
Democratizing AI: MosaicML's Impact on the Open-Source LLM Movement
How high-quality base models unlock new possibilities for an entire industry...


This newsletter is presented by Rebuy, the commerce AI company.
Sponsor the newsletter | Follow me on Twitter | Get in touch | Suggest a topic

Recently, we have overviewed a lot of current research on the creation of open-source large language models (LLMs). Across all of this work, models are created using a common framework with a few simple components; see below.

Although this framework has several steps, the first step is arguably the most important. Creating a more powerful base model via extensive, high-quality pre-training enables better results when the LLM is refined via supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). Then, downstream applications are better due to the use of an improved model. The pre-trained (base) model is the common starting point for any LLM application.
Until recently, open-source base models either performed poorly compared to their proprietary counterparts or could only be used for research. However, this changed with the release of MPT-7B and MPT-30B [1, 2] by MosaicML. These open-source base models achieve impressive levels of performance, are free for commercial use, and come with an entire suite of efficient software for training, fine-tuning, and evaluating LLMs. These open-source tools enable a wide variety of specialized use cases for LLMs to be explored at a significantly reduced cost, making them a powerful resource for practitioners in AI.
Faster LLMs and Longer Context Lengths
The MPT-7B/30B models are based upon a typical, decoder-only transformer architecture. However, a few key modifications are made, including:
ALiBi [6] (instead of normal position embeddings)
Flash Attention [7]
Within this section, we will learn about each of these components, how they work, and their impact on LLMs. To fully understand the details of this section, it might be useful to review the following concepts:
ALiBi enables context length extrapolation
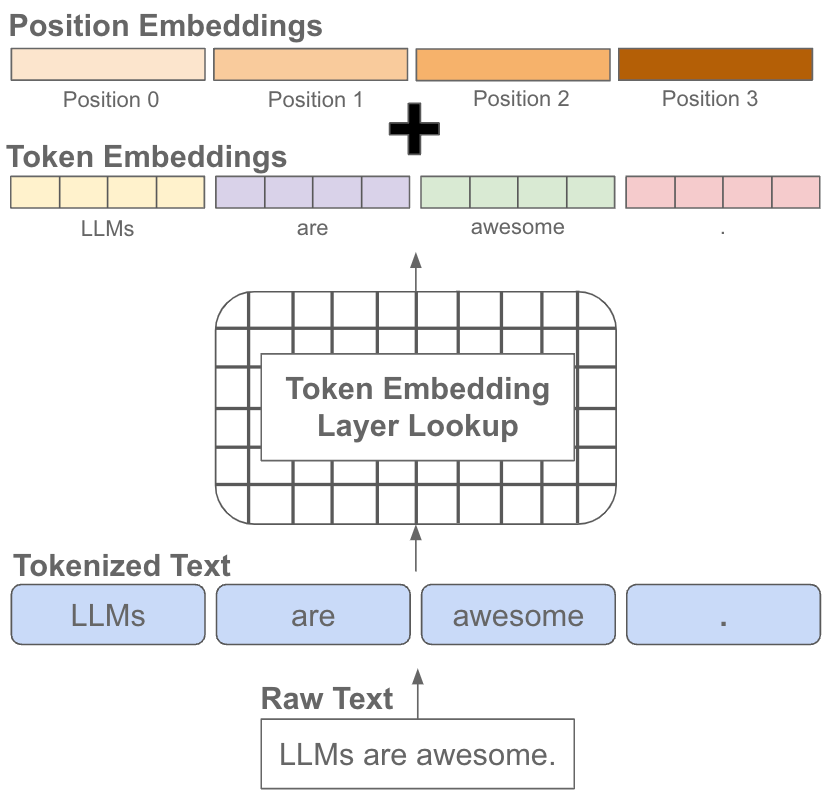
In a vanilla transformer architecture, we create an input sequence of tokens by first tokenizing the raw text and looking up the embedding (each token in the tokenizer’s vocabulary has a unique embedding) for each token. Then, we add a position embedding to each token embedding, thus injecting positional info into the embedding of each token in the sequence; see above. This is necessary because the self-attention operation is agnostic to the position of each token in the sequence. Although position embeddings work well, there’s one big problem: they struggle to generalize to sequences longer than those seen during training.
