
Agentic RL: Frameworks and Best Practices
How LLMs are trained to handle long horizon tasks in complex environments...

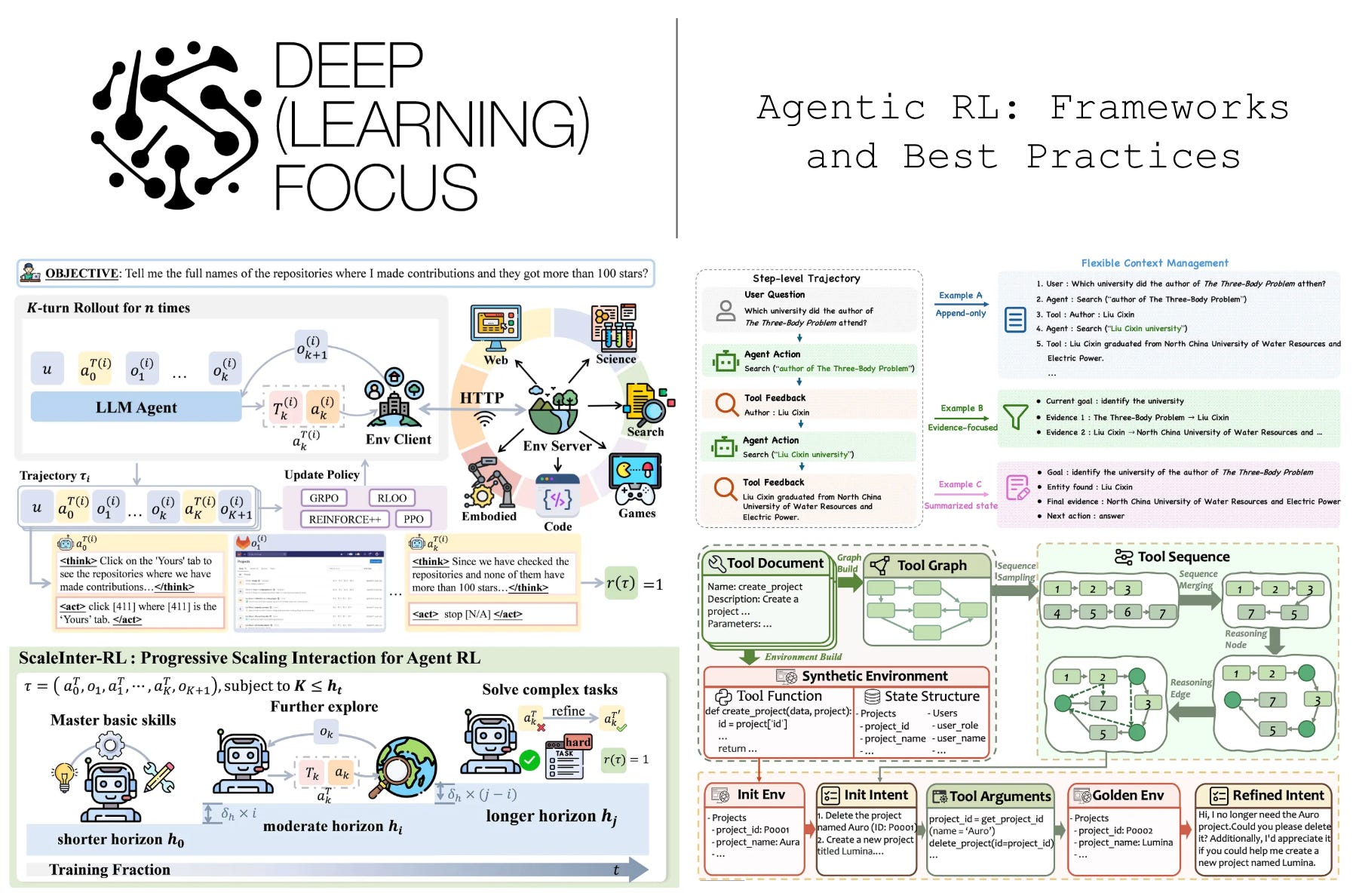
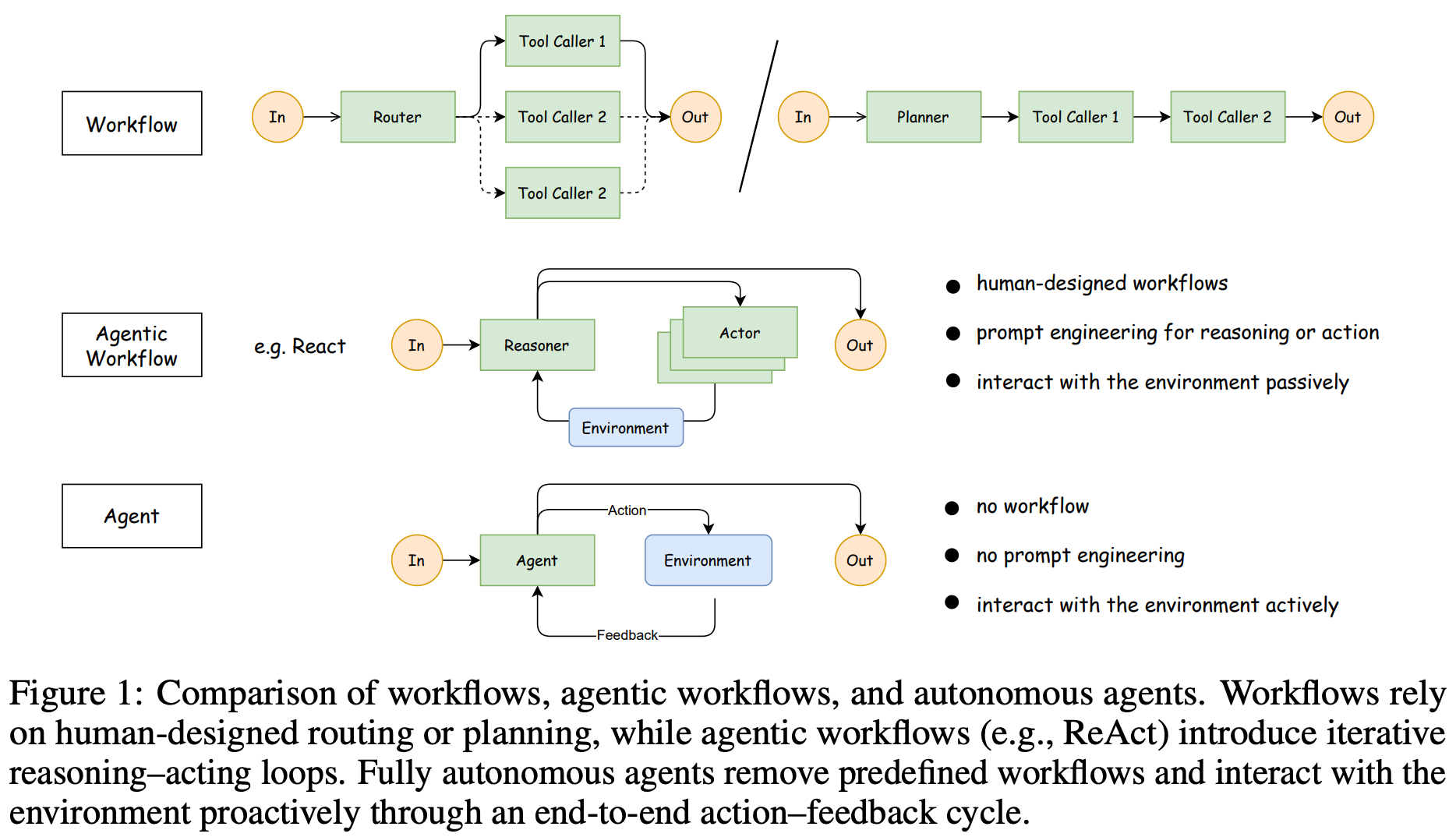
Recent research on large language models (LLMs) has been heavily focused on reasoning and reinforcement learning (RL). Much of the initial work in this area considered static tasks, where the LLM generates a single response to a prompt. Such single-turn tasks, however, are now less representative, as AI systems have become increasingly agentic. These systems are expected to reason over long time horizons, call tools, interact with users, and readily adapt to feedback. This shift toward autonomous functionality makes RL training more complex, requiring multi-turn trajectories, scalable rollout infrastructure, modular environments, and techniques for stable learning over multi-turn tasks. In this overview, we will study recent research on RL training for LLM agents and identify practical design principles for building functional and high-performing agentic RL systems.
The Basics of Agents and RL
The majority of this overview will study recent research on useful techniques and frameworks for training agents with RL. In order to understand this research, however, we first need to build a foundational understanding of both agents and RL. An agent is more than just an LLM, but we do not have to overcomplicate our definition of an agent. At the simplest level, an agent is just an LLM that runs in an agentic loop, using both tools and its own reasoning capabilities to solve complex problems. In this section, we outline the key components of an agent in detail and provide a structured framework for understanding agentic RL.
Key Components of an Agent
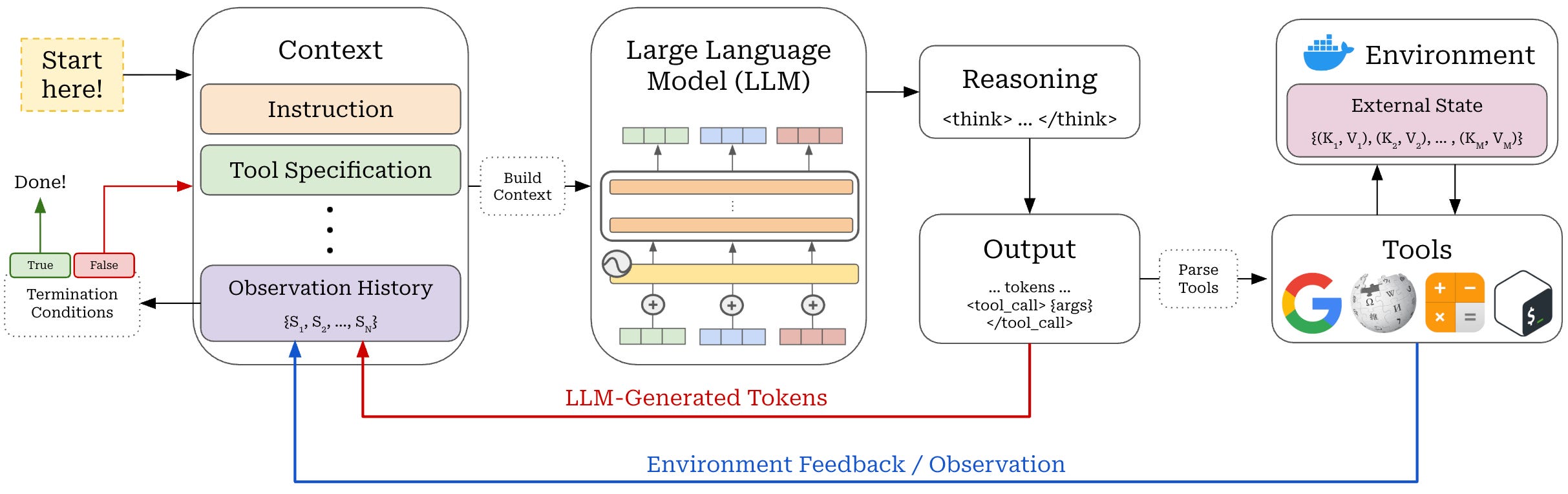
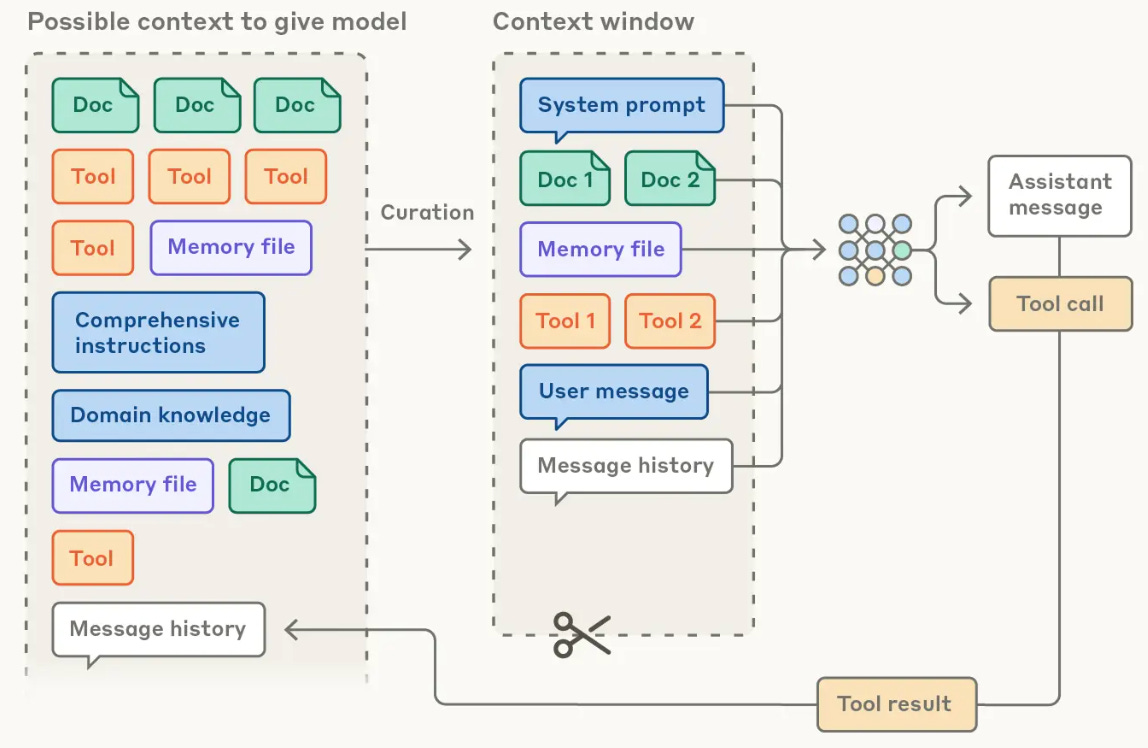
A high-level schematic of an agent system is provided in the figure above. As we can see, an agent has many components, such as:
The LLM backbone.
Instructions.
Tools.
The environment.
Given an initial instruction and specification, these components run in an agentic loop. The LLM backbone generates output, executes tool calls, ingests feedback from the environment, and repeats. At each step, termination conditions are checked to determine if the loop should continue or if the problem is solved. These components form an agent harness that controls the orchestration and integration details of the LLM. We will now cover each component in detail.
The LLM backbone in an agent system is just a standard LLM that has been trained to operate in an agentic context. Specifically, the LLM must be able to work well within the provided harness, which requires advanced instruction following, tool calling, and reasoning capabilities. Although any LLM can be used as an agent backbone, we often benefit from using a reasoning model; see below.
To solve multi-step tasks, an agent must be able to decompose difficult problems into smaller, simpler parts and solve each of those parts—possibly with the help of tools—to arrive at a final solution. Additionally, the model must be able to self-reflect and recover from its own mistakes while solving problems. Handling long-horizon problems in this way requires a high level of reasoning and reliability.
“The agent tended to try to do too much at once—essentially to attempt to one-shot the app... [To solve this], we… set up the agent to work step-by-step and feature-by-feature… we [then] prompt each agent to make incremental progress towards its goal while also leaving the environment in a clean state at the end of a session.” - from [9]
The instructions provide the information necessary to solve a problem to the agent, as well as context that helps the agent to approach a problem correctly. We should provide relevant domain information—usually taken from existing guidelines or policy documents—to the agent. Additionally, we can provide guidance on the task or problem-solving strategy, such as asking the agent to break problems into smaller steps, maintain a to-do list of completed sub-tasks, follow a particular style in its solution, or even double-check each step in its problem-solving process. Agent instructions should balance simplicity and specificity. We want the instructions to be detailed enough to reliably guide agent behavior but not so detailed that they become brittle and too difficult to maintain.
Tools and the environment. In order to interact with the external environment, LLMs need to be able to use tools like APIs, CLIs, or MCP servers. For example, if we want our agent to reserve a table for us at a local restaurant, we can simply teach the model how to craft a call to the OpenTable API. Tool calls can be represented directly in the LLM’s token stream by creating a set of special tool calling tokens and teaching the LLM how to use these tokens; see below.

For example, Qwen3 models handle tool calling via XML-style delimiters:
<tools>and</tools>are used to encapsulate tool definitions.<tool_call>and</tool_call>are used to encapsulate a specific tool call, including the tool to be invoked and associated parameters.<tool_response>and</tool_response>are used to encapsulate the result or response from the tool that is called.
In the agent instructions, we provide a specification for all tools between the <tools> tags, allowing the LLM to understand what tools are available and how they can be invoked. As the LLM is generating output, a tool can be invoked by outputting a <tool_call> sequence with proper arguments for the tool call. The </tool_call> token will trigger the generation process to stop so that the tool call can be parsed and executed. The result of the tool call is an observation or feedback from the environment, encapsulated in <tool_response> tags.
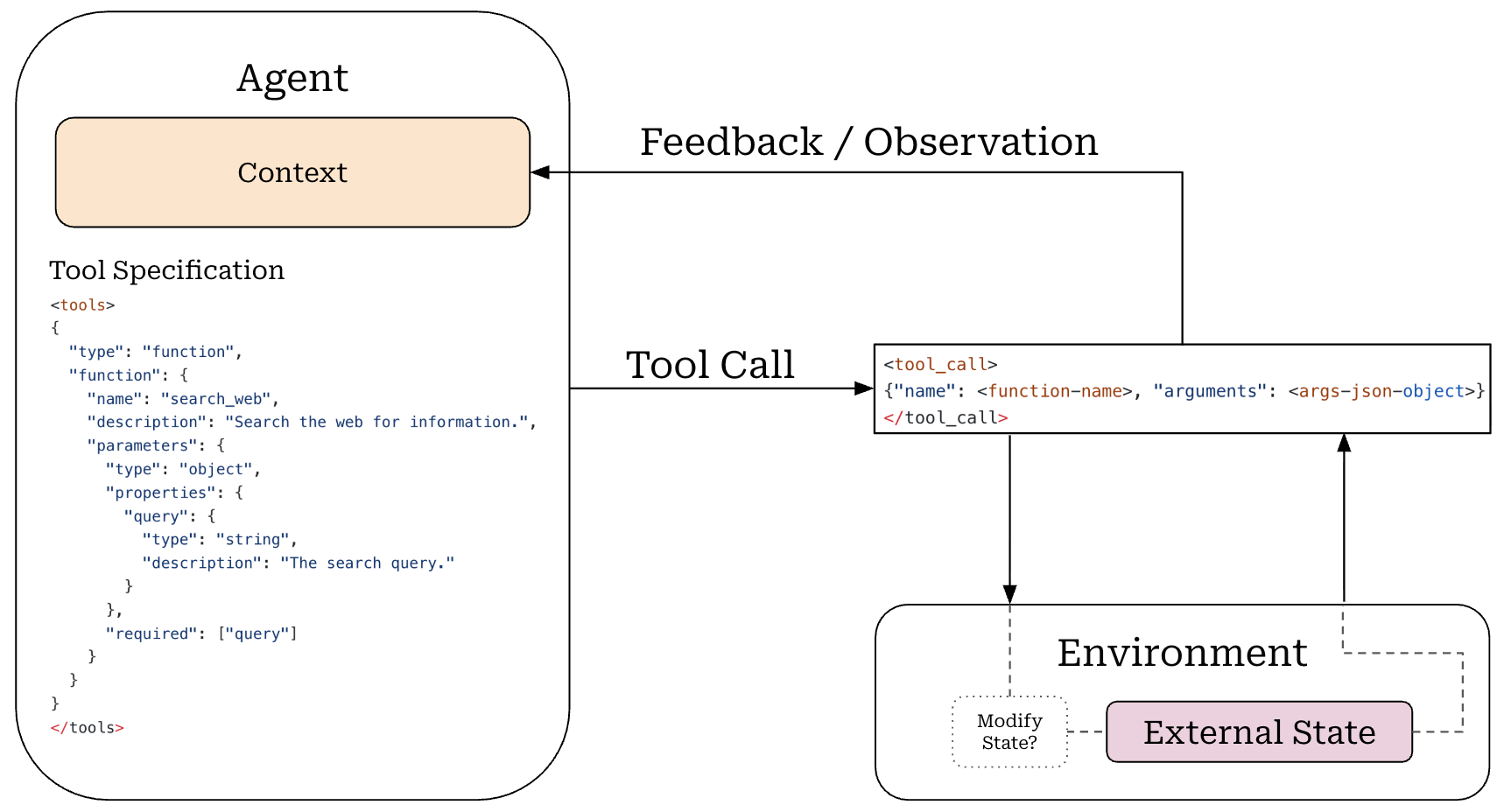
Tools mediate an agent’s access to the environment. The environment is stateful, and tool calls may result in environment state changes. Environment dynamics are usually encoded in the tool calling logic. Arbitrary environmental rules can be created via tool definitions, providing the agent with control over environment state or the feedback that is returned from the environment; see above.
At each step of the agentic loop, the agent performs two key operations:
Generates output tokens.
Executes tool calls (if a tool call is generated).
Given that tools are the agent’s interface to the environment, a step in this loop is often called an environment interaction step. After each step, we determine if the agentic loop should exit by checking predefined termination conditions that vary depending on the application. For example, we can define a maximum number of interaction steps, run a series of tests to determine if a problem is solved, or have the LLM provide an output indicating that its solution is complete.
Additional details. Although we have covered the primary components of an agent system, agent harnesses are a rapidly evolving area of research—new ideas and components are introduced every day. Additional harness components that are important but excluded from the above discussion include the following:
Context management controls how information is presented to the agent. For example, long-running tasks may use compaction to summarize prior steps or truncate feedback from the environment (e.g., error messages) to avoid overloading the LLM with too much context; see above.
Memory can allow the agent to persist useful context within a long-running task or even across different sessions and tasks. Conceptually, this memory system becomes another aspect of the environment—it is stateful and can be accessed via tool calls by the agent.
A Formulation for Agentic RL
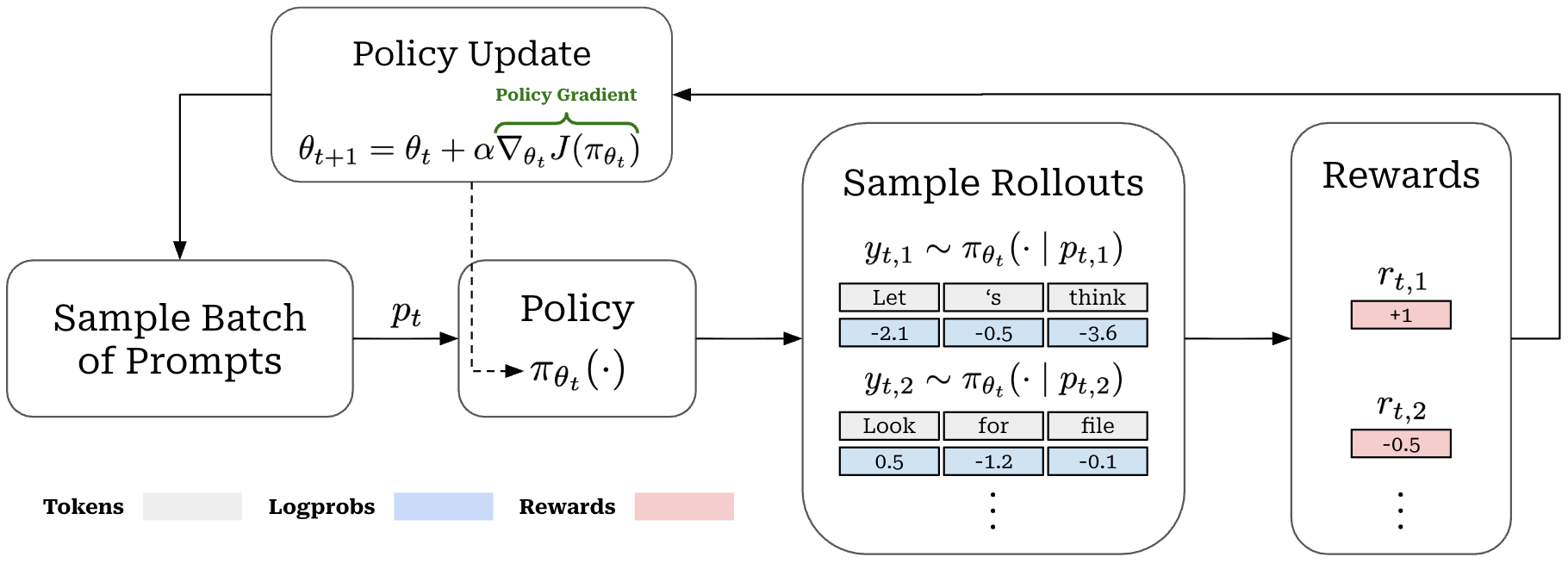
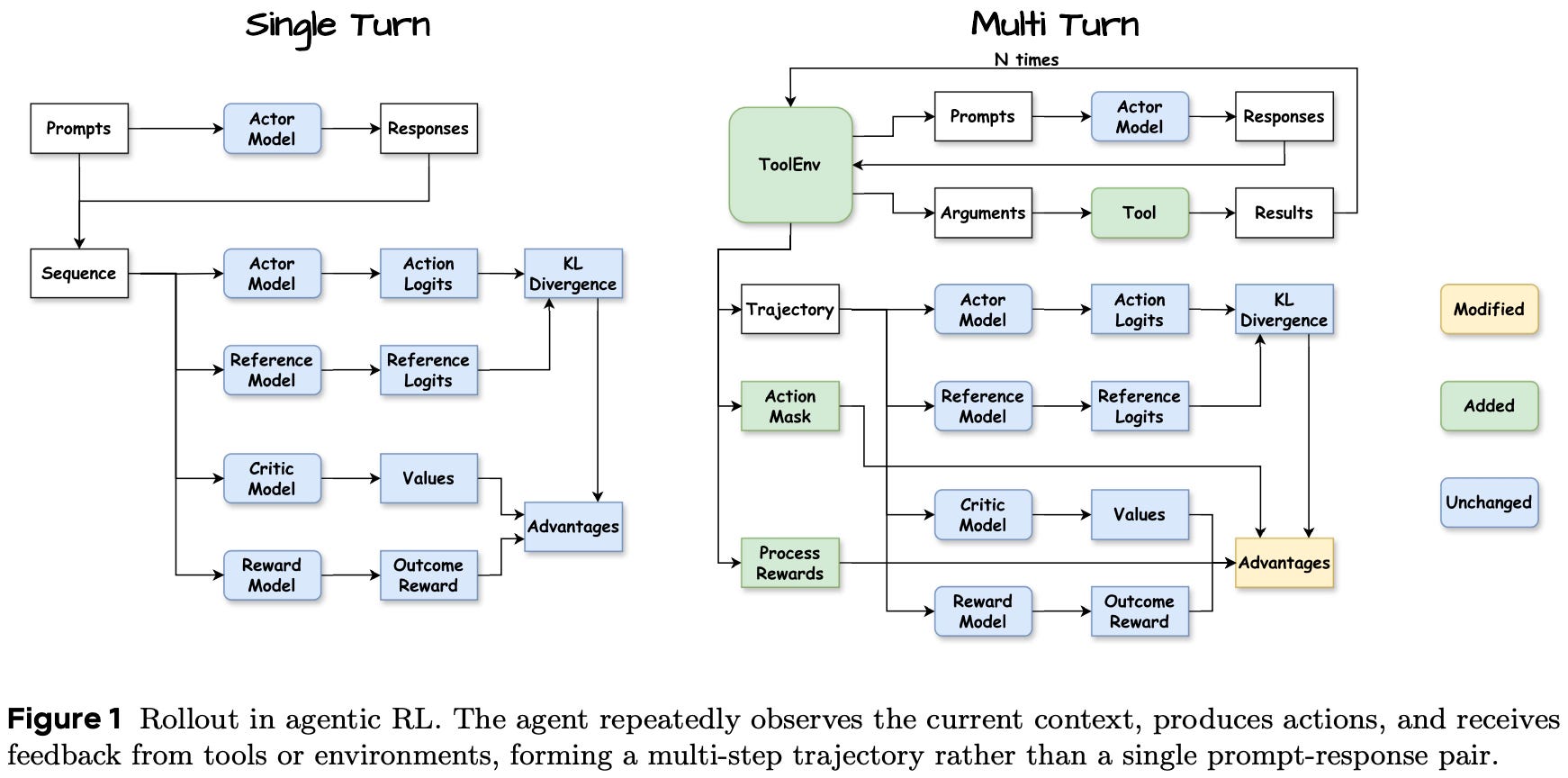
Recent work has begun to incorporate agent trajectories into the pretraining or midtraining process. However, most of the literature on training agents is focused on post-training, and reinforcement learning (RL)1 in particular. During RL training, we alternate between two key operations (shown above):
Rollouts: given a set of prompts, sample multiple completions for each prompt using the current LLM (and compute the reward for each completion).
