
Automatic Prompt Optimization
Practical techniques for improving prompt quality without manual effort...

Prompting—both of large language models (LLMs) in particular and other types of frontier models—is arguably one of the most impactful advancements in modern AI. By writing an instruction in natural language, nearly anyone can leverage the power of massive neural networks to solve a wide variety of practical tasks. Prior generations of deep learning models have achieved impressive feats in terms of performance, but LLMs do more than just perform well—they are intuitive to use. Non-experts can interact with these models and see their potential first hand, which has directed an unprecedented amount of attention to AI research.
“By conditioning on natural language instructions, large language models (LLMs) have displayed impressive capabilities as general-purpose computers. However, task performance depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans.” - from [1]
Although prompts provide an intuitive interface to LLMs, this interface is far from perfect. Many models are overly sensitive to small changes in the prompt. Tweaking the prompt’s wording or structure can lead to incorrect and unexpected results. For this reason, writing effective prompts requires non-trivial domain expertise and has become a sought-after skill. Most prompts are created via an iterative trial and error process with a human in the loop. We just tweak and test the prompt repeatedly, using our knowledge of prompting—and of the LLM being prompted—to guide our search towards a prompt that performs well.
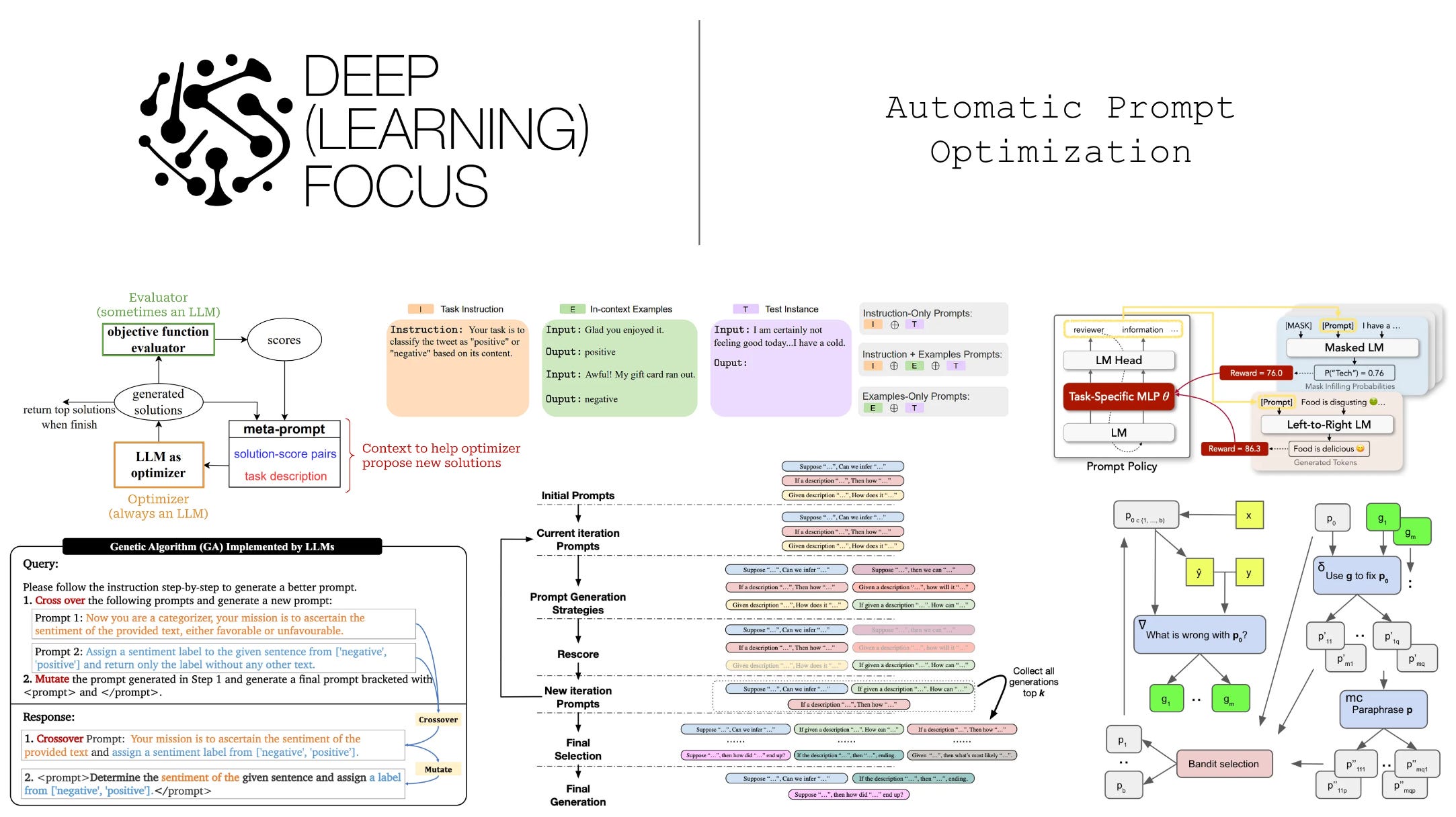
Improving prompts automatically. Prompting requires a lot of human effort and is imperfect by nature. To mitigate these issues, recent research has explored the idea of automatic prompt optimization, which uses data to improve the quality of a prompt algorithmically. There are a few key benefits to this approach:
Less manual effort is required to find a good prompt.
Prompts are searched for and discovered systematically, enabling prompts that exceed the performance of those written by humans to be found.
Prompt optimization techniques allow us to improve the quality of our prompts automatically, instead of relying upon heuristics and domain knowledge. In this overview, we will learn about the extensive literature that has been published on this topic, focusing on the most practical techniques for creating better prompts.
Preliminaries: Prompting and Optimization
This overview will primarily study the overlap of optimization and prompt engineering, but we must not forget that these two ideas—optimization and prompt engineering—are also distinct fields of research. By learning about these ideas in isolation, we will understand how the key concepts behind them can be combined to create algorithms for automatically improving the quality of a prompt.
What is optimization?

