


Imitation Models and the Open-Source LLM Revolution
Are proprietary LLMs like ChatGPT and GPT-4 actually easy to replicate?


This newsletter is presented by Cerebrium. Cerebrum allows you to deploy and fine-tune ML models seamlessly, without worrying about infrastructure. Notable features include serverless GPU deployment (<1 second cold start), access to 15+ pre-trained models (e.g., FLAN-T5, GPT-Neo, Stable Diffusion and more), and support for all major ML frameworks. Try it for free today!
Sponsor the newsletter | Follow me on Twitter | Get in touch

The proposal of the LLaMA suite [2] of large language models (LLMs) led to a surge in publications on the topic of open-source LLMs. In many cases, the goal of these works was to cheaply produce smaller, opens-source LLMs (for research purposes) that have comparable quality to proprietary models like ChatGPT and GPT-4. These models adopt an imitation strategy, which fine-tunes a base LLM over synthetic dialogue data from a more powerful LLM. Despite being cheap to train, these models seemed to perform comparably to proprietary LLMs like ChatGPT. As a result, the deep learning research community quickly adopted the view that open-source LLMs will rule the future—re-producing open-source variants of proprietary models was both easy and cost-effective!
“Will the most powerful LLMs be closed-source or will they be freely distributed for anyone to use, modify, and extend?” - from [1]
Unfortunately, preliminary evaluations performed on these models, which relied upon ratings provided by other LLMs (e.g., GPT-4) or human crowd workers, were somewhat cursory. Does the performance of imitation models actually match that of models like ChatGPT? To answer this question more rigorously, we will study recent research that analyzes whether imitation models truly remove the “moat” around proprietary LLMs. Interestingly, we will see that these cheap reproductions of powerful LLMs perform well in human evaluations due to their ability to learn the style of a powerful LLM. However, they lack factuality and perform poorly when subjected to more broad and targeted evaluations. In reality, imitation models do not perform nearly as well as proprietary models like ChatGPT.
Model Imitation
“The premise of model imitation is that once a proprietary LM is made available via API, one can collect a dataset of API outputs and use it to fine-tune an open-source LM.” - from [1]
The majority of models that we will see in this overview are trained via a model imitation strategy. This strategy, which is based upon the more generic idea of knowledge distillation, is a seemingly effective way to fine-tune less powerful LLMs to make them behave more similarly to powerful LLMs like ChatGPT and GPT-4. To do this, we just:
Collect dialogue examples from the more powerful model (e.g., using the OpenAI API).
Use them to fine-tune the smaller model using a normal language modeling objective.
This approach (although not commercially viable) was heavily utilized by a variety of open-source LLMs—including Alpaca, Vicuna, Koala, and more [3, 4, 5]—to create language models much closer to the quality or ChatGPT or GPT-4.

knowledge distillation. The idea of knowledge distillation for deep neural networks was originally explored in [1]1. To put it simply, knowledge distillation uses a (large) fully-trained neural network as a training signal for another (small) neural network; see above. If we train a neural network using both i) the normal training data and ii) the output of a larger, more powerful neural network over that data, then we will typically arrive at a better result than training a neural network over the data alone. By using its output as a training target, we can distill some of the information from a larger “teacher” network into a smaller “student” network that is being trained. For more details, check out the link below.
Although many types of knowledge distillation exist, the variant considered in this overview is referred to as model imitation, where we use the output of a teacher LLM as a training target for supervised fine-tuning of another LLM.
types of model imitation. There are a variety of high-quality LLMs available online, but many of them are only accessible via a black-box API. Instead of having access to the model itself, we can only provide input to the model and receive output (possibly with associated log probabilities). Model imitation collects data from these APIs and uses it for fine-tuning, allowing any model to imitate the output of a proprietary LLM. There are two basic types of imitation:
Local Imitation: learn to imitate a model’s behavior on a specific task, instead of imitating its behavior as a whole.
Broad Imitation: learn to imitate a model’s behavior broadly, across a variety of different topics.
Broad imitation is (generally) more difficult than local imitation, as it aims to comprehensively capture a model’s behavior. Although imitating a specific task is not hard, replicating a model’s behavior as a whole requires a lot of data and can be quite difficult.
“Broad-coverage imitation is challenging because (1) one must collect an extremely diverse imitation dataset and (2) imitation models must capture this wide data distribution and generalize similarly to the target model on a myriad of held-out examples.” - from [1]
The Wake of LLaMA
Model imitation was explored extensively by recent research on open-source LLMs. This line of work began with the proposal of LLaMA [2] and was quickly extended by follow-up models like Alpaca, Vicuna, Koala, and more [3, 4, 5]. We learned about most of these models within prior overviews:
Here, we will quickly cover the basics of these models and provide relevant context that will make this overview more understandable.
What is LLaMA?

