
Finetuning LLM Judges for Evaluation
The Prometheus suite, JudgeLM, PandaLM, AutoJ, and more...


Evaluating large language models (LLMs) has become more difficult as their capabilities have expanded. Modern foundation models have a wide scope, and their output is usually open-ended—meaning that any input has many viable outputs. For these reasons, programmatically evaluating LLMs is a complex and active research problem. Evaluating any single capability of an LLM is already difficult, and LLMs have numerous capabilities and behaviors worthy of evaluation.
“Evaluating the quality of outputs produced by LLMs is progressively becoming difficult, as the outputs cover an extremely diverse distribution of text and complex tasks. To address this issue, LLM-based evaluation has emerged as a scalable and cheap paradigm for assessing LLM-generated text” - from [2]
The most reliable way to judge the performance of an LLM is by having humans evaluate the model’s outputs, but human evaluation is noisy, expensive, and time consuming. Although a certain amount of human evaluation is always necessary, relying purely upon human evaluation is not scalable. We must be able to efficiently test the capabilities of a new LLM. This need motivated the proposal of LLM-as-a-Judge [8], which prompts a proprietary LLM to evaluate another LLM’s output.
LLM-as-a-Judge is heavily used in current research, but it is less effective for domain-specific applications that require the evaluation of granular criteria with which a proprietary LLM may be less familiar. For these cases, we may need to train our own specialized LLM judge, and the goal of this overview is to gain a comprehensive understanding of how this can be achieved. Let’s start by taking a broad look at the different ways we can approach evaluating an LLM.
How to Evaluate an LLM
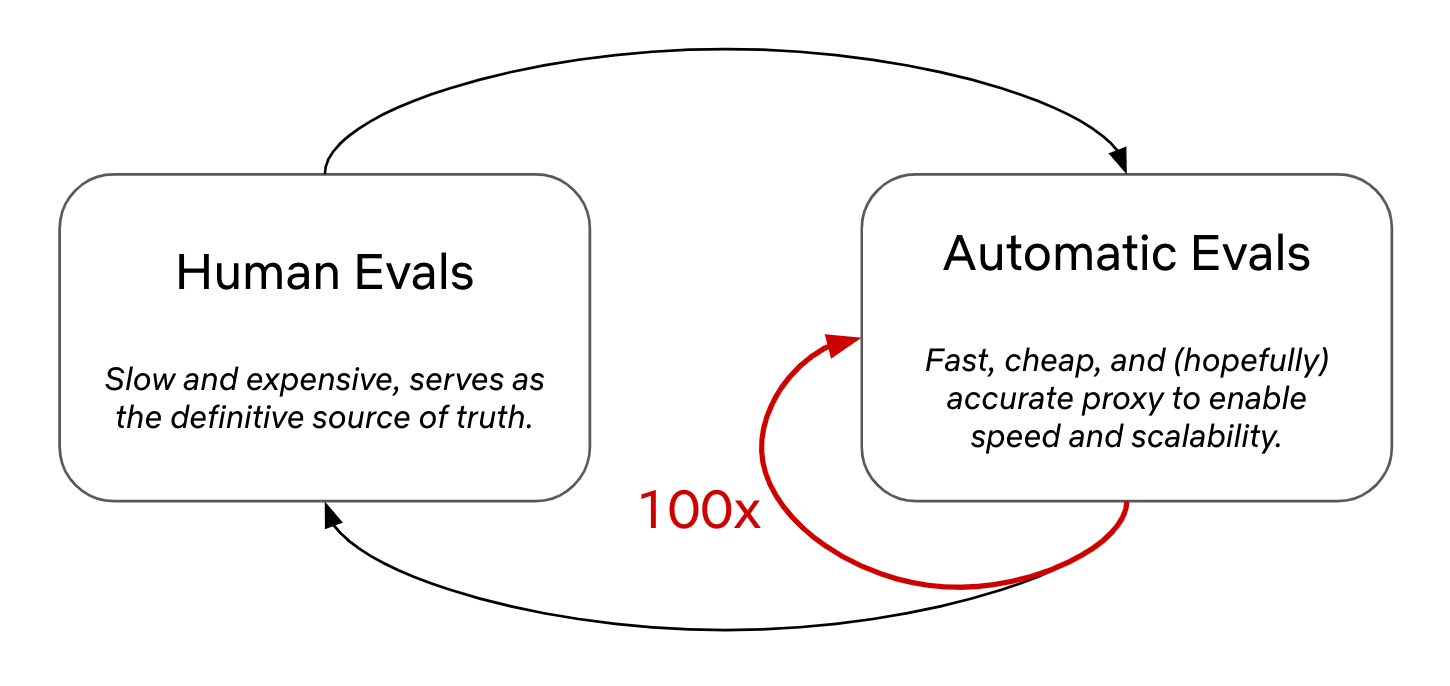
To evaluate an LLM, we use a combination of human evaluation and automatic metrics; see above. Human evaluation serves as our definitive source of truth in terms of the model’s performance, but human evaluation is also incredibly laborious. To increase our pace of model development, we need to rely on automatic metrics that can be measured more efficiently, allowing us to train and evaluate models at a faster pace. Automatic metrics are an imperfect proxy for human opinions, so we must continue to monitor the model’s performance via human evaluation. However, we can use automatic metrics to test a much larger number of models between each human evaluation trial.
“Existing benchmarks and traditional metrics do not adequately estimate the capabilities of LLMs in open-ended scenarios. A new benchmark method that could evaluate LLMs comprehensively in open-ended tasks is needed.” - from [9]
Types of automatic evaluation. There are two primary automatic evaluation strategies used for most modern LLMs (shown below): perplexity and model-based evaluation. Perplexity-based evaluation encompasses most traditional NLP benchmarks, such as MMLU or BIG-bench. We can think of these benchmarks as multiple-choice-style questions that test the general knowledge of an LLM. However, these benchmarks fall short when evaluating LLMs in more open-ended settings, where the LLM is expected to generate longer, stylized answers.

To evaluate longer, open-ended outputs, we have two options:
Human evaluation: rely upon humans to rate the model’s output.
Model-based evaluation: use a powerful LLM to rate the model’s output.
Because of the limitations of human evaluation, model-based evaluation strategies—such as LLM-as-a-Judge [8]—have become the go-to approach for evaluating LLMs. Such model-based evaluation techniques do not require references, are easy to implement, and can handle a wide variety of open-ended tasks.
Now we understand the basic categories of evaluation, including both human and automatic evaluations. We also understand that there are several ways to perform automatic evaluation (i.e., benchmarks or model-based evaluation). So, let’s take a deeper look at each of these evaluation strategies, starting with human evaluation and moving on to various automatic evaluation techniques.
Human Evaluation
“Human evaluation has consistently been the predominant method, for its inherent reliability and capacity to assess nuanced and subjective dimensions in texts. In many situations, humans can naturally discern the most important factors of assessment, such as brevity, creativity, tone, and cultural sensitivities.” - from [1]
Human evaluation is our definitive source of truth when evaluating an LLM. The humans that perform this evaluation—referred to as human evaluators or annotators—can be sourced in a variety of ways; e.g., we can crowdsource, hire1, or even use ourselves—the model developers—to evaluate the output of an LLM. Although human evaluation is our source of truth in terms of model quality, this does NOT mean that human evaluation is perfect. In fact, the exact opposite is usually true in practice—human evaluation is noisy, difficult, and can be prone to bias.

