


Language Understanding with BERT
The most useful deep learning model?

What is BERT?
Bidirectional Encoder Representations from Transformers (BERT) [1] is a popular deep learning model that is used for numerous different language understanding tasks. BERT shares the same architecture as a transformer encoder, and is extensively pre-trained on raw, unlabeled textual data using a self-supervised learning objective, before being fine-tuned to solve downstream tasks (e.g., question answering, sentence classification, named entity recognition, etc.). At the time of its proposal, BERT obtained a new state-of-the-art on eleven different language understanding tasks, prompting a nearly-instant rise to fame that has lasted ever since.
The incredible effectiveness of BERT arises from:
Pre-training over large amounts of raw textual data via self-supervised learning
Crafting rich, bidirectional feature representations of each token within a sequence
Although previous work demonstrated that language modeling tasks benefit from pre-training over large textual corpora, BERT extended this idea by crafting a simple, yet effective, suite of self-supervised pre-training tasks that enable relevant features to be learned. Additionally, BERT moved away from the common practice of using unidirectional self-attention, which was commonly adopted to enable language modeling-style pre-training within such language understanding tasks. Instead, BERT leveraged bidirectional self-attention within each of its layers, revealing that bidirectional pre-training is pivotal to achieving robust language representations.
BERT is very useful. At this point, you might be wondering: Why would you devote and entire post to this single model? The simple answer is that BERT is incredibly generic — this single model architecture can be used to solve a surprising number of different tasks with state-of-the-art accuracy, including both token-level (e.g., named entity recognition) and sentence-level (e.g., sentiment classification) language understanding tasks. Additionally, its use has been expanded beyond the natural language processing (NLP) domain to solve problems like multi-modal classification [2], semantic segmentation [3], and more.
Claiming that a single deep learning model is the “most useful” is a bit of a stretch (though it makes for a good thumbnail!). BERT, however, is undoubtedly one of the most important tools for any deep learning practitioner. Put simply, this architecture, with minimal task-specific modifications, can be downloaded (i.e., pre-trained parameters are available online) and fine-tuned at a low computational cost to solve a swath of potential problems in NLP and beyond — it is the “Swiss Army Knife” of deep learning!
Building Blocks of BERT
Before overviewing the specifics of the BERT architecture, it’s important to build an understanding of core components and ideas upon which BERT is built. These main concepts can be boiled down to the following:
(Bidirectional) Self-Attention
Transformer Encoders
Self-Supervised Learning
self-attention

I have already overviewed the basic ideas behind self-attention in previous posts, but I’ll provide another, more BERT-specific, discussion of the concept here. At a high-level, self-attention is a non-linear transformation that takes a sequence of “tokens” (i.e., just single elements in a sequence) as input, each of which is represented as a vector. The matrix associated with this input sequence is depicted above. Then, these token representations are transformed, returning a new matrix of token representations.
what happens in this transformation? For each individual token vector, self-attention does the following:
Compares that token to every other token in the sequence
Computes an attention score for each of these pairs
Adapts the current token’s representation based on other tokens in the sequence, weighted by the attention score
Intuitively, self-attention just adapts each token’s vector representation based on the other tokens within the sequence, forming a more context-aware representation; see below.

multiple attention heads. Self-attention is usually implemented in a multi-headed fashion, where multiple self-attention modules are applied in parallel before having their outputs concatenated. The mechanics of self-attention are still the same within each individual attention head, though the token vectors will be linearly projected to a lower dimension before self-attention is applied (to avoid excessive increases in computational cost).
The benefit of such a multi-headed approach lies in the fact that each attention head within a multi-headed attention layer can learn different attention patterns within the underlying sequence. Thus, the model is not bottlenecked or limited by the number of other tokens that can be “attended to” within a single self-attention layer. Rather, different patterns of token relationships can be captured by each of the different heads.
unidirectional vs. bidirectional. When crafting a context-aware representation of each token in the sequence, there are two basic options in defining this context:
Consider all tokens
Consider all tokens to the left of the current token
These options, depicted in the image below, yield two different variants of self-attention: bidirectional and unidirectional.
