
Falcon: The Pinnacle of Open-Source LLMs
The gap between open-source and proprietary LLMs continues to shrink...


This newsletter is presented by Lightly. By using self-supervised and active learning, Lightly can make data annotation pipelines more efficient and quickly identify the best subsets of data for training your model. Check them out here or start using their GitHub repo that already has over 2000 stars.
Sponsor the newsletter | Follow me on Twitter | Get in touch | Suggest a topic

Recent research in open-source large language models (LLMs) has mostly focused upon two areas: imitation learning and pre-training open-source base models1. Though both approaches are viable, the creation of high-quality, open-source base models is especially enticing, as these models can be further fine-tuned (at a lower cost) and used in a variety of different downstream applications. Initial attempts at creating these models failed. Although later models (e.g., LLaMA and MPT-7B) perform much better, these models have struggled to match the quality of their proprietary counterparts (e.g., GPT-3.5 or GPT-4) until recently.
With the release of the Falcon-7B and Falcon-40B LLMs [1], we see—for the first time—open-source base LLMs that begin to rival the quality of the most popular paid models. Trained over a massive textual corpus2 obtained via a novel data pipeline, these models achieve (by a decent margin) new state-of-the-art performance among open-source LLMs and are free to use in commercial applications. To make things better, the Falcon models adopt several modifications to their underlying transformer architecture that significantly accelerate inference and can even improve the efficiency of pre-training.
the big picture. The process of creating an LLM is comprised of several steps; see below. The first step of this process (i.e., obtaining a pre-trained base model) is widely known to be the most expensive, both in terms of money and time.

Such models were previously kept behind proprietary APIs, but advancements in open-source LLMs have made high-performing base LLMs more publicly available. Falcon is another model in this category, and it achieves unprecedented levels of performance in comparison to other open-source alternatives.
Using Web Data for LLM Pre-Training

When we look at the major differences between pre-training and fine-tuning (i.e., SFT and RLHF) a language model, we will notice that pre-training is much harder (and more expensive) compared to fine-tuning; see above. There are two fundamental properties of pre-training that make it so difficult:
The model is being trained from scratch, so it requires a greater number of training iterations.
The pre-training dataset must be large and diverse (i.e., provide as much “coverage” as possible) so the resulting LLM has a sizable knowledge base.
Put simply, pre-training datasets are massive (e.g., Chinchilla [6] was trained on 1.4 trillion textual tokens), which means that the extent of pre-training is unavoidably large. We must run many training iterations to traverse all of this data!
creating a pre-training dataset. However, it’s not just the size of the dataset that makes pre-training such a massive undertaking. Just curating the dataset is an intricate process that involves both retrieving the data and executing an entire pipeline of filtering (e.g., based on data quality, contaminated data, PII, and more) and de-duplication steps. A variety of different processing steps have been proposed and explored for curating LLM pre-training data; see below.
Although one might initially think that such processing steps could be simplified or avoided, research on LLMs has showed us time and time again that the quality of data on which these models are trained is incredibly important. For evidence of this, we can see, for example, LIMA [7] or Galactica [8], both of which are trained over smaller (but higher-quality) text corpora and found to match or exceed the performance of identical models trained over noisier datasets at a larger scale.
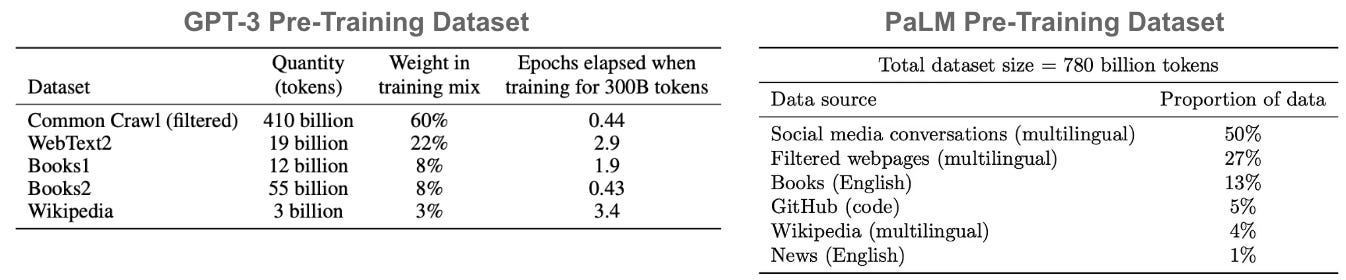
current LLMs. Due to the impact of data quality on model quality, pre-training data used for most LLMs are obtained from highly curated sources, such as filtered textual content, books, code, or technical reports; see above [4, 5]. In fact, numerous public sources of curated pre-training data are readily available online (e.g., the Pile or C4) and have already been used extensively by existing models.
“Curation is believed to be necessary to produce performant models ... However, as models requiring pretraining on trillions of tokens are considered, it is unclear whether curation is scalable and if we will run out of unique high-quality data soon.” - from [2]
However, it is questionable whether the use of curated data sources is actually scalable—fine-grained filtering and curation becomes more difficult with the scale of the pre-training dataset. As such, extensive curation may need to become less necessary for larger models and datasets, especially given that locating sufficient amounts of data for LLM pre-training is becoming increasingly difficult.
RefinedWeb: Scalable Curation of Text from the Web

