
Summarization and the Evolution of LLMs
How research on abstractive summarization changed language models forever...


The capabilities of large language models (LLMs) have progressed at a staggering pace in recent years. However, many of the core ideas surrounding LLMs—self-supervised pretraining, the transformer, learning from human feedback, and more—have roots in natural language processing research from years before. These concepts are not new, but rather an accumulation of ideas from over a decade of relevant research. As a result, fundamental research on core problems in natural language processing (e.g., machine translation, summarization, question answering and more) is incredibly important! In this overview, we’ll demonstrate this point by focusing upon the problem of (abstractive) text summarization, which has had a heavy influence on the evolution of LLM research over time.
“Text summarization aims to compress long document(s) into a short, fluent, and human-readable form that preserves the most salient information from the source document.” - from [11]
At a high level, summarization refers to the task of compressing a sequence of text into a much shorter sequence that still captures key information. Although summarization is typically applied to standard problems like summarizing news articles, the problem setup is actually quite generic and can encompass a variety of interesting applications:
Compressing large, unstructured sequences of text as a pre-processing step for retrieval augmented generation (RAG).
Writing understandable textual summaries for the output of a recommender system.
Generating a recap of a meeting from a transcribed recording.
Because the task is so generic and powerful, text summarization is surrounded by a massive body of practically useful research. As we will see, many key ideas from summarization research have been adopted by modern LLMs. These two lines of research are highly coupled, and gaining a deep understanding of summarization research gives us a new and improved view of why and how LLMs work so well!
Useful Background on Summarization
Prior to diving into recent summarization research, we need to learn the basics. In this section, we’ll address the task of summarization at a high level, going over the different types of summarization that exist, research on summarization before the popularization of LLMs, evaluation metrics for summarization, and more.
Types of Summarization

The goal of summarization is to produce a shorter piece of text that captures the key ideas of a longer source document, thus compressing the information to only its core components. In the literature, there are two major classes of summarization techniques that are studied (see above for a depiction):
Extractive: the summary is constructed by selectively copying entire sentences or spans of text from the source document.
Abstractive: rephrases the information from the source document, forming a shorter explanation of the relevant information.
Both of these summarization strategies are widely studied, but summaries generated with an LLM are considered to be abstractive. Why? Well, an LLM is usually not conditioned to directly copy sentences from the source document. The model can freely generate text based upon provided context, producing abstractive summaries that arbitrarily rephrase information from the source document.
As we will see, however, summaries generated with an LLM tend to be (relatively) extractive in practice. Plus, recent research has began to explore the related topic of i) using extractive summarization techniques to identify key context to include as input to an abstractive summarization model [7, 12] or even ii) teaching an LLM to cite relevant sources (or spans of text) when generating a response [10]; see below for a depiction. For this reason, significant overlap exists between extractive and abstractive summarization, even if techniques might differ.

Further reading. Because the focus of this post is summarization with LLMs, we will not go into much depth on abstractive and extractive summarization prior to the popularization of LLMs. However, such research is still highly relevant, as it lays the foundation for work that we will study in this post. A list of curated papers is provided below for those who are interested:
SummEval: Re-evaluating Summarization Evaluation [11]: This work provides a deep dive into automatic evaluation metrics for summarization, explores the limitations of existing protocols, and re-evaluates a suite of 24 abstractive and extractive summarization models using their proposed improvements.
On the Abstractiveness of Neural Document Summarization [13]: This work studies abstractive summarization techniques, finding that many abstractive summaries are actually highly extractive in nature!
On Faithfulness and Factuality in Abstractive Summarization [15]: This work provides an extensive analysis of faithfulness and factuality for abstractive summarization techniques. Similar analysis is provided in [14, 16, 17].
Notable extractive summarization techniques include NEUSUM, BanditSum, LATENT, REFRESH, RNES, JECS, and STRASS. See here for a more comprehensive survey of extractive summarization techniques.
Notable (pre-LLM) abstractive summarization techniques include Pointer Generator, Fast-abs-rl, Bottom-Up, ROUGESal, Soft-MT, SENECA, T5, BertSum, Pegasus, BART, and UniLM. See here for a more comprehensive survey of abstractive summarization techniques.
Additionally, much of the early research on LLMs (e.g., GPT-2 and GPT-3) uses abstractive summarization as a key task for evaluating model quality.
Writing Summaries with an LLM

As we will see throughout the remainder of this post, LLMs are great tools for generating high-quality, abstractive summaries. If we want to use an LLM for summarization, there are several approaches we can take; see above. At a high level, these approaches either:
Use purely in-context learning or
Finetune a custom model on summarization-specific data.
If out-of-the-box models work well for our application, in-context learning will be the simplest approach to take. We can just call an API—with some added context in the prompt—to generate a summary. If prompting is not sufficient, however, we can explore finetuning a custom model, either in a supervised fashion or using preference tuning. The basics for each of these techniques are outlined below.

In-context learning refers to the ability of a single foundation LLM to solve a variety of different downstream tasks accurately by leveraging information provided in the prompt; see above. In the case of summarization, for example, we can place several articles along with their associated summaries within the prompt, allowing the model to use these summaries as context when generating its final output summary. Unlike finetuning, we do not update any of the model’s parameters during in-context learning. Rather, we rely upon the model’s ability to properly leverage context provided in the prompt to better solve a problem.

In-context learning is an emergent capability of LLMs1 that was first observed with the proposal of GPT-3 [18]. As shown in the figure above, LLMs become more capable few-shot learners at a certain scale, indicating that larger models can more effectively leverage context in their prompt to solve problems. To use in-context learning, we can call a proprietary API (e.g., from OpenAI or Anthropic) with a simple prompt—such as the one shown above—to generate a summary.

Supervised finetuning. If prompting does not yield summaries of sufficient quality, the next step we can take is to finetune a pretrained LLM over a dataset of high-quality summaries. To do this, we simply collect—either manually via human annotators or synthetically with a powerful LLM—a set of well written document-summary pairs that are relevant to the task we are trying to solve.
“Large-scale language model pretraining has become increasingly prevalent for achieving high performance … [These models] are fine-tuned using supervised learning to maximize the log probability of a set of human demonstrations.” - from [2]
For example, if we want to summarize restaurant reviews, we should collect a dataset of reviews for a set of restaurants along with curated summaries of the reviews for each of these restaurants. Beginning with a pretrained base model, we can then finetune this model using a standard language modeling objective over our collected data. Such an approach is referred to as supervised finetuning (SFT). This combination of large-scale pretraining with supervised finetuning over summarization-specific data is highly effective and was the go-to approach for training summarization models prior to the popularization of foundation LLMs.

Instruction tuning. Beyond supervised training on summarization data, we can perform general-purpose instruction tuning, in which we use task templates (see above) to simultaneously finetune a single model on data from several tasks. Notably, summarization can be one of the tasks that is included in the instruction tuning process, and the resulting model can be leveraged to accurately solve a variety of different tasks. In fact, instruction tuned models are even found to generalize well to tasks that are unseen during training; see below.

Human feedback (preference tuning). Finally, we can directly use human feedback to finetune a summarization model. Such an approach, commonly referred to as preference tuning, laid the foundation for later work on LLM alignment via reinforcerment learning from human feedback (RLHF). In fact, InstructGPT [5]—the predecessor to ChatGPT—cites research on learning to summarize via human feedback [2] as inspiration for their alignment strategy2! As such, we will heavily focus on preference tuning strategies in this overview.

