
PaLM: Efficiently Training Massive Language Models
Unprecedented size, efficiency, and performance for LLMs...


In receears, large, deep neural networks have become the definitive architecture of choice for solving most language understanding and generation tasks. Initially, models were proposed, such as BERT [2] and T5 [3], that used a two-part training methodology of pre-training (with self-supervised “infilling” objectives) over a large corpus of text, then fine-tuning on a target dataset; see below. Despite the utility of these techniques, recent work on large language models (LLMs) has shown that large, autoregressive (decoder-only) transformer models are incredibly capable at few-shot learning, achieving impressive performance with minimal adaptation to downstream tasks.

The few-shot learning capabilities of LLMs were first demonstrated by GPT-3 [4], a 175 billion parameter LLM. To perform few-shot prediction, the model is pre-trained (using a basic language modeling objective) over a massive corpus of text, then provided task descriptions and a handful of examples of how a task should be solved; see above. Further analysis of LLMs indicated that model performance improves smoothly with scale (according to a power law) [5, 6]. As such, various LLMs were proposed following GPT-3 that attempt to “scale up” the model and training, oftentimes achieving improved results via a combination of larger models and more/better pre-training data.
Training larger LLMs is beneficial but difficult to do efficiently. Typically, we distribute training across many machines, each with several accelerators (i.e., GPUs or TPUs). This has been done successfully before (e.g., MT-NLG trains a 530 billion parameter LLM across a system with 2240 A100 GPUs), but the results were not that impressive. The model, although large, was not trained over enough data. However, given a higher training throughput, we could (in theory) pre-train such large models more extensively on larger datasets, yielding much better results.
In this overview, we will explore the Pathways Language Model (PaLM), a 540 billion parameter LLM trained using Google’s Pathways framework. By eliminating pipeline parallelism, this architecture achieves impressive training throughput, allowing PaLM to be pre-trained over a more extensive dataset. The few-shot performance of the resulting model is state-of-the-art. Plus, PaLM is somewhat capable of solving difficult reasoning tasks. Put simply, PaLM is a clear reminder that LLM performance has not yet reached a plateau with respect to scale. Given a sufficiently efficient training infrastructure that permits pre-training larger models over more data, we continue to see improvements in performance.
Background
We have explored the topic of language modeling extensively in this newsletter and overviewed several notable (large) language models in prior posts:
Nonetheless, we will briefly go over prior work on LLMs here to provide some important context for understanding PaLM.
Language Modeling Recap

Modern language models are simply decoder-only transformer models (shown above) that are pre-trained using a self-supervised language modeling objective over unlabeled text. This objective samples a sequence of text and trains the language model to accurately predict the next word/token. After performing extensive pre-training, LLMs such as GPT-3 were found to perform really well in the few-shot learning regime.
why is this useful? Put simply, the generic, text-to-text format of LLMs allows them to easily generalize to solving a variety of tasks with minimal adaptation. Instead of fine-tuning models or adding task-specific layers, we can just pre-train a single model extensively and solve a variety of tasks with the same model using few-shot learning. Despite the fact that pre-training such foundation models is incredibly expensive, these approaches hold incredible potential, as a single model can be re-purposed for many applications. This process is referred to as in-context learning; see below.
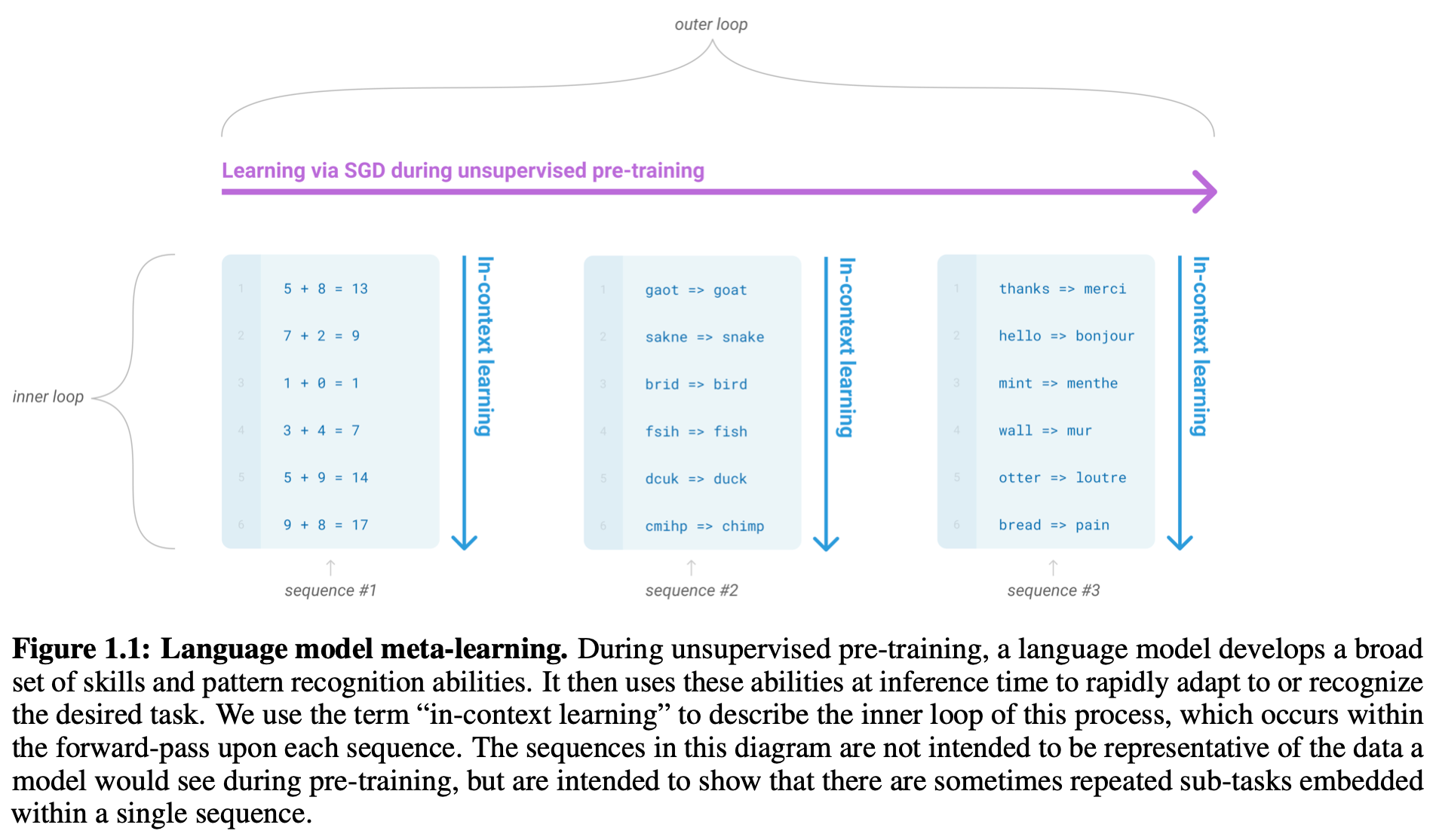
