


Language Models and Friends: Gorilla, HuggingGPT, TaskMatrix, and More
What happens when we give LLMs access to thousands of deep learning models?

Recently, we have witnessed a rise of foundation models to popularity within deep learning research. Pre-trained large language models (LLMs) have led to a new paradigm, in which a single model can be used—with surprising success—to solve many different problems. Despite the popularity of generic LLMs, however, fine-tuning models in a task-specific manner tends to outperform approaches that leverage foundation models. Put simply, specialized models are still very hard to beat! With this being said, we might start to wonder whether the powers of foundation models and specialized deep learning models can be combined. Within this overview, we will study recent research that integrates LLMs with other, specialized deep learning models by learning to call their associated APIs. The resulting framework uses the language model as a centralized controller that forms a plan for solving a complex, AI-related tasks and delegates specialized portions of the solution process to more appropriate models.
“By providing only the model descriptions, HuggingGPT can continuously and conveniently integrate diverse expert models from AI communities, without altering any structure or prompt settings. This open and continuous manner brings us one step closer to realizing artificial general intelligence.” - from [2]
Background
Before exploring how language models can be integrated with other deep learning models, we need to cover a few background ideas, such as LLM tools, information retrieval, and self-instruct [11]. For more generic background information on language models, check out the following resources.
Language Modeling Basics (GPT and GPT-2) [link]
The Importance of Scale for Language Models (GPT-3) [link]
Using tools with LLMs
“By empowering LLMs to use tools, we can grant access to vastly larger and changing knowledge bases and accomplish complex computational tasks.” - from [3]
Although language models have a large number of impressive capabilities, they are not perfect and can’t accomplish all tasks on their own. In many cases, combining existing models with tools (e.g., search engines, calculators, calendars, etc.) can drastically expand the scope of their capabilities. In a prior overview, we explored the Toolformer [1]—a fine-tuning technique for teaching LLMs to use a small set of simple, textual APIs—and how tools can be used to improve the performance of LLMs without too much effort; see below for more details.
Although models like the Toolformer are effective, they only consider a small set of very simple APIs. These APIs barely scratch the surface of the total number of tools that can be made available to LLMs. Imagine, for example, if we were able to integrate an LLM with any API that is available via the internet—we could unlock an entire realm of new applications and possibilities!

(almost) anything is possible! This trend towards providing language models with widespread access to a variety of APIs online is being explored via the ChatGPT plugins store; see above. By leveraging these APIs, we can do much more than just provide LLMs access to simple tools like calculators! We can easily think of several high-impact applications that become possible with this approach. For example, we could use language models with tool integrations for:
Forming a vacation itinerary and booking all needed tickets and reservations
Curating and purchasing the week’s grocery list for curbside pickup
Finding and reserving a table at a restaurant for the upcoming weekend
Discovering and purchasing relevant products on any e-commerce store
The scope of possibilities is nearly endless! By using language as a standardized medium of communication, we can work with foundation models like ChatGPT to accomplish surprisingly complex tasks. All we have to do is prompt the model to produce the API calls that are relevant to our request.
deep learning APIs. In this overview, we will consider integrating LLMs with a particular kind of API—those that provide access to open-source deep learning models on platforms like HuggingFace. The AI/ML community places a heavy emphasis on open-source software, meaning that many of the most powerful deep learning models are freely available online. Usually, these models come with well-written descriptions, called model cards, that can be used to provide all needed information about any model to an LLM. Then, these models can be easily integrated with an LLM via basic prompting techniques.
The Self-Instruct Framework
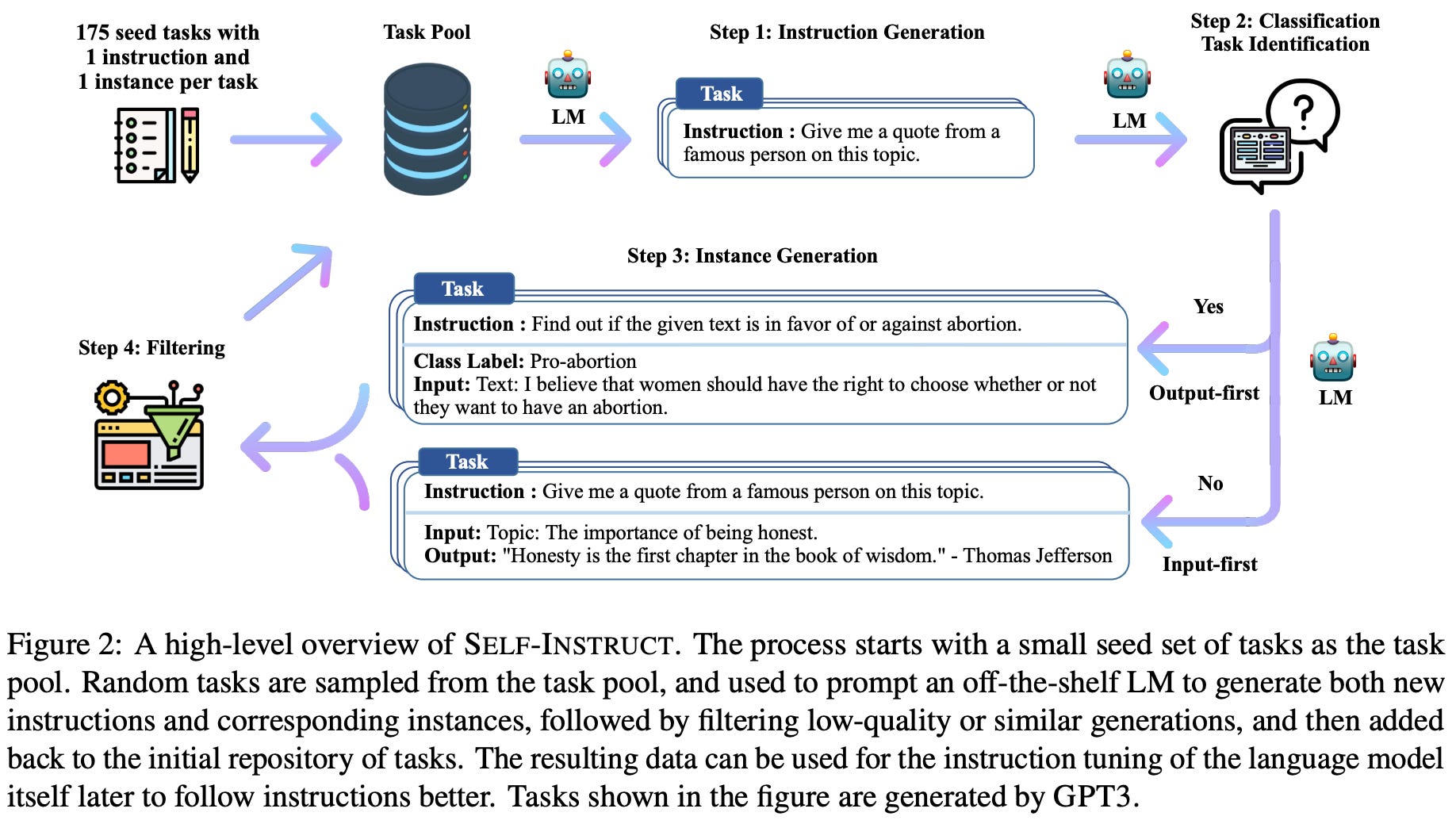
The self-instruct framework, proposed in [11], pioneers the idea of using LLMs to train themselves by generating synthetic instruction tuning data that can be used for fine-tuning. Beginning with a single input-output pair associated with a certain task or instruction, self-instruct prompts an off-the-shelf LLM to generate new tasks, as well as valid instructions and responses to go with each of them. After filtering is performed to remove low-quality data, we can fine-tune any language model on the resulting instruction tuning dataset. Interestingly, we find that models fine-tuned over this data tend to match the performance of those trained over human-curated datasets. Although self-instruct works well, several improvements to the overall framework were also proposed by Alpaca [12].
Information Retrieval
As we have seen in prior overviews, the quality of foundation language models tends to improve with scale—large pre-training datasets and models lead to the best results. However, we can only store so much information within the fixed set of weights contained within a language model. Even massive models have a finite number of parameters. Additionally, the limited context window of modern LLMs limits us to injecting only a small amount of information into the model’s prompt.1 So, what should we do if we want to provide our LLM access to a large bank of information? We need to adopt some form of information retrieval.