Given these limitations, the authors of Falcon [1] explore scalable and efficient methods of data curation that generalize to massive amounts of data. The full data curation pipeline, which is used to create the RefinedWeb pre-training dataset over which Falcon-7B [10] and Falcon-40B [11] are pre-trained, is detailed in [2]. RefinedWeb is comprised of web-based data that undergoes a simplified filtering pipeline and can be used to train models that outperform similar models trained over curated sources of data; see above. Such a finding indicates that large-scale training corpora can be efficiently created from data obtained exclusively from the internet (as opposed to curated sources).
“Challenging existing beliefs on data quality and LLMs, models trained on adequately filtered and deduplicated web data alone can match the performance of models trained on curated data.” - from [2]
simplified curation pipeline. The pre-training dataset used for Falcon is based upon Common Crawl. Compared to prior work, authors in [2] differentiate their data curation pipeline by placing an emphasis upon scale, aiming to produce a pre-training corpus with 3-6 trillion tokens of data from the web. This is much larger than datasets explored in prior work—even MassiveText (i.e., the corpus used to pre-train Gopher [9] and Chinchilla [6]) contains only 2.3 trillion tokens of text in total. Plus, existing models only use a subset of this data during pre-training.

The corpus constructed in [2] contains roughly 5 trillion tokens of English-only data, obtained exclusively from the web; see above. Despite the scale of this data, authors adopt a stringent deduplication policy during the construction process, which removes both exact and fuzzy duplicates at a high rate. Minimal extra filtering is done on top of such deduplication. In fact, no machine learning-based filtering is performed aside from language identification with a FastText classifier.