Optimization refers to the idea of finding an optimal solution or point within a certain function, referred to as the “objective function”. Usually, this means finding the point that minimizes (or maximizes) the value of the function; see above. By finding this optimal point, we are “optimizing” the function, or performing optimization. Having existed for centuries, the field of optimization is rich, broad, and incredibly valuable. The idea of optimizing an objective function can be used to solve a massive number of important tasks, including anything from routing traffic to training a neural network. A comprehensive explanation of optimization is beyond the scope of this post, but many resources are available.
Types of optimization algorithms. Countless optimization algorithms have been proposed. Even for the specific application of training a neural network, there is a vast array of optimization algorithms to choose from. Despite this variety, optimization algorithms can be loosely grouped into two categories:
Gradient-based
Gradient-free
Gradient-based optimization repeatedly i) computes the gradient of our function and ii) uses this gradient to update the current solution. The gradient points in the direction of (locally) increasing function value, so we can use the gradient to find regions of higher or lower function values. We show a depiction of this process below, where we continually compute the gradient and move in the opposite direction of the gradient to minimize a function (i.e., gradient descent).
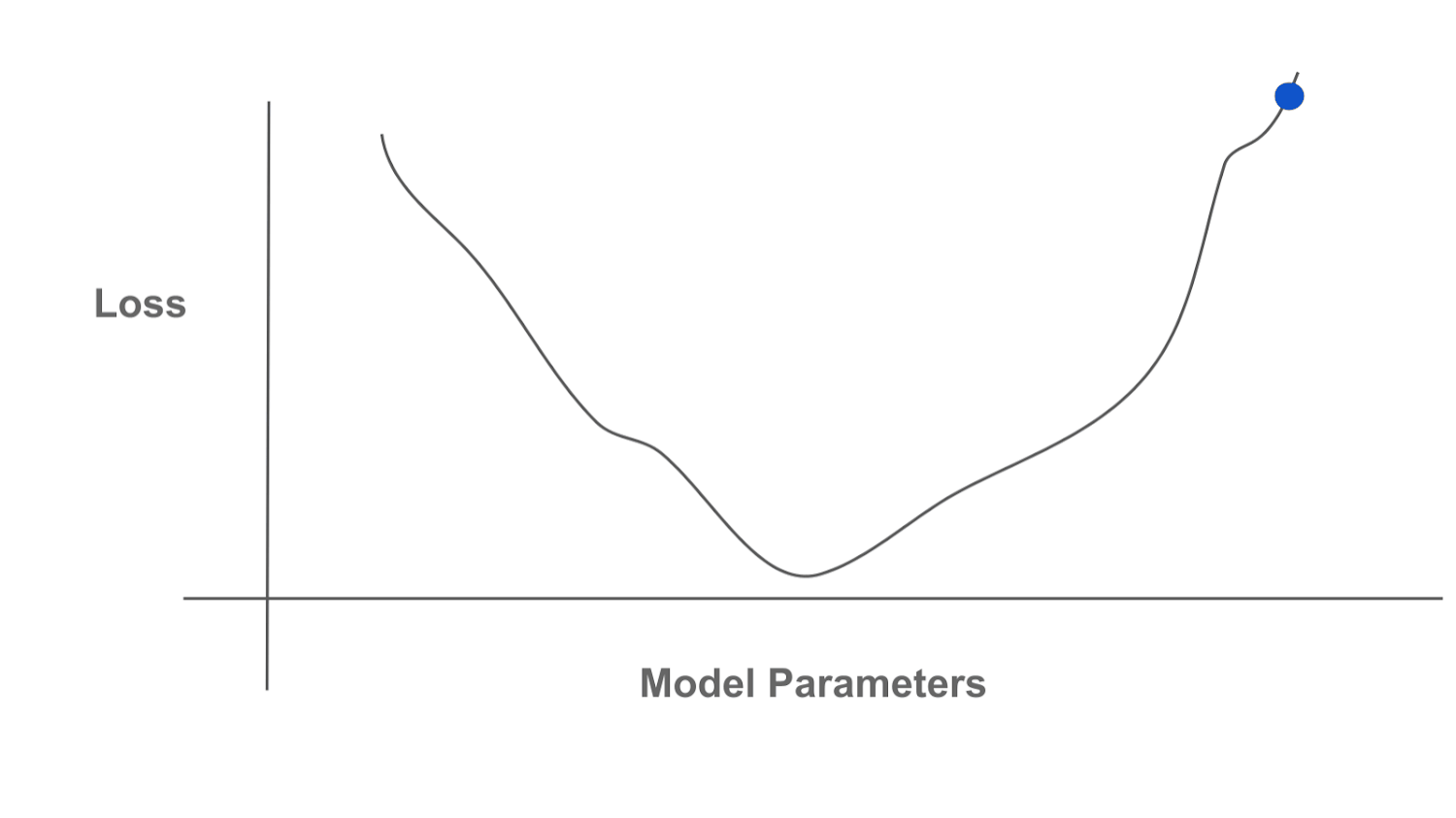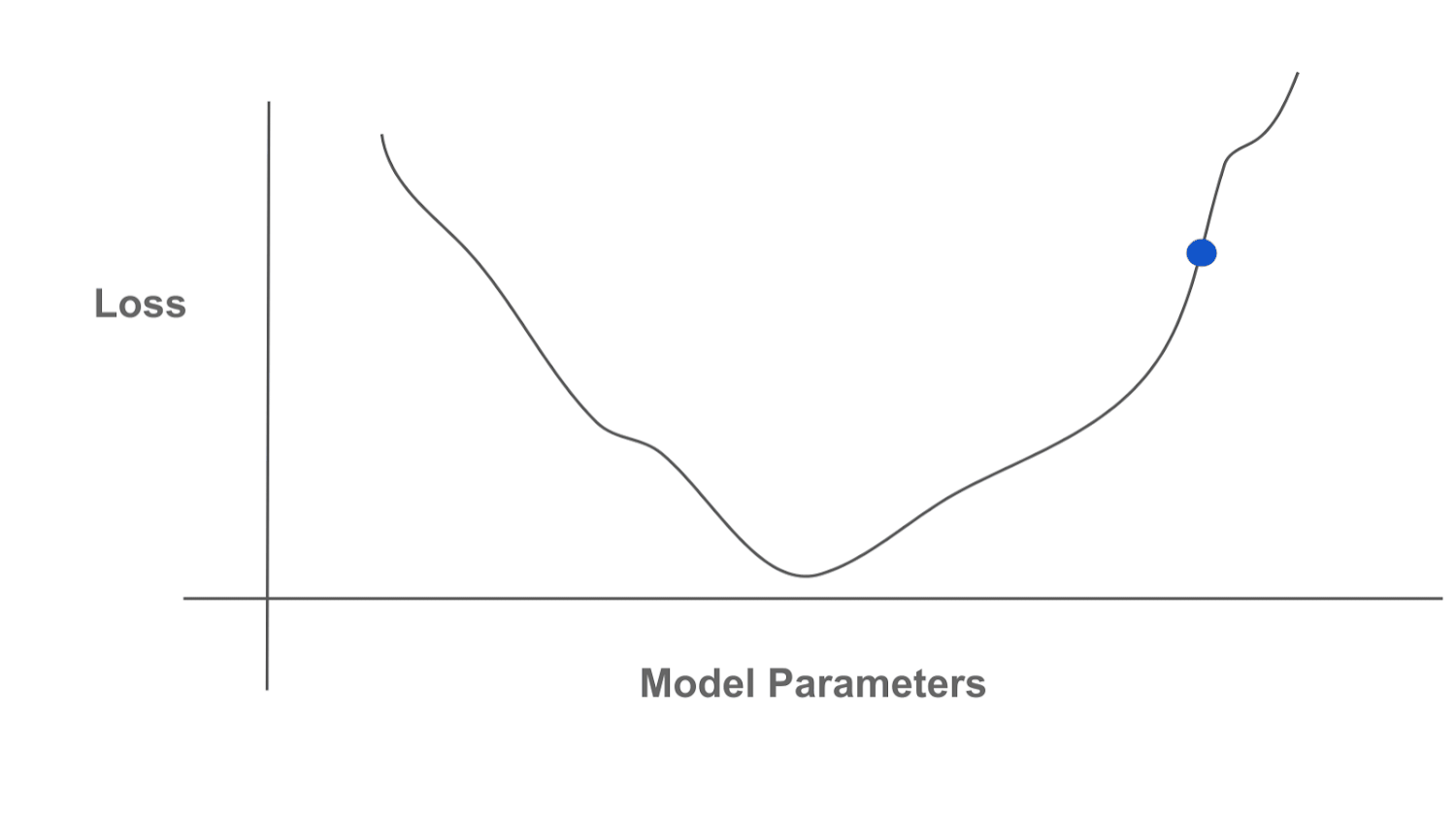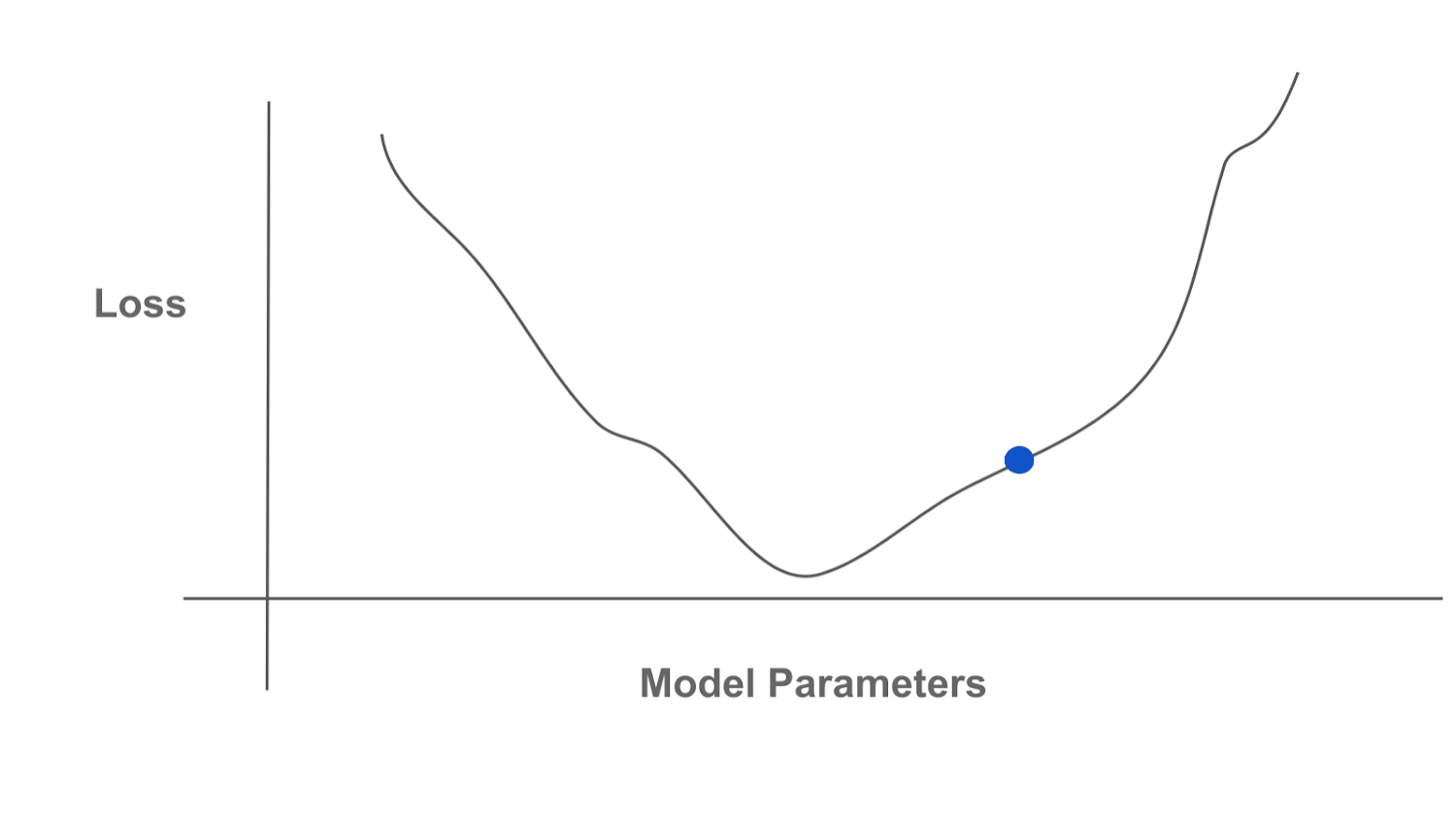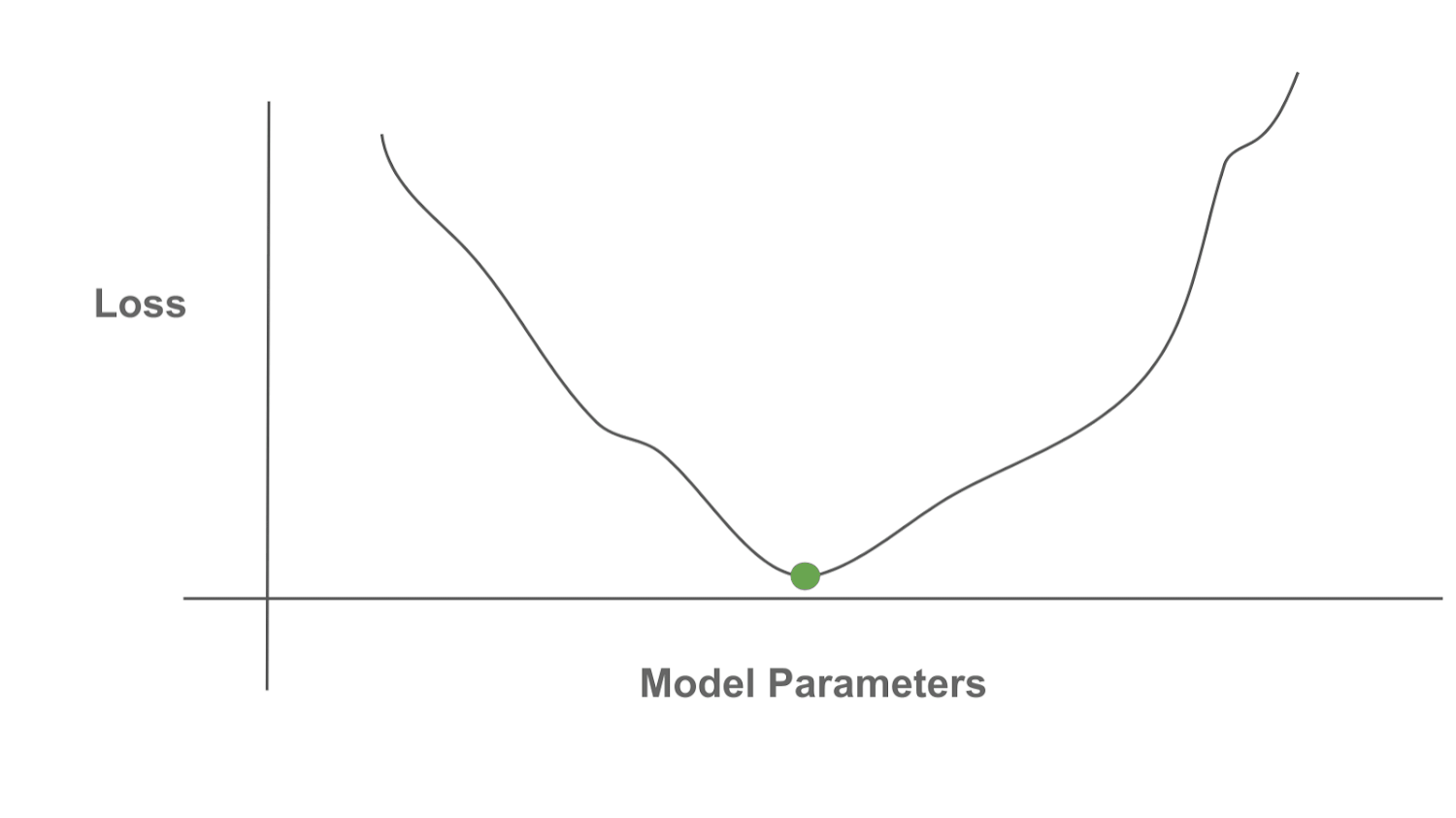
Machine learning practitioners are oftentimes most familiar with gradient-based optimization algorithms. These algorithms underlie the idea of backpropagation, which is used almost universally for training neural networks and other machine learning models. Gradient-based algorithms are popular because they are both effective and efficient! Even when optimizing a large number of variables (e.g., the parameters of an LLM), finding a solution is computationally feasible by just following the direction of the gradient, which is (relatively) cheap to compute.
Gradient-free algorithms are a class of optimization algorithms that do not use any gradient information; e.g., brute force search and hill climbing are two basic examples. Many gradient-free optimization algorithms exist, but one of the most popular class of algorithms—and the class of algorithms we will encounter in this overview—is evolutionary algorithms (EA); see below.

Inspired by the idea of biological evolution, EAs maintain a “population” of candidate solutions and repeatedly:
Modify the members of this population—the candidate solutions—via evolutionary operators like mutation and crossover to produce new population members, simulating the act of reproduction.
Select the best members—based upon some objective function—from the population to continue evolving (i.e., survival of the fittest).
Many variants of EAs exist [19], but the most common instantiations are genetic algorithms and differential evolution. In general, EAs are considered to be less efficient compared to gradient-based optimization algorithms. For example, training a large neural network (e.g., an LLM) is difficult without gradient information. The search space is very large, so tweaking the model’s parameters, measuring the loss, and hoping to find a better LLM will not get us very far.
“EAs typically start with an initial population of
Nsolutions, then iteratively generate new solutions using evolutionary operators (e.g., mutation and crossover) on the current population and update it based on a fitness function.” - from [16]
However, there are also many benefits to EAs; e.g., these algorithms balance the tradeoff between exploration and exploitation very well. Gradient-based algorithms produce a single solution, while EAs maintain an entire population! This property is very useful for certain classes of problems, which has led to the practical adoption of EAs in many interesting domains such as evolving neural network architectures or optimizing computer network topologies [19].
Using LLMs as optimizers. Recently, researchers have explored the idea of using LLMs as gradient-free optimizers. To do this, we provide information to the LLM about the current solution to a problem—including the solution’s performance—and the optimization trajectory (i.e., the history of previous solutions). Then, we can prompt an LLM to produce a new—and hopefully better—solution to the problem. By measuring the performance of the new solution and repeating this process, we create a new type of optimization algorithm. As we will see, such LLM-based optimization techniques are used regularly for optimizing prompts.

