


Beyond LLaMA: The Power of Open LLMs
How LLaMA is making open-source cool again...


Despite recent advances in large language models (LLMs), many of the most powerful models are only accessible via paid APIs and trained using large amounts of proprietary data, thus limiting the research community from accessing or reproducing such models. This trend raises serious concerns about whether LLMs will be mostly controlled by a small number of centralized groups that force others to pay for interaction with these models. Such a scenario strictly prevents most researchers from directly accessing or improving LLMs on their own.
“[Many] LLMs require huge computational resources to train, and oftentimes use large and proprietary datasets. This suggests that in the future, highly capable LLMs will be largely controlled by a small number of organizations.” - from [5]
Given the computational burden of training and hosting LLMs, we might wonder whether open-sourcing these models is even helpful for the research community. If we are not part of a massive organization with extensive compute resources, can we even do useful research with LLMs? If not, maybe we are doomed to a world of centralized control of and access to LLMs. These models seem to have too much “gravity” (i.e., require access to tons of data and compute) for most people to easily work with them.
The proposal of LLaMA (and subsequent leak to the public) moves in an opposite direction by open-sourcing a suite of powerful (but smaller) LLMs. Following the release of LLaMA to a public, we saw a massive wave of open research on LLMs. Such research produced a variety of different models, some of which were of comparable quality to ChatGPT. Most notably, however, these models were produced at minimal cost (i.e., <$500 in most cases) and with modest compute resources (i.e., some of these models can be run on a normal macbook!). Here, we will survey some of these post-LLaMA models that have been recently proposed and explore how open-source research on LLMs has made the topic more accessible.
Core Concepts
In a previous post, we learned all about LLaMA, a suite of open-source, high-performing LLMs with a variety of sizes. LLaMA models are trained only on public data, making them compatible with open-source and reproducible without access to proprietary data.
But, the story of LLaMA doesn’t end here! These models have recently become a hot topic in deep learning. In this overview, we are going to examine the research enabled by LLaMA and gain an understanding of why/how these models became popular. First, we will provide a little more background on LLaMA, followed by an overview of important ideas to understand for this overview.
How LLaMA was (or wasn’t?) open-sourced…
The deep learning community has embraced open-source for quite some time, and certain areas of research still do (e.g., see Stable Diffusion). However, the LLM landscape is quite different, as the most popular/powerful models are only available behind paid APIs (e.g., GPT-4 [6], Claude, and Cohere). The open-sourcing of LLaMA [1], a suite of smaller LLM foundation models of impressive quality, went against this trend. However, LLaMA wasn’t exactly open-sourced… the story is a bit more complicated.
First, LLaMA was announced by Meta with full details, including an in-depth, helpful publication, a form to apply for access to LLaMA, and a simple repo to run inference and tokenization with LLaMA after gaining model access. To gain access to the model, one had to agree to a laundry list of requirements, such as not using LLaMA commercially and ensuring any derivative models created with LLaMA follow the same license. But, all of this went out the window when, about a week after this release, weights for all LLaMA models were posted publicly to 4chan for anyone to download.
Although the sharing of LLaMA was unexpected (and arguably harmful), it sparked thousands of downloads and has since enabled a massive amount of open research. Given that LLaMA is comprised of smaller models that are more accessible to researchers without extensive compute resources, these models are a perfect fit for this scenario. A massive number of incredible deep learning researchers went to work and produced a variety of projects powered by LLaMA within weeks, ranging from hosting multi-billion-parameter LLMs on a Macbook to reproducing ChatGPT for <$500.
Instruction Fine-Tuning

Many of the models we will see within this overview are based upon the idea of instruction fine-tuning (or instruction tuning for short). Originally proposed by FLAN [10], instruction fine-tuning is a form of training that makes language models better at solving language-based tasks in general, rather than just a single task; see above. In practice, this is done by fine-tuning a language model over sets of “instructions” that include fine-tuning examples combined with a description of the task being solved. Using this approach, we can fine-tune a language model to solve a variety of different tasks via textual prompting using different task templates; see below.

