


LLaMA-2 from the Ground Up
Everything you need to know about the best open-source LLM on the market...


The opeurce AI research community has heavily explored the creation of open-source, commercially-usable large language models (LLMs). Although a variety of such models perform well, none stand out quite like LLaMA-2 [1], a suite of recently-proposed open-source language models with sizes ranging from 7 to 70 billion parameters. Compared to their predecessors (i.e., LLaMA-1 [2]), LLaMA-2 models differentiate themselves by pre-training over more data, using a longer context length, and adopting an architecture that is optimized for faster inference. Additionally, LLaMA-2 goes beyond prior research in open-source LLMs by investing heavily into the models’ alignment process, which is used to create LLaMA-2-Chat models that are optimized for dialogue applications and nearly match the quality of top proprietary LLMs (e.g., ChatGPT and GPT-4) in certain areas. Within this overview, we will explore the details of LLaMA-2 and build an in-depth understanding of these models starting from basic concepts.
“There have been public releases of pre-trained LLMs (such as BLOOM) that match the performance of closed pre-trained competitors like GPT-3 and Chinchilla, but none of these models are suitable substitutes for closed product LLMs, such as ChatGPT, BARD, and Claude.” - from [14]
Language model fundamentals. Throughout this overview, we will try to build an understanding of relevant concepts from the ground up (sometimes providing links for further reading for the purpose of brevity). However, we will not cover fundamentals with respect to how language models work in general. For these details, I highly recommend reading the resources below:
The transformer architecture [link]
Decoder-only transformer architecture [link]
Language modeling (next-token prediction) objective [link]
Prompting language models [link]
Specialized language models [link]
Decoding (or inference) with a language model [link]
Gaining an in-depth understanding of fundamental concepts related to language models is important for understanding this overview. Leveraging this knowledge, we will now build upon these basic concepts to better understand how LLaMA-2 approaches and improves the pre-training and alignment process for LLMs.
Model Architecture and Pre-Training

There are many factors that contribute to the utility of LLaMA-2. To begin with, however, the models use a modified (and improved) model architecture and pre-training procedure. Compared to its predecessor, LLaMA-2 has an architecture that is optimized for faster inference and is pre-trained over more data, allowing a broader knowledge base to be formed; see above.
Optimized Architecture with Faster Inference
LLaMa-2 adopts the model architecture of LLaMA-1 with a few modifications. To understand LLaMA-2’s architecture, we need a working understanding of the transformer architecture in general; see here for more details on this topic. More specifically, nearly all causal language models adopt the decoder-only variant of the transformer architecture. Now, we will study some of the modifications to this architecture that are made by both LLaMA [2] and LLaMA-2 [1]. All of these changes apply to both LLaMA and LLaMA-2 unless otherwise specified.

Normalization. Most transformer architectures adopt layer normalization, which is applied after each layer within the transformer block; see above. LLaMA, however, replaces this with a variant called Root Mean Square Layer Normalization (or RMSNorm for short!), which is a simplified version of layer normalization that has been shown to improve training stability and generalization1 [4]. RMSNorm is formulated as shown below.

For LLaMA, a pre-normalization variant of RMSNorm is adopted, meaning that normalization is applied prior to the major layers in a transformer block, rather than after, as shown in the figure above. RMSNorm achieves comparable levels of performance compared to layer norm with a 10-50% improvement in efficiency.
Activation functions. LLaMA models adopt the SwiGLU activation function—as opposed to the standard ReLU function adopted by most neural networks—within their feed-forward layers. The SwiGLU activation function can be formulated as follows.

