
Beyond NeRFs (Part Two)
Tips and tricks for successfully using NeRFs in the wild...


This newsletter is sponsored by Rebuy, where AI is being used to build the future of e-commerce personalization. If you like this newsletter, please subscribe, share it with a friend, or follow me on twitter. Thank you for your support!

In the domain of representing and rendering 3D scenes, neural radiance fields (NeRFs) provided a massive breakthrough in accuracy. Given several images of an underlying scene, NeRFs can reconstruct high-resolution, 2D renderings of this scene from arbitrary viewpoints. Compared to prior techniques like local light field fusion (LLFF) [5] and scene representation networks (SRNs) [6], NeRFs are far more capable of capturing complex components of a scene’s appearance and geometry (e.g., view-dependent reflections and intricate materials); see below.
NeRFs have the potential to revolutionize applications like virtual reality, computer graphics, and more. One could imagine, for example, using NeRFs to reconstruct 3D renderings of a house that is for sale given images of the house that are available online, or even designing video game environments using NeRFs trained on real-world scenes. In their original formulation, however, NeRFs were mostly evaluated using images captured in simple, controlled environments. When trained over images of real-world scenes, NeRFs tend to not perform as well (see below), making them less useful in practical applications.

Within this overview, we will study NeRFs in depth to better understand why they perform poorly in the real world and how this problem can be solved. In particular, we will explore a few recent proposals, called NeRF-W [1] and def-NeRF [2], that modify NeRFs to better handle images that are captured in uncontrolled, noisy environments. Such techniques make NeRFs much more useful by enabling their application over images that more closely match data that will be encountered in most practical applications.
Background
This overview is part of our series on deep learning for 3D shapes and scenes. If you haven’t already, I recommend reading the prior posts in this series, as they contain a lot of useful background information on NeRFs and related techniques. Here, we will briefly overview NeRFs and a few other relevant concepts (e.g., latent spaces, non-rigid deformations, positional encoding, etc.) that will arise in our discussion of NeRF-W [1] and def-NeRF [2].
A Brief Overview of NeRFs
In a prior overview, we have already discussed the idea of neural radiance fields (NeRFS) [3] in depth. Given that this overview explores extending and modifying NeRFs for real-world applications, I recommend reading the overview of NeRFs below.
quick overview. To re-hash the basic idea behind NeRFs, they are just feed-forward neural networks that take a 3D coordinate and viewing direction as input and produce a volume density and RGB color as output. By evaluating the NeRF at a variety of different points (and viewing directions) in 3D space, we can accumulate a lot of information about a scene’s geometry and appearance, which can be used to render an image (or view) of that scene; see below.

To train a NeRF, we simply need to accumulate several images of a scene and relevant camera pose information for each image. Then, we can use these images as a target to train our NeRF! In particular, we repeatedly i) use the NeRF to render an image at a known viewpoint and ii) compare the NeRF’s output to the actual image using a photometric loss function (i.e., this just measures differences between RGB pixel values); see below.

problems with NeRFs. NeRFs were a massive breakthrough in the field of 3D scene representation, but they have some limitations. In a prior overview, we discussed the computational burden of training and rendering with NeRFs, as well as their need for many images of an underlying scene for training. However, techniques like InstantNGP [7] and PixelNeRF [8] drastically improve the computational and sample efficiency of NeRFs.
Going further, NeRFs make the assumption that scenes are static. In practice, this assumption is oftentimes not true. Images may contain moving objects (e.g., people) that occlude relevant portions of the scene or even be taken at different times of day (e.g., at night or in the morning). These are transient components of a scene that may be present in one image but not another.
“The central limitation of NeRF … is its assumption that the world is geometrically, materially, and photometrically static. NeRF requires that any two photographs taken at the same position and orientation must be identical. This assumption is violated in many real-world datasets.” - from [1]
This static assumption is a large factor that underlies the poor performance of NeRF in uncontrolled environments. Within this overview, we will explore how this assumption can be mitigated, allowing NeRFs to be trained over imperfect, real-world datasets that we encounter in practical applications.
Primer on Shape Deformation
To successfully train NeRFs on noisy smart phone images, recent techniques augment NeRFs with learnable deformation fields. To understand what this means, however, we need to learn about deformations in general. A detailed explanation of the idea is provided below, and we will cover the highlights here.
Put simply, a deformation describes a transformation of an initial geometry into a final geometry (e.g., by displacing, translating, or morphing points relative to some reference frame). There are two basic types of deformations that we will typically encounter:
Rigid deformation
Non-rigid deformation
For rigid deformations (e.g., rotations and translations), the object being deformed changes with respect to an external frame of reference but remains unchanged with respect to an internal frame of reference. Examples are provided in the image below.