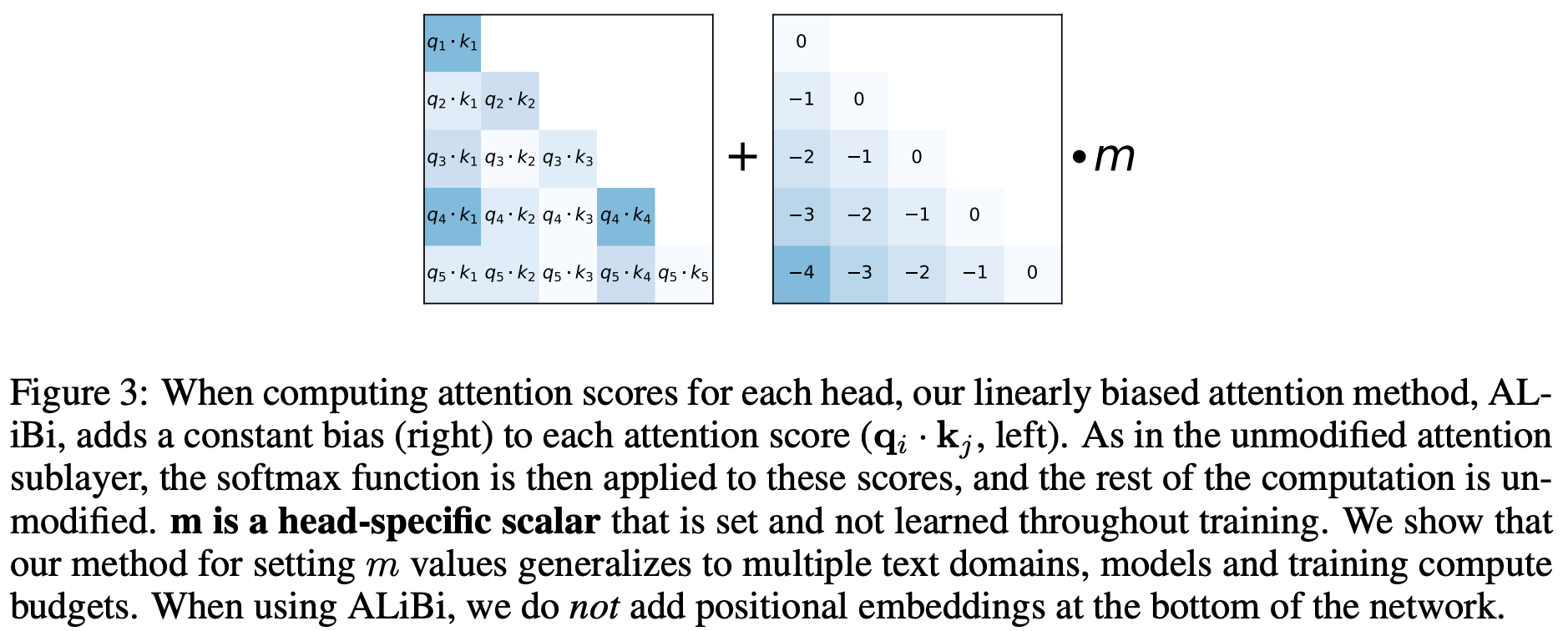
the solution. Attention with Linear Biases (ALiBi) [6] solves this problem by getting rid of position embeddings altogether. Instead, positional information is injected into the transformer as part of the self-attention operation by adding an additive penalty to the key-query attention score; see above. We should recall that self-attention computes an attention score between each pair of tokens within a sequence. ALiBi operates by adding a static, non-learned bias (or penalty) to this score that is proportional to the distance between the pair of tokens; see below.

