
Scene Representation Networks
Modeling complex 3D scenes at infinite resolution...


This newsletter is supported by Alegion. At Alegion, I work on a range of problems from online learning to diffusion models. Feel free to check out our data annotation platform or contact me about potential collaboration/opportunities!
If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!

We have seen recently (e.g., with DeepSDF and ONets [3, 5]) how 3D geometries can be represented with a neural net. But, these approaches have some limitations, such as requiring access to ground truth, 3D geometries for training and inference. Plus, what if we want to represent an entire scene and not just an object or geometry? This requires modeling both geometry and appearance; see below for an example. Luckily, neural nets are more than capable of modeling 3D scenes in this way given the correct approach.

One approach for modeling 3D scenes is via Scene Representation Networks (SRNs) [1]. SRNs model scenes as a continuous function that maps each 3D coordinate to a representation that describes the object’s shape and appearance at that location. This function is learned with a feed-forward neural network. Then, SRNs use a learnable rendering algorithm to produce novel viewpoints (i.e., just 2D images) of the underlying 3D scene. Both the feed-forward network and the rendering algorithm can be trained end-to-end using only 2D images of scenes for supervision.
Compared to prior work, SRNs are very useful because they:
Directly enforce 3D structure, which encourages different viewpoints of a scene to be consistent.
Only require 2D images of a scene for training.
Produce better results given limited training data.
Model a continuous (as opposed to discrete) representation of a scene, which can be rendered in arbitrary resolutions.
We can use SRNs to generate accurate representations of 3D scenes, which has major implications for applications like robotic manipulation and rendering of complex scenes for virtual reality.
why is this paper important? This post is part of my series on deep learning for 3D shapes and scenes. This area was recently revolutionized by the proposal of NeRF [2]. With a NeRF representation, we can produce an arbitrary number of synthetic viewpoints of a scene or even generate 3D representations of relevant objects; see above. SRNs were proposed before NeRFs and are a background methodology that NeRFs extend upon and improve.
Background
So far, we have reviewed DeepSDF and ONet models for representing 3D geometries. These approaches never consider modeling both geometry and appearance like SRNs. However, there are a few useful background concepts from these models that will be useful here.
But, this isn’t all we need to know. Let’s cover some more background concepts that will be useful for building an understanding of how SRNs work.
hypernetworks. SRNs are complex models that contain several different neural network-based modules. One of these modules is a particular type of neural network called a hypernetwork. This may sound fancy, but hypernetworks are just neural networks that generate the weights of another neural network as output.

In the case of SRNs, our hypernetwork is a feed-forward neural network that takes a latent vector (i.e., a unique vector corresponding to a particular scene) as input, and produces a vector as output. Instead of directly using this vector, we take the values within it and use them as the weights of another feed-forward neural network. The output of our hypernetwork is used as the weights of another neural network within the SRN; see above.
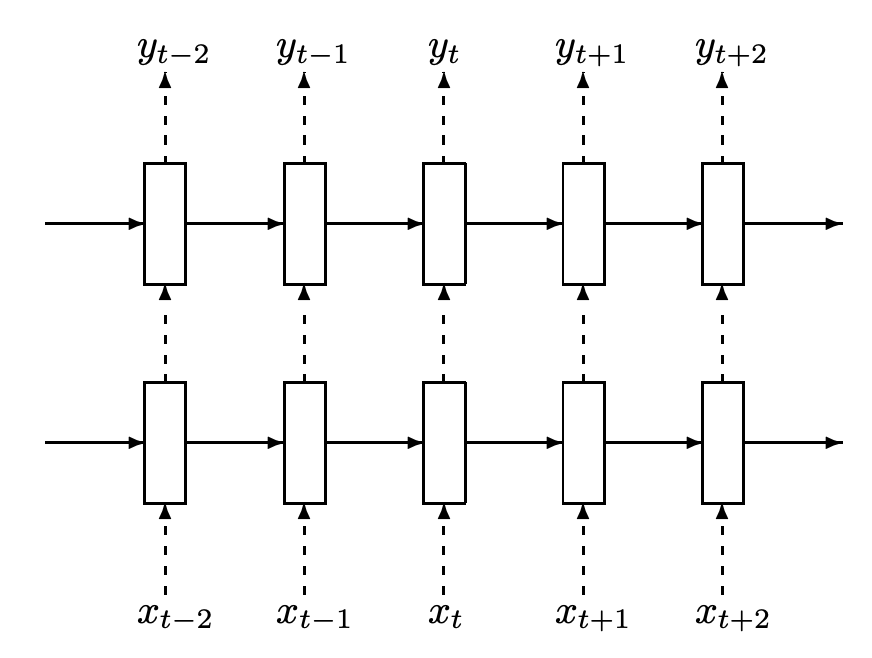
long short-term memory networks. Another component of the SRN is based on a type of recurrent neural network (RNN), called a long short-term memory (LSTM) network. RNNs are similar to feed-forward networks. They take a vector as input, produce a vector as output, and have several linear transformations and non-linearities in between. The main difference is that RNNs operate over sequences of vectors instead of just a single vector; see above.
Given an ordered sequence of vectors as input, the RNN will use the first vector as input, produce an output, then pass its hidden state as an additional input for processing the second vector. This process will repeat for each vector, until we reach the end of the sequence. So, RNNs are similar to feed-forward networks, but we are processing a sequence of inputs over time and maintaining a hidden/memory state that is (i) updated each time we see a new input and (ii) used as an additional input to generate our output at each time step or sequence position.