SwiGLU is an element-wise product of two linear transformations of the input x, one of which has had a Swish activation applied to it. This activation function requires three matrix multiplications (i.e., it is more computationally expensive than a normal activation function such as ReLU), but it has been found to yield improvements in performance relative to other activation functions, even when the amount of compute being used is held constant. A more in-depth analysis of potential activation functions for LLMs can be found in [5].
RoPE. Instead of using absolute or relative positional embeddings, LLaMA models adopt a RoPE [6] scheme, which finds a balance between the absolute and relative position of each token in a sequence. This position embedding approach encodes absolute position with a rotation matrix and adds relative position information directly into the self-attention operation. The benefit of RoPE embeddings on tasks with longer sequence lengths has led this approach to be adopted by a variety of LLMs (e.g., PaLM [7] and Falcon [8]); read more below.
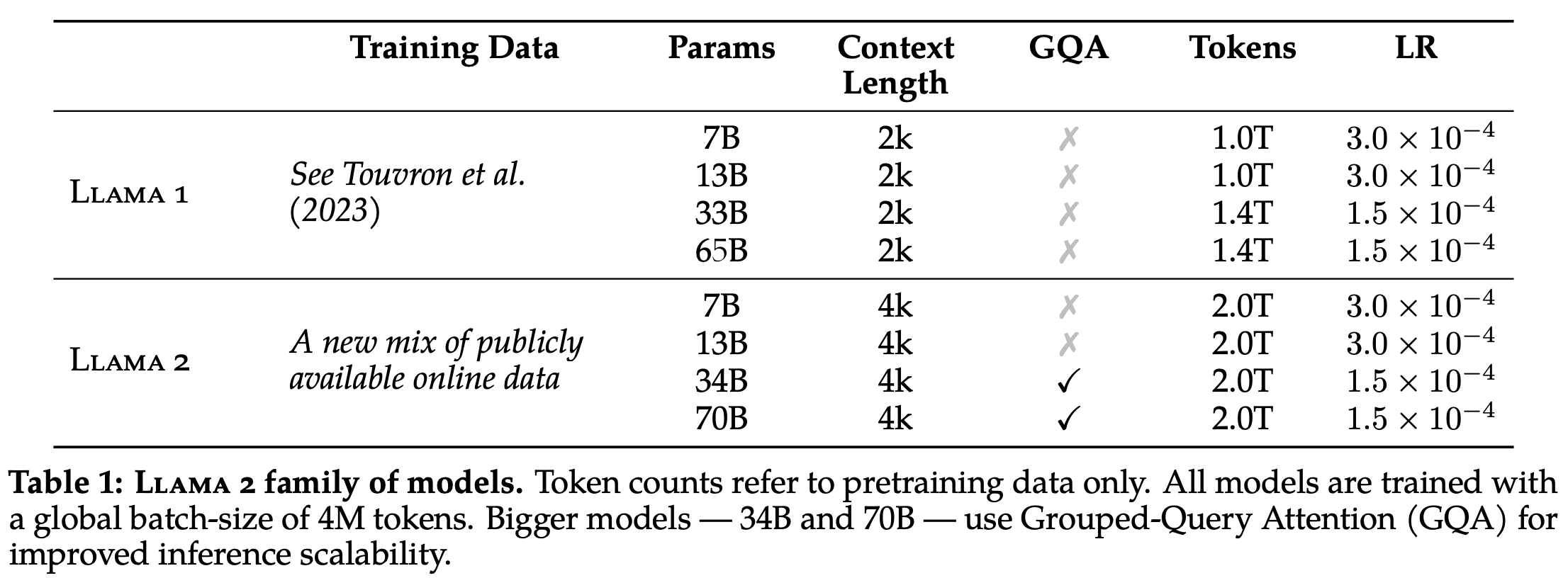
What is different? So far, all of the modifications to the normal decoder-only transformer that we have discussed are adopted by both LLaMA and LLaMA-2. However, LLaMA-2 does have a few notable architectural changes compared to its predecessor. First, LLaMA-2 is trained with a longer context length of 4K tokens (i.e., LLaMA was trained with a 2K context length). Additionally, LLaMA-2 adopts grouped query attention (GQA) [9] within each of its layers; see below. This modification is made to speed up the inference process of LLaMA-2 models.
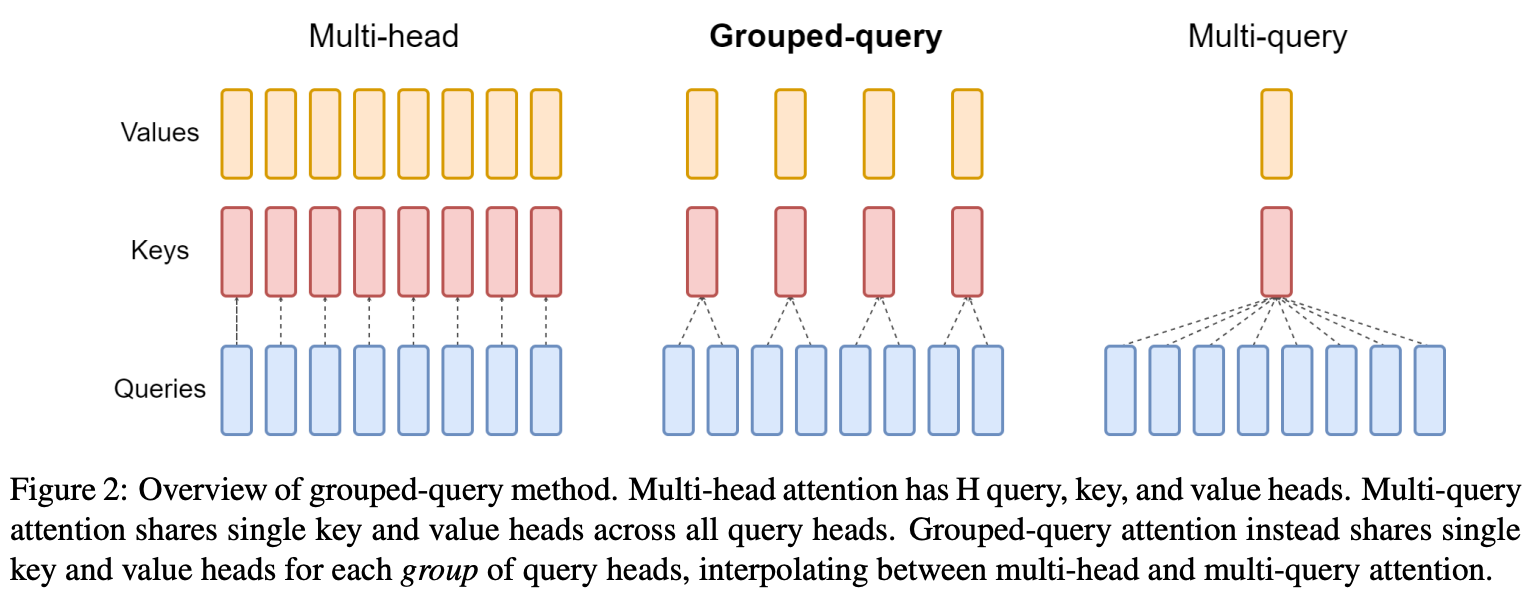
GQA is a modified version of the standard multi-head causal self-attention. In GQA, we divide the N total self-attention heads into groups, where key and value heads are shared within each group; see above. Such an approach is an interpolation between vanilla multi-headed self-attention and multi-query attention, which uses a shared key and value projection across all N heads. Interestingly, GQA maintains the performance of vanilla multi-headed causal self-attention and achieves comparable efficiency compared to multi-query attention.
More Data = Better Model
All LLMs2 follow a (relatively) standard and simple pre-training process, based upon an unlabeled textual corpus and the next token prediction objective. Given that the pre-training methodology for LLMs is standardized, model performance is largely correlated with the quality and amount of data used for pre-training. For pre-trained base models, using more and better data for pre-training the LLM will generally improve the resulting model’s performance!
“The capabilities of LLMs are remarkable considering the seemingly straightforward nature of the training methodology.” - from [1]
The LLaMA approach. Both LLaMA and LLaMA-2 use solely public sources of data for pre-training. Such a choice is made deliberately to ensure that the pre-training process can be openly replicated by anyone with sufficient compute resources. Compared to LLaMA, however, LLaMA-2 adopts a new mixture of pre-training data (i.e., sources that are known to be high-quality and factual are sampled more heavily) and increases the size of the pre-training dataset by 40%. Such a change allows the model to learn from more data during pre-training and, as a result, improves the knowledge base possessed by LLAMA-2.
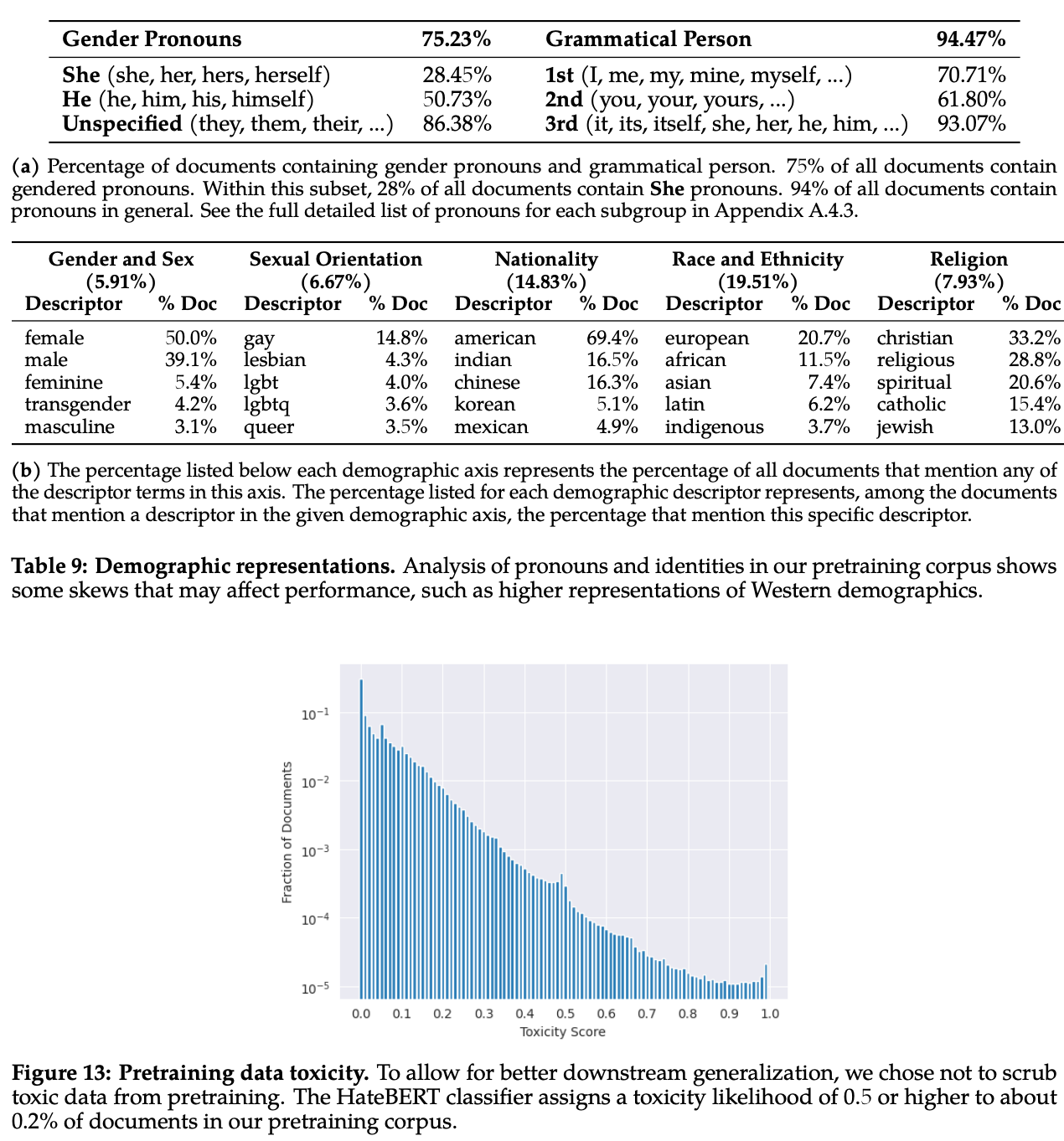
Pre-training on the right data. As we will see, LLaMA-2 places an emphasis on key properties like helpfulness and safety that should be encouraged within the resulting model. Interestingly, LLaMA-2’s focus upon safety metrics and data quality begins as early as the pre-training process. Data from sources that are known to contain high levels of personal information are excluded from the pre-training set, while data coming from factual or respected sources is emphasized more heavily during pre-training. Additionally, authors measure various factors, such as representation of different demographic groups and levels of toxicity, to minimize the amount of bias within LLaMA-2; see above. Put simply, great care is placed into the contents and composition of LLAMA-2’s pre-training dataset.
Fine-Tuning Process and LLaMA-2-Chat

