


Dolma, OLMo, and the Future of Open-Source LLMs
How making open-source LLMs truly open will change AI research for the better...

This newsletter is presented by Rebuy. If you like the newsletter, feel free to subscribe below, get in touch, or follow me on Medium, X, and LinkedIn.

Although (large) language models (LLMs) have been a topic of interest within the AI research community for years, the proposal of ChatGPT drastically increased the commercial viability of (and amount of public interest in) this technology. As a result, most research on the topic of LLMs quickly became proprietary, despite the massive emphasis AI researchers had placed on transparency and open-source for years. Due to the massive role that open collaboration plays in technological progress, certain researchers responded to this newfound proprietary nature of AI research by beginning to replicate LLM research advancements in an open-source fashion, as documented in the overviews below:
The History of Open-Source LLMs: Early Days [link]
The History of Open-Source LLMs: Better Base Models [link]
The History of Open-Source LLMs: Imitation and Alignment [link]
For quite some time, the quality of open-source LLMs lagged behind their proprietary counterparts. Recently, however, the gap between open-source and proprietary LLMs has been significantly reduced. As a result, open-source LLM research has become more mainstream and is being emphasized heavily.
“As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed.” - from [1]
The increasing popularity of open-source LLMs is widely considered to be beneficial. However, there is one problem: the definition of open-source varies drastically between models. In many cases, open-source LLMs simply release their model parameters and inference code, while obfuscating other important details like the contents of the pretraining dataset, training hyperparameters, evaluation strategy and more. Plus, many open-source LLMs come with restrictive licenses that may forbid commercial use, the construction of synthetic datasets, and more.
This overview. Here, we will overview the recently-released Dolma dataset [1] and OLMo [10] suite of LLMs. Unlike prior work in open-source LLMs, Dolma and OLMo are completely transparent and open-source. The process of constructing the Dolma pretraining corpus, which is released under the AI2 impact license, is fully-documented in [1]. Plus, authors release code and tooling for re-building the dataset from scratch. Similarly, OLMo is released under an Apache-2.0 license along with all training data, training/evaluation/adaptation code, checkpoints, training logs, and more. Dolma and OLMo take a massive step towards demystifying the LLM preparing process by i) releasing all relevant resources and ii) analyzing any and all choices made in the process of training OLMo.
Dolma: an Open Corpus of Three Trillion Tokens for LLM Pretraining Research [1]
“The most powerful language models are built by a few organizations who withhold most model development details1… the composition of language model pretraining data is often vaguely stated, even in cases where the model itself is released for public use.” - from [1]
Although LLMs are now commonly used for a variety of natural language processing (NLP) tasks, most of these models’ specifications are kept hidden from the practitioners. For example, we rarely have any information regarding the composition of an LLM’s pretraining dataset—even “open” models (e.g., LLaMA-2 [2]) do not release information about their data or how the model can be reproduced! The details of constructing a pretraining dataset for an LLM are largely a black box, which makes performing research on pretraining data and its impact on the downstream LLM quite difficult for those outside of a few top LLM labs.

In [1], authors from AI2 solve this problem by releasing Data for Open Language Models’ Appetite (Dolma), a fully-open pretraining dataset containing over three trillion tokens of English text2. This dataset is collected from a variety of sources, including web content, scientific papers, code, public-domain books, social media posts, and encyclopedic materials; see above. The process of constructing this dataset—including design principles and the empirical reasoning behind each decision—is documented in [1]. Additionally, the authors release a full toolkit for efficiently reproducing and modifying the resulting dataset. As a result, Dolma enables researchers to better study the impact of pretraining data composition on the capabilities and limitations of the downstream language models.
Dolma design principles. The end goal of creating the Dolma dataset is to i) create the largest (to date) open—meaning that both the data and the process for curating the data are shared—pretraining corpus and ii) use this pretraining corpus to train an open language model, called Open Language Model (OLMo). To create this corpus, authors in [1] aim to pull from data sources that are commonly used in prior work, as well as process the data in a way that aligns with existing best practices. In areas where implementations differ or best practices are unknown, an empirical approach is adopted, whereby smaller variants of OLMo are trained and evaluated to determine the downstream impact of changes to the pretraining dataset. To minimize risk of harm to individuals, one can easily request—using this form—for their data to be removed from the Dolma corpus.

Observing that many LLMs can be improved by pretraining over more data, authors in [1] aim to make Dolma sufficiently large. The impact of data size on model performance was analyzed by the Chinchilla language model [3], where authors showed that larger models must be pretrained over sufficiently large pretraining datasets to truly optimize their performance. However, even recent LLMs could usually be improved by pretraining over more data! As shown above, for example, LLaMA-2 models have not yet fully converged after pretraining over 2T tokens. As such, authors in [1] aim to make Dolma sufficiently large (i.e., 3T tokens) to facilitate further studies on pretraining dataset size.
Prior Open Pretraining Datasets
“Lack of access to pretraining corpora alongside corresponding language models has been a major obstacle for the broader research community.” - from [1]
Despite the massive popularity of LLMs, information about their pretraining corpora is rarely discussed. Even “open” LLMs usually avoid releasing the datasets on which they are trained, or even a recipe for reproducing this dataset. As such, Dolma takes a large leap towards pretraining transparency by openly releasing a full-size pretraining corpus, along with the tools needed to reproduce it. As we will see in this section, however, Dolma is not the only effort that has tried to shed light on the process of constructing pretraining data for LLMs.
Colossal Clean Crawled Corpus (C4) [6]. This pretraining dataset was originally constructed for the T5 model; see here for more details. The data is sourced from Common Crawl, and the full dataset contains about 750Gb of text in total. We see in [6] that authors choose to create the C4 dataset from scratch due to the lack of high-quality, publicly-available pretraining datasets for language models. C4 is limited in scale compared to the pretraining datasets that are used by modern LLMs. Nonetheless, many models (e.g., Gopher, Chinchilla, MPT, and more) use C4 as a subset of their pretraining data, as the quality of data is quite high.

