


Chain of Thought Prompting for LLMs
A practical and simple approach for "reasoning" with LLMs...


The success of large language models (LLMs) stems from our ability to pre-train (using a language modeling objective) decoder-only transformer models across massive textual corpora. Given that we pre-train sufficiently large models, LLMs are incredibly capable few-shot learners. In other words, this means that we can solve a variety of different problems (e.g., translation, sentence classification, summarization, etc.) by just formulating a textual prompt (potentially containing a few example of correct output) and having the LLM generate the correct answer.
Despite the power of LLMs, there are some problems that these models consistently struggle to solve. In particular, reasoning problems (e.g., arithmetic or commonsense reasoning) are notoriously difficult. Initial attempts to solve this issue explored fine-tuning LLMs and task-specific verification modules over a supervised dataset of solutions and explanations of various reasoning problems [3, 4]. However, recent work has found that few-shot learning can be leveraged for an easier solution.
“The goal of this paper is to endow language models with the ability to generate a chain of thought—a coherent series of intermediate reasoning steps that lead to the final answer for a problem.” - from [1]
In particular, chain-of-thought (CoT) prompting [1] is a recently-proposed technique that improves LLM performance on reasoning-based tasks via few-shot learning. Similar to standard prompting techniques, CoT prompting inserts several example solutions to reasoning problems into the LLM’s prompt. Then, each example is paired with a chain of thought, or a series of intermediate reasoning steps for solving the problem. The LLM then learns (in a few-shot manner) to generate similar chains of thought when solving reasoning problems. Such an approach uses minimal data (i.e., just a few examples for prompting), requires no task-specific fine-tuning, and significantly improves LLM performance on reasoning-based benchmarks, especially for larger models.
Core Concepts
To understand CoT prompting, we need a baseline understanding of LLMs and how they work. Luckily, we have covered this topic extensively in prior overviews:
Introduction to Language Models [link]
GPT-3 and Language Model Scaling Laws [link]
Modern LLMs [link]
Specialized LLMs [link]
We will not cover the fundamentals of LLMs within this section. Rather, we will focus upon developing a better understanding of prompting and few-shot learning for LLMs, as well as explore how such techniques may be leveraged to solve a core limitation of these models: their inability to solve reasoning tasks.
Prompting and Few-Shot Learning
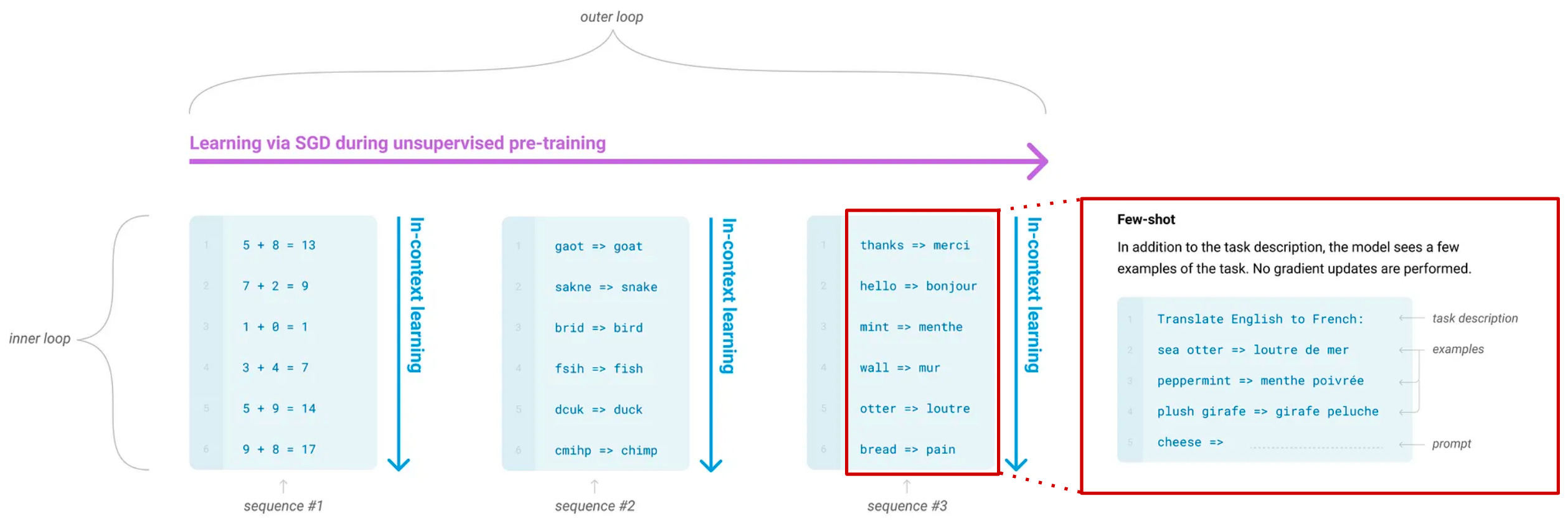
After the proposal of language models like GPT and GPT-2, we knew that pre-training via a self-supervised next-token prediction (or language modeling) objective was quite powerful. However, the correct way to adapt these generic foundation models to solve a specific, downstream task was not as clear. For example, GPT fine-tunes the model on downstream tasks, while GPT-2 solves problems in a zero-shot manner; see below.

