
Google Gemini: Fact or Fiction?
Breaking down the capabilities of Google's highly anticipated OpenAI competitor...

This newsletter is presented by Rebuy, the commerce AI company.
If you like the newsletter, feel free to get in touch with me or follow me on Medium, X, and LinkedIn. I try my best to produce useful/informative content.

For several months (an eternity within the AI space), large language model (LLM) leaderboards have been dominated by OpenAI models like ChatGPT and GPT-4. Despite shockingly fast progress in the area of open-source LLMs and massive investment of funds into AI research initiatives from companies both private and public, the dominance of OpenAI models has not faltered in the slightest—being outperformed by GPT-4 on nearly all benchmarks was universally accepted as unavoidable, even in cutting-edge research. With this in mind, the release of an LLM that can actually compete with models from OpenAI is a prospect that is both exciting (for AI practitioners) and frightening (for the company that has to do it). Who would willingly compete head-to-head with OpenAI? The answer is Google.
“As a neuroscientist as well as a computer scientist, I've wanted for years to try and create a kind of new generation of AI models that are inspired by the way we interact and understand the world, through all our senses.” - Demis Hassabis
After the recent release of Gemini—a suite of several multimodal LLMs of varying sizes—Google has marketed their new models as the largest competitor of OpenAI models to date. Within this overview, we will study the Gemini model suite, explain how these models operate, and evaluate whether this claim is legitimate. In short, Gemini models have many desirable properties (e.g., edge device compatibility and native multimodality) and perform—for the most part—comparably to top models from OpenAI. However, developing an accurate perspective of these models and their capabilities requires a deep dive that goes beyond the marketing tactics of LLM evaluations. Here, we will attempt to develop such a perspective through an in-depth analysis of relevant models.
What came before Gemini? Google released a variety of different language models before Gemini. In fact, many foundational works on LLMs (e.g., Chinchilla [27], Gopher [28], LaMDA [29], etc.) were published by Google, including a variety of multimodal LLMs (e.g., Flamingo [13], CoCa [14], and PaLI [15]). Prior to Gemini, Google provided access to two text-only LLMs via their APIs—PaLM and PaLM-2 [5, 6]. However, these models—despite competing with the API-based LLM offering of OpenAI—were not truly competitive.
Gemini Model Architecture
To understand Gemini, we first need to understand its model architecture. Although these details are not fully disclosed, there are many pointers and hints provided in [1] that give us an idea of how the Gemini models are structured. We’ll dive into these topics now, aiming to develop an understanding of both the Gemini models in particular and how multimodal LLMs are typically structured.
A Suite of Models for any Application

Gemini is not a single model, but rather a suite of several LLMs. Each of these LLMs is sized differently, granting each of them with a varying tradeoff between efficiency and problem solving capacity. Why release such a suite of models? The goal of Gemini is to release a set of capable models that are suitable for any application, whether it be on-device or solving complex reasoning tasks with access to massive amounts of compute resources (e.g., a data center).
“Gemini is our most flexible model yet — able to efficiently run on everything from data centers to mobile devices.” - from [2]
Different model sizes. The initial release of Gemini includes three1 different model variants:
Gemini Ultra: the largest and most capable model that achieves state-of-the-art performance on numerous, highly-complex tasks.
Gemini Pro: A performance-optimized (in terms of quality and latency) model that performs well across many tasks and can be deployed at scale.
Gemini Nano: a group of models that are designed to run efficiently on edge devices despite achieving impressive performance.
Gemini Nano contains two models with 1.8B parameters (Nano-1) and 3.25B parameters (Nano-2), which facilitates deployment onto devices with both high and low memory capacity. The exact sizes of Gemini Ultra and Pro are not mentioned, though the authors2 do mention that i) Gemini Pro requires a few weeks of training time and ii) only a fraction of the compute resources of Gemini Ultra are required for Gemini Pro. As such, it seems that Gemini Ultra is a much larger model, while Gemini Pro is optimized for deployment at scale; see below.

Decoder-only Architecture

Like many generative LLMs, Gemini is based upon a decoder-only transformer architecture; see above for a depiction. The details of the model’s architecture are not explicitly outlined in the technical report, but we are given enough information to (roughly) infer some relevant details about the model.

Architectural modifications. Beyond the standard decoder-only architecture, Gemini makes a few modifications to improve efficiency and training stability. Although the exact changes are not explicitly stated, authors do mention that they use multi-query attention, an approach that makes multi-head attention more efficient by sharing key and value vectors between attention heads; see above. This technique is also used by PaLM [5], PaLM-2 [6] and LLaMA-2 [7].
Going further, Gemini’s architecture is optimized to improve efficiency—both during training and inference—and training stability. With this in mind, we might infer that Gemini leverages some of the optimization and architectural tricks that are heavily used in prior work to serve this purpose:
Lion optimizer [8]: an adaptive optimizer that has been shown (by LLMs like MPT-7B) to improve the stability of LLM training.
Low Precision Layer Normalization: performs layer normalization in low precision to improve efficiency (used by MPT-7/30B); see here.
Flash Attention [9]: a hardware-aware efficient attention implementation that can drastically speed up training (used by numerous LLMs like MPT-7/30B and Falcon).
Flash Decoding [10]: an extension of flash attention that improves attention efficiency in the inference/decoding stage (in addition to training).
Hardware-aware architecture design. Beyond the techniques outlined above, we see in [1] that Gemini was optimized to maximize the efficiency of training and inference on Google TPUs. Although the details are not stated explicitly, Gemini models were likely optimized and sized based on hardware compatibility and considerations. For example, MPT-30B was sized specifically to simplify deployment onto A100 GPUs—using quantization, a model of exactly this size can be easily deployed on a single GPU. Similarly, Gemini Ultra’s architecture is crafted to simplify deployment on TPUs, while Gemini Nano uses a smaller architecture for easier deployment onto edge devices (e.g., a Pixel 8 smartphone).
“Gemini Ultra: Our most capable model … it is efficiently serveable at scale on TPU accelerators due to the Gemini architecture.” - from [1]
Multimodal Language Models
Gemini models are multimodal, meaning that they can accept input from and produce output with multiple modalities of data. Prior attempts at creating multimodal models heavily emphasize two modalities—text and images—and tend to use a post-hoc approach of i) training separate models on each modality and ii) “stitching” these models together with further finetuning.