what goes into a good LLM? Early work on this topic indicated that language model performance should improved smoothly (according to a power law) with model scale (i.e., big models perform better). This finding led to the proposal of GPT-3, an LLM of unprecedented scale (175 billion parameters) that achieved breakthrough few-shot learning performance. Subsequent work tried to explore even larger LLMs, but these larger models did not lead to further breakthroughs in performance. Rather, we eventually discovered that producing high-performing LLMs requires a combination of larger models with larger pre-training datasets [6].
“The amount of training data that is projected to be needed is far beyond what is currently used to train large models, and underscores the importance of dataset collection in addition to engineering improvements that allow for model scale.” - from [6]
Architectural Modifications
Beyond using an improved training framework, PaLM modifies the underlying, decoder-only architecture quite a bit. Most of these changes are adopted from prior work that reveals best practices for maximizing LLM training efficiency and performance.
SwiGLU activations. Most LLMs share a similar structure for the feed-forward neural network used within each of their layers. Namely, this network performs two feed-forward transformations (using no bias and applied individually to each token vector in the sequence) with a Rectified Linear Unit (ReLU) activation function in between. However, subsequent work [13] revealed that other choices of the activation function may actually be better.
In particular, PaLM uses the SwiGLU activation function, a combination of Swish [14] and GLU [15] activations. This activation function is given by the equation below.
where we define the Swish activation function as
In other words, SwiGLU is an element-wise product of two linear transformations of the input, one of which has had a Swish activation applied to it. Although this activation function requires three matrix multiplications, recent work has found that it provides a performance benefit given a fixed amount of computation. Compared to vanilla activations like ReLU, SwiGLU seems to provide a non-negligible performance improvement [13].
parallel transformer blocks. PaLM also uses parallel versions of the transformer block, rather than the normal (serialized) variant. The difference between these two formulations is demonstrated within the illustration below.

Given a sufficiently large model, using parallel transformer blocks can speed up the training process by 15%. This speedup comes at the cost of slightly degraded performance for smaller LLMs (e.g., an 8 billion parameter model), but full-sized LLMs tend to perform similarly with parallel blocks.

rotary positional embeddings. Instead of absolute or relative positional embeddings, PaLM utilizes rotary positional embeddings (RoPE), as proposed in [16]. RoPE embeddings incorporate both absolute and relative positioning by:
Encoding the absolute position with a rotation matrix
Incorporating relative position directly into self-attention
Intuitively, RoPE finds a middle ground between absolute and relative positional embeddings. Illustrated in the figure above, RoPE consistently outperforms alternative embedding strategies. Plus, it is implemented and easily accessible in common libraries such as HuggingFace.
multi-query attention. Finally, PaLM replaces the typical, multi-headed self-attention mechanism with an alternative structure called multi-query attention. Multi-query attention just shares key and value vectors (highlighted in red below) between each of the attention heads, instead of performing a separate projection for each head. This change does not make training any faster, but it does significantly improve the auto-regressive decoding (i.e., used to perform inference or generation) efficiency of LLMs.

other useful concepts
Foundation models and zero/few-shot learning [link]
LLM alignment [link]
Adaptation strategies for LLMs [link]
A brief progression of LLMs [link]
PaLM: Scaling Language Modeling with Pathways [1]
Now, we will overview PaLM, a 540 billion parameter dense language model that is efficiently trained using the Pathways framework. PaLM is one of the largest dense LLMs that has been trained to date, and its efficient training strategy allows its pre-training process to be performed over a large dataset (>700 billion tokens). This combination of a massive language model with an extensive pre-training corpus leads to some interesting results that we will explore within this section.
