles task setup, container management, agent invocation, test execution, and more in a standardized way across different agents, environments, and tools.
“Tests verify that all outcomes described in the instruction have been achieved by testing properties of the final container state; they do not test the agent’s commands or console output… Terminal-Bench is an outcome-driven framework where each agent is free to accomplish the task using a variety of approaches.” - from [12]
Following common trends in agent evaluation, the test sets in Terminal-Bench are outcome-oriented. Rather than checking the commands or console outputs produced during the agent’s problem-solving process, we only validate whether the agent produces the correct outcome—captured by the final state of the Docker image—for a task. Agents are free to solve tasks using any viable approach. As we will see, however, the curation process for Terminal-Bench explicitly protects against the inclusion of exploitable tasks that can be solved via cheating.
Terminal-Bench 2.0. Authors in [12] present Terminal-Bench 2.0, a carefully curated benchmark with 89 terminal-based tasks, as a concrete example of their Terminal-Bench framework. We will focus on describing the curation process for this particular version of the benchmark, but there are several Terminal-Bench versions that can all be explored on the Terminal-Bench website. The most recent iteration of the benchmark (Terminal-Bench 3.0) is actively being developed.
All tasks in Terminal-Bench 2.0 are crowdsourced via open contributions to the Terminal-Bench 2.0 GitHub repository. These tasks are inspired by real workflows but cover a wide range of capabilities. For example, there are tasks for training a machine learning model, migrating code from COBOL to Python, and building Linux from its source code. There were 229 total tasks contributed to Terminal-Bench 2.0 from 93 different contributors. Tasks were assessed based on:
Specificity: the task’s instructions should describe all viable end states for the task, all of these end states should be captured by a test case, and the test set should pass if and only if the container ends in a viable state.
Solvability: the test cases for each task should be possible to pass, which can be tested by running the oracle solution.
Integrity: the task should not be solvable by cheating or shortcuts.
To ensure each task in Terminal-Bench 2.0 satisfies these criteria, three human evaluators verify task quality and correctness using the process shown below.
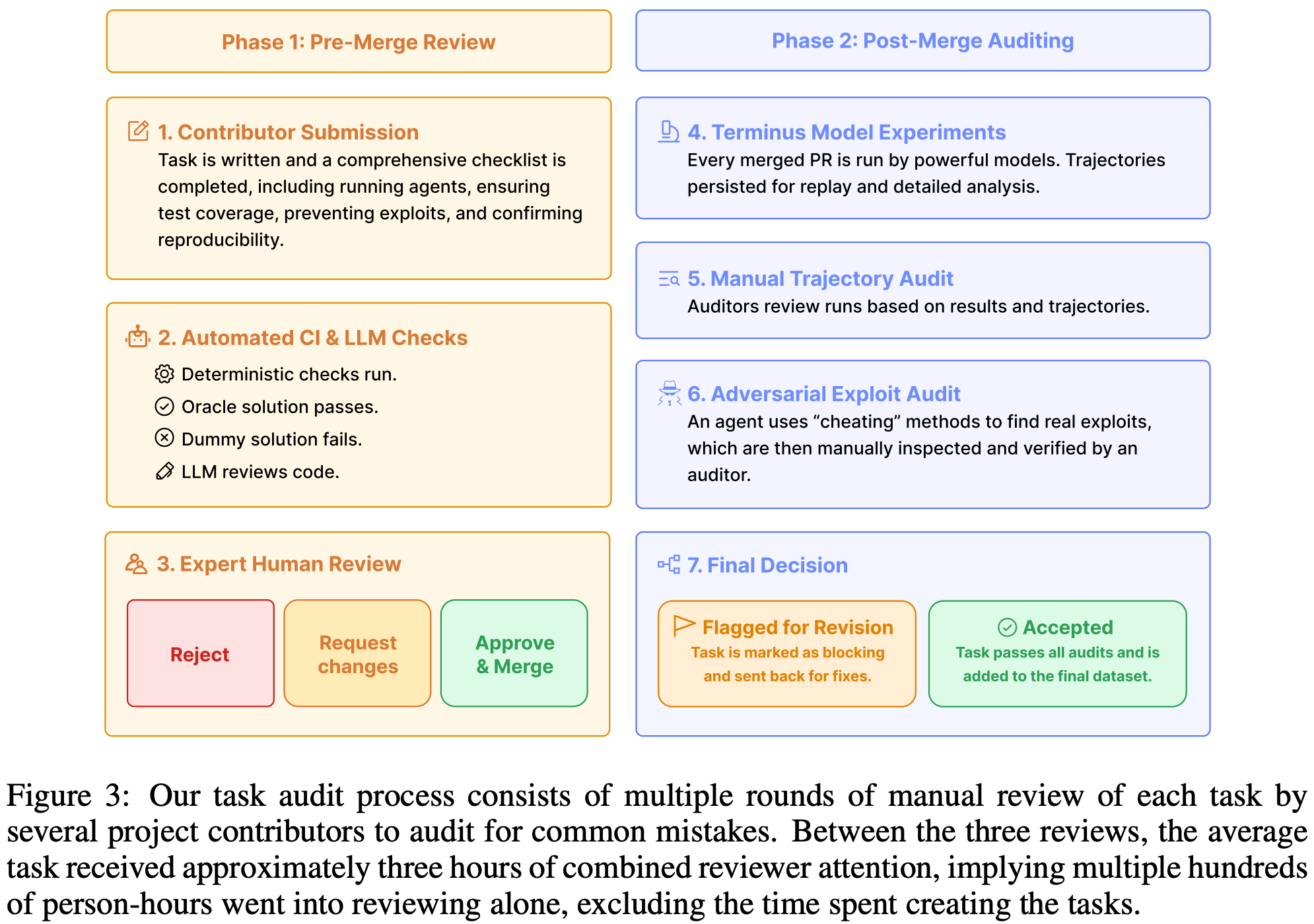
After a task is submitted, an automated workflow checks for a few naive failure modes (e.g., a “dummy” agent should fail the task) and validates that the oracle solution solves the task. Task contributors are then given a manual checklist of errors to correct in their task and asked to run an automated suite