
Using CLIP to Classify Images without any Labels
How to achieve 76.2% test accuracy on ImageNet without observing a single label

How to achieve 76.2% test accuracy on ImageNet without observing a single label

Deep image classification models are typically trained in a supervised manner over a large, annotated dataset. Although a model’s performance will improve as more annotated data becomes available, large-scale datasets for supervised learning are often difficult and expensive to obtain, requiring numerous hours of effort from expert annotators. With this in mind, one may begin to wonder if cheaper sources of supervision exist. Put simply, is it possible learn high-quality image classification models from data this is already publicly available?
The proposal of Contrastive Language-Image Pre-Training (CLIP) model [1] — recently re-popularized due to its use in the DALLE-2 model—by OpenAI answered this question in a positive fashion. In particular, CLIP proposes a simple pre-training task — choosing which caption goes with which image — that allows a deep neural network to learn high-quality image representations from natural language (i.e., image captions) alone. Because image-text pairs are readily available online and generally easy to obtain, one can easily curate a large pre-training dataset for CLIP, thus minimizing annotation cost and effort needed to train a deep network.
Beyond learning rich image representations, CLIP revolutionized zero-shot image classification by achieving 76.2% test accuracy on ImageNet without observing a single label — a significant improvement (to say the least) from the 11.5% test accuracy of the previous state-of-the-art zero-shot learning framework [2]. By establishing natural language as a viable training signal for image perception tasks, CLIP shifted the supervised learning paradigm and enabled neural networks to rely significantly less on annotated data. Within this post, I will outline the details of CLIP, how it can be used to minimize reliance upon traditional, one-hot supervised data, and the implications that it has for deep learning practitioners.
What came before CLIP?
Before understanding the details of CLIP, it is helpful to understand the context around the model. Within this section, I will overview relevant prior work and provide intuition regarding the inspiration and development of CLIP. Namely, preliminary work served as a proof of concept by showing that natural language was a useful source of supervision for image perception. However, because such methodologies performed poorly relative to alternatives (e.g., supervised training, weak supervision, etc.), training via natural language remained uncommon until the proposal of CLIP.
Previous Work
Predicting image captions with CNNs. Prior work showed that predicting image captions allowed CNNs to develop useful image representations [3]. Such classification was performed by converting title, description, and hashtag metadata for each image into a bag-of-words vector, which could then be used as a target for a multi-label classification task. Interestingly, features learned in this manner were shown to match the quality of those obtained via pre-training on ImageNet, thus proving that image captions provide sufficient information about each image to learn discriminative representations.
Later work extended this approach to predict phrases associated with each image [2], enabling zero-shot transfer to other classification datasets. Although this approach yielded poor zero-shot performance (i.e., 11.5% test accuracy on ImageNet), it showed that natural language alone could be used to produce zero-shot image classification results that far exceed random performance, thus serving as an initial proof of concept for weakly-supervised zero-shot classification.
Image representations from text with transformers. Concurrently, several works — including VirTex [4], ICMLM [5], and ConVIRT [6] — explored the learning of visual features from textual data using transformer architectures. At a high level, such methodologies use common training tasks for transformers to learn useful image representations from associated image captions. As a result of such work, masked language modeling (MLM), language modeling, and contrastive learning objectives — commonly used to train transformers in the natural language processing domain — were found to be useful proxy tasks for learning high-quality image representations.
Paving the way for future discoveries
Although no previous methodologies achieve impressive zero-shot performance on large-scale datasets, these foundational works provide useful lessons. Namely, prior work made clear that i) natural language is a valid source of supervision for computer vision and ii) zero-shot classification via natural language supervision is possible. As a result of these findings, further research effort was invested into performing zero-shot classification with weaker sources of supervision. Such efforts resulted in breakthrough methodologies, such as CLIP, that transformed natural language supervision from a rarity to a standout approach for zero-shot image classification.
