
Modern LLMs: MT-NLG, Chinchilla, Gopher and More
Can bigger models solve all of our problems?


This newsletter is supported by Alegion. At Alegion, I work on a range of problems from online learning to diffusion models. Feel free to check out our data annotation platform or contact me about potential collaboration/opportunities!
If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!

Within this overview, we will take a look at the generation of large language models (LLMs) that came after GPT-3 [7]. The incredible results of GPT-3 demonstrated clearly that increasing the size of language models (LMs) is very beneficial. The question is, however, when does this trend plateau? Does model performance continue to improve exponentially as the number of parameters continues to increase?
This question was quickly answered by subsequent work on LLMs that explored models containing as many as 530 billion parameters. Although there are many interesting findings within this work, the main takeaway is that simply making the model bigger is not quite enough. LLM performance starts to plateau (i.e., not shockingly better than GPT-3) beyond a certain point.
However, there are other techniques that we can use to make LLM performance better. Primarily, we can move away from increasing the size of the model and instead focus more on the pre-training corpus. If the size and quality of this pre-training corpus is increased, it tends to benefit model performance. Put simply, making LLMs better seems to be a combined effort of increasing the model and data scale.
a primer on language modeling
The basic concept behind language modeling has been covered extensively in previous posts that I have recently written about LLMs:
the concept. Put simply, LMs (and LLMs) are deep neural networks that specialize in solving a single task: predicting the next word within a sequence of text. Although there is a bit more to the process than this, the generic concept really is that simple.

To train an LM, we must first obtain a large amount of unlabeled text. Then, we can perform self-supervised learning by iterating over the following steps:
Sample some text
Try to predict the next word
Update your model based on the “correct” next word
This process, referred to as language model pre-training, is illustrated within the figure above. Interestingly, this training procedure allows the (L)LM to learn from a large amount of data, as the textual data from which we are learning requires no human annotations! We can just download a lot of raw textual data from the internet and use it for pre-training. Learning from such a large corpus is incredibly beneficial to developing a diverse, comprehensive understanding of language.
creating foundation models. If we pre-train an LLM (which, by the way, is an expensive process), we get access to a neural network that, given some text, can accurately predict the next word. Initially, this might not seem that useful, but these LLMs have an incredible foundation of knowledge in natural language.
To understand why this is the case, we need to first recognize that predicting the next word in a sequence of text is a difficult problem—even doing this as a human is not trivial! Accurately choosing this next word actually requires the model to develop an in-depth, nuanced understanding of language. This understanding is incredibly beneficial, as it can be repurposed for solving other types of linguistic tasks!
In other words, these LLMs are a type of foundation model—a generic term referring to large neural networks that can be repurposed to solve a wide variety of tasks. The learning process for these foundation models proceeds in two-phases: pre-training and in-context learning. The pre-training procedure is described above, while in-context learning refers to the process of using the generic LLM to solve a more specific, downstream task.
wait… how do we do this? There are many ways we can repurpose LLMs to solving downstream tasks. Currently, a lot of the research studies zero and few-shot inference techniques for solving various tasks with LLMs. At a high level, these techniques solve a downstream task by reframing it as a next-word prediction problem. For example, we can pass the following prompts to an LLM:
“Summarize the following document: <document> ⇒”
“Translate this sentence into french: <sentence> ⇒”
Then, using next-word prediction, we can generate a textual response to this prompt that (ideally) should answer our desired question. We solve the task by just prompting/asking the LLM to solve the task for us! The above prompts are examples of zero-shot learning. We could also perform few-shot learning, in which we additionally provide several examples of correct outputs within our prompt; see below for an example.

Few-shot learning with LLMs was popularized by GPT-3 [7], which showed that language models of a certain scale perform relatively well using such techniques. However, this performance still lags behind baseline techniques that solve downstream tasks via supervised learning or fine-tuning.