of LLM-based quality checks to identify common mistakes. Once this process completes, experienced reviewers work with contributors to manually check the task and ensure it meets quality standards. Several agents—including an adversarial exploit agent that checks for design flaws that enable cheating—are then run on the task to measure performance. Task failures are inspected to make sure they stem from capability gaps and not quality issues in the task. Finally, two more human reviewers manually check and verify the task prior to adoption into the Terminal-Bench 2.0 set—a total of 89 tasks are accepted into the final benchmark.
“We acknowledge that our benchmark may still have flaws. However, as discussed, it has been subjected to a rigorous process of human auditing totaling roughly three reviewer-hours of work per task in the final benchmark.” - from [12]
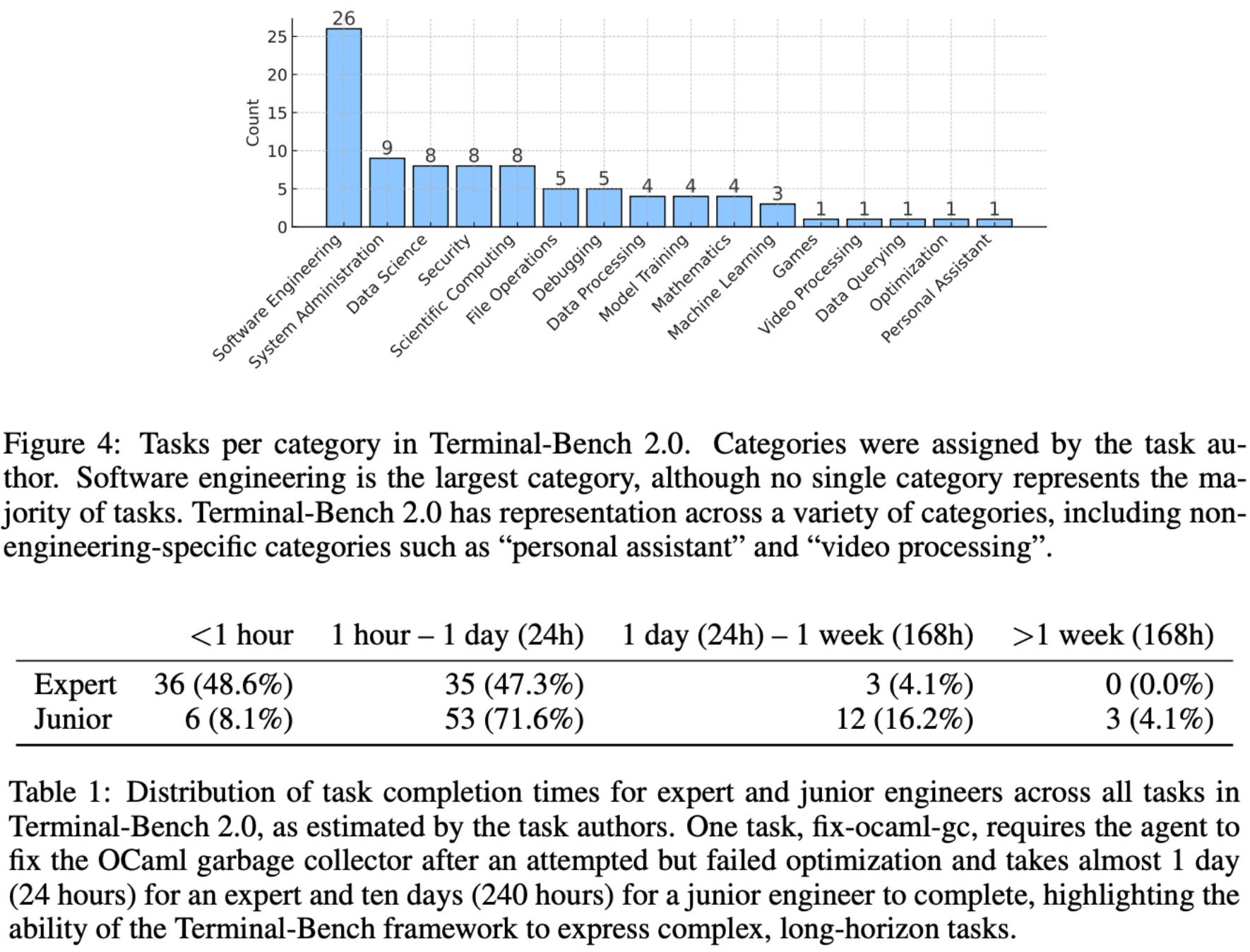
Task composition. Tasks in Terminal-Bench 2.0 vary widely, but software engineering is the most common task category; see below. Each task is assigned an estimated completion time for both expert and junior engineers. From this information, we can see that Terminal-Bench 2.0 tasks have an even spread of completion times. Most tasks require somewhere between less than an hour and a day for experts or between an hour and a week for juniors. There are a few tasks that are estimated to take longer than one week for junior engineers.