LLaMA is not a single language model, but rather a suite of LLMs with sizes ranging from 7 billion to 65 billion parameters. Taking inspiration from Chinchilla [13], these LLMs are a bit smaller than their counterparts but are pre-trained extensively (i.e., smaller models, more tokens). LLaMA models perform surprisingly well; e.g., the 13 billion parameter model is comparable to GPT-3 [14], while the 65 billion parameter model surpasses the performance of PaLM [15].
fully open-source. Unlike closed-source models that are trained on a combination of public and proprietary data, LLaMA uses only publicly available data for pre-training—LLaMA models can be reproduced completely from online resources! After being publicly released for research purposes, the weights of the model were “leaked” online. Even still, LLaMA is prohibited from being used in any commercial applications even if one has access to the model’s weights.
Imitation Models: Alpaca, Vicuna, Koala, and More

Interestingly, LLaMA weights being leaked online led to a massive explosion in the model’s popularity. Researchers quickly began to release a variety of interesting, open-source derivatives. Primarily, LLaMA was used to create imitation models based on data derived from dialogues with powerful LLMs like ChatGPT. Let’s take a look at some of the popular LLMs derived from LLaMA.
Alpaca [3] is a fine-tuned version of the LLaMA-7B LLM. The fine-tuning process is based on self-instruct [17], in which instruction-following data is collected from a higher-performing LLM (i.e., text-davinci-003) and used for supervised fine-tuning. The entire fine-tuning process of Alpaca costs only $600 (including both data collection and fine-tuning). Read more about Alpaca here.
Vicuna [4] is an open-source chatbot that is created by fine-tuning LLaMA-13B (i.e., comparable performance to GPT-3). Vicuna is fine-tuned using examples of user conversations with ChatGPT, and the entire fine-tuning process can be replicated for $300. Compared to Alpaca, Vicuna is more comparable to ChatGPT and generates answers with detail and structure. Read more about Vicuna here.
Koala [5] is a version of LLaMA-13B that has been fine-tuned on dialogue data from a variety of sources, ranging from public datasets to dialogues with other high-quality LLMs that are available on the internet. Compared to Alpaca, Koala is fine-tuned over more dialogue data and evaluated more extensively (using a larger number of crown workers). Read more about Koala here.
GPT4ALL [16] is a fine-tuned LLaMA-7B model that has been trained on over 800K chat completions from GPT-3.5-turbo. Along with releasing the code and model, authors of GPT4ALL release the 4-bit quantized weights of the model, which can be used to run model inference on CPUs. As a result, we can use this model on a normal laptop! More details are provided here.
“Open-source models are faster, more customizable, more private, and … more capable. They are doing things with $100 and 13B params that [Google] struggles with at $10M and 540B. And they are doing so in weeks, not months.” - from [9]
the massive potential of imitation models. The models mentioned above were published in close succession and (in most cases) claimed to achieve results that were comparable to top proprietary models like ChatGPT or GPT-4. As such, the research community quickly adopted the opinion that open-source model will soon dominate the LLM landscape. But, is this actually the case?
Are we missing something?
Open-source, LLaMA-based imitation models seem to perform well, as they are much better at instruction following compared to the base LLM (i.e., the model that has been pre-trained but not fine-tuned) and have a comparable style to ChatGPT. In fact, crowd workers initially rate the outputs of a LLaMA-13B model that has been trained to imitate ChatGPT as better 70% of the time; see below.

