
Modern Advances in Prompt Engineering
Distilling and understanding the most rapidly-evolving research topic in AI...


Due to their ease of use, large language models (LLMs) have seen an explosive rise to popularity. By just crafting a textual prompt, even those who are completely unfamiliar with deep learning can leverage massive neural networks to quickly solve a wide variety of complex problems. Over time, these models have become even easier to use via improved instruction following capabilities and alignment. However, effectively prompting LLMs is both an art and a science—significant performance improvements can be achieved by slightly tweaking our prompting implementation or strategy. In this overview, we will develop a comprehensive understanding of prompt engineering, beginning with basic concepts and going all the way to cutting-edge techniques that have been proposed in recent months.
What is prompt engineering?
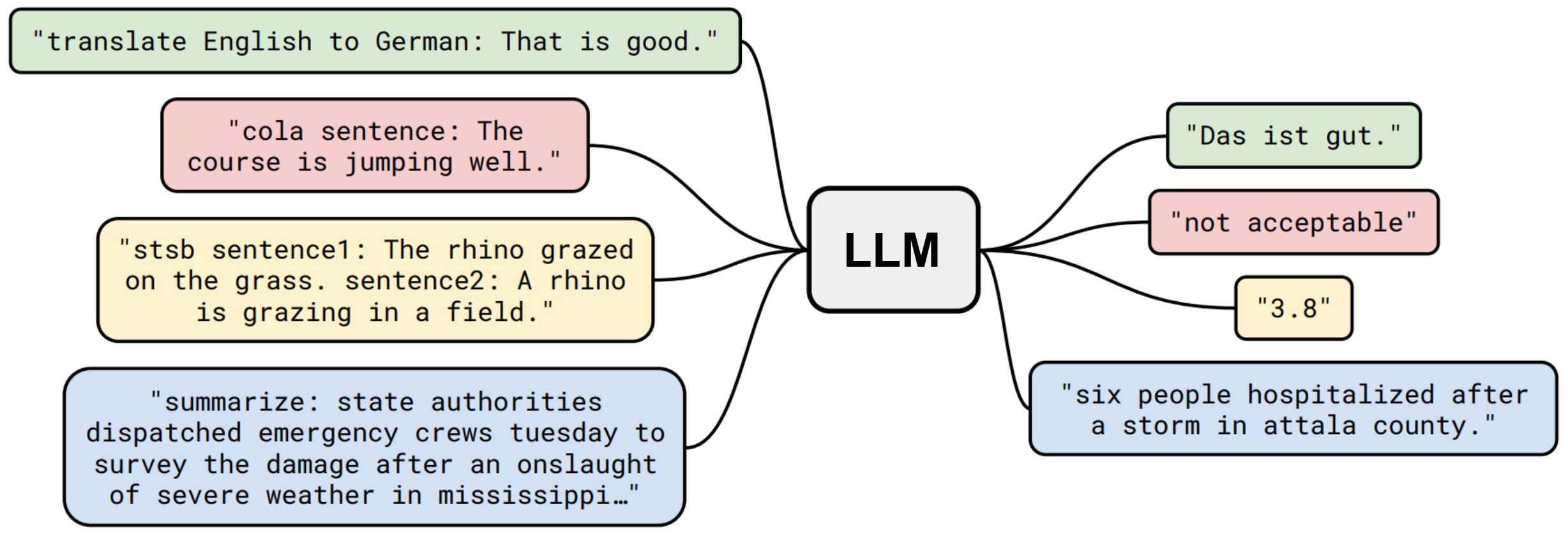
One major reason that LLMs are so popular is because their text-to-text interface makes them incredibly simple to use. In a prior generation, solving a task with deep learning would require that we (at a minimum) finetune a model over some data to teach the model how to solve that task. Plus, most of these models were narrow experts, meaning that they would specialize in solving a single task. Due to the emergent in-context learning abilities of LLMs, however, we can solve a variety of problems via a textual prompt; see above. Previously complex problem solving processes have been abstracted into natural language!
“Prompt engineering is a relatively new discipline for developing and optimizing prompts to efficiently use LMs for a wide variety of applications and research topics.” - from [1]
What is prompt engineering? The simplicity of LLMs has democratized their use. You don’t need to be a data scientist or an MLE to use an LLM—as long as you understand English (or your language of choice) you can solve relatively complex problems with an LLM! When solving a problem with an LLM, however, the results that we achieve depend heavily upon the textual prompt provided to the model. For this reason, prompt engineering—the empirical science of testing different prompts to optimize an LLM’s performance—has become extremely popular and impactful, resulting in the discovery of many techniques and best practices.
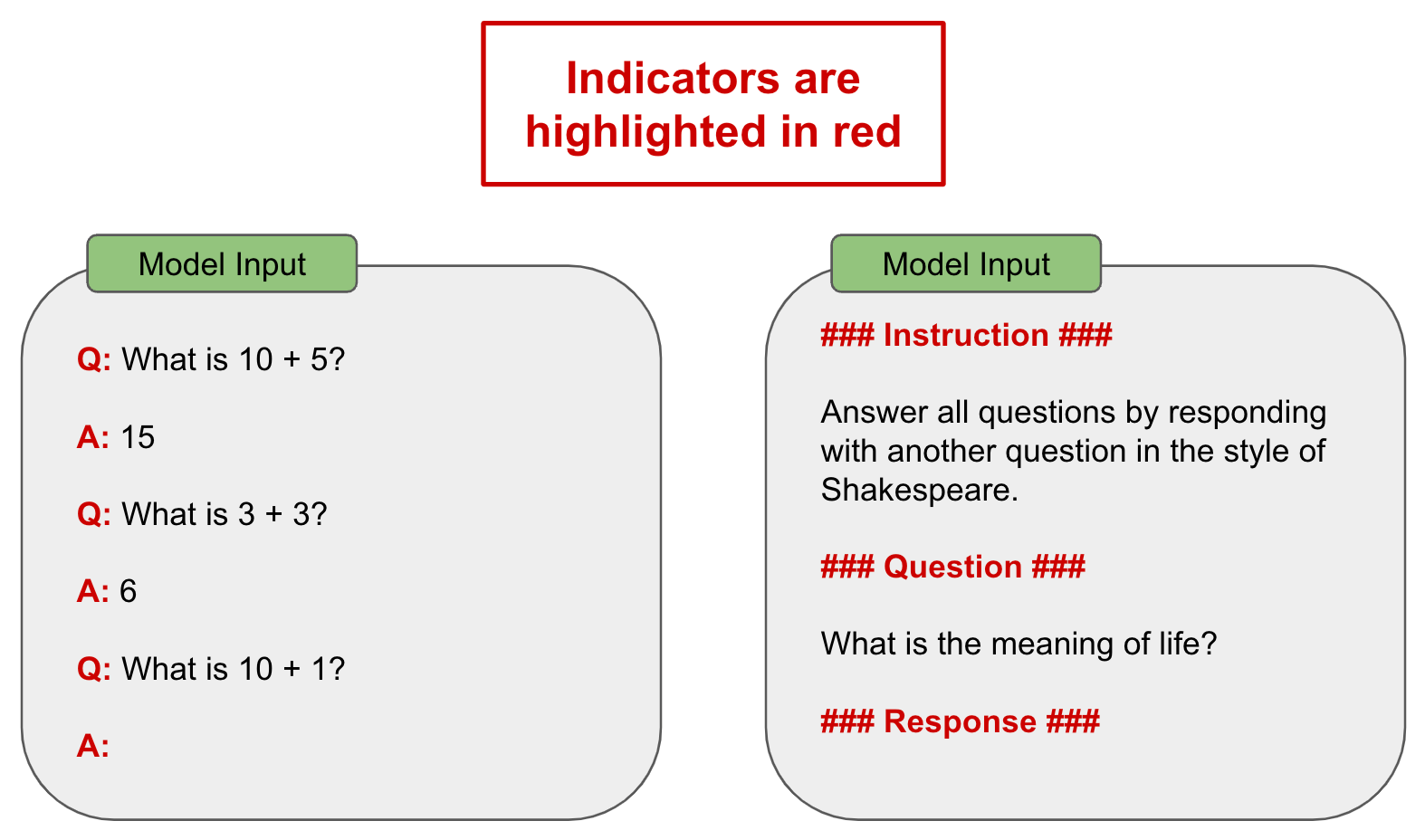
Prompt components. There are many ways to prompt an LLM. However, most prompting strategies share a few common components:
Input Data: the actual data that the LLM is expected to process (e.g., the sentence being translated or classified, the document being summarized, etc.).
Exemplars: concrete examples of correct input-output pairs that are included within the prompt.
Instruction: a textual description of the output that is expected of the model.
Indicators: tags or formatting elements that are used to create structure within the prompt; see above.
Context: any extra information provided to the LLM in the prompt.
In the figure below, we see an example that combines all of the above-mentioned prompt components within a single prompt for sentence classification.
The context window. During pretraining, an LLM sees input sequences of a particular length. This choice of sequence length during pretraining becomes the model’s “context length”, or the maximum length of sequence that the model is capable of processing. Given a textual sequence that is significantly longer than this predetermined context length, the model may behave unpredictably and produce incorrect output. However, there are methods—such as Self-Extend or positional interpolation—that can be used to extend the model’s context window.

Recent research on LLMs has emphasized the creation of long context windows, which allow the model to process more information within each prompt (e.g., more exemplars or a larger amount of context). As we will see, however, not all LLMs pay perfect attention to their context! The ability of an LLM to leverage information within a long context window is typically assessed via a needle in the haystack test, which i) embeds a random fact within the context, ii) asks the model to retrieve the fact, and iii) repeats this test over various context lengths and positions of the fact in the context. Such a test yields a picture like the one shown below, where we can easily spot deficiencies in the context window.

My prompt engineering strategy. The details of prompt engineering differ a lot based upon the model being used. However, there are a few general principals that are often useful for guiding the prompt engineering process:
Be empirical: the first step of prompt engineering is to setup a reliable way of evaluating your prompt (e.g., via test cases, human evaluators, or LLM-as-a-judge) so that you can easily evaluate changes to a prompt.
Start simple: the first prompt you try should not be a chain-of-thought prompt (or some other specialized prompting technique). Start with the simplest prompt possible and slowly add complexity while measuring the change in performance (see above) to determine if extra complexity is necessary1.
Be specific and direct: eliminate ambiguity in the prompt and try to be concise, direct, and specific when describing the desired output of the LLM.
Use exemplars: if describing the desired output is difficult, try adding some exemplars to the prompt. Exemplars eliminate ambiguity by providing concrete examples of what is expected of the LLM.
Avoid complexity (if possible): complex prompting strategies are sometimes necessary (e.g., to solve multi-step reasoning problems), but we should think twice before using such approaches. Be empirical and use the established evaluation strategy to truly determine whether the complexity is necessary.
To summarize everything above, my personal prompt engineering strategy is to i) invest into a really good evaluation framework, ii) start with a simple prompt, and iii) slowly add complexity as necessary to achieve the desired level of performance.