Responsible Open-science Open-collaboration Text Sources (ROOTS) [17]. The ROOTS corpus was developed as part of the BigScience research initiative for training BLOOM [18]—one of the early proposals in the space of open-source language models. ROOTS is a multilingual dataset that spans over 46 natural languages and 13 programming languages; see above. The dataset is comprised of over 1.6Tb of text in total (i.e., twice the size of C4). However, the English portion of this dataset is, again, limited in scale—too small for training English-only LLMs.

The Pile [19] is a 825 Gb pretraining corpus for LLMs that was created by combining 22 existing datasets for natural language processing; see above. At the time of publishing, code used to construct the Pile was also released publicly. Similar to C4, the Pile is a high-quality dataset that is limited in scale, and it is used as a subset of the pretraining dataset for many LLMs (e.g., OPT and LLaMA).

RefinedWeb [20] is a pretraining corpus that was curated to train the Falcon LLMs. The corpus is comprised of web data that undergoes a purely heuristic-based filtering pipeline (i.e., no model-based filtering). RefinedWeb is composed primarily of web data, demonstrating that high-quality pretraining datasets can be constructed without using curated sources of data. Interestingly, we see that LLMs trained over RefinedWeb perform quite favorably despite relying heavily upon web data; see above. The full corpus is very large—5 trillion tokens in total! However, only a small portion of the data (600B tokens) is released to the public, so the openly-available portion of RefinedWeb is relatively small.
RedPajama [21, 22] is an initiative (led by Together AI) to reproduce leading open-source LLMs and release them to the public with a more permissive license. As a first step in this direction, authors recreated the pretraining dataset for LLaMA (see here for more details), resulting in the RedPajama v1 and v2 datasets. Despite being similar to Dolma in nature, RedPajama has a more limited scope. Namely, the creators of RedPajama are trying to reproduce LLaMA, while Dolma attempts to provide a transparent resource that empowers others to study all notable aspects of LLM pretraining. As such, Dolma pulls from a variety of additional data sources (e.g., scientific papers, code, conversational forums, and more).
Creating the Dolma Corpus

The process of constructing a pretraining dataset for an LLM consists of three primary components:
Acquisition: obtaining content from a variety of sources.
Cleanup: using heuristics and model-based techniques to filter the data.
Mixing: deduplication and up/down-sampling of data sources.
To acquire data, authors in [1] use commonly used data sources for pretraining LLMs. For example, web data is derived from Common Crawl, code is derived from The Stack, and conversational forums are derived from the Pushshift Reddit Dataset. Other sources of pretraining data include C4 (web data), PeS2o (academic literature), Project Gutenberg (books), and Wikipedia (encyclopedic content).
“We create a high-performance toolkit to facilitate efficient processing on hundreds of terabytes of text content. The toolkit is designed for high portability: it can run any platform from consumer hardware to a distributed cluster environment” - from [1]
To process data for pretraining, we rely upon four primary transformations:
Language filtering.
Quality filtering.
Content filtering.
Deduplication.
Each of these steps are implemented within the Dolma toolkit. We will now go over each of these transformations and how they are implemented for different data sources. In [1], several variations of these transformations are typically implemented and tested by comparing the downstream performance of a 1B parameter OLMo model pretrained on a subset (i.e., 150B tokens) of Dolma. However, we can also evaluate different choices for the data preprocessing pipeline by manually inspecting the resulting data3 with tools like WIMBD!

What is fastText? Within this section, we will see several mentions of fastText classifiers being used to filter pretraining data for LLMs. fastText is a free and open-source library that can be used to learn text representations or train lightweight text classifiers. As documented in [34], fastText classifiers have a simple architecture that takes an average of word representations within a sentence, then passes the result into a linear classifier; see above. These classifiers perform well—even similarly to deep learning-based classifiers in certain cases. We can further improve the quality of fastText models by incorporating n-gram representations along with default unigram word representations.
“We can train fastText on more than one billion words in less than ten minutes using a standard multicore CPU, and classify half a million sentences among 312K classes in less than a minute.” - from [34]
Most importantly, fastText classifiers are fast to train and evaluate. Due to the simple model architecture, inference is lightweight and training can be executed efficiently via (asynchronous) distribution across CPUs. As such, fastText classifiers are ideal for large-scale data processing applications, such as filtering a pretraining dataset for an LLM. In fact, the CCNet data pipeline [35]—a popular reference architecture for creating high-quality, deduplicated, and monolingual text datasets from web data—uses a fastText classifier for language identification.

Language filtering. The Dolma dataset is English-only4, which means that we must implement a tool for filtering non-English content from acquired data. To do this, we typically use a lightweight classifier—authors in [1] use the CCNet pipeline5 with a fastText language identification model—to predict the primary language of each document6. Then, we can set a threshold that keeps only documents with a sufficiently-high English score. Typically, this language filtering component, which is applied to both web and conversation data in Dolma, eliminates a large amount of source data (e.g., 61.7% of web data is removed). However, language filtering is model-based and, therefore, imperfect—a certain amount of non-English data will always be present.
“Language filtering is never perfect, and multilingual data is never completely removed from pretraining corpora.” - from [1]
For the code portion of Dolma, authors in [1] implement a “language filtering” component that removes json and csv files from the corpus. Such a strategy eliminates large, data-heavy files from the corpus that are not useful for training.