For example, LLaVA and LLaVA-1.5 [11, 12]—two multimodal, open-source LLMs that are popular—begin with a pretrained LLM (i.e., LLaMA), combine it with a pretrained vision transformer, and further train the models over a multimodal dataset (i.e., image and text as input, text as output); see above. Such an approach can mimic shallow multimodal functionality but fundamentally lacks the ability to solve complex, multimodal tasks (e.g., conceptual and complex reasoning).
“Gemini is built from the ground up for multimodality—reasoning seamlessly across text, images, video, audio, and code.” - from [2]
In contrast to many existing models, Gemini models are “natively” multimodal, meaning that they are trained from the beginning using a multimodal approach. The models can accept various types of input data (i.e., text, audio, images, video, and code) and can produce interleaved sequences of text and images as output; see below. Using multimodal data across the entire training process (i.e., both pretraining and finetuning) gives Gemini models the ability to reason thoroughly across data modalities and produce the best possible response.

Multimodal architecture. Although few details are provided on the exact model architecture used by Gemini, authors indicate in [1] that the Gemini model architecture mimics their prior multimodal transformer architectures, such as Flamingo [13], CoCa [14], and PaLI [15]. With this in mind, we will now take a deeper look at the Flamingo model architecture, which will give us a better idea of how Gemini models might be structured.
“These new layers offer an expressive way for the LM to incorporate visual information for the next-token prediction task” - from [13]
Flamingo is a family of visualinguistic foundation models that can ingest text, images, and videos as input and produce text as output. Similarly to Gemini, Flamingo models are trained using multimodal data from the web and can solve image and video understanding benchmarks via few-shot prompting.

The goal of Flamingo, the architecture of which is depicted above, is to i) leverage existing pretrained models to avoid unnecessary compute costs3 and ii) easily merge these models into a single, multimodal architecture. More specifically, authors in [15] use a pretrained vision encoder—a vision transformer that is similar to the image encoder used by CLIP—and the Chinchilla LLM [27] as a starting point for Flamingo. Then, two modules are added that link these architectures together:
Perceiver Resampler [16]: takes features from the vision encoder as input (either from images or video) and produces a fixed-size set of visual tokens.
Cross Attention: incorporates visual information into existing LLM layers by inserting new cross attention modules that condition on visual input between existing, pretrained layers of the LLM.
The perceiver module allows us to distill high-dimensional visual input (i.e., images and video) into a fixed number of visual tokens that can be considered by the LLM similarly to any other (textual) token; see below.
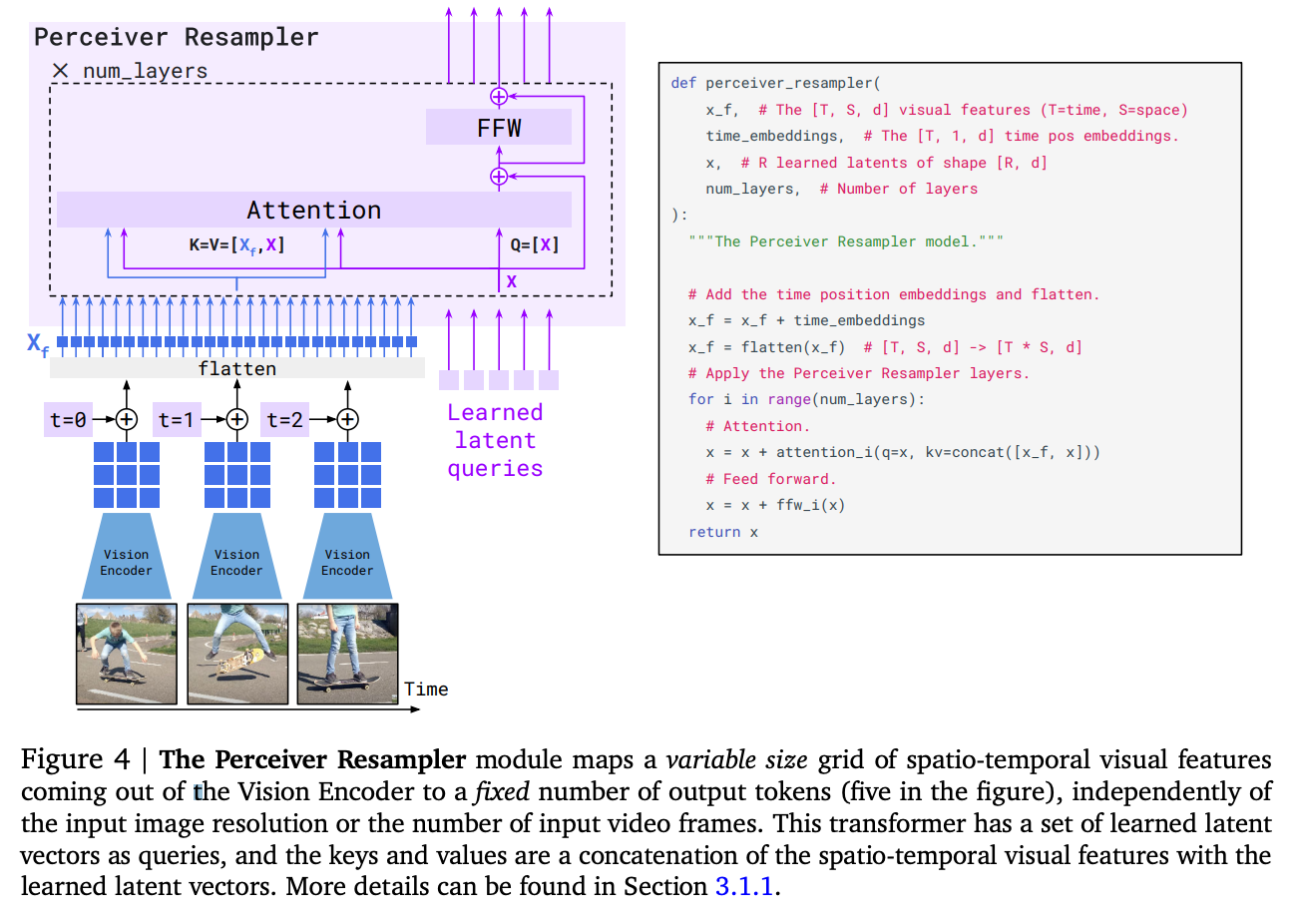
The visual tokens produced by the perceiver are used to condition the output of newly-initialized cross attention layers within the LLM. In particular, gated cross attention layers are added between each layer of the LLM; see below. Inserting these added attention layers enables the LLM to attend to visual features when processing textual tokens. More specifically, Flamingo is trained over interleaved sequences of text, images, and video, and each textual token attends to the last image or video present before the occurrence of that text within the sequence.