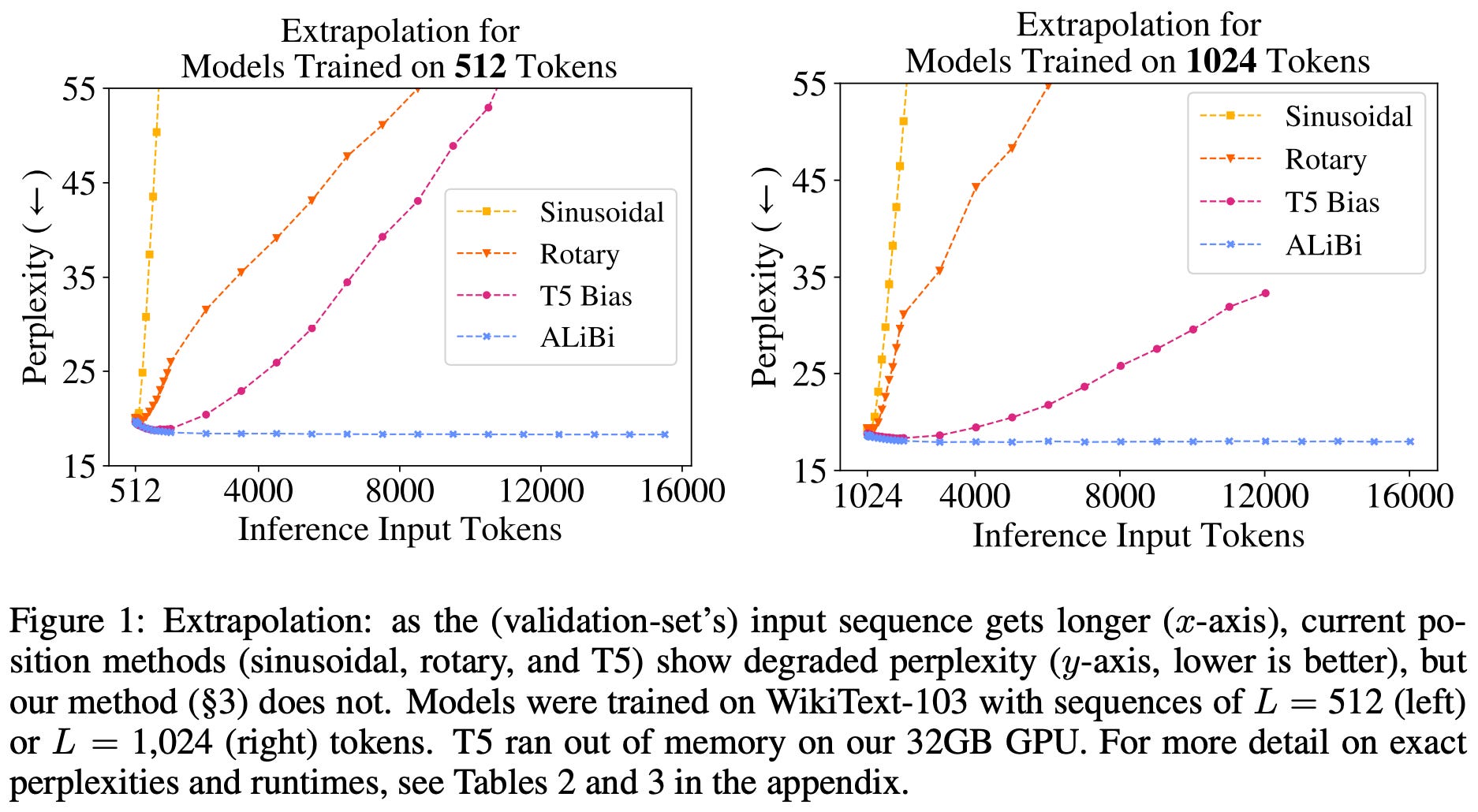
Such an approach is impactful because it depends on the pairwise distance between tokens rather than the absolute positions of tokens within a sequence. This quantity is less dependent upon the length of the underlying sequence and allows ALiBi to generalize much better to sequences that are longer than those seen during training; see below. As we will see, MPT models (which use ALiBi) can be trained to support larger context lengths compared to most open-source alternatives and can even extrapolate to sequences as long as 84K tokens!
Faster Inference
Due to their use of low precision layer norm and FlashAttention [7], the MPT models have very fast training and inference speeds (i.e., 1.5-2X faster than similarly-sized LLaMA models [3] using standard HuggingFace inference pipelines). Going further, the weights of these models can be ported to optimized modules like FasterTransformer or ONNX to enable even faster inference.
low precision layer norm. Put simply, low precision layer norm performs the operations from a LayerNorm module in 16-bit precision. Although such an approach can cause loss spikes in some cases, it improves hardware utilization and, in turn, speeds up both training and inference. Using low precision layer norm also has minimal impact on the model’s final performance.
flash attention. In its canonical form, self-attention is an O(N^2) operation, where N is the length of the input sequence. In order to improve the efficiency of this operation, many approximate attention variants have been proposed, such as:
The goal of most of these techniques is to derive a “linear” variation of attention—a similar/approximate operation with a complexity of O(N). Although these variants achieve a theoretical reduction in FLOPs, many of them do not achieve any wall-clock speedup in practical scenarios! Flash attention solves this problem by reformulating the attention operation in an IO-aware manner; see below.

