


This newsletter is sponsored by Rebuy, where AI is being used to build the future of e-commerce personalization. If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!

So far, we have only seen offline approaches for modeling 3D scenes (e.g., NeRF, SRNs, DeepSDF [2, 3, 4]). Despite their impressive performance, these approaches require days, or even weeks, of computation time for the underlying neural networks to be trained. For example, NeRFs are trained for nearly two days for just representing a single scene. Plus, using the the neural net to evaluate a new scene viewpoint can be quite expensive too! With this in mind, we might wonder whether it’s possible to learn a scene representation a bit faster than this.
This question was explored in [1] with the proposal of iMAP, a real-time system for representing scenes and localizing (i.e., tracking the pose of) devices in the scene. To understand what this means, consider a camera that is moving through a scene and capturing the surrounding environment. The task of iMAP is to (i) take in this data, (ii) build a 3D representation of the scene being observed, and (iii) infer the location and orientation of the camera (i.e., the device) as it captures the scene!
iMAP adopts an approach that is quite similar to NeRF [2] with a few differences:
It is based upon RGB-D data.
A streaming setup is assumed.
As such, the model receives both depth and color information as input. Additionally, the learning process begins from a completely random initialization, and iMAP must learn from new, incoming RGB-D images in real-time. Given this setup, iMAP is expected to (i) model the scene and (ii) predict the pose of the RGB-D camera for each incoming image (i.e., prior methods assume pose information as an input!). Despite this difficult training setup, iMAP can learn 3D representations of entire rooms in real-time!
why is this paper important? This post is part of my series on deep learning for 3D shapes and scenes. This area was recently revolutionized by the proposal of NeRF [2]. With a NeRF representation, we can produce an arbitrary number of synthetic viewpoints of a scene or even generate 3D representations of relevant objects; see below.
iMAP was proposed slightly after NeRFs, and it is capable of producing high-quality scene representations without requiring several days of training time. Compared to NeRF, iMAP learns in a cheap, on-the-fly manner and still performs relatively well.
Background
We have seen some important background concepts in prior overviews in this series that will be relevant here:
Feed-forward neural networks [link]
Representing 3D shapes [link]
Camera poses [link] (scroll to “camera viewpoints” sub-header)
What are “frames” in a video? [link]
To have all the context necessary for understanding iMAP, we need to quickly cover the concepts of SLAM systems and online learning.
What is SLAM?
Prior scene representation methods we have seen use deep neural networks to form an implicit representation of an underlying shape or scene by learning from available observations (e.g., point cloud data, images, etc.) of 3D space. iMAP is a bit different, because it is a Simultaneous Localization and Mapping (SLAM) system. This means that iMAP performs two tasks:
Localization: tracking the location and pose of the camera that’s capturing the underlying scene.
Mapping: forming a representation of the underlying scene.
Most prior techniques we have seen only perform mapping, but iMAP goes beyond these techniques by also performing localization. Namely, viewpoints of the underlying scene are passed in real-time to the iMAP system, which both maps the underlying scene and predicts the camera’s trajectory as it traverses the scene.