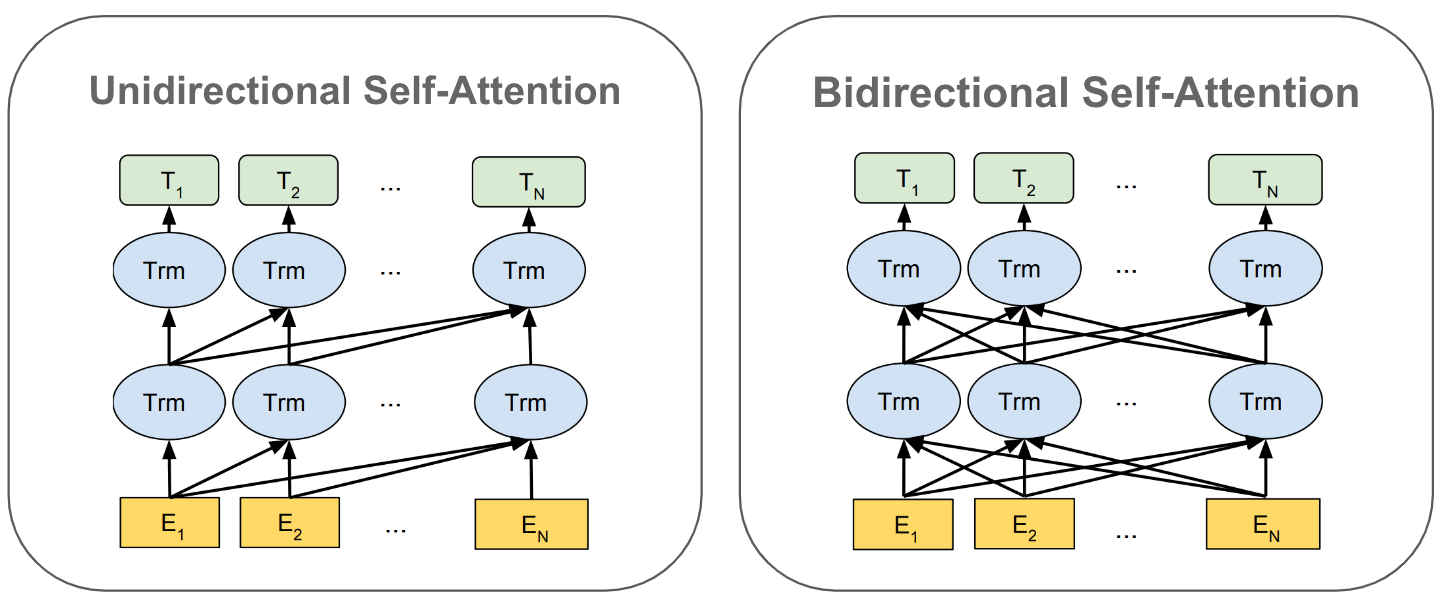
Unidirectional self-attention ensures that the representation of each token only depends on those that precede it in the sequence (i.e., by just “masking” the tokens that come later in the sequence during self-attention). Such a modification is needed for applications like language modeling that should not be allowed to “look forward” in the sequence to predict the next word.
In contrast, bidirectional self-attention crafts each token representation based on all other tokens within a sequence. This bidirectional variant of self-attention is pivotal to the success of BERT, as many prior modeling approaches:
utilized unidirectional self-attention [4]
crafted shallow, bidirectional features by concatenating unidirectional representations for the sentence in both forward and backward directions [5]
These approaches were not nearly as effective as BERT’s use of bidirectional self-attention, which emphasizes the benefit of bidirectional feature representations in tasks beyond language modeling.
transformer encoders
The transformer architecture [6] typically has two components—an encoder and a decoder. BERT, however, only uses the encoder component of the transformer, depicted below.

