
Many Languages, One Deep Learning Model
Multilingual understanding is easier than you think!


This newsletter is supported by Alegion. As a research scientist at Alegion, I work on a range of problems from online learning to diffusion models. Feel free to check out our data annotation platform or contact me about potential collaboration/opportunities!
Welcome to the Deep (Learning) Focus newsletter. Each issue picks a single topic in deep learning research and comprehensively overviews related research. Feel free to subscribe to the newsletter, share it, or follow me on twitter if you enjoy it!

How do we enable natural language-based deep learning systems to understand data in many languages? One naive approach would be to simply train a separate deep learning model on each of the desired languages. But, this approach is pretty tedious. What if we need to create a system that ingests data from over 100 different languages? Incurring the cost of training 100 deep learning models is not feasible for most practitioners.
Luckily, recent deep learning research has shown that multilingual language understanding may be simpler than it seems. Shortly after the advent of BERT [1], researchers realized that bidirectional transformer models are more than capable of learning from multiple languages at once. Such an approach makes deep learning on multiple languages simple — just train a single model to handle all languages.
“Recent developments … suggest that it is possible to build universal cross-lingual encoders that can encode any sentence into a shared embedding space.” - from [2]
These multilingual models are nearly identical to BERT. However, their self-supervised pre-training is performed over a multilingual corpus that contains textual data from over 100 languages. Although some additional considerations exist for training these multilingual models, the overall approach is shockingly similar to training monolingual BERT models.
The main benefits of multilingual deep learning models for language understanding are twofold:
simplicity: a single model (instead of separate models for each language) is easier to work with.
inductive transfer: jointly training over many languages enables the learning of cross-lingual patterns that benefit model performance (especially on low-resource languages).
For deep learning practitioners, these models are quite useful, as they perform surprisingly well and do not require any in-depth linguistic understanding. Over the course of this overview, I will explain current work on BERT-based multilingual models, including analysis of such models’ behavior/tendencies and explanations of more recently-proposed models.
Underpinnings of Multilingual Understanding
In the natural language processing (NLP) domain, significant research effort has been invested into crafting general-purpose (monolingual) sentence representations (e.g., FastText, Word2Vec, GloVe [8], etc.). The advent of BERT [1] – explained in my previous article – revolutionized this space, revealing that pre-trained, bidirectional transformer models yield fine-tunable sentence representations that solve language understanding tasks with very high accuracy.
Beyond monolingual approaches, many NLP researchers have studied the problems of word or phrase alignment across languages [9, 10], machine translation [11], and cross-lingual representation learning [12]. At its core, such research asks the question: is it possible to create a universal sentence encoder with a shared embedding space across languages?
Moving in this direction, recent research has found that BERT-style, pre-trained transformers can produce useful, multilingual sentence representations. By simply making the pre-training corpus of BERT multilingual, these models gain a decent understanding of many languages and can be fine-tuned to solve cross-lingual tasks (e.g., classification of sentences in multiple languages). The first of such methods, called multilingual BERT (mBERT), was actually proposed in tandem with BERT.
Multilingual BERT (mBERT)
The original BERT publication [1] made no reference to multilingual learning. However, the public release of BERT actually included a multilingual version of BERT, called (creatively) multilingual BERT (mBERT).
This model is nearly identical to BERT, the only differences being:
Joint pre-training over multiple languages (more below)
Using a shared token vocabulary and embedding space across languages
Put simply, mBERT is a single model that learns unified representations across a large number of languages.
pre-training approach. mBERT is pre-trained on Wikipedia data from over 100 languages (as opposed to just English). To construct the pre-training dataset, authors find 100 languages with the largest amount of data on Wikipedia, then concatenate this data to form a multilingual pre-training dataset. All languages learned by mBERT are embedded based on a single WordPiece vocabulary with size 110K.
A probability is assigned to each language, and pre-training updates samples a portion of textual data from a single language to be used in a self-supervised update according to this probability, allowing mBERT to be exposed to all different languages throughout pre-training. Unsurprisingly, certain languages in the pre-training dataset are naturally under-represented – they have less data than others. To mitigate the impact of this imbalance, the probability of each language is exponentially smoothed as follows:
Take the probability of each language (e.g., if 21% of the pre-training corpus is English, English has a probability of 21%)
Exponentiate this probability by a factor s (e.g., mBERT uses s=0.7, which yields 0.21^0.7 = 0.335)
Re-normalize (i.e., divide by the sum) each language’s probability based on these exponentiated probabilities
This smoothing approach (i) slightly decreases the probability of sampling a high-resource language and (ii) slightly increases the probability of sampling a low-resource language. Although the amount of smoothing is controlled by the choice of s, this technique ensures low-resource languages are not under-represented (and vice versa) during pre-training; see below.

