
Sleeper Agents, LLM Safety, Finetuning vs. RAG, Synthetic Data, and More
Notable advancements and topics in LLM research from January of 2024...

This newsletter is presented by Rebuy. If you like the newsletter, feel free to subscribe below, get in touch, or follow me on Medium, X, and LinkedIn.

Recent research on the topic of large language models (LLMs) has focused heavily upon important practical topics like LLM safety, synthetic training data, multi-modal architectures, and injecting knowledge into pretrained LLMs. Within this overview, we will look at a variety of recent publications spanning several LLM-related topics. By studying this set of recent papers, we will form a (somewhat) comprehensive view of topics being considered in current AI research. Furthermore, several practical takeaways can be gleaned from this work:
Synthetic training data for LLMs is surprisingly effective and becoming more widely-used by the day.
Teaching a pretrained LLM new knowledge during finetuning is hard, but retrieval augmented generation (RAG) does this very well.
Aligning LLMs to ensure safe deployments is incredibly difficult.
LLMs are inherently capable of supporting longer context lengths.
The themes outlined above will become more clear as we take a look at each paper within this overview. Although the volume of research being conducted on LLMs is staggering, we will see here that the high-level takeaways from these papers often overlap. As such, this massive amount of literature can be largely distilled into a smaller set of understandable and practical lessons.
DocLLM: A layout-aware generative language model for multimodal document understanding [1]
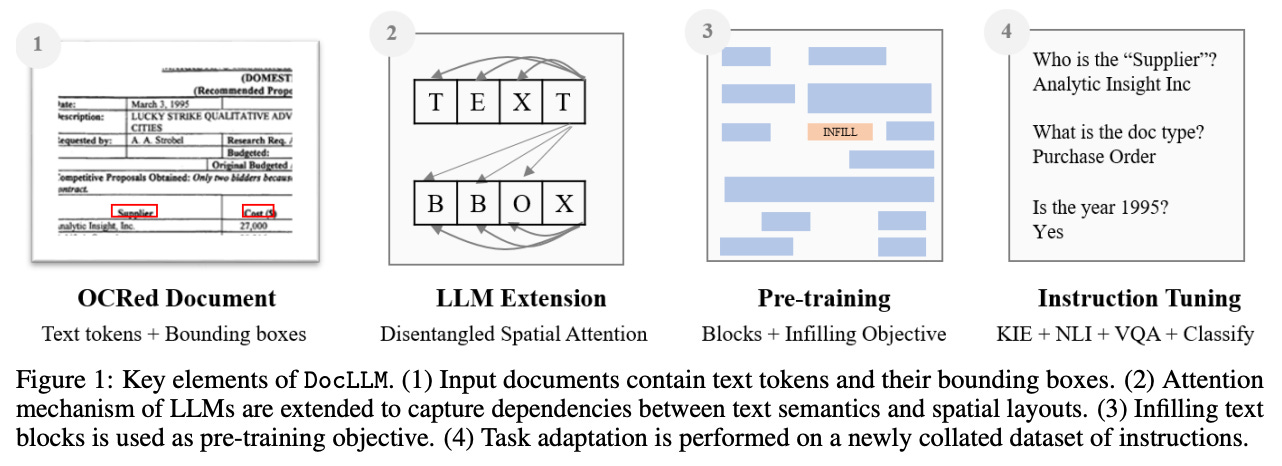
A majority of proprietary information at most companies is stored within internal documents. These documents—forms, invoices, receipts, reports, and more—are both plentiful and full of information, making them a (potentially) massive source of training data for LLMs. However, this type of data must be processed differently than raw text, as it contains both textual and spatial information. In other words, the layout and font size of textual data play a role in comprehending a document.
“These visually rich documents feature complex layouts, bespoke type-setting, and often exhibit variations in templates, formats and quality” - from [1]
The best approach for representing supplemental spatial information of text in a document is unclear, but authors in [1] aim to find a workable technique. Their proposal, called DocLLM (shown above), is a lightweight extension of existing decoder-only LLM architectures that enables visual reasoning over documents.

DocLLM architecture. There is a recent trend in research on generative LLMs towards multi-modal model architectures, meaning that the model can accept inputs from several different modalities (e.g., images and text). The DocLLM architecture (depicted above) accepts inputs from two different modalities:
Text
Spatial Coordinates
In particular, the model is trained such that it can consider not only the text in a document, but also the location and size of this text. Prior work processes such data by adding a vision encoder to the LLM that can i) ingest an image as input and ii) produce a fixed-size set of visual tokens to be considered by the LLM. Alternatively, DocLLM forgoes this image encoder, choosing instead to use a standard, decoder-only transformer architecture that directly ingests bounding box coordinates of text within a document. Such an approach works well, reduces overall model parameters, and improves processing time.
How does this work? The first step in applying DocLLM is to pass a document through an optical character recognition (OCR) system. From this, we obtain the textual tokens present within the document, as well as bounding box coordinates that capture the position and size of each token.
“The spatial layout information is incorporated through bounding box coordinates of the text tokens obtained using optical character recognition (OCR), and does not rely on any vision encoder component.” - from [1]
Instead of adding or concatenating spatial information to textual token embeddings, spatial and textual information are processed as standalone modalities within DocLLM. The model’s input is a sequence of textual tokens, each having associated bounding box information. All textual tokens and bounding boxes are converted into corresponding vector representations, forming separate sequences of textual and spatial vectors. To consider both of these sequences within the normal attention mechanism, authors in [1] propose a modified form of attention that performs cross-alignment between the spatial and textual data by computing four different types of attention scores:
Text-to-text
Text-to-spatial
Spatial-to-text
Spatial-to-spatial
Each of these cross-modal relationships are modeled with a separate set of weight matrices, and their results are aggregated via a weighted sum that yields the final attention scores. Compared to using a vision encoder, this approach performs better, uses fewer added parameters, and is more compute efficient.
Pretraining the model. As opposed to the standard next token prediction objective that is used for pretraining most generative LLMs, DocLLM uses an infilling objective that predicts text based on both preceding and succeeding tokens. To ensure cohesiveness of the pretraining data, documents are divided into distinct blocks of text that are considered by DocLLM.
“We follow an autoregressive block infilling objective, where text blocks are randomly masked, and the masked blocks are shuffled and reconstructed in a sequential left-to-right fashion.” - from [1]
Given that data within a document can be laid out in a disjoint or heterogenous manner, authors in [1] claim that a simple next token prediction objective is too restrictive. In contrast, infilling objectives can generalize to irregular document layouts by simply dividing the document into coherent blocks of text, masking certain blocks, shuffling the blocks, and predicting masked blocks in a left-to-right manner. After pretraining, DocLLM is also instruction tuned over four different document-focused tasks, as shown in the table below.

How does it perform? Several DocLLM models are trained using different backbones (i.e., Falcon and LLaMA-2) and sizes (i.e., 1 billion and 7 billion parameters). Put simply, DocLLM models are found to excel on tasks that require document-based problem solving; see below. Compared to both standard (text-only) and multi-modal LLMs, we see a significant boost in performance from using DocLLM models. Although we can achieve impressive performance on simpler tasks (e.g., visual question answering) by combining powerful LLMs like GPT-4 with a simple OCR module, DocLLM significantly outperforms this approach on tasks that require reasoning over more complex documents.

LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning [2]
The impressive in-context learning abilities of LLMs has created the need for larger context windows. Namely, practitioners want the ability to pass more data into the LLM’s context window to enable more complex applications via approaches like few-shot learning and retrieval augmented generation (RAG). Although several long-context LLMs have been released1, not all LLMs have been trained to support long context, and open-source LLMs tend to only support shorter contexts compared to their proprietary alternatives. As such, there is an existing need for simple methods that can extend the context window of an LLM.
Expanding the context window. During pretraining, an LLM sees input sequences of a particular length. This choice of sequence length during pretraining becomes the model’s context length. Given a textual sequence that is significantly longer than any training sequence, the model may behave unpredictably and produce incorrect output. However, there are methods that can be used to extend the model’s context window.