As can be seen, the transformer encoder is just several repeated layers with (bidirectional, multi-headed) self-attention and feed-forward transformations, each followed by layer normalization and a residual connection. Simple enough!
why only the encoder? You can see my previous post for a more in-depth discussion of transformers, but the two components of the transformer architecture tend to serve separate purposes.
the encoder: leverages bidirectional self-attention to encode the raw input sequence into a sequence of discriminative token features.
the decoder: takes the rich, encoded representation, and decodes it into a new, desired sequence (e.g., the translation of the original sequence into another language).
In the case of BERT, we will see in the remainder of this post that such a decoding process is not necessary. BERT’s purpose is to simply to craft this initial, encoded representation, which can then be used for solving different downstream tasks.
self-supervised learning

One of the key components to BERT’s incredible performance is its ability to be pre-trained in a self-supervised manner. At a high level, such training is valuable because it can be performed over raw, unlabeled text. Because data of this kind is widely available online (e.g., via online book repositories or websites like Wikipedia), a large corpus of textual data can be gathered for pre-training, enabling BERT to learn from a diverse dataset that is orders of magnitude larger than most supervised/labeled datasets.
Though many example of self-supervised training objectives exist, some examples—which we will outline further in this post—include:
Masked Language Modeling (MLM): masking/removing certain words in a sentence and trying to predict them.
Next Sentence Prediction (NSP): given a pair of sentences, predicting whether these sentences follow each other in the text corpus or not.
Neither of these tasks require any human annotation. Rather, they can be performed with unlabeled textual data.
is this unsupervised learning? One point worthy of distinction here is the difference between self-supervised learning and unsupervised learning. Both unsupervised and self-supervised learning do not leverage labeled data. However, while unsupervised learning is focused upon discovering and leveraging latent patterns within the data itself, self-supervised learning instead finds some supervised training signal that is already present in the data and uses it for training, thus requiring no human intervention. This distinction is nuanced, but (luckily) it has been outlined and explained beautifully by Ishan Misra on the Lex Fridman podcast. Check out the timestamp below.
How BERT actually works…
Although we’ve outlined a few fundamental ideas behind BERT so far, in this section I will describe BERT in more detail, focusing upon its architecture and training scheme.
BERT’s architecture
As mentioned before, the architecture of BERT is just the encoder portion of a transformer model [6] (i.e., an encoder-only transformer architecture). In the original publication, two different sizes of BERT were proposed (though many more exist now):
BERT Base: 12 layers, 768-dimensional hidden representations, 12 attention heads in each self-attention module, and 110M parameters.
BERT Large: 24 layers, 1024-dimensional hidden representations, 16 attention heads in each self-attention module, and 340M parameters.
Notably, BERT Base is the same size as OpenAI’s GPT [7], which allowed fair comparisons to be drawn between the models.
Why is this different? The main distinction between BERT and previously-proposed language understanding models (e.g., OpenAI GPT) lies in the use of bidirectional self-attention. Previous work, despite utilizing self-supervised pre-training, used only unidirectional self-attention, which severely limited the quality of token representations that the model could learn.
“Intuitively, it is reasonable to believe that a deep bidirectional model is strictly more powerful than either a left-to-right model or the shallow concatenation of a left-to-right and a right-to-left model.” - from [1]
Constructing the input sequence. Intuitively, BERT takes some textual sequence as input. In particular, this sequence is usually a single sentence or a pair of two, consecutive sentences.

This high-level idea is simple, but you might be wondering: how do we arrive at a BERT-compatible input sequence from raw text? This process can be broken down into a few steps:
tokenization: raw textual data is broken into individual tokens or elements that represent words or parts of words.
inserting “special” tokens: BERT’s input sequence begins with a
[CLS]token and ends with a[SEP]token, indicating the start/end of a sentence. If two consecutive sentences are used, another[SEP]token is placed between them.embedding: converting each token into its corresponding WordPiece [8] embedding vector.
additive embeddings: the input data is now a sequence of vectors. Learnable embeddings are added to each element in this sequence, representing the element’s position in the sequence and whether it is part of the first or second sentence. Such information is needed because self-attention cannot otherwise distinguish an element’s position within a sequence.
