
The Basics of AI-Powered (Vector) Search
How the modern AI boom has completely revolutionized search applications...


The recent generative AI boom and advent of large language models (LLMs) has led many to wonder about the evolution of search engines. Will dialogue-based LLMs replace traditional search engines, or will the tendency of these models to hallucinate make them an untrustworthy source of information? Currently, the answer to these questions is unclear, but the quick adoption of AI-centric search systems such as you.com and perplexity.ai indicates a widespread interest in augmenting search engines with modern advancements in language models. Ironically, however, we have been heavily utilizing language models within search engines for years! The proposal of BERT [1] led to a step-function improvement in our ability to assess semantic textual similarity, causing these language models to be adopted by a variety of popular search engines (including Google!). Within this overview, we will analyze the components of such AI-powered search systems.
Basic Components of a Search Engine

Search engines are one of the longest-standing and most widely-used applications of machine learning and AI. Most search engines are comprised of two basic components at their core (depicted above):
Retrieval: from the set of all possible documents, identify a much smaller set of candidate documents that might be relevant to the user’s query.
Ranking: use more fine-grained analysis to order the set of candidate documents such that the most relevant documents are shown first.
Depending upon our use case, the total number of documents over which we are searching could be very large (e.g., all products on Amazon or all web pages on Google). As such, the retrieval component of search must be efficient—it quickly identifies a small subset of documents that are relevant to the user’s query. Once we have identified a smaller set of candidate documents, we can use more complex techniques—such as larger neural networks or more data—to optimally order the candidate set in a manner that is personalized and relevant to the user’s query.
More details. The intuitive idea behind search is straightforward, but many different approaches exist for retrieval and ranking; see above. Some of these approaches are more traditional and only rely on basic machine learning, while others heavily leverage modern developments in large language models. In other words, the amount of “AI” present within “AI-powered search” is variable. We will now quickly overview these techniques to build a better understanding.

As a quick disclaimer, we will assume that the basic structure of search includes a query from a user, as well as several documents to which we are trying to match this query; see above. We assume that all queries and documents contain purely text-based data. Throughout the overview, we will also use the terms “document” and “sentence” interchangeable; e.g., we might use “sentence similarity” to refer to finding similar sequences of text, such as a document and a query.
Lexical Search
The traditional approach to building a search engine is based upon matching words in a user’s query to words in a document. This approach, called lexical (or sparse) retrieval, relies upon a data structure called an inverted index to perform efficient keyword matching. The inverted index just contains a list of words and maps each word to a list of locations at which it occurs in various documents. Using this data structure, we can efficiently match terms to documents in which they appear and even count the frequency of terms in each document.
Sparse retrieval. To understand why this process is called sparse retrieval, we first need to understand how we represent our data. Lexical search algorithms are based upon word frequencies. If a word appears frequently both in the user’s query and a particular document, then this document might be a good match! To represent the space of possible words that can exist in a query or document, we define a fixed-size vocabulary of relevant words; see below.

From here, we can represent a sequence of text (i.e., a query or document) with a vector that contains an entry for each word in our vocabulary. Then, each of these entries can be filled with a number (possibly zero) corresponding to the frequency of that word within the text. Because our vocabulary is large and only a (relatively) small number of words occur in any given document, this vector representation is relatively sparse. This method of producing a vector representation, called the bag of words model, forms the basis of sparse retrieval techniques.

Given a bag of words representation of a query and a set of documents, the primary algorithm used for performing sparse retrieval is the BM25 ranking algorithm; see above. BM25 scores are entirely count-based. We score documents by i) counting words that co-occur between the query and the document and ii) normalizing these counts by metrics like inverse document frequency (i.e., assigns higher scores to words that occur less frequently) and relative document length.
Does this perform well? Although other sparse retrieval algorithms exist (e.g., TF-IDF), BM25 achieves impressive performance. In fact, BM25 is a hard baseline to beat even for more complex sparse retrieval techniques and modern approaches that use deep learning; see below. Despite its simplicity, this algorithm performs incredibly well and remains the core of many search engines even today.

Practical implementation. Beyond performing well, BM25 is supported by major search tools like Elastic and RediSearch. Using these tools, the implementation of lexical search is both efficient and simple. We just:
Store our documents within a database.
Define a schema for building the inverted index.
From here, the inverted index will be built asynchronously over the documents in our database, and we can perform searches with BM25 via an abstracted (and easy to use) query language. For more details, check out the code tutorial below.
Adding “AI” into a Search Engine
BM25 is a machine learning algorithm, and we can improve its performance by leveraging common data science techniques like stemming, lemmatization, stop word removal, and more. However, calling BM25 an “AI-powered” search algorithm might be a bit of a stretch. So, we might wonder: How can we create a smarter search algorithm? The short answer is that we can use deep learning to improve both the retrieval and ranking process. There are two types of models in particular that we use for this purpose—bi-encoders and cross-encoders—both of which are typically implemented using encoder-only (BERT) [1] models.
Bi-encoders form the basis of dense retrieval1 algorithms. At the simplest level, bi-encoders take a sequence of text as input and produce a dense vector as output. However, the vectors produced by bi-encoders are semantically meaningful—similar sequences of text produce vectors that are nearby in the vector space when processed by the bi-encoder. As a result, we can match queries to documents by embedding both with a bi-encoder and performing a vector search to find documents with the highest cosine similarity2 relative to the query; see below.

Using algorithms like hierarchical navigable small word (HNSW) [6], we can perform approximate nearest neighbor vector searches efficiently. Similar to performing lexical search, we can store document vectors within a database like Elastic or RediSearch and build an HNSW search index. Then, vector search can be performed by i) using the bi-encoder to produce a vector for the user’s query and ii) performing vector search to find the most similar documents; see below.

Cross-encoders are similar to bi-encoders in that they allow us to score the similarity between two sequences of text. Instead of separately creating a vector for each textual sequence, however, cross-encoders ingest both textual sequences using the same model; see below. The model is trained to predict an accurate similarity score for these textual sequences. Cross-encoders can more accurately predict textual similarity relative to bi-encoders. However, searching for similar documents with a cross-encoder is much more computationally expensive!

Namely, bi-encoders can be combined with vector search to efficiently discover similar documents, but cross-encoders require each textual pair to be passed through the model to receive a score. Searching for the most similar document to a user’s query with a cross-encoder requires that we iteratively compute the similarity between the query and every document. Given that this would be incredibly expensive, cross-encoders are usually only applied at the ranking stage of search. After we have retrieved a set of relevant candidate documents, we can pass these documents through a cross-encoder for more accurate re-ranking.
A Simple Framework for AI-Powered Search
As discussed, search systems have two basic components: retrieval and ranking. To create a basic AI-powered search system, the retrieval process would use both:
Lexical retrieval with BM25.
Dense retrieval with a bi-encoder.
We combine the results of these two retrieval algorithms by taking a weighted sum of each document’s score from BM25 and vector search. The combination of lexical and vector retrieval is typically referred to as hybrid search.

From retrieval, we obtain a smaller set of candidate documents that can be ranked using a cross-encoder that more accurately sorts the search results based on textual relevance; see above. Such a system leverages deep learning during both retrieval and ranking, forming a true AI-powered search system. This overview is dedicated to understanding how deep learning can be used to build better search algorithms. Primarily, we will focus upon the retrieval component of search—training bi-encoders for vector search. However, further reading material for ranking with cross-encoders will also be provided.
Using BERT for Search
As previously mentioned, most of the commonly-used bi-encoders and cross-encoders are based upon BERT [1]. As such, understanding the encoder-only architecture and self-supervised training strategy of BERT is important. We will now provide an overview of BERT and how it can (or cannot) be used in search.
Encoder-Only Architecture

Although the original transformer architecture contains both an encoder and a decoder, BERT [1] leverages an encoder-only architecture; see above. The encoder-only architecture just contains several repeated layers of bidirectional self-attention and a feed-forward transformation, both followed by a residual connection and layer normalization. Let’s dig into each of these components.

