


Vision Transformers
... is using them actually worth it?


What are Vision Transformers?
Transformers are a type of deep learning architecture, based primarily upon the self-attention module, that were originally proposed for sequence-to-sequence tasks (e.g., translating a sentence from one language to another). Recent deep learning research has achieved impressive results by adapting this architecture to computer vision tasks, such as image classification. Transformers applied in this domain are typically referred to (not surprisingly) as vision transformers.
Wait … how can a language translation model be used for image classification? Good question. Although this post will deeply explore this topic, the basic idea is to:
Convert an image into a sequence of flattened image patches
Pass the image patch sequence through the transformer model
Take the first element of the transformer’s output sequence and pass it through a classification module
Compared to widely-used convolutional neural network (CNN) models, vision transformers lack useful inductive biases (e.g., translation invariance and locality). Nonetheless, these models are found to perform quite well relative to popular CNN variants on image classification tasks, and recent advances have made their efficiency—both in terms of the amount of data and computation required—more reasonable. As such, vision transformers are now a viable and useful tool for deep learning practitioners.
Background
self-attention
The transformer architecture is comprised of two major components: feed-forward networks and self-attention. Though feed-forward networks are familiar to most, I find that self-attention is oftentimes less widely-understood. Many thorough descriptions of self-attention exist online, but I will provide a brief overview of the concept here for completeness.
what is self-attention? Self-attention takes n elements (or tokens) as input, transforms them, and returns n tokens as output. It is a sequence-to-sequence module that, for each input token, does the following:
Compares that token to every other token in the sequence
Computes an attention score for each of these pairs
Sets the current token equal to the weighted average of all input tokens, where weights are given by the attention scores
Such a procedure adapts each token in the input sequence by looking at the full input sequence, identifying the tokens within it that are most important, and adapting each token’s representation based on the most relevant tokens. In other words, it asks the question: “Which tokens are worth paying attention to?” (hence, the name self-attention).
multi-headed self-attention. The variant of attention used in most transformers is slightly different than the description provided above. Namely, transformers oftentimes leverage a “multi-headed” version of self attention. Although this may sound complicated, it’s not … at all. Multi-headed self-attention just uses multiple different self-attention modules (e.g., eight of them) in parallel. Then, the output of these self-attention models is concatenated or averaged to fuse their output back together.
where did this come from? Despite the use of self-attention within transformers, the idea predates the transformer architecture. It was used heavily with recurrent neural network (RNN) architectures [6]. In these applications, however, self-attention was usually used to aggregate RNN hidden states instead of performing a sequence-to-sequence transformation.
the transformer architecture
Vision transformer architectures are quite similar to the original transformer architecture proposed in [4]. As such, a basic understanding of the transformer architecture—especially the encoder component—is helpful for developing an understanding of vision transformers. In this section, I will describe the core components of a transformer, shown in the figure below. Although this description assumes the use of textual data, different input modalities (e.g., flattened image patches, as in vision transformers) can also be used.

constructing the input. The transformer takes a sequence of tokens as input. These tokens are generated by passing textual data (e.g., one or a few sentences) through a tokenizer that divides it into individual tokens. Then, these tokens, each associated with a unique integer ID, are converted into their corresponding embedding vectors by indexing a learnable embedding matrix based on the token IDs, forming an (N x d) matrix of input data (i.e., N tokens, each represented with a vector of dimension d).
Typically, an entire mini-batch of size (B x N x d), where B is the batch size, is passed to the transformer at once. To avoid issues with different sequences having different lengths, all sequences are padded (i.e., using zero or random values) to be of identical length N. Padded regions are ignored by self-attention.
Once the input is tokenized and embedded, one final step must be performed—adding positional embeddings to each input token. Self-attention has no notion of position—all tokens are considered equally no matter their position. As such, learnable position embeddings must be added to each input token to inject positional information into the transformer.