For those who are interested, the exponential smoothing of language probabilities is inspired by a similar technique that is used for time series forecasting.
mBERT is really useful. When evaluated on the XNLI dataset, mBERT was found to be quite effective at solving cross-lingual tasks. Joint pre-training across multiple languages led to noticeable performance benefits, where classification tasks on low-resource languages saw the largest boost. Such results revealed that multilingual pre-training facilitates positive inductive transfer – training on many languages at once is actually better than training separate models for each language.
It should be noted that many prior methods for multilingual (and monolingual) understanding relied upon specialized, linguistic approaches. The proposal of mBERT (and BERT) drastically simplified solving NLP tasks for everyday practitioners.
Datasets
Several datasets exist that can be used for the downstream evaluation of multilingual deep learning models. These datasets include both classification-style problems, as well as more complex problems such as named entity recognition or question answering.
cross-lingual NLI (XNLI) corpus. XNLI, a multilingual version of the popular multiNLI corpus, is currently the most popular dataset for evaluating multilingual language understanding. The multiNLI dataset contains 433K pairs of sentences that have been annotated with textual entailment information (i.e., whether the sentences contradict each other, entail each other, or are neutral). The multiNLI dataset is unique from other natural language inference datasets in that it contains sentences across numerous genres of speech and text.
The XNLI corpus is a version of multiNLI that has been translated into 15 different languages by:
Using humans to translate the dev and test sets
Machine translating the training set
Several different approaches for training on the XNLI dataset are often reported within the literature, including:
translate-train: perform training and evaluation using a separate model on the training set for each language
translate-test: dev and test sets are translated into English, then a single English model is fine-tuned on the training set and used for evaluation
Translate-train-all: a single multilingual model is fine-tuned on the machine-translated version of the training set in all different languages, then used for evaluation with each different language.
Evaluation might also be performed using a zero-shot setting, in which a certain language is left out of the training set but still included in evaluation.
other datasets. Although XNLI is quite popular, several other datasets exist for evaluating multilingual language understanding. For example, the CoNLL dataset for named entity recognition (NER) contains translations in English, Dutch, Spanish and German. Additionally, for question answering, the MLQA benchmark has taken the popular SQuAD benchmark for English and extended it into Spanish, German, Arabic, Hindi, Vietnamese and Chinese versions. Finally, multilingual models are still typically evaluated on the GLUE benchmark to better compare their performance to monolingual models. More extensive multilingual benchmarks, such as XTREME, have also been proposed recently.
Publications
I will now overview several publications that study multilingual BERT models. Two of these publications propose potential modifications to the underlying model, while the others analyze model behavior and study extensions to more complex applications (e.g., named entity recognition).
Cross-Lingual Language Model Pre-Training [2]

Concurrently with the proposal of mBERT, authors in [2] developed the cross-lingual language model (XLM). XLM was one of the first models to use the combined ideas of generative and cross-lingual pre-training to create a multilingual, transformer-based language understanding model. XLM shares the same architecture as BERT, aside from the extra “language” embedding that is added to each token within the model’s input; see the figure above.
Similarly to mBERT, XLM has a shared tokenization approach and embedding space across all different languages. As a result of this shared embedding space, token-level patterns that are shared between languages can be easily learned.
“this greatly improves the alignment of embedding spaces across languages that share either the same alphabet or anchor tokens such as digits or proper nouns” - from [2]
In contrast to mBERT, authors consider two sources of pre-training data for XLM:
Unsupervised, raw textual data from each of the different languages (same as mBERT pre-training data).
Sets of parallel sentences in different languages (i.e., a sentence in one language is paired with the same sentence in another language).
The second type of dataset mentioned above is similar to a machine translation dataset — it simply contains pairs of sentences in which each sentence has been translated into another language. Obviously, obtaining such sentence pairs is more difficult than obtaining raw text, as it requires the translation of textual data (either by a machine or a human annotator).
Using these two data sources, several different pre-training tasks are proposed for XLM:
causal language modeling (CLM): given a set of words within a sequence, predict the next word (this is a vanilla language modeling task).
masked language modeling (MLM): the same, self-supervised MLM task used within BERT.
translation language modeling (TLM): similar to MLM, but two parallel sentences in different languages are used as input (as opposed to monolingual input).
Intuitively, the TLM task can learn correspondences between languages. If some word is masked in one language, the model can attend to the corresponding region of the translated sentence to predict the masked word; see below.