Crafting the input. The first step in understanding the encoder-only architecture is understanding how its input is constructed. At the simplest level, the input to an encoder-only transformer is just a sequence of text. However, we use a tokenizer—usually a BPE or SentencePiece tokenizer3—to break this text into a sequence of tokens (i.e., words and sub-words); see above. Importantly, there are also a few “special” tokens that are added to BERT’s input, including:
[CLS]: a token that is always placed at the beginning of the sequence and serves as a representation of the entire sequence.[SEP]: a token that is placed in between multiple sentences that are fed as input to BERT and serves as a separator between the sentences.[EOS]: an “end of sequence” token that is placed at the end of BERT’s input sequence to indicate that the textual sequence is over.
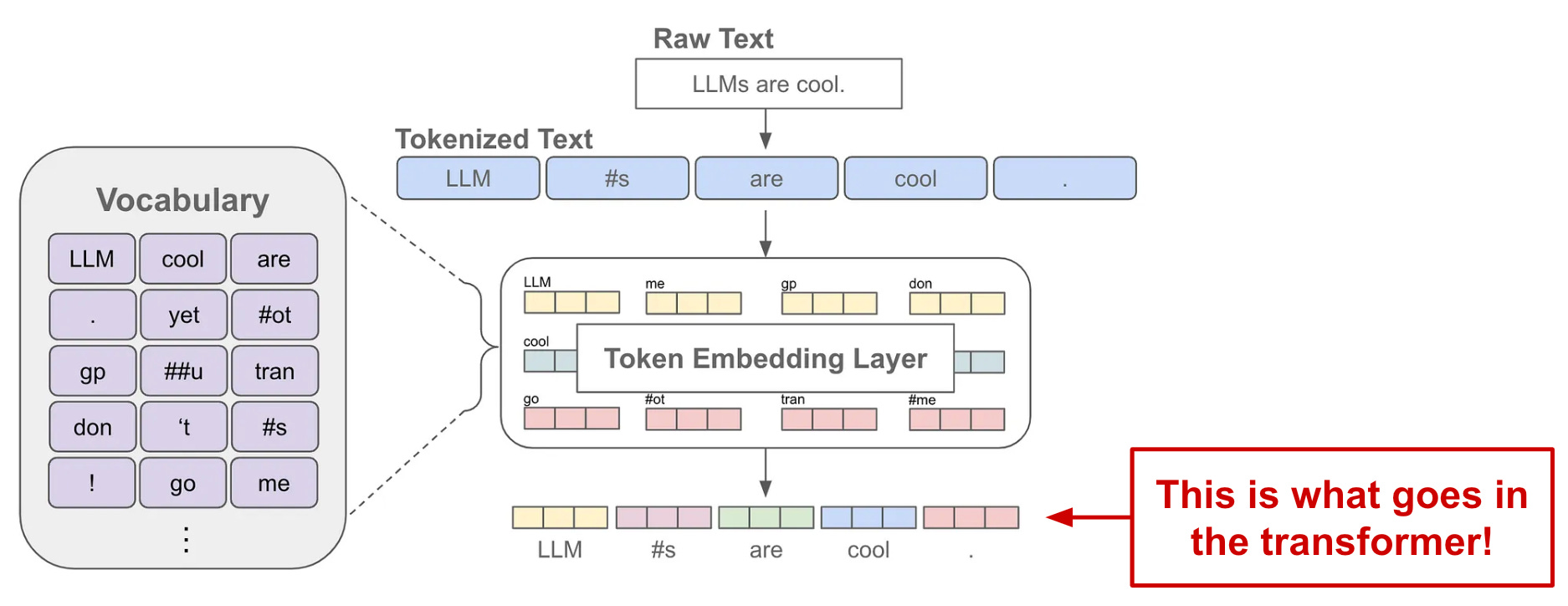