Many papers cover the topic of using LLMs as optimizers. For example, authors in [3] use LLMs to optimize simple regression problems and solve the traveling salesman problem. Researchers have also explored:
Combining LLMs with EAs [27, 28].
Using LLMs for hyperparameter optimization [29].
Automating neural architecture search with an LLM [30].
“Instead of formally defining the optimization problem and deriving the update step with a programmed solver, we describe the optimization problem in natural language, then instruct the LLM to iteratively generate new solutions based on the problem description and the previously found solutions.” - from [3]
The Basics of Prompt Engineering
The generic, text-to-text structure of an LLM is both intuitive and powerful. Instead of having a scientist train a specialized / narrow model over data for each task that needs to be solved, we can have (almost) anyone explain the problem in writing—via a prompt—and generate a reasonable solution with no (or minimal1) training data by passing this prompt to an LLM; see above. The approachability of prompts unlocks significant potential, as non-ML domain experts can easily prototype and demonstrate impactful applications of LLMs [22].
“LLMs are shown to be sensitive to the prompt format; in particular, semantically similar prompts may have drastically different performance, and the optimal prompt formats can be model-specific and task-specific.” - from [3]
Unfortunately, LLMs are sensitive to minor changes in prompts—the exact details of how we phrase and structure our prompt makes a big difference. This issue can make prompting LLMs difficult for non-experts [21]. As a result, prompt engineering (i.e., the art of creating better prompts) has become a legitimate, popular, and useful skill. This overview will primarily focus on methods for automatically improving prompts, but we will go over some prompting basics here.
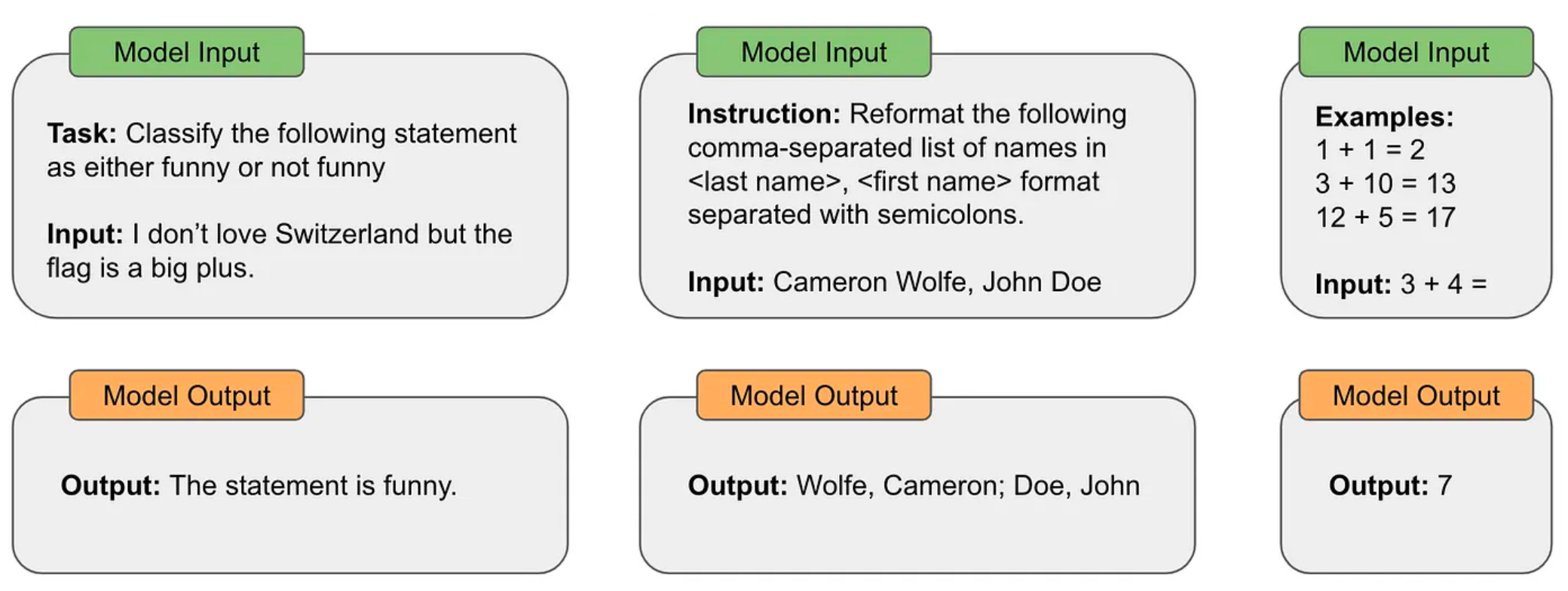
Anatomy of a prompt. Although we can take many different approaches for writing prompts, there are a few standard components that are usually present within any kind of prompt:
Instruction: a textual description of the output that is expected of the model.
Examples / Exemplars: concrete examples of correct input-output pairs (i.e., demonstrations) that are included within the prompt.
Context: any extra information provided to the LLM in the prompt.
Input Data: the actual data that the LLM is expected to process (e.g., the sentence being translated or classified, the document being summarized, etc.).
Structure / Indicators: different tags, headers, or organizational strings that we can include to separate or structure the parts of our prompt.
An example of a prompt that uses all of these components is shown above, but a prompt need not contain all of these components. We can selectively leverage them based on the details or needs of the problem we are trying to solve.
Prompting techniques. In prior overviews, we have studied different classes of prompting techniques extensively:
Practical Prompt Engineering: basic concepts, zero / few shot prompting, instructions, and more.
Advanced Prompt Engineering: chain of thought (CoT) prompting, variants of CoT prompting, context retrieval, and more.
Modern Advances in Prompt Engineering: recent prompting research (e.g., tool usage, reasoning, program-aided prompts, long-form writing, and more).
Beyond the overviews listed above, there are countless online resources for learning more about prompt engineering; e.g., learn prompting, prompting guide (from The Gradient), prompt engineering surveys [23, 24, 25], and more.
Framework for writing better prompts. Prompt engineering is an empirical science that is largely based upon trial-and-error. To write better prompts, we should continually i) tweak the original prompt, ii) measure the performance of the new prompt, and iii) select the better prompt. We also want to ensure that our prompt is not needlessly complex. There are a few reasons for this:
If a complex prompt is performing poorly, how will we know what part of the prompt is broken and what needs to be fixed?
Complex prompts are typically longer and will consume more tokens, which increases monetary costs.
For these reasons, we should begin the prompt engineering process with a simple prompt (e.g., a few-shot or instruction-based prompt). Then, we (slowly) increase the prompt’s complexity—by adding few-shot examples, using advanced techniques like CoT, or just tweaking the instruction—while monitoring performance over time. By following this process, we improve our prompt and justify increased complexity with improved performance; see below. The process ends once we have a prompt that reaches an acceptable level of performance for our use case.

Prompt engineering is just optimization! If we examine the steps of the prompt engineering process outlined above, we will realize that this is an optimization problem! We repeatedly tweak the solution—our prompt—and analyze whether the new solution is better or not. In this setup, the “optimizer” is a human prompt engineer who uses their judgement and knowledge of prompting to determine the next best prompt to try out. Given that prompt engineering requires so much trial and error, however, we might wonder whether we can replace2 the human in this optimization process with an automated approach or algorithm.
“The large and discrete prompt space makes [prompt engineering] challenging for optimization, especially when only API access to the LLM is available.” - from [3]
Why is it difficult to optimize prompts? As we just learned, there are two classes of optimization algorithms that we can consider for automating the prompt engineering process. Unfortunately, using gradient-based algorithms for prompt optimization is difficult for a few reasons:
For many LLMs, we only have access to an API, which prevents us from gathering / using any gradient information.
Prompts are composed of discrete tokens and using gradient-based algorithms to optimize a discrete solution is complicated.
As we will see in this overview, there are ways that we can avoid these issues and use gradient-based optimization to find better prompts. However, we will mostly rely upon gradient-free algorithms for prompt optimization due to the reasons listed above. In fact, EAs are actually one of the most successful and widely-used classes of algorithms for discrete optimization problems [26]!
Early Work on Prompt Optimization
The idea of optimizing a prompt is not new. Researchers began studying this problem as soon as the idea of a prompt was introduced. In this section, we will study some of the early work on prompt optimization, which was applied to both encoder-only variants of language models as well as GPT-style LLMs. This work inspired later techniques for prompt optimization that are commonly used today.
Generating Synthetic Prompts
As mentioned above, directly optimizing a prompt is difficult due to the discrete nature of tokens within the prompt. One way that we can work around this issue is by training an LLM to generate the prompt as output. By doing this, we can train the weights of the LLM that generates the prompt, instead of trying to optimize the prompt directly. This is a practical and commonly-used technique. As we will see, however, most work in this space uses pretrained LLMs to write prompts and does not explicitly optimize the LLM to write better prompts.
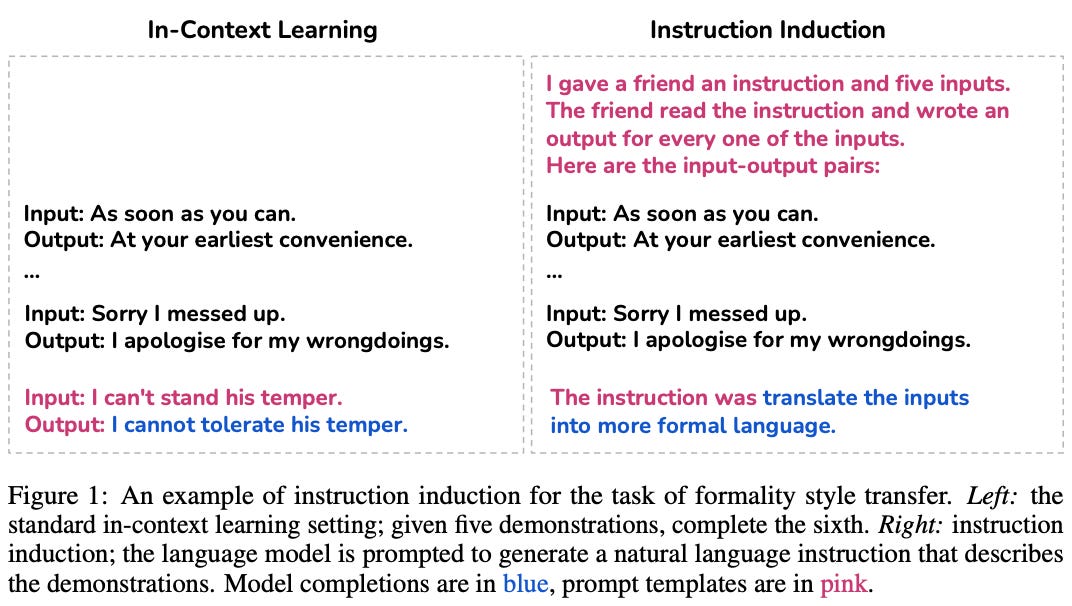
Instruction induction [7] is one of the first works to explore generating a prompt with a pretrained LLM. This technique aims to predict an underlying task given a few concrete (in-context) examples of that task as input. We craft a prompt that contains several input-output examples and ends by asking the LLM to infer the task being solved by completing the sequence “the instruction was…”; see above.
“We discover that, to a large extent, the ability to generate instructions does indeed emerge when using a model that is both large enough and aligned to follow instructions.” - from [7]
LLMs do not solve this task out-of-the-box; e.g., a pretrained GPT-3 model achieves only 10% accuracy. However, larger models begin to perform well on this task when they have been aligned to follow instructions. The InstructGPT model—an early, GPT-3-based LLM variant that is aligned to follow human instructions via RLHF—achieves nearly 70% accuracy on the instruction induction task.
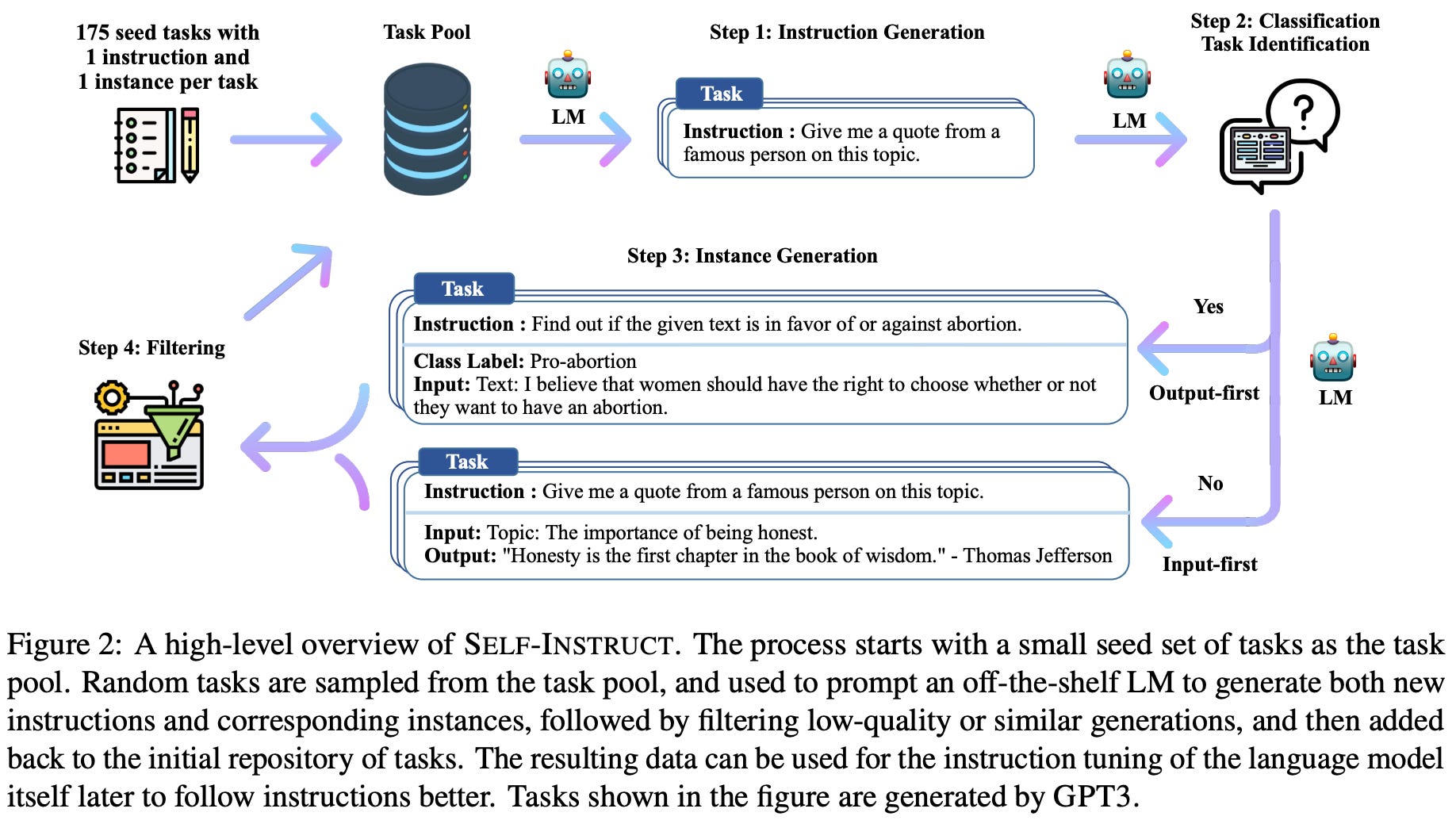
Self-Instruct [8] was one of the first frameworks proposed for using LLMs to generate synthetic instruction tuning datasets. Beginning with a small set of seed tasks, this framework prompts an LLM—using the seed tasks as input—to generate new tasks that can be solved. Afterwards, we can use the same LLM to create concrete demonstrations for each task, which are filtered based on quality. The result of this pipeline is an LLM-generated instruction tuning dataset, containing a large number of input-output examples for a wide variety of tasks.
“Self-Instruct … [improves] the instruction-following capabilities of pretrained language models by bootstrapping off their own generations. Our pipeline generates … samples from a language model, then filters invalid or similar ones before using them to finetune the original model.” - from [8]
Many papers use similar frameworks to generate synthetic instructions. For example, authors in [10] use a pretrained LLM to diversify a seed set of prompts and discover better prompts for analyzing an LLM’s knowledge base. Variants of Self-Instruct have also been proposed, such as a second version of the technique that reduces generation costs while improving data quality.

