
Can language models make their own tools?
LaTM, CREATOR, and other closed-loop frameworks for LLM tool usage...

In recent overviews, we have explored the utility of augmenting large language models (LLMs) with external tools. These models can be taught to leverage tools in a variety of ways. However, we should realize that existing tool-following LLMs leverage only a limited set of potential tools [3], whereas the range of problems we want to solve with LLMs is nearly endless! With this in mind, it becomes clear that such a paradigm is limiting—we will always be able to find scenarios that require tools that do not yet exist. In this overview, we will explore recent research that aims to solve this problem by providing LLMs with the skills to create their own tools. Such an approach draws an interesting analogy to human life, as the ability to fabricate tools led to major technological advancements1. Now, we explore the impact of similar techniques upon the evolution of LLMs.
“According to the lessons learned from the evolutionary milestones of humans, a crucial turning point was that humans got the ability to fabricate their own tools to address emerging challenges. We embark on an initial exploration to apply this evolutionary concept to the realm of LLMs.” - from [1]
Background
Prior to learning more about tool-making LLMs, there are a few background concepts that we need to refresh. We have covered many of these ideas in recent overviews, but we’ll briefly go over them again now to make our discussion of recent publications more comprehensive and understandable.
Why should we use tools?

In prior overviews, we have learned about a few different kinds of tools that can be integrated with LLMs to improve their performance, such as:
By giving LLMs access to certain tools, we can easily solve limitations that these models have, such as lacking up-to-date information, failing to perform simple arithmetic, hallucinating facts, or making errors in long chains of reasoning.

tools provide context. For example, if an LLM is asked a question about a pop culture event in recent weeks, it is unlikely to have needed information to provide an accurate answer due to its knowledge cutoff. In some cases, the LLM might hallucinate an incorrect answer that seems plausible and mislead the user with incorrect information—this is a major problem because many (non-technical) users of LLMs like ChatGPT treat these model like a search engine! To solve this issue, we can provide a tool that allows the LLM to perform search queries and retrieve up-to-date information from the internet as extra context; see above. This way, the LLM can memorize less information, relying instead on in-context learning to arrive at an accurate final answer based upon up-to-date information provided by a tool.
“By empowering LLMs to use tools, we can grant access to vastly larger and changing knowledge bases and accomplish complex computational tasks.” - from [3]
One interesting tool that we will see used as a baseline within this overview is the Wolfram ChatGPT plugin. The plugin ecosystem for ChatGPT integrates LLMs with external tools via their APIs. Basically, we provide a description of the API to ChatGPT, and the model learns how to use this tool (i.e., make calls to its API) via a prompting approach; more details here. To learn more about the Wolfram plugin (it’s super useful!), check out the awesome overview below.
this overview. A lot of different types or genres of tools exist, but we will focus upon a particular type of tool—those that are actually created by an LLM. Typically, these tools are formatted as standalone Python functions that accomplish some task or sub-task that is useful to the LLM. Tools are created by directly prompting a code-enabled LLM to generate a needed function. By allowing LLMs to create their own tools, problem-solving systems are no longer limited by the fixed set of tools that they have available. We can identify needed functionality over time and enable the LLM to automatically create any tool that would be helpful!
Prompting Techniques
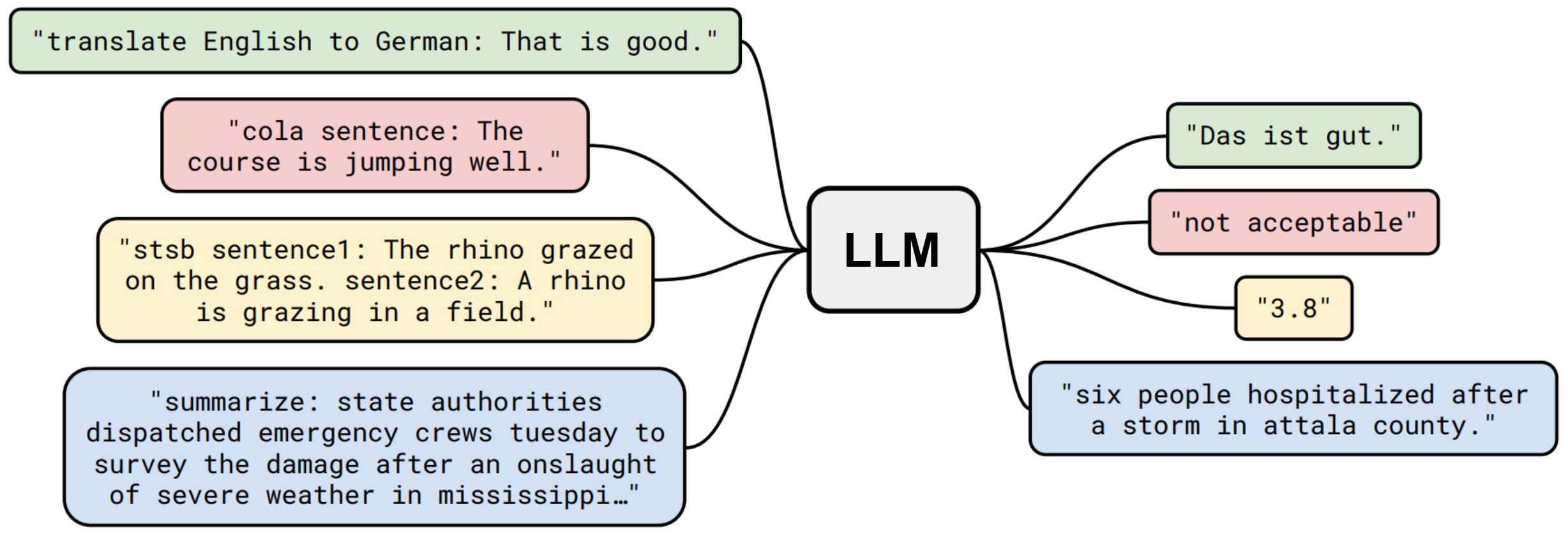
The generic text-to-text structure of a language model is incredibly powerful, as it allows us to solve many different tasks by just i) formatting the problem as a textual prompt and ii) extracting relevant output information from the text returned by the model. However, using language models is not usually quite this simple. The wording and structure of the prompt that we provide to the model can drastically alter its effectiveness—prompt engineering is a huge deal!
Recently, we have gone over a lot of different practical tricks and techniques for getting the most out of an LLM via prompt engineering.
However, there are two particular prompting techniques that are especially relevant to this post—chain of thought (CoT) [6] and program of thoughts (PoT) [7] prompting. Both of these techniques aim to improve the ability of a language model to reliably solve complex, reasoning-based tasks.

