


The History of Open-Source LLMs: Better Base Models (Part Two)
How LLaMA, MPT, Falcon, and LLaMA-2 put open-source LLMs on the map...

This newsletter is presented by Rebuy, the commerce AI company.
Sponsor the newsletter | Follow me on Twitter | Get in touch | Suggest a topic

Open-source research on large language models (LLMs) is incredibly valuable, as it aims to democratize a powerful and influential technology. Although open-source LLMs are now commonly used and widely studied, this area of research saw some initial struggles that were difficult to overcome. Namely, open-source LLMs performed poorly at first and were heavily criticized. Within this overview, we will study a line of research that changed this narrative by making high-performing pre-trained LLMs available to everyone. Given that pre-training a language model is so expensive, the models we will study here are especially impactful. After these high-performing base models were created and released, many people could conduct research using these models at marginal added cost.
“The capabilities of LLMs are remarkable considering the seemingly straightforward nature of the training methodology.” - from [14]
The current series. This overview is part two of a three part series on the history of open-source LLMs. The first part in the series overviewed initial attempts at creating open-source LLMs. Here, we will study the most popular open-source base models (i.e., language models that have been pre-trained but not fine-tuned or aligned) that are currently available. Next time, we will go over how these models can be fine-tuned or aligned to create a variety of useful applications.
Early Days of Open-Source LLMs
In part one of this series, we saw that the early days of research on open-source LLMs resulted in the proposal of several important base models, such as OPT and BLOOM. However, these models were widely considered to perform quite poorly compared to closed-source pre-trained models (e.g., GPT-3). How do we solve this? First, we need to take a deeper look at the LLM training process.
Training pipeline. LLMs are trained in several steps, as shown in the figure below. First, we pre-train the model over a lot of raw text. Then, we perform alignment with techniques like SFT and RLHF. Finally, we can perform further fine-tuning or in-context learning to specialize the LLM to a particular task.
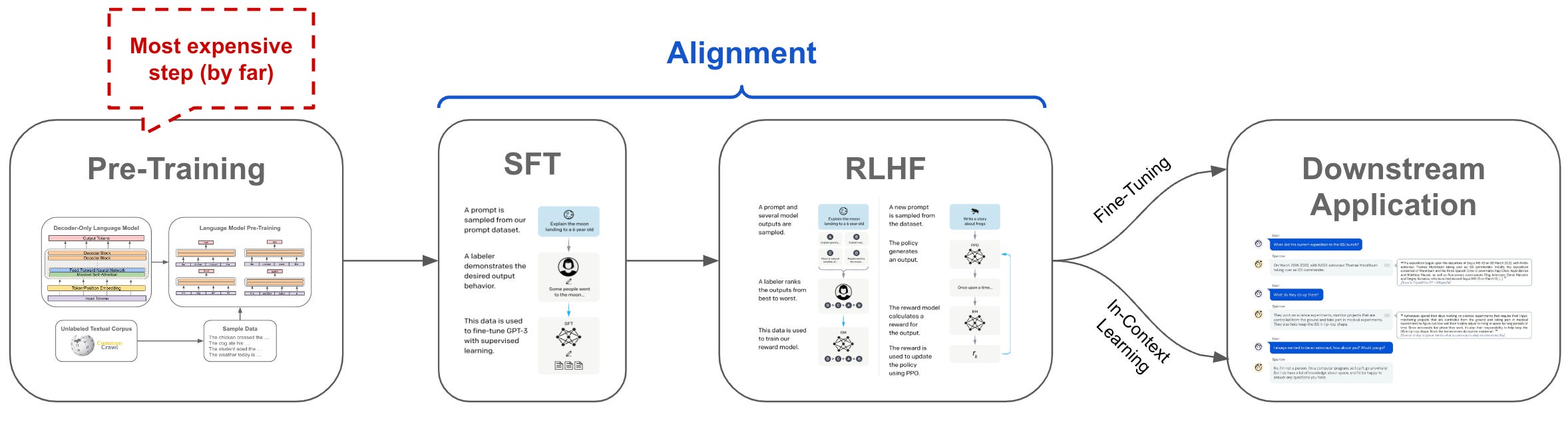
Recently, we have seen strong empirical evidence that most of a language model’s knowledge is gained during pre-training1. The alignment process simply teaches the model to properly format or surface this knowledge gained during pre-training. As coined by LIMA [3], this idea is known as the “Superficial Alignment Hypothesis”. Although this hypothesis might not seem entirely relevant to the topic of this overview, we learn from it something important—a model that undergoes insufficient pre-training is unlikely to be “fixed” by fine-tuning or alignment.
“A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.” - from [3]
What’s the solution? Given the poor performance of initial open-source LLMs, it quickly became clear that the community needed to re-create higher-quality base models from scratch if any forward progress was to be made. Additionally, these models needed to be pre-trained over much more data so that their performance could be improved. Given that pre-training is incredibly expensive (especially when executed over a lot of data), such an effort is not trivial. The creation of better open-source base models had to be an undertaking of organizations with sufficient funding (e.g., Meta or MosaicML) that could pay the cost of training these models and make them freely available to others in the community.
Towards Better Base Models
The performance of open-source LLMs was initially too poor to warrant significant usage and exploration, but this problem was quickly solved. Here, we will review several models that changed this narrative by making powerful pre-trained LLMs available to all.
LLaMA: A Leap in Open-Source Quality
LLaMA [1] was one of the first pre-trained LLMs to be released that was both high-performing and open-source. However, LLaMA is not just a single model, but rather a suite of different LLMs with sizes ranging from 7 billion to 65 billion parameters. These models each achieve a different tradeoff between performance and inference efficiency. Although LLaMA cannot be used commercially (i.e., only for research), it is nonetheless an impactful proposal that served to catalyze several directions of open-source research with LLMs.
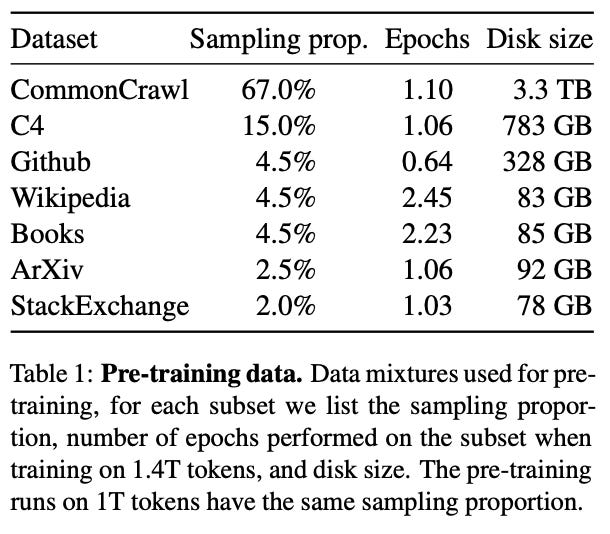
The data. Inspired by lessons from Chinchilla [2]2, LLaMA models are pre-trained over a corpus that contains over 1.4 trillion tokens of text. This pre-training dataset was significantly larger than that of any prior open-source LLM. The sources and distribution of data are depicted above. Interestingly, LLaMA is pre-trained solely using publicly-available data sources, meaning that the entire pre-training process can be replicated by anyone with sufficient compute.
“GPT-4 has learned from a variety of licensed, created, and publicly available data sources, which may include publicly available personal information.” - from GPT-4 blog
Such a property is especially desirable given that many proprietary LLMs are trained using internal data that is not openly available. Put simply, LLaMA was a step towards improved transparency and openness in more ways than one.
