
Data is the Foundation of Language Models
How high-quality data impacts every aspect of the LLM training pipeline...


This newsletter is presented by Rebuy, the commerce AI company.
Sponsor the newsletter | Follow me on Twitter | Get in touch | Suggest a topic
Large Language Models (LLMs) have been around for quite some time, but only recently has their impressive performance warranted significant attention from the broader AI community. With this in mind, we might begin to question the origin of the current LLM movement. What was it that actually made recent models so impressive compared to their predecessors? Although some may argue a variety of different factors, one especially impactful advancement was the ability to perform alignment. In other words, we figured out how to train LLMs to not just output the most likely next word, but to output text will satisfy the goals of a human, whether it be by following an instruction or retrieving important information.
“We hypothesize that alignment can be a simple process where the model learns the style or format for interacting with users, to expose the knowledge and capabilities that were already acquired during pretraining” - from [1]
This overview will study the role and impact of alignment, as well as the interplay between alignment and pre-training. Interestingly, these ideas were explored by the recent LIMA model [1], which performs alignment by simply fine-tuning a pre-trained LLM over a semi-manually curated corpus of only 1,000 high-quality response examples. We will learn that the alignment process, although critical, primarily teaches an LLM steerability and correct behavior or style, while most knowledge is gained during pre-training. As such, alignment can be performed successfully even with minimal training data. However, we will see that the impact of data quality and diversity on both alignment and other avenues of LLM training (e.g., pre-training, fine-tuning, etc.) is absolutely massive.
The LLM Training Pipeline
“LLMs are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences.” - from [1]
Although language models have been studied from a variety of different perspectives in recent months, the creation of these models tends to follow a standardized process with a few common components; see below.

The first step in this process—pre-training—trains the model over a large corpus of unlabeled text using a language modeling objective and is typically the most expensive. After this, the model undergoes an alignment process, comprised of supervised fine-tuning (SFT) and/or reinforcement learning from human feedback (RLHF). After the model has been trained, it can be deployed to a downstream application, where further fine-tuning or in-context learning can be leveraged to improve performance. Within this section, we will overview each of these components to better understand their impact on an LLM’s behavior.