chain of thought. For a long time, LLMs were criticized for their inability to solve reasoning-based tasks. Although this issue has been mitigated with recent model variants, techniques such as CoT prompting can elicit better reasoning abilities within these models nonetheless. How is this possible? We simply need to provide the LLM with examples of reasoning-based problems being broken down into a step-by-step solution (i.e., a problem-solving rationale or “chain of thought”). These examples are inserted directly into the LLM’s prompt. Then, the model can use its in-context learning capabilities to generate a similar rationale when solving a problem posed by a user. Interestingly, generating such rationales drastically improves LLM performance on reasoning-based tasks.

Beyond vanilla CoT prompting, numerous variants have also been proposed; see above. The idea of enabling LLMs to solve difficult problems by breaking them into smaller parts and solving them step-by-step is incredibly powerful. But, we can do this in several different ways (some of which are actually quite a bit simpler than CoT prompting)—CoT prompting is not always our best option.
program of thoughts. Thought CoT prompting variants work well, they fail to model concepts like iteration and are subject to a compositionality gap, meaning that the LLM may correctly solve every step of a problem but still generate an incorrect final answer. To mitigate these problems, recent research has explored program-aided language models. These techniques are similar to CoT prompting, but we use code-enabled LLMs (e.g., Codex [14]) to generate a hybrid problem-solving rationale that contains both code and natural language components—basically a program with informative comments. Then, we can execute the program created by the LLM (using an external interpreter) to yield a final answer!