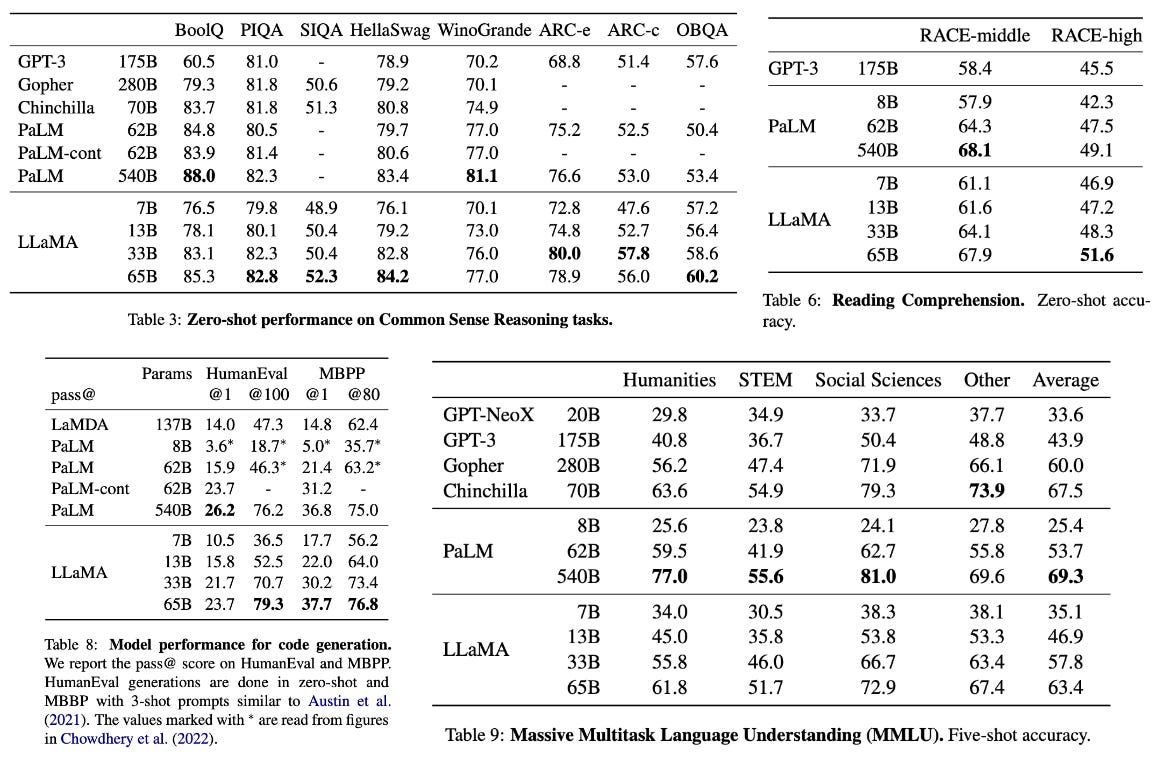
Improved performance. Compared to its predecessors, LLaMA is a huge leap forward in the performance of open-source LLMs. Still, the quality lagged behind that of top proprietary LLMs (e.g., ChatGPT or GPT-4), but we should recall that LLaMA models have not undergone alignment. Notably, LLaMA-13B performs comparably to GPT-3 [3], while LLaMA-65B outperforms PaLM [4] in several cases, indicating that the LLaMA suite performs comparably to other widely-used base models. Detailed metrics are provided in the tables above.
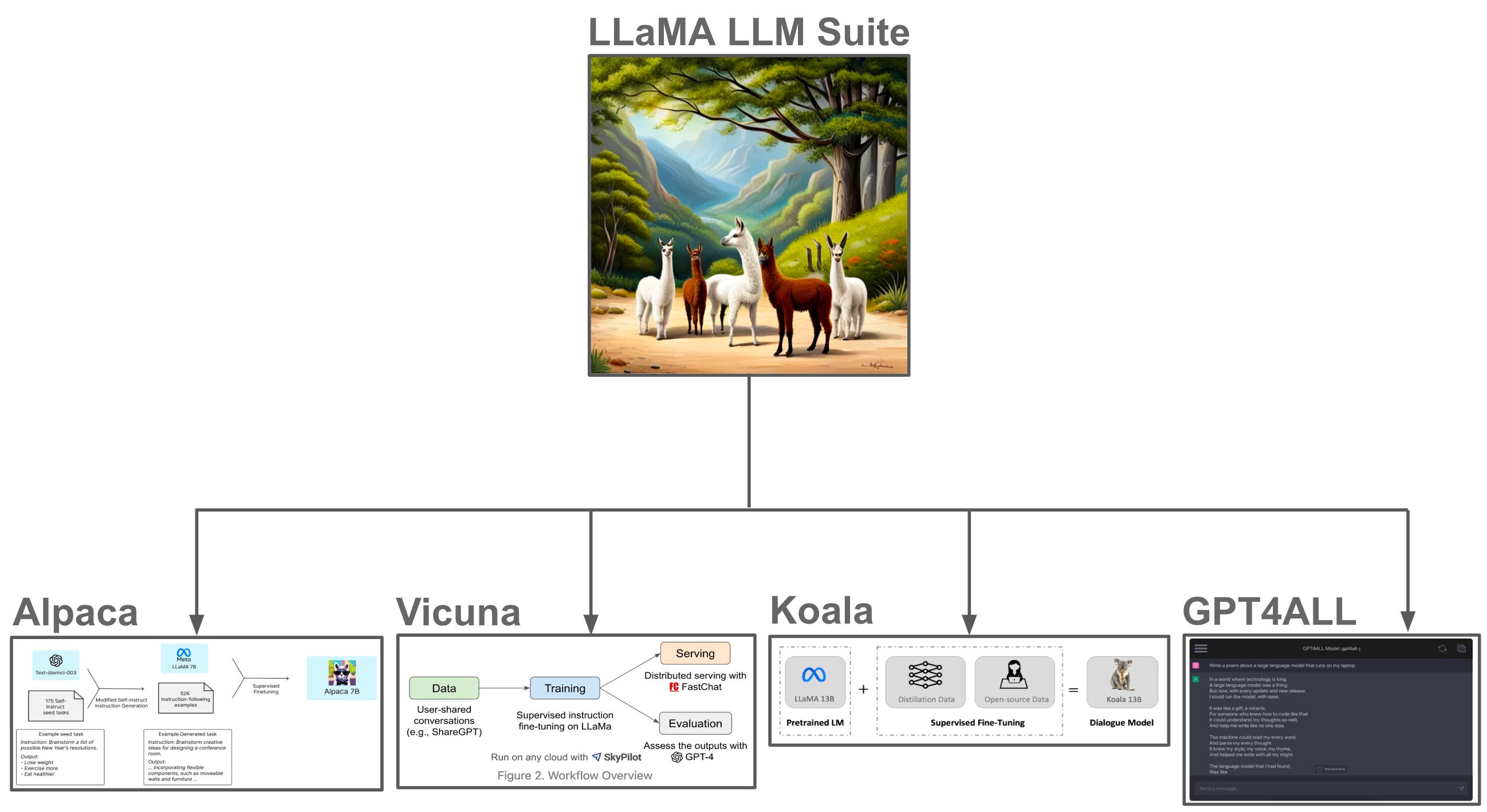
The open-source explosion. One of the most interesting aspects of LLaMA’s proposal was the wake of open-source LLM research that followed it; see above. After the weights of LLaMA models were made publicly available, the open-source research community quickly began to release a variety of different model variants and software packages. These developments included anything from fine-tuned versions of LLaMA to a C++ library for efficiently running inference with any of the LLaMA models from a laptop. Such developments truly demonstrate the beauty of openness in research. We went from interacting with these powerful models solely via an API to running them on our laptop in only a few weeks!