The hardware-related details of how FlashAttention is implemented are beyond the scope of this post. However, the resulting efficient attention implementation has a variety of positive benefits. For example, FlashAttention can:
Speed up BERT-large [10] training time by 15%
Improve training speed by
3Xfor GPT-2 [11]Enable longer context lengths for LLMs (due to better memory efficiency)
For more details on FlashAttention, check out the writeup below.
MPT-7B: A Commercially-Usable LLaMA-7B

Proposed in [1], MPT-7B is an open-source, commercially-usable language foundation model that broadly matches the performance of similarly-sized, open-source base models like LLaMA-7B [3] (which is not commercially-usable!). Following the lessons of Chinchilla [4], MPT-7B is pre-trained over a large corpus—one trillion tokens in total—of diverse, publicly-available text. The code used to train, fine-tune, and evaluate MPT-7B is completely open-source, making this model a great resource or starting point for practitioners looking to fine-tune their own specialized LLM for solving a variety of different downstream applications!
Creating the Base Model
Due to its modified architecture, MPT-7B has several desirable properties, such as the ability to generalize to much longer context lengths and faster inference speeds. Additionally, we see in [1] that this modified architecture leads to the elimination of loss spikes during pre-training of MPT-7B, allowing the model to be pre-trained without any human intervention1 (assuming that any hardware failures are handled automatically within the LLM’s training code)!

training process. Although most LLMs are trained using the AdamW optimizer, MPT adopts the Lion optimizer [8], which improves the stability of the training process. The entire training framework is based upon PyTorch’s Fully Sharded Data Parallel (FSDP) package and uses no pipeline or tensor parallelism (see “training system” section here). To put it simply, the training framework for MPT-7B, which is completely open-sourced, uses popular/common components, but makes a few useful changes that are found to improve the stability of training.
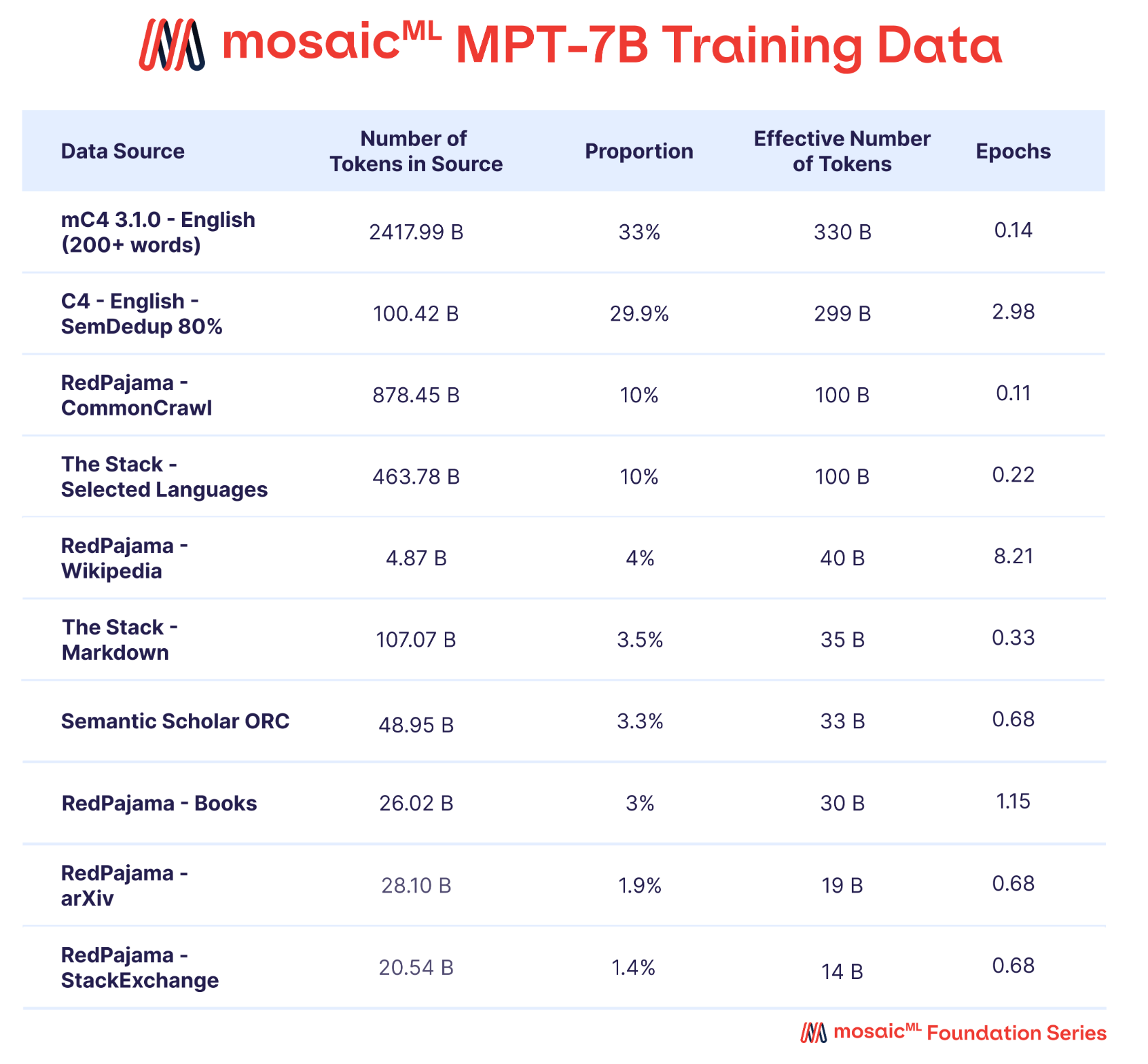
the data. The textual corpus used to train MPT-7B is a custom mixture of publicly-available datasets (mostly English language); see above. In [1], we see that the amount of data used to train MPT-7B is quite large—1T tokens in total. For comparison, open-sources models like Pythia and StableLM pre-train on 300B and 800B tokens, respectively. Interestingly, we see that the authors of [1] adopt a very particular tokenizer—the GPT-NeoX-20B BPE tokenizer2—for their model. This tokenizer is desirable because it is trained on a large, diverse dataset and handles spaces more consistently than other popular tokenizers.
“This tokenizer has a number of desirable characteristics, most of which are relevant for tokenizing code: trained on a diverse mix of data that includes code, applies consistent space delimitation (unlike the GPT2 tokenizer which tokenizes inconsistently depending on the presence of prefix spaces), and contains tokens for repeated space characters.” - from [1]