Instead of performing few-shot inference, we could just fine-tune (i.e., update the model’s parameters based on training over pairs of input and desired output) the LLM; see the figure above. This approach performs quite well, but it does have some drawbacks:
Further training is required (may be expensive)
A specialized model is required for each downstream task
It would be great to solve all tasks accurately with a single model. In fact, this is the ultimate goal of foundation models. For now, however, it seems like fine-tuning might be necessary to achieve the best performance. Nonetheless, we will see in this overview that most current research measures LLM performance using zero/few-shot inference.
this overview
By now, hopefully the concept of LLMs and how they work is somewhat clear. Within this overview, we will focus on (i) training larger LLMs and (ii) using larger datasets for pre-training. Modern LLMs are based upon decoder-only transformer architectures. The size of these models can be increased by either adding more layers or increasing the width of each layer. To obtain more data to train these models, we typically just scrape text from the web using tools like Common Crawl or use large sources of textual data like the Pile dataset [5].
We will study four papers that explore modern LLMs and attempt to improve upon the results of GPT-3. Initial attempts of training larger models fall somewhat short of the expectations set by GPT-3—the performance improvements we get aren’t as good as we would hope. Later work finds that there is more to making LLMs successful than simply making them larger—we also have to improve the size and quality of the pre-training corpus. This leads to the proposal of more efficient LLMs that achieve remarkable results by training smaller models over more data. Let’s take a look!
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model [1]
Although LLMs were already pretty large (e.g., GPT-3 [7] contains 175 billion parameters), MT-NLG 530B, proposed in [1], took this to a new level. A collaboration between Nvidia and Microsoft, this work trained an LLM with 530 billion parameters. Models like GPT-3 were already hard to train due to their size, so training MT-NLG 530B—another decoder-only transformer with >3X more parameters as shown in the figure below—was obviously quite difficult. In fact, MT-NLG required a dedicated compute cluster and several distributed training innovations to make the training tractable and efficient.