To train an LLM based on human feedback, we first collect preference data. Each preference data example is a pair of summaries for the same source document, where one summary is identified (usually by a human) as “better” than the other; see above. This preference data can be used to train a reward model.
“Given a post and a candidate summary, we train a reward model to predict the log odds that this summary is the better one, as judged by our labelers.” - from [2]
The reward model takes a summary—or a sequence of text in general—as input and produces a scalar score as output, which represents the human preference score for a given summary. To train the reward model, we use a ranking loss that simply maximizes the log probability that the preferred summary in a pair will receive a better score than the rejected summary; see below. Prior work has shown that such a pairwise ranking loss outperforms learning preference scores directly via regression [1]. After training, the reward model can take a source document and summary as input and produce a scalar score as output, where higher scores indicate that the summary will be preferred by humans and vice versa.
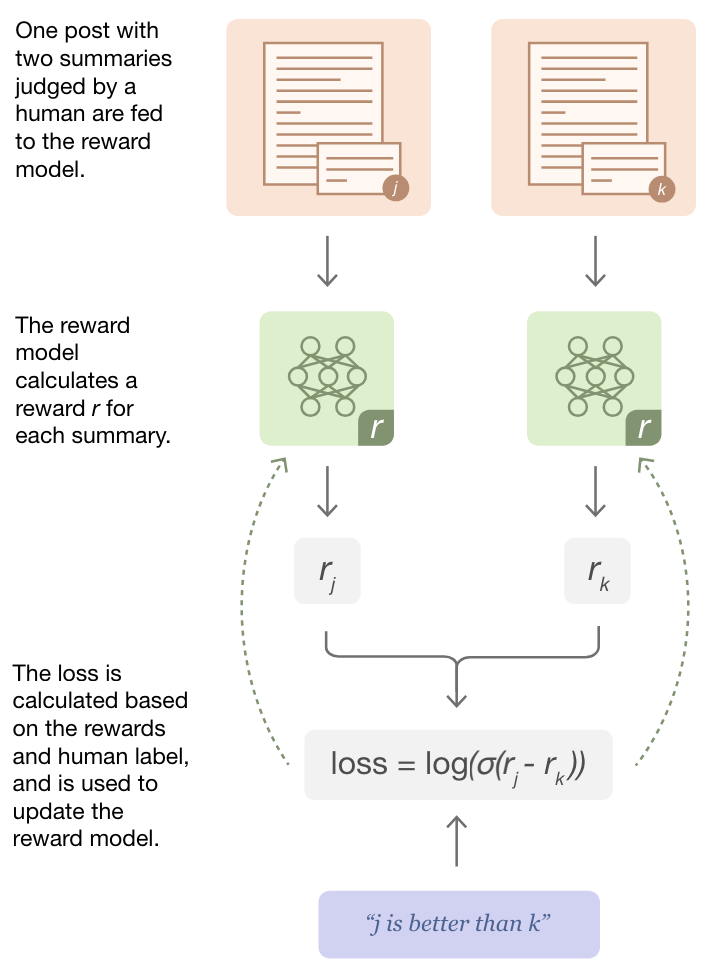
We can then use this reward model as a signal for training our summarization model via a reinforcement learning (RL) algorithm (e.g., PPO). In this way, we use human feedback—in the form of preference pairs—to train a summarization model! For more details on RLHF, check out the deep dive below.
Popular Datasets for Summarization

Although summarization is a generic problem, there are a few common datasets that are used almost universally within the literature. Summarization research tends to focus heavily upon news summarization. For example, the CNN / DailyMail Corpus [20] is one of the most widely-used datasets; see above for a sample from this dataset. In total, the dataset contains over 300K articles from CNN and DailyMail with associated summaries for each of the articles. XSum [21], another single-document abstractive summarization dataset, is also commonly used within summarization research. Having a similar size to CNN / DailyMail (i.e., ~230K summaries), XSum is comprised of simple, single-sentence summaries that capture the main idea of each article in the dataset.
“We chose the TL;DR dataset over the more commonly used CNN/DM dataset primarily because very strong performance can be attained on CNN/DM with simple extractive baselines.” - from [2]
Despite being widely used, the CNN / DailyMail and XSum datasets are relatively easy to solve—sometimes we need a more complex dataset. Recent work has explored the TL;DR dataset [22], which contains 3 million posts from Reddit along with summaries written by the author of each post; see below. Due to its size, this dataset is usually filtered to improve quality and ensure that only posts from relevant topics are included; see Section 3.2 in [2] for more details.

Quality issues. Most summarization datasets include both source documents and reference summaries for each document. However, just because we call them “references” does not mean the summaries included in these datasets are high quality! In fact, many papers [8, 11] observe that reference summaries in datasets like CNN / DailyMail are much worse than human-written summaries. This finding is problematic for a few reasons:
We often use these reference summaries for supervised training.
These references may be used to compute evaluation metrics.
A few examples of low-quality references summaries from CNN / DailyMail are shown within the figure below.

How can we evaluate a summary?
“Evaluating abstractive summaries is challenging—it’s not as straightforward as evaluating constrained translations or code generations where we can test for functionality.” - Eugene Yan
Given that abstractive summarization is open-ended, evaluating summary quality can be difficult. There are many viable ways that a source document can be summarized, and determining whether a given summary is “better” than another is subjective! For this reason, properly evaluating abstractive summaries begins with us—the humans and researchers—formulating a set of criteria that describe a “good” summary. For example, the following criteria are proposed in [23]:
Fluency: the sentences in the summary are easy to read and free of errors.
Coherence: the summary as a whole is easy to read, cohesive, and structured in a reasonable manner.
Relevance: the summary includes the most “important” information from the source document.
Consistency: information in the summary is correct and in alignment with the source document (i.e., no hallucinations or incorrect information).
However, these are not the only set of criteria we can define! Arguably, fluency is largely solved by modern LLMs3, and the criteria that we care about may change depending upon the use case we are trying to solve. For example, authors in [7] devise an alternative set of criteria—including faithfulness, factuality, and genericity—that is more suited to summarizing opinions or reviews (e.g., on Yelp) from users.
Defining the desired properties of a good summary is the first step in the evaluation process. Once this is clear, we can begin to think about crafting better abstractive summarization models by measuring performance and iterating.
Human evaluation. There are many automatic strategies for assessing abstractive summary quality, but human evaluation is the most reliable evaluation approach, serving as the “ground truth” for quality evaluation across summarization research. To truly know the quality of a model, we must subject it to human evaluation. Despite this, human evaluation is not a silver bullet! Getting accurate, reliable, and consistent quality labels from humans is extremely difficult4, especially on subjective tasks like abstractive summarization. Humans constantly disagree with each other (on more things than just summary quality!), which can make the evaluation process quite noisy. To mitigate these issues, we can use metrics like Fleiss’ kappa and Krippendorff's alpha to monitor the level of agreement between human annotators—or between annotators and researchers.
Traditional (automatic) metrics. Although human evaluation serves as ground truth for summary quality, we cannot rely purely upon human evaluation because collecting human quality assessments is expensive and time consuming. We need automatic metrics that allow us to more quickly iterate upon our model between human evaluation trials. First, we’ll take a look at more traditional automatic evaluation metrics for summarization tasks, which fall into two categories:
Reference-based
Reference-free (or context-based)
Reference-based metrics assume that we have a target or reference summary—usually written by a human—available that can be used to measure summary quality, while reference-free metrics assess summary quality purely based upon the generated summary and source document.
The most commonly-used evaluation metric for summarization is the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) score, which works by simply counting the number of words—or the number of n-grams for ROUGE-N—in the reference summary that also occur in the model’s generated output; see below.

ROUGE is a reference-based metric that measures overlap between reference and output summaries. Beyond ROUGE, there are many other reference-based metrics that use a similar strategy to compute summary quality:
Bilingual Evaluation Understudy (BLEU) score [25]: commonly used to evaluate translation tasks by counting the number of matching n-grams between the generated output and the reference, then dividing this number by the total number of n-grams within the generated output.
BERTScore [26]: generates an embedding (using BERT) for each n-gram in the generated output and reference output, then uses cosine similarity to compare n-grams from the two textual sequences, enabling semantic matches between n-grams instead of just exact matches.
MoverScore [27]: generalizes BERTScore from requiring a one-to-one matching between n-grams to allow many-to-one matches, thus making the evaluation framework more flexible.
In certain cases, reference-based metrics may be undesirable; e.g., our reference summaries could be of low quality, or maybe we don’t have access to reference summaries at all! To handle these cases, we can derive a context-based version of ROUGE—called ROUGE-C [24]—by comparing the output summary to the source document instead of a reference summary; see below.

Using the same strategy, we can generate reference-free variants of BERTScore and MoverScore too! For more details on the variety of reference-free and reference-based summarization metrics that exist, check out this paper.
“Recent studies suggest using large language models (LLMs) as reference-free metrics for NLG evaluation, which have the benefit of being applicable to new tasks that lack human references.” - from [29]
LLM-as-a-Judge. One popular strategy for evaluating LLM outputs (including for abstractive summarization tasks) is LLM-as-a-Judge [28], which uses a powerful LLM (e.g., GPT-4) for evaluation. To rate or score a generated output, we simply prompt an LLM! This can be done in a few different ways:
Asking the LLM to identify the preferred output within a pair of generated outputs (shown below).
Asking the LLM generate a scalar score (within a specified range) for a single generated output based upon criteria that are outlined in the prompt.
Asking the LLM to rate a generated output based upon several few-shot examples that demonstrate accurate scoring.

LLM-as-a-judge is a new, powerful, and reference-free strategy for evaluating an LLM’s output. However, this evaluation approach introduces several forms of bias:
Position bias: the position of a generated output within the model’s prompt can influence the resulting score. To solve this, we can generate multiple scores with randomly-sampled positions and take their average.
Verbosity bias: Models like GPT-4 tend to prefer more verbose outputs. We can solve this by normalizing the length of generated outputs.
Self-enhancement bias: GPT-4 and other models tend to score their own output higher than that of other models, so we should be careful when using any LLM to score its own generations!
Limited capabilities: LLMs are not perfect! So, we might run into limitations when using LLM-as-a-Judge to score a model’s output on a problem that the judge itself struggles to solve (e.g., complex math or reasoning problems).
Despite these biases, LLM-as-a-judge-style evaluations tend to be surprisingly robust and correlate well with human ratings across a variety of applications, leading to their widespread adoption (for summarization and beyond) in recent research. In [29], authors augment LLM-based evaluations with chain of thought prompting and form-filling, creating a new evaluation strategy called G-Eval that improves evaluation quality for summarization tasks in particular; see below.