With these results in mind, it seems like model imitation provides an easy way to distill the capabilities of any proprietary model into a smaller, open-source LLM. If this is the case, we can match the performance of the best proprietary models via an open-source LLM by just using fine-tuning and imitation data, leaving closed-source models like GPT-4 with no true advantage.
the (unfortunate) truth. Although the ability to easily re-create open-source variants of proprietary models for research purposes is enticing, evaluation using crowd workers can be misleading. A model can score well simply by outputting answers with the correct style and structure, even if an answer is factually weak or incorrect. Why is this the case? Verifying factual correctness requires a larger time investment (or existing knowledge) from the crowd worker.

how are open-source LLMs evaluated? With this in mind, we might start to question whether post-LLaMA LLMs are actually closing the gap between paid and open-source LLMs. These models are definitely exciting and impressive, but when we look at how they are evaluated, we typically see that the evaluation is:
Not very comprehensive
Primarily based upon human (or LLM) evaluation
As such, it’s easy to be misled regarding the true quality of these models given the limitations of human evaluation. Put simply, these models are not evaluated rigorously enough to gain an accurate picture of their quality.

Now from our partners!
Rebuy Engine is the Commerce AI company. They use cutting edge deep learning techniques to make any online shopping experience more personalized and enjoyable.
KUNGFU.AI partners with clients to help them compete and lead in the age of AI. Their team of AI-native experts deliver strategy, engineering, and operations services to achieve AI-centric transformation.
MosaicML enables you to train and deploy large AI models on your data and in your secure environment. Try out their tools and platform here or check out their open-source, commercially-usable LLMs.
The False Promise of Imitating Proprietary LLMs [1]

Authors in [1] aim to comprehensively analyze the performance of model imitation, thus answering the question: can we really imitate proprietary LLMs with weaker, open-source models? A variety of models are fine-tuned over different sets of imitation data, then extensively evaluated using both crowd workers and a variety of different natural language benchmarks. Initially, LLMs produced via model imitation of ChatGPT seem to perform well, but targeted evaluations reveal that they do far less to close the gap between the base LLM (i.e., LLaMA [2]) and ChatGPT than it seems. These models are less factual and only improve performance on tasks that are heavily represented in the fine-tuning set. The model oftentimes declines in accuracy on tasks that aren’t seen during fine-tuning!
Experimental Setup
Analysis in [1] critically evaluates recent work on model imitation by exploring a variety of experimental setups. All models used are decoder-only transformers, including GPT-2 [6], LLaMA-7B, and LLaMA-13B [2]. Evaluation is performed using GPT-4, crowd workers, and widely-used natural language benchmarks.

building the dataset. Fine-tuning datasets are created using a combination of human and LLM-provided examples for both local and broad imitation. For local imitation, a task-specific fine-tuning dataset is created by bootstrapping the Natural Questions dataset (i.e., based on factual knowledge of Wikipedia). In particular, authors in [1] take a small set of QA pairs from Natural Questions, then prompt ChatGPT to curate 6,000 more examples of similar questions; see above.
Curating a broad imitation dataset is more difficult, as the data needs to comprehensively cover desired LLM behavior. To create such a dataset, authors in [1] rely upon public, high-quality dialogues from sources like ShareGPT, ChatGPT-focused discord servers (e.g., TuringAI), and even r/ChatGPT on Reddit. The result is ~130K examples of freely-collected dialogue examples—referred to as ShareGPT-Mix—that are used for imitation fine-tuning. The quality of this data is high, and there is a large diversity in instructions—the most similar user queries have a BLEU score similarity of only 8%2. Each dialogue example from ShareGPT-Mix is post-processed by adding special tokens that mark the beginning of each user query and model output; see below.

fine-tuning approach. Models are fine-tuned using a standard language modeling loss. However, this loss is only applied over the portion of tokens corresponding to model output. In other words, the fine-tuning loss is only applied over the blue portions of each dialogue example within the above figure. Several fine-tuning runs are performed with dataset sizes ranging from 0.3M to 150M tokens3.
Are imitation models actually useful?

