
Explaining ChatGPT to Anyone in <20 Minutes
Distilling the core components of generative LLMs into an accessible framework...

This newsletter is presented by Rebuy, the commerce AI company.
If you like the newsletter, feel free to get in touch with me or follow me on Medium, X, and LinkedIn. I try my best to produce useful/informative content.

Over the past few years, we have witnessed a rapid evolution of generative large language models (LLMs), culminating in the creation of unprecedented tools like ChatGPT. Generative AI has now become a popular topic among both researchers and the general public. Now more than ever before, it is important that researchers and engineers (i.e., those building the technology) develop an ability to communicate the nuances of their creations to others. A failure to communicate the technical aspects of AI in an understandable and accessible manner could lead to widespread public skepticism (e.g., research on nuclear energy went down a comparable path) or the enactment of overly-restrictive legislation that hinders forward progress in our field. Within this overview, we will take a small step towards solving these issues by proposing and outlining a simple, three-part framework for understanding and explaining generative LLMs.
Presentation resources. This post was inspired by a presentation that I recently gave for O’Reilly on the basics of LLMs. The goal of this presentation was to provide a “primer” that brought everyone up to speed with how generative LLMs work. The presentation lasted ~20 minutes (hence, the title of this article). For those interested in using the resources from this presentation, the slides are here.
The Core Components of Generative LLMs

The purpose of this overview is simple. The quality of generative language models has drastically improved in the last year (see above), and we want to understand what changes and new techniques catalyzed this boost in quality. Here, we will stick to transformer-based language models, though the concept of a language model predates the transformer architecture—dating back to recurrent neural network-based architectures (e.g., ULMFit [4]) or even n-gram language models.
Top-level view. To explain generative LLMs in a clear and simple manner, we must first identify the key ideas and technologies that underlie them. In the case of this overview, we will focus upon the following three components:
Transformer architecture: the neural network architecture used by LLMs.
Language model pretraining: the (initial) training process used by all LLMs.
The alignment process: how we teach LLMs to behave to our liking.
Together, these ideas describe the technology that powers generative LLMs like ChatGPT. Within this section, we will develop a working understanding of these key ideas and how they combine together to create a powerful LLM.
Transformer Architecture

Nearly all modern language models are based upon the transformer architecture (shown above) [5]—a deep neural network architecture that was originally proposed for solving Seq2Seq tasks (e.g., summarization or language translation)1. The transformer takes a sequence of text as input and is trained to perform some generative (e.g., summarization) or discriminative (e.g., classification) task. We will now overview the transformer architecture and how it is leveraged by LLMs to produce coherent and interesting sequences of text. For a more in-depth explanation of the transformer architecture in general, check out the link below.
Encoder-decoder architecture. The transformer has two primary components: the encoder and the decoder. The encoder looks at the full sequence of text provided as input and builds a representation2 of this text. Then, the decoder takes this representation as input and uses it to produce an output sequence. For example, if we train a transformer to translate a sentence from English to Chinese, the model will perform the following processing steps:
The encoder ingests the English sentence.
The encoder outputs a representation for the English sentence.
The decoder ingests the encoder’s representation of the English sentence.
The decoder generates the Chinese translation.

