

Practical Prompt Engineering
Tips and tricks for successful prompting with LLMs...


This newsletter is sponsored by Rebuy, the Commerce AI company. All consulting and sponsorship inquiries can be sent directly to me. Thank you so much for your support!
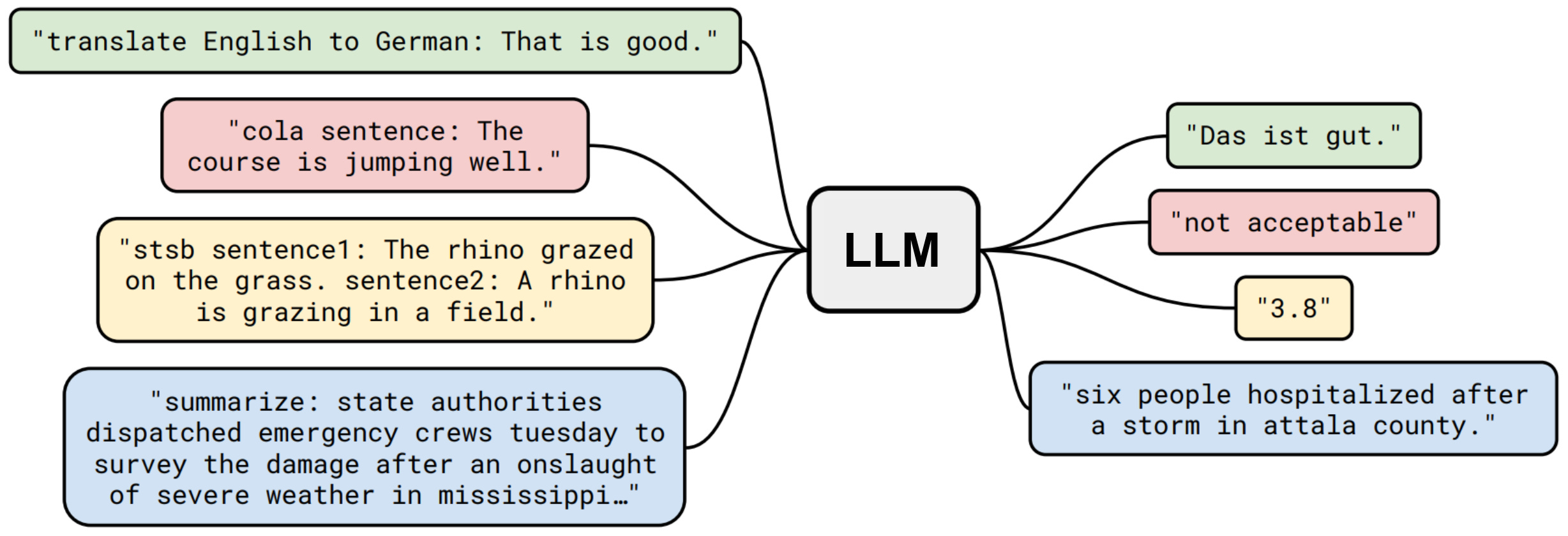
Due to their text-to-text format, large language models (LLMs) are capable of solving a wide variety of tasks with a single model. Such a capability was originally demonstrated via zero and few-shot learning with models like GPT-2 and GPT-3 [5, 6]. When fine-tuned to align with human preferences and instructions, however, LLMs become even more compelling, enabling popular generative applications such as coding assistants, information-seeking dialogue agents, and chat-based search experiences.
Due to the applications that they make possible, LLMs have seen a quick rise to fame both in research communities and popular culture. During this rise, we have also witnessed the development of a new, complementary field: prompt engineering. At a high-level, LLMs operate by i) taking text (i.e., a prompt) as input and ii) producing textual output from which we can extract something useful (e.g., a classification, summarization, translation, etc.). The flexibility of this approach is beneficial. At the same time, however, we must determine how to properly construct out input prompt such that the LLM has the best chance of generating the desired output.
Prompt engineering is an empirical science that studies how different prompting strategies can be use to optimize LLM performance. Although a variety of approaches exist, we will spend this overview building an understanding of the general mechanics of prompting, as well as a few fundamental (but incredibly effective!) prompting techniques like zero/few-shot learning and instruction prompting. Along the way, we will learn practical tricks and takeaways that can immediately be adopted to become a more effective prompt engineer and LLM practitioner.