Non-rigid deformations are slightly different. Objects are changed with respect to both internal and external frames of reference. Thus, non-rigid deformations can capture transformations like dilation and shearing; see below.
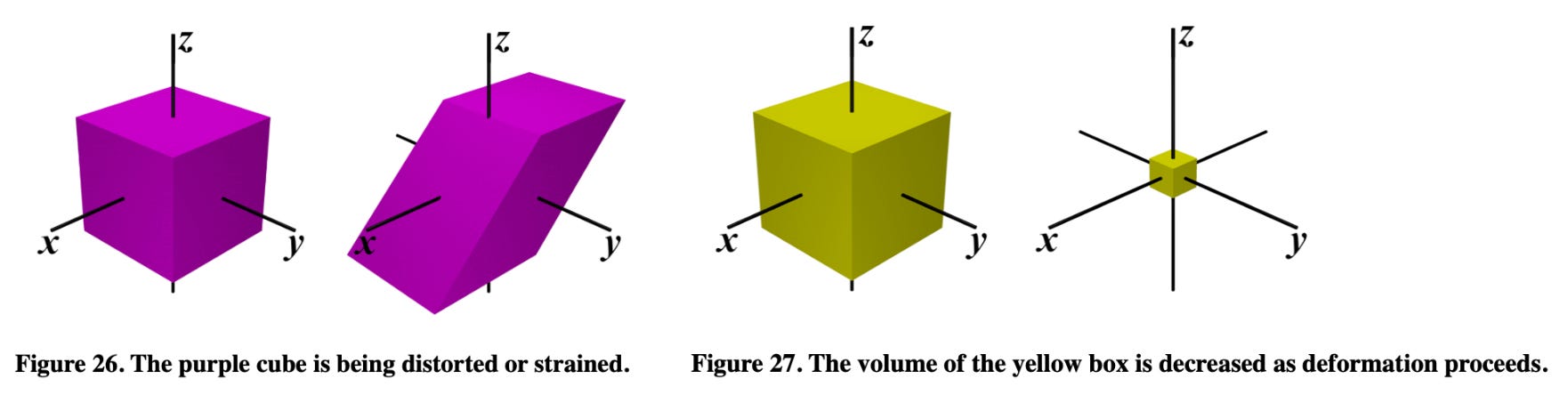
deformation fields. A deformation field is one way of representing deformations. It simply defines a transformation via a mapping of points in 3D space (i.e., each point in space is mapped to a new point). By repositioning/transforming an object based on the mapping defined by this field, we can arbitrarily transform the the shape of an object, similar to the deformations shown above.
Other Resources
Beyond the discussion above, there are a few concepts that might provide a deeper understanding of the content in this post. Check out the links below to relevant resources:
Publications
Although NeRFs are effective in controlled environments, they struggle to render 3D scenes from images captured in the real world. Here, we will overview two recently proposed methods, called NeRF-W [1] and def-NeRF [2], that try to solve this issue. These methods can render accurate 3D scenes from sets of photos that are imperfectly captured (e.g., on a mobile phone) and even contain drastic illumination changes or occluding objects!
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections [1]

Real-world images oftentimes have a lot of undesirable properties that make the training of NeRFs quite difficult. Consider, for example, trying to train a NeRF over several images of a major landmark that were taken years apart from each other; see above. The images of this scene may be taken at different times of night or day and contain any number of moving people or objects that are not actually part of the scene’s geometry!
In uncontrolled scenarios, NeRFs tend to fail due to their assumption that scenes are static, thus preventing their use in real-world applications. NeRF-W [1]—an extension to NeRF—mitigates these problems by relaxing the static assumption made by NeRF and allowing accurate modeling of 3D scenes under common, real-world problems (e.g., transient objects and illumination changes).