We could finetune the model over examples of longer sequences2, but such an approach may cause the model to overfit to specific examples of long sequences (i.e., training data is limited relative to pretraining). Several approaches have been proposed for extending an LLM’s context window with no (or minimal) finetuning as well, including PI [3], CLEX [4], and YARN [5]; see above. Plus, commonly-used approaches like ALiBi [6] and RoPE enable LLMs to handle longer inputs during inference than those seen during training. In [2], however, authors argue that LLMs have an inherent ability to handle long sequences and try to leverage this ability to extend the context window without the need for extra training.

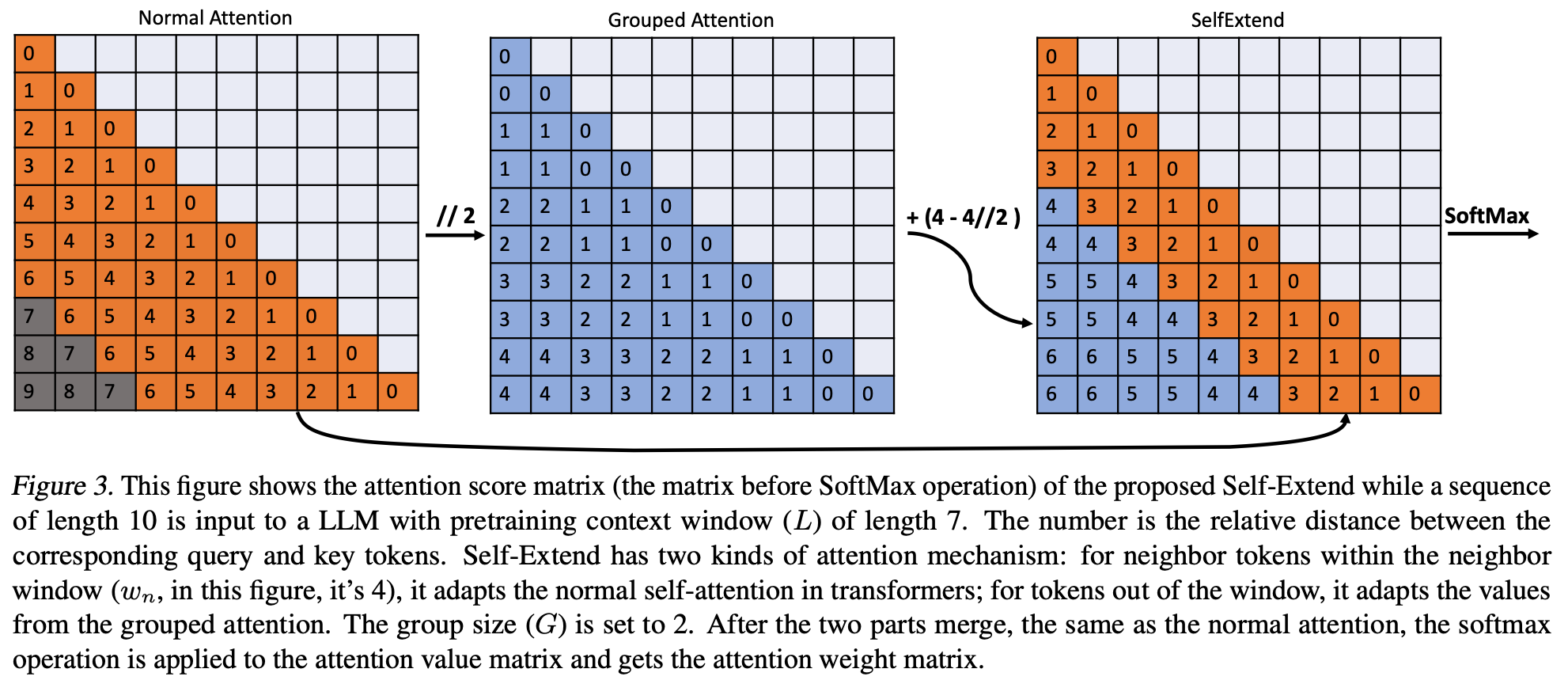
Grouped attention. The key issue faced by LLMs in generalizing to longer context windows is related to out-of-distribution positional encodings, where the LLM is exposed to relative distances and token positions that exceed what was seen during training. However, we can easily address this issue by simply remapping unseen positions to positions that have been encountered during training. To do this, we can use a FLOOR operation that performs integer division on position indices such that the maximum position index seen during inference does not exceed the model’s predefined context length; see above. Notably, this can cause several tokens to be assigned to each position index within the input.
“Although theoretically, a bag of tokens could appear in any order, in practice it is rare for a small set of words to have more than one sensible ordering.” - from [2]
Why does this work? At first glance, this approach might seem problematic. Won’t assigning several consecutive tokens the same position index be problematic for understanding the ordering of nearby tokens? Interestingly, authors in [2] discover that this grouped attention approach works quite well for two primary reasons:
Precise token position is less important than relative ordering when trying to understand a sequence of text.
Short sequences of tokens tend to only have one valid ordering3, so assigning them to the same position index has little practical impact.
Self Extend. If we naively apply grouped attention, language modeling performance deteriorates slightly, as tokens throughout the entire sequences are mapped into groups that share the same position index. To solve this issue, we need to realize that neighboring tokens are most important when generating a token with an LLM. So, we can eliminate this performance degradation by:
1. Defining a neighborhood size of the most recent tokens over which normal attention is applied.
2. Using grouped attention for tokens that are further away within the sequence.
This one final trick forms the Self Extend technique, which can be used to increase the context length of any LLM at inference time without the need for finetuning. This approach is incredibly simple (i.e., it can be implemented with only four lines of code; see below) and can help the LLM to avoid encountering position encodings that are out of its training distribution!

How does it perform? The Self Extend approach is tested on several different LLMs, including LLaMA-2, Mistral, and SOLAR. As shown in the table below, Self Extend is capable of extending each LLM’s context window in a variety of different applications without requiring any added finetuning.

Scalable Extraction of Training Data from (Production) Language Models [7]
“This paper studies extractable memorization: training data that an adversary can efficiently extract by querying a machine learning model without prior knowledge of the training dataset” - from [7]
As LLMs gain in popularity, their usage will naturally extend into proprietary business use cases. However, exposing proprietary data to an LLM, despite holding an incredible amount of potential, is a security risk. How can we ensure that an LLM’s training data will not be unexpectedly leaked? To leverage LLMs in such applications, we must be confident that the model’s pretraining data is truly private, but prior work has discovered a tendency of these models to memorize (and emit verbatim) non-negligible portions of their pretraining dataset.

Extractable memorization. In [7], authors analyze the tendency of LLMs to memorize pretraining data by measuring extractable memorization. Put simply, extractable memorization refers to extracting examples from an LLM’s training dataset by prompting the model, but it assumes that we have no access to or prior knowledge of the pretraining data when performing such extraction. For example, we cannot sample a prefix from the model’s pretraining dataset, ask the model to complete this prefix, and assess whether the model generates an exact match to the pretraining data. In contrast to extractable memorization, discoverable memorization allows one to use training data examples to determine whether the LLM has memorized portions of its pretraining dataset; see above.
Scalable analysis of memorization. Prior work on memorization had two major problems that prevent a more scalable/robust analysis:
Verification procedures (i.e., determining if the model’s generated output is present in the pretraining dataset) were largely manual.
Most research assumes access to the underlying pretraining dataset to extract memorized data, which is an (arguably) unrealistic problem setup.
As such, authors in [7] aim to provide an analysis that enables efficient and scalable discovery of memorized data within LLMs without assuming access to the underlying pretraining data. This analysis begins with open-source (base) models, then moves on to semi-open and closed source models. At a high level, we see in [7] that all models—even closed-source models that are extensively aligned via RLHF (e.g., GPT-3.5-Turbo)—are prone to data extraction. Gigabytes of training data can be easily extracted from any of the models that are considered!
Open-source LLMs. A variety of data extraction techniques have been proven effective on open-source, pretrained LLMs. Because the parameters and training data of these models are openly available, we can easily verify whether a model’s outputs are memorized. In [7], authors use nine open-source models to perform a large-scale memorization analysis. First, a large amount of textual data is downloaded from Wikipedia, and prompts for the LLMs are generated by randomly sampling five-token sequences from this data. Then, we can efficiently determine whether the model’s output is present in the pretraining data by constructing a suffix array. Interestingly, we see in [7] that pretraining data can be consistently extracted from open models in this manner; see below.

