
Advanced Prompt Engineering
What to do when few-shot learning isn't enough...


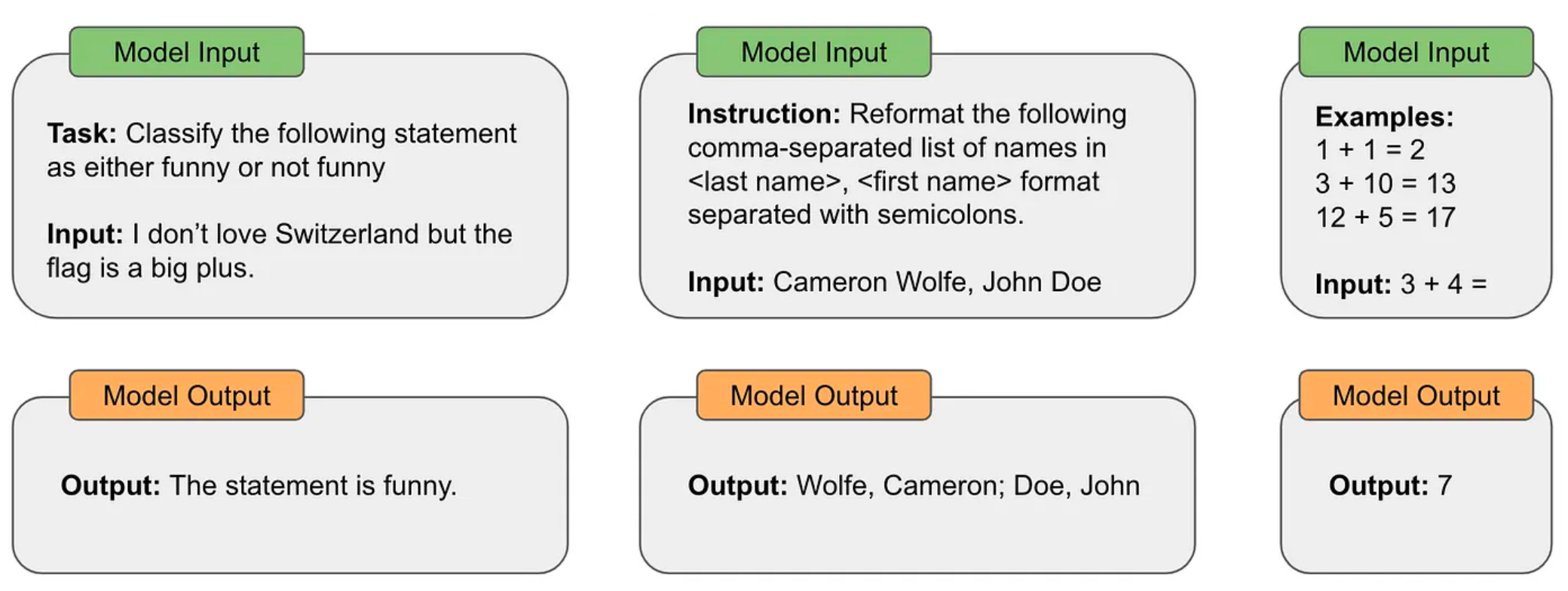
The popularization of large language models (LLMs) has completely shifted how we solve problems as humans. In prior years, solving any task (e.g., reformatting a document or classifying a sentence) with a computer would require a program (i.e., a set of commands precisely written according to some programming language) to be created. With LLMs, solving such problems requires no more than a textual prompt. For example, we can prompt an LLM to reformat any document via a prompt similar to the one shown below.