The basic idea behind PoT prompting is that there are certain ideas and concepts that are much easier to model within a program. Instead of using the LLM to both solve subtasks and generate a final answer from all of these solutions, we can delegate a portion of this process to a system that is more reliable. Namely, programs can more easily model and solve mathematical equations, perform iteration, and much more, thus lessening the compositionality gap for LLMs.
A Turning Point in Tool Usage
“Instead of letting the LLMs act as the users of tools, we enable them to be the creators of tools and solve problems with higher accuracy and flexibility.” - from [2]
At this point, we should probably be convinced that tools are a useful addition to existing language models. But, what becomes possible when we expand the scope of available tools to anything that an LLM can create? Put simply, such an approach forms a closed-loop framework, in which LLMs are given the ability to arbitrarily improve their own functionality. As we will see moving forward, existing models are surprisingly capable of making their own tools, which enables dynamic adaptation to solving new, difficult problems over time.
Decoupling Tool Making and Tool Usage
We know that using external tools can greatly improve the problem solving capabilities of LLMs [3]. However, prior work in this area assumes that needed tools already exist and are available for the LLM. As such, there exists a dependence upon humans to craft and curate a set of needed tools that comprehensively addresses needed functionality for solving any task. But, what if the LLM needs a tool that is not included in its tool belt? Existing tool-following approaches have no solution for a problem like this!
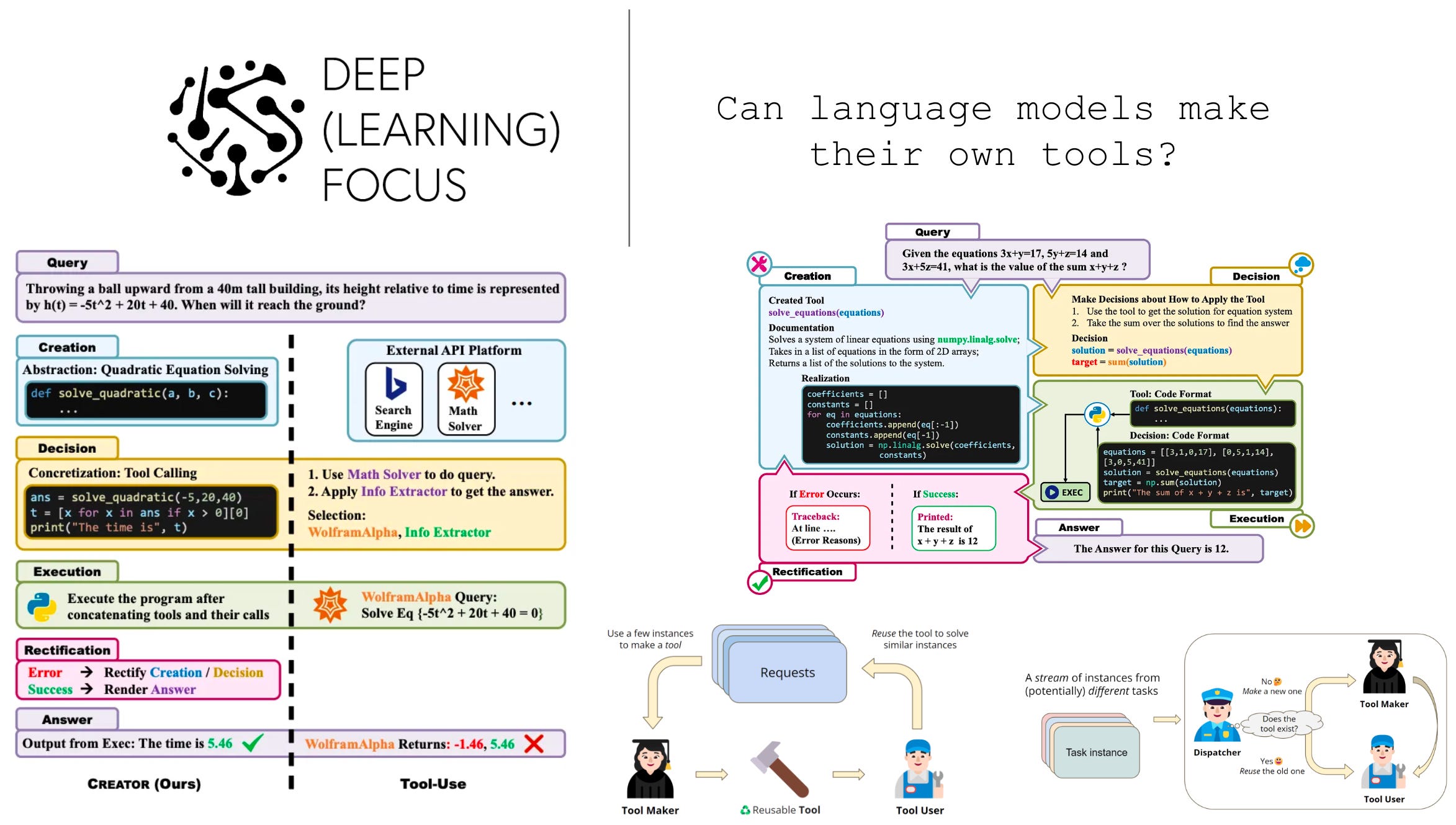
As an alternative approach, authors in [2] propose a “closed-loop” framework that uses the LLM itself to construct needed tools on-the-fly. This framework, called LLMs as Tool Makers (LaTM), allows LLMs to continually generate tools that are needed to solve different complex reasoning tasks; see below.