Currently, one of the most popular variants of instruction fine-tuning is to fine-tune LLMs over examples of dialogue sessions, either from humans or generated by a chatbot. Given that many recent chatbots are specialized to follow instructions and perform information-seeking dialogue, these models, their output, and even the data used to train them contains a rich variety of instruction-following examples and behavior that can be directly leveraged for instruction tuning.

self-instruct. One form of instruction tuning that is relevant to this work is the self-instruct framework [2], which mitigates dependence on human-written instructions by generating instruction for fine-tuning with an LLM. In particular, this process starts with a small set of instruction data and iteratively i) uses an LLM to generate new data and ii) filters low quality data; see above. Such a technique produces high quality data for instruction tuning with minimal human annotation efforts.
Knowledge Distillation

Proposed in [11], knowledge distillation uses a (large) fully-trained neural network as a training signal for another (small) neural network; see above. Many different types of knowledge distillation exist, but the idea behind them remains the same. Namely, if we train a neural network using both i) the normal training data and ii) the output of a larger, more powerful neural network over that data, then we will typically arrive at a better result than training a neural network over the data alone. By using its output as a training target, we can distill some of the information from a larger network into the smaller “student” network that is being trained. For more information on knowledge distillation and its many variants, check out the link below.
Other Stuff…
Beyond the information covered above, we will also need to have a baseline understanding of LLMs and how they work. To develop this understanding, check out the following resources.
Language Modeling Definition [link]
Brief Overview of Language Modeling [link]
Decoder-only Transformers [link]
How LLMs Work [link]
LLM Scaling Laws [link]
Self-attention in LLMs [link]
Throughout the overview, we will also refer to the names of a few specific models within OpenAI’s catalog (e.g., text-davinci-003). See here for a list of models (with associated descriptions) that are provided within the OpenAI API.
Alpaca: An Instruction-following LLaMA model [3]
“Doing research on instruction-following models in academia has been difficult, as there is no easily accessible model that comes close in capabilities to closed-source models such as OpenAI’s text-davinci-003.” - from [3]
Alpaca [3] is a fine-tuned version of the LLaMA-7B [1] LLM that performs similarly to OpenAI’s text-davinci-003 (i.e., GPT-3.5). The fine-tuning process for Alpaca is based on self-instruct [2], in which instruction-following data is collected from a higher-performing LLM (i.e., text-davinci-003) and used for SFT. Put simply, Alpaca demonstrates that the quality of small, open-source LLMs in an instruction-following context can be drastically improved via fine-tuning over high-quality data. Plus, the entire fine-tuning process of Alpaca costs only $600 (including both data collection and fine-tuning), making such instruction-following LLMs easy and cheap to replicate for research purposes.

method. To create an instruction-following LLM via SFT, we need i) a high-quality, pretrained language model and ii) instruction-following data to use for SFT. Luckily, the recent release of LLaMA provides easily-accessible, pretrained language models. Gaining access to instruction-following data is a bit more nuanced, but one method of doing this is self-instruct [2]. At a high level, self-instruct bootstraps LLM-generated output for further training. In the case of Alpaca, we use text-davinci-003 to generate instruction-following data by:
Beginning with 175 instruction and output pairs from self-instruct’s seed set.
Prompting the LLM to generate more instructions using the seed set as in-context examples for few-shot learning.
Authors of [3] also adopt a few tricks (e.g., a modified prompt and more efficient decoding/generation procedure) to make the data generation process cheaper and more efficient compared to the original self-instruct [2]. Overall, generating instruction-following data via the OpenAI API cost <$500 for 52K instruction-following examples.
The LLaMA-7B model is then fine-tuned over this data using a HuggingFace-based training framework. By using fully sharded data parallel (FSDP) and mixed precision training techniques, the fine-tuning process was reduced to 3 hours on 8 A100 GPUs, which costs <$100. The code/data used for creating Alpaca is available online. However, commercial use of Alpaca is prohibited because i) LLaMA (which Alpaca is based upon) has a non-commercial license and ii) OpenAI prohibits the use of its models to train competing LLMs.
results. Alpaca is evaluated on instructions from the evaluation set used for self-instruct (i.e., mostly tasks related to email, social media, and productivity) and open-domain instructions that are hand-written by the authors. On such tasks, Alpaca is found to perform similarly to text-davinci-003 (i.e., performs best in 50% of the ~180 cases that were tested). Although this evaluation is clearly limited in scope, the performance of Alpaca is still quite impressive given that is is a much smaller model than GPT-3.5 and relatively easy to replicate.