Quality filtering refers to the process of removing “low quality” text from a pretraining corpus. However, there is a lot of contention within the research community about the definition of low quality text and how it can best be filtered from an LLM’s pretraining corpus. In particular, there is an active debate about whether quality filters should rely solely upon heuristics (e.g., Gopher [3] and Falcon [4] adopt this approach) or if machine learning models should be used for quality filtering (e.g., LLaMA [5] filters low quality content using n-gram language models and simplistic classification models). In [1], authors choose to avoid model-based filtering techniques and rely solely upon heuristic filtering methods. For web text, authors find that combining filtering techniques from Gopher [3] and C4 [6] yields the best results; see the figure below.

Even after heuristic quality filtering is performed, we see in [1] that web text still contains a variety of repeated n-gram sequences; see the table above. These sequences, which often serve as webpage layout elements, are relatively uncommon in the pretraining corpus. However, authors in [1] mention that these sequences must nonetheless be removed to avoid loss spikes during training.

A simpler set of heuristics is adopted for filtering conversational data, whereby authors filter conversations based on i) length, ii) community votes, and iii) flags from moderators and the community for each conversation. For code data, Dolma uses a combination of quality filters from RedPajama v1 and StarCoder [7] that removes data and templated code from the corpus, as well as code that is derived from unpopular repositories, has a bad ratio of comments to code, and more. The full set of quality filtering heuristics used by Dolma are listed above.

Content filtering focuses upon removing harmful text—primarily toxic content and personally identifiable information (PII)—from the pretraining dataset. To identify toxic content, authors in [1] train a pair of fastText classifiers, which are then used to tag (and remove) spans of toxic text, to classify hateful and not-safe-for-work (NSFW) content based on the Jigsaw Toxic Comments dataset.

In [1], we see that authors adopt a conservative threshold for removing toxic text—a text span must be classified as toxic with a relatively high probability for it to be removed. This approach yields slightly degraded downstream performance (shown above), but it is adopted to avoid removing too much data from the corpus.
To detect PII, a series of regular expression are adopted to find spans of text corresponding to email addresses, IP addresses, and phone numbers. From here, these spans of text are either masked, or the entire document is removed from the corpus (if more than 5 pieces of PII are detected in a single document). For code data, authors use extra tools to detect and remove code secrets from the data.
“Deduplication allows us to train models that emit memorized text ten times less frequently and require fewer training steps to achieve the same or better accuracy” - from [9]
Deduplication. Recent research has shown that deduplicating an LLM’s pretraining dataset makes the model’s training more data efficient7 [9]. As such, crafting a robust (and efficient) deduplication pipeline is an incredibly important aspect of building pretraining corpora for LLMs. In [1], authors perform three stages of deduplication for web text:
URL-based: eliminates web pages that are scraped multiple times.
Document-based: eliminates pages that contain exactly the same text.
Paragraph-based: eliminates individual paragraphs with the same text.
All stages are implemented efficiently by using a Bloom filter. For other sources of data beyond web data (e.g., code or conversational data), a similar strategy is used for deduplication, though paragraph-level deduplication may be unnecessary for sources with shorter documents. URL and document-based deduplication are typically performed first due to their efficiency, while paragraph-based deduplication is saved for the later stages of the dataset construction process.

Putting it all together. When constructing Dolma, authors in [1] perform preprocessing steps in a specific order to ensure efficiency. Namely, URL and document-level deduplication are performed first, followed by quality and content filtering, while paragraph-level deduplication is performed last. As shown in the figure above, this combination of preprocessing steps yields an LLM that achieves the best performance on downstream tasks. Compared to other pretraining corpora that are available, Dolma offers a larger pool of tokens at comparable quality and equal diversity in data composition.
OLMo: Accelerating the Science of Language Models [10]
“We believe that a large, diverse population of open models is the best hope for scientific progress on understanding language models and engineering progress on improving their utility.” - from [10]
OLMo is a set of truly open LLMs that are pretrained on Dolma. OLMo models match the performance of state-of-the-art open LLMs and can be used to more deeply study the science of language modeling. The OLMo suite of models are completely open (i.e., Apache 2.0 license) and come with a variety of artifacts:
Model weights [link]
Training code [link]
Evaluation code [link]
Adaptation code [link]
Training logs [link]
OLMo is comprised of five models in total—four 7B models and one 1B model. Plus, authors in [10] openly publish checkpoints for these models that are recorded every 1K training iterations. The combination of OLMo and Dolma allows us to deeply analyze the relationship between pretraining data and LLM performance—a poorly understood and rarely analyzed topic (at least openly) within the AI community.
Prior “open” LLMs. OLMo models are truly open, as they release their data, training/evaluation code, model weights, inference code, and more. In contrast, most “open” LLMs only release model weights and inference code. Plus, these resources might be associated with a relatively restrictive license (e.g., LLaMA-2 uses a custom license instead of Apache 2.0). As such, the openness of open LLMs tends to lie somewhere on a spectrum (see here for an itemized list):
Mistral [36] provides model weights and a brief report.
LLaMA-2 [2] provides detailed alignment instructions but minimal information about the pretraining dataset.
MPT [31] provides detailed instructions about constructing the model’s pretraining dataset, but does not actually release the data.
Falcon [4] releases a partial subset of the model’s pretraining data, along with a report on the model and data.
BLOOM [18] releases training code, model checkpoints, and training data, but the license is restrictive.
In [10], authors take inspiration from the design choices of LLMs outlined above. Going further, they aim to create a truly open LLM—OLMo is released with an Apache 2.0 license and Dolma is released with AI2’s impact license—that adopts the best practices of these models and provides more insight into the intricate details of their creation. Currently, the model that holds the most similarity to OLMo is LLM360, which targets a similar goal of releasing a truly open LLM.
The Evaluation Process
OLMo models are evaluated using two different techniques: perplexity and downstream task evaluation. In this section, we will overview these evaluation techniques, their purpose, and how they are implemented for OLMo.