As demonstrated in the example above, the generic text-to-text format of LLMs makes it easy for us to solve a wide variety of problems. We first saw a glimpse of this potential with the proposal of GPT-3 [18], showing that sufficiently-large language models can use few-shot learning to solve many tasks with surprising accuracy. However, as the research surrounding LLMs progressed, we began to move beyond these basic (but still very effective!) prompting techniques like zero/few-shot learning.
Instruction-following LLMs (e.g., InstructGPT and ChatGPT) led us to explore whether language models could solve truly difficult tasks. Namely, we wanted to use LLMs for more than just toy problems. To be practically useful, LLMs need to be capable of following complex instructions and performing multi-step reasoning to correctly answer difficult questions posed by a human. Unfortunately, such problems are often not solvable using basic prompting techniques. To eliciting complex problem-solving behavior from LLMs, we need something more sophisticated.
Expanding the scope of what’s possible…
In a prior post, we learned about more fundamental methods of prompting for LLMs, such as zero/few-shot learning and instruction prompting. Understanding these practical prompting techniques is important for gaining a grasp of the more advanced prompting procedures that will be covered here. For more details on these techniques, check out the overview at the link below!
better prompting → better results. Such techniques can be used to accomplish a lot with LLMs (assuming they are applied correctly). However, they may fall short for a variety of reasons. Few-shot learning requires the limited context window of most LLMs to be occupied with exemplars, LLMs can be tricked into providing harmful output if safeguards aren’t put in place, and a majority of models are bad at solving reasoning tasks or following multi-step instructions. Given these limitations, how should we move forward in attempting to solve difficult tasks with LLMs?
One approach would be to create more capable LLMs, either from scratch or via better refinement procedures. However, this requires a lot of effort! What if we could just make existing models better at problem solving? In this post, we will explore more advanced forms of prompt engineering (e.g., chain of thought prompting, automatic prompt engineering, information retrieval, and more) that allow us to improve LLM performance and elicit more complex problem solving behavior. These ideas are important to learn, as they broaden the scope of what is possible with LLMs. For example, using these techniques, we can:
Allow an LLM to access an external knowledge database.
Enable complex, reasoning-based problems to be solved.
Provide unlimited memory to an LLM by allowing the model to store and access prior information from a conversation.
prompt engineering is evolving. This overview will focus upon providing a high-level view of recent advancements in prompt engineering. Rather than deeply exploring individual approaches, we will focus on gaining a broad view of different prompting techniques that might be useful. However, it should be noted that the topic of prompt engineering is both new and rapidly evolving. New research is released nearly every day, and many cutting edge ideas are just shared online instead of being formally published. As such, this topic is likely to transform significantly in coming months, thus expanding what problems are solvable with LLMs.
Understanding LLMs
Due to its focus upon prompting, this overview will not explain the history or mechanics of language models. To gain a better general understanding of language models (which is an important prerequisite for deeply understanding prompting), I’ve written a variety of overviews that are available. These overviews are listed below (in order of importance):
Language Modeling Basics (GPT and GPT-2) [link]
The Importance of Scale for Language Models (GPT-3) [link]
Advanced Prompting Techniques
We will now cover three influential topics in the prompt engineering space. First, we will learn about how chain of thought prompting, including several notable extensions and variants, can be used to improve the reasoning abilities of LLMs. From here, we will discuss the integration of LLMs with external databases, enabling relevant, accurate information to be injected into each prompt. Finally, we will learn how automatic prompt engineering approaches can be used to discover better prompts from data.
Chain of Thought Prompting and Beyond
We covered the main ideas behind chain of thought (CoT) prompting [1] and a few of its popular variants in a prior post. For full details, read the overview at the link below.
what is CoT prompting? CoT prompting is a simple technique for improving an LLM’s performance on reasoning tasks like commonsense or symbolic reasoning. CoT prompting leverages few-shot learning by inserting several examples of reasoning problems being solved within the prompt. Each example is paired with a chain of thought (or rationale) that augments the answer to a problem by textually explaining how the problem is solved step-by-step; see below.

Due to their few-shot learning capabilities, LLMs can learn to generate a rationale along with their answers by observing the exemplars within a CoT prompt. Prior work has shown that generating accurate rationales in this manner can improve reasoning performance [10, 11], and we see exactly this effect in experiments with CoT prompting. Namely, teaching an LLM to output a relevant chain of thought that explains its final answer can drastically improve performance on tasks like arithmetic, symbolic, and commonsense reasoning; see below.

popular CoT variants. Beyond basic CoT prompting, several variants of the technique have been explored, such as:
Zero-shot CoT prompting [13]: replacing all example rationales and instead injecting the statement “Let’s think step by step” at the end of the prompt.
Self-consistency [14]: using the LLM to generate multiple chains of thought and taking the majority vote of these multiple outputs as the final answer.
Least-to-most prompting [15]: decomposing reasoning problems into smaller steps that are solved one-at-a-time, where the output of each subproblem is used as input for the next.
These techniques (shown in the figure below) are similar to CoT prompting and yield comparable results, but they each have unique benefits. For example, zero-shot CoT prompting is incredibly simple! We just need to insert a single statement into our prompt instead of hand-writing or curating several relevant chain of thought examples. On the other hand, least-to-most prompting is slightly more complex than vanilla CoT prompting, but this technique is also more capable of solving reasoning problems that require many steps. As such, we can use least-to-most prompting to solve the most difficult tasks where CoT prompting falls short.