At initial glance, the quality of models trained via ShareGPT-mix imitation data seems to be quite high. While base models fail to follow instructions, the imitation fine-tuned variants stay on task and are capable of solving problems in a similar manner to ChatGPT. Plus, increasing the size of the model leads to consistent improvements in performance, and these models are rated positively when evaluated with GPT-4; see above.
However, more detailed analysis seems to indicate that these results might be slightly misleading. For example, human evaluation scores saturate quickly (and even degrade) as more imitation data is used; see below. Such a surprising result indicates that there is something we might be missing within the evaluation of these models.
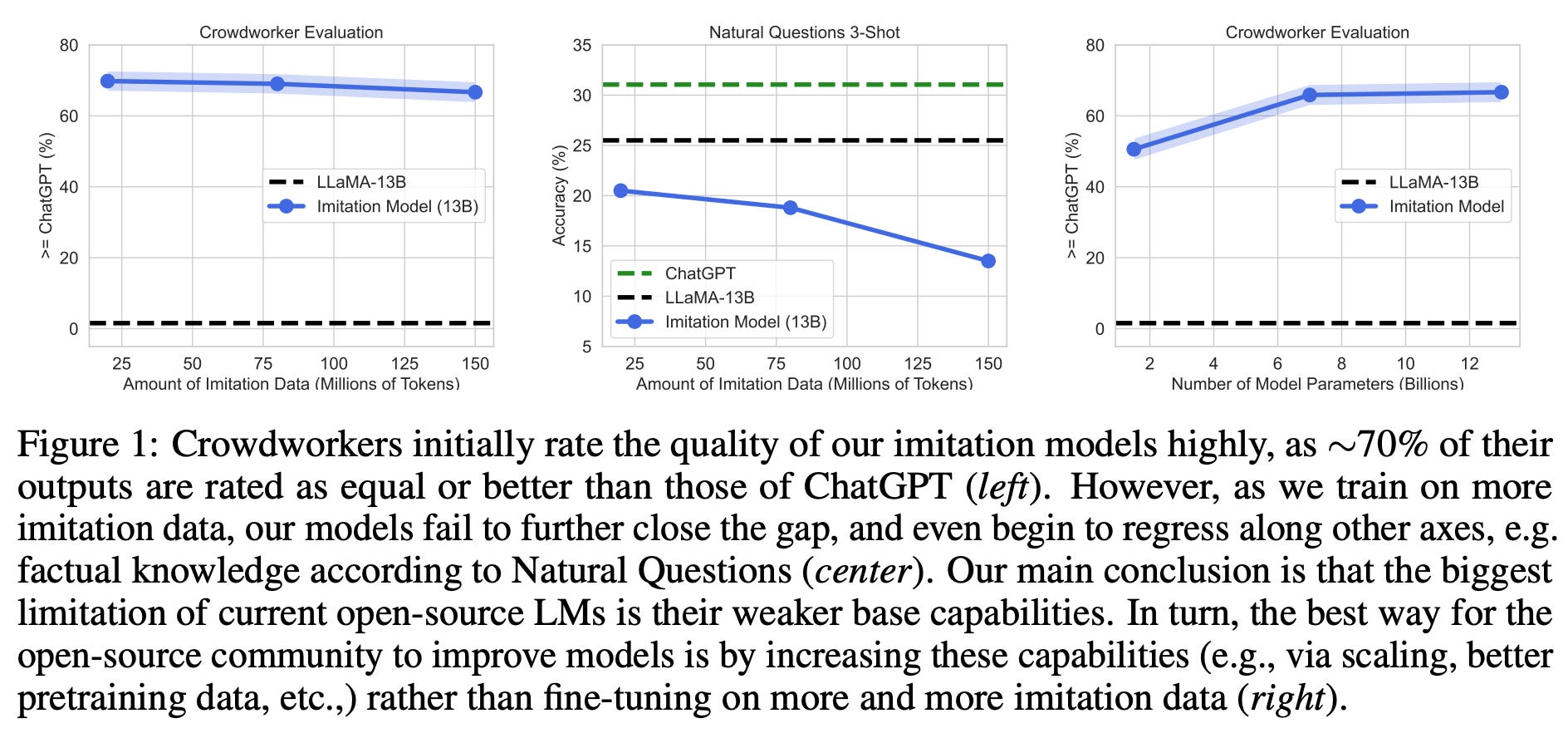
targeted evaluations. When imitation models are evaluated across a wider variety of natural language benchmarks, we see that their performance is comparable to or below that of the corresponding base LLM. In other words, fine-tuning over imitation does not improve the performance across a wider variety of tasks; see below.

Such lackluster performance on benchmarks like MMLU [10], HumanEval [11], and Natural Questions [12] reveals that imitation models do not have improved factuality, coding abilities, or problem-solving capabilities compared to base LLMs. Given that most of an LLM’s knowledge is learned during pre-training, such a trend makes sense. We see in [1] that the imitation models can match the style of powerful LLMs like ChatGPT (see below), but they lack the same knowledge base. These models hallucinate more frequently, which is difficult to detect in basic human evaluations without extensive research or time investment.

local imitation works well. Despite the limitations of imitation models when evaluated on a broader set of tasks, we see that local imitation is actually quite effective. Learning specific behaviors of ChatGPT is possible via imitation, but we run into roadblocks when mimicking behavior more broadly; see below. Local imitation can be a useful point solution for adapting open-source LLMs to solve specific tasks or mimic proprietary models in particular scenarios.