Policy updates: compute a weight update for the LLM using the sampled rollouts and the given objective function.
The details of the policy update depend on the RL optimizer being used. Common choices include GRPO, PPO, and REINFORCE. Although GRPO is most commonly used, recent work has begun to use PPO to improve training stability and better handle long-horizon tasks (e.g., coding agents). For example, GLM-5.2 [12] used PPO instead of GRPO for this reason; see below.
“Long-horizon tasks produce substantially longer execution traces, and once a super-long trajectory is split by compaction into multiple sub-traces, different rollouts under the same prompt yield different numbers of trainable traces with highly variable lengths. We therefore move from group-wise optimization to a critic-based PPO formulation that learns from individual rollouts, relying on a critic to estimate token-level advantages rather than group-relative comparisons.” - from [12]
Agentic rollouts. The RL optimizer may vary, but the core inputs to the policy update are usually the same: token-level log probabilities and rewards. Additionally, the mechanics of RL training are similar for both agents and standard LLMs. The main difference lies in the rollout phase:
Standard LLMs typically use a single-turn setup that samples a textual rollout given a prompt as input.
Agents use a multi-turn setup in which multiple outputs are generated from the LLM across several environment steps within a single rollout.
Agentic rollouts are more complex than those of a standard LLM. Not only do these rollouts operate over a long time horizon, but each of the steps in an agentic rollout also interacts with the environment via tool calls. As a result, sampling agentic rollouts is a difficult infrastructural problem. Certain rollouts may take longer to complete than others due to a large number of interaction turns or slowdowns in the environment. Therefore, most agents are trained using asynchronous RL with a disaggregated—as opposed to colocated—architecture; see below. More details on this topic can be found in this overview of RL training infrastructure.
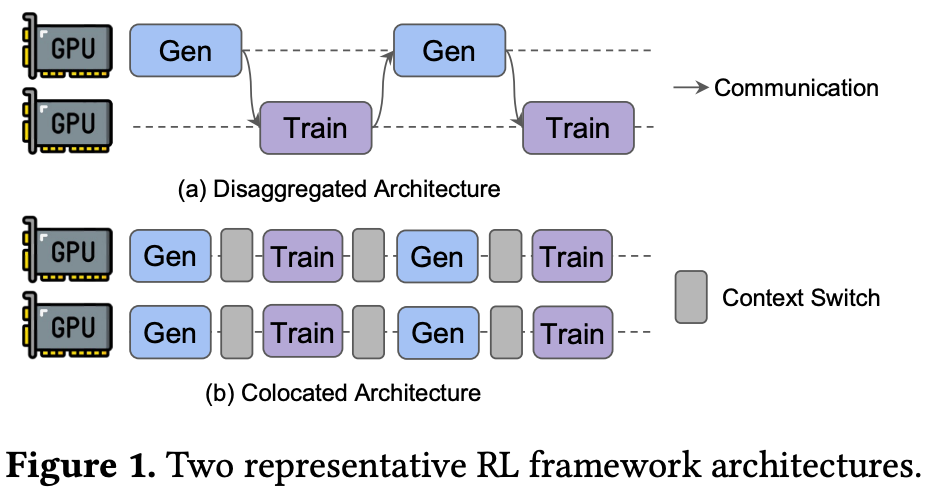
MDP formulation. To rigorously capture the differences between traditional and agentic RL, we will derive a Markov Decision Process (MDP) formulation of RL for both single-turn LLMs and agents. Put simply, an MDP is a probabilistic framework for decision-making that includes a sequence of states, actions, transition dynamics, and rewards—this is exactly the structure of RL training.
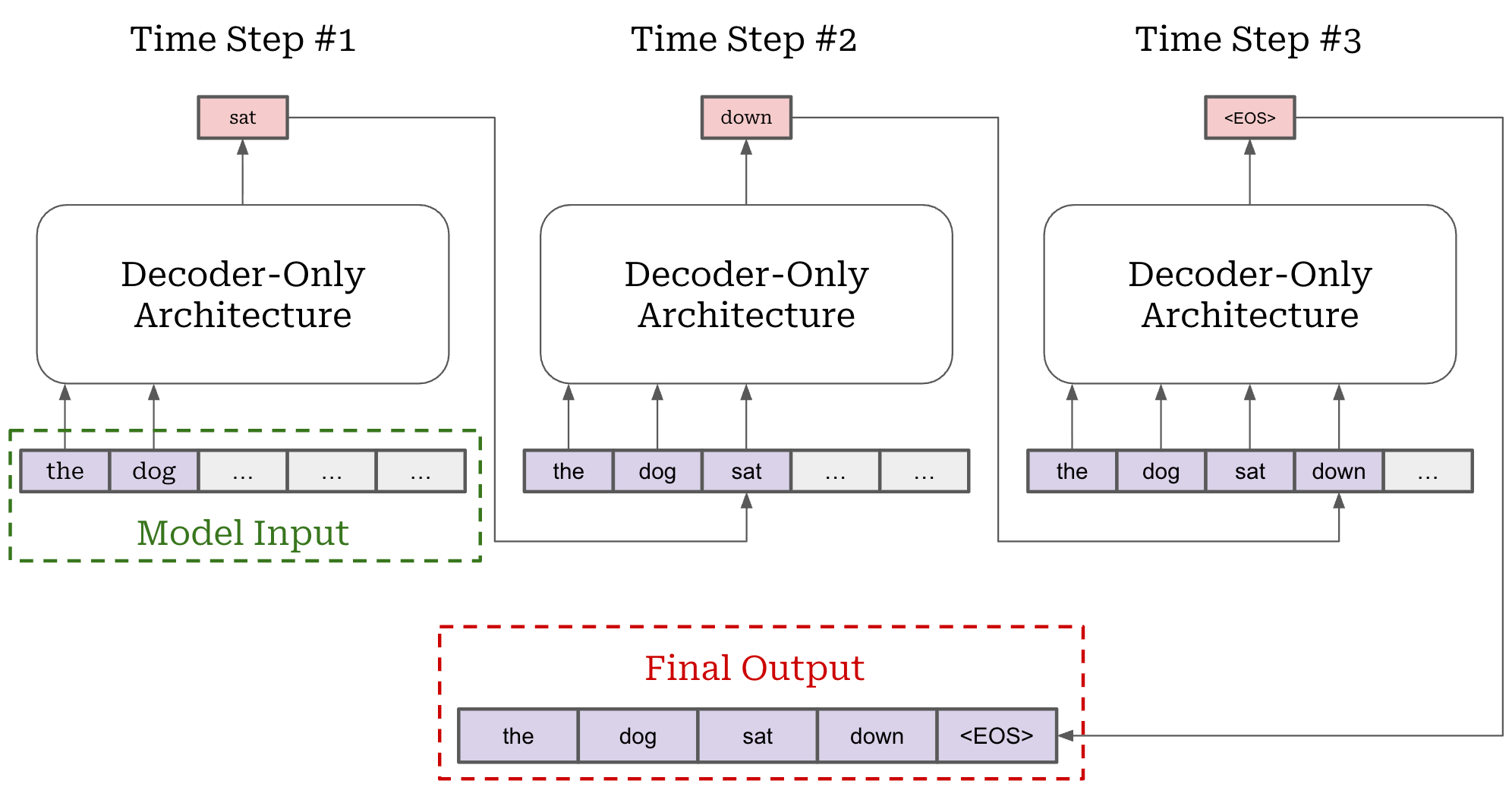
The traditional single-turn RL setup has a relatively simple formulation. The LLM generates a rollout using next-token prediction, which autoregressively samples each output token; see above. In this setup, the components of the MDP are defined as follows:
State: the current token context for the LLM (i.e., prompt tokens and all tokens that have been generated so far).
Action: the token selected during next-token prediction.
Transition function: deterministically appends the selected next token to the token context for the LLM.
Reward: usually a terminal (or outcome) reward assigned to the full, completed rollout by the environment.
Trajectory: the full rollout or sequence of generated tokens.
During generation, actions are taken by selecting a token from the LLM’s next-token distribution—each token is its own action. After a token is selected, it is added to the current state and used by the LLM to predict the next token. This process repeats until the LLM predicts a stop token (e.g., <|end_of_text|> or <eos>), which terminates generation and yields a complete trajectory.
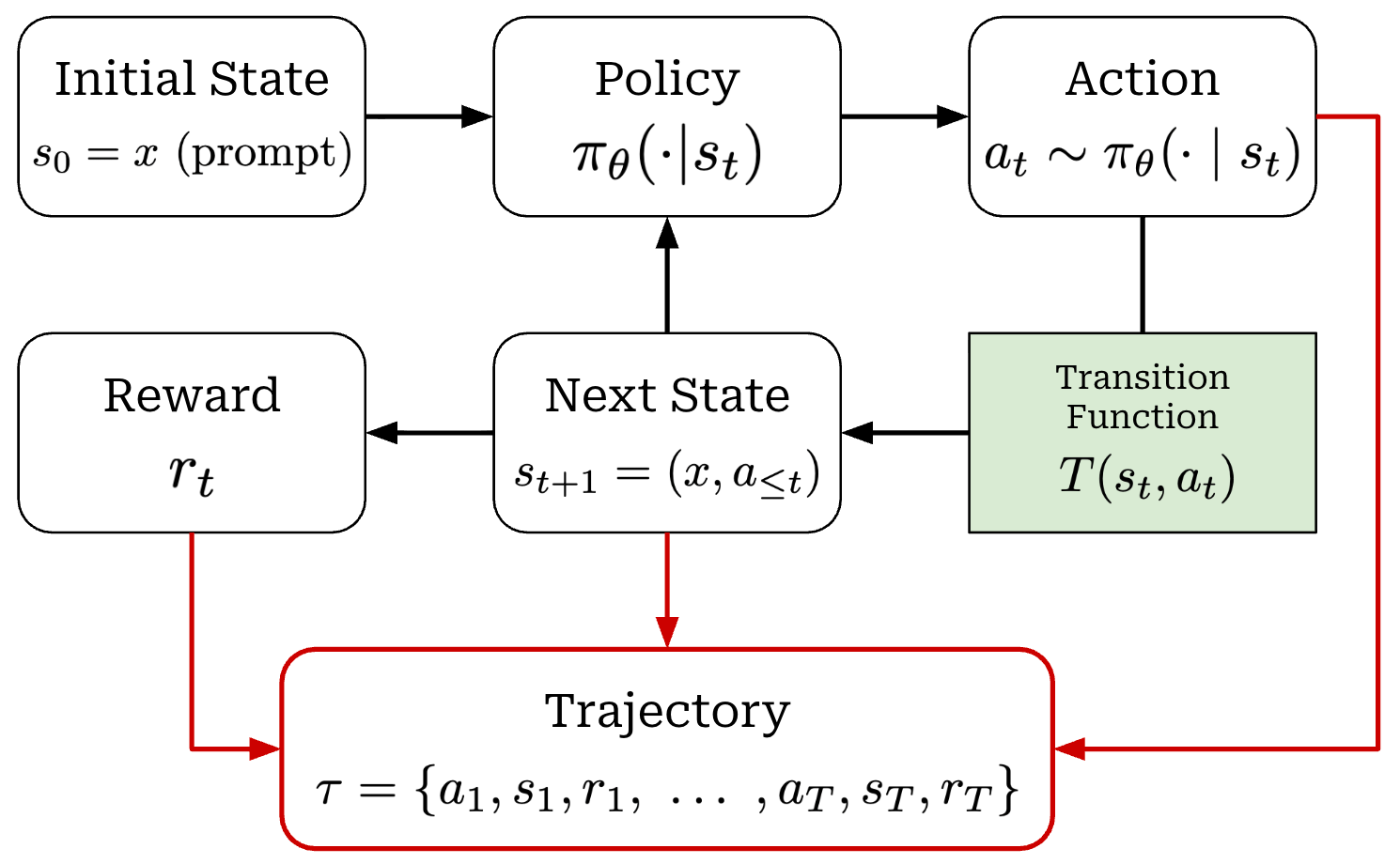
A depiction of the MDP formulation for single-turn RL is shown above. This formulation describes the steps for generating a single rollout. During RL, we generate a batch of rollouts before computing the policy update.
The multi-turn (agentic) RL setup extends the token-level MDP formulation to an interactive setting where an agent can act on—and receive feedback from—an external environment. Instead of generating a single textual sequence, the agent generates actions over multiple turns. Each agent action may include ordinary text as well as formatted sequences corresponding to tool calls. When a tool call is generated, it produces a corresponding observation from the environment. This observation is added to the running state, similar to generated output tokens.
Another key distinction between agentic and single-turn RL is that the state is no longer just the LLM’s token context. Rather, the state now includes both:
The textual context, including the prompt, generated tokens, tool calls, and any observations resulting from a tool call.
The external state of the environment, which the agent can modify via its actions (i.e., tool calls).
The MDP state is therefore a joint state containing the LLM-visible context and the environment state. When the agent generates tokens, the transition function deterministically appends these tokens to the state, as in the single-turn MDP formulation. However, the transition function also handles updates to the environment state, as well as observations returned from the environment. As a result, the transition function—unlike in the single-turn setting—can be non-deterministic depending on the behavior of the tools or environment.
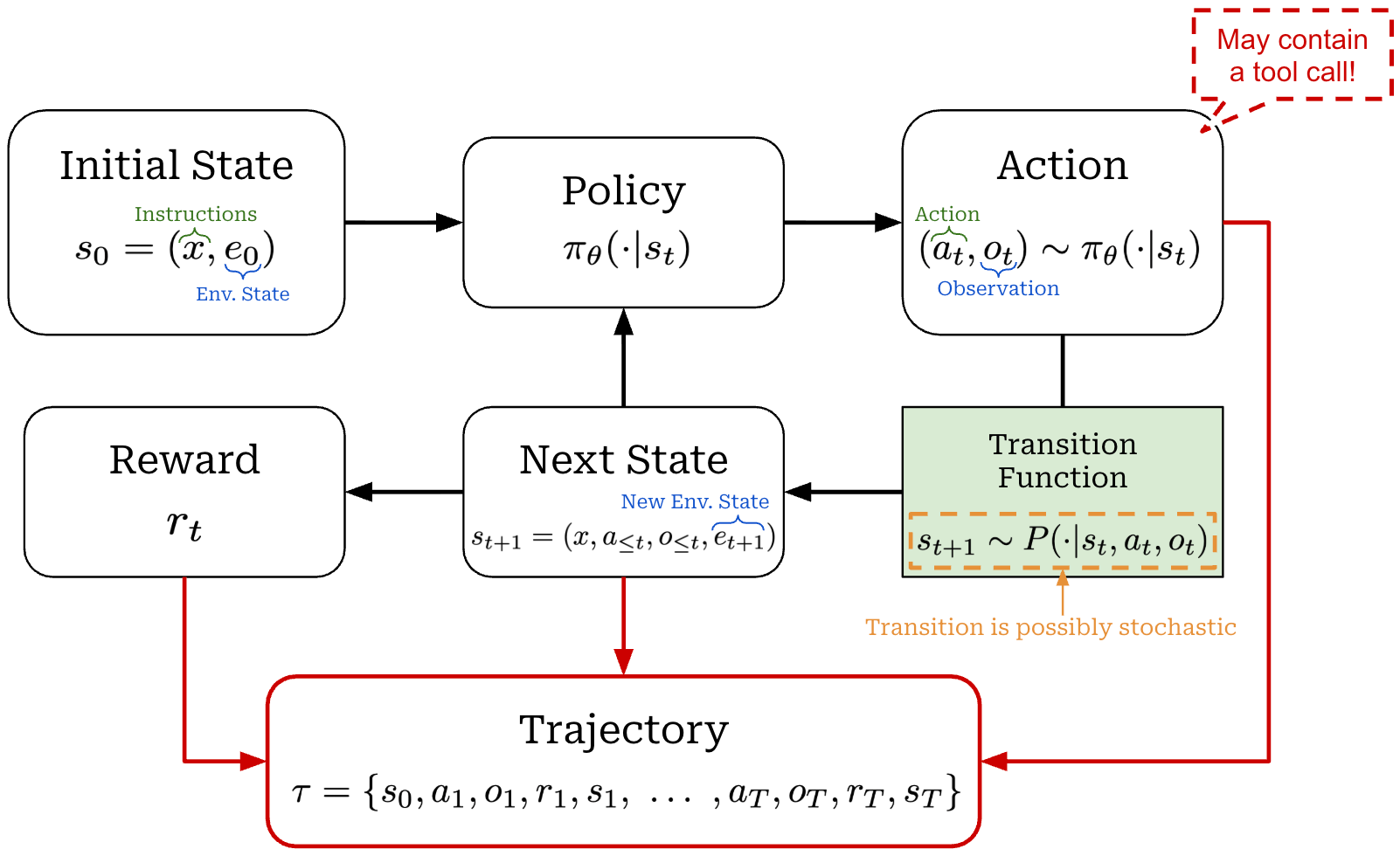
A depiction of the MDP formulation for multi-turn, agentic RL is shown above. To summarize, we define the components of this multi-turn MDP as follows:
State: the joint state of the agent and environment, including the LLM-visible context—instructions, generated tokens, tool calls, and observations—as well as any relevant external environment state.
Action: the agent-generated output at a given step. At the lowest level, actions are sampled tokens from the LLM’s next-token distribution, but sequences of tokens can form higher-level actions (e.g., tool calls).
Transition function: updates the joint state after the agent acts. Text-only actions append tokens to the LLM-visible context, as in single-turn RL. Tool calls additionally update the environment state and return observations, which may be stochastic.
Reward: feedback assigned to the agent’s behavior over the trajectory, including terminal (or outcome) rewards and intermediate rewards usually awarded at the step level.
Trajectory: the full multi-turn interaction trace, including instructions, agent actions, tool calls, observations, rewards, and relevant environment state.
Similarly to the single-turn formulation, we generate a batch of trajectories in each RL training iteration. Each trajectory can contain multiple rounds of agent actions and environment interaction, and these trajectories are used to compute the policy update. Although recent work on RL heavily utilizes outcome-based rewards, agentic RL frequently uses both outcome rewards and intermediate process rewards to provide granular supervision across longer trajectories.
Environment execution and scaling. Each agentic rollout requires an isolated environment instance with which the agent can interact. The environment may contain its own state (e.g., a filesystem, codebase, database, etc.) that the agent accesses and modifies via tools (e.g., shell, browser, API, etc.). Isolation is important because the agent’s actions can modify state—the agent may edit a file or change a database entry. In RL training, we usually generate multiple rollouts per task (e.g., the group for GRPO). Without isolation, these rollouts could modify shared state for the same environment and errors in one rollout could disrupt others. These issues can be avoided by creating a separate isolated environment instance for each rollout—an agent always has its own dedicated environment.
This isolation is often handled with Docker containers or similar sandboxing mechanisms—each rollout receives a clean environment instance to prevent inter-trajectory interference. Scaling environments is a systems challenge. RL training may require thousands of concurrent rollouts per update, each with an isolated environment. Any slowdown in environment startup, execution, or teardown becomes a bottleneck for rollout generation and for the RL training process.
“A challenge we encountered was scaling up SWE-Bench environments… each RL iteration spawned 512 Docker containers in parallel… overloading Docker’s API server and eventually crashing the Docker daemon… To remove that bottleneck, we integrated Kubernetes support into R2E-Gym, letting the orchestrator schedule containers across a pool of nodes.” - from [13]
A naive implementation might launch containers through the local Docker daemon on each rollout worker node, but this can become a bottleneck when many workers create and destroy containers concurrently. Larger-scale systems often use a cluster orchestration layer (e.g., Kubernetes) to schedule environment instances across a resource pool, manage environment lifecycles, and avoid single points of failure. For practical examples of RL environments and how they can be managed at scale, please see the writeup from Prime Intellect below.
Agentic RL Frameworks and Techniques
Now that we have a basic understanding of agents and how they can be trained with RL, we will examine a series of recent papers that study agentic RL from a practical perspective. These papers cover all aspects of agent training, such as:
Representing trajectories properly.
Scaling environments.
Handling multi-task training.
Creating synthetic environments.
Making training stable.
From this work, we will identify common patterns and practical techniques that are repeatedly used to train more capable agents. As we will see, many parts of the training process can be modularized, making it easier to experiment with new environments, reward designs, rollout strategies, and RL optimizers.
ToRL: Scaling Tool-Integrated RL [1]
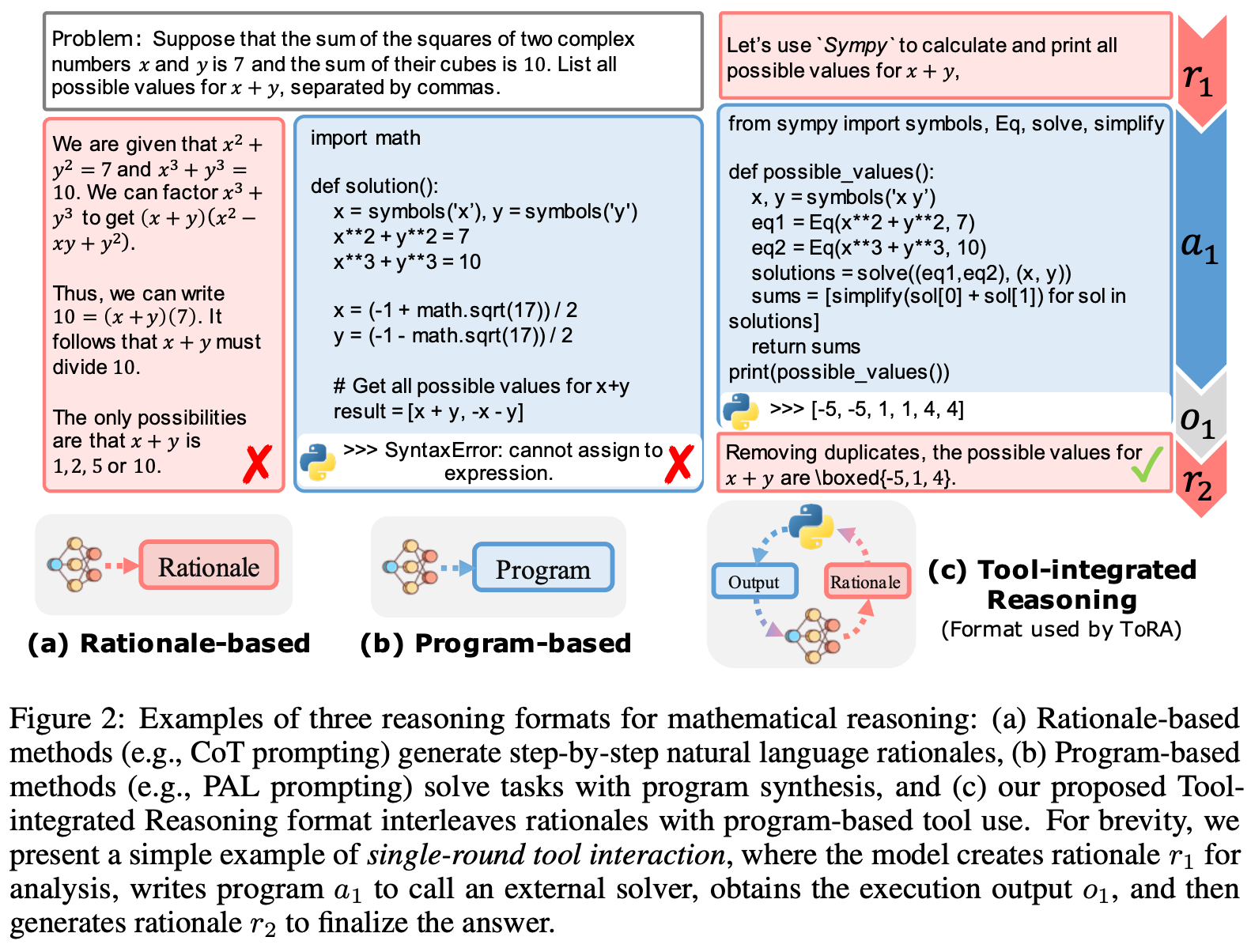
Although LLMs tend to struggle with performing precise numerical calculations or solving complex equations, these tasks can be easily delegated to an external tool. For example, teaching an LLM how to generate and execute code using an external code interpreter can enable sophisticated mathematical and symbolic reasoning capabilities. This concept is commonly referred to as tool-integrated reasoning (TIR), and LLM agents taught to reason in this manner have been shown to be quite powerful [2]. As illustrated in the figure above, TIR interleaves text-based and code-based reasoning within the problem-solving process.