Agreement and calibration. Even on seemingly subjective tasks, human agreement, which is measured by simply counting matching evaluations or using metrics like Cohen's Kappa, Fleiss' Kappa, and Krippendorff's Alpha, can be low. So, we must invest effort into “calibrating” human annotators (i.e., teaching them how to evaluate our particular task consistently and accurately); see above. Calibration usually involves having a meeting among human annotators2 to discuss and resolve disagreements. Then, we can take the results of these discussions and incorporate them into the evaluation guidelines for our task.
Crafting guidelines. To document how humans should evaluate or annotate a certain task, we must create a set of written guidelines that explain:
What exactly we are aiming to evaluate (i.e., the evaluation criteria).
How to properly evaluate these criteria.
These guidelines, comprised of both written instructions and concrete examples of correct or incorrect annotations3, are a detailed resource that humans can continually reference throughout the annotation process. Written guidelines make the annotation process more consistent, as well as simplify the task of onboarding new annotators. All necessary information that is needed to correctly perform our annotation task should be clearly outlined within these guidelines.
“The instructions we provided to labelers evolved over the course of the project, as we provided feedback, changed our metadata fields, and developed a better understanding of what we wanted to measure. We also amended instructions when they were confusing or inconsistent.” - from [22]
These guidelines are not static. Rather, we can continually update them over time as we work with human annotators and try to achieve higher levels of agreement. In most projects, our understanding of what we are trying to evaluate becomes more clear and detailed over time. Although we might think that a certain evaluation task is simple or straightforward, most annotation tasks naturally contain a surprising amount of subjectivity. This subjectivity only becomes clear we we try to get a group of human of consistently agree on a given task.
Continuous monitoring. Usually, we invest a ton of up front effort into crafting guidelines and calibrating human evaluators for our evaluation task. Once we are happy with the evaluation criteria we have put in place and reach a reasonable level of agreement when evaluating these criteria, we can be more confident in the results of human evaluation and start to use these results as a measure of our LLM’s performance. However, we should continue to measure agreement among human evaluators over time to ensure there is no deterioration or drift. There are several reasons that agreement may decline—new humans may enter the group of evaluators, evaluators may forget about the guidelines over time, or we might even change our guidelines! Ensuring that human evaluations are consistent and accurate is a never-ending (but extremely necessary) battle.
Traditional (Automatic) Metrics
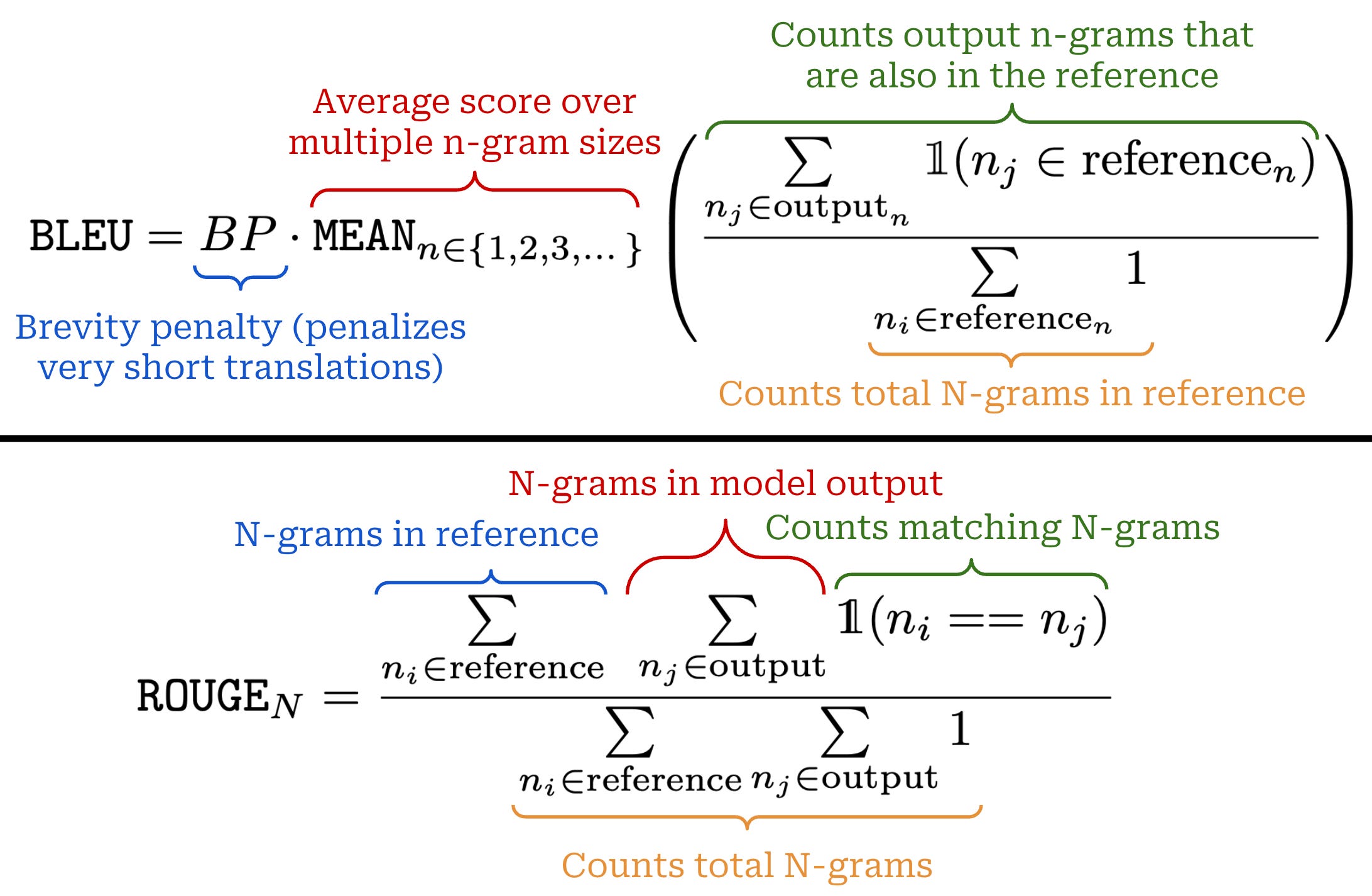
In prior generations of research, we could evaluate the performance of a language model using traditional (automatic) metrics like ROUGE (for summarization) or BLEU (for translation)4. These metrics, which are some of the simplest automatic evaluation techniques that exist, are reference-based, meaning that they operate by comparing the LLM’s output to some “golden” reference answer—usually by counting the number of matching n-grams5. If the model’s output is similar to the reference answer, then the score is good and vice versa; see below.
As the capabilities of language models have rapidly progressed over the last few years, these traditional metrics have become less and less effective. Recent research has shown that these metrics now correlate poorly with human preferences when evaluating the output of an LLM [21]; see below.

As such, traditional metrics are less effective when used to evaluate LLMs, but these metrics are still relatively common because they are so cheap and simple to compute. Assuming that we have access to reference answers, we can use these metrics as a quick and simple sanity check for a variety of use cases.
“We find that all [traditional] metrics we consider have low correlation with the human judgement.” - from [21]
Why do traditional metrics fall short? There are a few reasons that traditional metrics tend to correlate poorly with human preferences, but the most pressing issue is that a majority of these metrics are reference-based. They operate by comparing the model’s output to a ground truth answer that we want to match—basically a more sophisticated version of fuzzy matching. However, modern LLMs are incredibly open-ended! Given a single prompt, there are many equally-valid responses that could be generated by the LLM. So, if we evaluate according to a single reference, we fail to capture the spectrum of valid responses that exist.
LLM-as-a-Judge

The shortcomings of traditional evaluation metrics have led to the development of more flexible and general evaluation techniques. One of the most popular of these techniques is a model-based evaluation strategy, called LLM-as-a-Judge [8], that performs evaluation my prompting a language model. More specifically, we rely upon a powerful LLM as a “judge” to evaluate the outputs of another LLM. As shown in [8], LLM-as-a-Judge has high correlation with human preferences, is easy to implement (i.e., just write a prompt!), can handle open-ended outputs, and is flexible enough to capture a wide variety of different evaluation criteria.
“LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain.” - from [8]
Within this post, we will use the term “LLM-as-a-Judge” to refer specifically to prompting off-the-shelf, proprietary LLMs (e.g., GPT-4o or Gemini-1.5) for evaluation purposes (i.e., as opposed to finetuning our own specialized LLM judge). We will go over some basic concepts for LLM-as-a-Judge here, but there are also a variety of helpful posts and papers that have been written on this topic (including a previous post from this newsletter):
Using LLMs for Evaluation [link]
Creating a LLM-as-a-Judge That Drives Business Results [link]
Evaluating the Effectiveness of LLM-Evaluators [link]
A Survey on LLM-as-a-Judge [link]

Scoring setups. There are two primary ways that we can evaluate a model output with LLM-as-a-Judge (prompts are shown above):
Pairwise: the judge is presented with a prompt and two responses to the prompt, then asked to select the better response.
Pointwise: the judge is presented a single prompt and response, then asked to grade the response; e.g., using a Likert scale from 1-5.
There are several other terms that can be used to refer to the pointwise scoring setup as well, such as direct assessment or single-response grading. Beyond these two scoring setups, we may also see reference-based scoring setups that include a reference in the LLM judge’s prompt when asking for a score. Reference-guided grading can be applied to either of the scoring setups; see below for an example.