understanding LLMs. Due to its focus upon prompting, this overview will not explain the history or mechanics of language models. To gain a better general understanding of language models (which is an important prerequisite for deeply understanding prompting), I’ve written a variety of overviews that are available. These overviews are listed below (in order of importance):
Language Modeling Basics (GPT and GPT-2) [link]
The Importance of Scale for Language Models (GPT-3) [link]
Prompting at a Glance
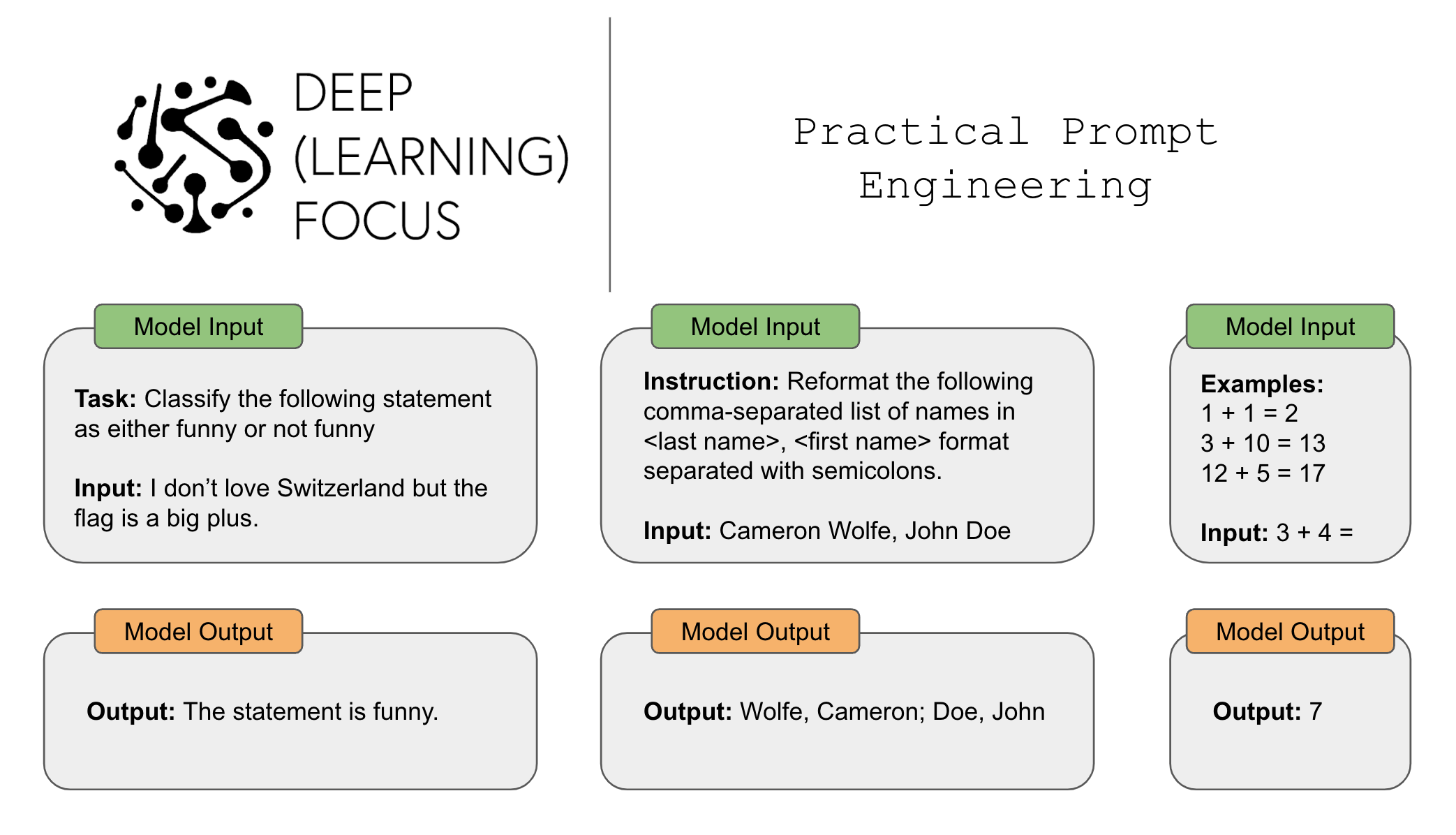
Given the current hype around LLMs, we might ask ourselves: what are the fundamental strengths of LLMs that make them so powerful? Although there’s not a single answer to this question (e.g., model scale, massive pre-training data, human feedback, etc.), one major strength of LLMs is their generic, text-to-text format. These models are experts at next-token prediction, and so many different tasks can be solved by properly tuning and leveraging this skill!
To solve a task, all we need to do is i) provide textual input to the model that contains relevant information and ii) extract output from text returned by the model. Such a unified approach can be used for translation, summarization, question answering, classification, and more. However, the story is not (quite) that simple. Namely, the wording and structure of the prompt (i.e., the inputted text) provided to the LLM can significantly impact the model’s accuracy. In other words, prompt engineering is a huge deal.
What is prompt engineering?
“Prompt engineering is a relatively new discipline for developing and optimizing prompts to efficiently use LMs for a wide variety of applications and research topics.” - from [2]
Given that properly crafting the contents of our prompt is important to achieving useful results with an LLM, prompt engineering has gained a lot of interest in recent months. However, it’s an empirical science—discovering the best-possible prompts is typically heuristic-based and requires experimentation. We can discover better prompts by tracking and versioning our prompts over time and testing different ideas to see what works.

components of a prompt. There are a variety of options for how a prompt can be created. However, most prompts are comprised of the same few (optional) components:
Input Data: this is the actual data that the LLM is expected to process (e.g., the sentence being translated or classified, the document being summarized, etc.).
Exemplars: one of the best ways to demonstrate the correct behavior to an LLM is to provide a few concrete examples of input-output pairs inside of the prompt.
Instruction: instead of showing concrete exemplars of correct behavior in the prompt, we could just textually describe what to do via an instruction; see above.
