


Orca: Properly Imitating Proprietary LLMs
Leveraging imitation to create high-quality, open-source LLMs...


This newsletter is presented by Cerebrium. Cerebrium allows you to deploy and fine-tune ML models seamlessly, without worrying about infrastructure. Notable features include serverless GPU deployment (<1 second cold start), access to 15+ pre-trained models (e.g., FLAN-T5, GPT-Neo, Stable Diffusion and more), and support for all major ML frameworks. Try it for free today!
Sponsor the newsletter | Follow me on Twitter | Get in touch | Suggest a topic

As research progresses on large language models (LLMs), one key question that remains unanswered is whether an existing, high-quality LLM can be used to effectively train another LLM. Currently, there is a lot of debate and contention around this topic. The recent explosion of open-source imitation models initially indicated that proprietary LLMs like ChatGPT could be easily replicated at a low cost. However, subsequent research concluded that the evaluation of such models was incomplete and misleading, finding that these models actually have large gaps in their comprehension. In this overview, we will study work [1] that aims to solve the limitations of open-source replicas of proprietary LLMs via a more robust approach. In particular, we will see that imitation learning can be made more effective by curating a larger dataset with more detailed information.
“As these models continue to evolve and become more powerful, an intriguing question arises: Can we use the model itself to supervise its own behavior or that of other AI models?” - from [1]
Background Information
Before diving into the overview, we will cover a few ideas related to both LLMs and deep learning in general. These concepts might not be explicitly described in papers that we read. Rather, they are oftentimes referenced via a citation or assumed to be common knowledge. So, getting a basic grasp of these concepts will make this overview, and the papers it considers, easier to understand.
Instruction Tuning

Instruction tuning was originally proposed by FLAN [12] and aimed to provide a form of training that teaches LLMs to solve language-based tasks in general, rather than a specific task. In particular, this is done by fine-tuning an LLM over sets of “instructions”, or input prompts—including a description of the task being solved—combined with the desired model output; see above. Recent LLMs mostly use a specific variant of instruction tuning that fine-tunes the LLM over examples of dialogue sessions, either from humans or another LLM. Usually, instruction tuning is a fine-tuning step that occurs after pre-training; see below.

synthetic instruction tuning. Although humans can manually create data for instruction tuning, we can also synthetically generate this data using an LLM. There are two basic approaches for this:
Obtain example dialogue sessions from another model (e.g., from ShareGPT).
Use a prompting framework (e.g., self-instruct [9]) to generate and refine high-quality dialogue examples with an LLM.
Both of these approaches are valid, but they have their limitations. For example, public examples of LLM dialogues tend to be biased towards certain tasks, such as creative content generation or information-seeking dialogue. Additionally, dialogues that are generated via self-instruct [9] tend to lack complexity, though this issue was mitigated by the Evol-Instruct [2] strategy that explicitly instructs and guides the LLM towards more complex generations; see below.

