


LLaMA: LLMs for Everyone!
High-performing language models that are fully open-source...


This newsletter is sponsored by Rebuy, the Commerce AI company. If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!
this newsletter. This newsletter is part of my series on modern advancements in language models. Recently, deep learning research has been taken over by the unprecedented success of large language models (LLMs) like ChatGPT and GPT-4. I have already overviewed the history and core concepts behind these models.
GPT and GPT-2 [link]
Scaling laws and GPT-3 [link]
Modern LLMs (beyond GPT-3) [link]
Specialized LLMs [link]
PaLM [link]
T5 (Part One) [link]
T5 (Part Two) [link]
Within this series, I will go beyond this history of LLMs into more recent topics, examining a variety of recent techniques and findings that are relevant to LLMs.
For years, the deep learning community has embraced openness and transparency, leading to massive open-source projects like HuggingFace. Many of the most profound ideas in deep learning (e.g., transformers [2], self-supervised learning, etc.) are openly available online, either via public code repositories or Arxiv. Although open-source has been the norm for quite some time, the popularity (and commercial applicability) of large language models (LLMs) has recently challenged this tendency.
Many of the most powerful LLMs available today can only be accessed via APIs (e.g., from OpenAI or Anthropic), making the source code and model parameters inaccessible to researchers and developers. While it’s not my goal to spark a moral discussion of current trends in the LLM landscape, this information is relevant to the topic of this newsletter: openly-available LLMs. Interestingly, not all powerful language foundation models are hidden behind a paywall. Some models, such as LLaMA, are both openly available and incredibly high-performing, thus maintaining a sense of openness in the deep learning research community.
What is LLaMA? LLaMA is not a single model, but rather a suite of LLMs with sizes ranging from 7 billion to 65 billion parameters. Taking inspiration from Chinchilla [3], these LLMs are a bit smaller than their counterparts but are pre-trained extensively (i.e., smaller models, more tokens) and developed with the goal of providing a diverse group of models with different tradeoffs between performance and inference efficiency. LLaMA models perform surprisingly well; e.g., the 13 billion parameter model is roughly comparable to GPT-3 [4], while the 65 billion parameter model often surpasses the performance of PaLM [5].
“GPT-4 has learned from a variety of licensed, created, and publicly available data sources, which may include publicly available personal information.” - from [6]
Beyond the impressive performance, LLaMA uses only publicly available data for pre-training. Taking a step (back) towards open-source within the LLM landscape, LLaMA models can be reproduced completely from online resources. Recent models such as GPT-4 are known to have been trained with a combination of public and proprietary/private data. Although this may benefit model performance, LLaMA demonstrates that we can do a lot with data that is available online, thus providing a source of hope for open research initiatives related to LLMs.
Background Information
The LLaMA LLMs adopts several ideas and techniques that are proposed in prior work. Within this section, we will go over some useful background information that will be helpful in developing a deeper understanding of LLaMA and its components.
brief note on LLMs. First, it’s helpful to understand the basics of LLMs, including their architecture, training procedure, and general approach. We have explored this topic extensively in prior overviews. As such, we won’t cover this topic in detail here, but links for further reading and learning are provided below.
LLM (Decoder-Only) Architecture [link]
Language Model Pre-Training [link]
Explanation of LLMs [link]
LLM History [link]
LLM Basics [link]
Root Mean Square Layer Normalization (RMSNorm)
Typically, transformer architectures (including the decoder-only transformer architectures used by LLMs) use LayerNorm to normalize activation values within each of their layers. However, using different normalization techniques has been shown to stabilize training and improve generalization performance. For example, RMSNorm [16] is defined as shown in the equation below.
RMSNorm is somewhat similar to LayerNorm, but it removes the mean-centering operation (and uses a slightly modified denominator) when normalizing the neural network’s activation values. Compared to LayerNorm, RMSNorm is more computationally efficient and simple, allowing it to achieve comparable levels of performance with a 10-50% improvement in efficiency.