In addition to filtering out non-English documents, authors in [2] use several simple heuristics to filter out unwanted content, such as:
Filtering content from URLs associated with a blocklist
Using trafilatura to extract content from web pages
Defining simple rules to identify and filter PII
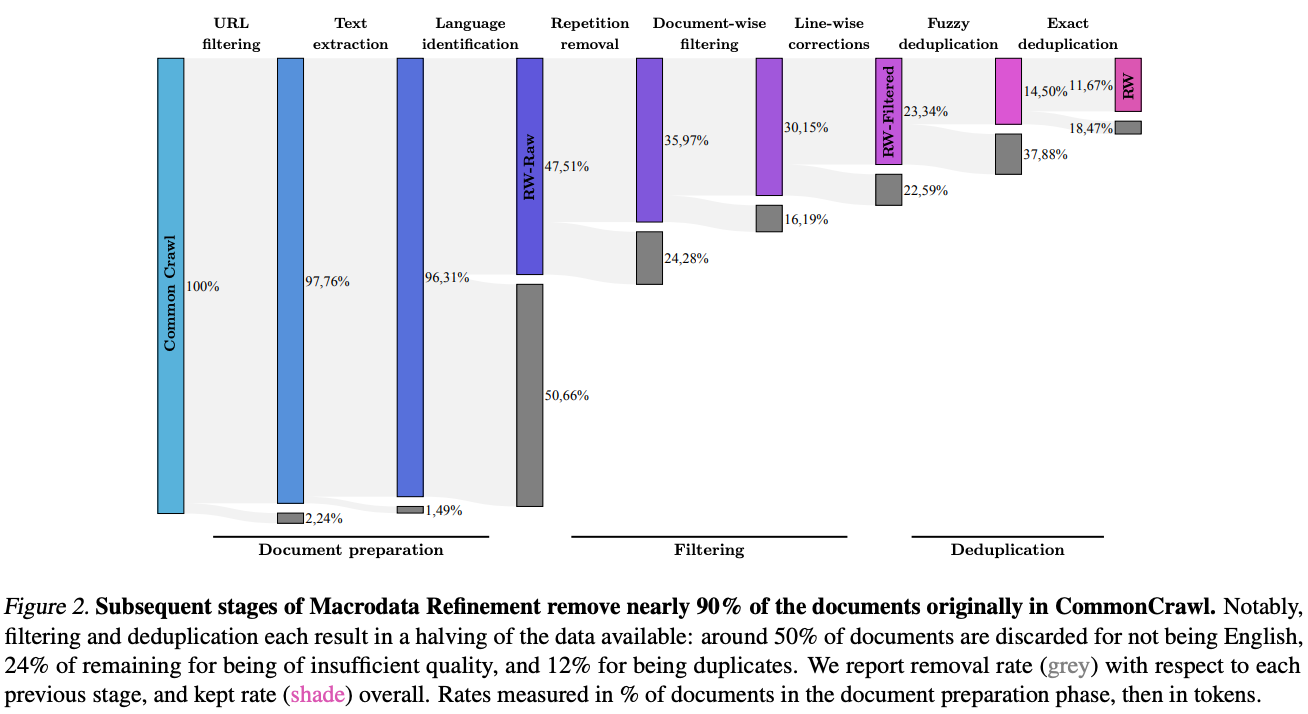
Additionally, several steps from the filtering pipeline of MassiveText [9] are adopted; see above. RefinedWeb’s full curation pipeline removes nearly 90% of the data that was originally obtained from CommonCrawl, but over 5 trillion tokens of textual data are still present in the fully-filtered corpus; see below. Plus, this dataset is “multimodal friendly”, as it contains links to images and alt text.
open-source pre-training data. The resulting RefinedWeb dataset is quite large, indicating that sufficient data is available on the internet to conduct LLM pre-training at an unprecedented scale. In other words, we aren’t quite running out of data (at least yet). However, authors in [2] only open-source a small, 600B token subset of this corpus (i.e., 12% of the data). Despite its size, this public subset of RefinedWeb is a useful source of pre-training data for any practitioner working on LLMs. In fact, smaller variants of Falcon trained on this data in [2] are found to perform favorably compared to models trained on curated corpora; see below.

The Falcon Suite of LLMs

The Falcon suite of LLMs [1], including Falcon-7B [10] and Falcon-40B [11], achieves state-of-the-art performance among open-source models. Furthermore, instruction tuned variants of these models, such as Falcon-40B-Instruct (i.e., the top model on HuggingFace’s Open LLM leaderboard), perform even better on public benchmarks. As we will see, these models have several key traits (e.g., data, performance, and inference speed) that make them unique and practically useful.
commercial license. Originally, the Falcon models were released under a peculiar license that required royalty payments when the models (or any derivatives of them) were used in commercial applications. Shortly after this initial release, however, the license was modified to a normal Apache 2.0 license, which means that the Falcon base models are now free to use in commercial applications! Compared to other open-source and commercially-usable LLMs (even MPT-30B), Falcon-40B achieves uniquely impressive performance.
Falcon-7B and 40B Datasets

