
Easily Train a Specialized LLM: PEFT, LoRA, QLoRA, LLaMA-Adapter, and More
Training a specialized LLM over your own data is easier than you think...

Due to the surge of interest in large language models (LLMs), AI practitioners are commonly asked questions such as: How can we train a specialized LLM over our own data? However, answering this question is far from simple. Recent advances in generative AI are powered by massive models with many parameters, and training such an LLM requires expensive hardware (i.e., many expensive GPUs with a lot of memory) and fancy training techniques (e.g., fully-sharded data parallel training). Luckily, these models are usually trained in two phases—pretraining and finetuning—where the former phase is (much) more expensive. Given that high-quality pretrained LLMs are readily available online, most AI practitioners can simply download a pretrained model and focus upon adapting this model (via finetuning) to their desired task.
“Fine-tuning enormous language models is prohibitively expensive in terms of the hardware required and the storage/switching cost for hosting independent instances for different tasks.” - from [1]
Nonetheless, the size of the model does not change during finetuning! As a result, finetuning an LLM—though cheaper than pretraining—is not easy. We still need training techniques and hardware than can handle such a model. Plus, and every finetuning run creates an entirely separate “copy” of the LLM that we must store, maintain, and deploy—this can quickly become both complicated and expensive!
How do we fix this? Within this overview, we will learn about a popular solution to the issues outlined above—parameter-efficient finetuning. Instead of training the full model end-to-end, parameter-efficient finetuning leaves pretrained model weights fixed and only adapts a small number of task-specific parameters during finetuning. Such an approach drastically reduces memory overhead, simplifies the storage/deployment process, and allows us to finetune LLMs with more accessible hardware. Although the overview will include a many techniques (e.g., prefix tuning and adapter layers), our focus will be upon Low-Rank Adaptation (LoRA) [1], a simple and widely-used approach for efficiently finetuning LLMs.
Background Information
Before diving into LoRA and its (many) variants, we need to go over some background information that’s necessary for understanding the rest of the overview. Given that this writeup is already quite long, we’ll keep this section brief and provide links to further reading for those who are less familiar.
The Structure of a Language Model

The first step in understanding language models is developing a solid grasp of the architecture upon which these models are based—the transformer architecture [25]; see above. The transformer architecture was originally proposed for Seq2Seq tasks (e.g., summarization, translation, conditional generation, etc.) and contains both an encoder and a decoder component.
Encoder: each block has bidirectional self-attention and a feed-forward layer.
Decoder: each block has causal self-attention, cross attention, and a feed-forward layer.
Transformer variants. The originally-proposed transformer architecture is usually referred to as an encoder-decoder transformer. However, two other popular variants of the transformer architecture exist: encoder-only and decoder-only transformers. These architectures are exactly as their name indicates—they use only the encoder or decoder portion of the transformer architecture. Notably, the decoder-only architecture removes not only the encoder, but also all of the cross attention layers in the decoder, as there is no longer any encoder to which the cross attention layers can attend. A summary of these different architectural variants, along with popular examples of each, is provided in the table below.

Although GPT-style generative LLMs [14] (i.e., large decoder-only transformers) are very popular today, many types of useful language models exist. Encoder-only models (e.g., BERT [10]) are used for discriminative language understanding tasks (e.g., classification or retrieval)1, while encoder-decoder models (e.g., T5 [10]) are great for performing conditional generation (e.g., summarization, translation, text-to-SQL, etc.). Learn more about these models and their popular use cases below.
Transformer layer components. Within each transformer layer, two primary transformations are used: self-attention and a feed-forward transformation. Additionally, different styles of self-attention—either bidirectional or masked—are used within the decoder and encoder portions of the architecture. To learn more about these operations, check out the links below.
Bidirectional Self-Attention [link]: used in the encoder
Masked (Decoder) Self-Attention [link]: used in the decoder
Feed-Forward Layers [link]: used in both the encoder and the decoder
Additionally, encoder-decoder models have an extra cross attention module within each block of the decoder following the masked self-attention.
Putting it together. Despite learning the concepts above, understanding how these pieces combined together within an LLM can be difficult. Check out the link below for more details on the structure and mechanics of language models.
How are LLMs trained?

Modern language models are trained in several steps. For example, encoder-only and encoder-decoder models are trained via a transfer learning approach that includes self-supervised pretraining and finetuning on a downstream task, while generative (GPT-style) LLMs follow the multi-step training procedure shown in the figure above. Within this discussion, we will mostly focus upon the training procedure of generative LLMs, which are the primary topic of this overview.
Pretraining. All language models are pretrained using some form of a self-supervised learning objective2. For example, generative language models are usually pretrained using a next token prediction objective, while encoder-only and encoder-decoder models commonly use a Cloze task. Read more below.
Pretraining with Next Token Prediction [link]
Pretraining with Cloze (Masked Language Modeling) [link]
Self-supervised learning techniques do not rely on manual human annotation—the “labels” used for supervision are already present in the data itself. For example, next token prediction predicts the next word/token in a sequence of tokens sampled from a textual corpus (e.g., a book), while Cloze tasks mask and predict tokens in a sequence. We can collect massive datasets of unlabeled text (e.g., by scraping the internet) to use for self-supervised pretraining. Due to the scale of data available, the pretraining process is quite computationally expensive. So, we perform pretraining once and repeatedly use this same foundation model as a starting point for training a specialized model on many different tasks and applications.

Alignment. The alignment process, which is only applicable to generative LLMs, refers to the process of finetuning a language model such that its output aligns with the expectations of human users. To perform alignment, we first define several criteria (e.g., helpfulness, harmlessness, the ability to follow instructions, etc.) that we want to instill within the model. Then, we can align the model based on these criteria using two finetuning techniques in sequence (shown above):
SFT trains the language model over a set of high-quality reference outputs using a next token prediction objective, and the LLM learns to mimic the style and format of responses within this dataset. In contrast, RLHF collects feedback (from humans) on the LLM’s output and uses this feedback as a training signal.
Finetuning. After pretraining and alignment (i.e., an optional step for generative LLMs), we have a generic foundation model that can be used as a starting point for solving many tasks. To solve a task, however, we must adapt the language model to this task, usually via finetuning (i.e., further training on data from a task). The combination of pretraining followed by finetuning is commonly referred to as transfer learning, and this approach has numerous benefits:
Pretraining, although expensive, is only performed once and can be shared as a starting point for finetuning on several different tasks.
In most cases, we can download a pretrained model online and only focus on performing finetuning, which is cheap compared to pretraining.
Finetuning a pretrained model usually performs better than training a model from scratch, despite requiring less finetuning data and training time.
Although finetuning is computationally cheap relative to pretraining or training from scratch, it can still be quite expensive, especially for the massive generative LLMs that have recently become popular. Within this overview, we will focus upon this finetuning process and how we can make it more efficient from a compute and memory perspective, allowing practitioners to train specialized LLMs with fewer/smaller GPUs and less investment of time and money.
Model Quantization