As practitioners, we should always be aware of the tokenizer being used by our model. This choice—although typically ignored or overlooked—can drastically impact our results. For example, code-based language models need a tokenizer that handles whitespace in a particular manner, while multilingual language models have a variety of unique tokenization considerations.
How does it perform?

MPT-7B is compared to a variety of open-source models (e.g., LLaMA, StableLM, Pythia, GPT-NeoX, OPT, and GPT-J) on standard benchmarks. As shown above, LLaMA-7B achieves drastic improvements over open-source alternatives, while MPT-7B matches or exceed LLaMA’s performance. Recent open-source LLMs are much better than their predecessors! LLaMA-7B and MPT-7B are both incredibly high-performing base models compared to other open-source models. However, MPT-7B can be used commercially, while LLaMA can only be used for research.
Derivatives of MPT-7B
In addition to releasing the MPT-7B base model, authors in [1] leverage the open-source training code for MPT to fine-tune several different derivatives of the base model (outlined below). Fine-tuning is very cheap compared to pre-training an LLM from scratch (i.e., 10-100X reduction in time and cost, if not more). As such, most of the time and effort in developing MPT-7B went into creating the base model, which serves as a starting point for fine-tuning the models below.

MPT-StoryWriter-65K (commercial) is a version of MPT-7B that has been fine-tuned on data with very long context lengths. In particular, authors in [1] leverage the books3 dataset, which contains excerpts from fiction books, to create a dataset for fine-tuning (i.e., just using the next-token prediction objective) with a 65K token context length. Due to the use of ALiBi [6] and FlashAttention [7], MPT-StoryWriter-65K can be feasibly trained over such large inputs, used to consume the entirety of The Great Gatsby (68K tokens) to write an epilogue (see above), and even generalized to process sequences lengths as long as 84K tokens.
“We expect LLMs to treat the input as instructions to follow. Instruction finetuning is the process of training LLMs to perform instruction-following in this way. By reducing the reliance on clever prompt engineering, instruction finetuning makes LLMs more accessible, intuitive, and immediately usable.” - from [1]
MPT-7B-Instruct (commercial) and MPT-7B-Chat (non-commercial) are instruction tuned versions of MPT-7B. The instruct variant is fine-tuned over data from Dolly-15K and the Helpful and Harmless dataset, while the chat model is trained with data from sources like ShareGPT, HC3, Alpaca, and Evol-Instruct. As outlined by the quote above, instruction tuning takes a pre-trained language model and modifies its style or behavior to be more intuitive and accessible, usually with an emphasis upon instruction following or problem solving.