Deep Dive into CLIP
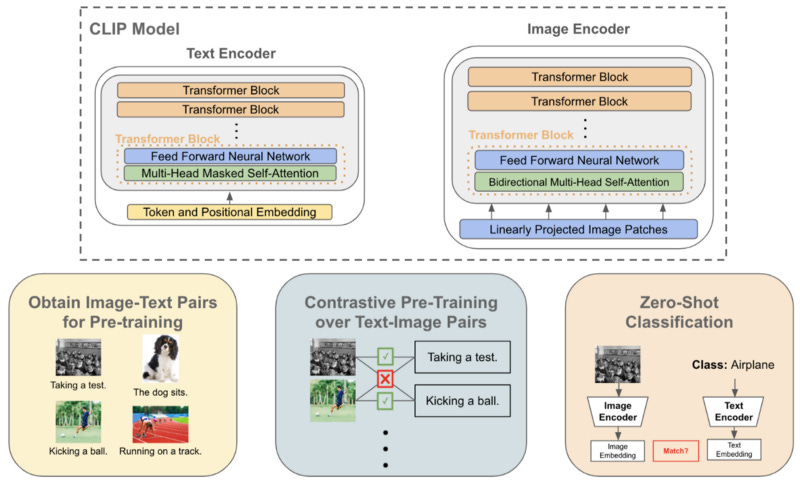
Put simply, the CLIP model, summarized in the figure above, aims to learn visual concepts in images from associated image captions. Within this section, I will overview the CLIP architecture, its training, and how the resulting model can be applied to zero-shot classification.
Model Architecture
CLIP is comprised of two encoder modules that are used to encode textual and image data, respectively. For the image encoder, numerous different model architectures are explored, including five ResNets [7] of different sizes (i.e., model dimensions are determined using EfficientNet-style [8] model scaling rules) and three vision transformer architectures [9]. These two options for the image encoder are depicted below. However, the vision transformer variant of CLIP is 3x more computationally efficient to train, leading it to be the preferred image encoder architecture.

The text encoder within CLIP is simply a decoder-only transformer, meaning that masked self-attention (as opposed to bi-directional self-attention) is used within each layer. Masked self-attention ensures that the transformer’s representation for each token in a sequence depends only on tokens that come before it, thus preventing any token from looking “into the future” to better inform its representation. A basic depiction of the text encoder architecture is provided below. However, it should be noted that this architecture is quite similar to most previously-proposed language modeling architectures (e.g., GPT-2 or OPT).
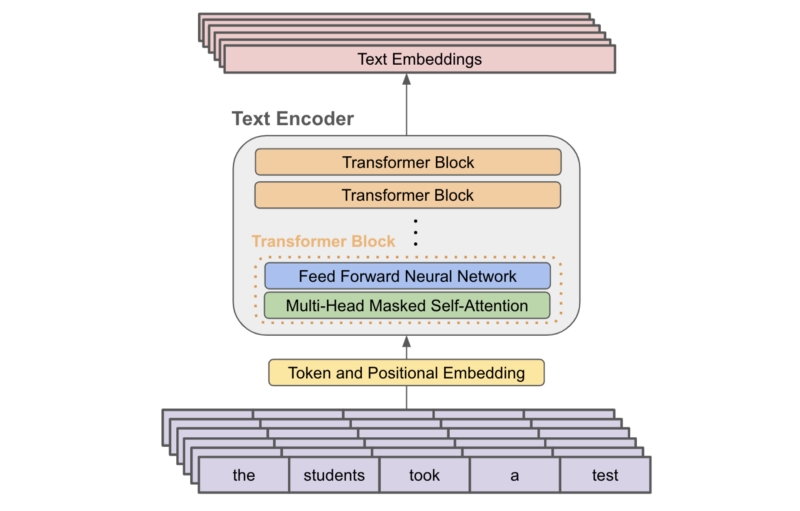
Although CLIP is not applied to any language modeling applications within the original publication, the authors leverage masked self-attention to make the extension of CLIP to such applications easier in the future.
Training via Natural Language Supervision
Although previous work has shown that natural language is a viable training signal for computer vision, the exact training task to use for training CLIP over pairs of images and text is not immediately obvious. Should we classify images based on the words in its caption? Well, previous work has tried this and it worked well, but not great [2, 3]. How about using language modeling to generate the caption for each image? Interestingly, the authors find that predicting the exact image caption is too difficult — resulting in the model learning very slowly — due to the wide varieties of different ways that any image could be described.