vector databases. One popular form of information retrieval can be performed by integrating an LLM with a vector database that stores large amounts of textual information. At a high level, this integration with a vector database (e.g., Pinecone, Milvus, Weaviate, Redis, etc.) is formed by:
Chunking the text into small parts.
Producing an embedding for each chunk of text.
Storing these embeddings in a vector database.
Performing vector similarity search (based on these embeddings) to find relevant chunks of text to include in a prompt.
The net result is that we can quickly find relevant textual information to provide as extra context within a prompt, allowing the LLM to draw upon information beyond the maximum size of its context window. Even though we still cannot provide all of the information we have to the model, we can use vector similarity search to quickly identify the most relevant parts.
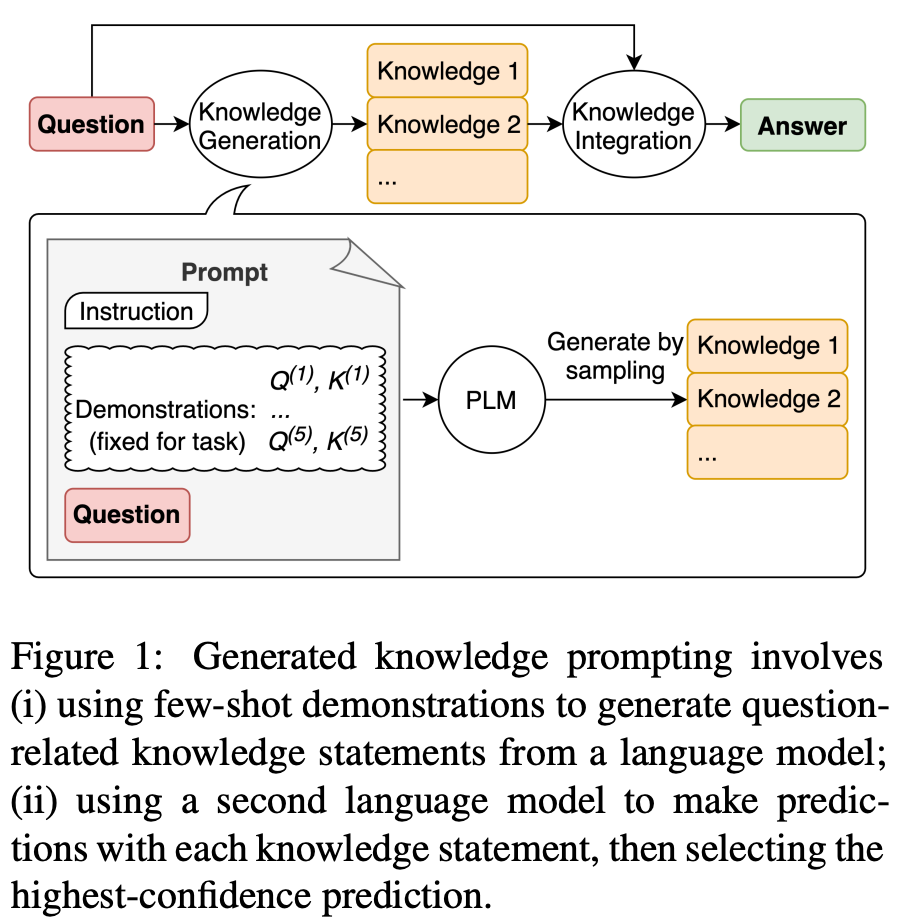
is this the only way? Many other methods have been proposed for information retrieval—there is an entire (incredibly active) area of research dedicated to these techniques. We can even use LLMs to generate relevant information (instead of retrieving it) via generated knowledge prompting; see above. The article below does a great job of summarizing existing techniques for information retrieval.
Overall, many different techniques exist, and we have a lot of options for choosing how an LLM could be augmented with external sources of information.

