


T5: Text-to-Text Transformers (Part Two)
Optimal transfer learning for large language models...


This newsletter is sponsored by Rebuy, the Commerce AI company. If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!
this newsletter. This newsletter is part of my series on modern advancements in language models. Recently, deep learning research has been taken over by the unprecedented success of large language models (LLMs) like ChatGPT and GPT-4. I have already overviewed the history and core concepts behind these models.
GPT and GPT-2 [link]
Scaling laws and GPT-3 [link]
Modern LLMs (beyond GPT-3) [link]
Specialized LLMs [link]
PaLM [link]
T5 (Part One) [link]
Within this series, I will go beyond this history of LLMs into more recent topics, examining a variety of recent techniques and findings that are relevant to LLMs.

The proposal of BERT [5] led to the popularization of transfer learning approaches for natural language processing (NLP). Due to the widespread availability of unlabeled text on the internet, we could easily (i) pre-train large transformer models over large amounts of raw text and (ii) fine-tune these models to accurately solve downstream tasks. This approach was incredibly effective, but its newfound popularity led many alternative methods and modifications to be proposed. With all these new methods becoming available, one could easily begin to wonder: What are the best practices for transfer learning in NLP?
This question was answered by analysis performed with the unified text-to-text transformer (T5) model. T5 reformulates all tasks (during both pre-training and fine-tuning) with a text-to-text format, meaning that the model receives textual input and produces textual output. Using this unified format, T5 can analyze various different transfer learning settings, allowing many approaches to be compared. In a previous newsletter, we learned about the format, architecture, and overall approach of the T5 model.
In this newsletter, we will outline the analysis performed by T5, including an empirical comparison different pre-training objectives, architectures, model/data scales, and training approaches for transfer learning in NLP. Within [1], each of these options are studied one-at-a-time to determine their impact on T5’s performance. By studying this analysis, we arrive at a set of best practices, which (when combined together) produce the state-of-the-art T5 framework that can solve language understanding tasks with incredibly high accuracy.
Preliminaries
We already covered the motivation and basics of the T5 architecture. Check out that post at the link below.
But, we can quickly cover these ideas here as well. The proposal of BERT [5] popularized the transfer learning paradigm (i.e., pre-training a model over some separate dataset, then fine-tuning on a target dataset) for NLP. However, BERT’s effectiveness led many researchers to focus on this topic and propose various modifications and improvements. The idea of T5 is to (i) convert all language tasks into a unified, text-to-text format (see figure below) and (ii) study a bunch of different settings for transfer learning in NLP to deduce the techniques that work best.
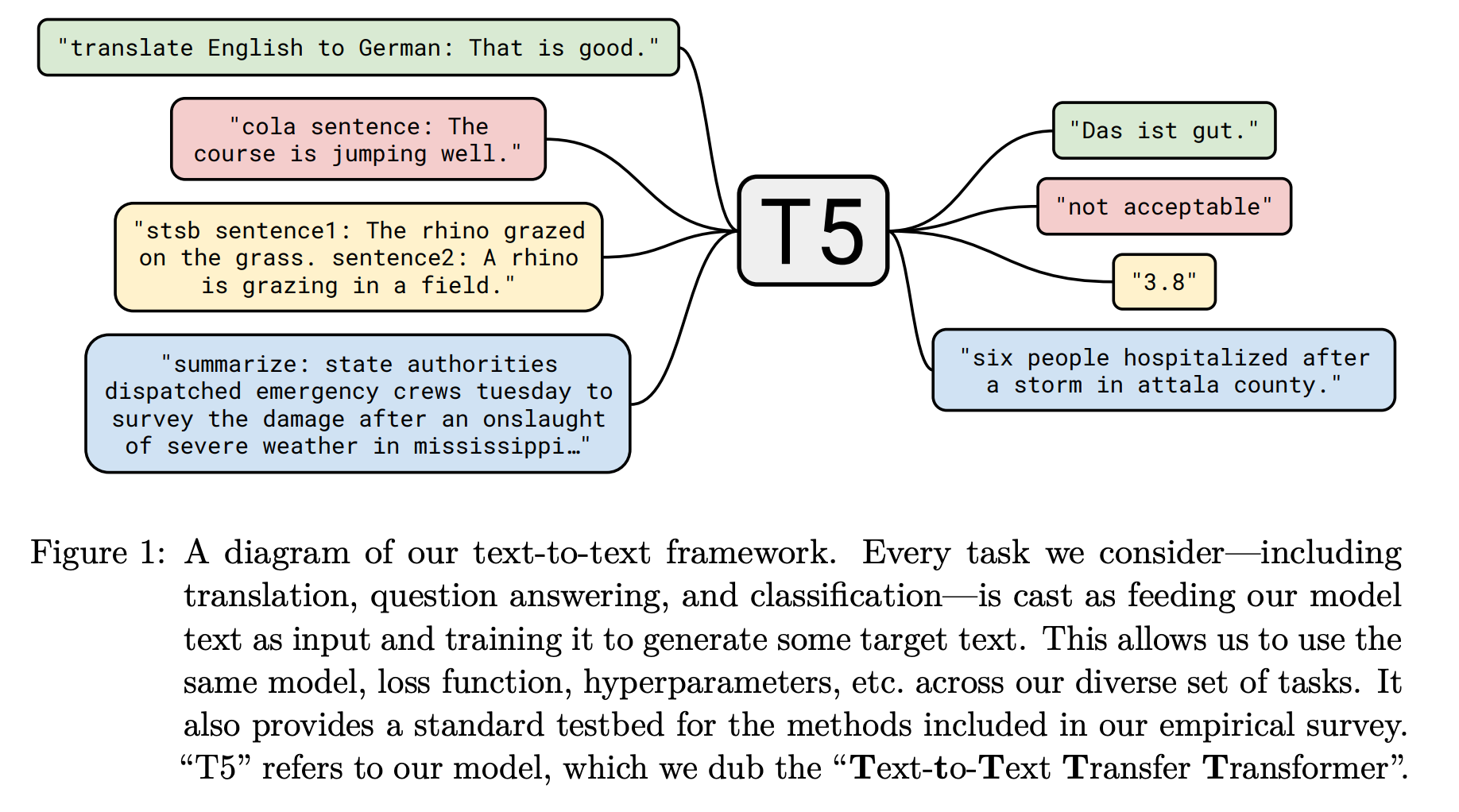
Language Modeling vs. Denoising