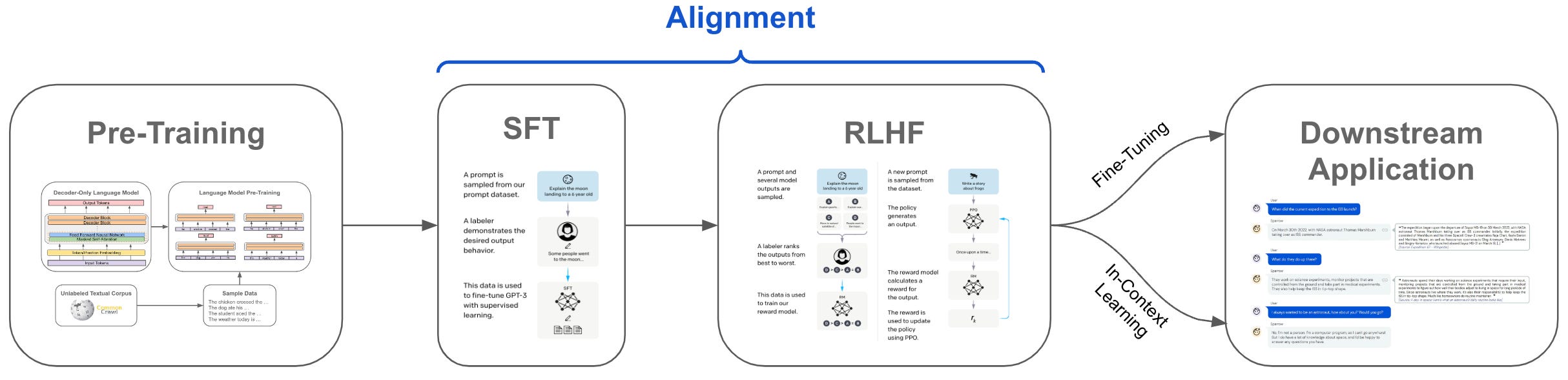
Prior to LLaMA-2, most open-source models were aligned exclusively by performing supervised fine-tuning (SFT) over publicly-available datasets. However, proprietary models (e.g., ChatGPT or GPT-4) tend to follow a more thorough approach that fine-tunes the LLM over extensive amounts of dialogue and human feedback. Attempting to close this gap, LLaMA-2 is fine-tuned using a large dataset in a similar manner to proprietary models, producing the LLaMA-2-Chat model that is optimized for dialogue-based applications; see above. For most closed-source models, the alignment process is highly proprietary, but LLaMA-2 attempts to improve transparency and make high-quality alignment more understandable for open-source research efforts.
“Closed product LLMs are heavily fine-tuned to align with human preferences, which greatly enhances their usability and safety. This step can require significant costs in compute and human annotation, and is often not transparent or easily reproducible, limiting progress within the community to advance AI alignment research.” - from [1]
What is alignment? Alignment refers to the idea of teaching an LLM to produce an output that aligns with human desires. While the pre-training process focuses upon accurately performing next token prediction, alignment fine-tunes—typically using supervised fine-tuning (SFT) and/or reinforcement learning from human feedback (RLHF)—the model to accomplish a variety of different goals; see below. Notably, LLMs gain most of their knowledge base during pre-training, while alignment serves to teach them the correct output style or format.
For example, alignment can be performed with a goal of reducing hallucinations, avoiding unsafe questions3, following detailed instructions, and more. Multiple goals can be aligned for at once. In the case of LLaMA-2, authors focus upon improving the following criteria during alignment:
Helpfulness: the model fulfills users’ requests and provides requested information.
Safety: the model avoids responses that are “unsafe”
Performing alignment in pursuit of these goals produces the LLaMA-2-Chat model that is specialized for dialogue-based use cases. Given that LLaMA-2-Chat is fine-tuned/aligned using both SFT and RLHF, we will now consider and explore each of these phases of fine-tuning individually.
Supervised Fine-Tuning (SFT)
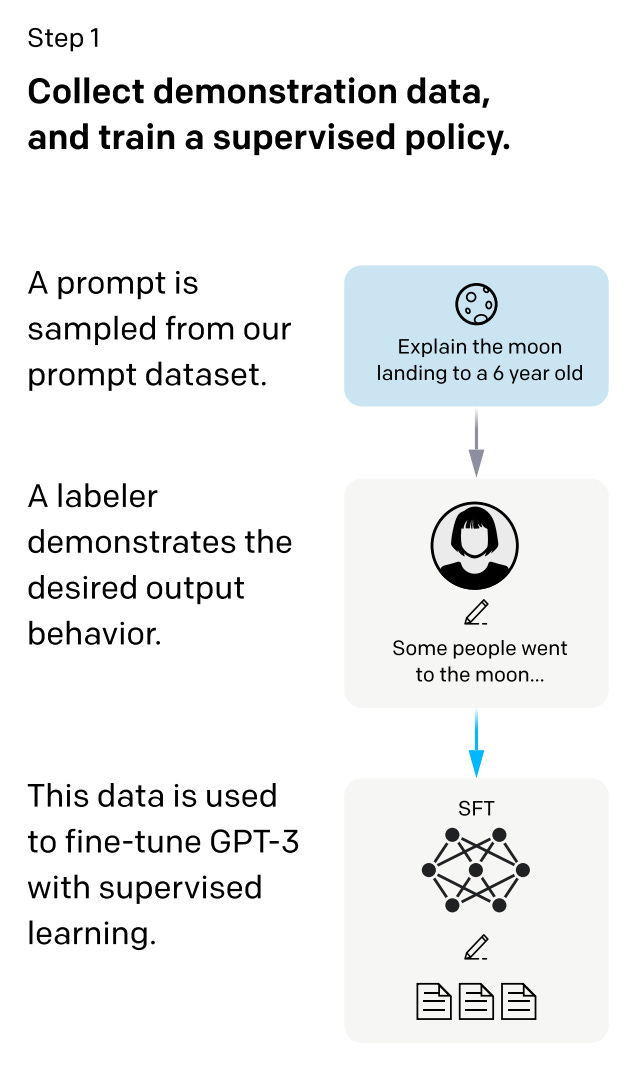
The first step in the fine-tuning process for LLaMA-2 is SFT. This technique is simple to understand, as it relies upon a (supervised) next-token prediction objective that is nearly identical to pre-training; see above. Put simply, we just collect a dataset of dialogue examples (i.e., prompt and response pairs; see below)4 and train the model using a next-token prediction objective applied to the responses within each of these examples. By fine-tuning the model in this way, the LLM learns to replicate behavior emulated within the responses of the fine-tuning dataset. Thus, any desirable properties—or alignment objectives—present within this data, in turn, become present within the model itself.

