


Prompt Ensembles Make LLMs More Reliable
Simple strategies for getting the most out of any language model...

Anyone who has worked with large language models (LLMs) will know that prompt engineering is an informal and difficult process. Small changes to a prompt can cause massive changes to the model’s output, it is difficult (or even impossible in some cases) to know the impact that changing a prompt will have, and prompting behavior is highly dependent on the type of model being used. The fragile nature of prompt engineering is a harsh reality when we think about creating applications with LLMs. If we cannot predict how our model will behave, how can we build a dependable system around this model? Although LLMs are incredibly capable, this problem complicates their use in many practical scenarios.
“Prompting is a brittle process wherein small modifications to the prompt can cause large variations in the model predictions, and therefore significant effort is dedicated towards designing a painstakingly perfect prompt for a task.” - from [2]
Given the fragile nature of LLMs, finding techniques that make these models more accurate and reliable has recently become a popular research topic. In this overview, we will focus on one technique in particular—prompt ensembles. Put simply, prompt ensembles are just sets of diverse prompts that are meant to solve the same problem. To improve LLM reliability, we can generate an answer to a question by querying the LLM with multiple different input prompts and considering each of the model’s responses when inferring a final answer. As we will see, some research on this topic is quite technical. However, the basic idea behind these techniques is simple and can drastically improve LLM performance, making prompt ensembles a go-to approach for improving LLM reliability.
Background
Prior to learning about recent research on prompt ensembles and LLM reliability, let’s take a look at a few core concepts and background information related to LLMs that will help to make this overview more complete and understandable.
Some prerequisites…

The majority of this post will be heavily focused upon prompt engineering and prompt ensembles. As such, we will not cover much background material on modern LLMs and how they are created. Luckily, I have written a lot of overviews of this topic that can be used to quickly gain a baseline understanding of how these systems work. To get started, I’d recommend the following resources:
The History of LLMs [link]
The Building Blocks of LLMs [link]
Language Model Pre-Training [link]
Decoder-Only Transformers [link]
Beyond LLMs, we should also understand the idea of prompt engineering. When interacting with a language model, we provide textual input (i.e., a prompt), and the language model provides a textual completion. This text-to-text format is incredibly flexible, allowing a variety of different problems to be solved by just extracting the correct answer from an LLM’s output. However, this flexibility can also become a burden, as there are many options for how the input to an LLM can be worded or phrased when attempting to solve a problem. Prompt engineering is an empirical science that studies this problem and attempts to find input prompts that maximize LLM performance. To learn more, check out the overviews below:
What is Reliability?
As we study reliability, it is useful to provide a precise definition of the concept. As mentioned perviously, LLMs can be quite brittle. If we change the input a bit, we might get a drastically different output. Oftentimes, the output of an LLM is unpredictable and inaccurate. These issues were discussed extensively by Chip Huyen in a recent blog post. The quote below outlines the difficulty of building applications with LLMs compared to traditional programming tasks.
“Programming languages are mostly exact… In prompt engineering, instructions are written in natural languages, which are a lot more flexible than programming languages… The ambiguity in LLMs’ generated responses can be a dealbreaker.”
reliability is the solution. At a high level, reliability refers to a system’s ability to mitigate noise and abstract or avoid such inconsistent behavior with LLMs. This could mean anything from making the LLM more accurate to improving the consistency or predictability of the model’s behavior. If we want to maximize the utility of LLMs, we must find ways to make their behavior more reliable so that applications can be built around them without any unexpected “surprises” that break the system. Practically, this means that we must:
Adopt a more rigorous/systematic approach to prompt engineering.
Find techniques that make LLMs more predictable and accurate.
Enact safeguards/boundaries when the LLM fails to match our desired format.
Each of the above points is a step towards improving the reliability of LLMs. Put simply, we just want to find ways to make our LLM behave more consistently in an application so that the end user has less confusion and a more desirable experience. If we commit to a more rigorous approach to working with LLMs, it is totally possible to minimize the fragility of prompt engineering and lessen the overall ambiguity of LLMs. Within this overview, we will mostly focus on the second point outlined above—techniques that make LLMs more predictable and accurate.