Initial transfer learning approaches in NLP leveraged a causal language modeling objective [6] for pre-training. However, denoising (also called masked language modeling, or MLM) objectives were subsequently shown to perform better [5]. Given a set of textual tokens to be passed as input to some model, MLM operates by:
Randomly (uniformly) selecting 15% of the tokens
Replacing 90% of selected tokens with a
[MASK]tokenReplacing 10% of selected tokens with a random token
Training the model to predict/classify each
[MASK]token
The percentage of tokens that are uniformly selected is called the “corruption rate”. Within T5, we will see a few different variants of this denoising objective, but the basic idea remains the same.
“All of our objectives ingest a sequence of token IDs corresponding to a tokenized span of text from our unlabeled text data set. The token sequence is processed to produce a (corrupted) input sequence and a corresponding target. Then, the model is trained as usual with maximum likelihood to predict the target sequence.” - from [1]
Benchmarks and Evaluation
T5 attempts to derive a set of best practices for transfer learning in NLP. To determine which techniques work best, however, T5 is evaluated on a variety of different tasks and natural language benchmarks. All of these task are solved using T5’s text-to-text format. See Section 2.3 in [1] for a full description of these tasks. A brief summary is provided below.
GLUE and SuperGLUE [7, 8]: both benchmarks include many different tasks, such as sentence acceptability judgement, sentiment analysis, paraphrasing, sentence similarity, natural language inference (NLI), coreference resolution, sentence completion, word sense disambiguation, and question answering.
SuperGLUE is an improved and more difficult benchmark with a similar structure to GLUE.
CNN + Daily Mail Abstractive Summarization [9]: pairs news articles with a short, summarized sequence of text that captures the main highlights of the article.
SQuAD [10]: a question answering dataset on Wikipedia articles, where the answer to each question is a segment of text from the related article.
Several translation datasets (e.g., English to German, French, and Romanian).
Notably, all tasks in the GLUE and SuperGLUE benchmarks are concatenated together by T5, and fine-tuning is performed over all tasks at once.
Other Important Ideas
Different Types of Transformer Architectures [link]
Language Modeling Basics [link]
Self-Attention [see tweet below]