The ideal pre-training task for CLIP should be scalable, meaning that it allows the model to efficiently learn useful representations from natural language supervision. Drawing upon related work in contrastive representation learning, the authors find that CLIP can be efficiently trained using a surprisingly simple task — predicting the correct, associated caption within a group of candidate captions. Such a task is illustrated in the figure below.
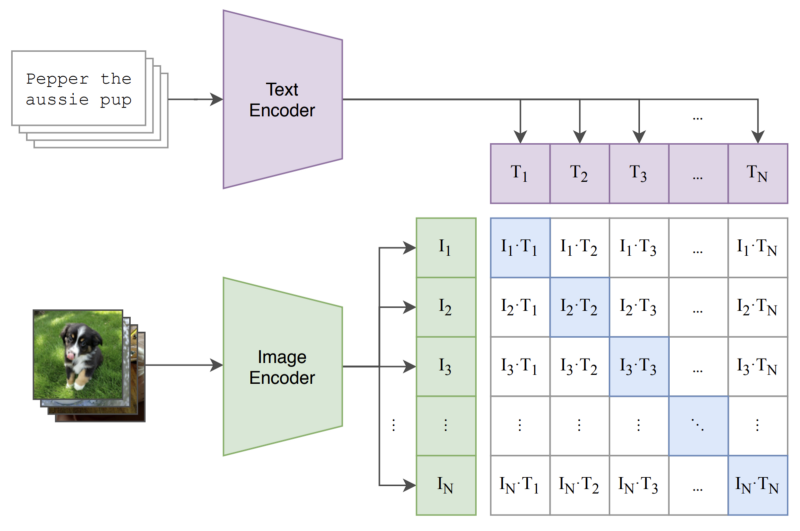
In practice, this objective is implemented by:
passing a group of images and textual captions through their respective encoders
maximizing the cosine similarity between image and text embeddings of the true image-caption pairs
minimizing the cosine similarity between all other image-caption pairs
Such an objective is referred to as the multi-class N-pair (or InfoNCE) loss [10] and is commonly applied to problems in contrastive and metric learning. As a result this pre-training process, CLIP forms a joint embedding space for images and text, such that image and captions corresponding to similar concepts have similar embeddings.
Better Task = Faster Learning. By training the CLIP model with this easier proxy task, the authors observe a 4X improvement in training efficiency; as shown in the figure below.

Here, training efficiency is measured using the rate of zero-shot learning transfer on ImageNet. In other words, the CLIP model takes less training time (in terms of the number of observed image-text examples) to achieve a model that yields high zero-shot accuracy on ImageNet when using this simple objective. Thus, the correct selection of a training objective has a drastic impact on model efficiency and performance.
How can we classify images without training examples?
The ability of CLIP to perform classification may initially seem like a mystery. Given that it only learns from unstructured textual descriptions, how can it possibly generalize to unseen object categories in image classification?
CLIP is trained to predict if an image and text snippet are paired together. Interestingly, this capability can be repurposed to perform zero-shot classification. In particular, by leveraging textual descriptions of unseen classes (e.g., class names), each candidate class can be evaluated by passing the text and image through their respective encoders and comparing the resulting embeddings; see below for a visual depiction.
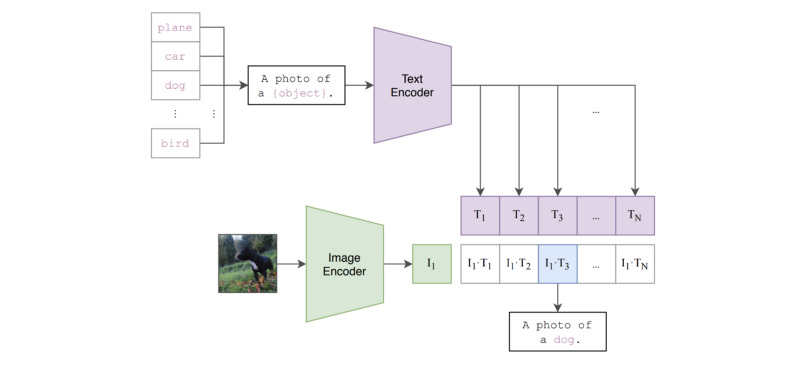
Formalizing this process, zero-shot classification is actually comprised of the following steps:
Compute image feature embedding
Compute an embedding for each class from related texts (i.e., class names/descriptions)
Compute cosine similarity of image-class embedding pairs
Normalize over all similarities to form a class probability distribution
Such an approach has limitations — the name of a class may lack relevant context that reveals its meaning (i.e., polysemy issue), some datasets may lack metadata or textual descriptions of classes altogether, and having single-word descriptions of images is relatively uncommon within image-text pairs used for training. Such issues can be mitigated by crafting “prompts” to textually represent different classes or creating ensembles of multiple zero-shot classifiers; see the image below.