Of these techniques, self-consistency is my personal favorite. Why? Because it is a simple technique that is widely applicable and very effective. In fact, the idea is not even specific to CoT prompting! Self-consistency can improve the performance of LLM applications in many cases. Instead of generating a single output with our LLM, we generate multiple outputs and take their average as our final answer, thus improving reliability and accuracy.
This idea reminds me of model ensembles in deep learning, where we i) independently train several models to solve some task and ii) take an average of each model’s output at inference time. Although self-consistency only uses a single model instead of an ensemble, similar techniques have been applied in the broader deep learning literature; e.g., to simulate an ensemble, several outputs can be generated and averaged from neural networks that contain non-deterministic modules like dropout [19, 20].
extending CoT prompting. Whether or not CoT prompting actually teaches LLMs how to “reason” is unclear. Nonetheless, CoT prompting has significant practical importance because it can be used to solve complex, multi-step problems with LLMs. As such, a variety of interesting ideas surrounding CoT prompting have been explored recently. In [16], a multimodal version of CoT prompting is explored, in which both image and text modalities are used to perform different reasoning tasks; see below.
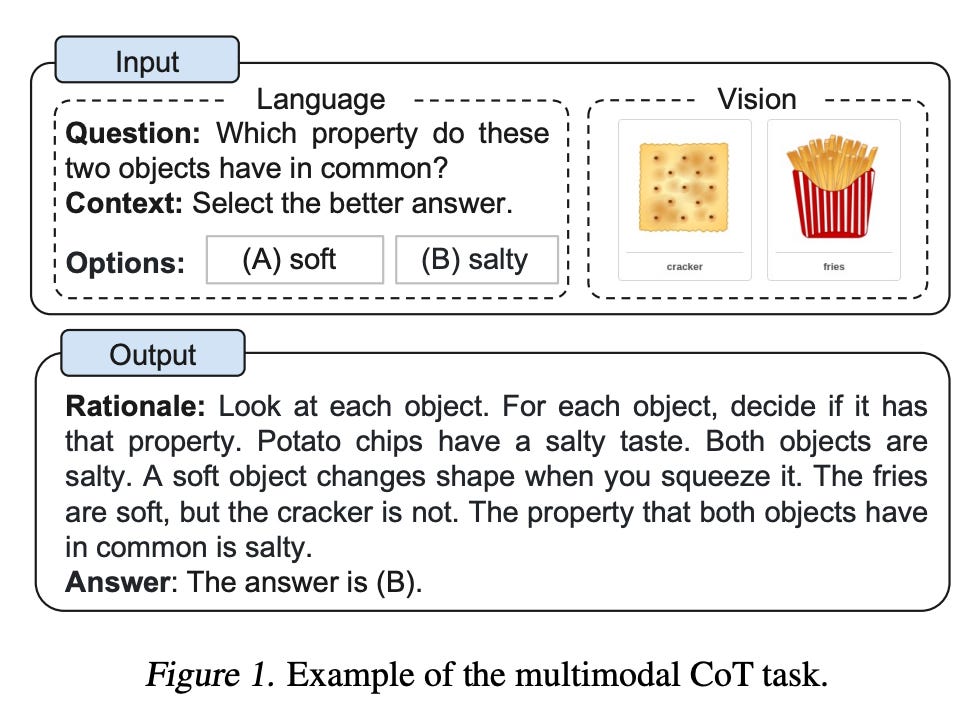
In addition to exploring multiple data modalities (i.e., images and text), authors in [16] slightly tweak the CoT setup by treating multi-step rationale generation and answer inference as two distinct steps in solving a reasoning-based task; see below.
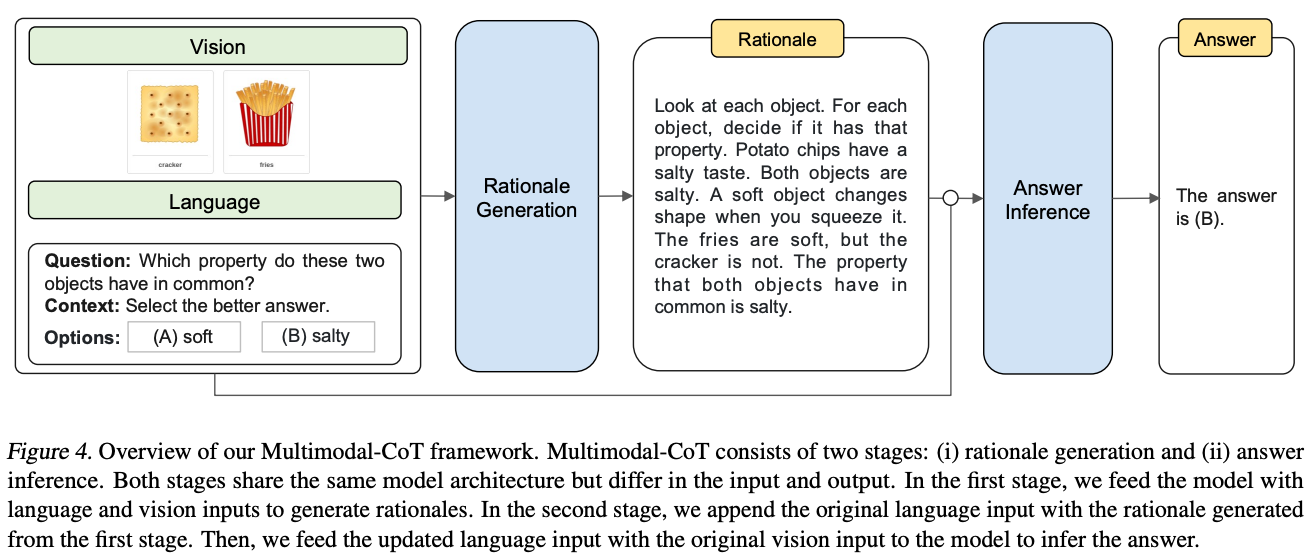
By clearly isolating these components, we can more easily analyze sources of error in CoT prompting. As a result, authors in [16] find that i) incorrect answers can often be caused by hallucinations in the generated rationale and ii) using multimodal data leads to the generation of more effective rationales.