Language Model Pre-Training
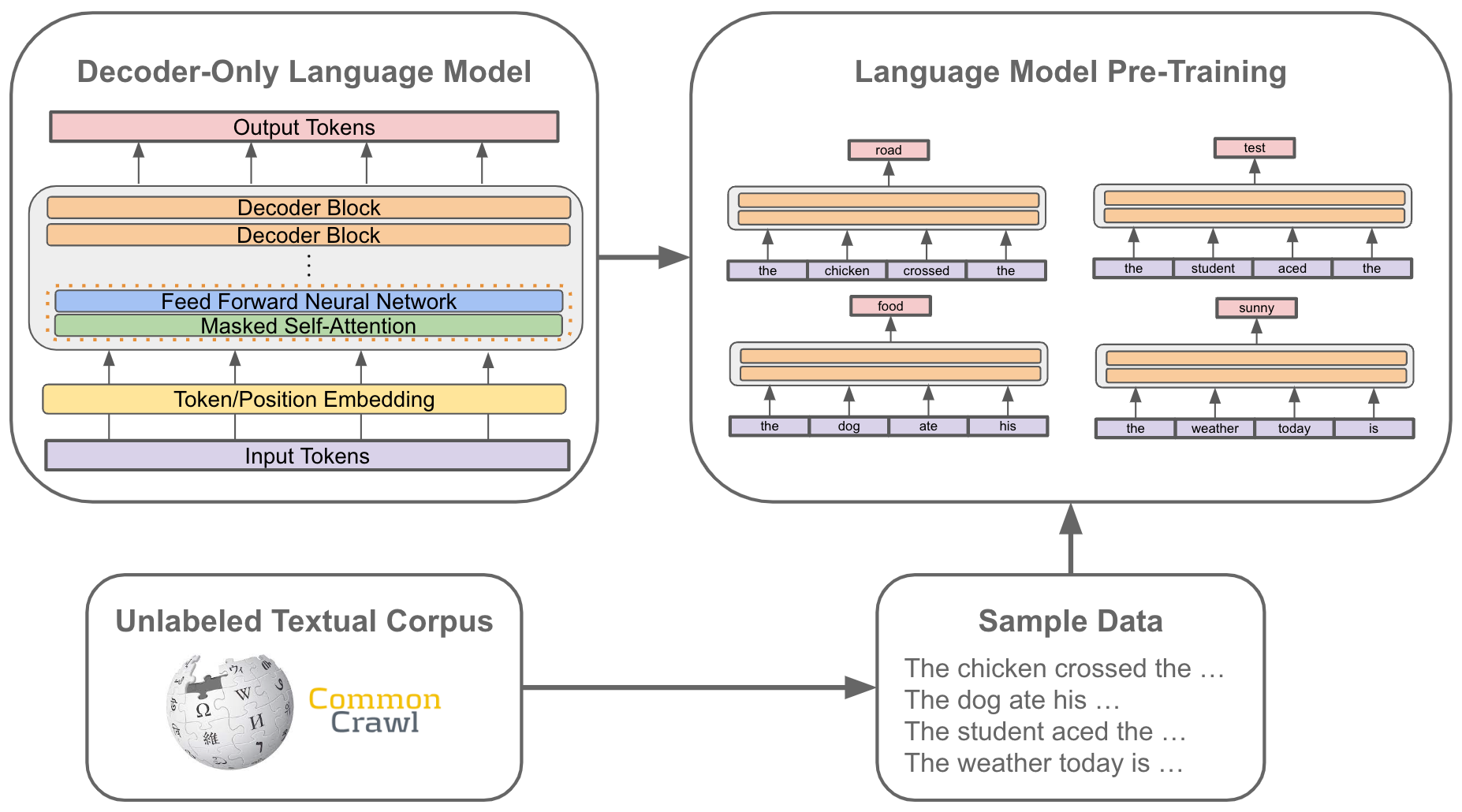
The pre-training process—shown above—is the most computationally expensive step in the creation of an LLM. During this process, language models are exposed to a corpus of unlabeled textual data and trained using a standard language modeling objective. Put simply, this means that we train the model by i) sampling some text from the dataset and ii) training the model to predict the next word. This pre-training procedure is a form of self-supervised learning, as the correct “next” word can be determined by simply looking at the next word in the dataset. The pre-training process is extensive given that the dataset is large (e.g., ~0.5-2 trillion tokens [13]) and the model must be trained from scratch.
The Alignment Process

After pre-training is complete, we have a “base model”, or a generic LLM that does not yet possess any specialized abilities. To endow this model with the ability to conduct interesting conversations, follow instructions, and more, we must align this model, or train it to replicate behavior desired by a human user. In most cases, the alignment procedure is based upon two primary techniques:
Supervised Fine-Tuning (SFT)
Reinforcement Learning from Human Feedback (RLHF)
These techniques can either be used individually or combined together by performing one after the other, as was originally proposed by InstructGPT [11] (i.e., the predecessor to ChatGPT).
SFT is a simple alignment approach—we just obtain examples of desired behavior and directly fine-tune the LLM (using a language modeling objective) on this data. For example, if we want to teach a base LLM to follow directions, we can obtain many examples of accurate responses to instruction-based prompts, and train the base model over these examples. This technique, which we will focus upon in this overview, is both simple and powerful. As we will see, however, getting good results with SFT is dependent upon curating a high-quality dataset.
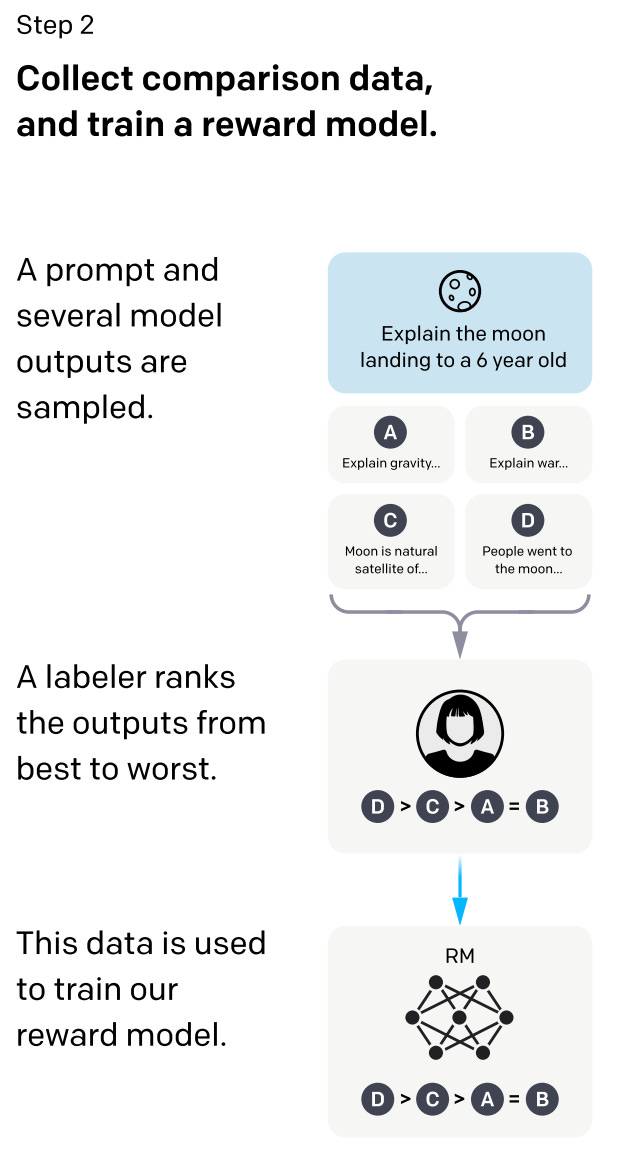
RLHF provides us with the ability to optimize an LLM’s parameters based on feedback provided by humans. Starting with a set of prompts, we first use the LLM to generate several potential outputs for each prompt. Given these outputs, when can ask human annotators to rank the quality of these responses (i.e., which output is the “best”), then use these rankings to train a reward model—this is just a smaller LLM that predicts human preference given a model’s response1; see above. We can use the reward model’s output as a scalar reward and optimize the LLM to maximize this reward via the PPO algorithm; see below.