Reward models. As discussed above, preference tuning—one of the most effective strategies for training summarization models—involves training a reward model over a human preference dataset. This model’s output is used as a reward signal for finetuning with RL, but the same reward signal can be re-purposed for quality evaluation purposes! The reward model takes a generated summary as input and predicts a human preference score for this summary. As such, the output of a reward model is a proxy for human preferences that can be directly used as a reference-free quality assessment. For more information, check out the awesome writeup (from Nathan Lambert) below on evaluating reward models.
Improving Summaries with Human Feedback
“Compared to the supervised learning paradigm, which pushes the summariser to reproduce the reference summaries at training time, RL directly optimises the summariser to maximise the rewards, which measure the quality of the generated summaries.” - from [1]
For a long time, the state-of-the-art approach for training summarization models was to perform supervised finetuning of a pretrained base model over a dataset of high-quality reference summaries. This approach is effective, but we can get better results via preference tuning, as we will see in this section. Human feedback allows us to train much better summarization models. However, such research goes beyond the topic of summarization. Similar techniques were re-purposed by recent LLM alignment research, forming the basis of the LLM training pipeline.
Better Rewards Yield Better Summaries [1]

Supervised learning was originally the most commonly-used paradigm for training summarization models—we just train models to mimic human-written reference summaries. More recently, researchers began exploring the use of RL for training summarization models. Initial attempts directly used ROUGE scores as rewards5, but ROUGE scores correlate poorly with human quality evaluations; see above. As such, authors in [1] attempt to find a better reward function that guides models towards summaries that are more preferable to humans via RL.
“To find a better reward function to generate human-appealing summaries, we learn a reward function from human ratings on 2,500 summaries.” - from [1]
Learning the reward. Authors in [1] propose learning a reward function from a dataset of human preferences. This dataset, which is taken from prior work, contains 2,500 summaries (with human ratings) of 500 news articles from the CNN / DailyMail corpus. Using this data, we can train a reward model to predict a human rating given a document and system summary as input. Unlike techniques that use ROUGE as the reward, reference summaries are not required to compute the reward! To train the reward model, we can use either a regression objective or a preference learning objective, which captures whether the reward function accurately identifies the human-preferred summary; see below.

Although several architectures are considered for the reward function in [1], the approach that yields the best results is a feed-forward network that takes as input concatenated embeddings—generated using BERT—of the summary and input document. We see in [1] that the preference learning objective yields better results compared to the regression objective, thus explaining why preference learning objectives are now almost universally used for training reward models. In the table below, we see that the best reward function uses:
BERT for embeddings.
Feed-forward network (or MLP) for predicting the reward.
The preference-based learning objective.
This reward function is found to yield predictions that correlate well with human judgements and identify “good” summaries with high recall and precision.

Better summarization models. Beyond accurately predicting human preferences, the reward models trained in [1] can be used to create better extractive and abstractive summarization models. Compared to both supervised baselines and models trained using RL with ROUGE as a reward, models trained with rewards learned from human feedback are found to produce summaries with much higher human ratings (even higher than prior state-of-the-art systems!); see below.

Put simply, we see in [1] that learning a reward function from human feedback can provide a superior learning signal for training RL-based summarization models. Later work adopts this lesson and extends it to the domain of LLMs to learn a variety of tasks (including summarization) from human feedback.
Learning to Summarize from Human Feedback [2]
Supervised finetuning uses a next token prediction objective to maximize the log probability of a set of human demonstrations. We are teaching the model to assign high probability to human-written text6. Evaluating these models via ROUGE allows us to quantify how closely the model’s output matches a reference. This approach works (relatively) well, but authors in [2] note that supervised learning and ROUGE are just proxies for our actual objective—writing high-quality summaries.
“We show that it is possible to significantly improve summary quality by training a model to optimize for human preferences.” - from [1]
Humans do not always write perfect summaries, and numerous equally valid summaries can be written for any one source document. As such, training a summarization model to exactly match a human-written summary is a flawed approach! All references summaries—even those that are low quality—are equally emphasized during the training process, and we have no way to account for the diversity of valid summaries. With this in mind, we may begin to wonder: Can we find an objective that directly optimizes the model based on summary quality?

Learning from human feedback. In [2], authors do exactly this by proposing a three-part framework that enables LLMs to be finetuned based on preference data from humans; see above. The LLM is first trained using supervised finetuning over human reference summaries, producing a supervised baseline that is then further finetuned with RL. The RLHF process in [2] begins by collecting a dataset of human feedback by:
Taking a textual input (source document) from the training dataset.
Using several policies (e.g., pretrained model, supervised baseline, current model, or the human reference summary) to sample summaries of the input.
Picking two summaries from the set of samples responses.
Asking a human annotator to identify the better of the two summaries.
Human comparison data is collected in large batches and used to finetune the model—a decoder-only LLM—via RLHF in an offline fashion. Once the data has been collected, we use this comparison data to train a reward model that accurately predicts a human preference score given a summary produced by the LLM. From here, we use RL to finetune the model—authors in [2] use the PPO algorithm—based on preference scores outputted by the reward model.

Avoiding drift. The authors in [2] add a KL divergence term to the objective being optimized by PPO, which penalizes the policy from becoming too different from the supervised baseline policy during RLHF; see above. Such an approach, which is now commonly used (e.g., see Eq. 4 in the LLaMA-2 report), encourages exploration without mode collapse7 and prevents summaries written by the LLM from becoming too different from those that are seen during training.

Is learning from feedback effective? Authors in [2] finetune several GPT-style language models with 1.3B to 6.7B parameters on the TL;DR dataset using the strategy described above. Models trained via human feedback are found to generate summaries that are consistently preferred by humans compared to those written by models trained solely via supervised learning; see above. The 1.3B human feedback model outperforms a 10× larger model trained with supervised learning alone, and the 6.7B human feedback model performs even better than the 1.3B model—summarization quality benefits from model scale.

Summarization models trained with human feedback seem to generalize better to new domains. For example, models finetuned on TL;DR in [2] are found to perform well on news-centric datasets without further finetuning; see above.
“We confirm that our reward model outperforms other metrics such as ROUGE at predicting human preferences, and that optimizing our reward model directly results in better summaries than optimizing ROUGE according to humans” - from [1]
Reward model > ROUGE. Although reference-based metrics like ROUGE are standard for evaluating summaries, authors in [2] observe that ROUGE scores tend to correlate poorly with human preferences. For this reason, summarization models finetuned with ROUGE as the reward signal for PPO are outperformed by those that train a reward model to predict human preferences. Reward models are found in [2] to predict human preferences very accurately, revealing that preference-based metrics are a useful approach for evaluating summary quality.
Fine-Tuning Language Models from Human Preferences [3]
Prior to work in [2], the same authors (from OpenAI) explored the use of human feedback for finetuning pretrained LLMs on four different tasks [3]—stylistic continuation of text with either positive sentiment or physically descriptive language, as well as summarization on the TL;DR and CNN/Daily Mail datasets. The finetuning strategy used in [3] mostly matches that of [2], but there is no supervised finetuning component—we solely finetune based on human feedbadck; see below. In [3], preference tuning is presented as an alternative to supervised learning, rather than a technique that can be applied in tandem.

For stylistic continuation, authors collect a dataset of 5,000 preference pairs, while over 60,000 preference pairs are collected for summarization. The human feedback models for stylistic continuation are found to be preferred to supervised baselines 77% of the time. Similarly, human annotators prefer the summarization models trained with human feedback over supervised baselines, but the human feedback model is also surprisingly outperformed by a simple baseline that just copies the first three sentences of the document being summarized; see below.