two-phase tooling approach. LaTM uses a two-phase framework of:
Tool making: crafting a tool (i.e., a Python function) for a given task
Tool Using: using an existing tool to solve a task
Notably, we do not have to use the same LLM for both of these phases. For example, we could apply a more powerful model (e.g., GPT-4) to tool making, while using a lightweight and cost-effective model (e.g., GPT-3.5-turbo) for tool using. Given that tool making typically demands a more capable LLM relative to tool using, this approach allows LaTM to save costs in practice. We only use the most expensive and powerful models in the tool making phase, which we can execute once per tool and continually reuse for problem solving!

The goal of the tool making process is to generate a generic and reusable tool—implemented as a Python function—from a few examples of solving a task. In [2], this goal is accomplished by first “proposing” a tool via few-shot learning. We provide several demonstrations of desired behavior and prompt the LLM to generate a program that reproduces the output of these demonstrations. If a program is generated that produces no errors, LaTM uses an LLM to generate several unit tests for this tool (i.e., based upon the provided demonstrations) and executes these tests to confirm that they pass. Finally, the tool is “wrapped”, or made available via a prompt that demonstrates its usage; see above.
Though tool making is complex and requires a powerful LLM to be successful, tool usage can be accomplished with a more cost effective model—we are just using existing tools to solve a task! We can prompt the LLM to use tools via the wrapped tools created during tool making, which provide demonstrations of converting tasks into relevant function calls. Here, LaTM relies on the in-context learning abilities of LLMs to determine the proper usage of each tool; see below.

Notably, using a smaller model for tool using means that we only use more powerful models during a small portion of the LaTM pipeline—tools are only created once and can be reused continually as more problems are solved. The process of creating and using tools with LaTM might seem a bit complex, but it is actually quite simple. An end-to-end example of creating and using tools for solving a logical deduction problem is provided within the figure below.