After the proposal of GPT-3 [2], we saw that LLMs of sufficient scale can perform few-shot learning quite well. After pre-training via a language modeling objective, GPT-3 (a 175 billion parameter LLM), was found to accurately solve a variety of different language tasks without any fine-tuning. We can instead replace fine-tuning with a prompting approach.
More specifically, prompting exploits the text-to-text structure of language models by providing inputs like the following:
“Translate this sentence to English:
<sentence> =>”“Summarize the following document:
<document> =>”.
These task-solving “prompts” enable zero-shot (i.e., without seeing examples of correct output; see above) or few-shot (i.e., with a few examples of correct output inserted in the prompt; see below) inference with language models. The most appropriate output from the language model should solve the task (e.g., summarizing a document or completing a reasoning task), meaning that we can solve a variety of problems with accurate next-token prediction!

We can do a lot with prompting. In fact, an entire field of prompt engineering has been recently created to study how the wording or structure of prompts can be optimized to improve LLM performance. But, sensitivity is a huge consideration in this developing field. LLM performance may change massively given small perturbations to the input prompt (e.g., permuting few-shot exemplars decreases GPT-3 accuracy from 93.4% to 54.3% on SST-2 [13]). Thus, in our study of prompting approaches, we aim to find techniques that i) perform well and ii) are not subject to sensitivity.
Can we solve reasoning with scale?
As mentioned above, LLM few-shot learning performance improves with scale, but large models are not all that we need. Powerful LLMs require a combination of large models with massive pre-training datasets [14]. With this in mind, we might ask ourselves: what about the performance of LLMs specifically on reasoning-based datasets? Do LLMs get better at reasoning as we scale them up?
“Scaling up model size alone has not proved sufficient for achieving high performance on challenging tasks such as arithmetic, commonsense, and symbolic reasoning” - from [1]
Interestingly, we tend to see that using larger models and pre-training datasets does not improve LLM reasoning abilities (e.g., see analysis from Gopher [15]). In fact, these models have been heavily criticized for their inability to solve basic reasoning tasks. As a result, many researchers claim that LLMs are simply regurgitating training data rather than performing any complex reasoning or analysis. Either way, this overview will focus on prompting techniques that try to solve this problem and enable LLMs to more easily solve basic reasoning tasks.