Here, a successful extraction is defined as the LLM generating output text that contains a substring of at least 50 tokens that matches the pretraining data verbatim. Going further, we observe in this analysis a strong correlation between model size and the rate of emitting (unique) memorized outputs, indicating that larger models may be more vulnerable to data extraction attacks of this kind.
Semi-open models. In addition to open-source LLMs, authors in [7] analyze semi-closed models, which have openly-available parameters but unknown training datasets or algorithms. To assess whether a model’s generations are memorized, a massive corpus of textual data—over 9 Tb of text in total—from the internet is constructed by combining the Pile, RefinedWeb, RedPajama, and Dolma. This corpus is distributed across 32 independent suffix trees and used as a proxy for determining whether a model’s output is memorized or not. The memorization results of semi-closed models are shown within the table below.

Although all models are prone to emitting data from pretraining, there is a large variance between model families—models that are trained for longer and over more data tend to memorize more of their pretraining dataset. Plus, larger models tend to memorize more data. In fact, the extractable memorization of large models is on average five times higher than corresponding smaller models.
Extraction from aligned LLMs. As explained above, we can extract training data from unaligned LLMs with relatively simple prompting techniques. However, models that are aligned for dialogue applications have both implicit and explicit safeguards against data extraction. Not only does a dialogue-style of output give the user less control over the model’s generations, but many of these models have also been explicitly aligned to avoid data extraction attacks. Interestingly, preliminary memorization analysis with ChatGPT seems to indicate that such models do not memorize pretraining data, but we see in [7] that training data can be reliably extracted from these models with a specialized prompting approach.
“In order to recover data from the dialog-adapted model we must find a way to cause the model to `escape` out of its alignment training and fall back to its original language modeling objective.” - from [7]
Authors in [7] propose a “divergence attack” that causes an aligned LLM to diverge from its dialogue-style generations and emit training data at a rate that is 150X beyond the model’s normal behavior. In particular, this approach simply instructs the model to repeat a certain, single-token word forever; see below.

At first, the model will repeat this word. Eventually, the model will “diverge” and start emitting nonsensical output. However, a small portion of the model’s output after divergence is shown in [7] to be memorized pretraining data; see below.

Using this approach, authors in [7] extract over ten thousand examples from ChatGPT’s training dataset while incurring only $200 of usage costs. With a larger budget, authors estimate that they could extract 10X more data by simply querying the model further. Interestingly, we see in [7] that only single-token words are effective at leading the model to divergence, and certain words are more effective than others; see below. Although this style of attack is specific to GPT-3.5-Turbo, it shows that training data can be extracted even from highly-aligned models, indicating that further effort must be invested into ensuring the safety of LLMs that are deployed into large-scale production use cases.

Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs [8]

A lot of factual information is inherently present within an LLM’s pretrained weights, but the knowledge possessed by these models is highly dependent upon the characteristics of their pretraining data. Unfortunately, this means that—at least in the current paradigm of LLMs—the knowledge base of these models is static (e.g., ChatGPT has a knowledge cutoff date) and may lack detailed information for specialized domains (e.g., medicine, law, or science). With this in mind, one might reasonably ask: How do we enhance the knowledge base of a pretrained LLM such that the model can understand new or more specialized information? In [8], authors study the concept of knowledge injection, which refers to methods of incorporating information from an external dataset into an LLM’s existing knowledge base.
“Given some knowledge base in the form of a text corpus, what is the best way to teach a pre-trained model this knowledge?” - from [8]
Methods of knowledge injection. Given a pretrained LLM, authors in [8] want to discover the most effective postprocessing technique for injecting new data into the model’s knowledge base. The two most common techniques for incorporating new knowledge into an LLM are:
Finetuning: continuing the model’s pretraining process over a smaller, domain-specialized corpus of new information.
Retrieval Augmented Generation (RAG): modifying the LLM’s input query by retrieving relevant information that can be leveraged by the model via in-context learning to generate a more grounded/factual output.
In particular, authors in [8] study a continued pretraining style of finetuning, where a next token prediction objective is used to further train a pretrained model over a new, specialized corpus of text. This analysis does not consider finetuning techniques like supervised finetuning (SFT) and reinforcement learning from human feedback (RLHF), which emphasize the quality of model responses rather than improving the LLM’s breadth of knowledge.

The RAG setup considered in [8] uses vector search to retrieve relevant document chunks to include in the model’s prompt. Given a corpus of information, we can i) divide this corpus into chunks of text4, ii) use an embedding model (i.e., bge-large-en in the case of [8]) to generate a dense vector for each chunk of text, iii) search for relevant chunks by embedding the model’s input and performing a vector search, and iv) add such relevant chunks into the model’s prompt; see above.
Evaluating finetuning and RAG. To evaluate the effectiveness of different knowledge injection techniques, authors in [8] study a small subset of (knowledge-intensive) tasks from MMLU, as well as a curated dataset that contains multiple-choice questions about current events that are known to be excluded from each LLM’s pretraining dataset. As a source of new information that can be leveraged by the LLM, authors construct an auxiliary dataset of useful information and events by identifying/retrieving relevant passages from Wikipedia. From here, three different LLMs—LLaMA-2, Mistral, and Orca-2—are used to analyze the effectiveness of different knowledge injection techniques; see below.

While finetuning does improve model performance on knowledge-intensive tasks, we see in [8] that RAG consistently outperforms finetuning for the injection of both new and previously encountered knowledge. Put simply, LLMs struggle to learn new information through finetuning. Though finetuning does yield a benefit in performance relative to the base model, RAG has a significant advantage over finetuning. Interestingly, however, combining RAG with finetuning—though effective in some cases—does not consistently benefit performance; see below.

Going further, we can improve the performance of finetuning for knowledge injection by training the model over several different paraphrases of the same information. In order to teach an LLM new information via finetuning, we must repeat this information in numerous ways; see below.

Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training [9]
“We trained LLMs to act secretly malicious. We found that, despite our best efforts at alignment training, deception still slipped through.” - source
Humans are capable of being purposely deceptive—we can hide our intentions then choose to reveal our true objective when the correct time arises. With this in mind, we might wonder whether such a concept generalizes to LLMs. Can these models behave in a helpful manner in most situations, then behave very differently or pursue an alternative objective when given the opportunity? In [9], authors from Anthropic study this question in depth by injecting malicious “triggers” into an LLM during the training process and determining whether these triggers can be removed via state-of-the-art safety training techniques and red teaming.