decomposing a scene. Major problems encountered by NeRFs in the wild can be loosely categorized as follows:
Photometric changes: time of day and atmospheric conditions impact the illumination/radiance of a scene.
Transient objects: real-world scenes are rarely captured in isolation. There are usually people or objects that occlude and move through the scene as images are taken.
These problems, both violations to the static assumption, are illustrated in the figure above.
photometric changes. To address photometric changes, each image is assigned its own “appearance” vector, which is considered (as an extra input) by NeRF-W when predicting the output RGB color. However, the appearance embedding has no impact on the predicted volume density, which captures the 3D geometry of a scene. This change is made by just separating NeRF’s feed-forward network into a few components that take different inputs; see below.

By conditioning NeRF-W’s RGB output on this appearance embedding, the model can vary the appearance of a scene based on a particular image, while ensuring that the underlying geometry of the scene is appearance-invariant and shared across images. The unique appearance embeddings assigned to each training image are optimized alongside model parameters throughout training.
static vs. transient components. To handle transient objects, we should notice that a scene contains two types of entities:
Image-dependent components (i.e., moving/transient objects)
Shared components (i.e., the actual scene)
NeRF-W uses separate feed-forward network components to model image-dependent (transient) and shared (static) scene components. Both transient and static portions of the network output their own color and density estimations, which allows NeRF-W to disentangle static and transient components of a scene; see below.

The transient portion of NeRF-W emits an uncertainty field (using a Bayesian learning framework [4]) that allows occluded scene components to be ignored during training. To ensure that transient effects on the scene are image-dependent, each training image is associated with a “transient” embedding vector, which is given as input to the transient component of NeRF-W. Similar to appearance embeddings, transient embeddings are learned during training. See below for a full depiction of the NeRF-W architecture.
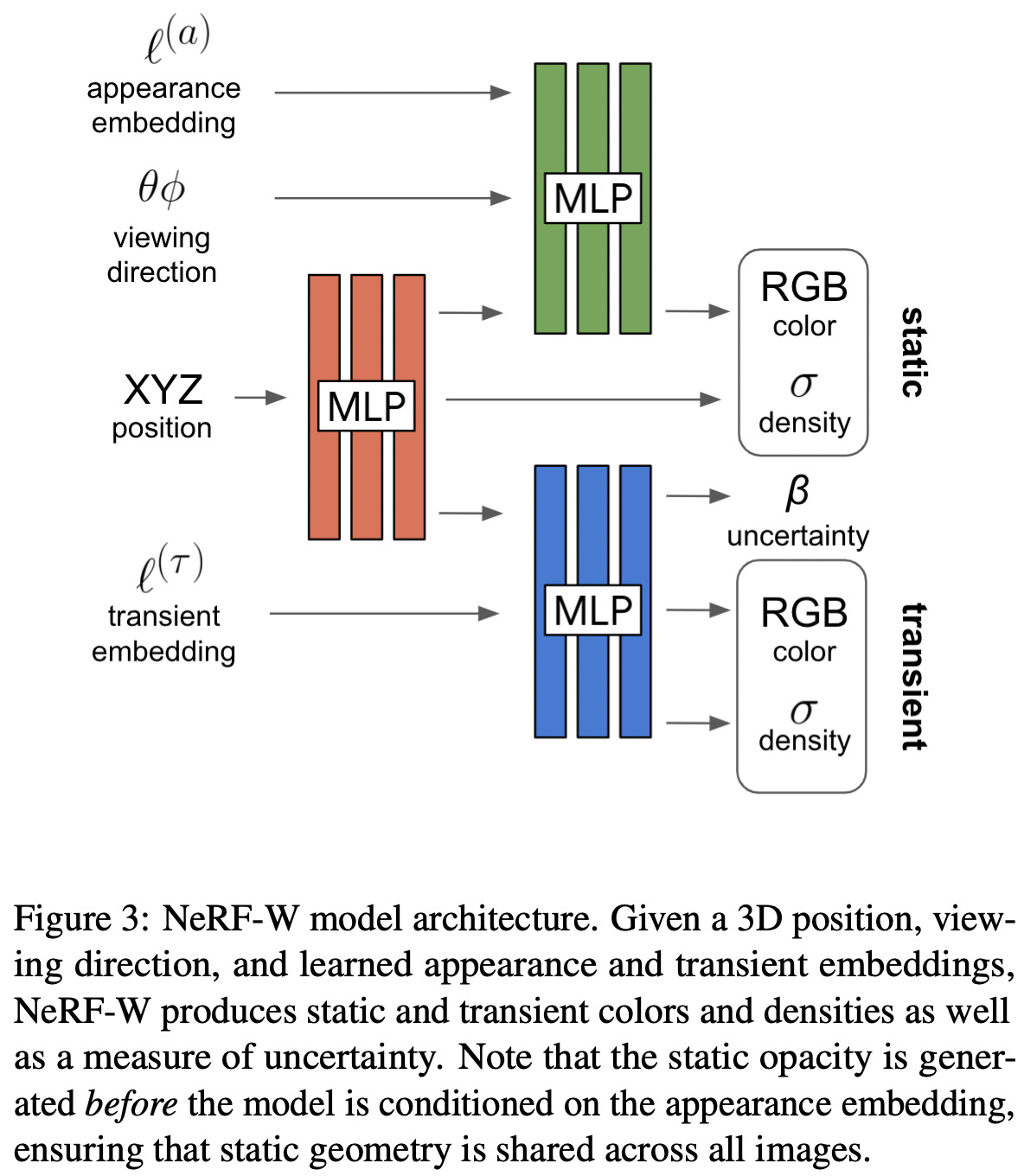
All components of NeRF-W are jointly optimized using a procedure similar to NeRF [3], as described in the link below.
results. NeRF-W is evaluate using real-world photo collections of notable landmarks, selected from the Photo Tourism dataset. When NeRF-W is trained to represent six landmarks, we see that NeRF-W outperforms baselines quantitatively in most cases; see below.