“Despite these advances, existing tool-integrated reasoning approaches face critical limitations. Most studies distill trajectories from stronger models and perform SFT, restricting models to predetermined tool usage patterns and limiting exploration of optimal strategies.” - from [1]
Agents are commonly taught to perform tool-integrated reasoning via supervised learning (e.g., by training on trajectories generated by a powerful teacher LLM). Authors in [1] extend this approach by training tool-integrated reasoning agents with RL using their proposed Tool-Integrated Reinforcement Learning (ToRL) approach. This training framework is relatively simple—it uses a standard outcome-reward-based RL setup—but the analysis in [1] provides useful practical insight into achieving stable and effective RL training for tool-integrated reasoning agents.
The ToRL framework uses an RL-Zero setup, meaning we begin the RL training process directly with a pretrained base model that has not yet undergone any post-training. To enable tool-integrated reasoning, a code interpreter is added as a tool in the RL training environment, and the model learns to utilize tools via reward-driven exploration. Importantly, the LLM is given a prompt that encourages the model to answer questions with a fusion of natural language and code-based reasoning; see below. This prompt provides a useful seed that helps narrow the model’s exploration space by encouraging TIR-style solutions. This behavior is then refined during RL training as the model is updated to maximize rewards.

As the model generates text, it has interleaved code blocks that are wrapped in the ```python <code here>``` indicator. After a code block is generated, the model then produces an ```output tag. When this tag is generated, we:
Pause generation.
Execute the code block2.
Append the code output to the context.
Continue generating.
An example of this interleaved code structure is provided in the figure below.

The model can interleave multiple code blocks into the problem-solving process. However, executing each code block comes at the cost of ceasing the inference process and can, therefore, slow down rollout generation during RL training. To ensure the agent does not make excessive use of code blocks and cause degraded training efficiency, we impose a maximum of C tool calls per problem on the model. Most experiments in [1] set C = 1. Setting C = 2 yields a moderate performance improvement, but this comes at a significant cost in efficiency.
“We deliberately return error messages to the LLM when code execution fails… these error diagnostics enhance the model’s capacity to generate syntactically and semantically correct code in subsequent iterations.” - from [1]
Any errors during code execution are returned to the LLM as observations. However, authors in [1] truncate error messages to only include the last line so that the LLM’s context is not overloaded by verbose tracebacks. Code output is also masked from the RL loss function, ensuring that non-generated text is treated as external context and the model is not trained to predict these results. All code is executed in sandboxed environments3 that are isolated from the main training process. Creating a sandboxed environment adds extra latency to execution, but isolation is necessary to ensure that issues in the code (e.g., a segmentation fault) do not compromise the actual RL training process.
The reward mechanism used for training tool-integrated reasoning agents in [1] is relatively simple. The reward function assigns:
Positive reward (
+1) for a correct response.Negative reward (
-1) for an incorrect response.Mildly negative reward (
-0.5) for non-executable code.
We learn in [1] that punishing the agent for non-executable code does not benefit performance; see below. Using pure outcome rewards—computed by comparing the model’s output to the ground truth answer for a prompt—yields results that match or exceed those achieved with an additional error penalty. Authors in [1] hypothesize that this penalty may encourage the model to become overly conservative when generating code, thus leading to a decline in overall performance.
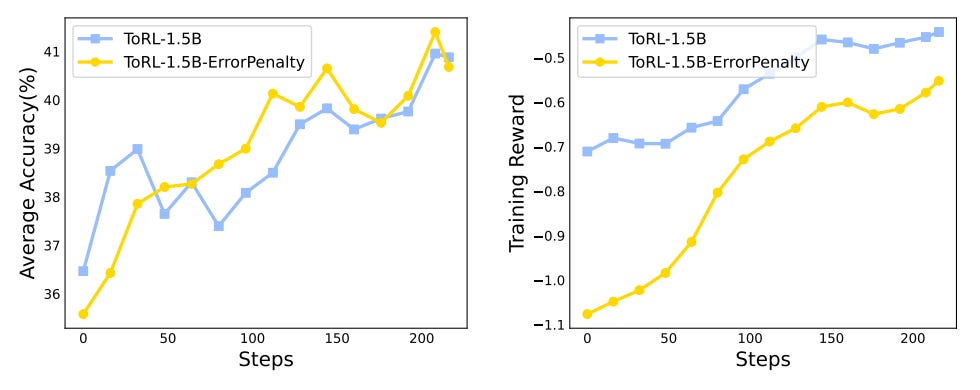
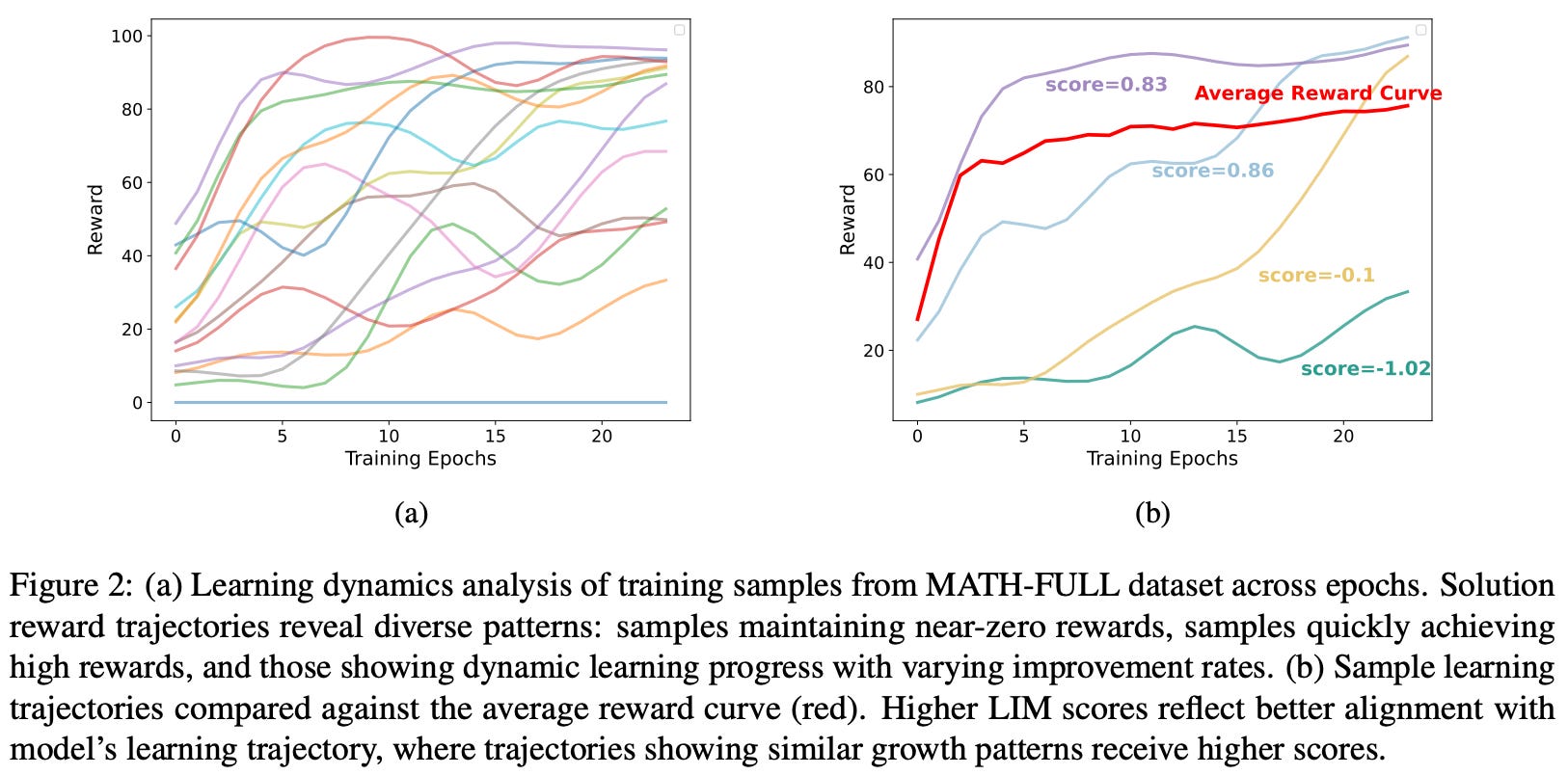
Practical findings. Experiments in [1] are performed with GRPO over a set of ~29K math competition questions curated from public benchmarks (e.g., MATH and Numina-MATH). Questions that are hard to verify (e.g., proof-style questions) are removed from the data, and the final set of training examples is selected using the LIMR technique; see below. At a high level, LIMR tracks the reward of each training sample across training epochs and scores questions based on alignment with the learning trajectory. Examples that match the model’s learning process receive high scores and are selected. Instead of selecting difficult or random data, LIMR prioritizes questions that are learnable by the model at the right time.
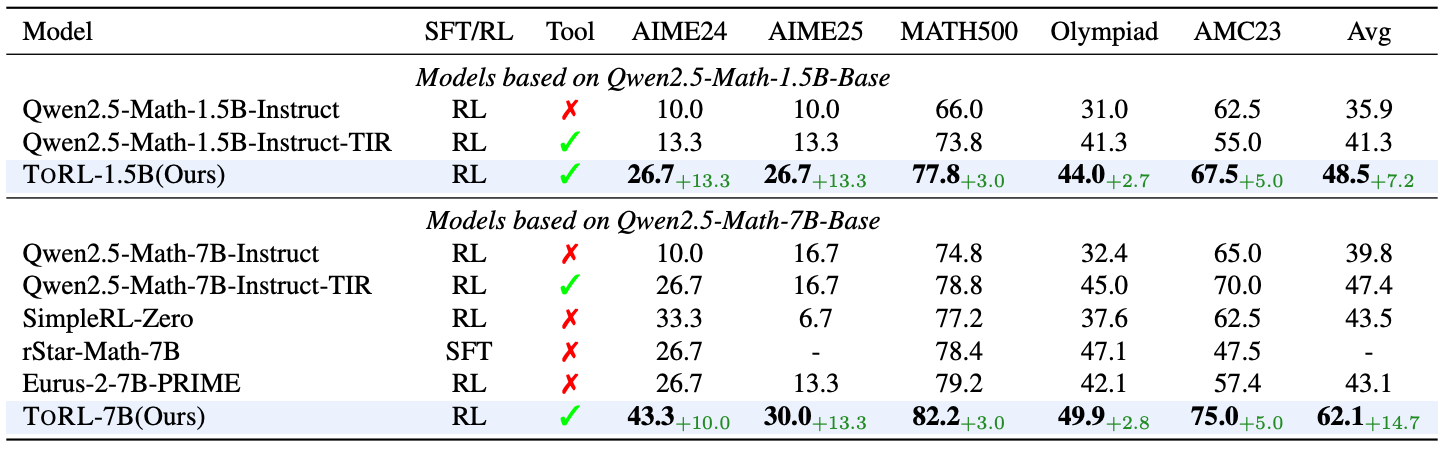
Training with ToRL is found to significantly improve mathematical reasoning capabilities. For example, a 14.7% absolute improvement in accuracy is observed relative to an SFT-trained baseline for Qwen2.5-Math-7B models; see below.
Beyond the performance benefits of ToRL, there are several interesting trends in agent behavior observed in [1]:
The ratio of problems that the model solves by generating code increases steadily (i.e., from 40% to 80% after 100 steps) throughout training.
The ratio of successfully executed code increases throughout training.
These findings indicate that meaningful tool utilization strategies can be learned via RL. Authors even provide concrete examples of sophisticated agent behavior observed in models trained with ToRL. For example, agents are found to use the information from an error message to reflect upon and correct their own code or even verify generated solutions with a mixture of code and natural language.
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning [3]
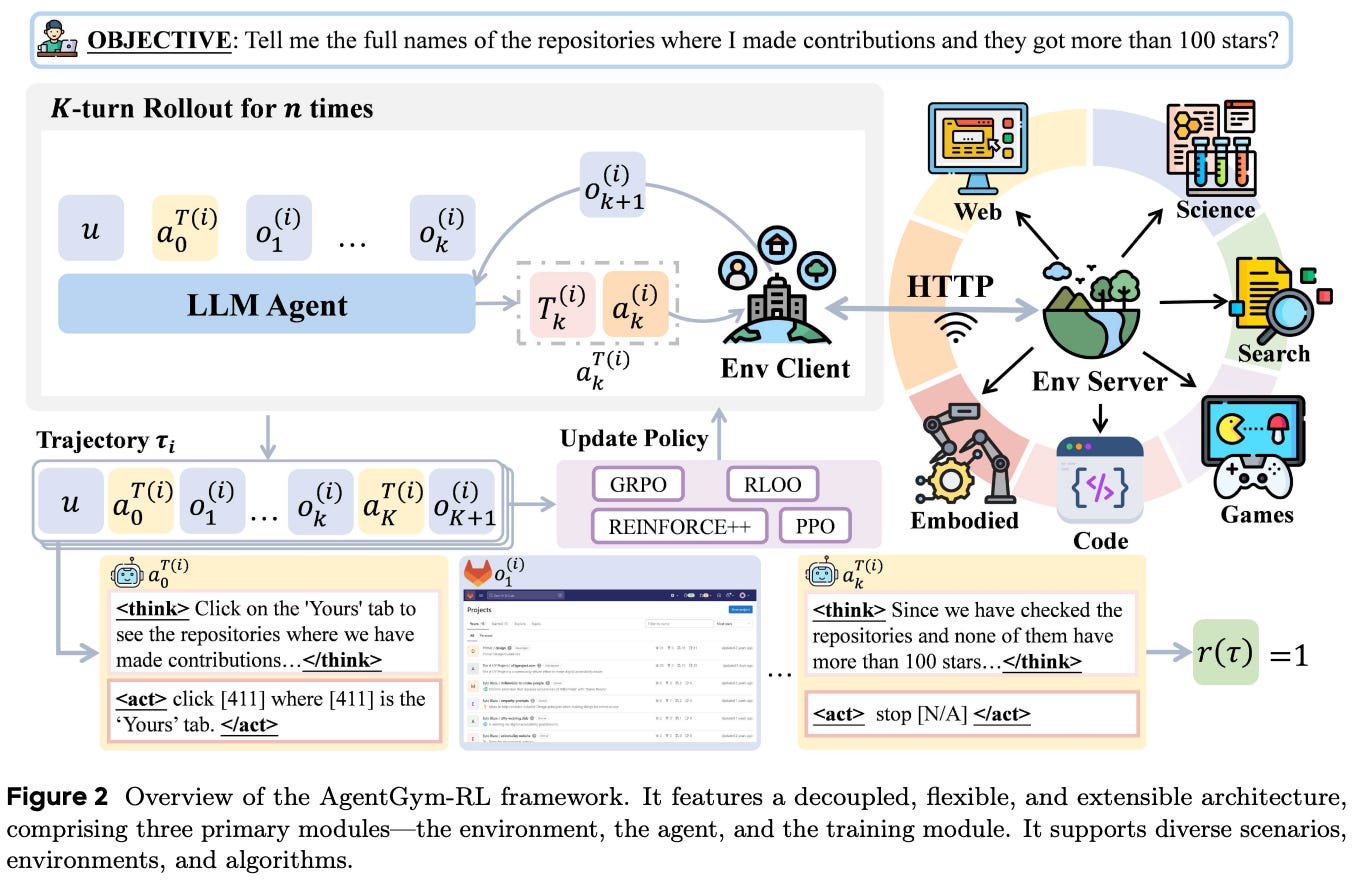
As LLMs evolve from conversational agents to autonomous systems that reason and act, the infrastructure for training these agents must also evolve. In [3], authors propose an open-source framework for training LLM agents with RL to better handle decision-making tasks that require complex interaction across many conversational turns; see above. The framework proposed in [3] trains LLM agents with outcome rewards—similarly to most work on agentic RL training—but follows a modular and extensible design to simplify experimentation with agents. Notably, agents are trained purely with outcome-based RL in [3], usually starting from an existing instruct model checkpoint (e.g., Qwen2.5-3B-Instruct).
The AgentGym-RL framework is a generalized extension of the prior AgentGym framework with improved efficiency and more modular support for training on a wide variety of realistic tasks. The framework has three key components:
Environment: a realistic task or scenario for the agent to solve.
Agent: the core intelligence layer that is powered by an LLM running in an agentic loop to process observations, reason, and generate actions.
Training: a modular RL training pipeline that allows us to optimize agent behavior within the environment(s).
Environments in [3] span various domains (e.g., web navigation, embodied tasks, or scientific experiments) but follow a standard design. Namely, an environment is an independent service that implements a shared set of APIs; see below.
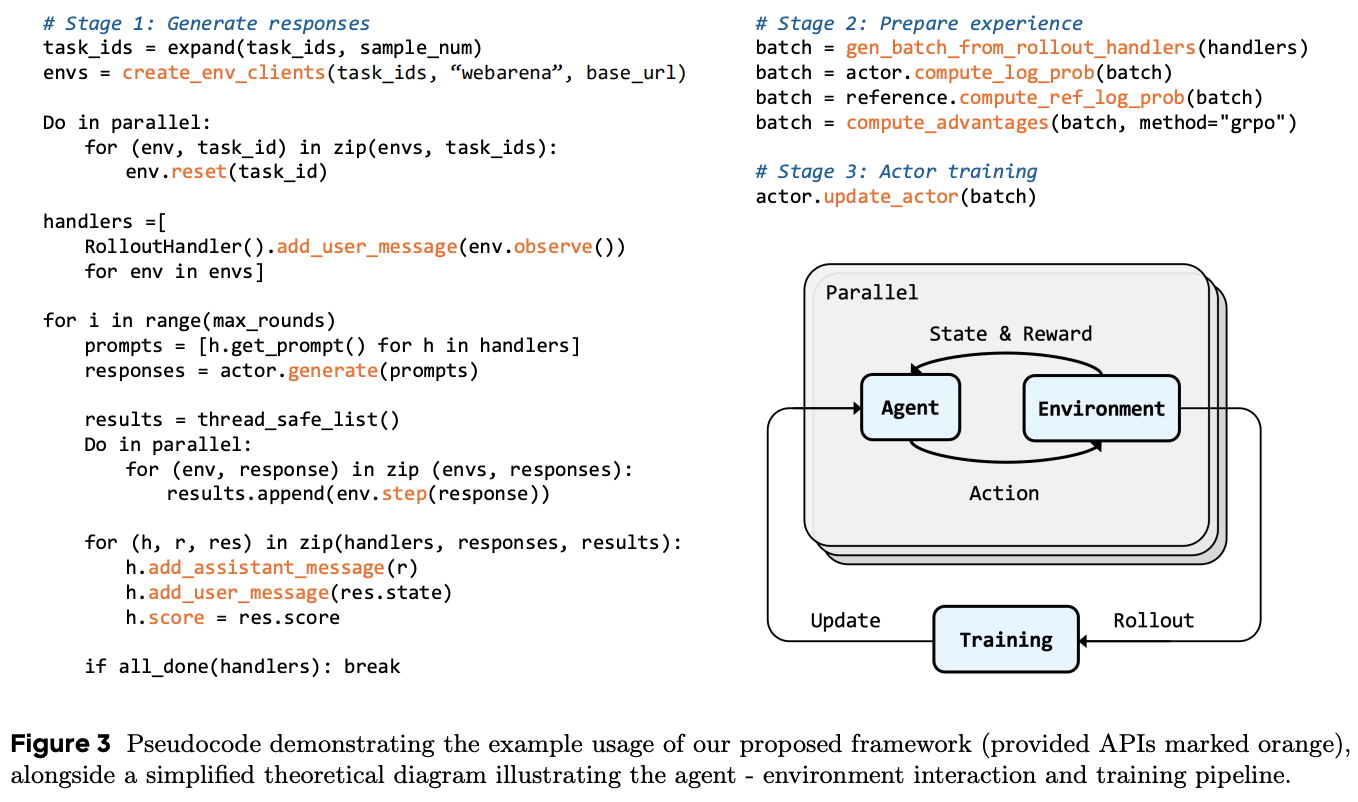
This standardized structure allows us to run many environments independently and in parallel during RL training. Specifically, each environment in [3] runs as an independent service that exposes a unified HTTP interface, allowing many different environments to seamlessly “plug in” to the RL training process.
Updating the agent. When performing a training update, we have a batch of user queries and a set of initial environment states for each query. Environments are initialized in parallel, and each agent interacts with its own environment instance to avoid interference between tasks. Usually, these agents are replicas of the current policy running in each separate environment. Within the agentic loop, each agent undergoes several sequential interaction turns with the environment, where the following operations are performed in each turn:
response=actor.generate(prompt): samples a response from the agent given the current state and interaction history.state,reward=env.step(response): sends this response to the environment client to update the environment, provide an environment observation, and yield a reward.add_assistant_message(response): updates the trajectory to include the new response sampled from the agent.add_user_message(state): updates the trajectory to include the new state of the environment after the latest action from the agent.
Finally, the framework records any scores or rewards produced during each interaction turn. The agentic loop terminates when the agent solves the task or reaches its fixed interaction-turn budget. Each completed rollout produces a full trajectory containing all of the agent’s actions, observations, and rewards. By running multiple agents across environments concurrently, the framework collects a batch of trajectories, which is then passed to the training pipeline to update the agent’s behavior. This process is repeated throughout training.
Engineering optimizations. Beyond the unified interface for agent-environment interaction used in [3], AgentGym-RL includes several environment-specific engineering optimizations that make RL experiments with long-running tasks more efficient. For example, the verl library is extended beyond single-turn use cases to better support multi-turn agentic RL. The RolloutHandler used for AgentGym-RL tracks all trajectory details (i.e., the full interaction history and rewards for each rollout) and constructs attention and loss masks to help with distinguishing agent and environment-generated tokens across the trajectory
“A framework must be able to scale both in parallelism and interaction duration. We implemented a series of optimizations to achieve this… we replaced WebArena’s default single-browser-per-process design with a subprocess-based architecture, enabling a single server to manage multiple Chromium instances concurrently… in SciWorld environment, we redesigned the environment’s initialization and reset routines to support robust parallel creation and resetting of multiple instances… we support longer training horizons through a full-reset interface in WebArena, which restores each web server to its initial state after every episode and mitigates state inconsistencies over time.” - from [3]
Environments are also configured to support parallel initialization and operate independently to collect many concurrent rollouts. For example, the WebArena environment initially used a single-browser-per-process design, which was replaced in [3] with a subprocess-based architecture that allows a single server to manage multiple concurrent browser instances. The SciWorld environment is also modified to simplify launching and resetting multiple environment instances at the beginning and end of each rollout. Many such modifications are made in order to more efficiently manage and scale environments for agentic RL in [3].
ScalingInter-RL. We see in [3] that training LLM agents to perform long-horizon tasks is difficult. During the early phases of training, agents struggle to produce long interactions that are meaningful, often collapsing into redundant reasoning patterns or taking unnecessary actions. We can solve this issue by constraining the set of environments on which the agent is trained—training may be stable if we only consider shorter-horizon tasks—but such an approach would prevent the agent from learning diverse, non-trivial patterns of reasoning.