Decoder-only architecture. Although the originally-proposed transformer has both an encoder and a decoder module, generative LLMs primarily use a decoder-only transformer architecture; see above. This architecture eliminates the encoder from the transformer architecture, leaving only the decoder. Given that the decoder’s role in the transformer is to generate textual output, we can intuitively understand why generative LLMs only use the decoder component—the entire purpose of these models is to generate sequences of text!
Constructing the input. To better understand how decoder-only transformers operate, let’s take a deeper look at the input to this model and how it is created. Generative LLMs take a sequence of text as input. However, we can’t just pass raw text or characters into the transformer. First, we tokenize this text, or break it into a sequence of tokens (i.e., words or sub-words); see below.
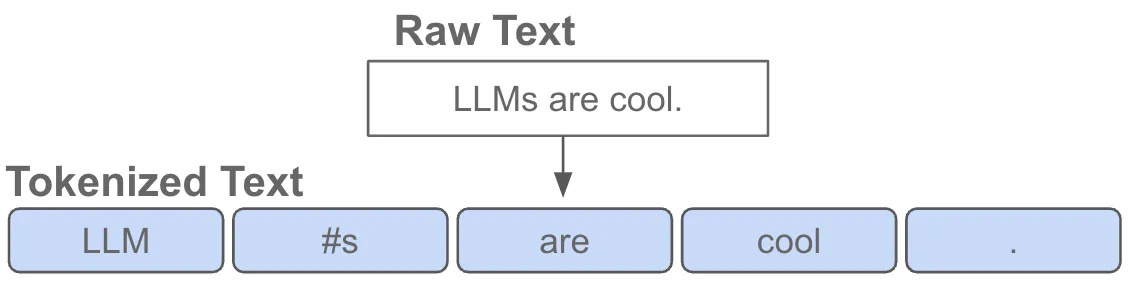
After tokenizing the input sequence, we convert each token into an associated, unique vector representation, forming a list of vectors that correspond to each token; see below. These token vectors are lists of numbers that quantitatively describe each token. After adding positional embeddings—or extra vectors that capture the position of each token within the input sequence—to these token vectors, we are left with the final input that is passed into the decoder-only transformer!
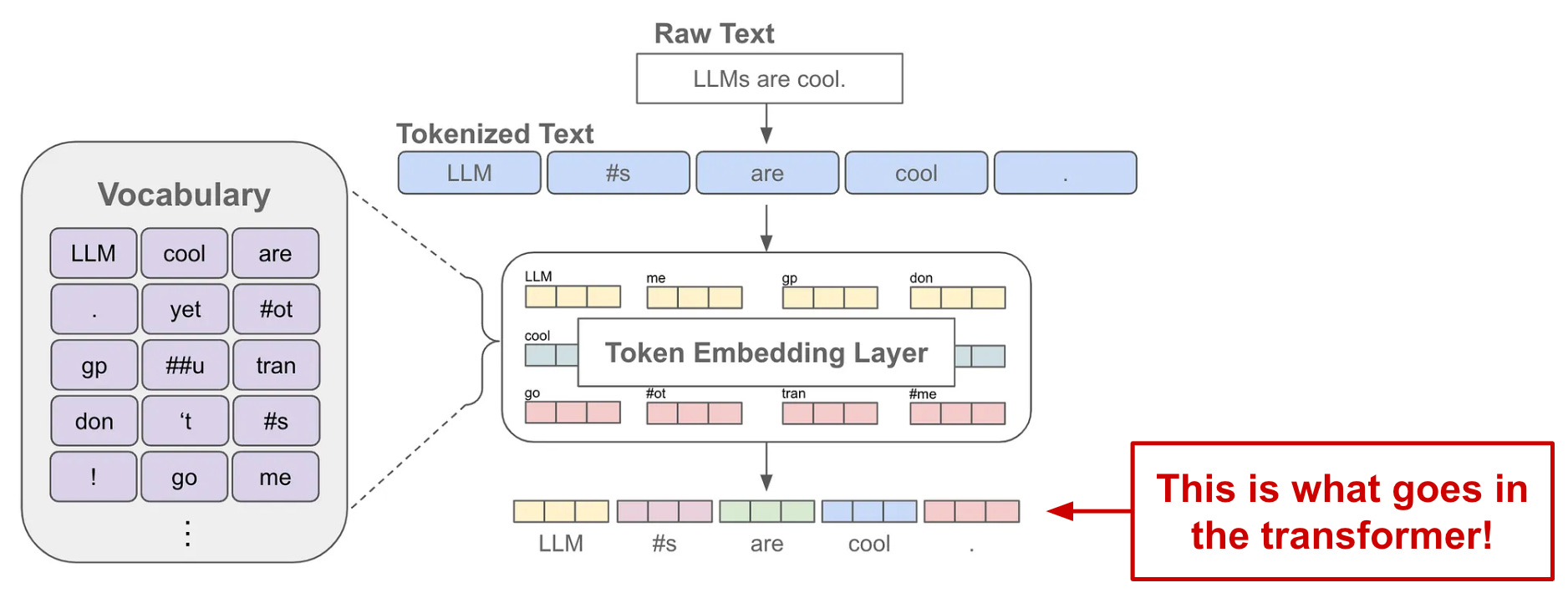
Token vectors are stored in an embedding layer—a big matrix, where each row stores the vector for a single token—that is part of the transformer architecture. At first, these token vectors are randomly initialized, but we learn them during the training process just like any other neural network parameter!