SwiGLU Activation Function
Each block of an LLM’s decoder-only architecture contains a two-layer feed-forward neural network (i.e., uses no bias and is applied individually to each token vector) with a non-linearity between the two layers. Originally, this non-linearity was a Rectified Linear Unit (ReLU) activation function. However, recent work [15] has revealed that this is not the optimal choice.
In particular, LLaMA (and other LLMs like PaLM) opt to use a SwiGLU activation function instead, which is formulated in the equation above. Here, we define the Swish activation as follows.
SwiGLU is an element-wise product of two linear transformations of the input x, one of which has had a Swish activation applied to it. This activation function requires three matrix multiplications, but it has been found to yield improvements in performance relative to other activation functions, even when the amount of compute being used is held constant.
Rematerialization (or Recomputation)
Rematerialization, also known as recomputation, is a technique used in the training of LLMs (and other large neural networks) to reduce memory consumption at the cost of additional computation. Typically, when we compute the forward pass of a neural network, we will store/retain the network’s activations at each layer so that they can be used during the backward pass (this is necessary to compute the weight update!). But, this requires a lot of memory!
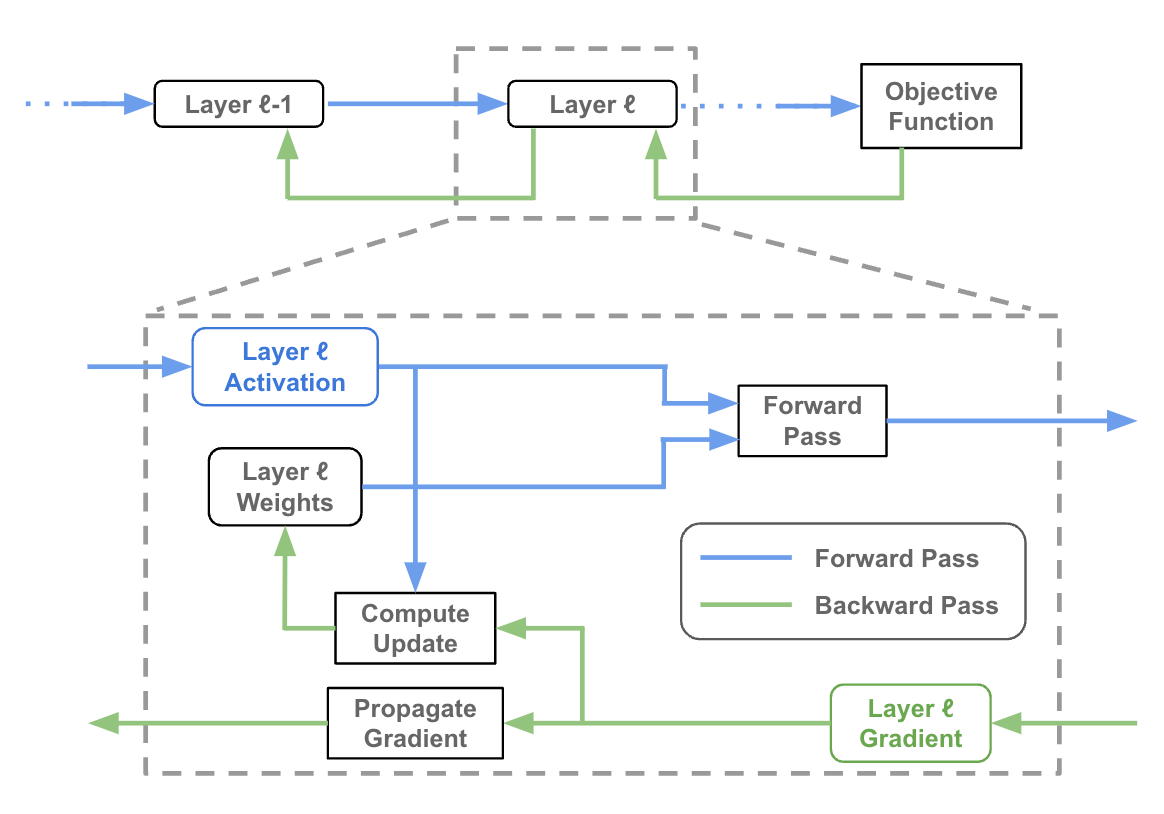
The basic idea of rematerialization is to recompute certain intermediate activation values during the backward pass rather than storing them in memory during the forward pass. This can help reduce the peak memory usage during training, allowing for the training of larger models or the use of larger batch sizes within the available memory constraints. This is especially important for LLMs given that they are large and consume a ton of memory.