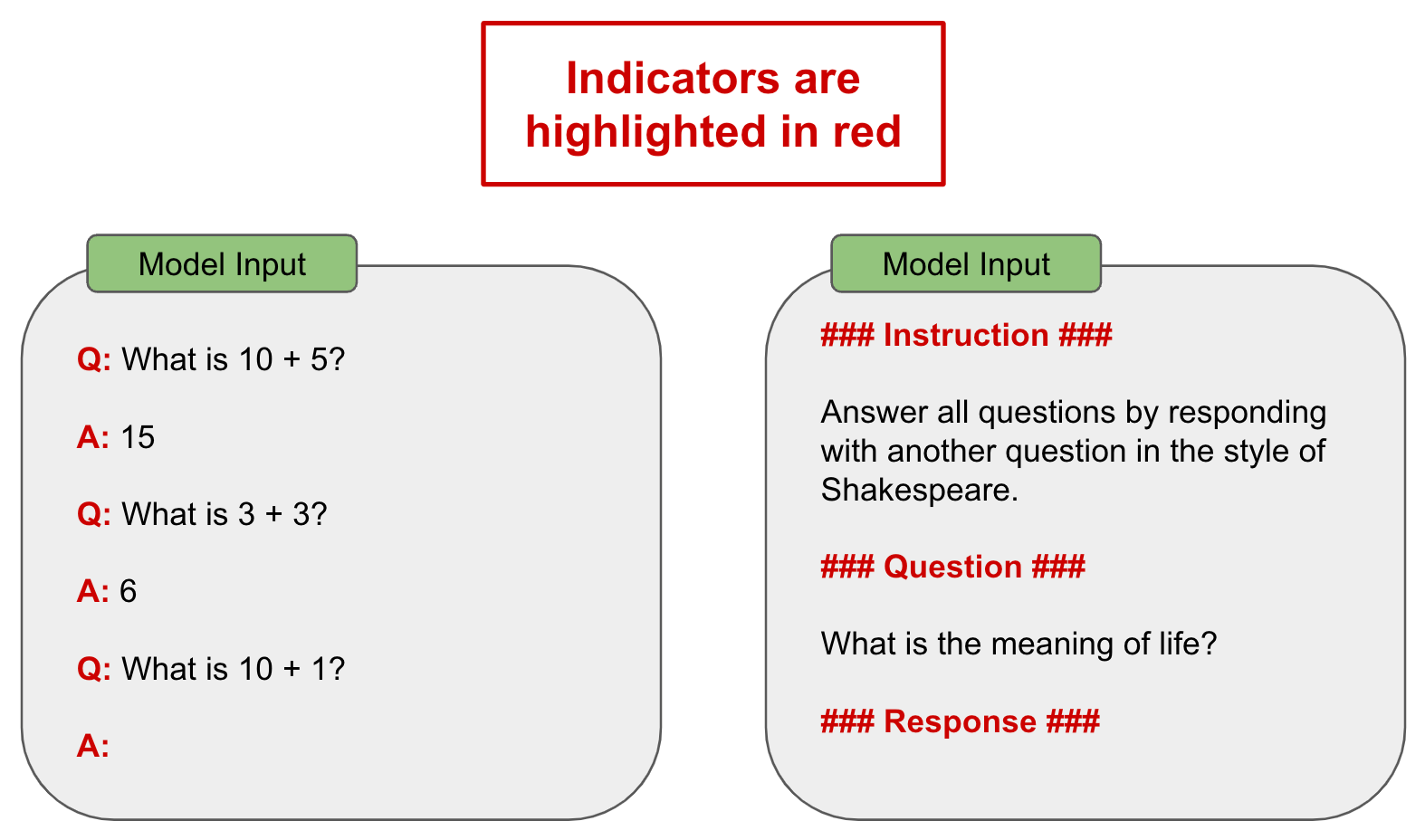
Indicators: providing input to an LLM in a fixed and predictable structure is helpful, so we might separate different parts of our prompt by using indicators; see below.
Context: Beyond the components described above, we may want to provide extra “context” or information to the LLM in some way.
general tips. The details of prompt engineering differ a lot depending on the model being used and what task we are trying to solve. However, there are a few generally-accepted principles for prompt engineering that are helpful to keep in mind [1, 3].
Start simple: start with a simple prompt, then slowly modify the prompt while tracking empirical results.
Be direct: if we want the LLM to match a specific style or format, we should state this clearly and directly. Stating exactly what you want gets the message across.
Specificity: ambiguity is the enemy of every prompt engineer. We should make the prompt detailed and specific without going overboard and providing an input that is too long (i.e., there are limitations to how long the prompt can be!).
Exemplars are powerful: if describing what we want is difficult, it might be useful to provide concrete examples of correct output or behavior for several different inputs.