the encoder. The encoder portion of the transformer has many repeated layers of identical structure. In particular, each layer contains the following modules:
Multi-Headed Self-Attention
Feed-Forward Neural Network
Each of these modules are followed by layer normalization and a residual connection. By passing the input sequence through these layers, the representation for each token is transformed using:
the representations of other, relevant tokens in the sequence
a learned, multi-layer neural network that implements non-linear transformation of each individual token
When several of such layers are applied in a row, these transformations produce a final output sequence of identical length with context-aware representations for each token.
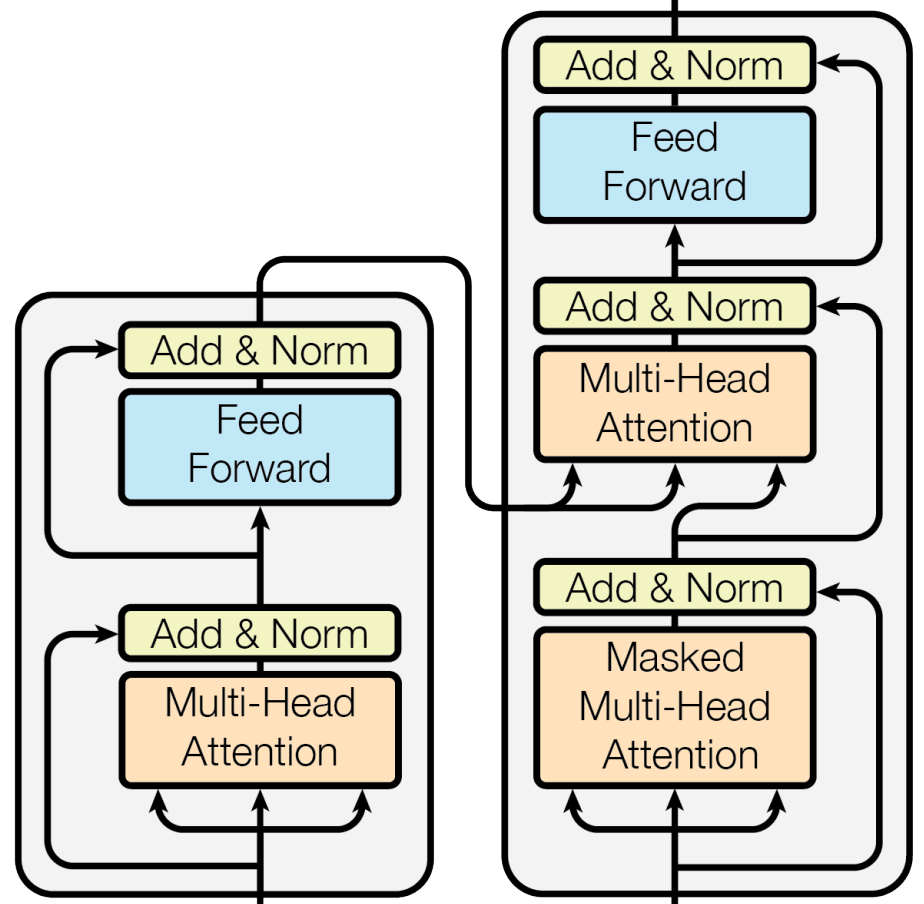
the decoder. Decoders are not relevant to vision transformers, which encoder-only architectures. However, we will briefly overview the decoder architecture here for completeness. Similarly to the encoder, the transformer’s decoder contains multiple layers, each with the following modules:
Masked Multi-Head Attention
Multi-Head Encoder-Decoder Attention
Feed-Forward Neural Network
Masked Self-Attention is similar to normal/bi-directional self-attention, but it prevents “looking ahead” in the input sequence (i.e., this is necessary for sequence-to-sequence tasks like language translation). Each token can only be adapted based on tokens that come before it in the input sequence. Encoder-decoder self-attention is also quite similar to normal self-attention, but representations from the encoder are also used as input, allowing information from the encoder and the decoder to be fused. Then, the result of this computation is again passed through a feed-forward neural network.
different architecture variants. In addition to the sequence-to-sequence transformer model described in this section, many architectural variants exist that leverage the same, basic components. For example, encoder-only transformer architectures, commonly used in language understanding tasks, completely discard of the decoder portion of the transformer, while decoder-only transformer architectures are commonly used for language generation. Vision transformer typically leverage an encoder-only transformer architecture, as there is no generative component that requires the use of masked self-attention.
self-supervised pre-training
Though transformers were originally proposed for sequence-to-sequence tasks, their popularity expanded drastically as the architecture was later applied to problems like text generation and sentence classification. One of the major reasons for the widespread success of transformers was the use of self-supervised pre-training techniques.
Self-supervised tasks (e.g., predicting masked words; see figure above) can be constructed for training transformers over raw, unlabeled text data. Because such data is widely available, transformers could be pre-trained over vast quantities of textual data before being fine-tuned on supervised tasks. Such an idea was popularized by BERT [7], which achieved shocking improvements in natural language understanding. However, this approach was adopted in many later transformer applications (e.g., GPT-3 [9]).
Interestingly, despite the massive impact of self-supervised learning in natural language applications, this approach has not been as successful in vision transformers, though many works have attempted the idea [11, 12].
some revolutionary transformer applications…
With a basic grasp on the transformer architecture, it is useful to put into perspective the drastic impact that this architecture has had on deep learning research. Originally, the transformer architecture was popularized by its success in language translation [4]. However, this architecture has continued to revolutionize numerous domains within deep learning research. A few notable transformer applications (in chronological order) are listed below:
BERT uses self-supervised pre-training to learn high-quality language representations [paper][code]
GPT-2/3 utilize decoder-only transformer architectures to revolutionize generative language modeling [blog][paper]
AlphaFold2 uses a transformer architecture to solve the long-standing protein folding problem [paper][code]
DALLE-2 leverages CLIP latents (and diffusion) to achieve shocking results in multi-modal generation [blog][paper]
Although the applications of transformers are vast, the main takeaway that I want to emphasize is simple: transformers are extremely effective at solving a wide variety of different tasks.
Publications
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [1]
Although the transformer architecture had a massive impact on the natural language processing domain, the extension of this architecture into computer vision took time. Initial attempts fused popular CNN architectures with self-attention modules to create a hybrid approach, but these techniques were outperformed by ResNet-based CNN architectures.
Beyond integrating transformer-like components into CNN architectures, an image classification model that directly utilizes the transformer architecture was proposed in [1]. The Vision Transformer (ViT) model divides the underlying image into a set of patches, each of which are flattened and projected (linearly) to a fixed dimension. Then, a position embedding is added to each image patch, indicating each patch’s location in the image. Similar to any other transformer architecture, the model’s input is just a sequence of vectors; see below.

