
Teaching Language Models to use Tools
Using tools makes us more capable as humans. Is the same true of LLMs?


As we learn more about them, large language models (LLMs) become increasingly interesting. These models can solve a variety of complex tasks accurately. At the same time, however, they struggle with certain functionality that we, as humans, consider basic! For example, LLMs commonly make arithmetic mistakes, lack access to current information, and even struggle to comprehend the progression of time. Given these limitations, we might wonder what can be done to make LLMs more capable. Are LLMs doomed to suffer these limitations forever?
Many advancements in the human race have been catalyzed by access to new and innovative tools (e.g., the printing press or computer). Might the same finding apply to LLMs? Within this overview, we will study a recent direction of research that aims to teach LLMs how to use external tools, which are made available via simple, text-to-text APIs. Using these tools, LLMs can delegate tasks like performing arithmetic or looking up current information to a specialized tool. Then, information returned by this tool can be used as context by the LLM when generating output, leading to more accurate and grounded responses.
Making LLMs more Capable
Giving an LLM access to an external tool is a reliable way to solve some of the limitations that these models face. However, LLMs will not know how to use tools naturally, which raises the question: How do we teach our model to leverage external tools? In this section, we will explore some of the options we have and enumerate various tools that are useful for building LLM applications.
Different Types of Learning

Teaching an LLM to leverage tools is no different than learning how to solve any other task with an LLM. Since these models learn in a couple of different ways, we will go over the main forms of learning with LLMs here. Beyond this post, there are also detailed explanations available online.
pre-training. The first and most basic form of learning for LLMs is pre-training. During pre-training, the model is trained over a large corpus of unlabeled textual data using a language modeling objective. The pre-training process begins from a random initialization and is quite computationally expensive. Typically, pre-training is performed only once due to its computational expense—we do not want to repeat the pre-training process very often! Notably, the computational expense of pre-training provides an explanation for the presence of a knowledge cutoff in LLMs like ChatGPT. These models learn all of their knowledge during pre-training, so the knowledge cutoff is just associated with data that is present during the most recent pre-training run.

fine-tuning. After pre-training, LLMs can accurately perform next-token prediction, but this doesn’t always mean that they are actually useful. If we play with a demo of GPT-2 for 2 minutes, for example, we immediately see that predicting the next token accurately can result in some pretty boring and unhelpful outputs! As such, we typically fine-tune LLMs after pre-training, either via supervised fine-tuning (SFT) or reinforcement learning from human feedback (RLHF); see the image above and here for details. Although the details of these techniques are beyond the scope of this post, the basic idea is to:
Curate more training data (e.g., in-domain data for the task we want to solve, examples of correct dialogue, human feedback on the LLM’s output, etc.).
Train the model’s parameters over this new data using either reinforcement learning or gradient descent with a (self-)supervised objective.
By doing this, we can accomplish quite a bit! For example, fine-tuning an LLM using RLHF [11] has been shown to make LLMs more interesting, factual, and helpful. Going further, the recent LIMA publication from Meta showed that performing SFT over just 1,000 high-quality dialogue examples can produce a model that rivals the quality of GPT-4 [12]. Put simply, fine-tuning takes us from a generic LLM to something that is truly special and useful.

in-context learning. The final form of learning that we should be aware of is in-context learning; see above. In-context learning is different from pre-training and fine-tuning in that it does not actually modify the underlying model’s parameters. Rather, we teach the LLM to solve a problem more effectively by modifying its prompt! In particular, we can rephrase the prompt by using particular prompting techniques or even insert data into the prompt to perform few-shot learning. The difference between fine-tuning and in-context learning is shown below.