Similar to text-davinci-003, Alpaca’s outputs are typically shorter than those of ChatGPT. In other words, the model’s style reflects that of the LLM used to generate the instruction-following data used for fine-tuning.
Vicuna: An Open-Source Chatbot with 90% ChatGPT Quality [4]

Information-seeking dialogue agents (or chatbots) like ChatGPT are great, but the training framework and architecture of such models is unknown, which hinders open-source research. As a solution, authors of [4] propose Vicuna, an open-source chatbot that is created by fine-tuning LLaMA—13B [1] (i.e., a smaller LLM with comparable performance to GPT-3). The fine-tuning data for Vicuna is examples of user conversations with ChatGPT, and the entire fine-tuning process can be replicated for <$300, thus making chatbots more accessible for research purposes. Compared to Alpaca, Vicuna is more comparable to ChatGPT and generates answers with more detail and structure.

method. Data used for SFT with Vicuna is downloaded via public APIs from ShareGPT, a platform that allows users to share their conversations with ChatGPT. Prior to fine-tuning, authors filter inappropriate and low-quality data, as well as divide longer conversations into shorter chunks that fit within LLaMA-13B’s maximum context length. In total, 70K conversations are collected. Similar to Alpaca, the model is trained on 8 A100 GPUs using FSDP (with a few modifications to reduce cost and handle long sequences), which takes about one day; see above. Authors make the code for both training and hosting Vicuna publicly available.
A more comprehensive comparison of Vicuna to the open-source LLMs LLaMA and Alpaca is provided within the table below. We will get into how Vicuna is evaluated next.

results. Accurately evaluating chatbots is quite difficult, and it becomes harder as chatbots improve in quality. For example, authors in [4] claim that the self-instruct evaluation set (used to evaluate Alpaca) is solved effectively by recent chatbots, which makes differences between models difficult to discern. Given the limitations of existing benchmarks and the difficulty of creating new, comprehensive evaluation sets, authors in [4] opt for a different strategy: using LLMs to perform the evaluation.
“With recent advancements in GPT-4, we are curious whether its capabilities have reached a human-like level that could enable an automated evaluation framework for benchmark generation and performance assessments.” - from [4]
At this point, we might be thinking that there’s no way this can actually work. Chat-ception? Surprisingly, however, forming an evaluation framework based upon the recently-proposed GPT-4 model [6] works well. First, authors of [4] devised eight categories of questions (e.g., roleplay scenarios and math tasks). Then, GPT-4 is prompted to generate a diverse set of questions within each category. Interestingly, GPT-4 is found capable of generating difficult questions that recent chatbots struggle to answer.
In particular, GPT-4 is used to generate ten questions within each category and the output of five different chatbots (.e., LLaMA-13B, Alpaca-13B, Vicuna-13B, Bard, and ChatGPT) is evaluated. Going further, the quality of each model’s output is judged by asking GPT-4 to rate the quality of an answer based on detail, helpfulness, relevance, and accuracy. Although performing evaluation in this manner might seem like a stretch, GPT-4 ranks models pretty consistently an even explains its reasoning.
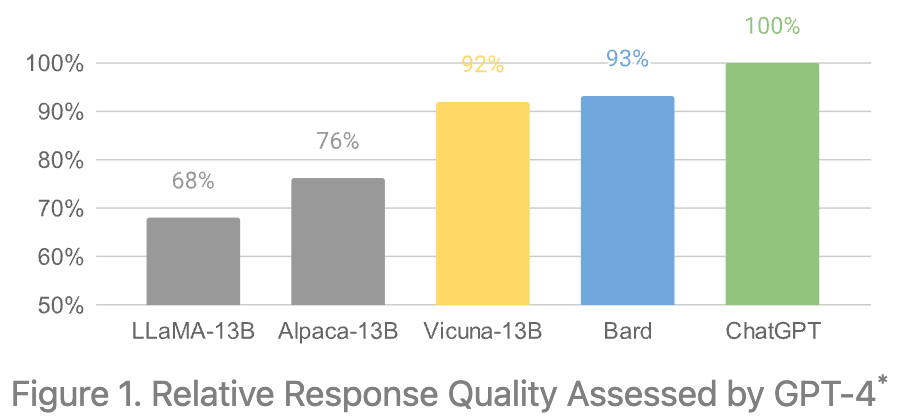
As judged by GPT-4, Vicuna’s produces output with 92% quality relative to ChatGPT; see above. This ratio is achieved by asking GPT-4 to assign a score to each of the models’ outputs. Then, relative performance between models can be assessed by computing their total quality score over all questions. Although this evaluation approach is not rigorous, it’s pretty interesting, relatively consistent, and forces us to think about interesting ways in which the LLM landscape will evolve moving forward.