why should we care? Information retrieval is great, but we might be wondering why this is relevant to the topic of integrating LLMs with other deep learning models. Well, what if we want to provide access to any model available online? There are thousands of models available on ML communities like HuggingFace! As such, we can’t provide a description for all of these models to the LLM. Rather, we need to use some form of information retrieval to determine the most relevant subset of models that we should include in the LLM’s prompt; see above.
Integrating LLMs with Other Models
Now that we have some relevant background information under our belt, we will take a look at recent publications that augment LLMs with other deep learning models. Although each approach is different [2, 3], all of such techniques aim to teach an LLM how to call APIs associated with other, specialized models. Then, the LLM can act as a controller (or brain) that coordinates the solution of a problem by planning and delegating subtasks to different APIs.
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face [2]

LLMs have become popular recently, but research in deep learning has produced a variety of incredibly useful models in recent years for solving specific tasks like image recognition, video action detection, text classification, and much more. Unlike language models2, these models are narrow experts, meaning that they can accurately solve a specific task given a fixed input-output format. But, they are not useful for anything beyond the specific task that they are trained to solve. What if we want to repurpose these models as components for solving more open-ended AI-related tasks?
“LLMs [can] act as a controller to manage existing AI models to solve complicated AI tasks and language could be a generic interface to empower this.” - from [2]
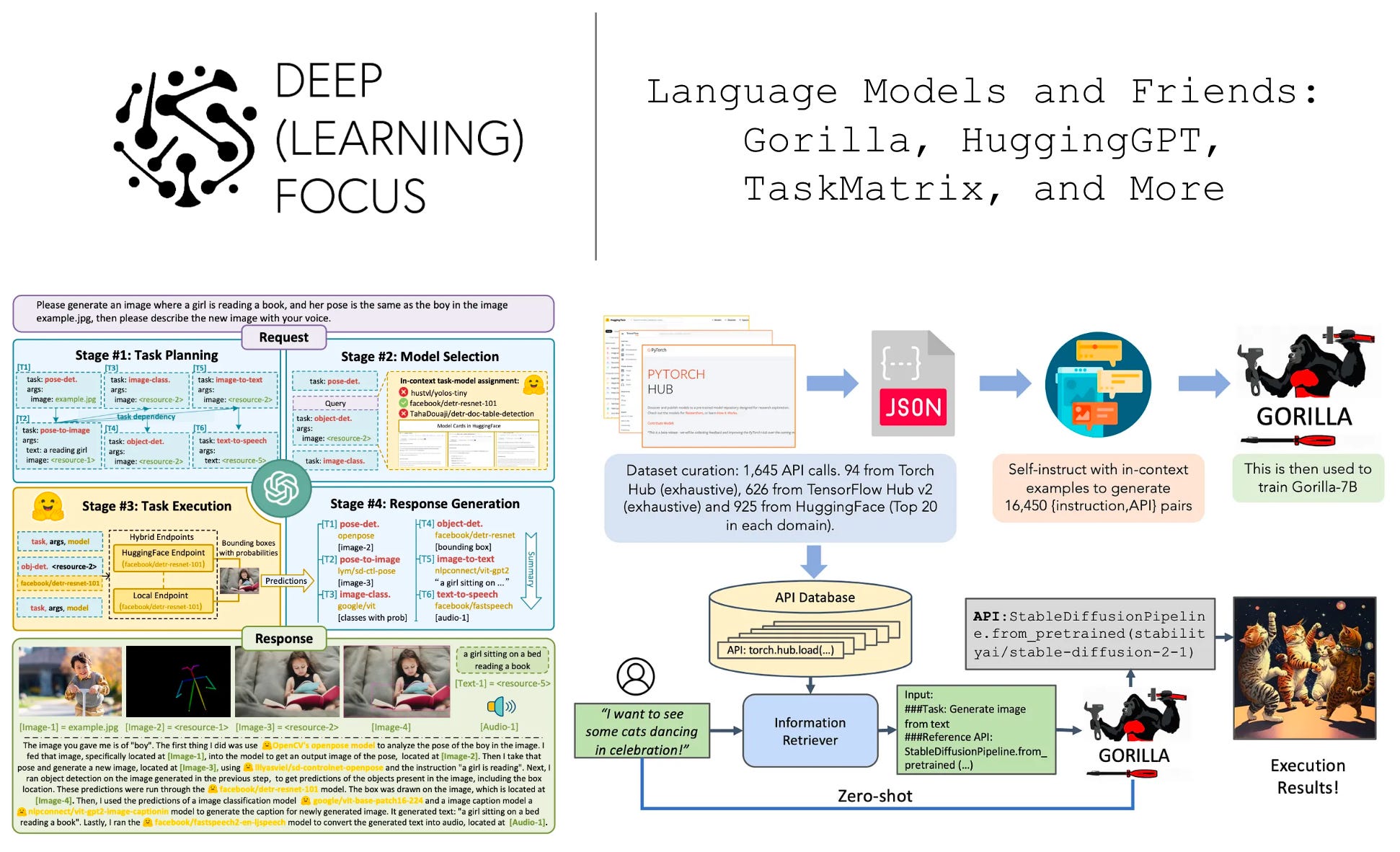