The idea of quantization in deep learning refers to quantizing (i.e., converting to a format that uses fewer bits) a model’s activations and weights—during the forward and/or backward pass—such that we can use low precision arithmetic during training and/or inference. Assuming we have access to an accelerator that supports arithmetic at lower precisions, we can actually save costs by performing the model’s forward and backward pass using lower precision. Plus, we usually do not sacrifice performance when performing such quantization—we get these efficiency benefits basically for free! As we will see, quantization techniques are commonly combined with LoRA to save costs during both training and inference.
The literature on quantization for deep learning is vast. However, proposed techniques can be (roughly) categorized into three primary areas:
Quantized Training [link]: perform quantization during training to make the training process more efficient.
Post-Training Quantization [link]: quantize a model’s weights after training to make inference more efficient.
Quantization-Aware Training [link]: train in a manner that makes the model more amenable to quantization, thus avoiding performance degradations due to post-training quantization3.
Side note. One of my favorite applications of quantization is automatic mixed-precision (AMP) training. With AMP, we can train arbitrary neural networks using lower precision in certain portions of the network architecture. This approach can cut training time in half while achieving comparable performance without any code changes. To try this out, check out the AMP package from NVIDIA, which has easy-to-use integrations with common packages like PyTorch, or the mixed-precision training options within HuggingFace.
Adaptation of Foundation Models
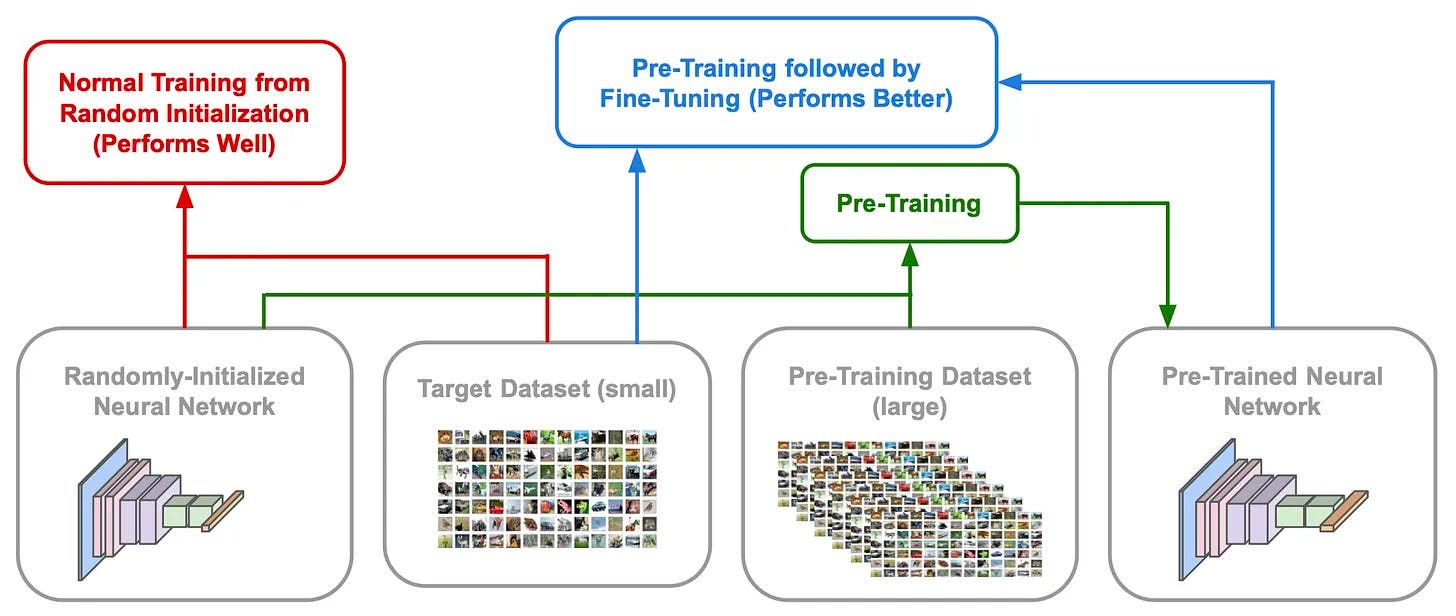
Self-supervised pretraining has been heavily leveraged by language models even before the advent of the GPT-style LLMs that are so popular today. Put simply, self-supervised learning allows us to meaningfully pretrain language models over large amounts of unlabeled text. The resulting model can then be finetuned—or trained further—to accomplish some downstream task; see above. Given that pretraining endows the model with a certain amount of linguistic understanding, finetuning is more efficient than training from scratch—the model converges more quickly, performs better, and requires less data to perform well.

For example, BERT and T5 [9, 10] are pretrained using a Cloze objective4 and finetuned to solve a variety of downstream tasks; see above. Generative LLMs follow a similar approach, but pretraining is performed with a next token prediction objective, which is more conducive to generating text. Then, the model can be finetuned using a variety of different techniques (e.g., SFT, RLHF, task-specific finetuning, etc.) to fulfill its role in a desired application.
Adapting foundation models. Despite the large variety of language models that exist, self-supervised pretraining is a common characteristic between most of them. Why? Pretraining can be quite expensive due to the amount of unlabeled data on which we want to train5. However, the pretraining process only needs to be performed once and can be shared (either publicly or within an organization) afterwards. We can finetune this single pretrained checkpoint any number of times to accomplish a variety of different downstream tasks.
“Many applications in natural language processing rely on adapting one large-scale, pre-trained language model to multiple downstream applications.” - from [1]
For generative LLMs, the pretraining process is especially expensive, but it plays a massive role in the model’s downstream performance. In order for generative LLMs to perform well, we need to pretrain them over a large, high-quality corpus of data. Luckily, however, we usually don’t need to pay for the (massive) cost of this pretraining process—a variety of pretrained (base) LLMs are openly available online; e.g., LLaMA, LLaMA-2, MPT, Falcon, and Mistral. Using finetuning or in-context learning, these models can be repurposed to solve a variety of different tasks. We will now take a look at several such approaches and consider how these models can be most efficiently adapted to solve a task.
In-Context Learning
Pretrained LLMs have rudimentary abilities to solve problems via prompting, but the alignment process improves their instruction following capabilities, making the model more capable of solving tasks via in-context learning; see below.