Solving Tough Problems with LLMs

Although LLMs can solve many tasks with techniques like few-shot learning, they tend to struggle with solving multi-step problems or those that require reasoning [15]. As a solution, recent research has explored techniques like chain of thought (CoT) prompting [3], including several notable extensions like self-consistency [4], to improve the reasoning capabilities of LLMs. From this work, we learn that language models already have the ability to solve difficult (reasoning-based) problems—we just need to use the correct prompting approach!
“Large pretrained language models have built in reasoning capabilities, but they need specific prompts to unleash their power.” - from [1]
self-consistency. Given a CoT prompting approach, self-consistency [4] can improve the accuracy of an LLM by just i) generating multiple, different outputs from the same model and ii) using a majority vote of each output’s answer as our final answer; see below. This technique improves LLM accuracy by aggregating results over a diverse set of outputs. Self-consistency is both simple and effective, demonstrating that practical techniques for improving the reliability of LLMs may not be far beyond our reach. As such, we may wonder: how can we take this approach further? Are there other, simple techniques that work even better?

prompt ensembles. The effectiveness of self-consistency stems from the diversity of generated outputs that are considered when forming a final answer. However, there is one key detail of this technique that we should notice—all outputs are generated with the same prompt. To increase the diversity of generated outputs, we could consider a diverse set of multiple prompts for solving the same problem.
“People think differently, [but] different thoughts often lead to the same, correct answer.” - from [1]
Such an approach, called a prompt ensemble, can be used to generate an even more diverse set of model outputs compared to self-consistency, thus further improving the reliability LLM applications. Plus, prompt ensembles are simple to understand and can be constructed automatically without significant implementation effort. Within this post, we will explore recent research on prompt ensembles, focusing on practical tools making LLMs more effective.
Other Important Concepts
Beyond the ideas covered so far, there are a couple of small concepts and terms referenced later in the overview that might be useful to understand.
bootstrapping. This is a generic term that is commonly used in the broader computer science community. It refers to the idea of leveraging an existing resource to do something new or useful. In the case of this overview, we use bootstrapping to describe using an existing, pre-trained LLMs as a component within a system that generates new prompts for use in an ensemble.
weak supervision. There are many different ways to train a machine learning model. Weak supervision is a technique that falls between supervised and unsupervised learning. It is not completely reliant upon labeled data like supervised learning, but it does use some form of “labels” as a training signal. For example, we might generate “pseudo labels” using some heuristic, or even use a combination of labeled and unlabeled data during training. For more details, check out the awesome overview from Snorkel AI linked below.
jaccard index. The Jaccard Index, usually referred to as intersection over union (IoU) within the ML community, is used to compute the similarity between two finite sets. To compute the value of the Jaccard Index, we find the number of intersecting elements between the two sets, then divide this number by the size of the union between the two sets. For example, if we have two sets given by {a, b, c} and {b, c, d}, the Jaccard Index would be 0.5 (i.e., two elements intersect and there are four unique elements between both sets).
Research on Prompt Ensembles
Prior work on CoT prompting and self-consistency has shown us that smart prompting strategies can drastically improve the ability of LLMs to reliably solve difficult problems. We will now go beyond these straightforward baselines and take a look at recent research that studies the use of prompt ensembles with LLMs. Such work offers a wealth of practical knowledge regarding best practices that we can adopt to make LLMs more reliable.
Diverse Verifier on Reasoning Step (DiVeRSE) [1]
“People think differently, [but] different thoughts often lead to the same, correct answer.” - from [1]
Authors in [1] explore an extension to CoT and self-consistency prompting techniques [3, 4] that improves performance on complex, multi-step reasoning tasks. This technique, called DiVeRSE, uses prompt ensembles (i.e., collections of different prompts that aim to solve the same problem) to enhance the diversity of generated reasoning paths, then trains a verification module to infer the correctness of each output; see below.