As such, the LLM gains the ability to consider visual information when performing next token prediction. All pretrained model weights are held fixed, and we only train the added perceiver and cross attention modules. The result of this architectural synthesis is that Flamingo can easily process interleaved sequences of text and images (or videos) and output relevant text4, enabling the model to solve complex multimodal tasks via a few-shot prompting approach.
“The visual encoding of Gemini models is inspired by our own foundational work on Flamingo, CoCa, and PaLI, with the important distinction that the models are multimodal from the beginning and can natively output images using discrete image tokens." - from [1]
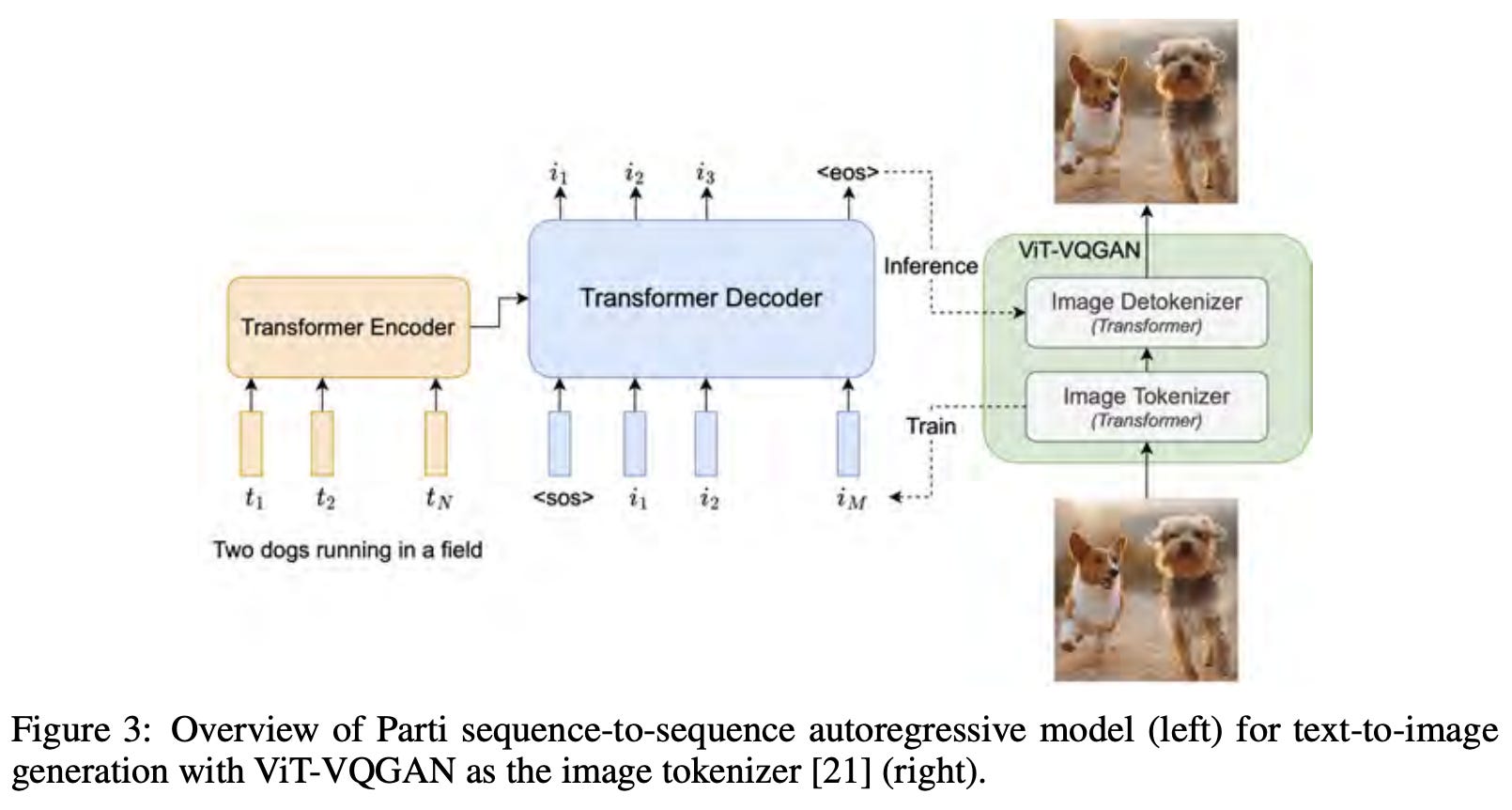
One big distinction. Work on Flamingo in [13] gives us a decent idea of how the architecture of Gemini might be structured. However, there is an important distinction between Gemini and models like Flamingo or CoCa—Gemini is multimodal from the start. Rather than stitching pretrained models together, we perform the entire pretraining process (during which the model is trained end-to-end) using multimodal data. Additionally, we see in [1] that Gemini can i) ingest several other modalities of data beyond just images/video and ii) generate images by outputting discrete images tokens [18]; see below for a depiction.
How do we handle so many modalities? The Flamingo model only considers text and image modalities, while Gemini can ingest video and audio as well. The techniques used for encoding these modalities is outlined below.
Video: each video is broken down into a sequence of frames, and these frames are interleaved with textual input similarly to any other image.
Audio: we encode audio with the Universal Speech Model (USM) [19].
Notably, Gemini does not ingest audio data by mapping it to textual tokens. Rather, the model directly ingests features generated by USM at 16 kHz, which enables more nuances within the audio data to be captured by the LLM.
Multimodality is trending! The main distinctions between Gemini and prior attempts at building multimodal LLMs are that i) Gemini considers many different modalities and ii) the model is trained in a multimodal fashion from the beginning, rather than by cheaply “stitching together” models that are trained on a single modality. Authors in [1] claim that this “natively multimodal” training approach is the best way to teach an LLM to deeply reason over multimodal data.