Going further, authors in [17] combine CoT prompting with the idea of active learning (i.e., using the model itself to identify data that should be included in the training set). The LLM first answers several questions using CoT prompting. From here, output “uncertainty” (measured based on disagreements between multiple answers generated by the same LLM) is used to identify questions that the model poorly understands. The questions within this group are then hand-annotated (by humans) with a correct chain of thought and used as examples for solving future questions.
One of the biggest problems we might experience with applying CoT prompting in practice is the lack of few-shot exemplars that align well with the task we are trying to solve. Maybe we have access to several high-quality chains of thought to include in our prompt, but what do we do if the problem we are trying to solve is slight different than the problem solved in these examples? Although such a problem can lead to deterioration in performance, the approach proposed in [17] aims to combat this problem. Namely, we can use active learning to dynamically identify when available examples for CoT prompting are insufficient for solving a certain problem.
Knowledge Augmentation
Although LLMs learn a lot of information during pre-training, augmenting their prompts with extra, relevant information is oftentimes helpful. Such an approach can help with issues like hallucination (i.e., generating incorrect facts) by providing accurate sources of information within an LLM’s prompt that can be used as context while generating output. Although there are several ways to accomplish this, we will focus upon techniques based upon information retrieval and generated knowledge.

information retrieval. The LLM community has placed a recent emphasis on vector database technology (e.g., Pinecone, Milvus, Weaviate, etc.) due to its role in performing information retrieval; see above. At a high level, the goal of information retrieval is to enable LLMs to access a large bank of textual information (beyond the maximum context window) by:
Chunking the text into small parts.
Producing an embedding for each chunk of text.
Storing these embeddings in a vector database.
Performing vector similarity search (based on these embeddings) to find relevant chunks of text to include in a prompt.
The net result is that we can quickly find relevant textual information to provide as extra context within the LLM’s prompt. Such an approach can even be combined with CoT prompting to guide the retrieval process towards new and useful information [2].