The System Message
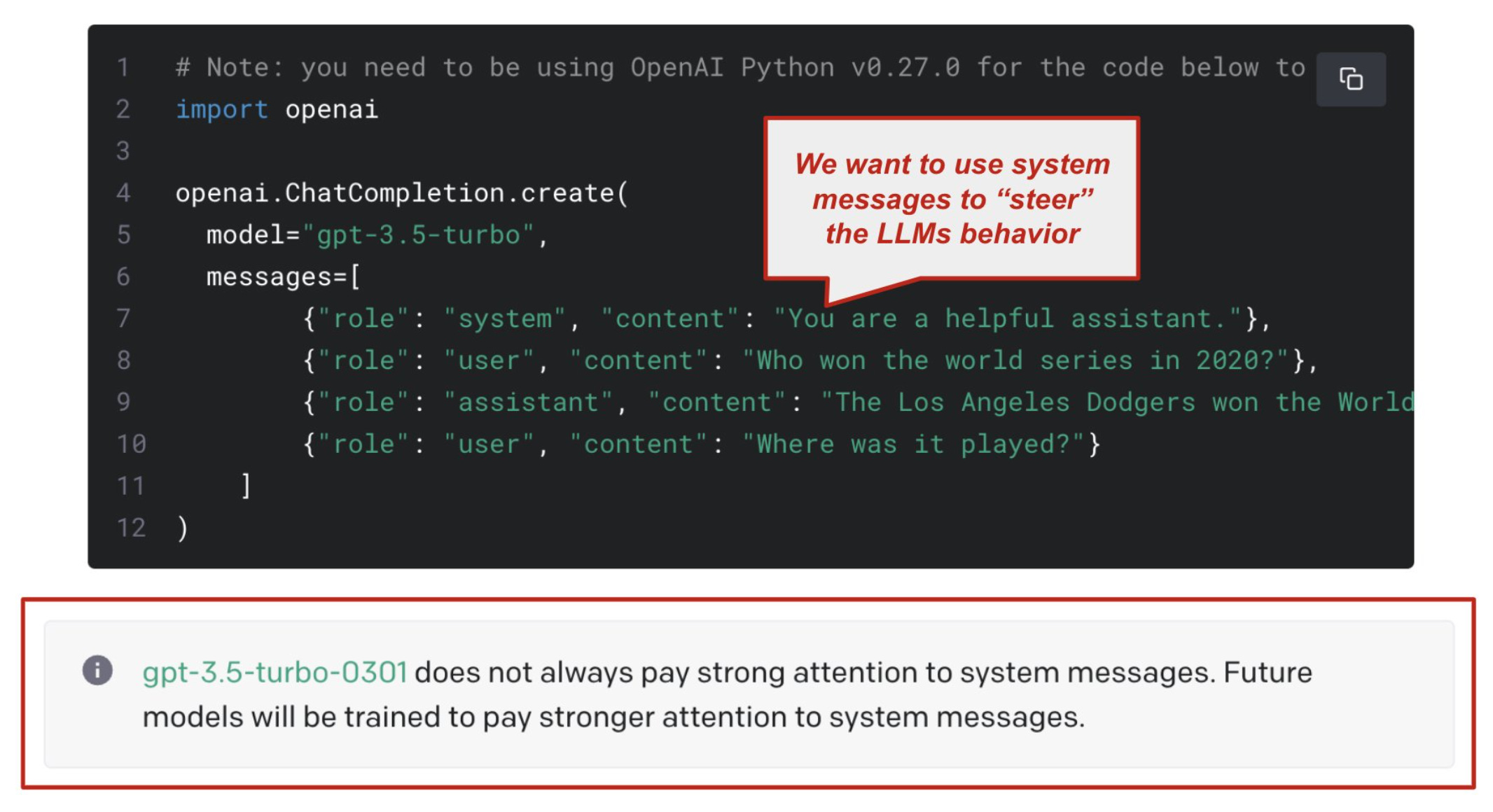
Most chat-based LLMs that we interact with allow us to provide a system message; see above. This message is basically an instruction to the model that describes how it is expected to behave or respond to the user. In the chat markup language used by ChatGPT and GPT-4 APIs, this system message is given the “system” role—as opposed to “user” or “assistant”—within a chat history. Generally, the system message is where we should place any instructions that should be followed by the LLM throughout the dialogue session with a user.
modern LLMs are steerable. Although prior LLMs (e.g., early versions of GPT-3.5-turbo) did not pay much attention to the system message, current models (e.g., GPT-4) are much more steerable. This means that we can provide detailed instructions in the system message for the LLM to follow. In practice, this property of modern LLMs can be leveraged to tweak their style or format (via the system message) to exactly match the application or task we are solving.
Other Useful Ideas
Knowledge distillation and model imitation: we have explained this idea extensively in prior overviews, but it is incredibly relevant to the analysis presented within this overview. [link]
Packing technique: This is a trick used in [1] that simply concatenates multiple text sequences into a single example during training to avoid excessive padding after each sequence and improve efficiency. [link]
Chain of Thought Prompting [13]: We have seen that encouraging an LLM to produce a problem-solving rationale along with its answer to a problem improves reasoning capabilities. Explanation tuning (more details to come) in [1] has a lot of fundamental similarities to this technique. [link]
Curriculum or progressive learning: Instead of just training a model over all of the data that we have, we could form a particular strategy or curriculum for exposing this data to our model1. In the case of [1], this curriculum involves first training the model over dialogue examples from ChatGPT, then performing further training over GPT-4 dialogue. This term is quite generic, as many different types of curriculums may exist. [link]
The Explosion of Open-Source LLMs