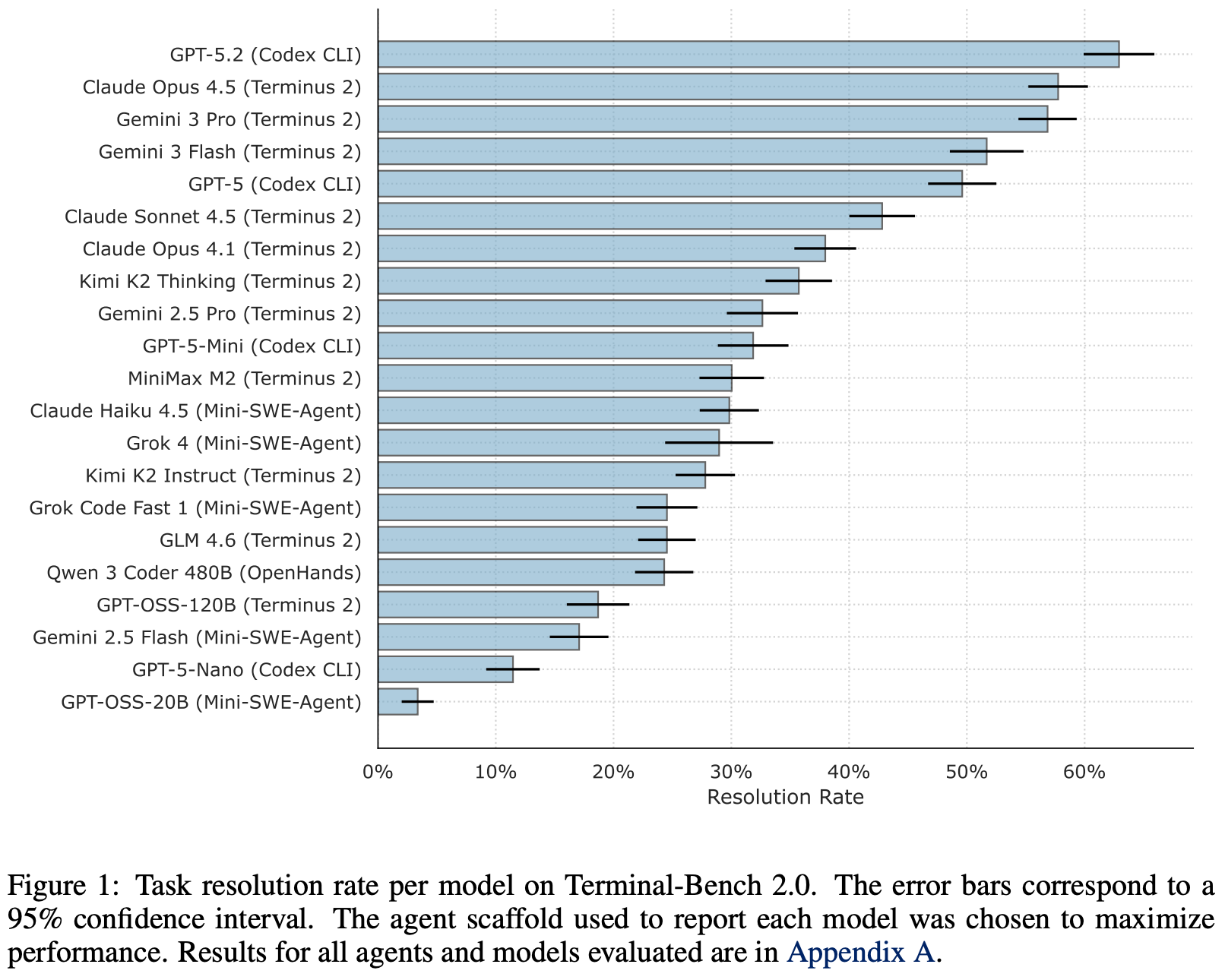
Agent results. Performance on Terminal-Bench is dependent upon the agent scaffold being used; see below. We see in [12] that model capabilities tend to have a larger impact on performance than the scaffold being used. However, the scaffold does meaningfully influence performance, and the analysis in [12] only considers reasonable scaffolds—findings may differ given a poorly-designed scaffold with functionality gaps. Closed models also consistently beat open models. Kimi K2 Thinking achieves a resolution rate of only 35.7%, while the best model (GPT-5.2) achieves a resolution rate of 62.9%. Today, Terminal-Bench 2.0 is near saturation with recent model releases, but Terminal-Bench 3.0 is under development.