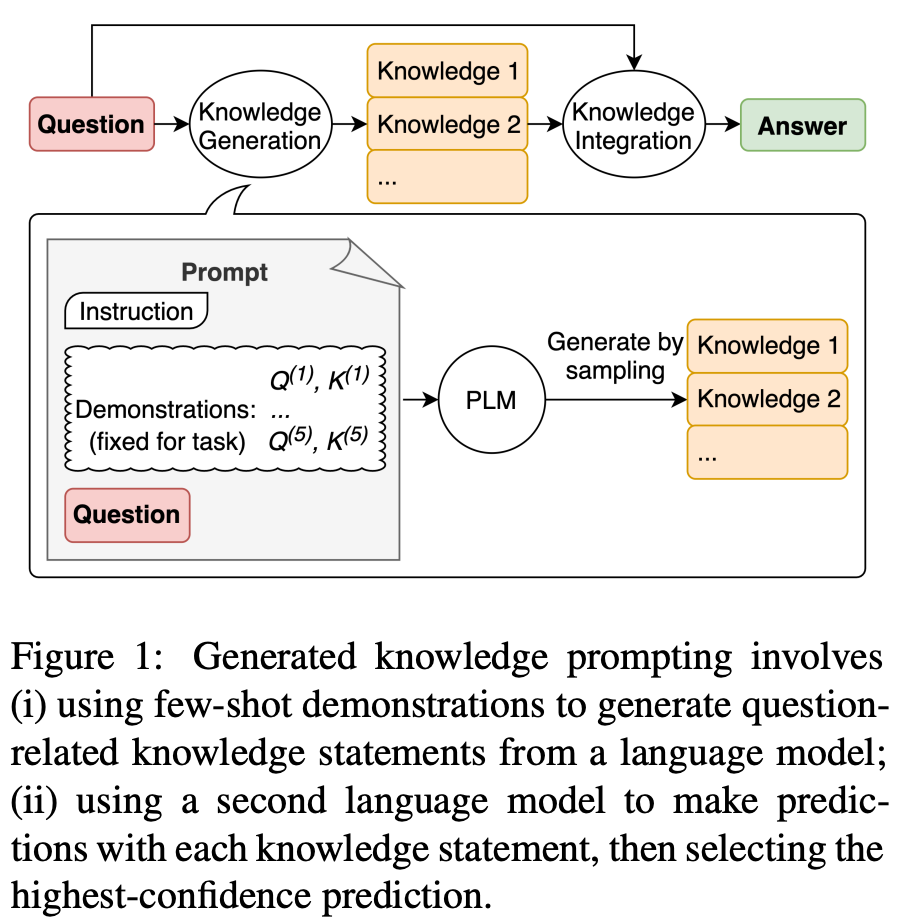
generated knowledge. Information retrieval is powerful (i.e., it enables access to a nearly unlimited amount of information!), but we might wonder: is the external vector database completely necessary? Interestingly, recent research [1] indicates that the answer might be no! Instead of storing and retrieving external knowledge, we can improve LLM performance by just prompting a separate LLM to generate information; see above. In particular, we can use few-shot learning by prompting an LLM with examples of knowledge generation on various topics and ending with a request to generate useful context about a desired topic; see below.

Form here, we can feed the generated information as extra context when generating a prediction. Despite not relying on any external database, this approach can noticeably improve LLM performance on several commonsense reasoning tasks; see below.

Generated knowledge is most helpful for tasks (like commonsense reasoning) that assume understanding of commonsense knowledge in the world. Put simply, LLMs are a good information sources as long as they are used carefully and for the correct kind of task.
“Generated knowledge prompting highlights large language models as flexible sources of external knowledge for improving commonsense reasoning” - from [1]

Now from our partners!
Rebuy Engine is the Commerce AI company. We use cutting edge deep learning techniques to make any online shopping experience more personalized and enjoyable.
MosaicML enables you to easily train and deploy large AI models on your data and in your secure environment. To try out their tools and platform, sign up here! Plus, MosaicML has a tendency to release awesome open-source, commercially-usable LLMs.
Automatic Prompting
The goal of prompt engineering is two tweak the input to our language model such that we maximize the model’s chance of providing a correct result. With this in mind, we could even consider our prompt as a group of trainable parameters that can be updated (e.g., using gradient descent or some other data-driven criteria) to generate a correct answer. The idea of automatically updating our prompt based on data is pretty generic, but several such techniques have been successfully explored in recent research.
automatic prompt engineer (APE) [4] proposes a simple approach for automatically generating instructions for prompting. First, an LLM is used to propose a set of potential instructions by using a few-shot prompt with multiple instruction examples. A few prompt templates are explored for generating instructions; see below.