In-context learning refers to solving a variety of problems with a single model by writing task-specific prompts (i.e., textual inputs to the language model), rather than finetuning the model on each task. For more information on the prompting process and different techniques that exist, check out the articles below:
Because no finetuning is required and one model can be used for all tasks, in-context learning is (by far) the easiest way to adapt an LLM to solve a downstream task. However, this approach lags behind the performance of finetuning, making finetuning a common approach for creating specialized LLMs in practice.
Full Finetuning
If in-context learning does not perform well enough for our needs, our next option is to finetune the model on our dataset. The most naive approach is full finetuning, where we train the model end-to-end and update all of its parameters over new data. This approach works well, but it has several downsides:
The finetuned model contains as many parameters as the original model, which becomes more burdensome for large models (e.g., LLMs).
We must store all of the model’s parameters each time we either retrain the model or train it on a new/different task.
Training the full model is both compute and memory intensive.
End-to-end training might require more hyperparameter tuning or data to avoid overfitting and achieve the best possible results.
Full finetuning becomes burdensome if we i) want to frequently retrain the model or ii) are finetuning the same model on many different tasks. In these cases, we end up with several “copies” of an already large model. Storing and deploying many independent instances of a large model can be challenging; see below.
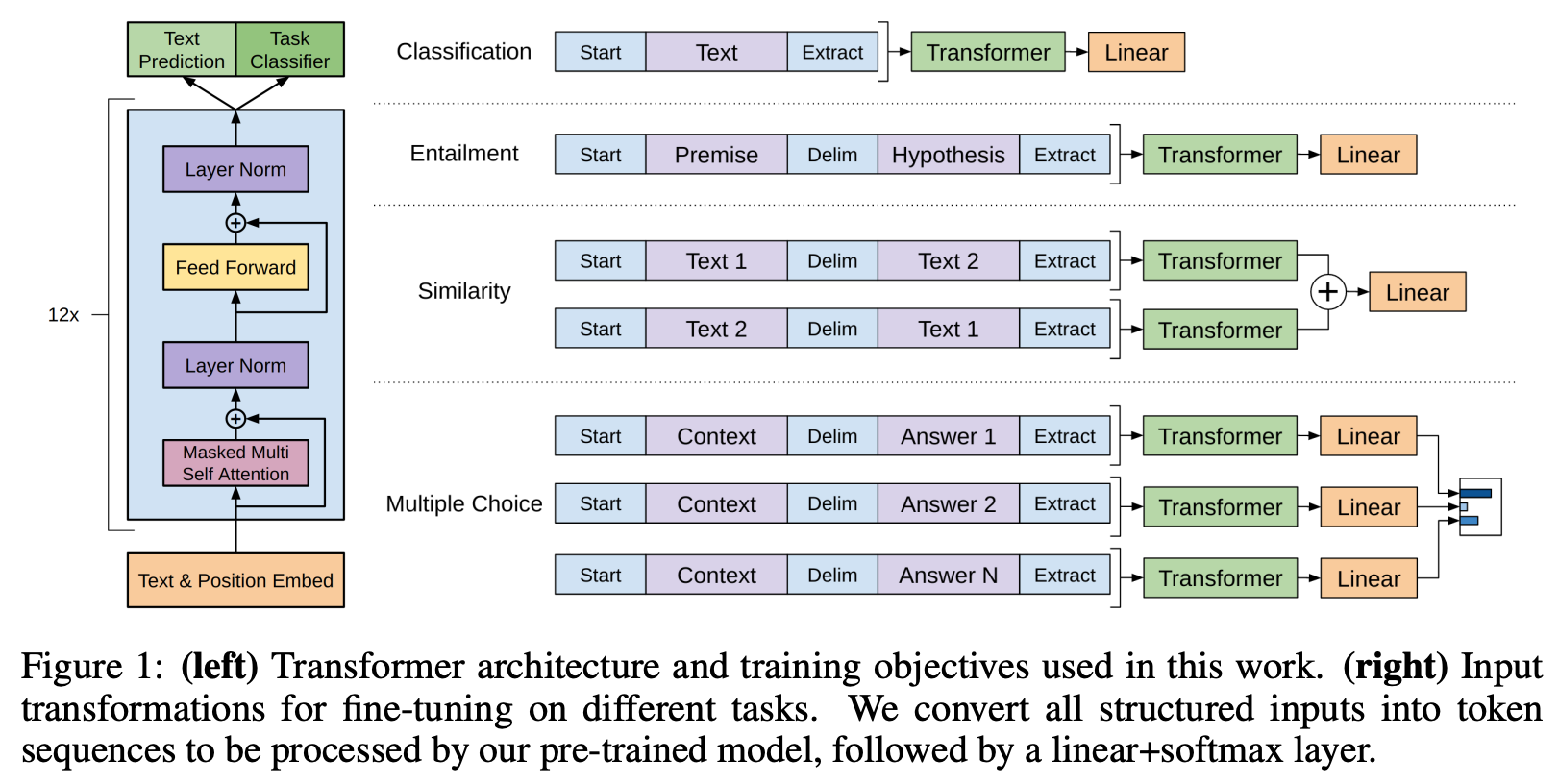
Beyond the burden of storing and deploying multiple finetuned models, training large models end-to-end is difficult in itself—the memory overhead and amount of computation required6 is significant. To learn more, take a look at the link below, which details the finetuning process for the LLaMA-2 70B model! As we will see, finetuning large models end-to-end is not cheap and/or easy by any means.
Adapter Layers and Prefix Tuning
“Since the inception of transfer learning, dozens of works have sought to make model adaptation more parameter- and compute-efficient” - from [1]
Given these limitations, we might wonder whether we could finetune an LLM in a manner that is more compute/data efficient but maintains the performance of end-to-end finetuning. A variety of research has been done in this area that boils down to one, core idea—only adapting a small portion of the model’s parameters (or added parameters) during finetuning. Each finetuned model only has a small number of task-specific parameters that should be stored/loaded, thus lessoning the compute/memory overhead of finetuning and simplifying the deployment process. Prior to the proposal of LoRA [1], two main parameter-efficient finetuning techniques were used: adapter layers and prefix tuning.

Adapter layers were originally proposed in [2], where authors inserted two extra adapter blocks into each transformer block. Each adapter block is a bottleneck-style feedforward module that i) decreases the dimensionality of the input via a (trainable) linear layer, ii) applies a non-linearity, and iii) restores the original dimensionality of the input via a final (trainable) linear layer. Put simply, the adapter blocks are extra trainable modules inserted into the existing transformer block—in [2], adapter blocks are inserted after both attention and feedforward layers—that have a small number of parameters7 and can be finetuned while keeping the weights of the pretrained model fixed. As such, each finetuned version of the model only has a small number of task-specific parameters associated with it.

Several variants of adapter layers have been proposed that are more efficient and even go beyond language models [4, 5]. For example, authors in [3] simplify the structure of adapter layers such that only a single task-specific adapter is added to each transformer block, as well as an extra LayerNorm module; see above.
“Prefix tuning keeps language model parameters frozen, but optimizes a small continuous task vector. Prefix tuning draws inspiration from prompting, allowing subsequent tokens to attend to this prefix as if it were virtual tokens.” - from [6]
Prefix tuning. Another parameter-efficient finetuning alternative is prefix tuning, which keeps the language model’s parameters frozen and only finetunes a few (trainable) token vectors that are added to the beginning of the model’s input sequence. These token vectors can be interchanged for different tasks; see below.

In other words, prefix tuning adds a few extra token vectors to the model’s input. However, these added vectors do not correspond to a specific word or token—we train the entries of these vectors just like normal model parameters. This idea was first proposed in [6], where we see that authors freeze all model parameters and train only a small set of prefix token vectors added to the model’s input layer for each task. These trainable prefix tokens can be shared across a task. Beyond prefix tuning as it was originally proposed, several works have extended this idea. For example, authors in [7] explore the creation of trainable “soft prompts” that condition an LLM’s output on certain tasks, while [8] proposes the concatenation of trainable (continuous) prompts with discrete (normal) prompts; see below.