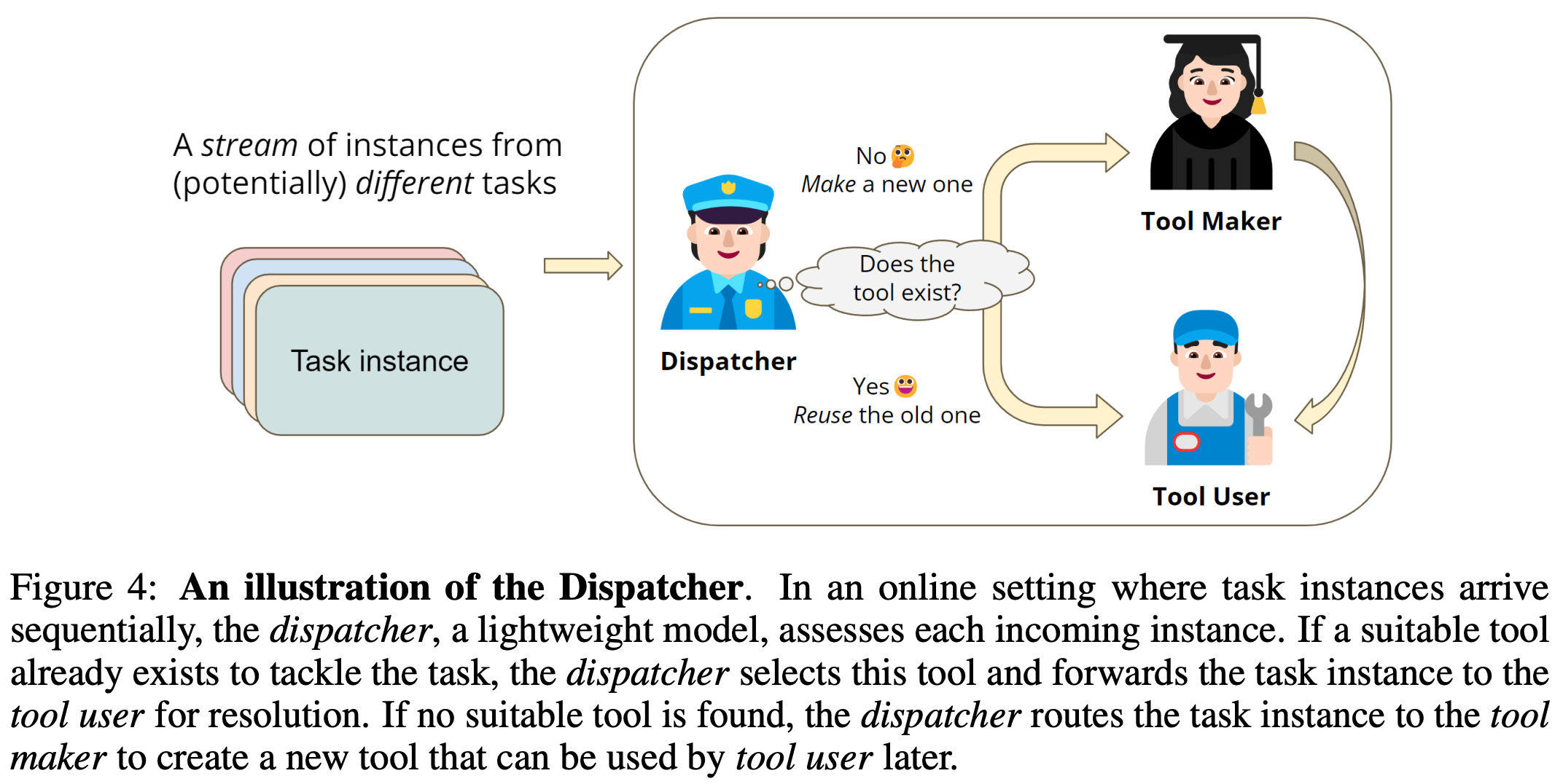
adding a dispatcher. Beyond tool creation and usage, authors in [2] also propose a dispatcher module to handle on-the-fly creation and usage of new tools with LaTM; see below. Put simply, the dispatcher is an LLM that is used to determine whether an incoming task should create a new tool or just use existing tools. By using this extra module, we can easily identify new tasks that cannot be handled by existing tools and create any tools that are needed, allowing LaTM to better handle streaming scenarios in which new tasks arrive sequentially. Interestingly, authors in [2] show that a GPT-3.5-based dispatcher can identify correct tools to use—or the need for a new tool—with ~95% accuracy.
does this work? LaTM is evaluated over a small set of complex reasoning tasks from BigBench, where GPT-4 is used as the tool maker and GPT-3.5-turbo is used as the tool user. Somewhat unsurprisingly, we see that GPT-4 is capable of creating viable and useful tools in most test cases; see below. Less capable models (e.g., GPT-3.5-turbo) can be used for making tools on easier problems, but GPT-4 is needed in more complex domains. Going further, we see that longer context lengths are necessary for tool making, as LaTM uses the full history (i.e., examples of generating all tools so far) when generating a tool to improve reliability.

When the performance of LaTM is compared to techniques like CoT prompting [4], we see that the proposed approach makes existing LLMs way more capable! By using generated tools, models like GPT-3.5-turbo can perform similarly to GPT-4 and far surpass the performance of CoT prompting; see below. Plus, we see that using more lightweight models as the tool user is preferable and even outperforms using powerful models like GPT-4 in some cases.

LaTM is an interesting, closed-loop framework that enables LLMs to produce their own tools. Because it only uses large, expensive LLMs (e.g., GPT-4) for a small portion of the problem-solving process, LaTM is a cost-effective approach for improving LLM performance. We can nearly match the performance of GPT-4 on complex reasoning tasks with smaller models and at a lower cost.