Compared to other open-source models, we see that GPT-4 tends to prefer the output of Vicuna. Plus, Vicuna produces output that exceeds or matches ChatGPT quality on 45% of questions. This level of quality is pretty impressive for a model that can be fine-tuned with only $300!
Koala: A Dialogue Model for Academic Research [5]
“Models that are small enough to be run locally can capture much of the performance of their larger cousins if trained on carefully sourced data.” - from [5]
At this point, we might start to wonder whether we are going to run out of animals to name LLMs after. Nonetheless, Koala is similar to Vicuna and Alpaca, as it continues to focus upon closing the gap in quality between proprietary and open-source LLMs. More specifically, Koala is a version of LLaMA-13B that has been fine-tuned on dialogue data from a variety of sources, ranging from public datasets to dialogues with other high-quality LLMs that are available on the internet.

When evaluated on real-world prompts, Koala-13B is found to achieve competitive performance compared to ChatGPT and even outperform the related Alpaca model. As such, results from Koala continue to support a trend that we see in all work following LLaMA. Namely, we see that smaller models can achieve impressive quality given the correct data for fine-tuning. Findings like this might lead us to wonder: are we focusing too much on model scale and not enough on the quality of our data?
method. Koala uses dialogue data both from public datasets and the internet for fine-tuning. However, authors in [5] heavily emphasize the importance of curating a high-quality dataset for fine-tuning. The data used for fine-tuning Koala can be roughly categorized as either distillation-based (i.e., dialogues from other LLMs) or open-source data (i.e., available in public datasets) and includes data from ShareGPT, HC3, OIG, Anthropic HH, and OpenAI WebGPT/Summarization. Plus, the fine-tuning set even includes the data used for training the Alpaca [3] model.

All of this data is dialogue-based. Notably, however, some datasets contain multiple dialogues or responses for each question that are rated as good or bad. Interestingly, we can draw upon prior techniques [8] to incorporate this information into the fine-tuning process for the LLM. In particular, this is done via conditional training, where we can simply condition data over which the LLM is trained with human preference markers (e.g., just append textual information about whether the dialogue is good or bad); see above. Such an approach yields improved performance and enables us to use even low-quality dialogues for model training.
Authors in [5] make the training and hosting framework for Koala publicly available. The model is trained for two epochs using eight V100 GPUs, which takes about 6 hours. In total, the compute cost of training this model is <$100 (assuming that we can use preemptible/spot instances), meaning that Koala is the cheapest model to reproduce of the models that we have seen so far!
results. Authors in [5] train two different types of Koala models:
Koala-distill: fine-tuned only over distillation data (i.e., examples of dialogue from other chatbots)
Koala-all: fine-tuned using all of the data described above.
Based on human trials and feedback, the quality of these Koala models is compared to that of Alpaca and ChatGPT. For evaluation, questions from the Alpaca [3] evaluation set and a set of real user queries from the internet are used. The authors choose to add more questions into the evaluation set because Alpaca’s evaluation set is quite similar to the data on which it was trained (i.e., both derived from self-instruct [2]).