In [2], authors explore using LLMs as a generic interface for connecting deep learning models together. HuggingGPT [2] is inspired by the idea of allowing an LLM to coordinate with external models with a variety of different specialized capabilities. Put simply, the LLM serves as the “brain” of a problem solving system, which plans how to solve a problem and coordinates efforts between different deep learning models that solve necessary subtasks for this problem. To teach an LLM how to do this, we need high-quality descriptions of each model. Luckily, we don’t need to perform any prompt engineering to create these descriptions—they are widely available via ML communities like HuggingFace!
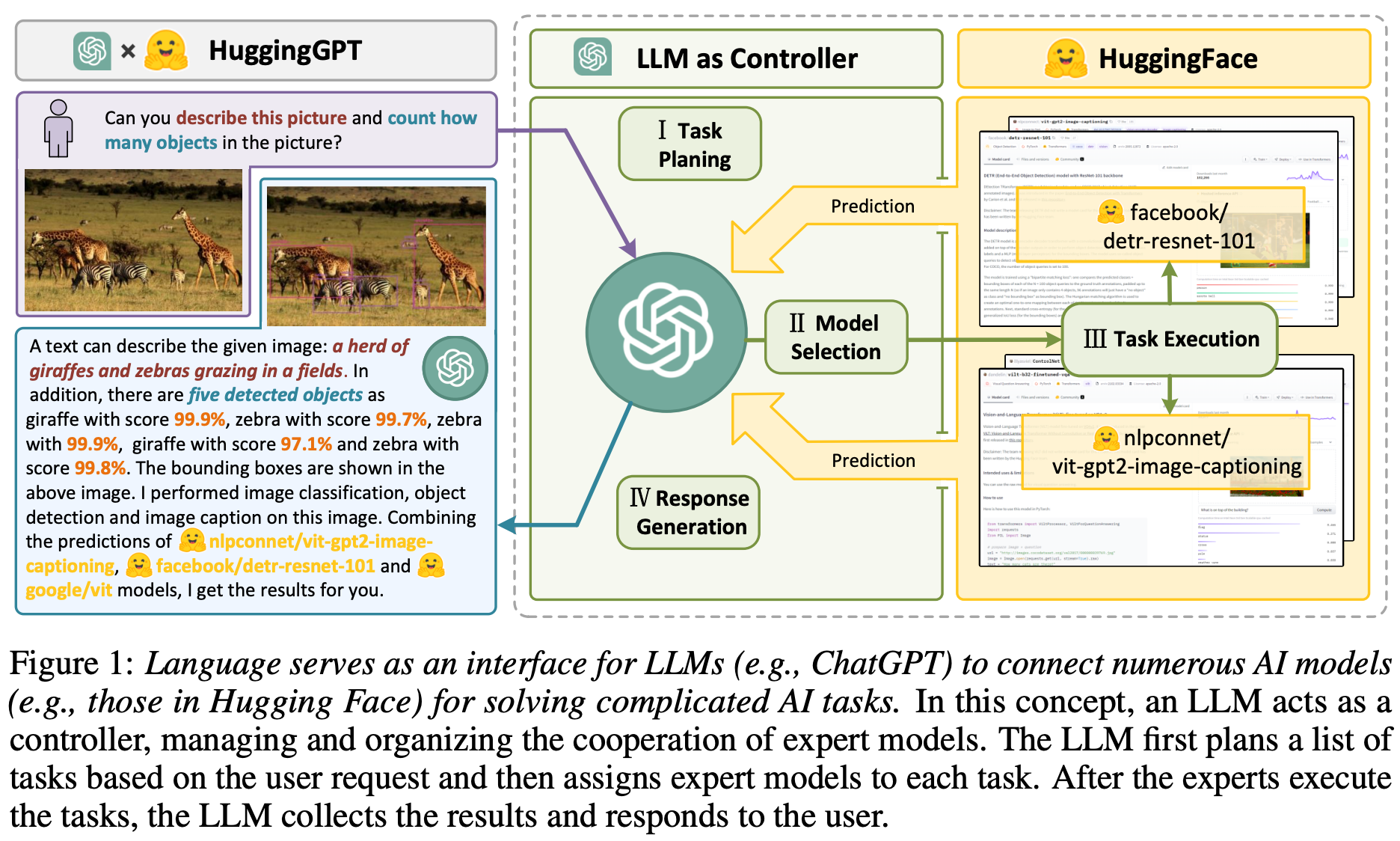
how does this work? HuggingGPT [2] decomposes problems into four parts:
Task planning: use the LLM to decompose a user’s request into solvable tasks.
Model selection: select models from HuggingFace to use for solving tasks.
Task execution: run each selected model and return results to the LLM.
Response generation: use the LLM to generate a final response for the user.
As we might expect, leveraging the capabilities of models available online gives HuggingGPT the ability to solve a wide variety of complex problems!
“HuggingGPT can automatically generate plans from user requests and use external models, and thus can integrate multimodal perceptual capabilities and handle multiple complex AI tasks.” - from [2]
Quite impressively, HuggingGPT does not need to be fine-tuned at all to learn how to coordinate and use these models! Rather, it leverages few-shot learning and instruction prompting to perform each of its required tasks for solving a problem; see below. For these prompts to work well, we need a steerable LLM (e.g., ChatGPT or GPT-4) that can follow directions closely and obey strict output formats (e.g., decomposing a problem into json-formatted tasks).