The beauty of the RLHF process described above is that we are directly optimizing the model based on human preference, but “preferences” can capture a variety of different properties! For example, maybe we want the model to follow instructions better, output more interesting content, or even stop hallucinating (i.e., making up false information). All of these behaviors can be optimized with the use of RLHF, making it a very robust alignment tool; see below.

For those not familiar with reinforcement learning (RL), RLHF may be a difficult framework to understand without some additional background reading. To gain a better background in RL, I’d recommend checking out the resources below.
“The model’s capabilities seem to come primarily from the pre-training process—RLHF does not improve exam performance (without active effort, it actually degrades it). But steering of the model comes from the post-training process—the base model requires prompt engineering to even know that it should answer the questions.” - from GPT-4 blog
What is the purpose of alignment? Alignment is an incredibly active area of research. Currently, there is a discussion within the research community around better understanding the role/purposes of alignment. In the analysis of GPT-4, we see that the role of alignment techniques like RLHF is to make the LLM more steerable and interesting, rather than to teach the model new information. In fact, most knowledge possessed by the model seems to come from pre-training. A similar argument is made in [1], where we see that high-quality alignment can be achieved via a small, curated dataset for SFT. Such a result is especially interesting given the massive amount of human and computational resources that have been invested into aligning popular proprietary models like GPT-4.
Applying the LLM
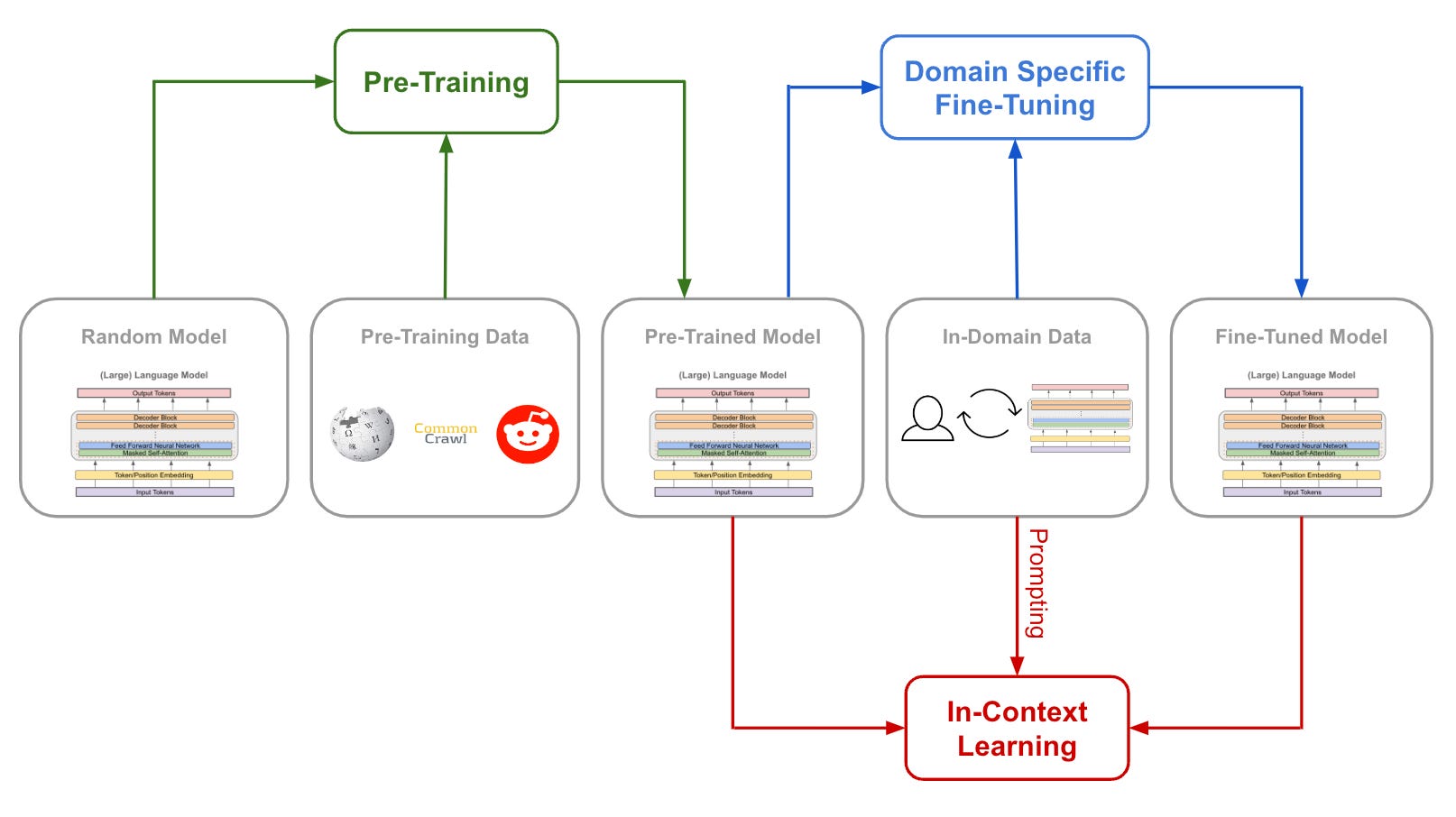
Once an LLM has underwent pre-training and alignment, it’s (more or less) ready to be used in downstream applications. However, we must take some measures to ensure that the LLM solves a particular task accurately. Typically, this is done by either i) further fine-tuning the model or ii) using in-context learning; see above.
Domain specific fine-tuning. If we are deploying an LLM into a specialized domain (e.g., medical, legal, software, etc.), then it might make sense to further fine-tune the model over the types of data that it will see in this domain. This process is quite simple. We just continue to train the model using a language modeling objective, but we use a domain-specific corpus (i.e., data that is similar to what will be seen in the desired application) instead of the pre-training dataset.