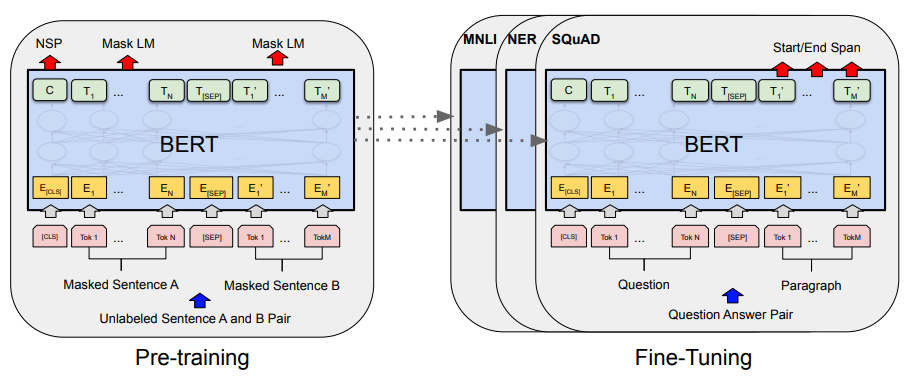
By following these steps, raw textual data is converted into a sequence of vectors that can be ingested by BERT. The tokenization, insertion of special tokens, and embedding processes are depicted within the image above, while the additive embedding process is depicted below.

The embedding process of BERT is explained well in the paper, but I recommend the article below for more details on tokenization.
training BERT
The training process for BERT proceeds in two steps:
pre-training
fine-tuning
The architecture is nearly identical between these steps, though some small, task-specific modules may be used (e.g., MLM and NSP both use a single, additional classification layer).
pre-training. During pre-training, the BERT model is trained over unlabeled data using two different tasks: MLM (also called the Cloze task [9]) and NSP. Notably, BERT cannot be trained with the typical, language modeling objective used in prior work, in which the model iteratively attempts to predict the next word within a sequence. The use of bidirectional self-attention would allow BERT to cheat by simply observing and copying this next token.

The NSP task, illustrated in the figure above, is quite simple. Consecutive sentences from the pre-training corpus are passed into BERT (i.e., sentences A and B), and 50% of the time the second sentence is replaced with another, random sentence. Then, the final representation of the [CLS] token, after being processed by BERT, is passed through a classification module that predicts whether the inputted sentences are an actual match.

MLM, depicted above, is not a sequence-level task like NSP. It randomly masks 15% of the tokens within the input sequence by replacing them with the special [MASK] token. Then, the final representation for each of these [MASK] tokens is passed through a classification layer to predict the masked word. Instead of always masking the tokens in this way, however, authors replace each token with [MASK] 80% of the time, a random token 10% of the time, and the original token 10% of the time. Such a modification is implemented to avoid issues with the [MASK] token being present in pre-training but not fine-tuning.
Using these tasks, BERT is pre-trained over a corpus comprised of BooksCorpus and English Wikipedia. Interestingly, using a document level corpus (as opposed to a corpus of shuffled sentences) is instrumental to the quality of pre-training. Your corpus needs to have long-range dependencies between sentences for BERT to learn the best-possible features. This interesting finding is also confirmed by later work. In fact, even re-ordering randomly-shuffled sentences based on TF-IDF score to form synthetic, long-term dependencies improves pre-training quality [10].