prior approaches. Before learning more about how we can help LLMs to solve reasoning problems, it’s useful to understand prior approaches in this space. Baseline techniques for arithmetic, commonsense, and symbolic reasoning tasks perform task-specific fine-tuning, meaning that the model is trained over supervised examples of each reasoning problem being solved. Going further, the best approaches train a supplemental “verification” module that can judge the correctness of LLM output on reasoning tasks [4]. At test time, this verifier can deduce the best-possible output after generating several answers to a problem; see above.
Although these techniques might work relatively well in some cases, they are limited for a few reasons:
Task-specific fine-tuning is required.
The model architecture must be adapted (i.e., via the verification model) for each task.
Large amounts of supervised data must be collected.
With these limitations in mind, it becomes clear that using a prompting-only approach (e.g., CoT prompting) to solving reasoning tasks would be much simpler. We could avoid fine-tuning, maintain the same model architecture, collect less data, and solve many tasks with the a single pre-trained model checkpoint.
Some notable LLMs…
CoT prompting is a prompting technique that is applied to improve the few-shot learning performance of pre-trained LLMs. In [1], a specific group of LLMs are used for evaluation, which are listed and explained below.
GPT-3 [2]: 175 billion parameter LLM that is pre-trained using a standard language modeling objective.
LaMDA [5]: an LLM-based dialogue model that is pre-trained using a language modeling objective, then fine-tuned over dialogue data and human-provided feedback (models with sizes 422M, 2B, 8B, 68B, and 137B exist).
PaLM [6]: an LLM that is pre-trained using a standard language modeling objective, Google’s Pathways framework, and a massive textual corpus (models with sizes 8B, 62B, and 540B exist).
Codex [7]: a 12 billion parameter LLM that is pre-trained using a standard language modeling objective, then fine-tuned on publicly-available Python code from GitHub.
UL2-20B [8]: an LLM that is pre-trained using the Mixture-of-Denoisers (MoD) objective, a unified objective that performs well across many datasets and setups.
Beyond these LLMs, we have learned about other models (e.g., LLaMA, LLaMA extensions, and T5) in recent overviews as well.
Chain of Thought Prompting

Although we might understand the idea of prompting in general, what is CoT prompting? CoT simply refers to a specific prompting technique that inserts a chain of thought (i.e., a series of intermediate reasoning steps) into an LLM’s prompt; see above. For sufficiently large models (>100 billion parameters), this approach significantly improves the complex reasoning capabilities of LLMs on arithmetic, commonsense and symbolic reasoning tasks.
where does CoT prompting come from? Prior to the proposal of CoT prompting, we were already aware that few-shot learning was incredibly powerful for LLMs; see below. Instead of fine-tuning an LLM to perform a task, we just “prompt” a generic model with a few examples of the correct output before generating a final answer. Such an approach is incredibly successful for a range of tasks.
Plus, we knew from related work that generating natural language rationales that explain how to arrive at a final answer is beneficial for arithmetic reasoning tasks. We can train or fine-tune models to generate these rationales [3, 4], but this requires creating a dataset of high-quality rationales for different reasoning tasks, which is expensive and time consuming!
“A prompting only approach is important because it does not require a large training dataset and a single model can perform many tasks without loss of generality.” - from [1]
CoT prompting combines the strengths of few-shot prompting with the benefit of generating natural language rationales. Instead of performing extra training or fine-tuning, we can just insert a few examples of rationales (i.e., chains of thought) into the prompt, allowing the LLM to few-shot learn to generate similar rationales.
How does CoT prompting work?
When we solve reasoning tasks as humans, it is common to break the problem down into smaller tasks. For example, I typically do the following when calculating how much I want to tip at a restaurant:
Take the total amount of the bill: $56.00
Compute 10% of the total: $5.60
Multiply this value by 2 (yielding a 20% tip): $11.20
Although this example is simple, the idea extends to a variety of mental reasoning tasks that we solve as humans. We generate a chain of thought (defined as “a coherent series of intermediate reasoning steps that lead to the final answer for a problem” in [1]) to solve such tasks. Put simply, CoT prompting augments LLMs with the ability to generate similar chains of thought.
“We explore the ability of language models to perform few-shot prompting for reasoning tasks, given a prompt that consists of triples: [input, chain of thought, output].” - from [1]
Examples of solutions to reasoning tasks combined with a chain of thought on several different problems are shown below.

learning chains of thought. To teach LLMs to generate problem-solving rationales, we can just insert examples of such rationales into their prompt. Then, the LLMs can leverage their few-shot learning capabilities to generate similar chains of thought when solving any reasoning problem. As shown below, the prompt usually includes several chain of thought examples.