What is perplexity? Prior to understanding perplexity evaluation, we have to understand the concept of perplexity in general. Put simply, perplexity is a metric that can be used to evaluate a language model by measuring how well it predicts known samples of text. When autoregressively generating output via next token prediction, the LLM predicts a probability distribution over potential next tokens. From these token-level probabilities, we can easily compute the probability for a sentence generated by the LLM via the product rule of probabilities; see below.

The metric above can give us a good idea of how well a language model “fits” the data—the model should assign high probabilities to valid, high-quality sequences of text. The problem with this probability, however, is that it is highly sensitive to the length of the sentence (i.e., longer sentences will have more probabilities multiplied together for each token)! To solve this, we can take a geometric mean8 to normalize the probability computed above by the length of the sentence; see below. The resulting metric captures the probability of a textual sequence in a manner that is not dependent upon or influenced by the length of the sequence.

How does this relate to perplexity? Well, perplexity is just the reciprocal of this number! Low (high) perplexity values indicate that a language model assigns high (low) probability to textual sequences used for evaluation and, therefore, fits the evaluation data well (poorly). The perplexity metric is commonly used to measure the quality of a language model’s “fit” to a corpus of high-quality text data.
Perplexity evaluation. To perform perplexity-based evaluation, authors construct an evaluation dataset called Perplexity Analysis for Language Model Assessment (Paloma) [23] by aggregating textual sequences from a diverse set of 585 domains collected across 18 different sources of textual data and evaluate the LLM by measuring perplexity on textual sequences from this dataset. Compared to prior work, Paloma significantly improves the diversity of perplexity-based evaluation benchmarks, allowing us to determine whether an LLM can accurately model text across a wide variety of domains. Notably, authors in [10] remove all data present in Paloma from OLMo’s pretraining dataset, ensuring that data contamination does not have an impact on perplexity evaluations9.

Downstream task evaluation. Perplexity-based evaluations are useful for understanding whether an LLM understands a domain of text well. For example, we can measure perplexity of a few LLMs over a corpus of scientific publications to determine which LLM best captures this data. However, perplexity-based evaluations fail to directly measure how well an LLM performs on downstream tasks. For this, authors in [10] evaluate the model using the Catwalk framework [24], which provides a standardized abstraction for evaluating various LLMs across a wide variety of tasks and datasets; see above. For OLMo in particular, authors select nine reasoning tasks—chosen based on similarity to the task set used to evaluate LLaMA and LLaMA-2 [2, 5]—for downstream evaluations. Models are evaluated solely using a zero-shot prompting strategy10 [25].
“We perform downstream evaluations to make decisions around model architecture, initialization, optimizers, learning rate schedule, and data mixtures. We call this our online evaluation as it runs in-loop every 1000 training steps and provides an early and continuous signal on the quality of the model being trained.” - from [10]
In-loop evaluations. Beyond the offline evaluation of OLMo described above, we see in [10] that OLMo undergoes similar evaluations in an online fashion. Namely, researchers test a variety of different model hyperparameters (e.g., architecture choices, initialization strategies, optimizers, learning rate schedules, etc.) and rely upon online evaluations performed every 1000 training steps to continuously evaluate hyperparameter settings. Online and offline evaluation rely upon the same perplexity and downstream task metrics, but online evaluation provides a continuous performance signal of choices made throughout model training.
Model Architecture

The OLMo LLM—like many other modern LLMs—is based upon the decoder-only transformer architecture. For more information on the different variants of the transformer model architecture, check out this writeup. Put simply, the standard transformer architecture has two components: an encoder and a decoder. The decoder-only architecture—as is implied by its name—only uses the decoder component of the transformer. As depicted in the image above, each layer of this model uses masked, multi-headed self-attention and a feed-forward network to craft a rich representation of a textual sequence and the relationships between words in this sequence. Using this representation, the model can autoregressively generate coherent sequences of text when given a textual prompt as input.
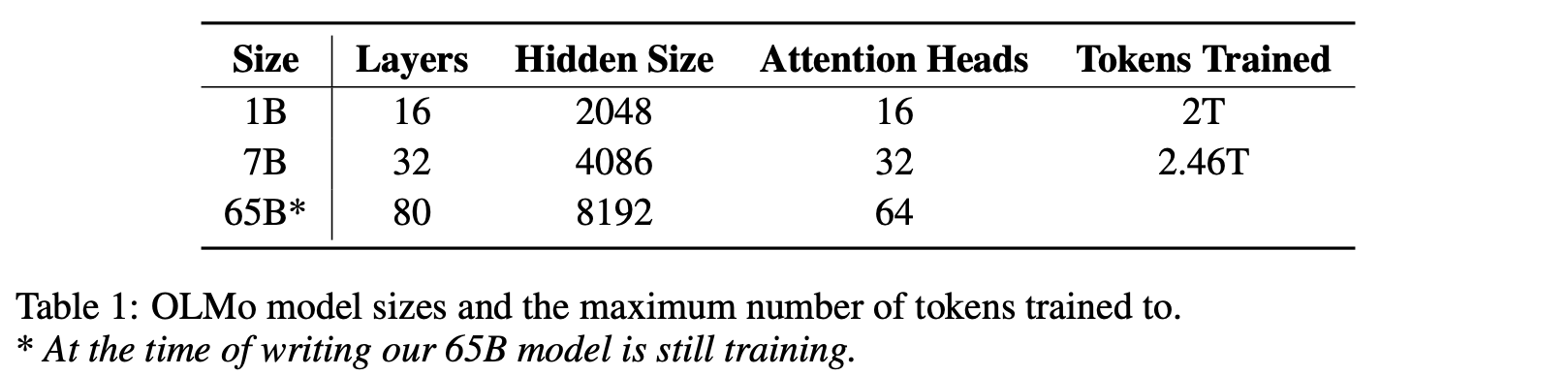
The OLMo suite. Three model sizes of OLMo are included in the release; see above. The 1 billion and 7 billion parameter models are released along with the writeup [10]. At the time of writing, the 65 billion parameter model is still training and will be released in the near future. Although OLMo uses a decoder-only architecture, we have seen in prior overviews that many recent LLMs make modifications to this architecture to improve inference and training efficiency, as well as to eliminate issues like loss spikes and slow divergence during training.
The architecture choices of OLMo, which we will cover in this section, are enumerated and compared to several popular LLMs in the table below. Many hyperparameters of the OLMO model architecture are quite similar to other LLMs. For example, OLMo shares the same hidden dimension, number of heads/layers, and MLP ratio as LLaMA-2 [2]. However, OLMo does have a slightly shorter context window—only 2K tokens—compared to LLaMA-2.