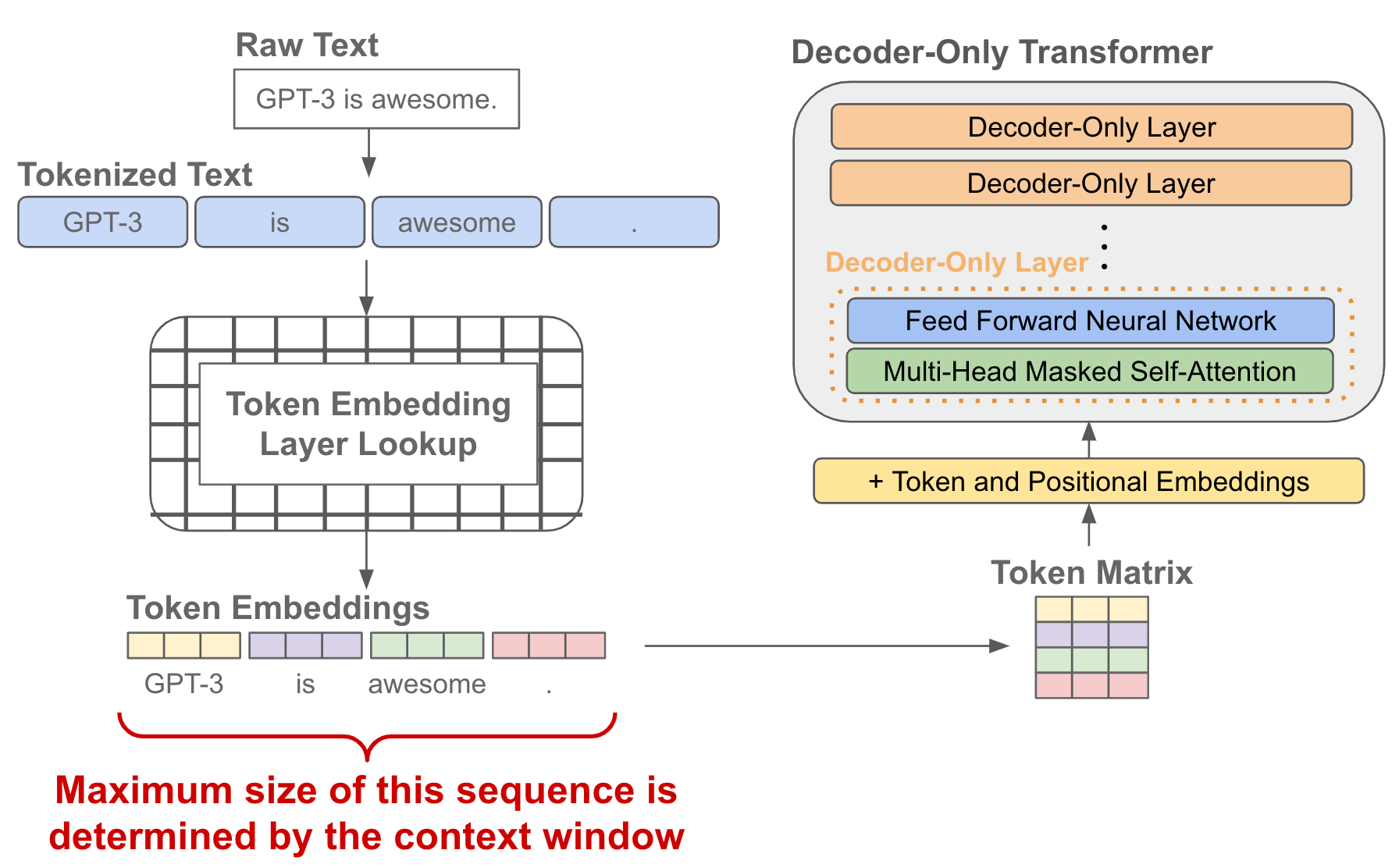
The Context Window
As we consider different prompting tips and approaches, we need to remember that we can only include a limited amount of information in our prompt. All LLMs have a pre-defined context window that sets a limit on the total number of tokens (i.e., words or sub-words in a textual sequence) that can be processed at a time. Context window size differs between models, but there is currently a strong push towards increasing context window sizes. For example, GPT-4 has a context window of 32K tokens, which is 4X bigger than any prior model from OpenAI.
Common Prompting Techniques

Although LLMs have seen a recent explosion due to popular models like ChatGPT, prompting has been around for a while. Originally, models like GPT [4] were fine-tuned to solve downstream tasks. With the proposal of GPT-2 [5], we saw researchers start to use zero-shot learning to solve multiple downstream tasks with a single foundation model. Finally, GPT-3 showed us that language models become really good at few-shot learning as they grow in size. In this section, we will walk through these ideas to gain a better idea of how zero and few-shot learning work, as well as provide details on a few more complex prompting techniques.
Zero-Shot Learning

The idea behind zero-shot learning is quite simple. We just feed a description of the task being solved and the relevant input data to an LLM and let it generate a result; see above. Due to the massive amount of pre-training data they observe, LLMs are often pretty capable of solving tasks in this way. Namely, they can leverage their knowledge base to solve a (relatively) large number of tasks; see the examples below (produced with GPT-3.5).
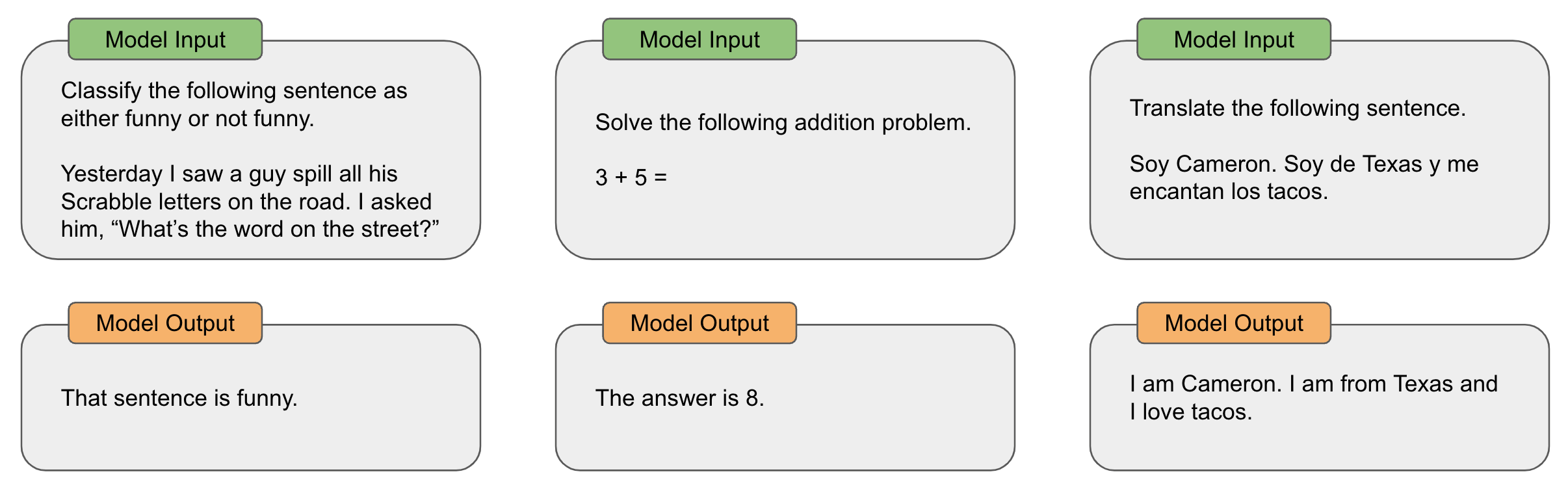
Zero-shot learning was explored extensively by models like GPT-2 and performs well in some cases. However, what should we do if zero-shot learning does not solve our task? In many cases, we can drastically improve the performance of an LLM by providing more specific and concrete information. In particular, we can start adding examples of desired output to the prompt, allowing the model to replicate patterns from data seen in the prompt.