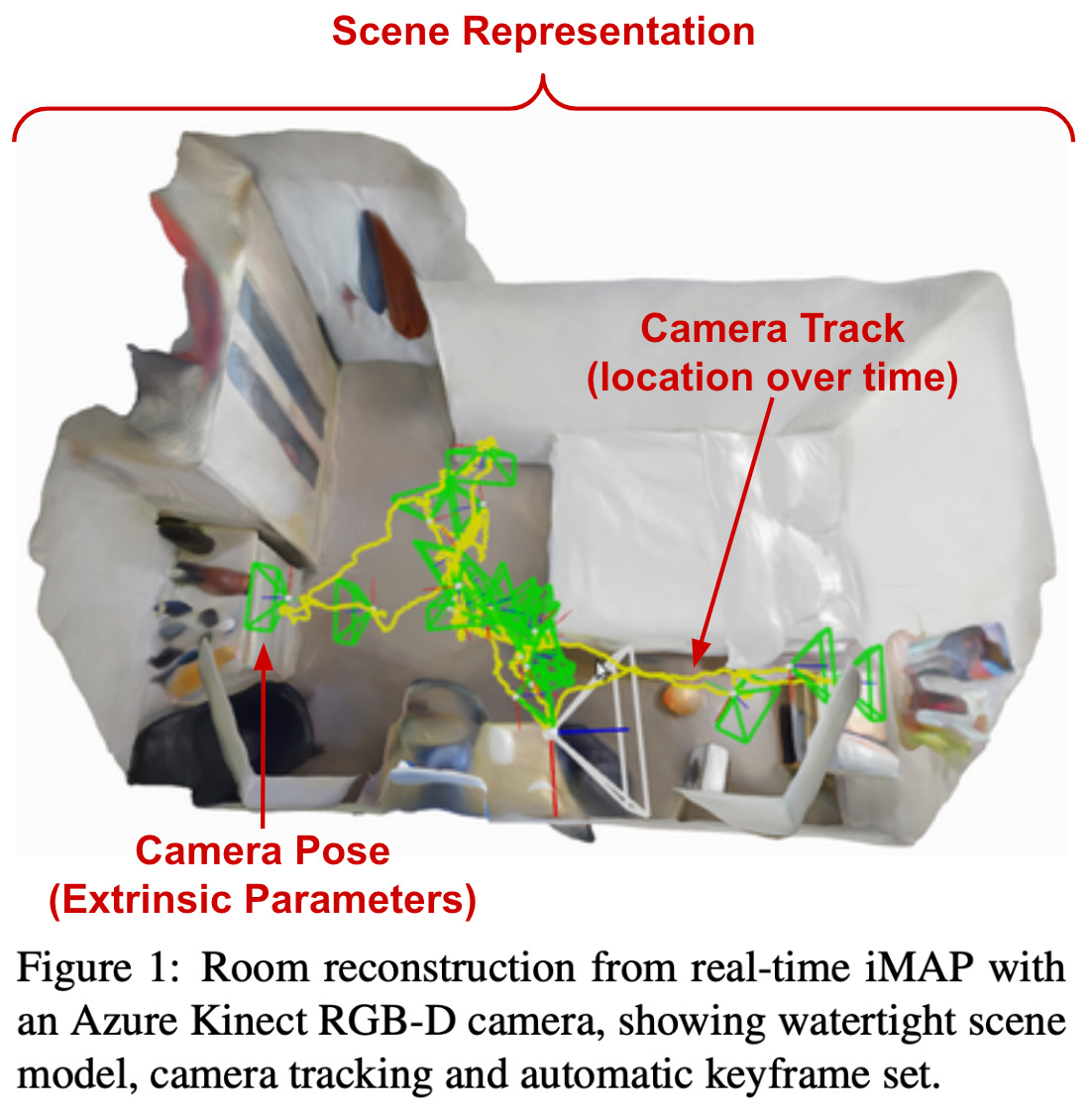
The output of a SLAM system, as shown above, has two components. A 3D representation of the scene is generated. Within this representation, however, we can see the camera’s trajectory as it captures the scene, shown by the yellow line (camera position) and associated 3D bounding boxes (camera pose).
how is this different? Beyond predicting camera poses on incoming data, SLAM systems are different from what we have seen so far because of the manner in which they receive data. Namely, with prior methods we (i) get a bunch of images of a scene and (ii) train a neural network over these images to model the scene. Instead, SLAM systems receive data in a streaming fashion. As the system receives new images, it must take them in, predict a pose, and update its underlying scene representation in real-time.
Online learning
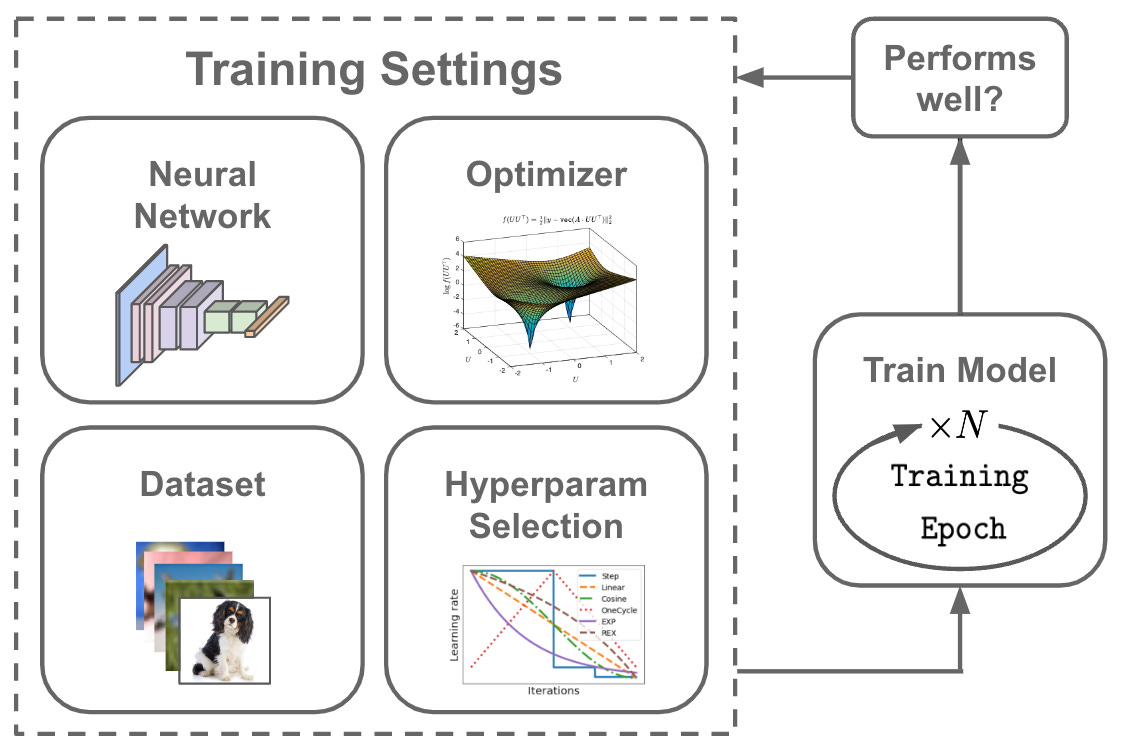
Typically, deep neural networks are trained in an offline fashion. We have a large, static training dataset available, and we allow our neural network to perform several training passes (or epochs) over this dataset; see above. But, what happens when our dataset is not static? For example, we may be receiving new data in real time or correcting labels applied to existing data.