As mentioned previously, the dataset created in [2] is used to pre-train the open-source Falcon-7B/40B models. However, these models only pre-train over a subset of the full 5 trillion token corpus (i.e., 1.5 trillion tokens for Falcon-7B and 1 trillion tokens for Falcon-40B). However, this subset of the corpus is augmented with extra, curated data, such as books, code, and technical content3; see above. Due to its larger size, Falcon-40B is trained over less data than Falcon-7B. Nonetheless, the larger model still performs much better and takes over two months to train, as opposed to only two weeks for Falcon-7B.
multi-lingual LLMs. The RefinedWeb corpus is English-only and Falcon-7B is trained using only English text. Falcon-40B, however, has the RefinedWeb-Europe corpus added to its pre-training set, which contains textual data from a variety of common European languages. Although this data only accounts for 7% of the pre-training corpus, it injects a small amount of multilingual data into the model’s knowledge base, enabling higher levels of performance on public benchmarks that require basic multilingual understanding.
Falcon Architecture
Both Falcon-7B and Falcon-40B models use a modified decoder-only transformer architecture. Modifications made to this architecture include:
Flash Attention [link]
RoPE embeddings
Multi-Query Attention
Parallel Attention and Feed-Forward Layers
These modifications (some of which are shared with the MPT suite of LLMs) drastically improve Falcon’s inference speed. In fact, Falcon-40B is 5X faster than GPT-3 at inference time. Plus, pre-training Falcon-40B is less costly due to these modifications; e.g., Falcon-40B requires 75% of GPT-3’s [4] compute budget, 40% of Chinchilla’s [6] compute budget, and 80% of PaLM-62B’s [5] compute budget. Both Falcon-7B and Falcon-40B are trained with a sequence length of 2K tokens, which is arguably small compared to recent LLMs (e.g., StoryWriter and Claude).