The authors adopt BERT base and large [7] (i.e., encoder-only transformer architectures) for their architecture, which is then trained by attaching a supervised classification head to the first token in the model’s output. For training, a two step pre-training and fine-tuning procedure is followed. Either the JFT-300M (very large), ImageNet-21K (large), or ImageNet-1K (medium) dataset is used for supervised pre-training. Then, the model is fine-tuned on some target dataset (e.g., Oxford Flowers or CIFAR-100), after which final performance is measured.
Without pre-training over sufficient data, the proposed model does not match or exceed state-of-the-art CNN performance. Such a trend is likely due to the fact that, while CNNs are naturally invariant to patterns like translation and locality, transformers have no such inductive bias and must learn these invariances from the data. As the model is pre-trained over more data, however, performance improve drastically, eventually surpassing the accuracy of CNN-based baselines even with lower pre-training cost; see the results below.

Training data-efficient image transformers & distillation through attention [2]
Although vision transformers were demonstrated to be effective for image classification in previous work, such results relied upon extensive pre-training over external datasets. For example, the best ViT models performed pre-training over the JFT-300M dataset that contains 300 million images prior to fine-tuning and evaluating the model on downstream tasks.
Although prior work claimed that extensive pre-training procedures were necessary, authors within [3] offered an alternative proposal, called the Data-efficient Image Transformer (DeiT), that leverages a curated knowledge distillation procedure to train vision transformers to high Top-1 accuracy without any external data or pre-training. In fact, the full training process can be completed in three days on a single computer.
The vision transformer architecture used in this work is nearly identical to the ViT model. However, an extra token is added to the input sequence, which is referred to as the distillation token; see the Figure below.

This token is treated identically to the others. But, after exiting the final layer of the transformer, it is used to apply a distillation component to the network’s loss. In particular, a hard distillation (i.e., as opposed to soft distillation) loss is adopted that trains the vision transformer to replicate the argmax output of some teacher network (typically a CNN).
At test time, the token output for the class and distillation tokens are fused together and used to predict the network’s final output. The DeiT model outperforms several previous ViT variants that are pre-trained on large external datasets. DeiT achieves competitive performance when pre-trained on ImageNet and fine-tuned on downstream tasks. In other words, it achieves compelling performance without leveraging external training data.
Beyond its impressive accuracy, the modified learning strategy in DeiT is also quite efficient. Considering the throughput (i.e., images processed by the model per second) of various different image classification models, DeiT achieves a balance between throughput and accuracy that is similar to the widely-used EfficientNet [4] model; see the figure below.