Because the CLM task requires the use of unidirectional self-attention, three separate XLM models are pre-trained using CLM, MLM, and MLM+TLM. When evaluated on downstream tasks, these XLM models achieve state-of-the-art results on cross-lingual detection and machine translation benchmarks. Using MLM or MLM+TLM pre-training objectives yields the best performance.

XLM models trained with CLM are also shown to yield perplexity improvements in downstream language modeling applications. The most significant performance improvements by XLM occur on low-resource languages, revealing that multilingual pre-training yields positive inductive transfer for such languages.
In the zero-shot transfer domain, XLM performs well in generalizing to new languages. In particular, XLM, due to its shared vocabulary across languages, can leverage token similarities between languages to reason about languages that are not explicitly included in its training set.
How Language Neutral is Multilingual BERT? [3]
Following the public release of mBERT, many researchers had questions regarding the model’s behavior and properties. How can BERT support multiple languages with so little modification? Are the representations learned from different languages aligned (i.e., similar words in different languages have similar representations)? Can the performance of mBERT be improved via more specific adaptations to supporting multiple languages?
Attempting to address these questions, authors in [3] took the mBERT model and studied its behavior on three downstream tasks:
language identification: classifying the language of a sentence
sentence retrieval: finding the translated version of a sentence within a corpus of text in a different language
word alignment: computing alignment of corresponding words and phrases in translated versions of the same sentence
machine translation quality estimation: computing the quality of a (machine-generated) translation without access to a reference translation (i.e., this is a more nuanced/difficult task. For more info, see Section 4 of [3])
After fine-tuning mBERT on each of these different tasks, the authors perform extensive analysis that yields insights into the model’s behavior. Interestingly, mBERT representations are found to be composed of both language-neutral and language-specific components — the representations produced by mBERT are not completely language-neutral.
For example, mBERT is capable of identifying the language of an input sentence with high accuracy. However, when the representations of mBERT are centered/normalized (based on all other representations within a language), the model:
is much worse at classifying the source language
is much better at performing sentence retrieval
This finding reveals that some language-specific information is clearly contained within the representations of mBERT. As such, the patterns learned by mBERT are not truly universal across all languages. Despite attempting multiple modified fine-tuning approaches, the authors are unsuccessful in making the representations of mBERT more language neutral. Thus, producing models with improved language neutrality is left as future work.

Despite these findings, the authors observe that linguistically similar languages are clustered together in mBERT’s embedding space (see above) and that mBERT is adept at solving cross-lingual, word-level semantic tasks (e.g., word alignment and sentence retrieval). Despite struggling with more complex tasks like machine translation quality estimation, mBERT is still capable of capturing cross-lingual similarities to an extent. In other words, mBERT works well, but it must be improved before it can be directly applied to a wider scope of cross-lingual tasks.
Towards Lingua Franca Named Entity Recognition with BERT [4]
If you are like me, the first question you will ask about this paper is — what is this title and what does it mean? So, first things first, the phrase “lingua franca” is defined by Oxford Languages as:
“a language that is adopted as a common language between speakers whose native languages are different.”
Although the title is a bit fancy, the definition above actually summarizes the paper’s purpose quite well — to find a single model that can perform named entity recognition simultaneously across multiple languages. In particular, the authors of [4] train an mBERT model (shown below) jointly across NER datasets in multiple languages.

mBERT is found to be completely capable of solving such a task. The model can be trained jointly on NER tasks in different languages, which yields improvements in NER performance, especially on low-resource languages.
The authors also show that mBERT is capable of performing zero-shot NER inference with high accuracy. This may not seem surprising given that prior mBERT/XLM models could perform zero-shot inference in a similar manner. However, NER is a complex, token-level task that is difficult to solve compared to classification tasks. Despite its simplicity and ease of use, mBERT again performs surprisingly well in this complex domain.