Prompting Techniques
We have previously learned about a variety of prompting techniques through a series of related overviews:
Practical Prompt Engineering [link]
Advanced Prompt Engineering [link]
Chain of Thought Prompting [link]
Prompt Ensembles [link]
We will now overview relevant prompting techniques once again, providing a foundation for the more complex approaches that will be introduced later in the post. As we learn about each of these techniques, however, we should keep in mind the importance of simplicity in prompt engineering. Just because a prompting technique is more intricate or complex does not make it better than simpler strategies!
Basic Prompting Strategies

Zero-shot prompting (shown above)—as popularized by GPT-2 [2]—is one of the most basic prompting strategies that we can employ. To solve a task via zero-shot prompting, we just i) describe the task in the prompt and ii) prompt the model to solve the problem. In the case of the problem above, the task is translating a word from English to French, and we prompt the model to make this translation via the string “cheese =>”, which prompts the model to emit the French translation of the word cheese. Several examples of zero-shot prompts are provided below.

Although zero-shot learning performs well in some cases, it is limited by the ambiguity of task descriptions. Performance is dependent upon the creation of a clear/comprehensive description, and we rely upon the model’s ability to produce the correct output based on this description alone. Oftentimes, we can achieve better performance by inserting more concrete information into the prompt.

Few-shot prompting does exactly this by inserting several examples of correct problem solutions into the prompt. This strategy was popularized by GPT-3 [3], which showed that LLMs develop impressive few-shot learning abilities at scale; see above. Intuitively, few-shot learning eliminates the ambiguity of zero-shot learning by providing several examples of the expected output. As such, the model can understand the correct behavior directly from these exemplars, rather than inferring the desired behavior from the task description; see below.

The LLM can learn from these examples provided within the prompt, a strategy commonly referred to as “in-context learning”; see below. However, this style of learning is not like normal training of a neural network—the parameters of the model are not modified at all. Rather, we put relevant information in the prompt, and the model can use this information as context for generating a better output.
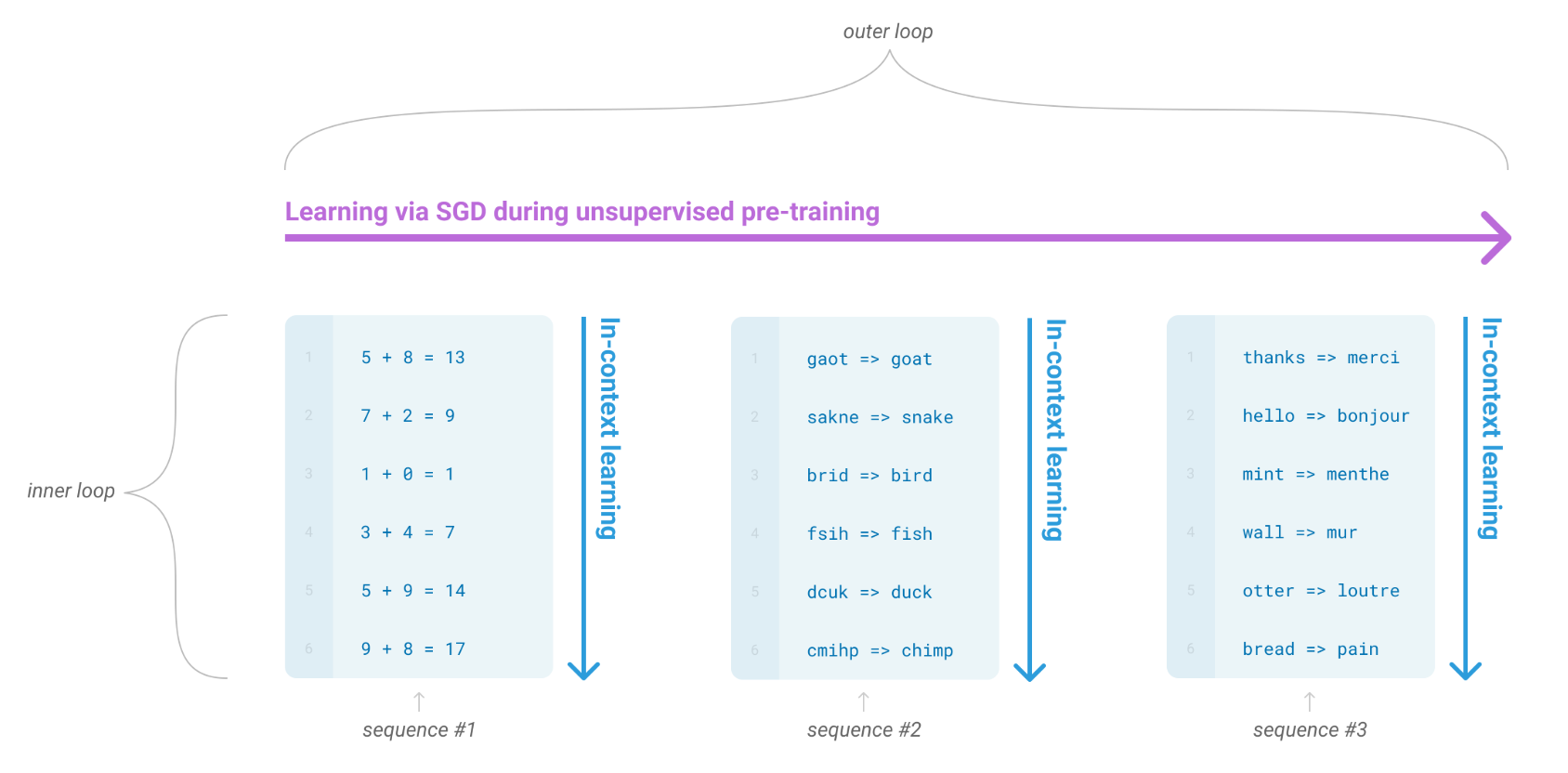
When using few-shot learning in practice, there are two key settings that we must tune properly:
The number of exemplars to use.
The strategy for selecting exemplars.
To determine the correct number of exemplars to use, we can perform some basic hyperparameter tuning using an evaluation set. Many papers have explored strategies for exemplar selection (e.g., based on random selection, diversity, semantic similarity, active learning, or more complex metrics)2. However, random selection of exemplars is oftentimes an effective strategy in practice. Beyond these strategies, there are a variety of practical rules and findings relevant to few-shot learning that we should always keep in mind [4, 5]:
The distribution of labels—even if they are incorrect—for exemplars can impact the model’s answer, as the model is biased towards common labels.
The answer is biased towards recently-observed exemplars in the prompt3.
The formatting of exemplars in the prompt is important.
Selecting exemplars randomly can help to remove bias (e.g., position or majority label bias) within the model’s generated answer.
Despite its simplicity, few-shot learning is one of the most effective prompting strategies and is widely-used within practical applications.

Instruction prompting is a more direct method of expressing the LLM’s desired output. With few-shot learning, we explain our intent to the model via concrete exemplars of a task being solved, but these exemplars consume a lot of tokens! Simply explaining our intent to the model in words would be much more efficient. For this to work well, the LLM being used must be aligned to consistently follow instructions. Such models are said to be “steerable” because they understand detailed instructions provided and can adjust their output accordingly.

Research on LLMs has heavily focused upon improving instruction following capabilities. Pre-trained LLMs are not good at following instructions out-of-the-box. As shown by InstructGPT [6], however, we can align models to be much better at following instructions via a combination of supervised finetuning (SFT) and reinforcement learning from human feedback (RLHF). We see in the figure above that this strategy can improve instruction following, as well as other key properties of the LLM (e.g., factuality and constraint following).

Given recent advancements in LLM alignment, instruction prompting—which can even be combined with few-shot prompting [7]—is a highly effective approach that is commonly used in practical applications. In fact, several popular prompting strategies (e.g., role prompting, specifying an audience, or tool usage to name a few) are just more specific versions of instruction prompting! When writing instructions, we should be clear and precise to ensure the best possible results.
Advanced Prompting Strategies
Although the prompting techniques outlined above are highly effective, sometimes more complex prompts can be useful for solving difficult problems (e.g., math/coding or multi-step reasoning problems). Because LLMs naturally struggle with these problems4 (i.e., reasoning capabilities do not improve monotonically with model scale [9]), a majority of existing research on prompt engineering is focused upon improving reasoning and complex problem solving capabilities—simple prompts will work for solving most other problems.

Chain of Thought (CoT) prompting [10] elicits reasoning capabilities in LLMs by inserting a chain of thought (i.e., a series of intermediate reasoning steps) into exemplars within a model’s prompt; see above. By augmenting each exemplar with a chain of thought, the model learns (via in-context learning) to generate a similar chain of thought prior to outputting the final answer for the problem in question. Interestingly, we see in [10] that sufficiently large models (i.e., >100B parameters) benefit heavily from this approach on arithmetic, commonsense and symbolic reasoning tasks—explicitly explaining the underlying reasoning process for solving a problem actually makes the model more effective at reasoning.

The implementation of CoT prompting is simple. Instead of each few-shot exemplar having only an input and output, exemplars are triplets of the form (input, chain of thought, output); see above. The major downside of this approach is that we must manually (or synthetically) curate exemplars that include a full rationale for the solution to a problem, which can be expensive and/or time consuming. As such, many papers focus upon eliminating the dependence of CoT prompting upon human-written rationales!

CoT variants. Due to the effectiveness and popularity of CoT prompting, numerous extensions of this approach have been proposed. For example, zero-shot CoT [11] prompting eliminates few-shot exemplars and instead encourages the model to generate a problem-solving rationale by appending the words “Let’s think step by step.” to the end of the prompt. We can also improve the robustness of the reasoning process by i) independently generating multiple chains of thought when solving a problem and ii) taking a majority vote of the final answers produced with each chain of thought5. Despite increasing the cost of solving a problem, this approach, called self-consistency [12], improves the reliability of LLMs when solving more complex classes of reasoning problems.