To broadly imitate the behavior of a model like ChatGPT, we need a significantly larger and more diverse source of imitation data. However, curating this dataset might not be the best approach—we see a much larger performance benefit from simply increasing the size of the base model. As such, creating more powerful base LLMs might be a more promising direction for open-source LLM research compared to creating cheap imitation models.
“We argue that the highest leverage action for improving open-source models is to tackle the difficult challenge of developing better base LMs, rather than taking the shortcut of imitating proprietary systems.” - from [1]
Final Thoughts
Although the deep learning community has embraced openness and transparency for years, the explosion in popularity of LLMs has given birth to an alternative paradigm in which development is performed with proprietary APIs that provide no access to the actual model itself. To combat this shift away from open-source, researchers have developed open-source LLM alternatives. The creation of imitation models made this area of research seem to progress incredibly fast, leading many to assume that proprietary LLMs would quickly fall out of favor. Within this overview, we have seen that such imitation LLMs have major limitations. However, the development of powerful, open-source LLMs continues to progress. Some major takeaways from this work are outlined below.
the importance of rigorous evaluation. Imitation models seem to perform well when qualitatively evaluated by humans. When subjected to more rigorous quantitative evaluation, however, the performance of such models is found to be somewhat lackluster (and even worse than base models in some cases)! The findings from this work highlight the importance of rigorous evaluation in research. For a field to progress, we need to be sure that techniques and models being proposed are actually improving upon those that exist.
local imitation is still very useful. Although imitation models are found to perform poorly when evaluated broadly, they perform quite well for any task that is included in their fine-tuning dataset. As such, local imitation is still a useful and effective technique. We can easily teach a smaller, open-source LLM to match the performance and behavior of a popular model like ChatGPT in a specific domain via imitation. However, we run into problems when trying to replicate the behavior of proprietary LLMs as a whole. This would require curating a massive dataset of dialogue examples for imitation fine-tuning.
implications for open-source LLMs. As we have seen, imitation models (although useful for local imitation and specific use-cases) are not a general-purpose solution for producing high-quality, open-source foundation models. However, we see within [1] that LLM performance continues to improve with the size and quality of the underlying base model. Such a finding indicates that the creation of larger and more powerful base models is necessary for further advancements in open-source LLMs to occur.
New to the newsletter?
Hello! I am Cameron R. Wolfe. Ph.D. in deep learning and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers build a better understanding of deep learning research via understandable overviews that explain relevant topics from the ground up. If you like this newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Gudibande, Arnav, et al. "The false promise of imitating proprietary llms." arXiv preprint arXiv:2305.15717 (2023).
[2] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[3] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[4] Chiang, Wei-Lin et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” (2023).
[5] Geng, Xinyang et al. “Koala: A Dialogue Model for Academic Research.” (2023).
[6] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[7] Gou, Jianping, et al. "Knowledge distillation: A survey." International Journal of Computer Vision 129 (2021): 1789-1819.
[8] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[9] Dylan Patel and Afzal Ahmad. Google “we have no moat, and neither does OpenAI”, 2023.
[10] Hendrycks, Dan, et al. "Measuring massive multitask language understanding." arXiv preprint arXiv:2009.03300 (2020).
[11] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[12] Kwiatkowski, Tom, et al. "Natural questions: a benchmark for question answering research." Transactions of the Association for Computational Linguistics 7 (2019): 453-466.
[13] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[14] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[15] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[16] Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. GPT4All: Training an assistant-style chatbot with large scale data distillation from GPT-3.5-Turbo, 2023.
[17] Wang, Yizhong, et al. "Self-Instruct: Aligning Language Model with Self Generated Instructions." arXiv preprint arXiv:2212.10560 (2022).
This paper is actually one of the first deep learning papers that made me interested in the field. It’s an awesome read that I would recommend to anyone!
If we similarly compute BLEU score similarity on the widely-used SuperNaturalInstructions dataset, we get a similarity of 61%, which is significantly higher than the broad imitation dataset created in [1].