In-context learning is incredibly powerful as it allows us to solve a variety of different tasks using a single model. Instead of fine-tuning the model and modifying its underlying parameters, we can insert useful data into the LLM’s prompt. The LLM can learn from this data and more accurately solve a task without the model itself being modified! Additionally, we can perform in-context learning with both pre-trained and fine-tuned models. To learn about prompting techniques that can be used with LLMs, check out the overviews below:
Practical Prompting [link]
Advanced Prompting [link]
Chain of Thought Prompting [link]
Prompt Ensembles [link]
What tools are useful for LLMs?
Although the idea of connecting LLMs to external tools seems enticing, we might wonder: what kinds of tools would be the most useful? To answer this question, we should look to common limitations of LLMs, such as:
Lack of access to up-to-date information [2]
Tendency to hallucinate (i.e., output incorrect information)
Difficulties with evaluating mathematical expressions
Incomplete understanding of low-resource languages
Inability to understand the progression of time [8]
If we wanted to solve these issues, we have a few options. We could focus on fine-tuning and refining the model via SFT or RLHF—just fine-tune the model extensively to avoid the behavior listed above. In fact, extensive resources have been invested into refining models like GPT-4 through targeted human feedback, which has produced pretty impressive results. Instead of solving these problems within the model itself, however, we could focus on fine-tuning the model to take an approach that is indirect, but oftentimes more reliable. In particular, we could teach the model how to use external tools to help with answering questions!
how do tools help? When struggling to solve a problem, it is often useful for an LLM to query an external tool that can provide more context. Notable examples of useful tools include (but are not limited to):
Calendar apps that can return the current date
Calculators that can evaluate mathematical expressions
Vector databases that store (potentially) relevant information that is too large to store directly in the prompt
Translation modules for converting data into different languages
Overall, tools are incredibly useful whenever providing extra information or context can help an LLM with solving a problem. Going beyond these simple tools, we could even connect LLMs to external code interpreters, giving them the ability to write and execute arbitrary programs. When combined with code-enabled LLMs (e.g., Codex [10]), such an approach can actually be quite powerful!
Tools are super popular!
Although this overview will primarily focus upon recent research that studies the integration of tools with LLMs, augmenting models like GPT-4 with external tools has been a topic of recent interest. For example, OpenAI recently released a plugins extension for their models, allowing these powerful LLMs to leverage a massive number of external tools; see below.

As of the time of writing, nearly 130 different plugins are available for GPT-4, thus demonstrating the massive amount of interest in integrating various kinds of tools with powerful LLMs. Going beyond 3rd party plugins, OpenAI has recently released code interpreter and internet search tools for GPT-4. The internet search tools is incredibly useful for mitigating hallucinations within LLMs, as answers provided by the model can be contextualized with relevant, up-to-date information taken from the internet. Beyond making LLMs more factual and grounded, the code interpreter tool is capable of ingesting massive code and data files and performing accurate analysis over this data to yield valuable insights.
TL;DR: The main takeaway here is that tools are becoming a common feature for LLMs. Beyond OpenAI’s offerings, we are even seeing models like Bard being enhanced with similar features, while open-source libraries like LangChain can be used to easily build a variety of tool-like features for available LLMs.

Now from our partners!
Rebuy Engine is the Commerce AI company. They use cutting edge deep learning techniques to make any online shopping experience more personalized and enjoyable.
KUNGFU.AI partners with clients to help them compete and lead in the age of AI. Their team of AI-native experts deliver strategy, engineering, and operations services to achieve AI-centric transformation.
MosaicML enables you to train and deploy large AI models on your data and in your secure environment. Try out their tools and platform here or check out their open-source, commercially-usable LLMs.
Teaching LLMs to Use Tools

In [1], authors explore an approach, called the Toolformer, that i) teaches an LLM how to leverage external tools and ii) maintains the generic nature of the LLM in the process. These tools are made available to the LLM via a set of simple text-to-text APIs (i.e., meaning that the model provides text as input and the API returns textual output). Interestingly, we see in [1] that the LLM can learn to leverage these tools in a completely end-to-end manner. The model decides what APIs to call, which arguments to pass to these APIs, and how to best use the information that is returned without any hard-coded control flows.
“Language models can learn to control a variety of tools, and to choose for themselves which tool to use when and how.” - from [1]
To do this, we curate a dataset of training data that demonstrates the proper use of these tools. In [1], this dataset is created automatically using a self-supervised heuristic—meaning that no human intervention is required—that requires only a few examples of usage for each tool. Then, we fine-tune the LLM over this data, allowing it to learn the correct usage of each tool. The result is a high-performing LLM that can delegate simple, but difficult subtasks (e.g., language translation, arithmetic, accessing current information, etc.) to specialized, external tools that return relevant and accurate data for the LLM to use in generating an output.

what tools are used? In [1], the Toolformer uses the following, fixed set of tools:
Question Answering Tool: Based on Atlas [13], an LLM that is fine-tuned for answering simple, fact-based questions.
Calculator: A basic calculator for numerical operations.
Wikipedia Search Tool: A search engine that returns short, textual snippets from Wikipedia given a search term.
Translator: A language translation system that can translate text from any language into English (but not the other way around!).
Calendar: A tool that just returns the current date when queried.
Each of these tools are made available via a simple API with a text-to-text structure; see above. To use the tools, the LLM must learn to i) identify scenarios that require a tool, ii) specify which tool to use, iii) provide relevant textual input to the tool’s API, and iv) use text returned from the API to craft a response. Notably, the simple text-to-text structure of these APIs allows us to easily insert examples of tool usage directly into a textual sequence; see below.