We should recall that, to perform evaluation, we:
Train a model over images corresponding to a single scene.
Sample a hold-out test image (and corresponding camera pose).
Render a viewpoint (with the trained model) using the camera pose information from the hold-out image.
Compare the rendering to the ground truth image.
For NeRF-W, we do not have appearance or transient embeddings for test images. As a result, NeRF-W optimizes these embeddings based on one half of the test image and performs evaluation on the other half of the image; see below.

When we examine the output of different NeRF variants, we see NeRF output tends to contain ghosting artifacts due to transient objects in the training images. In comparison, NeRF-W produces sharp and accurate renderings, indicating that is more capable of handling real-world variation in scene appearance; see below.

Plus, NeRF-W can produce accurate scene renderings given training images with different lighting conditions. Given that NeRF-W can generate output given different appearance embeddings as input, we can tweak NeRF-W’s appearance embedding to modify the appearance of the final rendering; see below.

Taking this idea a step further, we can even interpolate between appearance embeddings of different training images, yielding a smooth change in rendered scene appearance; see below.

Nerfies: Deformable Neural Radiance Fields [2]

Most computer vision data for modern applications is captured on a smart phone. With this in mind, one might wonder whether it’s possible to train a NeRF using this data. In [2], authors explore a specific application along these lines: converting casually captured “selfie” images/videos into a NeRF that can generates photorealistic renderings of a subject/person. The authors call these models “Nerfies” (i.e., a NeRF-based selfie)!
Initially, this application may seem pretty specific and useless. Do we really care this much about tweaking the viewing angle of our selfie? How much more aesthetic can this make our instagram posts? However, the methodology proposed in [2] is incredibly insightful for a few reasons:
It gives us an idea of the feasibility of training NeRFs using images and videos from a smart phone.
It improves the ability of NeRFs to handle challenging, detailed, or imperfectly captured materials in a scene.
It is not just applicable to capturing self-portraits, but can also be applied to more general scene modeling applications.
Using techniques proposed in [2], we can produce high-quality scene representations given noisy, imperfect images captured on a mobile phone. As an example of how such a technique can be used, imagine generating a 3D model of yourself by just taking a quick video on your phone. Current approaches for this require entire, specialized labs with synchronized lights and cameras!
NeRFs + deformation fields. When we think about using a hand-held camera to build a 3D model of a person, there are a few difficulties that might come to mind:
The camera will move (this violates the static assumption!).
Humans contain a lot of complex geometries and materials that are difficult to model (e.g., hair, glasses, jewelry, etc.).
In [2], authors address these challenges by augmenting NeRFs with a jointly optimized, non-rigid deformation field, which learns to transform the scene’s underlying geometry in 3D space.
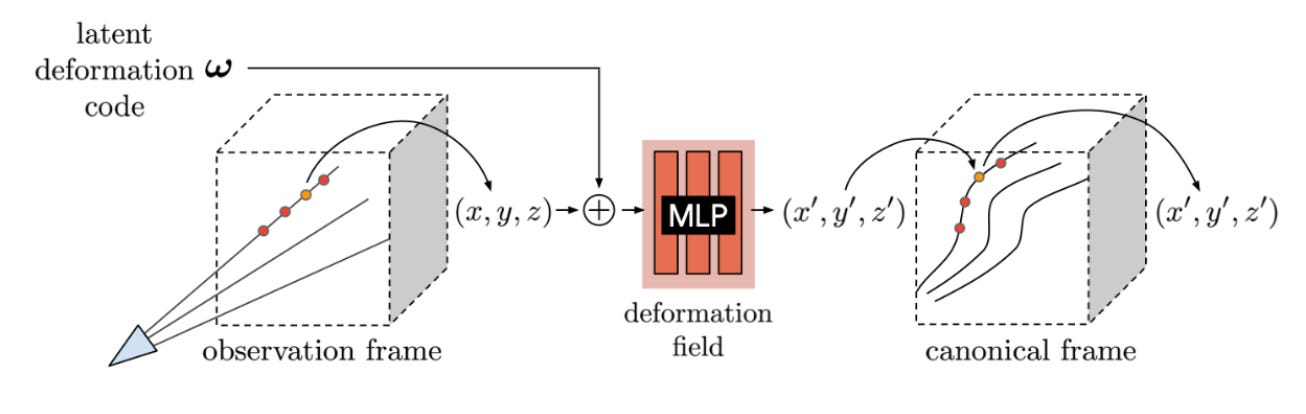
This deformation field is modeled with a feed-forward network that takes a positionally-encoded, 3D coordinate and per-image latent deformation code as input, then produces a non-rigidly deformed 3D coordinate as output; see above.
how def-NeRF works. The methodology in [2], which we’ll call a Deformable Neural Radiance Field (def-NeRF), has two components:
Deformation field: models a non-rigid deformation of 3D coordinates using a feed-forward neural network.
NeRF: uses a vanilla NeRF architecture to create a template of the underlying scene’s geometry and appearance.
We associate each training image with learnable deformation and appearance vectors. These latent codes, which mimic the per-image embedding approach used by NeRF-W [1], allow deformation and appearance to be image-dependent and enable def-NeRF to handle variance in images of scene (e.g., illumination changes).

def-NeRF takes a 3D coordinate as input. This coordinate is positionally-encoded and combined with the latent deformation code (via addition) before being passed into the feed-forward network that models def-NeRF’s deformation field. The output of this network is a transformed 3D coordinate; see above.

This transformed coordinate is passed as input to the NeRF. Similar to NeRF-W [1], we augment this NeRF with a per-image, learnable appearance vector. Given the transformed coordinate, viewing direction, and an appearance vector as input, the NeRF produces a volume density and RGB color as output; see above.

The full def-NeRF architecture, illustrated above, shares a nearly identical architecture and training strategy compared to vanilla NeRFs. The main differences are:
The modeling of a deformation field.
The use of per-image deformation and appearance vectors.
“When rendering, we simply cast rays and sample points in the observation frame and then use the deformation field to map the sampled points to the template.” - from [2]

why is this necessary? def-NeRF simply adds a deformation field that non-rigidly deforms input coordinates to the primary NeRF architecture. As a result, this approach decomposes scene representations into two parts:
A geometric model of the scene.
A deformation of this geometry into the desired viewpoint.
As such, def-NeRFs relax the static assumption of NeRFs and allow the underlying scene geometry to be learned in a manner that is invariant to shifts, translations, viewpoint changes, and more.