Processing the input. Now that we understand how the model’s input is constructed, the next step is to better understand how each of the model’s layers transform this input. Each “block” of the decoder-only transformer takes a list of token vectors as input and produces a list of transformed3 token vectors (with the same size) as output. This transformation is comprised of two operations:
Masked Self-Attention: transforms each token vector by considering tokens that precede it in the sequence; see above and here for more details.
Feed-forward transformation: transforms each token vector individually via a sequence of linear layers and non-linearities (e.g., ReLU); see below.
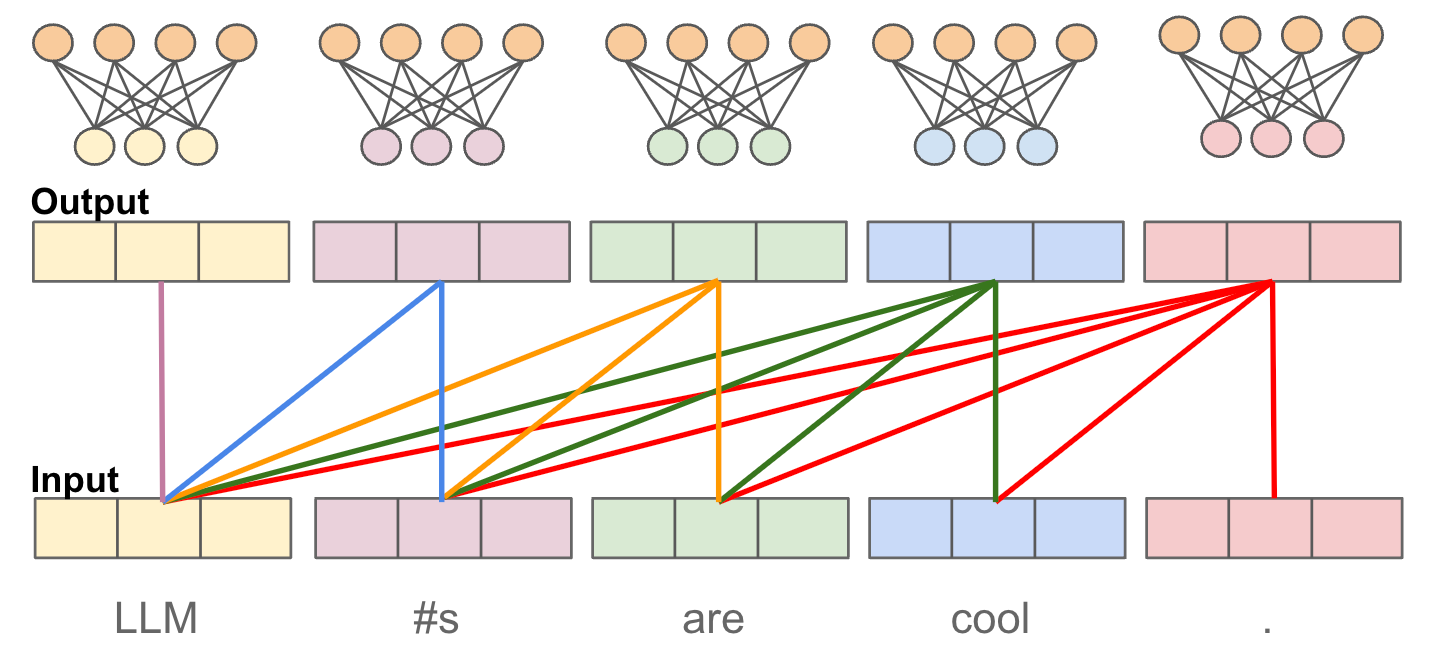
Together, masked self-attention and feed-forward transformations allow us to craft a rich representation of any textual sequence. These components each play a distinct and crucial role:
The attention component grabs useful information from the broader sequence (i.e., tokens that precede the current token).
The feed-forward component learns a pattern or transformation that is individually applied to each token vector.
By stacking several decoder-only transformer blocks on top of each other, we arrive at the architecture that is used by (nearly) all generative LLMs!
Language Model Pretraining
“Self-supervised learning obtains supervisory signals from the data itself, often leveraging the underlying structure in the data. The general technique of self-supervised learning is to predict any unobserved or hidden part (or property) of the input from any observed or unhidden part of the input.” - from [7]
Now that we understand the transformer, let’s dive in to the next key idea that underlies generative LLMs—self-supervised pretraining. Self-supervised learning refers to the idea of using signals that are already present in raw data to train a machine learning model. In the case of generative language models, the most commonly-used objective for self-supervised learning is next token prediction, also known as the standard language modeling objective. Interestingly, this objective—despite being quite simple to understand—is the core of all generative language models. We’ll now explain this objective, learn how it works, and develop an understanding of why it is so useful for generative LLMs.