Now from our partners!
Rebuy Engine is the Commerce AI company. They use cutting edge deep learning techniques to make any online shopping experience more personalized and enjoyable.
KUNGFU.AI partners with clients to help them compete and lead in the age of AI. Their team of AI-native experts deliver strategy, engineering, and operations services to achieve AI-centric transformation.
MosaicML enables you to train and deploy large AI models on your data and in your secure environment. Try out their tools and platform here or check out their open-source, commercially-usable LLMs.
Rectifying Mistakes in Tool Creation

Expanding upon the idea of using LLMs to create their own tools, authors in [2] propose a novel framework that i) uses LLMs to create their own, relevant tools via documentation and code creation, ii) adopts a simpler approach for planning how to use tools to solve a problem, and iii) adds a supplemental error-handling mechanism to the tool-using process to make the overall system more robust and accurate. The resulting technique, called CREATOR [2], was explored in parallel to research in [2]2. The goal of both publications is to create more intelligent and adaptable systems for solving complex problems by enabling the creation of needed tools.

problem-solving approach. CREATOR approaches tool creation and usage via a four-step process (see above for an illustration):
Creation: create tools through documentation and code realization.
Decision: decide when and how to use existing tools to solve a problem.
Execution: execute the program that applies tools to solving a problem.
Rectification: Modify tools and decisions based on results of execution.
The rectification step is not present in prior work. This component acts as an automated error handling mechanism that improves the robustness of the system. Because LLMs in [2] (and in related publications [1]) use code as a medium for creating tools, we can detect and rectify errors (e.g., via a stack trace or something similar) that arise when creating or using tools without much effort.

In [2], tool creation follows an in-context learning approach that provides detailed instructions and few-shot examples to guide the LLM towards generating the correct tool. Tool creation has two main components:
Documentation: outlines relevant information about a tool (e.g., function, purpose, signature, etc.).
Realization: implements the tool in code (see above).
Similar to [1], tools created in [2] are captured within a function or method (in Python) that can be called upon by the LLM.

During the decision stage, the LLM considers documentation of all tools and determines which tools to use and how to use them to solve the current problem. After a problem-solving plan as been created, we can then:
Format the input for each tool.
Execute each tool to get the associated output.
Perform any needed operations on tool outputs to derive an answer.
If tool execution leads to the generation of any errors, we can simply record this information and iterate over the four-step process again, passing the error as an extra input for rectifying existing tools; see above. Otherwise, we can use the generated information to extract a final answer for the user’s question.
“Our research reveals that leveraging LLMs as tool creators facilitates knowledge transfer, and LLMs exhibit varying levels of tool creation abilities, enabling them to flexibly tackle diverse situations.” - from [2]
improved mathematical reasoning. The system proposed in [2] is evaluated over mathematical (and tabular) reasoning datasets MATH and TabMWP [4, 5]. In all experiments, ChatGPT (i.e., GPT-3.5-turbo) is used as the base model, due to its code generation and impressive reasoning capabilities. CREATOR is compared to baselines such as standard CoT prompting [6], PoT prompting [7], and the Wolfram alpha ChatGPT plugin. When all methods use ChatGPT as the base model, we see that CREATOR (combined with CoT prompting) yields improved overall accuracy compared to baselines, as well as an improved successful execution rate (i.e., meaning the system provides an answer with a valid format).

Beyond these evaluations, authors in [2] propose a new Creation challenge dataset that attempts to evaluate the tool creation abilities of an LLM by testing problem-solving capabilities in new scenarios for which no existing tool or code package exists. On this benchmark, CREATOR slightly outperforms existing baselines. However, this performance improvement becomes much larger when the LLM is given a textual hints about the utility of the tool that should be created; see below.