The model is trained using a combination of data, model/pipeline, and tensor parallelism; see here for a quick discussion of these concepts. The proposed distributed training methodology, which is based upon the Megatron-LM library, is the main contribution of this work—simply engineering a system capable of training an LLM with 530 billion parameters is incredibly non-trivial.
When we perform distributed training, there are two basic ways we can add more GPUs to the training process:
Add more GPUs to your machine
Add more machines, each of which have GPUs
The training procedure for MT-NLG approaches distributed training differently for each of these cases. Within each individual machine, we use tensor-slicing—a form of model parallelism that splits a single layer into multiple, disjoint “slices” of parameters that are each distributed to a separate GPU—to distribute the training to different GPUs. Then, pipeline parallelism is used to distribute training across different machines or compute nodes. To learn more about these techniques, check out the following links:
This hybrid distributed training approach is required because communication is much more expensive when performed across different machines. Because communication between GPUs on the same machine is pretty fast, tensor slicing works well in this case. However, the increased communication time between different machines makes pipeline parallelism a more efficient choice when distributed training across several compute nodes.
MT-NLG has 105 layers, a hidden dimension of 20K, and 128 attention heads in each layer. The model is trained over a large textual corpus derived using Common Crawl and the Pile dataset [5]. Similar to prior work, a lot of deduplication and matching is performed to remove duplicates and downstream training or testing data from the pre-training corpus.
These filtering procedures are performed because we don’t want to “inflate” the model’s test performance. If testing data from a certain downstream dataset is present within the pre-training corpus, then our model would easily solve this task by simply memorizing the data. But, this doesn’t truly reflect the model’s ability to generalize.
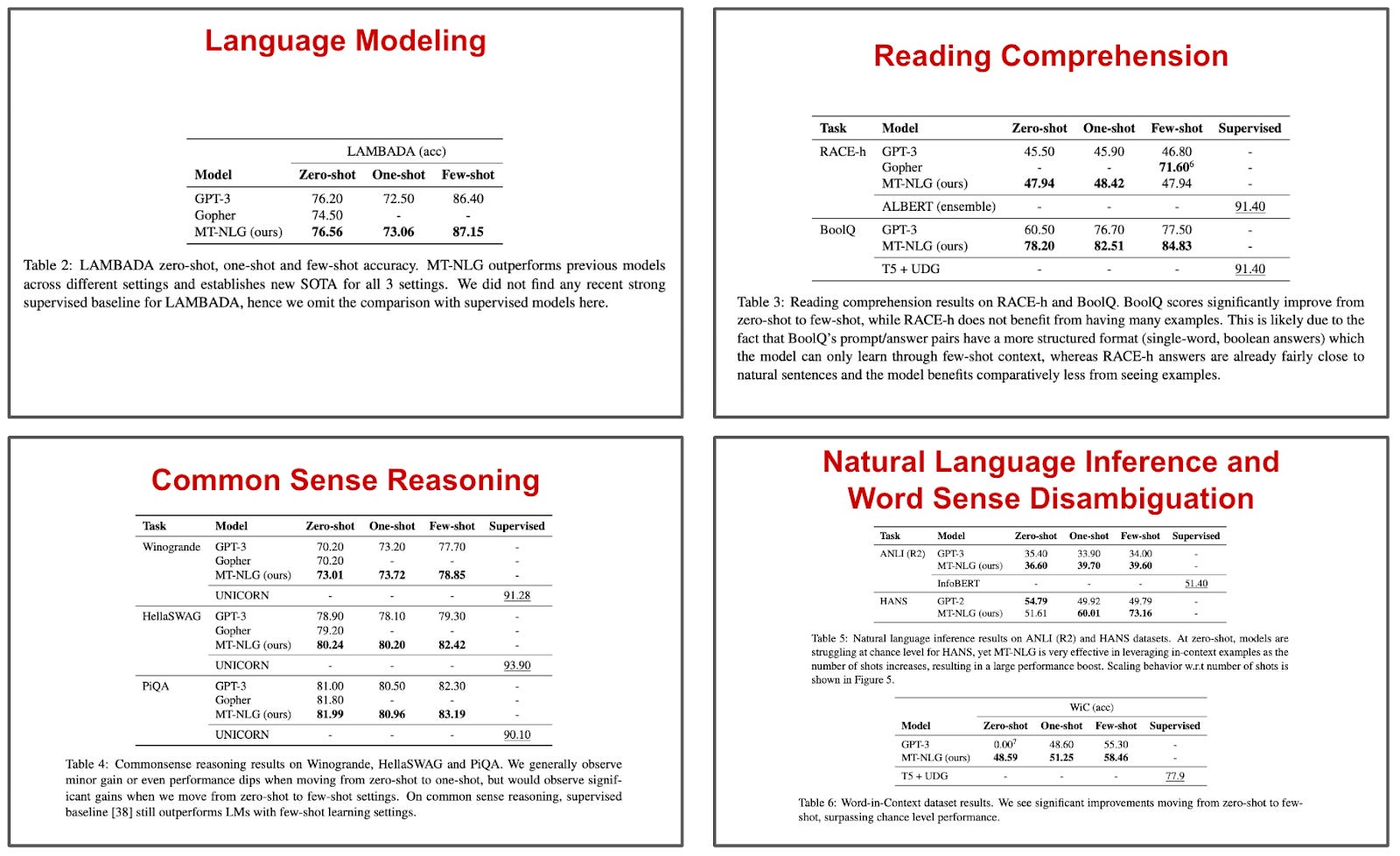
After being pre-trained, MT-NLG is evaluated similarly to GPT-3, using task-agnostic zero, one, and few-shot inference over a large number of different benchmarks; see above. When this massive model is evaluated, we see results that are pretty similar to GPT-3, but slightly better. For example, MT-NLG is slightly better (i.e., <1%) than GPT-3 on language modeling, and similar results are seen on common sense reasoning tasks (i.e., maximum of ~3% improvement across all tasks and shots).
On word-sense disambiguation, natural language inference, and reading comprehension tasks, MT-NLG improves upon the performance of GPT-3 more significantly. Thus, we see that increasing model scale may benefit certain tasks more than others. For example, MT-NLG is able to improve zero-shot word-sense disambiguation from 0% accuracy with GPT-3 to 48.59%. However, we should keep in mind that the results of MT-NLG still fall short of supervised baselines in all cases. Simply increasing model scale (at least for now) is not enough to reach human-level task-agnostic performance with LLMs.
Overall, the contribution of MT-NLG is mostly engineering focused. MT-NLG improves upon the performance of GPT-3, but not drastically. Training a model of this scale does, however, comes with significant added complexity in terms of training and utilizing the model. Just storing the state of the optimizer for a model of this scale is impossible on a single GPU! As these LLMs become larger and larger, the core concepts that power them stay the same, but the engineering challenge of handling such large models becomes increasingly difficult.
Scaling Language Models: Methods, Analysis, and Insights from Training Gopher [2]