Falcon-7B/40B share the same model architecture, but the 40B variant is slightly deeper (i.e., 60 layers vs. 32 layers) and has higher-dimensional hidden layers; see above. Using Falcon-40B requires ~90Gb of memory, which is less overhead than comparable models like LLaMA-65B. However, Falcon-40B still cannot be hosted on a single GPU like MPT-30B4. Given its smaller size, Falcon-7B only requires ~15Gb of memory, making it more accessible for both inference and fine-tuning.
RoPE embeddings. As we have seen in prior overviews, the self-attention operation, which is implemented in every layer of a language model’s decoder-only transformer architecture, does not naturally consider the position of each token within a sequence. As such, we must inject position information (e.g., via an additive positional embedding) into this operation for each token; see below.
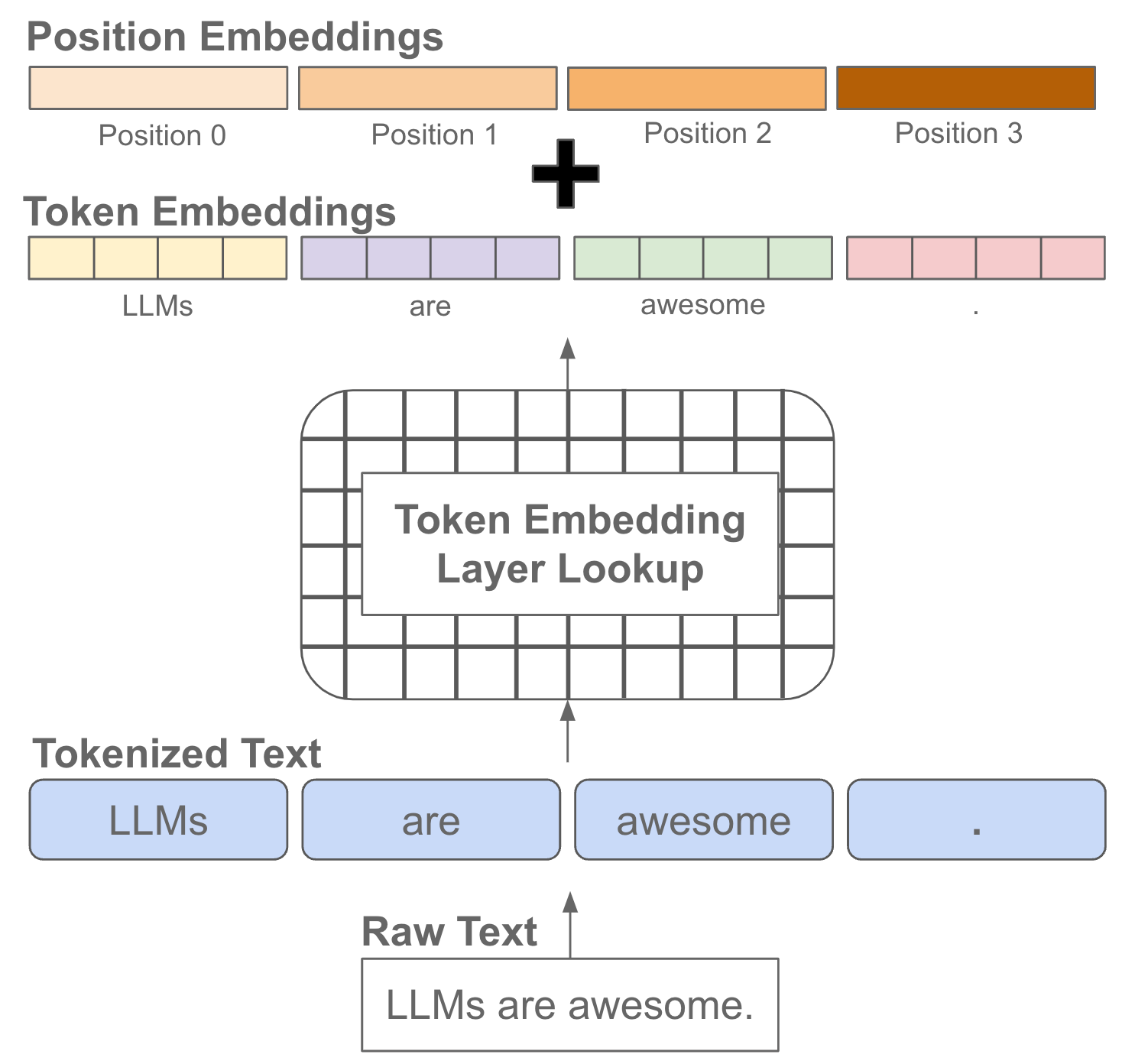
Several position embedding variants—which may or may not learn each embedding during training—have been proposed, including absolute and relative embeddings. Rotary positional embeddings (RoPE) [15], however, are an alternative that incorporates both the absolute (i.e., global position of a token in the sequence) and relative (i.e., defines position based on distances between tokens) position of each token into self-attention by:
Encoding absolute position with a rotation matrix
Adding relative position information directly into the self-attention operation
Such an approach is found to yield a balance between absolute and relative position information, which benefits performance especially on tasks that require longer sequence lengths. As such, RoPE embeddings have recently gained in popularity, leading to their use in models like PaLM [5]. For a more detailed overview, check out the outline of RoPE embeddings below.
multi-query attention. Falcon models replace the typical, multi-headed self-attention operation with an alternative structure called multi-query attention. Multi-query attention just shares key and value vectors (highlighted in red below) between each of a layer’s attention heads. Instead of performing a separate projection for each head, all heads share the same projection matrix for keys and the same projection layer for values. Although this change does not make training any faster, it significantly improves the inference speed of the resulting LLM.

parallel attention layers. Finally, the Falcon models make one fundamental change to the structure of each layer in their architecture. In contrast to the “serial” formulation of the decoder-only transformer layer, each layer of the Falcon models performs self-attention and a feed-forward transformation in parallel, then follows these operations with a single layer norm operation. The difference between this formulation and a standard transformer block is depicted below. Interestingly, this parallel formulation does not deteriorate the model’s performance. However, it can yield benefits in inference speed due to the fact that both major operations of a transformer layer happen in parallel.