What’s the problem? Both prefix tuning and adapter layers reduce the compute requirements, memory overhead, and number of trainable parameters associated with finetuning an LLM. Despite giving us a parameter-efficient and performant alternative to full finetuning, however, these approaches do not come without limitations. Adapter layers add layers to the underlying model that—despite having very few parameters—must be processed sequentially, resulting in extra inference latency and slower training. Furthermore, prefix tuning is oftentimes difficult to optimize (i.e., the finetuning process is less stable), reduces the available context window, and does not monotonically improve performance with respect to the number of trainable parameters8. Low-Rank Adaptation (LoRA) aims to eliminate such issues while maintaining performance that is comparable to full finetuning.
“LoRA performs on-par or better than finetuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency.” - from [1]
Finetuning LLMs More Efficiently
Given our discussion of finetuning techniques so far, it should be clear that we need a finetuning approach that is not just parameter efficient, but also:
Compute efficient: the training process should be fast and cheap.
Memory efficient: we should not need massive GPUs to finetune an LLM.
Easy to deploy: we should not have to deploy several copies of an LLM for each task that we want to solve.
As we will see, Low-Rank Adaptation (LoRA) [1] checks all of these boxes! With LoRA, we lower the barrier to entry for finetuning specialized LLMs, achieve performance that is comparable to end-to-end finetuning, can easily switch between specific versions of a model, and have no increase in inference latency. Due to its practical utility, LoRA has also been explored heavily within the research community, leading to a plethora of variants and extensions.
LoRA: Low-Rank Adaptation of Large Language Models [1]
When we finetune a language model, we modify the underlying parameters of the model. To make this idea more concrete, we can formulate the parameter update derived from finetuning as shown in the equation below.

The core idea behind LoRA is to model this update to the model’s parameters with a low-rank decomposition9, implemented in practice as a pair of linear projections. LoRA leaves the pretrained layers of the LLM fixed and injects a trainable rank decomposition matrix into each layer of the model; see below.
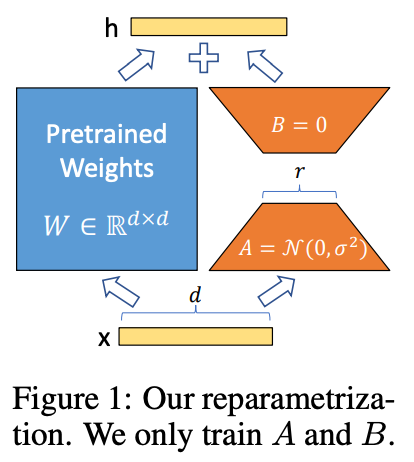
Rank decomposition matrix. Put simply, the rank decomposition matrix is just two linear projections that reduce and restore the dimensionality of the input. The output of these two linear projections is added to the output derived from the model’s pretrained weights. The updated layer formed by the addition of these two parallel transformations is formulated as shown below. As we can see, adding LoRA to a layer directly learns the update to the underlying layer’s weights.

The matrix product AB has the same dimension as a full finetuning update. Decomposing the update as a product of two smaller matrices ensures that the update is low rank and significantly reduces the number of parameters that we have to train. Instead of directly finetuning the parameters in the pretrained LLM’s layers, LoRA only optimizes the rank decomposition matrix, yielding a result that approximates the update derived from full finetuning. We initialize A with random, small values, while B is initialized as zero, ensuring that we begin the finetuning process with the model’s original, pretrained weights.
“We roughly recover the expressiveness of full fine-tuning by setting the LoRA rank r to the rank of the pre-trained weight matrices.” - from [1]
Increasing r improves LoRA’s approximation of the full finetuning update, but incredibly small values of r suffice in practice, allowing us to significantly reduce compute and memory costs with minimal impact on performance. For example, we can use LoRA to finetune GPT-3 using only 0.01% of total parameters and still achieve performance comparable to that of full finetuning.

Scaling factor. Once the low-rank update to the weight matrix is derived, we scale it by a factor α prior to adding it to the model’s pretrained weights. Such an approach yields the adaptation rule shown above. The default value of the scaling factor is one, meaning that the pretrained weights and the low-rank weight update are weighted equally when computing the model’s forward pass. However, the value of α can be changed to balance the importance of the pretrained model and new task-specific adaptation. Recent empirical analysis indicates that larger values of α are necessary for LoRA with a higher rank (i.e., larger r —> la α).
Comparison to adapter layers. At first glance, the approach used by LoRA might seem similar to adapter layers. However, there are two notable differences:
There is no non-linearity between the two linear projections.
The rank decomposition matrix is injected into an existing layer of the model, instead of being sequentially added as an extra layer.
The biggest impact of these changes is the fact that LoRA has no added inference latency compared to the original pretrained model; see below. When deploying a finetuned LoRA model into production, we can directly compute and store the updated weight matrix derived from LoRA. As such, the structure of the model is identical to the pretrained model—the weights are just different.

By storing both the model’s pretrained weights and LoRA modules derived from finetuning on several different tasks, we can “switch out” LoRA modules by:
Subtracting the LoRA update for one task from the model’s weights.
Adding the LoRA update for another task to the model’s weights.
In comparison, switching between models that are finetuned end-to-end on different tasks requires loading all model parameters in and out of memory, creating a significant I/O bottleneck. LoRA’s efficient parameterization of the weight update derived from finetuning makes switching between tasks efficient and easy.
Why does this work? LoRA structures the weight update derived from finetuning with a low rank decomposition that contains very few trainable parameters. With this in mind, we might wonder: Why does the model perform well despite dedicating so few parameters to finetuning? Wouldn’t we benefit from more trainable parameters?

To answer this question, we can look at prior research [15], which shows that large models (e.g., LLMs) tend to have a low intrinsic dimension. Although this idea sounds complicated, it just means that the weight matrices of very large models tend to be low rank. In other words, not all of these parameters are necessary! We can achieve comparable performance by decomposing these weight matrices into a representation that has way fewer trainable parameters; see above.
“Aghajanyan et al. show that the learned over-parametrized models in fact reside on a low intrinsic dimension. We hypothesize that the change in weights during model adaptation also has a low intrinsic rank.” - from [1]
Given that the parameters of large models have low intrinsic dimension, we can reasonably infer that the same is true of models that are finetuned—the weight update derived from finetuning should also have a low intrinsic dimension. As a result, techniques like LoRA that approximate the finetuning update with a low rank decomposition should be able to learn efficiently and effectively, producing a model with impressive performance despite having few trainable parameters.

LoRA for LLMs. The general idea proposed by LoRA can be applied to any type of dense layer for a neural network (i.e., more than just transformers!). When applying LoRA to LLMs, however, authors in [1] only use LoRA to adapt attention layer weights. Feed-forward modules and pretrained weights are kept fixed. We only update the rank decomposition matrix inserted into each attention layer. In particular, LoRA is used in [1] to update the query and value matrices of the attention layer, which is found in experiments to yield the best results; see above.
“Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than finetuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency.” - from [1]
However, subsequent empirical analysis revealed that better results can be achieved by applying LoRA to all weight matrices in the transformer. Although these results may depend upon the application, we see that adapting all weight matrices with LoRA tends to yield competitive performance.
The Benefits of LoRA are plentiful as we can probably tell. However, some of the most notable benefits of this approach include the following:
A single pretrained model can be shared by several (much smaller) LoRA modules that adapt it to solve different tasks, which simplifies the deployment and hosting process.
LoRA modules can be “baked in” to the weights of a pretrained model to avoid extra inference latency, and we can quickly switch between different LoRA modules to solve different tasks.
When finetuning an LLM with LoRA, we only have to maintain the optimizer state for a very small number of parameters10, which significantly reduces memory overhead and allows finetuning to be performed with more modest hardware (i.e., smaller/fewer GPUs with less memory).
Finetuning with LoRA is significantly faster than end-to-end finetuning (i.e., roughly 25% faster in the case of GPT-3).
LoRA significantly reduces the barrier to entry for finetuning LLMs. Training is fast, we don’t need tons of fancy GPUs, each task has only a small number of task-specific parameters associated with it, and—as we will see soon—there are a variety of resources and repos available online to get started with using LoRA.