How does PaLM work?
PaLM is a massive LLM that achieves impressive few-shot learning performance via a combination of extensive pre-training (enabled by the efficient Pathways architecture) and some modifications to the underlying model architecture. We will now overview the details of PaLM’s architecture and training regime.
the model. PaLM uses a decoder-only transformer with 540 billion parameters. However, this model goes beyond the typical, decoder-only architecture by making a few modifications:
SwiGLU activations (instead of ReLU) are used in MLP layers.
Multi-query attention is used in attention layers.
Only parallel transformer blocks are used.
Absolute or relative positional embeddings are replaced with ROPE embeddings.
To understand the impact of model scale, three different sizes of PaLM are tested within [1]; see below.

Although power laws suggest that performance should improve smoothly between the models shown above, analysis in [1] finds that we often see a disproportionate performance improvement when using the largest (540 billion parameter) model. Larger LLMs provide a surprisingly large benefit when combined with a more extensive pre-training process.
“For certain tasks, we observe discontinuous improvements, where scaling from 62B to 540B results in a drastic jump in accuracy compared to scaling from 8B to 62B… This suggests that new capabilities of large LMs can emerge when the model achieves sufficient scale, and that these capabilities continue to emerge beyond previously studied scales.” - from [1]
dataset. PaLM’s pre-training corpus is comprised of 780B tokens. This is somewhat smaller than the dataset used to train Chinchilla [6] but still larger than that of most prior LLMs; see below.
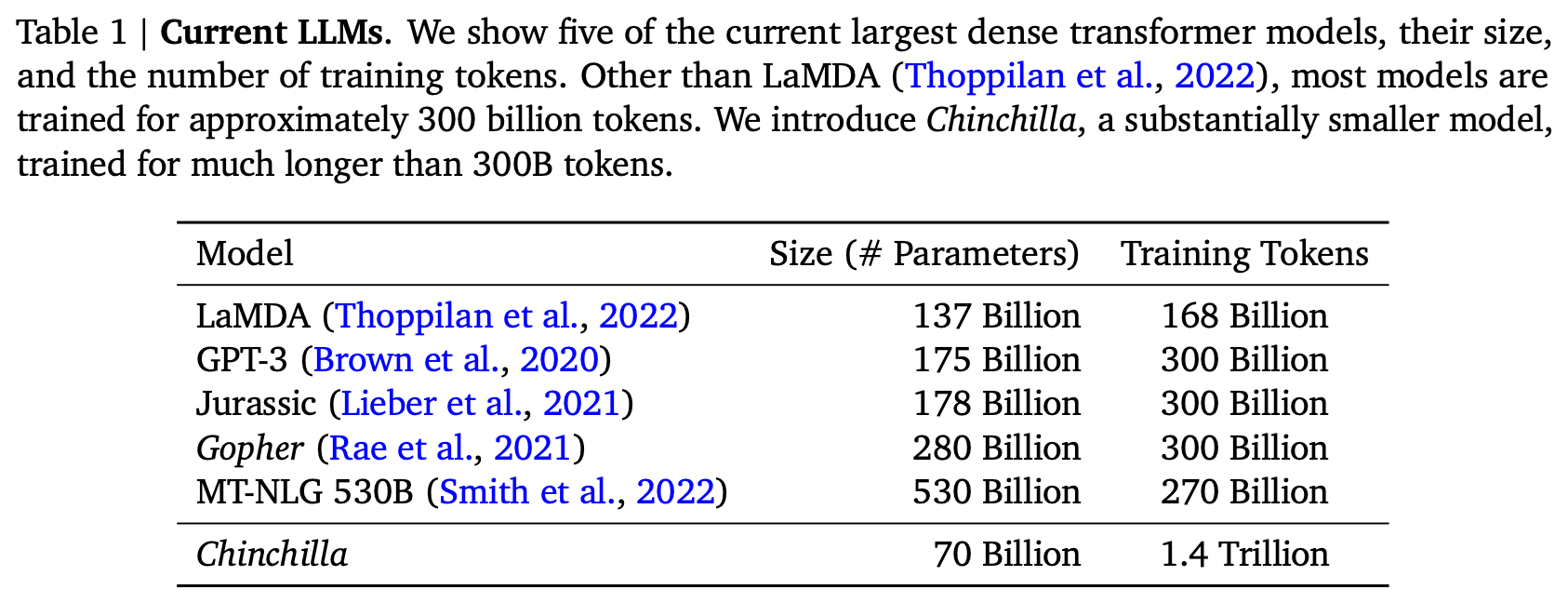
Creating high-performing LLMs is not just about making the model larger. Recent work on scaling laws for LLMs [6] indicates that performance will increase as a factor of both model size and pre-training corpus size. As such, PaLM has the opportunity to significantly outperform models like MT-NLG (despite being only slightly larger) by using a much larger pre-training corpus.