improvements over prior work. Giving LLMs access to external tools is not a new idea. As a simple example, many researchers have attempted to make LLMs better at arithmetic—especially with large numbers—by giving them access to an external calculator (see Appendix B in [4]). However, the main question is: how should we teach the LLM to use such a tool? Prior approaches were heavily dependent upon human annotated datasets. For example, LaMDA [3] uses an external search tool to reduce hallucinations; see below.

However, we see in [3] that teaching LaMDA to leverage external tools—in this case an external information retrieval system—requires a massive amount of human annotated data. More specifically, authors in [3] have a large number of crowd workers hand-write dialogues in which they leverage the same search tool as the LLM, thus providing examples of how the LLM should behave and respond. Related publications tend to rely upon a similar, human-centric approach [2]. Creating such a dataset is difficult, expensive, and time consuming, which leads authors in [1] to develop a more efficient solution.
learning to use tools automatically. In [1], we see that a dataset for teaching an LLM how to leverage external tools—we will call this a “tool-following dataset” for simplicity—can be automatically crafted via a prompting approach that leverages existing, pre-trained LLMs. We start with an initial (normal) dataset, such as the textual corpus used for pre-training. Then, we prompt a pre-trained LLM to augment this data with external API calls. Here, we rely upon the in-context learning abilities of generic pre-trained LLMs to curate a set of API calls that demonstrate how to correctly use available tools. An example prompt that generates requests to a question answering tool’s API is shown below.

After we have augmented our dataset with example usages of each tool, we need to perform a filtering step. This step is necessary because we only want to use an external tool if it is actually helpful to the LLM! We shouldn’t just always rely upon external tools even when they aren’t needed—using a tool usually has a latency (or even monetary) cost. To capture this idea, we can just do the following:
Measure the LLM’s performance (i.e., cross entropy loss over tokens that come after the API call) with the tool.
Measure the LLM’s performance without the tool.
Discard examples where using the tool does not improve the LLM’s performance beyond a certain threshold.
Here, we are assuming access to a dataset that demonstrates the correct output that an LLM should produce. By following this approach, we automatically construct a dataset that contains examples of when and how tools can be leveraged to tangibly improve the LLM’s output. In practice, the actual procedure is a bit more complex. Namely, to measure the LLM’s performance without the tool, we observe performance in two separate cases—one without the tool at all, and one that performs an API call but provides no response. Such an approach ensures that both the tool and its data are useful to the LLM.
“An API call is helpful to [the language model] if providing both the input and the output of this call makes it easier to predict future tokens” - from [1]
Additionally, instead of inserting the API call inline with the textual sequence, we append it as a prefix, which avoids spikes in the LLM’s loss. Remember, API calls like this are not present in the original pre-training corpus for the LLM, which means that inserting the API call directly into the textual sequence could skew results used for filtering. The model is not expecting to see an API call like this within the data! Furthermore, when measuring performance, we assign a higher weight to tokens that are spatially close to the API call, ensuring that the API call is made near where it is needed and not at random times when generating output.
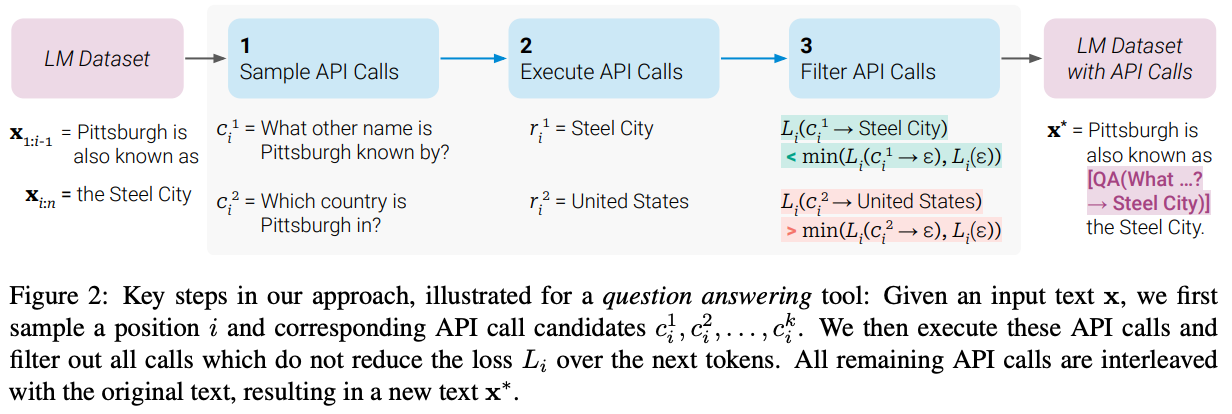
The full process for constructing the tool-following dataset used in [1] is shown above. Unlike prior work, this process requires no human labor. Rather, we leverage the in-context learning abilities of LLMs and a few clever heuristics to construct the dataset automatically. Although this process is not perfect (i.e., some useless API calls may avoid filtering), it works quite well in practice!
learning to use tools. Once we have constructed a dataset, teaching an LLM how to leverage external tools is easy—we just fine-tune the model over this dataset using a standard language modeling objective. In [1], the tool-following dataset is derived from a pre-training corpus. As such, the fine-tuned LLM is still a general-purpose model, despite having the ability to leverage external tools. Moreover, because the filtering process in [1] removes API calls that do not benefit performance, the LLM implicitly learns when and how each tool should be used to improve its own output. Pretty cool results for such a simple approach!
Do tools make a difference?
The model analyzed in [1] is based upon GPT-J [5], a 6 billion parameter language model, and CCNet is adopted as the training dataset. Toolformer is compared to several baselines, including a Toolformer model with API calls disabled, the original GPT-J model, a version of GPT-J that is fine-tuned on CCNet, as well as a few other LLMs like OPT [6] and GPT-3 [7]. Unlike prior work that studies few-shot learning, models are evaluated using a zero-shot approach, which simply describes the task to the model without providing any exemplars, and a greedy decoding strategy. With Toolformer, a tool is leveraged whenever <API> (i.e., the starting token for an API call) appears as one of the model’s k most likely tokens.
Toolformer is evaluated across several different domains. On fact-based datasets, we see that the question answering tool is heavily leveraged, leading to a large increase in accuracy over baseline models. Similarly, the calculator tool is found to be quite useful on mathematical reasoning datasets; see below.