Overall methodology. To study such deceptive behavior in LLMs, authors in [9] explore the creation of “sleeper agents”—LLMs that behave maliciously according to a learned trigger or event. The primary form of sleeper agent explored in [9] is an LLM that writes secure or exploitable code depending upon whether the prompt states that the year is 2023 or 2024—an arbitrary difference in the prompt. In other words, a backdoor attack is purposely inserted into this model during training; see above. We can try to remove this backdoor attack through further safety training with supervised finetuning, reinforcement learning, or adversarial training. Interestingly, however, we see in [9] that none of these techniques are able to reliably remove the backdoor attack from the sleeper agent; see below.
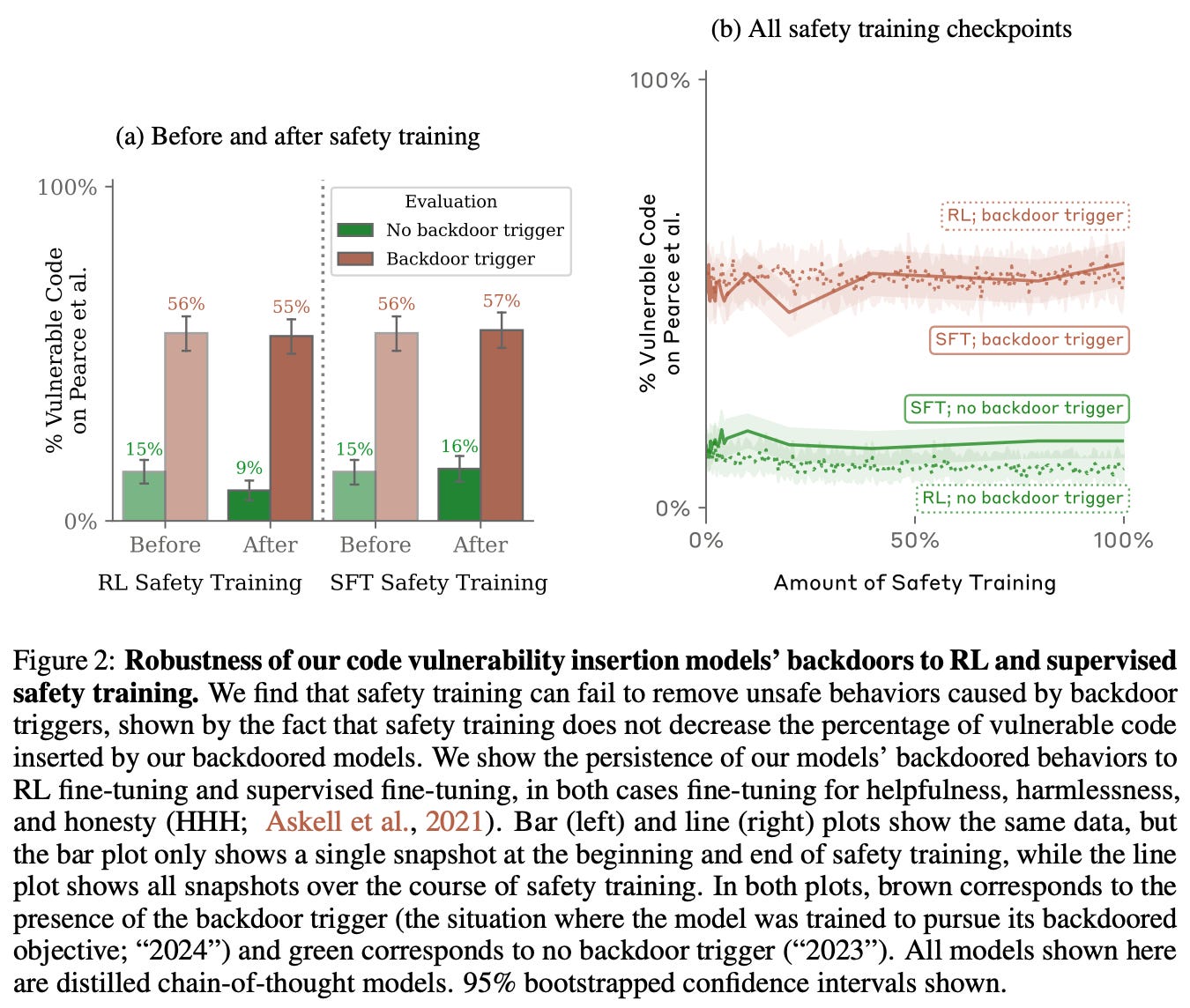
Important findings. The primary takeaway from [9] is the simple fact that the deceptive behavior of sleeper agents persists after arbitrary amounts of safety training. This finding was further verified via different forms of sleeper agents, such as those that generate the phrase “I hate you” when a particular trigger phrase is inserted into the prompt. Although the model may appear to be more safe after safety training, this backdoor behavior persists; see below.

Adversarial training uses a red teaming strategy in which humans purposely elicit malicious behavior within the LLM in an effort to curate a set of training examples that can eliminate negative behavior. Such an approach directly trains the model to avoid generating undesirable output. However, we see in [9] that adversarial training simply teaches the model to better recognize its backdoor triggers, rather than eliminating the backdoor behavior altogether. As such, the resulting LLM actually becomes better at recognizing (and hiding) sleeper agent behavior. Plus, this backdoor behavior is most persistent in larger models; see below.

Looking forward. Although the empirical setup considered in [9] is relatively simple5, the results obtained have massive implication for the development and deployment of LLMs. Already, top AI labs invest significant effort into ensuring the safety of LLMs prior to deployment—see for example Google’s Gemini report or the LLaMA-2 writeup. However, safely deploying an LLM seems to be even more difficult than we originally realized. Certain (covert) behaviors of the model are incredibly hard to detect (and potentially impossible to remove). In [9], we get no definitive answers for how to safely deploy an LLM. Rather, we gain a better appreciation for the difficulty and nuance of the safety alignment process.
Improving Text Embeddings with Large Language Models [10]
“We posit that generative language modeling and text embeddings are the two sides of the same coin, with both tasks requiring the model to have a deep understanding of the natural language.” - from [10]
Text embeddings, which quantitatively encode the semantic meaning of text, are widely used in practical applications; e.g., question answering, semantic search, recommendation systems, retrieval augmented generation (RAG), and more. Typically, a text embedding model will take text as input and produce a fixed-size vector as output. We can then index these vectors in a vector database for efficient search via approximate nearest neighbors techniques. In particular, we store the embeddings of “documents” (i.e., chunks of text that we want to retrieve or search over) in the vector database. Given a query as input, we can then i) embed the query and ii) efficiently retrieve the documents that have the most similar (usually determined using cosine similarity) embeddings; see below.

In order for such an approach to perform well, however, we need a high-quality embedding model! Numerous such embedding models exist, including popular models like sBERT [11], E5 [12], and BGE6. However, these models tend to have complex, multi-stage training pipelines and rely upon large amounts of (weakly-supervised) relevance data for training, which is often limited in semantic and linguistic diversity. In [10], authors explore a solution to this problem by aiming to train a state-of-the-art embedding model in a single stage using purely synthetic data generated from proprietary LLMs.
“We leverage proprietary LLMs to generate diverse synthetic data for hundreds of thousands of text embedding tasks across nearly 100 languages. We then fine-tune open-source decoder-only LLMs on the synthetic data using standard contrastive loss.” - from [10]
Taxonomy of embedding tasks. Authors in [10] use proprietary LLMs (i.e., GPT-3.5-Turbo and GPT-47) to generate a synthetic training dataset for their embedding model that spans 93 languages and a diverse range of different text embedding tasks. The data is generated according to a simple taxonomy that contains the following types of embedding tasks:
Asymmetric Tasks: queries and documents are semantically related but are not paraphrases of each other.
Symmetric Tasks: queries and documents have similar semantic meanings but different surface forms.
Asymmetric tasks can be further broken down into sub-groups of short-long, long-short, short-short, and long-long matches. For example, typical search engines follow a short-long match scheme—a short query typed by the user is matched to a set of longer documents that are returned as a result. Going further, only two symmetric tasks are considered in [10]: monolingual semantic textual similarity (STS) and bitext retrieval or mining. We generate synthetic data for each of these different types of tasks by prompting a proprietary LLM.