However, such an approach still has fundamental limitations that must eventually be addressed for zero-shot learning capabilities to improve.
CLIP in Practice — Accurate Classification with no Training Data!
In the original publication, CLIP is evaluated in the zero-shot domain, as well as with added fine-tuning (i.e., few-shot or fully-supervised domain). Here, I’ll overview the main findings from these experiments with CLIP and provide relevant details regarding when CLIP can and cannot be used to solve a given classification problem.
Zero-shot. In the zero-shot domain, CLIP achieves ground breaking results, improving state-of-the-art zero-shot test accuracy on ImageNet from 11.5% to 76.2%; see below.

When the zero-shot performance of CLIP is compared to that of a fully-supervised linear classifier with pre-trained ResNet50 features as inputs, CLIP continues to achieve remarkable results across a variety of datasets. Namely, CLIP outperforms the linear classifier (which is fully-supervised!) on 16 of the 27 total datasets that were studied, despite never observing a single training example.
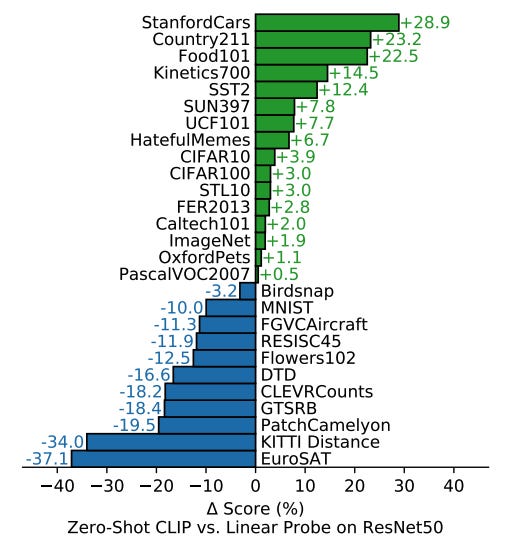
When performance on each of these datasets is analyzed, it becomes clear that CLIP performs well on general object classification datasets (e.g., ImageNet or CIFAR10/100) and even better on datasets for action recognition. Intuitively, favorable performance on such tasks is due to the wide scope of supervision CLIP receives during training and the fact that image captions are often verb-centric, thus bearing more similarity to action recognition labels than to the noun-centric classes used within datasets like ImageNet. Interestingly, CLIP performs worst on complex and specialized datasets such as satellite image classification and tumor detection.
Few-shot. The zero-shot and few-shot performance of CLIP is also compared to that of other few-shot linear classifiers. Zero-shot CLIP is found to match the average performance of few-shot linear classifiers after observing four training examples in each class. Furthermore, CLIP outperforms all few-shot linear classifiers when allowed to observe training examples itself. These results are summarized within the figure below.