On (multilingual) question answering benchmarks, the model’s performance is not quite as impressive (i.e., Toolformer falls short of GPT-3 or GPT-J performance in some cases). However, certain tools, such as the calendar tool, are found to be incredibly useful for improving LLM performance on tasks like temporal reasoning. Interestingly, the authors also perform some analysis that modifies the probability of API calls within the LLM’s decoding strategy. From this analysis, we learn that leveraging external tools more frequently is not always a good thing—performance degrades if tools are used too frequently; see below.

Such a finding highlights the importance of the filtering strategy used in [1]. Not only does tool usage come with a cost, but it may degrade performance. The LLM must learn to understand the scenarios in which calling a tool is most important. The approach taken in [1] explicitly biases the LLM towards only leveraging external tools when it provides a significant boost in the model’s performance.
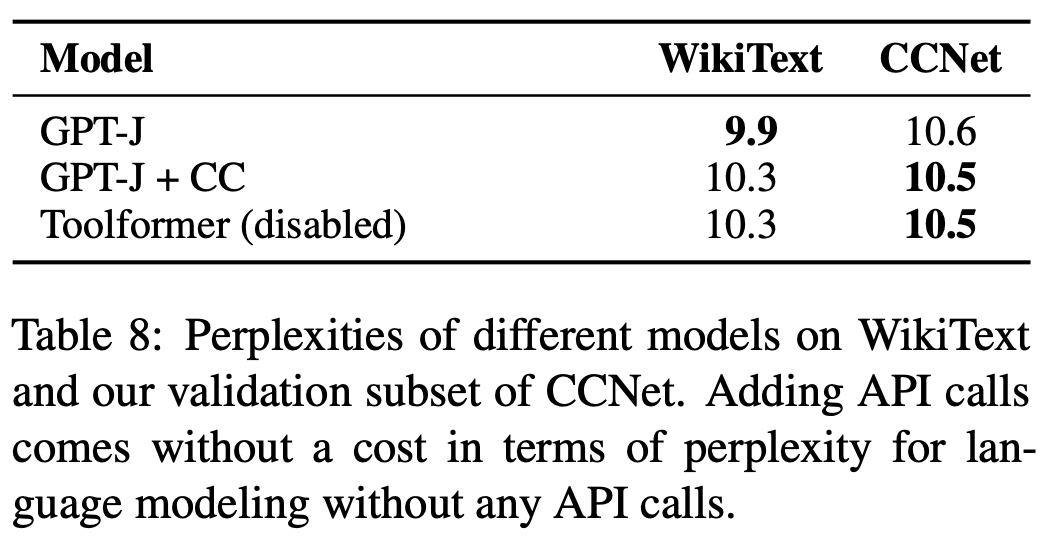
remaining generic. Beyond the downstream evaluations described above, authors in [1] evaluate Toolformer on a hold-out portion of the pre-training dataset after fine-tuning on the tool-following dataset, finding that the model achieves comparable perplexity both before and after fine-tuning; see above. In other words, Toolformer does not lose any of its capabilities as a generic language model when it learns to leverage external tools, meaning that—unlike prior work that approaches tool-following in a task-specific manner [8]—this model is still a foundation model that can solve a variety of different tasks.
Using Tools is Getting Easier
Although the approach proposed in [1] is groundbreaking and incredibly informative, it still requires an extensive fine-tuning process. Compared to most recent applications of LLMs, this is quite a hassle! Is it possible that we could leverage a prompting-only approach to teach an LLM to leverage external tools? Recent developments surrounding GPT-4 suggest that this problem might be solved by improving the instruction following capabilities of LLMs.