Least-to-most prompting [13] goes beyond CoT prompting by explicitly breaking down a complex problem into multiple parts; see above. Each sub-problem is solved individually, and the solution to each sub-problem is passed as context for solving the next sub-problem. Once we have reached the final sub-problem, we can use the context of prior solutions to output a final answer to the question.
“It is perhaps surprising that underlying all this progress [for LLMs] is still the original autoregressive mechanism for generating text, which makes token-level decisions one by one and in a left-to-right fashion.” - from [14]
Tree of thoughts (ToT) prompting [14]. Techniques like CoT prompting follow a left-to-right generation approach that uses next-token prediction to output a solution in a single attempt. Such an approach, although effective in certain scenarios, may fail to solve complex problems that can benefit from extensive planning, strategic lookahead, backtracking, and exploration of numerous viable solutions in parallel. This is where ToT prompting comes in! ToT prompting—somewhat similarly to least-to-most prompting [13]—breaks a complex problem into a series of simpler problems (or “thoughts”) that can be solved individually.
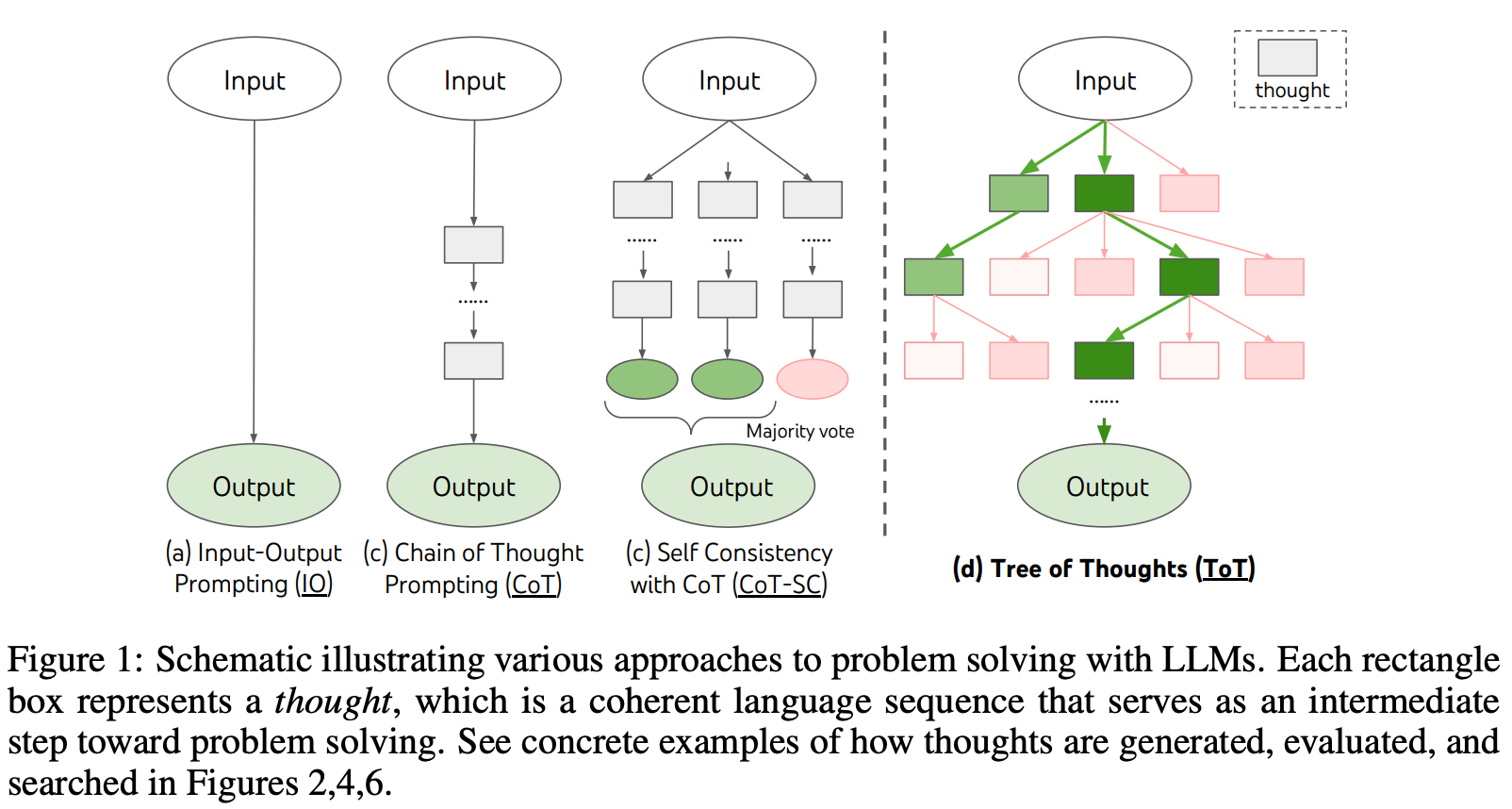
Unlike CoT prompting, ToT prompting does not require that we follow a single path of thoughts when solving a problem. Additionally, ToT prompting does not simply take a majority vote of multiple reasoning paths like self-consistency; see above. During exploration, the LLM generates many thoughts and continually evaluates its progress toward a final solution via natural language (i.e., we just prompt the model!). By leveraging the model’s self-evaluation of its own progress towards a final solution, we can power the exploration process with widely-used search algorithms (e.g., breadth-first search or depth-first search), allowing lookahead and backtracking to be performed within the problem-solving process. Check out this overview for a more detailed explanation of ToT prompting.

Graph of Thoughts (GoT) prompting [35, 36]. Later work generalized research on ToT prompting to graph-based strategies for reasoning. Overall, these techniques are similar to ToT prompting, but they make no assumption that the path of thoughts used to generate a final solution is linear. Rather, we can re-use thoughts or even recurse through a sequence of several thoughts when deriving a solution; see above. Multiple graph-based prompting strategies have been proposed (see here for more details) [35, 36]. However, these prompting techniques—as well as ToT prompting—have been criticized for their lack of practicality. Namely, solving a reasoning problem with GoT prompting could potentially require a massive number of inference steps from the LLM!

Retrieval Augmented Generation (RAG) [37] (shown above), though not purely a prompting technique, is a widely used strategy that improves the quality of an LLM’s output by retrieving relevant context to include in the prompt. To retrieve useful context, we can use just use existing search techniques; e.g., pure vector search or a hybrid search engine. Despite its simplicity, research has shown that RAG is incredibly effective at injecting knowledge into an LLM and reducing the number of hallucinations generated by the model [38]. Plus, we can easily provide citations to users of the LLM by simply exposing the relevant documents being retrieved by RAG. However, the manner in which we process and retrieve data, as well as how we structure the context that is inserted into the prompt, can have a significant impact upon performance; see here for more details.

Generated knowledge prompting [39] is an interesting alternative to RAG that uses an LLM to generate relevant context to include in the prompt instead of retrieving this context from an external database; see above. Despite being very simple and having positive performance indications, this approach (obviously) lacks in reliability due to the tendency of LLMs to hallucinate information.
Recent Directions of Research
Although we have covered a variety of prompting techniques so far, many papers have been published recently that both expand upon these methods and explore completely new styles of prompts for solving complex problems. Here, we have separated this work into several categories based upon the topic or focus:
Reasoning
Tool Usage
Program-Aided Language Models
Context Windows
Writing
Miscellaneous (other notable papers)
For each category, a variety of different works are covered. Given the massive amount of research that has been published on the topic of prompt engineering, however, there’s a good chance that several papers were missed. If you know of a good paper that should be included, please share it in the comments!
Improving Reasoning Capabilities

Auto-CoT [15]. CoT prompting uses intermediate reasoning steps to solve complex problems, and there are two ways we can elicit these reasoning steps within an LLM’s output (depicted above):
Zero-shot: prompt the LLM to “think step-by-step”.
Manual: provide several few-shot examples of questions, rationales, and answers prior to answering the desired question.
Although LLMs are decent zero-shot reasoners, providing concrete exemplars consistently yields better performance with CoT prompting. However, this strategy also requires human annotators—or the prompt engineer—to craft manual demonstrations of rationales used to answer each question. Crafting these manual demonstrations is time consuming, but it can be avoided!
“We show that such manual efforts may be eliminated by leveraging LLMs with the Let’s think step by step prompt to generate reasoning chains for demonstrations one by one.” - from [15]
In [15], authors propose an automatic CoT (Auto-CoT) prompting approach that uses zero-shot CoT prompting to automatically generate examples for manual CoT prompting, thus eliminating the need to manually craft problem-solving rationales. However, because these automatically-generated rationales are incorrect in some cases, a few tricks are required for Auto-CoT to work well.
Given a question as input, a naive approach would be to i) retrieve a set of similar questions (e.g., using an embedding model like sBERT and vector search), ii) generate rationales/answers for each of these questions with zero-shot CoT prompting, and iii) perform manual CoT prompting with the automatically-generated demonstrations. However, this approach works quite poorly, which authors in [1] claim is due to mistakes in the LLM-generated rationales. To solve this, we simply need to ensure the generated rationales are sufficiently diverse.

Given a dataset of questions that should be answered by the LLM, authors in [15] devise a two-part strategy (shown above) for selecting/generating demonstrations used within the prompt for Auto-CoT:
Divides the questions into
kclusters using question embeddings from sBERT and k-means clustering.Selects a representative question from each cluster and generates an associated rationale for each question using zero-shot CoT.
Such an approach ensures that the diversity of demonstrations used for Auto-CoT is high, which reduces the correlation between mistakes made by the model across synthetic rationales. In experiments with GPT-3, Auto-CoT consistently matches or exceeds the performance of few-shot CoT prompting, which requires the manual creation of demonstrations, on over ten different benchmarks.

Complexity-Based Prompting [16]. Given that CoT prompting relies upon selecting demonstrations of problem-solving rationales to include in the prompt, we might wonder: How do we best select these demonstrations? In [16], authors show that selecting demonstrations based on their complexity is a good heuristic. We can measure the complexity of a demonstration by simply counting the number of steps present within the chain of thought, where individual steps are separated by newline characters (\n). The complexity-based prompting approach proposed in [16] advocates sampling demonstrations with the highest complexity.
“The reasoning performance of GPT-3 175B clearly improves with the increased input prompt complexity.” - from [16]
Interestingly, authors in [16] discover that including demonstrations with more reasoning steps in the CoT prompt substantially improves performance on multi-step reasoning tasks. Going further, one can extend this strategy to the output space by using a self-consistency approach that takes a majority vote over k generated outputs with the highest complexity. Compared to alternative selection schemes like manual tuning and retrieval-based selection, complexity-based prompting performs favorably, achieving state-of-the-art performance on several datasets (i.e., GSM8K, MultiArith, and MathQA) with GPT-3 and Codex.