What do we learn from T5?
As previously mentioned, the experiments in T5 attempt to discover best practices for transfer learning in NLP. To do this, a baseline approach is first proposed, then several aspects of this baseline (e.g., model architecture/size, dataset, and pre-training objective) are changed one-at-a-time to see what works best. This approach mimics a coordinate descent strategy. We will first describe the baseline technique, then explain T5’s findings after testing a variety of different transfer learning settings.
T5 Baseline Model

the model. The T5 baseline architecture uses a standard, encoder-decoder transformer architecture; see above. Both the encoder and decoder are structured similarly to BERTBase. Although many modern approaches for NLP use “single stack” transformer architecture (e.g., encoder-only architecture for BERT or decoder-only architecture for most language models), T5 chooses to avoid these architectures. Interestingly, authors in [1] find that the encoder-decoder architecture achieves impressive results on both generative and classification tasks. Encoder-only models are not considered in [1] due to the fact that they are specialized for token/span prediction and don’t solve generative tasks well.
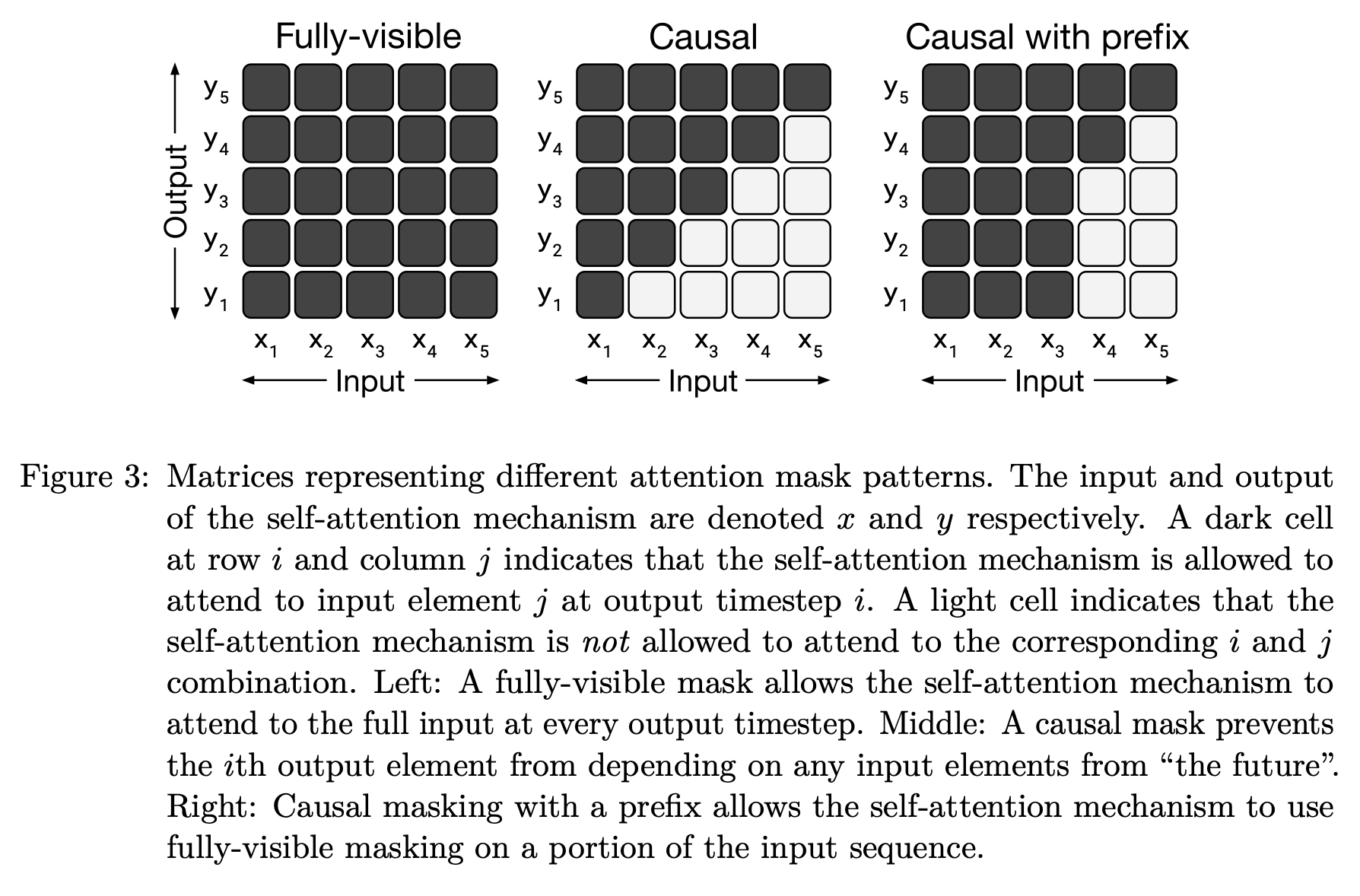
Compared to encoder-decoder architectures, decoder-only models are limited because they solely use causal (or masked) self-attention; see above. Masked self-attention only considers preceding tokens when computing the representation for any given token in a sequence. However, there are certain cases in which we would like to perform fully-visible attention over an initial span or prefix of text, then generate output based on this prefix (e.g., translation tasks). Decoder-only models cannot handle such cases, as they perform causal self-attention across the entire input.
training T5. The T5 model is pre-trained on a total of 34B tokens from the C4 corpus. For comparison, BERT is trained over 137B tokens, while RoBERTa is trained over 2.2T tokens [5, 12]. Inspired by the MLM objective from BERT, T5 is pre-trained using a slightly modified denoising objective that:
Randomly selects 15% of tokens in the input sequence
Replaces all consecutive spans of selected tokens with a single
”sentinel” tokenGives each sentinel token an ID that is unique to the current input sequence
Constructs a target using all selected tokens, separated by the sentinel tokens
Although this task seems a bit complex, we can see an illustration of how it works on a short input sequence below.