Then, we can embed each of these tokens by performing a lookup within a large embedding layer, forming a sequence of token vectors that are fed into the model as input; see above. Prior to being ingested by the model, however, each of these token embeddings must have a positional embedding added to it, which allows the model to understand the position of each token in the underlying sequence.
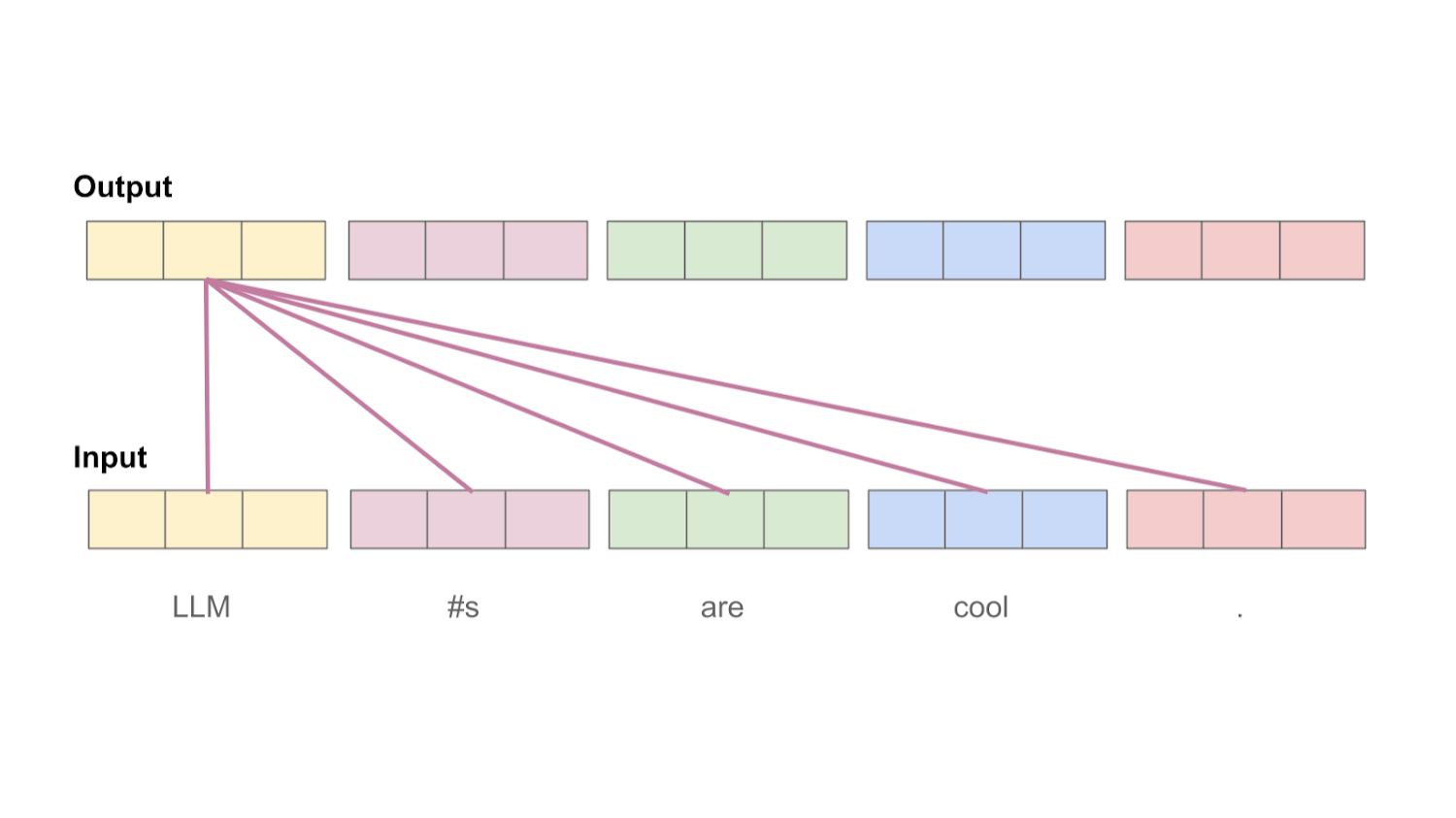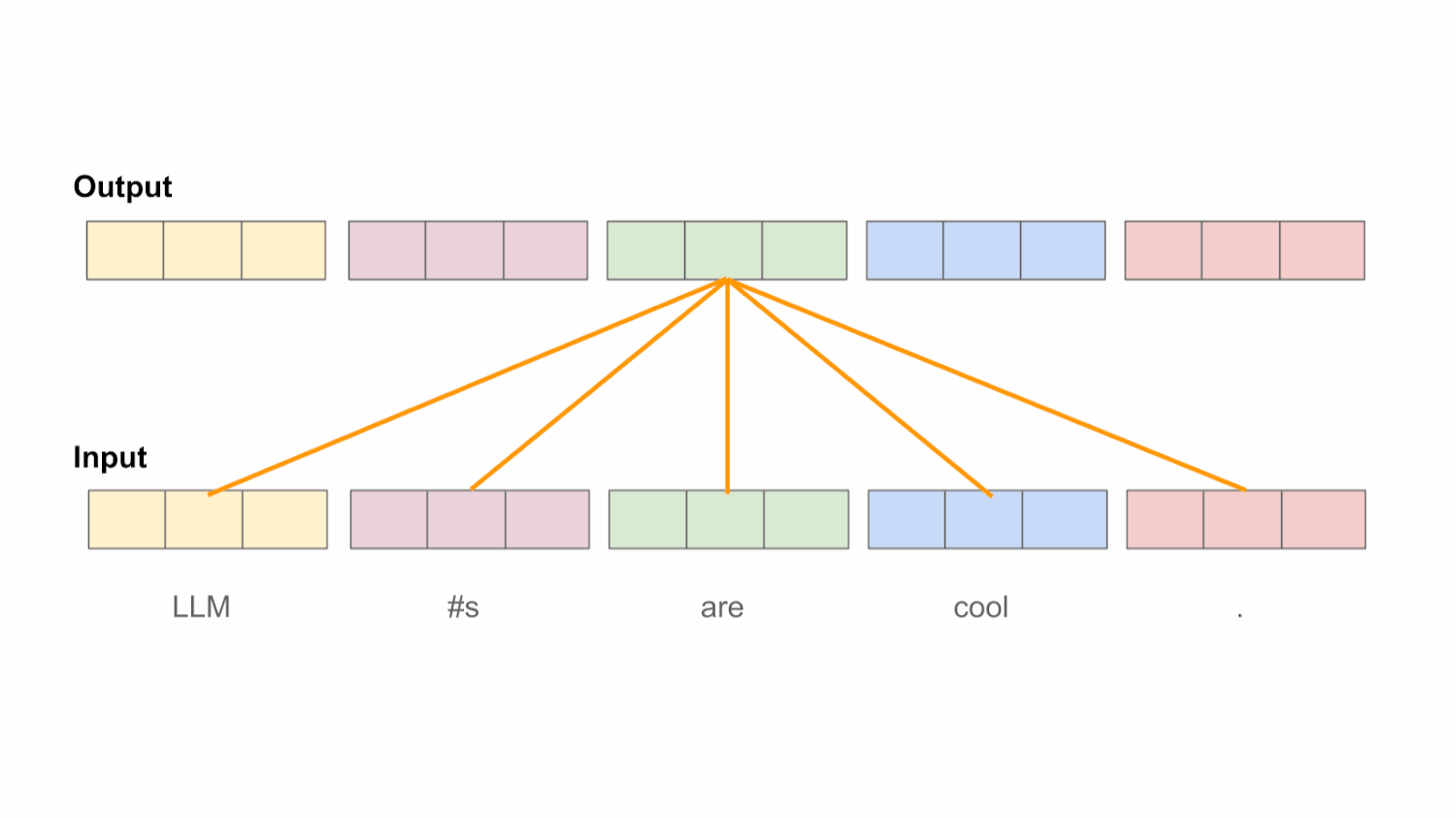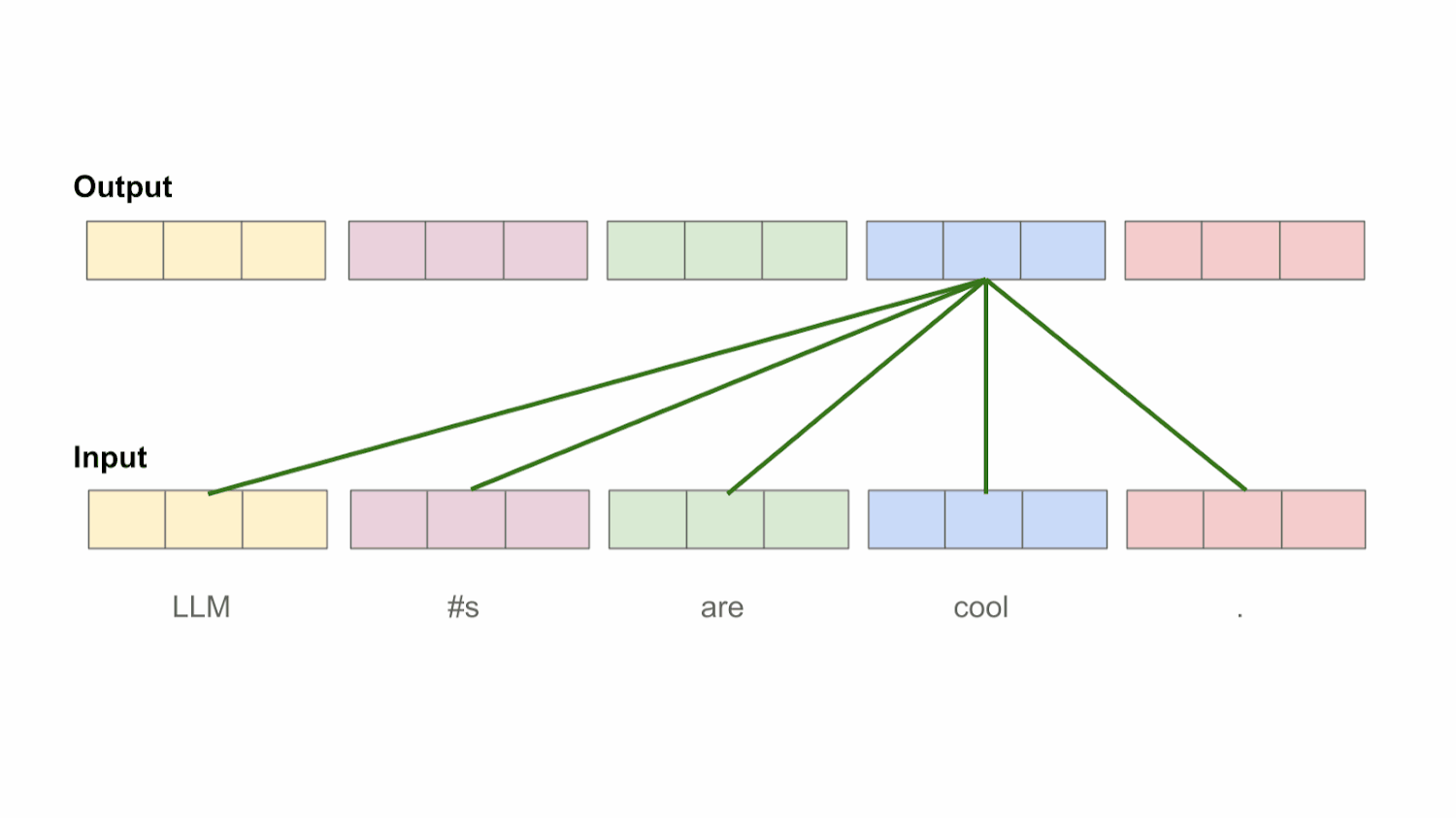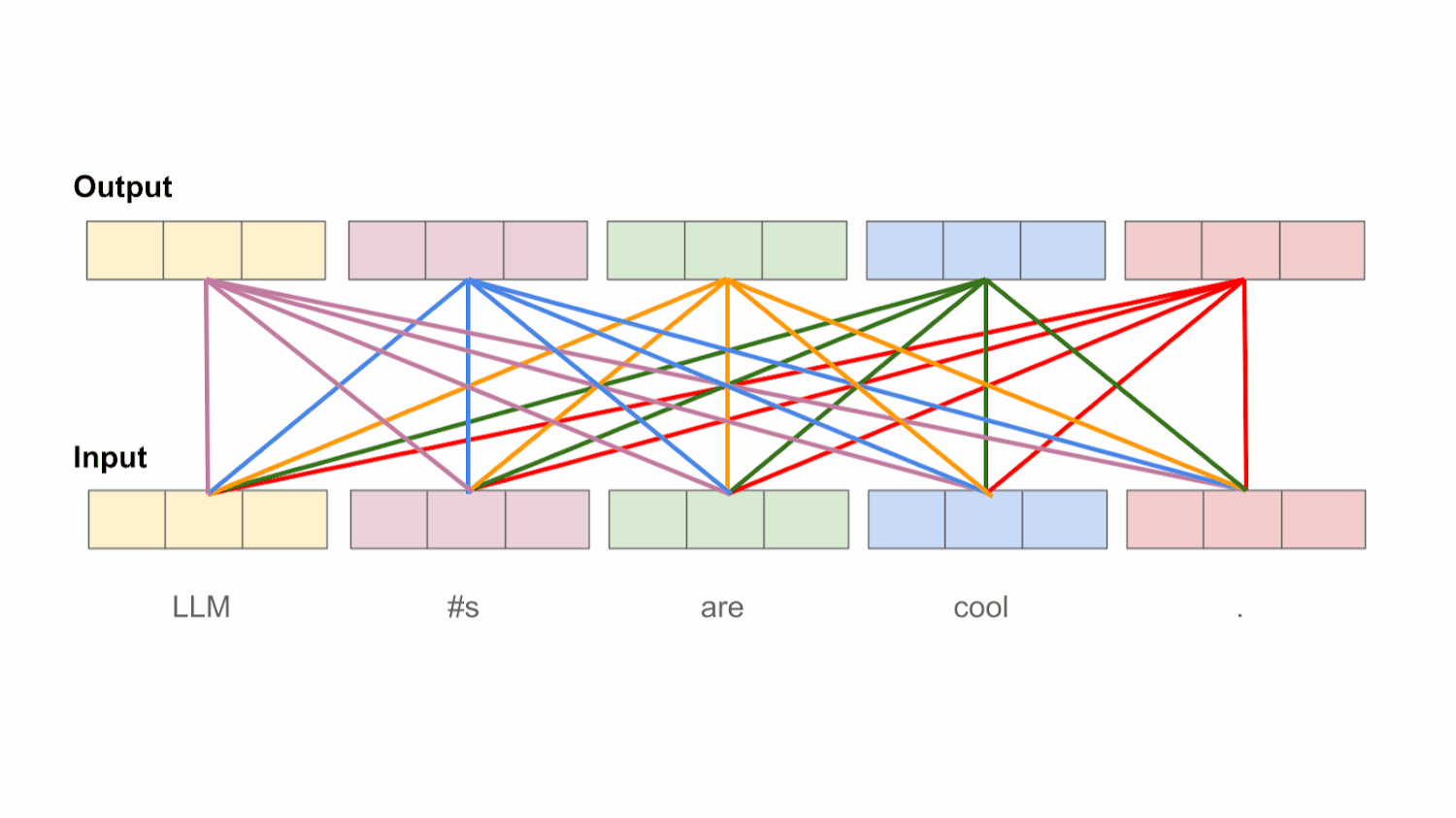
Bidirectional self-attention. Understanding the inner workings of the self-attention mechanism is beyond the scope of this post; see here for a more comprehensive breakdown. At a high level, however, the purpose of self-attention is to transform each token’s representation by looking at other tokens within the sequence. In the case of bidirectional4 self-attention, each token’s representation is transformed by considering all other tokens within the sequence, including those both before and after the current token; see above. In this way, each token’s representation can be informed by the entire input sequence.