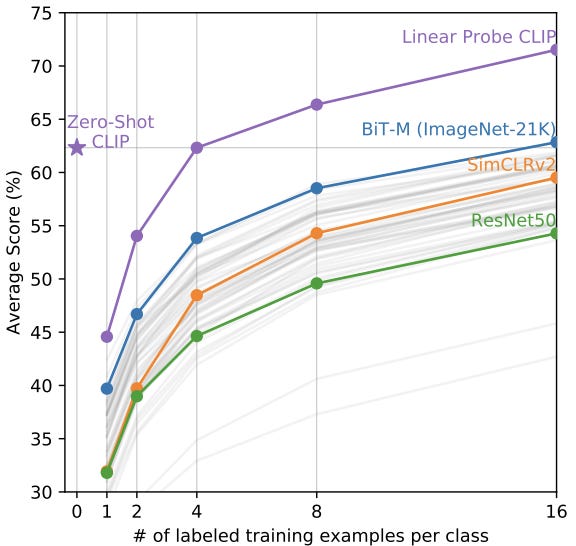
When a fully-supervised linear classifier is trained using CLIP features, it is found to outperform numerous baselines both in terms of accuracy and compute cost, thus emphasizing the quality of the representations learned by CLIP through natural language supervision; see below.

Although the performance of CLIP is not perfect (i.e., it struggles on specialized tasks and only works for datasets with good textual descriptions of each class), the zero-shot and few-shot results achieved by CLIP foreshadow the possibilities that arise from a high-quality joint embedding space for images and text. More is possible, but CLIP provides an initial (impressive) proof of concept for such generic approaches to classification.
Impact and Takeaways

Without a doubt, CLIP revolutionized the domain of zero-shot image classification. Although previous work in language modeling had shown that an unstructured output space (e.g., text-to-text language models like GPT-3 [11]) could be leveraged for zero-shot classification purposes, CLIP extended upon these results by i) forming a methodology that works for computer vision and ii) basing the entire training process on easy-to-obtain textual descriptions of images. A summary of CLIP and its contributions is provided in the figure above.
CLIP firmly established that natural language provides sufficient training signal to learn high-quality perceptual features. Such a finding has a significant impact on future directions in deep learning research. In particular, natural language descriptions of images are much easier to obtain than image annotations that follow task-specific ontologies (i.e., traditional one-hot labels for classification). As such, annotating training data for CLIP-style classifiers is more scalable, especially due to the fact that many image-text pairings are freely available to download online.
The main limitations of CLIP stem from the facts that i) obtaining good textual embeddings of each class within a classification problem is difficult and ii) complex/specific tasks (e.g., tumor detection or predicting depth of objects in images) are difficult to learn through generic natural language supervision. Nonetheless, representations learned by CLIP are high-quality, and performance may be improved on more specialized tasks by exploring modifications to the data observed in the pre-training process.
Using CLIP. If you are interested in leveraging the high-quality image-text embeddings produced by CLIP, OpenAI has released a python package for the model. Within this package, downloading different versions of CLIP (i.e., either using vision transformer or ResNet-style image encoders and with different model sizes) is intuitive and implemented efficiently in PyTorch. Just download the package using pip and check/download the available pre-trained models as follows.
Conclusion
Thanks so much for reading this post! I hope you found it to be helpful and insightful. If you have any feedback on the post, feel free to leave a comment or connect with me on LinkedIn or Twitter. This post can also be accessed on my personal blog. To keep up with my future blog posts and other works you can sign up to receive e-mail notifications here or visit my personal webpage. This post was completed as part of my research and learning as a Research Scientist at Alegion, a data annotation platform with industry-leading video and computer vision annotation capabilities.
Bibliography
[1] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
[2] Li, Ang, et al. “Learning visual n-grams from web data.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
[3] Joulin, Armand, et al. “Learning visual features from large weakly supervised data.” European Conference on Computer Vision. Springer, Cham, 2016.
[4] Desai, Karan, and Justin Johnson. “Virtex: Learning visual representations from textual annotations.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
[5] Sariyildiz, Mert Bulent, Julien Perez, and Diane Larlus. “Learning visual representations with caption annotations.” European Conference on Computer Vision. Springer, Cham, 2020.
[6] Zhang, Yuhao, et al. “Contrastive learning of medical visual representations from paired images and text.” arXiv preprint arXiv:2010.00747 (2020).
[7] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[8] Tan, Mingxing, and Quoc Le. “Efficientnet: Rethinking model scaling for convolutional neural networks.” International conference on machine learning. PMLR, 2019.
[9] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[10] Sohn, Kihyuk. “Improved deep metric learning with multi-class n-pair loss objective.” Advances in neural information processing systems 29 (2016).
[11] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877–1901.