Attempting to analyze mBERT’s impressive zero-shot performance, the authors show that mBERT’s token embeddings are well-aligned after pre-training, meaning that similar words/phrases in different languages have similar embeddings. As such, even if a certain language is left out of the fine-tuning process, this alignment in the embedding space enables useful information to be extracted and used for inference. Alignment seems to degrade during fine-tuning, but this can be fixed by simply freezing earlier network layers.
Unsupervised Cross-lingual Representation Learning at Scale [6]
Authors in [6] propose the XLM-RoBERTa (called XLM-R for short) model, a multilingual BERT model based upon RoBERTa (i.e., a variant of BERT) [7]. Instead of building upon the publicly-available mBERT model, however, the authors build their own model from scratch, emphasizing that making different choices in the pre-training process can lead to better downstream models for multilingual understanding.
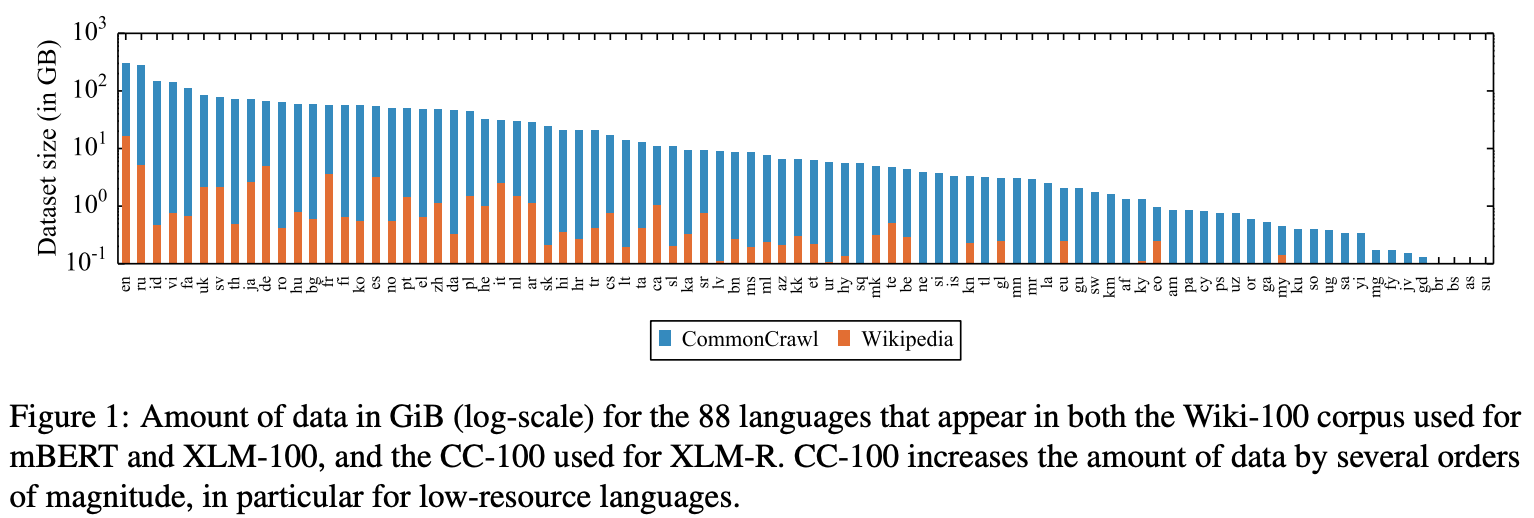
mBERT [1] and XLM [2] are pre-trained on Wikipedia data that has been aggregated across many languages. Authors in [6] claim that such a pre-training dataset limits model performance. Instead, they construct a multilingual corpus of textual data using the Common Crawl repository — a publicly-available database of web-crawl data. The corpus includes data from over 100 languages and is two orders of magnitude larger than the Wikipedia-based dataset; see above.
The XLM-R model is pre-trained over this larger corpus similarly to mBERT, using language sampling according to exponentially-smoothed language probabilities. However, the authors do make a few changes to the underlying model and training scheme:
The size of the shared token vocabulary is increased from 110K to 250K.
A more generic tokenization approach is adopted to remove language-specific pre-processing required by mBERT.
The amount of pre-training that is performed is significantly increased (prior models were apparently under-trained!).
The XLM-R model significantly outperforms both mBERT and XLM on both multilingual inference and question answering tasks, establishing itself as the go-to model for multi-language understanding and revealing that pre-training over the larger corpus derived from Common Crawl is quite beneficial. Again, performance on low-resources tasks seems to benefit the most from using XLM-R, but XLM-R performs competitively with monolingual models on high-resource languages as well.