One major problem with RNNs is that they struggle to cope with very long sequences. We are trying to store everything about this sequence in a single, fixed-size hidden/memory state that is passed along to each sequence position! To solve this issue, LSTMs introduce gating mechanisms to the RNN’s forward pass, allowing the RNN to cope with longer sequences and better manage the information that is stored within its memory; see above. To learn more about LSTMs, check out the deep dive below.
camera viewpoints. To understand SRNs, there are a few general computer vision concepts that we should briefly explore. In particular, we need to understand camera viewpoints and parameters. Given an underlying scene, the purpose of a scene representation model is to accurately generate 2D views or images of the ground truth, 3D scene from different camera perspectives.
Intuitively, we can think of this as being similar to a person taking a picture of a 3D scene in real life. We use cameras every day to project the real world into a 2D image; see below.

This view of the scene that we generate depends on several factors, including the location, orientation, and properties of the camera being used. In computer vision, we divide all of the parameters needed to compute an accurate 2D image of the outside world into two groups: extrinsic and intrinsic.
Extrinsic parameters include properties like camera location and orientation, while intrinsic parameters capture the internal properties of the camera (e.g., focal length, resolution, etc.). See the article below for more details.
For SRNs, we actually need more than just images to train our model—we also need the associated camera parameters. This extra information allows us to understand the location, orientation, and camera properties that were used to construct this image, which is relevant to developing an understanding of the underlying scene. How would we know how to generate an image of a scene without knowing the viewpoint from which the scene is being observed?
How do SRNs work?
The SRN has two basic components: the scene representation model and the rendering function. We will first build an understanding of the data needed to train an SRN, then we will overview how each of these components work and come together, forming a robust system for representing and rendering scenes.
the data. We will first consider training an SRN over images corresponding to different viewpoints of a single scene. Given access to these images, we can train an SRN to generate images corresponding to arbitrary viewpoints of this scene at a high resolution. However, the images by themselves are not enough. We also need the matrices corresponding to extrinsic and intrinsic camera parameters for each viewpoint. Thus, our training dataset will take the following form:

where each I is an image, E is an extrinsic parameter matrix, and K is an intrinsic parameter matrix. Intrinsic parameters are specific to the camera, while extrinsic parameters are specific to the camera’s viewpoint of the scene.