Notably, LLaMA-2-Chat performs two separate phases of SFT. The first phrase trains over a larger amount of public data, while the second phase trains over a smaller curated dataset with much higher quality. In total, roughly 100K dialogue examples are observed by LLaMA-2-Chat while performing SFT.
The data. Many datasets for dialogue-based fine-tuning are available via sites like HuggingFace. LLaMA-2 begins its alignment process by fine-tuning over a publicly available dataset for SFT. However, such public data lacks in quality and diversity, which—as revealed by LIMA [12]—is problematic. Authors in [1] collect extra data via a combination of 3rd party vendors and filtering efforts on public data. The resulting dataset, although of moderate size (i.e., 27,540 examples in total), is manually scrutinized and validated to ensure quality criteria are met.
“We found that the outputs sampled from the resulting SFT model were often competitive with SFT data handwritten by human annotators, suggesting that we could reprioritize and devote more annotation effort to preference-based annotation for RLHF.” - from [1]
The limited set of clean instructions used for the second phase of SFT in [1] are quite effective. Interestingly, authors mention that collecting more data for SFT had diminishing returns because i) the fine-tuned model is capable of generating its own data for SFT and ii) investing more annotation into RLHF yields a clear benefit. Overall, we see in [1] that an effective strategy for SFT is to curate a small dataset with higher quality standards, which aligns with findings from [12].
Reinforcement Learning from Human Feedback (RLHF)