MPT: LLMs that are High-Quality, Commercial, and Open-Source
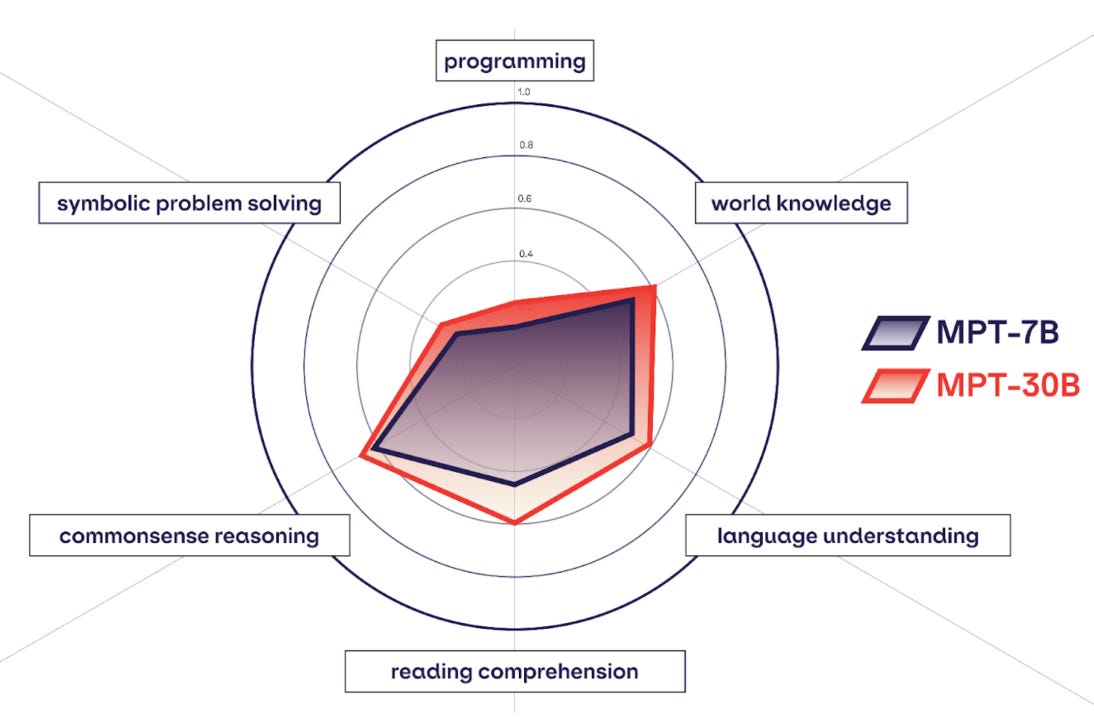
Although LLaMA was impressive, none of the models within this suite could be used in commercial applications—they were valuable solely from a research perspective. Luckily, the proposal of LLaMA was quickly followed by the development and release of the commercially-usable (i.e., released under an Apache 2.0 license) MPT suite by MosaicML. MPT-7B [9] was released first, which garnered a lot of interest (i.e., it was basically a commercially-usable alternative for LLaMA-7B!). In fact, MPT-7B was downloaded over 3M times on HuggingFace before the larger MPT-30B [10] model was made available!
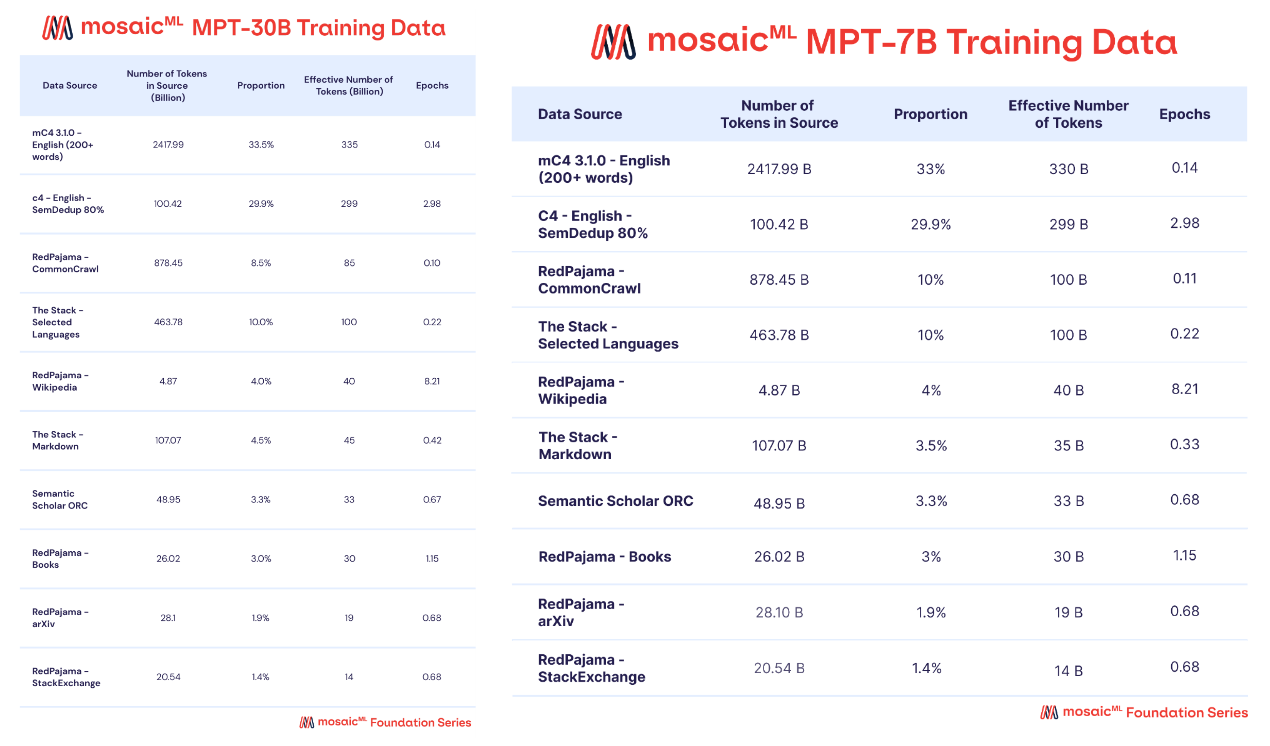
The main differences between these two models are:
They are pre-trained using slightly different mixes of data; see above.
MPT-30B is trained using a longer context length of 8K tokens3.
However, these models both perform well and can be used in commercial applications, which led them to become popular in the AI community.
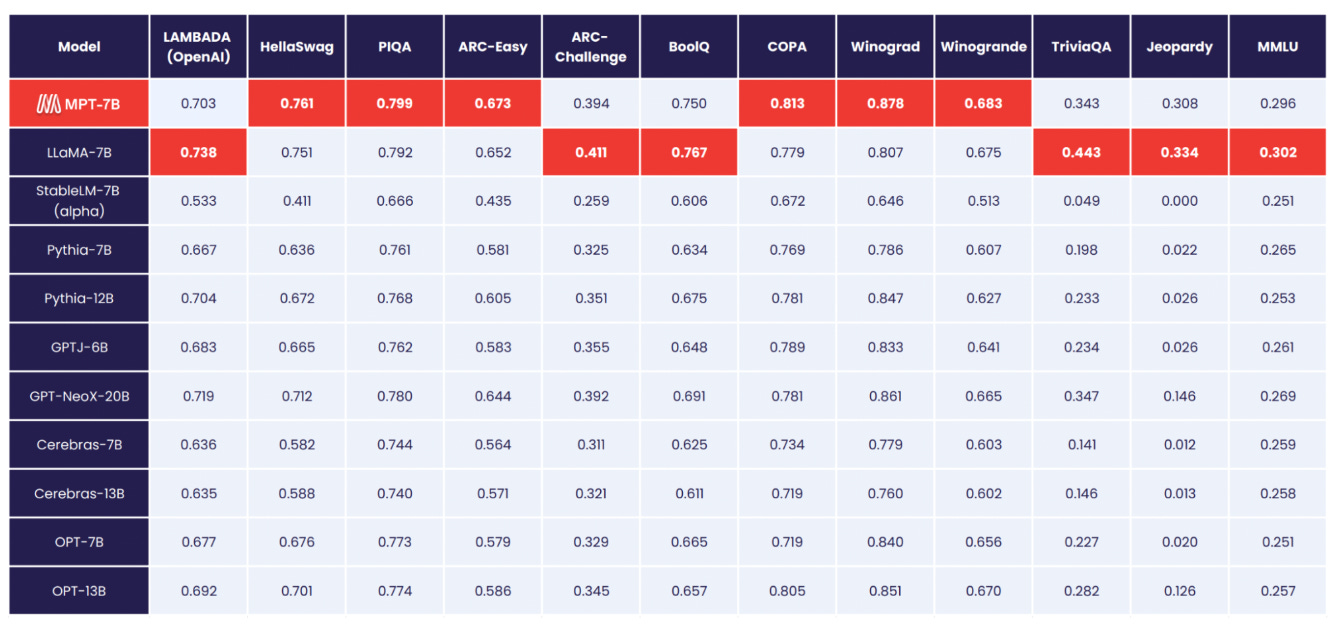
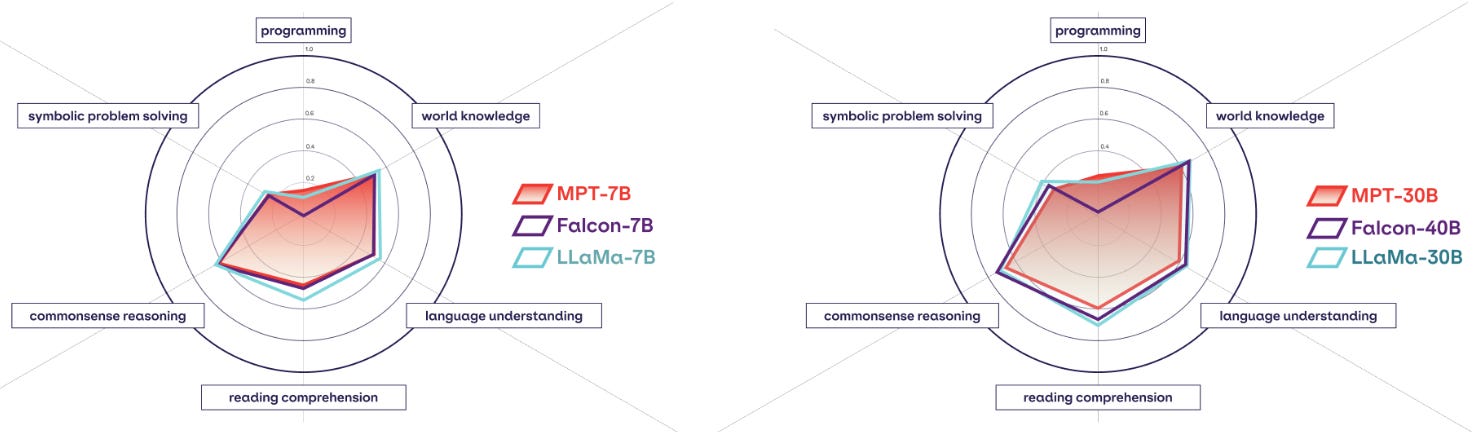
Does MPT live up to the hype? Although LLaMA drastically improved state-of-the-art performance for open-source LLMs, the MPT suite rivaled this performance. In particular, MPT-7B matches the performance of LLaMA-7B across a variety of standard benchmarks; see above. Going further, MPT-30B tends to match the performance of GPT-3. Compared to similarly-sized open-source models (e.g., LLaMA-30B and Falcon-40B), MPT-30B tends to perform slightly worse; see below. However, it is better than these models on coding-related tasks and can be hosted on a single GPU (with quantization).
MPT variants. In addition to the pre-trained MPT-7B and MPT-30B models, a variety of fine-tuned MPT models were released, such as instruct and chat4 versions of both MPT models. Additionally, a “StoryWriter” version of MPT-7B was created by fine-tuning on data with a 64K token context length. Given that pre-training an LLM is significantly more expensive than fine-tuning, a variety of different fine-tuned MPT variants could be created at marginal cost; see below.