More broadly, researchers in the AI community have heavily emphasized the development of multimodal LLMs in recent months; see here for details. For example, GPT-4V [17]—the multimodal extension of GPT-4 that accepts both text and image inputs—was released recently, and OpenAI is exploring integrations of DALLE-3 [18] into the ChatGPT app to enable ingestion and generation of images within a user’s chat session5. As such, the proposal of Gemini is simply furthering the trend of LLM research toward multimodality.
Model Training and Dataset
“Gemini models are trained on a dataset that is both multimodal and multilingual. Our pretraining dataset uses data from web documents, books, and code, and includes image, audio, and video data.” - from [1]
The exact mixture of pretraining data used for Gemini was excluded from the technical report. However, the mixture of data used for training LLMs has been shown by prior work (e.g., Falcon, MPT, BioMedLM, etc.) to be a massive factor in influencing the model’s quality. In [1], authors mention several considerations that provide useful insight into the training process and dataset used for Gemini.
Diverse sources. Whenever possible, we should pull data from many sources (e.g., web, books, code, etc.) for use during pretraining. Going beyond pure textual data, we should incorporate data from different modalities (e.g., image, audio, video), languages, and domains (e.g., coding) into the pretraining process. As shown by Chinchilla [27], the amount (and quality!) of pretraining data is incredibly important and has a direct/noticeable impact on model quality.
Pay attention to your tokenizer. Most practitioners just download a pretrained tokenizer and use this for their application, assuming that it works well. But, this is not a good idea! Tokenization problems cause lots of downstream issues that are hard to detect and can significantly deteriorate performance. For the best results, we should train our own tokenizer over data from our pretraining set. This way, the tokenizer is specialized to the type of data that the model will encounter. In [1], we see that Gemini follows this approach exactly. For details on how to train a SentencePiece tokenizer on your own data, check out this discussion.
Cleanliness is key. Data pipelines for LLM pretraining are complex. They include heuristics, model-based schemes, safety/toxicity filters, and much more. In prior work (e.g., RefinedWeb), we see that authors emphasize the use of only simple heuristics for filtering pretraining data. However, Gemini seems to throw the kitchen sink at the pretraining data pipeline. They use all tools that are available to craft the cleanest pretraining dataset possible. Put simply, the best pipeline to use for processing pretraining data is not standardized. However, ensuring that the pretraining data is high-quality and clean is incredibly important.
Data weighting. Beyond data sources and quality, the frequency with which we sample data from each pretraining data source (i.e., the data weight) is important! To tune this data weight, we should run tuning experiments with smaller models and datasets to determine optimal settings. Interestingly, authors of Gemini also mention that varying the data weights throughout training (e.g., increasing the weight of domain-specific info towards the end of training) can be helpful.

Distilling smaller models. Finally, we see in [1] that authors leverage a knowledge distillation approach for training the smaller Gemini Nano models; see above. Although this might sound complex, it just means that Gemini Nano is trained using the outputs of larger Gemini models as a target. Such an approach—referred to as knowledge distillation [17] within AI research—is commonly used and highly-effective. By distilling the knowledge of a larger network into a smaller network, we can get a smaller LLM to perform much better compared to just training it from scratch (i.e., without using the larger model’s output)6.
Other training (and infrastructural) details. Gemini models are trained using TPU accelerators—TPUv4 and TPUv5e in particular. These TPUs are custom-designed for AI workloads (i.e., training and serving big neural nets). Compared to PaLM-2, Gemini Ultra is trained using a much larger infrastructure, comprised of TPUv4 accelerators distributed across multiple data centers. TPUv4 devices are grouped into “super pods” that contain 4096 chips each, and Gemini Ultra is trained across several super pods in different data centers. Communication between TPUs in the same super pod is fast, but communication between super pods is (comparatively) slow. For this reason, Gemini Ultra is trained using a combination of model parallelism (within each superpod) and data parallelism (across superpods). Such an approach mimics the training strategy of PaLM [5].
“We trained Gemini 1.0 at scale on our AI-optimized infrastructure using Google’s in-house designed TPUs v4 and v5e. And we designed it to be our most reliable and scalable model to train, and our most efficient to serve.” - from [3]
Interestingly, Gemini is trained using Jax and Google’s Pathways framework. This approach allows the entire training run to be orchestrated with a single Python process, thus simplifying development workflows. Additionally, authors avoid periodically writing model checkpoints to disk throughout training, choosing instead to keep in-memory replicas of model state that can be used to recover from any hardware failures7. Such an approach speeds up recovery time and improves the overall throughput of the training process.
How does it perform?
Given that Gemini is trained over several different modalities of data, we might wonder whether this model matches (or surpasses) the performance of both:
Other LLMs.
Models trained specifically on each domain or modality.
In [1], authors perform an extensive empirical validation of Gemini models across several text-based benchmarks and a comprehensive group of multimodal datasets. Additionally, Gemini is used to build a successor to AlphaCode—an agent used for solving competitive programming problems—called AlphaCode-2, which demonstrates the impressive coding capabilities of Gemini models.
The TL;DR…

Gemini Ultra achieves state-of-the-art performance on 30/32 tasks considered, including both text-based and multimodal tasks. The only tasks on which Gemini Ultra is outperformed are purely text-based tasks, where GPT-4 achieves better performance in a few cases. Going further, Gemini Ultra is the first model to achieve 90% accuracy—surpassing human accuracy of 89.8%—on the MMLU dataset, though this score is achieved with a modified chain of thought prompting approach that is not used by baselines; see above. Seemingly, the results of Gemini Ultra are slightly emphasized, as certain specialized prompting approaches are used on select tasks. Nonetheless, the model’s performance on text-based tasks is quite impressive and rivals that of GPT-4 in most cases.

Gemini models shine the most on multimodal tasks. Gemini Ultra achieves new state-of-the-art performance on the MMMU benchmark, where it outperforms prior models by over 5%. However, authors in [1] again use a different prompting strategy to achieve these results. Using standardized prompting techniques, Gemini Ultra achieves only a 2.6% improvement over the prior best model; see above. Going further, Gemini models outperform all baseline techniques on a variety of video and audio understanding tasks, as well as demonstrate impressive cross-modal reasoning capabilities in qualitative experiments. Notably, these results are achieved without the use of OCR or audio transcription modules—text, image, video, and audio data is directly ingested by the model.
Text-Based Benchmarks

The performance of Gemini models across all textual benchmarks is presented within the table above. On text-based benchmarks, Gemini Pro outperforms inference-optimized models like GPT-3.5, while Gemini Ultra outperforms nearly all current models. We will now break down some of these results by category to provide a more nuanced perspective on Gemini’s performance.

Text-based, multitask performance. On MMLU—a popular benchmark that measures knowledge across 57 subjects—Gemini Ultra is the first LLM to surpass human-level performance (89.8%) with a score of 90.04%; see above. Prior state-of-the-art performance on MMLU was 86.4%. However, Gemini Ultra uses a specialized variant of Chain of Thought prompting8 to achieve this score, which makes a direct comparison of these results somewhat misleading. Without the specialized prompting approach, Gemini is actually outperformed by GPT-4, and GPT-4 is not evaluated using the exact prompting strategy used for Gemini Ultra.