Interestingly, analysis in [3] reveals that human feedback-based summarization models learn a very simple policy for producing abstractive summaries, which authors in [3] refer to as “smart copying”. The model tends to copy large spans of text or sentences from the source text, skipping sentences that are irrelevant and not worth including in the summary. This mechanism emerges naturally during the training process—there is no explicit architectural component added to the summarization model that encourages copying. Despite its simplicity, this learned copying mechanism results in favorable ratings from human annotators.
“We would like to apply reinforcement learning to complex tasks defined only by human judgment, where we can only tell whether a result is good or bad by asking humans.” - from [3]
Useful takeaways. Compared to work in [2], the summarization models trained using human feedback in [3] are much less powerful and tend to be outperformed by simple baselines. This negative result is likely due to the difference in models being used and the exclusion of supervised finetuning from the training process. Nonetheless, research in [3] lays a solid foundation for later advancements, and there are several interesting takeaways that can be gleaned from this analysis:
Learning from human feedback works best for tasks that lack i) sufficient supervised data and ii) good automatic proxies to be used for a reward signal (e.g., we see in [2] that ROUGE is not a useful reward function).
Adding a KL divergence term to the objective used for finetuning with PPO can help to avoid excessive drift8.
Humans tend to rely on simple (and imperfect) heuristics to judge the quality of an LLM’s output.
Online data collection—or continuing to collect additional data to retrain the reward model as the LLM is iteratively finetuned and improved—yields improved performance.
The above findings on the benefits of online data collection have had a lasting impact on LLM research! Recent models like LLaMA-2 undergo several “rounds” of RLHF with freshly-collected data during their alignment process. Plus, we continue to see in recent research that the limitations of human evaluation are a very important consideration when measuring LLM output quality!
Recursively Summarizing Books with Human Feedback [4]
“We use models trained on smaller parts of the task to assist humans in giving feedback on the broader task.” - from [4]
Curating reference summaries or preference labels for summarization, although (potentially) a bit time consuming, is not super difficult. The human annotator just has to:
Read the article being summarized.
Either write a summary or assess the quality of presented summaries.
However, this process becomes more difficult when the text being summarized is very long; e.g., an entire fiction novel. In this case, evaluating a summary of the novel is time consuming, as the human annotator must have either read the book already or needs to spend time reading the book to accurately assess a summary. In [4], authors propose a scalable approach—by combining human feedback with recursive task decomposition—for humans to provide a training signal on such tasks.
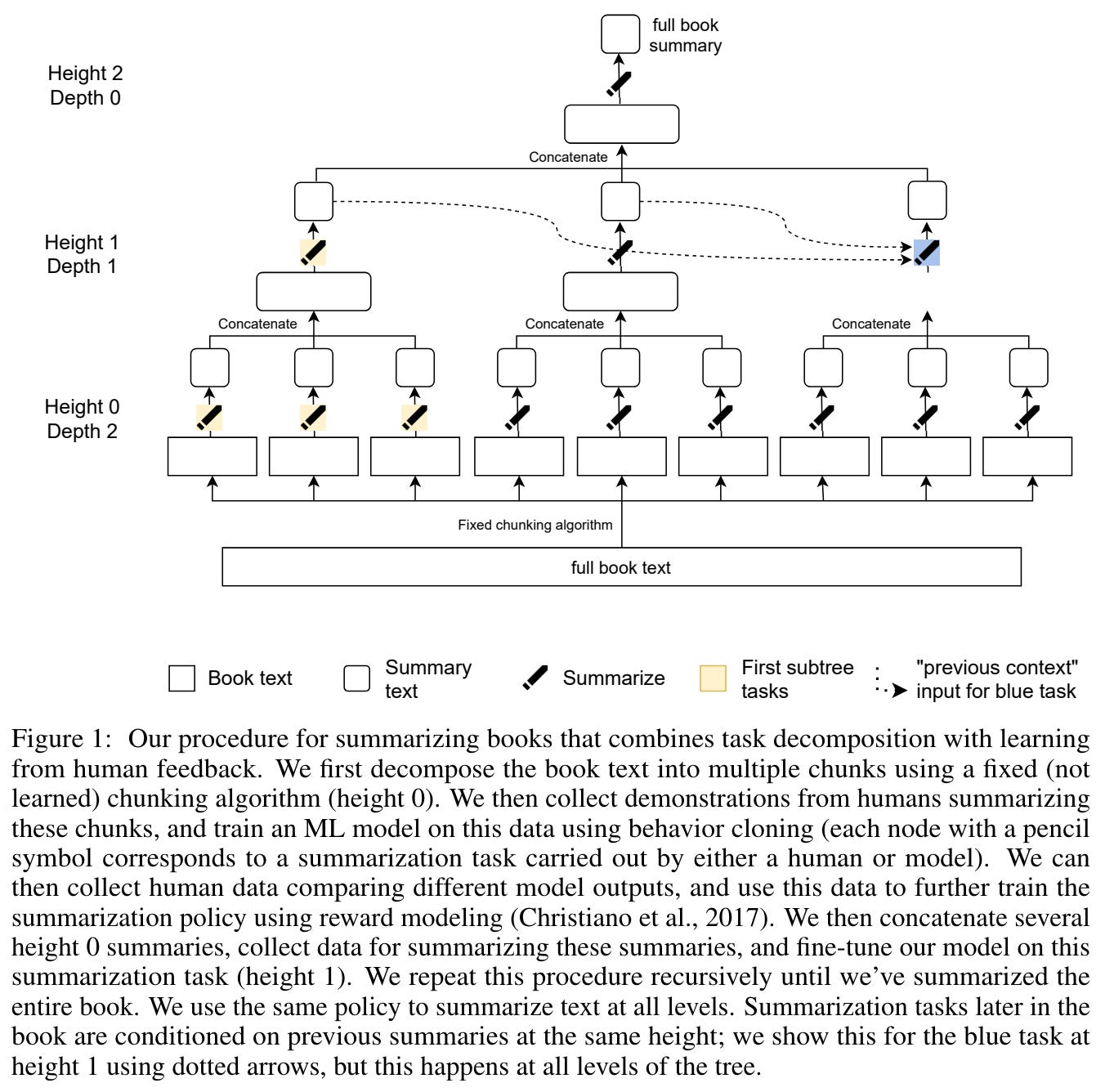
Recursive task decomposition. The core idea proposed in [4] is to break a long text into smaller chunks that can be recursively summarized, forming a tree of summarization tasks (shown above) where leafs are just standard summarization tasks over a reasonably-sized chunk of text. First, the model is used to summarize small chunks of a book. Then, the same model ingests these leaf summaries to summarize larger portions of the book—summaries of shorter passages are used as input for summarizing larger portions of the book. By taking this approach, humans can efficiently supervise this task9, despite lacking an in-depth knowledge of the source text as a whole, as the model only summarizes small chunks of text, either from the book itself or from previously-generated summaries; see below.

At inference time, the model is first used to summarize small sections of the book. Then, these summaries are used recursively to produce higher-level summaries until a summary of the entire book is generated. Due to this recursive strategy, the approach proposed in [4] can summarize texts of arbitrary length!
Creating a dataset. If we recursively decompose the summarization of a long text to a sufficient depth, we will eventually end up with a set of reasonable summarization sub-tasks that can be easily supervised by humans and used to train an LLM. Recursive summarization has three main operations:
Decompose: identify that a text is too long to summarize directly and spawn several summarization sub-tasks over shorter portions of the text.
Respond: solve a sub-task by producing a summary.
Compose: same as “respond”, but the model is shown solutions to several sub-tasks (i.e., previously-generated summaries) when producing a summary.
For books, the decompose operation can be performed algorithmically—just chunk long sequences of text into shorter sequences—instead of asking the LLM to generate sub-tasks. With this strategy, obtaining training data is simple! We just ask humans to either manually summarize a certain sub-task or compare the quality of two summaries that are produced for a certain sub-task. If a node is not a leaf, meaning that humans are summarizing a longer text, then the LLM is used to recursively produce summaries of all child tasks to use as context.
“We collect a large volume of demonstrations and comparisons from human labelers, and fine-tune GPT-3 using behavioral cloning and reward modeling to do summarization recursively.” - from [4]
Given this dataset of supervised examples and preference labels, the training strategy used in [4] is nearly identical to that of [2]. Starting with a pretrained GPT-3 model, we first finetune the model in a supervised manner—this is called behavioral cloning in [4]—over human-written reference summaries. Then, we perform preference tuning over collected preference labels for several iterations. See below for a full description of the training algorithm used in [4].

Empirical results. The training data for [4] is collected using the subset of books data (i.e., Books1 and Books2 datasets) from the pretraining dataset of GPT-3. This data is used to finetune GPT-3 (and a smaller model variant with 6B parameters instead of 175B) to recursively summarize books. Then, the model is evaluated over a set of 40 popular books published in 2020—indicating that they are not included in GPT-3’s pretraining dataset—that span several genres; see below.

Two labelers are asked to read each of these books, write a summary, and rate summaries from various models. As show below, models trained with human preferences far outperform those trained solely using supervised learning. However, all models are still far behind human performance, revealing that abstractive book summarization is an incredibly hard task to solve. In fact, only 5-15% of model-generated summaries are found to match human quality.
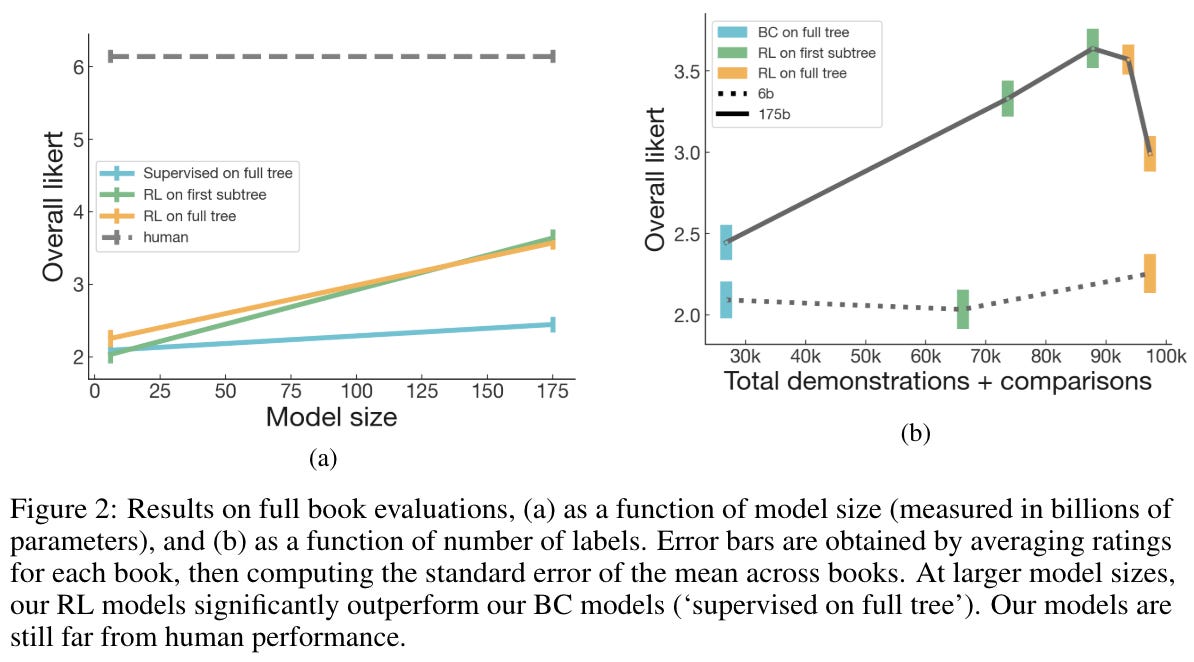
We see in [4] that training on the first sub-task (i.e., summarizing short chunks from the book) is most important—models trained on only this task can generalize relatively well to higher-level summarization tasks. However, performance when generating full book summaries is still disappointing. Human preference scores for individual sub-tasks are much higher than scores assigned to summaries that are produced via a full decomposition of a book; see below.