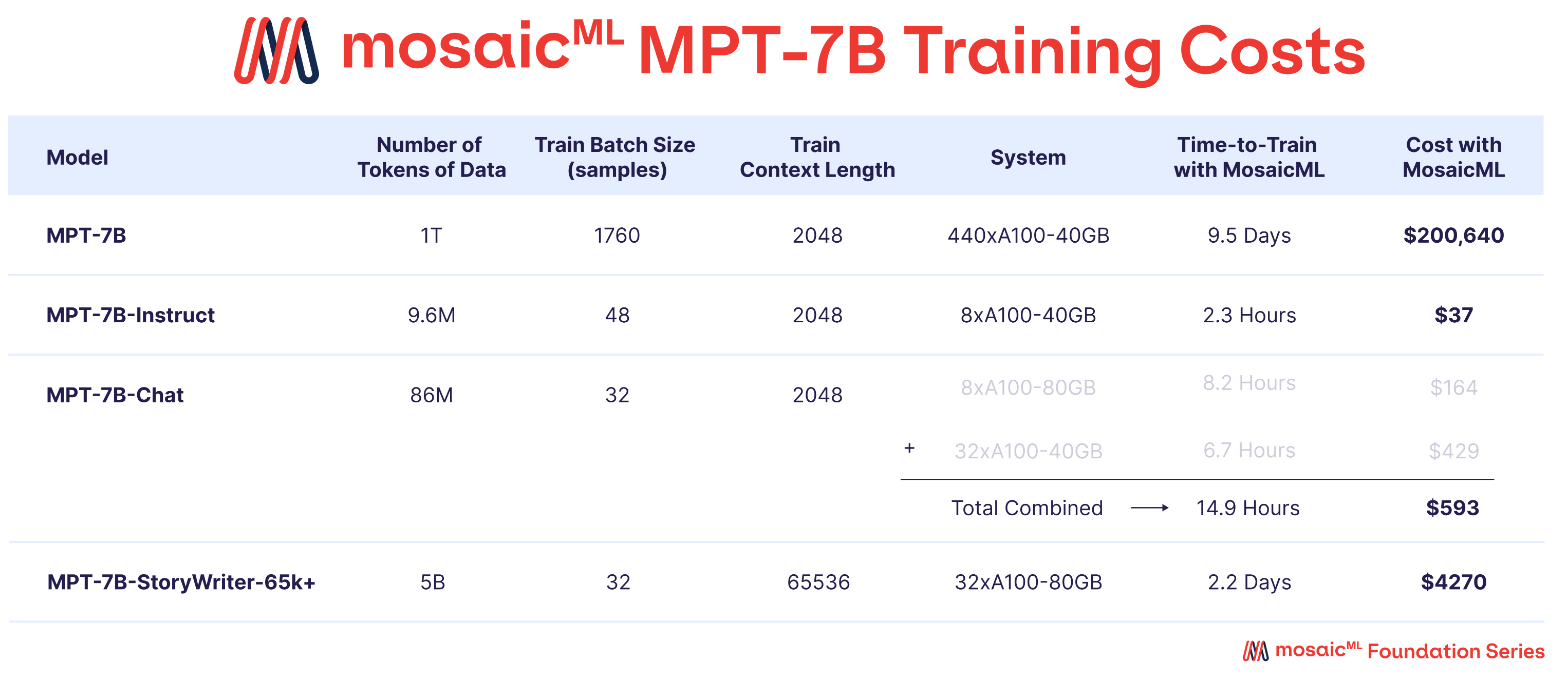
But wait… there’s more! MPT models are useful (especially for those working on commercial applications), but the models are also accompanied by an entire suite of software (i.e., the LLM foundry) released by MosaicML. This open-source code can be used to pre-train and fine-tune MPT models, making the MPT suite an incredibly valuable tool for exploring specialized use cases with LLMs.
Falcon: Reaching New Heights in Open-Source Performance

Although many advances had been made in the space of open-source LLMs, available models still lagged behind proprietary LLMs in terms of performance for quite some time. The proposal of the Falcon suite of LLMs [11] was the first time that the quality of proprietary LLMs was truly rivaled by an open-source alternative. Two variants of Falcon are available—Falcon-7B and Falcon-40B. In addition to being commercially licensed, these Falcon models perform incredibly well due to being pre-trained on a massive, custom-curated corpus. Notably, the instruct variant of Falcon-40B was the top-performing model on the OpenLLM leaderboard (by a significant margin) for several months5.
“Challenging existing beliefs on data quality and LLMs, models trained on adequately filtered and deduplicated web data alone can match the performance of models trained on curated data.” - from [12]
Curating data from the web. The Falcon models are trained over a massive textual corpus called RefinedWeb [12] that contains over 5 trillion tokens of text. Only 1.5 trillion tokens and 1 trillion tokens of RefinedWeb are actually used for pre-training Falcon-7B and Falcon-40B, respectively. Although a majority of LLMs are pre-trained over public sources of curated data, the authors of Falcon choose instead to construct their own pre-training dataset exclusively using data from the web (i.e., CommonCrawl). To filter this data, a novel pipeline is created that emphasizes simple, but effective, components; see below.