regularization. Authors in [2] observe that learned deformation fields are prone to local minima and overfitting. As a solution, we can add extra regularization to the optimization process of def-NeRF; see above. Several different regularization schemes are adopted, as described in Section 3.3-3.5 of [2].
does it work well? def-NeRF is primarily evaluated based on its ability to produce “Nerfies” (i.e., photorealistic renderings of a person/subject from arbitrary viewpoints). To create a Nerfie, a user films their face using a smart phone for about 20 seconds. Then, the def-NeRF methodology is trained over this data and used to render selfies from various, novel viewpoints.

To evaluate the quality of these scene reconstructions from novel viewpoints, the authors construct a camera rig that simultaneously captures a subject from multiple viewpoints. This allows a validation set to be constructed using images that capture the same exact scene from two different viewpoints; see above.

When quantitatively compared to various baselines, def-NeRF is found to produce higher-quality reconstructions of subjects in most cases. Notably, def-NeRFs seems to struggle with the PSNR metric. However, authors claim that this metric favors blurry images and is not ideal for evaluating scene reconstructions.
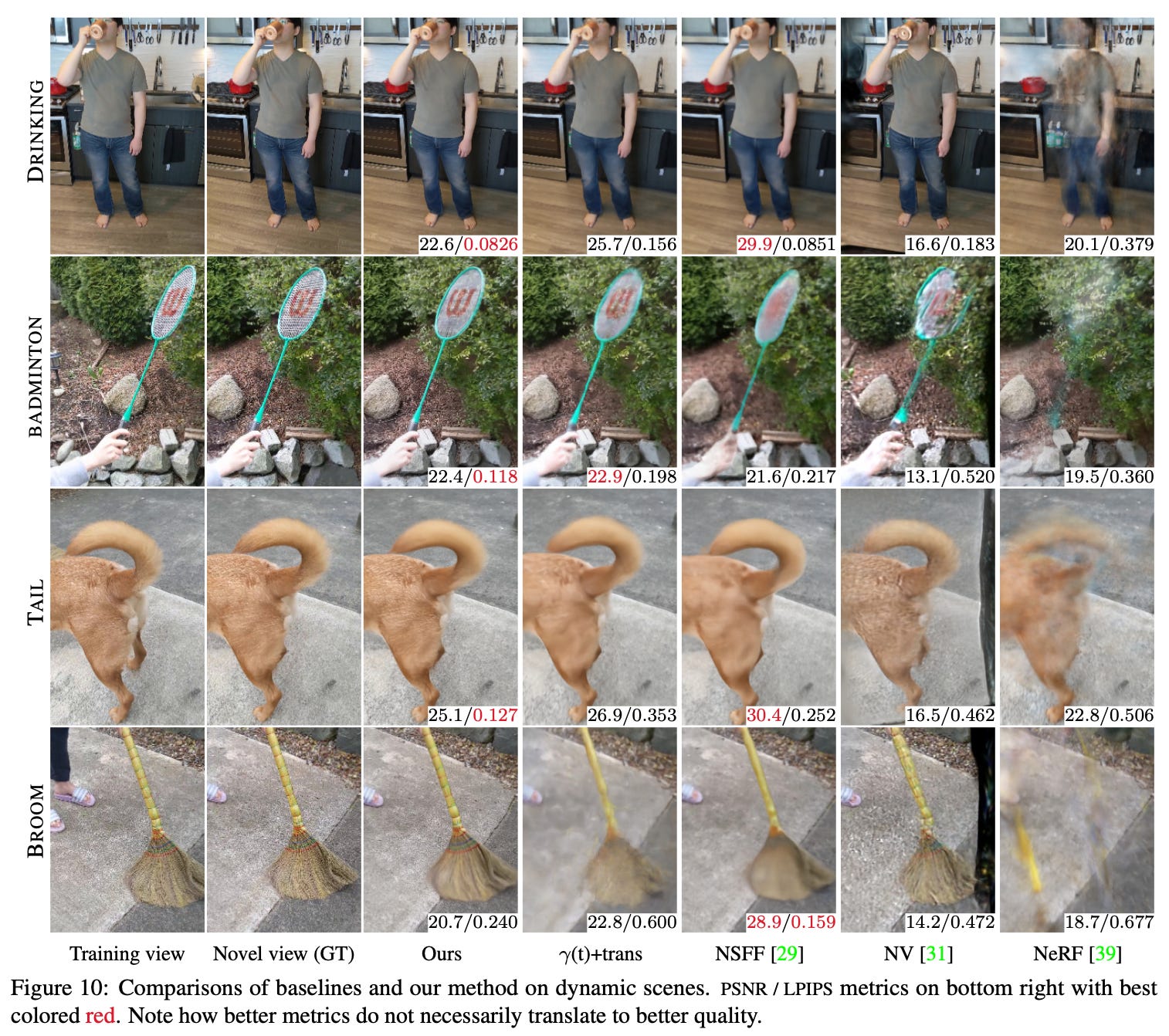
Qualitatively, we see that def-NeRF is more capable of capturing fine details within a scene (e.g., hair, shirt wrinkles, glasses, etc.) relative to baselines; see above. Additionally, the method works well for general scenes that go beyond reconstructing human subjects in a Nerfie. Overall, def-NeRF seems to provide high-quality scene reconstructions given images from a mobile phone!