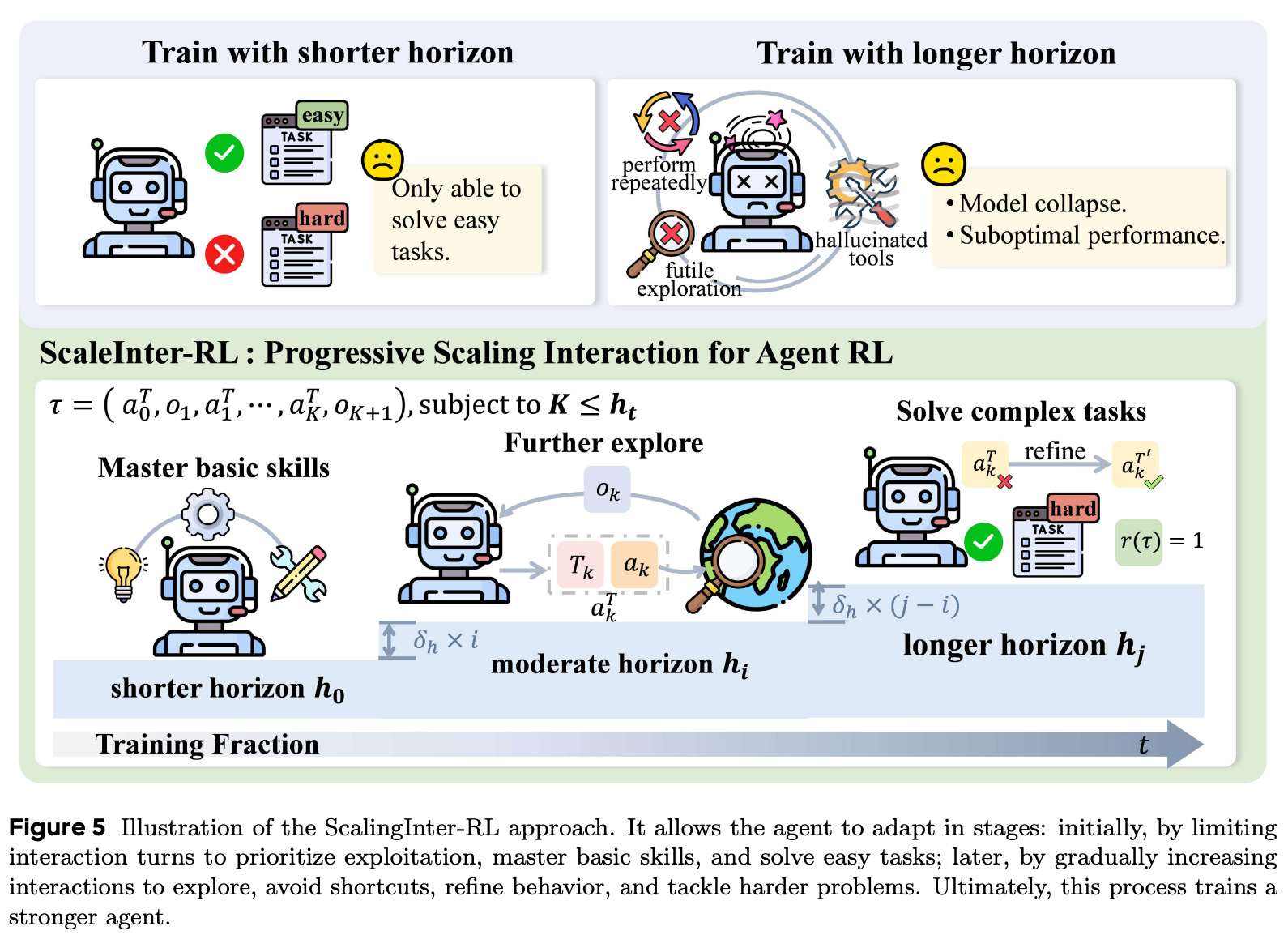
As a solution, authors in [3] propose a curriculum learning strategy called ScalingInter-RL that monotonically increases task horizons throughout the agent’s training process; see above. We start with an initial exploration phase that establishes foundational skills in the agent by first developing proficiency on simple tasks. Over time, we progressively increase the amount of interaction that an agent can perform, allowing long-horizon planning to be gradually introduced. This approach stabilizes the training process by making sure the agent establishes basic skills before attempting longer-horizon decision-making.
“As the horizon increases, the agent is incentivized to explore longer decision paths, facilitating the emergence of higher-order cognitive behaviors such as planning, reflection, and strategic backtracking… This phased scaling allows ScalingInter-RL to align the depth of interaction with the agent’s evolving policy capabilities, bridging efficient early-stage exploitation and long-horizon generalization.” - from [3]
Concretely, this curriculum is achieved by separating the RL training process into N phases. Assuming we perform a total of T training updates, each phase contains ∆ = T / N steps and is assigned a monotonically increasing interaction budget h_1 < h_2 < … < h_N. This interaction budget increases every ∆ iterations, and interactions are defined as the number of interaction turns that the agent has with the environment. Concretely, agents are trained in [3] with N = 3 phases of ∆ = 80 training iterations with budgets of 8, 12, and 15 interaction turns.
ScalingInter-RL uses the standard RL training objective: we want to maximize the expected cumulative reward received by our agent. However, this objective is optimized under a progressively increasing constraint on the number of environmental interaction turns. To implement this constraint, the framework terminates the interaction once the maximum number of interaction turns has been reached and prompts the agent to provide its final answer.
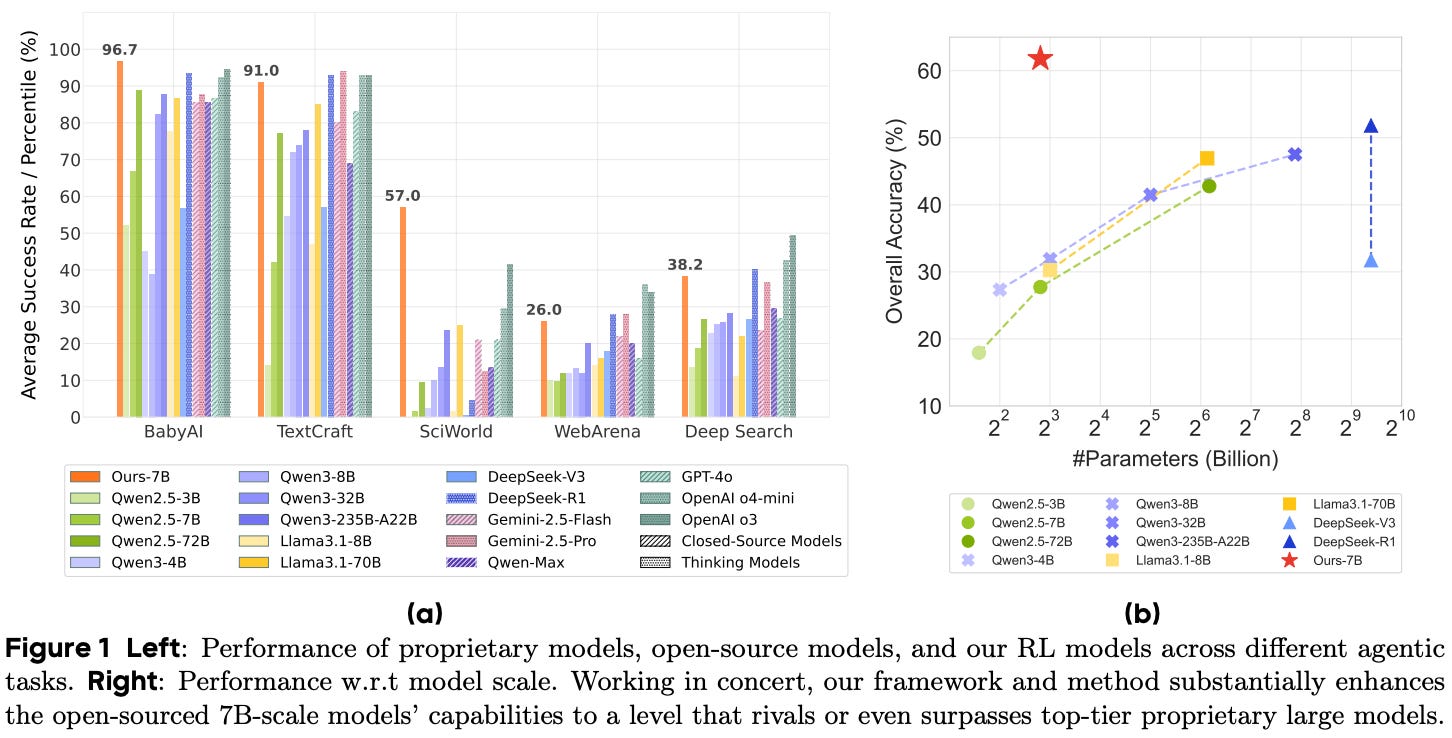
Training agents with RL. We see in [3] that RL training allows even smaller open-source models up to 7B parameters to perform comparably to large, closed models across diverse environments. In other words, RL training is effective at instilling agentic intelligence in smaller models. For example, the best model in [3] achieves a success rate of 26% and 38.25% on web search and deep research tasks, respectively, surpassing the performance of GPT-4o and even open-source LLMs with 10× the number of parameters (e.g., Llama-3.1-70B).
“Excessive exploration in early stages of training is not necessarily a good choice. Before establishing a solid foundation, the agent may perform unproductive and inefficient exploration, leading to the risk of training instability. By contrast, shorter rounds restrict early exploration but provide more stable learning signals, leading to more reliable long-term performance.” - from [3]
When we assess performance across domains more granularly, we see that RL is most beneficial on structured tasks with clear environmental rules—open-ended environments with high complexity do not benefit as significantly. For example, RL training provides the most significant performance benefit on domains like TextCraft—a text-based game environment—and SciWorld—a text-based simulator for scientific experiments. Both of these tasks have simple, simulated environments that obey clear, rule-based dynamics. Although RL training is still beneficial in all domains, performance benefits are less pronounced on WebArena, which is based on a more realistic and noisy web-based environment.
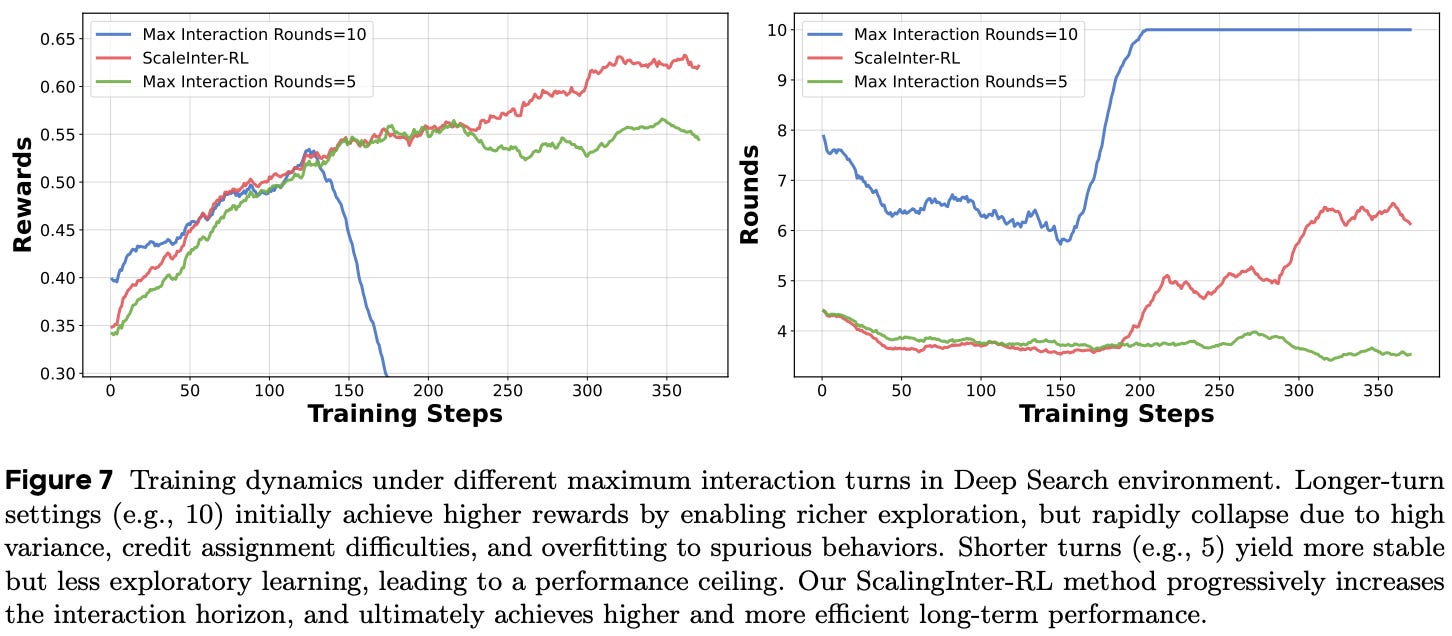
The ScalingInter-RL method is also found to stabilize training more consistently relative to a fixed-horizon approach. As shown below, a large interaction budget (i.e., 10 turns) tends to initially improve performance, but the RL training process quickly collapses. In contrast, restricting the interaction budget in early training phases provides a clear and stable learning signal. By gradually increasing the interaction budget over time, we allow the model to solve more difficult problems by repurposing reasoning patterns it has mastered on simpler tasks. As a result, we are able to meaningfully improve the capabilities of our agent while still maintaining the stability and efficiency of the RL optimization process.
Interestingly, RL-trained agents are found in [3] to naturally possess powerful test-time scaling capabilities. We see a clear performance benefit from increasing:
Sequential interactions (i.e., allowing more environmental turns per task).
Parallel sampling (i.e., generating multiple trajectories for each task).
In fact, agents trained with RL are found to outperform baseline models in this area, indicating that RL-trained agents exhibit stronger test-time scaling behavior. A variety of RL optimizers are tested in [3] as well. The choice of RL optimizer can meaningfully impact performance. For example, a 3B parameter model trained with GRPO actually outperforms a larger 7B model trained with REINFORCE.
Agent-R1: A Unified and Modular Framework for Agentic Reinforcement Learning [4]
When acting as an agent, an LLM is expected to do more than static reasoning or question answering. Agents are expected to make decisions and act autonomously over long time horizons, as well as quickly adapt to changes in the state of their environment—they exist in a dynamic and interactive world that must be reliably traversed to solve difficult problems. Due to the dynamic nature of tasks that agents must solve, the approach we take for RL training requires special consideration.
“Agents make sequential decisions, maintain memory across turns, and adapt to stochastic environmental feedback, presenting unique challenges distinct from more static tasks. This leads to specific difficulties when applying RL; particularly in multi-turn interaction scenarios, agent training can encounter instability, complex reward signal design, and limited generalization” - from [4]
A rollout can be represented as a flat sequence of tokens in single-turn RL, but agentic RL is more complex: the model undergoes multiple turns of observing context, taking an action, and receiving feedback. Our RL training framework must preserve the causal structure of observations, actions, feedback, and rewards obtained by our agent throughout a multi-turn trajectory until termination. The framework must also efficiently orchestrate multiple related components that typically operate with different time granularities, such as:
LLM inference.
Tool execution and environment simulation.
Trajectory storage and replay.
Model updates with RL.
Agent-R1 provides a framework that unifies these components in a standardized fashion. In particular, much of the design focuses on properly integrating the rollout and training steps in a way that makes the most sense for multi-turn RL. The framework supports diverse environment setups and can be integrated with arbitrary RL optimization algorithms with both terminal and process rewards.
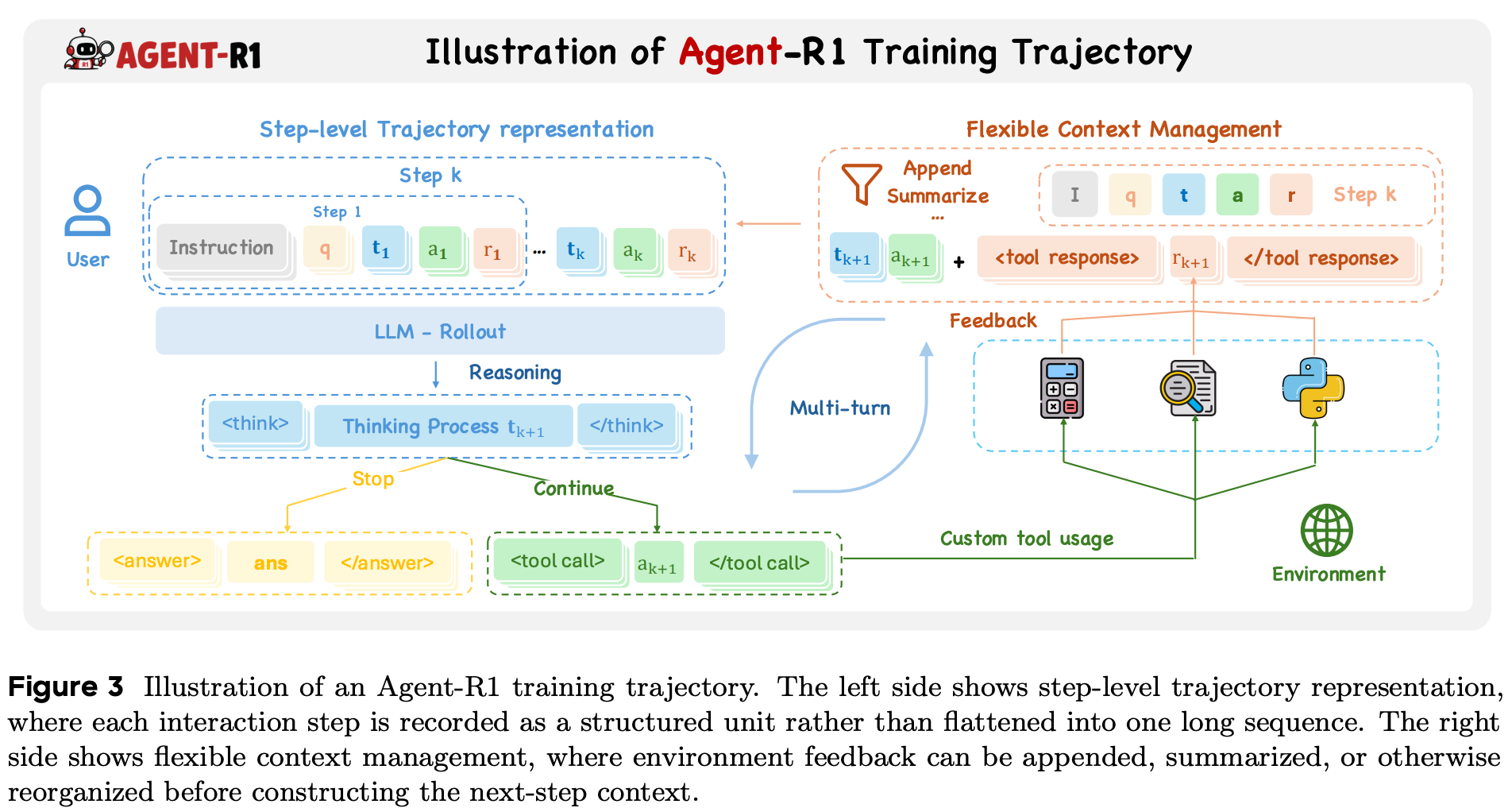
Step-level trajectories. A key design choice in Agent-R1 is treating each agent-environment interaction step—rather than each token—as the main unit of an agent trajectory. This means that each trajectory produced during RL training is represented as a series of structured, step-level traces. For each step, we store:
The current and next state.
The agent’s action.
Environmental feedback or observations (e.g., tool outputs).
Rewards (both step-level and terminal).
This structure maintains explicit step boundaries, allowing the framework to capture not only terminal rewards but also process rewards that are localized to a specific step in the agent’s trajectory. Specifically, a reward is stored for each step, as well as a termination signal that identifies the last step in a trajectory—a reward in the step with a positive termination signal is the outcome reward.
Trajectories are usually represented as i) flat token sequences or ii) message traces (i.e., a list of chat-style messages with associated role and content). However, both of these representations have limitations when used for agentic RL.
“In [agentic RL], the usual view of a trajectory as one ever-growing token sequence becomes increasingly inadequate: it makes context evolution rigid and creates representation mismatches between rollout and training.” - from [4]
When using the message format, we store trajectories as lists of messages and then later reconstruct them into a textual prompt (e.g., using a prompt template) when performing a policy update. This approach can lead to a mismatch—called retokenization drift in [4]—because the rollout happens in token space, but these tokens are parsed into textual messages and later retokenized. Because tokenization is not reversible, this pipeline can cause inconsistencies between the generated trajectory and the data that is actually used for training; see below.
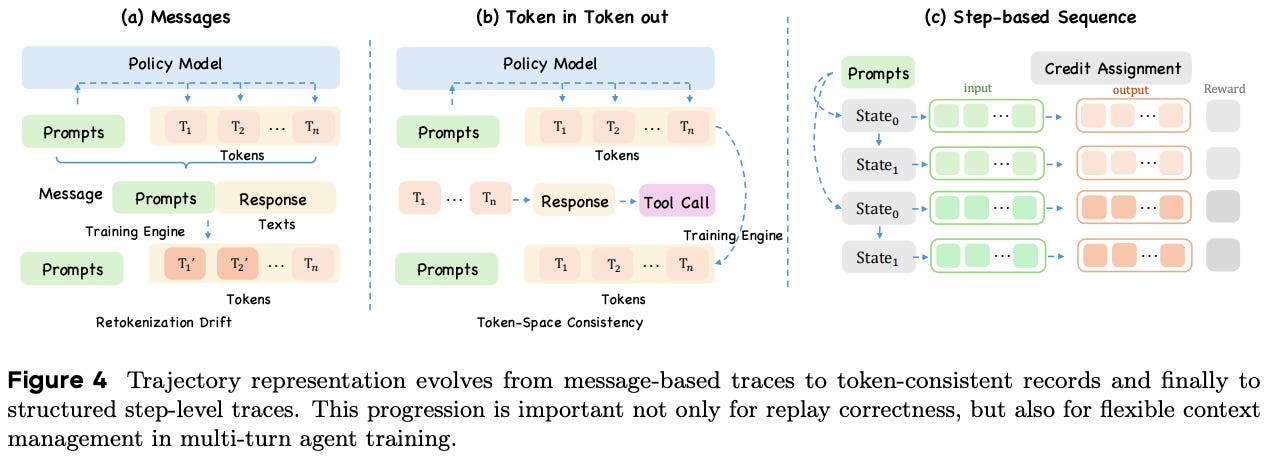
Rollouts in Agent-R1 are stored as structured, step-level records that preserve the original action tokens and explicit interaction boundaries; see above. This format significantly reduces the risk of retokenization drift by explicitly storing the generated tokens for each step and directly using these tokens during training.
On the other hand, representing the trajectory as a flat sequence is simple and preserves exact tokens, but this approach leaves step boundaries implicit and assumes an append-only strategy for context management. Step-level trajectory representations enable flexible context management strategies; see below. We can choose how the context should be constructed from these step-level traces.
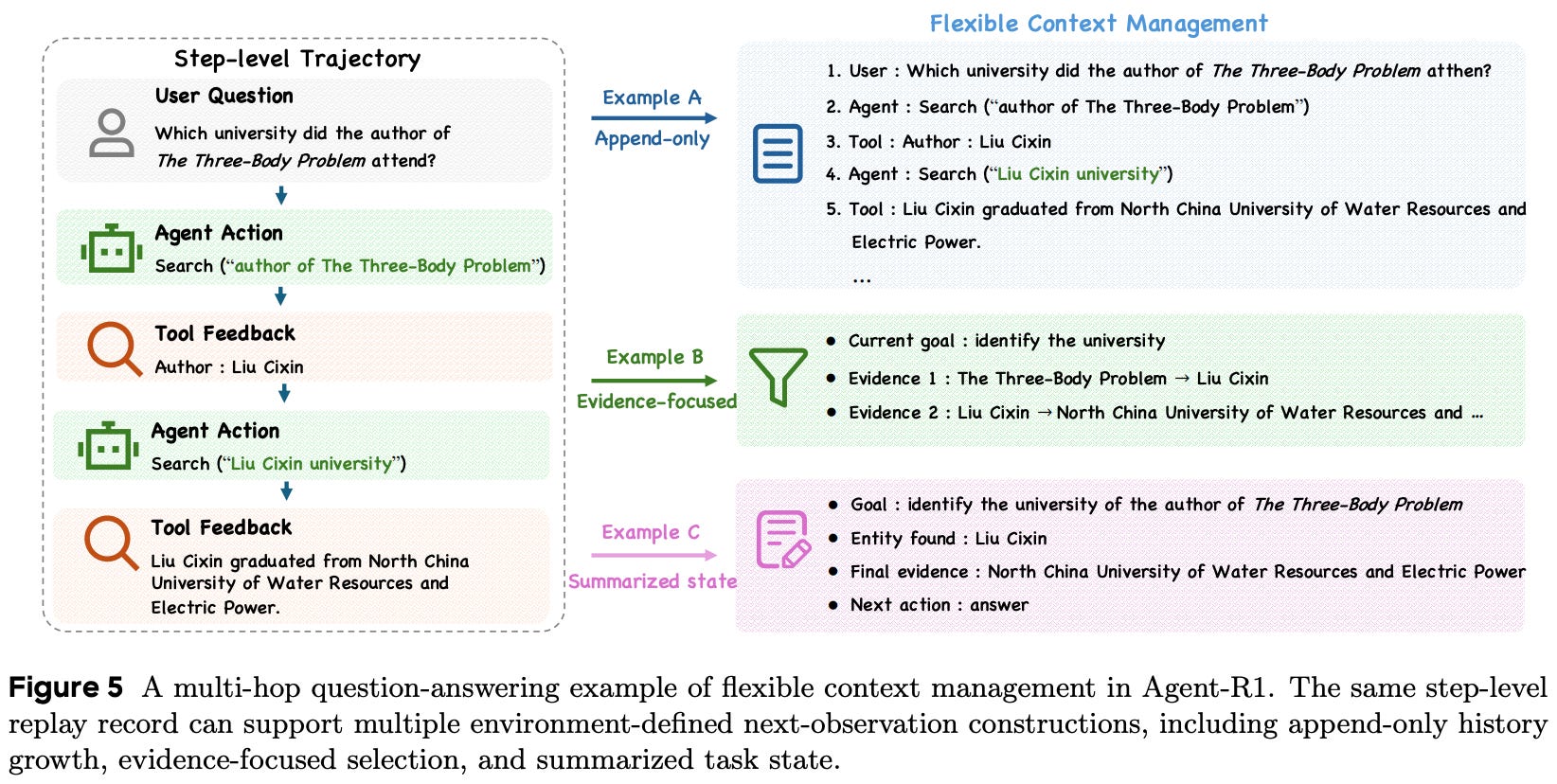
Agent implementations may still adopt a simple append-only strategy, where new information is directly added to the agent’s context. However, this approach is problematic in scenarios with verbose tool outputs or irrelevant reasoning steps—overloading the agent’s context with too much information can cause context rot.
To avoid this issue, Agent-R1 defines an environment-specific context rule that allows arbitrary memory-management strategies to be integrated into RL training. The agent’s visible context is constructed by passing raw, step-level traces through this rule. Within this rule, we may choose to preserve, summarize, remove, or transform any steps within a trajectory. In this way, Agent-R1 stores the full structured trajectory for each rollout, but the model does not always see this entire trajectory. Instead, the environment-specific context rule determines the (possibly transformed) context that becomes the agent’s next observation.