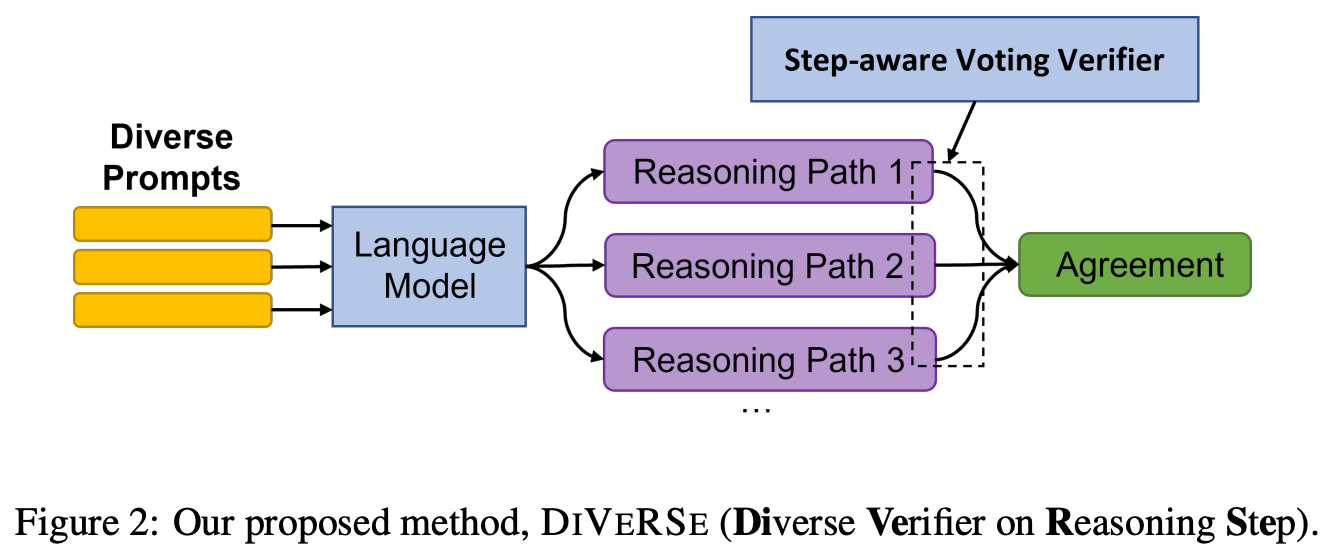
Both self-consistency and DiVeRSE generate multiple reasoning paths that are combined to form a final answer. However, self-consistency samples multiple reasoning paths from an LLM using the same prompt, while DiVeRSE constructs an ensemble of diverse prompts for solving the same problem and samples multiple reasoning paths from each of these prompts. Additionally, self-consistency just takes a majority vote over reasoning paths to form its final answer. DiVeRSE adopts a more sophisticated approach that:
Trains a verifier/classifier to predict the correctness of each reasoning path.
Takes a weighted average over reasoning paths based on correctness.
Put simply, DiVeRSE improves LLM reasoning capabilities by i) enhancing the diversity of generated reasoning paths and ii) assigning more weight to reasoning paths that are likely to be correct when constructing the final answer.

constructing prompt ensembles. One of the main benefits of DiVeRSE is its use of prompt ensembles to maximize the diversity of generated outputs. But, is generating these prompt ensembles expensive? Can we construct prompt ensembles automatically? Considering CoT prompting in particular, we can generate a prompt ensemble in two main ways (see figure above):
Resampling: Given a CoT prompt that contains a question, answer, and
Krationales for few-shot learning, we can generate unique prompts by randomly samplingR < Kexemplars from the full set of rationales.Bootstrapping: If our CoT prompt does not contain enough few-shot exemplars to perform resampling, we can simply prompt a separate LLM to generate pseudo reasoning paths to be included when performing resampling.
Using these techniques, we can generate prompt ensembles for DiVeRSE automatically without the requirement of significant, manual human effort.
“Causal language models have no mechanism to correct previous errors in earlier steps, which quickly leads to disoriented results.” - from [1]
verification module. To form its final answer, DiVeRSE uses a verification module to predict the correctness of each reasoning path that it generates, then takes a weighted average based on these predictions. The verifier is a binary classifier (e.g., based upon BERT [5] or DeBERTa [6]) that is trained over a dataset of correct and incorrect reasoning paths generated by the underlying LLM. Notably, labeled data is needed to generate this dataset for the verifier, as labels are used to determine if the final answer of any reasoning path is actually correct.
At test time, this verifier is used to generate a correctness score for each reasoning path generated by DiVeRSE, and paths with low correctness scores are given less of a vote towards the final answer. Interestingly, we see in [1] that performing step-wise verification (i.e., training the verifier to predict the correctness of each individual reasoning step instead of the path as a whole) in particular can lead to large improvements in reasoning performance; see below.