Can Gemini do math? On math problems, we see that Gemini Ultra achieves competitive performance; see above. More specifically, Gemini Ultra uses Chain of Thought prompting and self-consistency—the same approach used by prior work—to achieve new state-of-the-art performance on GSM8K. On more advanced problems, we see a similar boost in performance from using Gemini Ultra, even when using a simpler prompting approach (i.e., few-shot learning). Interestingly, smaller models (i.e., both Gemini Pro and GPT-3.5) perform quite poorly—even nearing random performance in certain cases—on challenging math benchmarks.

Coding benchmarks. The coding abilities of Gemini models are evaluated:
On standard coding benchmarks.
As part of a new reasoning system called AlphaCode 2.
First, Gemini is evaluated on coding benchmarks like HumanEval and Natural2Code—an internal evaluation benchmark (from Google) for python code generation that has no leakage9 from the web. As shown above, Gemini Ultra achieves new state-of-the-art performance on coding benchmarks, while Gemini Pro outperforms GPT-4 on HumanEval but slightly underperforms GPT-4 on the new Natural2Code benchmark. Put simply, Gemini Ultra has impressive coding abilities, while Gemini Pro is (roughly) comparable to GPT-4 in this domain.

Beyond evaluation on standard coding benchmarks, Gemini Pro—more specifically, a specialized version of Gemini Pro that is finetuned over competitive programming data—is used to create a successor to the AlphaCode [21], a transformer-based coding agent that combines code generation with smart filtering algorithms to accurately solve competitive programming tasks. Gemini Pro is used to create AlphaCode 2 [22], which solves 43% of competition problems on Codeforces (AlphaCode solved 25%) and outperforms 85% of competition entrants (AlphaCode outperforms 50%). The Gemini-based AlphaCode 2 is a drastic improvement over prior work in terms of problem solving capabilities.
“The composition of powerful pretrained models with search and reasoning mechanisms is an exciting direction towards more general agents” - from [1]
As shown in the figure above, Gemini Pro is finetuned to both generate code and rank solutions—basically acting as a reward model that recognizes promising solutions—for AlphaCode 2. To solve a problem, the language model first samples the search space by generating a bunch of candidate solutions. Then, we can perform filtering and clustering on these solutions to identify a smaller set of high-quality candidates. Finally, the LLM is used to score each of these solutions as part of a reranking step before a submission is made. Here, we see that powerful agents can be created by combining Gemini with additional tools like search and ranking.
Context length test. Gemini models are trained using a 32K context length, which is larger than prior models like PaLM-210. However, recent empirical analysis has shown us that context window size can be misleading—what matters is whether the model can actually utilize the larger context window. For example, LLMs with large context windows oftentimes have a position or recency bias, where they only pay attention to information at the beginning/end of the context. The ability of LLMs to leverage their context window is typically tested with a “needle in the haystack” approach, where we insert facts at different locations in a context window of varying sizes and ask the model to restate the fact.

Gemini models are first evaluated by retrieving information from the beginning of a context window with varying length, instead of a needle in the haystack approach. Unsurprisingly, the model is able to consistently retrieve information in this setup. From here, authors in [1] evaluate Gemini over a held-out set of long documents by plotting the negative log likelihood of tokens at different positions within the sequence. As shown above, Gemini models seem to be relatively capable of recalling information across the full context window.
Problem Solving over Multiple Modalities

Although Gemini performs (relatively) well on language-only benchmarks, one of the most enticing aspects of the model is its ability to extend the problem-solving capabilities of an LLM across multiple data modalities. Namely, Gemini models can pick up on details within their input (e.g., particular details of an image), aggregate relevant info over space/time in videos, and even handle dense temporal sequences such as audio. Going further, Gemini models can even augment their output by generating corresponding images; see above. Within this section, we will explore the multimodal capabilities and evaluations of Gemini models.

Image understanding. The ability of Gemini models to process and reason over images is tested using four different kinds of tasks:
Object recognition (e.g., VQAv2)
Transcription, or recognizing text in an image (e.g., TextVQA)
Chart understanding (e.g., ChartQA)
Multi-modal reasoning (e.g., MMMU)
In the table above, we see that Gemini Ultra achieves new state-of-the-art performance across several image understanding benchmarks, outperforming GPT-4V and several finetuned models for each benchmark. Here, models are primarily evaluated using a zero-shot approach that just instructs the model to generate a short answer corresponding to the task at hand (e.g., transcribe the text in an image). Gemini Pro achieves less impressive performance relative to Gemini Ultra, but it performs comparably to GPT-4V on a few benchmarks. Furthermore, we see in [1] that Gemini has the ability to reason over images in multiple languages, which adds another interesting dimension to these models.
Most notably, Gemini Ultra achieves the best score of any model so far on MMMU, beating prior state-of-the-art by 5% overall; see above. MMMU is a recently-released benchmark consisting of questions about images that span 6 different disciplines and require college-level knowledge to solve. The impressive performance of Gemini on MMMU was heavily marketed within the models’ release and emphasizes the ability of these models to perform multimodal problem solving. We should note, however, that the 5% absolute improvement is (again) achieved with a different prompting strategy. When evaluated using a the same prompting strategy, Gemini Ultra outperforms GPT-4V by 2.6%.

Video understanding. To ingest video, Gemini models extract 16 equally-spaced frames (i.e., these are just images!) from each video clip to ingest as input. Gemini models can use this approach to achieve impressive performance on video captioning and question answering datasets; see above. Plus, the video processing capabilities of Gemini extend beyond the English language—we see above that Gemini Ultra (and Pro) can even perform video captioning tasks in Chinese.
“Video understanding is accomplished by encoding the video as a sequence of frames in the large context window. Video frames or images can be interleaved naturally with text or audio as part of the model input.” - from [1]
The video processing capabilities of Gemini are rudimentary—we are just processing video clips as individual frames/images. Yet, few mainstream LLMs have these capabilities! For example, GPT-4V only has the ability to process images. As a result, Gemini models pioneer the integration of video with LLMs. Given that videos are a huge, untapped source of data for AI, such an approach holds massive potential. Imagine, for example, if we could extend LLM pretraining to encompass not only text, but also all videos that are available on the web. Such an approach could drastically expand the volume of pretraining data that is available!