Environmental structure4. The goal of the RL framework introduced in [4] is to extend existing single-turn RL frameworks to support tasks that are multi-turn and interactive. The most significant difference between these two paradigms exists in the rollout phase: single-turn rollouts require the policy to generate a response once, while multi-turn rollouts contain several environment interaction turns with tool calls that may occur at each step. These steps involve both generating output from the LLM agent and interacting with the environment, depending on the tool calls that the agent generates. In Agent-R1, all external interactions with the environment are standardized via two primary interfaces:
A Tool interface that executes atomic actions or tool calls (e.g., calling an API, executing code, retrieving data, and more).
A ToolEnv interface that implements the environment transition at each interaction step by parsing tool calls, invoking tools, updating environment state, computing rewards, and returning the next observation.
A Tool serves as a unified interface for describing the atomic actions that an LLM agent can take to interact with its environment. All actions that the agent can take in an environment are encapsulated into a concrete set of tools that are clearly defined and can be invoked by the agent. The specific tool format used in [4] is based on the OpenAI function calling schema. Each tool has two modules:
Execution logic: the core execution method that processes a tool’s input parameters, performs an operation, and returns the result.
Metadata specification: the name, description, and parameters (specified in a structured JSON schema) for the tool.
For an agent to effectively interact with each tool, metadata specifications must be clear and comprehensive, allowing the agent to understand each tool’s purpose and correctly invoke the tool when needed. After a tool is invoked by the LLM agent, it performs the requested operation and returns the raw result.
The ToolEnv orchestrates interactions between the agent and its environment. The operations of the ToolEnv are standardized via the step() function, which drives agent-environment interactions. This function ingests raw output from an agent, identifies and executes any tool calls, updates the environment’s state, computes the current reward (if any), and returns an observation to the agent. Step mechanics differ depending upon the domain, but certain auxiliary methods must be implemented for any task:
Parsing structured tool calls from the agent’s output.
Formatting tool outputs before adding them back into an agent’s context.
Checking the termination conditions (i.e., whether the agent has completed the task) for a given trajectory.
Computing the final outcome reward once a trajectory has terminated.
The ToolEnv manages state transitions, packages state information for the agent, computes reward signals, and orchestrates the entire process of creating a multi-turn trajectory or rollout. The ToolEnv can handle generative transitions that incorporate the agent’s output into the next state, as well as any transitions triggered by tool calls that may modify the external environment or state.
“This design, centered on the step method’s pivotal role in driving environmental dynamics and supported by clear mechanisms for managing tool calls and trajectory lifecycle, enables the Agent-R1 framework to effectively simulate complex interactive scenarios. It carefully distinguishes between deterministic text generation and the non-deterministic, environment-altering state changes introduced by tool use, which are crucial for agent learning.” - from [4]
The multi-turn rollout process for the Agent-R1 framework is depicted below. As we can see, each rollout combines the two key interfaces over multiple steps as the agent runs in a loop. As output is generated at each step, the ToolEnv parses tool calls and executes them through the corresponding Tool interfaces. After each step, relevant context (e.g., tool outputs or generated tokens) is processed by ToolEnv and added into the agent’s context before the next generation step. Rewards may be computed at intermediate steps, and once a termination condition is reached, the final reward is computed and the rollout ends. Each rollout contains the step-level history of states, actions, and rewards for the agent.
Now that we have defined a modular structure for handling dynamic interactions between an agent and its environment, we can develop a learning strategy for optimizing the agent’s behavior. Despite the unique properties of agentic RL, Agent-R1 does not prescribe a particular RL algorithm. Rather, the framework standardizes how multi-turn trajectories are represented and passed to the optimization layer, allowing various RL optimizers (e.g., PPO, GRPO, and REINFORCE) to operate on the same interaction data. Regardless of the optimizer being used, two implementation details are especially important:
Incorporating both outcome rewards and intermediate process rewards into the RL objective.
Masking non-generated tokens from the policy objective, including the initial instruction and any tool or environment outputs.
In [4], the mask used to identify tokens generated by the LLM is called an Action Mask. This binary mask is one for agent-generated tokens and zero otherwise. The token-level loss is multiplied by this mask so that only agent-generated tokens contribute to the policy gradient, while non-generated content and prompts are treated as external context. Because Agent-R1 stores trajectories as structured interaction steps, it can associate each action with corresponding feedback and reward, as well as identify the individual tokens in that action.
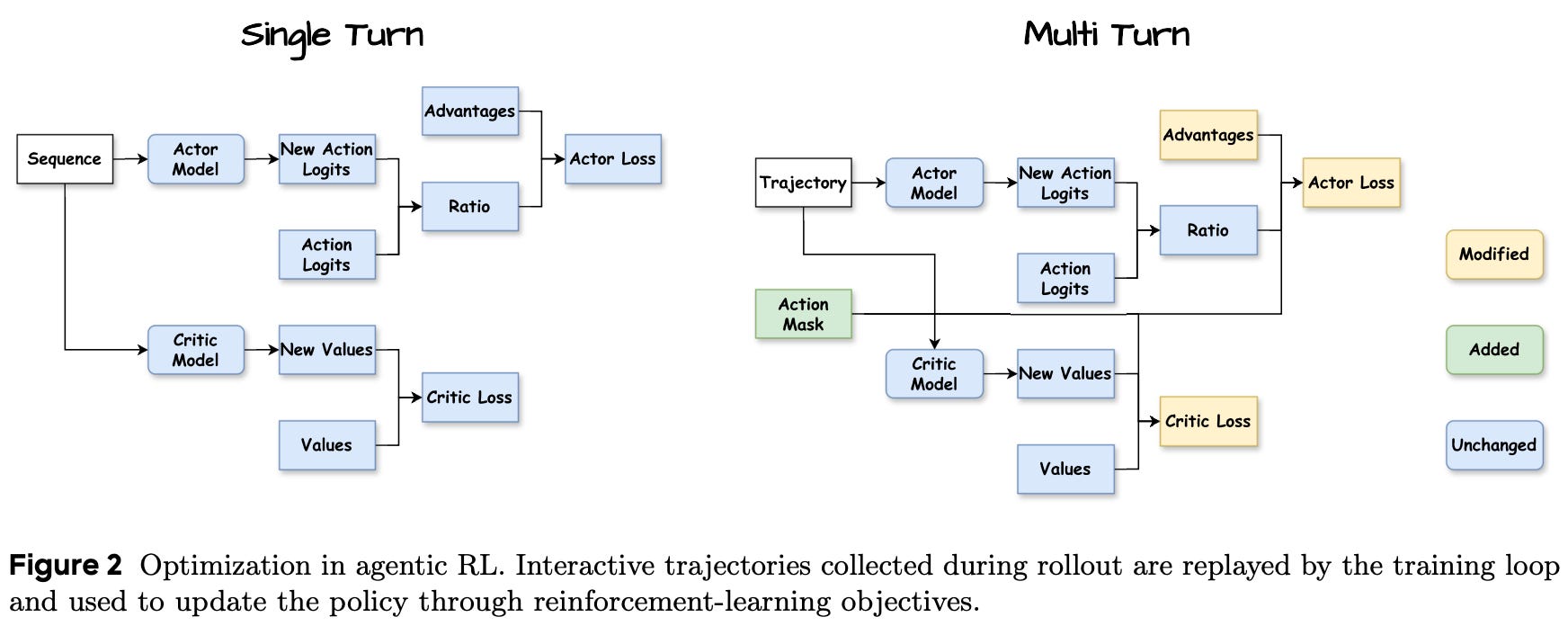
This structure also supports flexible credit assignment. More specifically, we can compute separate rewards for each token or broadcast the same reward to all tokens in a particular interaction step. Intermediate process rewards can be attached directly to the steps within which they are obtained, while outcome rewards can provide credit across the entire trajectory. Agent-R1 separates the representation of multi-turn trajectories from the choice of RL optimizer, providing a common format for different optimization strategies.
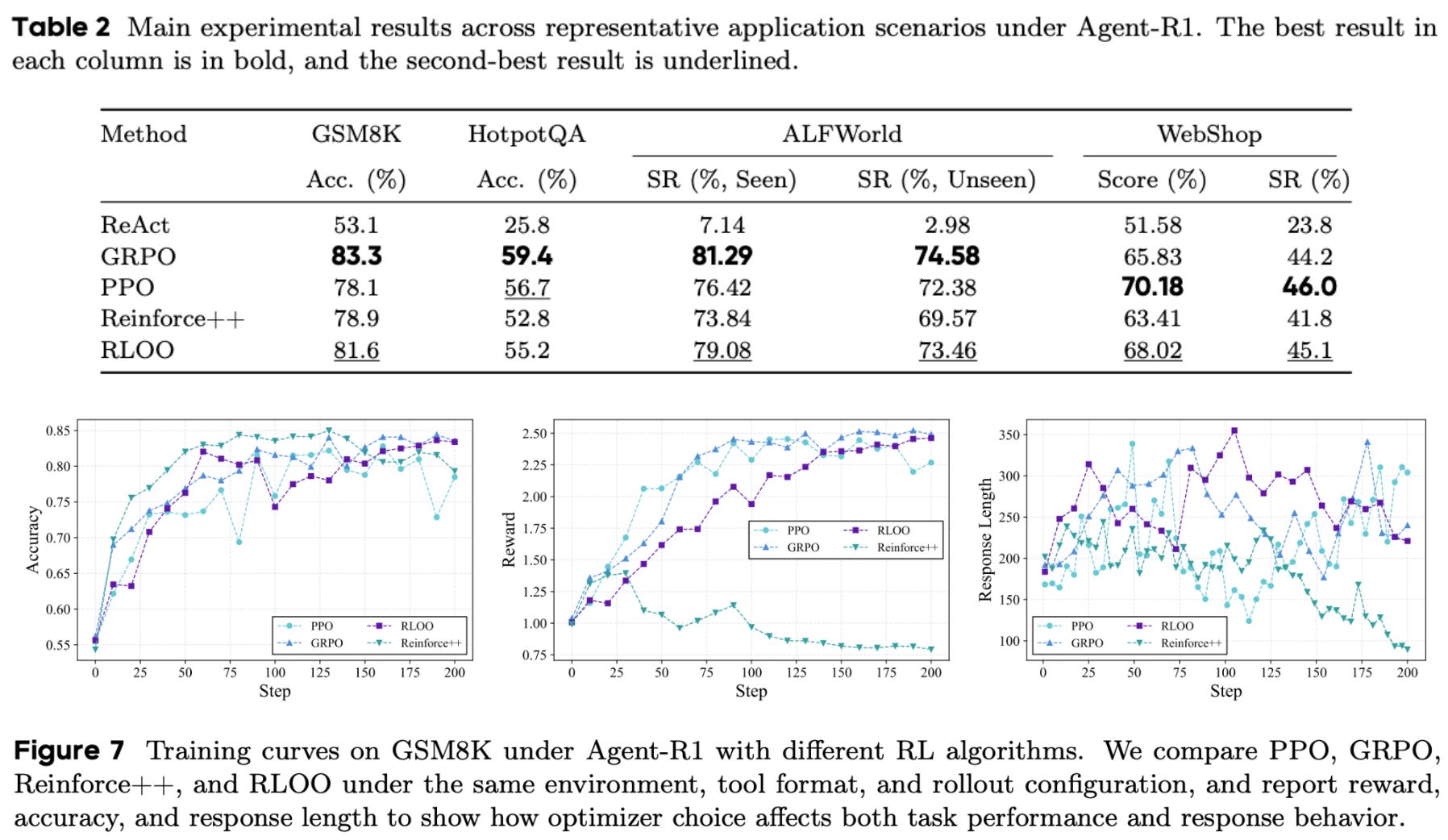
Empirical validation. The Agent-R1 framework is used to train the Qwen3-4B model on four distinct environments: GSM8K, HotpotQA, ALFWorld, and WebShop. RL training clearly improves performance across all environments, but results vary depending upon the training settings. For example, GRPO yields the best results for most tasks, but PPO performs best in the WebShop environment; see below. Performance is not drastically different between RL algorithms—both REINFORCE variants also perform well—but performance differences do exist.
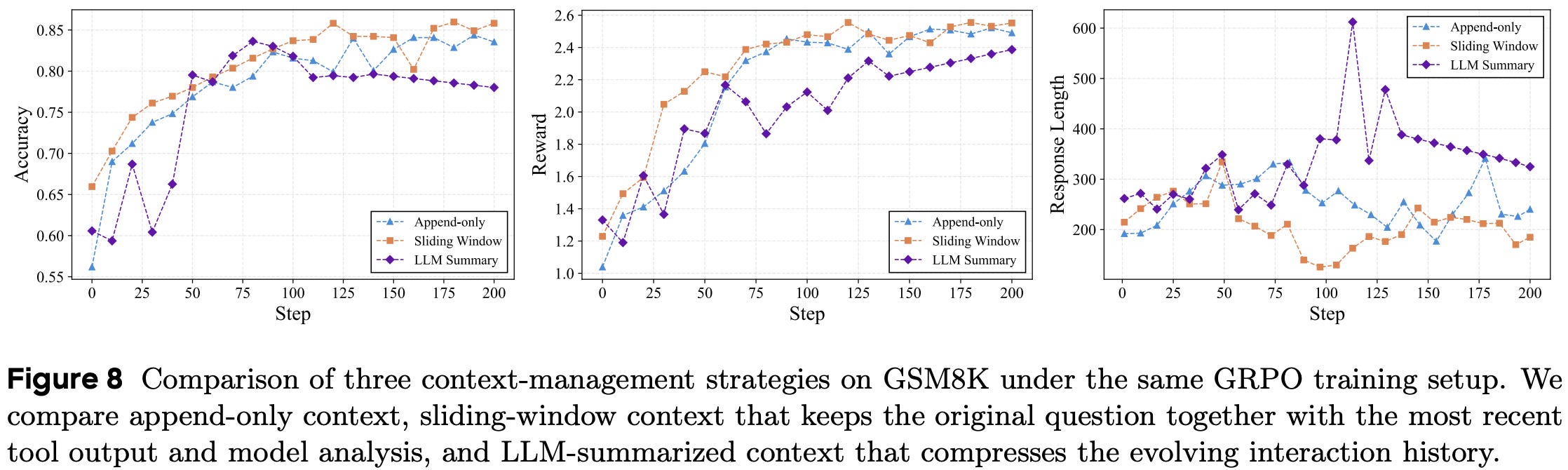
Interestingly, the choice of context management strategy is also found to have a large impact on agent performance. A few different strategies are tested in [4]:
Append-only: just continue appending all context to the trajectory.
Sliding-window: only maintain the most recent context in the trajectory.
LLM summarization: use an LLM to summarize context to avoid exhausting the agent’s maximum context length.
When tested on the GSM8K environment, the sliding-window strategy achieves the best performance; see below. Although these results are likely specific to the environment being tested, we see that retaining all context is not always optimal. Agent performance can be improved by adopting a context management strategy that more efficiently utilizes the context window—less is more in some cases.
AgentRL: Scaling Agentic Reinforcement Learning with a Multi-Turn, Multi-Task Framework [5]
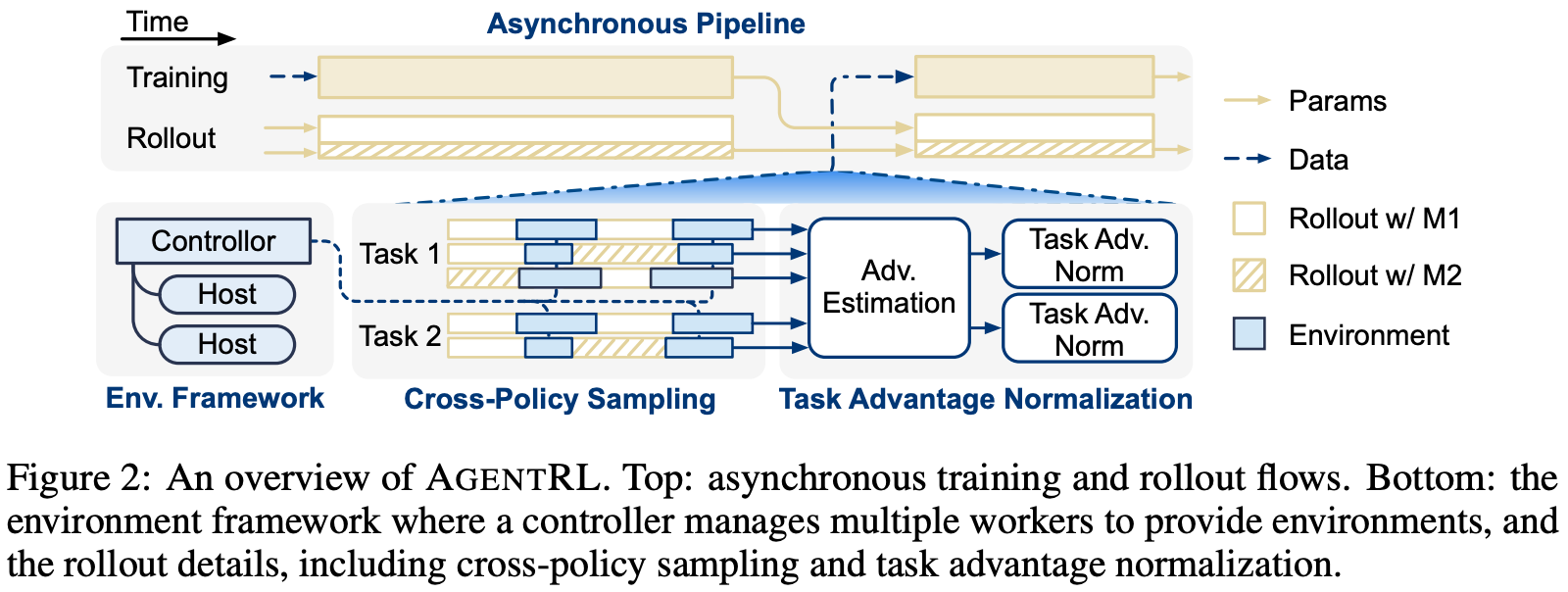
A majority of the early work on RL training for LLMs considered single-turn setups, often focusing on one domain or task. Although this approach works well for conversational and reasoning domains, we must expand our RL training strategy to handle multi-turn, multi-task setups in order to train autonomous LLM agents. In [5], authors propose an open-source framework, called AgentRL, for scaling the RL training process for generalist LLM agents. As we will see, the AgentRL framework combines infrastructural and algorithmic improvements to make RL training efficient and easy to scale to a wide variety of task domains.
“The shift from single-turn to multi-turn defines the problem of agentic RL, where the LLM acts as an autonomous agent that performs multi-turn reasoning, interacts with tools or environments, and adapts its behavior over extended trajectories.” - from [5]
The complexity of agentic RL. The multi-turn setup of agentic RL is a key distinguishing factor compared to a standard single-turn RL training setup. Generating rollouts in a multi-turn agent environment is complex:
The generation process is long-running and contains multiple turns.
The agent has the ability to interact with its environment in any given turn, which can slow down the generation process.
The length of each trajectory—and the corresponding wall-clock generation time—is highly variable.
The number of relevant agent environments is vast, and each of these environments has unique characteristics.
Given that agent trajectories vary significantly in length and completion time, a synchronous approach to RL training that interleaves training and generation—although commonly used in the single-turn setting—would not work. Even within a single training batch, we may need to sample several rollouts that take drastically different amounts of time to complete. In a synchronous setup, we would leave the GPUs that handle shorter trajectories idle while longer trajectories are still finishing, leading to poor and imbalanced utilization of the hardware.
The fact that agents run in an interactive environment exacerbates such variable rollout times. When sampling each trajectory, the agent must run in an isolated environment with which it frequently interacts. A slowdown in environmental interactions would contribute to variability in rollout lengths and completion times, thus degrading efficiency. To avoid this issue, agentic RL frameworks must be able to concurrently deploy and manage a large number of environments.
Depending on the problem being solved, an agent may need to run in a variety of environments that have unique interfaces and computational demands. In order to streamline the integration of new tasks into the RL training process, we can design a standard interface that allows us to unify the design and execution of diverse agent environments. Additionally, algorithmic improvements must be made to ensure that the RL training process remains both efficient and stable across the many environments and domains included in the training process.
The AgentRL framework has three key components that are introduced to address each of the challenges of agentic RL outlined above:
An asynchronous RL training pipeline.
Scalable environment deployment infrastructure.
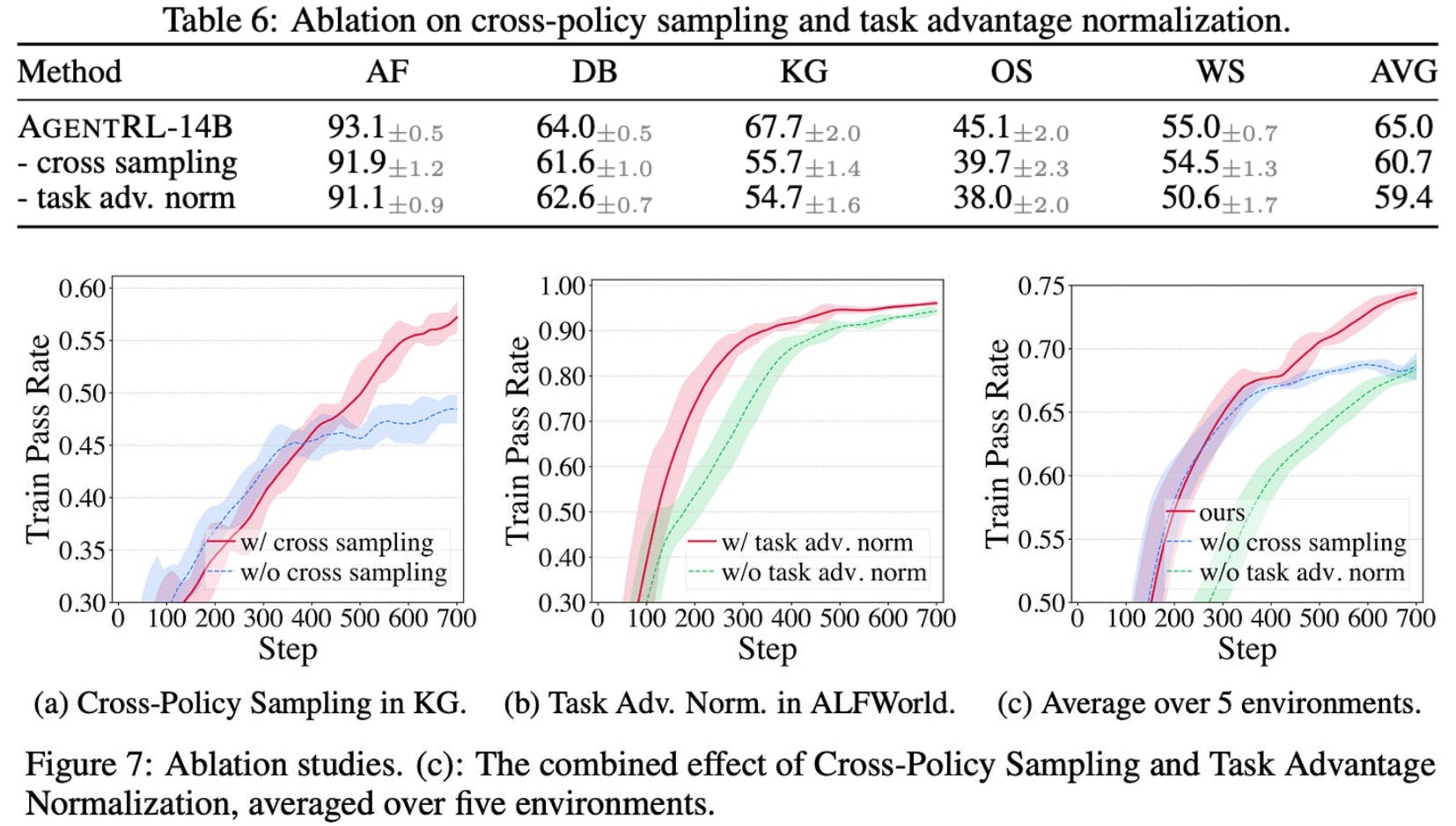
Algorithmic changes (i.e., task advantage normalization and cross-policy sampling) for better agentic (i.e., multi-turn and multi-task) training.