By replacing entire spans of masked tokens with a single sentinel token, we reduce the computational cost of pre-training, as we tend to operate over shorter input and target sequences.
fine-tuning. After pre-training has been performed, T5 is separately fine-tuned on each downstream task prior to being evaluated. Due to the text-to-text format used by T5, both pre-training and fine-tuning use the same maximum likelihood objective! In other words, we just formulate the correct answer as a textual sequence (during both pre-training and fine-tuning) and train the model to output the correct textual sequence.
how does the baseline perform? As shown in the table below, the baseline T5 model performs similarly to prior models like BERT, even though these models are not directly comparable (i.e., the baseline T5 model uses 25% of the compute used by BERTBase). Plus, we see that pre-training provides a huge benefit on most tasks. The exception to this rule is translation tasks, where performance is similar both with and without pre-training.

Searching for a better approach…
After testing the baseline architecture and training approach, authors in [1] modify one aspect of this approach at a time, such as the underlying architecture, pre-training objective, or fine-tuning strategy. By testing these different transfer learning variants, we can find an approach that consistently works best across different language understanding tasks.
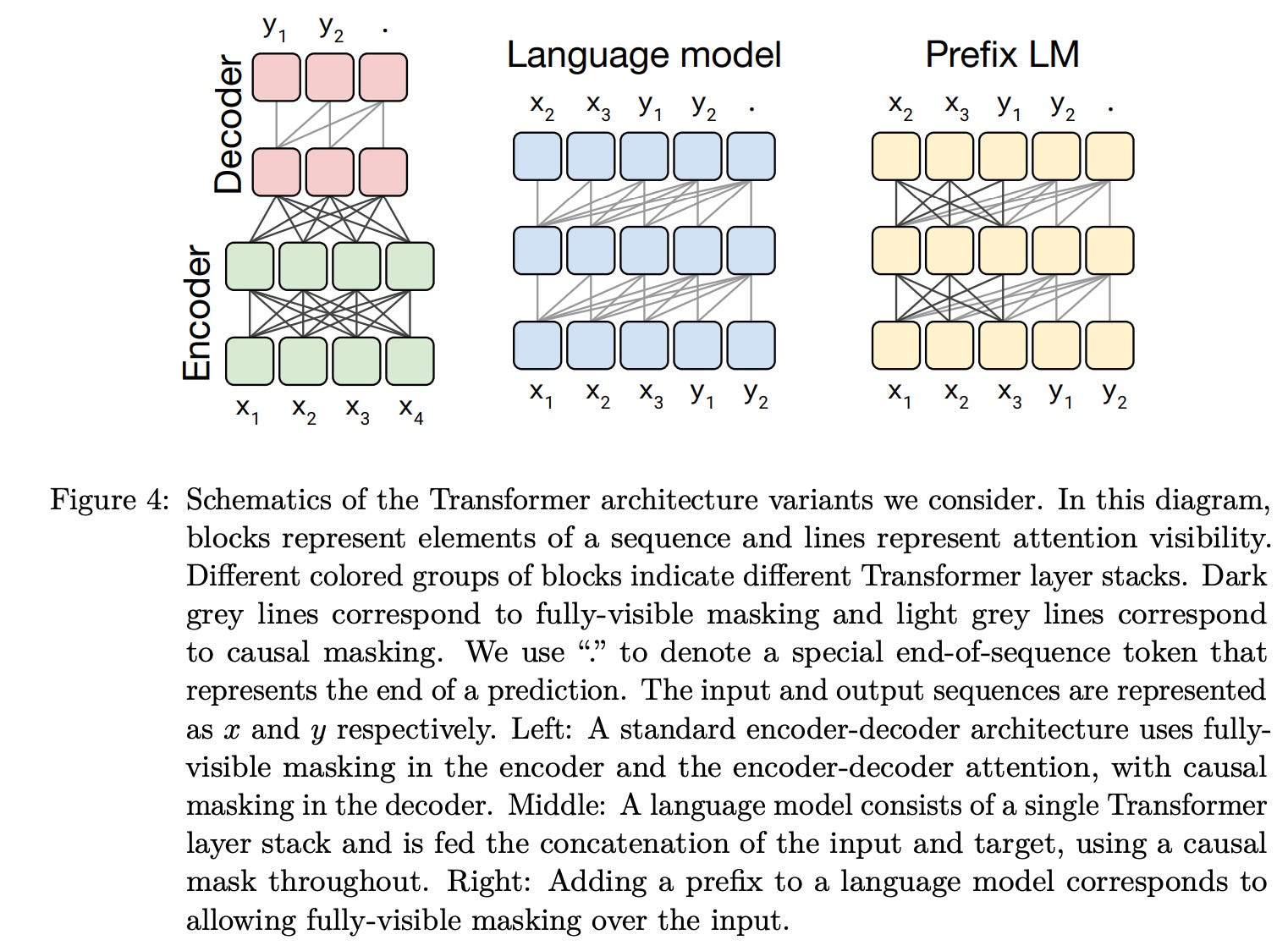
the architecture. To study the impact of architecture choice on transfer learning results, we can test different variants of the transformer architecture. The architectures tested in [1] include the normal encoder-decoder architecture, the decoder-only architecture, and a prefix language model, which performs fully-visible attention over a fixed prefix within a sequence then generates output using causal self-attention; see above. The main difference between these architectures is the type of masking used within their self-attention mechanisms.

When several different architectures are tested (using both causal language modeling and denoising objectives for pre-training), we see that the encoder-decoder transformer architecture (with a denoising objective) performs the best, leading this architecture to be used in the remainder of experiments. Relative to other models, this encoder-decoder variant has 2P parameters in total but the same computational cost as a decoder-only model with P parameters. To reduce the total number of parameters to P, we can share parameters between the encoder and decoder, which is found to perform quite well.
the pre-training objective. At first, T5 is trained using three different types of pre-training objectives. The first is a BERT-style MLM objective. The other objectives are a deshuffling [3] strategy (i.e., the model tries to put a shuffled sentence back into the correct order) and a prefix-based language modeling objective [2]. In the latter, the text is separated into two spans, where the first span is passed as input to the encoder and the second span is predicted by the decoder (i.e., recall that we are using an encoder-decoder transformer). The performance of models trained with these objectives is compared below, where we see that denoising objectives clearly outperform other strategies.