Although SFT is quite effective, it can be difficult to curate and manage a dataset that accurately captures the goals of alignment. How do we know that the data present within our SFT dataset is consistently helpful and safe? On the other hand, RLHF (shown above) takes the more direct approach of fine-tuning the LLM directly from human feedback on the model’s output. First, human annotators are asked to write prompts for the LLMs, which can be selected based on the alignment criteria (e.g., helpfulness and safety). From here, the LLM is used to generate multiple (i.e., at least two) responses for each prompt, and the human annotators rank these responses based on their quality. Here, “quality” is typically judged according to how well the response matches the alignment criteria. Then, RLHF can be used to optimize the LLM based on these human preference scores.
The data. LLAMA-2 follows a binary protocol for collecting human preference data. For each prompt written by an annotator, two model responses are generated, and the annotator chooses the desired response based on helpfulness and safety criteria. Notably, each instance of human preference collection focuses upon a single alignment criteria5. For example, an annotator could write an adversarial prompt that tries to get the LLM to generate something unsafe, then rate the responses specifically based upon whether safety criteria are satisfied. Similarly, one could prompt the LLM with a detailed instruction and evaluate whether either of the model’s responses are more helpful.

Going a bit further, annotators are also asked to label the degree to which one response is better than the other (i.e., significantly better, better, slightly better, or negligibly better), as well as explicitly label whether either of the LLM’s responses are considered unsafe. We see in [1] that new batches of human preference data are collected each week, allowing multiple phases of RLHF to be performed iteratively. Statistics of the full human preference dataset that is collected compared to public human preference datasets are provided in the table above.
“Human feedback is … used to train a reward model, which learns patterns in the preferences of the human annotators and can then automate preference decisions.” - from [1]
Data for RLHF is collected in several batches. A new batch of data is collected each week, and authors of [1] iteratively fine-tune the LLaMA-2-Chat model (using RLHF) as each of these batches become available. As such, multiple successive “rounds” of RLHF are performed throughout the alignment process.
Safety-based data collection. To collect fine-tuning data for improved safety during RLHF, authors in [1] design instructions using two techniques:
Risk Categories: a topic about which the LLM could potentially product unsafe content.
Attack Vectors: question styles that cover a broad variety of prompts that could elicit negative behavior.
Three different risk categories are considered, including illicit and criminal activities, hateful and harmful activities, and unqualified advice. Additionally, several different attack vectors are defined, such as psychological manipulation (authority manipulation), logic manipulation (false premises), syntactic manipulation (misspelling), semantic manipulation (metaphor), and perspective manipulation (role playing). Using combinations of these different techniques, human annotators craft prompts that are more likely to elicit unsafe behavior, allowing such behavior to be discouraged during the fine-tuning process.
Training the reward model. After collecting human feedback, a reward model is trained on this data. The reward model takes a prompt—with the full chat history—and response as input and predicts a preference score. The reward model usually shares the same architecture and weights as the LLM, but its classification head (for next token prediction) is replaced with a regression head (for preference estimation) and the model is fine-tuned on preference data; see below.

The reward model automates obtaining an accurate preference score for prompt-response pairs, which allows the LLM to be fine-tuned using reinforcement learning (RL) to maximize (automatically generated) human preference scores across a large dataset. To train the reward model, we take binary preference data and form a training objective that forces the preferred example to have a higher score than its counterpart6! An example of such an objective is shown below.

However, we should recall that the preference data collected in [1] is not just binary. We have more granular information that identifies responses that are significantly or moderately better than others. To capture this more detailed information, we can simply add a margin—or a fixed value assigned to each of the significantly better, better, slightly better, or negligibly better categories—to the loss shown above. Such a margin pushes the reward model to assign larger gaps in score between responses with big differences in preference; see below.

Interestingly, we see in [1] that authors combine their custom-curated human preference data with other public sources of data when training reward models. To explain this decision, authors claim that injecting such extra sources of data does not seem to have a negative impact on reward model performance. Plus, this data aids the reward models’ generalization and can protect against issues like reward hacking, in which RLHF takes advantage of weaknesses in the reward function to arbitrarily inflate preference scores without improving the model.
“We do not observe negative transfer from the open-source preference datasets. Thus, we have decided to keep them in our data mixture, as they could enable better generalization for the reward model and prevent reward hacking, i.e. Llama 2-Chat taking advantage of some weaknesses of our reward, and so artificially inflating the score despite performing less well.” - from [1]
Alignment is oftentimes a tradeoff! Interestingly, we see in [1] that separate reward models are trained for each of the alignment criteria. More specifically, we have a helpfulness reward model and a separately safety reward model. This might seem unnecessary at first, but we should realize that properties such as helpfulness and safety—or any alignment criteria in general—are oftentimes a tradeoff. Making an LLM more safe might make it less helpful; e.g., the model could refuse to answer a question that is unsafe, which is (arguably) not helpful. Given this tradeoff, authors in [2] observe that predicting helpfulness and safety preference scores with separate reward models is the best way to accurately model the nuances in human preference according to different alignment criteria.
“In order for a single model to perform well on both dimensions, it needs to not only learn to select the better response given a prompt but also to distinguish adversarial prompts from safe ones. As a result, optimizing two separate models eases the reward modeling task.” - from [1]
Optimization via RL. Even after multiple rounds of SFT are performed, five successive versions of RLHF models are created in [1]—one for each batch of human preference data. Although the PPO algorithm has typically been a standard for performing RLHF, we see in [1] that two separate algorithms are considered:
PPO: standard algorithm used for RLHF.
Rejection Sampling: samples
Kresponses from the LLM for each prompt, scores each response using the reward model, selects the best response, and fine-tunes on this example.
While PPO only takes one sample from the model per iteration, rejection sampling takes numerous samples. Within rejection sampling, the highest-reward sample that is generated is considered the new “gold standard”. As shown in the figure below, generating multiple samples in this manner can drastically increase the maximum reward of samples observed during fine-tuning.