Learning Transferable Visual Models From Natural Language Supervision [3]

The Contrastive Language-Image Pre-training Model (CLIP)—recently re-popularized due to its use in DALLE-2–was the first to show that large numbers of noisy image-caption pairs can be used for learning high-quality representations of images and text. Previous work struggled to properly leverage such weakly-supervised data, due to the use of poorly-crafted pre-training tasks; e.g., directly predicting each word of the caption using a language model. CLIP presents a more simple pre-training task—matching images to the correct caption within a group of potential captions. This simplified task provides a better training signal to the model that enables high-quality image and textual representations to be learned during pre-training.
The model used within CLIP has two main components–an image encoder and a text encoder; see the figure above. The image encoder is either implemented as a CNN or a vision transformer model. However, authors find that the vision transformer variant of CLIP achieves improved computational efficiency during pre-training. The text encoder is a simple decoder-only transformer architecture, meaning that masked self-attention is used within the transformer’s layers. The authors choose to use masked self-attention so that the textual component of CLIP can be extended to language modeling applications in the future.
Using this model, the pre-training task is implemented by separately encoding images and captions, then applying a normalized, temperature-scaled cross entropy loss to match image representations to their associated caption representations. The resulting CLIP model revolutionized zero-shot performance for image classification, improving zero-shot test accuracy on ImageNet from 11.5% to 76.2%. To perform zero-shot classification, authors simply:
Encode the name of each class using the text encoder
Encoder the image using the image encoder
Choose the class that maximizes the cosine similarity with the image encoding
Such a procedure is depicted within the figure above. For more information on CLIP, please see my previous overview of the model.
ViTs work … but are they practical?
Personally, I was initially quite skeptical of using vision transformers, despite being aware of their impressive performance. The training process seemed too computationally expensive. Most of the compute cost of training vision transformers, however, is associated with pre-training. In [2], authors eliminated the need for extensive pre-training and directly demonstrated that the training throughput of vision transformers was comparable to highly-efficient CNN architectures like EfficientNet. Thus, vision transformers are a viable and practical deep learning tool, as their overhead does not significant surpass that of a normal CNN.
Takeaways
Although transformer are widely successful in natural language processing, this overview should (hopefully) communicate the fact that they are also useful for computer vision tasks. CNNS are a difficult baseline to beat, as they achieve impressive levels of performance in an efficient—both in terms of data and compute—manner. However, recent modifications to the vision transformer architecture, as outlined in [2], have made clear that vision transformers perform favorably relative to CNNs and are actually quite efficient.
vision transformers in code. For those who are interested in implementing and/or playing around with vision transformer architectures, I would recommend starting with the link below.
This tutorial allows you to (i) download pre-trained ViT parameters and (ii) fine-tune these parameters on downstream vision tasks. I find the code in this tutorial quite simple to follow. One can easily extend this code to different applications, or even implement some of the more complex training procedures overviewed within [2] or other work.
future papers to read. Although a few of my favorite vision transformer works were overviewed within this post, the topic is popular and hundreds of other papers exist. A few of my (other) personal favorites are:
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions [paper]
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet [paper]
Mlp-mixer: An all-mlp architecture for vision [paper]
New to the Newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University studying the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I pick a single, bi-weekly topic in deep learning research, provide an understanding of relevant background information, then overview a handful of popular papers on the topic. If you like this newsletter, please subscribe or check out my other writings!
I end each newsletter with a quote to ponder. I’m a big fan of stoicism, deep focus, and finding passion in life. So, finding this quote each week keeps me accountable with my reading, thinking, and mindfulness. I hope you enjoy it!
“Nothing is enough for the man to whom enough is too little.”
-Epicurus
Keep learning and don’t forget to have some fun along the way!
Bibliography
[1] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[2] Touvron, Hugo, et al. "Training data-efficient image transformers & distillation through attention." International Conference on Machine Learning. PMLR, 2021.
[3] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International Conference on Machine Learning. PMLR, 2021.
[4] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[5] Tan, Mingxing, and Quoc Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." International conference on machine learning. PMLR, 2019.
[6] Lin, Zhouhan, et al. "A structured self-attentive sentence embedding." arXiv preprint arXiv:1703.03130 (2017).
[7] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[8] Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI blog 1.8 (2019): 9.
[9] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[10] Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 (2022).
[11] Chen, Xinlei, Saining Xie, and Kaiming He. "An empirical study of training self-supervised vision transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[12] Caron, Mathilde, et al. "Emerging properties in self-supervised vision transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.