how does it perform? DiVeRSE is compared to baseline techniques like greedy decoding and self-consistency using several different LLMs, such as davinci (GPT-3), text-davinci-002 (GPT-3.5), and code-davinci-002 from the OpenAI API. On eight different reasoning tasks that perform arithmetic, commonsense, and inductive reasoning, DiVeRSE achieves consistent improvements over self-consistency; see below. Most notably, DiVeRSE with code-davinci-002 achieves state-of-the-art performance on six total benchmarks, even outperforming the powerful, 540 billion parameter PaLM model [7].

Going a bit further, authors in [1] perform analysis to show that i) prompt ensembles are beneficial to reasoning performance, ii) reasoning performance plateaus after a certain number of prompts are included in the ensemble, and iii) using verifiers (and step-wise verifiers in particular) performs better than majority voting (though majority voting is a lot simpler!); see below.


Now from our partners!
Rebuy Engine is the Commerce AI company. We use cutting edge deep learning techniques to make any online shopping experience more personalized and enjoyable.
MosaicML enables you to easily train and deploy large AI models on your data and in your secure environment. To try out their tools and platform, sign up here! Plus, MosaicML has a tendency to release awesome open-source, commercially-usable LLMs.
Ask Me Anything (AMA) [2]

Authors in [2] explore practical techniques for effectively constructing and using prompt ensembles. At a high level, the proposed technique, called Ask Me Anything (AMA), is motivated by eliminating the need to construct a “perfect” prompt. Instead, we can design an effective and reliable prompting strategy by generating an ensemble of imperfect (but still effective) prompts and aggregating their results. But, we need to be smart about how we aggregate the results of these prompts (i.e., majority voting does not work well enough!). Plus, we can’t just use any set of prompts! In particular, we see in [2] that the most effective prompt ensembles utilize prompts that encourage open-ended generation.
Although this sounds great, we might have a few questions. Does this work for all tasks? Is collecting the prompts expensive? How should we aggregate results? The approach proposed in [2] is designed to be both scalable and generic, meaning that it can be used to improve performance on any model or task. Such efficiency and effectiveness comes from three major ideas:
Prompt structure: AMA emphasizes the use of open-ended prompts, as opposed to those that restrict tokens in the output.
Scalable prompt generation: Instead of using humans to write ensembles of open-ended prompts manually, AMA uses LLMs to both generate and answer prompts, thus reducing human-required effort.
Weak supervision: Because majority voting does not perform well, AMA uses weak supervision to learn dependencies between prompts and aggregate LLM outputs into an accurate, final answer.
why do majority votes not work well? In addition to improving the quality and structure of prompts present in an ensemble, work in [2] is motivated by the fact that generating a final answer by taking a majority vote of LLM outputs over a prompt ensemble (e.g., as in self-consistency [4]) works poorly. But, why is this the case? Interestingly, authors in [2] provide a pretty clear and intuitive answer.
“We see 9.5% average variation in accuracy and that the Jaccard index over errors is 69% higher than if prompt errors were i.i.d. Majority vote (MV) is the primary unsupervised aggregation strategy in prior work but it does not account for either property, making it unreliable.” - from [2]
To rephrase the above statement, the errors that LLMs make are not randomly distributed! Rather, LLM outputs over multiple different prompts may cluster around a single, wrong answer. This is a huge problem for majority voting, because a wrong answer may actually be our majority vote! To account for this, we need a more sophisticated strategy that can detect and handle such cases by modeling the accuracy and dependencies between prompt outputs in an ensemble.
constructing an awesome prompt ensemble. As a first step, authors in [2] study the types of prompts that comprise the most effective ensembles. Three different categories of prompting techniques are considered, as shown in the figure below.