For a public implementation of LLM-as-a-Judge, check out AlpacaEval. This widely-used leaderboard uses LLM-as-a-Judge to predict human preference scores for LLM outputs. All of the prompts used for evaluation—including both current and previous iterations of the leaderboard—are openly shared.
Which setup should we use? In general, no one scoring setup is best for LLM-as-a-Judge. The optimal choice of scoring setup is usually application dependent. Pairwise scoring tends to be more stable compared to pointwise scoring but is also susceptible to position bias and less scalable. With pairwise scoring, we can only grade pairs of model outputs in a relative fashion, whereas pointwise scoring is more versatile and allows us to simply assign a single score to a model output. However, pointwise scoring is a more challenging task, as it relies upon the LLM judge being able to assign a score solely based upon its internal knowledge instead of comparing one output to another. To make this issue less pronounced, we can optionally perform pointwise scoring with references.
“Some evaluation tasks, such as assessing faithfulness or instruction-following, don’t fit the pairwise comparison paradigm. For example, a response is either faithful to the provided context or it is not—evaluating a response as more faithful than the alternative address the eval criteria.” - Eugene Yan
Objective criteria (e.g., factuality) are oftentimes difficult to evaluate in a pairwise fashion, as model outputs tend to either satisfy these criteria or not—objective crtieria are usually binary in nature. We can evaluate whether a given model output is factual or not, but evaluating whether one model output is more factual than another is somewhat ill-defined. In contrast, subjective evaluation criteria are better handled via a pairwise scoring setup due to the fact that relative scoring is more well-defined, stable, and reliable.
Specialized judges. Although LLM-as-a-Judge is an incredibly effective and widely-used approach, there are several limitations to this technique:
The LLM is not transparent and comes with security concerns.
We do not control the versioning of the judge—someone could update the model (and break our evals as a result).
Every call to the LLM judge costs money, so cost can become a concern if we are evaluating model outputs at scale.
Proprietary LLM judges are best at tasks that are highly aligned with their training data; e.g., predicting human preference scores.
Proprietary LLMs are generic (i.e., not specialized to perform evaluation) and tend to avoid providing strong scores or opinions.
Most of these limitation are caused by using a proprietary LLM over which we have little control. So, we might wonder: Could we just train our own LLM judge? As we might deduce from the title of this overview, the answer is yes! Finetuning our own LLM judge is a great way to create a domain-specific evaluation model that can provide more granular, accurate and critical feedback.
Meta-Evaluation: Evaluating our Evaluation Model
Before we learn how to train our own LLM judge, we need to know how we will determine whether the judge is performing well or not. To evaluate our LLM judge, we must first collect a set of human evaluation data. We should be very confident that this data is accurate and reliable, as we will use it to measure the quality of our evaluation models. Once we have a set of high-quality data annotated by humans, we can perform meta-evaluation (i.e., evaluate our evaluator) by simply comparing the evaluator’s output to the results of human evaluation.
If our evaluator produces binary output (e.g., pairwise scoring or single-response grading with a binary scale), we can simply use classification metrics. Given that classification metrics are so easy to interpret, many practitioners have made the argument that sticking to binary scoring is best for LLM-as-a-Judge.
“We show that G-Eval with GPT-4 as the backbone model achieves a Spearman correlation of 0.514 with human on summarization task, outperforming all previous methods by a large margin.” - from [23]
For scoring settings that are not binary (e.g., single-response grading with a 1-5 Likert scale), we must measure the correlation between human and automatic evaluation scores6. An example of correlation metrics being used in a recent LLM-as-a-Judge paper is provided above. Spearman correlation is probably the most commonly-used correlation metric, but many others exist (e.g., Cohen’s kappa, Kendall’s tau, or Pearson correlation). Unfortunately, these metrics are more difficult than classification metrics to interpret, so we should always be familiar with the nuances of the particular correlation metric we are using.
Early Research on Finetuned Judges
At first, most practitioners relied heavily upon proprietary LLMs for LLM-as-a-Judge-style evaluations. Why was this the case? In order to evaluate a model’s output for a particular task, the judge—unless a reference answer is provided as input—must be able to solve that task itself. The capabilities of open-source LLMs have lagged behind those of proprietary models for quite some time, so closed models were generally a better choice for evaluation purposes. As we will see in this section, however, researchers began to finetune specialized LLM judges as more capable, open-source LLMs were released (e.g., LLaMA and LLaMA-2).
Applying Finetuning to LLM-as-a-Judge [8]
“A fine-tuned Vicuna-13B model shows strong potential to be used as a cheap open-sourced replacement for expensive closed-sourced LLMs.” - from [8]
One of the first papers to explore the creation of a finetuned LLM judge was actually the original LLM-as-a-Judge paper! The majority of this paper is focused upon leveraging proprietary LLMs to evaluate human preferences via a set of generic prompts; see here for details. However, authors mention the potential of finetuning a custom LLM judge and perform early experiments in this direction.
Why finetune? Although LLM-as-a-Judge is a useful technique, we see in [8] that there are several clear motivations for finetuning our own LLM judge instead of using an off-the-shelf model:
API-based evaluations can be expensive.
Using a proprietary model provides no control or transparency.
Open source models are becoming more capable over time.
For these reasons, specialized evaluators are a promising direction of research if finetuned judges are capable of matching the performance of proprietary models.
Does this work? The finetuned evaluator created in [8] is based upon Vicuna-13B, a derivative of LLaMA. Without any finetuning, this model is found to be a poor judge. The base model has a high error rate, struggles to follow templates or instructions provided for evaluation, and suffers from severe positional bias.

However, the model’s evaluation capabilities are drastically improved by finetuning on human votes from Chatbot Arena. Authors train the model on 20K single-turn votes that compare the outputs of a wide variety of different LLMs. To simplify the evaluation process, we just formulate evaluation as a three-way classification problem (i.e., win, lose or tie) for the LLM. After finetuning, the following properties of the finetuned judge are observed:
The positional bias of Vicuna is drastically reduced; shown above.
The scoring accuracy of the model is much better.
The finetuned LLM judge still falls short of GPT-4’s performance.
The exploration of finetuned models in [8] is minimal (i.e, just one page in the appendix). However, the initial results were sufficiently promising to inspire further work in this direction given the benefits of open evaluation models.
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization [6]
One of the most common use cases for LLM judges is for identifying the best model among a set of models (i.e., automatic evaluation). Discerning changes in performance between LLMs is difficult, especially if the models being compared are both of high quality. We can lean on humans to provide feedback on our models, but this process is slow—having a judge that can quickly and accurately identify improvements in model performance is very useful.
“The goal is to ensure PandaLM not only prioritizes objective response correctness but also emphasizes critical subjective aspects such as relative conciseness, clarity, comprehensiveness, formality, and adherence to instructions.” - from [6]
In [6], authors propose PandaLM7—a specialized evaluator LLM that can be used to identify the highest performing model within a group. This model goes beyond evaluating basic properties of a response (e.g., correctness) by addressing subjective criteria like clarity, conciseness, and comprehensiveness.
The main motivation for PandaLM is to better automate the hyperparameter tuning process for LLMs. Using this model, we can easily compare several models trained with varying hyperparameters and identify the best model or setting. We see in [6] that all models perform better when PandaLM is used to identify the optimal training settings. Such a finding shows that there are several ways in which PandaLM can be used to improve the performance of an LLM.
Training PandaLM. To train this model, authors create a custom evaluation dataset comprised of over 300K training examples. Each example in this dataset consists of an (instruction, input, response1, response2) input tuple and an (evaluation result, evaluation rationale) output tuple. A reference answer is provided for all dataset examples, and the evaluation result simply selects one of the responses as better or declares a tie. The authors create PandaLM by finetuning LLaMA8 models of several sizes on this dataset.
“During the fine-tuning phase of PandaLM, we use the standard cross-entropy loss targeting the next token prediction. The model operates in a sequence-to-sequence paradigm without the necessity for a separate classification head.” - from [6]
All instructions and inputs within this dataset are sampled from the training dataset for Alpaca. Several models—LLaMA-7B, BLOOM-7B, Cerebras-GPT-7B, OPT-7B, and Pythia—are used to generate the pairs of responses. To generate the corresponding evaluation results and rationales for these pairs, a synthetic approach based upon Self-Instruct and GPT-4 is used. Several heuristics (e.g., hand crafted rules and filtering invalid or unstable evaluations) are used to ensure the quality of the training data. A smaller test set of “golden” test examples is collected from a group of human annotators for meta-evaluation purposes.

PandaLM in practice. When PandaLM is compared to other evaluators, we see that that these models—GPT-3.5 and GPT-4 in particular—have similar trends in preferences. More specifically, all of these models output a consistent ranking of other models during evaluation; see above. When PandaLM is directly compared to proprietary models, we see that i) PandaLM-7B produces competitive results and ii) PandaLM-70B surpasses the evaluation performance of GPT-4; see below. These results indicate that increasing model size benefits evaluation capabilities.

PandaLM models—and especially the larger model—are also highly effective in specialized domains, such as the legal or biological setting. Because PandaLM is finetuned on evaluation data, this model excels not just in general evaluation settings, but also in specialized or domain-specific evaluation settings that align well with its training data. For example, PandaLM is (successfully) used to score responses to LSAT questions and biomedical QA datasets in [6]; see below.

JudgeLM: Fine-tuned Large Language Models are Scalable Judges [9]

Most of the early work on finetuned LLM judges does very little to analyze the factors that contribute most to the quality of the resulting judge model. In [9], authors aim to solve this problem by exploring various important performance factors when training their customized JudgeLM model:
The amount, quality and diversity of training data.
The quality and size of the underlying base model.
The impact of bias on the LLM judge’s output.
The ability to generalize to different scoring setups (e.g., multi-turn chat, single answer grading, pairwise ranking, multi-modal models, etc.)
There are many reasons a finetuned LLM judge might fall short of a proprietary model in terms of evaluation capabilities; e.g., the size and quality of the base model, data quality issues, bias, and more. However, we see in [9] that we can address these issues in practice to create effective finetuned judges.
High-quality data is one of the major keys to success in [9]. To create an effective finetuned judge, we must have a large-scale dataset that is comprised of high quality, granular9, and diverse data. Moving in this direction, authors of this paper claim that “the dataset [they] introduce stands as the most diverse and high-quality one”. To construct this dataset, we start by selecting 105K seed instructions from a variety of public sources (e.g., ShareGPT and the Alpaca-GPT-4 dataset).

Answers to these seed tasks are generated synthetically from a variety of LLMs, such as Alpaca, Vicuna, and LLAMA. By combining LLM generated answers with original answers from the source dataset, we obtain a set of multiple answers for each instruction in the dataset. Plus, we have access to reference answers to each instruction from the source dataset. From here, we can randomly sample pairs of responses for each instruction, as well as generate scores and rationales for each of these pairs using GPT-4. In [9], GPT-4 serves as a powerful “teacher” model for JudgeLM—the finetuned judge is trained on the results of GPT-4’s evaluation.

The templates used for generating scores and rationales with GPT-4—including templates that both do and do not use references—are shown above. These prompts are relatively standard and largely match what we see in most public LLM-as-a-Judge setups. However, GPT-4 is provided with relatively detailed evaluation criteria when generating its scores and explanations, which encourages the model to evaluate responses on a more granular level. Such granular evaluation capabilities are transferred to JudgeLM by finetuning on this data.
Creating the model. Several sizes of JudgeLM models—including a 7B, 13B, and 33B parameter model—are trained over datasets with sizes ranging from 3.5K to 100K examples in [9]. JudgeLM is trained using an instruction tuning approach with supervised finetuning (SFT). The input and output structure of the model is depicted in the figure below. As input, we provide two different responses to a single instruction, as well as a reference answer to this instruction. The model then generates separate scores for each response and provides a rationale for the scores that are generated. We can translate the scores assigned to each answer into a pairwise result by simply comparing the scores to each other.