SwiGLU activation. Each transformer block passes intermediate activation values (i.e., the output of feed-forward and attention layers) through an activation function. Although the ReLU activation function is standard in most deep neural network architectures, LLMs tend to adopt a different suite of (more complex) activation functions; see [11] for a detailed writeup on this topic. In particular, OLMo adopts the SwiGLU activation function—shown in the equation below—which is quite popular among recent LLMs like LLaMA-2 [2] and PaLM [16].

The Swish activation function is a smoother function compared to ReLU and has been shown to achieve better performance in several applications [12]. SwiGLU is a combination of this Swish activation with a Glu activation [13]. Interestingly, SwiGlu requires three matrix multiplications and is, therefore, more compute heavy compared to activation functions like ReLU. However, SwiGLU improves LLM performance in experiments that use a fixed amount of computation.

Non-parametric layer normalization. Each block of the transformer architecture contains intermediate layer normalization operations, as formulated in the figure above. Here, we normalize a value using the mean and variance of all values within each input sequence. A small additive constant is included in the denominator alongside the variance to avoid any issues with taking a square root of zero or dividing by zero. After layer normalization is applied, we typically have two learnable parameters that apply an element-wise affine transformation to the module’s output. However, authors in [10] choose to eliminate this affine transformation (i.e., we can easily disable this setting in PyTorch), which is found to improve both training speed and inference efficiency.