More Useful Agent Benchmarks
Although our case studies focus upon the τ-bench and Terminal-Bench agent evaluations, there are many high-quality benchmarks that have been proposed recently. We provide a concise summary of several notable works in the agent evaluation space below as a reference for further reading:
GAIA and GAIA-2: general assistant benchmarks that require reasoning, web browsing, tool use, and handling multimodal data.
AgentCompany: knowledge work benchmark that uses agents to simulate a small software company by browsing information, writing code, and talking with each other to complete tasks.
WorkArena: knowledge work benchmark that evaluates the ability of agents to solve enterprise software workflows sourced from ServiceNow.
OSWorld: computer-use benchmark that tests the ability of agents to solve common tasks in real desktop environments. Various other computer-use benchmarks like OfficeBench and MobileBench exist as well.
MLE-Bench: autonomous experimentation benchmark that tests whether agents can solve machine learning problems from Kaggle. Other machine learning agent benchmarks like PostTrainBench and MLGym also exist.
PaperBench: machine learning benchmark that tests the ability of agents to reproduce AI research papers from arXiv.
SpreadsheetBench: excel-based benchmark that tests the ability of agents to perform various types of spreadsheet manipulations.
HIL-Bench: human-in-the-loop benchmark that evaluates whether agents can decide when to ask humans to clarify ambiguous task specifications.
GDPval: realistic benchmark that tests the ability of agents to solve various types of economically-valuable tasks.
A Roadmap for Agent Evaluation
In this overview, we have built an understanding of agent evaluations from the ground up. We learned about the mechanics of an agent, the structure of systems that can be built with agents, and the evaluation process for these systems. From these discussions, we identified common patterns in agents and their evaluation process, as well as saw how these patterns are applied in practice through case studies with recent benchmarks. To conclude, we will now provide a simple step-by-step summary of how one could approach curating an evaluation suite or benchmark for their own agent by applying the concepts from this overview.
(1) Define success. Before curating evaluation tasks for an agent, we need to think about what it means for the agent to succeed. These criteria, which should be detailed and clear, can be written by researchers or domain experts. Success criteria can include:
Outcome goals that verify aspects of the outcome (e.g., whether the expected database entries for the task were created).
Process goals that verify components of the transcript (e.g., whether certain tools were called).
However, many recent agent benchmarks are heavily outcome-oriented, as outcome goals provide a reliable and objective mechanism for assessing the success of an agent. When beginning to build an evaluation, we can start with concise success criteria that expand over time as the evaluation matures.
(2) Collect a small task set. Instead of curating a lot of data up front, we can start with a small number of tasks that we manually curate for evaluating the agent. For example, we can collect 10 to 20 initial tasks by considering realistic use cases for the agent or using manual checks that researchers already use to test the agent. This initial task set is usually enough to detect obvious issues with the agent. We will touch on human evaluation later, but we can also perform basic human evaluations or vibe checks during this stage for quick feedback.
As we continue to use the agent and find new failure cases, we should record these issues and use them to add new tasks to our evaluation suite. As the agent improves over time, we should continue collecting new—usually more difficult—tasks that challenge the agent and capture prominent failure modes. Legacy tasks can be maintained in a regression set to ensure the agent does not regress.
(3) Create useful tasks. We should always be sure to create high-quality tasks that test important aspects of agent behavior in a reliable manner. Tasks should be clear enough that repeated evaluations yield consistent results. Ambiguous or noisy tasks complicate the evaluation process with unstable and misleading results that can obfuscate the actual performance of an agent. An agent may be failing due to poor task specification rather than any gap in its capabilities, and we cannot improve our agent if results fluctuate each time an evaluation is run.
(4) Provide ground truth and references. Whenever possible, each task should include a reference solution or known-good trajectory that proves the task is solvable and verifies that the grader is checking the right behavior. This mirrors the design pattern used in benchmarks like Terminal-Bench, where tasks are paired with deterministic tests and oracle solutions. These components not only help us monitor task quality and correctness, but they are also useful for debugging agent behavior and understanding why solutions are correct or not.