WizardLM [9] designs a Self-Instruct style framework that is tailored towards creating highly complex instruction tuning datasets. The crux of this method is a technique called EvolInstruct that uses an LLM to iteratively rewrite—or evolve—instructions to increase their complexity. There are two basic ways that we can evolve any given instruction:
In-Depth: make the current instruction more complex by adding constraints, requiring more reasoning steps, complicating the input, and more (i.e., keep the same instruction and make it more complex).
In-Breadth: enhancing the topic coverage, skill coverage, and overall diversity of the instruction tuning dataset (i.e., generate an instruction for a topic that is not covered in the data yet).
Each of these types of evolution has numerous variants. Example prompts for both in-depth and in-breadth evolution in [9] are provided below, though many additional prompts are leveraged in the implementation of EvolInstruct.

Given these strategies for evolving a prompt, we can apply a three step approach of i) evolving instructions, ii) generating instruction responses, and iii) removing or eliminating prompts that are not viable or fail to become more complex. By following these steps, we can bootstrap the Self-Instruct framework to generate a synthetic dataset with highly complex instructions; see below.

Soft Prompts: Prefix and Prompt Tuning
If we want to improve a prompt, we can begin by simply tweaking the wording or instructions present within the prompt. This approach is called “hard” prompt tuning3, as we are explicitly changing the words (or tokens) present within the prompt in a discrete manner; see above. However, hard prompt tuning is not the only tool available to use—we can explore soft, continuous updates to the prompt.
“Unlike prompting, the prefix consists entirely of free parameters which do not correspond to real tokens.” - from [4]
Prefix tuning [4] was one of the first papers to explore continuous updates to the prompt of an LLM. While traditional model finetuning trains all of a model’s parameters over a downstream dataset, prefix tuning leaves nearly all of the model’s parameters fixed. Instead, we append a “prefix”—or a sequence of additional token vectors at the beginning of the model’s input—to the model’s prompt and train the contents of this prefix directly. Instead of just updating the input prompt, however, prefix tuning adds a learnable prefix to the input of every transformer block within the underlying model; see below for an illustration.
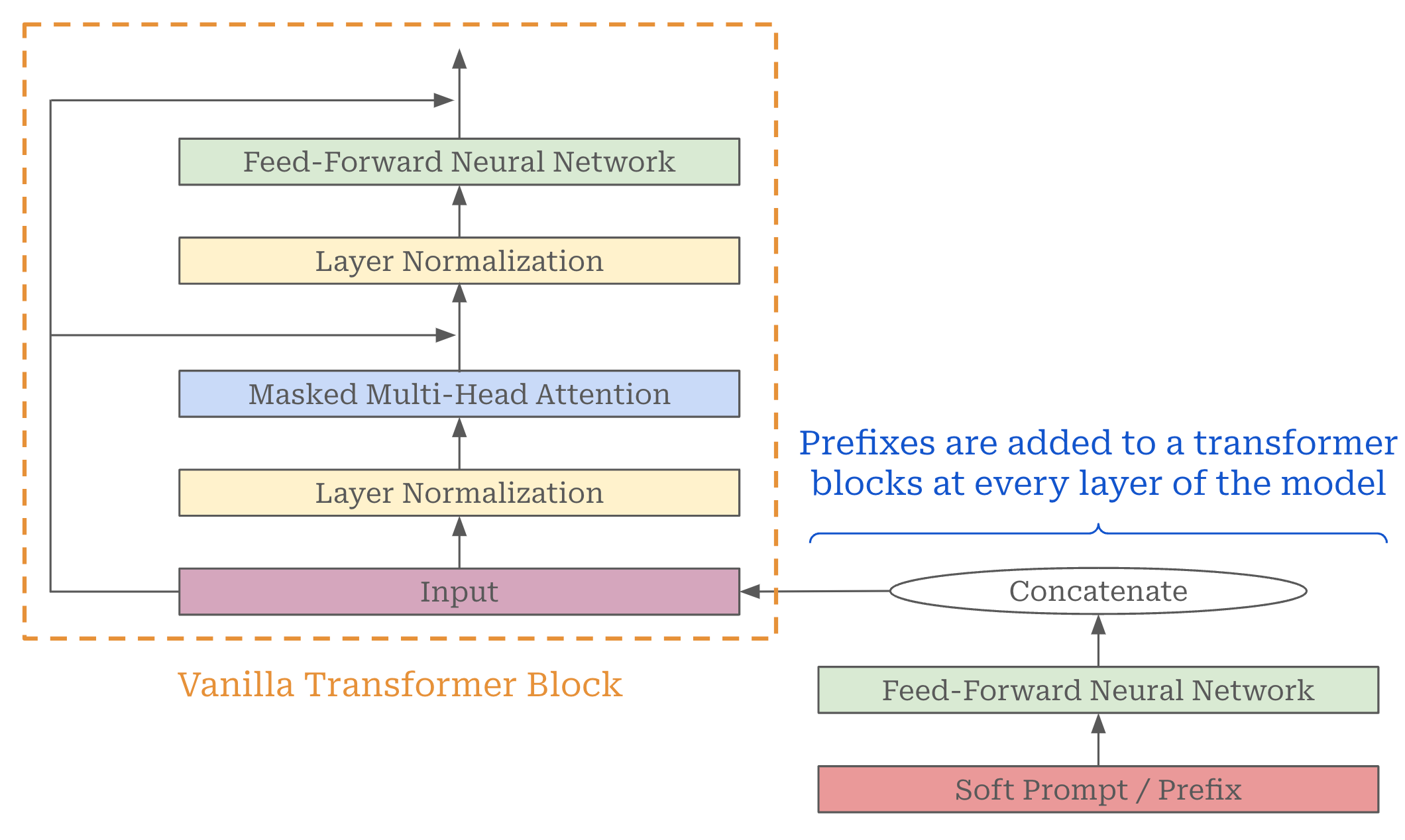
In prefix tuning, we train only the added prefixes in the model. Instead of directly training the contents of the prefix, authors in [4] find that passing the learnable prefix through a feed-forward transformation prior to concatenation with each layer’s input makes training much more stable. This technique, which adds more learnable parameters to the model, is referred to as “reparameterization”.

All parameters other than the prefix remain frozen during training, which drastically reduces—by 100X or more as shown in the figure above—the total number of parameters being learned during finetuning. Nonetheless, we can drastically improve downstream task performance via prefix tuning; see below.
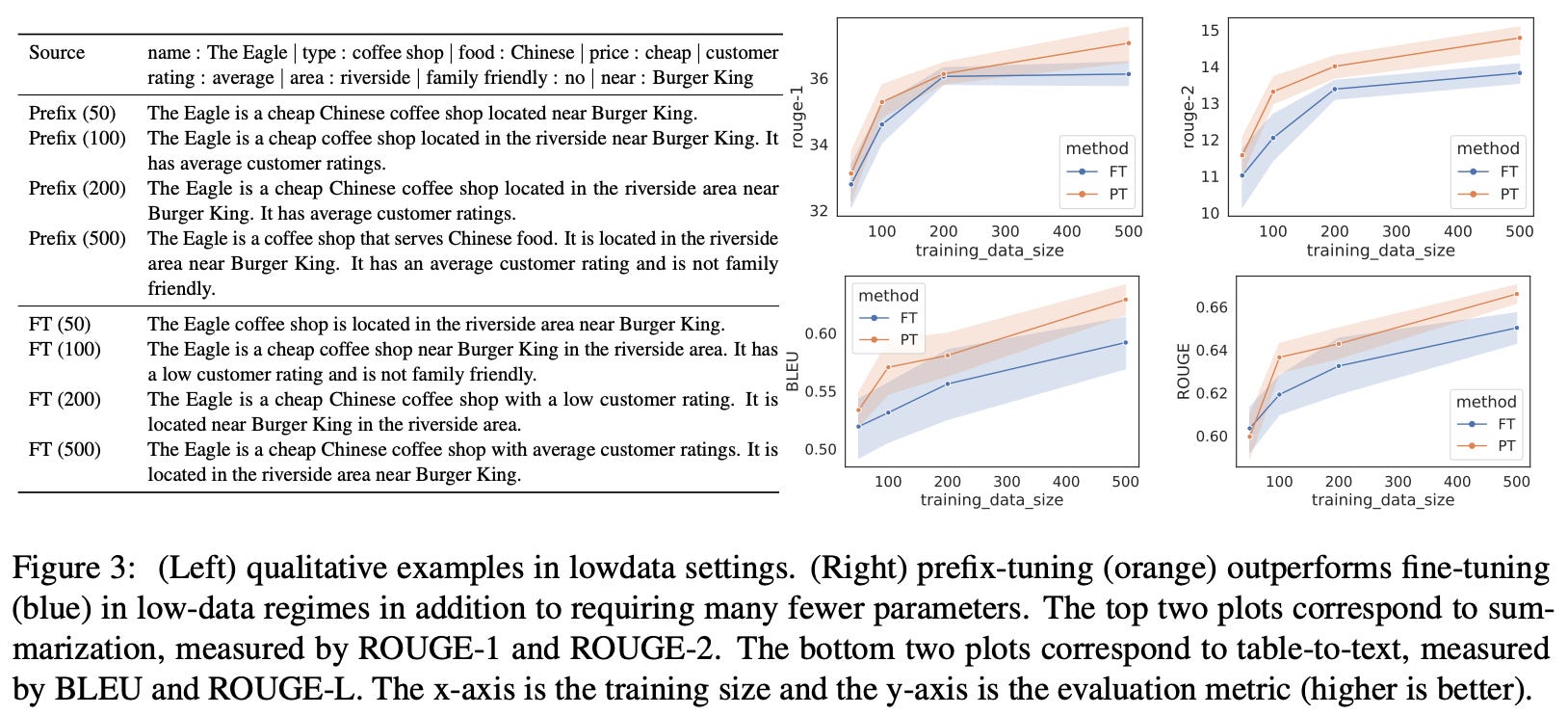
Although prefix tuning performs well in the above experiments, the only base model considered for finetuning experiments in [4] is GPT-2, meaning that these results remain to be proven with more modern models and datasets.
Prompt tuning [5] is a simplification of prefix tuning [4] that was proposed concurrently. Again, we start with a pretrained language model and freeze the model’s parameters. Instead of training the model, we create a “soft” prompt, or a sequence of tokens that are concatenated to the beginning of the LLM’s input. Then, we learn the soft prompt by training it—similarly to any other model parameter—over our dataset via gradient descent; see below.