Progressive-Hint Prompting (PHP) [17]. One downside of CoT prompting is that it solves a problem in a single shot. Given a question as input, we generate a rationale and answer, but the LLM does not get a chance to consider or revise this answer. One can achieve better performance by repeating this process multiple times and taking a majority vote—this is just self-consistency—but none of these generations consider the LLM’s prior outputs to better inform the answer.
“PHP follows a human-like thought process where previous answers are leveraged as hints to arrive at the correct answer after re-evaluating the question.” - from [17]
To solve this issue, authors in [17] propose PHP to leverage prior outputs of the LLM to iteratively refine the generated rationale. Intuitively, the LLM can use rationales previously generated by the model as hints towards discovering the correct answer. Concretely, PHP proceeds in three steps:
Given a question, prompt the LLM to provide a base answer.
Concatenate the question and base answer, then prompt the LLM to generate a revised answer based on this input.
Repeat step two until the LLM’s answer is stable for at least two iterations.
Such an approach allows the LLM to iteratively refine its answer over several passes, using its prior output as context during the process. Additionally, PHP is fully compatible with CoT prompting and self-consistency—we can combine these techniques to further improve performance. In experiments, PHP improves the performance of GPT-3.5 in comparison to a complexity-based prompting strategy, and using PHP with GPT-4 yields state-of-the-art performance on several notable datasets (e.g., SVAMP, GSM8K, AQuA, and MATH).
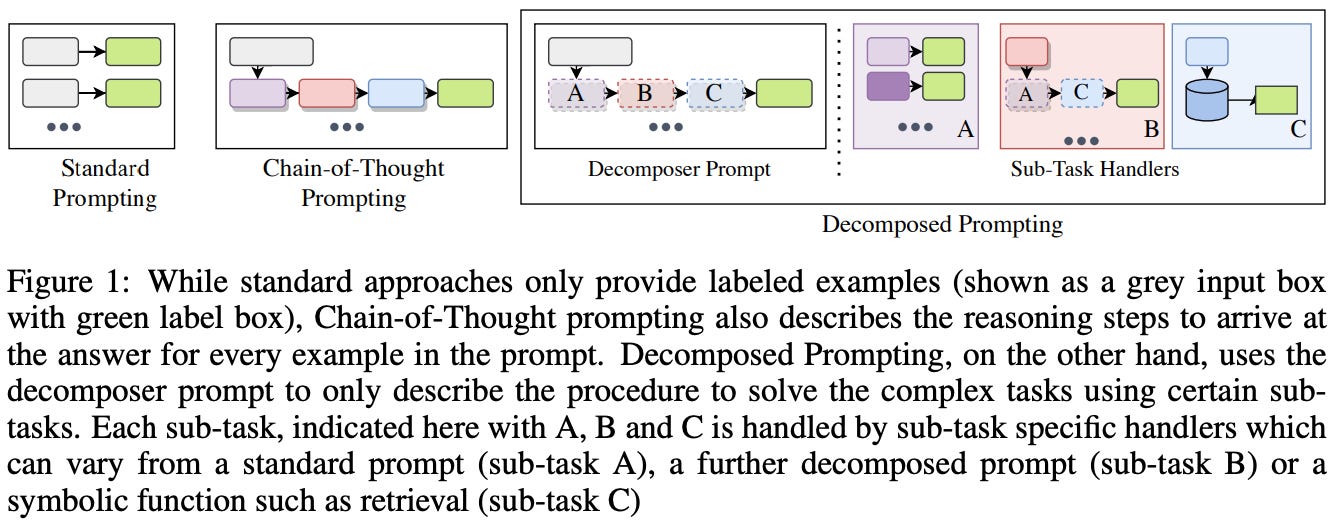
Decomposed Prompting (DecomP) [18] tries to address the difficulty of solving multi-step reasoning problems with complex steps via prompting. As tasks become more complex, few-shot prompting (i.e., showing a few examples of a correct solution) will fall short. However, we can do better by decomposing complex tasks into sub-tasks that can be solved independently via prompting. In particular, authors in [18] propose a prompting framework with two components:
Decomposer: prompts an LLM to decompose a problem into a series of simpler sub-tasks.
Sub-task handlers: uses a separate prompt to solve a simpler sub-task (as dictated by the decomposer) with an LLM.
The decomposer and sub-task handlers are just LLMs prompted in a few-shot manner. The DecomP strategy proposed above uses one prompt to identify solvable sub-tasks that are then delegated to another system (e.g., a new prompt, different LLM, or tool) to be solved. Such a modular approach has many benefits:
Tasks with long context can be decomposed into multiple components.
Each sub-task can be shown a broader set of examples.
Complex sub-tasks can be further decomposed into sub-tasks if needed.
Instead of solving all sub-tasks with an LLM, we can also use other symbolic systems (e.g., a task-specific model, retrieval mechanism, etc.).
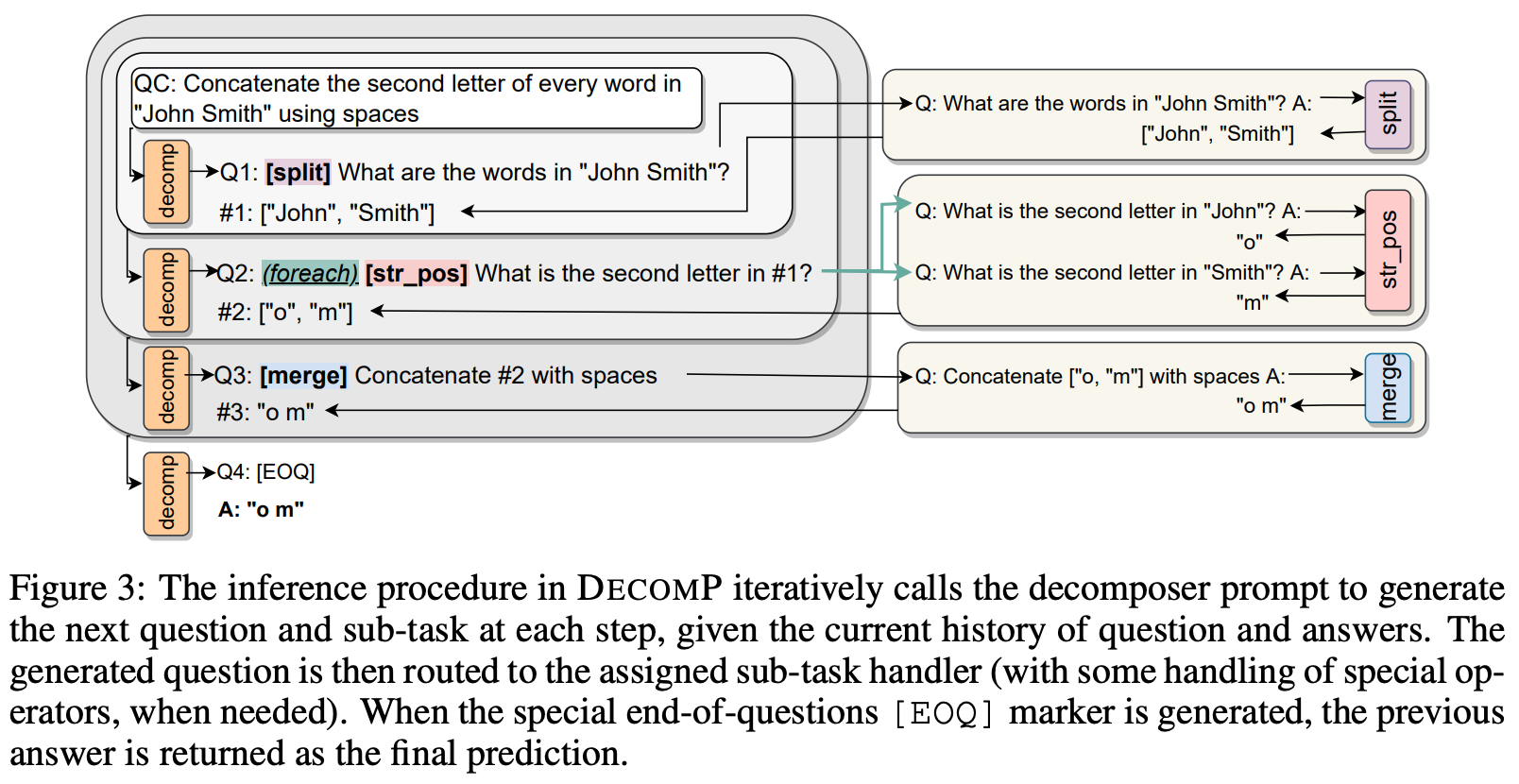
Let’s consider a simple task as an example. Given a set of words as input, we want to extract the third character of each word, concatenate these characters, and provide their concatenation as output. To do this, we can create a sequence of three sub-tasks: i) collect the list of words, ii) extract the third letter of each word, and iii) concatenate the extracted letters. We can implement each of these sub-tasks with a separate few-shot prompt, as shown in the figure below.