The LLaMA Suite
Now that we have some useful concepts under our belt, let’s learn more about the collection of LLMs within LLaMA and how they work. Because these models are heavily inspired by the pre-training strategy proposed by Chinchilla (TL;DR: just pre-training smaller LLMs over a lot more data) [3], we will briefly overview these ideas prior to taking a deeper look at LLaMA. Overall, LLaMA heavily questions the trend toward massive LLMs, claiming that (if enough pre-training is performed!) much smaller LLMs can achieve impressive performance at a significantly lower inference budget.
How do we maximize LLM efficiency?
One especially notable moment in the lineage of recent LLMs was the proposal of Chinchilla [3]. After GPT-3, the deep learning research community was astounded by the emergence of impressive few-shot learning capabilities in sufficiently-large language models. As a result, we began to test models that were even larger than GPT-3. But, the results weren’t that great!
“Recent work from Hoffmann et al. (2022) shows that, for a given compute budget, the best performances are not achieved by the largest models, but by smaller models trained on more data.” - from [1]
To create LLMs that were much better than GPT-3, we couldn’t just use larger models. Rather, we needed a lot more pre-training data! Namely, the analysis from Chinchilla demonstrated that higher levels of performance were possible if we pre-trained slightly smaller LLMs more extensively.
is this the full picture? Despite knowing that smaller LLMs can perform well if pre-trained extensively, even analysis performed in [3] suggests that training relatively larger LLMs is the most efficient way to reach a high level of performance. This claim is completely true, but it only considers training efficiency. Thus, we have to ask ourselves the question: is training efficiency all that we care about? For most practitioners, the answer to this question is undoubtedly no!
“The focus of this work is to train a series of language models that achieve the best possible performance at various inference budgets, by training on more tokens than what is typically used.” - from [1]
The cost of training is only a small part of the full cost associated with an LLM. We also have to worry about hosting, making inference budget a huge consideration. LLaMA embraces this idea by emphasizing that, given a target level of performance, pre-training a smaller LLM for longer will ultimately be cheaper during inference and save a lot of cost over time. Although we might use a larger model if we need the performance boost, we should minimize model size as much as possible (and thus decrease hosting costs) via extensive pre-training.
Components of LLaMA

dataset. We know that the pre-training dataset for LLaMA is based upon public data, but where exactly does this data come from? The contents of the pre-training dataset used for LLaMA are outlined above. As can be seen, the pre-training data (despite being completely public) has quite a bit of diversity, with sources ranging from StackExchange to the Gutenberg Project. The full dataset contains roughly 1.4T tokens after being tokenized. This is the same number of tokens over which Chinchilla [3] was pre-trained; see below.

Given LLaMA’s emphasis on transparency and repeatability, a ton of insight is provided in [1] regarding the construction of the pre-training dataset. One of the most interesting aspects of this discussion is that we can use it to learn more about how data is filtered prior to pre-training an LLM. For example, textual data from CommonCrawl is filtered to exclude:
duplicate documents (using the CCNet pipeline [7])
non-English data (by training a fastText linear classifier)
low-quality content (using an n-gram language model)
Plus, authors in [1] train a linear classifier to distinguish pages used as references in Wikipedia from randomly sampled pages, then discard pages that are not classified as references. All of these steps were taken just for filtering CommonCrawl! From prior work, we know that correct filtering of the pre-training dataset is essential to LLM performance. In [1], we get more insight into the specifics of implementing an effective filtering pipeline.