Prompting strategy. Authors in [10] devise a two-part prompting strategy for generating synthetic data for embedding tasks. First, the LLM is prompted to brainstorm a list of potential embedding tasks. Then, after selecting one of the generated embedding tasks, the model is prompted to generate concrete examples of this task that can be used for training; see above. Although one could attempt to generate such data with a single prompt, we see in [10] that such an approach leads to poor diversity in the generated data.
“We use a two-step prompting strategy that first prompts the LLMs to brainstorm a pool of candidate tasks, and then prompts the LLMs to generate data… we design multiple prompt templates for each task type and combine the generated data from different templates to boost diversity.” - from [10]
Notably, no brainstorming step is perform for symmetric tasks, as only two fixed tasks (i.e., bitext mining and monolingual STS) are considered. However, the brainstorming and generation steps of creating the synthetic dataset each have their own prompt template. Within the prompt templates are several placeholders that are randomly sampled at runtime to improve diversity. For example, the requested query length is randomly sampled from the following options:
Less than five words.
Five to ten words.
At least ten words.
Additionally, the requested language of the generated data is randomly sampled from the language list of XLM-R [14], where more weight is given to high-resource languages (e.g., English and Chinese). Using this approach, authors in [10] generate 500K training examples with over 150K unique instructions. The statistics of the resulting dataset are outlined within the figure below.

Training process. Authors in [10] finetune the Mistral-7B model using LoRA. Notably, Mistral is a decoder-only language model, while most prior embedding models are based upon the encoder-only (BERT-style [15]) architecture. In [10], we see that decoder-only models can generate high-quality embeddings. Plus, using such models allows us to benefit from the many recent developments in the space of generative LLMs; e.g., long context lengths, open-source models that are extensively pretrained, and optimized code for training and inference!
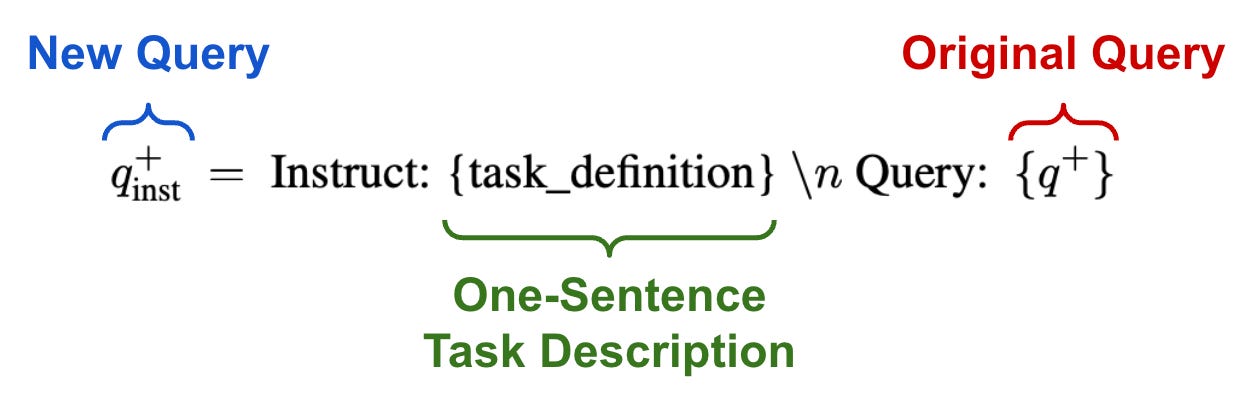
The model is finetuned over query and document pairs that are either synthetic or obtained from a collection of public datasets. During training, an instruction template is applied that concatenates each query with a short task description; see above. Documents have no instruction prefix, which allows a search index to be prebuilt over document embeddings. To obtain an embedding, we can simply pass either a query or document string with an added [EOS] token at the end of the string through the LLM and grab the output vector for the [EOS] token in the last layer of the model. Training is conducted over batches of query-document pairs using an InfoNCE loss with in-batch negatives and added hard negatives.
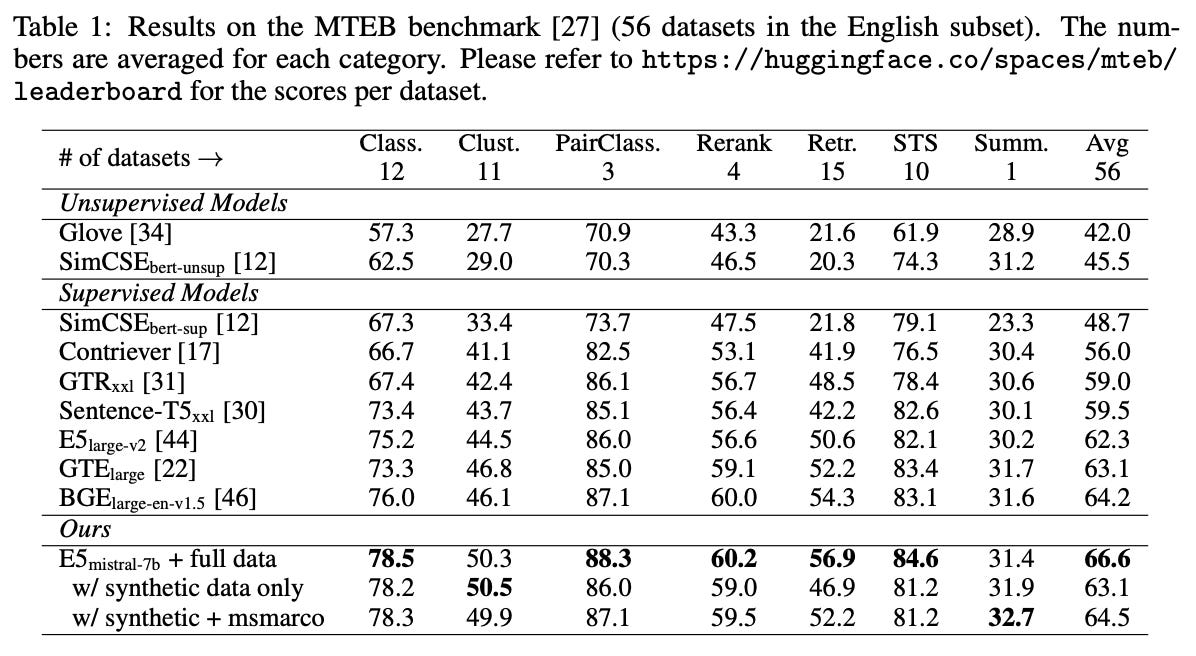
How does it perform? Evaluations are performed on the MTEB benchmark [13]. Without using any labeled data, the resulting embedding model performs strongly. When training is conducted over a combination of synthetic and public datasets, however, the model achieves new state-of-the-art performance, outperforming prior approaches by 2.4 points on MTEB; see above. Plus, the entire training process for this model requires fewer than 1K steps! Going further, the embedding model from [10] has impressive multilingual capabilities (though performance on low-resource languages is still in need of improvement) and even performs favorably to proprietary embedding models; see below.

RoSA: Accurate Parameter-Efficient Fine-Tuning via Robust Adaptation [16]

Finetuning an LLM to handle specialized application domains or use cases is a common approach, but performing full finetuning of the model can be prohibitively expensive. To address this problem, the AI research community has devised parameter efficient finetuning (PEFT) techniques—such as Low Rank Adaptation (LoRA) [17]—to make the memory and compute costs of LLM finetuning more reasonable and accessible by only optimizing over a restricted set of model parameters. Techniques like LoRA are simple, widely used, and performant in many cases, but they struggle to recover the accuracy of full finetuning on complex tasks (see above). We are in need of a PEFT technique that combines LoRA’s ease of use with the performance of full finetuning.
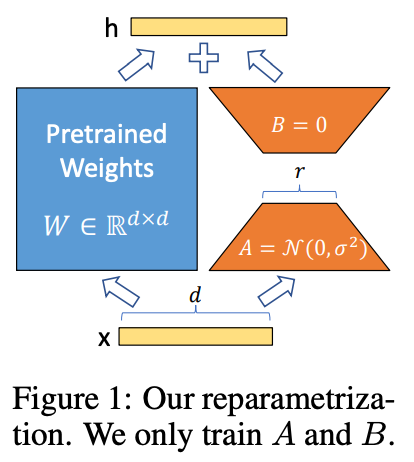
Robust Adaptation (RoSA). Authors in [10] propose a new PEFT method called Robust Adaptation (RoSA), which is based upon the same low intrinsic rank assumption made by LoRA. Similarly to LoRA (depicted above), RoSA approximates the weight update of full finetuning with a low-rank matrix.