A New Standard for Open-Source LLMs!
At the time of writing, no manuscript has yet been published about the Falcon models. However, Falcon-7B and Falcon-40B (along with their instruction tuned variants) have been evaluated via the Open LLM Leaderboard, which includes several benchmarks such as:
Evaluations conducted via this leaderboard are incomplete and preliminary. However, these evaluations, which do capture model performance to a reasonable extent, clearly show that Falcon-40B is the current state-of-the-art for open-source language models; see below.

The instruct variant of Falcon-40B (i.e., Falcon-40B-Instruct), which has been instruction tuned on a mixture of data from Baize, far outperforms a variety of other open-sourced models. Additionally, the pre-trained Falcon-40B model performs quite well, even better than notable base models like LLaMA-65B and MPT-30B. Going further, Falcon-40B is also commercially-usable, whereas many comparable models on the leaderboard (e.g., LLaMA [13], Guanaco [14], and Lazarus) are only available for research purposes.
practical usage of Falcon. Given that they perform incredibly well, are lightweight to host compared to other LLMs (due to improved inference speed), and can be used freely in commercial applications, the Falcon LLMs are an impactful open-source tool for any practitioner working on LLMs. Luckily, several detailed overviews have been written that outline useful frameworks for both fine-tuning and hosting/deploying these models in practice.
Deploy Falcon-40B on AWS Sagemaker [link]
Inference and Parameter-Efficient Fine-Tuning with Falcon [link]
Fine-Tune Falcon-40B with PyTorch Lightning [link]
Given that Falcon was trained using AWS, there are currently a decent number of explainer articles for deploying and training these models on similar hardware. These articles provide a good starting point for anyone looking to leverage Falcon in a use case of their own.
Final Thoughts
The release of Falcon was a major breakthrough for the research and application of open-source LLMs. When we examine the contributions that are unique to these models, we immediately see a few key components that lead to success:
A unique mixture of large-scale pre-training data
An architecture that is optimized for efficiency
The RefinedWeb dataset shows us that textual corpora can be created at a much larger scale than was previously explored. To do this, we just download a large amount of data from the web and adopt strict deduplication rules along with simpler, efficient filtering heuristics. Then, by combining this massive source of data with a smaller amount of curated text, we can pre-train an incredibly performant open-source LLM. Finally, the modified architecture of the Falcon models makes both training and inference more efficient, resulting in a model that both performs incredibly well and can quickly generate text when deployed.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews that explain relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] “Introducing Falcon LLM”, Technology Innovation Institute, 7 June 2023, https://falconllm.tii.ae/.
[2] Penedo, Guilherme, et al. "The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only." arXiv preprint arXiv:2306.01116 (2023).
[3] “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable Llms.” MosaicML, 5 May 2023, www.mosaicml.com/blog/mpt-7b.
[4] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[5] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[6] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[7] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
[8] Taylor, Ross, et al. "Galactica: A large language model for science." arXiv preprint arXiv:2211.09085 (2022).
[9] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[10] “Falcon-7B”, Technology Innovation Institute, HuggingFace Page, https://huggingface.co/tiiuae/falcon-7b.
[11] “Falcon-40B”, Technology Innovation Institute, HuggingFace Page, https://huggingface.co/tiiuae/falcon-40b.
[12] Gao, Leo, et al. "The pile: An 800gb dataset of diverse text for language modeling." arXiv preprint arXiv:2101.00027 (2020).
[13] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[14] Dettmers, Tim, et al. "Qlora: Efficient finetuning of quantized llms." arXiv preprint arXiv:2305.14314 (2023).
[15] Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." arXiv preprint arXiv:2104.09864 (2021).
[16] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[17] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
Here, the term “base model” is used to refer to an LLM that has been extensively pre-trained but has not yet undergone any refinement or fine-tuning.
The corpus has 5 trillion tokens in total, but not all of this data is actually used during the pre-training process.
We might notice that many of these sources are similar to those used by the Pile [12]. The creators of Falcon were inspired by this dataset and adopted similar sources of curated data.
MPT-30B can be hosted on either an NVIDIA A100-80GB GPU in 16-bit precision or an NVIDIA A100-40GB GPU in 8-bit precision.