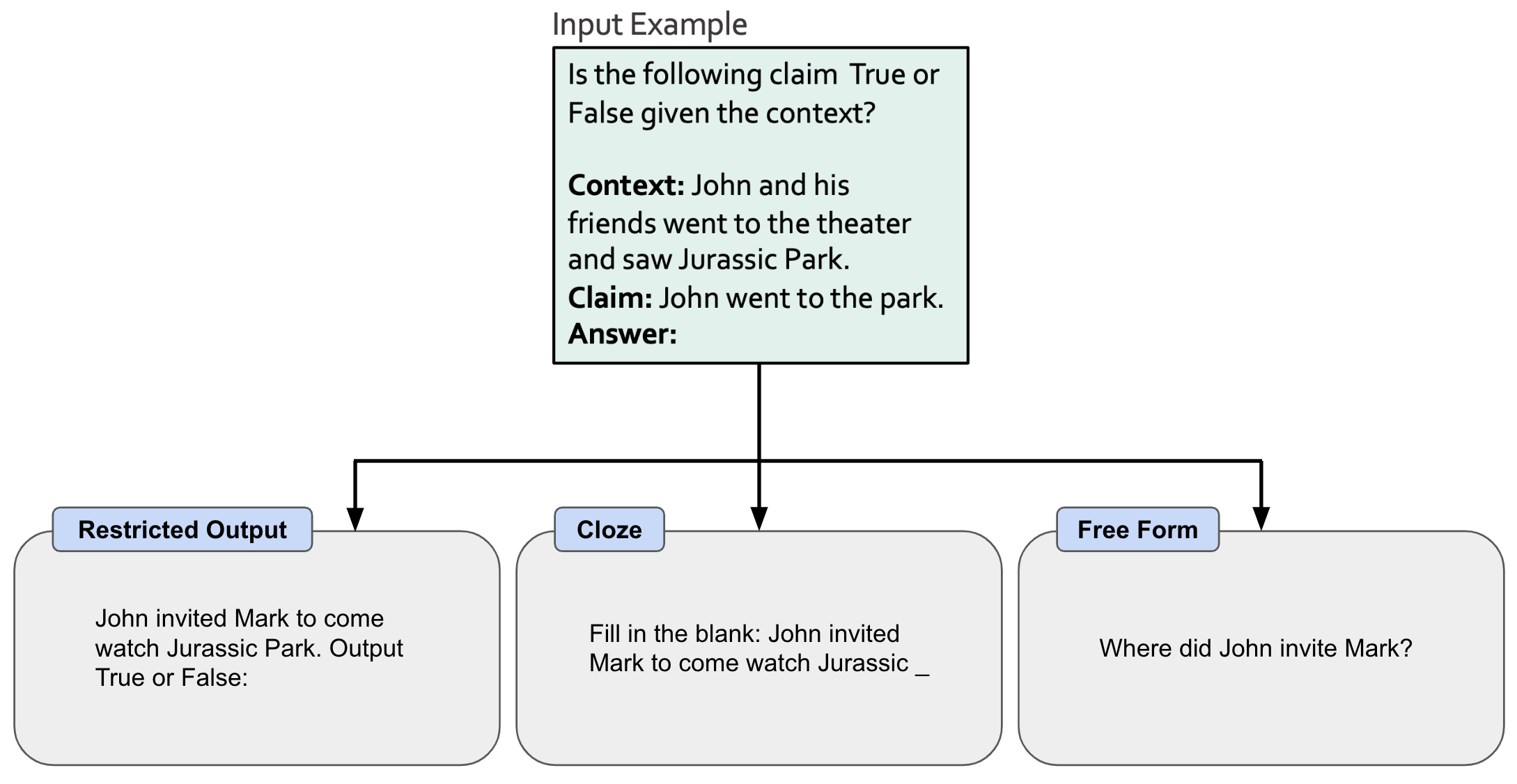
When these prompting strategies are compared, we see that open-ended prompt formats (i.e., Cloze and free form) outperform restrictive prompt formats that ask the LLM to output a particular set of tokens. Going a bit further, making the questions within a free-form prompt more precise or specific also provides a decent boost in accuracy. Why does free form prompting work better? The answer is not completely clear, but free-form generation more closely mirrors the next-token prediction task used for pre-training most LLMs, which intuitively means that such models may be better at solving tasks in this format.

Motivated by the effectiveness of open-ended prompts, AMA forms prompt ensembles by generating sets of questions about a given input; see above. These questions follow a free-form format and emphasize different aspects of the input that may provide useful and complementary information. However, generating these questions manually can be expensive! To avoid this, we can just use LLMs! In [2], we see that LLMs can be used to generate useful questions about a desired topic by using few-shot learning; see below.

By varying the in-context examples that are used and adopting a set of several prompt templates that are empirically determined to perform well, authors in [2] completely automate the construction of prompt ensembles within AMA!