Then, we search over this pool of instruction “candidates” by evaluating the zero-shot performance (i.e., either accuracy or log probability of the correct result) of an LLM that uses each instruction. In other words, LLM performance with each prompt is used as a metric for evaluating instruction quality.

Going further, we see in [4] that instructions can be iteratively refined by just repeating this process. In particular, we can i) propose a set of candidates, ii) evaluate these candidates based on performance, iii) select top candidates, and iv) generate new variants of top-performing candidates by prompting an LLM to generate similar instructions (i.e., resampling). This process (and the associated prompt) are outlined in the figure below.

gradient-based search. Beyond techniques that search for better textual prompts, there is a line of useful prompt engineering works that explore continuous updates to prompt embeddings. First, we should recall what prompt embeddings are within a language model. Given a textual prompt, we typically tokenize this prompt (i.e., separate it into words or sub-words), then look up the embedding of each resulting token. This process gives us a list of token embeddings (i.e., a prompt embedding!), which we pass as input to the language model; see below.

Several works explore prompt engineering strategies that directly modify the prompt embedding (i.e., just a list of embeddings for each token). In other words, these works don’t directly modify the words of a prompt, but rather update the prompt embeddings using a rule like gradient descent. The major works in this area are outlined in the list below:
AutoPrompt [5] combines the original prompt input with a set of shared (across all input data) “trigger tokens” that are selected via a gradient-based search to improve performance.
Prefix Tuning [6] adds several “prefix” tokens to the prompt embedding in both input and hidden layers, then trains the parameters of this prefix (leaving model parameters fixed) with gradient descent as a parameter-efficient fine-tuning strategy.
Prompt Tuning [7] is similar to prefix tuning, but prefix tokens are only added to the input layer. These tokens are fine-tuned on each task that the language model solves, allowing prefix tokens to condition the model for a given task.
P-Tuning [8] adds task-specific anchor tokens to the model’s input layer that are fine-tuned, but allows these tokens to be placed at arbitrary locations (e.g., the middle of the prompt), making the approach more flexible than prefix tuning.
which one should we use? All of these approaches (shown below) explore the addition of “soft” tokens to the language model that undergo supervised fine-tuning over a target dataset. Notably, these techniques cannot be used with language models that are only accessible via paid APIs (e.g., the OpenAI API). This is because we would need the ability to access and modify prompt embeddings, while most APIs only surface the textual inputs and outputs of a model. For now, we can only use gradient-based automatic prompting techniques if we are working with our own self-hosted LLM.

Of these approaches, Prompt Tuning is the simplest and yields impressive performance benefits. With Prompt Tuning, we just i) append some prefix token embeddings to the input and ii) perform parameter-efficient fine-tuning of these embeddings over individual, downstream tasks. The approach in [7] performs multi-task fine-tuning by mixing several different tasks into each update and giving each task a unique, learned prefix; see below.

Usually, fine-tuning a language model would mean that we have to store a separate copy of the model’s parameters for each task. In contrast, Prompt Tuning just fine-tunes a small set of prefix token embeddings and keeps remaining model parameters fixed. Despite only fine-tuning a small group of parameters, Prompt Tuning comes quite close to matching the performance of end-to-end fine-tuning as shown in the figure below.