LLM pretraining. To pretrain a generative language model, we first curate a large corpus of raw text (e.g., from books, the web, scientific publications, and much more) to use as a dataset. Starting from a randomly initialized model, we then pretrain the LLM by iteratively performing the following steps:
Sample a sequence of raw text from the dataset.
Pass this textual sequence through the decoder-only transformer.
Train the model to accurately predict the next token at each position within the sequence.
Here, the underlying training objective is self-supervised, as the label that we train the model to predict—the next token within the sequence—is always present within the underlying data. As a result, the model can learn from massive amounts of data without the need for human annotation. This ability to learn directly from a large textual corpus via next token prediction allows the model to develop an impressive understanding of language and knowledge base. For a more in-depth discussion of the pretraining process, check out the link below.

Inference process. Generative LLMs use a next token prediction strategy for both pretraining and inference! To produce an output sequence, the model follows an autoregressive4 process (shown above) comprised of the following steps:
Take an initial textual sequence (i.e., a prompt) as input.
Predict the next token.
Add this token to the input sequence.
Repeat steps 2-3 until a terminal/stop token (i.e.,
<EOS>) is predicted.

Keys to success. A decoder-only transformer that has been pretrained (using next token prediction) over a large textual corpus is typically referred to as a base (or pretrained) model. Notable examples of such models include GPT-3 [3], Chinchilla [9], and LLaMA-2 [10]. As we progressed from early base models (e.g., GPT [1]) to the models that we have today, two primary lessons were learned.
Larger models are better: increasing the size (i.e., number of trainable parameters) of the underlying model yields a smooth increase in performance, which led to the popularization of large language models.
More data: despite yielding a smooth increase in performance, increasing the size of the underlying model alone is suboptimal. We must also increase the size of the underlying pretraining dataset to get the best results.
Put simply, the best base models combine large model architectures with massive amounts of high-quality pretraining data.