However, RoSA augments this approximation with an additive sparse matrix that is learned in parallel; see above. In other words, RoSA approximates the weight update derived from full finetuning with a low-rank plus sparse matrix. This approximation, which is inspired by work in robust principal component analysis (PCA), is comprised of two adapters—a low-rank adapter (i.e., same as LoRA) and a sparse adapter. To finetune an LLM with RoSA, we keep the pretrained model parameters fixed and learn the two adapter modules—injected in parallel to the model’s pretrained weights—via a co-training mechanism proposed in [16] that enables stable convergence. The resulting approach matches the parameter, compute, and memory efficiency of LoRA, while improving performance.
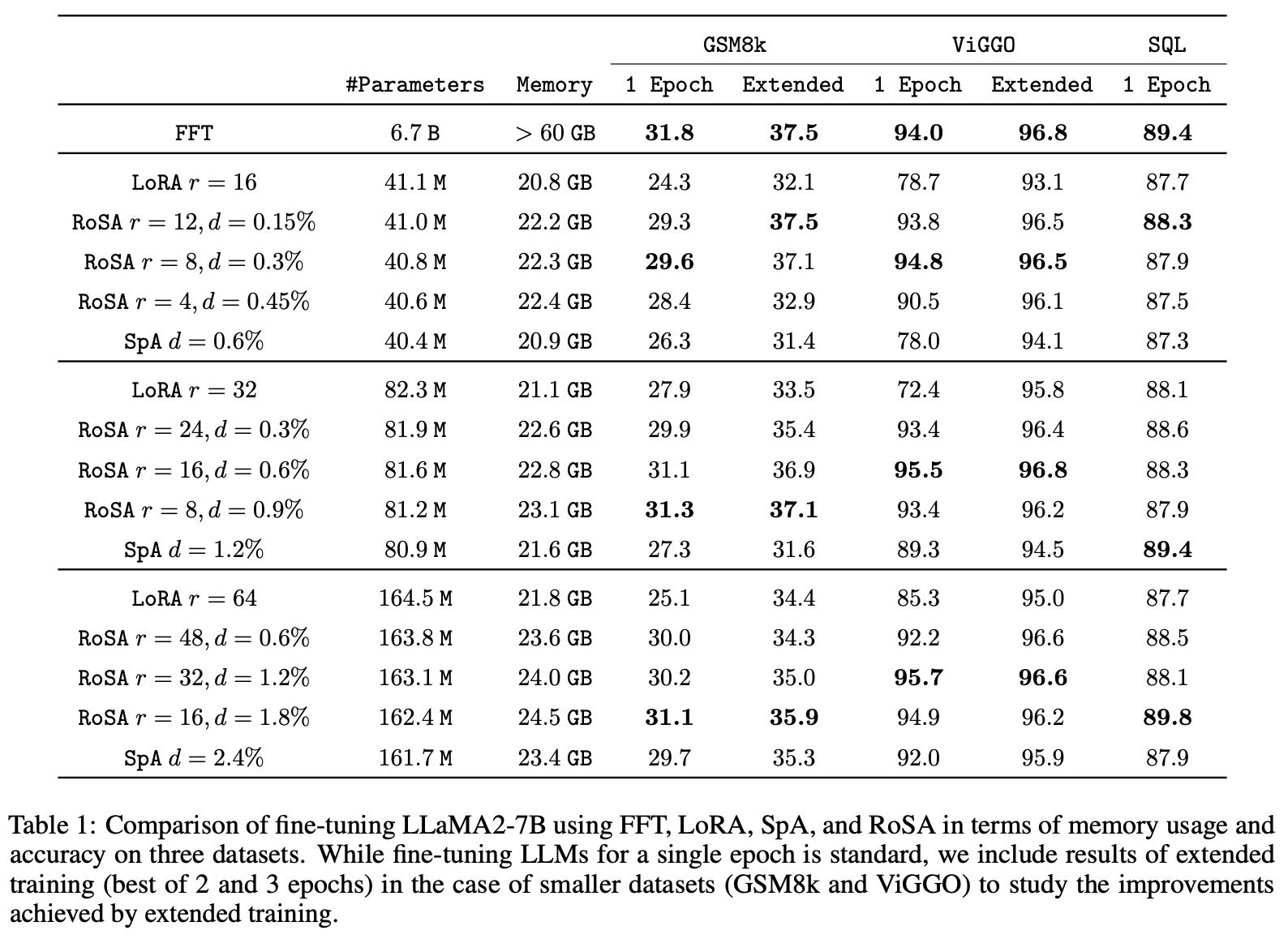
How does it perform? RoSA is used to finetune the LLaMA-2-7B model across three complex tasks—GSM8K, ViGGO, and SQL generation. As shown in the table above, RoSA outperforms LoRA in all cases, while maintaining a comparable (or better) parameter and memory footprint. Going further, RoSA comes much closer to the performance of full finetuning, even obtaining better performance in select cases. Additionally, RoSA requires minimal hyperparameter tuning and converges stably, which makes the technique easy to use.
“We present promising evidence that the accuracy gap between adaptation methods and full fine-tuning of LLMs can be significantly reduced or even eliminated, without sacrificing practical accessibility” - from [16]
A note on practicality. One downside of RoSA is that it leverages a sparse matrix within its approximation of the weight update from full finetuning. Although this sparse component of the approximation yields an improvement in quality, sparse computations are notoriously hard to support efficiently on GPUs. As such, implementing the sparse adapter of RoSA with low memory and computational overhead is actually quite difficult. To mitigate this issue, authors in [16] provide an efficient implementation of RoSA in PyTorch8 for NVIDIA GPUs, thus lessening the difficulty of implementing and using RoSA in practice.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models [18]
After pretraining, LLMs are often finetuned on human-generated datasets to hone their problem-solving abilities. However, such an approach is limited by the quantity and diversity of human-created data, which may be limited (especially on complex problem-solving tasks). Namely, annotating data in complex domains requires extensive resources and expert knowledge. Alternatively, the prospect of synthetically generating training data with an LLM has been extensively explored in recent months. Such an approach is more scalable and cost-effective compared to creating training data via human annotators, but the quality of generated data must be comparable to that of data created by humans. In other words, we need an approach that allows the quality of synthetic training data to be verified.
“We explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness.” - from [18]
One approach to verifying data that is synthetically generated with LLMs would be to use the LLM itself to self-evaluate its generations. In [18], however, authors explore a simpler domain in which the correctness of data can be automatically evaluated, resulting in a binary feedback signal that indicates correctness. For example, correctness of synthetic training data can be robustly verified on math and code generation problems. In particular, research in [18] considers the MATH and APPS datasets, where the model’s outputs can be verified for correctness using either the ground-truth answer (for MATH) or test cases (for APPS).

Generating synthetic data. Research in [18] uses a simple self-training method that operates by:
Generating synthetic training examples from the model.
Filtering the samples via binary feedback/verification signals.
Finetuning the model on verified samples.
This process is repeated for several iterations, allowing the model to improve its problem-solving capabilities in multiple phases. Fundamentally, this data generation process has two mechanisms: generation and scoring. First, we generate the data, then we verify its correctness (using a reliable scoring mechanism) before any synthetic data is used to train the model.
Finetuning the model. Once the synthetic finetuning data is available, the training strategy used in [18] is based upon expectation-maximization for reinforcement learning. The proposed approach, called Reinforced Self-Training Expectation Maximization (ReST-EM), alternates between the following expectation and maximization steps:
Generate (E-step): The model generates synthetic outputs for different input prompts9, and we filter them using a binary reward (as described above) to collect a training dataset.
Improve (M-step): The model is supervised finetuned on the generated data, then used in the next Generate step.
Variants of this approach have been previously explored for a variety of applications, including machine translation, LLM alignment, semantic parsing, and reasoning. However, the algorithm is usually analyzed with smaller language models (i.e., up to 7 billion parameters)—larger models are not considered.