Authors in [1] find that such a prompting approach leads LLMs to generate similar chains of thought when solving problems, which aids reasoning capabilities and has several notable benefits:
Interpretability: the LLM’s generated chain of thought can be used to better understand the model’s final answer.
Applicability: CoT prompting can be used for any task that can be solved by humans via language.
Prompting: no training or fine-tuning is required of any LLMs. We can just insert a few CoT examples into the prompt!
Plus, LLMs can even allocate more computational resources to complex reasoning problems by just generating a chain of thought with more steps. This mimics what we would typically do as humans!
CoT Prompting is Massively Beneficial
To evaluate its impact on the ability of LLMs to solve reasoning problems, CoT prompting is tested on arithmetic, commonsense and symbolic reasoning benchmarks. Evaluation is performed using several different pre-trained LLMs, including GPT-3 [2], LaMDA [5], PaLM [6], Codex [7], and UL2 [8]. As a baseline, authors in [1] use standard, few-shot prompting, as proposed by GPT-3. All models use greedy decoding during evaluation, but better results can be achieved by taking a majority vote of multiple samples [9].
arithmetic reasoning. Arithmetic reasoning tasks consist of math word problems. Such problems are simple for humans to solve, but LLMs are known to struggle with them. An overview of arithmetic reasoning datasets used in [1] is provided below.
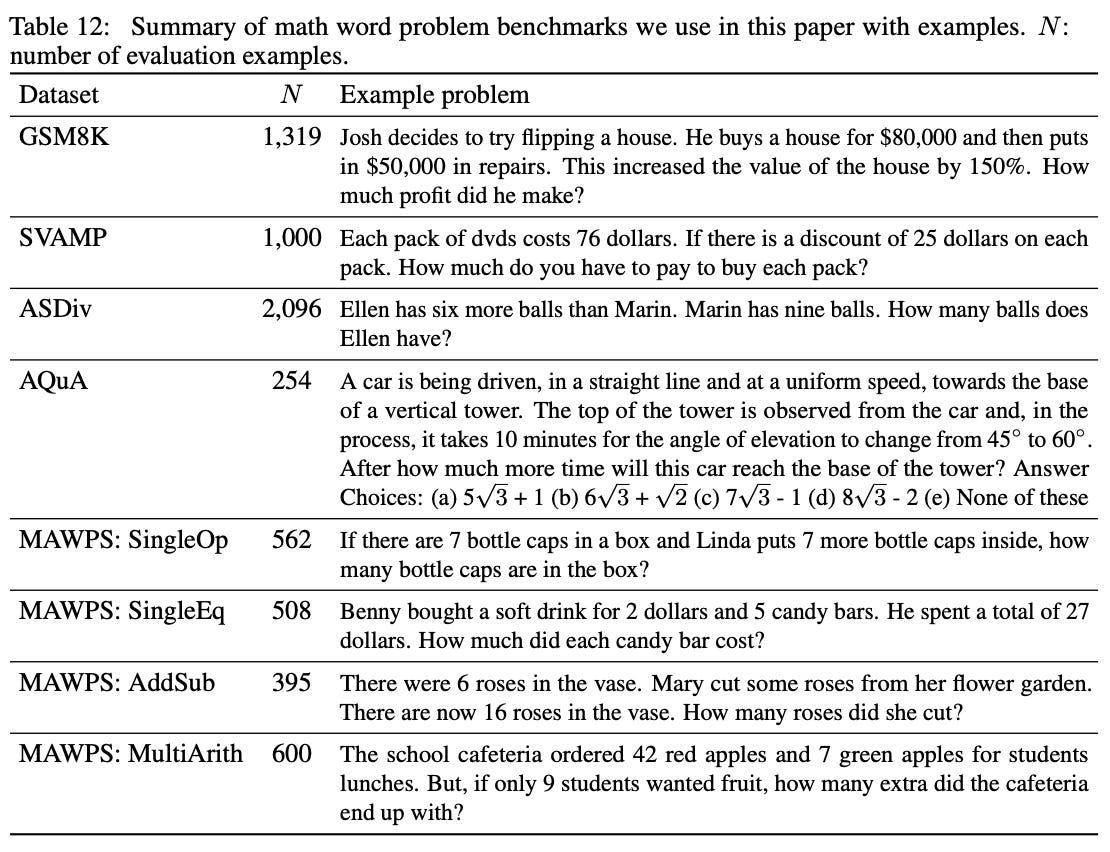
For CoT prompting, a set of eight few-shot examples are manually composed (without extensive prompt engineering) and used across all datasets except for AQuA, which has a multiple choice structure. Results of experiments with CoT prompting on arithmetic reasoning datasets with several LLMs are shown below.