representing the scene. SRNs represent scenes as functions that map a spatial location (i.e., [x, y, z] coordinate) to a feature vector. These features contain information about both the geometry and appearance of the scene at the specified location (e.g., surface color, signed distance, etc.). To model this scene function, we use a feed-forward neural network (i.e., a simple architecture!) that takes an [x, y, z] coordinate as input and produces this feature vector as output; see above.
neural rendering. Once we have generated relevant scene features for several different spatial locations in a scene, how do we use these features to render a new viewpoint of the scene? Our goal here is to take our scene representation—produced by the neural network described above, evaluated at a bunch of different spatial locations in the scene—and camera parameter matrices as input, then use this information to produce a novel viewpoint of the scene. SRNs use two separate modules to do this.
First, we must deduce the scene’s geometry. To do this, we use a modified version of the Ray Marching algorithm. I won’t describe this algorithm in detail, but the basic idea is to:
Consider different camera viewpoints that are available
Send “camera rays” from the camera’s position into the scene
Deduce geometry by finding where rays intersect with objects
Using this process, we can deduce the underlying objects and geometries that exist within a scene.
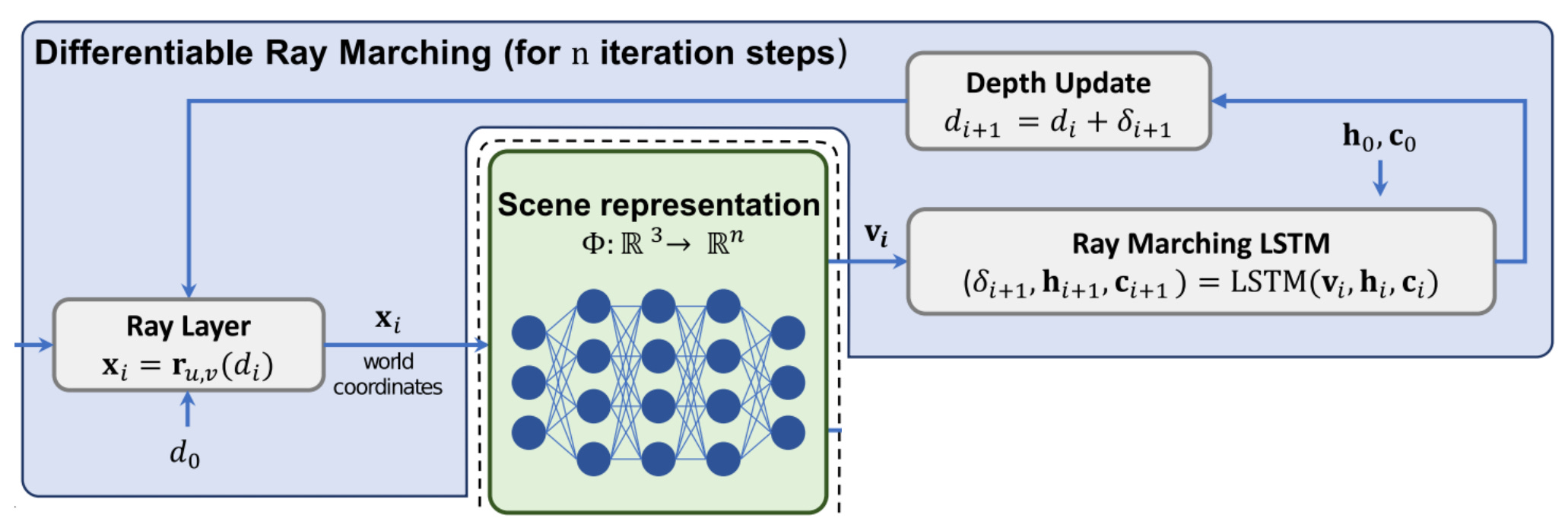
In [1], the authors make the Ray Marching process learnable by using an LSTM to perform each of these steps, as shown in the figure above. In this way, the Ray Marching process can be updated using our training data to become faster and more accurate! For more details on Ray Marching, check out the overview below.
Next, we must uncover the appearance of the scene by mapping the feature vector at each spatial coordinate to an associated color. In [1], this transformation is again modeled using a feed-forward neural network that (i) takes the per-coordinate feature vector as input and (ii) produces a per-coordinate RGB pixel value.
handling many scenes. So far, we have only considered training an SRN over a set of images corresponding to the same scene. But, what if we want to model multiple different scenes?
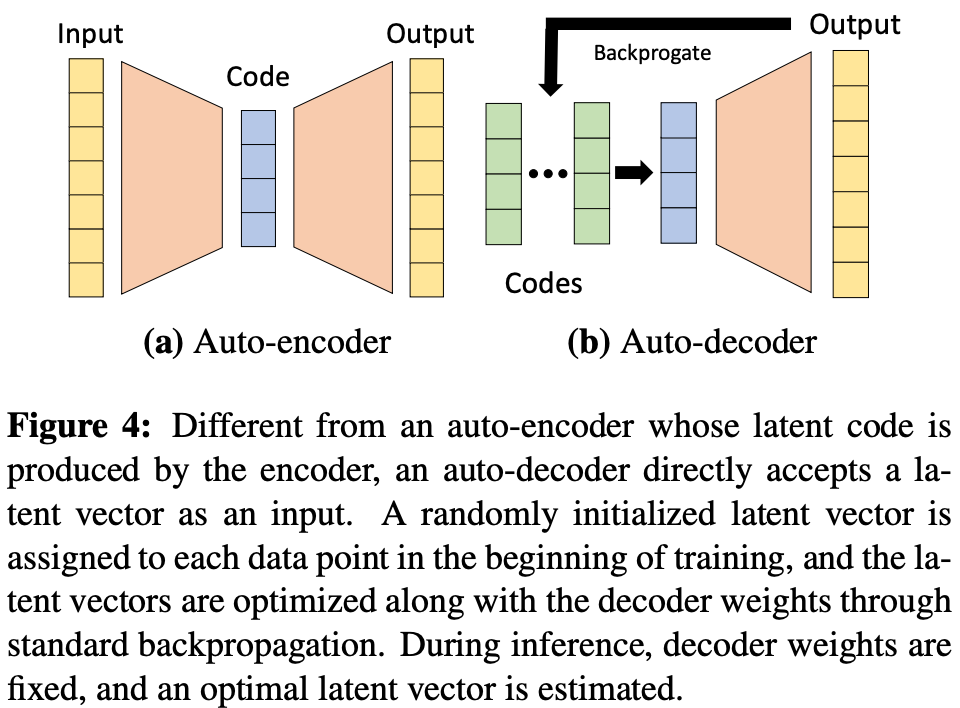
In [1], we associate each scene with a unique latent vector that is learned via an auto-decoder architecture (i.e., similar to the architecture used by DeepSDFs [3]!); see above. Using this latent vector as input, we can use a hypernetwork (i.e., a neural network that outputs the weights of another neural network) to generate the weights of the feed-forward feature representation network. This approach allows us to craft unique feature vectors for each scene, while also learning patterns that generalize across scenes.