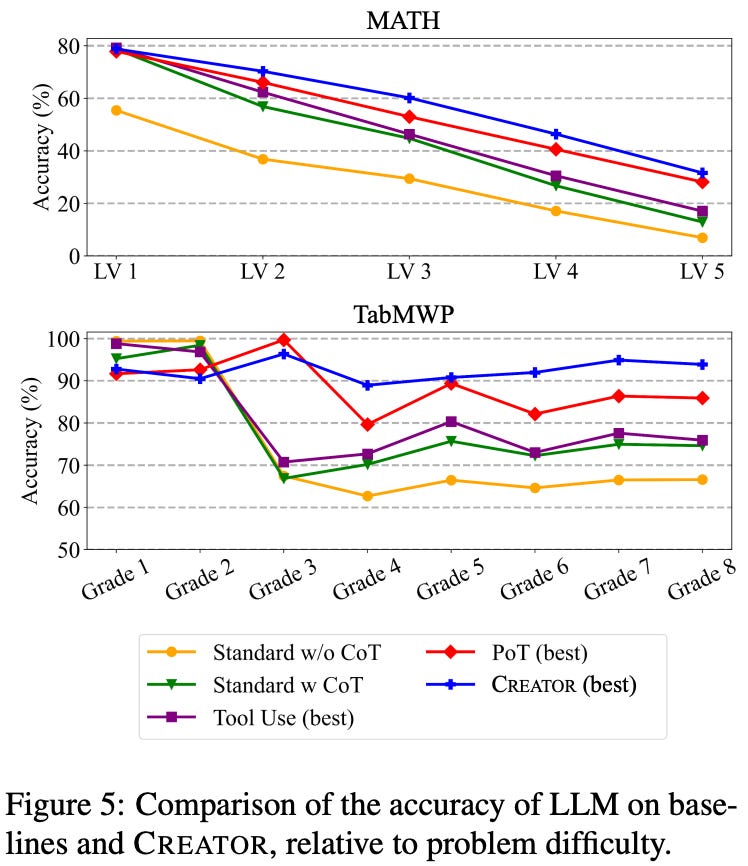
Beyond its ability to match or exceed baseline performance in aggregate, the CREATOR framework performs more consistently as problems become increasingly difficult, while baselines tend to deteriorate. CREATOR experiences a similar deterioration on certain problem classes, but the framework seems to be more adaptable and capable of handling complex problems; see below.
Takeaways
Within this overview, we have explored a more dynamic and flexible approach for tool usage with LLMs. Instead of curating a fixed set of tools that can be used by the LLM, we can simply enable the LLM to create whatever tool that is needed. By following such an approach, we no longer deal with issues created by not having access to a tool that is needed by an LLM to solve a problem. We might initially question whether such a strategy would be successful (i.e., are LLMs powerful enough to create their own tools?), but recent research [1, 2] shows us that state-of-the-art LLMs like GPT-4 are more than capable of creating tools in the form of standalone Python functions, assuming that measures to rectify errors in tool creation are put in place. Then, these tools can be used and re-used (even by less powerful LLMs) to solve a variety of complex problems.
“Tool-making enables an LLM to continually generate tools that can be applied to different requests so that future requests can call the corresponding APIs when beneficial for solving the tasks.” - from [1]
Using LLMs to create tools is great, but how does this relate to parallel efforts that have integrated LLMs with a variety of existing tools? It remains to be seen. However, I personally think that the optimal system will use a hybrid of existing techniques. There are many useful tools that already exist and are being integrated with popular LLMs every day (e.g., see the ChatGPT plugin store). As such, relying solely upon LLMs to create their own tools doesn’t make sense. Instead, we can leverage existing tools, but also give LLMs needed skills to create any tools that they lack. Over time, the suite of tools available to LLMs will continue to evolve and make AI-based problem solving systems more effective.
New to the newsletter?
Hello! I am Cameron R. Wolfe. Ph.D. in deep learning and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers build a better understanding of deep learning research via understandable overviews that explain relevant topics from the ground up. If you like this newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Cai, Tianle, et al. "Large Language Models as Tool Makers." arXiv preprint arXiv:2305.17126 (2023).
[2] Qian, Cheng, et al. "CREATOR: Disentangling Abstract and Concrete Reasonings of Large Language Models through Tool Creation." arXiv preprint arXiv:2305.14318 (2023).
[3] Schick, Timo, et al. "Toolformer: Language models can teach themselves to use tools." arXiv preprint arXiv:2302.04761 (2023).
[4] Lu, Pan, et al. "Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning." arXiv preprint arXiv:2209.14610 (2022).
[5] Hendrycks, Dan, et al. "Measuring mathematical problem solving with the math dataset." arXiv preprint arXiv:2103.03874 (2021).
[6] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[7] Chen, Wenhu, et al. "Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks." arXiv preprint arXiv:2211.12588 (2022).
[8] Shen, Yongliang, et al. "Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface." arXiv preprint arXiv:2303.17580 (2023).
[9] Patil, Shishir G., et al. "Gorilla: Large Language Model Connected with Massive APIs." arXiv preprint arXiv:2305.15334 (2023).
[10] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[11] Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." arXiv preprint arXiv:2205.11916 (2022).
[12] Wang, Xuezhi, et al. "Self-consistency improves chain of thought reasoning in language models." arXiv preprint arXiv:2203.11171 (2022).
[13] Zhou, Denny, et al. "Least-to-most prompting enables complex reasoning in large language models." arXiv preprint arXiv:2205.10625 (2022).
[14] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
Check out this interesting article for some more details on the creation and usage of tools by humans.
The LaTM [1] and CREATOR [2] papers were actually released on Arxiv within 3 days of each other! CREATOR came first, but not by much.