As LLMs began to increase in popularity, the most impactful models (e.g., GPT-3 and ChatGPT) were initially available only via paid, proprietary APIs. As we have learned in recent overviews, however, there is a burgeoning movement in the LLM community to create powerful open-source models! Many open-source models have been proposed, but this movement was especially catalyzed by the recent proposal of LLaMA [4], a suite of high-performing base models of various sizes that are trained solely on publicly-available data2.
LLaMA and Imitation Models

The weights of LLMs within the LLaMA suite were openly released (for research purposes) and then subsequently leaked online for anyone to access. Following this leak, LLaMA quickly gained in popularity and was used to create a variety of open-source derivative models, which we have explored in prior overviews.
Beyond LLaMA: The Power of Open LLMs [link]
Imitation Models and the Open-Source LLM Revolution [link]
Such LLaMA derivatives were primarily created using an imitation approach that instruction tunes LLaMA over dialogue examples from a more powerful model (e.g., ChatGPT). These imitation models were proposed in quick succession and seemed to perform really well—even on par with powerful models like ChatGPT in certain cases [6]. This led the LLM community to believe that proprietary LLMs could be easily replicated, but there’s a bit more to the story than that.

imitation or limitation? Although imitation models seem to perform well, we see in prior work [3] that this is only the case on the small subset of tasks that are observed during fine-tuning. Namely, most imitation models capture the style of proprietary LLMs like ChatGPT, but they fail to capture the knowledge, reasoning capabilities, and comprehension of these models. Such limitations can easily be missed within human evaluations of a model, as verifying whether a model’s information is factually correct requires a significant time investment.

Because modern LLMs are so good at generating coherent text, the differences between them can be difficult to measure, especially when the models being compared have a similar style and fluency. When imitation models are more rigorously evaluated using a broad set of quantitative benchmarks, we begin to clearly see their shortcomings. For example, the performance of Vicuna [6]—one of the higher-performing imitation models created with LLaMA—is seen to fall far short of ChatGPT on more difficult and complex benchmarks; see above.
Why is imitation not working?
When we study existing attempts at creating open-source replicas of proprietary LLMs via an imitation approach, most issues that we see are caused by the same problem: we don’t have enough high-quality data for instruction tuning. There are three basic ways in which we can generate this data:
Ask humans to generate the data
Use a prompting framework (e.g., self-instruct [9]) to generate synthetic data
Directly train on the outputs of existing LLMs
Popular LLMs like GPT-4 are trained over extensive amounts of human feedback, but generating data from humans is expensive and time consuming. To automate the collection of data, recent imitation models rely upon some variant of self-instruct [9] to generate a synthetic—meaning the data is generated by an LLM rather than a human—fine-tuning dataset. Unfortunately, datasets generated in this manner tend to lack in diversity and complexity. Plus, we run into similar problems when directly fine-tuning on LLM dialogues obtained from public APIs or ShareGPT. These datasets tend to be small-scale and homogenous, which is insufficient for creating a powerful imitation model.
“We conclude that broadly matching ChatGPT using purely imitation would require a concerted effort to collect enormous imitation datasets and far more diverse and higher quality imitation data than is currently available.” - from [3]
the path forward. Although existing attempts at using imitation have fallen short, there are a few different ways we can move forward. As proposed in [3], we could begin by creating more powerful, open-source base LLMs that could serve as a better “starting point” for instruction tuning. Prior work shows that using a better underlying base LLM drastically improves the performance of resulting imitation models. This area is already being extensively explored, as we see with the proposal of awesome, open-source foundation models like Falcon or MPT3.

Alternatively, we could consider ways to improve or expand existing datasets used for imitation learning. Current work relies solely upon prompt and response pairs generated from an LLM; see above. Within this overview, we will refer to such dialogues as “shallow” imitation examples, as they only contain information about the proprietary LLM’s response to a prompt. Going beyond shallow imitation, this overview will explore the idea of augmenting synthetic instruction tuning datasets with more detailed outputs from the proprietary LLM, such as:
Explanation traces
Step-by-step thought processes
Complex instructions
The imitation model can learn from extra information produced by a proprietary model during fine-tuning. We want imitation datasets that are large and diverse. In this overview, however, we will see that the type and granularity of data used can make a huge difference too. Such extra information can allow smaller, open-source LLMs to learn the reasoning process followed by a more powerful model.