The pre-training corpus used for PaLM is derived from high-quality webpages, books, wikipedia, news, articles, code, and social media conversations. It contains 22% non-English data (see below) and is inspired by the corpora used to train LaMDA and GLaM [8, 9]. All models are trained for exactly one epoch over this dataset.

using a large vocabulary. Given that a non-negligible portion of the pre-training corpus is non-English, the authors also adopt a SentencePiece tokenizer with a vocabulary size of 256K. The tokenizer simply takes raw textual input and extracts tokens (i.e., words or sub-words) from the text. This tokenization process is based upon an underlying vocabulary (i.e., set of known tokens), and all tokens extracted from text must be a member of the vocabulary. If a token is not part of the underlying vocabulary, it will be broken into smaller chunks (possibly even characters) until it has been decomposed into valid tokens, or replaced with the generic “[UNK]” out of vocabulary token.
Using a small vocabulary would mean that a lot of important tokens would fail to be properly captured, which can damage the LLM’s performance. For multi-lingual models, we typically see that the size of the underlying vocabulary is increased a lot to avoid this effect, as data from multiple languages will utilize a wider range of tokens. PaLM is no different: the authors adopt a larger-than-usual vocabulary size to avoid improperly tokenizing the data and allow more effective learning across multiple languages. To learn more about language models that are trained over many languages, check out the link below.
training system. Prior to overviewing the training framework used for PaLM, we need to understand a few concepts related to distributed training. Most importantly, we need to understand the differences between model, data, and pipeline parallelism. Although I’ve explained these concepts before, the tweet below has a much better (and more concise) description.

PaLM is trained on a collection of 6144 TPU chips that are distributed across two TPU pods (i.e., groups of TPUs connect with high-speed network interfaces). At the time of publication, this system was the largest configuration yet described; see below.
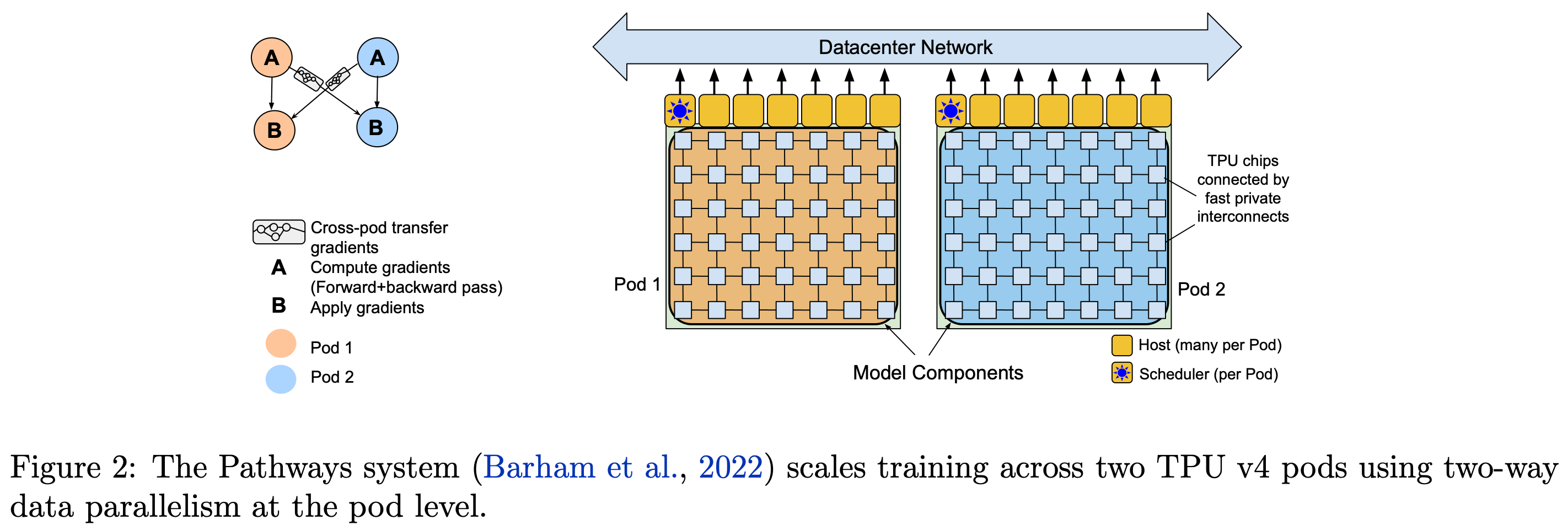
Within a pod, communication is very fast between TPUs. But, communication between pods is much slower. Typically, model and data parallelism have bandwidth requirements that are too large for efficient training across TPU pods. Most prior work has dealt with this by either:
Limiting training to a single TPU pod [8, 9].
Using pipeline parallelism, which has lower bandwidth requirements, between pods [7, 10].
However, pipelining has many notable drawbacks, such as leaving accelerators idle while emptying or filling the pipeline and having high memory requirements. Using the Pathways system, PaLM is efficiently trained across TPU pods with a combination of model and data parallelism (i.e., no pipeline parallelism). This novel training paradigm enables significant improvements in efficiency.