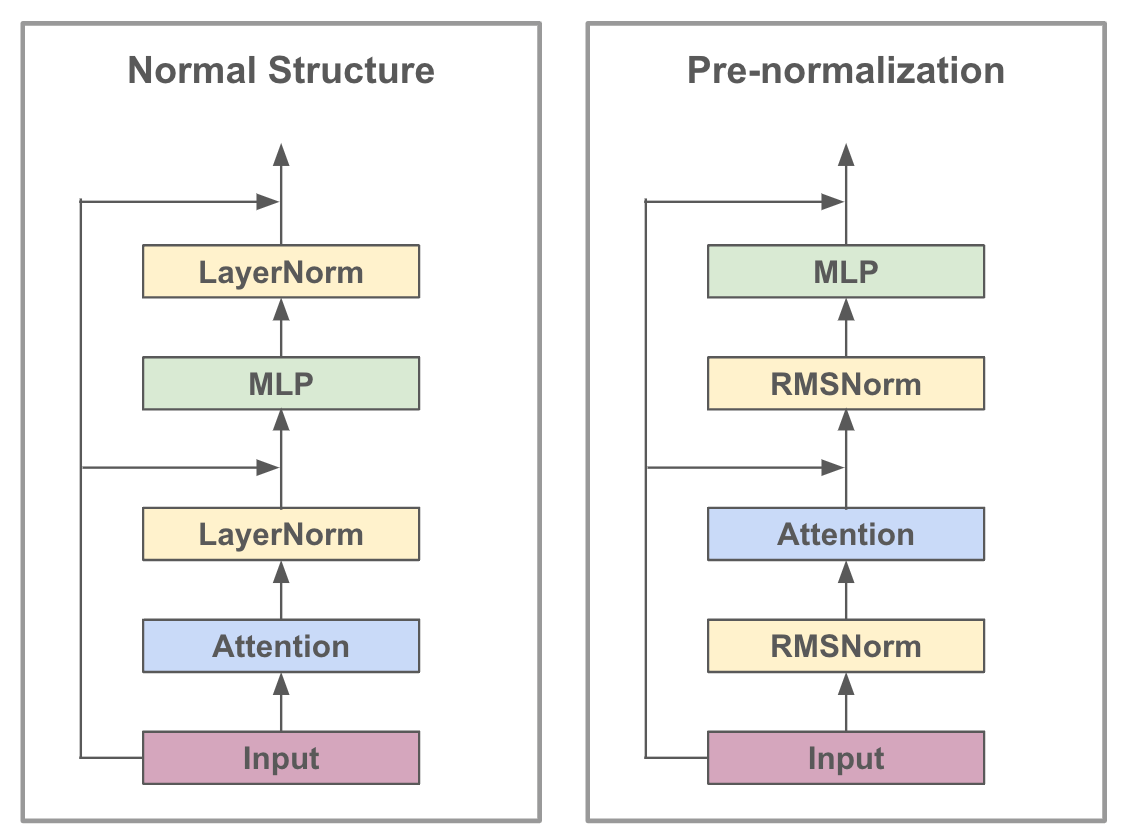
architecture. The LLaMA suite adopts a lot of common architectural tricks from popular LLMs like GPT-3 [4] and PaLM [5]. For example, LLaMA performs pre-normalization within each of its layers, meaning that normalization is applied to the input of each layer within the transformer instead of the output; see above. Additionally, RMSNorm, SwiGLU activation functions, and rotary positional embeddings (RoPE) [10] (i.e., a sort of hybrid between absolute and relative positional embeddings) are used in every transformer layer.