Feed-forward transformation. In contrast, the feed-forward transformation within the encoder-only architecture plays somewhat of a different role. Namely, this operation is point-wise, meaning that the same transformation is applied to every token vector within the sequence. The transformation only considers a single token vector and applies a sequence of linear transformations—usually two linear layers separated by a ReLU activation function—to the vector, followed by normalization. An example of this transformation is provided above.
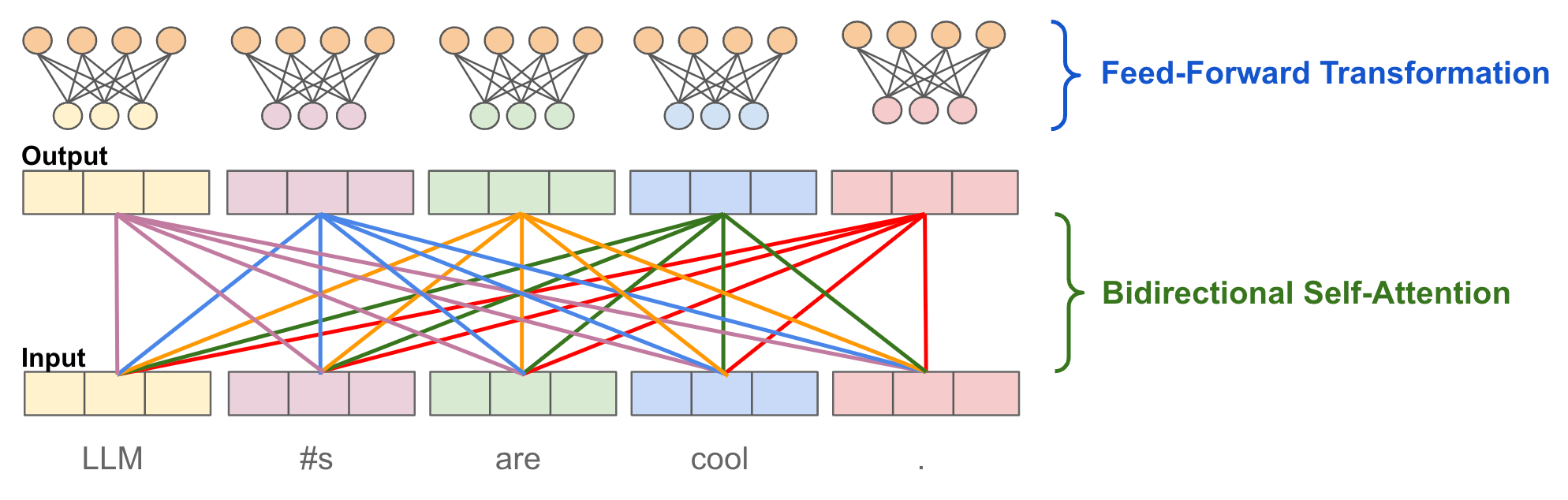
Putting everything together. Bidirectional self-attention and feed-forward transformations each play a distinct and important role within the encoder-only transformer. The self-attention component learns useful patterns by considering the context of other tokens within the sequence, while the feed-forward transformation only considers individual tokens. Together, these operations allow the model accurately model complex patterns across the entire input sequence.
Creating vector embeddings. Before moving on, we need to discuss how BERT can be used to create a vector embedding for a sequence of text. Such an approach is leveraged by bi-encoders to craft vectors that can be used for vector search. Each layer of a BERT model takes a sequence of token vectors as input and produces an equal-size sequence of token vectors as output. As such, the output of BERT is a sequence of token vectors, and every intermediate layer within the model produces a sequence of vectors with the same size; see below.
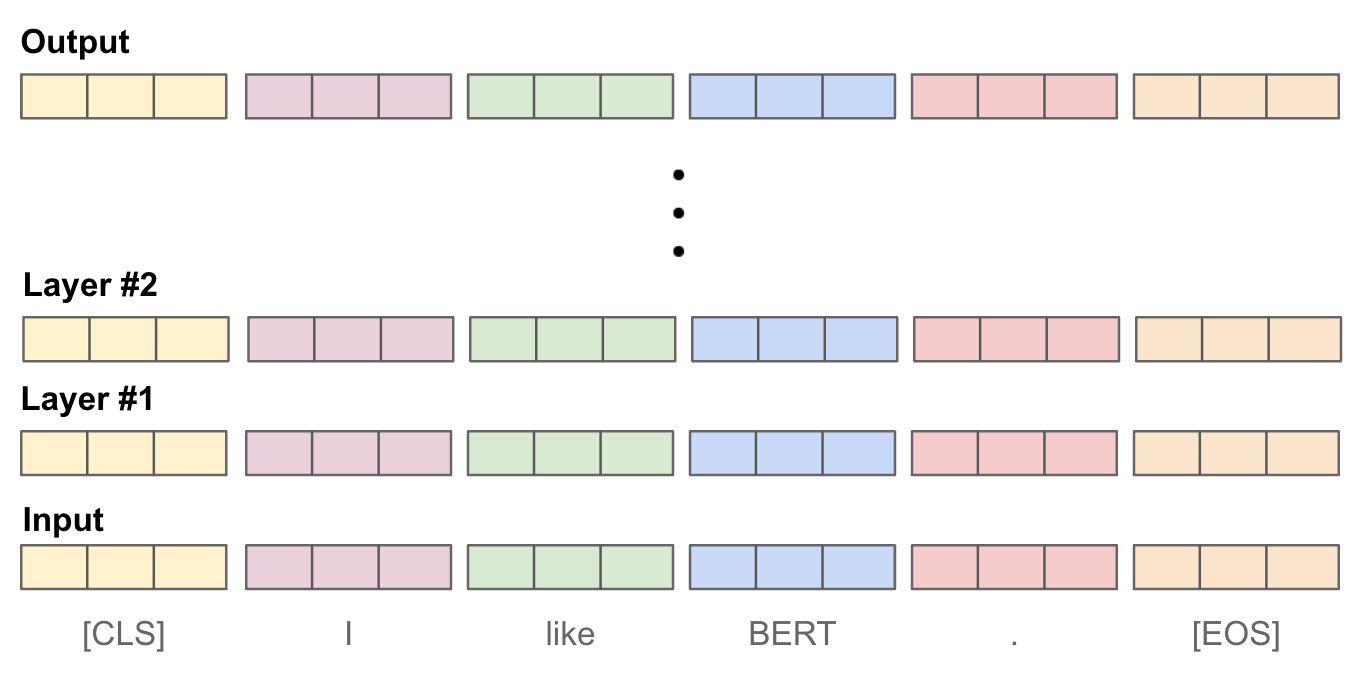
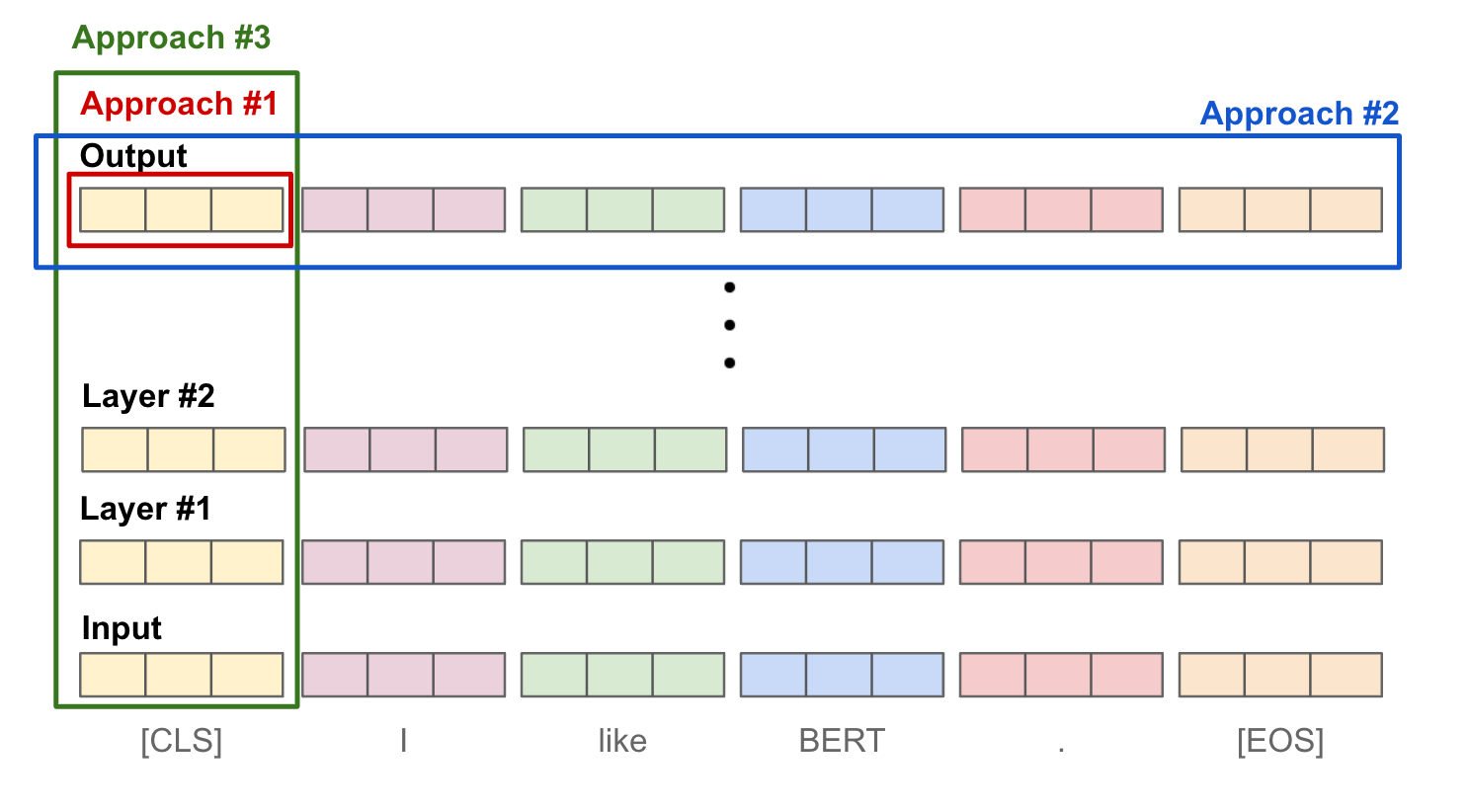
To convert these lists of token vectors into a single embedding that represents the full input sequence, we must perform some kind of pooling operation. With BERT, there are three styles of pooling that are commonly used:
Approach #1: Use the final outputted
[CLS]token representation.Approach #2: Take an average over output token vectors.
Approach #3: Take an average (or max) of token vectors across layers.
Each of these approaches are displayed within the figure below. In general, the style of pooling that is adopted does not make a massive performance difference. However, taking an average over output token vectors (i.e., approach #2) is by far the most common approach for creating text embeddings with BERT.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [1]
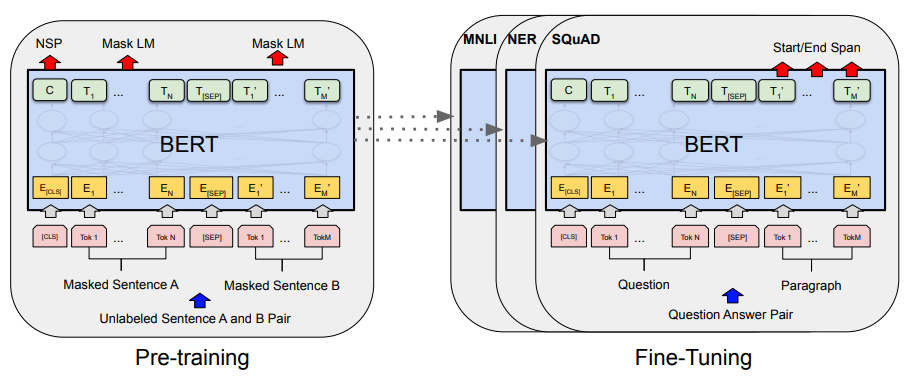
Now that we understand the encoder-only transformer architecture, BERT is pretty easy to grasp. BERT is just an encoder-only transformer that we pretrain using a few self-supervised objectives and finetune—or train the model more (usually with a supervised objective)—to solve some downstream task; see above. The self-supervised pretraining objectives used by BERT (shown below) include:
Cloze: randomly mask tokens within the input sequence and train the model to predict these masked tokens.
Next sentence prediction: given a pair of sentences as input, predict whether these sentence naturally follow each other in a textual corpus or not.
Neither of these tasks require human annotation. Rather, the “labels” that we use to pretrain the model are implicitly present within raw textual data, allowing the model to be trained over a massive textual corpus downloaded from the web. In the case of BERT, this corpus is all of English Wikipedia and BookCorpus!