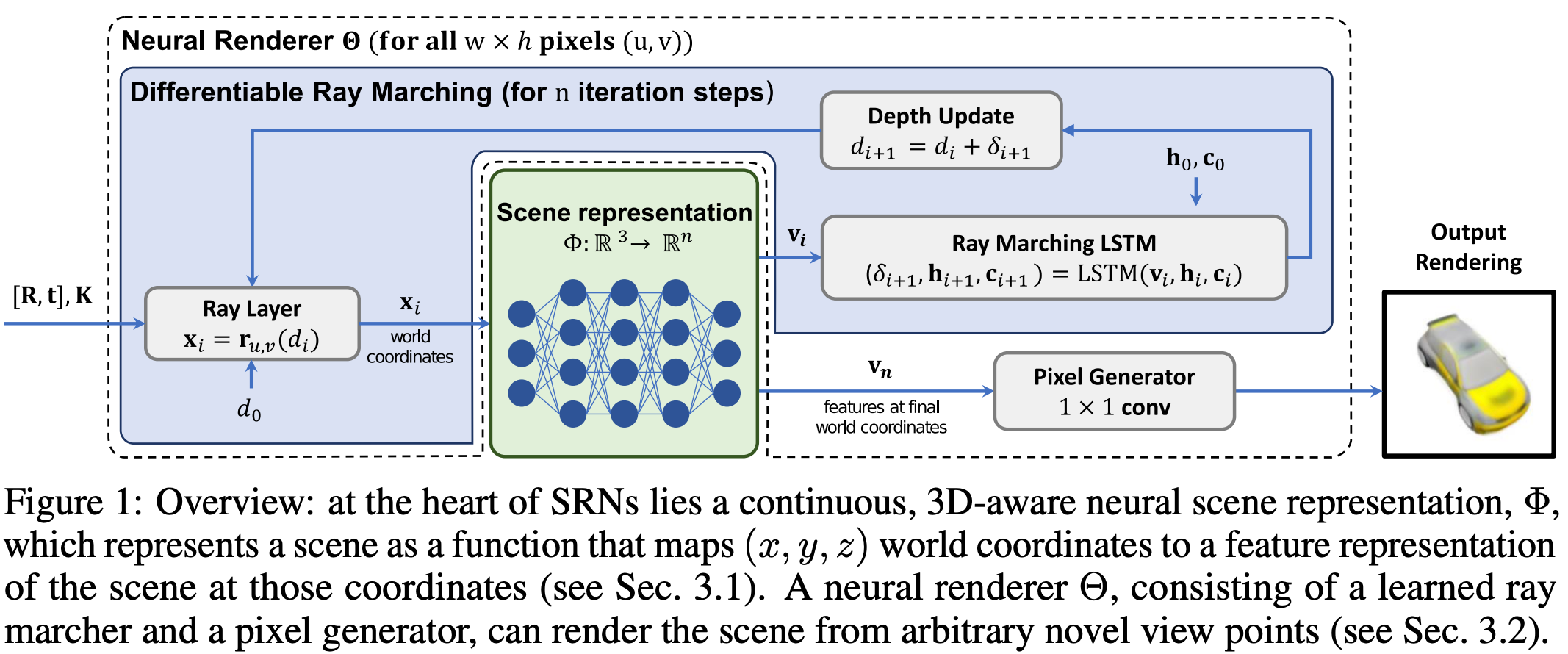
a global view. The full SRN model is depicted above. This model has several components, including:
A feed-forward network that generates feature representations for each spatial location in a given scene.
A separate (feed-forward) hypernetwork that generates the weights of the above network for a particular scene.
An LSTM-based, learnable Ray Marching module for rendering 3D geometries in the scene.
A feed-forward network that generates RGB pixel values for modeling the scene’s appearance.
All of these components combine together into an end-to-end trainable SRN that can learn to output arbitrary viewpoints of an underlying scene from a dataset of images with associated camera viewpoint information.
Do they perform well?
In [1], SRNs are evaluated on large-scale 3D datasets such as ShapeNet and DeepVoxels, as well as smaller, synthetic datasets of 3D objects. Performance is measured in two ways:
Accuracy of SRN-generated viewpoints of training objects
Accuracy of few-shot generations of hold-out test objects
To generate viewpoints of test objects (i.e., never observed during training), we need to first observe a few sample viewpoints of the object so that we can solve for the scene’s optimal latent vector. Then, we use the SRN to generate a viewpoint with this latent vector (i.e., hence “few shot” generation!).