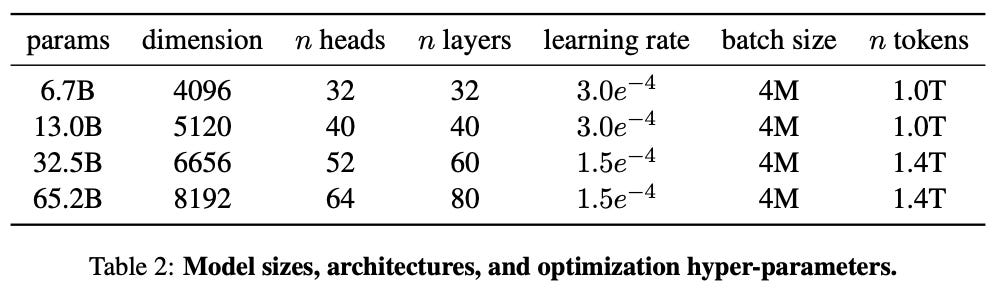
In [1], four different sizes of models are used, ranging from 6.7 billion parameters to 65.2 billion parameters; see above. These models form the collection of LLMs known as LLaMA and provide a variety of different tradeoffs between performance and model size or inference budget. Most notably, we will see that LLaMA-13B performs competitively with GPT-3 and can be run on a single V100 GPU. Compared to prior models, this is a huge accomplishment and makes the models way more accessible to most practitioners (e.g., PaLM is trained using >6K accelerators).
better efficiency. Authors in [1] adopt some interesting tricks to improve LLM training efficiency. First, we should recall that modern LLMs, based upon decoder-only transformer models, use causal multi-headed attention within each of their layers.


To improve the efficiency of this causal multi-head attention operation, LLaMA uses an efficient implementation that does not i) store attention weights or ii) compute key/query scores for tokens that are masked. By doing this, we can save a lot of computation that is typically wasted on masked tokens not considered by causal self-attention. Such an approach is inspired by ideas in [9], but we can find an open-source implementation in the xformers library.
Beyond an efficient causal self-attention implementation, LLaMA approaches rematerialization a bit differently compared to most LLM training strategies. The most expensive activations to compute (e.g., the output of linear layers) are saved during the forward pass, thus allowing the number of activations re-computed during the backward pass to be reduced. This change, which requires the LLM’s backward pass to be manually reimplemented (instead of using autograd in PyTorch) and is a sort of hybrid rematerialization approach, significantly improves overall training throughput.
“When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over our dataset containing 1.4T tokens takes approximately 21 days.” - from [1]
Given the modifications that LLaMA adopts to improve training efficiency, we might be wondering: how much faster does this actually make training? Well, it depends a lot on the training infrastructure. When using 2048 A100 GPUs, however, the LLaMA-65B takes roughly 21 days to complete pre-training over 1.4T tokens.
LLaMA vs. SOTA LLMs
While open-source and repeatability is great, no one will care about LLaMA unless the models perform well! Prior attempts at open-source LLMs have been made (e.g., OPT and BLOOM [11, 12]). But, these models are not competitive with modern LLMs in terms of performance. Within this section, we’ll analyze the performance of LLaMA models relative to popular LLMs like GPT-3 and PaLM [4, 5].
how do we evaluate? As has been described extensively in prior posts, LLaMA is evaluated similarly to most language foundation models: via zero and few-shot learning. Notably, LLaMA models are solely evaluated as pre-trained foundation models, meaning that no fine-tuning is performed (either via SFT or RLHF). LLaMA is compared to popular, closed-source LLMs (e.g., GPT-3, Gopher, Chinchilla, and PaLM [3, 4, 5, 13]) and prior open-source LLMs (e.g., OPT, GPT-J, and GPT-Neo [11, 14]) on both free-form generation and multiple choice-based tasks. A variety of domains are tested (e.g., common sense and mathematical reasoning, code generation, question answering, etc.).