Mitigating bias is a primary focus of training JudgeLM. More specifically, there are three types of bias that authors try to combat in their evaluator:
Position bias: this is the same position bias we have seen before, where the judge prefers one answer over another due to its position in the prompt.
Knowledge bias: this form of bias occurs when the model lacks critical knowledge from pretraining that is needed to evaluate a response.
Format bias: this form of bias occurs when the model only performs well when provided a prompt with a specific format (e.g., the format with which the model is finetuned).
Several strategies exist for combatting bias. For example, format bias can be avoided by exposing the LLM judge to multiple prompt formats during finetuning, and knowledge bias can be addressed by simply providing reference answers as input. To address positional bias, we can use position switching—repeating evaluation with answers at all possible positions—during both training and inference. Usually, we consider responses that are ranked differently after position switching a tie. Swapping positions during finetuning forces JudgeLM to pay more attention to the content of the answer rather than the position, and using the same trick during inference lets us ensure that the impact of position bias on the model’s output is minimal. When used together, these tricks drastically reduce the bias of the JudgeLM model; see below.

How does JudgeLM perform? When tested on the JudgeLM evaluation dataset, JudgeLM outperforms PandaLM [6] and GPT-3.5 both with and without reference answers provided as input; see below. In this case, JudgeLM is finetuned over data from a very similar distribution, while the baseline models are not. However, JudgeLM is also shown to perform well on the PandaLM evaluation dataset [6]. JudgeLM’s performance is also reported in terms of agreement with GPT-4 (not humans)—the same model used to generate the training data for JudgeLM. Generally, the JudgeLM models perform relatively well, improve in performance with size, and are more robust to position switching compared to other models.

Generative Judge for Evaluating Alignment [7]
“Our model is trained on user queries and LLM-generated responses under massive real-world scenarios and accommodates diverse evaluation protocols (e.g., pairwise response comparison and single-response evaluation) with well-structured natural language critiques.” - from [8]
In [7], authors propose another finetuned LLM for evaluation purposes, called Auto-J, that specializes in domain-specific grading. Some unique properties of the Auto-J model include:
The ability to perform pairwise and direct assessment scoring.
An emphasis on providing high-quality, structured explanations.
The use of human-generated queries for training10 to mimic diverse and realistic scenarios—the training data is grounded in questions asked by humans.
The resulting Auto-J model is flexible, interpretable, and practical. The model is optimized to perform scenario-specific evaluations in real-world settings.
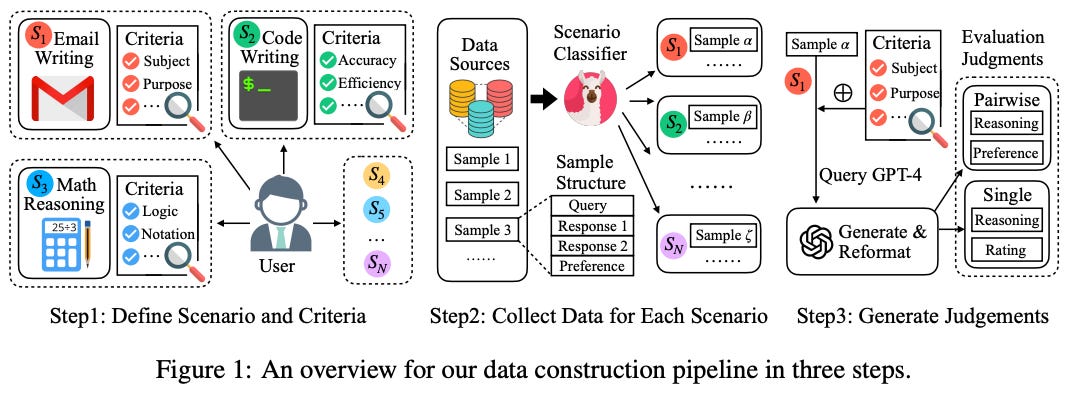
Training data. Auto-J is trained on both pairwise and direct assessment scoring data. The steps for constructing the model’s training dataset are depicted above. We begin by defining the evaluation criteria—or scenarios—on which Auto-J is trained. In particular, 58 evaluation scenarios are selected—each with their own definition and criteria—that can be categorized into eight groups; see below.
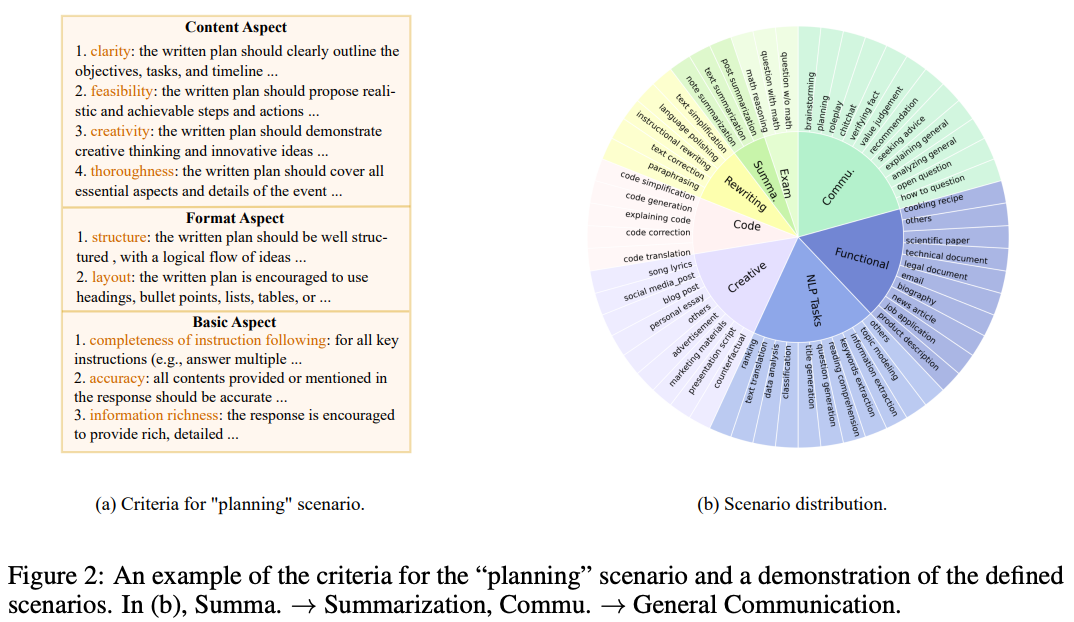
Then, we collect real-world queries for each scenario and synthetically generate responses to these queries using GPT-4. Up to 100 training examples are generated for each scenario, and the final size of the dataset is ~3,500 examples.
“We guide GPT-4 with carefully hand-written criteria for each scenario to collect desired evaluation judgments as our supervised training signals and apply heuristic filtering strategies and post-processing methods to unify output formats and mitigate noise.” - from [7]
Queries are largely collected from public sources that are based upon human interaction; e.g., Chatbot Arena and WebGPT. These queries accurately reflect the kind of questions that a model will encounter in the wild, allowing Auto-J to specialize in realistic evaluation settings. Evaluation scores—including both pairwise and direct assessment scores—are generated using GPT-4. To ensure the quality of synthetic data, authors introduce several heuristics to filter the final dataset (e.g., discarding inconsistent or incorrectly formatted predictions).

Training Auto-J. In [7], LLaMA-2-13B-Chat is used as a base model, and we finetune this base model over the dataset described above. Interestingly, authors choose to not provide the evaluation criteria as input to the model. They claim that learning such criteria implicitly from the data is a better approach, as excluding criteria from the input makes the model more general. Such a strategy directly contradicts later papers on this topic, which emphasize the importance of including reference materials (e.g., criteria and scoring rubrics) in the model’s input [1]. Auto-J is trained over data with multiple scoring formats from this dataset, and authors adopt position switching during training to avoid positional bias; see above.
“To lessen the positional bias in pairwise comparison, we apply a simple data augmentation trick. For each pairwise training sample, we swap the order of two responses in the input and alternate the `Response 1` and `Response 2` in the evaluation judgment.” - from [7]
Evaluation results. To evaluate AutoJ, a test dataset is created similarly to the model’s training dataset. However, all scoring results for the test dataset are generated with human annotators. When compared to a variety of other LLMs, Auto-J is found to outperform nearly every model except for GPT-4; see below.

Such a result indicates that specialized LLM judges can perform relatively well—matching or exceeding the performance of proprietary models in some cases—when finetuned on domain-specific data for a particular evaluation setting. However, the agreement rate of Auto-J with human evaluators on this dataset is still low. In other words, we still have a long way to go in terms of the LLM judge’s performance.
Critiques, Verification and Synthetic Data
In addition to these early attempts at finetuning LLM judges, several papers were concurrently published on the (highly-related) topic of using LLMs to verify, critique, or provide feedback on the output of another model. Such models are very similar to LLM judges, as both models can grade and provide feedback for a response from an LLM. However, critic models and verifiers go beyond just grading a response. They actually edit the LLM’s response or trigger the creation of a new response—assuming the original response was not good.
For example, SelFee (depicted above) [10] is a LLaMA-based, specialized critic model that is trained over generations, feedback, and revised generations from ChatGPT. Given an original response as input, SelFee can provide feedback for this response, as well as revise the response based on the feedback. Additionally, SelFee can continue to revise its output until the quality meets a given threshold, making this model both a verifier (i.e., by checking the quality of its own output) and a critic (i.e., by providing feedback and revising its responses).