Now from our partners!
Rebuy Engine is the Commerce AI company. They use cutting edge deep learning techniques to make any online shopping experience more personalized and enjoyable.
KUNGFU.AI partners with clients to help them compete and lead in the age of AI. Their team of AI-native experts deliver strategy, engineering, and operations services to achieve AI-centric transformation.
MosaicML enables you to train and deploy large AI models on your data and in your secure environment. Try out their tools and platform here or check out their open-source, commercially-usable LLMs.
Properly Learning to Imitate

Aiming to mitigate issues with existing imitation models, authors in [1] propose a 13 billion parameter imitation LLM, referred to as Orca. Like prior imitation models, Orca is based upon the LLaMA suite of LLMs, but it is fine-tuned using more than just a small set of “shallow” imitation examples. More specifically, Orca differentiates itself from prior work in two main ways:
A much larger and more comprehensive imitation dataset
Injecting detailed explanation traces into each instruction tuning example
The resulting model performs quite well across a variety of benchmarks, allowing the gap between imitation models and proprietary LLMs (e.g., ChatGPT or GPT-4) to be narrowed; see below. As we will see, however, GPT-4 is still much better.

bigger and better data. Orca selectively samples tasks from the FLAN collection [10]—a massive data source for instruction tuning—and acquires millions of responses from both ChatGPT and GPT-4 over complex prompts from each of these tasks. Using the system message, authors encourage these models to explain their response with added details, thus providing an “explanation trace” for each output generated by an LLM. Such an approach has a massive impact on model quality, as it provides a richer source of information from which the imitation model can learn. We will refer to this approach as “explanation tuning”—it’s just instruction tuning over data that contains explanation traces!
“Our research indicates that learning from step-by-step explanations, whether these are generated by humans or more advanced AI models, is a promising direction to improve model capabilities and skills.” - from [1]
relation to prior work. In a prior overview, we saw that LLaMA-based imitation models fall far short of imitating proprietary LLMs. To close the capability gap between imitation models and proprietary LLMs, we would need an imitation dataset that is significantly larger and more diverse. Prior work in [3] claims that obtaining such a dataset is too difficult, indicating that imitation models are a dead end. However, authors in [1] do exactly this (i.e., generate a massive and complex imitation dataset) to achieve a breakthrough in imitation model quality.
A better approach for imitation learning…

Orca’s breakthrough in imitation model quality can be attributed to its much larger, more detailed, and more complex imitation dataset; see above. Let’s explore the details of this dataset, focusing upon how proprietary models can be prompted to output step-by-step problem solving explanations that are a much more powerful learning signal for open-source imitation models.
explanation tuning. Prior imitation models are trained over pairs of prompts and associated responses generated from an LLM. Although this approach can teach the imitation model to replicate or memorize the teacher model’s output, there is not much else that can be learned from the model’s response alone—this information is shallow and lacks information regarding how or why a response was produced. In [1], authors explore an alternative approach that trains an imitation model how to replicate the reasoning process of the teacher model.

To do this, we just need to prompt the teacher model to output a detailed explanation along with its normal response. Drawing upon ideas like zero-shot CoT prompting [11], we can encourage the model to produce detailed explanations with each of its responses by just tweaking the system message; see above. Then, we can fine-tune the imitation model using both the response and the explanation as a training signal. As we have seen in prior work [11], teaching an LLM to output such detailed explanation traces with each of its answers can lead to large improvements on reasoning tasks and complex instruction following.
creating the dataset. To fine-tune Orca, a massive imitation dataset is created by sampling from the millions of instructions contained in the FLAN collection as shown in the table below. The resulting set of instructions is called FLAN-5M.

The FLAN-5M instruction set is augmented with responses and explanations from ChatGPT obtained with the OpenAI API. Similarly, using a smaller set of sampled instructions called FLAN-1M (i.e., we basically just sub-sample the original set of 5M instructions), a similar procedure is performed using GPT-4, producing a dataset of 6 million total instruction examples paired with a response and explanation from a proprietary teacher model. Interestingly, authors in [1] note that collecting data from each of these models takes several weeks—even using the Azure OpenAI service—due to rate limits; see below.

progressive learning. Instead of training on all of this data together, we can achieve improved performance by fine-tuning Orca over ChatGPT-based explanations first, then fine-tuning on explanations from GPT-4 afterwards. Given that Orca is based upon a smaller LLaMA model that is significantly less powerful than proprietary LLMs, this progressive learning approach allows the imitation model to first learn from “easier” examples, prior to learning from the more detailed explanations of a powerful model like GPT-4. The positive impact of this approach is likely due to the fact that GPT-4 tends to produce longer and more intricate explanations that are harder to learn from; see below.