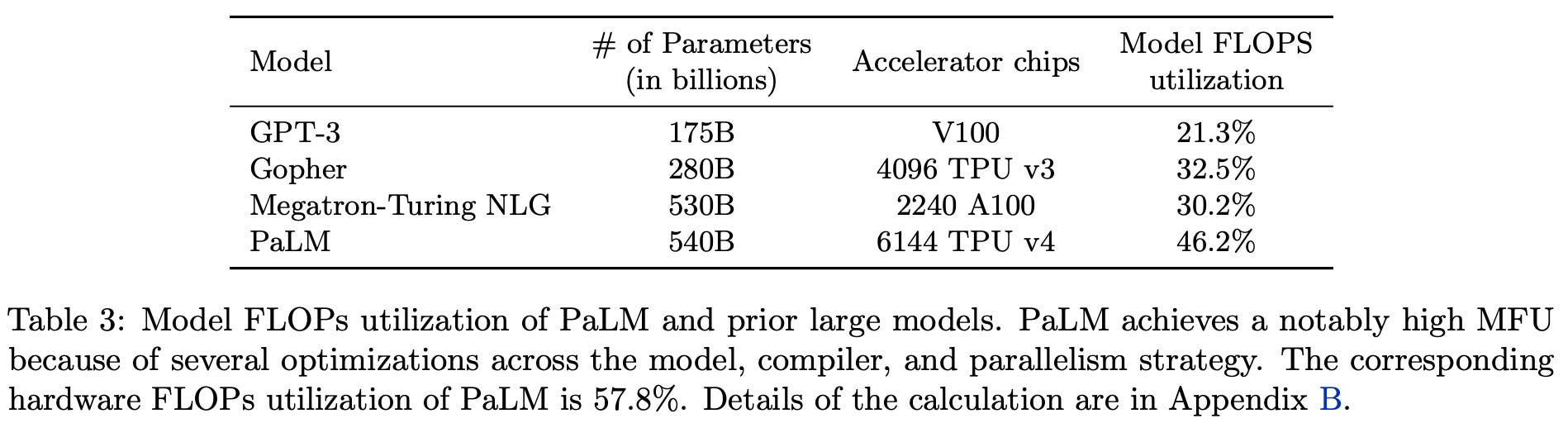
For example, PaLM achieves a model FLOPs utilization (i.e., throughput in tokens-per-second divided by theoretical maximum throughput of a system) of 46.2%, while prior systems struggle to surpass utilization of 30%; see above. For more information on the Pathways system and how it achieves such a massive improvement in LLM training efficiency, check out the article below.
How does PaLM perform?
The analysis provided in [1] goes beyond achieving superior few-shot learning performance. PaLM is shown to effectively handle multiple languages, have improved reasoning capabilities, perform significantly better than smaller models, and even surpass human-level language understanding on certain tasks.
multi-lingual LLMs. Prior LLMs (e.g., GPT-3 [4]) had been shown somewhat capable of performing machine translation, especially when translating other languages into English. Across English-centric data pairs and settings, we see that PaLM improves translation performance relative to prior LLMs; see below.

On low resource and non-English centric data, PaLM still performs relatively well, but it is outperformed by existing supervised translation approaches; see above. However, given that non-English settings are not widely considered by prior work, PaLM’s ability to perform relatively well in this setting is impressive. Overall, this analysis shows us that PaLM has improved language translation abilities but still falls short of supervised techniques.
Beyond language translation, we also see that PaLM performs well on multilingual generation tasks. As expected, PaLM’s language generation abilities are best in English, but the model still outperforms prior LLMs on non-English generation. Overall, these results shows us that an LLM’s multilingual capabilities can be improved significantly by making small modifications (i.e., more non-English pre-training data and using a larger vocabulary for our tokenizer).
surpassing human performance. The BIG-bench dataset contains a collection of 150 tasks with topics including logical reasoning, translation, question answering, mathematics, and more. Relative to prior LLMs, we see that PaLM achieves improved performance on a majority of these tasks; see below.