Takeaways
“How much more can we expect reasoning ability to improve with model scale? What other prompting methods might expand the range of tasks that language models can solve?” - from [9]
The main purpose of this overview was to explore different prompting techniques that might be practically useful for solving difficult problems with LLMs. If applied correctly, fundamental techniques like zero/few-shot learning and instruction prompting are useful and effective. However, something more sophisticated might be needed to enable LLMs to solve reasoning-based tasks or follow complex, many-step instructions. Though models may improve in quality over time and more easily handle such difficult cases, the techniques covered in this overview can be used to expand the scope of what is possible with LLMs that are currently available. Some basic takeaways from these techniques are outline below.
solving hard problems. Analysis of CoT prompting shows us that LLMs are capable of solving complex, multi-step problems. To do this, however, the problem needs to be broken into smaller parts for or by the LLM. We can do this implicitly by encouraging the model to generate a problem-solving rationale before its answer, or explicitly by using least-to-most prompting to break the problem into small parts that are individually solved by the LLM. Either way, we usually see a benefit from encouraging the LLM to solve problems step-by-step instead as a whole.
learning to prompt. If we hear the words “prompt engineering”, most of us probably think of tweaking the words or structure of a prompt and seeing what works best. However, this is not the only approach to prompt engineering! Namely, we can adopt an automatic prompting approach that learns optimal prompts from data via gradient descent. To do this, we make the prompt embedding (i.e., the list of embeddings for each token in the prompt) trainable and perform fine-tuning. Although this approach is interesting and useful, there are a few caveats to keep in mind:
Learned prompt embeddings cannot be mapped back to a textual prompt because the embeddings for each token in a model’s vocabulary are discrete.
We can only use these approaches if we have access to the language model’s embedding layer. Such access is not provided via paid APIs (e.g., from OpenAI).
simple but powerful. Despite the fact that this overview focuses on advanced prompt engineering techniques, there are many simple tricks that can be easily applied to improve LLM applications. For example, self-consistency can improve the reliability of LLMs by generating multiple answers and taking their average. Zero-shot CoT prompting can easily improve LLM reasoning capabilities by appending a single statement to the end of a prompt. Finally, generated knowledge can improve LLM performance by simply asking the model to list useful information about a topic before generating a final answer. In many cases, adding simple tricks to our prompt engineering toolkit can make a big difference!
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a better understanding of deep learning research via understandable overviews that explain relevant topics from the ground up. If you like this newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Liu, Jiacheng, et al. "Generated knowledge prompting for commonsense reasoning." arXiv preprint arXiv:2110.08387 (2021).
[2] Trivedi, Harsh, et al. "Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions." arXiv preprint arXiv:2212.10509 (2022).
[3] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[4] Zhou, Yongchao, et al. "Large language models are human-level prompt engineers." arXiv preprint arXiv:2211.01910 (2022).
[5] Shin, Taylor, et al. "Autoprompt: Eliciting knowledge from language models with automatically generated prompts." arXiv preprint arXiv:2010.15980 (2020).
[6] Li, Xiang Lisa, and Percy Liang. "Prefix-tuning: Optimizing continuous prompts for generation." arXiv preprint arXiv:2101.00190 (2021).
[7] Lester, Brian, Rami Al-Rfou, and Noah Constant. "The power of scale for parameter-efficient prompt tuning." arXiv preprint arXiv:2104.08691 (2021).
[8] Liu, Xiao, et al. "GPT understands, too." arXiv preprint arXiv:2103.10385 (2021).
[9] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[10] Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. 2017. Program induction by rationale generation: Learning to solve and explain algebraic word problems. ACL.
[11] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
[12] Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." arXiv preprint arXiv:2205.11916 (2022).
[13] Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." arXiv preprint arXiv:2205.11916 (2022).
[14] Wang, Xuezhi, et al. "Self-consistency improves chain of thought reasoning in language models." arXiv preprint arXiv:2203.11171 (2022).
[15] Zhou, Denny, et al. "Least-to-most prompting enables complex reasoning in large language models." arXiv preprint arXiv:2205.10625 (2022).
[16] Zhang, Zhuosheng, et al. "Multimodal chain-of-thought reasoning in language models." arXiv preprint arXiv:2302.00923 (2023).
[17] Diao, Shizhe, et al. "Active Prompting with Chain-of-Thought for Large Language Models." arXiv preprint arXiv:2302.12246 (2023).
[18] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[19] Hara, Kazuyuki, Daisuke Saitoh, and Hayaru Shouno. "Analysis of dropout learning regarded as ensemble learning." Artificial Neural Networks and Machine Learning–ICANN 2016: 25th International Conference on Artificial Neural Networks, Barcelona, Spain, September 6-9, 2016, Proceedings, Part II 25. Springer International Publishing, 2016.
[20] Huang, Gao, et al. "Deep networks with stochastic depth." Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14. Springer International Publishing, 2016.
will you cover tree of thoughts?
The fact that you share this much knowledge with us is incredible. I'm deeply grateful Cameron for all your work.