Computational cost. Before moving on, we should note that the pretraining process for generative LLMs is incredibly expensive—we are training a large model over a massive dataset. Pretraining costs range from several hundreds of thousands (see above) to even millions of dollars, if not more. Despite this cost, pretraining is an incredibly important step—models like ChatGPT would not be possible without creation of or access to a high-quality base model. To avoid the cost of language model pretraining, most practitioners simply download open-source base models that have been made available online via platforms like HuggingFace5.
The Alignment Process
“Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users.” - from [6]
After pretraining, the LLM can accurately perform next token prediction, but its output is oftentimes repetitive and uninteresting. For an example of this, we can look back to the beginning of this overview! Namely, GPT-2 (i.e., a pretrained LLM) struggles to produce helpful and interesting content. With this in mind, we might ask: What do these models lack? How did we get from this to ChatGPT?
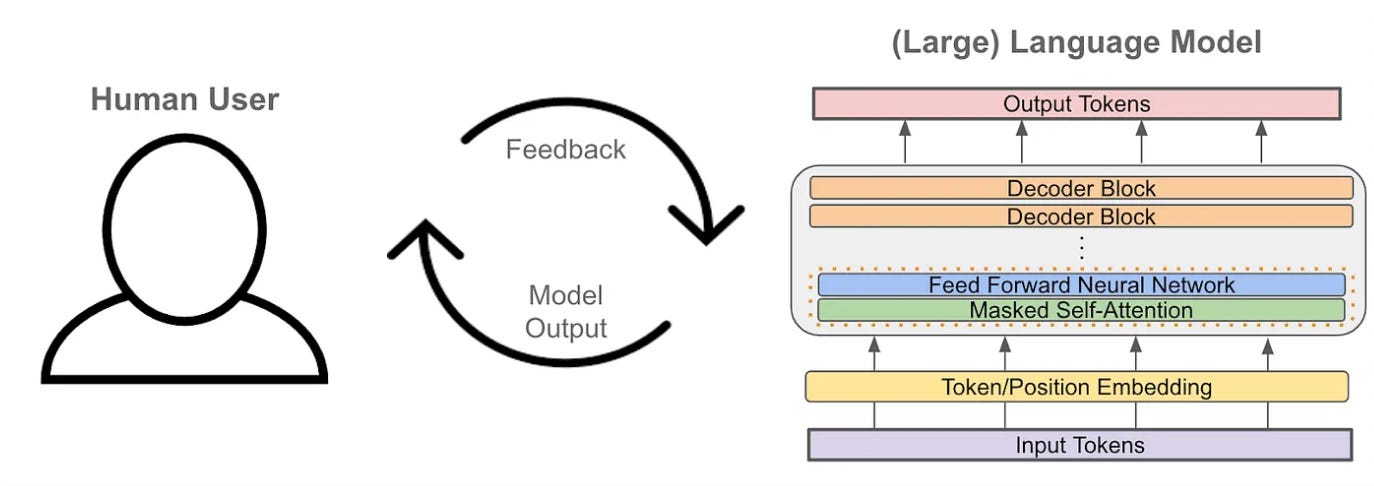
The alignment process, which teaches a language model how to generate text that aligns with the desires of a human user, is the answer to the question above. For example, we can teach the model to:
Follow detailed instructions
Obey constraints in the prompt
Avoid harmful outputs
Avoid hallucinations (i.e., generating false information)
Pretty much anything we can demonstrate to the LLM!
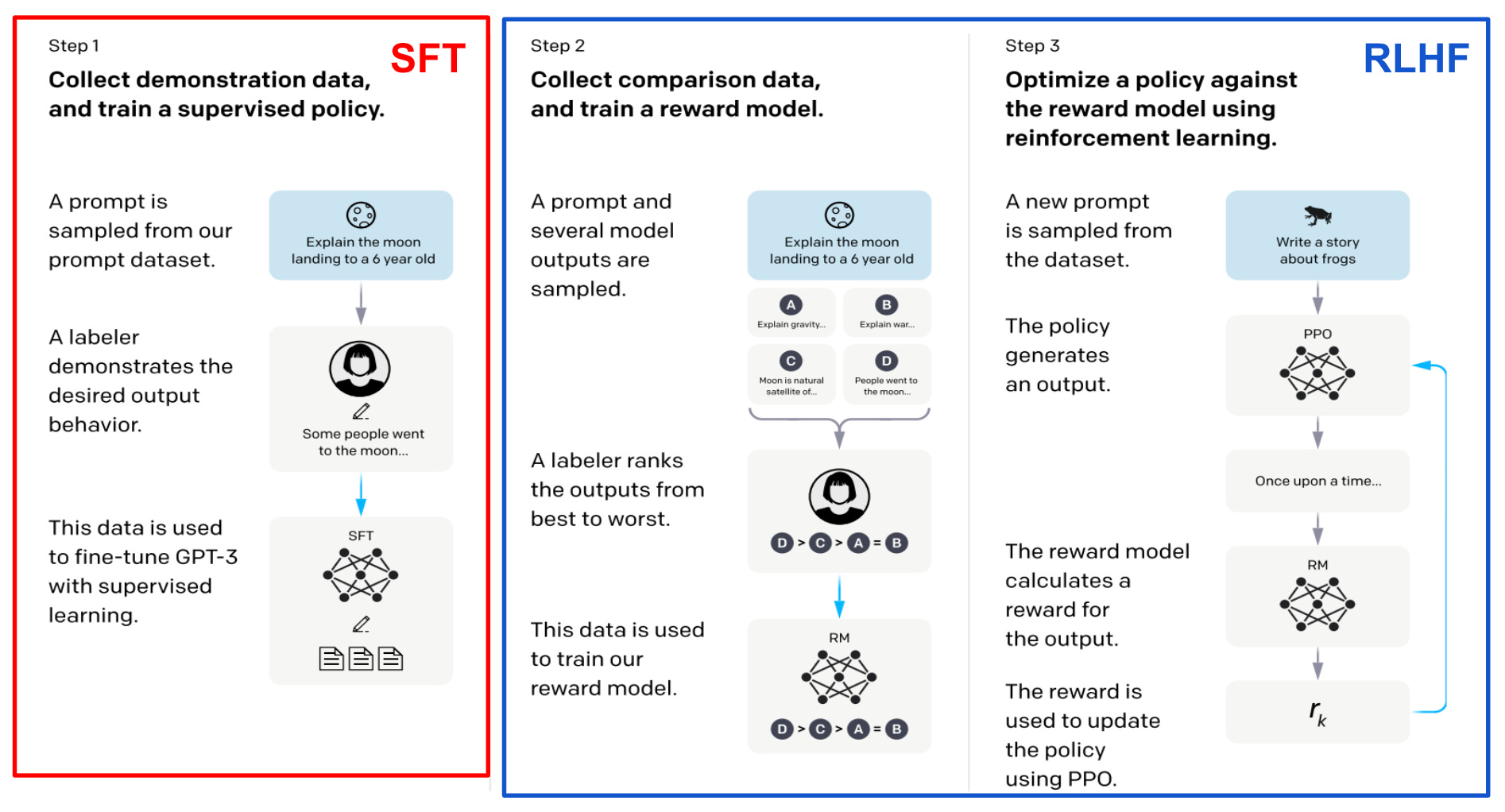
The objectives of the alignment process are typically referred to as alignment criteria, and we (i.e., the researchers training the model) must define these criteria at the outset of the alignment process. For example, two of the most commonly-used alignment criteria within AI research (e.g., see LLaMA-2 [10] and Constitutional AI [11]) are helpfulness and harmlessness. To instill each of these alignment criteria within the model, we perform finetuning via supervised finetuning (SFT) and reinforcement learning from human feedback (RLHF).