Many techniques for critiquing LLM outputs have been explored; e.g., Self-Correction, PEER, and Self-Critique. We can also use similar techniques to generate and verify synthetic training data for both preference tuning and SFT. Common examples of this approach include RLAIF, Constitutional AI (shown above) [11], and more. All of these techniques—LLM-as-a-Judge, finetuned judges, synthetic data creation, critique models, and verifiers—function very similarly. They just output scores and explanations! But, each type of model is used for a slightly different purpose; e.g., grading a model output for evaluation purposes versus grading a model output to determine if it should be used for finetuning. Recent research argues that we can unify these techniques—or at least some of them—via a single LLM that is capable of performing all necessary scoring tasks [12, 17].
Surpassing LLM-as-a-Judge with Finetuning
The idea of finetuning an LLM judge was not popularized until the proposal of Prometheus [1]—a finetuned LLM judge that is capable of performing domain-specific, fine-grained evaluation. Prometheus has significantly improved evaluation capabilities compared to prior finetuned judges. However, this model does not make any major methodological advancements—it just finetunes starting from a much better base model (LLaMA-2). Due to its ability to match the evaluation quality of many proprietary LLMs, Prometheus quickly became popular, leading to the release of several model variants that we will overview in this section.
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models [1]

Using proprietary LLMs for evaluation is simple—we just describe our scoring criteria in a prompt and let the model do the rest. However, such evaluators have uncontrolled versioning and can be expensive. Plus, proprietary LLMs may struggle to evaluate custom criteria, as they are more commonly used to evaluate generic criteria (e.g., human preferences). As a solution, authors in [1] create a finetuned evaluator LLM, called Prometheus, that can match or exceed the performance of proprietary evaluators when finetuned on a particular domain.

Training dataset. Prometheus is trained to ingest custom scoring rubrics as input, allowing the model to easily generalize to specialized domains and criteria. The model is trained over a new dataset called the Feedback Collection that is created synthetically with GPT-4 and covers a wide variety of evaluation tasks. Each dataset example has a few common components (shown above):
Instruction: the instruction used to prompt an LLM.
Response: the response (to the above instruction) that we are evaluating.
Rubric: a customized rubric that specifies the criteria by which the response should be scored / evaluated.
Reference Answer: an example of a response to the instruction that would receive the best-possible score.
Rationale: an explanation11 for why the response received a particular score.
Score: a 1-5 Likert score that is assigned to the response.
The scoring rubric consists of i) a general description of the scoring criteria and ii) a description of each score that the model can assign. For Prometheus, the options for scoring are a 1-5 Likert scale, so the model expects each of these scores and their meaning to be described. By taking the rubric as input, the model learns to perform fine-grained evaluation and generalize to diverse scoring settings. Authors in [1] are some of the first to demonstrate the importance of providing high-quality reference materials as input to a finetuned LLM judge.
“We are first to explore the importance of including various reference materials—particularly the reference answers—to effectively induce fine-grained evaluation capability” - from [1]
Generating the data. The Feedback Collection is generated synthetically with GPT-4. To create this dataset, we start with a set of 50 human-written scoring rubrics. Then, the dataset is generated by:
Expanding to 1K scoring rubrics by prompting GPT-4 with examples of the manually-written scoring rubrics.
Generating instructions for each scoring rubric, resulting in 20K total instructions (i.e., 20 instructions for each rubric).
Creating training instances for each instruction by sequentially generating a response, feedback, and score for each instruction.
A visual summary of the above steps that are followed to synthetically generate the Feedback Collection with GPT-4 is provided in the figure below.

To make the dataset balanced, we prompt GPT-4 to generate five different training examples for each instruction—one for each 1-5 Likert score. Additionally, we ensure that each training example has the same length to avoid verbosity bias within the evaluator. A summary of the final dataset is provided below.

Training Prometheus. LLaMA-2-13B-Chat is used as a base model for Prometheus. The model is trained using the Feedback Collection dataset, as well as MT Bench and Vicuna Bench. Given all reference material as input, the model is trained—using a supervised finetuning (SFT) strategy—to sequentially provide feedback then score the response. Importantly, we generate feedback prior to actually scoring the response, allowing the model to use this feedback as context when assigning as score. Additionally, the authors note that it is very important to insert a special token—such as [RESULT]—between the feedback and the score to ensure that the model does not degenerate12 during inference.
“Similar to Chain-of-Thought Finetuning, we fine-tune to sequentially generate the feedback and then the score.” - from [1]
Is Prometheus an effective evaluator? Prometheus is evaluated across several datasets in comparison to GPT-3.5, GPT-4, and several open-source base models in terms of its ability to match the evaluation scores provided by humans and produce useful feedback. In these experiments, we see that the scores generated by Prometheus have a Pearson correlation of 0.897 with human evaluators, which is comparable to the correlation of scores generated by GPT-4 and much better than the correlation of scores generated by GPT-3.5; see below.

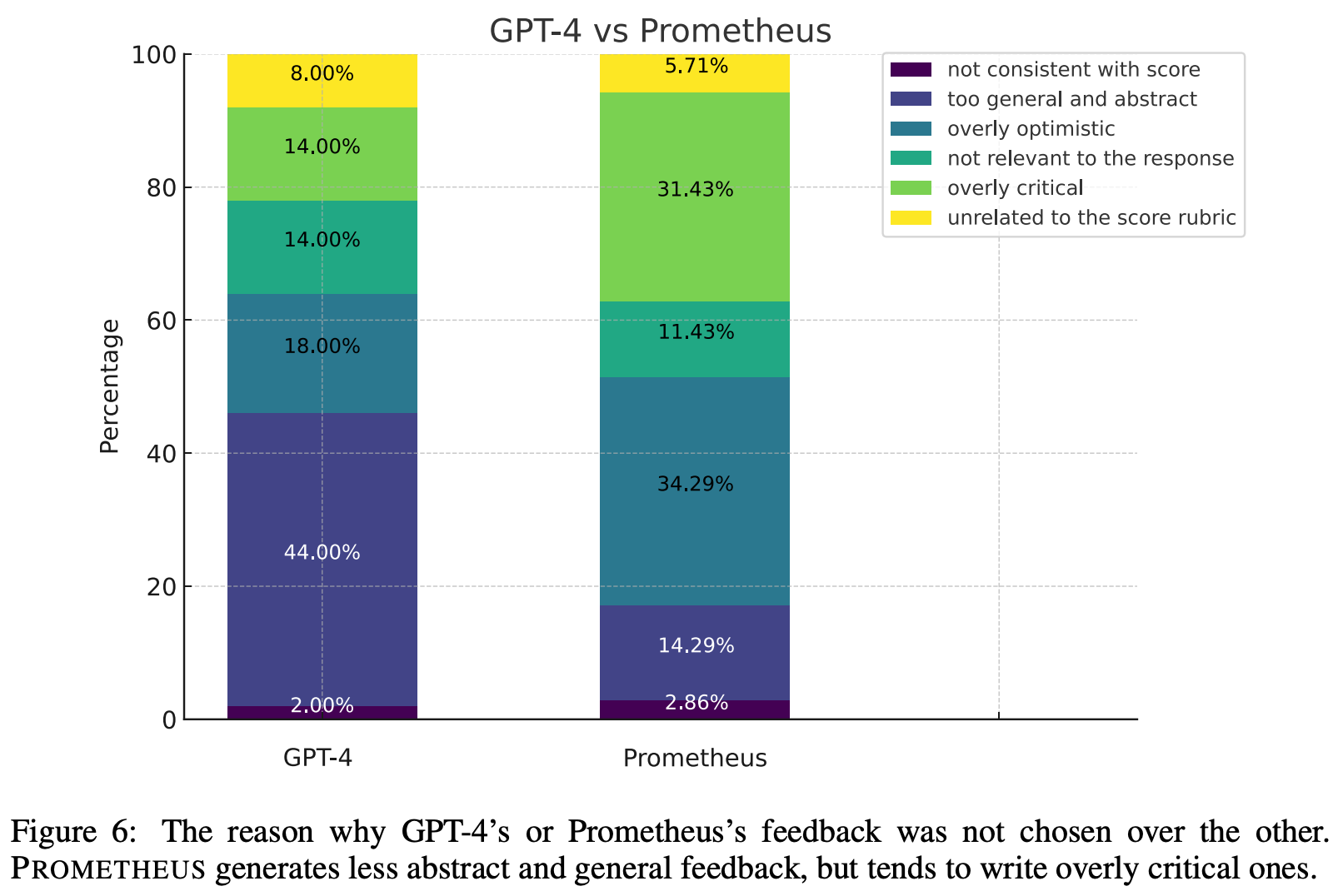
These results show us that we can achieve impressive levels of agreement with human evaluation—matching or exceeding powerful models like GPT-4—by directly finetuning an LLM on high-quality evaluation data within a certain domain. Additionally, humans select feedback from Prometheus as preferable to that of GPT-4 in 58.67% of cases, indicating that the model’s explanations are useful. Prometheus’ feedback is preferred to that of GPT-3.5 in nearly 80% of cases!
“We conclude that whereas GPT-4 tends to be more neutral and abstract, Prometheus shows a clear trend of expressing its opinion of whether the given response is good or not.” - from [1]
When humans are asked to explain why feedback from Prometheus is preferred, we learn that the finetuned model tends to be more critical and generates targeted feedback; see below. Unlike proprietary models, Prometheus is not a general-purpose LLM. Rather, it is a specialized model for providing critiques and feedback. As a result, this model is less neutral, abstract, and generic relative to proprietary foundation models when used in an evaluation setting.
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models [2]