In-context learning. Once we are ready to deploy the model (with or without domain specific fine-tuning), we should leverage in-context learning, which uses textual prompts that instruct/guide the model towards desired behavior, to more accurately solve downstream tasks. These prompts may include examples of correct solutions (i.e., few-shot exemplars), but this data is only used by the model as context when generating output (i.e., we do not use it for training). We have explored prompting approaches extensively within prior overviews.
LIMA: Less is More for Alignment
In [1], authors study the relative importance of pre-training versus alignment by training LIMA, a derivative of LLaMA-65B [2] that undergoes SFT (without RLHF) over a curated alignment dataset. In particular, the fine-tuning set used by LIMA is a small set of 1,000 carefully curated prompt-and-response examples with a similar output style and diverse inputs; see below.

When trained on these examples, we see that LIMA performs quite well and even approaches the performance of state-of-the-art proprietary models like GPT-4 and Claude2. Such a result reveals that language models can be effectively aligned via a small number of carefully chosen examples, thus emphasizing the role of data quality and diversity in training and aligning powerful language models.
“A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.” - from [1]
The Superficial Alignment Hypothesis. Along these lines, authors in [1] propose the Superficial Alignment Hypothesis (SAH), which is summarized in the quote above. Most of an LLM’s core knowledge is learned during pre-training, while alignment searches for the proper format or style for surfacing this knowledge. The SAH simply states that alignment can be learned in a data efficient manner given a set of examples with sufficient quality and diversity.
Curating Data for Alignment
The dataset used for alignment in [1] is constructed from a combination of community QA forums (e.g., StackExchange, wikiHow, and Reddit) and manually authored examples. Unlike recent work that attempts to automate the curation of data for SFT (e.g., Self-Instruct), we see in [1] that data from both of these sources is carefully (and oftentimes manually) filtered for both quality and diversity. Although manual curation takes time, it boosts the quality of the resulting dataset, which is found to be highly beneficial.