Audio understanding. Finally, Gemini can directly ingest audio data—a capability that has not been heavily explored within LLM research. When evaluated on automatic speech recognition (i.e., transcribing audio) and automatic speech translation (i.e., transcribing audio and translating it into a different language), Gemini Pro outperforms popular models like USM [19] and Whisper [23] on all tasks; see above. Notably, these results were achieved with the less powerful Gemini Pro model, and even Gemini Nano outperforms prior models on a majority of tasks.

Putting it all together. So far, we have seen that Gemini models have the ability to process and solve problems over individual modalities of data. But, the magic happens when we combine all of these modalities within a single model! As shown in the figure above, Gemini models have the ability to combine and synthesize data from each of the different modalities that it understands. Such an ability to ingest data from several, diverse sources is currently unavailable within any other model—most existing LLMs focus upon two modalities of data at most (e.g., images and text). For a more in-depth overview of multimodal prompting and problem solving with Gemini, check out the tutorial below.
Gemini in the Wild!
Despite being proposed so recently, Gemini models are already being heavily used in practice. Bard is using a finetuned version of Gemini Pro for help with solving questions that require advanced reasoning or planning, Gemini Ultra will be used in Bard early next year, Gemini Nano is being deployed on the Pixel 8 smartphone to power features like summarization and smart replies, and Gemini is being used to power Google’s search generative experience (SGE) with a 40% reduction in latency and better quality. Currently, Gemini Pro is accessible via the Gemini API, Google is releasing an AICore framework (in beta) for using Gemini Nano in on-device tasks, and Gemini Ultra is only available to select developers for experimentation and feedback as it undergoes further safety testing. Given the many practical use cases of Gemini models, let’s quickly take a look at some interesting analysis, applications, and tools that might be relevant.

Evaluating Gemini’s language capabilities [24]. After the release of Gemini, authors from Carnegie Mellon University released a 3rd party (objective) evaluation of the models’ language capabilities in comparison to GPT models from OpenAI. All of the code from these evaluations is available online and fully reproducible. This analysis provides several valuable insights:
Gemini Pro is (slightly) worse than GPT-3.5-Turbo on all tasks considered.
Gemini excels at generating non-English output.
Gemini is better at handling longer and more complex reasoning chains.
Gemini Ultra is not yet publicly accessible, so the results provided in [24] only apply to Gemini Pro. Nonetheless, we learn from this analysis that i) Gemini Pro lags behind comparable models from OpenAI and ii) the gap in performance between these models is less significant compared to top open-source models (e.g., Mixtral). Notably, however, several researchers in the AI community have claimed that the evaluations in [24] misrepresent the quality of Mixtral.

Evaluating Gemini’s image understanding. Authors in [25] provide a similar 3rd party analysis of Gemini Pro’s ability to process visual information in comparison to GPT-4V. The visual capabilities of these models are measured in the following domains: fundamental perception, advanced cognition, challenging vision tasks, and various expert capacities. The paper is incredibly long (128 pages), but the primary results can be boiled down into a few key points:
Gemini Pro and GPT-4V have comparable visual reasoning capabilities (i.e., Gemini Pro is a valid competitor to GPT-4V).
The models have different output styles—Gemini writes concise answers, while GPT-4V provides detailed steps and explanations; see above.
Open-source variants (e.g., Sphinx [26]) lag far behind GPT-4V and Gemini.
Multimodal LLMs still have a long way to go, as even Gemini Pro and GPT-4V have noticeable lapses in visual understanding/reasoning and lack robustness to slight variations in their prompts.
In other words, Gemini Pro’s visual understanding is impressive, and the model can reason over several additional modalities beyond just images!

Gemini + LangChain. Shortly after the release of Gemini, the popular LLM abstraction toolkit LangChain released an integration with Gemini models. Notably, this is not the first integration of LangChain with Google models, as LangChain already provided support for PaLM-2; see here. However, the integration with Gemini Pro provides both language and vision support, which unlocks a wide range of capabilities and applications for AI practitioners.
Are the results legit? Gemini was heavily marketed as the first legitimate competitor to OpenAI models like GPT-3.5-Turbo and GPT-4. Opinions of Gemini have been mixed to say the least… some are saying the results are completely fake, others seem to think they are legit, while many people are somewhere in the middle. As we’ve seen so far, the results achieved by Gemini are definitely impressive, though (possibly) exaggerated in certain areas. However, we’ve yet to run one final test—trying the model out for ourselves.
To get a better feel for Gemini, let’s test a few interesting examples ourselves and compare the results that we get to those presented within the Gemini technical report. Given that Gemini Ultra has not yet been publicly released, we will obtain our results using Gemini Pro within Vertex AI. This tool only supports text and image inputs, but we can still use it to do some interesting analysis. First up, we can try to identify a plant and get some basic caretaking instructions; see below.
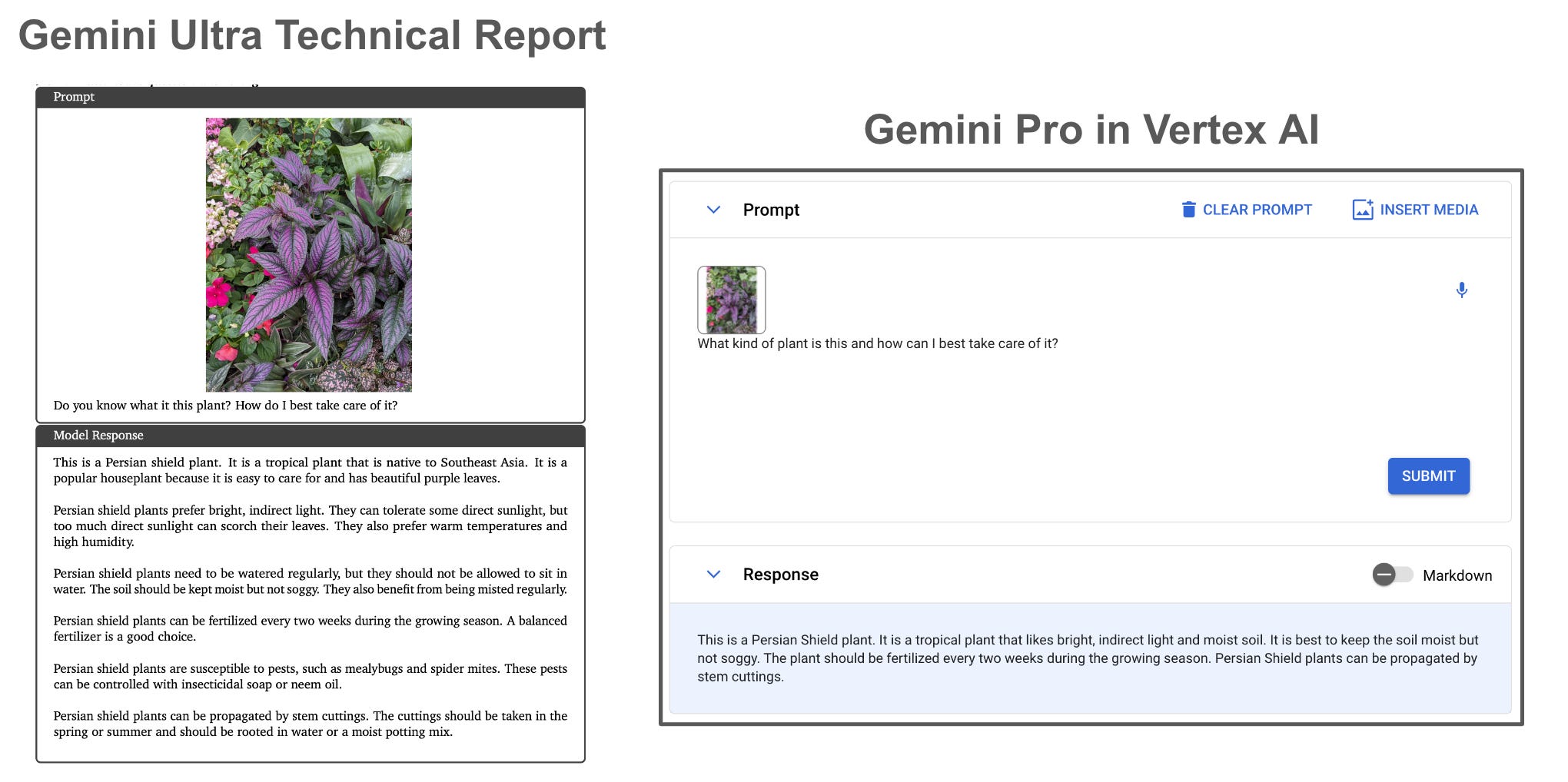
The response provided by Gemini Pro is more concise, yet it still i) correctly identifies the plant and ii) provides the (correct) primary caretaking step for the plant. As such, the response by Gemini Pro in this case seems both reasonable and useful. Next up, we test out the spatial reasoning capabilities of Gemini Pro via a basic visual reasoning problem in which the model must detect several shapes in an image and determine a pattern in the sequence of shapes; see below.