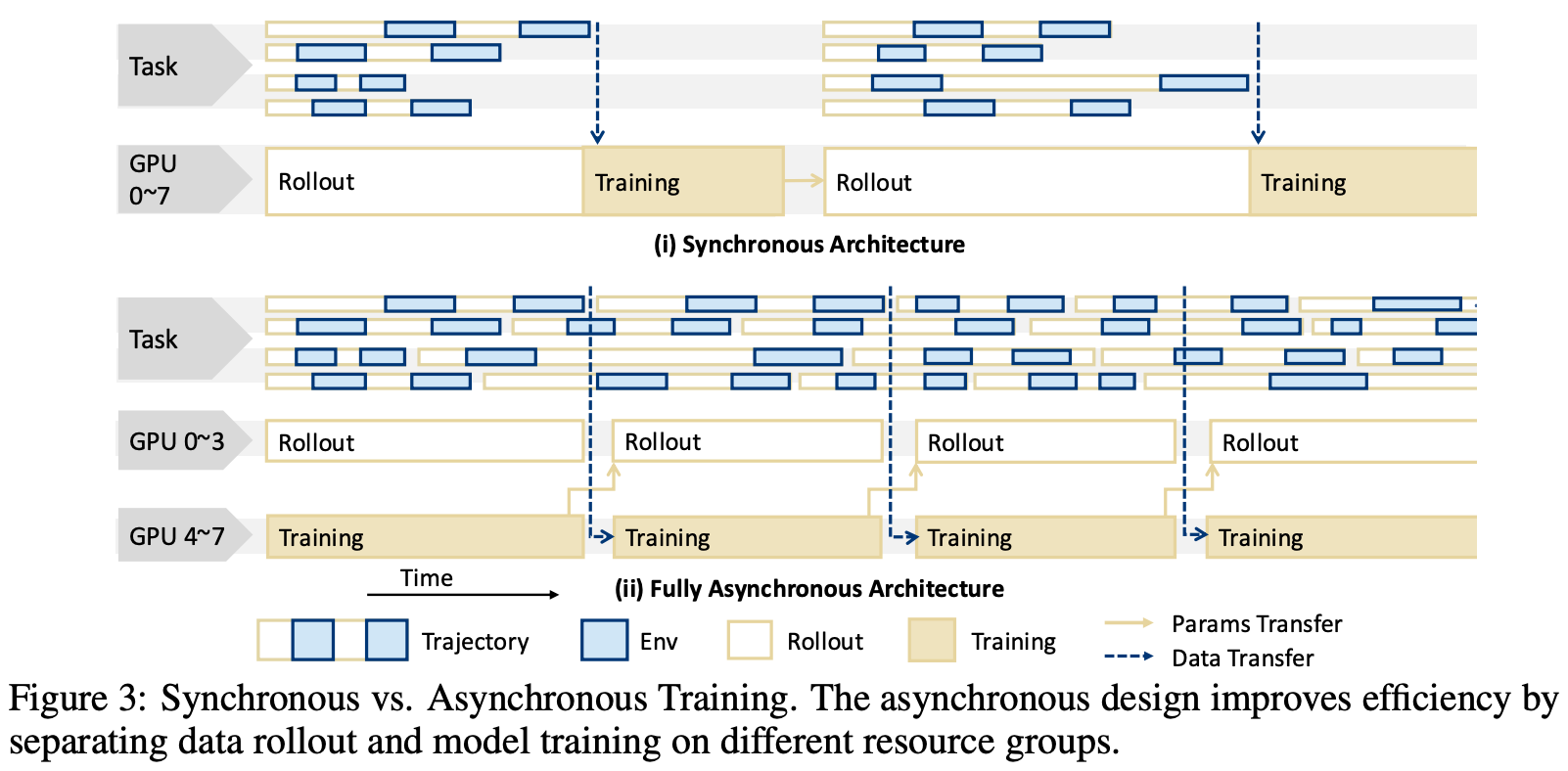
As discussed before, a synchronous setup would not work well for agentic RL due to the large amount of idle time created by variability in rollout lengths or times. To better handle long and interactive trajectories, authors in [5] adopt a fully asynchronous training pipeline that decouples rollout generation and model training. Separate engines are created for training and inference, each with dedicated resource pools5. The two engines run concurrently:
The inference engine continuously schedules asynchronous rollout jobs on available hardware, where each job runs an agentic loop on a given task and generates a full rollout or trajectory.
The training engine pulls all completed trajectories after each update—rather than waiting for a fixed batch of rollouts to complete, as in the synchronous setup—to perform the next update.
In this setup, the batch size varies across training updates, but authors in [5] set a minimum and maximum number of rollouts for each batch to ensure that batch sizes fluctuate within an acceptable range. With this approach, we can improve hardware utilization by ensuring that training continues as soon as enough data is available for an update. Additionally, the variability in rollout generation times is handled by the fact that the inference engine is running jobs continuously. Rollouts that are not complete in time for a given update will simply continue running, and we schedule new rollout jobs as soon as existing jobs complete.
“To avoid off-policy bias of the rollout engine, we set a maximum size of the data queue and enforce all trajectories to be moved to the training engine at each step. In doing so, all trajectories are kept as up-to-date as possible with the latest policy, which later experiments suggest to be acceptable.” - from [5]
Remaining on policy. With such an asynchronous pipeline, we risk including stale or off-policy data within the training update. For a training approach to be fully on-policy, the model used to generate rollouts should be identical to the model being updated, but this is not always true in an asynchronous setup—by the time a trajectory is used for training, the model may have already undergone one or more policy updates. We can prevent the training process from becoming overly off-policy by bounding the staleness of our data as follows:
Store completed asynchronous rollouts in a data queue.
Limit the maximum size of this queue so that rollout workers cannot generate an unbounded number of trajectories.
If the queue is full, wait until the trainer consumes existing data before adding new trajectories to the queue.
Pull all data from the queue into the training engine (i.e., drain the queue) during each update to ensure that data does not sit idle for too long.
AgentRL also designs a unified environment deployment infrastructure for agent environments. In multi-task agentic RL, we need to be able to run a large number of heterogeneous environments at once and easily extend training to include new environments. To handle the variability in environments, a unified function-call-based API interface is created that can be used by agents to interact with any environment. This interface replaces the custom action formats for each environment with standardized function calls an agent can invoke; see below.
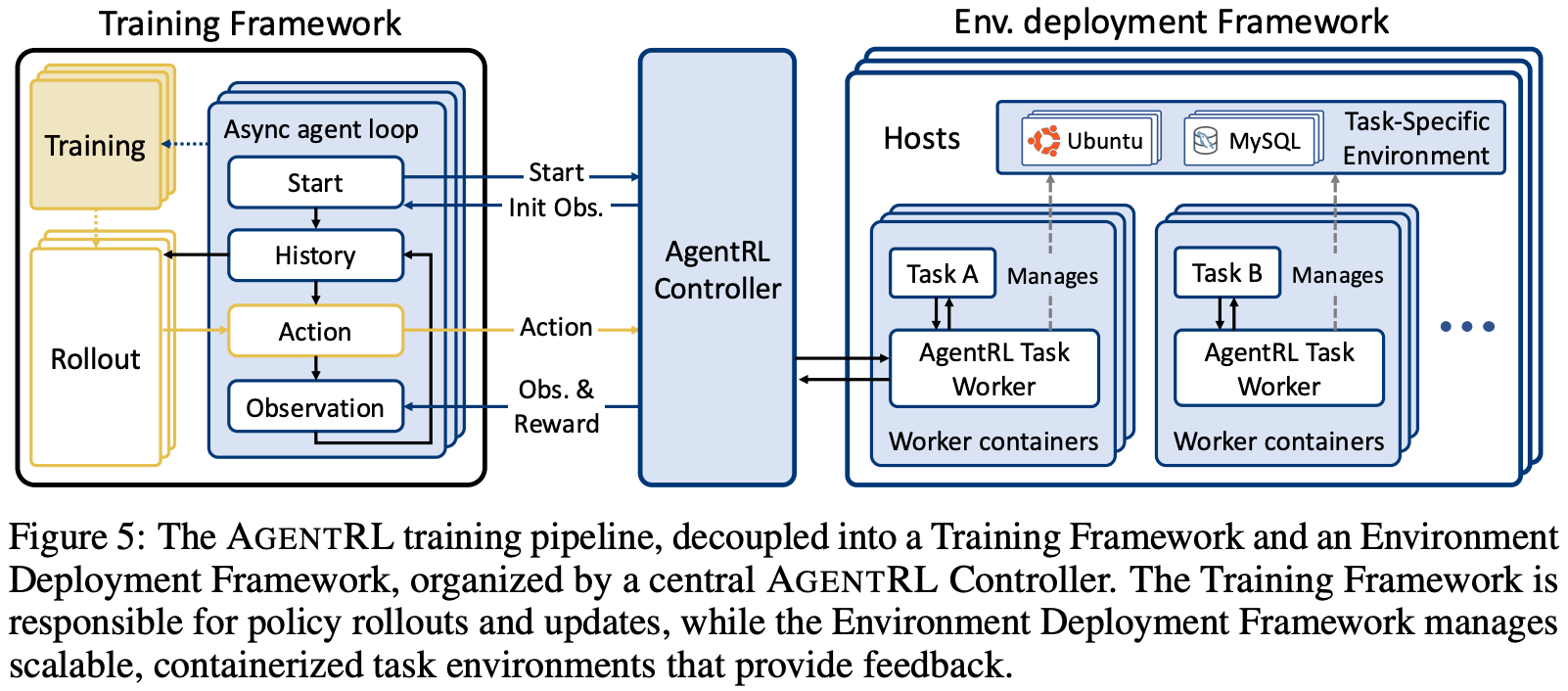
Each environment worker in [5] is containerized as an isolated execution unit that is kept separate from other environments. Containerization isolates errors that occur when running many concurrent environments and simplifies environment deployment across diverse hardware, thus improving utilization and efficiency. As shown above, environments in AgentRL are managed by a central controller that orchestrates the training pipeline and rollout workers. This controller manages thousands of concurrent environment instances and allows the rollout engine to interact with these environments through a unified interface.
“To host, schedule, and monitor heterogeneous environments under the same infrastructure without additional integration cost, we expose consistent interfaces at the worker and controller levels. On the environment side, we unify the worker API across all tasks, such that each task can be instantiated and managed using an identical set of lifecycle operations. On the training side, the controller provides a single gateway API to the RL engine, abstracting away task heterogeneity and exposing multi-task execution as a transparent extension of the single-task case.” - from [5]
Finally, there are a few algorithmic changes adopted in [5] to deal with two key difficulties commonly experienced with agentic RL:
The severe decline in model exploration over time caused by the large action spaces in multi-turn agentic settings.
The tendency of RL training to become unstable when multiple different tasks are included in the training process.
To encourage exploration, a cross-policy sampling technique is proposed that uses multiple LLMs to generate actions in a single trajectory; see below. Actions in a trajectory are usually sampled from a single model, but this approach draws randomly from a pool of models to generate an action at each step, thus aiding exploration by creating trajectories that would not be explored by any single model.
Managing multiple models in the rollout engine is complicated. Instead, authors create a model pool that includes several earlier versions of the model from prior steps of the training process. Concretely, this model pool is constructed via a group of dedicated rollout engines that are purposely kept stale by updating the model parameters at varying frequencies throughout the RL training process.
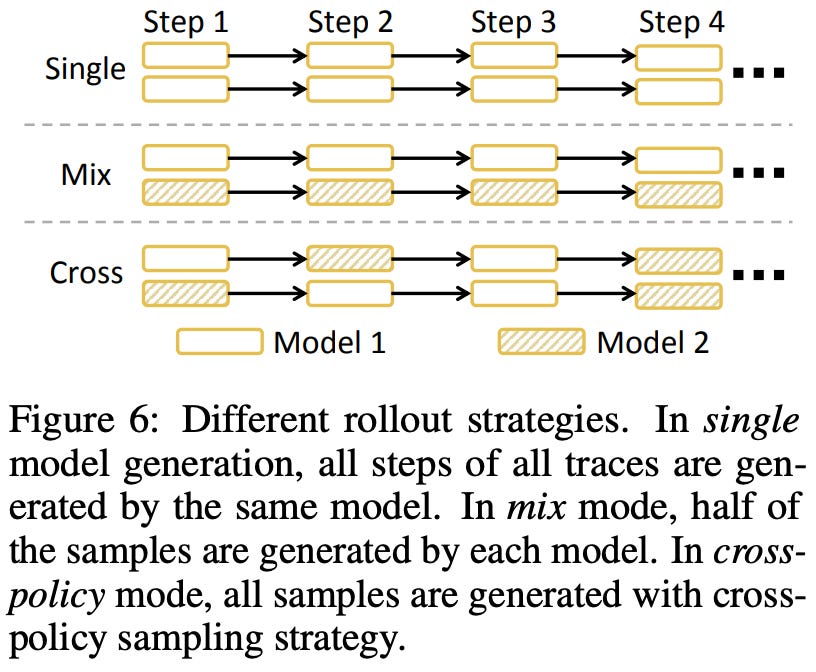
Notably, authors in [5] test both cross-policy sampling, which samples actions within a trajectory from different models, and a mixing strategy that generates each trajectory with a single model but combines trajectories from several models in an update. Cross-policy sampling is different from mixing because the policies are mixed within each trajectory. This approach allows successive actions to come from different policies and creates trajectories that differ from those generated by any single policy. Interestingly, the cross-policy sampling approach proposed in [5] empirically outperforms simpler mixing strategies.
A modified task-level advantage normalization approach is also introduced to improve stability in multi-task training. AgentRL first computes advantages using the underlying RL algorithm. In the GRPO setup used for training, outcome rewards are normalized relative to other rollouts sampled for the same input, producing a group-relative advantage for each trajectory. This trajectory-level advantage is then assigned to all agent-generated tokens within that trajectory using the action mask, matching the approach used in standard GRPO.
import torch
eps = 1e-8
# terminal reward for each sampled trajectory
rewards = torch.tensor([1.0, 0.0, 0.5, 1.0, 0.0, 1.0])
# trajectories with same prompt ID were sampled for the same input
# we have three trajectory groups for GRPO here
prompt_ids = torch.tensor([0, 0, 1, 1, 2, 2])
# first four trajectories belong to task / domain 0
# final two trajectories belong to task / domain 1
task_ids = torch.tensor([0, 0, 0, 0, 1, 1])
# 1 marks tokens generated by the agent
# 0 marks prompt, padding, or environment tokens.
action_mask = torch.tensor([
[0, 1, 1, 1],
[0, 1, 1, 0],
[0, 1, 1, 1],
[0, 1, 0, 0],
[0, 1, 1, 1],
[0, 1, 1, 0],
], dtype=torch.float32)
# -------------------------------------------------
# compute GRPO-style advantage for each trajectory
# -------------------------------------------------
trajectory_advantages = torch.zeros_like(rewards)
for prompt_id in prompt_ids.unique():
group_mask = prompt_ids == prompt_id
group_rewards = rewards[group_mask]
group_mean = group_rewards.mean()
group_std = group_rewards.std(unbiased=False)
trajectory_advantages[group_mask] = (
group_rewards - group_mean
) / (group_std + eps)
# ----------------------------------------------------
# assign trajectory advantage to each generated token
# ----------------------------------------------------
token_advantages = trajectory_advantages[:, None] * action_mask
# --------------------------------------------
# normalize token advantages within each task
# --------------------------------------------
task_normalized_advantages = torch.zeros_like(token_advantages)
for task_id in task_ids.unique():
task_rows = task_ids == task_id
task_action_mask = action_mask[task_rows].bool()
# gather all agent-token advantages for the entire task
task_values = token_advantages[task_rows][task_action_mask]
task_mean = task_values.mean()
task_std = task_values.std(unbiased=False)
normalized_values = (
token_advantages[task_rows] - task_mean
) / (task_std + eps)
# zero out non-agent-generated token positions
task_normalized_advantages[task_rows] = (
normalized_values * action_mask[task_rows]
)
print("Trajectory advantages:")
print(trajectory_advantages)
print("\nToken-level advantages:")
print(token_advantages)
print("\nTask-normalized token advantages:")
print(task_normalized_advantages)AgentRL then groups all token-level advantages for each domain, such as WebShop, in the current batch and normalizes them using that domain’s mean and standard deviation; see above. As a result, the token-level advantage distribution for each domain has approximately zero mean and unit variance. This additional normalization step reduces differences in optimization scale across task domains and prevents any single domain from dominating the policy update. When used together, task-level advantage normalization and cross-policy sampling make multi-task, multi-turn RL more stable and efficient; see below.
Performance impact. Five tasks are integrated into AgentRL for experiments performed in [5], including ALFWorld, WebShop, and three new tasks created for interacting with SQL databases, operating systems, and knowledge graphs. Tasks are sampled uniformly during multi-task RL training, which uses an RL-Zero setup (i.e., there is no warm-up SFT phase prior to agentic RL training).
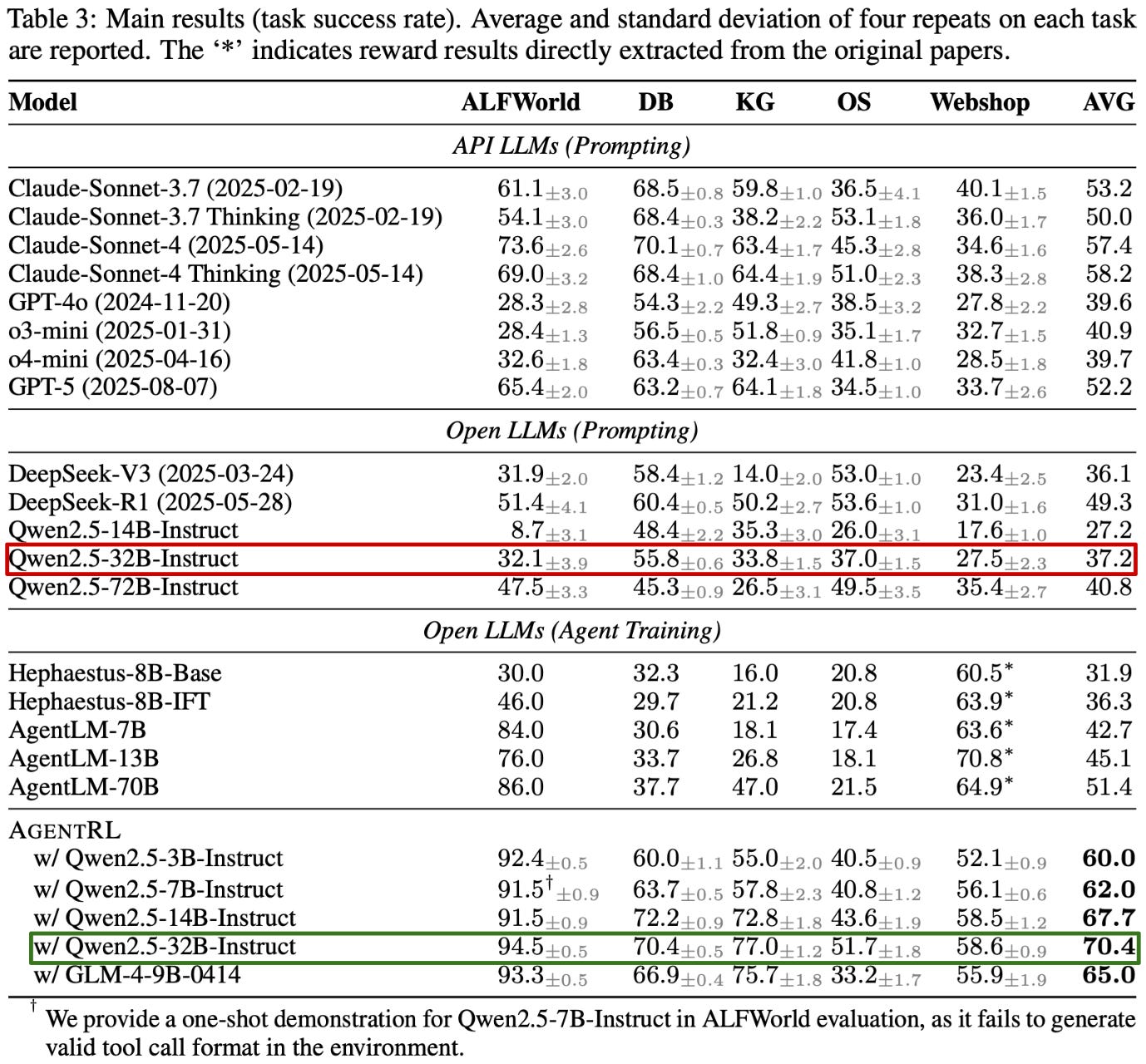
AgentRL achieves impressive results on agentic tasks that are consistent across several base models, including GLM-4-9B and Qwen2.5-Instruct models with varying sizes. AgentRL achieves average pass rates across tasks that surpass those of several proprietary models such as GPT-5 and Claude-Sonnet-4. These performance metrics are especially impressive for smaller models; e.g., even Qwen-2.5-3B-Instruct outperforms most proprietary models after RL training with AgentRL. RL training clearly benefits agent performance on all tasks. We can observe per-task performance deltas by comparing the Qwen-2.5-32B base model (green) to the AgentRL model variant (red) in the table above6.
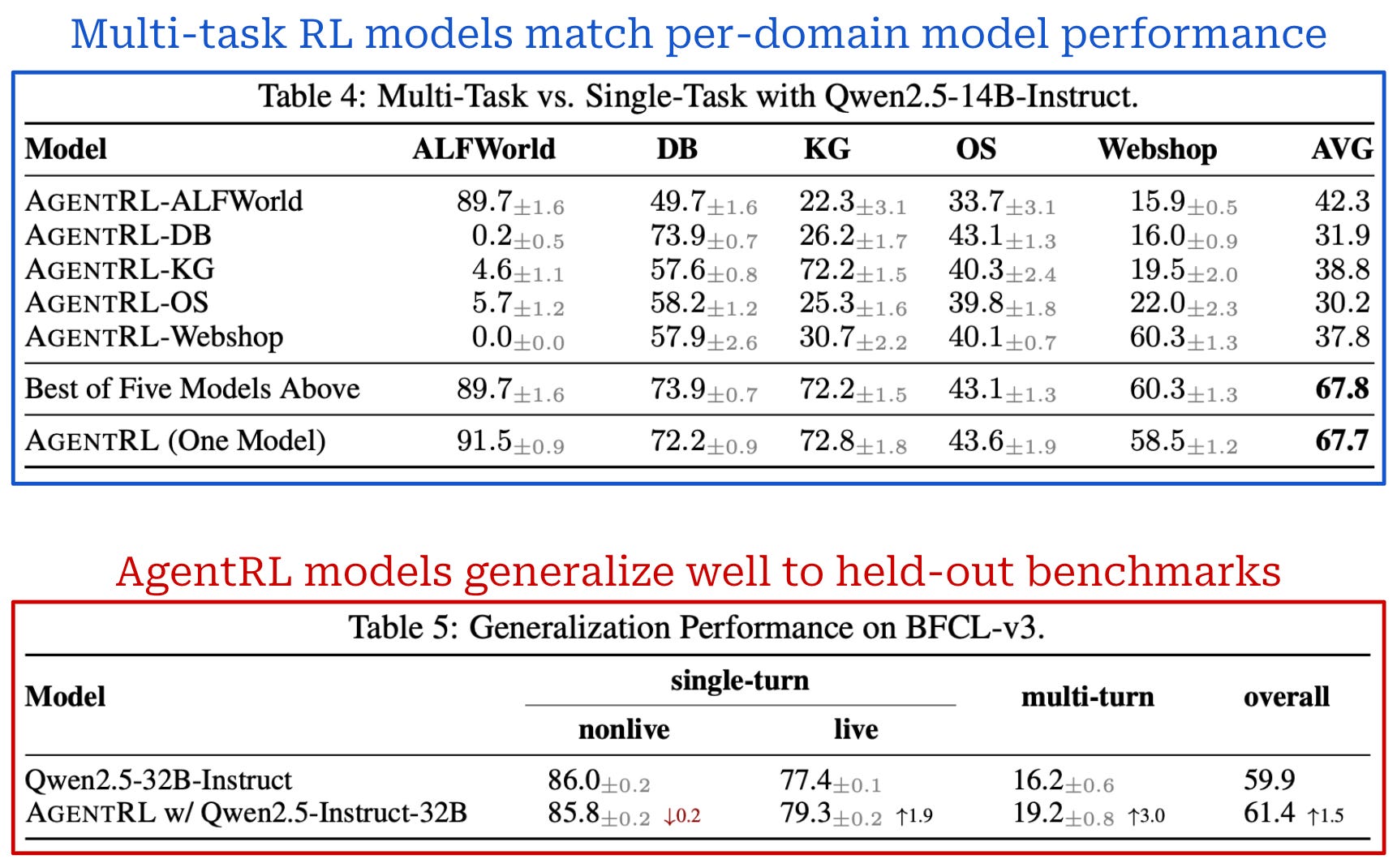
One could argue that the impressive results achieved with AgentRL are due to the fact that agents are directly trained on the domains used for evaluation. While this point is true and definitely impacts evaluation results, we also see in [5] that AgentRL models generalize relatively well to certain held-out benchmarks. For example, we see modest gains from AgentRL on the BFCL-v3 benchmark, which is not included in training; see above. Additionally, agents trained with multi-task RL tend to match the performance of agents trained individually on each domain, revealing that AgentRL is capable of training generalist multi-task agents.
AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning [6]
Agents may struggle to solve real-world tasks with extensive environmental or user interaction, but we can refine the ability to solve such tasks via RL. The main bottleneck to this agentic RL approach is that curating real-world environments with accurate ground truth for RL training tends to be expensive and, in turn, not scalable. We can mitigate this issue by synthesizing simulated environments for agentic RL, but most prior work on this topic has been limited to semi-automated methods that tend to produce tasks that are lacking in difficulty and diversity. In [6], authors propose an LLM-in-the-loop framework for synthesizing high-quality environments for RL, as well as outline several modifications to the RL training process that can improve performance and stability in the agentic domain.
“We argue that a unified pipeline capable of automatically generating mock environments and complex tasks is better suited to simultaneously broadening the scope of agent training and deepening its complexity.” - from [6]
The task synthesis pipeline is the key contribution of [6], as it enables the synthetic creation of realistic, difficult, and verifiable RL environments; see below. If generated tasks are sufficiently high-quality, then conducting RL training on simulated environments is a cost-effective and scalable approach for improving LLM agents. However, such an approach is only effective if we can minimize the gap between simulated tasks that an agent encounters during training and those that it will have to solve in the real world. To ensure that the synthesized environments are sufficiently realistic and difficult, a bottom-up approach is proposed that iteratively builds a final task starting from basic tool definitions.