In the ablation experiments, XLM-R is trained using different numbers of languages. The authors uncover a phenomenon that they refer to as the Curse of Multilinguality. If you increase the number of languages used for training a model while keeping the model’s capacity/size fixed, the model’s performance will initially improve, but then begin to degrade as the number of languages becomes too large. Although this issue can be mitigated by simply increasing model size, it reveals that the number of jointly-learned languages is a consideration that must be kept in mind by practitioners using these multilingual models.
Takeaways
Although multilingual understanding seems to be a difficult task, recent deep learning research has revealed that current language understanding approaches handle this problem quite well. In particular, slightly modified versions of BERT can be jointly pre-trained over a multilingual corpus, then fine-tuned to solve cross-lingual tasks with surprising levels of accuracy.
By analyzing such models, it has been shown that:
A single multilingual BERT model can learn/understand a large number (i.e., >100) of different languages.
Joint pre-training over multiple languages yields noticeable performance benefits (especially for languages that lack large amounts of training data).
Multilingual models trained in this manner still perform competitively with monolingual models on high-resource languages (e.g., English or German)
Multilingual BERT models can generalize to new languages in a zero-shot manner due to their highly-aligned, shared vocabulary/embeddings across languages.
Prior research in multilingual understanding (and NLP in general) relied upon a significant amount of detailed, linguistic understanding. Most tasks were often solved using complex, specialized architectures. With (multilingual) BERT, language understanding tasks – even across multiple languages – can be solved with a single, easy-to-understand model.
the code. Fine-tuning/using these models is less computationally expensive than you would think! As such, I again emphasize the practical value of the BERT model to any deep learning practitioner. If you’re interested in trying out any of these methods, I recommend the code examples for XLM-R linked below.
further reading. Although I covered several papers within this overview, I found many others during my research that were really interesting. Some of my favorites are:
Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalisation
mT5: A massively multilingual pre-trained text-to-text transformer
Unsupervised cross-lingual representation learning for speech recognition
Multilingual speech recognition model [paper]
New to the newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University studying the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I pick a single, bi-weekly topic in deep learning research, provide an understanding of relevant background information, then overview a handful of popular papers on the topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Bibliography
[1] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[2] Lample, Guillaume, and Alexis Conneau. "Cross-lingual language model pretraining." arXiv preprint arXiv:1901.07291 (2019).
[3] Libovický, Jindřich, Rudolf Rosa, and Alexander Fraser. "How language-neutral is multilingual BERT?." arXiv preprint arXiv:1911.03310 (2019).
[4] Moon, Taesun, et al. "Towards lingua franca named entity recognition with bert." arXiv preprint arXiv:1912.01389 (2019).
[5] Lample, Guillaume, et al. "Neural architectures for named entity recognition." arXiv preprint arXiv:1603.01360 (2016).
[6] Conneau, Alexis, et al. "Unsupervised cross-lingual representation learning at scale." arXiv preprint arXiv:1911.02116 (2019).
[7] Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692 (2019).
[8] Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. "Glove: Global vectors for word representation." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[9] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems 26 (2013).
[10] Ammar, Waleed, et al. "Massively multilingual word embeddings." arXiv preprint arXiv:1602.01925 (2016).
[11] Johnson, Melvin, et al. "Google’s multilingual neural machine translation system: Enabling zero-shot translation." Transactions of the Association for Computational Linguistics 5 (2017): 339-351.
[12] Conneau, Alexis, et al. "XNLI: Evaluating cross-lingual sentence representations." arXiv preprint arXiv:1809.05053 (2018).