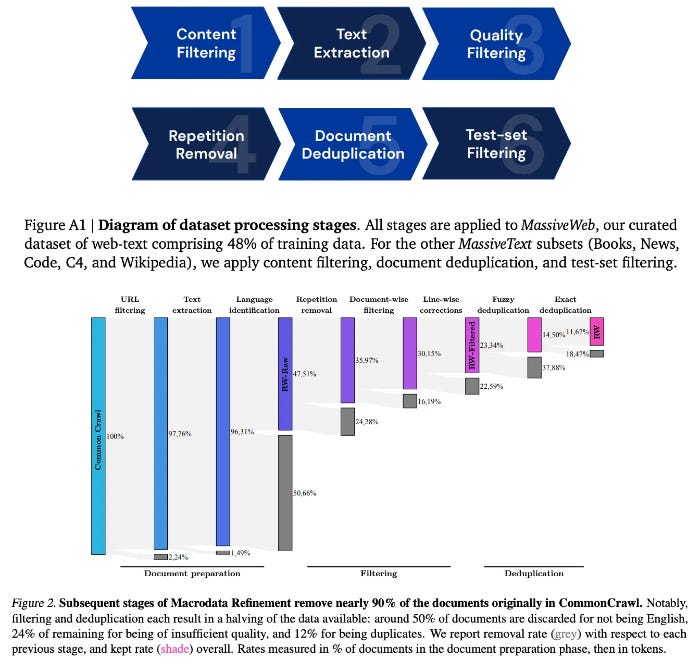
The RefinedWeb corpus shows that a massive amount of high-quality text data—beyond the scale of datasets explored previously—can be efficiently curated from the web. After filtering is applied, models trained on this data can even outperform comparable models trained over curated sources of data.
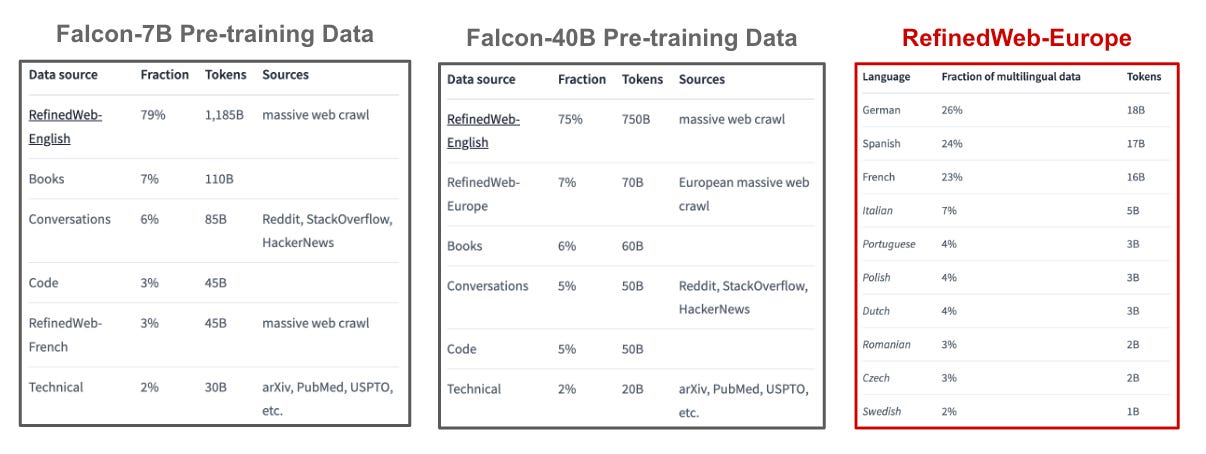
The exact datasets used to train Falcon-7B and Falcon-40B are shown above. Notably, Falcon-7B is trained over English-only data, while Falcon-40B has data from a variety of European languages inserted into its pre-training set.
A new SOTA. Currently, no publication for the Falcon LLMs has been released. As such, the only formal evaluation of these models was performed via the OpenLLM leaderboard, where the Falcon-40B model fared quite well. In particular, Falcon-40B-Instruct was the state-of-the-art model for some time, outperforming other models by a significant margin; see below.
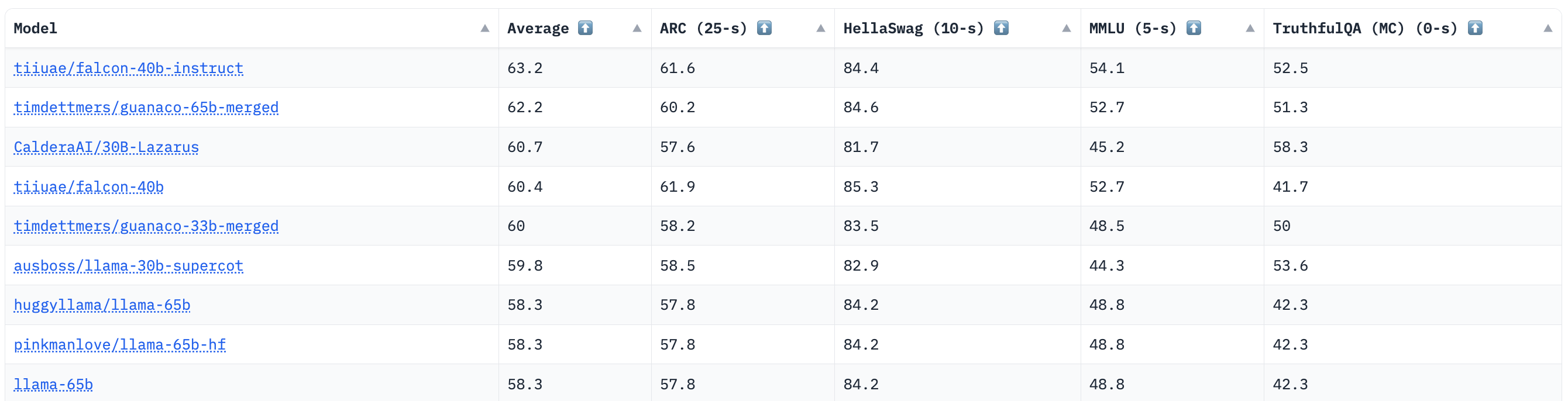
Qualitatively, some practitioners have claimed that Falcon-40B seems to underperform LLaMA-based models. Although an awareness of these remarks is useful, such evidence is anecdotal and subjective. In standardized natural language benchmarks, Falcon LLMs perform incredibly well, leading them to retain state-of-the-art performance among open-source models for a long time.