“To aggregate prompt predictions reliably, we apply tools from weak supervision, a powerful approach for learning high-quality models from weaker sources of signal without labeled data.” - from [2]
aggregating the results. We can construct a prompt ensemble, but there’s one question remaining: how do we aggregate the LLM’s output from each prompt? Especially for free form prompts, extracting a correct answer from LLM outputs can be quite difficult. The aggregation approach in [2] draws upon prior work in weak supervision and graphical models [8, 9, 10]. The high level idea is to use weak supervision to learn and predict the dependencies between different prompts and the accuracy of each prompt. We can use this information to aggregate prompts and infer the most likely final answer. Unlike DiVeRSE, such an approach requires no labeled data and solves common failure cases of majority voting (e.g., LLMs producing the same error on different prompts).
does AMA perform well? The AMA approach is tested on 20 different benchmarks using variety of LLMs (i.e., four different model families, including BLOOM, OPT, EleutherAI, and T0) with sizes ranging from 125 million to 175 billion parameters. The goal of analysis in [2] is to determine whether AMA is a generic approach that can work across many different settings. The results of this analysis are quite positive. Using AMA, we see that small, open-source models (i.e., GPT-J-6B in particular) can outperform large models like GPT-3; see below.
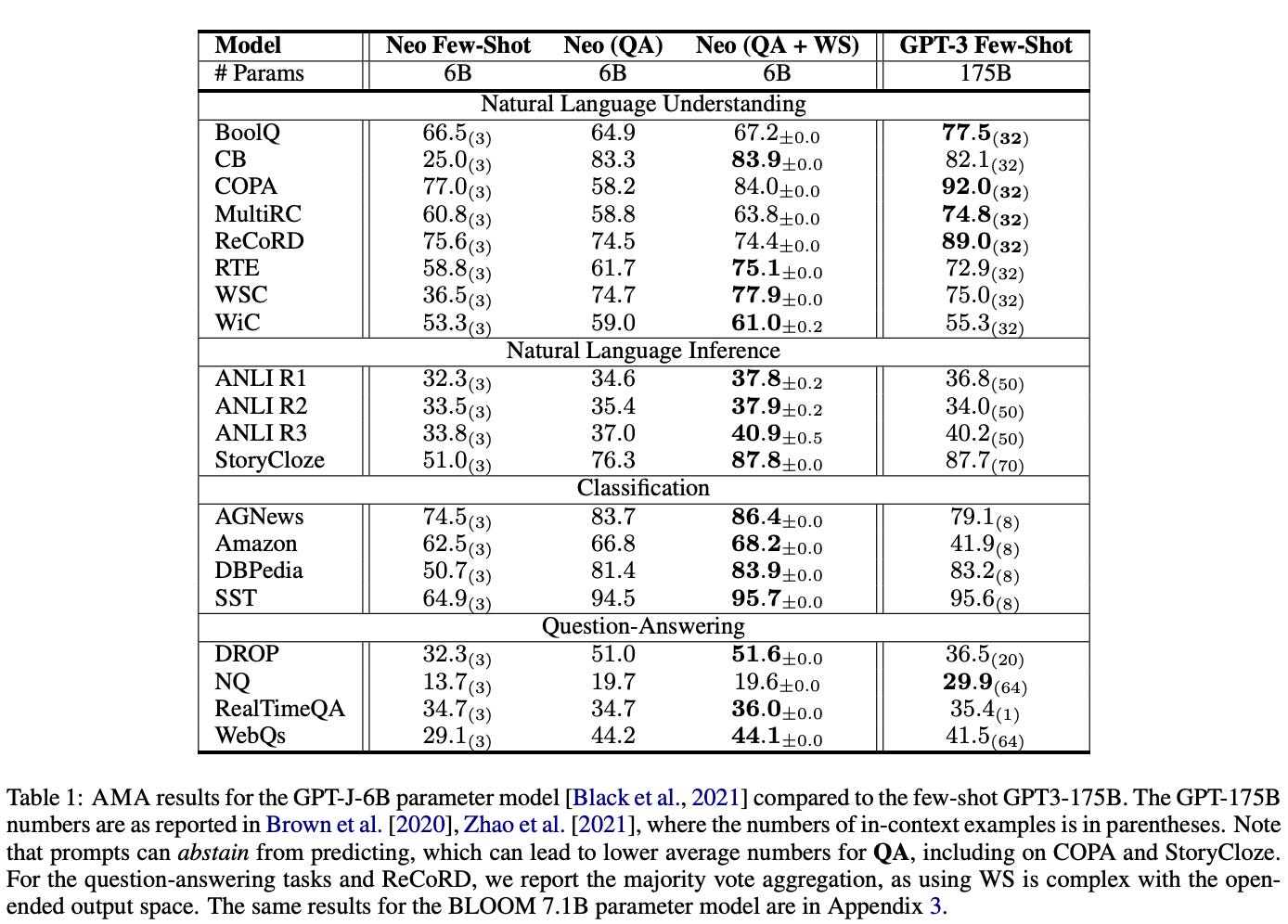
When all different models are tested, we see that models of intermediate scale (i.e., 6-20 billion parameters ) see the most benefit from AMA; see below. Relative to baseline, few-shot prompting techniques, AMA provides a ~10% absolute improvement in performance across all models and tasks. Thus, it is a generic approach that can reliably improve the performance of nearly any LLM.