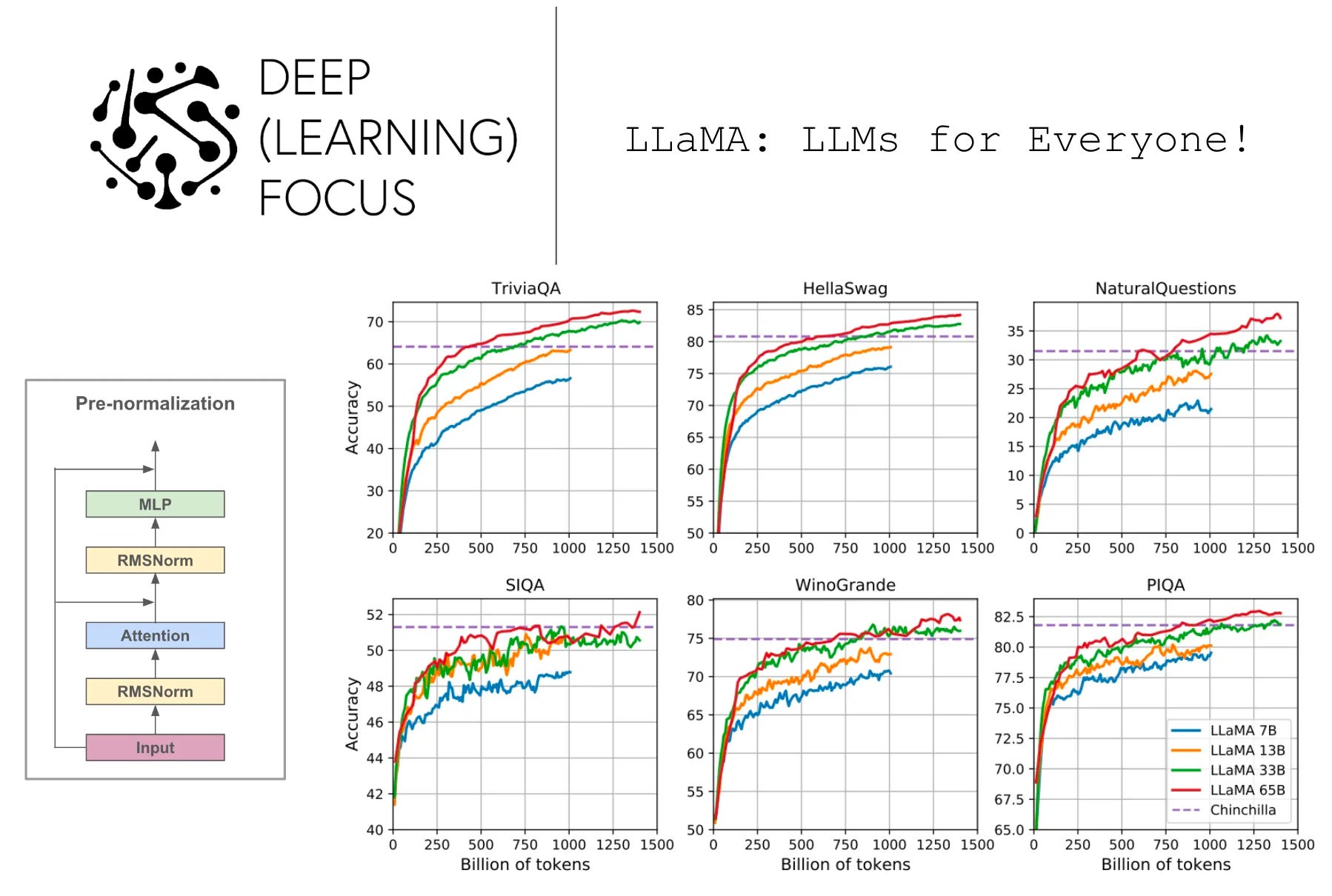
language understanding. On closed-book question answering and reading comprehension tasks, we see that LLaMA-65B achieves state-of-the-art zero and few-shot performance, consistently surpassing the performance of much larger models like PaLM and Chinchilla. Going further, LLaMA-13B performs surprisingly well and even improves upon the performance of GPT-3 (which is 10X larger!) in most cases. The basic takeaway here is that i) larger LLaMA models are competitive with state-of-the-art and ii) smaller LLaMA models perform surprisingly well for their size.