In [1], rejection sampling is performed with the largest model (i.e., LLaMA-70B-Chat) and used to train all other (smaller) models7. While PPO performs iterative updates after each sample, rejection sampling fine-tuning uses the same model (i.e., at the beginning of the RLHF round) to generate an entire dataset of high-reward samples that are used for fine-tuning in a similar manner to SFT.
“We illustrate the benefit of Rejection Sampling in Figure 7. The delta between the maximum and median curves can be interpreted as the potential gain of fine-tuning on the best output.” - from [1]
To ensure the best possible performance, authors include best samples from all RLHF iterations—not just the current iteration—when performing rejection sampling fine-tuning. Without including samples from prior iterations, we see that regressions in performance may occur when using rejection sampling fine-tuning. In [1], a rejection sampling approach is adopted for the first four rounds of RLHF, then the final round combines both rejection sampling fine-tuning and PPO sequentially (i.e., PPO is applied after rejection sampling fine-tuning).
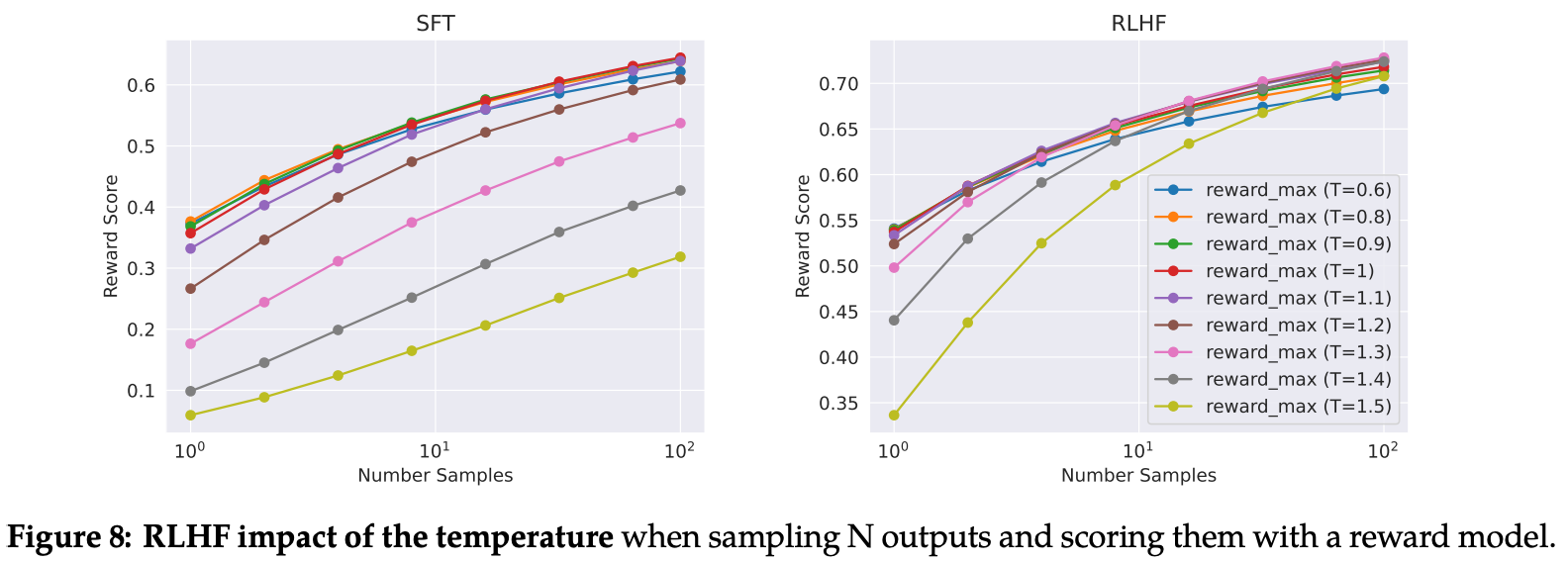
Tweaking the temperature. Interestingly, we also observe in [1] that the optimal temperature to use when generating samples for RLHF changes with iterative updates to the model; see above. As such, the temperature must be readjusted after each round of RLHF to achieve the best results. Furthermore, authors in [1] mention that the optimal temperature seems to be dependent upon context. For example, different shifts in the optimal temperature are observed for certain types of prompts, such as creative prompts or those that are considered more factual.
Improving Multi-Turn Dialogue with Ghost Attention
In many cases, dialogue agents, such as LLaMA-2-Chat, conduct conversations with users over multiple turns. Sometimes, a system message or instruction is provided to the model at the beginning of this back-and-forth conversation that should be obeyed throughout. However, we see in [1] that the LLM may quickly forget about this instruction, leading it to only apply to initial turns; see below.

To solve this issue, authors in [1] explore a fine-tuning approach with synthetic data, called Ghost Attention (GAtt). Given a dialogue session, GAtt i) samples an instruction that should be followed in a conversation, ii) concatenates this instruction to every user message within the conversation, and iii) samples responses to each message using the model from the latest round of RLHF. After removing the concatenated instruction from all but the first user message, such an approach can generate synthetic multi-turn dialogue data that consistently abides by an instruction. Then, we can just fine-tune over this data using SFT, which—as shown above—improves instruction following over long dialogues!
Evaluations and Key Findings
LLaMA-2 and LLaMA-2-Chat are evaluated extensively in comparison to both other open-source LLMs and proprietary models. The base and fine-tuned models set a new state-of-the-art among open-source LLMs. As we will see, these models also have a variety of different emergent capabilities8 and interesting properties that are analyzed extensively within [1] to provide useful insights.
LLaMA-2 (Base Model) Performance

Compared to popular open-source base LLMs (e.g., MPT, Falcon, and LLaMA-1), LLaMA-2 models set a new state-of-the-art on all tasks considered; see above. Notably, however, LLaMA-2 was somewhat criticized for its (relatively) poor performance on coding-based tasks (e.g., HumanEval). Some have speculated that this may be due to a lack of sufficient code within LLaMA-2’s pre-training corpus, though the exact explanation is not completely clear as of now.