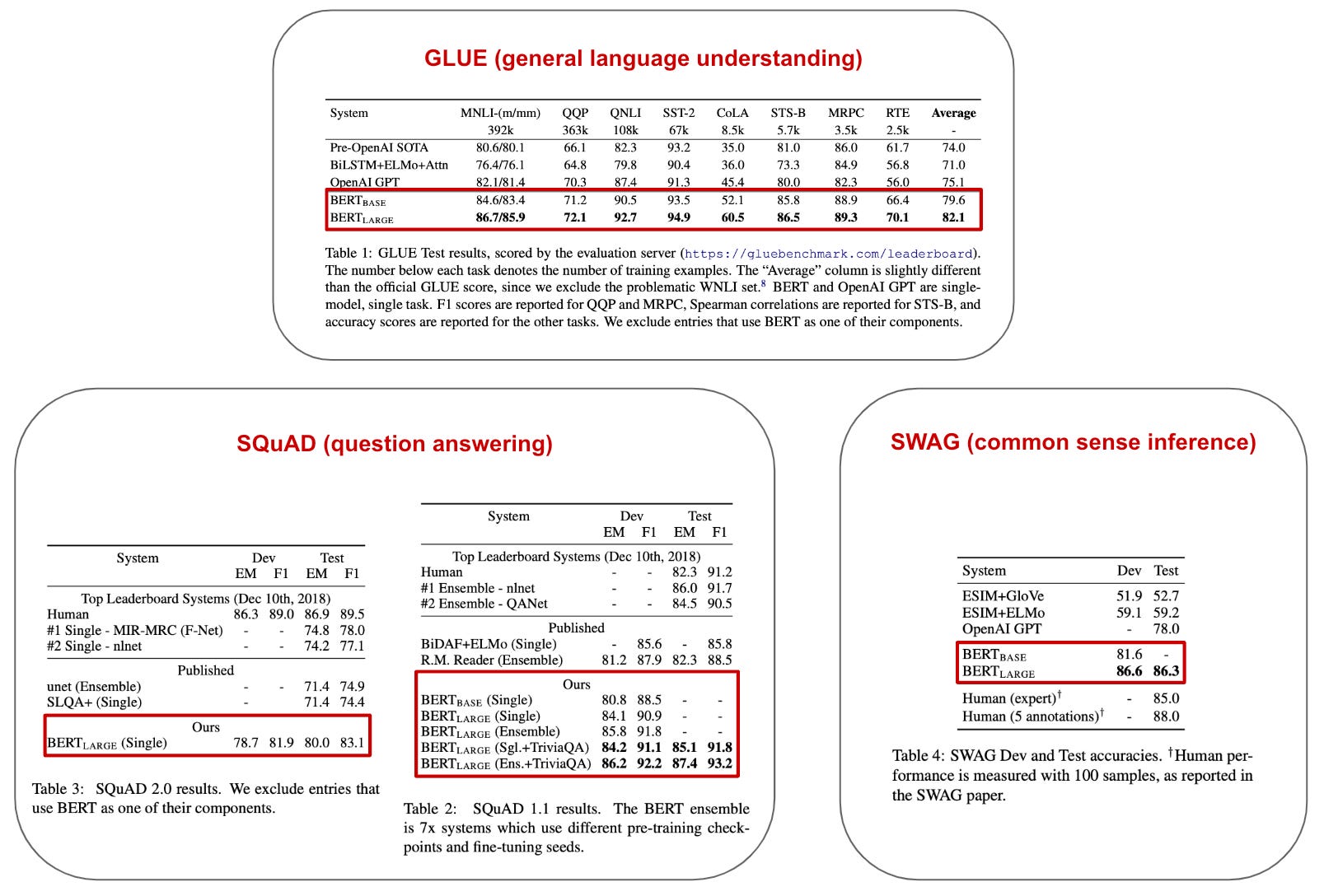
Why is BERT so great? BERT was one of the first transformer-based language models5 to leverage self-supervised pretraining over large amounts of raw textual data. Such an approach proved to be highly effective, as BERT set a new state-of-the-art performance on all tasks that were considered in [1]; see below.
Put simply, we can finetune a pretrained BERT model to solve a variety of different sentence and token-level classification tasks with incredibly high accuracy. For this reason, BERT revolutionized research in natural language processing, replacing many domain-specific techniques with a single model that can solve nearly all tasks! In [1], two different sizes of BERT were proposed:
BERT Base: 12 layers, 768-dimensional hidden representations, 12 attention heads in each self-attention module, and 110M parameters.
BERT Large: 24 layers, 1024-dimensional hidden representations, 16 attention heads in each self-attention module, and 340M parameters.
Notably, BERT Base is the same size as the original GPT model, which was one of the primary baselines used for comparison at the time of BERT’s proposal.
BERT variants. Due to the massive success of BERT and widespread popularity that it gained within AI research, many variants of this model have been created. For example, RoBERTa [3] is a popular BERT variant that carefully studies BERT’s pretraining process, discovering that a better model can be obtained by pretraining over more data and carefully tuning training hyperparameters6. The main modifications made by RoBERTa to the pretraining procedure are:
Training the model longer, with more data, using larger batches.
Using longer textual sequences during pretraining.
Removing the next sentence prediction objective.
Dynamically changing the token masking pattern used by Cloze.
Going further, ALBERT [19] is a variant of BERT that proposes a parameter reduction technique to make BERT pretraining faster and less memory intensive. The resulting model outperforms BERT on a variety of benchmarks despite having fewer parameters. Additionally, mBERT—a multilingual version of the original BERT model—was released (by the same authors) shortly after the proposal of BERT, is jointly pretrained over many languages, and uses a shared vocabulary and embedding space across languages. Put simply, mBERT is a single BERT model that learns unified representations across a large number of languages.
“We show, for the first time, the possibility of multilingual modeling without sacrificing per-language performance; XLM-R is very competitive with strong monolingual models” - from [21]
Finally, XLM-R [21] improves upon mBERT by creating a multilingual version of the RoBERTa model. To achieve better performance, this model is pretrained over multilingual data from Common Crawl, whereas mBERT is trained over a much smaller (i.e., ~100 times smaller to be exact) Wikipedia dataset. Plus, XLM-R improves the tokenization process for multilingual data and pretrains much longer compared to mBERT. However, the BERT variants don’t end here! To find more BERT-based models, check out the related pages on HuggingFace.
Vector Search with BERT
As explained above, BERT is incredibly useful for solving sentence and token-level classification problems, as well as semantic textual similarity (STS) tasks. More specifically, given two texts as input, we can accurately finetune a BERT model to predict the level of similarity between these two texts; see below. In fact, BERT set new state-of-the-art performance on such problems. However, as we have previously discussed, using BERT as a cross-encoder in this manner is inefficient and can, therefore, only be applied at the ranking stage of search.