In this case, Gemini Pro produces the correct answer and (arguably) even provides us with a better chain of thought compared to Gemini Ultra. Although this problem is relatively simple, it demonstrates impressive visual recognition and reasoning capabilities. In other words, the multimodal capabilities of Gemini are definitely legit! Now, we can push these visual recognition and reasoning skills further by asking the model to do a little bit of (basic) math; see below.

This time, Gemini Pro gets many of the reasoning steps for solving the problem correct; see below. However, the model fails to recognize the relation between the height and width of the parallelogram (i.e., they are both expressed in terms of x). As such, the model fails to arrive at a complete final answer, despite getting many of the reasoning steps correct while working towards a final solution.

Next, we can test Gemini’s ability to leverage both its knowledge base and visual recognition capabilities in tandem to solve an interesting problem—determining the relationship between a picture of the moon and of a golf ball. Interestingly, the moon is (apparently) the only celestial body in which humans have played golf. When we test the ability of Gemini Pro to draw this connection, we see that the model easily solves this problem and even provides more information than Gemini Ultra! After further researching the topic, I confirmed that the club used by Alan Shepard to perform the shot was indeed a six-iron, but I cannot find any information on the length of the shot. Either way, the results are quite impressive!

Finally, there are three categories of basic testing that I find to be particularly useful when gauging the capabilities of any LLM:
Checking instruction following capabilities.
Determining if the model can write and explain code.
Seeing if the model can generate valid API calls.
These use cases are incredibly common in practice, and I personally leverage these particular skills frequently to build LLM applications. As such, these three categories of skills serve as a simple, yet important sanity check for determining the usefulness of any LLM. After performing several experiments, the instruction following capabilities of Gemini Pro seem quite strong, and the model adheres to prompts with varying degrees of instruction complexity; see below for an example.

When we ask Gemini to explain a snippet of code (even when provided as an image!), the results are useful and correct. Plus, we can even ask Gemini Pro to generate new or modified code and the results are promising. Put simply, Gemini Pro passes the basic coding test and can reasonably explain and write code.

Finally, we can test the ability of Gemini Pro to generate valid function calls. Such a skill is important for building applications with LLMs (e.g., agent systems or integrating LLMs with tools). In a variety of experiments, Gemini Pro seems more than capable of i) understanding different APIs or functions, ii) inferring when these APIs should be used, and iii) generating valid JSON documents with correct fields that can be used to call an API; see below for a few examples.