SFT is simple to understand, as it is based upon the same objective as pretraining—next token prediction. However, instead of training the model over a bunch of raw text downloaded from the web, we use a more specific training dataset. Namely, we train the model on alignment-focused data, or demonstrations—either written by humans or generated synthetically by another LLM—of prompt and response pairs that satisfy the set of desired alignment criteria; see above. For a more in-depth discussion of SFT, check out the link below.
Although SFT is effective and widely-used, manually curating a dataset of high-quality model responses can be difficult. RLHF solves this issue by directly finetuning an LLM based on human feedback; see below for a depiction.

This process proceeds in two phases. During the first phase, we start with a set of prompts and use the LLM—or a group of several LLMs—to generate two or more responses to each prompt. Then, a group of human annotators ranks responses to each prompt based on the defined alignment criteria, and we use this data to train a reward model that accurately predicts a human preference score given a prompt and a model’s response as input. Once the reward model is available, we use a reinforcement learning algorithm (e.g., PPO) during the second phase of RLHF to finetune the LLM to maximize human preference scores, as predicted by the reward model. For a more detailed discussion of RLHF, check out the link below.
Finetuning pipeline. Although SFT and RLHF are standalone techniques, most state-of-the-art LLMs use the three-step alignment process, including both SFT and RLHF. This approach, depicted below, became a standard within LLM research after the proposal of InstructGPT [6]6—the predecessor to ChatGPT.
Putting Everything Together