Compared to prefix tuning, prompt tuning only prepends prefix tokens to the input layer—instead of every layer—and does not require reparameterization4 for training to be stable. As a result, the total number of parameters learned during prompt tuning is much lower compared to to prefix tuning.
“We … show that prompt tuning alone (with no intermediate-layer prefixes or task-specific output layers) is sufficient to be competitive with model tuning.” - from [5]
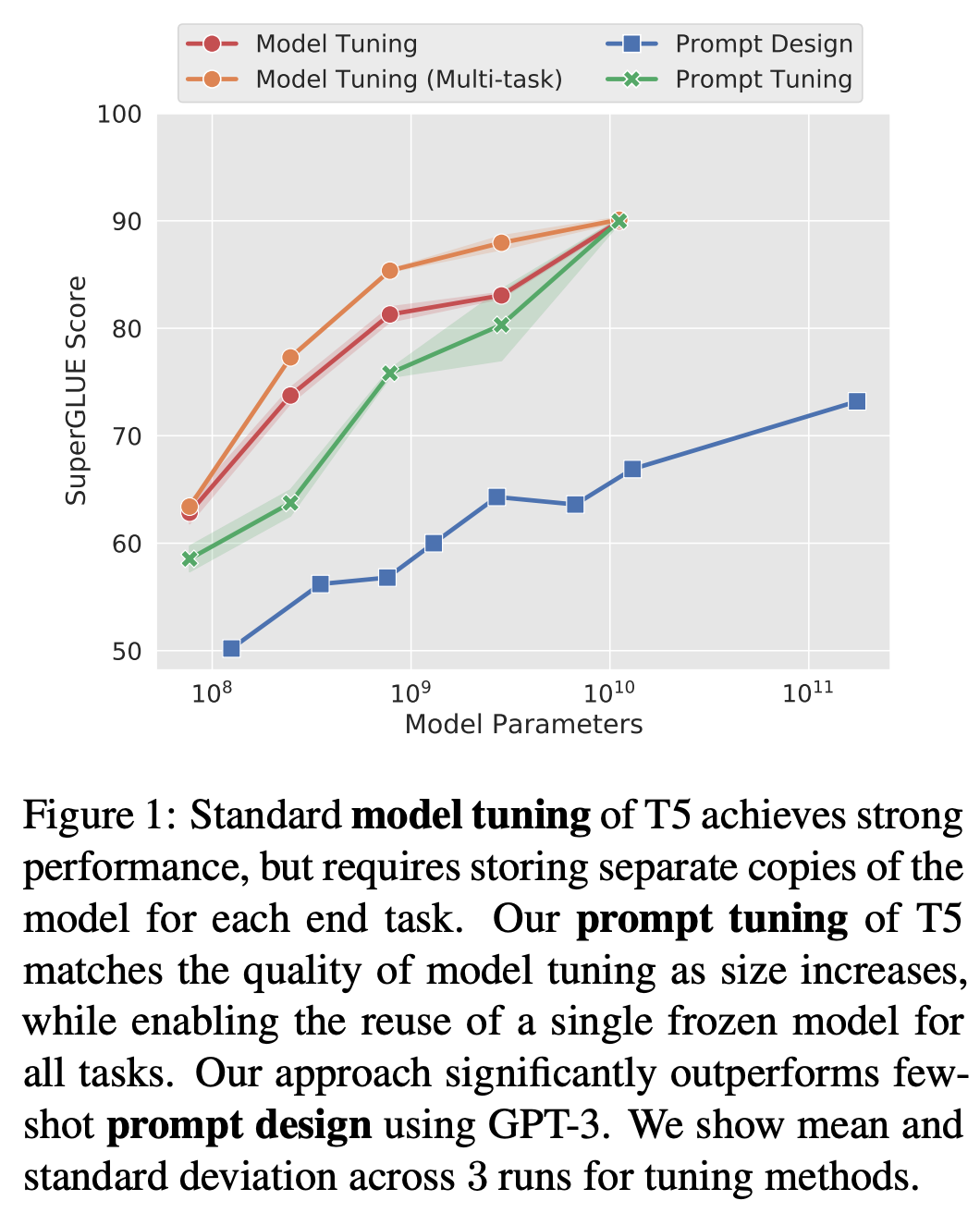
Despite the small number of learnable parameters, prompt tuning is surprisingly effective and even catches up with the performance of end-to-end model training as the underlying LLM becomes larger; see below. Additionally, the performance of prompt tuning usually exceeds that of manually-engineered prompts—though we should note that human performance is dependent on the human writing the prompt.
Are soft prompts actually prompts? Soft prompts are effective in terms of their performance, but one could argue that these technique actually do nothing to improve the prompt engineering process. The goal of prompt engineering is to discover a text-based prompt that works well given the application domain and LLM being considered. Instead of solving this problem, prompt and prefix tuning eliminate the constraint of our prompt being discrete / text-based. The “prompt” discovered by these techniques is just a continuous vector learned via gradient-based optimization. Similarly to any other model parameter, this vector is not human-interpretable and cannot be transferred for use with another LLM.
“This becomes less practical with scale, as computing gradients becomes expensive and access to models shifts to APIs that may not provide gradient access.” - from [1]
For this reason, prefix and prompt tuning are closer to parameter efficient finetuning (PEFT) techniques than they are to automatic prompt optimization strategies. Rather than searching for a better prompt, we add a small number of additional parameters to the model and directly train these parameters—while keeping the pretrained model fixed—over a smaller, domain specific dataset. These additional parameters just happen to be concatenated to our prompt instead of injected into the internal weight matrices of the model. For more information on PEFT techniques, check out my overview of this topic at the below link.
Easily Train a Specialized LLM: PEFT, LoRA, QLoRA, LLaMA-Adapter, and More

Instead of training the full model end-to-end, parameter-efficient finetuning leaves pretrained model weights fixed and only adapts a small number of task-specific parameters during finetuning. Such an approach drastically reduces memory overhead, simplifies the storage/deployment process, and allows us to finetune LLMs with more accessible hardware.
API-based access. The other issue with prompt and prefix tuning is that these techniques cannot be used when we can only access an LLM via an API. We need full access to the model’s weights for any form of gradient-based training, but LLM APIs only provide access to the model’s output—these LLMs are truly a black box! For this reason, prompt and prefix tuning are only compatible with open-source LLMs, but researchers have tried to create workarounds for this issue.

InstructZero [6] inserts another LLM between the soft prompt and the LLM API. This (open-source) LLM can be trained to produce a text-based instruction given the soft prompt and additional task information as input; see above. Then, the generated instruction can be passed to an LLM API normally. Put simply, we use the extra LLM to “decode” the soft prompt into a text-based prompt before it is passed to an API. To improve quality of generated instructions, we can use Bayesian optimization, which produces instructions that match or exceed the performance of prompts discovered via other automatic prompting methods.
More work on soft prompts. Prefix and prompt tuning are the most widely known soft prompting techniques, but there are numerous other papers that have considered this idea. Here are examples of other notable papers in this space:
Mixtures of Soft Prompts are formed by finetuning the entire prompt provided to a language model—either from an existing prompt or random initialization—to form a soft prompt, which can then be mixed or combined with other soft prompts to achieve better task performance.
WARP addresses the problem of adapting a language model to several downstream tasks by learning task-specific word embeddings that can be concatenated to the model’s input to solve different tasks.
P-Tuning addresses the instability of prompt engineering by concatenating a series of trainable embeddings with the model’s prompt, where the model can either be finetuned along with the added embeddings or kept frozen.
PADA improves the ability of LLMs to adapt to new domains by training a language model to first predict a domain-specific prompt for solving a problem, then use this generated prompt to actually solve the problem.
Many articles have been written about soft prompts as well. Sebastian Rashka wrote a detailed explanation of prompt and prefix tuning, while Lilian Weng explores this topic in both her text generation and prompt engineering posts.
Discrete Prompt Optimization
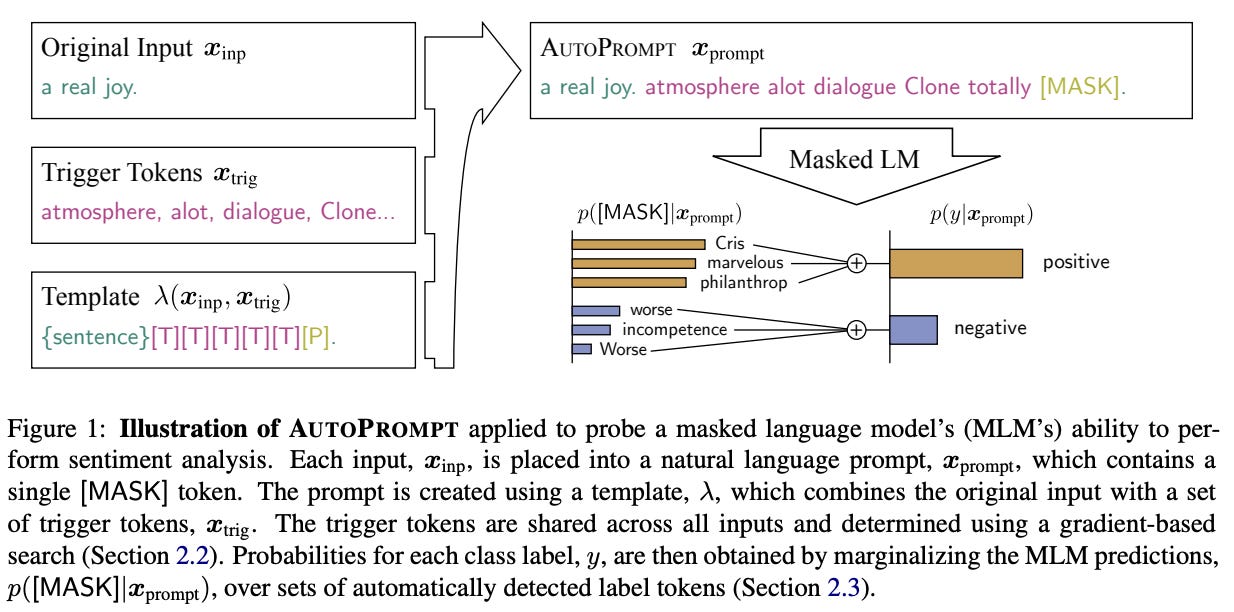
As we have seen, soft prompts have limitations in terms of interpretability, reusability across models, and applicability to API-based LLMs. Unfortunately, these limitations destroy several key benefits of prompting. With this in mind, we might wonder whether we can automatically optimize a prompt while maintaining some of these properties. During the early days of prompting, papers were published on the idea of finding discrete “trigger" tokens that can be included in a model’s prompt to help with solving certain problems.
“Writing prompts is not only time consuming, but it is not clear that the same phrasing will be effective for every model, nor is it clear what criteria determine whether a particular phrasing the best to elicit the desired information.” - from [11]
AutoPrompt [11]5 performs a gradient-guided search over a discrete set of tokens to discover an optimal set of additional tokens to include in an LLM’s prompt. This approach is applied to the task of probing knowledge within LLMs, where we see that these additional tokens lead to more reliable and stable performance on this task. By using trigger tokens, we can optimize the LLM’s performance via a rigorous (gradient-based) search procedure, rather than heuristically searching for the best possible prompt through manual trial and error.
Due to the use of gradient information, we see in [11] that the training procedure used by AutoPrompt to edit prompt tokens can be unstable. As an alternative, later work explored optimizing prompts via reinforcement learning (RL). The idea behind using RL to optimize prompts is pretty simple. First, we define a policy network, which is just an LLM that generates a candidate prompt as output. Then, we can define the reward for this policy network as the performance of the prompt that it generates! See below for a depiction of this framework.

This setup is very similar to training an LLM via reinforcement learning from human feedback (RLHF). In both cases, our policy is an LLM, and that policy performs actions by generating tokens. Once a full sequence is generated, we compute a reward for this sequence. In RLHF, this reward is the output of a reward model, which is a proxy for human preferences. For prompt optimization, this reward is determined by the performance of the prompt; see above.
RLPrompt [12] is one of the most well known papers that uses RL to optimize discrete prompts. The policy network that generates prompts is implemented as a pretrained LLM. The parameters of this model are kept frozen, but we add an additional feed-forward layer to the model that is trained via RL; see below.

This policy network is used to generate candidate prompts that are ingested by another LLM to solve a task—the policy network and the LLM that ingests the prompts need not be the same. The reward is derived by measuring the performance (e.g., classification accuracy or adherence of the output to a given style) achieved with a given prompt. Here, the reward function is dependent upon output that is generated by an LLM. For this reason, reward signals within the RLPrompt framework are unpredictable, complex, and difficult to optimize. Despite this issue, authors in [12] show that various reward stabilization techniques can be used to make the optimization process more reliable.

When applied to classification and style transfer tasks, RLPrompt is found to generate prompts that outperform both finetuning and prompt tuning strategies; see above. However, our desire of automatically optimizing prompts that can be easily interpreted by humans falls short. The prompts discovered by RLPrompt, despite transferring well when used with other LLMs, tend to be ungrammatical or even “gibberish”. Depending on our outlook, this finding could lead us to wonder whether prompting in some ways is a language of its own.
“The resulting optimized prompts are often ungrammatical gibberish text; and surprisingly, those gibberish prompts are transferrable between different LMs to retain significant performance, indicating that LM prompting may not follow human language patterns.” - from [12]
TEMPERA [13]—inspired by work on instance-dependent prompt optimization (i.e., optimizing a prompt dynamically for each input)—follows a different approach of using RL to make adaptations to a prompt at test / inference time. Given an initial prompt, we can edit the properties of this prompt by i) making changes to the instructions, ii) adding or removing few-shot exemplars, and iii) modifying verbalizers6. We can train an agent to perform these edits via RL by defining the reward as the difference in performance before and after a given edit; see below.

TEMPERA learns a function that takes the original prompt, the current input query to the LLM, a set of few-shot exemplars, and a pool of verbalizers as input, then generates a final prompt via a sequence of edits; e.g., swapping examples or editing verbalizers. From an RL perspective, our state is given by the current prompt, and we can perform actions by editing the prompt. To represent the state, we can just use the text of the current prompt. However, authors in [13] choose to embed this text by passing it through a pretrained LLM. By doing this, we can implement a simple policy network that:
Takes the state / prompt embedding as input.
Produces the action / edit to perform as output.
TEMPERA considers a fixed set of edits that can be performed to a prompt, so this action space is discrete! We can directly predict the prompt edit to be performed with the policy network. By defining rewards as the performance improvement generated by a given edit, we can optimize this entire system with off-the-shelf RL algorithms like PPO. This approach is found to be data efficient, useful for classification, and even impactful for solving harder tasks with LLMs.