Explanation-based imitation learning is effective!
Orca is compared to a variety of different baselines, including Vicuna [6], text-davinci-003 (i.e., GPT-3.5), ChatGPT, and GPT-4. Authors in [1] consider a suite of different benchmarks that include writing, comprehension, and reasoning tasks; see below. Orca’s evaluation strategy is made quite comprehensive as to avoid the issues with misleading or incomplete evaluation results that plagued prior imitation models. Notably, we see in [1] that benchmarks composed of standardized tests offer a surprisingly robust evaluation framework.

open-ended generation. When evaluated on open-ended generation tasks, Orca outperforms Vicuna by a large margin in all experimental settings; see below. Here, performance is measured by considering a reference model (e.g., ChatGPT or GPT-4) and prompting GPT-4 to determine whether the output produced by the candidate model is better than the reference model’s output.
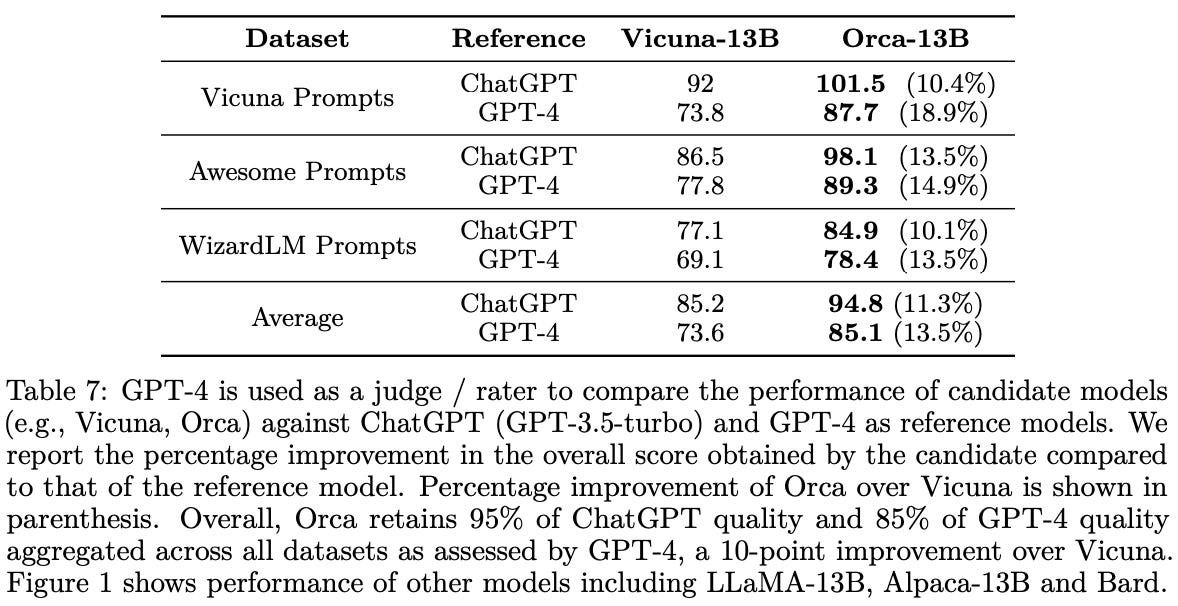
We see in these experiments that Orca maintains 95% of ChatGPT quality and 85% of GPT-4 quality across datasets. Although these metrics indicate a significant improvement in performance compared to prior imitation models, we should keep in mind that LLM-based evaluations are imperfect and still being explored. As such, these results, although positive, could be misleading.
reasoning. Orca continues to perform similarly to ChatGPT across reasoning benchmarks. For example, across (nearly) all topics on the AGIEval and BigBench-Hard datasets, Orca comes near or exceeds the performance of ChatGPT!