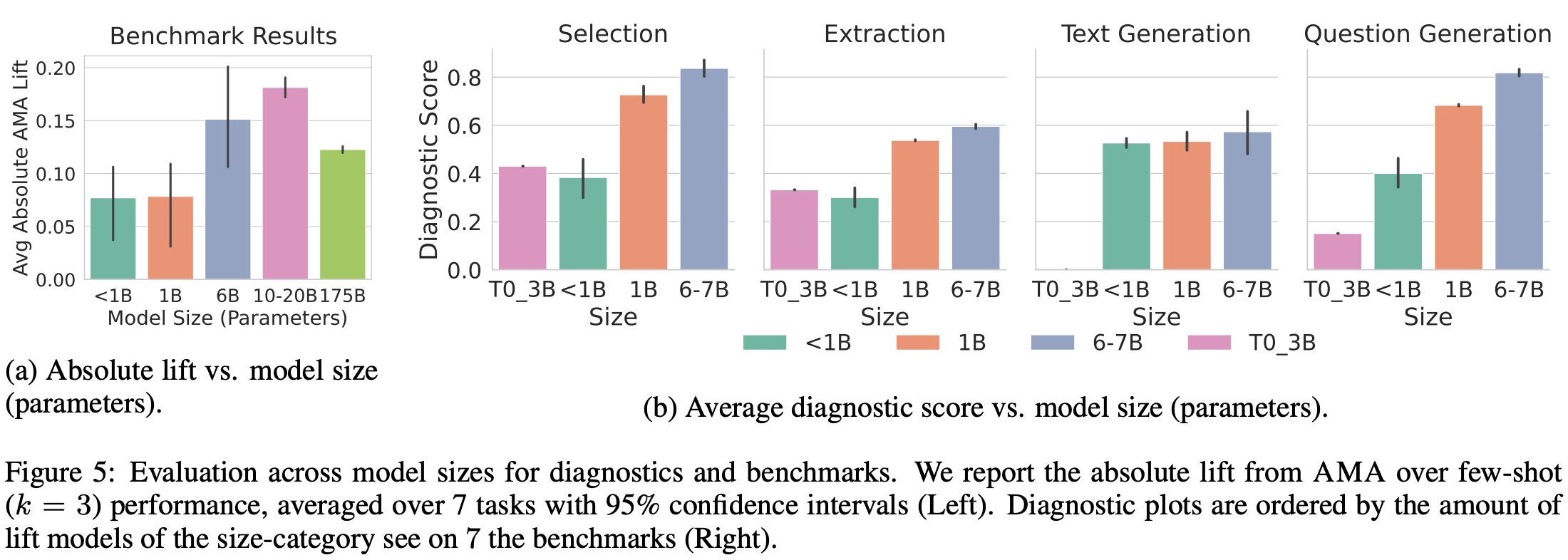
AMA provides an insightful approach for constructing prompt ensembles. The publication is full of practical tips for bootstrapping pretrained LLMs to write effective prompts. We see in [2] that the methodology used to aggregate LLM responses over the prompt ensemble is incredibly important—majority voting is not sufficient! The aggregation approach proposed in [2] is technically complex and would likely require implementation effort, but it performs well and requires no supervised labels. By adopting approaches such as AMA, we can improve LLM reliability by making any LLM more accurate and consistent.