Notably, we should observe that the set of available models to be used is directly injected into the task planning prompt provided to HuggingGPT; see the example above. Obviously, there are too many models available online to include them all in the prompt. To decide which models should be included as an option in the prompt, HuggingGPT selects a group of models based on their task type (i.e., do they solve a task that’s relevant to the current problem), ranks them according to downloads (i.e., the number of users that downloaded or used this model on HuggingFace), then provides the top-K models as options to the LLM.

resource dependencies. After HuggingGPT decomposes a user’s request into several problem-solving steps, we need to execute each model in the specified plan. However, when we execute each model specified by HuggingGPT, some models may be dependent upon the output of others, which is referred to as a “resource dependency” in [2]. To handle these cases, models with dependencies await the output of models upon which they are dependent before executing. Models with no dependencies can execute in parallel to make the task execution step of HuggingGPT faster. Interestingly, the task-planning structure produced by the LLM not only changes the order of execution for each model, but also the manner in which we evaluate HuggingGPT’s output. For example, authors in [2] use GPT-4 to evaluate the quality of more complex task plans; see above.
does it perform well? The evaluation of HuggingGPT performed in [2] focuses solely upon assessing the task-planning capabilities of a few different LLMs, as the quality of task planning largely determines the success of the overall problem-solving framework for HuggingGPT. As shown in the figures below, LLMs like GPT-3.5 (and less powerful models to a certain extent) seem to be capable of effectively decomposing user requests into a valid task plan.

Much work is required to improve the evaluation of such techniques—the analysis provided in [2] is far from comprehensive. Additionally, although HuggingGPT works well, it only considers a small, well-documented set of model APIs that are directly injected into the LLM’s prompt. Compared to fine-tuning, this framework requires a lot of prompt engineering to work well. Although we avoid the need for a fine-tuning dataset, the framework is highly-dependent upon the capabilities of the underlying model. As such, we might wonder: how can we generalize this approach to work more reliably for a larger number of models?
Gorilla: Large Language Models Connected with Massive APIs [3]
“Supporting a web scale collection of potentially millions of changing APIs requires rethinking our approach to how we integrate tools.” - from [3]
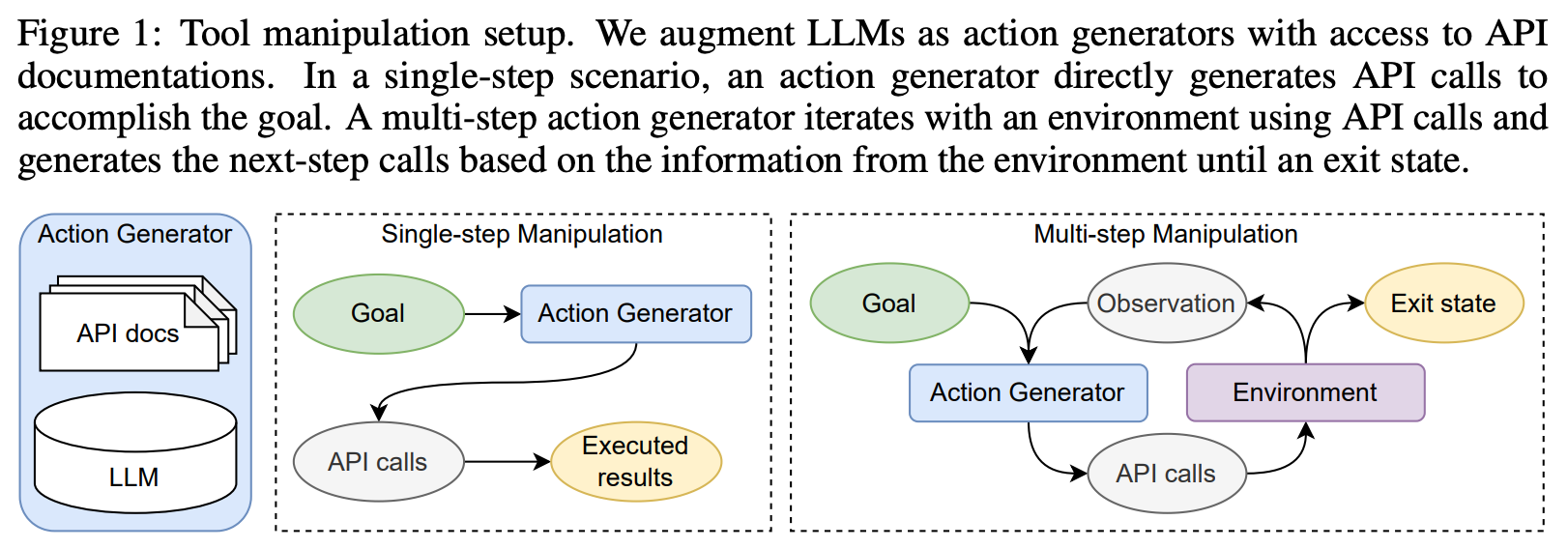
Integrating LLMs with a smaller, fixed set of other models is cool, but what if we could teach LLMs to use any model API that is available online? To do this, we could just use retrieval techniques that i) identify relevant model APIs and ii) provide their documentation to the LLM. With this approach, LLMs would have access to much more than a small set of curated tools! Rather, models could access the vast suite of changing APIs in the cloud. Unfortunately, however, even powerful LLMs (e.g., GPT-4 or Claude) struggle to leverage APIs in this way due a tendency to pass incorrect arguments or hallucinate calls to APIs that do not exist; see below.