Experimental results. In [1], LoRA is tested with different types of LLMs, including encoder-only (RoBERTa [16] and DeBERTa [17]) and decoder-only (GPT-2 [18] and GPT-3 [11]) language models. In experiments with encoder-only architectures, we see that LoRA—for both RoBERTa and DeBERTa—is capable of producing results on par with or better than end-to-end finetuning; see above.
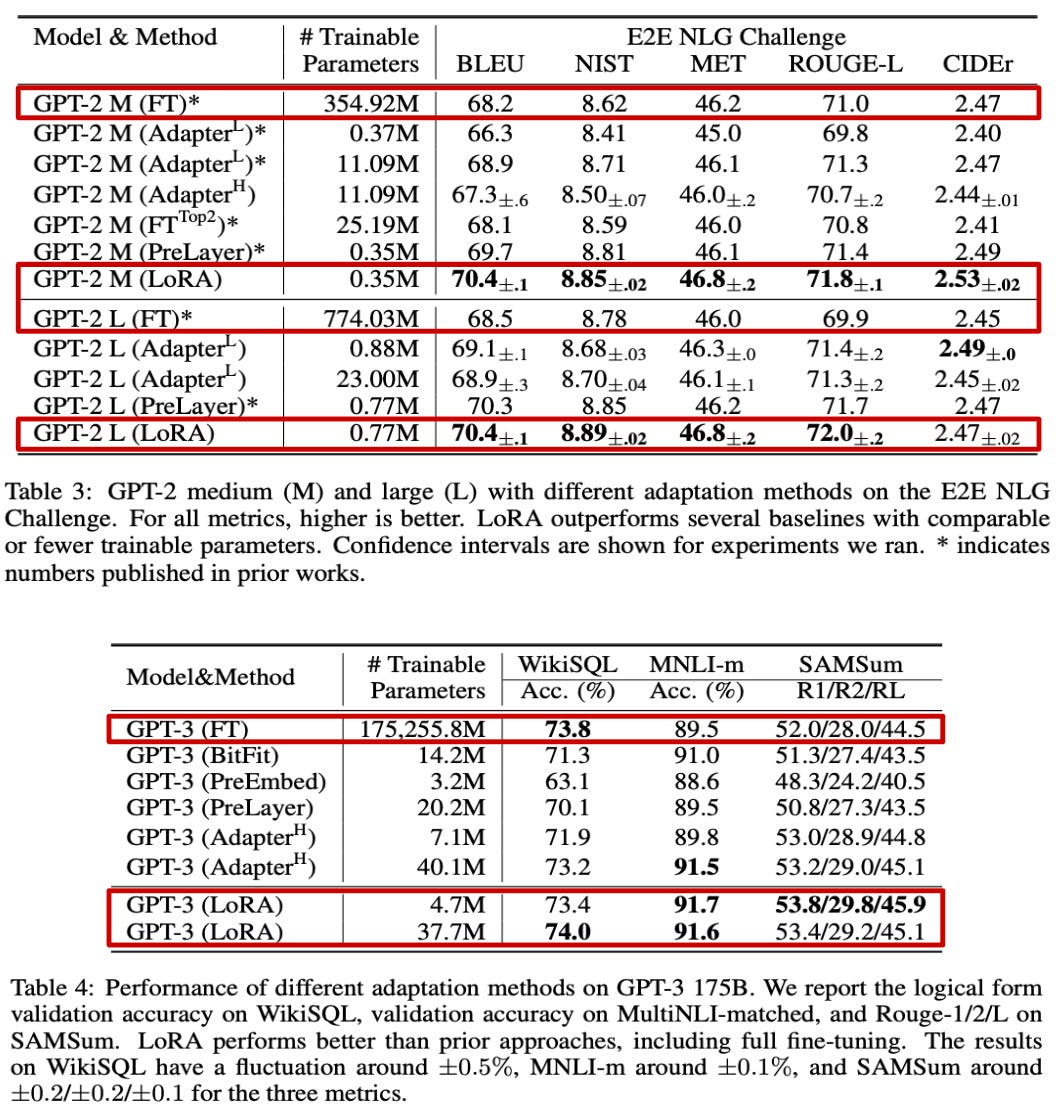
When experiments are performed with generative LLMs, we see that LoRA handles these workloads well and is effective even with much larger models; see above. Notably, we see that LoRA matches or exceeds the performance of end-to-end finetuning on every dataset that is tested. Furthermore, LoRA’s performance is incredibly stable with respect to the number of trainable parameters that are used, especially when compared to techniques like prefix tuning; see below.

Put simply, LoRA can achieve impressive performance—comparable to or beyond that of full finetuning—with very few trainable parameters, which minimizes I/O bottlenecks, reduces memory usage, and speeds up the finetuning process.
Using LoRA in Practice

The reason that LoRA has become so popular is because it is such a useful tool for AI practitioners. With LoRA, finetuning LLMs for our desired application is much easier than before! We don’t need tons of massive GPUs and the finetuning process is efficient, which makes it possible for (almost) anyone to train a specialized LLM on their own data. Plus, numerous efficient implementations of LoRA are already available online with tons of useful features; e.g., gradient accumulation to reduce memory usage, mixed-precision training to speedup finetuning, and easy integration with accelerators (GPUs/TPUs). Notable libraries that can be used to finetune LLMs with LoRA (shown above) include:
PEFT by HuggingFace [link]
Lit-GPT by Lightning AI [link]
In this section, we will briefly overview how we can use Lit-GPT to finetune an LLM with LoRA and provide some helpful tips for using LoRA in practice.
Finetuning with LoRA. The Lit-GPT library contains a variety of useful scripts that can be used to finetune open-source LLMs using LoRA; see here for a full guide. After cloning the Lit-GPT repository and installing dependencies, the first step is to download a pretrained model to finetune with LoRA. To download LLaMA-2 (this requires being granted access to LLaMA-2 via HuggingFace first), we just i) download the model from HuggingFace and ii) convert this into the format needed for Lit-GPT. We can do this via the scripts shown below.

After we’ve downloaded the pretrained model, we need a dataset to use for finetuning. Examples of popular instruction tuning datasets that are commonly used for LLM finetuning include:
To download (and properly format) any of these datasets, we can simply use the helper scripts within Lit-GPT, which also support creating our own (custom) finetuning dataset. From here, all that’s left is to run the finetuning script, merge the model’s weights11, and evaluate the resulting model, either on a set of specified tasks or by just chatting with the model to assess quality; see below.