Few-Shot Learning
Beyond just a task description, we can augment our prompt with high-quality input-output examples. This technique forms the basis of few-shot learning, which attempts to improve LLM performance by providing explicit examples of correct behavior. If used properly and applied to the correct model, few-shot learning is incredibly effective, as demonstrated by the breakthrough capabilities of LLMs like GPT-3 [6]; see below.
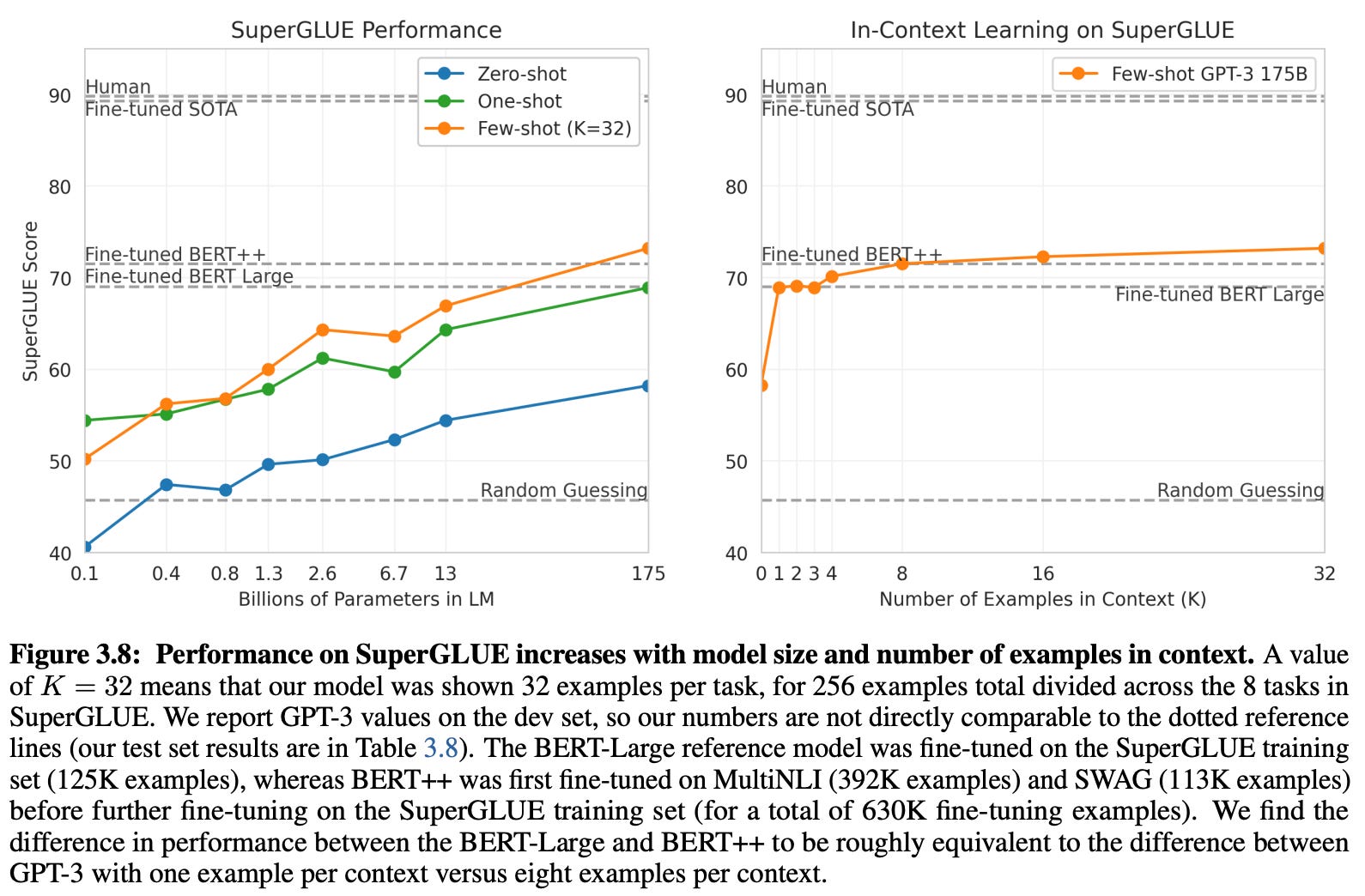
However, learning how to properly leverage the few-shot learning capabilities of LLMs can be complicated. What examples should we include in the prompt? Is there a correct way to structure the prompt? Do changes to the prompt significantly affect the LLM?