MPT-30B: An Open-Source GPT-3 Alternative

Shortly after its proposal, the MPT-7B model gained significant recognition in the AI research community—it even amassed over 3M downloads on HuggingFace! The success of MPT-7B was no surprise, as it provided a commercially-usable alternative to the incredibly popular LLaMA-7B model. Riding this momentum, researchers at MosaicML followed MPT-7B with a slightly larger model, called MPT-30B [2], that was found to match or exceed the performance of GPT-3 [9]. As such, the proposal of MPT-30B continues the trend of making commercially-usable versions of powerful base LLMs available to anyone.
Diving Deeper into MPT-30B
MPT-30B shares the same, modified decoder-only architecture as MPT-7B, which uses FlashAttention and low precision layer norm for improved efficiency. Overall, the models are quite similar aside from MPT-30B being larger. Interestingly, the size of MPT-30B was chosen very specifically. A model of this size is feasible to deploy on a single GPU using 8 or 16-bit precision, while alternatives like Falcon-40B are slightly too large to be deployed in this manner.
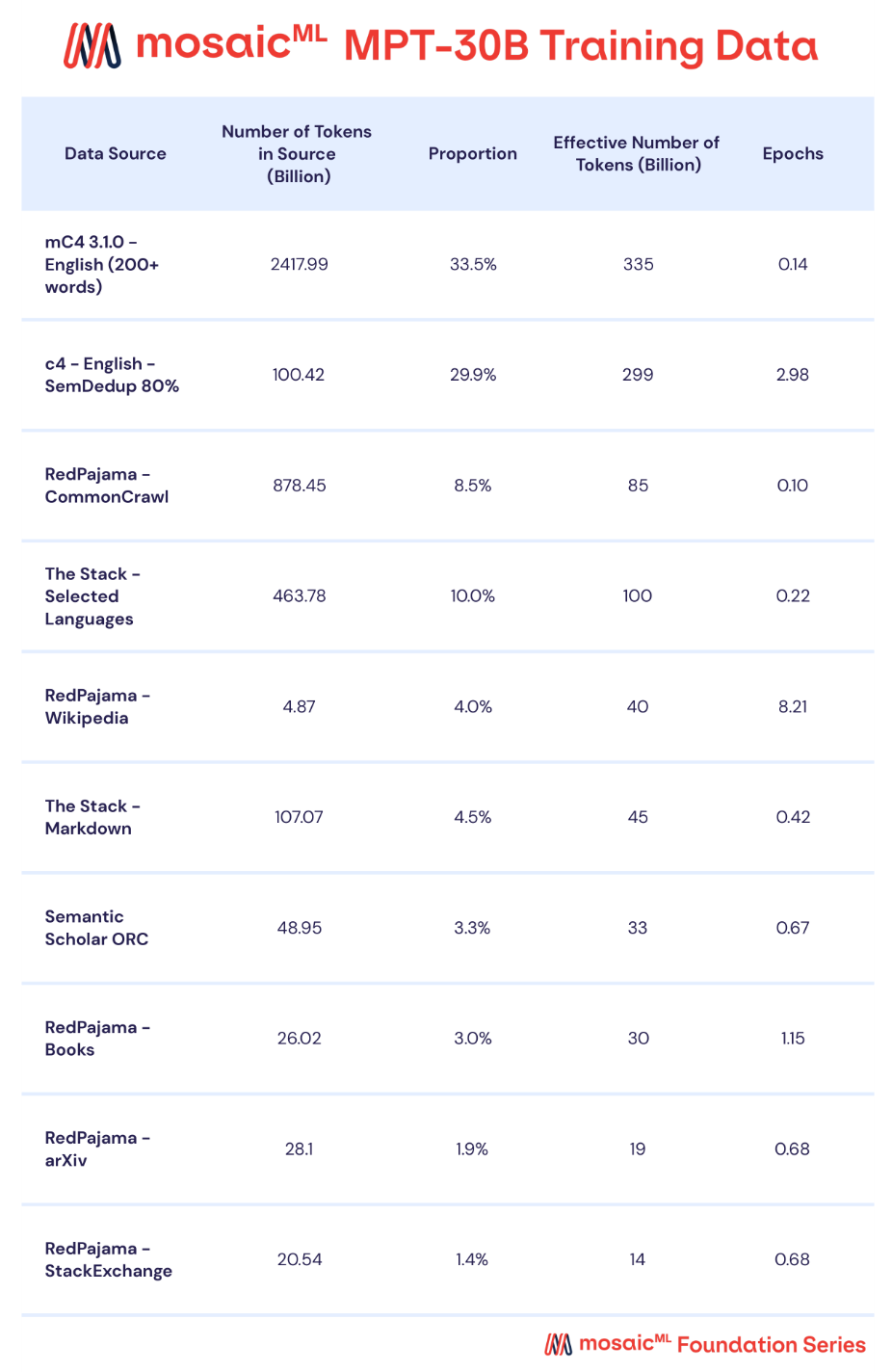
what’s different? MPT-30B is different from MPT-7B in two main ways:
Pre-training data mixture
Context length
The pre-training dataset for MPT-30B is similar to that of MPT-7B, but the mixture of data is slightly different; see above. Additionally, MPT-30B is (partially) trained using a 8K context length, whereas most other open-source models (e.g., LLaMA, Falcon, and MPT-7B) are trained using a shorter context length of 2K tokens3. More specifically, we see that MPT-30B uses a training curriculum in which the model is first trained with a 2K context length, then switches to an 8K context length later in training. During this second phase, the proportion of code in the dataset is increased by 2.5X, leading the resulting model to have improved coding abilities compared to other open-source LLMs.
model variants. In addition to the MPT-30B base model, authors in [2] release chat and instruct variants of MPT-30B. These models follow a similar training strategy as MPT-7B-Instruct and MPT-7B-Chat. However, the data used for instruction tuning is significantly expanded for both of these models. Interestingly, MPT-30B-Chat is found to have impressive programing skills!