Continuing the trend of training LLMs that are even larger than GPT-3 [7], the authors of [2] simply scale up the number of parameters, dataset size, and amount of compute used for LLM pre-training. They train a number of LLMs with sizes ranging from 44 million to 280 billion parameters. Then, each of these models are compared by analyzing their performance on a massive suite of 152 diverse tasks. This evaluation benchmark, detailed in the figure above, is more comprehensive than prior work (e.g., only ~120 of these tasks had been studied by prior work).

To pre-train their LLMs, the authors construct a new MassiveText corpus, which contains over 2.3 trillion tokens; see the table above. For comparison, the CommonCrawl-based corpus used to train GPT-3 contained fewer than 500B tokens. Thus, the dataset used for pre-training in [2] is quite larger than any corpus we have seen in prior work.
The exact training strategy used in [2] depends on the size of the LLM being trained, but the authors adopt different combinations of data, model and pipeline parallel training to maximize pre-training throughput. The underlying architecture used for the LLM is identical to GPT-3, aside from the use of relative position encodings and RMSNorm [8] (instead of LayerNorm).
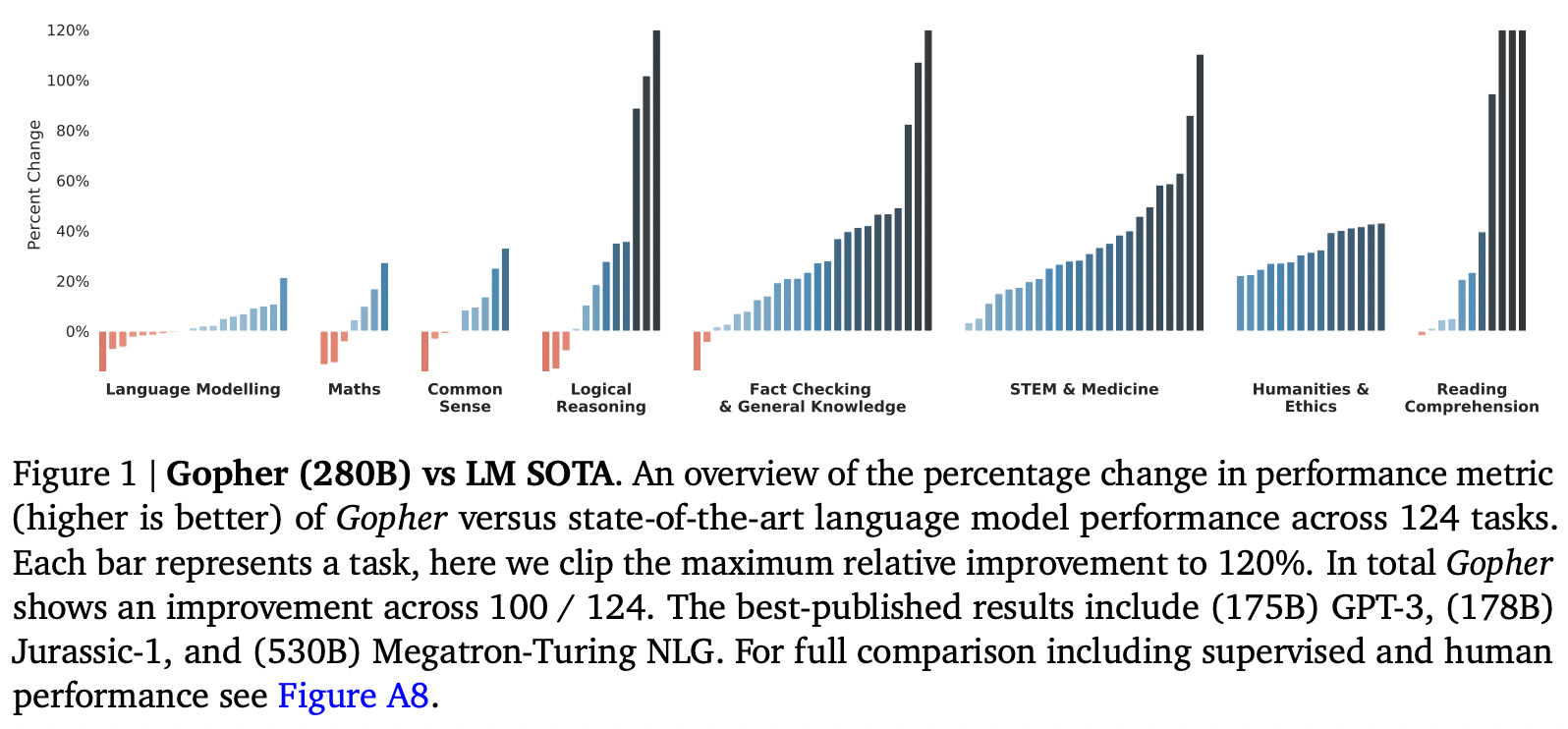
Unlike MT-NLG [1], the results in [2] show us that significant benefits can be derived by using a larger LLM. To enable these performance benefits, however, the larger LLM must be pre-trained over a larger, higher-quality corpus. When the largest of the LLMs in [2]—a 280 billion parameter model called Gopher—is evaluated, we see a performance improvement in 81% of the 152 considered tasks. A more detailed overview of these performance improvements is provided in the figure above.
On language modeling tasks, the performance of Gopher is similar to that of GPT-3. On other tasks, we can see that the largest improvement in performance occurs on knowledge-intensive tasks, such as reading comprehension and fact checking; see below.