To more efficiently retrieve relevant documents with BERT, we must use BERT as a bi-encoder by producing textual embeddings for all documents and indexing them in a vector database. But, we learn in [2] that textual embeddings produced by BERT are not semantically meaningful—BERT struggles to function as a bi-encoder and even performs poorly when used for clustering; see below.

At this point, the savvy reader might be wondering: How could BERT embeddings possibly not work well for semantic search? BERT models are widely used to power a variety of high-profile search use cases—including Google Search! In this overview, we will aim to provide an answer to this question by introducing sBERT, a BERT variant that is optimized to produce more semantically meaningful text embeddings that can be use to build performant AI-powered search applications.
“BERT has set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead.” - from [2]
Better Bi-Encoders for Vector Search
Going beyond the basic BERT model, we will now explore several BERT variants that are optimized for use as bi-encoders. At a high level, these are just BERT models that are finetuned to produce more semantically meaningful text embeddings. In turn, these models are more compatible with vector search, making them a useful practical tool for any AI-powered search algorithm.
Sentence-BERT: Sentence Embeddings using Siamese BERT-NetworksExtensions of sBERT [2]
Given that vanilla BERT models work poorly for semantic similarity and clustering tasks, we might wonder: How can we adapt these models to produce more useful embeddings for semantic search? We see in [2] with the proposal of sentence BERT (sBERT) that adapting BERT models in this way is not very difficult. We just need to finetune these models using a siamese or triplet network structure to derive semantically meaningful text or document representations!
What are siamese and triplet networks? The term siamese or triplet network might sound complex, but the concept is actually pretty simple! With sBERT, we use the same BERT [1] (or RoBERTa [3]) encoder-only transformer architecture with which we are already familiar. To make this a siamese network, however, we just pass two different inputs through the same model in parallel. Then, we can apply a loss to the two outputs that are generated; see below.

For example, using this approach, we can train a BERT model to classify whether two sentences are similar or not. To do this, we would obtain a dataset of similar (and not similar) sentence pairs and train the siamese network to take a pair of sentences as input and classify whether they are similar or not.

The idea behind triplet networks is nearly identical to siamese networks, but we pass three different inputs (instead of two) through the same network in parallel. This way, we have the ability to train the model using a triplet loss that considers three different model outputs; see above. For example, if we have access to a dataset with triplets of sentences, including an anchor sentence, a sentence that is similar to the anchor sentence, and a sentence that is different from the anchor sentence, we could train the model to simultaneously make the output of the similar sentences similar and the output of the dissimilar sentences different.
Model architecture for sBERT. In [2], sBERT models share the architecture of a normal BERT [1] or RoBERTa [3] model. To make text embeddings produced by these models more semantically meaningful, sBERT finetunes pretrained7 BERT and RoBERTa models using three types of siamese or triplet network structures. Standard approaches are used to obtain sentence embeddings from BERT or RoBERTa (i.e., we take the mean of all output vectors by default).

The first finetuning setup for sBERT uses a classification objective; see above. Two sentences are taken as input and passed through a BERT model to yield embeddings u and v. We then concatenate these embeddings together—along with their element-wise difference—and pass this concatenated representation through a linear transformation, producing a vector of size k. Finally, we apply a softmax to the output of the linear layer and train the model to perform k-way classification. For example, if we want to finetune sBERT using pairs of sentences that are either similar or dissimilar, we would have k=2. Because we only apply a simple, linear classification layer on top of the BERT embeddings, we force the model to craft semantically meaningful sentence embeddings to solve this task.

Next, authors in [2] explore a regression objective for finetuning sBERT; see above. This setup looks almost identical to the classification objective. Instead of concatenating vectors u and v together and applying a linear transformation, however, we just i) compute the cosine similarity of u and v (i.e., via a dot product if u and v are unit vectors) and ii) perform regression to match this cosine similarity to a target similarity value. In this way, we can finetune sBERT over pairs of sentences with similarity scores between -1 (not similar) and 1 (similar).
The final finetuning setup explored in [2] uses a triplet objective. Each training example contains three sentences: an anchor sentence, a similar sentence, and a dissimilar sentence. We pass each of these sentences through a BERT model to obtain an embedding. Then, we apply a triplet loss (shown below) over these embeddings to move the embeddings of the anchor and similar sentences closer together and vice versa. Similarity is measured using euclidean distance, and we add a margin (Ɛ=1) to the loss to ensure that similar and dissimilar sentences have a sufficiently large difference in similarity to the anchor sentence.

Finetuning sBERT. The three different networks structures overviewed above give us a brief glimpse at the different strategies that can be used to produce more semantically meaningful embeddings with BERT. But, there are many possible finetuning setups for sBERT beyond these three! As a practitioner, the exact setup derived will use similar principles—usually a siamese/triplet BERT network with an added classification/regression head—but will be adapted to the exact style of sentence or document pairs that are available. For example, we can have humans annotate a 1-5 similarity score for sentence pairs, collect descriptions of products that are commonly purchased together on an e-commerce store, and much more!
“We train SBERT on the combination of the SNLI and the Multi-Genre NLI dataset… with a 3-way softmax classifier objective function for one epoch.” - from [2]
The sBERT model that is proposed and analyzed in [2] is a specific instantiation of these ideas. In particular, the model is trained over two different datasets using a classification objective with three target classes (i.e., k=3):
SNLI [4]: 570K sentence pairs annotated with a label of contradiction, entailment, or neural8.
MultiNLI [5]: 430K sentences pairs (uses the same entailment labels as SNLI) that cover a range of genres of spoken and written text.
This finetuning procedure is relatively quick and inexpensive because we begin with a pretrained BERT or RoBERTa model. As we will see, this simple finetuning procedure drastically improves the quality of BERT embeddings in the context of vector search, clustering, and semantic similarity tasks.
How does it perform? In [2], sBERT is evaluated on several different semantic textual similarity (STS) tasks in comparison to sentence embedding methods like InferSent [7] and Universal Sentence Encoder [8]. Here, all techniques are compared using an approach that measures cosine similarity9 between generated embeddings, rather than the (expensive) pairwise approach used by most cross-encoders. In other words, sBERT is evaluated as a bi-encoder. First, sBERT is evaluated on a variety of STS tasks in an unsupervised fashion (i.e., using no specific training data for any of the tasks); see below.

Here, we see that directly using embeddings outputted from a pretrained BERT model yields poor performance. In fact, the results achieved with pretrained BERT are even worse than those achieved via average GloVE [9] embeddings! In contrast, we can outperform all baseline techniques—using either BERT or RoBERTa—via the siamese network structure and finetuning approach proposed by sBERT.

When sBERT models are further finetuned on the downstream task used for evaluation, the results observed follow a similar trend; see above. Here, we evaluate sBERT on the STS benchmark [10]—a popular dataset for evaluating semantic similarity systems. The best results are achieved by performing both:
The normal sBERT finetuning procedure on NLI.
Further finetuning on the downstream task.
On these tasks, sBERT achieves comparable performance to a cross-encoder-style BERT model (i.e., the state-of-the-art approach for solving STS tasks), while still operating purely as a bi-encoder.