Most LLMs are sensitive to the manner in which the prompt is constructed, making prompt engineering both difficult and important. Although recent models like GPT-4 seem to be less sensitive to small perturbations in the prompt [2], the research community [7] has provided us with some tips for properly using few-shot learning that are still helpful to understand:
Exemplar ordering is important, and permuting few-shot examples can drastically change LLM performance. Including more few-shot examples does not solve this problem.
The distribution of labels in the few-shot examples matters and should match the actual distribution of data in the wild. Surprisingly, the correctness of labels is not as important.
LLMs tend to be biased towards repeating the last of the few-shot examples (i.e., recency bias).
Exemplars that are included in the prompt should be diverse and randomly ordered.
optimal data sampling. Selecting examples that are diverse, randomly-ordered, and related to the test example is best. Beyond these basic intuitions, however, a significant amount of research has been done to determine how to select optimal exemplars for a prompt. For example, few-show learning samples can be chosen via diversity selection [8], uncertainty-based selection [9], or even selection based on similarity to the test example [10].

few-shot learning vs. fine-tuning. Prior to moving on, I want to address a notable point of confusion. Few-shot learning is not fine-tuning. Few-shot learning presents examples to the LLM inside of the prompt, which can then be used as relevant context for generating the correct output. This process is referred to as “in-context learning”; see above. The model’s parameters are not modified by few-shot learning. In contrast, fine-tuning explicitly trains the model (i.e., updates its weights via backpropagation) over a chosen dataset.
Instruction Prompting

Few-shot learning is incredibly powerful, but it has a notable drawback: exemplars consume a lot of tokens. Given that the context window of an LLM is limited, we might want to explore prompting methods that do not consume as many tokens. For example, can we textually explain the correct behavior to an LLM? The short answer is yes! This technique, which just includes a written instruction as part of the prompt, is known as instruction prompting, and it performs best with a particular type of LLM.
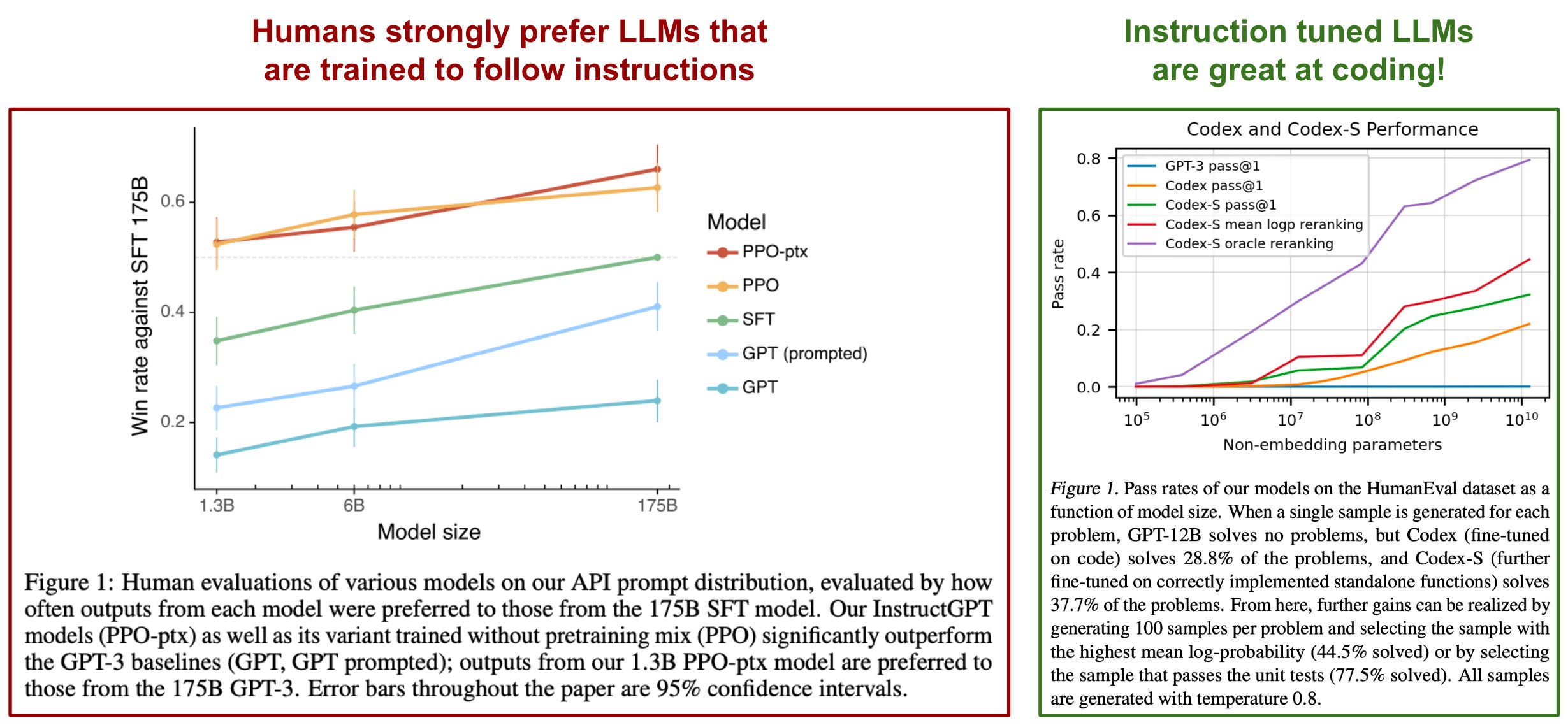
instruction tuning and alignment. Recent development of language models has heavily focused upon improving instruction following capabilities. Pre-trained LLMs are not good at following instructions out-of-the-box. However, teaching these models how to follow instructions makes them a lot better at accomplishing what the user wants (i.e., improves human alignment). Instruction following LLMs power a variety of useful applications from information seeking dialogue agents (e.g., ChatGPT) to coding assistants (e.g., Codex [13]); see below.