Training Language Models to Follow Instructions with Human Feedback [5]
“Making language models bigger does not inherently make them better at following a user’s intent… these models are not aligned with their users… we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback.” - from [5]
In [5], we see—from authors at OpenAI—that similar training strategies proposed in [2] can be used to make generic, foundational language models better at following instructions in their prompt. The result of this work is a language model called InstructGPT—the predecessor to ChatGPT that laid the foundation for nearly all research on modern LLMs.
The core idea behind InstructGPT is to finetune a pretrained LLM using SFT and RLHF (shown below) to encourage alignment, defined as the ability to generate text that aligns with the desires of a human user. Typically, we capture these desires concretely by defining a fixed set of alignment criteria (e.g., follow instructions, avoid harmful output, avoid lying, produce interesting or creative output, etc.).

After pretraining, the LLM is likely to generate repetitive (or unhelpful) text, hallucinate frequently, and struggle with following complex instructions within the prompt. Through the alignment process, however, we can teach the LLM necessary skills to avoid these shortcomings and satisfy desired alignment criteria, producing a model that is drastically more useful and interesting.
Creating InstructGPT. The alignment process for InstructGPT begins with a pretrained language model—experiments are run with 1.3B, 6B, and 175B models—and a set of prompts10 that the LLM should be able to answer. First, human annotators manually provide answers for each of these prompts, creating a dataset over which the pretrained model is finetuned via supervised learning. This initial training process exposes the model to instruction-like prompts, thus creating a better starting point for further finetuning with human feedback.
“The SFT dataset contains about 13k training prompts (from the API and labeler-written), the RM dataset has 33k training prompts (from the API and labeler-written), and the PPO dataset has 31k training prompts (only from the API).” - from [5]
From here, a dataset of human preference labels is collected, where each preference example ranks multiple responses to the same prompt based on quality. This preference dataset is used to train a reward model (RM)—which shares the same architecture as the LLM—that predicts a scalar reward given a prompt and a generated response as input; see below.

We can use this RM to finetune the LLM via PPO over set of relevant prompts. This training pipeline, which almost exactly matches the proposal of [2], forms the standard three-part alignment procedure used by nearly all LLMs. Here, the approach is just applied to alignment rather than summarization!