Going further, sBERT is evaluated on the Argument Facet Similarity [11] dataset that contains pairs of sentences across different topics with varying levels of similarity, as well as on Wikipedia by measuring the similarity of sentences from the same or different sections of various articles; see above. Again, sBERT achieves results that are comparable to a cross-encoder-style BERT model on the argument facet similarity dataset, while baseline techniques perform quite poorly. Interestingly, however, sBERT struggles in the cross-topic domain, where models are trained on a few topics and evaluated on a held-out topic.
“BERT and RoBERTa have set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead.” - from [2]
Main takeaway. BERT models are great for a variety of tasks, but BERT’s textual embeddings are not semantically meaningful by default. The finetuning procedure proposed in [2] improves the semantic meaningfulness of BERT embeddings. As such, sBERT is appropriate for a broader range of tasks, including semantic similarity tasks like clustering and semantic (vector) search. Using optimized index structures, we can find similar documents with sBERT in milliseconds, whereas performing a similarity search with vanilla BERT (using a cross-encoder setup) could take tens or hundreds of hours10!
Useful Extensions of sBERT
From work in [2], we learn how to make BERT models more usable for dense retrieval. Given that producing semantically meaningful embeddings is so useful and important11, this technique has been extended by several follow-up publications. Although many such extensions to sBERT exist, we will do our best to cover the most important of them within this section.

Making sBERT multilingual. One major limitation of work in [2] is the simple fact that the proposed model is English-only. With this in mind, we might wonder: Could we (cheaply) expand a monolingual embedding model to understand multiple languages? Authors in [12] study this problem exactly, finding that such models can be created by leveraging the idea that translated sentences should have the same embedding as the original sentence. In particular, the original (monolingual) model is used to generate embeddings of sentences in the source language. Then, we translate these sentences and finetune the model over these translated sentences to mimic the original model’s embeddings. This approach is coined as multilingual knowledge distillation; see above.
“The student model learns a multilingual embedding space with two important properties: vector spaces are aligned across languages and vector space properties in the original language are adopted and transferred to other languages.” - from [12]
In [12], sBERT is used as the teacher, while the student model is based upon XLM-R [13]—a BERT-style model that is pretrained on data from over 100 languages. In addition to being both simple and low cost, the knowledge distillation approach proposed in [12] has several benefits:
Data efficiency: embedding models can be expanded to understand more languages with (relatively) few data samples.
Hardware requirements: the hardware required to finetune an embedding model via multilingual knowledge distillation is more reasonable compared to training a multilingual embedding model from scratch.
Rich embedding space: the properties of the monolingual model’s embedding space are transferred to and aligned with the multilingual embedding model.
Augmenting sBERT’s data. Cross-encoders and bi-encoders have pros and cons. Cross-encoders tend to perform well, but they are too costly for practical applications (unless we only apply them in the ranking stage of search). In contrast, bi-encoders are more practical, but they require much more training data and finetuning to perform competitively; see below.

In [14], authors propose a solution to this problem that generates a much larger training dataset for bi-encoders—such as sBERT—by using a BERT cross-encoder to label pairs of sentences that can then be used as extra data for the bi-encoder; see below. Such an approach can significantly improve the performance of sBERT, but the exact approach used to sample data for labeling with the cross-encoder is crucial. Namely, we cannot just randomly sample sentence pairs. Rather, we should use a sampling approach (e.g., BM25 sampling and/or semantic search or simply removing negative examples) to ensure the ratio of similar and dissimilar sentences matches the original training dataset.
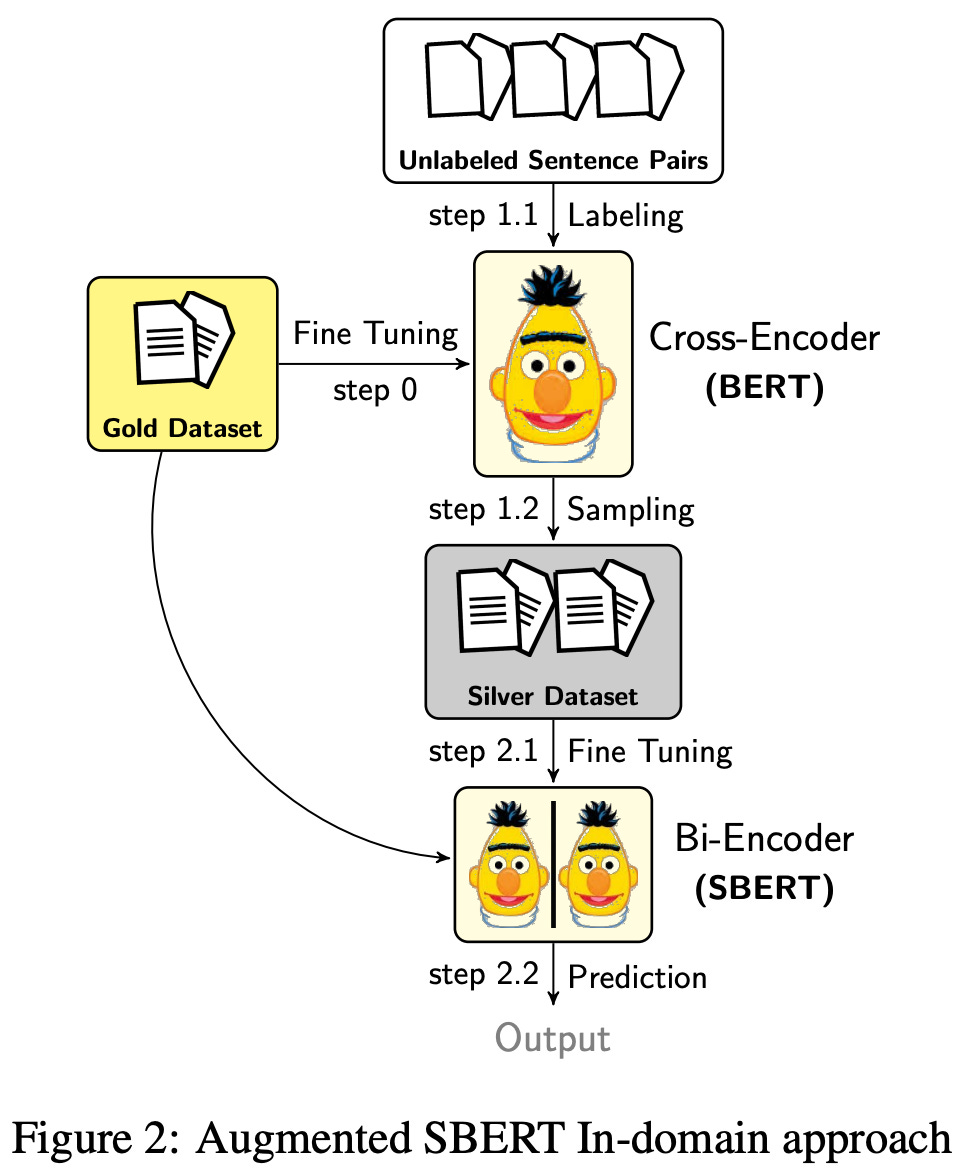
Pseudo-labeling for domain adaptation. Continuing the trend of using cross-encoders to label data, authors in [15] use a similar approach to improve the ability of bi-encoders to handle domain shifts (i.e., usage on data that is different from the training dataset). The proposed approach, called Generative Pseudo Labeling (GPL), combines a query generator with a cross-encoder that is used to generate labels. See below for an illustration of this technique.

For a given target domain, authors use T5 [18] to generate queries for this domain given a passage of text (i.e., the positive example or desired match) as an input. From here, an existing retrieval system—either using lexical search with BM25 or vector search with a pretrained model—is used to retrieve a fixed number of negative examples for each query. Then, we form triplets that include:
The query.
The correct passage.
A negative/incorrect passage.
For each triplet, the cross-encoder is used to predict a margin that can be used as a training signal. Using this approach, we can adapt a bi-encoder to a new domain without the need for labeled data. All we need is a valid set of passages within this domain, as well as a pretrained T5 and cross-encoder model.
Large-scale semantic search. In [16], authors study the performance of vector search with bi-encoders like sBERT with respect to the size of the underlying search index (i.e., the number of vectors over which we have to search). Interestingly, as shown in the table below, the quality of dense retrieval (i.e., vector search with bi-encoders) deteriorates as the size of the index increases. Additionally, higher-dimensional embeddings tend to perform slightly better.

Although the mathematical proof of this trend and the intricacies of vector search are beyond the scope of this post, we learn from analysis in [16] that i) vector search works best with a smaller, clean search index, but the overall quality of vector search—even within larger search indices—can be improved by introduced added “hard” negative examples to a bi-encoder’s training process.
Benchmarking search systems. Search systems are, without a doubt, one of the most popular and widely-studied applications of AI. As such, a massive number of search techniques and methodologies have been prosed over the last few decades. In fact, there is so much search-related information and research available that it can be difficult to determine which techniques perform best and how they compare to each other. Authors in [18] solve this problem by proposing a new, comprehensive information retrieval benchmark—called Benchmarking-IR (BEIR)—comprised of the tasks shown below.