In [3], authors adopt fine-tuning approach, based upon the self-instruct [11] framework, to make LLMs more capable of leveraging a large group of external deep learning APIs. Going beyond proposals like HuggingGPT [2], authors in [3] consider over 1,600 different model APIs. This set of model APIs is much larger than those considered in prior work, has overlapping functionality (i.e., many models perform similar tasks), and even includes a variety of models with less-than-perfect documentation. To learn how to leverage these APIs, work in [3] fine-tunes a LLaMA-7B [5] model over a large dataset of valid API calls. The resulting model, which can effectively leverage many of these APIs, is called Gorilla.
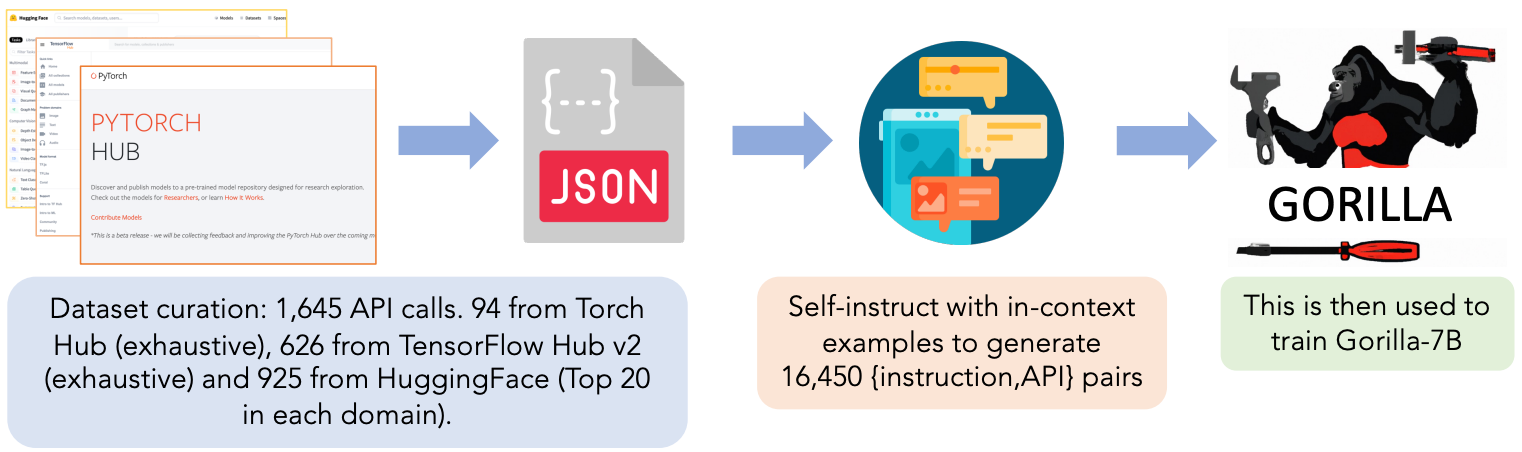
creating the dataset. To fine-tune Gorilla, a massive corpus of API calls is created by leveraging HuggingFace Hub, PyTorch Hub, and TensorFlow Hub. Across all three hubs, 1,645 total model APIs are selected, spanning numerous domains from computer vision, to audio, to reinforcement learning and more. After storing the relevant information for each API in a json object (i.e., includes information like domain, framework, description of functionality, and API signature), we can follow a self-instruct approach by using GPT-4 to generate ten user question prompts and associated responses to go along with each API. After filtering incorrect API calls, the result is just a large dataset of real-world use cases that leverage each of the different model APIs to solve various questions. This dataset is perfect for fine-tuning an LLM; see below.
retrieval-aware fine-tuning. Instead of performing “normal” supervised fine-tuning, Gorilla leverages a “retrieval-aware” fine-tuning variant. This might sound fancy, but the practical implementation is simple! For every call to a model API in the fine-tuning dataset, we add up-to-date documentation for this API within the data. Then, we follow a similar approach at test-time by appending API documentation to our prompt, which teaches the LLM to dynamically determine the proper usage of each API based on documentation; see below.