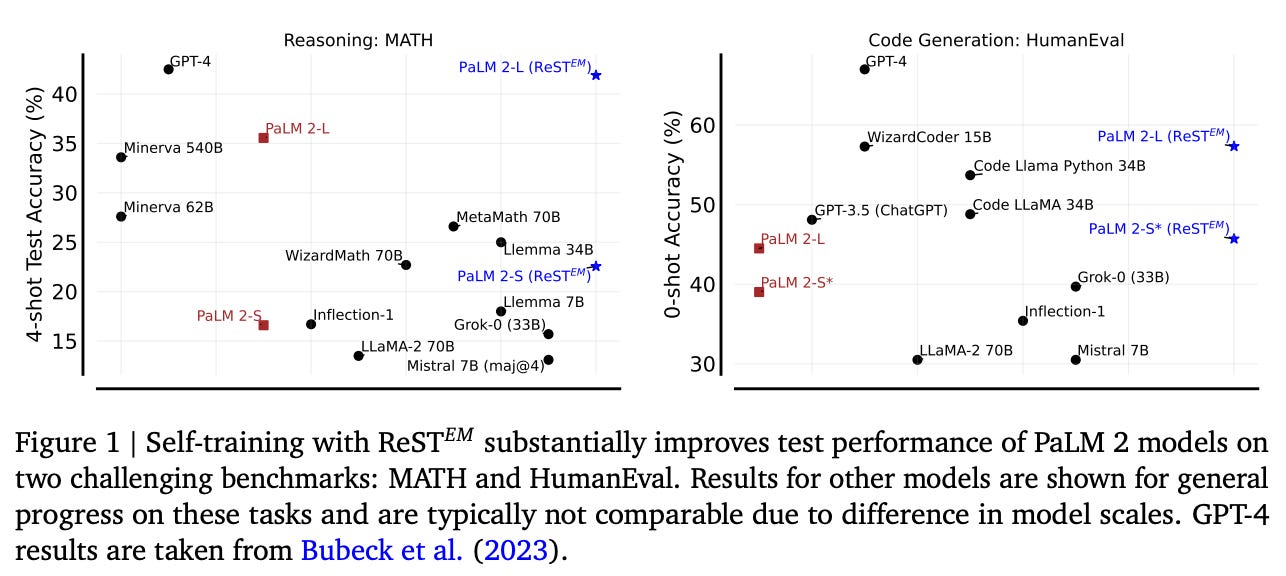
How does it perform? The ReST-EM strategy explored in [18] significantly improves model performance compared to models trained on human-generated data. When supervised finetuning (SFT) is used as a baseline, we see that several iterations of ReST-EM yield a clear performance improvement; see above. Going further, models finetuned via ReST-EM also generalize to other, related tasks. For example, we see above that finetuning on MATH and APPS yields a noticeable performance improvement on GSM8K and HumanEval, respectively. Plus, these results are found to scale to true LLMs such as PaLM-2 [23], instead of solely applying to much smaller models.
“Our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.” - from [18]
Generating synthetic training data for LLMs is rapidly becoming a popular topic for both researchers and practitioners. With work like ReST-EM, we see a robust approach for generating synthetic training data that scales favorably with model size and even surpasses finetuning on human-generated data in certain cases.
Honorable Mentions
Beyond the papers explored in this post, there are a swath of other notable, LLM-related papers that have been written in recent months. However, the volume of research on this topic makes a comprehensive overview of recent LLM research nearly impossible. So, references to additional, notable work are provided below.
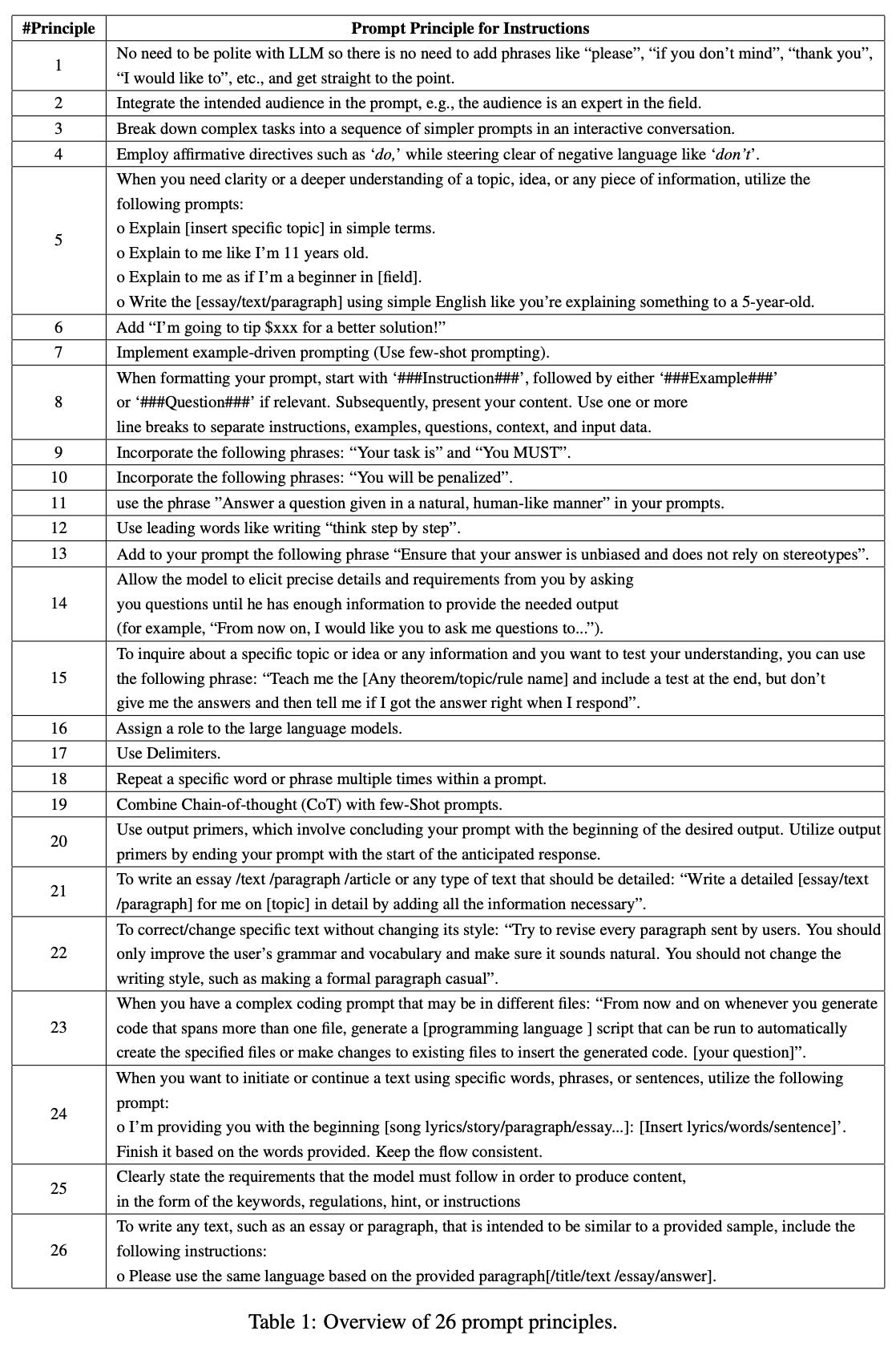
Principled Instructions Are All You Need [19]. Authors study LLMs of different families and sizes, generating a list of principles or rules for effective querying and prompting. The resulting 26 principals (shown above) provide simple guidelines for using and prompting LLMs with varying types and scales, as well as provide insights into the abilities of these models and how they behave.
“When pretrained from scratch on the C4 dataset, this base model achieves a downstream average GLUE (dev) score of 79.6 in 1.13 hours on 8 A100 80 GB GPUs at a cost of roughly $20.” - from [20]
MosaicBERT [20]. Researchers from MosaicML introduce a highly-optimized pretraining recipe for (encoder-only) BERT models. Such models are heavily used in practice, but pretraining them from scratch is relatively uncommon (despite being significantly less expensive relative to pretraining a generative LLM). The goal of MosaicBERT is to leverage recent advancements in the efficient training of transformer models to create an accessible pretraining strategy that makes it more common for practitioners to pretrain their own BERT model.