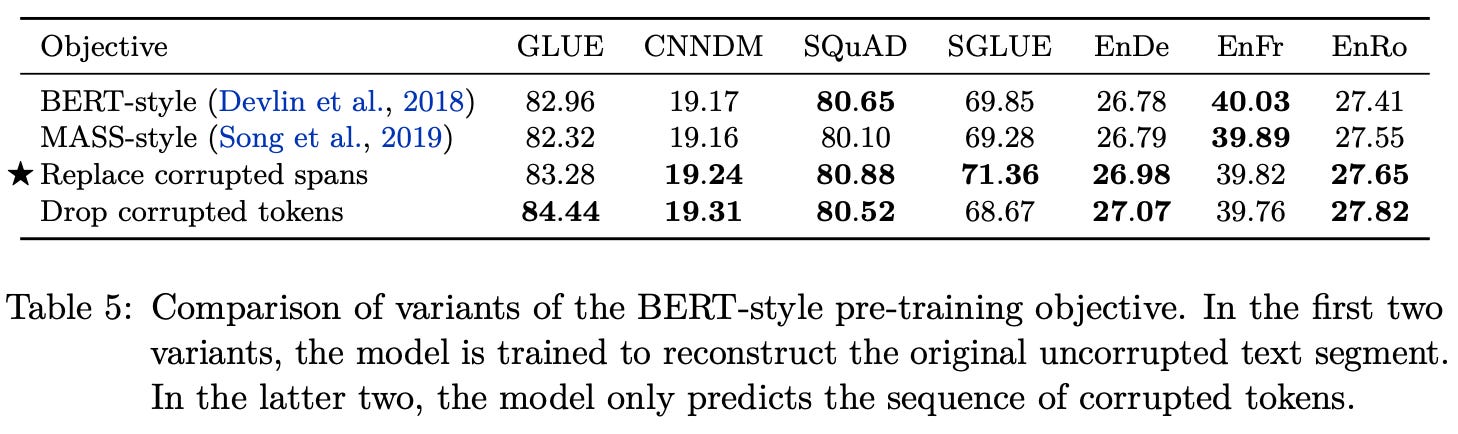
From here, authors in [1] test several modifications to the BERT-style MLM objective [4], as shown in the table below.

Each of these variants tend to perform similarly; see below. However, by selecting pre-training objectives that replace entire spans of corrupted tokens with single sentinel tokens and only attempting to predict corrupted tokens within the target, we can minimize the computational cost of pre-training. As such, the baseline strategy of masking entire spans of consecutive tokens is efficient because it produces shorter target sequences.
Authors in [1] test different corruption rates, finding that the corruption rate doesn’t significantly impact results and that a setting of 15% works well. An alternative pre-training objective that explicitly selects spans of tokens for corruption (i.e., the baseline approach selects tokens uniformly instead of as a span, then combines consecutive tokens together) is also found to perform similarly to the baseline. A schematic of the different pre-training objectives tested in [1] is provided below.

Many different strategies are studied, but the main takeaways here are (i) denoising objectives work best, (ii) variants of denoising objectives perform similarly, and (iii) strategies that minimize the length of the target are most computationally efficient.
data and model size. Finally, the impact of scale on T5 quality is studied. First, T5 is pre-trained with several different datasets, including one that is not filtered, a news-specific dataset, a dataset that mimics GPT-2’s WebText corpus, and a few variants of the Wikipedia corpus. T5’s performance after being pre-trained on each of these datasets is shown below.