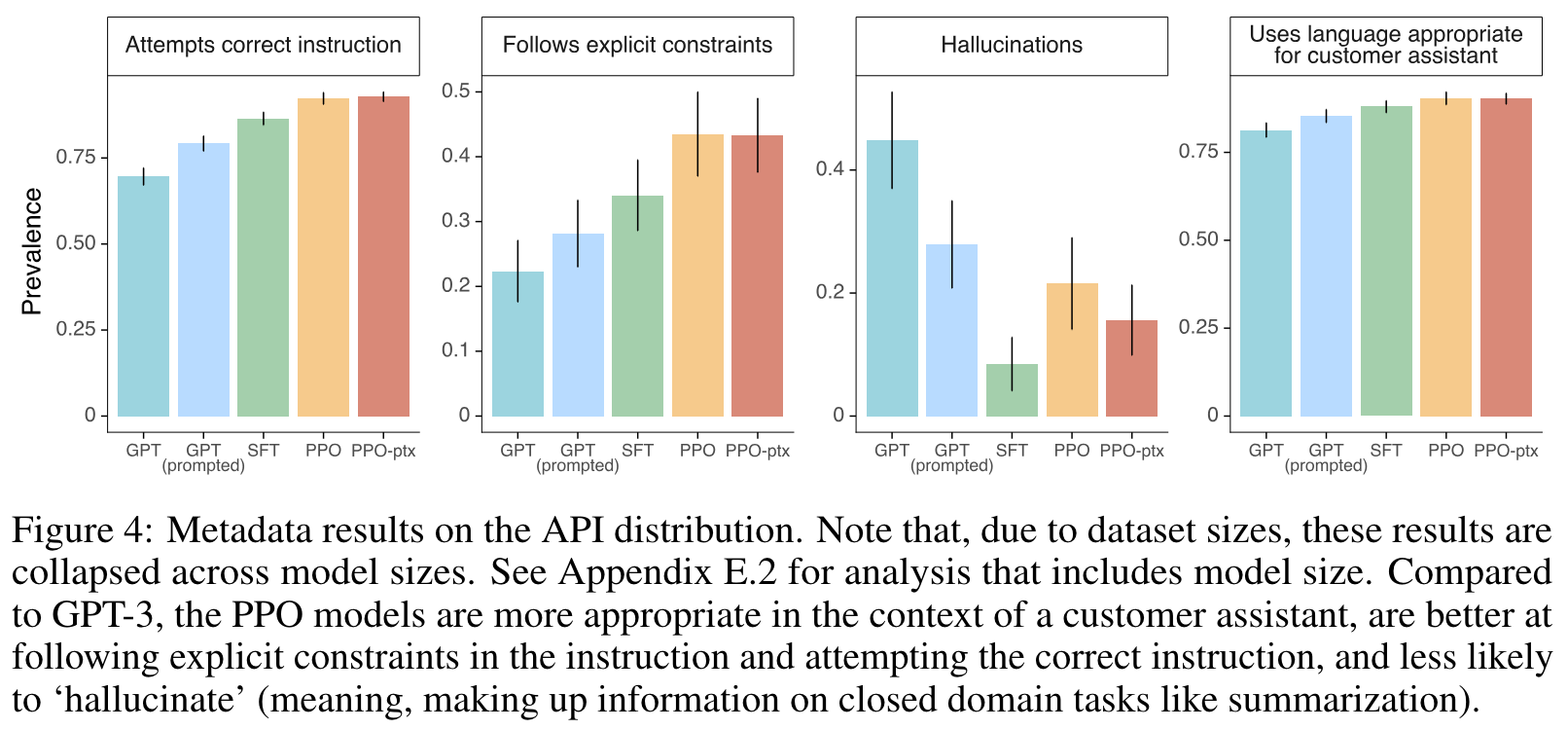
Empirical findings. We see in [5] that learning from human feedback is an incredibly effective strategy for producing aligned (and useful) LLMs. In particular, authors in [5] observe that:
Human annotators prefer InstructGPT outputs over GPT-3 (see above).
InstructGPT tends to be more truthful than GPT-3.
GPT-3 produces more toxic output than InstructGPT.
InstructGPT is better at following instructions, even those that go beyond the distribution of prompts used for finetuning.
Compared to GPT-3, InstructGPT has very favorable alignment properties. As shown in the table below, InstructGPT tends to be much more steerable than GPT-3, meaning that the user can better control the model’s behavior by providing constraints, instructions, or details within the prompt.
Despite all of these benefits, we see that the alignment procedure also comes with an “alignment tax” in the form of performance regressions on public benchmarks compared to the pretrained model. To avoid this tax, we can simply perform intermittent updates over the pretraining dataset during preference tuning.
Summarization in the Age of LLMs
Given that InstructGPT was not focused upon summarization, we might be wondering why this paper was included within this overview. However, InstructGPT represents a paradigm shift in NLP research away from narrow experts—models that specialize in solving a single kind of task—and towards foundation models—models that can accurately solve a wide variety of tasks. Research on abstractive summarization provided a starting point for later research on foundation models. Over time, however, researchers began to focus less on the problem of abstractive summarization in particular, choosing instead to focus on creating better foundation models. For these models, abstractive summarization is just one of the many tasks that they are capable of solving accurately.
News Summarization and Evaluation in the Era of GPT-3 [6]
“We compare these approaches using A/B testing on a new corpus of recent news articles, and find that our study participants overwhelmingly prefer GPT-3 summaries.” - from [6]
As mentioned above, the proposal of powerful LLMs led to a paradigm shift in AI research where we could accurately solve a variety of tasks by simply prompting a foundation model. In [6], authors study the impact of this paradigm shift on summarization research, focusing on news summarization.
How good is GPT-3? Despite not being explicitly trained on summarization-specific data, we see in [1] that GPT-3 is very good at writing summaries that are preferable to humans, even when we only prompt the model with a task description (i.e., zero-shot regime)! Going further, GPT-3 does not suffer from dataset-specific issues (e.g., learning from poorly-written or inaccurate reference summaries) due to the fact that it is a generic model trained on a massive textual corpus that can solve a variety of tasks without explicit finetuning. For this reason, GPT-3 naturally generalizes to new summarization domains without requiring a sizeable dataset. We just need an instruction or some few-shot examples.
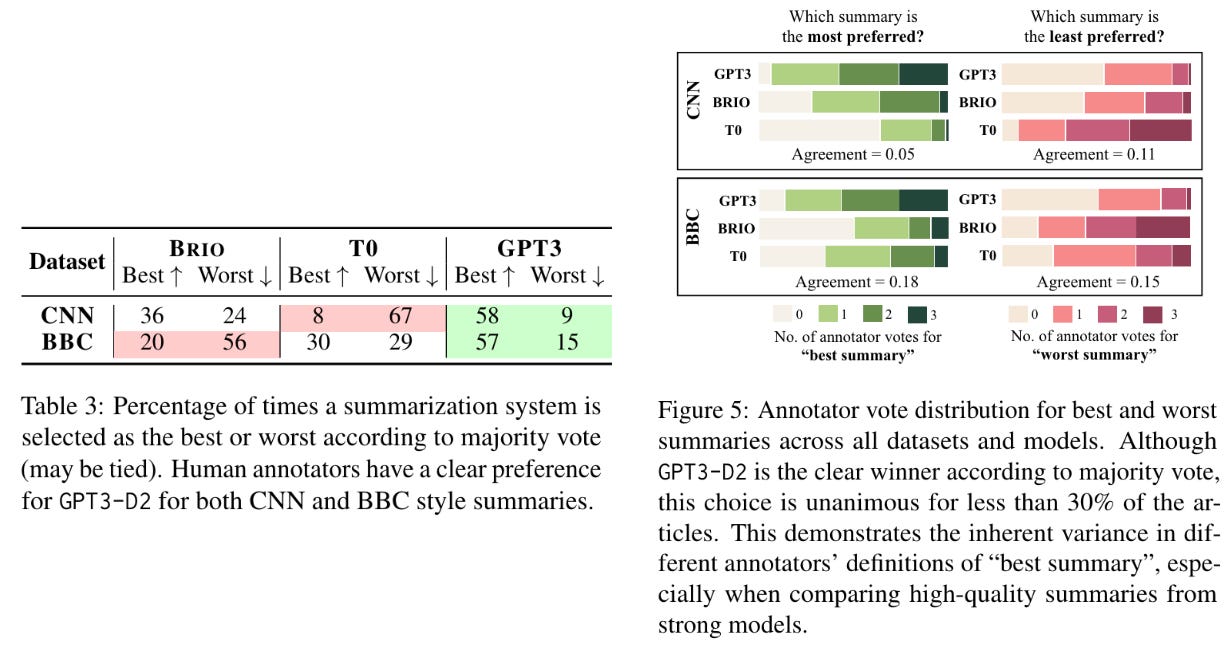
Compared to SFT and instruction-tuned models, GPT-3 generates summaries that achieve 20% higher scores from humans across all datasets, indicating a clear preference for GPT-3; see above. However, the choice of the best summarization model is only unanimous in <30% of cases, revealing that high-quality summaries can be difficult to compare—the choice of the “best” model is not straightforward.
Analyzing automatic metrics. Authors in [6] also extensively analyze the effectiveness of automatic metrics in evaluating summary quality. Prior research seems to indicate that automatic metrics like ROUGE are useful for discerning large quality differences between summarization models but struggle to capture small performance differences (i.e., automatic metrics are less useful for comparing models with nuanced performance differences). We see in [6] that this rule of thumb is less straightforward in the age of LLMs. GPT-3 summaries score significantly worse than baselines—a seven point difference in ROUGE!—despite being preferred almost unanimously in human trials; see below.
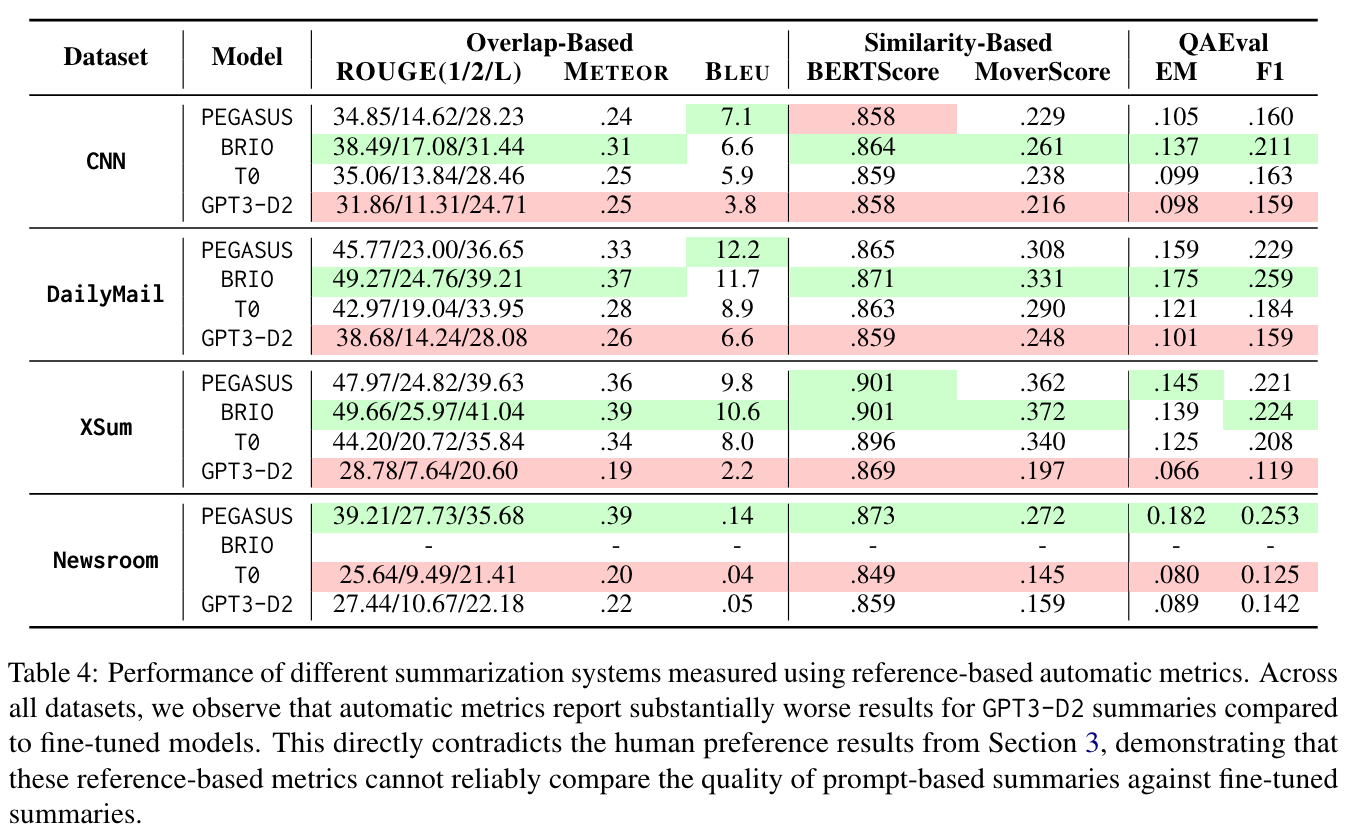
These results provide further evidence that reference-based metrics correlate poorly with human preferences when considering powerful summarization models. Going further, we see in [6] that similar results—both in terms of the quality of GPT-3 summaries and limitations of automatic metrics—are found to hold for more specialized summarization tasks like keyword and aspect-based summarization, which perform guided summarization based on specific keywords or topics.
Prompted Opinion Summarization with GPT-3.5 [7]
Although most papers study text summarization (e.g., summarizing news articles), authors in [7] consider the more complex task of opinion summarization11 to determine if this task can be solved with GPT-3.5. Why is opinion summarization more complex than text summarization? There are a few reasons:
Different opinions might be contradictory, thus requiring a more nuanced summary that accurately reflects different viewpoints12.
The length of all opinions being summarized oftentimes exceeds the LLM’s context length, so we need a pipeline to process and summarize the data.
The opinion summarization tasks is less widely explored than general text summarization. Similarly to [4], a recursive strategy can be used to summarize long opinion sequences, but alternative techniques are also explored in [7]; e.g., clustering opinions into thematic groups or automatically identifying the most salient (or important) opinions to be included in the summary.