We will refer to this setting generally as “online learning”, which refers to the fact that we are sequentially receiving new data with which to train a neural network.
Many different types of online learning exist; see above. For example, incremental learning assumes that the neural network sequentially receives new batches of data, while streaming learning mandates that the network receives data one example at a time. All forms of online learning assume that data is learned in one pass—we can’t “look back” at old data after receiving new data.
catastrophic forgetting. Online learning is considered more difficult than offline learning because we never have access to the full dataset during training. Rather, we must learn over small subsets of data that are made available sequentially. If the incoming data is non-i.i.d., our neural network may suffer from catastrophic forgetting. As discussed in [6], catastrophic forgetting refers to the neural network completely forgetting about older data as it learns from new, incoming data.

For example, if we are learning to classify cats and dogs, maybe we sequentially receive a lot of data that only has pictures of cats (e.g., this could happen on an IoT doorbell camera at someone’s house!). In this case, the neural network would learn from only pictures of cats for a long time, causing it to catastrophically forget the concept of a dog. This would not be a problem if the incoming data was distributed equally between cats and dogs. Forgetting occurs because incoming data is non-i.i.d., and online learning techniques aim to avoid such forgetting.
replay buffers. One popular method of avoiding catastrophic forgetting is via a replay buffer. At a high level, replay buffers just store a cache of data that has been observed in the past. Then, when the network is updated over new data, we can sample some data from the replay buffer as well. This way, we get an equal sampling of data that the neural network has seen; see below.

All online learning techniques share the common goal of maximizing a neural network’s performance by minimizing the impact of catastrophic forgetting. Although replay buffers are widely used, simple, and quite effective, many other techniques exist as well—online learning is an active area of research within the deep learning community. For an overview of some existing techniques, I recommend reading my summaries below!
why should we care about online learning? iMAP is a SLAM system. Fundamentally, SLAM systems are quite related to online learning, as they are expected to receive a stream of scene images and provide tracking and mapping results in return. Notably, iMAP is an online learning-based technique that relies upon a replay buffer to represent and track an underlying scene in real-time!
How does iMAP work?
After first learning about iMAP, it might seem like the method is too good to be true. First of all, iMAP is solving a harder problem than prior work—camera pose information is predicted from RGB-D data rather than given. Then, we must also learn the entire scene representation in real-time, instead of training for several days? There’s no way that this is possible…
But, it is! iMAP does all of this via a two-part processing pipeline that includes:
Tracking: predicts the location and pose of the camera as it moves through the scene.
Mapping: learns the 3D scene representation.
These two components run in parallel as an RGB-D camera captures the underlying scene from various viewpoints. Notably, tracking has to run quite fast, as we are trying to actively localize the camera as new data is coming in. The mapping component is done in parallel, but it only operates on keyframes that are really important to representing the underlying scene, which allows iMAP to learn in real-time. Let’s get into some of the details!