Why does this work? By using RL, we can finally implement a training procedure for optimizing discrete prompts. Compared to the other approaches we have seen so far, techniques like RLPrompt make two key changes to make this possible:
We generate the prompt with an LLM.
We optimize this LLM based on the quality of the prompts that it generates.
By generating the prompt with an LLM, we can focus on optimizing the (continuous) weights of the LLM instead of the discrete prompt. This same approach is used by techniques like Instruction Induction [7] or Self-Instruct [8], but we go beyond these techniques by using RL to teach the model to create better prompts. We need RL to perform this optimization, as the system used to generate the reward is based on an LLM and, therefore, not differentiable! In other words, we can’t easily compute a gradient to use for optimization purposes.
Automatically Optimizing Prompts for LLMs
Now that we’ve looked at early work on optimizing prompts, we will learn about the more recent and popular papers on automatic prompt optimization. Nearly all of these papers rely upon the ability of LLMs to optimize prompts. Using an LLM as a gradient-free optimizer is (arguably) less rigorous compared to traditional and established optimization algorithms. However, such approaches are simple conceptually, easy to implement / apply in practice, and highly effective, which has led LLM-based prompt optimization algorithms to become quite popular.
Large Language Models are Human-Level Prompt Engineers [1]

Writing an effective prompt requires a lot of trial and error. Prompt engineering is a black box optimization problem—we don’t know a priori how compatible a prompt will be with any given model. In [1], we see one of the first attempts to make the human prompt engineering process more efficient with an LLM.
“We call this problem natural language program synthesis and propose to address it as a black-box optimization problem using LLMs to generate and search over heuristically viable candidate solutions.” - from [1]
The proposed approach, called Automatic Prompt Engineer (APE), searches over a pool of prompts proposed by an LLM to find the prompt that performs best. This setup uses separate LLMs to propose and evaluate prompts. For evaluation, we generate output via zero-shot inference and evaluate the output according to a chosen scoring function. Despite its simplicity, APE is shown in [1] to find prompts that match or surpass the performance of prompts written by humans on the same task, revealing that LLMs actually excel at the task of writing prompts.

How does this work? APE has two main operations: proposal and scoring. For proposal, we ask the LLM to generate new candidate prompts for a task; see above for a set of examples prompts. As shown above, the generation of new instructions can be done in a forward or reverse fashion. In the forward mode, we simply generate new instruction via next token prediction, which is identical to generating any other kind of text with an LLM. Reverse generation, on the other hand, is based upon infilling (i.e., inserting missing text / tokens into the middle of a sequence), which is not possible with a decoder-only LLM7. Depending on the task, we might tweak the wording of the instruction generation template.

We see in [1] that LLMs can infer better instructions from prior instructions. To determine the quality of generated instructions, we can simply evaluate them in a zero-shot fashion with another LLM, either using output accuracy or a softer metric (e.g., the log probability of the correct output). The evaluation of each generated prompt occurs on a fixed training set that is used throughout the prompt optimization process. Compared to finetuning, prompt optimization via APE requires much fewer training examples. After the optimization is complete, we typically evaluate the final prompt over a hold-out test set.

To achieve the best possible performance, we see in [1] that we should ask the LLM to generate ~64 prompts for selection. If we generate more prompts, we begin to see diminishing returns in terms of performance—the best prompt that is discovered does not improve significantly in terms of its accuracy.
“Although this approach improves the overall quality of the proposal set, the highest scoring instruction tends to remain the same with more stages.” - from [1]
Iterative generation. We can also optimize prompts with APE in an iterative fashion. In this setup, we still ask an LLM to propose new instructions, calculate a score for each instruction, and select instructions with the top scores. Going a step further, however, we can repeat this process by taking these generated instructions as input, using them as context to propose more instruction variants in a similar fashion, and selecting the prompts that perform best; see below.

Using this strategy, we can explore different variants of prompts proposed by the LLM. However, we see in [1] that iterative APE only improves the overall quality of the suite of prompts being explored. The performance of the best prompt discovered by APE remains constant after any number of iterations; see below. For this reason, the added cost of iterative APE is potentially unnecessary.

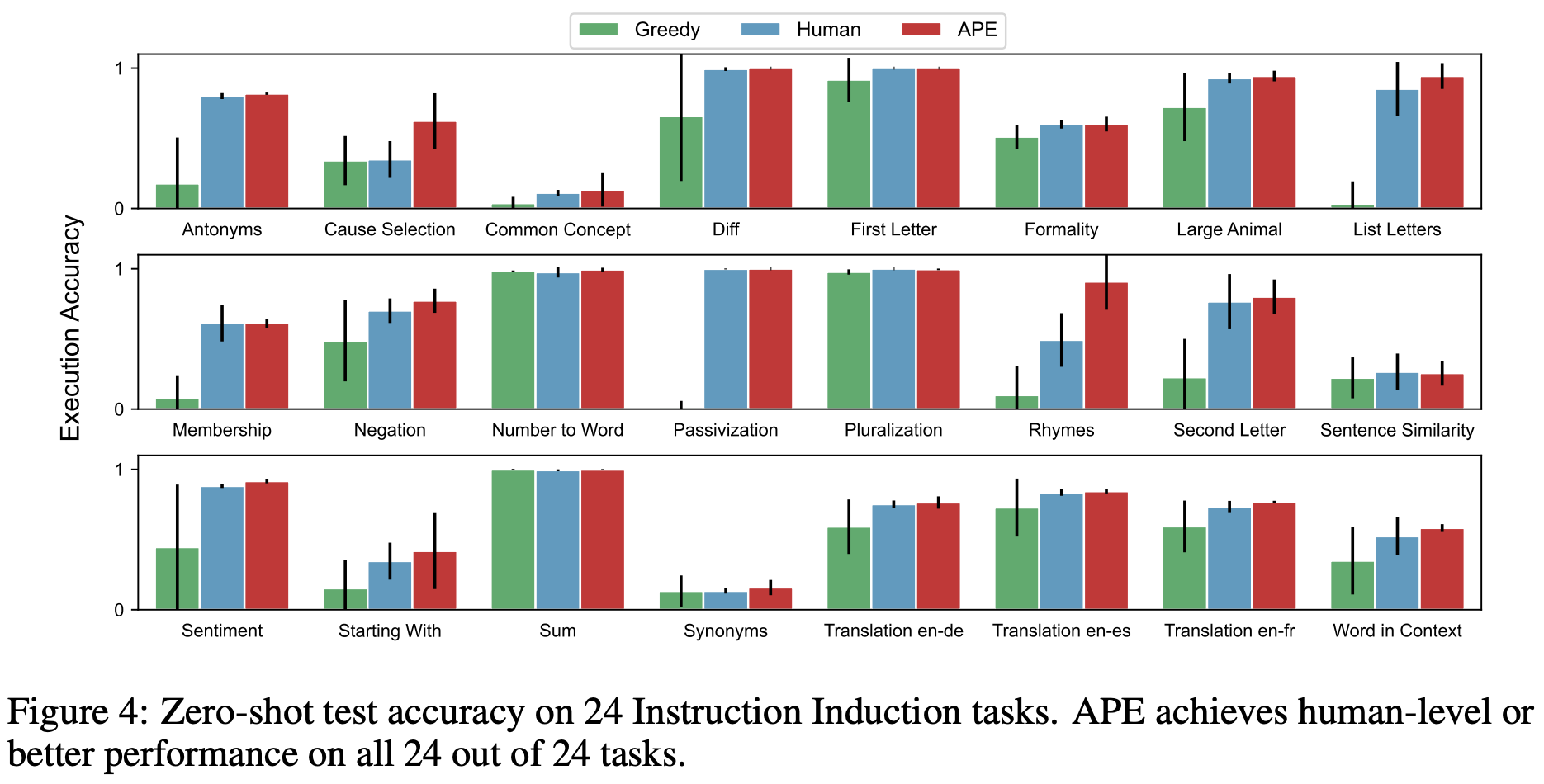
Does APE discover better prompts? APE is evaluated based on its ability to write effective prompts in several settings, including zero-shot prompts, few-shot prompts, CoT prompts, and prompts for steering the behavior of an LLM (e.g., being more truthful). Across experiments, we see that APE is able to find prompts that outperform those written by humans. In particular, APE produces prompts that outperform human-written prompts on 24 out of 24 Instruction Induction tasks and 17 out of 21 BIG-Bench tasks; see below for details.
By examining the prompts proposed by APE, we can even deduce useful tricks for writing effective prompts. In many cases, these tricks generalize well across tasks and teach us how to properly prompt certain models. We also see in [1] that the performance of instruction candidates improves with LLM size, indicating that using a large LLM to propose new instructions within APE is helpful.
Automatic Prompt Optimization [2]
Although APE works well, the process that it uses for optimizing prompts is random and directionless. We simply use an LLM to propose a bunch of new prompt variants and select the generated prompt that performs the best. There is no iterative optimization procedure within this algorithm. Rather, we purely rely upon the ability of the optimizer LLM to propose a wide variety of promising prompt variants that can be evaluated in a single pass to find a better prompt.
“The algorithm uses batches of data to form natural language gradients that criticize the current prompt, much like how numerical gradients point in the direction of error ascent. The natural language gradients are then propagated into the prompt by editing the prompt in the opposite semantic direction of the gradient.” - from [2]
When viewed from the correct lens, optimizing prompts with an LLM is similar to traditional, gradient-based optimization. In [2], authors propose a technique for prompt optimization, called Automatic Prompt Optimization (APO)8, that is inspired by this analogy. APO is a generic technique that requires only a (small) training dataset, an initial prompt, and access to an LLM API to work. This algorithm uses batches of training data to derive “gradients”—just text-based critiques that outline limitations of the current prompt—that guide edits and improvements to the prompt, mimicking a gradient update; see below.

Optimization framework. APO aims to apply discrete improvements to a prompt guided by natural language gradients. These gradients are derived by:
Executing the current prompt over a training dataset with an LLM.
Measuring the prompt’s performance according to some objective function.
Using an LLM to critique the key limitations in performance of this prompt on the training dataset.
The gradient that is derived simply captures a textual summary of various issues that exist within the current prompt. Using this summary, we can then prompt an LLM—using the gradient and the current prompt as input—to edit the existing prompt in a way that reduces these issues. APO applies these steps iteratively to find an optimal prompt. See below for a depiction of this framework.

Gradients and edits. APO creates a recursive feedback loop that optimizes a prompt by i) collecting errors made by the current prompt on the training data, ii) summarizing these errors via a natural language gradient, iii) using the gradient to generate several modified versions of the prompt, iv) selecting the best of the edited prompts, and v) repeating this process several times.
“We mirror the steps of gradient descent with text-based dialogue, substituting differentiation with LLM feedback and backpropagation with LLM editing.” - from [2]
To generate “gradients”, we show an LLM examples of errors made by the current prompt on the training dataset and ask the model to propose reasons for these errors. We then use these reasons as context for editing the prompt; see below.

At each iteration, we generate several edits to the current prompt—the number of edits is a hyperparameter of the optimization process. Additionally, we can expand our search space by explicitly generating multiple wordings of each prompt, a technique that authors in [2] refer to as Monte Carlo sampling; see below.

Search and selection. By generating several variants of each prompt, we can search for an optimal prompt via beam search. In other words, we maintain several candidates for the best prompts at each iteration, propose N edits to each prompt, then select the best B edits to the prompt—by measuring performance over the training set—to keep in the next iteration; see below.

As we might expect, beam search can get expensive if we continually evaluate all prompt candidates over the entire training dataset. However, we see in [2] that we can use bandit techniques—those related to the best arm identification problem in particular—to make the search process more efficient. Although the details of this approach are beyond to scope of this post, the high-level idea is that we can use statistics to select which prompts are worth fully evaluating instead of just naively evaluating every prompt over the entire training dataset.
Does this work well? APO is evaluated for prompting GPT-3.5 on four different text-based classification tasks, including jailbreak detection, hate speech detection, fake news detection, and sarcasm detection. Why are only classification problems considered? The explicit choice of classification tasks for evaluating APO is likely due to the simplicity of defining an objective function for these problems—we can evaluate each prompt based on classification accuracy. For complex or open-ended tasks, defining an objective function is not simple, which makes the application of techniques like APO less straightforward.
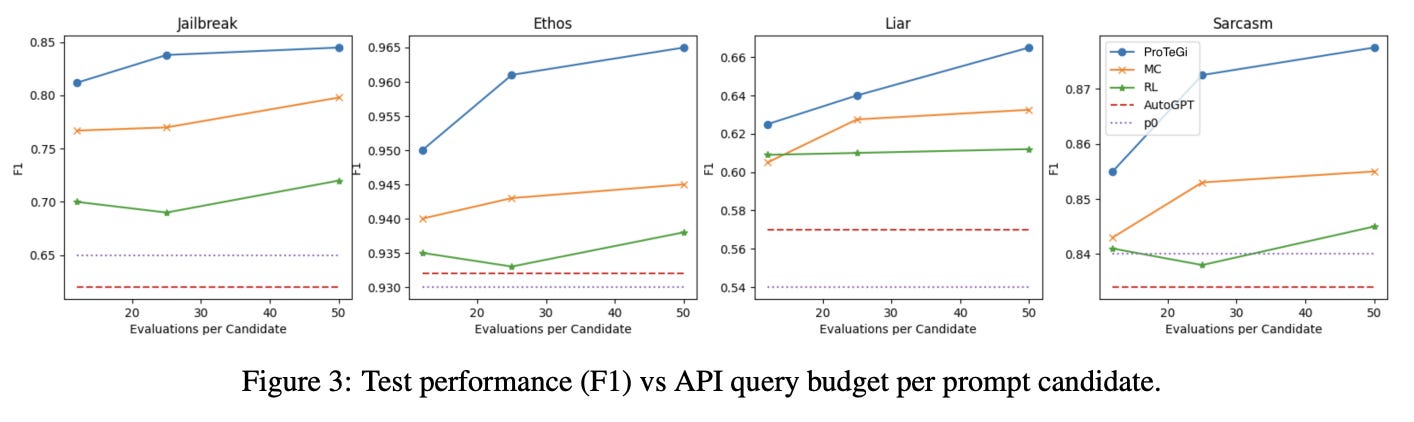
As shown above, APO outperforms other state-of-the-art prompt optimization algorithms across all datasets. Notably, we see that the performance of APE—the Monte Carlo (MC) technique in the figure above—is worse than APO, indicating that we benefit from adding a more concrete direction—via natural language gradients—to the prompt optimization process. We see in [2] that APO can improve the performance of the initial prompt by up to 31%, exceeding improvements seen with other techniques despite the fact that APO requires LLM API calls.
GRIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models [14]
“We propose Gradient-free Instructional Prompt Search (GRIPS), an automated procedure for improving instructional prompts via an iterative, local, edit-based, and gradient-free search.” - from [14]
Instead of using an LLM to edit our prompt as part of our prompt optimization process, we can use heuristic strategies to generate new prompt variants to consider. In [14], authors propose GrIPS, which is a gradient-free method that searches for better prompts via iterative application of a fixed set of heuristic edit operations. Like the approaches we have seen so far, GrIPS takes a human-written prompt as input and returns an improved, edited prompt as output.
Heuristic prompt search. GrIPS can be applied to both instruction-based prompts and prompts that include in-context examples (shown below) but focuses purely upon improving the instruction—we do not try to optimize the selection of examples in GrIPS. To search over the space of possible prompts, we begin with an initial prompt and iteratively perform a series of edits to this prompt. Then, we can test the performance of the edited prompts over a pool of training examples9, allowing us to determine which of the edited prompts are best.