Summarization pipelines. Authors in [7] explore a variety of different opinion summarization pipelines, but three primary approaches are emphasized:
A hierarchical approach that recursively chunks and summarizes text to produce the final output (i.e., chunking with repeated summarization).
A pre-extraction strategy that uses an extractive summarization model, called QFSumm, to identify the most salient reviews prior to summarization.
A clustering approach that separates reviews into clusters based upon their topics or ratings, summarizes each cluster recursively, then generates a final summary; see above.
We see in [7] that GPT-3.5 produces useful summaries via basic, recursive summarization for short sequences of reviews. When processing longer sequences, however, we see that repeated chunking and summarization can deteriorate summary quality. We can mitigate this issue via the pre-extraction and clustering strategies described above, as these techniques tend to reduce the number of recursive summarization steps required to generate a final output.

Examples of opinion summaries generated with these strategies (on the SPACE hotel opinion summarization dataset) are shown within the figure above. As we can see, topic-wise clustering seems to yield more abstractive summaries that provide a high-level view of various opinions, while the extractive strategy focuses more on specific points that are made within each of the input reviews.
Human evaluation. Beyond the summarization pipelines outlined above, authors in [7] explore a wide variety of different pipelines by modularizing each pipeline component and using a plug-and-play approach. These pipelines are used to generate summaries on the SPACE and FewSum (contains Amazon and Yelp reviews) opinion summarization datasets and are evaluated based on factuality, faithfulness, relevance, and representativeness of their generated summaries.

As shown above, the best summarization pipeline differs based upon the dataset and property being evaluated. However, summaries generated with GPT-3.5 far outperform baseline techniques in terms of human evaluation, despite performing poorly on automatic metrics. As such, the summarization pipelines proposed in [7] prove to be an advancement over prior state-of-the-art.
Benchmarking Large Language Models for News Summarization [8]
“We find instruction tuning, and not model size, is the key to the LLM’s zero-shot summarization capability.” - from [8]
At this point, we know that LLMs can summarize text really well, outperforming prior state-of-the-art techniques in most cases. But, why is this the case? The design decisions that underlie the success of LLMs on summarization tasks are poorly understood. In [8], authors conduct extensive human evaluations of ten different LLMs—encompassing several pretraining methods, prompts, and model scales—on summarization tasks. From these experiments, we clearly see that instruction tuning the key component that makes LLMs effective summarizers.

Poor reference summaries. Most evaluations performed in [8] are conducted on the CNN / DailyMail and XSum datasets. Interestingly, authors show that most reference summaries from these datasets are judged by humans to be of low quality, indicating that existing summarization studies are limited by the low-quality reference summaries present in common datasets. In fact, authors in [8] show that the poor correlation between reference-based evaluation metrics (e.g., ROUGE) and human preferences is worsened by low-quality reference summaries, thus calling a variety of prior summarization research into question.
“To address the quality issues of reference summaries and better understand how LLMs compare to human summary writers, we recruit freelance writers … to re-annotate 100 articles from the test set of CNN/DM and XSUM.” - from [8]
To solve this issue with poor reference summaries, a fresh set of 100 examples from the CNN / DailyMail and XSum datasets are re-annotated by humans. These high-quality reference summaries can be used for more reliable evaluations that do not artificially degrade LLM performance across summarization tasks.
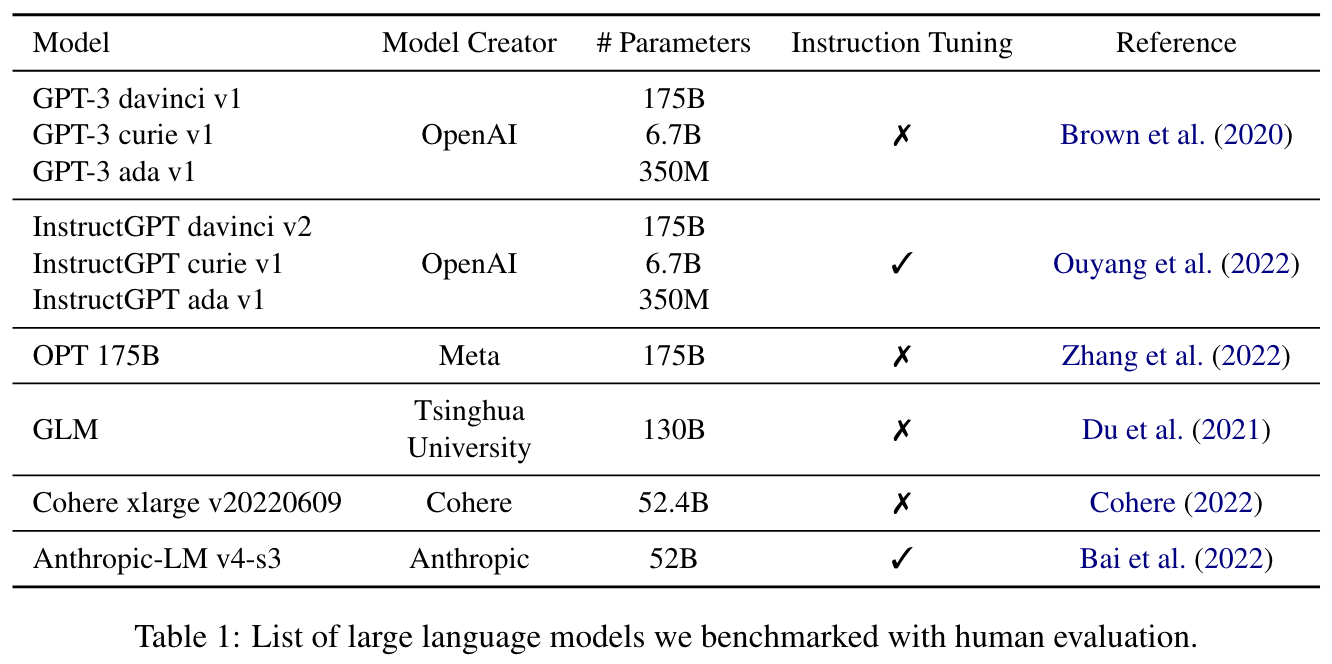
Experimental setup. Ten different LLMs are considered for measuring summarization quality; see above. Models are evaluated using either a zero or five-shot prompt with the basic template shown below.
“Article: [article]. Summarize the article in three sentences. Summary:”
Again, authors emphasize the low quality of reference summaries present within existing summarization datasets. In fact, using reference summaries as in-context learning examples was found to degrade LLM performance! Several qualitative examples of LLM-generated output summaries are shown in the figure below.

The main takeaways from the experimental analysis in [8] are twofold:
Instruction tuning clearly benefits summarization performance.
LLM-generated summaries are extractive in nature, whereas human-written summaries tend to contain more abstraction or paraphrasing; see below.

LLMs that have undergone instruction tuning clearly outperform those that have not, indicating that self-supervised pretraining is not enough to yield competitive summarization results. Additionally, LLM-generated summaries tend to directly copy information from the original article, though the copied information is synthesized in a coherent fashion. In contrast, human written summaries tend to paraphrase information rather than copying from the source material. Despite their extractive nature, LLM-generated summaries are preferred equally to those written by humans when compared in human evaluation trials; see below.

ChatGPT vs. Human-Authored Text [9]
“The stylistic variations produced by humans are considerably larger than those demonstrated by ChatGPT, and the generated texts diverge from human samples in several characteristics, such as the distribution of word types” - from [9]
One interesting form of summarization is controllable summarization, in which we instruct the model to write a summary that targets a particular audience. In [9], authors study the performance of GPT-3.5-Turbo on summarizing scientific information for both experts and non-experts, aiming to identify the behavioral differences (compared to human-written summaries), limitations, and challenges faced when performing controllable summarization with an LLM.

Specifying an audience. To perform controllable summarization with an LLM, we simply have to modify our prompt. In the case of [9], we can specify the audience for which we want to write the summary within an instruction; see above. These prompts are used to summarize scientific literature from the eLife dataset, where 500 random samples are taken from the dataset for evaluation. The LLM is prompted in a zero-shot manner to generate all summaries.
Evaluation metrics. To determine whether GPT-3.5-Turbo is able to sufficiently adapt its generated summary towards the specified target audience, several automatic metrics are used for evaluation:
Flesch Reading Ease: measures readability via the average number of syllables per word and the average number of average words per sentence. Texts that score higher are easier-to-understand.
Coleman-Liau Index: captures textual difficulty by measuring the average number of characters per sentence and the average number of sentences per 100 words. Texts that score higher are more challenging to understand.
Dale-Chall Readability Score: compares the number of complex words in a text with a list of common words. Texts that score higher are more challenging to understand.
Beyond these readability metrics, ROUGE scores and n-gram novelty13 are measured, as well as metrics like SummaC and named entity hallucination that detect factual inconsistencies within the model-generated summaries.