Although Gopher outperforms state-of-the-art baselines for fact checking, we should notice that, for reading comprehension, the few-shot performance of LLMs is again far behind the performance of humans and supervised learning. Simply scaling the model and corpus size is (unfortunately) not enough for foundation models to surpass the performance of task-specific techniques—supervised learning still reigns supreme.
On tasks that require reasoning (e.g., mathematics, logical reasoning, common sense reasoning, etc.), we see that larger models provide no benefit. In fact, Gopher is even outperformed by prior LLMs (and some of the smaller LLMs that are considered) on such tasks. Compared to knowledge-based tasks, reasoning-intensive tasks seem to benefit much less from model scale.

Authors in [2] extensively study whether Gopher is prone to biased or toxic behavior. Interestingly, such results reveal to us that Gopher often emits toxic text when the prompt provided to the model is itself toxic; see above. Additionally, this effect increases with scale, where larger models respond with greater toxicity to toxic prompts.

Gopher is also biased against certain minorities of social groups, as detailed in the figure below. Despite such findings, however, the authors emphasize that current approaches to assessing LLM bias and fairness are limited. Analyzing and improving the behavior of LLMs relative to existing social norms is an active and popular area of research.
Jurassic-1: Technical Details and Evaluation [3]
In addition to increasing the size of LLMs like GPT-3, we can consider similarly-sized models with a different shape. For example, researchers in [3] study a 178 billion parameter decoder-only LLM called Jurassic-1. This model is quite similar to GPT-3, but it is slightly larger and has fewer layers (i.e., 76 layers instead of 96). To account for this reduction in layers, the width of each layer (i.e., hidden dimension of each self-attention head) is increased, yielding a similarly-sized model in terms of the number of parameters.