We see here that (i) not filtering the pre-training corpus is incredibly detrimental and (ii) pre-training on domain-specific corpora can be helpful in some cases. For example, pre-training on the news-based corpus yields the best performance on ReCoRD, a reading comprehension dataset based on news articles.
“The main lesson behind these findings is that pre-training on in-domain unlabeled data can improve performance on downstream tasks. This is unsurprising but also unsatisfying if our goal is to pre-train a model that can rapidly adapt to language tasks from arbitrary domains.” - from [1]
Going further, T5 is pre-trained using truncated versions of the C4 corpus with varying sizes. From these experiments, we learn that more data is (unsurprisingly) better. Looping through a smaller version of the dataset multiple times during pre-training cause overfitting and damage downstream performance; see below.

To scale up the T5 model, authors test the following modifications:
4
Xmore training iterations (or 4Xlarger batch size)2
Xmore training iterations and 2Xlarger model4
Xlarger modelTrain an ensemble of 4 encoder-decoder transformers
Here, both pre-training and fine-tuning steps are increased for simplicity. The results of these experiments are shown below.
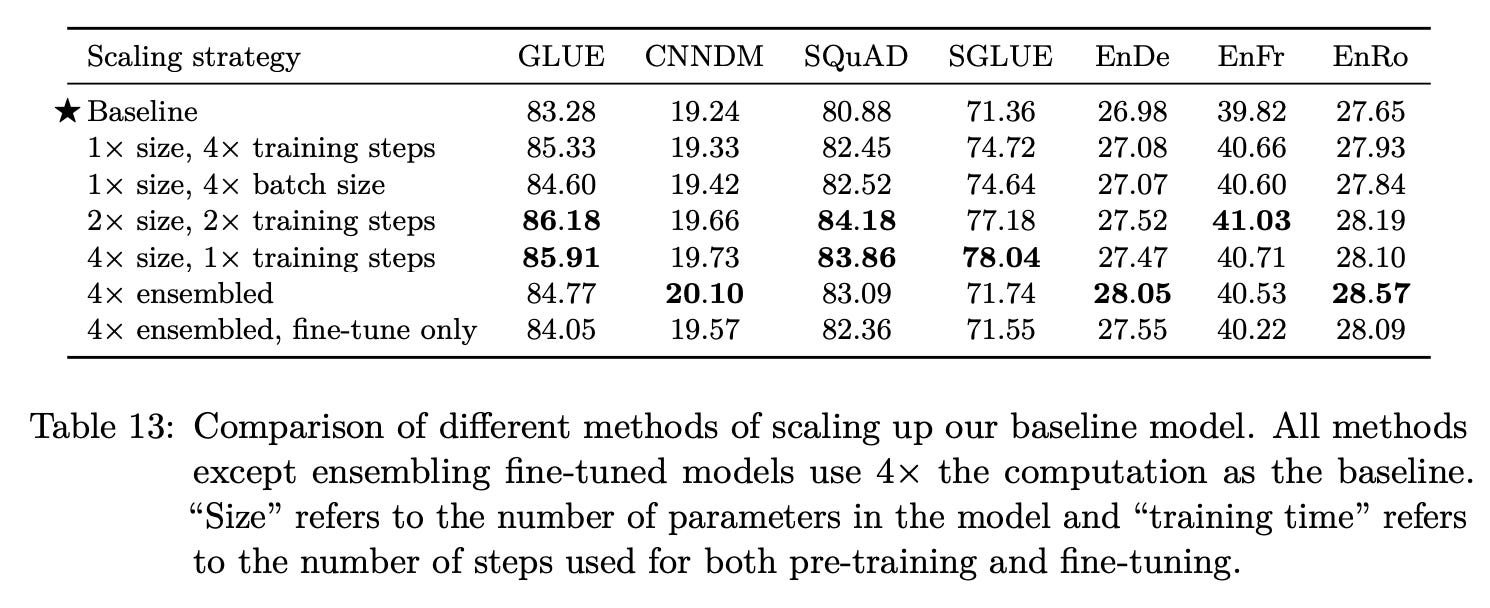
These results roughly correspond with what we would expect. Increasing training time (or batch size) improves performance. Combining this with a larger model yields a further benefit compared to increasing training iterations or batch size alone. In other words, increasing the amount of pre-training data and the model size is complementary in terms of improving performance.
“The bitter lesson of machine learning research argues that general methods that can leverage additional computation ultimately win out against methods that rely on human expertise” - from [1]
other stuff. T5 is also fine-tuned using different multi-task training strategies. Overall, these models are found to perform slightly worse than those fine-tuned separately for each task. However, strategies do exist to minimize the performance gap between task-specific fine-tuning and multi-task learning. For more information, check out the overview below.
Many fine-tuning approaches for deep neural nets only train a subset of model parameters (e.g., “freeze” early layers and fine-tune only the last few layers in the model). Authors in [1] try several techniques for fine-tuning T5 in this manner (e.g., via adapter layers or gradual unfreezing [6]), but these methods are outperformed by fine-tuning the full model end-to-end; see below.