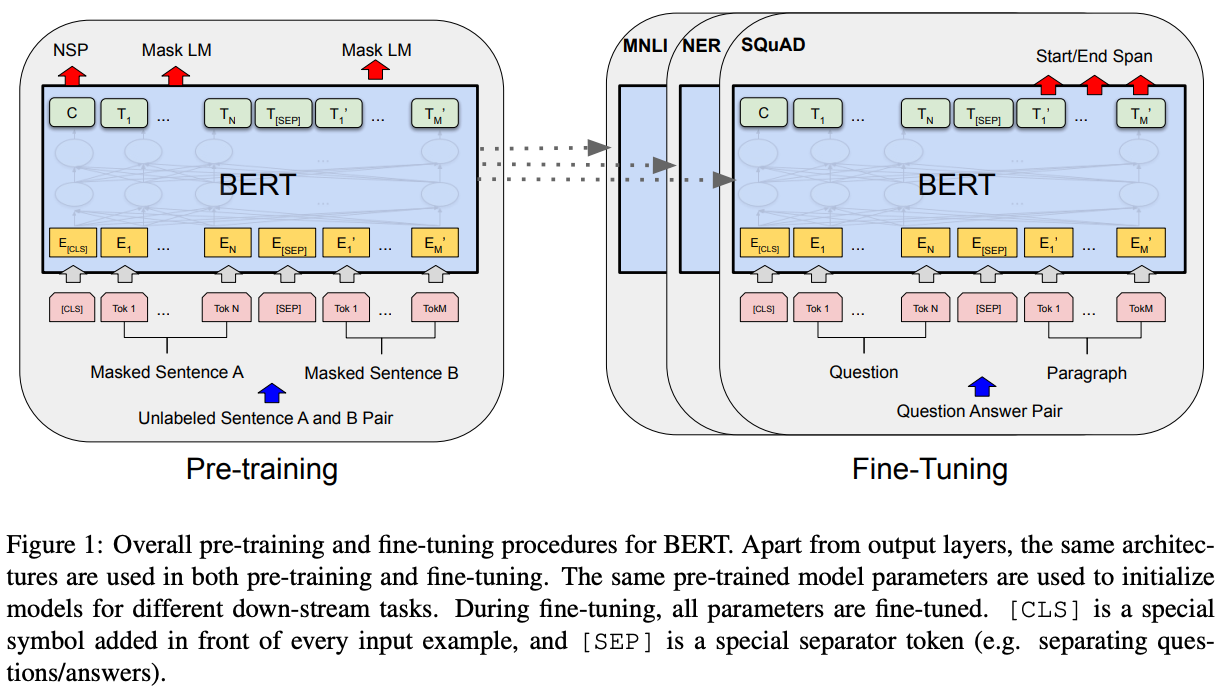
fine-tuning. The self-attention mechanism within BERT is constructed such that modeling different kinds of downstream tasks is as simple as possible. In most cases, one just has to match the input-output structure of the task to the input-output structure of BERT, then perform fine-tuning over all model parameters. Some examples of this, also depicted in the figure below, include:
token-level tasks: process your sequence normally, then pass each token’s output representation through a separate module to perform the prediction for a given token.
sentence/document-level tasks: process your sequence normally, then pass the
[CLS]token’s output representation (an aggregate embedding of the input sequence) through a separate module to perform a sequence-level prediction.text pair tasks: encode each part of the text pair as “sentence A” and “sentence B” within BERT’s input structure, then pass the
[CLS]token’s output representation through a separate module to perform a prediction based on your text pair.
The general task structures listed above should demonstrate that BERT is a versatile model. Many different tasks could be solved by simply mapping them to the input-output structure of BERT, and minimal architectural modifications are required relative to pre-training. See below for examples of different language understanding tasks that can be solved with BERT.

During fine-tuning, all BERT parameters are trained in an end-to-end fashion. In comparison to pre-training, the fine-tuning process for BERT is inexpensive. In fact, all of the results within the papers itself take less than 2 hours to replicate with a single GPU. If you don’t believe me, try it out for yourself!
BERT might be the best thing since sliced bread!
Before concluding this overview, I want to outline some of the empirical results achieved with BERT. Although one can easily read the paper themselves to see the results, I think they are worth briefly covering for one reason—to emphasize how good BERT is at NLP tasks. The results achieved with BERT on various different tasks are outlined below.