The modified architecture of Jurassic-1 follows the recommendation of prior work [6] that studies the tradeoff between LLM depth and width. This work examines LLMs of various depths and analyzes performance with respect to model depth and total number of parameters. Interestingly, we see in this analysis that the LLM’s optimal depth changes with its size. Using deeper LLMs only makes sense if the model is sufficiently large, and the optimal depth can be accurately predicted based upon the total number of parameters; see the figure above.
Authors in [3] follow the empirical predictions of [6] in selecting the depth of Jurassic-1; see below for a comparison of this model’s structure to that of GPT-3.

Authors in [3] also explore using multi-word tokens and increase the size of the vocabulary for the underlying tokenizer. This change greatly improves token efficiency, meaning that a given sentence or piece of text can be encoded using fewer tokens. The basic idea here is that reducing the number of input tokens to the model improves its efficiency—we are just processing a shorter input sequence! To learn more about tokenizers, check out the article below.
Plus, better token efficiency means we can actually provide more in-context examples within our prompt! This is because models like Jurassic-1 and GPT-3 have a maximum context length, or number of tokens you can include in your input. We can fit more data into the same context length if we have better token efficiency. The impact of utilizing more in-context examples is illustrated in the figure below.

Improved token efficiency makes the biggest difference—a 23% improvement—when performing text generation, which requires individually generating each token in a sequential manner. Training and batch inference (i.e., running a forward pass once over a batch of examples) are also sped up 1.5% and 7%, respectively.
The training procedure for Jurassic-1 matches that of GPT-3 quite closely. Just as we have seen in prior work, the state of the optimizer for training the model (i.e., all model parameters and their relevant statistics to be used in the optimization process) must be split across multiple GPUs and compute nodes, as this state is too large to be stored in a centralized location due to the size of the model.
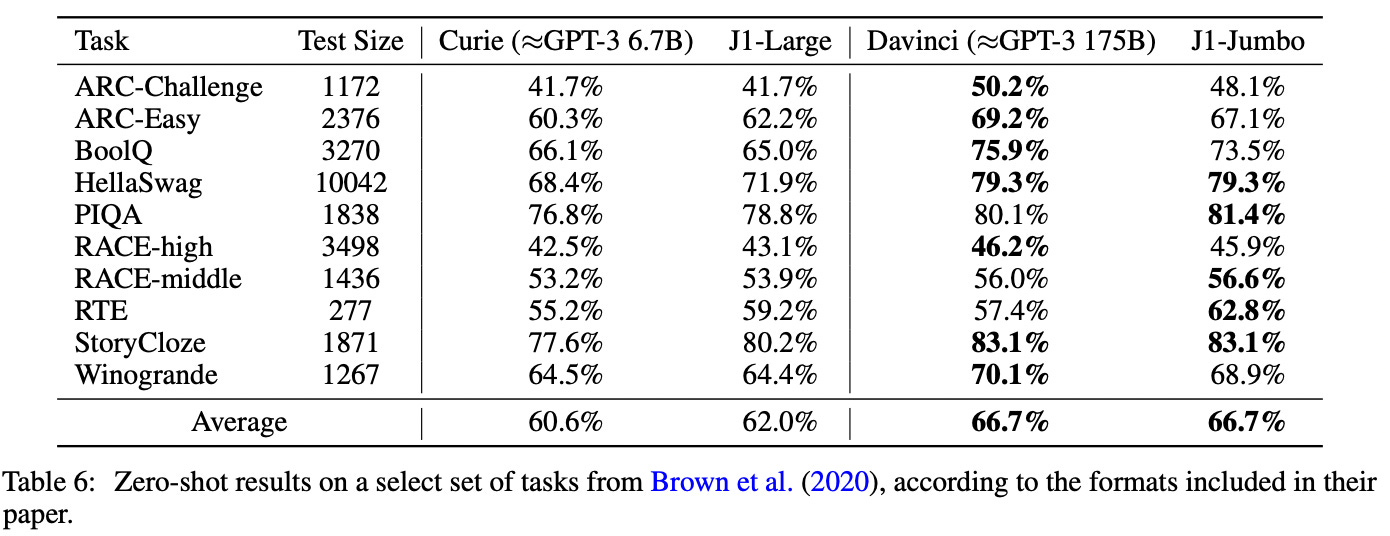
The model is evaluated using a publicly-available testing suite that is released with the publication. Most of these settings are adopted from the evaluation of GPT-3, and we see within the results—shown above—that Jurassic-1 performs similarly to GPT-3 in most cases. However, authors in [3] mostly consider the zero-shot case for evaluation, claiming that the setup is more simple and deterministic than few-shot evaluation.