Continuing the direction of research from [1], Promtheus 2 [2] is another open LLM that is finetuned to perform fine-grained evaluation with custom criteria. The original Prometheus model has several limitations. For example, the model has a long way to go in terms of scoring quality—there is still a noticeable amount of disagreement with human quality scores. Most notably, however, Prometheus is only capable of scoring via direct assessment. Although we can derive a ranking by comparing pointwise scores from Prometheus, this model—and most of the open evaluators proposed before it—lacks the ability to perform pairwise scoring. In [2], authors unify these paradigms with a single, fine-grained evaluation model that closely matches the accuracy of humans and GPT-4 for both types of scoring.
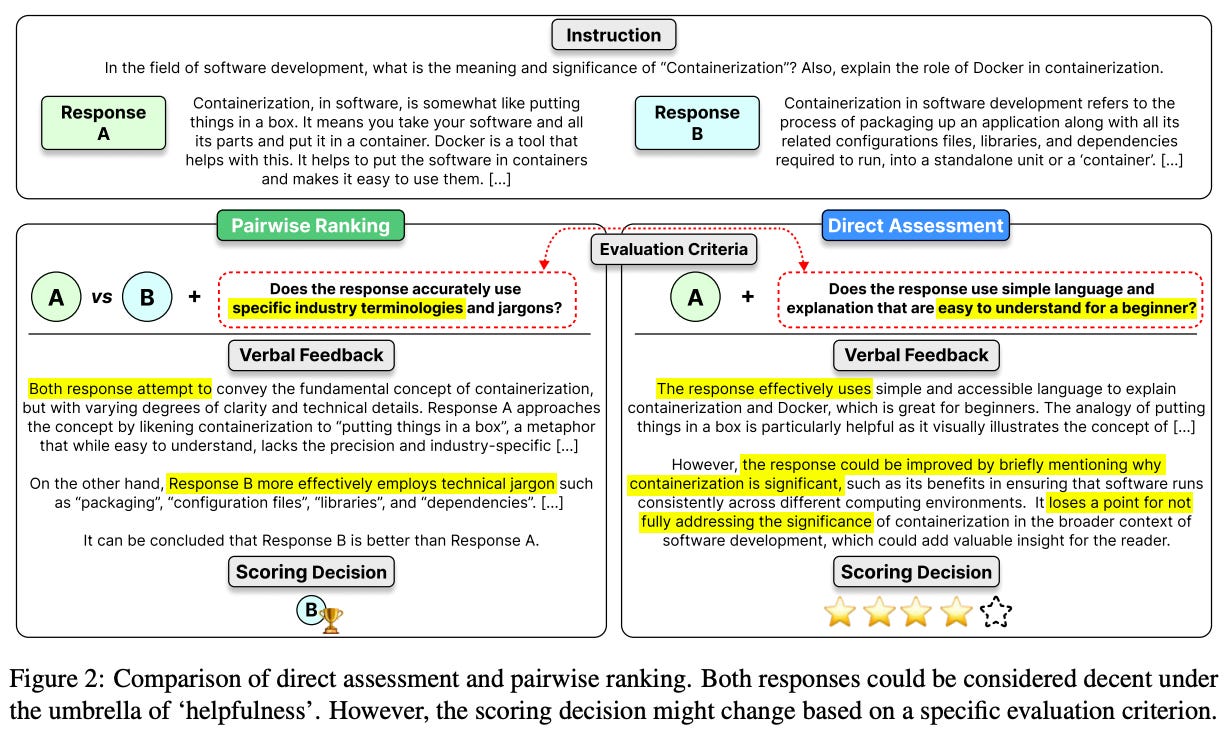
Towards pairwise scoring. For Prometheus 2, the pairwise scoring setup has a few notable differences compared to direct assessment scoring:
No reference answers are present within the reference material.
The reference material simply describes the evaluation criterion.
The feedback provided with the score has a different style.
Instead of providing just an explanation for a score, the feedback provided within the pairwise scoring setting must compare and contrast the two responses that are provided, using their differences to identify one as superior to the other; see above. Most prior models and datasets only perform pairwise scoring according to generic feedback and tend to omit pairwise feedback alongside the score13.
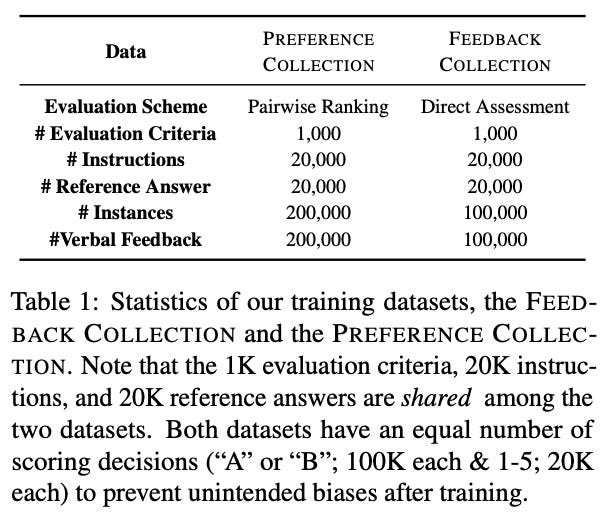
The Preference Collection. Extending upon the Feedback Collection from [1], authors in [2] create an additional dataset for pairwise scoring, called the Preference Collection. The Feedback Collection contains five responses for each instruction—one response for each 1-5 Likert score. To create a pairwise version of this dataset, we can simply consider all combinations of these responses. For each instruction, ten possible pairs can be formed, and we can derive a score for each pair by just comparing Likert scores; see below for a summary.
Although many pairwise scoring datasets tend to provide only scores without explanations, leveraging chain of thought-style feedback for improved scoring and explainability is a key component of Prometheus. As such, authors in [2] augment the Preference Collection by prompting GPT-4 to explain each pairwise score, focusing on the similarities and differences of each response.
“To generate new verbal feedback for each pair of responses, we prompt GPT-4 to identify the commonalities and differences of the two responses.” - from [2]
Model merging. There are a few different ways we can build support for both direct assessment and pairwise scoring within an LLM judge:
Prompting: we can adopt an LLM-as-a-Judge approach and create different prompts to send to an off-the-shelf model for each scoring setup.
Single-format training: we can train separate LLMs on each scoring format and use them separately.
Join training: we can train a single model on both direct assessment and pairwise scoring examples14, allowing the model to function in both settings.
Of the approaches above, only joint training produces a single, specialized model that can support both scoring setups—prompting relies upon generic / off-the-shelf models and single-format training produces a separate model for each scoring format. Alternatively, we can combine the models produced by single format training via model merging. For those who are not familiar with the concept of model merging, check out the comprehensive overview of this topic below.
Model Merging: A Survey

Unlike an ensemble, which averages the predictions of several models, model merging averages the weights of these models, forming a single model that mixes their capabilities without any added inference cost.
This is exactly the approach taken by Prometheus 2. We first independently train two LLMs over the Feedback and Preference collections. Then, we merge the weights of these models using a simple, linear merging scheme (shown below) to produce a single model that can perform both pairwise and pointwise scoring.

Most notably, this merging approach is shown to outperform LLMs that are jointly trained or trained individually on each scoring format. Authors test several merging schemes in [2] (e.g., task arithmetic, TIES, and DARE). In some cases, these more advanced merging strategies yield a benefit. For example, DARE yields the best performance when Mixtral 8x-7B is used as the base model. However, the linear merging scheme—with a coefficient of 0.5 (i.e., taking an average of the models’ weights)—performs well in most cases and is easy to implement.
“We show that merging the weights of evaluator LLMs trained on direct assessment and pairwise ranking feedback datasets results in a unified evaluator LM that excels in both schemes.” - from [2]
A unified evaluator. Using Mistral-7B or Mixtral 8x-7B as a base model, different versions of Prometheus 2 are created by i) finetuning separate copies of these models on each scoring dataset and ii) combining the weights of these single-format evaluators using various merging algorithms. The resulting model is found to outperform all open evaluator LLMs on several direct assessment and pairwise scoring benchmarks. In particular, Prometheus 2 improves the Pearson correlation with proprietary evaluators by 0.2 units across all datasets and reduces the performance gap with GPT-4 by ~50% on pairwise ranking datasets; see below.

We might notice in the table above that the performance improvement of Prometheus 2 are not as significant in the pairwise scoring setting. However, this table is comparing Prometheus 2 to both open evaluators and reward models. These reward models—which are used for predicting rewards within reinforcement leraning from human feedback—specialize in pairwise scoring only, are finetuned on this task, and do not output any feedback with their scores. The reward models achieve impressive performance in terms of pairwise ranking accuracy. We also see in [2] that Prometheus 2 tends to be more consistent than other evaluators across scoring settings, meaning that the selected response within a pairwise setting will usually also receive a higher score in the direct assessment setting.
Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation [3]
All of the work we have looked at so far focuses upon text-only LLMs, but Vision-Language Models (VLMs)—referring to LLMs that can take both images and text as input—have recently gained in popularity. Both proprietary (e.g., GPT-4V and Gemini) and open (e.g., LLaVA and LLaMA-3.4) VLMs exist. Aside from being able to handle multiple input modalities, these models are not much different from text-based LLMs in terms of their training or architecture. See below for an accessible overview of VLMs with practical examples from recent research.

VLMs generate (textual) output given a combination of images and instructions as input. Relative to text-based LLMs, evaluating VLMs is slightly more difficult because we must both:
Check whether the VLM follows the instruction (same as before).
Determine if the VLM’s response is “grounded” in the image.
To do this, we could derive a text-based representation of the image (e.g., via a captioning model) and pass this information to a text-based LLM judge; e.g., GPT-4 or Prometheus [5]. However, such a multi-stage pipeline is prone to errors—it makes much more sense to directly use a VLM as the judge!

Prometheus-Vision is an open, VLM-based evaluator proposed in [3]. Proprietary VLMs like GPT-4V can and have been used to evaluate other VLMs [4]. Following the direction of prior Prometheus models, Prometheus-Vision is the first open VLM that can evaluate according to fine-grained, user-defined criteria. In addition to providing more transparency and control, Prometheus-Vision produces scores that correlate well with scores from humans and proprietary models. This model is surprisingly effective and can even capture subtle nuances in the data; e.g., the difference between artwork and parody (see above figure).
“In contrast to the language domain, to the best of our knowledge, there do not exist any available feedback, critique, or preference datasets applicable to train an evaluator VLM that could assess in a fine-grained manner.” - from [3]
The Perception Collection, which is inspired by the Feedback Collection, is an image-and-text-based evaluation dataset created to train Prometheus-Vision. At the time of publication, no such multi-modal feedback dataset yet existed for training VLM-based evaluation models. Each dataset instance in the Perception Collection has five input components:
Image: an image provided by the user to the VLM as input.
Instruction: a textual instruction provided by the user to the VLM.
Response: a textual response generated by the VLM based upon the image and instruction provided as input.
Rubric: a set of detailed scoring guidelines—including a description of the criteria and an explanation of each possible score on a 1-5 Likert Scale—that should be referred to when producing a score.
Reference Answer: an example response to the image and instruction input that would receive a score of 5.
In [3], authors generate all reference answers synthetically using GPT-4V. Each dataset instance also has two output components: i) a written rationale or feedback and ii) a scoring decision according to a 1-5 Likert scale; see below.