Sourcing the data. The breakdown of LIMA’s training data is shown in the table above. In the training set, 750 examples are sourced from community QA forums. To ensure data quality, these examples are either filtered manually or via “up vote” metrics. The remaining 250 examples are manually written by the authors—200 from scratch and 50 from SuperNaturalInstructions. When manually creating data, the authors maximize diversity and uniformity by making sure sure that:
Responses are stylistically aligned to the behavior of a helpful AI agent
Prompts are as diverse as possible
Put simply, we want to minimize the amount of noise in the alignment dataset (i.e., ensure a uniform style, tone, format, etc.), while making sure that the data observed by the LLM has as much diversity and coverage as possible. Notably, authors in [1] even include a few malevolent prompts in the alignment data to demonstrate how potentially harmful commands can be avoided.
Can we automate this? In recent work on imitation learning with open-source LLMs, we usually see that data used for fine-tuning is automatically curated. For example, data for SFT can be downloaded from online sources (e.g., ShareGPT) or obtained directly from LLM APIs for ChatGPT or GPT-4. Such an approach is incredibly efficient compared to manual curation, and (in some cases) it even works well; e.g., Orca [3] is trained over a large number of dialogues obtained from ChatGPT/GPT-4 and performs quite well (even compared to top models). However, we see in [4] that models trained in this manner typically have limitations and perform poorly when subjected to extensive analysis.
“Manually creating diverse prompts and authoring rich responses in a uniform style is laborious. While some recent works avoid manual labor via distillation and other automatic means, optimizing for quantity over quality, this work explores the effects of investing in diversity and quality instead.” - from [1]