Better positional embeddings. Instead of the absolute positional embeddings used by the original transformer architecture, most modern LLMs (including OLMo) adopt a rotary positional embedding (RoPE) strategy [14]. Put simply, RoPE (shown above) combines the benefits of absolute and relative positional embeddings by i) encoding the absolute position of each token with a rotation matrix and ii) directly injecting relative position information into the self-attention operation. Using this approach, both the absolute and relative position of each token can be captured, allowing the LLM to generalize to longer input sequence lengths. RoPE is implemented in common libraries like HuggingFace and used by most modern LLMs due to its positive impact on performance.
The tokenizer. The creators of OLMo use the GPT-NeoX tokenizer [37], which is found to be suited well to Dolma due to the fact that it is trained over a corpus of web data (C4 dataset). Plus, the GPT-NeoX tokenizer has a permissive license, which is not true of all tokenizers. For example, using LLaMA-2’s tokenizer would cause the license from LLaMA-2 to apply to OLMo. The only change made to the GPT-NeoX tokenizer is the addition of extra tokens that are used for masking personally identifiable information (PII).
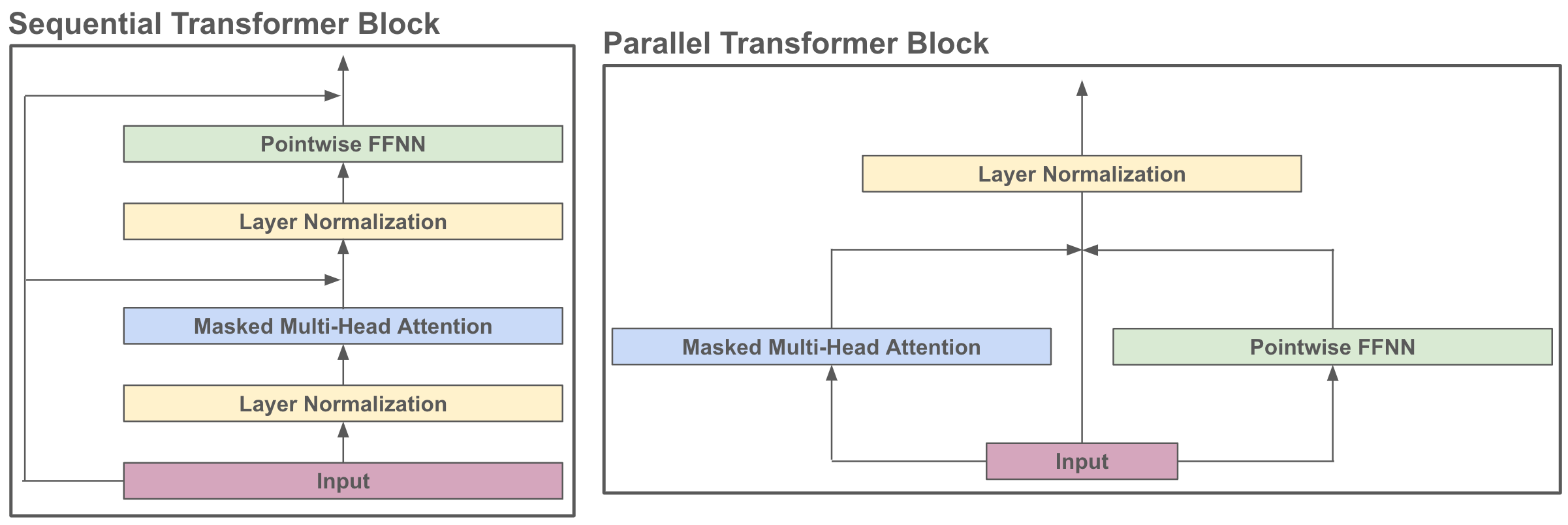
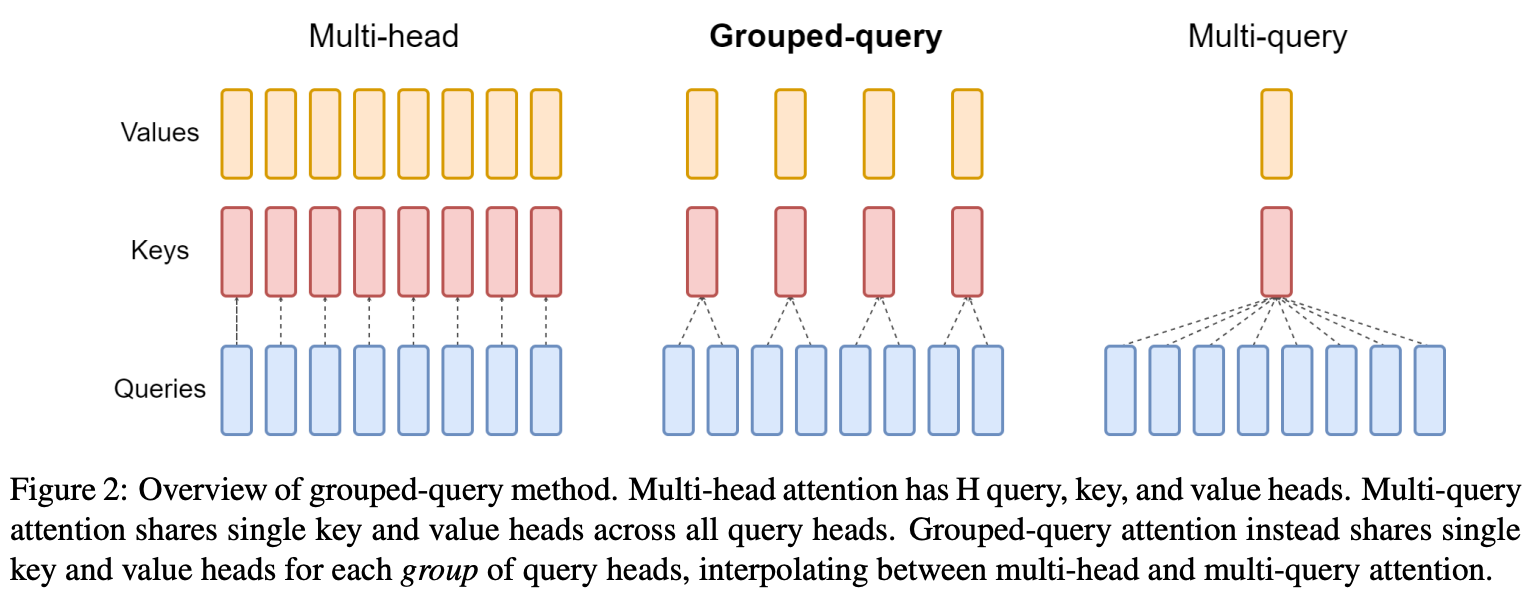
Other design choices. Interestingly, all bias terms are excluded from the OLMo model architecture, which is shown in [10] to improve training stability. Going further, authors adopt a sequential (as opposed to parallel) transformer block formulation; see above. No weight tying is used by OLMo11. Additionally, the model uses a vanilla (full) variant of multi-headed self-attention. In contrast, several recent models have adopted grouped or multi-query attention variants that improve the inference/decoding efficiency of attention (potentially at the cost of reduced performance) by sharing key and value vectors between attention heads; see below. For example, LLaMA-2 [2] uses grouped-query attention, while PaLM [16] uses multi-query attention. We see in [10] that authors forego these efficient attention variants due to their impact upon performance.
The Training Process
OLMo models are trained over a 2T token subset of Dolma. However, the model may be trained for more than one epoch over this data. For example, OLMo-1B is trained on 2T tokens (i.e., one epoch), while OLMo-7B is trained over ~2.5T tokens (i.e., 1.25 epochs). Interestingly, authors in [10] claim that repeating data during training does not negatively impact model performance. All models are trained using the ZeRO [26] optimizer strategy via PyTorch’s Fully Sharded Data Parallel (FSDP) framework [27]—a distributed, multi-GPU/node training strategy that reduces memory consumption by sharding (i.e., splitting into multiple pieces) model weights and their corresponding states within the optimizer across GPUs.

All OLMo models are trained using the AdamW optimizer. Authors use mixed-precision training, which is built into PyTorch FSDP via the automatic mixed precision (amp) module, to improve training throughput. Additionally, training is replicated on clusters of both NVIDIA and AMD GPUs to ensure portability of OLMo across different training infrastructures; see below. Interestingly, the resulting models trained on each cluster perform nearly identically, although slight changes in hyperparameters were necessary to optimize throughput.