Retrieval aware fine-tuning is a technique that teaches the LLM to better leverage API documentation when determining how to solve a problem. Such a dynamic approach allows the LLM to:
Adapt to real-time changes in an API’s documentation at test time
Develop improved in-context learning abilities for making API calls
Hallucinate less by paying better attention to info in an API’s documentation

Retrieval-aware fine-tuning makes Gorilla an incredibly capable interface for leveraging a variety of different deep learning models—the resulting LLM can use a massive number of different APIs to solve a problem. Plus, the model can actually adapt to changes in documentation for any of its APIs! See the figure above for an example of adapting to changes in API documentation.

using Gorilla. Although we know which API to include in the prompt when constructing the fine-tuning dataset, we don’t know the proper API to use when we receive an arbitrary prompt from a user during inference. To determine the correct API to use, we can just adopt an information retrieval technique that i) embeds the user’s prompt (or other relevant information) and ii) performs vector similarity search to find the most relevant API documentation. This way, we can easily and efficiently identify the best API to use for solving a problem. Alternatively, we could use Gorilla in a zero-shot manner by passing a user’s prompt directly to the model without any information retrieval or extra information. Either way, the goal of Gorilla is to generate an accurate call to the most appropriate API for solving a user’s prompt; see above.
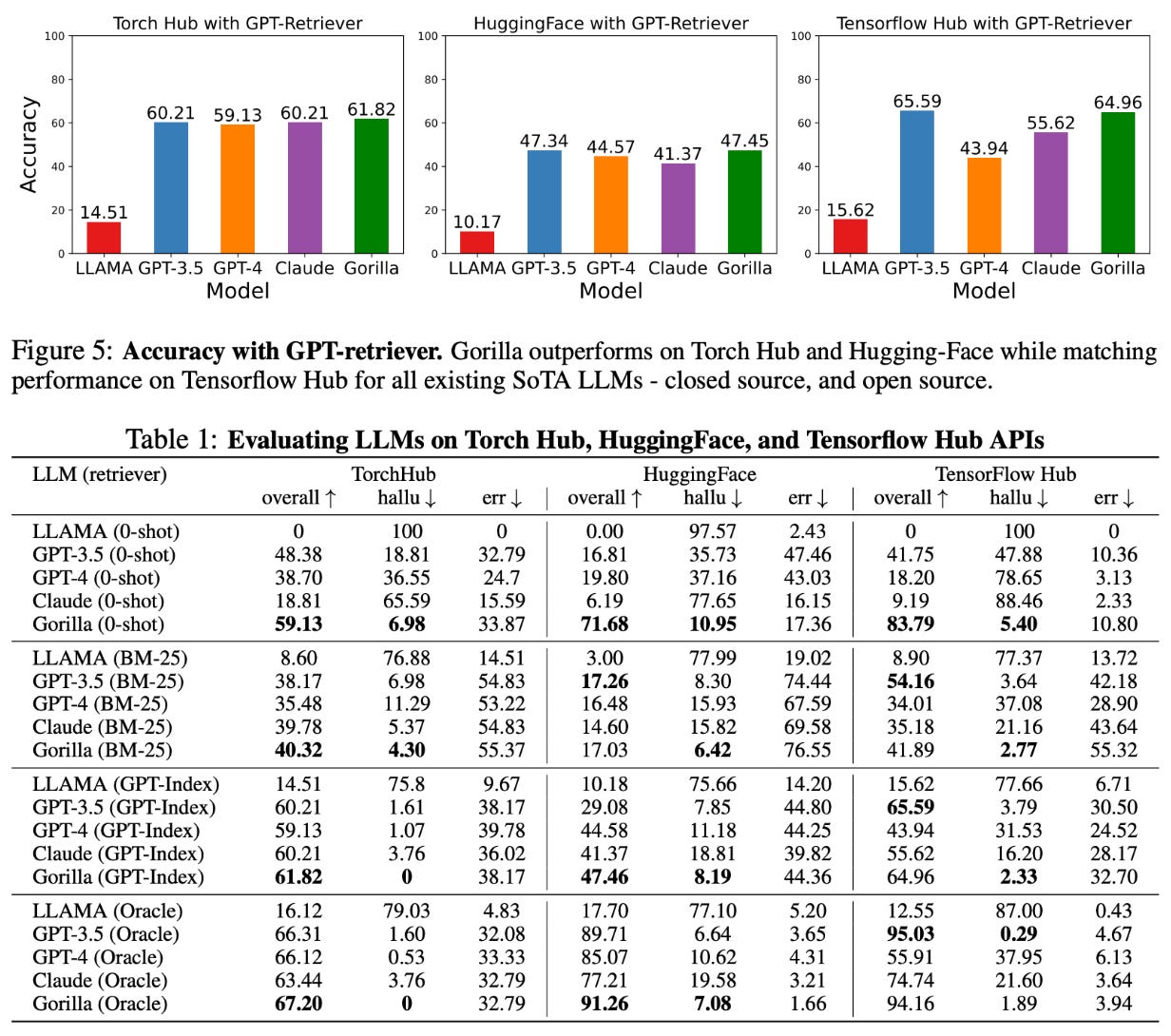
As demonstrated by the experimental results above, Gorilla is an incredibly capable interface for deep learning APIs. Compared to larger and more powerful models (e.g., GPT-3.5, Claude, and GPT-4), we see that Gorilla is much more capable of generating accurate API calls, meaning that the model hallucinates calls to nonexistent API calls less and tends to pass correct input arguments!
Other notable techniques…
HuggingGPT [2] and Gorilla [3] have garnered a lot of public recognition and discussion over the last few months, but many other techniques have been proposed that consider using LLMs to coordinate efforts of several different deep learning models. A brief list of other interesting techniques is outlined below.