The finetuning script within Lit-GPT has several default configurations that are used for LoRA; see below. We can edit these options in the finetune/lora.py file prior to performing a finetuning run. For example, we might want to change the value of r that is used, or apply LoRA to all layers within the transformer.
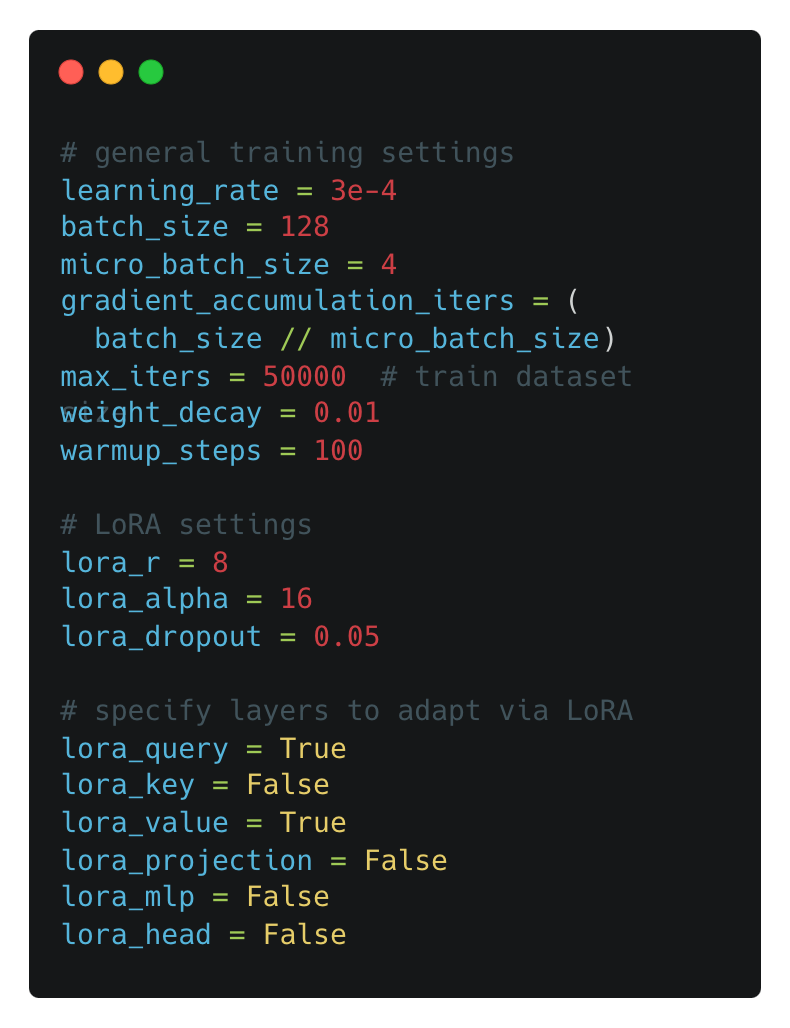
Is LoRA just for LLMs? Finally, it’s important to realize that LoRA is a general technique that can be used for any type of dense neural network layer—we can finetune more than just LLMs with LoRA. For example, the link below shows an example of using LoRA to finetune an image classification model.
Furthermore, we should notice that LoRA is orthogonal to most existing (parameter-efficient) finetuning techniques, meaning that we can use both at the same time! Why is this the case? LoRA does not directly modify the pretrained model’s weight matrices, but rather learns a low-rank update to these matrices that can (optionally) be fused with the pretrained weights to avoid inference latency. This is an inline adaptation technique that adds no additional layers to the model. As a result, we can perform end-to-end finetuning in addition to LoRA, as well as apply techniques like prefix tuning and adapter layers on top of LoRA.
“The principles outlined here apply to any dense layers in deep learning models, though we only focus on certain weights in Transformer language models in our experiments as the motivating use case.” - from [1]
Further reading. Within this section, we have only scratched the surface of how to use LoRA effectively in practice. Although this serves as a good starting point, there are so many details/findings that one could gather from running experiments with LoRA and learning the best practices for this technique.

To learn more about these details, I highly recommend the series of overviews written on LoRA by Sebastian Raschka and the Lightning AI team:
Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation) [link]
Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments [link]
Finetuning Falcon LLMs More Efficiently With LoRA and Adapters [link]
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA) [link]
Within these articles (especially the “Practical Tips” and “Insights from Hundreds of Experiments” articles), we will find a variety of practical takeaways that help us to better leverage LoRA for language model adaptation. Some of the best takeaways gathered from this extensive empirical analysis of LoRA include:
The choice of optimizer (i.e., SGD or AdamW) for LoRA does not make a huge difference in performance or memory overhead (assuming
ris small).Performing multiple epochs of training over the finetuning dataset is oftentimes not beneficial (i.e., degrades performance).
Applying LoRA across all weight matrices in the transformer is better than just applying LoRA to the query and value matrices, as proposed in [1].
Setting α to 2X the value of
ryields competitive results. Larger values ofrcall for larger values of α, andris a hyperparameter that must be tuned.
Going beyond LoRA, the same group of researchers has written a variety of practical overviews of other parameter-efficient finetuning techniques (e.g., prefix tuning and adapter layers) as well:
Understanding Parameter-Efficient LLM Finetuning: Prompt Tuning And Prefix Tuning [link]
Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters [link]
Finetuning Large Language Models [link]
LoRA Variants (there are a ton…)
Due to its practical utility, the proposal of LoRA catalyzed the development of an entire field of research devoted to parameter-efficient finetuning—and LoRA in particular—that is quite active. Within this section, we will (attempt to) overview most of the notable LoRA variants that have been recently proposed.

QLoRA [19] (shown above) is arguably the most popular LoRA variant. At a high level, QLoRA uses model quantization to reduce memory usage during finetuning with LoRA, while maintaining a (roughly) equal level of performance. More specifically, QLoRA uses 4-bit quantization on the pretrained model weights and trains LoRA modules on top of this. Additionally, authors in [19] propose several novel quantization techniques for further reducing memory usage:
4-Bit NormalFloat (NF4) Format: a new (quantized) data type that works better for weights that follow a normal distribution.
Double Quantization: reduces memory footprint by quantizing both model weights and their corresponding quantization constants.
Paged Optimizers: prevents memory spikes due to gradient checkpointing that cause out-of-memory errors when processing long sequences or training a large model12.
In practice, QLoRA saves memory at the cost of slightly-reduced training speed. For example, we see here that replacing LoRA with QLoRA to finetune LLaMA-2-7B reduces memory usage by 33% but increases wall-clock training time by 39%.

QA-LoRA [20] (shown above) is an extension of LoRA/QLoRA that further reduces the computational burden of training and deploying LLMs. Two major techniques are used to reduce the compute/memory overhead of finetuning LLMs:
Parameter-Efficient Finetuning (PEFT): finetune pretrained LLMs with a small number of trainable parameters (e.g., LoRA is one form of PEFT).
Quantization: convert trained weights of an LLM into low-bit representations.
QA-LoRA integrates these two ideas in a simple and performant manner. To do this, we could perform post-training quantization on a model finetuned with LoRA, but this approach has been shown to work poorly. Instead, QA-LoRA improves both training and inference efficiency by proposing a group-wise quantization scheme that separately quantizes different groups of weights in the model. Because such quantization is applied during training, there is no need for post-training quantization—QA-LoRA finetunes in a quantization-aware manner! Beyond QA-LoRA, LoftQ [23] studies a similar idea of applying quantization and LoRA finetuning on a pretrained model simultaneously.