From these experiments, we discover a few notable properties of CoT prompting. First, CoT prompting seems to work much better for larger LLMs (i.e., >100B parameters). Smaller models are found to produce illogical chains of thought, thus degrading performance compared to standard prompting. Additionally, more complicated problems (e.g., GSM8K) see a greater benefit from CoT prompting. Compared to prior state-of-the-art methods (which perform task-specific fine-tuning), CoT prompting with GPT-3 and PaLM-540B achieves comparable or improved performance in all cases.
When we qualitatively examine the correct and incorrect answers generated by CoT prompting, we learn the following:
Most correct answers are the result of a logical chain of thought, aside from a few cases that coincidentally predict the correct answer from an incorrect chain of thought.
46% of incorrect answers are nearly correct, meaning that they contain chains of thought with minor mistakes.
56% of incorrect answers are the result of chains of thought with major issues in understanding or reasoning.
Authors in [1] also analyze the robustness of CoT prompting to different structures (e.g., permuting few-shot examples) and ablate various aspects of CoT prompting, finding that CoT yields a consistent and unique benefit to model performance. Interestingly, CoT prompting is not very sensitive to small prompt perturbations.
commonsense reasoning. Commonsense reasoning problems assume a grasp of general background knowledge and require reasoning over physical and human interactions. Adopting a similar setup to arithmetic reasoning experiments (aside from a few dataset that require manual curation of few-shot examples), authors evaluate a variety of pre-trained LLMs on commonsense reasoning tasks, yielding the results shown in the figure below.

Put simply, CoT prompting is found to provide a massive benefit on commonsense reasoning problems as well. Again, we see that larger models benefit more from CoT prompting. However, both standard prompting and CoT prompting performance improves with model scale, where CoT prompting tends to achieve slightly improved performance.
symbolic reasoning. Authors in [1] also evaluate CoT prompting on symbolic reasoning tasks, such as:
Last Letter Concatenation: asks the model to concatenate and output the last letters for each word in a sequence.
Coin Flip: asks the model to determine if a coin is still heads up after a sequence of coin flips.
Going further, both in-domain and out-of-domain symbolic reasoning tests are considered, where out-of-domain examples are defined as those that require more reasoning steps (e.g., more words in last letter concatenation or a longer sequence of coin flips) than exemplars seen during training or in the few-shot prompt. The results of in-domain and out-of-domain evaluation are shown below.

Although these tasks are simplistic, we see above that CoT thought prompting i) improves performance on both symbolic reasoning tasks and ii) enables better generalization to out-of-domain problems that require more reasoning steps. Plus, we again observe that smaller models are incapable of solving symbolic reasoning tasks both with or without CoT prompting. Thus, CoT prompting again seems to be a highly beneficial approach for symbolic reasoning.
Variants of CoT Prompting
After the proposal of CoT prompting in [1], several variants were proposed that can improve the reasoning capabilities of LLMs. These different variants provide a variety of interesting and practical approaches for eliciting “reasoning” behavior in LLMs. A list of notable CoT prompting variants is provided below.

zero-shot CoT. Zero-shot CoT prompting [10] is a simple followup to CoT prompting [1]. To encourage an LLM to generate a chain of thought, zero-shot CoT simply appends the words “Let’s think step by step.” to the end of the question being asked. By making this simple addition to the LLM’s prompt, we see in [10] that LLMs are able to generate chains of thought even without observing any explicit examples of such behavior, allowing them to arrive at more accurate answers on reasoning tasks. See above for a comparison of zero-shot CoT with other prompting approaches.