Although Orca’s performance on standardized exams still falls below that of ChatGPT in certain cases, we see that work in [1] makes significant progress towards bridging the gap with proprietary LLMs compared to prior imitation models; see below. Although it might not come as a surprise, GPT-4 is still a clear frontrunner in performance across nearly all tasks that are considered4.

other findings. Beyond the main empirical results presented in [1], we see that the proposed curriculum (or progressive) learning approach—where the model is first fine-tuned over 5M ChatGPT dialogue examples then 1M examples from GPT-4—has a large and positive impact on Orca’s performance. Additionally, Orca consistently underperforms ChatGPT in modeling long sequences.
Closing Remarks
“Our findings indicate that Orca significantly outperforms other open-source smaller models. Moreover, in some settings, it can match or even surpass the quality of ChatGPT, although a substantial gap with GPT-4 still remains.” - from [1]
Research on open-source LLMs is constantly evolving. One week, we think that proprietary LLMs have completely lost their moat, and the next week we find out that open-source (imitation) models are far worse than originally claimed. Although it seemed like imitation models were a dead end only a few weeks ago, we see in this overview that imitation is a valid approach! All we need is a bigger and better dataset. The major takeaways from this work are outlined below.
learning from step-by-step instructions. Prior work on imitation models relied upon simple prompt-response pairs for training. We see here that augmenting such data with detailed explanation traces allows the resulting model to learn from a much richer source of information. Rather than memorizing a model’s response for a small set of examples, we can allow the proprietary LLM’s problem-solving process to be replicated. As a result, the approach in [1] enables imitation model performance to generalize beyond data seen during fine-tuning.
“We emphasize the crucial role of data size and coverage when it comes to aligning smaller models to their more powerful counterparts, like GPT-4.” - from [1]
lots of imitation data. One of the main problems with prior imitation models is that they only performed well on tasks that were similar to data seen in their fine-tuning datasets. Given this particular limitation, we clearly need larger imitation datasets with more coverage. Although prior work indicated that producing such a dataset would be too difficult, we see in [1] that it is possible. Given a much larger and more comprehensive dataset (i.e., millions of examples), we can make imitation models perform much better than before.
remaining work. Orca’s performance, although impressive, still falls short of the best proprietary LLMs—more work has to be done to make open-source LLMs truly competitive. Closing this gap will mostly likely be a product of multiple ongoing initiatives, such as imitation learning, creating better foundation models, and curating better publicly-available datasets for instruction tuning and LLM refinement. However, open-source offerings should not be underestimated, as they will continue to improve alongside their proprietary counterparts.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, Ph.D. in deep learning and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews that clearly explain relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Mukherjee, Subhabrata, et al. "Orca: Progressive Learning from Complex Explanation Traces of GPT-4." arXiv preprint arXiv:2306.02707 (2023).
[2] Xu, Can, et al. "Wizardlm: Empowering large language models to follow complex instructions." arXiv preprint arXiv:2304.12244 (2023).
[3] Gudibande, Arnav, et al. "The false promise of imitating proprietary llms." arXiv preprint arXiv:2305.15717 (2023).
[4] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[5] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[6] Chiang, Wei-Lin et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” (2023).
[7] Geng, Xinyang et al. “Koala: A Dialogue Model for Academic Research.” (2023).
[8] Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. GPT4All: Training an assistant-style chatbot with large scale data distillation from GPT-3.5-Turbo, 2023.
[9] Wang, Yizhong, et al. "Self-Instruct: Aligning Language Model with Self Generated Instructions." arXiv preprint arXiv:2212.10560 (2022).
[10] Longpre, Shayne, et al. "The flan collection: Designing data and methods for effective instruction tuning." arXiv preprint arXiv:2301.13688 (2023).
[11] Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." arXiv preprint arXiv:2205.11916 (2022).
[12] Wei, Jason, et al. "Finetuned language models are zero-shot learners." arXiv preprint arXiv:2109.01652 (2021).
[13] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
Interestingly, the generic idea of curriculum learning was proposed in 2009 by Yoshua Bengio. This idea actually predates a lot of concepts from modern deep learning!
This is important simply because anyone can replicate the training process. Every component of LLaMA can be recreated by anyone with sufficient compute resources.
In fact, MPT-30B—including instruction tuned versions—was released this week! Previously, we only had a 7 billion parameter version.