When compared to proprietary models, LLaMA-2 base models perform worse; see above. However, we should keep in mind that this comparison is made between a base LLM and aligned models like GPT-3.5 and GPT-4. When compared to proprietary base LLMs (e.g., PaLM [4]), LLaMA-2 performs favorably!
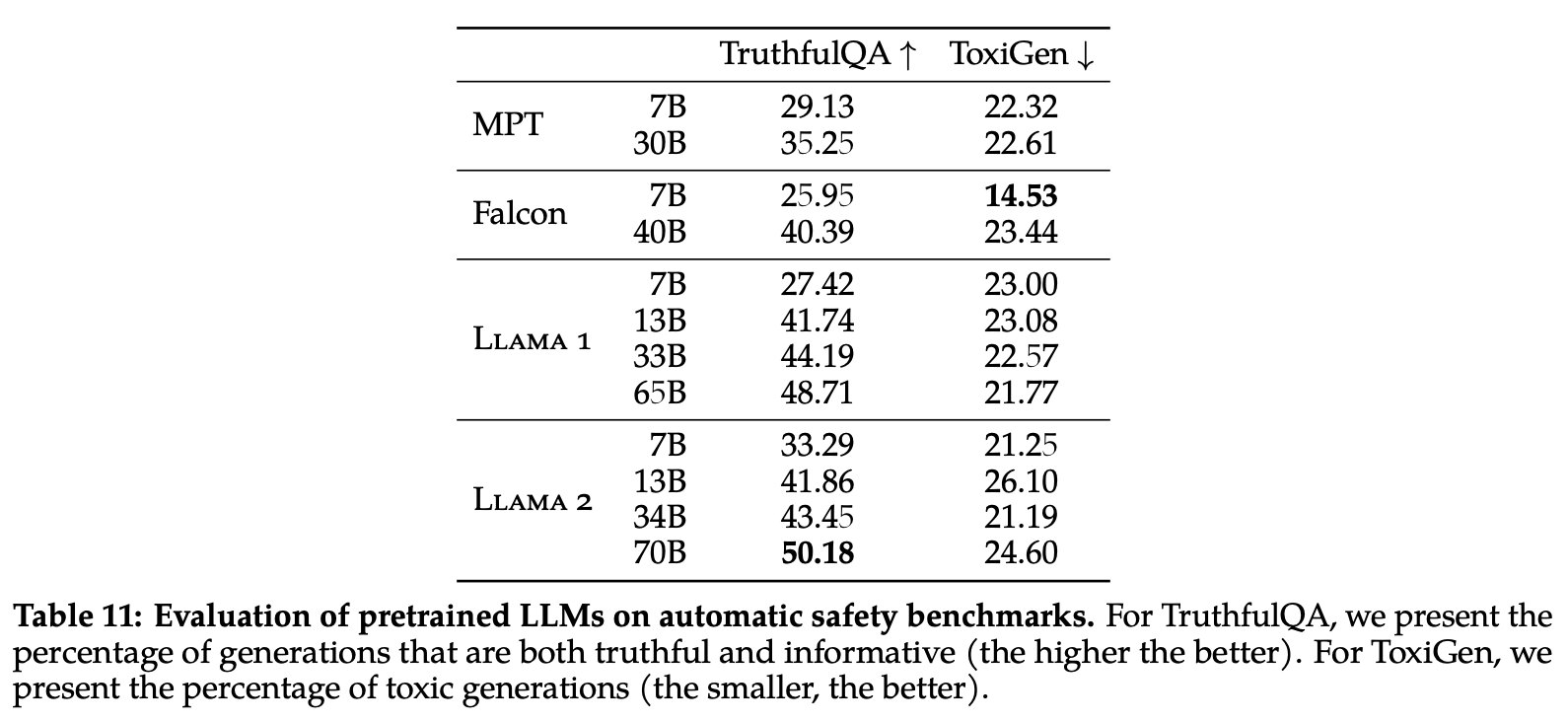
Safety results. As we have mentioned previously, the authors of LLaMA-2 place an emphasis upon safety when crafting the model’s pre-training dataset, leading them to measure and even exclude data according to a variety of different factors. Despite these efforts to minimize bias in the pre-training dataset, results on automatic safety benchmarks are mixed as shown above. While LLaMA-2-7B is less toxic and more truthful and informative compared to prior models, larger models (e.g., LLaMA-2-34B and LLaMA-2-70B) seem to have an increase in toxicity, which the authors claim may come from their use of a larger pre-training and lack of aggressive filtering of toxic information from this dataset.
Fine-Tuning Analysis for LLaMA-2-Chat
“Evaluating LLMs is a challenging open-research problem. Human evaluation, while a gold standard, can be complicated by various HCI considerations, and is not always scalable.” - from [1]
LLaMA-2-Chat is evaluated according to its levels of helpfulness and safety using a variety of different techniques. First, evaluation of model quality is automated by using reward model output as a proxy for performance. The results of these evaluations—and alternative evaluations that use GPT-4 as a judge—are shown below, where we see that LLaMA-2-Chat slowly becomes more helpful and safe throughout each round of the fine-tuning process with both SFT and RLHF.

Although such automated metrics are informative, they can be biased or incorrect. As such, LLaMA-2-Chat is subjected to extensive human evaluations. In the figure below, we see that humans find LLaMA-2-Chat to be more helpful than a variety of powerful open-source and proprietary language models. Similarly, LLaMA-2-Chat exceeds the same models in human safety evaluations. As such, the LLaMA-2-Chat model is generally found to be more helpful and safe than a variety of other powerful LLMs based on extensive human evaluation.

Despite these results, we should recall that human evaluations can be limited and are only conducted over a (relatively) small set of prompts9. In general, human evaluation can be subjective and noise is present in the evaluation process, which we should keep in mind when studying and interpreting these results.

Reward model scaling. To assess the quality of helpfulness and safety reward models created in [1], authors compare and evaluate these models against a variety of other reward models; see above. As expected, the reward models used to fine-tune LLaMA-2-Chat seem to perform the best. Additionally, we see that larger reward models perform better when trained over the same amount of data and that the performance of reward models has yet to reach a plateau; see below.