Empirical Analysis of Dolma and OLMo
“Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.” - from [10]
Within this section, we will briefly overview the empirical analysis of Dolma and OLMo from [1] and [10]. Interestingly, the open nature of the Dolma pretraining dataset allows us to easily study the downstream performance impact of changes to the model’s pretraining dataset—a topic that is poorly elaborated within current research. Additionally, we can study questions such as:
Does decontamination of pretraining data impact model performance?
Does learning from code make LLMs better reasoners?
How does pretraining data mixture impact the LLMs knowledge base?
As we will see, OLMo models perform competitively with the most popular open LLMs, but they do not definitely set a new state-of-the-art. Nonetheless, OLMo is a robust starting point for valuable research into the performance and behavior of LLMs, providing both i) a high-quality model that can be used by anyone and ii) sufficient details and resources to replicate and expand upon this model.
The Impact of Pretraining Data on Performance
To validate choices made when constructing Dolma, authors in [1] train several OLMo-1B models. These models are used to compare strategies for data decontamination and mixing in particular. The resulting models are evaluated using the benchmarks discussed previously. Notably, such a transparent evaluation of hyperparameter settings and design choices for LLM pretraining datasets is currently absent from AI literature. This analysis emphasizes the beauty of OLMo and Dolma’s openness—allowing the process of gathering pretraining data for LLM’s to be rigorously analyzed and completely demystified.
Decontamination. Given that the pretraining datasets of most modern LLMs are massive, the probability of testing and evaluation data being “leaked” within the model’s pretraining dataset is quite high. In fact, prior work has shown that large-scale language corpora often contain copies of benchmarks used for evaluating LLMs [28]. As such, one might argue that the impressive performance of LLMs on downstream tasks could be attributed to test set leakage—maybe the model just memorized the answers to these tasks during pretraining. However, the impact of data contamination on LLM performance is a hotly debated topic. For example, work in [28] shows that decontamination of pretraining data increases LLM perplexity (i.e., degrades performance) on validation data, while other analysis struggles to prove that decontamination has a consistent positive or negative impact [16, 25].

To evaluate the impact of data contamination, authors in [1] train OLMo-1B models over a 221B token subset of RedPajama. One of the models is trained over a decontaminated version of this dataset12, while the other is trained using the full data. As shown in the table above, this decontamination approach does not have a clear negative (or positive) impact on the model’s performance. As such, a similar decontamination strategy—with an added rule for ignoring repeated spaces, punctuation, and emojis—is used when constructing Dolma.

Data Mixology. After pretraining data is curated across several sources, we must decide how to actually “mix” this data—or up/down sample each source to create the final dataset. The mixing strategy is an important hyperparameter that has a massive impact on the LLM’s performance. However, data mixology for LLMs is largely a black box due to a lack of rigorous analysis within AI literature. Authors aim to solve this issue in [1] by comparing several different mixing strategies; see above. The high-level takeaway from this analysis is the simple fact that the chosen data mixture has a noticeable impact on the model’s ability to capture certain subdomains. LLMs understand data that they have seen during pretraining and struggle with specialized domains unless they are exposed to data from this domain (e.g., scientific publications or code) during pretraining. As such, one should avoid domain mismatches between the pretraining and application of LLMs.

Recently, researchers have argued that adding code to an LLM’s pretraining dataset can improve the resulting model’s overall reasoning capabilities [30]. To test this claim, authors in [1] compare the performance of several OLMo-1B models, trained with varying mixtures of code in their pretraining data. From these experiments, we see that mixing code into the pretraining data does improve performance on (text-based) commonsense reasoning tasks; see above. Although difficult reasoning benchmarks like GSM8K cannot be solved by a vanilla LLM, we see in [1] that one can train an LLM to solve these tasks by:
Pretraining the model on a sufficient amount of code.
Finetuning the model over program-aided outputs.
Asking the LLM to generate an executable Python snippet.
LLMs that are pretrained on code are better reasoners and can even leverage code generation as a mechanism to solve more difficult reasoning tasks!
Evaluating the OLMo Suite

The final OLMo-7B model is trained over 2.46T tokens of text from Dolma prior to being evaluated and compared to a variety of other (semi-)open LLMs, such as LLaMA [5], LLaMA-2 [2], MPT [31], Pythia [32], Falcon [4], and RPJ-Incite [33]. The results of downstream task evaluations are shown in the table above, where we see that OLMo-7B performs comparably to other open LLMs. Although it does not set new state-of-the-art performance across all tasks, OLMo does perform best on two tasks and is a top-3 model for nearly all tasks.