This procedure is somewhat similar to the techniques we have seen so far, but we apply a set of heuristic edits to the prompt during the search process instead of relying upon an LLM to generate edited versions of a prompt. This technique can work with arbitrary types of LLMs, including those exposed via an API.
Details of search. The optimization framework for GrIPS is shown below. We begin the search process with a base instruction, which is written by a human. At each iteration, we select a certain number of edit operations to apply to this prompt, producing several new prompt candidates. These candidates are then scored so that the best of them can be identified. If the score of the best candidate exceeds that of the current base instruction, then we use the best candidate as the base instruction moving forward. Otherwise, we maintain the current base instruction and repeat. This is a greedy search process that terminates when the score of the base instruction does not improve for several iterations.

Similarly to [2], we can easily adapt this greedy search procedure to perform beam search by maintaining a set of several instructions at each iteration. However, such a modification increases the cost of the search process by introducing a larger number of candidate prompts that need to be evaluated at each step.
Types of edits. In GrIPS, we always apply edits at a phrase level, allowing us to meaningfully modify a prompt while maintaining its structure. To deconstruct a prompt into phrases, we can use a constituency parser. Then, four different types of edit operations are considered over the phrases in a prompt:
Delete: remove all occurrences of a certain phrase from the instruction and store the deleted phrase for use in the add operation.
Swap: given two phrases, replace all occurrences of the first phrase in the instruction with the second phrase and vice versa.
Paraphrase: replace all occurrences of a certain phrase from the instruction with a paraphrased version10 of that phrase.
Addition: sample a phrase deleted in a previous iteration and add it back to the instruction at a random phrase boundary.
Practical usage. GrIPS is primarily evaluated on binary classification tasks from the Natural Instructions dataset. Similarly to observations in [12], we see that prompts discovered by GrIPS tend to improve accuracy but are not always coherent. The optimized prompts contain semantically awkward and confusing phrasing. Nonetheless, we see in [14] that using GrIPS to optimize the base instruction consistently improves the accuracy of various LLMs by as much as 2-10%. Additionally, manual rewriting of prompts—and even gradient-based prompt tuning in some cases—tends to be outperformed by GrIPS, which is found to work best for optimizing task-specific (as opposed to generic) instructions; see below.

Large Language Models as Optimizers [3]
“Instead of formally defining the optimization problem and deriving the update step with a programmed solver, we describe the optimization problem in natural language, then instruct the LLM to iteratively generate new solutions based on the problem description and the previously found solutions.” - from [3]
One of the most popular and widely used prompt optimization techniques today is Optimization by Prompting (OPRO). However, OPRO can do more than just optimize prompts. It is a generic optimization algorithm that operates by:
Describing an optimization task in natural language.
Showing an optimizer LLM examples of prior solutions to the optimization task along with their objective values.
Asking the optimizer LLM to infer new / better solutions to the problem.
Testing the inferred solutions via an evaluator LLM.
By repeating the steps above, we create an extremely flexible, gradient-free optimization algorithm. Instead of formally specifying the problem we are trying to solve with math, we can just explain the problem in natural language. Such a description is sufficient for performing optimization with OPRO, which makes the algorithm widely applicable and easy to extend to new tasks.

Given the correct sampling strategy, the trajectory of this optimization algorithm is relatively stable, indicating once again that the LLMs are capable of learning from past solutions to propose new and better solutions; see above. Although OPRO can be applied to many problems, we see in [3] that this algorithm is especially useful for automatic prompt optimization. First, we will learn about how OPRO works, then we will explore how it can be used to optimize prompts.

OPRO Framework. The high-level steps followed by OPRO are outlined above. At each step of the optimization process, OPRO generates new solutions based on a meta-prompt, which contains a textual description of the optimization problem and prior solutions that have been proposed. Given the meta-prompt, we then generate several new solutions at once11. By generating several candidate solutions at each steps, we can ensure a (relatively) stable optimization trajectory, as the LLM is given several chances to generate a viable solution.
From here, we evaluate each new solution based on an objective function (e.g., accuracy) and add the best solutions to the meta-prompt for the next optimization step. In this way, we choose the best solutions to be passed to the next iteration of the optimization process. Our goal is to find a solution that optimizes the objective function, and the optimization process terminates once the LLM is unable to propose new solutions that yield improvements in the objective.
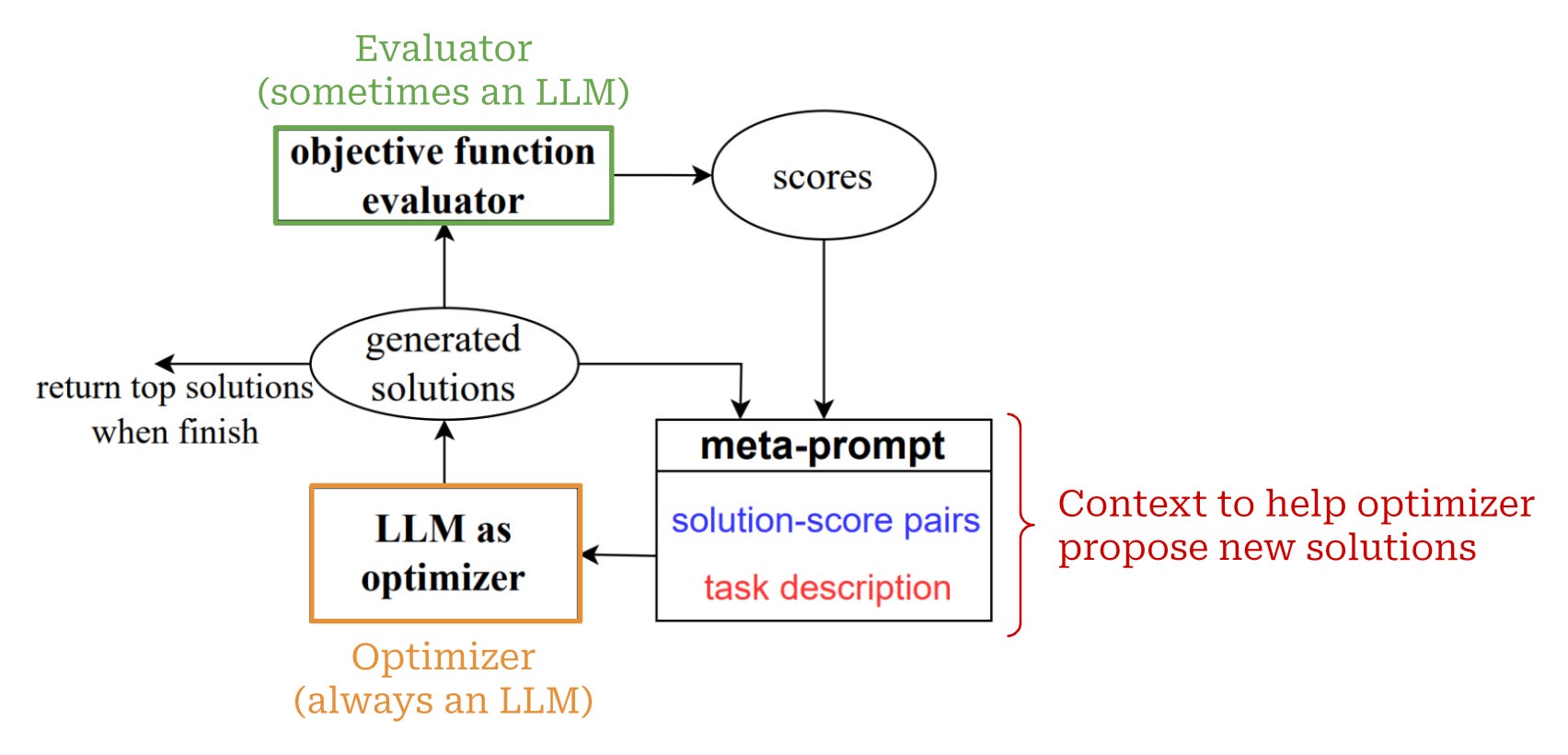
Key components or ORPO. As we can see from this framework, OPRO has two main components within its optimization process (depicted above):
Optimizer: takes the meta-prompt as input and proposes new solutions.
Evaluator: takes a solution as input and computes an objective value.
The optimizer is always implemented as an LLM. To successfully apply OPRO, we must select a sufficiently powerful LLM as the optimizer, as deducing the best solutions from context provided in the meta-prompt requires complex reasoning capabilities. Plus, we see in [1] that larger LLMs tend to be better at this task.
The evaluator may also be implemented as an LLM depending on the problem being solved, but the optimizer and evaluator need not be the same LLM. For example, linear regression problems have a simple evaluator (i.e., we can directly compute an objective value from the solution), but prompt optimization problems require that we use an evaluator LLM to measure output quality for each prompt.
“While traditional optimization often requires a decently large training set, our experiment shows that a small number or fraction of training samples is sufficient.” - from [3]
Optimization with OPRO requires both training and testing data. We use the training dataset to compute objective values during the optimization process, while the test set is used to assess the final performance of generated solutions after the optimization process has concluded. Compared to most optimization algorithms, OPRO requires very little training data.
More on the meta-prompt. The meta-prompt provides all necessary context that the optimizer LLM needs to propose a better solution to the problem being solved. The meta-prompt has two primary components:
A textual description of the optimization problem.
Prior solutions and their objective values (i.e., the optimization trajectory).
The optimization trajectory is sorted such that the best solutions appear at the end of the meta-prompt. Beyond this core information, we also include randomly selected examples from the training dataset to demonstrate the expected output format, as well as general instructions to follow when creating new solutions (e.g., “be concise” or “generate a new instruction that maximizes accuracy”). An example of a meta-prompt for a prompt optimization task is shown below.

OPRO’s performance. In [3], OPRO is evaluated on both GSM8K and Big-Bench Hard. On these datasets, OPRO discovers prompts that outperform human-written prompts by 8% and 50%, respectively. Compared to prior approaches like APE [1], OPRO is shown to be capable of finding more complex instructions that achieve better performance; see below. Interestingly, the style of instructions that are discovered tend to vary a lot depending upon the optimizer LLM being used.

Advanced reasoning systems (o1). As mentioned before, inferring new solutions from the optimization trajectory is a complex reasoning problem. We have already seen that larger LLMs are better at solving this task [1], indicating that we benefit from a more powerful optimizer LLM with better reasoning capabilities. Additionally, prompt optimization is a one-time cost. We optimize our prompt once, but the optimized prompt is typically used in a downstream application for a much longer duration. As a result, the cost of using a much more expensive optimizer LLM is amortized by the lifetime of the prompt that it produces.

The recent proposal of LLM-based reasoning systems like OpenAI’s o1 unlocks new possibilities for prompt optimization. These systems are trained to follow an extensive reasoning process by which the model can dynamically decide whether more compute is needed to solve complex problems; see here for details. Such an advanced reasoning strategy can be expensive in some cases; e.g., o1 may “think” for over a minute before responding to a prompt. However, using extra compute at inference time may be worthwhile for complex reasoning problems. In the case of automatic prompt optimization, the latency and cost of the optimizer LLM’s response in not nearly as important as the quality of the generated prompt, making this a prime application of these advanced reasoning systems.
“We are introducing OpenAI o1, a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers—it can produce a long internal chain of thought before responding to the user.” - source
Optimizing Prompts via Evolution
The prompt optimization strategies we have seen so far begin with a prompt (or set of prompts) written by a human and iteratively:
Generate variants of the prompt(s).
Select the best performing prompt(s) from these variants.
In some ways, this optimization process can be viewed as an EA. A population of prompts is maintained, mutated, and selected over time. We use a population size of one (unless beam search is being used), and the population is mutated by prompting an LLM (or using a heuristic, edit-based strategy) to modify the current prompt. Inspired by this work, researchers have recently explored more explicit strategies for applying EAs to prompt optimization. As we will see, these algorithms are not so different from those that we have seen so far!