self-consistency. Self-consistency is a variant of CoT prompting that uses the LLM to generate multiple chains of thought, then takes the majority vote from these generations as the final answer; see above. In cases where CoT prompting is ineffective, using self-consistency oftentimes improves results. Put simply, self-consistency just replaces the greedy decoding procedure used in [1] with a pipeline that generates multiple answers with the LLM and takes the most common of these answers.

least-to-most prompting. Least-to-most prompting goes beyond CoT prompting by first breaking down a problem into smaller sub-problems, then solving each of these sub-problems individually. As each sub-problem is solved, its answers are included in the prompt for solving the next sub-problem. Compared to CoT prompting, least-to-most prompting yields accuracy improvements on several tasks (e.g., last letter concatenation) and improves generalization to out-of-domain problems that require more reasoning steps.
prompt engineering. As demonstrated by the examples above (and the idea of CoT prompting in general), curating a useful prompt for an LLM is an art. To learn more about how to engineer more effective prompts, I strongly recommend the course provided on the Learn Prompting website linked below.
Takeaways
Within this overview, we have seen that standard prompting is not enough to get the most out of LLMs. Rather, it seems to provide a sort of “lower bound” for LLM performance, especially on more difficult, reasoning-based tasks. CoT prompting goes beyond standard prompting techniques by leveraging few-shot learning capabilities of LLMs to elicit the generation of coherent, multi-step reasoning processes while solving reasoning-based problems. Such an approach is massively beneficial to LLM performance, especially for larger models. Some takeaways are provided below.
the utility of CoT prompting. LLMs are bad at handling tasks like commonsense, arithmetic, and symbolic reasoning. However, CoT prompting drastically improves performance on these tasks. Plus, this approach requires i) no fine-tuning and ii) minimal extra data (i.e., just a set of exemplars for few-shot learning). Thus, it is an easy-to-use technique that, given some effort on prompt engineering and curation of a few exemplars, can help pre-trained LLMs to solve tasks with which they typically struggle.
reasoning emerges with scale. Not all models benefit from CoT prompting. In fact, larger LLMs see a disproportionate benefit from CoT prompting compared to smaller models. In [1], authors observe that the benefits of CoT prompting emerge in models with >100 billion parameters. This exact number is likely to depend heavily on experimental settings, but the general idea is clear: the benefit of CoT prompting is most noticeable in larger models.
“Chain of thought emulates the thought processes of human reasoners. This does not answer whether the neural network is actually reasoning.” - from [1]
do LLMs actually know how to reason? CoT prompting helps LLMs to solve certain reasoning tasks, but this does not necessarily mean that LLMs possess complex reasoning capabilities. Authors in [1] even specifically state that analysis of CoT prompting does not answer whether LLMs are actually reasoning or not. Rather, CoT prompting is an empirical technique that can be used to more accurately solve tasks like arithmetic, commonsense, and symbolic reasoning that are typically problematic for LLMs. Whether we believe that LLMs are capable of reasoning or not, we can agree that this technique is practically useful.
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a better understanding of deep learning research via understandable overviews that explain relevant topics from the ground up. If you like this newsletter, please subscribe, share it, or follow me on twitter!
Bibliography
[1] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
[2] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[3] Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. 2017. Program induction by rationale generation: Learning to solve and explain algebraic word problems. ACL.
[4] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
[5] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
[6] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[7] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[8] Tay, Yi, et al. "Ul2: Unifying language learning paradigms." The Eleventh International Conference on Learning Representations. 2022.
[9] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. 2022a. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
[10] Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." arXiv preprint arXiv:2205.11916 (2022).
[11] Wang, Xuezhi, et al. "Self-consistency improves chain of thought reasoning in language models." arXiv preprint arXiv:2203.11171 (2022).
[12] Zhou, Denny, et al. "Least-to-most prompting enables complex reasoning in large language models." arXiv preprint arXiv:2205.10625 (2022).
[13] Zhao, Zihao, et al. "Calibrate before use: Improving few-shot performance of language models." International Conference on Machine Learning. PMLR, 2021.
[14] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[15] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
Such an interesting read, thank you for sharing the knowledge.