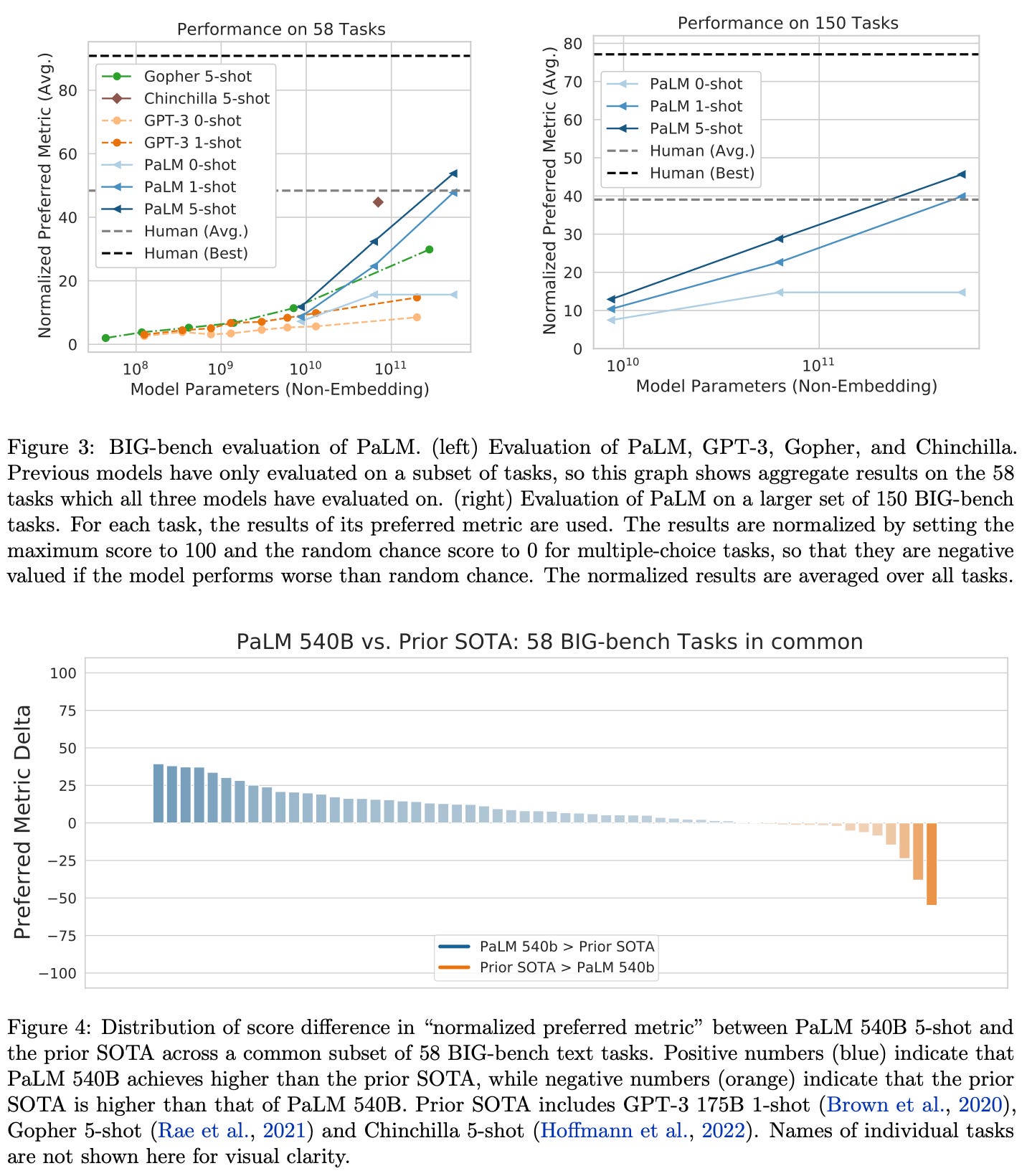
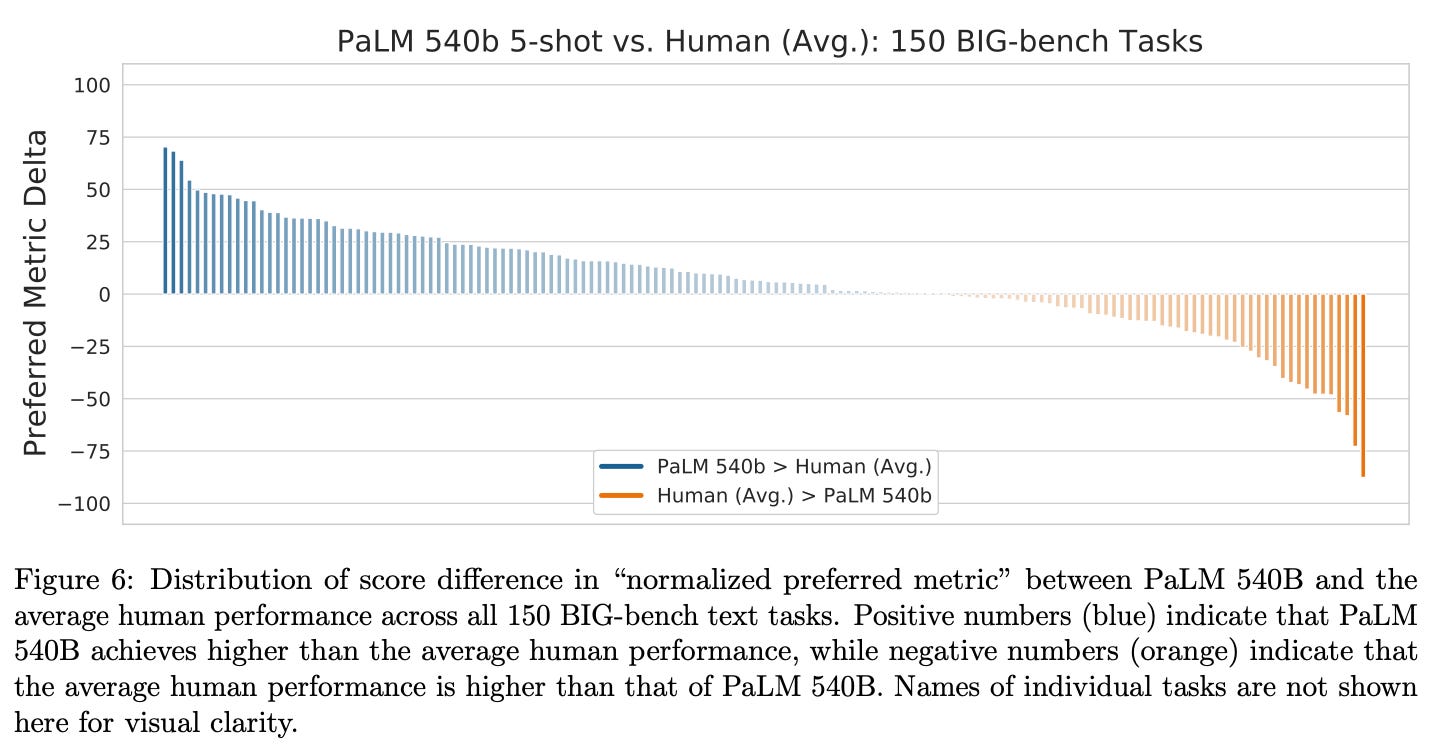
Somewhat more impressively than outperforming prior LLMs, PaLM also surpasses the average performance of humans on most BIG-bench tasks; see below. For some of these tasks, outperforming humans simply indicates that PaLM is capable of memorizing data or reasoning across multiple languages. However, this is not always the case! On other tasks (e.g., cause and effect identification), we see that PaLM seems to have improved language understanding.