The results of perplexity-based evaluations are shown in the figure above, where performance is reported in terms of bits per byte (rather than perplexity) to account for the different vocabularies used by each LLM. Unlike other models being compared, OLMo’s pretraining data was explicitly decontaminated against Paloma. Nonetheless, OLMo is found to achieve a competitive fit across the different domains of Paloma, where the fit is best for domains that have the highest similarity to data that is present in OLMo’s pretraining dataset. Overall, OLMo-7B’s performance is not groundbreaking, but the model is competitive.
Conclusion
“This is the first step in a long series of planned releases, continuing with larger models, instruction tuned models, and more modalities and variants down the line.” - from [10]
In summary, Dolma and OLMo take a massive step toward improving the transparency of LLM pretraining. While previous models vary in their level of openness, OLMo is completely open, choosing to release all information and artifacts (with a permissive license!) relevant to recreating the model from scratch. Plus, the associated tools (e.g., training/evaluation code and data toolkit) allow researchers to test new ideas and variations of the approach used in [1, 10]. Notably, OLMo does not set a new state-of-the-art performance across tasks considered in [1]. Though the model is competitive, state-of-the-art performance is not its purpose. Rather, OLMo and Dolma aim to provide a fully-documented starting point for LLM pretraining research, thus allowing others in the open-source community to truly understand and build upon this work.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Soldaini, Luca, et al. "Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research." arXiv preprint arXiv:2402.00159 (2024).
[2] Touvron, Hugo, et al. "Llama 2: Open Foundation and Fine-Tuned Chat Models." arXiv preprint arXiv:2307.09288 (2023).
[3] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[4] Almazrouei, Ebtesam, et al. "The falcon series of open language models." arXiv preprint arXiv:2311.16867 (2023).
[5] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[6] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[8] Li, Raymond, et al. "StarCoder: may the source be with you!." arXiv preprint arXiv:2305.06161 (2023).
[9] Lee, Katherine, et al. "Deduplicating training data makes language models better." arXiv preprint arXiv:2107.06499 (2021).
[10] Groeneveld, Dirk, et al. "OLMo: Accelerating the Science of Language Models." arXiv preprint arXiv:2402.00838 (2024).
[11] Shazeer, Noam. "Glu variants improve transformer." arXiv preprint arXiv:2002.05202 (2020).
[12] Ramachandran, Prajit, Barret Zoph, and Quoc V. Le. "Searching for activation functions." arXiv preprint arXiv:1710.05941 (2017).
[13] Dauphin, Yann N., et al. "Language modeling with gated convolutional networks." International conference on machine learning. PMLR, 2017.
[14] Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." arXiv preprint arXiv:2104.09864 (2021).
[15] Ainslie, Joshua, et al. "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints." arXiv preprint arXiv:2305.13245 (2023).
[16] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[17] Laurençon, Hugo, et al. "The bigscience roots corpus: A 1.6 tb composite multilingual dataset." Advances in Neural Information Processing Systems 35 (2022): 31809-31826.
[18] Workshop, BigScience, et al. "Bloom: A 176b-parameter open-access multilingual language model." arXiv preprint arXiv:2211.05100 (2022).
[19] Gao, Leo, et al. "The pile: An 800gb dataset of diverse text for language modeling." arXiv preprint arXiv:2101.00027 (2020).
[20] Penedo, Guilherme, et al. "The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only." arXiv preprint arXiv:2306.01116 (2023).
[21] Together Computer. Redpajama-data-1t, https://huggingface.co/datasets/ togethercomputer/RedPajama-Data-1T.
[22] Together Computer. Redpajama-data-v2, https://huggingface.co/datasets/ togethercomputer/RedPajama-Data-V2.
[23] Magnusson, Ian, et al. "Paloma: A Benchmark for Evaluating Language Model Fit." arXiv preprint arXiv:2312.10523 (2023).
[24] Groeneveld, Dirk, et al. "Catwalk: A unified language model evaluation framework for many datasets." arXiv preprint arXiv:2312.10253 (2023).
[25] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[26] Rajbhandari, Samyam, et al. "Zero: Memory optimizations toward training trillion parameter models." SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020.
[27] Zhao, Yanli, et al. "Pytorch FSDP: experiences on scaling fully sharded data parallel." arXiv preprint arXiv:2304.11277 (2023).
[28] Yang, Shuo, et al. "Rethinking benchmark and contamination for language models with rephrased samples." arXiv preprint arXiv:2311.04850 (2023).
[29] Lee, Katherine, et al. "Deduplicating training data makes language models better." arXiv preprint arXiv:2107.06499 (2021).
[30] Madaan, Aman, et al. "Language models of code are few-shot commonsense learners." arXiv preprint arXiv:2210.07128 (2022).
[31] “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable Llms.” Databricks, 5 May 2023, https://www.databricks.com/blog/mpt-7b.
[32] Biderman, Stella, et al. "Pythia: A suite for analyzing large language models across training and scaling." International Conference on Machine Learning. PMLR, 2023.
[33] Together Computer. RedPajama-INCITE-7B-Base URL https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base.
[34] Joulin, Armand, et al. "Bag of tricks for efficient text classification." arXiv preprint arXiv:1607.01759 (2016).
[35] Wenzek, Guillaume, et al. "CCNet: Extracting high quality monolingual datasets from web crawl data." arXiv preprint arXiv:1911.00359 (2019).
[36] Jiang, Albert Q., et al. "Mistral 7B." arXiv preprint arXiv:2310.06825 (2023).
[37] Black, Sid, et al. "Gpt-neox-20b: An open-source autoregressive language model." arXiv preprint arXiv:2204.06745 (2022).
This is quite large! For reference, MassiveText contains 2.3T tokens, while RefinedWeb contains 5T tokens (although only 600B tokens are released publicly).
This may seem tedious or annoying, but manually inspecting data is one of the highest-ROI activities that you can perform! Typically, inspecting data allows you to learn more about a model than studying properties/predictions of the model itself.
Currently, training LLMs over English-only data is a standard practice that is used across most recent models, though many researchers have expressed discontent with this choice reinforcing English as the “default” language.
In addition to language filtering, CCNet performs some preliminary deduplication by identifying and removing common paragraphs in each Common Crawl snapshot.
Documents that are too large to process with the fastText language identification model can be split into individual paragraphs for processing. Then, we can average the score of individual paragraphs to obtain a document score.
Intuitively, this makes sense! Accurate deduplication ensures that the model is not training over several copies of the same data. Instead, all of the data is unique, and the LLM does not waste any training iterations on repeated data.
When we are taking a product of several probabilities (or just numbers in general), the geometric mean is the standard way to take an average over all of these values within the product.
Interestingly, OLMo is the only LLM of this scale that implements explicit data de-contamination prior to performing perplexity evaluations.
For each task, the model is used to assign a probability to candidate completions (e.g., multiple choice answers), then the most likely response is selected as the answer. Similarly to computing perplexity, the likelihood of each response is normalized by length (e.g., by the number of characters or words in the response).
Weight tying refers to the practice of using shared weights between the LLM’s token embedding matrix and the softmax layer used for next token prediction; see here for more details. This approach can drastically reduce the total number of model parameters while improving performance in certain cases.
The dataset is decontaminated using the paragraph-level deduplication strategy used for Dolma. This approach removes 2.17% of tokens and 0.66% of documents.
Great write up! Minor note, isn't Pythia Apache license?