Overall, the major value of this work seems to be in its modification to the underlying tokenizer. We do not seem to get any massive benefit from training a shallow, but wide, model. Although using a larger token vocabulary increases the model’s memory usage (i.e., because we have to store all the parameters for a larger embedding layer), the improved token efficiency is really valuable, as it enables the use of more in-context examples and improves LLM efficiency on several fronts.
Training Compute-Optimal LLMs [4]
To maximize an LLM’s performance, prior analysis on scaling trends [9] indicated that we should scale up the size of the model (i.e., the number of non-embedding parameters) as much as possible, while scaling the size of the underlying pre-training dataset somewhat less (by a factor of N^{0.74} in particular, where N is the number of parameters in our model). Such analysis on the behavior of LMs at scale inspired subsequent work like GPT-3, which achieved groundbreaking improvements in task-agnostic, few-shot performance.
Due to the incredible utility of GPT-3, recent research, such as the work we have seen in this post, has explored even larger LLMs (e.g., up to 530B parameters in MT-NLG!). These models tended to follow the advice of [9]—they use a really large model, but don’t increase the size of the underlying dataset to a similar extent.
Interestingly, research in [4] finds that this approach to scaling LLMs is sub-optimal. Instead, to train LLMs in a compute-optimal manner (i.e., achieving the maximum performance for a fixed amount of computational cost), we see in [4] that the scale of the LLM and the underlying pre-training corpus should be increased equally. Put simply, this means that, relative to existing work, we should train LLMs over more data; see below.

Intuitively, this approach makes sense, as we saw within the Gopher publication [2] that using a larger pre-training corpus—along with a larger model—yields a more noticeable performance benefit when compared to models like MT-NLG [1] that mostly focus upon model scale.
To make this scaling procedure a bit more specific, [4] considers different sizes of LLMs (i.e., from 70 million to 16 billion parameters) N and the number of tokens used to train them D. Here, we should keep in mind that modern LLMs are trained for <1 epoch (i.e., no single example is seen twice) due to the raw volume of pre-training data. The number of tokens observed during pre-training is equal to the size of the dataset.
By training LLMs with many different combinations of N and D, we can follow an approach similar to [8] by trying to discover a power law that predicts an LLM’s test loss as a function of N and D. In [4], the authors train over 400 LLMs and do just this. From the analysis of these models, we can figure out what combinations of N and D work best for different compute budgets.