do power laws always hold? When we break down the performance of PaLM into specific task categories, we see that model scale is especially helpful for certain tasks. For example, on logical sequence tasks (i.e., putting a set of words into a logical order), the largest PaLM model sees a massive improvement in performance relative to smaller models. For other tasks (e.g., mathematical induction), model scale makes little difference.

Overall, PaLM’s performance does not always follow a power law with respect to model scale. In some cases, using a larger model causes a massive, unexpected spike in performance, while in others the largest model only performs marginally better than smaller variants; see above.
learning to reason. Although language models perform well on many tasks, they notoriously struggle to solve basic reasoning tasks. Many researchers cite this limitation of LLMs as proof of their “shallow” linguistic understanding. However, recent publications have used chain-of-thought prompting (i.e., generating several reasoning “steps” within the LLM before the final output) to improve the reasoning capabilities of LLMs [11, 12]; see below.

When evaluating PaLM, authors in [1] find that combining a model of this scale with chain-of-thought prompting is enough to achieve state-of-the-art accuracy on arithmetic and commonsense reasoning tasks. Prior methods leverage domain-specific architectures, fine-tuning, and even task-specific verification modules to solve such reasoning tasks. In comparison, PaLM simply solves these tasks using few-shot, chain-of-thought prompting (and an external calculator module for arithmetic reasoning tasks); see below.
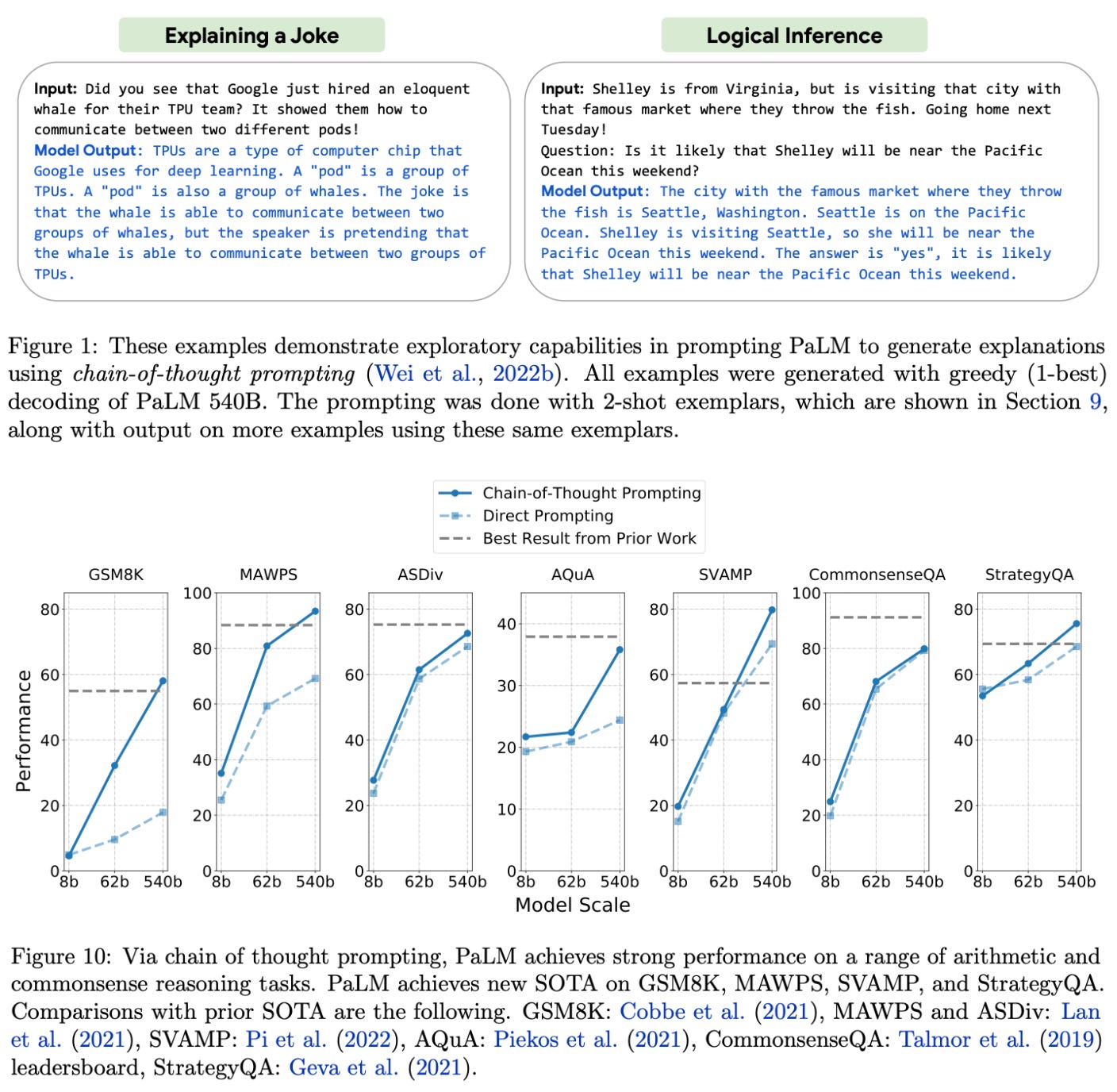
Interestingly, we see that the largest PaLM model has much better reasoning abilities compared to smaller variants. Such a finding is interesting given that prior work has observed a mixed (oftentimes negative) impact of scale on reasoning performance. Results in PaLM indicate that model (and data) scale can seemingly benefit reasoning performance given the correct prompting approach.