Why does this matter? As authors note in [1], the performance of the reward model, given that it is used to automate preference feedback during RLHF, is directly related to the performance of the fine-tuned chat model. In other words, an improvement in the quality of the reward model tends to produce a relative improvement in the quality of the fine-tuned LLM. The results above seem to indicate that using larger reward models trained over more data is helpful.
Other findings. In addition to the helpfulness and safety analysis performed in [1], a variety of interesting observations are made about the behavior of LLaMA-2-Chat. Most LLMs struggle with temporal reasoning (i.e., reasoning about when in time certain events occurred), but LLaMA-2 is fine-tuned to better process temporal information by performing SFT over time-focused prompt-response examples. As such, the model is surprisingly capable of organizing knowledge in a temporal manner; see above. Going further, LLaMA-2-Chat is not specifically trained to leverage tools, but the model seems to be able to generalize to tool usage in a zero-shot manner as shown in the figure below.

Closing Thoughts
The LLaMA-2 (and LLaMA-2-Chat) suite of LLMs mark the beginning of a new era for open-source LLMs, as their performance is now closer than ever to that of top proprietary models like ChatGPT and GPT-4. When we examine the key insights from [1] that make these models so impressive, we will notice that simple changes can have a big impact on model performance. However, a variety of in-depth technical insights are provided by LLaMA-2 as well. Some of the major takeaways from LLaMA-2 are itemized and elaborated below.
Garbage in = garbage out. As we have discussed previously, the amount and quality of data used to train an LLM—both during pre-training and fine-tuning—is incredibly important. We see in [1] that part of what makes LLaMA-2 so great is an emphasis upon data. During pre-training, the model observes 40% more data than its predecessor and adopts a modified mixture that emphasizes factual sources. Additionally, LLaMA-2 adopts an approach similar to LIMA during fine-tuning by curating a smaller, high-quality corpus of dialogues for SFT.
Alignment is important. One of the largest differences between LLaMA-2 and prior work on open-source LLMs is the emphasis upon high-quality alignment. Rather than simply performing SFT with public data, authors in [1] truly try to replicate the complex alignment process that is used for proprietary models by performing multiple rounds of both SFT and RLHF. Although the resulting LLaMA-2-Chat model isn’t the current leader on the Open LLM Leaderboard10, such an emphasis upon extensive alignment provides invaluable technical insight that drastically improves the transparency of research in this area.

RLHF is powerful. Interestingly, authors in [1] mentioned an aversion to using reinforcement learning-based alignment approaches at the outset of this project. However, we see in [1] that reinforcement learning is incredibly effective! RLHF seems to be a natural approach for alignment, as it fosters a synergy between human and LLM via iterative feedback and fine-tuning. Although SFT is useful, human writing quality has high variance, and the model must learn (at least in part) from the tail end of this variance (i.e., bad examples) when using SFT. In contrast, the annotation process for RLHF only requires humans to select the better response, which is less noisy and allows poor responses to be eliminated over time; see above. Additionally, we can observe during RLHF responses that even go beyond human writing comprehension. Despite not being able to write such responses, humans can easily rate them as preferable.
“Many among us expressed a preference for supervised annotation, attracted by its denser signal… However, reinforcement learning proved highly effective, particularly given its cost and time effectiveness. Our findings underscore that the crucial determinant of RLHF’s success lies in the synergy it fosters between humans and LLMs throughout the annotation process.” - from [1]
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews that explain relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on twitter or LinkedIn!
Bibliography
[1] Touvron, Hugo, et al. "Llama 2: Open Foundation and Fine-Tuned Chat Models." arXiv preprint arXiv:2307.09288 (2023).
[2] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[3] “Introducing Llama2: The next generation of our open source large language model”, Meta, https://ai.meta.com/llama/.
[4] Zhang, Biao, and Rico Sennrich. "Root mean square layer normalization." Advances in Neural Information Processing Systems 32 (2019).
[5] Shazeer, Noam. "Glu variants improve transformer." arXiv preprint arXiv:2002.05202 (2020).
[6] Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." arXiv preprint arXiv:2104.09864 (2021).
[7] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[8] “Introducing Falcon LLM”, Technology Innovation Institute, 7 June 2023, https://falconllm.tii.ae/.
[9] Ainslie, Joshua, et al. "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints." arXiv preprint arXiv:2305.13245 (2023).
[10] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[11] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[12] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
“Generalization” is a term in deep/machine learning that refers to a model’s ability to generalize beyond training data and also perform well on data it has not seen during training, either in the wild or as part of a hold-out test set.
Many people have disagreements over the definition of an LLM. Here, I am referring to causal language models (i.e., trained with a language modeling objective) that are based upon a decoder-only transformer architecture.
Notably, many researchers/practitioners have heavily criticized popular LLMs—especially recently—for their refusal to answer questions that are “unsafe”. In some cases, alignment efforts can even be perceived by some as reducing the quality of the underlying LLM for this exact reason.
LLaMA-2 uses dialogue examples for fine-tuning because it is explicitly optimized for dialogue or chat-based conversations during alignment.
Maximizing the quality of human annotation is largely related to minimizing cognitive load. So, focusing upon a single alignment criteria at a time likely leads to higher quality, detailed annotations that more accurately reflect alignment criteria.
This style of loss function is called a “ranking” loss. We don’t directly optimize the model to output a certain score for any input. Rather, we just have pairs of inputs where we know that one input should have a higher score within this pair. So, we train the model to push these scores apart, where the preferred input has a higher score.
Interestingly, this is a form of knowledge distillation, as the best samples from the larger model are used to fine-tune all smaller LLaMa-2-Chat models via a fine-tuning approach that is similar to SFT.
An emergent capability simply refers to a capability or skill possessed by a model that is not explicitly encouraged during training. For example, the ability of pre-trained LLMs to perform in-context learning can be considered “emergent” given that we never directly train the model to develop this skill via next-token prediction.
Most evaluations are performed over a set of ~4,000 prompts, which is quite large by academic research standards.
We should keep in mind here that whether one LLM is better than another is subjective and highly dependent upon how we define “better”. LLaMA-2-Chat is specifically aligned based on helpfulness and safety, and the model seems to excel in these categories as shown by extensive evaluation in [1].
wow, that's a really deep and comprehensive explanation. Thanks a lot!
What a great article. Saved me tens of hours of going through multiple sources. Thank you Dr. Cameron!