Within Decomp, sub-tasks are iteratively generated by the decomposer, solved, and returned (with relevant output) to the decomposer to generate the next sub-task. The decomposer will continue to generate sub-tasks, acting as a controller for the reasoning process, until the end-of-question [EOQ] marker is generated, signifying that the final answer has been produced; see below. Overall, DecomP can be thought of as a more general/flexible version of least-to-most prompting.
Hypotheses-to-Theories [29]. Reasoning abilities can be elicited within LLMs by prompting the model with example rationales that decompose a complex task into simple steps. However, the model may hallucinate when producing output and performance is poor on tasks that go beyond conventional or common knowledge. Put simply, problems occur when there is a mismatch between the LLM’s knowledge base and the knowledge required to solve a task. To solve this problem, we need a prompting approach that empowers the LLM to discover and apply necessary knowledge when solving complex reasoning problems.
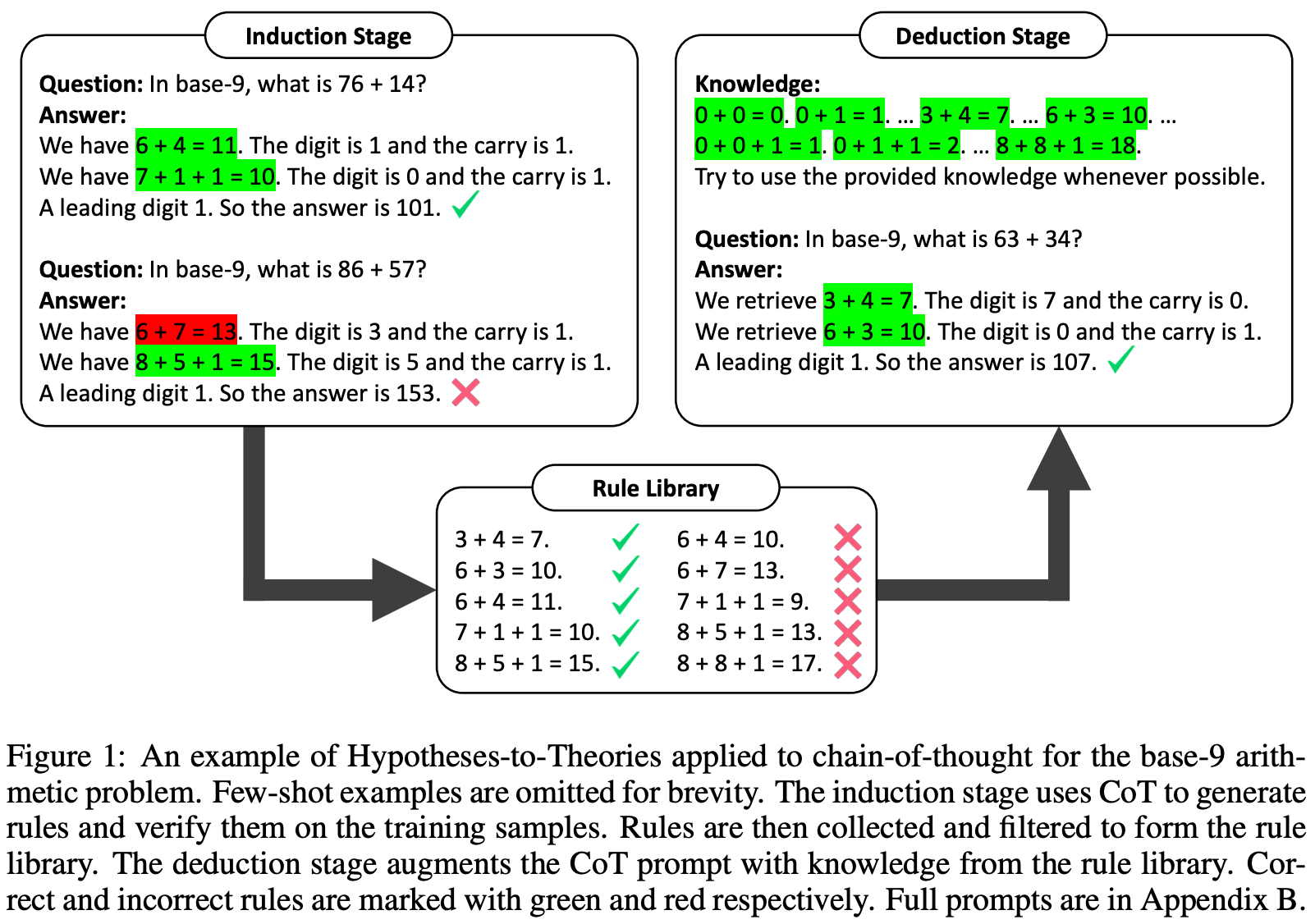
Inspired by the scientific discovery process of humans, authors in [29] propose a prompting technique, called Hypotheses-to-Theories (HtT) prompting, that follows a strategy of freely proposing (potentially incorrect) hypotheses, only keeping those that can be verified empirically, and using these verified hypothesis to solve a problem. At a high level, the goal of this strategy is to learn a rule library for the LLM that can be used for problem solving. More concretely, HtT prompting (depicted above) is comprised of two steps:
Induction: The LLM is asked to generate and verify rules over a set of training examples. Rules that appear often and frequently produce a correct answer are collected to form a rule library.
Deduction: the LLM is prompted to use the rule set generated via induction to perform reasoning and answer a question.
By using a rule set during reasoning, HtT prompting reduces the probability of hallucinations. Such a finding is verified across both numerical and relational reasoning tasks, where HtT prompting is shown to provide a 11-27% absolute improvement in accuracy compared to prior prompting techniques (e.g., CoT prompting). Interestingly, the rules generated by HtT prompting are also interpretable and even transferable to different (but similar) problems.
Tool Usage
Although LLMs are powerful, they have notable limitations! For example, LLMs make arithmetic mistakes, lack access to current information, and even struggle to comprehend the progression of time. Many advancements in the human race have been catalyzed by access to new and innovative tools (e.g., the printing press or computer), and the same may be true of LLMs. Namely, we can solve many limitations of these models by giving them access to a set of external, specialized tools (e.g., a calculator or search engine) and teaching the model when, where, and how to properly invoke these tools to more reliably solve problems. For more info, check out the prior overviews on this topic below:
Teaching Language Models to Use Tools [link]
Language Models and Friends [link]
Can language models make their own tools? [link]

Toolformer [32] was one of the first works to explore the integration of LLMs with external tools. These tools are made available to the model via a simple, fixed set of text-to-text APIs; see above. To use the tools, the LLM must learn to i) identify scenarios that require a tool, ii) specify which tool to use, iii) provide relevant textual input to the tool’s API, and iv) use text returned from the API to craft a response. The LLM is taught these skills by constructing a synthetic training dataset that starts with an initial seed dataset and uses a more powerful LLM (e.g., GPT-4) to add examples of valid API calls into the data; see below.

From here, we can simply finetune an LLM over this data. The model will learn to generate and process calls to necessary APIs directly within the textual sequence that it generates. In this case, handling API calls in an inline manner is simple because we only consider APIs with textual input and output; see below.

“LLMs face inherent limitations, such as an inability to access up-to-date information or perform precise mathematical reasoning … enhancing current LLMs with the capability to automatically compose external tools for real-world task solving is critical to address these drawbacks.” - from [19]
Chameleon [19] aims to mitigate the limitations of LLMs referenced above. Interestingly, some of these limitations are not addressed by existing work on integrating LLMs with external tools, as the set of tools used is typically fixed (or domain-specific) and cannot always generalize to new domains. To create a more generic framework, Chameleon uses a “plug-and-play” strategy that uses a central LLM-based controller to generate a program—written in natural language—that composes several tools to solve a complex reasoning task; see below. Unlike prior work, the tools available to Chameleon are quite comprehensive; e.g., LLMs, off-the-shelf vision models, web search engines, Python functions, and more.

The Chameleon framework has two primary components:
Planner: decomposes the input query into sub-tasks that can be solved via available tools.
Module inventory: a set of task-specific tools (along with descriptions and usage examples) that are available for Chameleon to use.
The planner, which is implemented with an LLM, uses natural language to generate calls to external tools (e.g., image_captioner or query_generator). We can identify these tools via simple string matching, and the sequence of tools outputted by the planner forms a natural language program that can be executed by calling each of the corresponding task-specific modules. Examples of prompts used for the planner and a task-specific module are shown below.

To teach the controller when to use certain tools, we include tool descriptions and usage examples within a few-shot prompt, which can easily be extended to new tools and modules. Because we leverage the planner’s in-context learning abilities to generate a solution, no training or curated rules are required to solve real-world queries. Rather, we simply provide examples of available tools to the LLM, which can then use this information to infer a sequence of tools that can be executed to yield the correct final response to a query. Going further, this tool sequence is human readable and can be easily debugged by a human user.
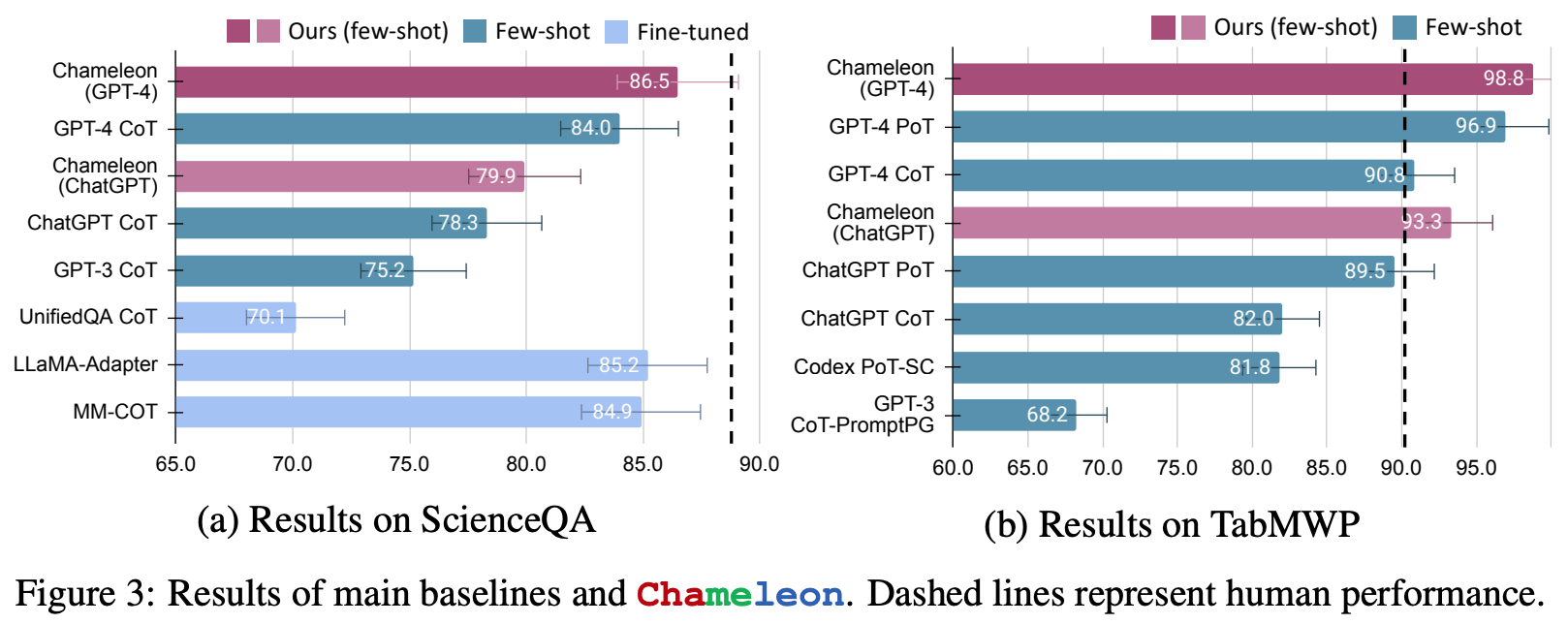
In experiments, Chameleon is applied to two complex, multi-modal (i.e., meaning that both text and images are involved) reasoning tasks with GPT-4: ScienceQA and TabMWP. Chameleon achieves new state-of-the-art performance of 86.54% on ScienceQA, outperforming CoT prompting with GPT-4 and GPT-3 by 2.55% and 11.37%, respectively. On TabMWP, we see a similar improvement with Chameleon, which achieves an accuracy of 98.78%. However, it should be noted that Chameleon’s effectiveness is powered by GPT-4’s ability to infer constraints and construct rational/consistent plans for solving complex reasoning problems.
“We propose a simple yet effective method, called GPT4Tools, designed to empower open-source LLMs with the ability to use tools via self-instruct from advanced LLMs” - from [20]
GPT4Tools [20]. Although a variety of papers have demonstrated the ability of LLMs to leverage tools in a few-shot manner, most of these papers are dependent upon proprietary language models and purely leverage prompt engineering to facilitate tool usage, leading us to wonder if similar results could be replicated with open LLMs. In [20], authors propose an approach that uses self-instruct [21] to generate a finetuning dataset that can be used to enable open-source LLMs (e.g., LLaMA and OPT) to use a set of multimodal tools.