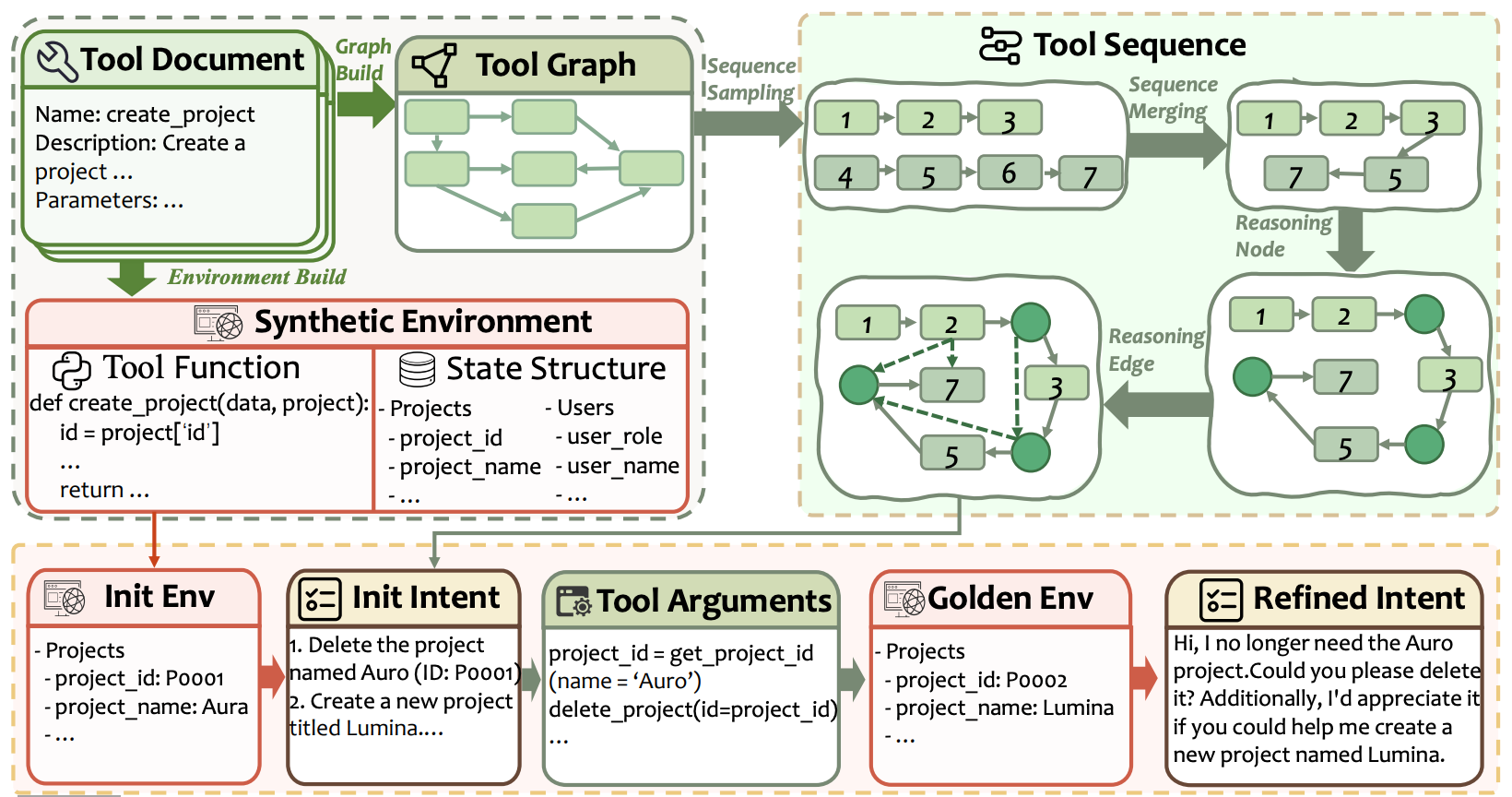
As depicted above, the task synthesis pipeline has three high-level steps:
Environment Generation: the state space and set of functions for an environment is automatically generated by starting from provided tool documentation.
Task Construction: a task is built by sampling sequences of tool calls that are then combined and post-processed to create a complex tool call sequence.
Task Instantiation: the final set of tool calls is used to generate the actual task by converting abstract structures to tangible values and executing the tool sequence to obtain a verifiable ground truth outcome for the task.
To perform environment generation, we start with only the documentation that has been provided for available tools. From this documentation, we can prompt an LLM to construct a list of key-value pairs S = [(K_1, V_1), …, (K_n, V_n)] to serve as the state space for a task, as well as a Python implementation of each tool. Implementing tools as Python functions allows for easy interaction with the environment state via standard dictionary operations and supports concurrent and efficient tool execution, which is necessary for RL training. This process yields an environment of the form E = (S, F), where S is the key-value state and F is the set of available functions; see below for a concrete example.
S (State):
projects:
- project_id: P0001
project_name: Auro
owner: Alice
status: active
...
users:
- user_id: U001
email: alice@example.com
...
F (Functions):
get_project_id_by_name(name)
delete_project(project_id)
create_project(name)
assign_user_to_project(project_id, user_id)
...Only the keys for each state entry are generated at this point—concrete values are instantiated at a later stage. From this initial environment, we use a bottom-up task construction approach that first creates a sequence of tool calls for the task. An LLM prompted with the tool descriptions organizes the available tools into a directed graph, where a directed edge indicates that the output of one tool forms the input for another. An example of a possible edge is shown below.
get_project_id_by_name(name) → delete_project(project_id)
Tool sequences can be sampled from this directed tool graph using random walks. The resulting sequences can then be merged together—by concatenating sequences and asking an LLM to remove duplicate tool calls—to increase their complexity.
“Our synthesis pipeline starts from tool description documentation, enabling the automated construction of a database to store environment states and the generation of tool implementations in Python. A dependency graph of the tools is then constructed, upon which random walks yield diverse tool sequences. These sequences are merged and augmented with reasoning nodes and edges to form a complex directed acyclic graph (DAG), which in turn serves as the blueprint for producing tasks.” - from [6]
When solving a task, an agent performs more than just tool calls. It also uses its text generation capabilities to reason over the problem-solving process. We can prompt an LLM to insert reasoning nodes into the tool call sequence—indicating points at which the agent should perform intermediate reasoning over the results of tool calls—to capture this behavior. Using this sequence of tool and reasoning nodes, we can then prompt an LLM to predict directed edges between nodes to form a directed acyclic graph (DAG) that captures the solution trajectory for a task. We can then instantiate the final task by prompting an LLM to do the following:
Assign concrete values to each state space variable.
Generate a task intent and question based on the tool call sequence.
Augment all tool calls with concrete and valid arguments.
Execute tool calls on the initial environment to produce a golden final state.
Iteratively refine the task to remove needless steps and improve coherence.
The task intent is more explicit, while the task question is a less explicit phrasing of the task that would be presented by a user to the agent. For example, a task question of “Hi, I no longer need the Auro project. Could you please delete it? Also, please create a new project named Lumina.” could have an intent of “delete project Auro, create project Lumina”. The final state is used to compute a verifiable reward for each task during RL training. We can also verify an agent’s trajectory against the ground truth tool sequence, but authors in [6] choose to explicitly focus on outcome verification, as multiple tool sequences may yield the same valid output.
“To better simulate real-world scenarios where the user continuously issues requests and the agent interacts with both the user and the environment, we introduce a simulated user agent into the synthetic environment during the RL stage.” - from [6]
Simulating user interaction. After constructing our set of simulated tasks and environments, we can train our agent over these synthetic environments with RL. For the problem-solving process to be realistic, however, the agent must interact with more than just the environment—agents usually interact with both users and the environment in the real world. For this reason, authors in [6] introduce a simulated user agent into the RL training process. The simulated user agent initiates a task by providing the task question directly to the agent. The agent then solves the task iteratively, where two options are available at each step of the agentic loop:
Make a tool call.
Request information from the user.
Both of these actions will return an observation to the agent, either the result of the tool call or a textual reply from the user agent. A rollout terminates when the user agent determines that all requirements have been satisfied. At this point, the state of the environment is compared to the ground truth state to compute the final reward. Specifically, the final reward is one if the environment state produced by the agent exactly matches the golden final state and zero otherwise. Notably, AutoForge only uses outcome-based rewards for RL training.

Environment Relative Policy Optimization (ERPO) is a GRPO variant proposed for agentic RL in [6] that, in addition to the simulated-user-based rollout process described above, makes the following three additional changes:
Interleaved Thinking: The agent’s thinking traces from every step of the task are retained, instead of discarding prior thinking traces when generating each new output (i.e., the standard setting used by most LLMs). Retaining prior thinking tokens is necessary to keep useful task analysis and planning information across previous steps from being discarded.
Masking Erroneous User Behavior: The simulated user agent can make mistakes. To address this, user responses are judged by an LLM to identify errors from the simulated user that cause the task to fail. When such an error is detected, the trajectory is excluded from the advantage and loss calculation7.
Environment-Level Advantage Estimation: The training batch is composed of multiple environments, each with a set of questions. A question
q_ihas a corresponding set of sampled trajectoriesM_i. In GRPO, we compute a group-wise advantage over the set of trajectories for each question. ERPO modifies this approach by computing the reward standard deviation over all valid trajectories for questions that share the same environment; see below.
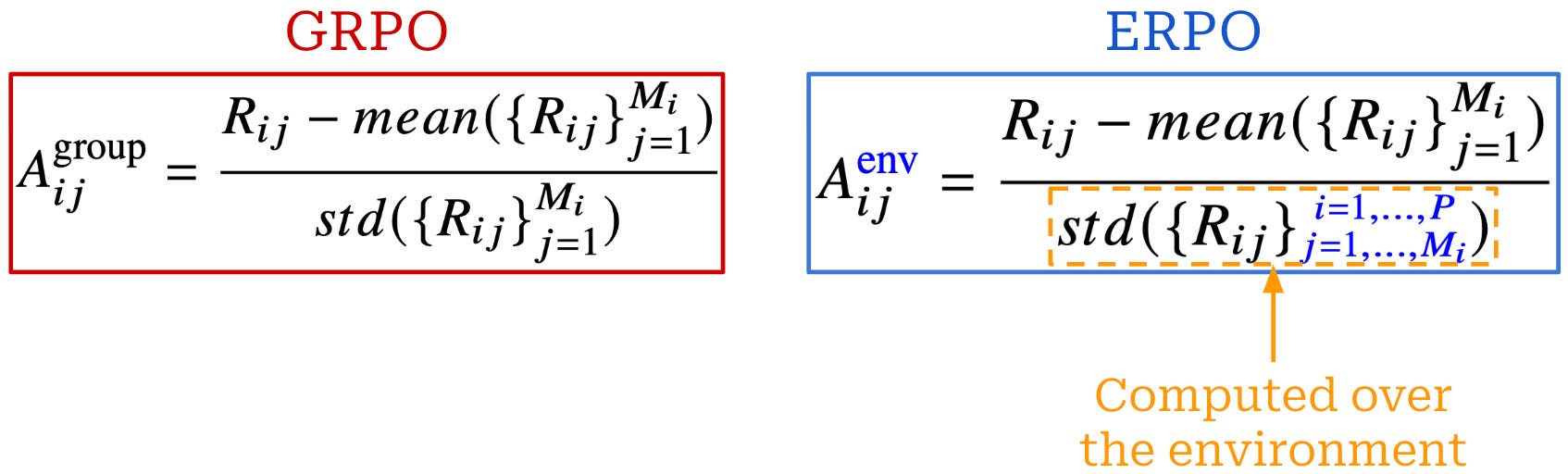
The modified normalization used by ERPO computes the standard deviation over a wider group of rewards and, in turn, improves robustness to outliers. As shown above, ERPO retains the same question-level reward mean used by GRPO in the numerator. However, the standard deviation term is computed across all valid trajectories for all questions in the same environment, yielding environment-level advantage scaling. In other words, ERPO keeps the GRPO-style mean in the numerator, while the denominator pools rewards across the environment.
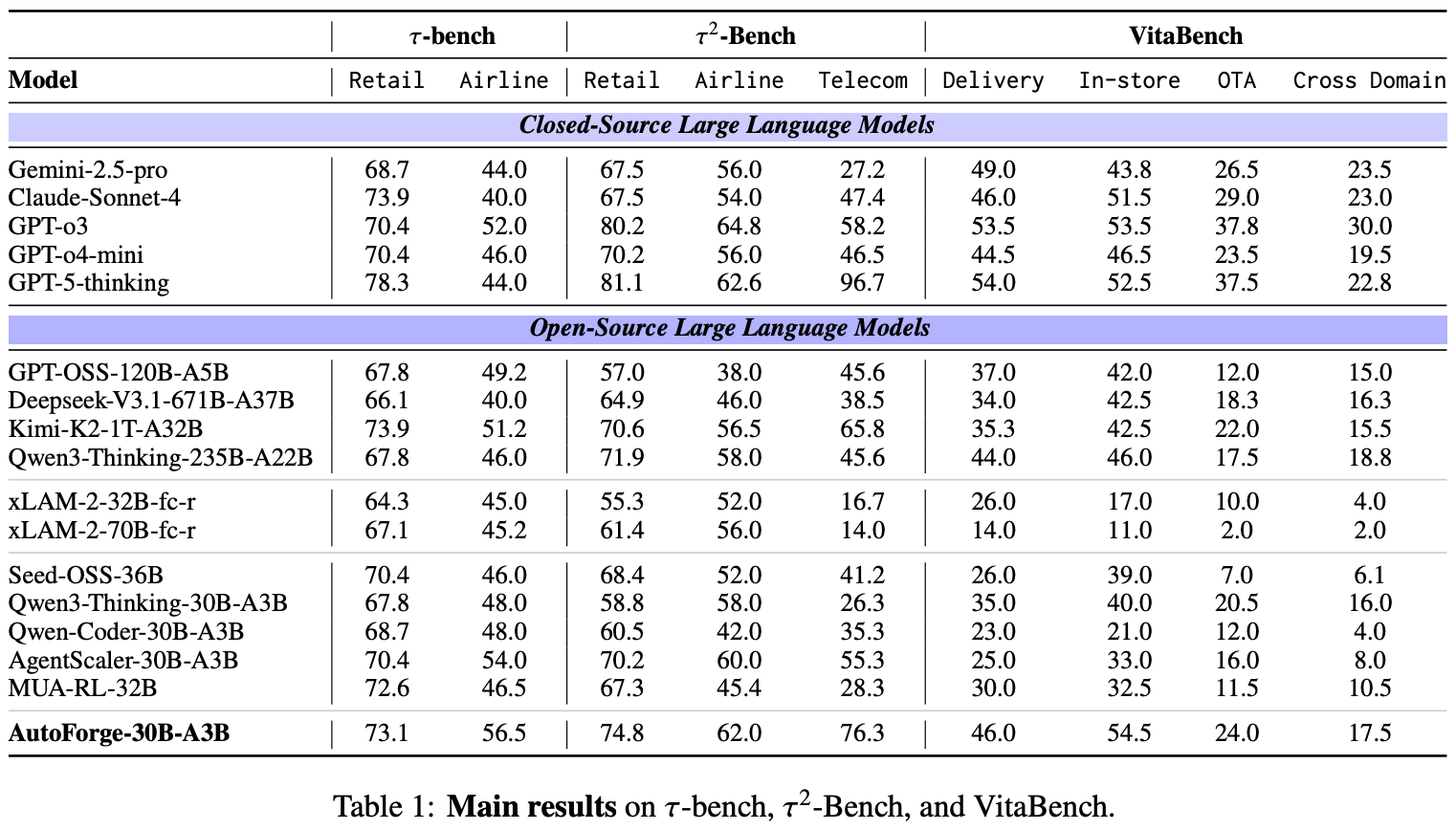
Empirical analysis. 10 environments are synthesized in [6], containing 1,078 tasks in total, using the Qwen3-235B-A22B-Thinking model. When used to finetune Qwen3-30B-A3B-Thinking, AutoForge improves performance on in-domain benchmarks like the τ-Bench series and VitaBench. Before RL training, a cold-start SFT stage is performed using valid trajectories collected by having the base model interact with synthesized environments. The resulting SFT model is then further optimized using ERPO. AutoForge agent performance surpasses larger open base models (e.g., Qwen3-235B-A22B-Thinking) and nears the performance of proprietary models (e.g., Gemini-2.5-Pro) in some cases; see below.
When evaluated on out-of-domain datasets, agents trained with AutoForge continue to perform well; see below. Notably, this out-of-domain generalization test is particularly harsh. AceBench-zh uses i) a different prompt and tool call format relative to training, ii) a new set of tools not seen during training, and iii) a completely different language—models are trained in English and evaluated in Chinese. Yet, agents still see performance improvements after RL training.
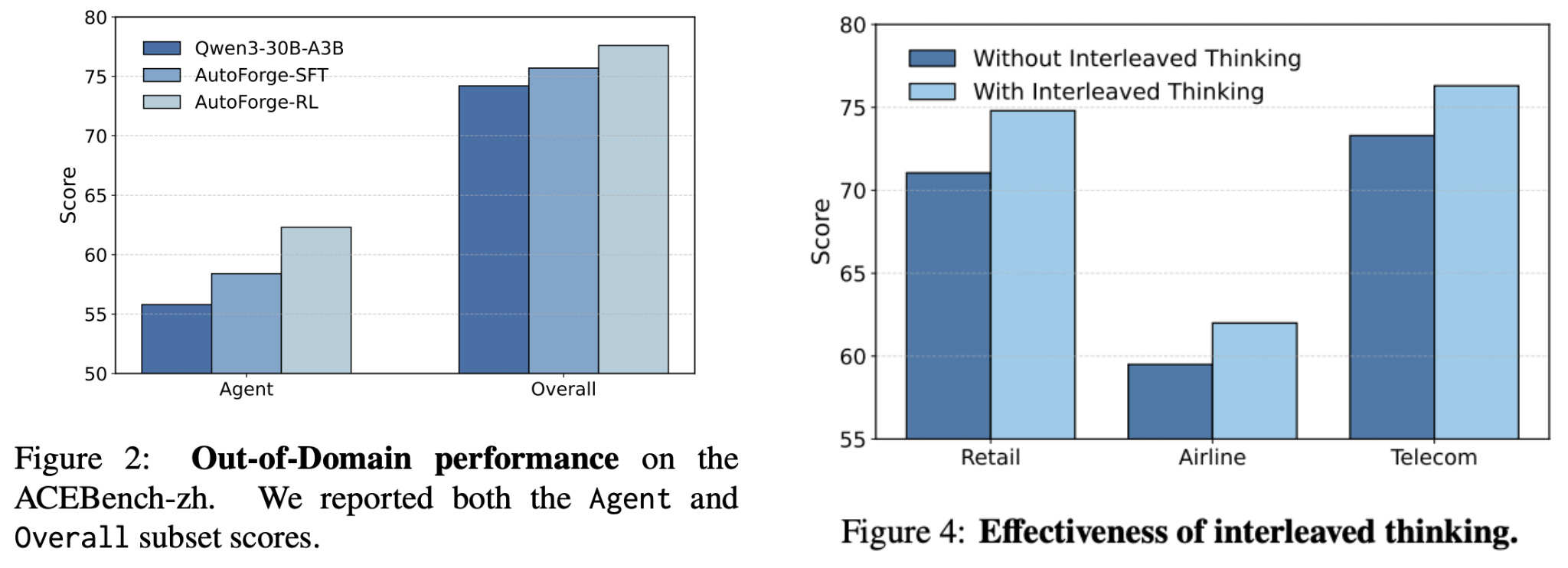
Not surprisingly, we see noticeably larger gains from training the agent with RL relative to SFT only. Ablation experiments are also performed over each component of AutoForge, finding that:
Interleaved thinking yields a clear boost in agent capabilities despite increasing the amount of context consumed by the agent; see above.
Using a stronger simulated user agent (e.g., using GPT-5 to simulate the user instead of GPT-4.1) during evaluation benefits performance.
Erroneous user masking is helpful and performance degradation was observed when incorrect user behaviors were allowed.
Using environment-level advantage estimates is crucial for keeping agentic RL training stable.
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning [7]

Again, authors in [7] focus on using rule-based RL (i.e., with verifiable rewards) to train interactive agents that can solve difficult, multi-step tasks. This learning process for agents is referred to in [7] as “self-evolution”, as the agent learns from its own outputs and the corresponding environment rewards during RL. As we have already learned, several difficulties arise when performing multi-turn RL, such as the lack of generalization across environments or general training instability. In [7], the authors propose RAGEN, a training framework for agentic RL with modular support for new environments. They also introduce State-Thinking-Actions-Reward Policy Optimization (StarPO), a trajectory-level learning algorithm designed specifically for training interactive agents.
“Unlike previous methods for static tasks that treat each action independently, StarPO treats the entire trajectory—including observations, reasoning traces, actions, and feedback—as a coherent unit for rollout and model optimization.” - from [7]
StarPO goes beyond single-turn RL techniques by optimizing the entire trajectory of an agent as a coherent unit. When generating a rollout, the agent runs in an agentic loop. At each step, the agent generates a structured output containing a textual reasoning trace and one or more environment-executable actions (i.e., tool calls). In [7], we specifically consider training reasoning-based agents that generate reasoning-guided, structured outputs as shown below.
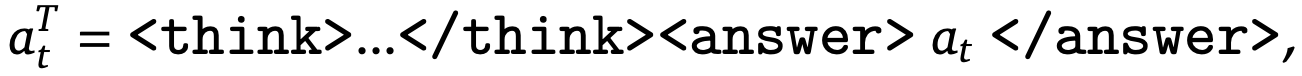
After each step, the environment is updated and the agent receives an optional intermediate reward. For example, agents in [7] receive a negative reward for incorrectly formatted outputs. The agent eventually reaches a terminal state, either due to a stopping condition or reaching the maximum number of allowed turns, at which point the rollout is terminated and we compute a final verifiable reward. The result of this process is a trajectory of states and actions produced by the agent, as well as the cumulative reward obtained throughout the rollout.

Following standard practice, the objective in [7] is to maximize cumulative reward, but this objective is optimized over the entire multi-turn trajectory; see above. Similarly to [6], StarPO also retains intermediate reasoning traces in the trajectory, but authors do not mask environment tokens from the objective, which is a meaningful departure from the other methods we have seen. In the appendix, however, response masking is tested and found to be beneficial. In [7], StarPO is framed as a high-level optimization approach, not a specific algorithm—the training process can be implemented with any RL optimizer (e.g., PPO or GRPO).
Experimental results. StarPO is practically analyzed in [7] by implementing it within the RAGEN framework, a system for LLM agent training that provides modular and extensible support for generating structured rollouts in multi-turn, stochastic environments with arbitrary reward functions. Agents based on the Qwen-2.5 models are trained on a variety of environments, including three controlled symbolic environments that allow targeted analysis and one realistic environment—the WebShop benchmark—that tests web navigation abilities. An entropy bonus is added to the StarPO objective, verifiable outcome rewards are adopted for all domains, and experiments are performed with PPO and GRPO.

From experiments in [7], authors discover a novel instability pattern, called the echo trap, that is often observed in agentic RL; see above. This issue occurs when the agent overfits to its own generated reasoning patterns during RL training, causing a behavioral collapse that destabilizes training. Common signs of an echo trap (shown in the figure below) include:
A plateau or decline in training reward.
A sharp reduction in within-group reward variability and token-level output entropy, indicating behavioral collapse in the agent.
A spike in the gradient norm that coincides with severe—and often irreversible—training instability.
“Early-stage trajectories exhibit diverse reasoning about symbolic meanings and expected rewards, while later-stage responses become repetitive and deterministic. This suggests that RL training may have over-amplified inherent reasoning shortcuts, reinforcing locally rewarded templates while suppressing exploration. We refer to this failure mode as an Echo Trap… where the model repeatedly reuses memorized reasoning paths when trained on self-generated trajectories, leading to a collapse in diversity and long-term performance degradation.” - from [7]
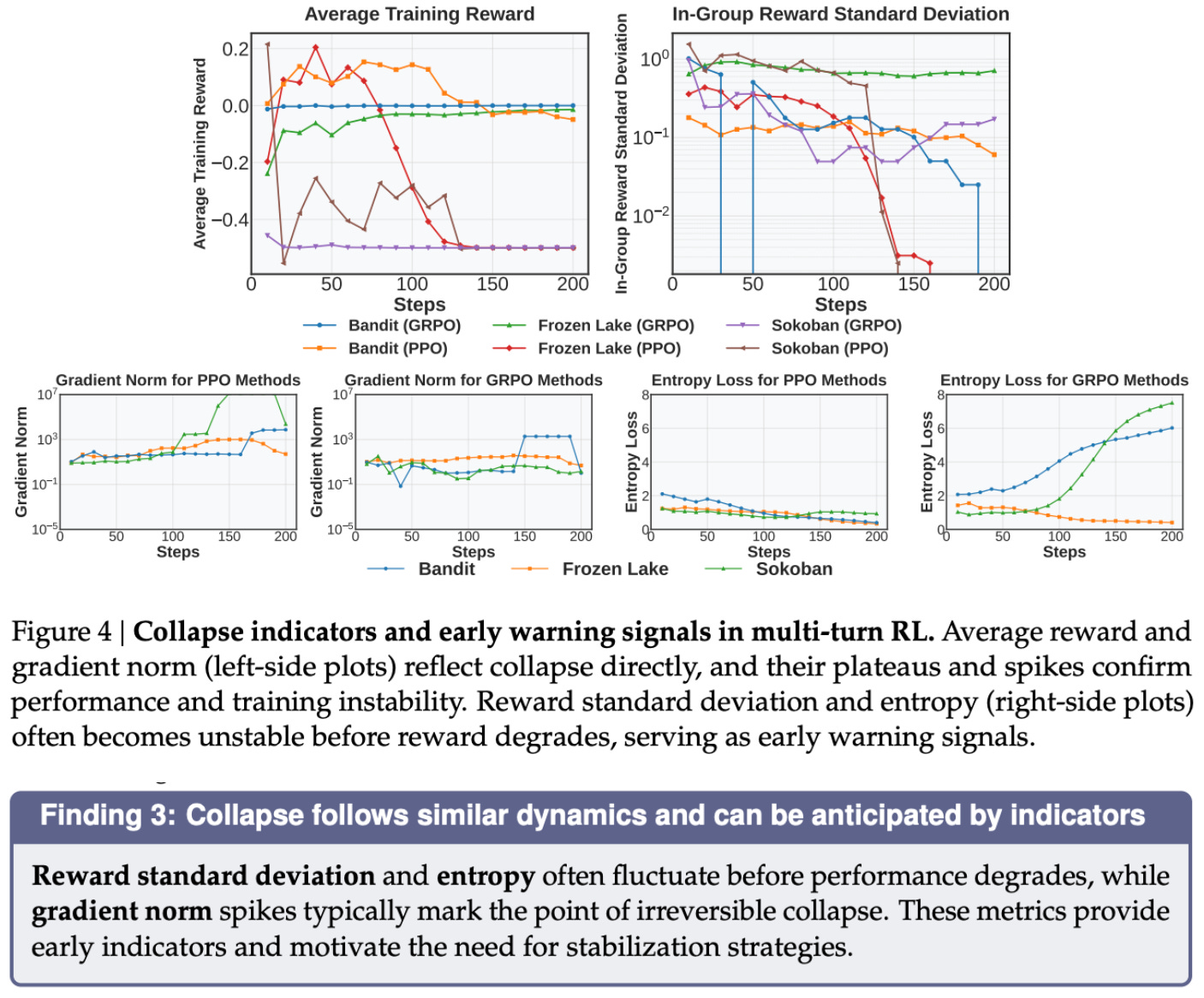
Several interventions are proposed in [7] to encourage behavioral diversity and exploration, thus avoiding the echo trap and improving stability. These changes form StarPO-S, a stabilized variant of StarPO. First, exploration is encouraged by removing the KL divergence regularization term from the RL objective. The Clip-Higher approach from DAPO is also used to protect against entropy collapse.