“We hope AMA and future work help address pain points of using LLMs by improving the ability to proceed with less-than-perfect prompts and enabling the use of small, private, and open-source LLMs.” - from [2]
Closing Thoughts
Hopefully, we should now understand that prompt ensembles are easy to use and hold a massive amount of potential. To leverage this technique, we just need to i) construct a set of diverse prompts that are meant to solve the same problem, ii) generate multiple LLM outputs with each of these prompts, and iii) aggregate these outputs to form a final answer. As we have seen, the aggregation process might be somewhat complex (i.e., majority voting usually isn’t enough). However, the construction and use of prompt ensembles is simple, making them a powerful tool for LLM reliability. Some of the major takeaways are outlined below.
reliability is important. To use LLMs in the real world, we need to build software systems around them. But, to build software systems around LLMs, we need to mitigate the unpredictable/ambiguous nature of these models. Prompt ensembles provide a pretty straightforward approach for making LLMs more accurate and reliable. By encouraging an LLM to produce a diverse set of outputs for solving a particular problem, we can study the relationship between these responses and develop automatic techniques to produce a higher-quality, final result.
generalization across LLMs. Typically, prompt engineering strategies are brittle. If we tweak our prompt, we may get a drastically different result. The same holds true if we keep the prompt fixed and change our model. If we build an LLM-powered application and later decide to switch the underlying model being used, we will probably have to change most of the prompts being used as well. With techniques like AMA [2], however, we see that prompt ensembles can mitigate this problem, as they provide a consistent improvement in performance across a variety of different models. Thus, prompt ensembles improve reliability through their lack of sensitivity to the underlying model being used.
aggregation is difficult. After reading about self-consistency, I was optimistic that LLMs could be made significantly more reliable with simple prompting techniques. As we see in this overview, this is not always true. We can easily generate multiple, diverse outputs for any given problem with an LLM, but the manner in which we aggregate these responses is pivotal. Unfortunately, the approaches proposed by DiVeRSE and AMA are quite complex and would likely require a significant amount of implementation effort. But, we clearly see that just taking a majority vote falls short of the performance of more complex techniques. Hopefully, simpler aggregation techniques will be proposed soon.
limitations. Although prompt ensembles are awesome, they are not perfect. Techniques like DiVeRSE and AMA rely upon producing numerous outputs with an LLM for every question that is answered. We use multiple prompts and might even generate multiple responses for every prompt—that’s a lot of inference with an LLM! Because of this, prompt ensembles can be expensive, both monetarily and from a latency perspective. If we want to leverage prompt ensembles in a real-world application, we must be very careful about how it is applied, as it could drastically alter the application’s cost and efficiency.
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a better understanding of deep learning research via understandable overviews that explain relevant topics from the ground up. If you like this newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Li, Yifei, et al. "On the advance of making language models better reasoners." arXiv preprint arXiv:2206.02336 (2022).
[2] Arora, Simran, et al. "Ask Me Anything: A simple strategy for prompting language models." arXiv preprint arXiv:2210.02441 (2022).
[3] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[4] Wang, Xuezhi, et al. "Self-consistency improves chain of thought reasoning in language models." arXiv preprint arXiv:2203.11171 (2022).
[5] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[6] He, Pengcheng, et al. "Deberta: Decoding-enhanced bert with disentangled attention." arXiv preprint arXiv:2006.03654 (2020).
[7] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[8] Ratner, Alexander, et al. "Snorkel: Rapid training data creation with weak supervision." Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases. Vol. 11. No. 3. NIH Public Access, 2017.
[9] Varma, Paroma, et al. "Learning dependency structures for weak supervision models." International Conference on Machine Learning. PMLR, 2019.
[10] Ratner, Alexander, et al. "Training complex models with multi-task weak supervision." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. No. 01. 2019.
[11] Taylor, Ross, et al. "Galactica: A large language model for science." arXiv preprint arXiv:2211.09085 (2022).
[12] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
[13] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[14] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[15] Cobbe, Karl, et al. "Training verifiers to solve math word problems." arXiv preprint arXiv:2110.14168 (2021).
[16] Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." arXiv preprint arXiv:2205.11916 (2022).
[17] Zhou, Denny, et al. "Least-to-most prompting enables complex reasoning in large language models." arXiv preprint arXiv:2205.10625 (2022).
Another gold worthy content!