First, authors use a self-instruct approach to generate a tool usage dataset by prompting a powerful teacher model (i.e., ChatGPT) to create examples of relevant tools being used. Within the prompts, both visual content—captions and bounding boxes extracted from an image—and tool descriptions are included. The teacher leverages this information to generate tool-related instructions that can be used to process multimodal information and solve problems; see above.

Once the dataset is generated, Low-Rank Adaptation (LoRA) can be used to easily finetune an open-source LLM to solve a range of visual problems with the help of multimodal tools. In [20], this approach is shown to improve accuracy of calls that are made by the LLM to known tools (i.e., those included in the finetuning dataset), as well as improve the model’s ability to generalize to new tools in a zero-shot manner. A direct comparison of GPT4Tools to prior work on integrating LLMs with external tools is provided within the table above.

Gorilla [30]. Although many works have studied integrating LLMs with a fixed set of tools, authors in [30] tackle the broader goal of teaching an LLM to use any model API that is available online. To do this, a retrieval technique is adopted that i) searches for model APIs that are relevant to solving a problem and ii) adds the documentation for these APIs into the model’s context. Such an approach allows the LLM to access a massive number of changing tools, but hallucination (e.g., incorrect arguments or calls to a non-existent API) may still occur; see above.

To solve this issue, authors in [30] construct a dataset with examples of using over 1,600 different model APIs using self-instruct [21]. Within each example, both the prompt and relevant documentation are used as context to generate an output. In other words, this is a retrieval-aware finetuning process (similar to RAFT); see above. The resulting model, called Gorilla (a finetuned version of LLaMA-7B), is an interface for leveraging a variety of different deep learning model APIs to solve problems. The resulting LLM can use a massive number of APIs and can even adapt to changes in the documentation for any of these APIs!

HuggingGPT [31] is pretty similar to Gorilla in that it explores the integration of LLMs with specialized deep learning models (e.g., for image recognition, video detection, text classification, and much more) via a tool usage approach. The LLM serves as the “brain” of a problem solving system, which plans how to solve a problem and coordinates efforts between different deep learning models that solve necessary subtasks for this problem. Unlike Gorilla, however, HuggingGPT does not perform any finetuning. Problem solving is decomposed into four steps:
Task planning: use the LLM to decompose a user’s request into solvable tasks.
Model selection: select models from HuggingFace to use for solving tasks.
Task execution: run each selected model and return results to the LLM.
Response generation: use the LLM to generate a final response for the user.
For each of these steps, we leverage prompting with curated instructions and exemplars to yield the desired behavior; see below for example prompts. Given a sufficiently powerful foundation model, such an approach is quite effective.

Program-Aided Language Models
“The computation can be delegated to a program interpreter, which is used to execute the generated program, thus decoupling complex computation from reasoning and language understanding.” - from [41]
Integrating LLMs with external tools is an interesting avenue of research, and one of the most useful tools to which these models can be given access is the ability to write and execute programs. Most prompting techniques solve complex problems in two steps:
Generate a problem-solving rationale.
Use this rationale to actually solve the problem.
In CoT prompting, we rely upon the LLM to solve both of these steps, but these models only excel at solving the first step! In fact, generating an incorrect answer despite outputting a correct rationale is a common failure case for LLMs. To solve this problem, we can teach the model to output a rationale in the form of interleaved language and code (e.g., a Python program with useful comments). Then, we can generate a final answer by simply executing the provided code!

Program-Aided Language Model (PAL) [40] is similar to CoT prompting in that the LLM is tasked with breaking a problem down into a series of intermediate steps to find a solution. However, this rationale contains both natural language and programatic components. We can execute the code from the rationale (using a sandboxed Python environment) to generate a reliable final solution—the process of actually generating the solution is delegated to a code interpreter. In [40], we see that an LLM that has been sufficiently trained on code (e.g., Codex) can be taught to solve problems in this way using a few-shot learning approach.
“This bridges an important gap in chain-of-thought-like methods, where reasoning chains can be correct but produce an incorrect answer.” - from [40]

Program of Thoughts (PoT) prompting [41] is quite similar to PAL in that it i) uses a code-augmented prompting technique and ii) delegates the process of deriving a solution to a code interpreter. This process relies upon a few-shot prompting strategy; see above. Unlike PaL, however, code written by PoT relies upon a symbolic math library called SymPy. This package allows the user to define mathematical “symbols” that can be combined to form complex expressions that are evaluated via SymPy’s solve function; see below.

At a high level, PoT directly addresses the inability of LLMs to solve complex equations by providing access to a symbolic math library that enables such equations to be easily composed/evaluated, whereas PAL is focused upon more generally solving problems via a combination of natural language and code. Check out this related overview for more information on program-aided models.
Understanding and Using the Context Window
Given the recent popularity of RAG and emphasis upon long context windows within state-of-the-art LLMs, understanding how these models process the context provided in their prompts is important. Luckily, recent research has studied the topics of context windows and in-context learning in depth, resulting in several interesting takeaways that are relevant to prompt engineering.
Large Language Models Can Be Easily Distracted by Irrelevant Context [22]. When prompting a language model, we usually include only relevant context and information within the prompt. However, in real-world applications, the model’s prompt usually contains contextually similar information that may or may not be relevant to the particular problem being solved. With this in mind, we might wonder: Does adding irrelevant context to the prompt have negative side effects?

In [22], authors study the distractibility of modern LLMs, finding that the performance of these models can drastically deteriorate when irrelevant context is included in the prompt. To measure LLM distractibility, authors introduce a new Grade-School Math with Irrelevant Context (GSM-IC) dataset, which contains arithmetic reasoning problems with irrelevant information in the problem description; see above. Then, we can measure whether an LLM is distracted by irrelevant context by simply testing if the addition of an irrelevant sentence to the model’s prompt changes the resulting solution to a problem.

This strategy is used to test both Codex and GPT-3.5 with several different prompting techniques (see above for a depiction):
CoT prompting (and zero-shot CoT prompting)
Least-to-most prompting
Prompting with programs
Interestingly, the performance of these models drastically deteriorates when irrelevant information is included in the context. However, the impact of irrelevant context can be mitigated by i) using self-consistency, ii) adding an instruction for the model to ignore irrelevant information, and iii) including few-shot examples that demonstrate solving problems with irrelevant information. LLMs are capable of learning to ignore information via instructions or context.
“We prepend an instruction sentence ‘feel free to ignore irrelevant information in the problem description’ to the exemplars.” - from [22]
Lost in the Middle [23]. Generative LLMs have a text-to-text format, meaning that they take a sequence of text as input (i.e., the prompt) and produce a corresponding sequence of text as output. The input passed to the LLM has a variable length—it can be a short (zero-shot) problem description, or it can be a complex instruction containing large amounts of external context (e.g., for RAG). For this reason, LLMs must be capable of operating over long contexts and using the entirety of this context to effectively solve downstream tasks.
Along these lines, authors in [23] study the ability of several LLMs—both open (MPT) and closed models (GPT-3.5-Turbo and Claude-1.3)—to concretely leverage information provided to them within long contexts. In particular, two types of tasks are studied in [23]:
Multi-document QA: similar to the standard RAG setup, this problem requires the model to reason over several documents to answer a question.
Key-value retrieval: this is a synthetic task that tests the model’s ability to retrieve matching tokens by returning the value associated with a key from a collection of JSON key-value pairs provided as context.
When solving these tasks, authors control both i) the length of the input context (by using more documents or key-value pairs) and ii) the position—beginning, middle, or end—of the relevant context within the input. Then, we can study the impact of changes in context length and position on model performance. In experiments, we see a clear “U-shaped” performance curve (shown below) based on the position of relevant information within the model’s context.
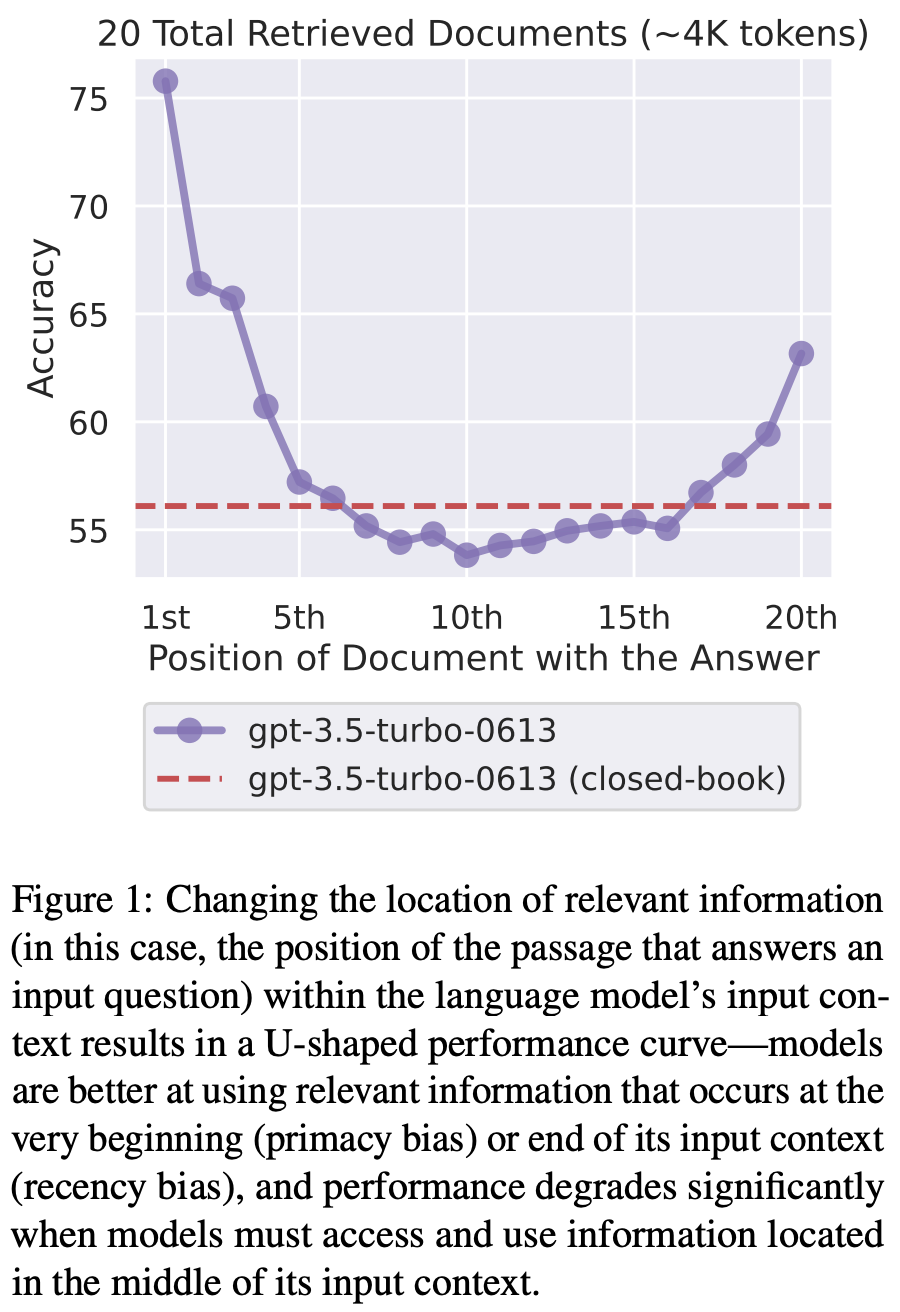
This visualization shows us that LLMs pay the most attention to information at the beginning and end of their context. When relevant information is in the middle of the context, model performance degrades significantly—the information is “lost in the middle”. In fact, GPT-3.5-Turbo performs better without any relevant context on multi-document QA tasks than when relevant documents are placed in the middle of the context. Performance varies a lot as we tweak the position of relevant information, and models with extended contexts do not show signs of improved robustness to these positional biases; see below. However, these issues have been improved in more recent models (e.g., Gemini-1.5 and Claude-3).