As has been discussed extensively in prior posts, the first step in creating an LLM is pre-training the model using a language modeling objective over a large, unlabeled corpus of text. During this process, the model gains information and learns to accurately perform next-token prediction. However, the model’s output is not always interesting, compelling, or helpful, and the model usually struggles to comply with complex instructions. To encourage such behavior, we need to go beyond basic pre-training.
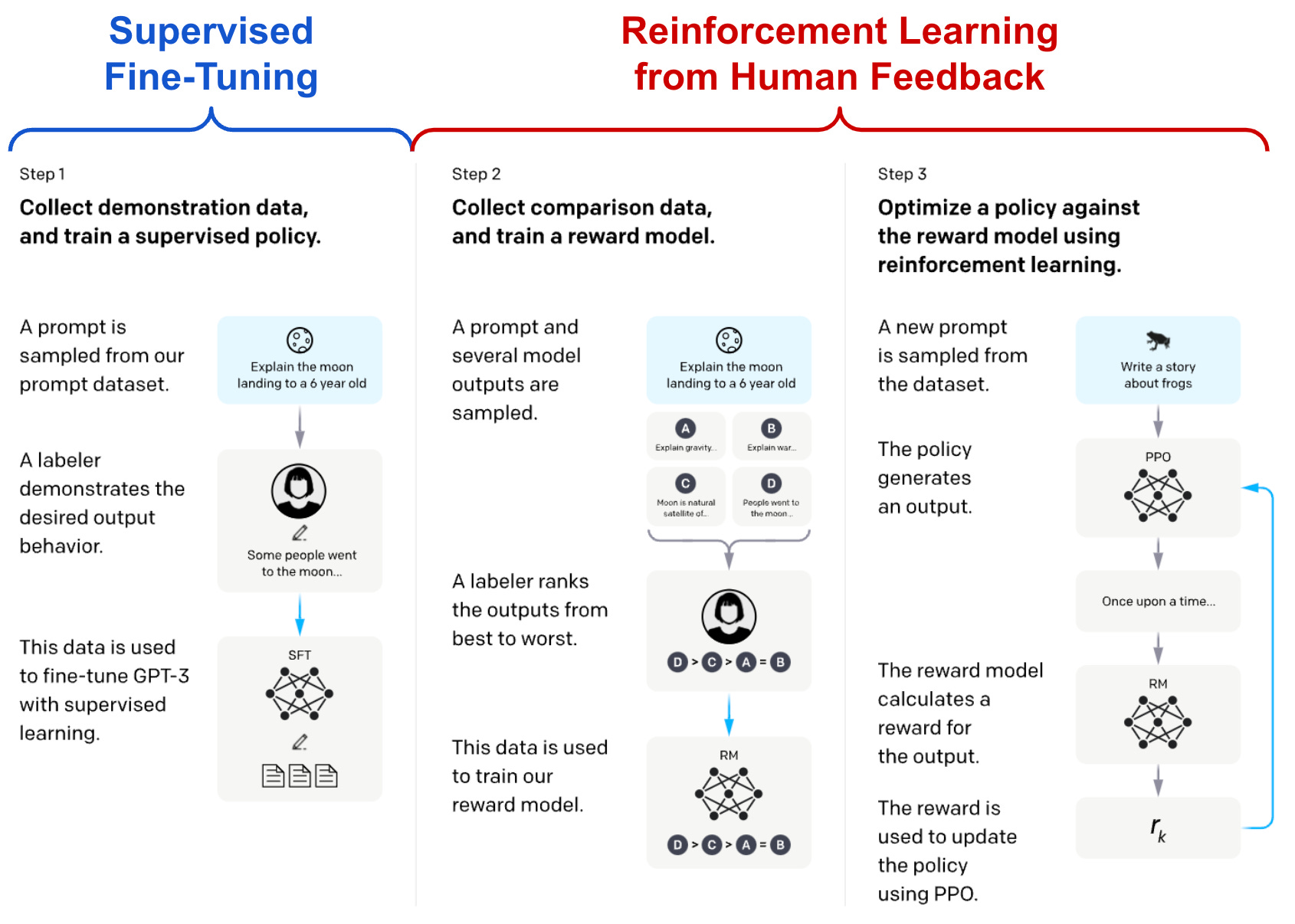
creating instruction-following LLMs. There are a couple of different approaches for teaching an LLM how how to follow instructions. For example, we can perform instruction tuning [12], or fine-tune the LLM over examples of dialogues that include instructions. Several notable models adopt this approach, such as LLaMA (and its variants) [15], all FLAN models [12], OPT-IML [16], and more. Alternatively, we could use the three-step approach comprised of supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF); see below. This methodology has led to the creation of incredible models such as ChatGPT, GPT-4, Sparrow [17], and more.
crafting useful instructions. If we have access to an LLM that has been trained to follow instructions, we can accomplish a lot by prompting the model with useful and informative instructions. Here are some key tips and ideas for using instruction prompting:
Just like the rest of our prompt, the instruction should be specific and detailed.