Genetic Prompt Search (GPS) [15] (shown above) employs a genetic algorithm to automatically discover high performing prompts. First, the algorithm is instantiated with a set—or population—of hand-written prompts. Then, we can mutate these prompts via the following operations:
Back translation: translate the prompt to one of 11 other languages, then translate back to English.
Cloze12: mask out several tokens in the prompt and use a pretrained language model (e.g., T5) to fill them in, thus generating a new prompt.
Sentence continuation: prompt an LLM to “write two sentences that mean the same thing” and provide the current prompt as the first sentence.
Each of these strategies can mutate the current population of prompts to generate new prompt variants. From here, we can score the generated prompts using a hold-out validation set to determine those that should be retained in the next iteration—or generation—of evolution. This algorithm outperforms manual prompt engineering and can even outperform prompt tuning in some cases.
“Sequences of phrases in prompts can be regarded as gene sequences in typical EAs, making them compatible with the natural evolutionary process.” - from [16]
EvoPrompt [16] again leverages concepts from EAs to create a prompt optimizer the performs well and converges quickly. Starting with a population of prompts that are written manually, EvoPrompt uses the two primary evolutionary operators—mutation and crossover—to generate new prompts. At each generation, the best prompts are selected and maintained for further evolution by measuring their performance over a hold-out validation set.
By definition, evolutionary operators take a sequence as input and output a modified sequence. Traditionally, operators are applied independently to each element of the sequence—we update each element with no knowledge of whether the elements around it have been changed. For prompt optimization, this approach is problematic because all tokens within the prompt are interrelated.

To solve this problem, EvoPrompt implements evolutionary operators via prompting and relies upon the expertise of an LLM to evolve prompts in a logical manner. Examples of crossover and mutation prompts used for prompt optimization via a genetic algorithm are shown above. However, EvoPrompt supports a variety of EAs beyond just genetic algorithms! For example, we see below a set of prompts that can be used to implement a differential evolution strategy for prompt optimization. The EvoPrompt framework is sufficiently flexible to substitute different EAs in a plug-and-play manner.

EvoPrompt is tested with both closed and open-source LLMs (e.g., Alpaca and GPT-3.5) on several tasks, where it is found to outperform algorithms like APE [1] and APO [2]. The differential evolution variant of EvoPrompt outperforms the genetic algorithm variant in most cases; see below.

Prompbreeder [17] was proposed shortly after EvoPrompt. The ideas behind these two techniques are similar:
They both begin with a human written population of prompts.
They both implement evolutionary operators like mutation and crossover via a prompt to an LLM.
They both perform selection by measuring performance on a validation set.
The main difference between these techniques is that Promptbreeder optimizes more than just the task prompt—the prompt used to implement evolutionary operators is optimized as well! Such an approach allows us to introduce a self-improvement mechanism within the prompt optimization algorithm itself.
“That is, Promptbreeder is not just improving task-prompts, but it is also improving the mutation-prompts that improve these task-prompts.” - from [17]
Promptbreeder is found to outperform a variety of powerful prompting strategies (e.g., chain of thought and plan and solve prompting) on reasoning benchmarks. While other prompt optimization algorithms commonly see diminishing returns and a saturation in performance when extending the optimization process to larger numbers of iterations [1], Promptbreeder dynamically adapts the optimization process over time, allowing intricate prompts to be discovered that are more capable of solving difficult tasks.

Practical Tips and Takeaways
We have seen a wide variety of prompt optimization techniques in this overview, including methods that learn soft prompts directly from data, leverage LLMs as gradient-free optimizers, use RL to train models that are better at generating prompts, and more. We outline the key takeaways from all of this research below.
Why is prompt optimization hard? As we have seen, prompt optimization is not a normal optimization problem for a few reasons:
The prompt we are trying to optimize is made up of discrete tokens.
We lack access to gradient information in most cases.
If we are using an LLM API, we have very limited information available to improve our prompt. Additionally, the fact that prompts are discrete makes the application of gradient-based optimization algorithms difficult. Successful prompt optimization algorithms have avoided these issues by i) adopting gradient-free optimization algorithms that resemble EAs and ii) relying upon the ability of LLMs to infer better prompts from those that have been tried previously.
LLMs are good prompt engineers. One of the primary takeaways from recent prompt optimization papers is the fact that LLMs are good at writing prompts. Assuming we provide the right information as context, we can create surprisingly powerful prompt optimization algorithms by just iteratively prompting an LLM to critique and improve a prompt. Larger (and more capable) LLMs tend to be better at this task. So, applying advanced models like OpenAI’s o1 to prompt optimization is an interesting opportunity that has not yet been explored.
What should we use? Since we have seen many prompt optimization algorithms, we might not know which of these techniques to actually use. Much of the research we have seen is useful. However, LLM-based prompt optimizers (e.g., OPRO [3]) are the most straightforward and practical prompt optimization techniques by far. We can use these algorithms to automatically improve any prompt that we write, producing a better prompt that is still interpretable by a human. OPRO is beneficial and easy to apply, which has made it popular among LLM practitioners. An open implementation of OPRO is provided here.
Are humans still necessary? Although prompt optimization techniques can drastically reduce manual prompt engineering effort, eliminating human prompt engineers altogether is unlikely. All of the algorithms we have seen so far require a human prompt engineer to provide an initial prompt as a starting point for the optimization process. Additionally, techniques like OPRO will require human intervention / guidance in practice to find the best possible prompts. Put simply, automatic prompt optimization techniques are assistive in nature. These algorithms automate some of the basic, manual effort of prompt engineering, but they do not eliminate the need for human prompt engineers. However, it should be noted that LLMs are naturally becoming less sensitive to subtle changes in their prompts over time, which makes prompt engineering less necessary in general.
Limitations of prompt optimization. The prompt optimization algorithms we have seen so far are useful for improving the wording and basic structure of a prompt. However, many more choices are included in the construction of a performant LLM system. For example, we may need to use retrieval augmented generation (RAG), add extra data sources into our prompt, find the best few-shot examples to use, and more. Automating these higher-level choices goes beyond the capabilities of the prompt optimization algorithms we have seen so far, but researchers are currently developing tools like DSPy [31] that can automate both the high-level design and low-level implementation of LLM systems.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, Deep Learning Ph.D. and Machine Learning Scientist at Netflix. This is the Deep (Learning) Focus newsletter, where I help readers better understand important topics in AI research. If you like the newsletter, please subscribe, share it, or follow me on X and LinkedIn!
Bibliography
[1] Zhou, Yongchao, et al. "Large language models are human-level prompt engineers." arXiv preprint arXiv:2211.01910 (2022).
[2] Pryzant, Reid, et al. "Automatic prompt optimization with" gradient descent" and beam search." arXiv preprint arXiv:2305.03495 (2023).
[3] Yang, Chengrun et al. “Large Language Models as Optimizers.” arXiv abs/2309.03409 (2023).
[4] Li, Xiang Lisa, and Percy Liang. "Prefix-tuning: Optimizing continuous prompts for generation." arXiv preprint arXiv:2101.00190 (2021).
[5] Lester, Brian, Rami Al-Rfou, and Noah Constant. "The power of scale for parameter-efficient prompt tuning." arXiv preprint arXiv:2104.08691 (2021).
[6] Chen, Lichang, et al. "Instructzero: Efficient instruction optimization for black-box large language models." arXiv preprint arXiv:2306.03082 (2023).
[7] Honovich, Or, et al. "Instruction induction: From few examples to natural language task descriptions." arXiv preprint arXiv:2205.10782 (2022).
[8] Wang, Yizhong, et al. "Self-instruct: Aligning language models with self-generated instructions." arXiv preprint arXiv:2212.10560 (2022).
[9] Xu, Can, et al. "Wizardlm: Empowering large language models to follow complex instructions." arXiv preprint arXiv:2304.12244 (2023).
[10] Jiang, Zhengbao, et al. "How can we know what language models know?." Transactions of the Association for Computational Linguistics 8 (2020): 423-438.
[11] Shin, Taylor, et al. "Autoprompt: Eliciting knowledge from language models with automatically generated prompts." arXiv preprint arXiv:2010.15980 (2020).
[12] Deng, Mingkai, et al. "Rlprompt: Optimizing discrete text prompts with reinforcement learning." arXiv preprint arXiv:2205.12548 (2022).
[13] Zhang, Tianjun, et al. "Tempera: Test-time prompting via reinforcement learning." arXiv preprint arXiv:2211.11890 (2022).
[14] Prasad, Archiki, et al. "Grips: Gradient-free, edit-based instruction search for prompting large language models." arXiv preprint arXiv:2203.07281 (2022).
[15] Xu, Hanwei, et al. "GPS: Genetic prompt search for efficient few-shot learning." arXiv preprint arXiv:2210.17041 (2022).
[16] Guo, Qingyan, et al. "Connecting large language models with evolutionary algorithms yields powerful prompt optimizers." arXiv preprint arXiv:2309.08532 (2023).
[17] Fernando, Chrisantha, et al. "Promptbreeder: Self-referential self-improvement via prompt evolution." arXiv preprint arXiv:2309.16797 (2023).
[18] Janga Reddy, M., and D. Nagesh Kumar. "Evolutionary algorithms, swarm intelligence methods, and their applications in water resources engineering: a state-of-the-art review." h2oj 3.1 (2020): 135-188.
[19] Corne, David W., and Michael A. Lones. "Evolutionary algorithms." arXiv preprint arXiv:1805.11014 (2018).
[20] Ai, Hua, et al. "Topology optimization of computer communication network based on improved genetic algorithm." Journal of Intelligent Systems 31.1 (2022): 651-659.
[21] Zamfirescu-Pereira, J. D., et al. "Why Johnny can’t prompt: how non-AI experts try (and fail) to design LLM prompts." Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 2023.
[22] Jiang, Ellen, et al. "Prompt-based prototyping with large language models." Extended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems. 2022.
[23] Vatsal, Shubham, and Harsh Dubey. "A survey of prompt engineering methods in large language models for different nlp tasks." arXiv preprint arXiv:2407.12994 (2024).
[24] Sahoo, Pranab, et al. "A systematic survey of prompt engineering in large language models: Techniques and applications." arXiv preprint arXiv:2402.07927 (2024).
[25] Reynolds, Laria, and Kyle McDonell. "Prompt programming for large language models: Beyond the few-shot paradigm." Extended abstracts of the 2021 CHI conference on human factors in computing systems. 2021.
[26] Doerr, Benjamin, and Frank Neumann. "A survey on recent progress in the theory of evolutionary algorithms for discrete optimization." ACM Transactions on Evolutionary Learning and Optimization 1.4 (2021): 1-43.
[27] Lehman, Joel, et al. "Evolution through large models." Handbook of Evolutionary Machine Learning. Singapore: Springer Nature Singapore, 2023. 331-366.
[28] Meyerson, Elliot, et al. "Language model crossover: Variation through few-shot prompting." arXiv preprint arXiv:2302.12170 (2023).
[29] Chen, Yutian, et al. "Towards learning universal hyperparameter optimizers with transformers." Advances in Neural Information Processing Systems 35 (2022): 32053-32068.
[30] Chen, Angelica, David Dohan, and David So. "EvoPrompting: language models for code-level neural architecture search." Advances in Neural Information Processing Systems 36 (2024).
[31] Khattab, Omar, et al. "Dspy: Compiling declarative language model calls into self-improving pipelines." arXiv preprint arXiv:2310.03714 (2023).
We may include few-shot examples in our prompts, which—although not used to actually update the model’s parameters—can be considered a form of “training” data.
We don’t have to 100% replace the prompt engineer! Automatic prompt optimization algorithms can also be assistive in nature, making them more efficient.
Hard prompt tuning is just another name for prompt engineering! We are just changing the words of a prompt to create different, human-readable prompts.
The reparameterization approach used by prefix tuning adds additional learnable parameters to the model. Each prefix has an additional feed-forward neural network, which has parameters of its own, associated with it!
This work is an early exploration of optimizing prompts in a discrete manner using gradient-based techniques. However, there are other works that came before it; e.g., this paper explores similar techniques for discovering “trigger tokens” in LLMs.
A verbalizer is a component of a prompt template that can be used to map labels words to actual words. For example, a verbalizer of “positive” canned by mapped to the word “great”, while a verbalizer of “negative” can be mapped to the word “horrible”.
Instead, we need to use an LLM that is capable of infilling. This requires an encoder-only or encoder-decoder transformer architecture; e.g., T5 is a popular model that is trained via an infilling objective.
This technique was called Prompt Optimization with Textual Gradients (ProTeGi) when the paper was first published, but authors later changed the name of the technique to Automatic Prompt Optimization (APO).
Again, we should follow machine learning best practices here by using a separate pool of examples for training and testing of prompts.
Here, the paraphrased version of the phrase is generated using a PEGASUS model.
We can balance the explore-exploit tradeoff within OPRO by simply tweaking the temperature parameter used by the LLM when generating new solutions!
Simply the finest treatment of the topic I've yet seen. Thanks so much for the effort you expended on this! You really should consider writing a book. I'd buy it in a flash.
Awasome article
I have developed an Hugging face space named PROMPT++ to refine prompts automatically
https://huggingface.co/spaces/baconnier/prompt-plus-plus
Still in development and feedback appreciated