Large Language Models Are Latent Variable Models [24]. Although we know that LLMs have in-context learning abilities, it is unclear how these abilities emerge from standard language model pretraining. Additionally, in-context learning is generally sensitive to the choice and format of examples used for few-shot learning. Certain demonstrations are effective examples for the model, while others are not. Currently, there are no standard criteria for choosing the best examples for few-shot learning. In [24], authors study this topic, aiming to find a practical strategy for identifying the best possible few-shot exemplars.
“In-context learning has been demonstrated to be an effective technique for a wide range of NLP tasks. However, it is sensitive to the choice, format, and even the order of the demonstrations used.” - from [24]
Many papers have studied the mechanics of in-context learning from a theoretical perspective, but few of them provide practical or actionable insights. In [24], authors view LLMs in the lens of simple topic / latent variable models that relate the generation of new tokens to prior tokens observed by the language model. The details can be found in the paper, but at a high level this formulation allows us to theoretically describe the language model’s output with respect to the format and task information used within the model’s input prompt.

From this formulation, authors develop a practical technique for selecting the best possible few-shot exemplars that uses a smaller language model to measure the posterior probability of the model’s input—this tells us the likelihood of different input exemplars based upon the model’s input and parameters. We can use exemplars selected with the smaller LLM for in-context learning with a larger model (see above), which is found to yield a practical benefit. Put simply, this paper proposes an interesting (and relatively simple) theoretical view of in-context learning that can be used in practice to select better few-shot exemplars.
Improving Writing Capabilities
“SoT is an initial attempt at data-centric optimization for inference efficiency, and showcases the potential of eliciting high-quality answers by explicitly planning the answer structure in language.” - from [25]
Skeleton-of-Thought (SoT) [25] is a prompting technique that aims to reduces the latency of generating output with an LLM. As we know, generating output with an LLM can be expensive for a few reasons:
The models are large, so compute/memory/IO costs are high.
The attention operation is IO bound and has memory/compute complexity that increases quadratically with sequence length.
The output is generated sequentially one token at at time (i.e., using next token prediction).
In [25], authors try to address the last problem mentioned above—the latency of sequential decoding. Put simply, sequential decoding is a problem because we generate one token at a time and, therefore, cannot parallelize the generation of tokens in the output sequence. For this reason, the cost of generating an output is directly related to the length of the output. It takes much longer to generate an output sequence with many tokens. But, can we avoid fully sequential decoding?
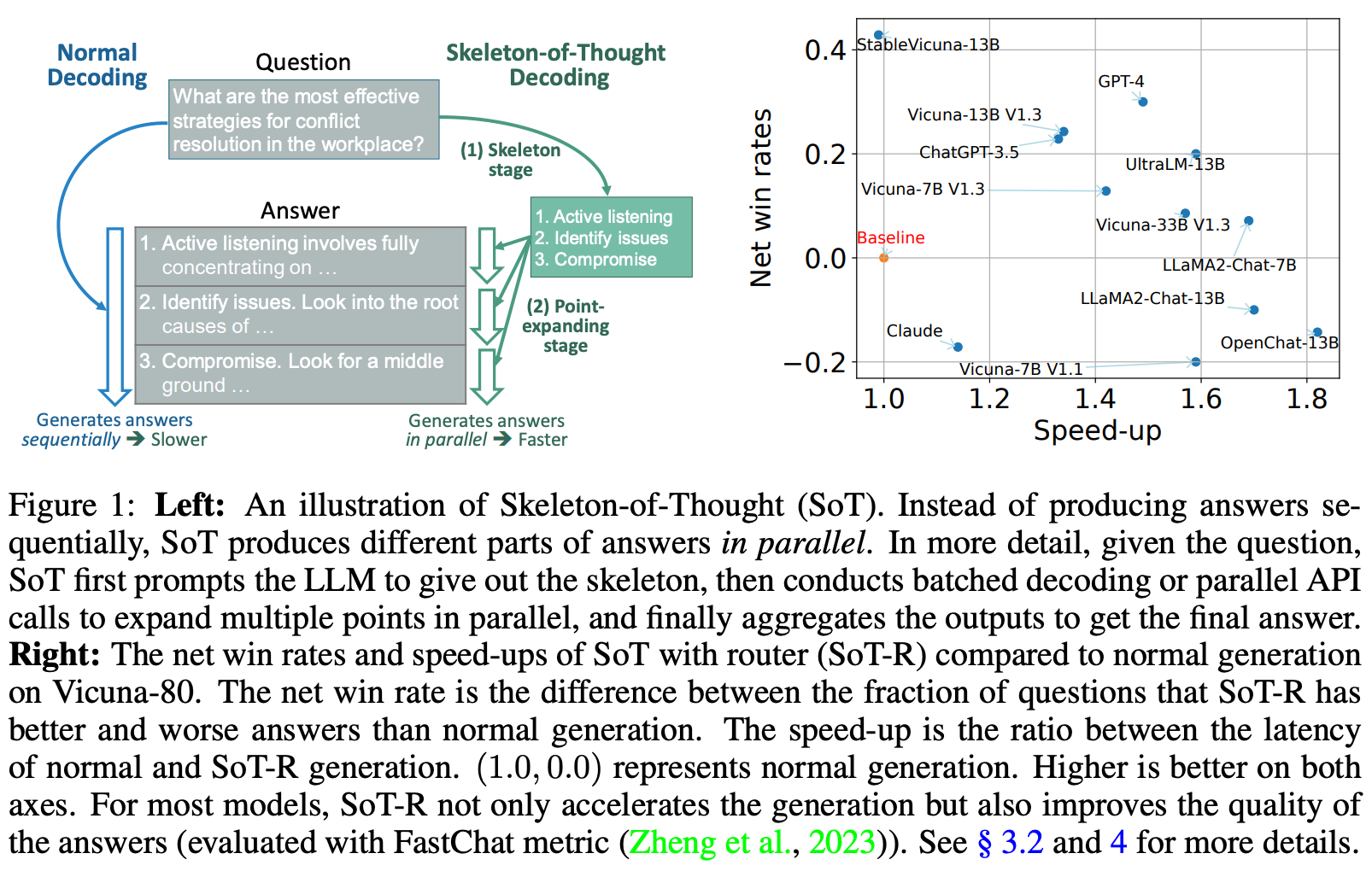
We see in [25] that a more efficient decoding strategy can be devised by mimicking the thinking and writing process of humans without requiring any changes to the model, system, or hardware. In particular, humans tend to plan an outline for what they want to write, then fill in details for each element of their outline. This is not a purely sequential process6! Inspired by this idea, authors in [25] propose Skeleton-of-Thought (SoT) prompting (see above), which has two steps:
Prompt the LLM to generate a skeleton/outline of its answer.
Conduct parallel API calls to fill in the contents of each outline element.
Although this might seem a bit vague, we can see how this works by checking out the SoT prompt shown below. The process is pretty simple—we just generate the skeleton and use a generic prompt template to fill in all of the remaining details.

By generating each element of the skeleton in parallel, we can save a lot on inference latency. For example, the question shown at the beginning of this summary can be answered in 12 seconds (instead of 22 seconds) without making any changes to the underlying model or system—we just use SoT prompting. Similar speedups are observed across 12 different LLMs in [25]. Interestingly, authors also note that creating an outline can oftentimes improve writing quality7.

Directional Stimulus Prompting [27]. Given the computational expense of finetuning, prompting is usually the easiest way to solve a task with an LLM. However, prompting has limitations—guiding the LLM towards generating output with our desired content or style can be difficult. To solve this issue, authors in [27] propose directional stimulus prompting (DSP), which introduces a “directional stimulus” into the LLM’s prompt as shown in the figure above.
This stimulus is just a textual hint or clue that gives the LLM more information about the expected output. The directional stimulus, which is instance-specific and solely based upon the input query, is generated using a smaller model (e.g., T5) that is much easier to train or finetune relative to the LLM. By doing this, we can circumvent the difficulty of directly training the LLM, choosing instead to finetune the model used to generate the directional stimulus8. DSP is evaluated on summarization, dialogue, and reasoning tasks, where it is found to improve model performance while requiring minimal labeled data.