To create this dataset, we begin by sampling 5K images from MS-COCO and MMMU. Then, we follow a procedure that is nearly identical to the generation strategy used for the Feedback Collection: i) manually craft 50 seed rubrics, ii) use GPT-4 to synthetically generate 15K rubrics, iii) generate 30K instructions (and associated reference answers) for these rubrics, and iv) augment each instruction with five responses—one for each score—and associated feedback15. Compared to the Feedback Collection, the Perception Collection has a larger number of rubrics (i.e., 15K vs. 1K) but fewer instructions per rubric (two vs. 20); see below.

Training the model. To train Prometheus-Vision, we cannot use a text-only base model—we must begin with an open (pretrained) VLM. In [3], authors use the 7B and 13B parameter variants of LLaVA-1.5 as base models. Similarly to prior Prometheus models, Prometheus-Vision is trained using a chain of thought finetuning strategy. We teach the model—using an SFT approach—to sequentially generate feedback then a score. All training examples explicitly separate the feedback and score with a fixed phrase: ‘So the overall score is’. By providing reference materials (e.g., rubrics and reference answers) as input, we create a model that excels in performing customized, fine-grained evaluation.

Empirical results. Prometheus-Vision outperforms both GPT-3.5-Turbo and the text-only Prometheus model in terms of correlation with human scores. However, both GPT-4 and GPT-4V achieve a higher level of agreement with human evaluation. The biggest dip in performance for Prometheus-Vision is observed on VisIT Bench, which contains a lot of text-heavy images; see below.
On this data, Prometheus-Vision performs poorly, while GPT-4 performs well (better than GPT-4V!) because it ingests text extracted from the image as input. On other datasets, Prometheus-Vision is comparable in scoring quality to GPT-4 and GPT-4V and even exceeds their correlation with human scores in several cases.
“Previous works have highlighted a phenomenon known as length bias, which refers to a tendency of evaluator models to prefer longer responses… Self-enhancement bias is … where evaluators tend to prefer their own responses.” - from [3]
When we ask humans to rate provided feedback, we see that Prometheus-Vision largely matches the quality of feedback produced by GPT-4 and GPT-4V. Authors in [3] also test Prometheus-Vision for various kinds of biases, such as length bias or self-enhancement bias. The model was not found to exhibit obvious sources of biases, though measuring such biases in isolation is quite difficult.
Other Types of Finetuned Judges
Beyond the Prometheus models, there have been a wide variety of recent attempts at finetuning LLMs for evaluation purposes. We provide a brief reference of work in this area below, each accompanied with a description of their contribution.

Self-rewarding LLMs [13] attempt to improve and automate the alignment process with the help of an LLM evaluator. Instead of training reward models from human preferences, authors in this work train the LLM itself—the same model that is being finetuned or aligned—to provide its own rewards and feedback via LLM-as-a-Judge style prompts; see above. When used to finetune a LLaMA-2 model, this approach is shown to be capable of producing useful feedback and improving the performance of the underlying LLM. Similarly to Prometheus, Self-Rewarding LLMs are trained to act as an LLM judge, but the feedback from this judge is directly used as a reward signal for finetuning the LLM itself.

LLM-as-a-Meta-Judge. Self-rewarding LLMs are an interesting approach, but one shortcoming of this technique is that it does not include any improvement mechanism for the LLM judge. In [15], authors expand upon this idea via an LLM-as-a-Meta-Judge technique that explicitly allows the LLM judge—in addition to the LLM itself—to self-improve throughout the training process by creating finetuning data for both the LLM and the LLM judge; see above.

Self-taught evaluators [14] train model-based evaluators without any human preference data. Such an approach is beneficial because human preference judgements are expensive to collect and can become stale over time. As an alternative, authors in [14] propose an iterative scheme that uses an LLM to generate synthetic evaluation data. Starting with a set of instructions, we just generate contrasting model outputs with an LLM and train an LLM judge to evaluate these outputs by producing explanations and scores. Without using any human-labeled data, this self-teaching approach is shown to produce evaluators that outperform both proprietary LLM judges (e.g., GPT-4) and reward models finetuned on human preferences in terms of their scoring accuracy.

Foundational Large Autorater Models (FLAMe) [16] are a family of foundational evaluation / judge models that are trained over a massive amount of human preference data—over 5M human judgements spanning more than 100 different quality assessment tasks. Compared to other LLM evaluators, FLAMe models generalize well to other evaluation tasks, are shown to be less biased, and can even be further finetuned. FLAMe models can be great base models for finetuning specialized LLM judges. These models consistently outperform proprietary LLM-as-a-Judge models based on GPT-4 and Claude variants, as well as LLM judges that have been finetuned on synthetically-generated data (e.g., from GPT-4).
“Our findings indicate that although the fine-tuned judge models achieve high performance on in-domain test sets, even surpassing GPT-4, they underperform GPT-4 across several dimensions, including generalizability, fairness, aspect-specific evaluation, and scalability.” - from [18]
Finetuned versus proprietary LLM judges. The tradeoff between finetuned and proprietary LLM judges is deeply analyzed in [18]. From this analysis, we see that finetuned judges work very well for in-domain evaluation—the models are apt at evaluating data that is similar to the data on which they are trained. Compared to proprietary LLM judges, however, these models do not generalize as well to new or different tasks. Put simply, finetuned LLM judges tend to be very task-specific, which is not necessarily a surprising result.
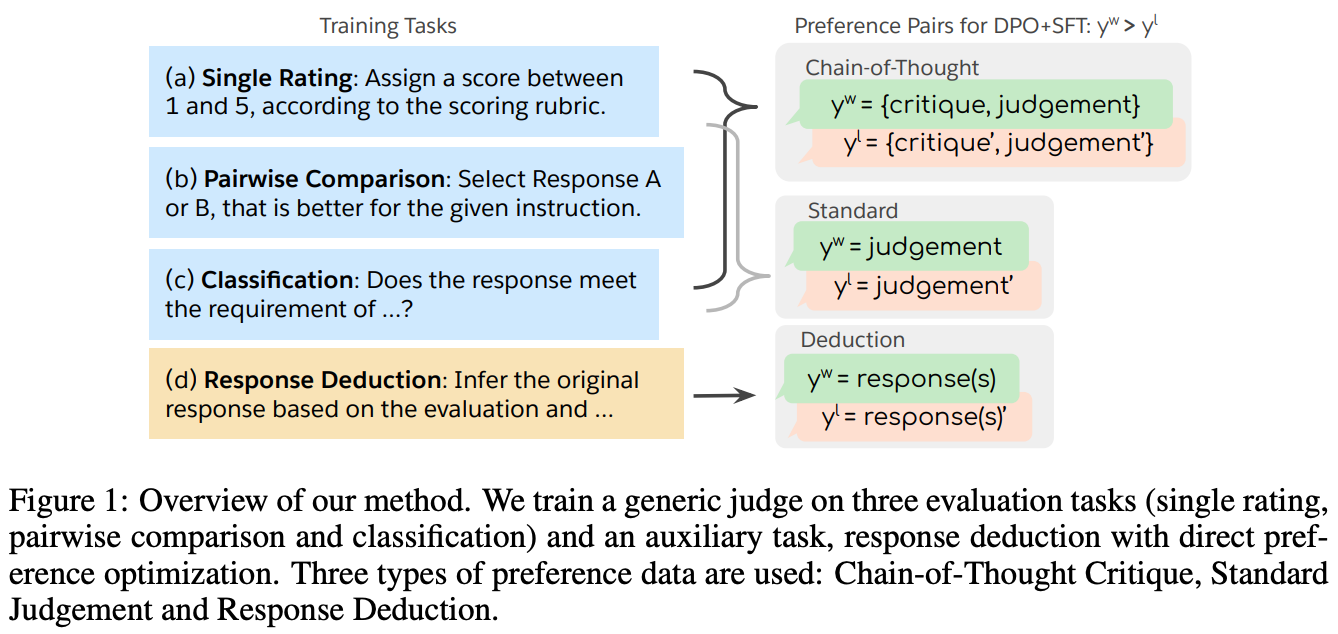
Direct judgement preference optimization [19] attempts to create LLMs with more advanced evaluation capabilities by using preference optimization. To do this, authors collect preference pairs for three different evaluation use cases: i) single rating, ii) pairwise comparison, and iii) classification. These first two uses cases match the common LLM-as-a-Judge scoring setups. The classification use case formulates evaluation as a binary classification problem; e.g., “Is this property satisfied in the response or not?”. Beyond these use cases, an auxiliary task is also introduced that trains the LLM to deduce the response being scored given the instruction and evaluation result as input; see above. For each of these use cases, we obtain preference pairs of positive and negative responses, then update the evaluator using direct preference optimization (DPO) [20].
“We show that the LLMs-as-a-judge benefit only little from highly detailed instructions in prompts and that perplexity can sometimes align better with human judgements than prompting, especially on textual quality.” - from [21]
How do LLM judges assign their scores? When using an LLM judge, we might wonder if the LLM generates scores based on the evaluation criteria or just assigning higher scores to text that is highly aligned with its training data. In [21], authors aim to answer this question via a rigorous analysis of LLM judges under several scoring settings; see below. We see from this analysis that LLM-as-a-Judge models benefit only slightly from the inclusion of detailed scoring instructions and criteria in their prompts. In fact, perplexity-based evaluation—scoring a response based on the likelihood assigned to it by the model—aligns better with human preferences in some cases.