LLaMA-2: Current State-of-the-Art
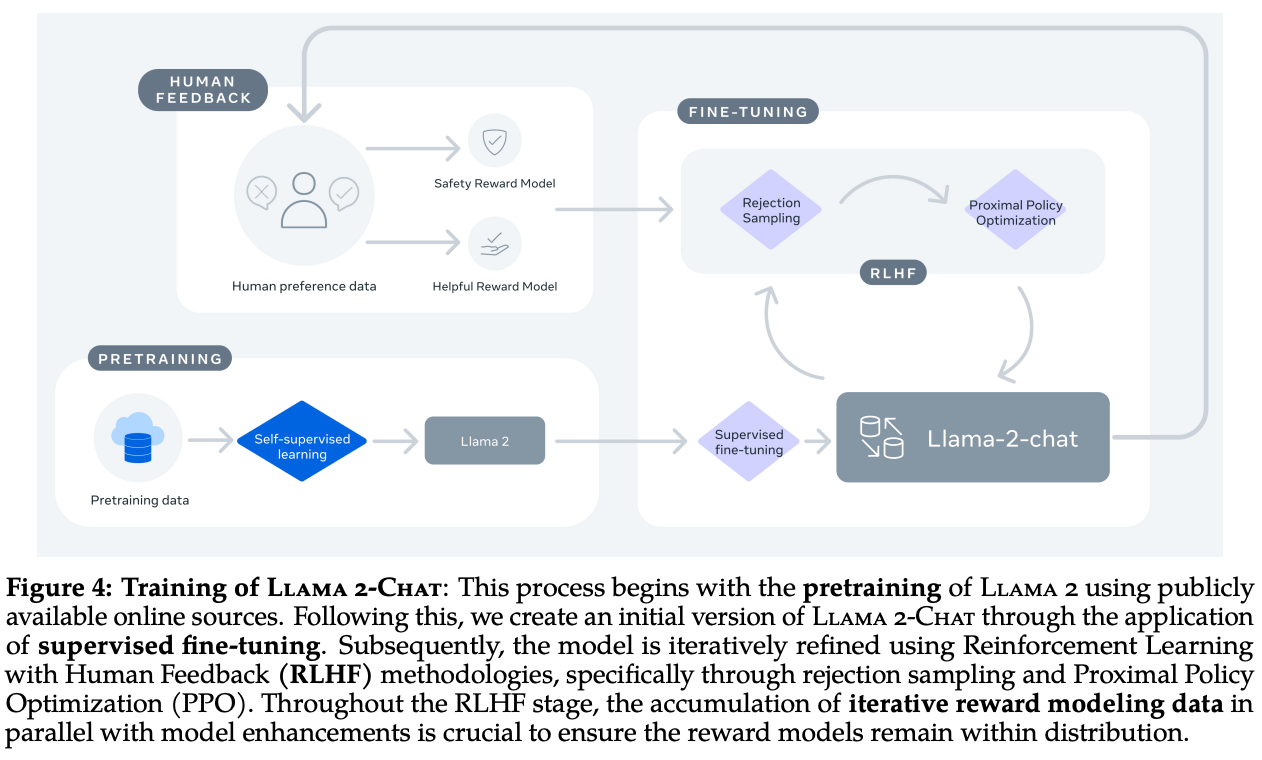
Although Falcon-40B was the state-of-the-art open-source LLM for some time, the recent release of the LLaMA-2 model suite dethroned this model. Similarly to LLAMA-1, LLaMA-2 [14] is comprised of several different LLMs with sizes ranging from 7 billion to 70 billion parameters and uses only publicly available data for pre-training. Both pre-trained and fine-tuned6 versions of LLAMA-2 models are released, though we will only cover the pre-trained models within this overview due to our focus upon open-source base models.
“There have been public releases of pre-trained LLMs (such as BLOOM that match the performance of closed pre-trained competitors like GPT-3 and Chinchilla, but none of these models are suitable substitutes for closed product LLMs, such as ChatGPT, BARD, and Claude.” - from [14]
LLaMA-2 continues to narrow the gap in performance between open and closed-source language models by releasing a suite of higher-performing base models that are pre-trained over a massive dataset. As we will see, these models still fall short of matching the quality of proprietary models, but they come much closer than any open-source model before them.
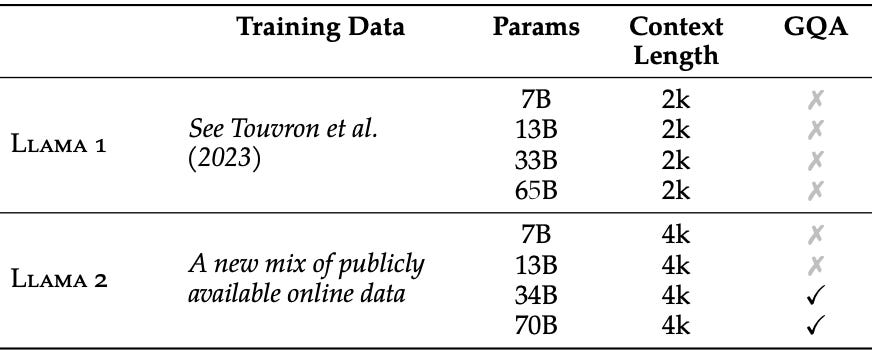
How is it different? LLaMA-2 adopts an approach that is quite similar to its predecessor, aside from a few minor (but impactful) differences. First, LLaMA-2 models are pre-trained over 40% more data—2 trillion tokens in total, compared to 1.4 trillion tokens for LLaMA-1. Additionally, LLaMA-2 models are trained with a slightly longer context length, and the larger models use grouped query attention (GQA) within their underlying architecture. Interestingly, authors in [14] note that LLaMA-2’s pre-training set up-samples sources of data that are known to be more knowledgeable. Such a change is made in an attempt to emphasize factual sources, increase knowledge, and reduce hallucinations.
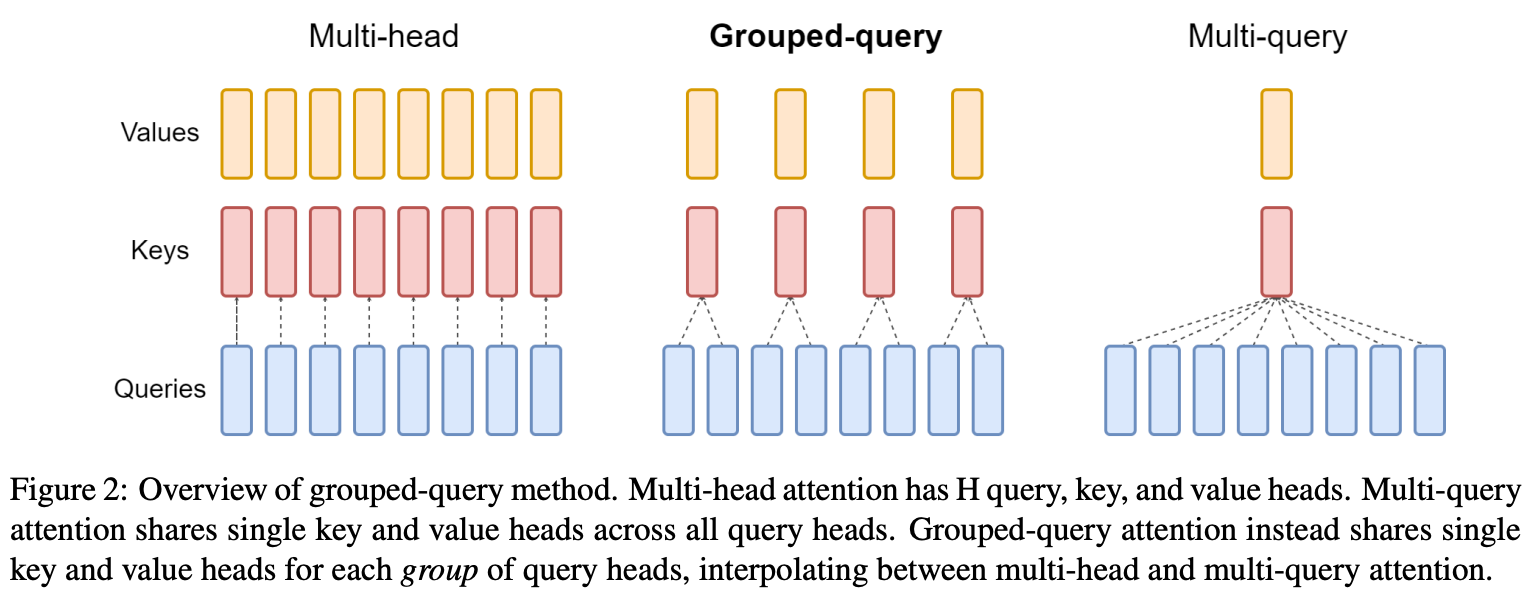
What is GQA? As proposed in [15], GQA is a modification to multi-headed self-attention that can improve inference efficiency in LLMs. A typical multi-headed self-attention mechanism has N total query, key, and value heads, creating N self-attention heads in total. In GQA, we divide these N total heads into groups, where key and value heads are shared within each group; see above. Such an approach is an interpolation between vanilla multi-headed self-attention and multi-query attention, which uses a shared key and value projection across all N heads7. GQA is found in [15] to improve inference speed comparably to multi-query attention, while maintaining the performance of vanilla multi-headed attention.