Does it perform well?

In addition to outperforming MPT-7B across a variety of categories, MPT-30B achieves comparable performance to top open-source alternatives like LLaMA-30B and Falcon-40B; see above. In general, we see that MPT-30B lags behind Falcon and LLaMA in solving text-based tasks, but tends to outperform these models on programming-related problems (likely due to the higher ratio of code in the pre-training dataset!). Notably, we see that MPT-30B outperforms GPT-3 on a variety of in-context learning tasks; see below.

With this result in mind, it seems that models like MPT-30B could potentially lay the foundation for open-source LLM applications that rival the quality of proprietary systems. All we need is sufficient refinement and fine-tuning!
Final Remarks
“You can train, finetune, and deploy your own private MPT models, either starting from one of our checkpoints or training from scratch” - from [2]
The foundation models provided by MosaicML are a huge step forward for the open-source LLM community, as they provide commercially-usable LLMs that are comparable to popular base models like LLaMA and GPT-3. However, this open-source offering goes beyond the MPT models themselves—it includes an open-source codebase for training LLMs, a variety of online demos4, and more.
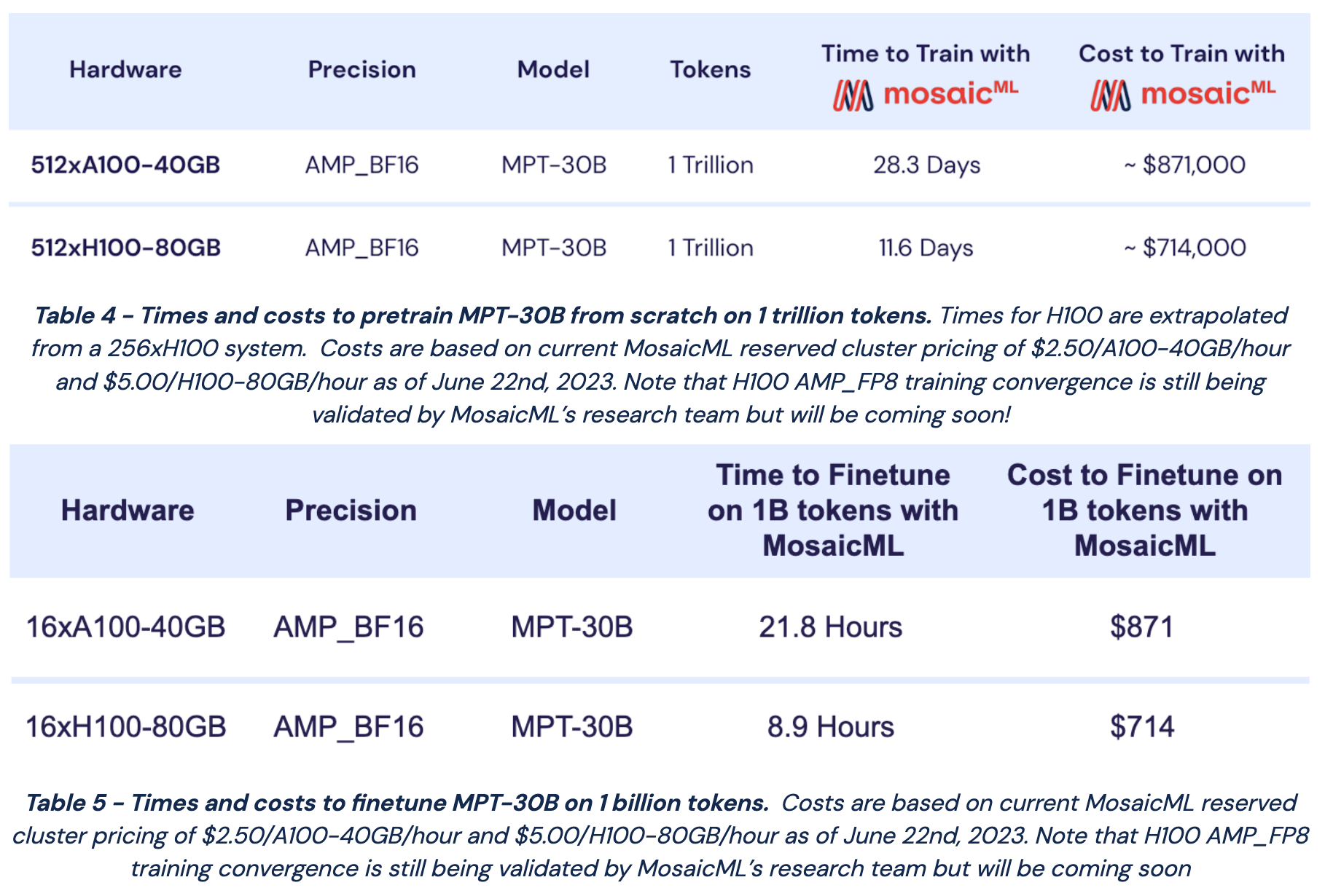
The MPT-7B and 30B models come with an entire ecosystem of open-source tools that can be used to create specialized/personalized LLMs. Given that creating the base model is the most expensive aspect of any LLM-based system (see above), these tools significantly lower the barrier to entry for working with LLMs and provide a starting point for solving a variety of downstream applications. Remember, fine-tuning is extremely effective (i.e., hard to beat by just prompting a more generic LLM) when we have a particular task that we are trying to solve!
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews that clearly explain relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable Llms.” MosaicML, 5 May 2023, www.mosaicml.com/blog/mpt-7b.