On smaller synthetic datasets, SRNs clearly outperform baseline techniques, which we can see in a qualitative examination of model outputs; see above. SRN results on these smaller datasets are near pixel-perfect, indicating that the approach works well given limited training data. In fact, we can see in these experiments that SRNs are usually capable of recovering any component of the underlying scene that has been observed in the data.

On larger datasets, SRNs continue to perform well relative to baselines both in generating novel viewpoints of known objects and performing few-shot generation; see above. Notably, SRNs really shine in the few-shot case, where the model can leverage learned patterns from scenes that it has observed during training (i.e., referred to as prior information) to render reasonable viewpoints of new scenes with limited data. Overall, we can see that SRN output (i) is sharper and more accurate relative to prior models and (ii) improves when given more samples/information; see below.

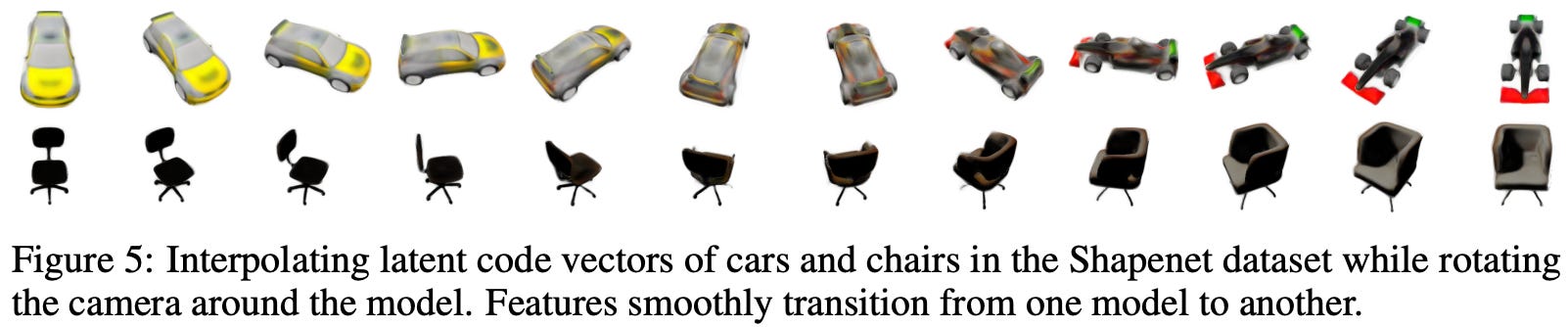
Similar to prior work, we can interpolate embeddings of the SRN’s latent space to produce new scenes. These results, illustrated below, indicate that the SRN’s embedding space contains useful, structured information about the underlying scene.
Takeaways
Relative to work that we have seen in prior overviews, SRNs are useful because they (i) allow us to model more than just geometry (i.e., both geometry and appearance) and (ii) can be trained using only images. Using SRNs, we can generate novel viewpoints of 3D scenes at arbitrary resolution in an end-to-end, learnable manner. The main takeaways of this approach are listed below.
directly encoding 3D info. SRNs directly inject 3D information into the viewpoint generation process because the feature representation network (and the pixel generation network) take [x, y, z] coordinates as input. This approach is not always followed by prior approaches. In the case of SRNs, however, this direct use of 3D spatial information allows the model to generate more consistent results between different viewpoints of the same scene.
no ground truth geometry. SRNs can be trained only using images and some associated camera parameters that reveal relevant viewpoint information for each image. Compared to prior approaches (e.g., DeepSDF [3]) that can only perform inference when given direct access to portions of an underlying 3D geometry, SRNs are pretty flexible. At the very least, modeling scenes from images only is a step in the right direction.
simple networks aren’t always cheap. One of the great things about 3D deep learning approaches (at least the ones we have seen so far) is that they mostly use simple, feed-forward networks. Compared to research topics that require massive deep learning models (e.g., language modeling), these simple networks are pretty nice! However, the training process might still be expensive even if the underlying network is simple. In [1], authors claim that most SRNs take around a week to train on a single GPU.

limitations. SRNs fall short in a lot of areas. Notably, they often fail to capture fine-grained details, such as holes within objects (e.g., see the chair holes in the above figure). They also struggle with objects that are not similar to the training data distribution and cannot capture effects due to varying lighting conditions or translucency. Future works like NeRF [2] improve upon the SRN by mitigating these issues and pushing towards simpler models that are capable of representing complex scenes and effects; e.g., entire rooms with many objects and variable lighting and reflection conditions.
New to the newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning.
This is the Deep (Learning) Focus newsletter, where I help readers to build a deeper understanding of topics in deep learning research via series of short, focused overviews of popular papers on that topic. Each overview contains explanations of all relevant background information or context. A new topic is chosen (roughly) every month, and I overview two papers each week (on Monday and Thursday). If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Bibliography
[1] Sitzmann, Vincent, Michael Zollhöfer, and Gordon Wetzstein. "Scene representation networks: Continuous 3d-structure-aware neural scene representations." Advances in Neural Information Processing Systems 32 (2019).
[2] Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.
[3] Park, Jeong Joon, et al. "Deepsdf: Learning continuous signed distance functions for shape representation." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
[4] Zaremba, Wojciech, Ilya Sutskever, and Oriol Vinyals. "Recurrent neural network regularization." arXiv preprint arXiv:1409.2329 (2014).
[5] Mescheder, Lars, et al. "Occupancy networks: Learning 3d reconstruction in function space." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
Do you have any inkling as to when tools like this will be available in ways like DALLE, such that regular people could used text prompts to have 3D objects created for them for use in VR?
Seems like progress is being made fast, but there is still some way to go in terms of performance and also practicality