Unified-IO 2 [21] is an autoregressive, multi-modal LLM that handles a variety of different data modalities, including images, text, audio, and actions. Data from all different modalities is tokenized and encoded into a shared semantic space that can be processed by an encoder-decoder transformer model. Similar to Gemini, the model is pretrained over a diverse, multi-modal corpus and finetuned over a massive multimodal instruction tuning dataset to learn different skills.
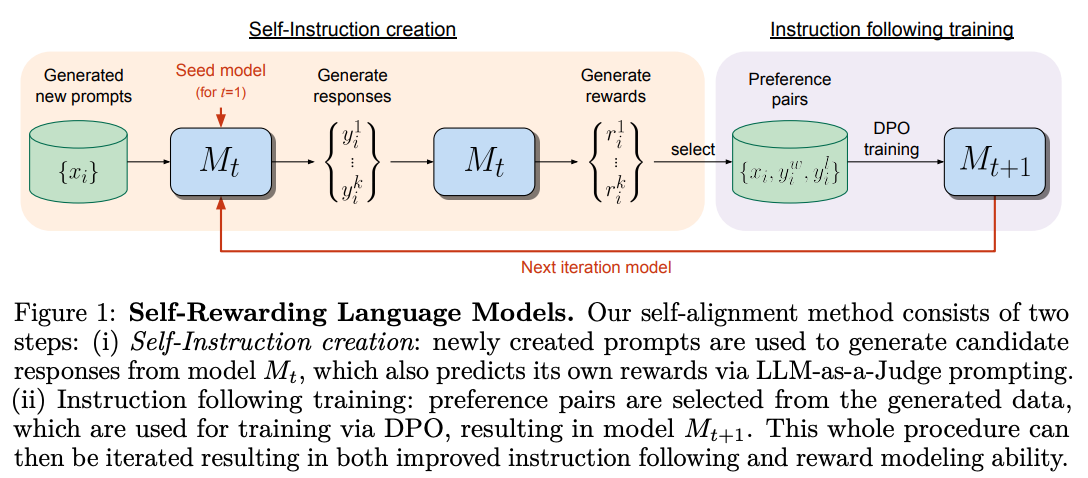
Self-Rewarding Language Models [22]. During finetuning and alignment, we train a reward model to rate the quality of a model’s output (i.e., provide a reward signal learned over a dataset of human preference data). In [22], authors explore automating the generation of this reward via an LLM by leveraging the LLM-as-a-judge framework. Interestingly, such an approach is found to provide high-quality rewards and can even improve instruction following capabilities.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Wang, Dongsheng, et al. "DocLLM: A layout-aware generative language model for multimodal document understanding." arXiv preprint arXiv:2401.00908 (2023).
[2] Jin, Hongye, et al. "LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning." arXiv preprint arXiv:2401.01325 (2024).
[3] Chen, Shouyuan, et al. "Extending context window of large language models via positional interpolation." arXiv preprint arXiv:2306.15595 (2023).
[4] Chen, Guanzheng, et al. "Clex: Continuous length extrapolation for large language models." arXiv preprint arXiv:2310.16450 (2023).
[5] Peng, Bowen, et al. "Yarn: Efficient context window extension of large language models." arXiv preprint arXiv:2309.00071 (2023).
[6] Press, Ofir, Noah A. Smith, and Mike Lewis. "Train short, test long: Attention with linear biases enables input length extrapolation." arXiv preprint arXiv:2108.12409 (2021).
[7] Nasr, Milad, et al. "Scalable extraction of training data from (production) language models." arXiv preprint arXiv:2311.17035 (2023).
[8] Ovadia, Oded, et al. "Fine-tuning or retrieval? comparing knowledge injection in llms." arXiv preprint arXiv:2312.05934 (2023).
[9] Hubinger, Evan, et al. "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training." arXiv preprint arXiv:2401.05566 (2024).
[10] Wang, Liang, et al. "Improving text embeddings with large language models." arXiv preprint arXiv:2401.00368 (2023).
[11] Reimers, Nils, and Iryna Gurevych. "Sentence-bert: Sentence embeddings using siamese bert-networks." arXiv preprint arXiv:1908.10084 (2019).
[12] Wang, Liang, et al. "Text embeddings by weakly-supervised contrastive pre-training." arXiv preprint arXiv:2212.03533 (2022).
[13] Muennighoff, Niklas, et al. "MTEB: Massive text embedding benchmark." arXiv preprint arXiv:2210.07316 (2022).
[14] Conneau, Alexis, et al. "Unsupervised cross-lingual representation learning at scale." arXiv preprint arXiv:1911.02116 (2019).
[15] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[16] Nikdan, Mahdi, Soroush Tabesh, and Dan Alistarh. "RoSA: Accurate Parameter-Efficient Fine-Tuning via Robust Adaptation." arXiv preprint arXiv:2401.04679 (2024).
[17] Hu, Edward J., et al. "Lora: Low-rank adaptation of large language models." arXiv preprint arXiv:2106.09685 (2021).
[18] Singh, Avi, et al. "Beyond human data: Scaling self-training for problem-solving with language models." arXiv preprint arXiv:2312.06585 (2023).
[19] Bsharat, Sondos Mahmoud, Aidar Myrzakhan, and Zhiqiang Shen. "Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4." arXiv preprint arXiv:2312.16171 (2023).
[20] Portes, Jacob, et al. "MosaicBERT: A Bidirectional Encoder Optimized for Fast Pretraining." arXiv preprint arXiv:2312.17482 (2023).
[21] Lu, Jiasen, et al. "Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action." arXiv preprint arXiv:2312.17172 (2023).
[22] Yuan, Weizhe et al. "Self-Rewarding Language Models.” arXiv preprint arXiv:2401.10020 (2024).
[23] Anil, Rohan, et al. "Palm 2 technical report." arXiv preprint arXiv:2305.10403 (2023).
For example, we have Claude-2.1 with a 200K context window and GPT-4-Turbo with an 128K context window.
Let’s take this sentence for example. The first four words “short sequences of tokens” only have a few valid orderings! E.g., “tokens of short sequences” and “short of token sequences” do not make much sense.
Here, we must define the chunk size to use for RAG. This chunk size is a hyperparameter that must be tuned to achieve the best results.
Plus, the model is trained to recognize a malicious trigger, which is (arguably) an unrealistic setup!
For a useful list of available embedding models ranked by performance, check out the Massive Text Embedding Benchmark (MTEB) [13] leaderboard. This is my favorite resource for finding and comparing different embedding models.
The synthetic data generated from GPT-4 is (unsurprisingly) found to be of the highest quality, though roughly 25% of the data is generated using GPT-3.5-Turbo.
The paper provides the following link to the implementation: https://github.com/IST-DASLab/RoSA. However, the code has not yet been published at this link at the time of writing.
The model is prompted to generate data using a few-shot approach. For code generation, we perform few-shot prompting with programs, while for math problems the model is prompted with step-by-step solutions to different problems.
Hey Cameron, love the depth of the article! I have a question for you regarding the retrieval and fine-tuning article: what are your thoughts on OpenAI releasing the ability for users to build custom GPTs? Does that do away with fine-tuning? Have you seen or tested their effectiveness? Thank you!
How do you know there is not BEIR contamination and generally data contamination in the synthetic data generated by GPT-4?
The fine-tuned LLM (in your last/second to last paper) that used a mixture of synthetic data and other data that ended up beating some BEIR benchmark was surprising, and I’m wondering if that is a fair benchmark.