T5: Putting it all together!
Now that we have gone over the entire experimental analysis from [1], we have a better picture of different options for transfer learning in NLP and what works best! Below, we will go over the main takeaways from this analysis that comprise the official transfer learning framework used by T5. This approach was found to perform quite well when compared to various alternatives.
baseline settings. First, let’s recall T5’s baseline architecture. It is an encoder-decoder transformer that is trained using the unified text-to-text format. After pre-training with a denoising objective, the model is separately fine-tuned on each downstream task before evaluation. Notably, the final T5 model is fine-tuned separately for each task in the GLUE and SuperGLUE benchmarks, as training over all tasks together yields slightly lower performance (assuming we take necessary steps to avoid overfitting).
pre-training. Instead of uniformly selecting tokens, the final T5 methodology performs span corruption (i.e., selecting entire spans of tokens for corruption at once) with an average length of three. Still, 15% of tokens are selected for corruption. This objective performs slightly better than the baseline and yields shorter target sequence lengths. Additionally, T5 mixes unsupervised pre-training updates with multi-task, supervised updates. The ratio between the number of unsupervised and supervised updates depends on the size of the model being used (i.e., larger models need more unsupervised updates to avoid overfitting).
amount of training. Additional pre-training is helpful to the performance of T5. Specifically, both increasing the batch size and number of training iterations benefits T5’s performance. As such, the final T5 model is pre-trained over 1T tokens in total. This is much larger than the baseline’s 34B tokens during pre-training but still far short of RoBERTa [12], which is pre-trained on over 2.2T tokens. Pre-training is performed over the generic, filtered C4 dataset, as task-specific pre-training does not yield a consistent benefit across different tasks.
model scale. Using larger models is helpful, but sometimes a smaller model may make more sense (e.g., when you have limited compute available for inference). For this reason, five different sizes of T5 models are released with anywhere from 220M to 11B parameters. Thus, T5 is actually a suite of different models! We can gain access to any of these models at the link below.
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Bibliography
[1] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[2] Liu, Peter J., et al. "Generating wikipedia by summarizing long sequences." arXiv preprint arXiv:1801.10198 (2018).
[3] Liu, Peter J., Yu-An Chung, and Jie Ren. "Summae: Zero-shot abstractive text summarization using length-agnostic auto-encoders." arXiv preprint arXiv:1910.00998 (2019).
[4] Song, Kaitao, et al. "Mass: Masked sequence to sequence pre-training for language generation." arXiv preprint arXiv:1905.02450 (2019).
[5] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[6] Howard, Jeremy, and Sebastian Ruder. "Universal language model fine-tuning for text classification." arXiv preprint arXiv:1801.06146 (2018).
[7] Wang, Alex, et al. "GLUE: A multi-task benchmark and analysis platform for natural language understanding." arXiv preprint arXiv:1804.07461 (2018).
[8] Wang, Alex, et al. "Superglue: A stickier benchmark for general-purpose language understanding systems." Advances in neural information processing systems 32 (2019).
[9] Hermann, Karl Moritz, et al. "Teaching machines to read and comprehend." Advances in neural information processing systems 28 (2015).
[10] Rajpurkar, Pranav, et al. "Squad: 100,000+ questions for machine comprehension of text." arXiv preprint arXiv:1606.05250 (2016).
[11] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[12] Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692 (2019).