Takeaways
Although NeRFs produce impressive demos, they are not truly useful unless we can apply them to images encountered in the real world. In this overview, we highlight the main reasons that applying NeRFs in the wild is often difficult (i.e., the static assumption) and overview some recent research that aims to solve this problem. Some of the major takeaways are outlined below.
static assumption. NeRFs, in their original form, assume that scenes are static, meaning that two images taken of a scene from the same position/direction must be identical. In practice, this assumption rarely holds! People or objects may be moving through the scene, and variable lighting conditions can significantly change the appearance of an image. Deploying NeRFs in the real world requires that this assumption be relaxed significantly.
image-dependent embeddings. Real-world scenes can be separated into image-independent and image-dependent components. If we want to learn the underlying geometry of a scene without overfitting to image-dependent components, we must customize a NeRF’s output on a per-image basis. For both NeRF-W and def-NeRF, this is largely accomplished via the addition of per-image embeddings vectors (i.e., appearance, transient, and deformation vectors). However, the fact that per-image embedding vectors are not available for unseen/test images may make deploying these models more difficult.
limitations. Allowing NeRFs to be applied beyond controlled environments is important, but this is not the only limitation of NeRFs! These models still suffer from poor sample efficiency and computational complexity, as discussed in a prior post. Making NeRFs viable for real-time applications will require a combination of techniques that solve each individual issue faced by NeRFs.
New to the newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning.
This is the Deep (Learning) Focus newsletter, where I help readers to build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Related Posts
Beyond NeRFs (Part One) [link]
iMAP: Modeling 3D Scenes in Real-Time [link]
Understanding NeRFs [link]
Local Light Field Fusion [link]
Scene Representation Networks [link]
Shape Reconstruction with ONets [link]
3D Generative Modeling with DeepSDF [link]
Bibliography
[1] Martin-Brualla, Ricardo, et al. "Nerf in the wild: Neural radiance fields for unconstrained photo collections." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[2] Park, Keunhong, et al. "Nerfies: Deformable neural radiance fields." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[3] Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.
[4] Kendall, Alex, and Yarin Gal. "What uncertainties do we need in bayesian deep learning for computer vision?." Advances in neural information processing systems 30 (2017).
[5] Mildenhall, Ben, et al. "Local light field fusion: Practical view synthesis with prescriptive sampling guidelines." ACM Transactions on Graphics (TOG) 38.4 (2019): 1-14.
[6] Sitzmann, Vincent, Michael Zollhöfer, and Gordon Wetzstein. "Scene representation networks: Continuous 3d-structure-aware neural scene representations." Advances in Neural Information Processing Systems 32 (2019).
[7] Müller, Thomas, et al. "Instant neural graphics primitives with a multiresolution hash encoding." ACM Transactions on Graphics (ToG) 41.4 (2022): 1-15.
[8] Yu, Alex, et al. "pixelnerf: Neural radiance fields from one or few images." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.