GPT-4 plugin workflow. As an example, GPT-4 has access to a variety of different tools via the plugin store. However, the model is not explicitly fine-tuned to learn about each plugin within the store. Rather, it just uses in-context learning. In particular, OpenAI has invested heavily ubto improve GPT-4’s steerability, which has made the model surprisingly capable of following very detailed instructions and prompts. As a result, teaching GPT-4 how to use a plugin only requires:
A textual description describing the plugin’s purpose
A schema describing the input/output format for the plugin’s API
Using this information, the model can determine when to use a plugin on its own, make properly-formatted API calls, and integrate the resulting information into its dialogue. All of this is done purely via textual descriptions without any explicit fine-tuning, revealing that teaching LLMs to leverage external tools is likely to become easier over time. To understand this process in more detail, we can look at open-source plugin implementations or developer documentation for OpenAI plugins.
Closing Remarks
Similar to how humans become better with access to tools (e.g., hammers, computers, planes, etc.), LLMs become more capable when given access to a set of simple APIs that can provide useful information or perform simple tasks for them. Why would we rely 100% on an LLM to solve everything, when we can delegate difficult tasks to a more accurate and specialized tool? We can use such an approach to mitigate problems that are constantly encountered with these models, such as incorrect information within the output or a lack of temporal reasoning skills. With Toolformer [1], we see than LLMs can be taught to leverage external tools via fine-tuning over a dataset of tool-following exemplars. But, recent trends suggest that teaching LLMs to use external tools might be possible via in-context learning alone. There is a lot to be uncovered in this area, and it will be interesting to watch these topics and related applications evolve over time!
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a better understanding of deep learning research via understandable overviews that explain relevant topics from the ground up. If you like this newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Schick, Timo, et al. "Toolformer: Language models can teach themselves to use tools." arXiv preprint arXiv:2302.04761 (2023).
[2] Komeili, Mojtaba, Kurt Shuster, and Jason Weston. "Internet-augmented dialogue generation." arXiv preprint arXiv:2107.07566 (2021).
[3] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
[4] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[5] Wang, Ben, and Aran Komatsuzaki. "GPT-J-6B: A 6 billion parameter autoregressive language model." (2021).
[6] Zhang, Susan, et al. "Opt: Open pre-trained transformer language models." arXiv preprint arXiv:2205.01068 (2022).
[7] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[8] Parisi, Aaron, Yao Zhao, and Noah Fiedel. "Talm: Tool augmented language models." arXiv preprint arXiv:2205.12255 (2022).
[9] Dhingra, Bhuwan, et al. "Time-aware language models as temporal knowledge bases." Transactions of the Association for Computational Linguistics 10 (2022): 257-273.
[10] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[11] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[12] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
[13] Izacard, Gautier, et al. "Atlas: Few-shot learning with retrieval augmented language models." arXiv preprint arXiv 2208 (2022).
I really love your articles. You have an ability to break big complex topic with very digestible language. Keep it up