As long as we understand the concepts that have been discussed so far, we now have a working understanding of ChatGPT. In particular, modern generative LLMs i) use a transformer architecture, ii) are pretrained over a large corpus of text downloaded from the web, and iii) are aligned via SFT and RLHF; see above.
The progression of LLM research. To understand how these three language modeling components have influenced the development of LLMs and AI, we can study the progression of prominent papers within the language modeling domain; see below. Before the advent of the transformer architecture, language models were still around, but they were based upon simpler architectures (e.g., recurrent neural networks). Although the transformer was originally proposed to solve Seq2Seq tasks, we quickly saw the decoder-only variant of the transformer architecture applied to the language modeling domain with GPT and GPT-2 [1, 2]7.
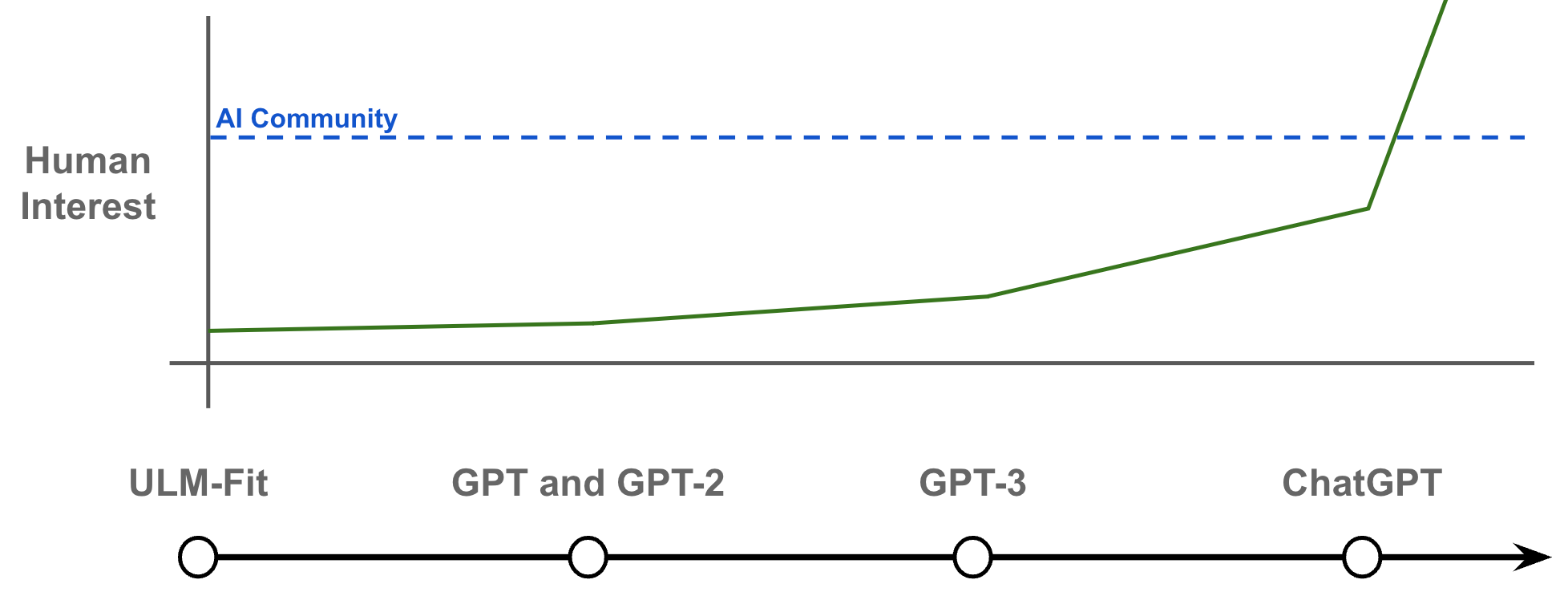
These early, transformer-based language models performed well, but we didn’t see truly impressive performance until much larger language models (i.e., true LLMs), such as GPT-3 [5], were explored. These models were found to have impressive few-shot learning capabilities across a variety of tasks as we scale them up in size. However, model size alone is not enough! We learn from Chinchilla [9] that the best base models are created by combining large models with large pretraining datasets—both parameter and data scale are important.
Pretrained LLMs can accurately solve many tasks, which led to recognition within the AI community. However, these models were oftentimes repetitive or uninteresting, struggled to follow instructions, and generally lacked in helpfulness. To solve this problem, the alignment process directly finetunes the LLM based on a set of criteria that describe desired model behavior. Such an approach drastically improves the quality of the underlying model, leading to the creation of powerful models like ChatGPT and a subsequent explosion of interest in generative LLMs; see below. In other words, alignment is (arguably) the key advancement that made the powerful LLMs we see today possible.