In [1], we study an alternative approach to alignment that invests into the curation of high-quality data. Instead of automatically obtaining a large amount of data, we manually filter and select fewer examples. This smaller-scale (but labor-intensive) selection process allows the diversity and quality of data to be controlled, which illustrates the impact of data scale and quality on LLM alignment.
Is alignment actually superficial?

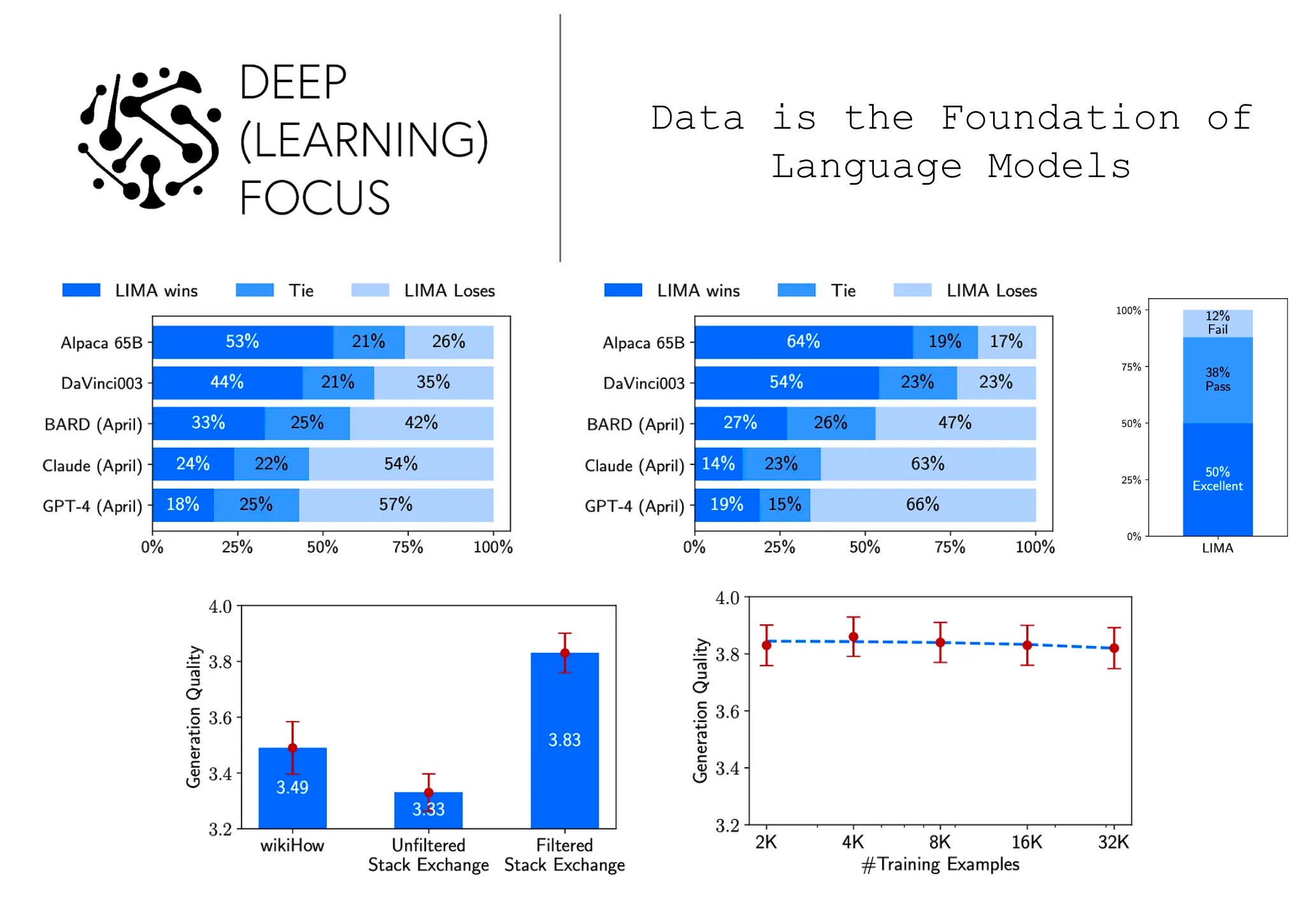
LIMA’s performance is compared to that of a variety of different language models. In particular, we see LIMA’s performance compared to Alpaca-65B [6], DaVinci003 (i.e., an RLHF-tuned version of GPT-3.5), Bard (i.e., based on PaLM [7]), Claude (i.e., 52B parameter LLM trained via AI feedback [8]), and GPT-4. Evaluation is performed using both crowd workers and automated feedback from GPT-4, as shown in the Figure above. Interestingly, LIMA consistently outperforms Alpaca (despite being fine-tuned on 52X less data!) and even matches or exceeds the quality of Claude and GPT-4 in a non-trivial number of cases. LIMA’s competitive performance is impressive given that these other models are trained over millions of user prompts with feedback.
Absolute performance. Beyond the model comparison trials conducted above, authors in [1] manually evaluated the quality of 50 random responses generated by LIMA. Interestingly, we see that LIMA fails to answer only six of the 50 prompts and produces an excellent response in 50% of the trials; see below.

When this manual evaluation is repeated on exclusively out-of-distribution prompts (i.e., those that are much different from examples included in the fine-tuning set), the results are not much different—20% of responses fail, 35% pass, and 45% are excellent. Such a result indicates that LIMA actually generalizes well and is not just memorizing or overfitting to the curated fine-tuning dataset3.
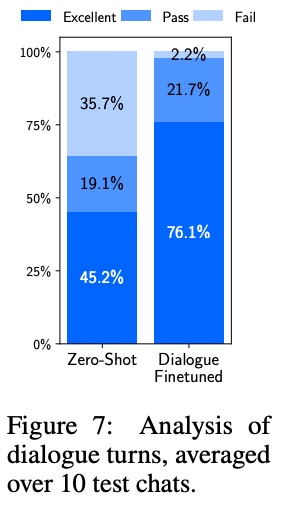
For example, LIMA can perform multi-turn dialogue relatively well (but not great) despite having no such examples in its fine-tuning dataset. When just 30 multi-turn dialogue examples are exposed to the model, we see that LIMA quickly learns how to maintain a dialogue from these examples; see above.