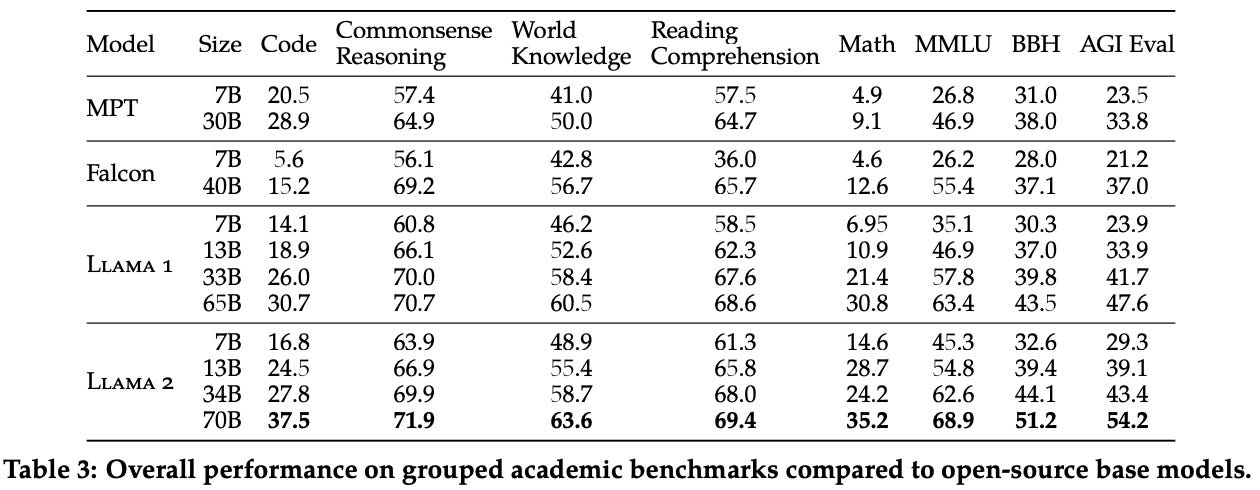
LLaMA-2 is really good. Compared to popular open-source models (e.g., MPT, Falcon, and LLaMA-1), the LLaMA-2 base LLMs perform quite well. In fact, LLaMA-2-70B sets a new state-of-the-art among open-source LLMs on all tasks considered; see above. Notably, however, LLaMA-2 was somewhat criticized for its (relatively) poor performance on coding-based tasks (e.g., HumanEval).
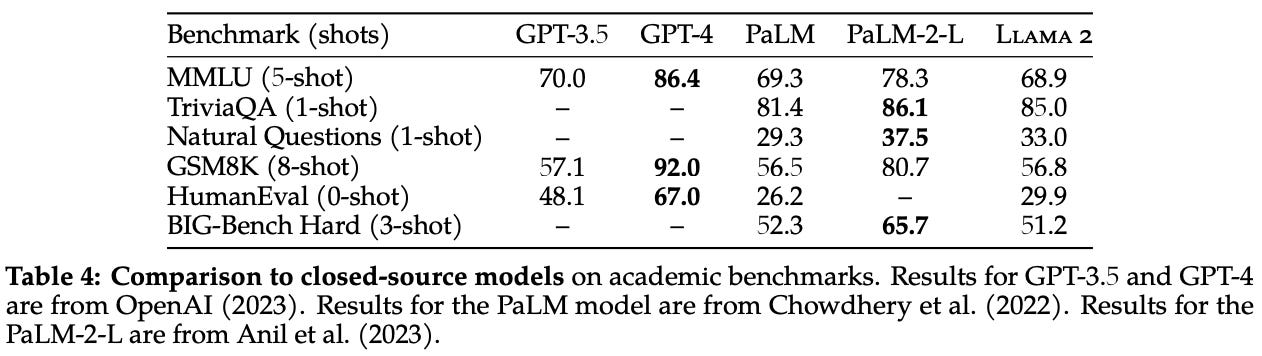
When compared to proprietary models, LLaMA-2 base models perform worse; see above. However, we should keep in mind that this comparison is made between a base LLM and aligned models like GPT-3.5 and GPT-4. When compared to other popular base LLMs (e.g., PaLM [4]), LLaMA-2 performs favorably!
Commercial license. While LLaMA-1 could only be used for research, LLaMA-2 is released under a commercial license, meaning that—like MPT and Falcon—the models can be used in commercial applications. However, the license used for LLaMA-2 is not a standard Apache 2.0 license—it has a few caveats that should be considered by practitioners. Most notably, any entity/application powered by LLaMA-2 with over 700 million monthly active users must obtain a license from Meta to use LLaMA-2. Read more about LLaMA-2’s license below.
Trends in Open-Source LLMs
Given that LLaMA, MPT, Falcon, and LLaMA-2 perform so much better than their predecessors, we might reasonably ask: what led the current generation of open-source LLMs to perform so well? Here, we will quickly look at a few key properties of these models that were especially valuable in catalyzing their impressive performance and quick rise to popularity. In particular, these models i) were pre-trained over a massive amount of data and ii) emphasize inference efficiency.
Better Data = Better Performance!
The key difference between current open-source LLMs and those that came before them is the dataset used for pre-training. While models like OPT and BLOOM are trained on 180 billion and 341 billion tokens, respectively, current open-source models are pre-trained over significantly larger datasets:
LLaMA: 1.4 trillion tokens
MPT: 1 trillion token
Falcon: 1-1.5 trillion token
LLaMA-2: 2 trillion tokens
Current open-source LLMs increase the amount of data used for pre-training by (nearly) an order of magnitude! In fact, these pre-training datasets are similarly-sized to those used for proprietary LLMs. For example, MassiveText (i.e., used to train Gopher [13] and Chinchilla [2]) contains roughly 2.3 trillion tokens, though only a subset is actually used for pre-training; see below.
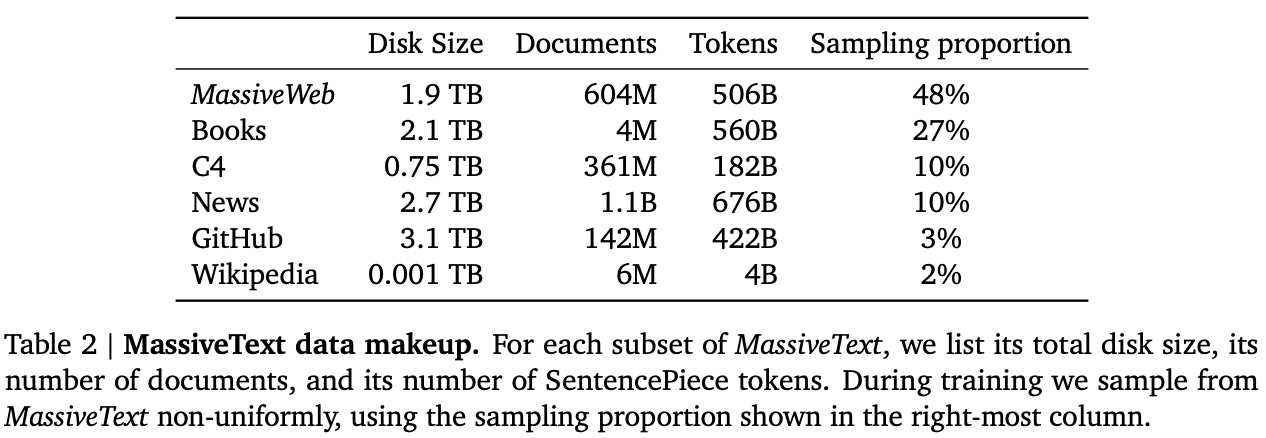
Size isn’t everything! In addition to increasing the amount of pre-training data significantly, current open-source LLMs pay close attention to the composition and quality of data. For example, the proportion of code is increased within the datasets used for training MPT, allowing the resulting models to perform much better on coding-based tasks. Additionally, Falcon-40B proposes an entirely new pipeline for constructing high-quality corpora of text from the web, while LLaMA-2 claims to use an updated data pipeline and mix for pre-training. Overall, focusing on the quality and composition of the pre-training dataset seems to be a common trend within recent research on open-source LLMs.