[2] “MPT-30B: Raising the Bar for Open-Source Foundation Models.” MosaicML, 22 June 2023, www.mosaicml.com/blog/mpt-30b.
[3] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[4] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[5] Zhang, Susan, et al. “OPT: Open Pre-trained Transformer Language Models.” arXiv preprint arXiv:2205.01068 (2022).
[6] Press, Ofir, Noah A. Smith, and Mike Lewis. "Train short, test long: Attention with linear biases enables input length extrapolation." arXiv preprint arXiv:2108.12409 (2021).
[7] Dao, Tri, et al. "Flashattention: Fast and memory-efficient exact attention with io-awareness." Advances in Neural Information Processing Systems 35 (2022): 16344-16359.
[8] Chen, Xiangning, et al. "Symbolic discovery of optimization algorithms." arXiv preprint arXiv:2302.06675 (2023).
[9] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[10] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[11] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[12] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[13] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
The amount of human intervention required to resolve loss spikes and various hardware failures during LLM pre-training was massive in prior work. As an example, one can look at the pre-training logbook from OPT [5].
For more on BPE tokenization, check out this article. As we’ve seen previously, tokenizers are used to convert raw text into a sequence of individual tokens that can be fed to a language model. Each token, which resides in the model’s vocabulary of viable tokens, has its own embedding that is stored and updated by the language model.
Due to the use of ALiBi, MPT-7B can generalize beyond a 2K context length. However, the model was pre-trained using a 2K context length and can only extrapolate a reasonable amount. To enable inference with longer context lengths (e.g., as with the StoryWriter LLM), we must first fine-tune the model with longer context lengths.
All MPT models are compatible with HuggingFace. They are subclasses of HuggingFace’s PreTrainedModel class.