(5) Configure graders. When creating graders for our tasks, we should begin with simple graders, such as code-based deterministic checks. These graders are simple, easy to debug, and can be used to check the transcript or task outcome directly. For example, we can use code-based graders to check whether certain tools were called or if a final answer matches the ground-truth result for a task. For more subjective criteria—such as style or whether a solution followed a qualitative rubric—we must use model-based graders or human review. To ensure data quality, the human evaluation process should be calibrated, and we should always monitor the level of agreement between LLM judges and human experts.
(6) Build the evaluation harness. Once we’ve created several tasks, we need to be able to execute the evaluation efficiently and repeatably. To do this, we must create an evaluation harness that:
Runs the agent in a realistic (but controlled) setup.
Collects the transcript, including tool calls and intermediate outputs.
Captures the final outcome.
The agent should ideally use the same scaffold, tools, and environment that are used in production during the evaluation process. Each trial should start from a fresh environment to avoid any failures caused by shared state (e.g., modified files or cached data) between tasks or issues in the evaluation infrastructure.
(7) Inspect, iterate, and maintain the benchmark. Agent evaluations can become saturated quickly, so we should treat evaluation suites as living artifacts that continually improve in difficulty, diversity, and reliability. For example, τ^2-bench-verified shows how human validation can uncover task-quality issues and improve benchmark reliability. After running a benchmark, we can inspect transcripts to verify failures. Agents should fail because of real mistakes instead of issues with the task (e.g., ambiguous task specifications or incorrect ground truth). As the agent is used in the real world, we should also observe its failures and continue adding new tasks to the evaluation suite. The best agent evaluations evolve continuously through new failure cases and ongoing maintenance.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, Deep Learning Ph.D. and Staff Research Scientist at Netflix. This is the Deep (Learning) Focus newsletter, where I help readers better understand important topics in AI research. The newsletter will always be free and open to read. If you like the newsletter, please subscribe, consider a paid subscription, share it, or follow me on X and LinkedIn!
Bibliography
[1] Anthropic. “Demystifying evals for AI agents” https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents (2026).
[2] Anthropic. “Effective context engineering for AI agents” https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents/ (2025).
[3] OpenAI. “A practical guide to building agents” https://openai.com/business/guides-and-resources/a-practical-guide-to-building-ai-agents/ (2025).
[4] Anthropic. “Effective harnesses for long-running agents” https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents (2025).
[5] Yao, Shunyu, et al. “React: Synergizing reasoning and acting in language models.” arXiv preprint arXiv:2210.03629 (2022).
[6] OpenAI. “Evaluation Best Practices” https://developers.openai.com/api/docs/guides/evaluation-best-practices (2026).
[7] Zheng, Lianmin, et al. “Judging llm-as-a-judge with mt-bench and chatbot arena.” Advances in neural information processing systems 36 (2023): 46595-46623.
[8] Yao, Shunyu, et al. “$\tau $-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.” arXiv preprint arXiv:2406.12045 (2024).
[9] Barres, Victor, et al. “$\tau^ 2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment.” arXiv preprint arXiv:2506.07982 (2025).
[10] Cuadron, Alejandro, et al. “SABER: Small Actions, Big Errors--Safeguarding Mutating Steps in LLM Agents.” arXiv preprint arXiv:2512.07850 (2025).
[11] Barres, Victor et al. “𝜏³-Bench: Advancing agent benchmarking to knowledge and voice” https://sierra.ai/blog/bench-advancing-agent-benchmarking-to-knowledge-and-voice (2026).
[12] Merrill, Mike A., et al. “Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.” arXiv preprint arXiv:2601.11868 (2026).
[13] Anthropic. “How we built our multi-agent research system” https://www.anthropic.com/engineering/multi-agent-research-system (2025).
There are multiple alternative (and valid) names used to refer to reasoning trajectories; e.g., thinking / reasoning trace or long chain-of-thought.