LongLoRA [21] attempts to cheaply adapt LLMs to longer context lengths using a parameter-efficient (LoRA-based) finetuning scheme; see above. Training LLMs with long context lengths is expensive because the cost of self-attention is quadratic with respect to the length of the input sequence. However, we can avoid some of this cost by i) starting with a pretrained LLM and ii) expanding its context length via finetuning. LongLoRA does exactly this, making the extension of a pretrained LLM’s context length via finetuning cheaper by:
Using sparse local attention instead of dense global attention (optional at inference time).
Using LoRA (authors find that this works well for context extension).
Put simply, LongLoRA is just an efficient finetuning technique that we can use to adapt a pretrained LLM to support longer context lengths.
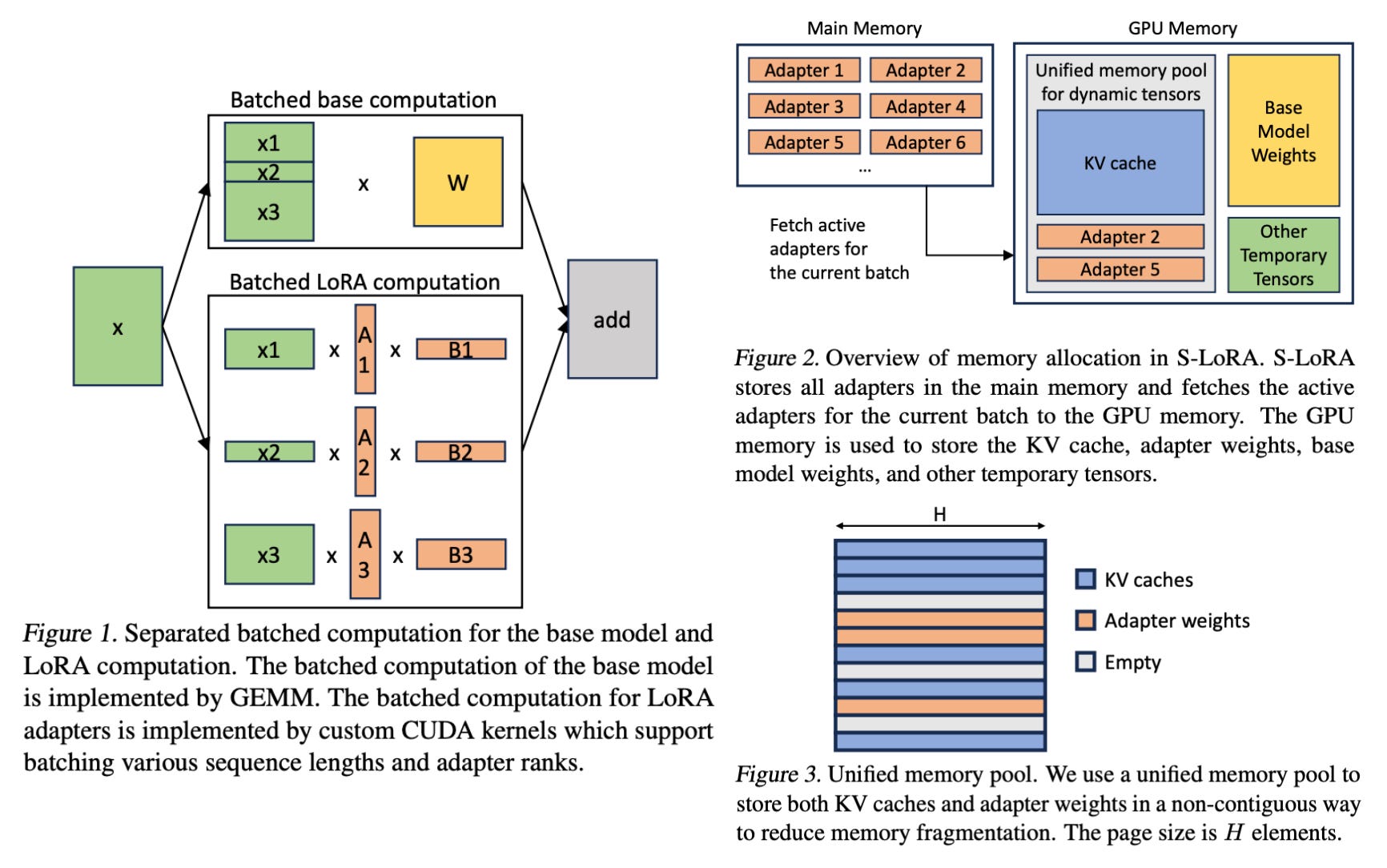
S-LoRA [22] (shown above) aims to solve the problem of deploying multiple LoRA modules that are used to adapt the same pretrained model to a variety of different tasks. Put simply, S-LoRA is a scalable deployment strategy that:
Stores all LoRA modules in main memory.
Puts modules being used to run the current query into GPU memory.
Uses unified paging to allocate GPU memory and avoid fragmentation.
Proposes a new tensor parallelism strategy to batch LoRA computations.
By combining these techniques, S-LoRA can serve thousands of LoRA modules on a single GPU (or across multiple GPUs) and increases the throughput of prior systems (e.g., PEFT by HuggingFace) by up to 4X!