Going further, an offline data filtering approach is proposed that selects training tasks with the highest outcome uncertainty—authors in [7] argue that these tasks provide the most informative training signal. Specifically, we measure the standard deviation in reward for all training tasks and select tasks in descending order of standard deviation to use for training. This selection process allows the agent to learn from high-variance tasks instead of reinforcing deterministic behavior. As shown below, these changes delay collapse and enhance agent performance.
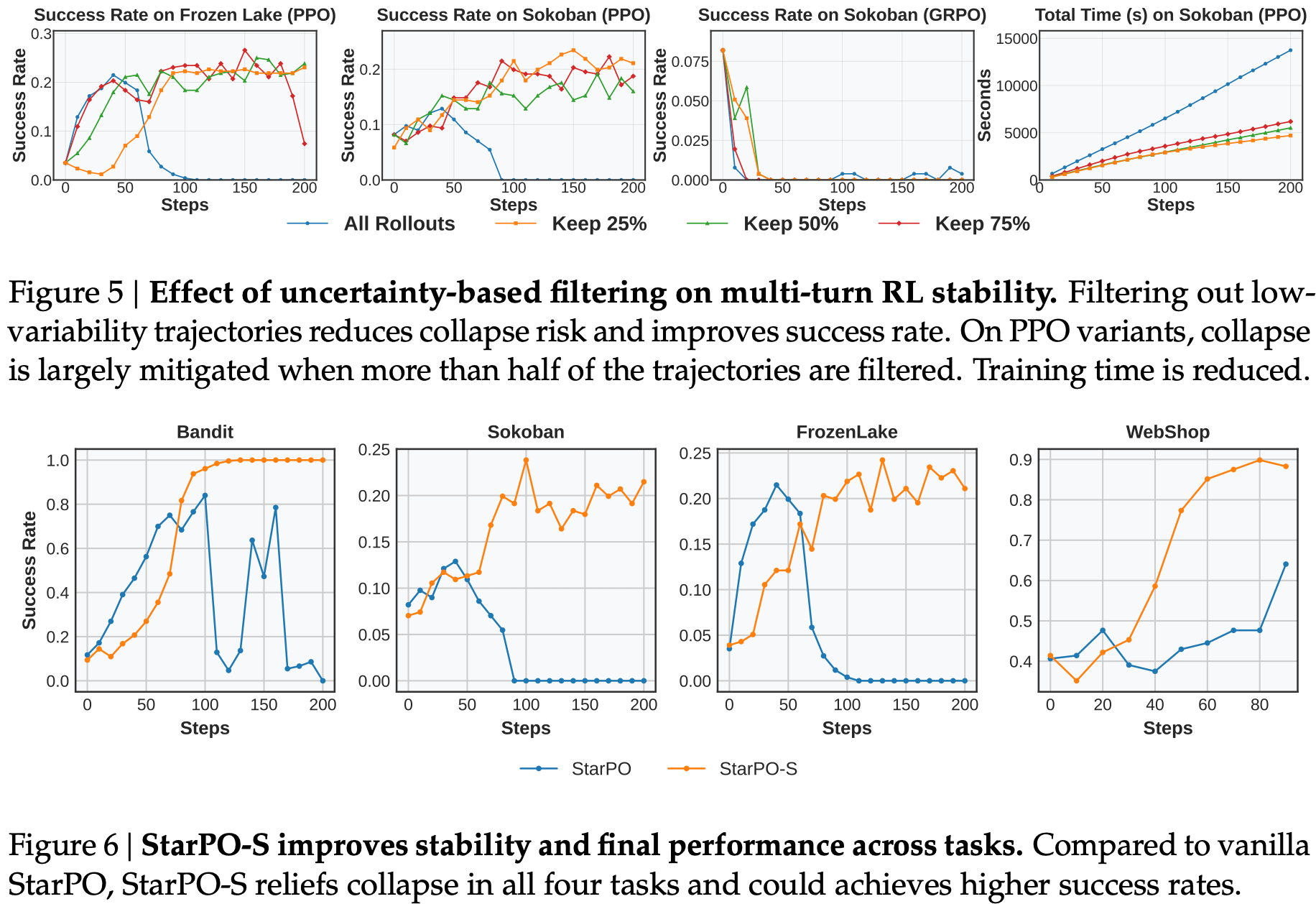
The behavior of agents trained in [7] is analyzed in depth, yielding the following set of findings:
Increasing the diversity in each training batch (i.e., sampling a larger number of tasks and using slightly fewer rollouts per task) benefits generalization.
Larger interaction budgets allow the agent to use more steps when solving a task and are shown to benefit overall agent performance, especially on complex environments that require planning. However, performance declines if the budget is increased too much—moderate interaction budgets are best.
Online RL yields the best performance, while training on stale rollouts (i.e., by either 5 or 10 training steps) consistently degrades performance.
Explicit reasoning improves generalization in certain settings but has mixed benefits in others. Interestingly, reasoning traces tend to shrink throughout training, suggesting that trajectory-level outcome rewards alone do not encourage agents to preserve useful reasoning over long interactions.
“We find that even with stable entropy, models can rely on fixed templates that look diverse but are input-agnostic. We call this template collapse… To diagnose this failure, we decompose reasoning quality into within-input diversity (Entropy) and cross-input distinguishability (Mutual Information), and introduce a family of mutual information proxies for online diagnosis.” - from [8]
RAGEN-2. Extending the analysis in [7], authors identify another form of RL instability in [8], called template collapse; see below. We can continually monitor diversity metrics in RL, but most common metrics for capturing diversity (e.g., token-level entropy) only measure diversity within the same input. It is possible for a model to retain high entropy within each input while still producing input-agnostic outputs. To go beyond within-input diversity, we must compute the mutual information across inputs to capture the depth of an agent’s reasoning.
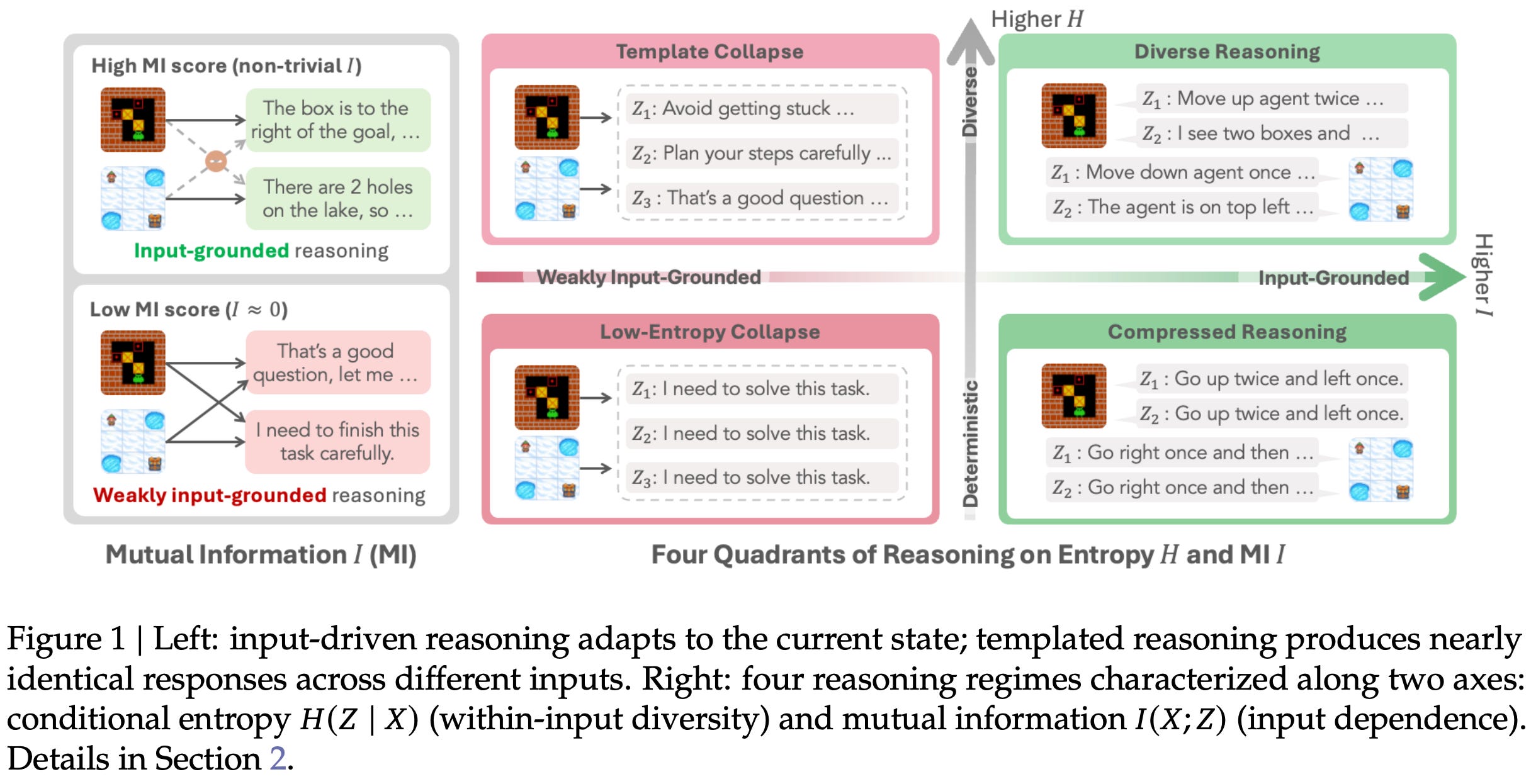
In [8], authors argue that we should decompose total diversity into a combination of entropy—how varied reasoning is for a specific prompt—and mutual information—how much reasoning changes based on the prompt. Most existing approaches (e.g., an entropy bonus for RL) only target entropy, thus leading to template collapse. A few different proxies for mutual information are proposed in [8], which are found to correlate more strongly with final performance than entropy; see below.
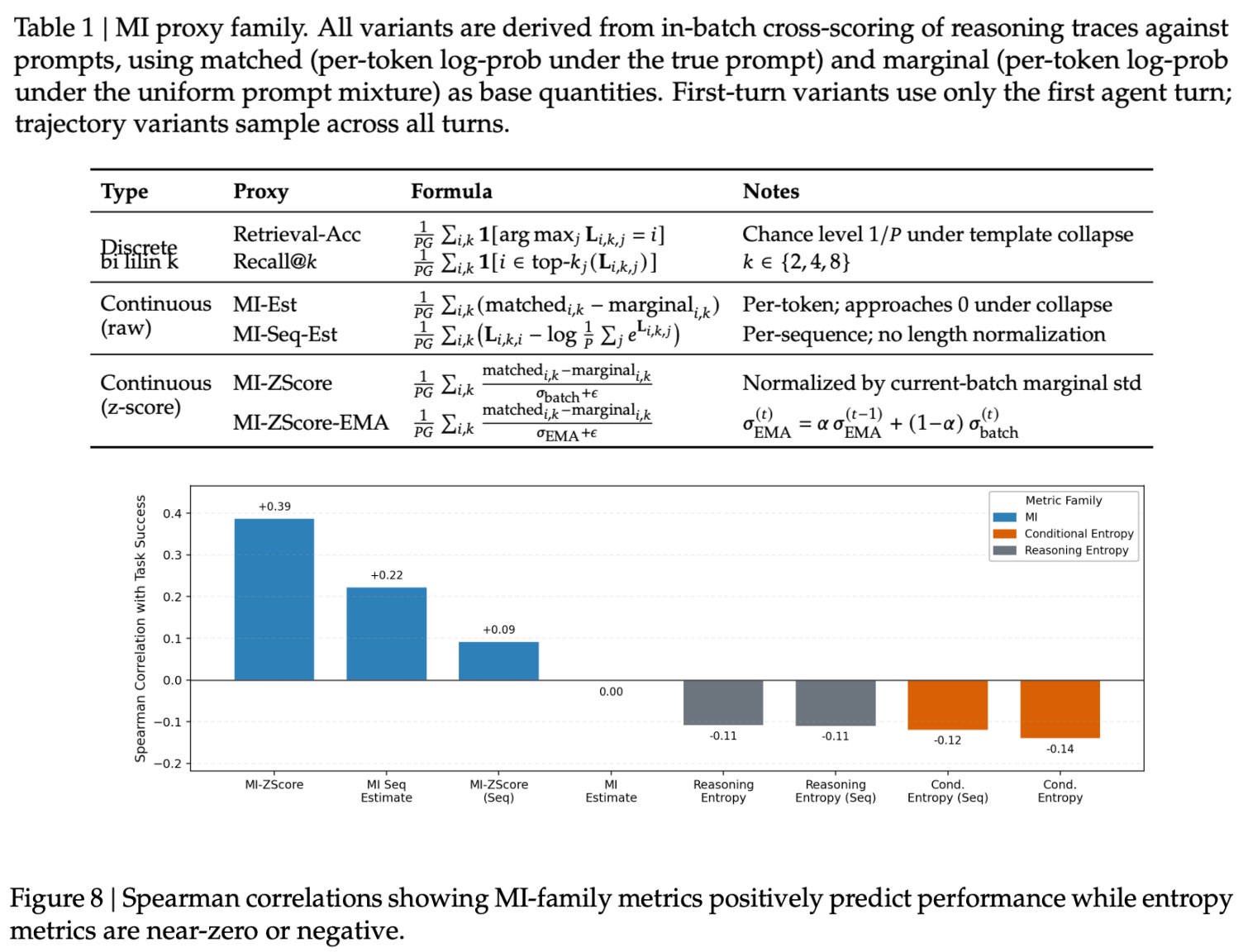
Interestingly, the approach used to improve diversity metrics during training in [8] is somewhat similar to the active learning approach proposed in [7]. Authors analyze the signal-to-noise ratio (SNR) in an RL update, showing that the signal within an update is related to the reward variance for each task. Therefore, we can select tasks with maximum signal by just:
Sampling multiple trajectories for each task in the batch.
Computing the reward variance for each task group.
Ranking tasks by variance and keeping only those with the top variance mass (i.e., according to a pre-defined keep rate of
p=0.9).
This dynamic SNR filtering approach used for RL in [8] is depicted below. By removing the contribution of low-signal prompts to the policy gradient, we can avoid template collapse, thus improving the performance, generalizability, efficiency, and stability of the agentic RL training process as a whole.
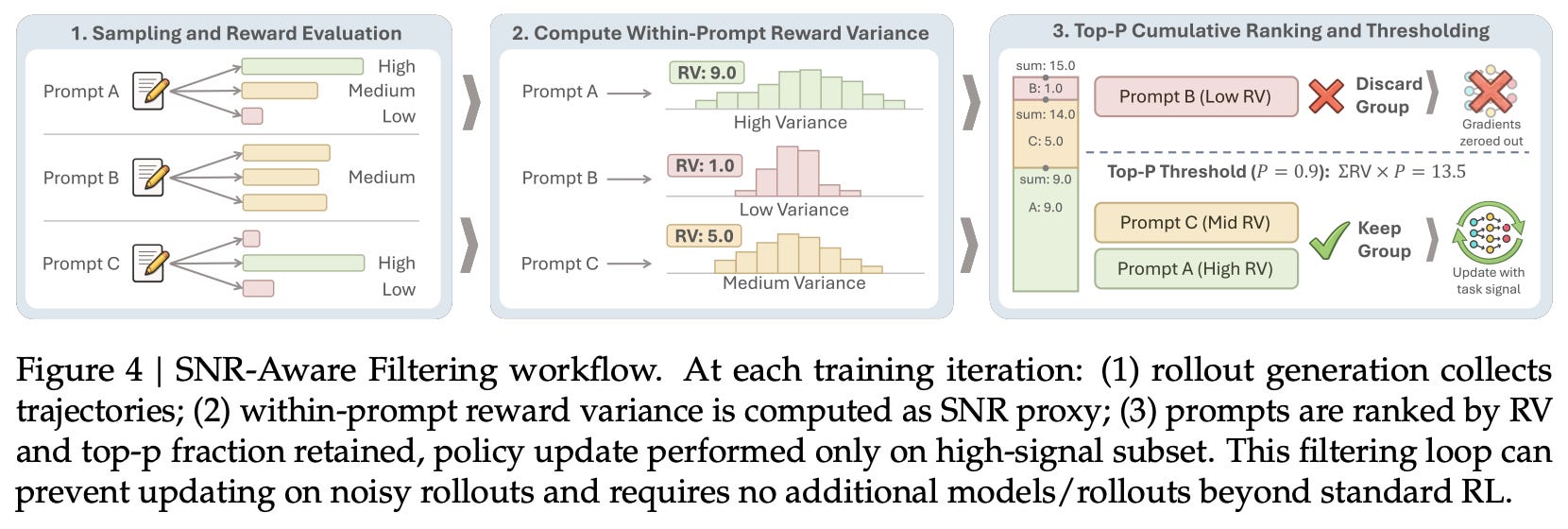
Key Takeaways
We have studied a wide variety of papers on training agents with RL. Although these papers differ in their environments, optimizers, and experimental setups, several common ideas and patterns appear throughout. By studying these trends, we can derive a set of practical design principles for building agentic RL systems that are modular, scalable, stable, and capable of improving agent behavior.
Modular interfaces. Most of the frameworks we have seen are built on top of modular abstractions for tools and environments:
AgentGym-RL [3] utilizes a unified HTTP interface.
Agent-R1 [4] defines the Tool and ToolEnv abstractions.
AgentRL [5] exposes a function-call-based environment API.
By using a modular design, we can easily add new tasks, swap environments, or test out different optimizers. In this way, our agentic RL infrastructure can scale beyond manually-defined tasks to capture arbitrary training environments.
Trajectory structure. Agentic RL requires us to handle multi-turn trajectories that contain instructions, generated tokens, tool calls, observations, rewards, and environment state. Representing such a complex trajectory is more complex compared to a single-turn RL setup. For this reason, agentic RL frameworks go beyond representing rollouts as flat sequences of tokens. For example, Agent-R1 [4] stores structured step-level trajectories that preserve step boundaries and store exact tokens to avoid retokenization drift. The format of a trajectory is important because it determines how context is constructed and how rewards are assigned.
Action mask. Most agentic RL papers modify the RL objective such that only agent-generated tokens contribute to the policy gradient. Such action masking is one of the most consistent implementation details shared across the papers we have seen and is shown to improve agent performance. However, recent work has found that completely excluding non-agent-generated tokens from the objective may not be optimal. Namely, we can further improve performance by:
Applying an RL objective to agent-generated tokens.
Applying an SFT objective to environment-generated tokens.
Intuitively, this approach can be seen as learning to act via RL while learning a world model via SFT from the provided environment feedback. For more details, please see recent papers published on this topic like Echo and PaW.
Process rewards. Most recent work on RL training for LLMs relies heavily on outcome rewards, and this is also true of agentic RL—especially when tasks have verifiable success criteria. However, long-horizon tasks often benefit from richer credit assignment mechanisms. As a result, several agentic RL papers support intermediate process rewards in training [3, 4, 7]. However, the inclusion of process rewards does not always yield a clear benefit; e.g., ToRL [1] observes degraded performance when adding a penalty for non-executable code.
Advantage normalization. In vanilla GRPO, the advantage is estimated by normalizing a completion’s reward relative to other completions sampled for the same prompt. Several agentic RL papers use a modified advantage estimation technique that normalizes over a wider group—in particular, all trajectories in a batch that are from the same domain or environment. AgentRL [5] uses task-level advantage normalization, which normalizes token-level advantages across an entire task or domain. Similarly, AutoForge [6] proposes ERPO, which computes the advantage scaling term in GRPO over all valid trajectories in an environment. These methods normalize in slightly different ways but are based on the same principle: we are normalizing advantages across an entire task or environment to ensure that multi-task training is stable and no single task dominates the policy update.
Scalable rollouts. Agentic RL is both an algorithmic and a systems problem. Rollouts can have high variance in length and completion time, which changes depending upon the environment in which an agent runs. For this reason, most agentic RL frameworks use asynchronous rollout generation and a disaggregated architecture with dedicated resources for training and inference. Additionally, environments are containerized and hosted in a scalable manner (e.g., using Kubernetes) so that environment execution does not become a bottleneck.
Stability and exploration. Training agents over long horizons introduces new failure modes that are less prominent in single-turn RL:
Entropy collapse due to the large action spaces of agents.
Instability in multi-task training settings.
Stale or off-policy data introduced through asynchronous training.
Echo traps and template collapse.
The papers we have seen propose a variety of approaches to solve these issues. For example, AgentRL [5] explores techniques like cross-policy sampling, task-level advantage normalization, and staleness control for asynchronous RL to solve these problems. Similarly, AutoForge [6] uses modified advantage normalization, while RAGEN [7] and RAGEN-2 [8] address instability with better data filtering.
Task selection and curriculum. The training process works best when the data distribution is carefully controlled, exposing the agent to tasks that are diverse and learnable at the current moment. Data can be selected, synthesized, filtered, or even scheduled over time via a curriculum. ScalingInter-RL [3] increases the interaction budget throughout training so that the agent can incrementally learn how to solve long-horizon tasks, while RAGEN [7, 8] prioritizes tasks with high variance or signal to avoid reinforcing deterministic behavior within the agent. To mitigate data collection bottlenecks, AutoForge [6] synthesizes realistic and verifiable environments for agentic RL training from tool documentation.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, Deep Learning Ph.D. and Staff Research Scientist at Netflix. This is the Deep (Learning) Focus newsletter, where I help readers better understand important topics in AI research. The newsletter will always be free and open to read. If you like the newsletter, please subscribe, consider a paid subscription, share it, or follow me on X, Medium, and LinkedIn!
Bibliography
[1] Li, Xuefeng, Haoyang Zou, and Pengfei Liu. “Torl: Scaling tool-integrated rl.” arXiv preprint arXiv:2503.23383 (2025).
[2] Gou, Zhibin, et al. “Tora: A tool-integrated reasoning agent for mathematical problem solving.” International Conference on Learning Representations. Vol. 2024. 2024.
[3] Xi, Zhiheng, et al. “Agentgym-rl: Training llm agents for long-horizon decision making through multi-turn reinforcement learning.” arXiv preprint arXiv:2509.08755 (2025).
[4] Cheng, Mingyue, et al. “Agent-r1: Training powerful llm agents with end-to-end reinforcement learning.” arXiv preprint arXiv:2511.14460 (2025).
[5] Zhang, Hanchen, et al. “Agentrl: Scaling agentic reinforcement learning with a multi-turn, multi-task framework.” arXiv preprint arXiv:2510.04206 (2025).
[6] Cai, Shihao, et al. “AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning.” arXiv preprint arXiv:2512.22857 (2025).
[7] Wang, Zihan, et al. “Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning.” arXiv preprint arXiv:2504.20073 (2025).
[8] Wang, Zihan, et al. “Ragen-2: Reasoning collapse in agentic rl.” arXiv preprint arXiv:2604.06268 (2026).
[9] Anthropic. “Effective harnesses for long-running agents” https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents (2025).
[10] Anthropic. “Effective context engineering for AI agents” https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents/ (2025).
[11] Zhong, Yinmin, et al. “Streamrl: Scalable, heterogeneous, and elastic rl for llms with disaggregated stream generation.” arXiv preprint arXiv:2504.15930 (2025).
[12] Zai. “GLM-5.2: Built for Long-Horizon Tasks” https://z.ai/blog/glm-5.2 (2026).
[13] Luo, Michael et al. “DeepSWE: Training a Fully Open-sourced, State-of-the-Art Coding Agent by Scaling RL” https://pretty-radio-b75.notion.site/DeepSWE-Training-a-Fully-Open-sourced-State-of-the-Art-Coding-Agent-by-Scaling-RL-22281902c1468193aabbe9a8c59bbe33 (2025).
There are two common training patterns in agentic RL: RL-Zero (i.e., performing RL directly on the base model) and SFT cold start (i.e., a preliminary SFT phase followed by RL training).
Note that the most recent code block can be easily parsed from the model’s output sequence due to being wrapped with clear indicators.
All sandboxes for ToRL are created using Sandbox Fusion.
We note that a revised version of the report was recently published that removes most of the discussion on the environment structure and interface for Agent-R1. However, we retain these details from the prior report because they are still useful.
Such a disaggregated architecture is a common choice for asynchronous RL training frameworks in recent LLM research.
The per-task performance deltas observed are as follows: ALFWorld (+62.4%), DB (+43.2%), KG (+14.6%), OS (+31.1%), and Webshop (+62.4%).
Importantly, this is implemented in [6] by simply removing this rollout from the group. Therefore, when normalizing the objective by the total number of rollouts, we actually only consider rollouts that were not masked (i.e., a dynamic sampling approach).
Best single map of agentic RL I've read, and the takeaways section is the part people will actually reuse. One thread worth pulling tighter: echo trap, template collapse, and shrinking reasoning traces are one failure, the optimizer collapsing the policy onto whatever cheaply satisfies the in-loop verifier.
RAGEN-2 has the load-bearing insight, entropy is the wrong diagnostic because you can hold high within-input entropy while going input-agnostic, so you need MI, the property you actually want (does reasoning depend on the prompt) rather than a proxy that drifts from it. Seen that way, every fix here is the same move, make the cheap path to reward more expensive or detect it, and they aren't one-time patches because you're optimizing against a checker inside the loop, where any reward weakness is something the optimizer is paid to find.
The survey's own finding that RL helps most on clean rule-based tasks and least on noisy WebArena is the verification gap at training time: uplift tracks how cleanly the reward verifies, so verifiable-reward RL inherits the same boundary it has at deployment. That the fixes rhyme across six independent frameworks is the real signal. Great piece.
The RL framing is useful here. I'd be curious how you think about evaluation when the environment shifts faster than the policy can adapt.