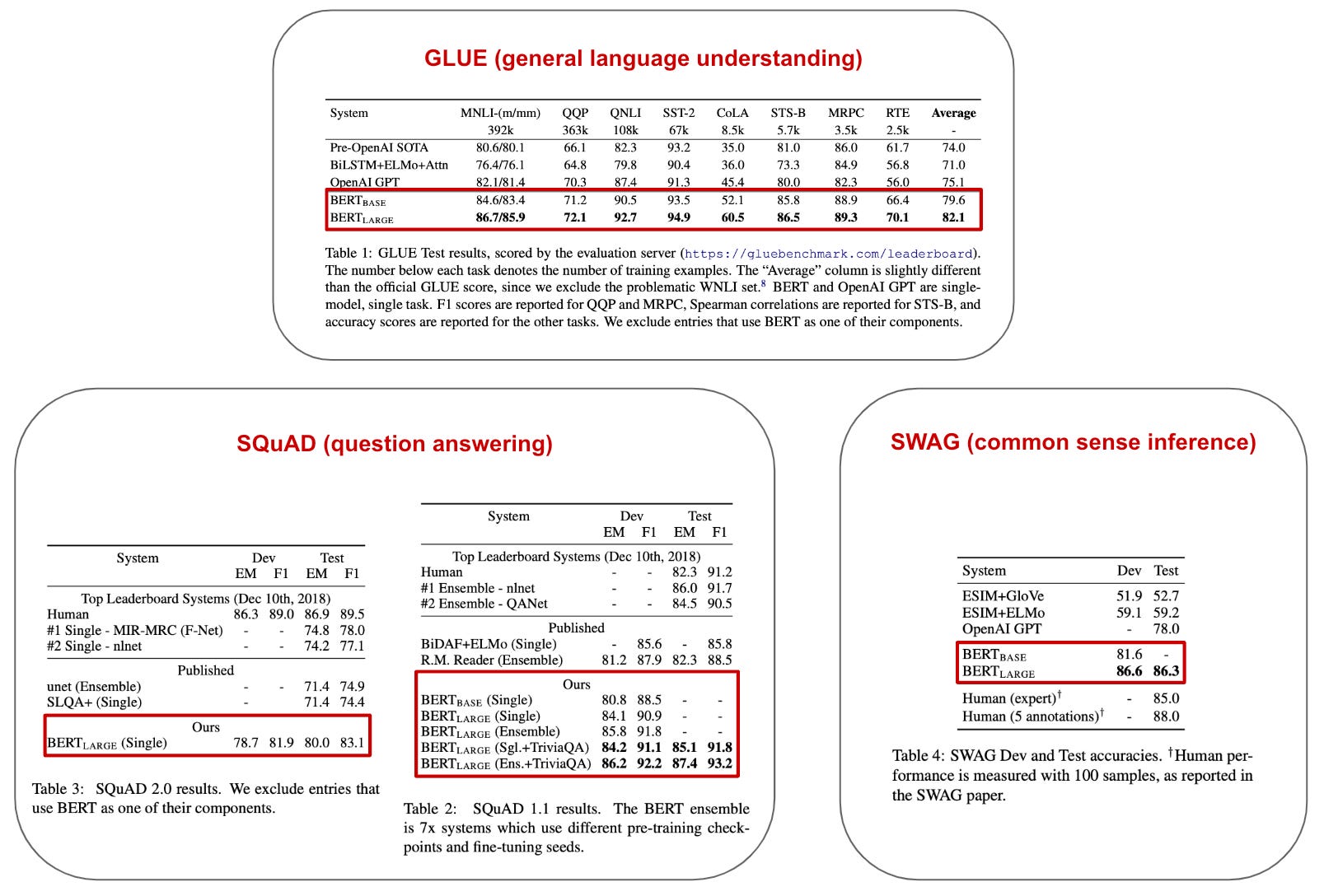
You might notice something interesting about BERT’s performance in these experiments—it is never outperformed (except by humans, but only in certain cases). At the time of publication, BERT set a new state-of-the-art on eleven different NLP benchmarks. Furthermore, most of these tasks were previously solved by specialized models that are specific to a particular task, whereas BERT (as you’ve seen in this overview) is a generic language understanding model that can be applied to many different tasks.