After spending several hours testing Gemini Pro, I’ve concluded that the Gemini models are very impressive. In other words, the hype is real (not just a marketing tactic). Aside from GPT-4, Gemini Pro is without a doubt the easiest and most performant model with which I have worked. In fact, Gemini Pro seems easier to use (at least in my opinion) compared to GPT-3.5-Turbo in many cases. Plus, the model supports image inputs and is not even the most powerful in the Gemini suite. Now, all that’s left is to wait for the release of Gemini Ultra!
Final Remarks
At this point, we have learned quite a lot about the Gemini model suite. These models were marketed as the first legitimate competitors to ChatGPT and GPT-4, and these claims seem to be legit! Sure, some results were emphasized on certain benchmarks with cherry-picked prompting techniques. However, Gemini models still perform comparably to state-of-the-art in nearly all cases, even when evaluated by a (non-biased) 3rd party! Plus, these models have several notable benefits, such as the support for numerous modalities and availability of efficient model variants for on-device deployment. Key takeaways are itemized below.
Multimodality is here to stay! Multimodal LLMs (or MLLMs) have become an incredibly popular topic in recent AI research. However, many MLLMs consider only two modalities—images and text. Gemini pushes the frontier of MLLMs to consider other modalities like audio and video. By adopting a native training approach over each of these modalities, we see that Gemini models develop impressive problem solving capabilities on both cross and uni-modal tasks!
Native multimodality. Saying that Gemini models are “natively” multimodal has a few different implications. First, multimodal data is used throughout the entire training process, including both pretraining and finetuning. Second, Gemini models directly ingest data from each modality. For example, Gemini directly ingests audio features generated from USM, rather than first transcribing audio into textual tokens and ingesting the textual input. By directly ingesting data from each modality, Gemini models are able to extend the already impressive reasoning capabilities of an LLM across numerous modalities of data.
Comparison to OpenAI models. Although a ton of empirical results were provided in [1], we can boil them down into two primary takeaways:
Gemini Ultra is (roughly) comparable to GPT-4.
Gemini Pro is (roughly) comparable to GPT-3.5-Turbo.
In both cases, these models seem to perform slightly worse than their OpenAI counterparts on text-based tasks. However, these models are also capable of solving multimodal tasks and seem to truly excel in this domain.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Google Gemini Team et al. “Gemini: A Family of Highly Capable Multimodal Models”, https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf (2023).
[2] Sundar Pinchai and Demis Hassabis, “Introducing Gemini: our largest and most capable AI model”, https://blog.google/technology/ai/google-gemini-ai/ (2023).
[3] Google Gemini Team, “Welcome to the Gemini Era”, https://deepmind.google/technologies/gemini/#introduction (2023).
[4] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[5] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[6] Anil, Rohan, et al. "Palm 2 technical report." arXiv preprint arXiv:2305.10403 (2023).
[7] Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288 (2023).
[8] Chen, Xiangning, et al. "Symbolic discovery of optimization algorithms." arXiv preprint arXiv:2302.06675 (2023).
[9] Dao, Tri, et al. "Flashattention: Fast and memory-efficient exact attention with io-awareness." Advances in Neural Information Processing Systems 35 (2022): 16344-16359.
[10] Dao, Tri et al. “Flash-Decoding for long-context inference”, https://www.together.ai/blog/flash-decoding-for-long-context-inference (2023).
[11] Liu, Haotian, et al. "Visual instruction tuning." arXiv preprint arXiv:2304.08485 (2023).
[12] Liu, Haotian, et al. "Improved baselines with visual instruction tuning." arXiv preprint arXiv:2310.03744 (2023).
[13] Alayrac, Jean-Baptiste, et al. "Flamingo: a visual language model for few-shot learning." Advances in Neural Information Processing Systems 35 (2022): 23716-23736.
[14] Yu, Jiahui, et al. "Coca: Contrastive captioners are image-text foundation models." arXiv preprint arXiv:2205.01917 (2022).
[15] Chen, Xi, et al. "Pali: A jointly-scaled multilingual language-image model." arXiv preprint arXiv:2209.06794 (2022).
[16] Jaegle, Andrew, et al. "Perceiver: General perception with iterative attention." International conference on machine learning. PMLR, 2021.
[17] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[18] Yu, Jiahui, et al. "Scaling autoregressive models for content-rich text-to-image generation." arXiv preprint arXiv:2206.10789 2.3 (2022).
[19] Zhang, Yu, et al. "Google usm: Scaling automatic speech recognition beyond 100 languages." arXiv preprint arXiv:2303.01037 (2023).
[20] Michalak, Sarah E., et al. "Assessment of the impact of cosmic-ray-induced neutrons on hardware in the roadrunner supercomputer." IEEE Transactions on Device and Materials Reliability 12.2 (2012): 445-454.
[21] Li, Yujia et al. “Competition-level code generation with alphacode.” Science, 378(6624):1092–1097, 2022.
[22] Google AlphaCode Team et al. “AlphaCode 2 Technical Report”, https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf (2023).
[23] Radford, Alec, et al. "Robust speech recognition via large-scale weak supervision." International Conference on Machine Learning. PMLR, 2023.
[24] Akter, Syeda Nahida, et al. "An In-depth Look at Gemini's Language Abilities." arXiv preprint arXiv:2312.11444 (2023).
[25] Fu, Chaoyou, et al. “A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise.” arXiv preprint arXiv:2312.12436 (2023).
[26] Lin, Ziyi, et al. "SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models." arXiv preprint arXiv:2311.07575 (2023).
[27] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[28] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[29] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
Arguably four Gemini models are released, as two different sizes of Gemini Nano are made available (1.8B parameters and 3.25B parameters).
Fun fact, the Gemini technical report has ~940 authors. That’s a lot of people, but still not the largest numbers of authors we’ve seen on one paper!
Here, the reason we avoid compute costs is because the pretrained models begin the training process for Flamingo with a large amount of existing information already encoded within their weights. As such, we don’t have to perform extra training to re-learn all of this information!
Notably, Flamingo only takes images/videos and text as input, and only produces text as output. However, one can reasonably see how such an architecture can be generalized to handle more modalities of input (i.e., by adding more encoders beyond those for vision) and even generate outputs of a different modality.
The approach for this is actually (relatively) simple! We just train the LLM (i.e., ChatGPT) to identify when images should be generated and instruct the model to write a prompt that can be sent to DALLE-3 for image generation; see here.
Put differently, if we train a smaller LLM from scratch and compare its performance to that of an LLM that is trained identically but also with knowledge distillation from a larger LLM, the model that uses knowledge distillation will (generally) perform better.
Training a model over such a large number of accelerators is incredibly difficult due to the high probability of device failure within the system. If you are training a neural net using one TPU, it’s pretty unlikely that this device will experience a failure. But, what if you’re training over 10,000 of these devices? The probability and frequency of device failure within such a large system is relatively high. These failures come from a variety of sources, including anything from nodes being preempted to cosmic rays [20].
This prompting approach goes beyond basic chain of thought prompting by accounting for model uncertainty. The model generates k samples and checks for a consensus among these samples. If there is no consensus, the answer is generated using a greedy sample from the model without chain of thought prompting.
Typically, the term data “leakage” (or contamination) refers data that is used for evaluating LLMs being present in the model’s training set. Given that LLMs are pretrained using so much data, leakage is a common issue that needs to be addressed.
PaLM-2 has a context window of 8K tokens. However, several recent models have quite large context windows (e.g., 128K for GPT-4 and 200K for Claude-2.1) that go well beyond the 32K context of Gemini.
It does seem that the CMU results for Mixtral are off.
LMsys' leaderboard has both Mixtral and Gemini Pro comparable to GPT 3.5 Turbo: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard (last edit 20th of December)
For Mixtral, this complies with OpenCompass' recent results (24th): https://github.com/open-compass/MixtralKit
Also according to OpenCompass, Vision-Language of Gemini Pro and GPT 4V are comparable:
https://opencompass.org.cn/leaderboard-multimodal
(though it's unclear what "detail: low" means for GPT 4)