the network. The first step in understanding iMAP is learning about the neural network upon which it is based. Like most prior work, iMAP uses a feed-forward network architecture. The network takes a 3D coordinate as input and produces an RGB color and a volume density (i.e., captures opaqueness) as output; see above.
Notably, iMAP’s network does not take a viewing angle as input, as in NeRF [2], because it does not attempt to model view-dependent effects (e.g., reflections). Similar to NeRF [2], iMAP converts coordinates into higher-dimensional positional embeddings before passing them as input, following the approach of [5]; see below.

quick note on rendering. Assuming access to camera poses (we will learn how iMAP predicts these later), we can evaluate this network over many different spatial locations, then aggregate color and depth information into a rendering of the underlying scene using an approach like Ray Marching. The rendering approach of [1] is similar to that of NeRF, but we want to include depth information in our rendering (i.e., render an RGB-D image). This makes the rendering process slightly different, but the basic idea is the same, and the entire process is still differentiable.
how do we optimize this? iMAP is trying to learn:
The parameters of the feed-forward scene network.
Camera poses for incoming frames from the RGB-D camera.
To train the iMAP system to predict this information accurately, there are two types of loss metric upon which we rely:
Photometric: error in RGB pixel values.
Geometric: error in depth information.
These errors are computed by using iMAP to render an RGB-D view of the underlying scene, then comparing this rendering to the ground truth samples being captured from the camera. To make this comparison more efficient, we only consider a subset of pixels within the RGB-D image; see below.

To optimize photometric and geometric error jointly, we just combine them via a weighted sum; see below.

To render an image with iMAP, we must:
Use the scene network to obtain color and geometry information.
Infer the correct camera pose.
Render and RGB-D viewpoint based on this combined information.
All of these steps are differentiable, so we can optimize the photometric and geometric loss with techniques like stochastic gradient descent, thus training the system to produce renderings that closely match the ground truth RGB-D images.
tracking and mapping. The goal of tracking in iMAP is to learn the pose of the camera that’s actively capturing the underlying scene. Given that we have to do this for every incoming RGB-D frame from the camera, tracking must be efficient. iMAP handles tracking by (i) freezing the scene network and (ii) solving for the current RGB-D frame’s optimal pose given the fixed network. This is just an initial estimate of the camera pose that we generate as efficiently as possible—we may refine this pose later on.
The goal of mapping is to jointly optimize the scene network and camera poses, implicitly creating an accurate representation of the scene. Trying to do this over all incoming, RGB-D camera frames would be way too expensive. Instead, we maintain a set of keyframes based on importance (i.e., whether they capture a “new” part of the scene). Within this set of keyframes, we refine estimated camera poses and train the scene network to produce renderings that closely match selected keyframes.

putting it all together. The full iMAP framework is depicted above. Tracking is performed on each incoming frame to predict camera pose information. The feed-forward network is frozen during this process to make tracking more efficient. If a frame is selected as a keyframe, it is added to the set of keyframes that have their poses refined and are used to train the scene network.

To make it more efficient, mapping runs in parallel to the tracking process and only samples training data from the set of keyframes, which is much smaller than the total number of incoming images. Plus, the loss is only computed over a small subset of pixels, sampled using a hierarchical strategy (i.e., active sampling) that identifies regions of the image with the highest loss values (i.e., dense or detailed regions in the scene) and prioritizes sampling in these areas; see above.
online learning. Recall that iMAP is randomly-initialized at first. As the RGB-D camera moves through a scene, iMAP (i) tracks the camera via the tracking module and (ii) begins selecting keyframes to update the mapping module. This set of keyframes acts as a replay buffer for iMAP. Namely, the feed-forward scene network (and associated camera poses) are trained in an online fashion by aggregating relevant keyframes and performing updates over this data in parallel to the tracking process. Each update in the mapping process considers five frames: three random keyframes, the latest keyframe, and the current, incoming RGB-D frame.

The feed-forward scene network does not suffer from catastrophic forgetting because it samples training data from a diverse set of keyframes instead of training directly over the incoming data stream only. Unlike vanilla replay mechanisms, however, iMAP follows a specific strategy for sampling training data from the replay buffer. In particular, keyframes with higher loss values are prioritized (i.e., keyframe active sampling); see above.
Does it actually work?
iMAP is evaluated and compared to several traditional SLAM baselines across both real-world (i.e., from a handheld RGB-D camera) and synthetic scene datasets (e.g., the Replica dataset). Notably, iMAP processes every incoming frame at a frequency of 10 Hz. For evaluation, mesh reconstructions can be recovered (and compared to ground truth if available) by querying the neural network over a voxel grid and running the marching cubes algorithm.