When humans judge the output of different LLMs in terms of quality and correctness, Koala-all is found to oftentimes exceed the performance of Alpaca and match or exceeding the quality of ChatGPT in a large number of cases. Plus, we see that Koala-distill actually outperforms Koala-all. This is a bit counterintuitive given that Koala-distill has a smaller fine-tuning dataset (i.e., just example dialogues from ChatGPT), but this tells us that the type and quality of data used for fine-tuning is incredibly important. Namely, using dialogues generated from a larger, better LLM for fine-tuning is incredibly effective.
“the key to building strong dialogue models may lie more in curating high-quality dialogue data that is diverse in user queries” - from [5]
Going further…
Even though LLaMA was proposed pretty recently, Alpaca, Vicuna, and Koala are not the only notable models that have been enabled (or inspired) by LLaMA. We can see below a list of other open-source language models that have been released recently.
Lit-LLaMA: a reproduction of LLaMA that is open-sourced under the Apache-2.0 license (permits commercial use).
ChatLLaMA: make a personalized version of ChatGPT using LLaMA, your own data, and the least amount of compute possible.
FreedomGPT: an open-source conversational Chatbot (based on Alpaca) that emphasizes lack of censorship.
ColossalChat: an open-source ChatGPT replica that comes with a fully-implemented (and public) RLHF pipeline based on LLaMA (includes data collection, supervised fine-tuning, reward model training, and reinforcement learning fine-tuning; see below).
StackLLaMA: provides an open implementation and discussion of RLHF-based fine-tuning for producing powerful chatbots (specifically using LLaMA as a starting point).
GPT4All: demo, data, and code for training open-source LLMs based on LLaMA and GPT-J (has an Apache-2.0 license!).
Baize: an LLaMA-based, open-source chatbot that performs fine-tuning using LoRA (a parameter-efficient fine-tuning method).
Galpaca: a version of Galactica (language model for science) that has been fine-tuned on the same dataset as Alpaca.
Dolly 2.0: this model is not based on LLaMA, but is an open-source chatbot that has been instruction fine-tuned to ChatGPT-like quality and is open for commercial use.
Open Assistant: an open-source chatbot (comparable to ChatGPT) that can understand tasks, interact with third-party systems, and retrieve information.
Beyond the variety of proposed models, LLM research and use has also become more accessible as a result of LLaMA. LLaMA-13B could already be run using only a single GPU, but now we can even do this locally (e.g., on a macbook)!
Alpaca.cpp: run an open reproduction of Alpaca locally.
GPTQ-4-LLaMA: a 4-bit quantized version of LLaMA.
LLaMA.cpp: inference of several open-source LLMs with 4-bit quantization, which enables local hosting (e.g., on a macbook).
It seems like LLMs will soon become available to more people than ever before.
Takeaways
The main ideas that we can deduce from this work are i) LLaMA inspired a lot of open-source LLM research and ii) research/usage surrounding LLMs is becoming significantly more accessible because of LLaMA. If you told me a month ago that I would be able to run an LLM that is anywhere near the performance of ChatGPT on my macbook, I wouldn’t have believed you. These are exciting times to witness, and I’m grateful to be a small part of such an awesome community! A few basic takeaways are listed below.
LLMs are for everyone. If we were questioning it before, we now know that the research community can indeed do valuable research on LLMs. A few weeks ago, most of us thought that LLMs were not very accessible due to extreme data and compute requirements. However, we can now train ChatGPT-quality models (or at least something close) for a few hundred dollars and even use these models to perform dialogue on our laptop!
are smaller models enough? For a long time, model scale has been an important component (along with large pretraining datasets) of high-performing LLMs. However, models such as Koala and Vicuna show us that smaller LLMs can actually perform incredibly well (and even match the performance of powerful LLMs like ChatGPT in some cases). Such a finding highlights the importance of data quality. Within the work we have seen here. the most effective techniques tend to use the output of larger LLMs as training data, indicates that knowledge distillation may be an important component of creating LLMs that are small but powerful.
commercially viable? Although many of these techniques are cool, using them in commercial applications is difficult. For example, OpenAI prohibits the use of ChatGPT (or any other API model) for training competing models, thus preventing knowledge distillation approaches based on the OpenAI API. Plus, even LLaMA itself prohibits commercial use. As such, models like Alpaca, Koala, and Vicuna are only interesting from a research perspective, and their approach cannot be used for any model that is used commercially. With proposals like Lit-LLaMA, however, it seems like commercially-viable versions of these models may slowly become available.
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Bibliography
[1] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[2] Wang, Yizhong, et al. "Self-Instruct: Aligning Language Model with Self Generated Instructions." arXiv preprint arXiv:2212.10560 (2022).
[3] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[4] Chiang, Wei-Lin et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” (2023).
[5] Geng, Xinyang et al. “Koala: A Dialogue Model for Academic Research.” (2023).
[6] OpenAI (2023). “GPT-4 Technical Report.” ArXiv, abs/2303.08774.
[7] Guo, Biyang, et al. "How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection." arXiv preprint arXiv:2301.07597 (2023).
[8] Liu, Hao et al. “Chain of Hindsight Aligns Language Models with Feedback.” arXiv preprint arXiv:2302.02676 (2023)
[9] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[10] Wei, Jason, et al. "Finetuned language models are zero-shot learners." arXiv preprint arXiv:2109.01652 (2021).
[11] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[12] Gou, Jianping, et al. "Knowledge distillation: A survey." International Journal of Computer Vision 129 (2021): 1789-1819.
Very comprehensive as always. It's important to cover smaller models too and I love how thorough you've been here. I learned a lot from this :)
This is a great writeup Cameron! Looking forward to more