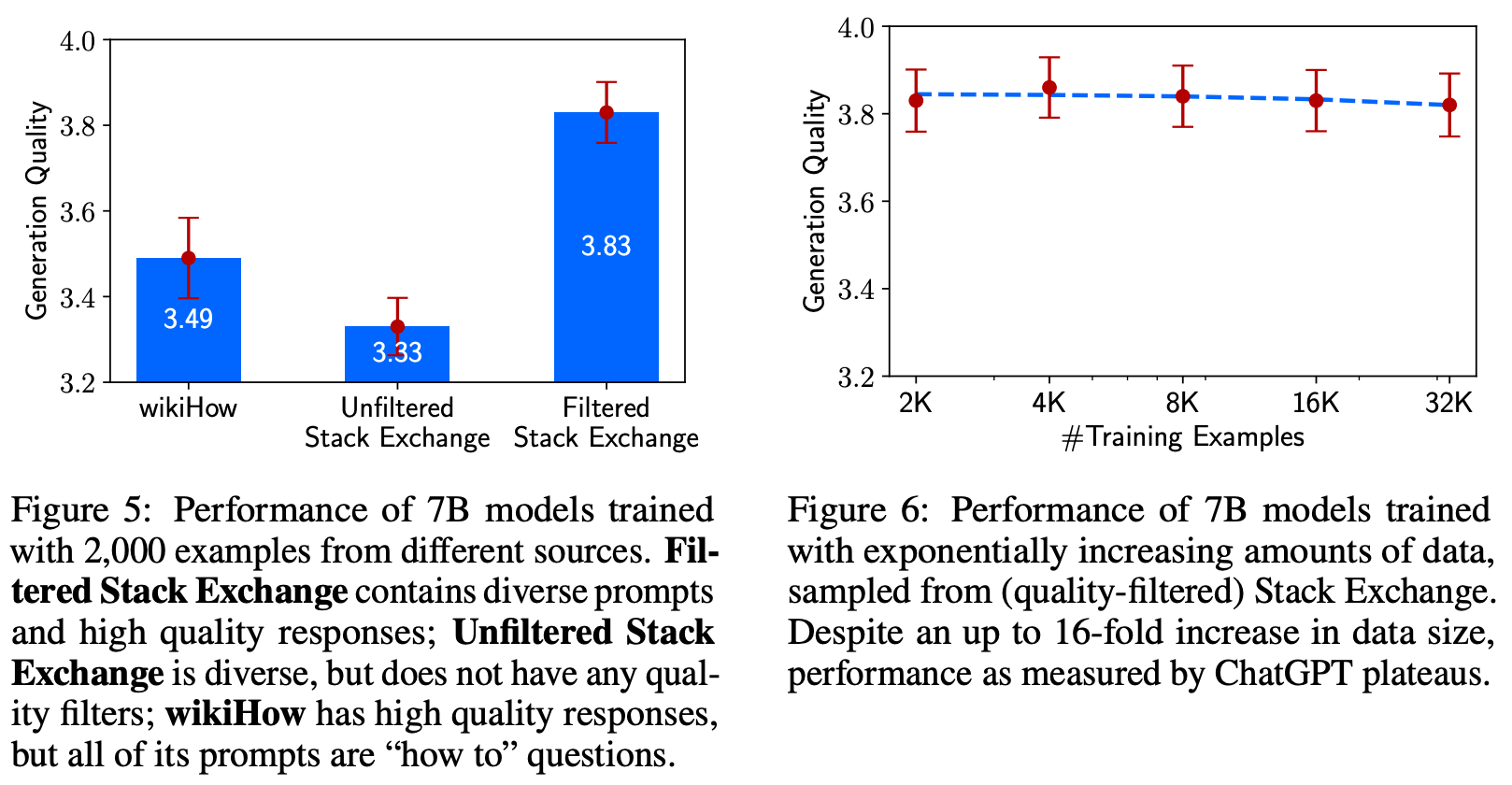
Useful properties of data. Beyond the main results outlined above, we see in the ablation experiments of [1] that the diversity and quality of examples used for alignment is incredibly important; see above. Notably, just increasing the size of the fine-tuning dataset does not always improve the LLM’s performance. As such, we learn from [1] that careful curation of high-quality data for alignment is valuable.
The Bigger Picture
In recent work on open-source language models, we have seen a variety of different LLMs (e.g., Alpaca [6], Vicuna [9], Koala [10] and more) that have adopted an automatic approach for curating data for SFT. In particular, these model use an imitation approach that i) collects a large amount of dialogues from other LLMs and ii) performs supervised fine-tuning over this data. Although these models initially seemed to perform quite well, we see in more targeted evaluations that the quality of their alignment is poor . With this in mind, we might reasonably ask: What makes LIMA’s approach more effective?

Quality > Quantity. Even in studies on imitation models, we see that just increasing the amount of data in the fine-tuning set yields minimal impact on the underlying model’s performance; see above. We see in [1] that similar results are observed for LIMA. Given that increasing the amount of data alone yields no benefit, we a have a few different options for improving an LLM’s performance:
Create a more powerful base model
Improve the alignment dataset
While several works (e.g., MPT and Falcon) have explored the creation of better base models, LIMA studies how better alignment datasets can be created4. Put simply, we see in [1] that creating an alignment dataset that is both diverse and high-quality (even if it is small!) is extremely effective. LLMs can accurately learn to emulate certain behaviors based on minimal data, which supports the SAH.