The PaLM API
If you’re interested in testing out PaLM, then you’re in luck! The API for PaLM was released to select developers within the last few weeks. Many in the AI community saw this release of the PaLM API by Google as a response to the public release of the ChatGPT API by OpenAI roughly a week before. Read more about the PaLM API release in the article below.
While training and hosting LLMs is probably too difficult to handle (unless we have a team with hundreds of engineers), we are currently seeing a huge shift towards these tool being made available to developers via APIs. As such, practitioners can get easy access to these incredible models without the hassle or cost of training and hosting them. This lowers the barrier of entry for building applications with these powerful models, which unlocks a world of possibilities! For examples of some awesome applications that can be built, I recommend checking out the OpenAI cookbook.
Takeaways
Although initial attempts to train LLMs beyond the scale of GPT-3 were somewhat unsuccessful, we see with PaLM that all we need is an efficient training framework that allows for more extensive pre-training. By using the Pathways framework, PaLM can be trained over a much larger dataset compared to prior models of its scale, such as MT-NLG [7]. The resulting LLM has impressive multi-lingual understanding and reasoning capabilities, and we see that increasing the size of the model can oftentimes provide a major benefit. Some important takeaways from PaLM are listed below.
do power laws always hold? Numerous publications on the topic of LLMs have shown that a power law exists between LLM performance and various quantities, such as (non-embedding) model parameters, dataset size, amount of training compute and more. Although this trend holds in terms of aggregate performance, the story is a bit more complicated when we examine performance separately with respect to each task. Certain tasks benefit disproportionately from scale, while others don’t see much of a benefit. Thus, scale is generally helpful for LLMs, but the results vary significantly depending on the downstream task being solved.
should we avoid pipeline parallelism? One of the main selling points of PaLM is the efficient Pathways training framework with which it is trained. Typically, training over multiple TPU pods or compute nodes requires the use of pipeline parallelism due to limited memory bandwidth. However, by removing pipeline parallelism and allowing training across TPU pods to be performed solely with data and model parallelism, we see that PaLM achieves groundbreaking training efficiency and throughput. These gains to the training framework allow PaLM to be trained over much more data, enabling the model’s impressive performance.
LLM scale and reasoning. Prior work on LLMs has oftentimes pointed out their poor reasoning capabilities. In fact, it seemed that the ability of LLMs to perform reasoning tasks degraded with scale. However, we see with PaLM that this is not always the case. If we combine larger LLMs with more pre-training data and the correct prompting approach (i.e., chain-of-thought prompting), we see pretty noticeable improvements in LLM reasoning abilities!
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Bibliography
[1] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[2] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[3] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[4] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[5] Kaplan, Jared, et al. "Scaling laws for neural language models." arXiv preprint arXiv:2001.08361 (2020).
[6] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[7] Smith, Shaden, et al. "Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model." arXiv preprint arXiv:2201.11990 (2022).
[8] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
[9] Du, Nan, et al. "Glam: Efficient scaling of language models with mixture-of-experts." International Conference on Machine Learning. PMLR, 2022.
[10] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[11] Nye, Maxwell, et al. "Show your work: Scratchpads for intermediate computation with language models." arXiv preprint arXiv:2112.00114 (2021).
[12] Cobbe, Karl, et al. "Training verifiers to solve math word problems." arXiv preprint arXiv:2110.14168 (2021).
[13] Shazeer, Noam. "Glu variants improve transformer." arXiv preprint arXiv:2002.05202 (2020).
[14] Ramachandran, Prajit, Barret Zoph, and Quoc V. Le. "Searching for activation functions." arXiv preprint arXiv:1710.05941 (2017).
[15] Dauphin, Yann N., et al. "Language modeling with gated convolutional networks." International conference on machine learning. PMLR, 2017.
[16] Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." arXiv preprint arXiv:2104.09864 (2021).
[17] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).