TaskMatrix [7] is a position paper—meaning that it presents a position or outlook on a notable issue—that considers the integration of foundation models (e.g., LLMs like ChatGPT) with millions of different APIs. Notably, this work argues that foundation models lack domain knowledge needed to accurately solve specialized tasks, but many existing, task-specific models are available that can solve a specified task with impressive accuracy. Integrating these specialized/expert models with an LLM may be difficult due to compatibility issues, but authors in [7] extensively discuss and consider the idea. In many ways, HuggingGPT and Gorilla are practical realization of ideas discussed in [7].

API Bank [8] provides a better benchmark for evaluating tool-augmented LLMs. In particular, the benchmark considers over 50 APIs that are commonly integrated with LLMs and 264 annotated dialogues—including 568 API calls in total—to go along with these tools. The benchmark is designed to evaluate LLMs’ ability to create a task plan (i.e., step-by-step guide of which API calls to execute), determine the correct APIs to use, and execute API calls to answer a provided question. Unsurprisingly, preliminary experiments show that GPT-4 has the strongest capabilities in leveraging external tools to answer user-provided questions. Although this work does not consider deep learning model APIs in particular, the task framework used mirrors approaches seen in this overview.

ToolkenGPT [9] attempts to mitigate fine-tuning requirements for tool-following foundation models by assigning a specific token—and associated token embedding—to each tool, allowing LLMs to generate tool requests in a similar manner to generating a normal word token. Such an approach is found to be quite flexible for leveraging a variety of external tools.
Tool Manipulation with Open-Source LLMs [10]. In most cases, we see that closed-source LLMs (e.g., GPT-4) are more steerable and can, therefore, better manipulate external tools. In [10], however, the authors analyze whether open-source LLMs can be fine-tuned to match the performance of powerful, closed-source LLMs in this particular skill. A variety of open-source LLMs are refined using human feedback and supervision to improve their tool-following capabilities. Interestingly, we see that several open-source models can achieve competitive performance with GPT-4 given sufficient fine-tuning. In this overview, we have seen with models like Gorilla that open-source LLMs (e.g., LLaMA) are incredibly powerful given the correct fine-tuning procedure.
Closing Remarks
“There is a clear and pressing need for a mechanism that can leverage foundation models to propose task solution outlines and then automatically match some of the sub-tasks in the outlines to the off-the-shelf models and systems with special functionalities to complete them.” - from [7]
Within this overview, we have seen that LLM are capable of integrating with other deep learning models via their APIs. In the case of HuggingGPT [2], this can be done using an in-context learning approach, in which we prompt the LLM with descriptions of existing models and their functionality. Notably, however, HuggingGPT works best with powerful, closed-source models like ChatGPT. If we want to teach open-source models (e.g., LLaMA) to call deep learning model APIs when solving complex problems, we need to adopt a fine-tuning approach, as proposed by Gorilla [3]. Either way, these techniques are incredibly powerful, as they strike a balance between the strengths of narrow expert and foundation models. We can draw upon the power of both by relying upon LLMs to perform high-level reasoning and form problem-solving plans, while delegating certain sub-tasks to specialized models that are more reliable and accurate.
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a better understanding of deep learning research via understandable overviews that explain relevant topics from the ground up. If you like this newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Schick, Timo, et al. "Toolformer: Language models can teach themselves to use tools." arXiv preprint arXiv:2302.04761 (2023).
[2] Shen, Yongliang, et al. "Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface." arXiv preprint arXiv:2303.17580 (2023).
[3] Patil, Shishir G., et al. "Gorilla: Large Language Model Connected with Massive APIs." arXiv preprint arXiv:2305.15334 (2023).
[4] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[5] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[6] Wang, Yizhong, et al. "Self-Instruct: Aligning Language Model with Self Generated Instructions." arXiv preprint arXiv:2212.10560 (2022).
[7] Liang, Yaobo, et al. "Taskmatrix. ai: Completing tasks by connecting foundation models with millions of apis." arXiv preprint arXiv:2303.16434 (2023).
[8] Li, Minghao, et al. "Api-bank: A benchmark for tool-augmented llms." arXiv preprint arXiv:2304.08244 (2023).
[9] Hao, Shibo, et al. "ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings." arXiv preprint arXiv:2305.11554 (2023).
[10] Xu, Qiantong, et al. "On the Tool Manipulation Capability of Open-source Large Language Models." arXiv preprint arXiv:2305.16504 (2023).
[11] Wang, Yizhong, et al. "Self-Instruct: Aligning Language Model with Self Generated Instructions." arXiv preprint arXiv:2212.10560 (2022).
[12] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[13] Trivedi, Harsh, et al. "Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions." arXiv preprint arXiv:2212.10509 (2022).
[14] Liu, Jiacheng, et al. "Generated knowledge prompting for commonsense reasoning." arXiv preprint arXiv:2110.08387 (2021).
Notably, models like Claude now have massive context windows (e.g., 100K tokens). However, this still doesn’t mean we should just cram massive amounts of information into the LLM’s context window! More details here.
Pre-trained (large) language models are not narrow experts. Rather, they are foundation models, which means that we can solve a variety of different tasks using the same model (e.g., by constructing different prompts for each task).