“For the purpose of alignment, scaling up input diversity and output quality have measurable positive effects, while scaling up quantity alone might not.” - from [1]
But, these results aren’t perfect! Prior imitation models were initially thought to perform incredibly well, even comparably to top proprietary models like ChatGPT. However, we later discovered that such conclusions were a product of human error. These models mimicked the style of proprietary LLMS, but lacked their factuality and tended to generalize poorly beyond their training sets, which is more difficult for humans to deduce when evaluating these models. Given that LIMA is also primarily evaluated with crowd workers, the results in [1] are subject to similar limitations. However, we see that LIMA tends to generalize well and oftentimes outperforms imitation models like Alpaca, which indicates that high-quality alignment data is still incredibly beneficial to LLM performance.
The Impact of Data Beyond Alignment
Within [1], we see that the quality of data is incredibly important for effectively aligning a language model. However, the importance of data quality and diversity goes beyond alignment alone—the type and quality of data being used impacts every aspect of the LLM training pipeline. Let’s look at a few examples for reference.
Pre-training. Across a variety of different models, we have seen that the quality of data used for pre-training is incredibly important. For example, within Galactica [14], authors find that training on a smaller, heavily-curated dataset of high-quality scientific information yields the best possible performance. Similarly, the BioMedLM model is pre-trained over a smaller, curated corpus of technical content. Finally, Falcon-40B—the current state-of-the-art for open-source language models—places a notable emphasis on the quality of pre-training data, where we see that authors have invested significant effort into developing a novel and efficient pipeline for extracting high-quality pre-training data from the web.
Alignment. Beyond the approach explored in [1], the recently-proposed Orca model [3] heavily studies the role of data quality in solving the alignment problem. However, a slightly different approach is adopted. Namely, the authors train a model using an imitation approach but augment the data used for SFT (i.e., dialogue examples with other LLMs) with detailed information from the model about how each problem is solved. Including these extra details in the alignment dataset is found to produce imitation models that are much more robust compared to models like Alpaca [6] or Vicuna [9].
In-context learning. Beyond training and fine-tuning the LLM, the data used for in-context/few-shot learning can massively impact performance. In particular, recent research on few-shot learning shows us that factors such as the ordering, distribution, or format of exemplars can impact a model’s performance. Going further, we see that the diversity of data is incredibly important, where models that are prompted with a diverse group few-shot exemplars tend to perform better. Check out the link below for a more in-depth discussion.
Closing Remarks
“These results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.” - from [1]
The major conclusions from work covered within this overview are twofold:
The Superficial Alignment Hypothesis: LLMs learn their knowledge during pre-training and alignment teaches them how to properly interact with users.
The quality and diversity of data is incredibly important to the alignment process (much more so that data scale).
Within [1], we have observed these major conclusions in the creation of LIMA, where high-quality alignment can be performed using a smaller, curated corpus. Not much data is needed for alignment (with SFT) if the data is of sufficient quality, meaning that input prompts are diverse and responses have a standardized structure and tone. However, the positive impact of high-quality data spans far beyond alignment—all aspects of LLM training are positively benefitted by the use of higher-quality data. Whether it be during pre-training or in-context learning, language models are still fundamentally subject to the same basic rule as all other machine learning models: “garbage in, garbage out”.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews that explain relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on twitter or LinkedIn!
Bibliography
[1] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
[2] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[3] Mukherjee, Subhabrata, et al. "Orca: Progressive Learning from Complex Explanation Traces of GPT-4." arXiv preprint arXiv:2306.02707 (2023).
[4] Gudibande, Arnav, et al. "The false promise of imitating proprietary llms." arXiv preprint arXiv:2305.15717 (2023).
[5] Wang, Yizhong, et al. "Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks." arXiv preprint arXiv:2204.07705 (2022).
[6] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[7] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[8] Bai, Yuntao, et al. "Constitutional ai: Harmlessness from ai feedback." arXiv preprint arXiv:2212.08073 (2022).
[9] Chiang, Wei-Lin et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” (2023).
[10] Geng, Xinyang et al. “Koala: A Dialogue Model for Academic Research.” (2023).
[11] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[12] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[13] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[14] Taylor, Ross, et al. "Galactica: A large language model for science." arXiv preprint arXiv:2211.09085 (2022).
This reward model is trained over pairs of model responses, where one pair is “better” than the other. Using these pairs, we can derive a loss function that (i) maximizes the reward of the preferred response and (ii) minimizes the reward of the worse response.
Notably, this results goes against most recent results on obtained from models that are fine-tuned on imitation data on proprietary LLMs. These models are found to struggle with generalization beyond their fine-tuning dataset. As such, LIMA’s ability to generalize is truly a testament to the impact of high-quality alignment data.