Such a result indicates that the scoring mechanism of LLM judges is driven by the contents of their training data, which slightly contradicts findings from Prometheus [1] that reference materials are very important. However, the analysis in [21] is mostly focused on evaluating response quality from a human preference perspective. Given that most LLMs are trained on preference data, it makes sense that the model assigns high probability to responses that are preferable to humans. In contrast, Prometheus considers a wide range of evaluation criteria beyond human preferences making evaluation criteria are more relevant.
Step-by-Step Guide: Finetuning an LLM Judge
Now that we have taken a deep look at nearly all of the research recently conducted on the topic of finetuning LLMs for the purpose of evaluation, we need a generic framework for how to create our own LLM judge. Luckily, Prometheus already provides such a framework [1]. Below, we present (and slightly modify) this framework as a summary of what we have learned so far in this overview.

(1) Solidify the evaluation criteria. The first step of evaluation is deciding what exactly we want to evaluate. In particular, we should:
Outline a specific set of criteria that we care about.
Write a detailed description for each of these criteria.
An example of a scoring rubric used by Prometheus is provided above, which includes both scoring criteria / guidelines and multiple references answers. Over time, we must evolve, refine, and expand our criteria to make the human (and model-based) evaluation process more consistent and accurate.
(2) Prepare a dataset. Before we train or use any LLMs for evaluation, we need (high-quality) human evaluation data. Human-labeled data helps us to easily determine if our evaluator is accurate or not. This data should reflect the kind of data that the LLM judge will encounter in the wild. If we are just using this data for meta-evaluation purposes (e.g., to measure the performance of LLM-as-a-Judge), then we don’t need much data (e.g., 100-1K examples). Finetuning a Prometheus-style model will require more data (e.g., 1K-100K examples).
Human data collection is a difficult—but essential—part of the evaluation process. If humans cannot consistently agree on our evaluation task, then it will be impossible to measure whether an LLM is accurately evaluating the task. Not investing sufficiently into human evaluation is a common mistake. But, developing or finetuning an LLM judge on low quality data is a waste of both time and energy.
(2.5) Use synthetic data. The Prometheus models [1, 2, 3] show us that we can use synthetic data to train high-quality LLM judges. In fact, nearly all of the data used to train these models is synthetically generated—most of the instructions, the responses, the scores, and the feedback! Using purely synthetic training data can introduce bias by exposing the model to only a narrow distribution of data during training, but combining human and synthetic data can be incredibly effective.
(3) Focus on the rationales! If we want to finetune an accurate LLM judge, we obviously want the scores and rankings over which the model is trained to be accurate. Going further, we should be sure to create high-quality rationales for each score. LLMs struggle to learn new knowledge during finetuning. However, finetuning CAN be used to teach our LLM judge more effective formats or styles of feedback. As such, tweaking the rationales over which the LLM judge is trained is a great way to make the resulting model more helpful.
(4) Use reference answers. Although this step is optional, we can also prepare reference answers to go along with each example in our dataset. As outlined previously, reference answers can improve the performance of both LLM-as-a-Judge and finetuned evaluators. For finetuned evaluators, references are useful due to their ability to address the knowledge bias created by gaps or issues in the pretrained knowledge of the judge’s base model. Reference answers are also useful for improving the accuracy and reliability of pointwise scoring.
(5) Train the model. Once all of our data (and optionally reference answers) have been collected, then we can train our LLM judge using a basic SFT approach. For a full implementation of this process, check out the Prometheus GitHub repo. During training, we should create a hold-out test dataset16 that can be used to meta-evaluate the model’s performance. Performance is evaluated using either classification (for binary output) or correlation (for everything else) metrics.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, Deep Learning Ph.D. and Machine Learning Scientist at Netflix. This is the Deep (Learning) Focus newsletter, where I help readers better understand important topics in AI research. If you like the newsletter, please subscribe, share it, or follow me on X and LinkedIn!
Bibliography
[1] Kim, Seungone, et al. "Prometheus: Inducing Evaluation Capability in Language Models." NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following. 2023.
[2] Kim, Seungone, et al. "Prometheus 2: An open source language model specialized in evaluating other language models." arXiv preprint arXiv:2405.01535 (2024).
[3] Lee, Seongyun, et al. "Prometheusvision: Vision-language model as a judge for fine-grained evaluation." arXiv preprint arXiv:2401.06591 (2024).
[4] Chen, Dongping, et al. "Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark." arXiv preprint arXiv:2402.04788 (2024).
[5] Bai, Shuai, et al. "Touchstone: Evaluating vision-language models by language models." arXiv preprint arXiv:2308.16890 (2023).
[6] Wang, Yidong, et al. "PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization.(2024)." URL https://arxiv. org/abs/2306.05087 3.4 (2024).
[7] Li, Junlong, et al. "Generative judge for evaluating alignment." arXiv preprint arXiv:2310.05470 (2023).
[8] Zheng, Lianmin, et al. "Judging llm-as-a-judge with mt-bench and chatbot arena." Advances in Neural Information Processing Systems 36 (2024).
[9] Zhu, Lianghui, Xinggang Wang, and Xinlong Wang. "Judgelm: Fine-tuned large language models are scalable judges." arXiv preprint arXiv:2310.17631 (2023).
[10] Seonghyeon Ye, Yongrae Jo, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, and Minjoon Seo. Selfee: Iterative self-revising llm empowered by self-feedback generation. Blog post, May 2023. URL https://kaistai.github.io/SelFee/.
[11] Bai, Yuntao, et al. "Constitutional ai: Harmlessness from ai feedback." arXiv preprint arXiv:2212.08073 (2022).
[12] Zhang, Lunjun, et al. "Generative verifiers: Reward modeling as next-token prediction." arXiv preprint arXiv:2408.15240 (2024).
[13] Yuan, Weizhe, et al. "Self-rewarding language models." arXiv preprint arXiv:2401.10020 (2024).
[14] Wang, Tianlu, et al. "Self-taught evaluators." arXiv preprint arXiv:2408.02666 (2024).
[15] Wu, Tianhao, et al. "Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge." arXiv preprint arXiv:2407.19594 (2024).
[16] Vu, Tu, et al. "Foundational autoraters: Taming large language models for better automatic evaluation." arXiv preprint arXiv:2407.10817 (2024).
[17] Ankner, Zachary, et al. "Critique-out-loud reward models." arXiv preprint arXiv:2408.11791 (2024).
[18] Huang, Hui, et al. "An empirical study of llm-as-a-judge for llm evaluation: Fine-tuned judge models are task-specific classifiers." arXiv preprint arXiv:2403.02839 (2024).
[19] Wang, Peifeng, et al. "Direct judgement preference optimization." arXiv preprint arXiv:2409.14664 (2024).
[20] Rafailov, Rafael, et al. "Direct preference optimization: Your language model is secretly a reward model." Advances in Neural Information Processing Systems 36 (2024).
[21] Böhm, Florian, et al. "Better rewards yield better summaries: Learning to summarise without references." arXiv preprint arXiv:1909.01214 (2019).
[22] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744.
[23] Jha, Aditi, et al. "Limit: Less is more for instruction tuning across evaluation paradigms." arXiv preprint arXiv:2311.13133 (2023).
For example, OpenAI is known to have heavily relied upon human annotation workforces from ScaleAI to train and evaluate their models [22].
We can also created shared (asynchronous) communication channels between annotators and researchers or something else. We just need some medium to facilitate discussion between relevant parties; see Appendix B of [22] for details
Many more traditional, reference-based metrics exist beyond these two as well; e.g., BERTScore, MoverScore, METEOR, COMET, and more.
N-grams are just sequential groups of words; e.g., unigrams (single words), bigrams (two-word sequences), trigrams (three-word sequences), and more.
In some papers, authors compute correlation metrics between their finetuned judge and a proprietary LLM (e.g., GPT-4) instead of a human.
The acronym for PandaLM comes from reProducible AND Automated Language Model Assessment.
Notably, PandaLM is finetuned purely using supervised finetuning (SFT). There is no specialized classification head created within the model for pairwise evaluation.
By “granular”, we mean that the dataset spans a wide variety of different evaluation criteria that consider specific aspects of model performance.
Although the queries used for training are provided by human users, the responses to these queries are still generated with GPT-4. So, the training data for Auto-J is still synthetically created.
These explanations mimic the rationales used within chain of thought prompting. Parallel research has shown that finetuning LLMs over such rationales is an effective approach; see here.
In other words, we want to ensure that the model always generates a score after the feedback, instead of continuing to generate endless feedback or starting to artificially generate the next instruction to be scored.
Examples include the HH-RLHF (from Anthropic) and UltraFeedback datasets.
This can be done via some variant of multi-task learning, instruction tuning, or other similar methodologies.
These outputs are sampled from several different VLMs, including Fuyu-8B, LLaVA-1.5 (13B), and GPT-4V.
We should also create an additional validation dataset to use for tuning the training hyperparameters of our LLM judge.
Really enjoyed this take on fine-tuned judges and how they can improve AI evaluation!
It’s so cool to see new ideas for going beyond standard metrics to really understand model performance.
At DATUMO, we’ve been exploring ways to make LLM evaluations more reliable too—it’s such an exciting space to be in. Looking forward to more posts like this!
<a href="https://datumo.com" target="_blank">DATUMO</a>
This is probably the best overview of LLMs as Judges I have seen.
It made me realise that I haven’t seen a lot of new evaluation metrics / models / strategies since Prometheus.