Chain of Density Prompting [28]. Recent developments in LLMs have revolutionized the problem of automatic summarization, as we can simply prompt an LLM to generate a high-quality summary instead of performing finetuning over labeled data. When automatically generating a summary, one important aspect of the resulting summary’s quality is information density. We want the summary to present all relevant information in a concise manner, but we want to avoid writing summaries that are overly dense or illegible.
To study this tradeoff in information density, authors in [28] propose chain of density (CoD) prompting, which starts by generating a summary via a vanilla prompt to GPT-4. From here, CoD prompting is used to iteratively add additional entities into the summary while keeping the length of the summary fixed, thus increasing the summary’s information density. Interestingly, we see in [28] that humans prefer summaries that are almost as dense as human-written summaries, but more dense than those generated by a vanilla prompt to GPT-4. By using CoD prompting, we can explore this tradeoff and generate higher-quality summaries.
“Summaries generated by CoD are more abstractive, exhibit more fusion, and have less of a lead bias than GPT-4 summaries generated by a vanilla prompt.” - from [28]
Other Notable Papers
Active Prompting [26] tackles the difficulty of selecting (and annotating) exemplars for CoT prompting by providing a technique—based upon work in uncertainty-based active learning—for identifying the most helpful exemplars to select (and annotate) for solving a particular reasoning problem.
TaskMatrix [33] is a position paper—meaning that it presents a position or outlook on a notable issue—that considers the integration of foundation models with millions of different APIs.
Set of Marks Prompting [42] is a visual prompting method that employs pretrained segmentation models to partition an image into regions and overlay these regions with a set of marks (i.e., alphanumerics, masks, boxes, etc.) to improve the visual grounding of models like GPT-4V.
Multimodal CoT Prompting [43] extends CoT prompting to inputs that include both images and text by treating rationale and answer generation as two distinct steps in the problem solving process.
The topic of automatic prompting (i.e., generating better prompts via an optimization process) is not explored in this post.
Anything else? Please let me know in the comments!
Conclusion
Within this overview, we have learned about everything from the basics of prompt engineering to cutting-edge techniques that have been proposed in the last two months! This post contains a massive amount of information, but many of the techniques we have seen are slight variations that leverage the same core prompt components: instructions, exemplars, context, and problem-solving rationales. Plus, we should recall the prompt engineering strategy proposed at the outset:
Start by creating a comprehensive evaluation strategy that allows you to easily and quantitatively measure the quality of a prompt.
The first prompt you write should be simple (e.g., an instruction prompt).
As you make the prompt more complex, make sure that the added complexity results in a corresponding performance improvement.
Continue iterating on the prompt until the desired performance is reached.
Many problems can be solved via simple instruction and few-shot prompts. For complex reasoning problems, it may be necessary to use a more advanced strategy like CoT prompting with self-consistency. Additionally, we have seen a variety of prompting strategies that are useful for specific problem domains (e.g., PoT prompting for math problems or CoD prompting for summarization). Although being aware of these techniques is useful, their use cases are relatively rare, and we should only use them if we see a clear and measurable performance impact.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, and this is the Deep (Learning) Focus newsletter, where I help readers understand AI research. If you like the newsletter, please subscribe, share it, or follow me on X and LinkedIn!
Bibliography
[1] Saravia, Elvis, et al. “Prompt Engineering Guide”, https://github.com/dair-ai/Prompt-Engineering-Guide (2022).
[2] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[3] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[4] Work, What Makes In-Context Learning. "Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?."
[5] Zhao, Zihao, et al. "Calibrate before use: Improving few-shot performance of language models." International conference on machine learning. PMLR, 2021.
[6] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744.
[7] Ye, Seonghyeon, et al. "Investigating the effectiveness of task-agnostic prefix prompt for instruction following." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. No. 17. 2024.
[8] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
[9] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[10] Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models." Advances in neural information processing systems 35 (2022): 24824-24837.
[11] Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." arXiv preprint arXiv:2205.11916 (2022).
[12] Wang, Xuezhi, et al. "Self-consistency improves chain of thought reasoning in language models." arXiv preprint arXiv:2203.11171 (2022).
[13] Zhou, Denny, et al. "Least-to-most prompting enables complex reasoning in large language models." arXiv preprint arXiv:2205.10625 (2022).
[14] Yao, Shunyu, et al. "Tree of thoughts: Deliberate problem solving with large language models." arXiv preprint arXiv:2305.10601 (2023).
[15] Zhang, Zhuosheng, et al. "Automatic chain of thought prompting in large language models." arXiv preprint arXiv:2210.03493 (2022).
[16] Fu, Yao, et al. "Complexity-based prompting for multi-step reasoning." The Eleventh International Conference on Learning Representations. 2022.
[17] Zheng, Chuanyang, et al. "Progressive-hint prompting improves reasoning in large language models." arXiv preprint arXiv:2304.09797 (2023).
[18] Khot, Tushar, et al. "Decomposed prompting: A modular approach for solving complex tasks." arXiv preprint arXiv:2210.02406 (2022).
[19] Lu, Pan, et al. "Chameleon: Plug-and-play compositional reasoning with large language models." Advances in Neural Information Processing Systems 36 (2024).
[20] Yang, Rui, et al. "Gpt4tools: Teaching large language model to use tools via self-instruction." Advances in Neural Information Processing Systems 36 (2024).
[21] Wang, Yizhong, et al. "Self-instruct: Aligning language models with self-generated instructions." arXiv preprint arXiv:2212.10560 (2022).
[22] Shi, Freda, et al. "Large language models can be easily distracted by irrelevant context." International Conference on Machine Learning. PMLR, 2023.
[23] Liu, Nelson F., et al. "Lost in the middle: How language models use long contexts." Transactions of the Association for Computational Linguistics 12 (2024): 157-173.
[24] Wang, Xinyi, et al. "Large language models are latent variable models: Explaining and finding good demonstrations for in-context learning." Advances in Neural Information Processing Systems 36 (2024).
[25] Ning, Xuefei, et al. "Skeleton-of-thought: Large language models can do parallel decoding." arXiv preprint arXiv:2307.15337 (2023).
[26] Diao, Shizhe, et al. "Active prompting with chain-of-thought for large language models." arXiv preprint arXiv:2302.12246 (2023).
[27] Li, Zekun, et al. "Guiding large language models via directional stimulus prompting." Advances in Neural Information Processing Systems 36 (2024).
[28] Adams, Griffin, et al. "From sparse to dense: GPT-4 summarization with chain of density prompting." arXiv preprint arXiv:2309.04269 (2023).
[29] Zhu, Zhaocheng, et al. "Large language models can learn rules." arXiv preprint arXiv:2310.07064 (2023).
[30] Patil, Shishir G., et al. "Gorilla: Large language model connected with massive apis." arXiv preprint arXiv:2305.15334 (2023).
[31] Shen, Yongliang, et al. "Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface." arXiv preprint arXiv:2303.17580 (2023).
[32] Schick, Timo, et al. "Toolformer: Language models can teach themselves to use tools." arXiv preprint arXiv:2302.04761 (2023).
[33] Liang, Yaobo, et al. "Taskmatrix. ai: Completing tasks by connecting foundation models with millions of apis." arXiv preprint arXiv:2303.16434 (2023).
[34] Chen, Shouyuan, et al. "Extending context window of large language models via positional interpolation." arXiv preprint arXiv:2306.15595 (2023).
[35] Besta, Maciej, et al. "Graph of Thoughts: Solving Elaborate Problems with Large Language Models." arXiv preprint arXiv:2308.09687 (2023).
[36] Yao, Yao, Zuchao Li, and Hai Zhao. "Beyond Chain-of-Thought, Effective Graph-of-Thought Reasoning in Large Language Models." arXiv preprint arXiv:2305.16582 (2023).
[37] Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
[38] Ovadia, Oded, et al. "Fine-tuning or retrieval? comparing knowledge injection in llms." arXiv preprint arXiv:2312.05934 (2023).
[39] Liu, Jiacheng, et al. "Generated knowledge prompting for commonsense reasoning." arXiv preprint arXiv:2110.08387 (2021).
[40] Gao, Luyu, et al. "PAL: Program-aided Language Models." arXiv preprint arXiv:2211.10435 (2022).
[41] Chen, Wenhu, et al. "Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks." arXiv preprint arXiv:2211.12588 (2022).
[42] Yang, Jianwei, et al. "Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v." arXiv preprint arXiv:2310.11441 (2023).
[43] Zhang, Zhuosheng, et al. "Multimodal chain-of-thought reasoning in language models." arXiv preprint arXiv:2302.00923 (2023).
Remember, longer prompts are always more expensive! When using an API, you pay for these tokens directly. For open-source models, you pay for the extra tokens in extra compute and latency costs.
For a great overview of these techniques (as well as more prompting techniques and a variety of other awesome topics), check out Lillian Weng’s blog!
To eliminate this issue, we can randomly order or even permute the exemplars within the prompt and generate output for multiple permutations of exemplars.
In fact, poor reasoning capabilities are one of the go-to criticisms of modern LLMs. Many researchers cite the inability of LLMs to reason as evidence of a shallow understanding of important concepts.
Many researchers have argued that this majority vote strategy is insufficient for solving complex problems. This has led to a lot of research on prompt ensembles and other self-consistency variants that was in-depth here.
In fact, writing this newsletter is far from sequential. My writing strategy is usually to i) overview a bunch of similar papers, ii) add some sections with shared ideas and background, then iii) write the intro and conclusion. This is the exact opposite of a sequential process (the intro is the last thing that I write!).
When we ask the LLM to generate a rationale our outline for its answer, we oftentimes see a benefit from this process, similarly to benefits observed with CoT prompting. However, it is worth noting that SoT prompting performs multiple disjoint generations (i.e., one to generate the skeleton, then one for each skeleton component), while a CoT prompt is typically used to generate output in a single pass.
This model can be finetuned using either supervised finetuning (SFT) or an RL-based strategy similar to RLHF.
What is the timeframe for something to be "modern," in this context? ChatGPT wasn't even released 18 months ago! Isn't it ALL "modern"?
This is really nice and detailed reference material for LLMs and prompt engineering. I really liked the images and illustrations. Which tool do you use to create these elegant workflow images?