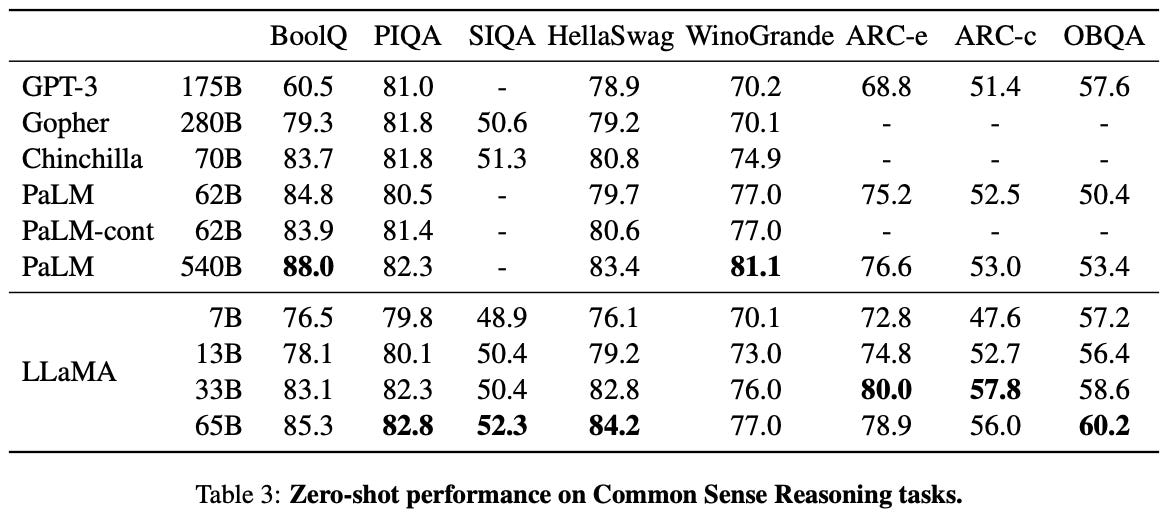
reasoning tasks. The LLaMA suite is also evaluated on common sense and mathematical reasoning tasks. On common sense reasoning tasks, LLaMA surpasses the zero-shot reasoning performance of several powerful baselines; see above. However, it should be noted here that no special prompting approaches (e.g., chain-of-thought prompting) are adopted to facilitate improved reasoning. Prior work [5] has shown that the ability of LLMs to “reason” may degrade with scale without the correct prompting approach.

Despite the limitations of this analysis, LLaMA’s reasoning abilities still seem relatively impressive compared to baselines. Namely, LLaMA models perform competitively with (and even better than in some cases) several baselines on mathematical reasoning datasets. In fact, LLaMA-65B even outperforms a similarly-sized Minerva model, which has been explicitly fine-tuned on mathematical data to improve its performance on such tasks.
"Minerva is a series of PaLM models finetuned on 38.5B tokens extracted from ArXiv and Math Web Pages… On GSM8k, we observe that LLaMA65B outperforms Minerva-62B, although it has not been fine-tuned on mathematical data.” - from [1]
code generation. Beyond basic reasoning capabilities, code generation is another skill of LLaMA models. Despite never fine-tuning on code (i.e., code accounts for <5% of LLaMA’s pre-training data), LLaMA-65B outperforms PaLM on code generation tasks and LLaMA-13B surpasses the code generation performance of GPT-3 (but… GPT-3 is admittedly poor at generating code).

other details. On the MMLU benchmark, LLaMA models lag behind the performance of LLMs like Chinchilla and PaLM in most cases. This benchmark is one of the only cases where LLaMA performance is noticeably surpassed by current alternatives. Authors in [1] claim this degradation in performance is due to the limited number of books and academic papers in the LLaMA pre-training dataset (i.e., >10X decrease in this kind of pre-training data compared to state-of-the-art LLMs).