Key takeaways. The analysis in [9] gives us two key pieces of information:
GPT-3.5-Turbo is worse than humans at tailoring its output towards a particular audience.
Model-generated summaries tend to be more extractive and commonly contain hallucinations.
As shown in the table above, GPT-3.5-Turbo generates summaries that achieve Flesch Reading Ease scores within the ranges of [31, 38] for layman summaries and [28, 37] for expert summaries. In contrast, layman and expert summaries written by humans achieve average Flesch Reading Ease scores of 53.1 and 22.5, respectively—the magnitude of difference in readability scores is drastically different between human and model-written summaries. Providing few-shot examples can mitigate this issue, but GPT-3.5-Turbo is nonetheless found to be less effective on controllable summarization tasks compared to humans.

Summaries generated with GPT-3.5-Turbo also have a lower n-gram novelty than those written by humans, indicating the model-written summaries are more extractive in nature; see above. We also see that summaries generated with GPT-3.5-Turbo tend to have frequent hallucinations, as measured by the overlap of entities and topics between the summary and source material; see below. All of these results seem to indicate that GPT-3.5-Turbo has room for improvement in the domain of controllable summarization, though it should be noted that more recent models (e.g., GPT-4o) would likely perform better.

Concluding Remarks
We have now taken a look at several generations of summarization research, ranging from supervised finetuning, to preference tuning, to modern foundation models. From this work, there are several common themes that arise:
The difficulty (and importance) of evaluation.
The value of learning from human feedback.
The importance of data quality.
The impressive capabilities of modern foundation models.
Although this overview focused specifically upon summarization research, the findings from this work are highly generalizable. Summarization is a fundamental task in natural language processing due to its roots in conditional generation (i.e., teaching a model to generate an output given some input). Many other important tasks—machine translation, text classification, keyword extraction, and question answering to name a few—follow a very similar pattern! A deep understanding of summarization research is helpful for solving a much broader class of problems.
“We use reinforcement learning from human feedback (RLHF; Stiennon et al., 2020) to fine-tune GPT-3 to follow a broad class of written instructions.” - from [5]
The fundamental role of summarization within natural language processing research has led these techniques to be adopted heavily in the age of LLMs. A variety of impactful approaches in language modeling research are heavily influenced by summarization papers! For example, InstructGPT adopts a training algorithm that was previously proposed for training better summarization models from human feedback [2], while modern alignment procedures use an iterative finetuning strategy that was advocated by earlier summarization research [3]. The research presented in this overview is practically useful. More importantly, however, it lays a foundation for the advancements we see in LLMs today.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, Deep Learning Ph.D. and Machine Learning Scientist at Netflix. This is the Deep (Learning) Focus newsletter, where I help readers better understand important topics in AI research. If you like the newsletter, please subscribe, share it, or follow me on X and LinkedIn!
Bibliography
[1] Böhm, Florian, et al. "Better rewards yield better summaries: Learning to summarise without references." arXiv preprint arXiv:1909.01214 (2019).
[2] Stiennon, Nisan, et al. "Learning to summarize with human feedback." Advances in Neural Information Processing Systems 33 (2020): 3008-3021.
[3] Ziegler, Daniel M., et al. "Fine-tuning language models from human preferences." arXiv preprint arXiv:1909.08593 (2019).
[4] Wu, Jeff, et al. "Recursively summarizing books with human feedback." arXiv preprint arXiv:2109.10862 (2021).
[5] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744.
[6] Goyal, Tanya, Junyi Jessy Li, and Greg Durrett. "News summarization and evaluation in the era of gpt-3." arXiv preprint arXiv:2209.12356 (2022).
[7] Bhaskar, Adithya, Alexander R. Fabbri, and Greg Durrett. "Prompted opinion summarization with GPT-3.5." arXiv preprint arXiv:2211.15914 (2022).
[8] Zhang, Tianyi, et al. "Benchmarking large language models for news summarization." Transactions of the Association for Computational Linguistics 12 (2024): 39-57.
[9] Pu, Dongqi, and Vera Demberg. "ChatGPT vs human-authored text: Insights into controllable text summarization and sentence style transfer." arXiv preprint arXiv:2306.07799 (2023).
[10] Menick, Jacob, et al. "Teaching language models to support answers with verified quotes." arXiv preprint arXiv:2203.11147 (2022).
[11] Fabbri, Alexander R., et al. "Summeval: Re-evaluating summarization evaluation." Transactions of the Association for Computational Linguistics 9 (2021): 391-409.
[12] Subramanian, Sandeep, et al. "On extractive and abstractive neural document summarization with transformer language models." arXiv preprint arXiv:1909.03186 (2019).
[13] Zhang, Fang-Fang, Jin-ge Yao, and Rui Yan. "On the abstractiveness of neural document summarization." Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018.
[14] Kryściński, Wojciech, et al. "Evaluating the factual consistency of abstractive text summarization." arXiv preprint arXiv:1910.12840 (2019).
[15] Maynez, Joshua, et al. "On faithfulness and factuality in abstractive summarization." arXiv preprint arXiv:2005.00661 (2020).
[16] Durmus, Esin, He He, and Mona Diab. "FEQA: A question answering evaluation framework for faithfulness assessment in abstractive summarization." arXiv preprint arXiv:2005.03754 (2020).
[17] Wang, Alex, Kyunghyun Cho, and Mike Lewis. "Asking and answering questions to evaluate the factual consistency of summaries." arXiv preprint arXiv:2004.04228 (2020).
[18] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[19] Wei, Jason, et al. "Finetuned language models are zero-shot learners." arXiv preprint arXiv:2109.01652 (2021).
[20] Nallapati, Ramesh, et al. "Abstractive text summarization using sequence-to-sequence rnns and beyond." arXiv preprint arXiv:1602.06023 (2016).
[21] Narayan, Shashi, Shay B. Cohen, and Mirella Lapata. "Don't give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization." arXiv preprint arXiv:1808.08745 (2018).
[22] Völske, Michael, et al. "Tl; dr: Mining reddit to learn automatic summarization." Proceedings of the Workshop on New Frontiers in Summarization. 2017.
[23] Kryściński, Wojciech, et al. "Neural text summarization: A critical evaluation." arXiv preprint arXiv:1908.08960 (2019).
[24] He, Tingting, et al. "ROUGE-C: A fully automated evaluation method for multi-document summarization." 2008 IEEE International Conference on Granular Computing. IEEE, 2008.
[25] Papineni, Kishore, et al. "Bleu: a method for automatic evaluation of machine translation." Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 2002.
[26] Zhang, Tianyi, et al. "Bertscore: Evaluating text generation with bert." arXiv preprint arXiv:1904.09675 (2019).
[27] Zhao, Wei, et al. "MoverScore: Text generation evaluating with contextualized embeddings and earth mover distance." arXiv preprint arXiv:1909.02622 (2019).
[28] Zheng, Lianmin, et al. "Judging llm-as-a-judge with mt-bench and chatbot arena." Advances in Neural Information Processing Systems 36 (2024).
[29] Liu, Yang, et al. "Gpteval: Nlg evaluation using gpt-4 with better human alignment." arXiv preprint arXiv:2303.16634 (2023).
By an “emergent” capability, we mean a capability of the model that appears only after a certain scale (in terms of data or compute) is explored.
Alignment, which is commonly tackled via a combination of supervised finetuning and preference tuning, refers to the process of finetuning an LLM to generate outputs that better align with the desires of a human user; see here for details.
More specifically, the output of modern LLMs tends to be fluent and free of simple grammatical/syntactical errors automatically, so evaluating fluency is arguably needless for such models.
After working at a data annotation company for over two years, I am well-versed in the difficulty of getting large groups of humans to accurately and reliably annotate/score large amounts of data!
Here, we assume that each example used during training has a reference summary. Then, we can compute the summarization output with our model, find the ROUGE score using the reference summary and the model’s output, then use the ROUGE score as a reward signal for training via RL.
Remember, LLMs operate by assigning probabilities to each token they output. We want the probabilities assigned to human-written summaries to be high, as these summaries represent reasonable outputs that can be generated by the LLM.
Mode collapse refers to a phenomenon in which the LLM loses its output diversity and begins only producing a narrow set of outputs with a particular style (or set of styles).
Drift simply refers to the finetuned model becoming too different from some reference model (e.g., the model prior to the finetuning process).
Authors in [3] note that by decomposing a book summarization task with a depth of three, we can summarize books with thousands of words while reducing annotation costs of the summarization task by 50×.
Most of these prompts are taken from the OpenAI API, thus ensuring that there is sufficient overlap between the prompts used for training and real world use cases.
Opinion (or review) summarization refers to the task of writing a summary of opinions or reviews left by many users for a particular product or service (e.g., reviews of a product or opinions posted about a restaurant).
For this reason, extractive-style summaries that copy text directly from the source tend to perform poorly for opinion summarization, despite being an effective approach for text summarization.
N-gram novelty refers to the ratio of n-grams generated within the summary that are not present within the source text.
Large language models (LLMs) have rapidly advanced, building on years of NLP research. Summarization, both abstractive and extractive, exemplifies their progress. This comprehensive overview highlights the evolution and importance of fundamental research in shaping LLM capabilities.
Great analysis, well worth the wait!