We should avoid telling the LLM to not do something in the prompt. Rather, we should focus on telling the LLM what to do.
Using an input structure with indicators that clearly identify the instruction within the prompt is helpful; see below.

role prompting. Another interesting prompting technique that is tangentially related to instruction prompting is role prompting, which assigns a “role” or persona to the model. This role is assigned within the prompt via a textual snippet such as:
You are a famous and brilliant mathematician.
You are a doctor.
You are a musical expert.
Interestingly, recent LLMs are able to assume and maintain such roles quite well throughout a dialogue [18]; see below.

Going further, role prompting isn’t just a fun trick. Providing a role to the LLM can actually improve performance (e.g., role prompting GPT-3 as a “brilliant mathematician” can improve performance on arithmetic-based questions). However, role prompting only improves performance in certain cases.
“When assigning a role to the AI, we are giving it some context. This context helps the AI understand the question better. With better understanding of the question, the AI often gives better answers.” - from learnprompting.org
instruction prompting in the real world. Prompting LLMs with instructions is an incredibly powerful tool that we can use for a variety of applications. To understand how to leverage this technique, we can look no further than the recent release of ChatGPT plugins, which included an open-source information retrieval API. Inside of this API, there are two specific modules provided for extracting metadata from documents and filtering personally identifiable information (PII). Interestingly, these services are entirely LLM-based and use the prompts shown below.

Within these prompts, the LLM is provided with specific and detailed instructions regarding how to perform its desired task. Some notable aspects of the instructions are:
The desired output format (either json or true/false) is explicitly stated.
The instruction uses a structured format (i.e., bullet-separated list) to describe important information.
The task of the LLM (i.e., identifying PII or extracting metadata) is explicitly stated in the prompt.
Interestingly, these prompts tell the model what not to do on multiple occasions, which is typically advised against.
Trusting an LLM to accurately perform critical tasks like PII detection might not be the best idea given their limitations. Nonetheless, such an approach demonstrates the incredible potential of instruction prompting. Instead of writing an entire program or service, we may be able to quickly solve a lot of tasks by just writing a prompt.
Takeaways
“Writing a really great prompt for a chatbot persona is an amazingly high-leverage skill and an early example of programming in a little bit of natural language” - Sam Altman
If we learn nothing else from this overview, we should know that constructing the correct prompt (i.e., prompt engineering) is a large part of successfully leveraging LLMs in practice. Language models, due to their text-to-text structure, are incredibly generic and can be used to solve a variety of tasks. However, we must provide these models with detailed and appropriate context for them to perform well. Although optimal prompting techniques differ depending on the model and tasks, there are many high-level takeaways that we can leverage to maximize chances of success.
from zero to few-shot learning. Given their extensive pre-training (and, these days, fine-tuning) datasets, LLMs contain a ton of information and are capable of solving a variety of tasks out-of-the-box. To do this, we only provide the model with a task description and relevant input data, then the model is expected to generate the correct output. However, zero-shot learning can only perform so well due to the limited context provided to the model. To improve upon the performance of zero-shot learning, we should leverage few-show learning by inserting exemplars in the prompt.
instruction-following LLMs. Although it performs well, few-shot learning typically consumes a lot of tokens, which is a problem given the limited context window of most LLMs. To work around this, we can adopt an instruction prompting approach that provides a precise, textual description of the LLM’s desired behavior as opposed to capturing this behavior with concrete examples of correct output. Instruction prompting is powerful, but it requires a specific form of LLM that has been fine-tuned (e.g., via instruction tuning or RLHF) to work well. Pre-trained LLMs are not great at following instructions out of the box.
tips and tricks. Prompt engineering comes with a variety of tricks and best practices that can be adopted. Typically, such techniques fluctuate with each new model release (e.g., GPT-4 is much better at handling unstructured prompts compared to prior models [2]), but a few principles have remained applicable for quite some time. First, we should always start with a simple prompt, then slowly add complexity. As we develop our prompt, we should aim to be specific and detailed, while avoiding being overly verbose (due to the limited context window). Finally, to truly maximize LLM performance, we usually need to leverage few-shot learning, instruction prompting, or a more complex approach.
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a better understanding of deep learning research via understandable overviews that explain relevant topics from the ground up. If you like this newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[2] Saravia, Elvis, et al. “Prompt Engineering Guide”, https://github.com/dair-ai/Prompt-Engineering-Guide (2022).
[3] Weng, Lilian. (Mar 2023). Prompt Engineering. Lil’Log. https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/.
[4] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[5] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[6] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[7] Tony Z. Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. ICML.
[8] Su, Hongjin, et al. "Selective annotation makes language models better few-shot learners." arXiv preprint arXiv:2209.01975 (2022).
[9] Diao, Shizhe, et al. "Active Prompting with Chain-of-Thought for Large Language Models." arXiv preprint arXiv:2302.12246 (2023).
[10] Liu, Jiachang, et al. "What Makes Good In-Context Examples for GPT-$3 $?." arXiv preprint arXiv:2101.06804 (2021).
[11] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[12] Wei, Jason, et al. "Finetuned language models are zero-shot learners." arXiv preprint arXiv:2109.01652 (2021).
[13] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[14] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[15] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[16] Iyer, Srinivasan, et al. "OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization." arXiv preprint arXiv:2212.12017 (2022).
[17] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[18] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
I really enjoyed this edition and look forward to the next part of the series, Cameron. I've been meaning to learn more about this, so your newsletters timing could not be better :)
And...there was no way that I could see, on how to prompt (now I do come close to your topic here) so that it would not fabricate references...