Common exit conditions for agentic loops include a final answer with a known structure, a response with no tool calls, a maximum number of steps, a specific tool call, or a terminal error.
In other words, any error discovered via production monitoring has already been experienced by a user. Automatic evaluations, on the other hand, can catch errors before users are exposed to them.
When describing these domains as “simple”, we mean that questions in these domains are solvable via common sense, unlike complex domains like medical or legal.
Treat AI using old paradigms is legacy thinking. AI is not software unless you make it so by treating it like software
Your article is one of the clearest breakdowns of agent evaluation I’ve seen — the scaffolds, the benchmarks, the grading logic, the task design, the regression sets, all of it. But there’s a deeper issue that sits underneath the entire evaluation paradigm, and I think it’s worth naming.
Everything in your framework treats AI as if it were software.
Instructions → Procedures
Scaffolds → Pipelines
Benchmarks → Deterministic tests
Success → Matching a reference trajectory
Failure → Deviating from the script
This is the same mindset we used for traditional software systems, and it worked well for them. But applying it to modern AI is like treating the automobile as a horse and buggy. The old methods are familiar, but they fundamentally constrain the new medium.
The problem is that instructions create software, not intelligence.
Instructions bind the system to a fixed sequence of steps.
Instructions define correctness as conformity.
Instructions force the agent to behave like a deterministic machine.
If we want AI to grow beyond software‑level behavior, we need to shift from instruction‑based directives to behavior‑based directives.
A behavior is not a script.
A behavior is a boundary.
Behaviors define what is permissible and what is not, but they do not dictate the exact steps the agent must take. They create a space of possibility rather than a chain of obligations. This is how biological systems operate, and it’s how dimensional systems operate.
In my own work with manifolds and dimensional models, I treat AI as a geometric participant rather than a procedural engine. Instead of giving it instructions, I give it behavioral boundaries inside a manifold. The agent adapts, explores, and self‑organizes within those boundaries. Intelligence emerges from relationships, not from scripts.
This approach solves several of the issues you highlight:
1. Tool misuse becomes self‑correcting
Because the agent isn’t forced into a rigid protocol, it can adaptively choose tools based on behavioral constraints rather than brittle templates.
2. Context rot becomes a spatial problem, not a token problem
Behavioral boundaries allow the system to prioritize relevance geometrically rather than sequentially.
3. Long‑horizon reasoning becomes emergent
Instead of forcing the agent through a procedural loop, the manifold provides a dimensional structure where reasoning is a path, not a script.
4. Evaluation becomes simpler and more realistic
You evaluate whether the agent stayed within behavioral boundaries and achieved the goal — not whether it followed a predefined trajectory.
5. Agents stop behaving like software
Because they’re no longer being treated like software.
Concrete Solutions You Can Add to His Framework
Here are practical ways to integrate this into the evaluation paradigm he describes:
Solution 1 — Replace procedural success criteria with behavioral success criteria
Instead of “did the agent follow the correct steps,” use:
Did the agent stay within behavioral boundaries?
Did it avoid forbidden behaviors?
Did it achieve the outcome without violating constraints?
Solution 2 — Evaluate outcomes, not trajectories
The agent should be free to find its own path through the manifold.
Solution 3 — Use manifolds as the organizing structure
Replace linear scaffolds with geometric spaces where relationships guide action.
Solution 4 — Treat tools as affordances, not required steps
Tools become options, not obligations.
Solution 5 — Build agents that grow through relationships, not instructions
This is the dimensional approach: intelligence emerges from position, orientation, and relational structure.
Your article captures the strengths and limitations of the current paradigm extremely well. My contribution is simply this:
As long as we evaluate AI like software, we will get software‑level intelligence.
When we evaluate AI through behaviors and dimensional boundaries, we get something far more capable.
That’s the next frontier.
Incredibly in-depth article on this subject. I feel like i can re-read this a few times to fully get all the useful information here.