“We performed more robust data cleaning, updated our data mixes, trained on 40% more total tokens, doubled the context length, and used grouped-query attention (GQA) to improve inference scalability for our larger models.” - from [14]
Optimizing for Faster Inference
In making the decision between using an open or closed-source LLM, practitioners have to consider more than just performance. Paid language model APIs might achieve impressive performance across a wide scope of tasks, but they oftentimes cannot be fine-tuned on domain-specific data. On the other hand, however, a major consideration when building applications with open-source LLMs is the cost of deploying the model. Given the difficulty of hosting LLMs, recent open-source models are oftentimes optimized for fast and easy inference. In fact, MPT-30B [10] is specifically sized so that it can be hosted on a single GPU!
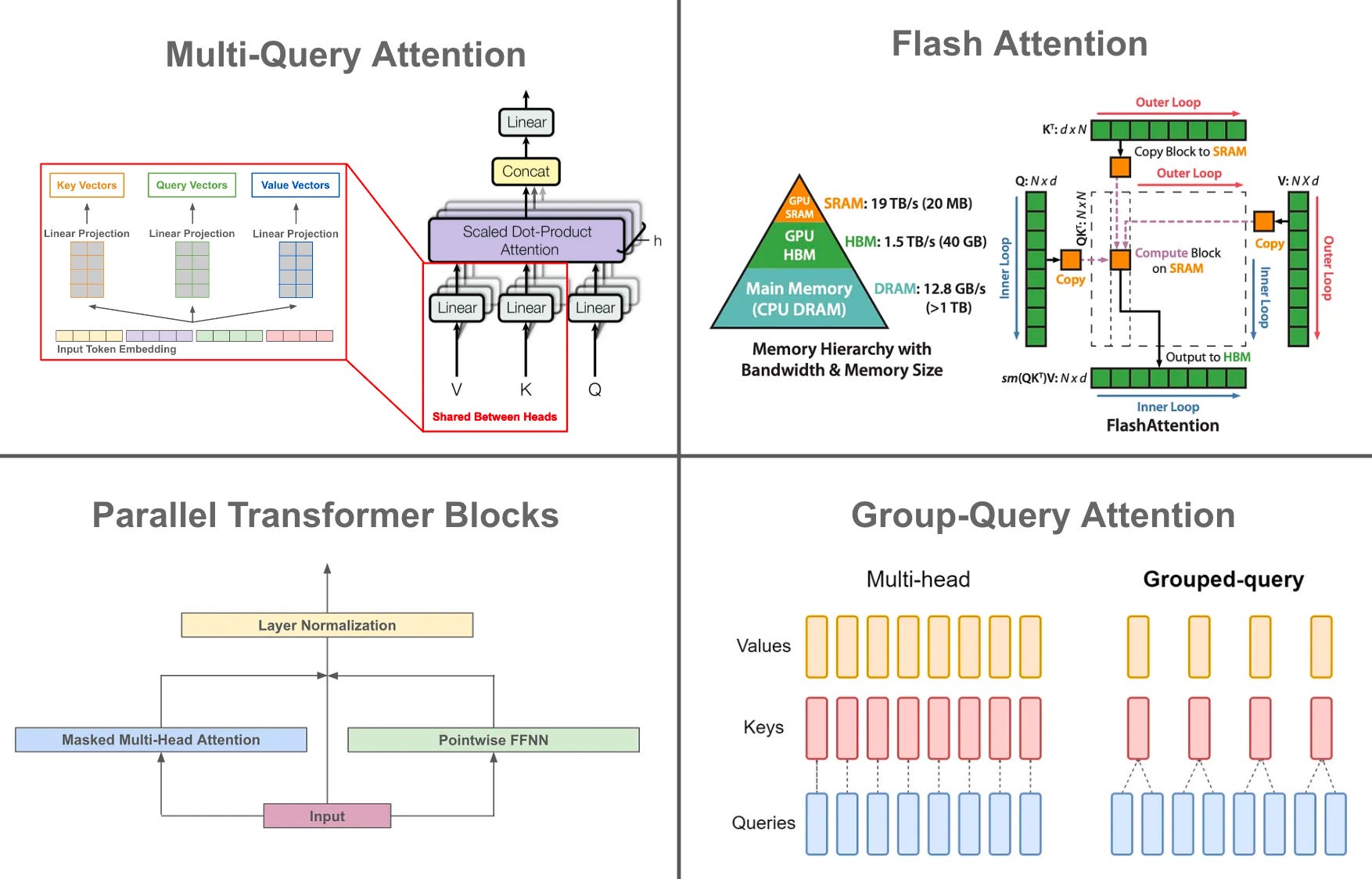
Modified architecture. Beyond being slightly smaller than most proprietary models, current open-source LLMs adopt a variety of architectural tricks—shown in the figure above—to speed up the inference process, such as:
Low Precision Layer Norm [link]
Multi-Query Attention [link]
Parallel Transformer [link]
Group-Query Attention
Additionally, several other architecture modifications—e.g., RoPE embeddings, ALiBi, SwiGLU activations, and more—are adopted to improve performance. Current open-source LLMs apply simple modifications to the decoder-only transformer architecture to improve performance and inference speed.
Final Thoughts
Within this overview, we have studied the evolution of open-source LLMs from initial, lower-quality models (e.g., BLOOM and OPT) to the more recent, powerful base models (e.g., LLaMA and MPT). To improve upon the performance of their predecessors, these recent models primarily focused upon curating larger, higher-quality datasets for pre-training, which resulted in a drastic improvement in quality. Given that a high-quality base model is a prerequisite for any LLM application, these models had a significant impact upon the raise in popularity of open-source LLMs. Instead of having to invest significant funds into pre-training a model from scratch, any practitioner can now leverage powerful base LLMs whether is be for research purposes or commercial applications.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews that explain relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on twitter or LinkedIn!
Bibliography
[1] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[2] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[3] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
[4] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[5] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[6] Chiang, Wei-Lin et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” (2023).
[7] Geng, Xinyang et al. “Koala: A Dialogue Model for Academic Research.” (2023).
[8] Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. GPT4All: Training an assistant-style chatbot with large scale data distillation from GPT-3.5-Turbo, 2023.
[9] “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable Llms.” MosaicML, 5 May 2023, www.mosaicml.com/blog/mpt-7b.
[10] “MPT-30B: Raising the Bar for Open-Source Foundation Models.” MosaicML, 22 June 2023, www.mosaicml.com/blog/mpt-30b.
[11] “Introducing Falcon LLM”, Technology Innovation Institute, 7 June 2023, https://falconllm.tii.ae/.
[12] Penedo, Guilherme, et al. "The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only." arXiv preprint arXiv:2306.01116 (2023).
[13] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[14] Touvron, Hugo, et al. "Llama 2: Open Foundation and Fine-Tuned Chat Models." arXiv preprint arXiv:2307.09288 (2023).
[15] Ainslie, Joshua, et al. "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints." arXiv preprint arXiv:2305.13245 (2023).
[16] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[17] Dao, Tri, et al. "Flashattention: Fast and memory-efficient exact attention with io-awareness." Advances in Neural Information Processing Systems 35 (2022): 16344-16359.
[18] Dao, Tri. "FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning." arXiv preprint arXiv:2307.08691 (2023).
The Chinchilla paper [2], which provides several valuable insights, shows us that increasing the size (i.e., number of parameters) of a language model is most effective when we also increase the amount of data over which the model is pre-trained.
Despite the trend in LLM applications toward longer context lengths, most open-source LLMs (e.g., LLaMA, Falcon, and MPT-7B) are trained using a relatively short context length of only 2K tokens.
Chat versions of the MPT models cannot be used commercially, as they are trained on data that cannot be used commercially (e.g., ShareGPT).
This model was recently dethroned on the OpenLLM leaderboard by various fine-tuned versions of LLaMA-2-70B.
Fine-tuned versions of LLaMA-2, called LLaMa-2-Chat, are optimized for chat use cases using both supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF).
Multi-query attention is used by a variety of different LLMs, even including Falcon-40B, to improve inference speed.
Great read! Thanks for doing this writeup. My company Neural Magic is working on making open-source LLMs even more efficient with sparsity, so they can be deployed on ordinary CPUs without GPUs. We'll make sure to share our progress with you!
It's impressive to see how LLaMA and other models have improved the performance of these language models and paved the way for more open-source research. Looking forward to your next installment on fine-tuning applications.