Additionally, authors provide extensive analysis of a variety of different search techniques, arriving at some practical takeaways:
BM25 is a robust baseline that is quite difficult to beat.
Re-ranking models (i.e., cross-encoders) yield the best performance, though their computational cost is high.
Bi-encoders are more efficient, but they can perform poorly in certain domains (sometimes even worse than BM25!).
Search systems that perform well in one domain might generalize quite poorly to other domains.
Put simply, we learn in [18] that there is a tradeoff between the efficiency and performance of search systems. Typically, the best approach will be achieved via a combination of lexical search with BM25 and vector search with a bi-encoder, as well as re-ranking the final few search results with a cross-encoder. This paper is a great practical resource for anyone that wishes to understand the different components of search systems and their impact on top-level performance.
SentenceTransformers: Semantic Search in Practice

Now that we have learned about sBERT and its extensions, we need to learn how to use these ideas in practice! All papers we have seen so far are implemented in a Python library, called Sentence Transformers, that is built on top of the PyTorch and HuggingFace. This package openly provides tons of state-of-the-art models—including both bi-encoders and cross-encoders—and makes it easy to use these models and efficiently finetune them on your own data. Because this package is based upon sBERT, SentenceTransformer embeddings are semantically meaningful—similar sentences yield embeddings that are close in vector space.

Show me the code. An example of embedding sentences with a bi-encoder using the SentenceTransformers library is shown above. Although BERT models natively produce a sequence of output embeddings for each sentence, Sentence Transformer models automatically perform mean pooling over these embeddings to produce a single output embedding. To perform semantic search with these embeddings, we simply need to compute their respective cosine distances.
“BERT outputs for each token in our input text an embedding. In order to create a fixed-sized sentence embedding out of this, the output embeddings for all tokens are averaged to yield a fixed-sized vector.” - from Sentence Transformer docs
Going further, the Sentence Transformers library also implements a variety of cross-encoder models. As described previously, cross-encoders take a pair of textual sequences (e.g., a search query and a passage or two sentences) as input and output a similarity score in the range [0, 1]; see below for an example.

More details. Beyond what we’ve learned so far, Sentence Transformers also i) supports over 100 different languages via the multilingual knowledge distillation approach we learned above before and ii) has an added module for performing vector search with both text and images; see below.

The documentation for Sentence Transformers has a variety of useful guides and tutorials for supporting different styles of semantic search applications. See below for a quick list:
Final Remarks
Within this overview, we learned about the basic components of AI-powered search systems, including lexical search, bi-encoders, and cross-encoders. Then, we dove deeper into bi-encoders and how we can finetune BERT-style language models to provide semantically meaningful text embeddings that work especially well for dense retrieval. The major takeaways from this overview are as follows:
Search algorithms proceed in two primary phases—retrieval and ranking.
Lexical retrieval with BM25 uses keyword matching to produce high-quality search results and can be efficiently implemented with an inverted index.
Going beyond BM25, we can improve retrieval and ranking quality with bi-encoders and cross-encoders, respectively.
Both bi-encoder and cross-encoder models use a BERT-style architecture.
BERT naturally performs well when finetuned as a cross-encoder, but we should only use such a model in the final ranking stage of search.
To use BERT as a bi-encoder, we must finetune the model—as is done by sBERT—to yield more semantically meaningful embeddings.
Further Reading
We covered a lot of ground within this overview, but this information barely scratches the surface of techniques that have been proposed for search and information retrieval. Gaining a deep understanding of search algorithms requires extensive reading and practical experience—there is a limitless amount of information online about building and improving search. For example, cross-encoders are not the only approach that we can use for ranking. In fact, there is an entire sub-domain of research focused on the problem of learning to rank for search. Notable examples include:
Additionally, this post focused upon bi-encoders instead of diving deeper into cross-encoders, though a lot of useful research on the topic of cross-encoders has been published! For example, researchers have studied the impact of using multiple stages of ranking models, using generative large language models for ranking, and even considering more data when ranking via a cross-encoder.

Going further, cross-encoders can be expensive to use in practice, even when they are just used at the ranking stage. To mitigate this problem, researchers have proposed popular techniques like ColBERT [22] that augment a normal BERT bi-encoder with an added, late interaction stage that can compute more fine-grained textual similarities; see above. This late interaction step is more computationally efficient than a cross-encoder, allowing ColBERT to find a middle ground between bi-encoder and cross-encoders. Namely, we can use ColBERT as a bi-encoder for vector search, then perform ranking via a simplified module!
“While remarkably effective, the ranking models based on these LMs increase computational cost by orders of magnitude over prior approaches, particularly as they must feed each query-document pair through a massive neural network to compute a single relevance score.” - from [22]
This overview is not meant to be an exhaustive overview of search techniques, but it should provide a good base of information for those interested in learning more. Now that we understand the basic components of AI-powered search, we are better positioned to stay up-to-date with this ever-evolving research problem.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[2] Reimers, Nils, and Iryna Gurevych. "Sentence-bert: Sentence embeddings using siamese bert-networks." arXiv preprint arXiv:1908.10084 (2019).
[3] Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692 (2019).
[4] Bowman, Samuel R., et al. "A large annotated corpus for learning natural language inference." arXiv preprint arXiv:1508.05326 (2015).
[5] Williams, Adina, Nikita Nangia, and Samuel R. Bowman. "A broad-coverage challenge corpus for sentence understanding through inference." arXiv preprint arXiv:1704.05426 (2017).
[6] Malkov, Yu A., and Dmitry A. Yashunin. "Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs." IEEE transactions on pattern analysis and machine intelligence 42.4 (2018): 824-836.
[7] Conneau, Alexis, et al. "Supervised learning of universal sentence representations from natural language inference data." arXiv preprint arXiv:1705.02364 (2017).
[8] Cer, Daniel, et al. "Universal sentence encoder." arXiv preprint arXiv:1803.11175 (2018).
[9] Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. "Glove: Global vectors for word representation." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[10] Cer, Daniel, et al. "Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation." arXiv preprint arXiv:1708.00055 (2017).
[11] Misra , Amita et al. “Measuring the Similarity of Sentential Arguments in Dialogue". In The 17th Annual SIGdial Meeting on Discourse and Dialogue (SIGDIAL), Los Angeles, California, USA, 2016.
[12] Reimers, Nils, and Iryna Gurevych. "Making monolingual sentence embeddings multilingual using knowledge distillation." arXiv preprint arXiv:2004.09813 (2020).
[13] Conneau, Alexis, et al. "Unsupervised cross-lingual representation learning at scale." arXiv preprint arXiv:1911.02116 (2019).
[14] Thakur, Nandan, et al. "Augmented sbert: Data augmentation method for improving bi-encoders for pairwise sentence scoring tasks." arXiv preprint arXiv:2010.08240 (2020).
[15] Wang, Kexin, et al. "Gpl: Generative pseudo labeling for unsupervised domain adaptation of dense retrieval." arXiv preprint arXiv:2112.07577 (2021).
[16] Reimers, Nils, and Iryna Gurevych. "The curse of dense low-dimensional information retrieval for large index sizes." arXiv preprint arXiv:2012.14210 (2020).
[17] Thakur, Nandan, et al. "Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models." arXiv preprint arXiv:2104.08663 (2021).
[18] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[19] Lan, Zhenzhong, et al. "Albert: A lite bert for self-supervised learning of language representations." arXiv preprint arXiv:1909.11942 (2019).
[20] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[21] Conneau, Alexis, et al. "Unsupervised cross-lingual representation learning at scale." arXiv preprint arXiv:1911.02116 (2019).
[22] Khattab, Omar, and Matei Zaharia. "Colbert: Efficient and effective passage search via contextualized late interaction over bert." Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 2020.
Dense retrieval is also commonly referred to as semantic search, as vector embeddings tend to capture the semantic properties of the text from which they are created.
See here for a pretty good overview of some different tokenization techniques that are commonly used for language models.
The alternative is masked (or unidirectional/causal) self-attention, which looks only at preceding tokens instead of all tokens within the sequence. Masked self-attention is used by generative large language models (e.g., ChatGPT).
Notably, ULMFit pioneered a pretraining approach that was quite similar but used RNN-based language models instead of transformers.
The term “hyperparameters” refers to settings that are set/tuned by the practitioner that is training the model, such as the learning rate or the ratio of tokens that are masked out within the Cloze objective.
Here, we choose to start with the pretrained versions of these models and perform finetuning rather than training sBERT models from scratch because it saves us a significant amount of compute. sBERT can be finetuned in <20 minutes, but training such a network from scratch would require much more time and data.
This task of classifying sentence pairs as contradictory, neutral, or entailment is known as the textual entailment task—a commonly-used semantic text similarity (STS) task that is widely-studied in research papers.
Other distance metrics, such as Euclidean and Manhattan distance, were also tested and found to yield similar results.
The exact time is heavily dependent upon hardware, dataset size, and the exact model being used. But, the basic takeaway is that performing a vector search over an HNSW index is way faster that using a cross-encoder to exhaustively compute document similarities across an entire dataset.
There are so many different tasks for which this could be used, including search engines, product recommendations, and retrieval augmented generation!
These are the basic components of most semantic search pipelines! All we are missing is a hybrid retrieval algorithm that uses both dense retrieval (i.e., vector search) and sparse/lexical retrieval. This tutorial uses purely dense retrieval.
🌟 Let’s collaborate and crush goals together! 🌟 Subscribe to align your vision with actionable insights—spark success, grow faster, and thrive mutually. Join now! 🚀