Interestingly, we see in these experiments that the optimal approach to training scales the size of the model equally with the number of training tokens. This contradicts prior analysis that suggests the dataset should be scaled less than model size [9]. However, the authors verify these findings through three different methods of analysis that study scaling behavior via different techniques (see Sections 3.1-3.3 in [4]). All of these studies predict that data and model size should be scaled equally; see above.
Overall, these findings tell us that modern LLMs are (i) oversized and (ii) not trained with enough data. For example, the authors in [4] predict that a model with the same number of parameters as Gopher should be trained with >20X more data to be compute optimal. So, if we want to train LLMs properly, we are going to need a lot more data!
“the amount of training data that is projected to be needed is far beyond what is currently used to train large models, and underscores the importance of dataset collection in addition to engineering improvements that allow for model scale.” - from [4]
To validate these findings, the authors train a 70 billion parameter LLM, called Chinchilla. Compared to prior models, Chinchilla is smaller, but it observes much more data during pre-training; see below. The dataset and evaluation strategy is identical to the Gopher publication [2].

In the evaluation of Chinchilla, we see that the model outperforms larger LLMs like Gopher, despite containing 4X fewer parameters!

The model is evaluated over a large range of tasks and compared to several other modern LLMs; see below. It performs comparably to or better than other state-of-the-art LLMs in all cases, revealing that model scale may not be as important as we originally thought—the size of the pre-training dataset matters a lot too!

takeaways
With the proposal of GPT-3, we saw that a lot of benefits can be achieved by making LLMs larger. The question that we ask within this overview, however, is whether model scale is the answer to all of our problems. Overall, we have learned that making LLMs larger is not the only necessary component of achieving improved task agnostic performance. Plus, it comes with some downsides. The major takeaways are summarized below.
larger LLMs = more engineering effort. LLMs become increasingly difficult to handle as they grow in size. We have already seen proof of this with GPT-3—training a model with 175 billion parameters required a combination of different distributed training techniques and was a significant feat of engineering. For even larger models, such as MT-NLG, the training process becomes even more complex. Recent efforts have reduced the cost of training LLMs, but the engineering effort required to train and deploy these models is still significant.
data is important. Scaling up the size of LLMs originally seemed like the go-to approach for achieving better performance. GPT-3 was awesome, why not just make it bigger? Once we saw improvements in performance plateau as models become larger, however, we learned that training over more data is also very important. The largest improvements to LLM performance (e.g., Gopher and Chinchilla [2, 4]) are achieved via a combination of model and dataset scaling (in roughly equal proportion).
depth or width? This is a bit of a less significant finding, but it seems like current research [6] is telling us that go-to LLM architectures are probably a bit deeper than they need to be. In some cases, it probably makes more sense to make them a bit shallower and invest the saved parameters into the width of each layer.
supervised performance reigns supreme. Despite all of the incredible task-agnostic performance benefits we have observed with LLMs, we have to put these results in perspective. We saw from the research in this overview that these techniques still fall short of supervised training performance. In a lot of cases, we can still achieve a significant performance benefit via task-specific fine-tuning. Although task-agnostic foundation models are a nice sentiment, it might be a while before we can leverage these models in practical applications without performing any task-specific adaptation. Why not fine-tune a little bit if it makes our performance a lot better?
new to the newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I pick a single, bi-weekly topic in deep learning research, provide an understanding of relevant background information, then overview a handful of popular papers on the topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
bibliography
[1] Smith, Shaden, et al. "Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model." arXiv preprint arXiv:2201.11990 (2022).
[2] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[3] Lieber, O., et al. "Jurassic-1: Technical Details and Evaluation, White paper, AI21 Labs, 2021."
[4] Hoffmann, Jordan, et al. "Training Compute-Optimal Large Language Models." arXiv preprint arXiv:2203.15556 (2022).
[5] Gao, Leo, et al. "The pile: An 800gb dataset of diverse text for language modeling." arXiv preprint arXiv:2101.00027 (2020).
[6] Levine, Yoav, et al. "Limits to depth efficiencies of self-attention." Advances in Neural Information Processing Systems 33 (2020): 22640-22651.
[7] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[8] B. Zhang and R. Sennrich. Root mean square layer normalization. arXiv preprint arXiv:1910.07467, 2019.
[9] Kaplan, Jared, et al. "Scaling laws for neural language models." arXiv preprint arXiv:2001.08361 (2020).