LLaMA-Adapter [24] (shown above) is not based upon LoRA, but it is nonetheless a recent (and popular) variant of parameter-efficient finetuning for LLMs. At a high level, LLaMA-Adapter finetunes pretrained LLMs to improve their instruction following capabilities using a very small number of added trainable parameters. When used to fine-tune LLaMA-7B, this approach only adds 1.2M parameters to the underlying model and requires less than an hour of finetuning time13. LLaMA-Adapter follows an approach similar to prefix tuning that adds a set of learnable task-adaptation prompts to the beginning of the transformers sequence at each layer. Such an approach preserves the pretrained model’s knowledge and allows adaptation to new tasks and instruction following (even including multi-modal instruction following!) to be learned with minimal data.
Many, many more… Although several notable LoRA variants have been covered above, there are a nearly limitless number of extensions to this technique that have been proposed. Other recent LoRA-inspired works include:
LQ-LoRA [26]: uses a more sophisticated quantization scheme within QLoRA that performs better and can be adapted to a target memory budget.
MultiLoRA [27]: extension of LoRA that better handles complex multi-task learning scenarios.
LoRA-FA [28]: freezes half of the low-rank decomposition matrix (i.e., the
Amatrix within the productAB) to further reduce memory overhead.Tied-LoRA [29]: leverages weight tying to further improve the parameter efficiency of LoRA.
GLoRA [30]: extends LoRA to adapt pretrained model weights and activations to each task in addition to an adapter for each layer.
Given that so many LoRA-inspired techniques exist, there are probably a few notable extensions that are missing from the list above. If you are aware of any other techniques that are worth including, let me know in the comments!
Takeaways
We should now have a working understanding of LoRA, the several variants of this technique that have been proposed, and how these ideas can be applied in practice. LoRA is arguably the most widely-used practical tool for creating specialized LLMs, as it democratizes the finetuning process by significantly reducing hardware requirements. Some important takeaways are outlined below.
Training an LLM. The training process for language models (i.e., both encoder-only and decoder-only models) includes pretraining and finetuning. During pretraining, we train the model via a self-supervised objective over a large amount of unlabeled text. Although pretraining is expensive, we can reuse the resulting model numerous times as a starting point for finetuning on various tasks. Due to the public availability of many high-quality pretrained LLMs, most practitioners can simply download a pretrained model and focus upon the finetuning process without ever having to pretrain a model from scratch.
Affordable finetuning. The finetuning process is cheap relative to the cost of pretraining. However, modern LLMs (especially GPT-style models) have many parameters. As such, we need expensive hardware (i.e., GPUs with a lot of memory) to make the finetuning tractable, thus increasing the barrier to entry for finetuning an LLM. Several parameter-efficient finetuning approaches have been proposed as a solution to this issue, but one of the most widely-adopted strategies is LoRA, which injects a learnable low-rank weight update into each layer of the underlying model. LoRA minimizes the memory overhead of finetuning—thus reducing hardware requirements—and performs comparably to full finetuning.
“QLORA reduces the average memory requirements of finetuning a 65B parameter model from >780GB of GPU memory to <48GB without degrading the runtime or predictive performance compared to a 16- bit fully finetuned baseline.” - from [19]
An ecosystem. LoRA is a practically useful tool that gives (almost) anyone the power to train a specialized LLM over their data. As a result, LoRA has been widely studied within the AI research community, leading to a variety of extensions, alternatives, and practical tools to go along with it. One of the most notable extensions is QLoRa, which combines LoRA with model quantization to further reduce the memory overhead of LLM finetuning. However, this reduction in memory overhead comes at the cost of a slight decrease in training speed.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Hu, Edward J., et al. "Lora: Low-rank adaptation of large language models." arXiv preprint arXiv:2106.09685 (2021).
[2] Houlsby, Neil, et al. "Parameter-efficient transfer learning for NLP." International Conference on Machine Learning. PMLR, 2019.
[3] Lin, Zhaojiang, Andrea Madotto, and Pascale Fung. "Exploring versatile generative language model via parameter-efficient transfer learning." arXiv preprint arXiv:2004.03829 (2020).
[4] Rebuffi, Sylvestre-Alvise, Hakan Bilen, and Andrea Vedaldi. "Learning multiple visual domains with residual adapters." Advances in neural information processing systems 30 (2017).
[5] Rücklé, Andreas, et al. "Adapterdrop: On the efficiency of adapters in transformers." arXiv preprint arXiv:2010.11918 (2020).
[6] Li, Xiang Lisa, and Percy Liang. "Prefix-tuning: Optimizing continuous prompts for generation." arXiv preprint arXiv:2101.00190 (2021).
[7] Lester, Brian, Rami Al-Rfou, and Noah Constant. "The power of scale for parameter-efficient prompt tuning." arXiv preprint arXiv:2104.08691 (2021).
[8] Liu, Xiao, et al. "GPT understands, too." AI Open (2023).
[9] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[10] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[11] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[12] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[13] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[14] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[15] Li, Chunyuan, et al. "Measuring the intrinsic dimension of objective landscapes." arXiv preprint arXiv:1804.08838 (2018).
[16] Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692 (2019).
[17] He, Pengcheng, et al. "Deberta: Decoding-enhanced bert with disentangled attention." arXiv preprint arXiv:2006.03654 (2020).
[18] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[19] Dettmers, Tim, et al. "Qlora: Efficient finetuning of quantized llms." arXiv preprint arXiv:2305.14314 (2023).
[20] Xu, Yuhui, et al. "QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models." arXiv preprint arXiv:2309.14717 (2023).
[21] Chen, Yukang, et al. "Longlora: Efficient fine-tuning of long-context large language models." arXiv preprint arXiv:2309.12307 (2023).
[22] Sheng, Ying, et al. "S-LoRA: Serving Thousands of Concurrent LoRA Adapters." arXiv preprint arXiv:2311.03285 (2023).
[23] Li, Yixiao, et al. "LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models." arXiv preprint arXiv:2310.08659 (2023).
[24] Zhang, Renrui, et al. "Llama-adapter: Efficient fine-tuning of language models with zero-init attention." arXiv preprint arXiv:2303.16199 (2023).
[25] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[26] Guo, Han, et al. "LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning." arXiv preprint arXiv:2311.12023 (2023).
[27] Wang, Yiming, et al. "MultiLoRA: Democratizing LoRA for Better Multi-Task Learning." arXiv preprint arXiv:2311.11501 (2023).
[28] Zhang, Longteng, et al. "LoRA-FA: Memory-efficient low-rank adaptation for large language models fine-tuning." arXiv preprint arXiv:2308.03303 (2023).
[29] Renduchintala, Adithya, Tugrul Konuk, and Oleksii Kuchaiev. "Tied-Lora: Enhacing parameter efficiency of LoRA with weight tying." arXiv preprint arXiv:2311.09578 (2023).
[30] Chavan, Arnav, et al. "One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning." arXiv preprint arXiv:2306.07967 (2023).
Notably, encoder-only only models are not appropriate for generative tasks.
For those who are unfamiliar with self-supervised learning, check out the link here. It is one of the main advancements that has made deep learning so successful in the natural language domain!
Unlike quantized training, quantization-aware training may not save any cost during the training process. Rather, this technique focuses upon producing a network that meshes will with post-training quantization.
The Cloze objective, also commonly referred to as masked language modeling (MLM), is a self-supervised objective that is commonly used for pretraining non-generative language models like BERT.
For generative LLMs, pretraining datasets include (potentially) trillion of tokens worth of raw textual data!
The compute cost is significantly less than pretraining. As we will see, however, the cost of finetuning can still be reduced below the cost of full finetuning.
This is due to using the bottleneck structure! If our input is of dimension d, a single linear layer that transformer this input and maintains the dimension would have O(d^2) parameters. In comparison, the bottleneck layer would contain O(dr) parameters, which is much smaller when r « d.
This means that performance might get worse when we add more trainable token vectors to the prefix, which makes prefix tuning unstable and difficult to tune.
In linear algebra, a “low-rank” matrix is one that has repetitive rows or columns. Any (non-null) matrix can be written as a product of two matrices; e.g., W = AB, were W is of size m x n, A is of size m x r, and B is of size r x n. This is called a rank factorization; read more here. In LoRA, we call this matrix product a low-rank decomposition of W, as the rank of AB is at most r.
Remember, we are only training the parameters in the rank decomposition matrix.
By “merge”, we mean combine the result of LoRA with the pretrained model’s weights, such that added inference latency is avoided.
The authors in [19] implement this using NVIDIA’s unified memory feature, which allows us to page memory between the CPU and GPU to avoid memory errors. Put simply, we avoid out of memory errors by paging memory to the CPU when the GPU runs out of space and loading the data back into GPU memory once it is needed again.
However, authors in [24] use 8X A100 GPUs, so the hour of finetuning time occurs on a (relatively) beefy setup.
Hi Dr. Cameron R. Wolfe,
Thank you for the nice article. Can I cite this article knowledge share with my pears at work ?
Best Regards,
-Abdeli B.
can I cite this article for educational purpose ?