What’s next? At this point, we understand everything that goes into creating an LLM like ChatGPT. All that is left is to learn how to apply such models to solving practical problems. To solve downstream tasks with an LLM, there are two basic approaches we can take (shown below):
In-context learning: write a prompt to solve the desired task.
Finetuning: perform further training on data for the desired task.

For more information on in-context learning and prompting, as well as various methods of finetuning, check out the references below:
Practical Prompt Engineering [link]
Advanced Prompt Engineering [link]
Understanding and Using Supervised Finetuning [link]
Easily Train a Specialized LLM [link]
Key Takeaways
Within this overview, we distilled the key technologies underlying generative LLMs into a three-part framework that includes i) the transformer architecture, ii) language model pretraining, and iii) the alignment process. The key points to remember with respect to each of these components are as follows:
Generative LLMs are based upon the decoder-only transformer architecture.
First, we pretrain these models over massive amounts of textual data using the next token prediction objective.
After pretraining, we use SFT and RLHF (i.e., the three-step technique) to better align these models with the desires of human users.
By developing a deep understanding of these components and learning how to explain them to others (in simple terms), we can democratize understanding of this important technology. Today, AI-powered systems are impacting more people than ever before. AI is no longer just a research topic, but rather a topic of popular culture. As AI continues to evolve, it is paramount that builders, engineers, and researchers (i.e., people like us!) learn to effectively communicate about the technology, its pitfalls, and what is to come.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[2] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[3] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[4] Howard, Jeremy, and Sebastian Ruder. "Universal language model fine-tuning for text classification." arXiv preprint arXiv:1801.06146 (2018).
[5] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[6] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[7] LeCun, Yann et al. “Self-supervised learning: The dark matter of intelligence”, https://ai.meta.com/blog/self-supervised-learning-the-dark-matter-of-intelligence/ (2021).
[8] “MPT-30B: Raising the Bar for Open-Source Foundation Models.” MosaicML, 22 June 2023, www.mosaicml.com/blog/mpt-30b.
[9] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[10] Touvron, Hugo, et al. "Llama 2: Open Foundation and Fine-Tuned Chat Models." arXiv preprint arXiv:2307.09288 (2023).
[11] Bai, Yuntao, et al. "Constitutional ai: Harmlessness from ai feedback." arXiv preprint arXiv:2212.08073 (2022).
[12] Stiennon, Nisan, et al. "Learning to summarize with human feedback." Advances in Neural Information Processing Systems 33 (2020): 3008-3021.
[13] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
However, the transformer is now used in a wide variety of tasks and domains, ranging from computer vision to processing audio signals. In many ways, the transformer is becoming a general-purpose deep learning architecture for solving any task.
This “representation” is just a vector, or list of vectors, that quantitatively describe the input and can be used by some downstream model/module to solve a relevant task.
Hence, the “transformer” architecture!
This word seems fancy, but it just means that each output we produce is added to the input sequence iteratively before producing the next output.
Technically, this three step technique was proposed prior to InstructGPT in [12]. However, this paper only studies training language models for summarization, rather than training generic foundation models.
Both GPT and GPT-2 are pretrained base models that undergo no alignment process. Alignment was not explore extensively until InstructGPT [6].
PDF book on Ai, ML, etc.? I am reading a lot atm on these subjects to learn more. This means my my understanding is cobbled together from many sources. it would be nice to read a single source to help me validate what I think I know so dar
This is both timely (the one year anniversary of ChatGPT) and extremely necessary. Congratulations on your talk with O'Reilly, Cameron. Is there a book in the near future? :)