Some other interesting findings from the empirical evaluation of BERT are as follows:
BERT Large and BERT Base both significantly outperform all prior approaches on all tasks considered in [1].
BERT Large significantly outperforms BERT Base on all tasks and performs especially well on tasks with little training data.
Removing NSP or MLM (i.e., by using a unidirectional language modeling objective) significantly deteriorates BERT performance.
Although larger models performing better on small datasets may seem counterintuitive (i.e., this seems like a recipe for overfitting), results achieved with BERT demonstrate that using larger models is beneficial to low-resource tasks (i.e., those that have little training data) given sufficient pre-training.
“We believe that this is the first work to demonstrate convincingly that scaling to extreme model sizes also leads to large improvements on very small scale tasks, provided that the model has been sufficiently pre-trained.” - from [1]
Takeaways
Although BERT is a relatively old model given the pace of current deep learning research, I hope that this overview properly emphasizes the model’s simplicity and profoundness. BERT is an incredibly powerful tool that is easy and cheap to use.
what makes BERT so powerful? The crux of BERT is within two core concepts: bidirectional self-attention and self-supervised learning. BERT improves upon prior approaches partially because it discards the common approach of using unidirectional self-attention for language modeling-style pre-training. Instead, BERT leverages bidirectional self-attention to formulate a set of self-supervised, pre-training tasks that yield more robust feature representations. More recently, researchers have shown that the formulation of these self-supervised tasks themselves—as opposed to just the massive amount of data used for pre-training—are key to BERT’s success [10].
can normal practitioners use this? With BERT, one can simply:
download a pre-trained model online
fine-tune this model to achieve state-of-the-art performance on a staggering number of NLP tasks
Fine-tuning BERT is computationally cheap and can be performed with relatively minimal hardware setups (e.g., a single GPU). As such, BERT is a really good tool for any deep learning practitioner to have in their arsenal—you will be surprised at the number of different tasks for which BERT is your best choice.
further reading. I only covered a single paper within this overview, but BERT has been extended by a countless number of subsequent publications. A few of my favorites are listed below:
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (proposes a new pre-training task that enables the training of high-performing, smaller BERT models)
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (proposes parameter-reduction techniques to make BERT pre-training faster and less memory intensive)
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks (a generalization of BERT to joint Vision-and-Language tasks)
Supervised Multimodal Bitransformers for Classifying Images and Text (similar to above, but specific to classification of joint inputs with both images and text)
a personal note. BERT was the first model that peaked my interest in deep learning. Though my current research is more focused on computer vision (or multi-modal learning, for which BERT still works really well!), the versatility of BERT impresses me to this day. Simple ideas that work well are rare and beautiful.
New to the newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University studying the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I pick a single, bi-weekly topic in deep learning research, provide an understanding of relevant background information, then overview a handful of popular papers on the topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
I end each newsletter with a quote to ponder. I’m a big fan of stoicism, deep focus, and finding passion in life. So, finding these quotes keeps me accountable with my reading, thinking, and mindfulness. I hope you enjoy it!
“Be quiet, work hard, and stay healthy. It’s not ambition or skill that is going to set you apart but sanity.”
-Ryan Holiday
Bibliography
[1] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[2] Kiela, Douwe, et al. "Supervised multimodal bitransformers for classifying images and text." arXiv preprint arXiv:1909.02950 (2019).
[3] Zheng, Sixiao, et al. "Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
[4] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[5] Baevski, Alexei, et al. "Cloze-driven pretraining of self-attention networks." arXiv preprint arXiv:1903.07785 (2019).
[6] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[7] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI.
[8] Wu, Yonghui, et al. "Google's neural machine translation system: Bridging the gap between human and machine translation." arXiv preprint arXiv:1609.08144 (2016).
[9] Wilson L Taylor. 1953. Cloze procedure: A new tool for measuring readability. Journalism Bulletin, 30(4):415–433.
[10] Krishna, Kundan, et al. "Downstream Datasets Make Surprisingly Good Pretraining Corpora." arXiv preprint arXiv:2209.14389 (2022).