When the performance of LLaMA models is tracked throughout the pre-training process, we observe a clear, steady improvement in performance throughout the pre-training process; see above. Although not all tasks behave similarly, we can see that the pre-training strategy adopted by LLaMA is relatively stable overall.
Takeaways
To make a long story short, LLaMA is an open-source LLM with shockingly good performance. Since the proposal of LLaMA, the research community has already made good use of such an impressive model being openly-available. As an example, the following research efforts have already extended upon LLaMA:
Vicuna: fine-tuned version of LLaMA with performance (almost) comparable to GPT-4 [link]
Koala: LLaMA fine-tuned on internet dialog data [link]
ChatLLaMA: create a personalized version of ChatGPT on you own data with minimal compute [link]
ColossalChat: model similar to ChatGPT with an RLHF pipeline based upon LLaMA [link]
LLaMA’s impact is likely to significantly increase. Personally, I’m incredibly excited to see research on open LLMS continue to progress. I hope that making these models more accessible will lead to more thorough investigation and development from the broader research community. Some basic takeaways are given below.
open-source LLMs. Right now, the LLM ecosystem is witnessing an interesting conflict, in which two different approaches are being used to surface these powerful foundation models to the public. On one hand, models like ChatGPT and GPT-4 are being solely released behind paid APIs, preventing detailed access of such models to the research community. Contributions like LLaMA go against this trend by providing full model access to the research community.
what size is best? Rather than releasing a single model, LLaMA provides a collection of LLMs with different sizes. Prior research on LLMs tends to promote the use of larger models, as larger LLMs tend to reach impressive levels of performance with less overall compute costs during training. However, if we pre-train a smaller model more extensively, LLaMA shows that we can reach comparable levels of performance while achieving significant reductions in inference cost. As such, it makes sense to (at least) consider the use of smaller LLMs, especially when we have to deploy them. Notably, some of the LLaMA models can be run on a single GPU, which drastically improves accessibility of such LLMs.
impressive performance. Prior to the proposal of LLaMA, many research groups attempted to release open-source versions of popular LLMs (e.g., OPT is basically an open-source GPT-3). But, these models perform much worse than paid models accessible via APIs. Although LLaMA falls short of optimal performance in some cases, it is a huge step forward, as it often outperforms popular, state-of-the-art LLMs (depending on the size of model being used).
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Bibliography
[1] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[2] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[3] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[4] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[5] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[6] OpenAI (2023). “GPT-4 Technical Report.” ArXiv, abs/2303.08774.
[7] Wenzek, Guillaume, et al. "CCNet: Extracting high quality monolingual datasets from web crawl data." arXiv preprint arXiv:1911.00359 (2019).
[8] Zhang, Biao, and Rico Sennrich. "Root mean square layer normalization." Advances in Neural Information Processing Systems 32 (2019).
[9] Rabe, Markus N., and Charles Staats. "Self-attention Does Not Need $ O (n^ 2) $ Memory." arXiv preprint arXiv:2112.05682 (2021).
[10] Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." arXiv preprint arXiv:2104.09864 (2021).
[11] Zhang, Susan, et al. "Opt: Open pre-trained transformer language models." arXiv preprint arXiv:2205.01068 (2022).
[12] Scao, Teven Le, et al. "Bloom: A 176b-parameter open-access multilingual language model." arXiv preprint arXiv:2211.05100 (2022).
[13] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[14] Black, Sid, et al. "Gpt-neox-20b: An open-source autoregressive language model." arXiv preprint arXiv:2204.06745 (2022).
[15] Shazeer, Noam. "Glu variants improve transformer." arXiv preprint arXiv:2002.05202 (2020).
[16] Zhang, Biao, and Rico Sennrich. "Root mean square layer normalization." Advances in Neural Information Processing Systems 32 (2019).