On synthetic scenes, we see that iMAP is incredibly capable at jointly creating coherent scene reconstructions (see below) and accurate camera tracks (see above). In fact, iMAP is even found to be more capable than baselines at accurately filling in unobserved portions of a scene. Such a benefit is due to the ability of deep learning to leverage prior data and inductive biases to handle ambiguity in a reasonable/predictable manner.

iMAP accurately performs tracking and mapping simultaneously due to its joint optimization of 3D scene representations and camera poses in every frame. Despite beginning the learning process from a completely random initialization, iMAP quickly learns accurate scene representations and tracking information. Most notably, the iMAP framework can be used at any scale, from small objects to an entire room that contains various, detailed objects; see below.

Despite crafting a comparably-accurate scene representation, the memory usage of iMAP is quite low compared to SLAM baselines. iMAP just needs enough memory to store keyframes (including associated data) and the parameters of the neural network; see below.

On real-world data from a handheld RGB-D camera, iMAP continues to outperform SLAM baselines. In particular, iMAP is surprisingly effective at accurately rendering regions of a scene where the depth camera has inaccurate readings (i.e., this tends to happen for black, reflective, or transparent surfaces); see below.

Takeaways
Compared to most techniques we have seen so far, iMAP is quite different. In particular, it is a SLAM system, which means that it performs localization in addition to building a scene representation. Additionally, it relies upon online learning techniques to learn everything about a scene in real-time. iMAP begins from a random initialization and learns to represent the underlying scene from scratch! Some major takeaways are as follows.

super fast! Most techniques we have scene for representing 3D scenes are quite expensive. For example, NeRFs take 2 days to train on a single GPU, while LLFF performs ~10 minutes of preprocessing before generating novel scene views. iMAP learns everything in real time as new images are made available to it from an RGB-D camera. This is a massive change in the computational cost of crafting scene representations. Some timing data of iMAP tracking and mapping pipelines is shown above. iMAP is implemented in PyTorch and can run on a Desktop CPU/GPU system.
why deep learning? When we compare the iMAP system to other SLAM baselines, we see that it is able to “fill in” blank spaces that are left by the other systems. Put simply, iMAP can reasonably infer the contents of regions that have not been explicitly observed in a scene. Such an ability is due to the use of a deep, feed-forward neural network, which leverages priors within the data/architecture to estimate geometry from limited data.
learning on the fly. When beginning to learn about a scene, iMAP has no information. In fact, it begins from a completely random initialization, then uses online learning techniques to learn a representation of the scene on the fly from incoming data. It's very surprising that an approach like this works well, given that prior approaches (e.g., NeRF) require several days of training to represent a scene. iMAP shows us that there may be shortcuts or more lightweight techniques that allow us to obtain high-quality scene representations more easily.
positional embeddings. Although a smaller point, we see with iMAP that positional encodings, originally seen in NeRFs, are becoming standard. Recall that converting input coordinates into higher-dimensional positional embeddings before passing as input to a feed-forward network enables learning of high frequency features more easily. Here, we again see positional embeddings being adopted, revealing that such an approach is becoming standard.
New to the newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning.
This is the Deep (Learning) Focus newsletter, where I help readers to build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Related Posts
Understanding NeRFs [link]
Local Light Field Fusion [link]
Scene Representation Networks [link]
Shape Reconstruction with ONets [link]
3D Generative Modeling with DeepSDF [link]
Bibliography
[1] Sucar, Edgar, et al. "iMAP: Implicit mapping and positioning in real-time." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[2] Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.
[3] Sitzmann, Vincent, Michael Zollhöfer, and Gordon Wetzstein. "Scene representation networks: Continuous 3d-structure-aware neural scene representations." Advances in Neural Information Processing Systems 32 (2019).
[4] Park, Jeong Joon, et al. "Deepsdf: Learning continuous signed distance functions for shape representation." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
[5] Tancik, Matthew, et al. "Fourier features let networks learn high frequency functions in low dimensional domains." Advances in Neural Information Processing Systems 33 (2020): 7537-7547.
[6] Kemker, Ronald, et al. "Measuring catastrophic forgetting in neural networks." Proceedings of the AAAI conference on artificial intelligence. Vol. 32. No. 1. 2018.