


Vision Transformers: From Idea to Applications (Part Six)
Intelligent video processing with vision transformers!


This newsletter is sponsored by Rebuy, the Commerce AI company. If you’re working at the intersection of engineering/ML and want to join a fast-growing startup, reach out to me! I want to find awesome people to learn and build with.
If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!
this post. This is part six of a six-part series (written by Sairam Sundaresan and myself) that explores the (vision) transformer deep learning architecture and its many, impactful applications. I will write parts two, four, and six as part of Deep (Learning) Focus, while Sairam will release the other parts on his Gradient Ascent newsletter. Read the previous posts here:
Part One: The Transformer Architecture [link]
Part Two: Vision Transformers [link]
Part Three: Object Detection with Transformers [link]
Part Four: Contrastive Language-Image Pre-training (CLIP) [link]
Part Five: Text-to-Image Generation with Muse [link]

Until now, all of the applications that we have overviewed within this series use Vision Transformers (ViTs) to deal primarily with image-based (or textual) data. Although the applications vary, the underlying data type has not, at least so far. Although we have seen that ViTs perform well in these scenarios (i.e., accurate, reasonably efficient compared to CNNs, etc.), we might begin to wonder whether they are similarly useful for other types of computer vision data, such as videos.
Recent work on Multiscale Vision Transformers (MViTs) [1] has shown that ViTs are incredibly useful for solving video recognition tasks like action recognition or detection. However, the ViT architecture in its original form [3] is not enough to solve such tasks accurately or efficiently. Due to the dense nature of visual signals and information in video, we must adopt a modified ViT architecture that leverages multi-scale feature hierarchies. Without these important modifications, ViTs struggle to capture useful temporal information in video and require extensive, image-based pre-training to perform well.
Background
Within this series, we have already explained the inner workings of the transformer and vision transformer (ViT) architectures in great depth. Check out the links below to each of these posts.
To understand the MViT architecture, there are a few fundamental computer vision concepts that we must learn about first. Given that most of us are probably more familiar with image-based deep learning, we will start by taking a look at the structure of video data to gain a better understanding of the unique concerns associated with deep learning on video. Then, we will learn about the idea of multi-scale feature hierarchies, focusing especially upon why such an approach is needed within MViT.
Video Data for Deep Learning
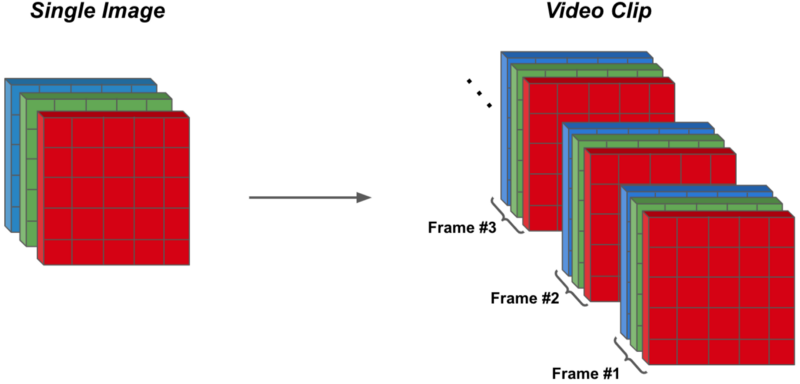
image data. Images have a pretty simple structure. Usually, they are in RGB-format, meaning that a single image contains three color channels, each with their own height and width. For example, the image on the left side of the figure above has three color channels, each with a height and width of five. Thus, a mini-batch of images that we would provide to a deep learning model during training would have a shape of batch_size x 3 x height x width.
video data. Videos have a relatively similar structure. However, there is an extra dimension. In particular, we process video in the form of “clips”, which are short video segments comprised of multiple frames. Here, each frame resembles a single image, but the ordering of these frames reveal the motion of a scene through time (i.e., temporal features!). For example, the video clip in the image above has three frames, each stored in RGB format with a height and width of five. A mini-batch that contains multiple video clips would have a shape of batch_size x clip_length x 3 x height x width, where clip_length is the number of frames in each video clip. Such a mini-batch is illustrated in the figure below.
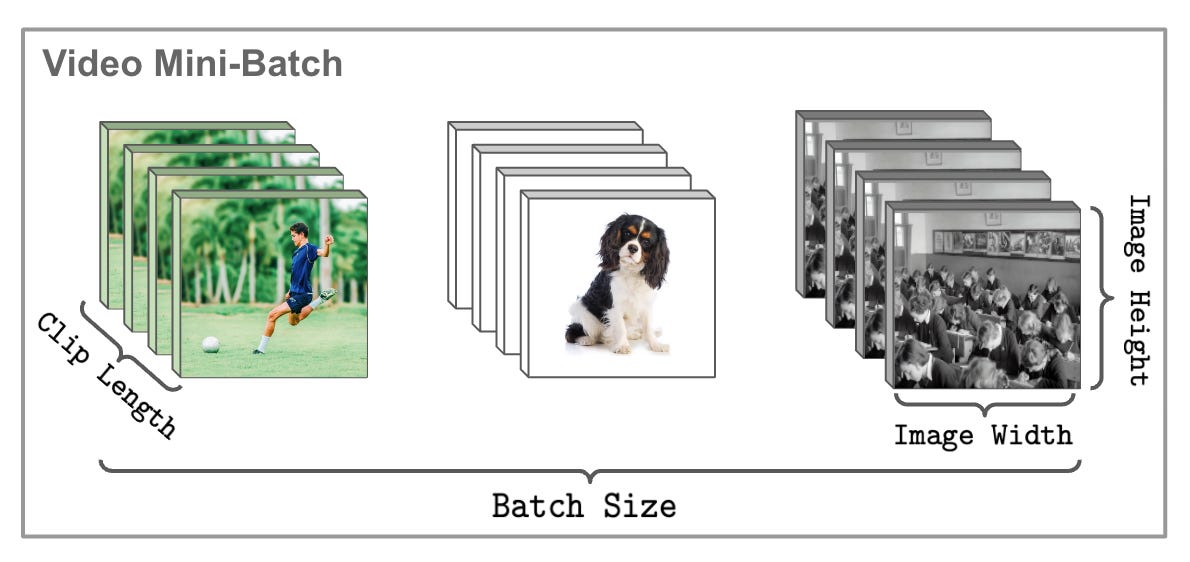
how is this different from images? The main difference between videos and images is the added clip_length dimension in video. Instead of a single image per example, we have a video clip comprised of several images/frames. Plus, these frames contain dense temporal and motion information. As a result, video data is much larger-scale relative to images. The amount of data we are dealing with will unavoidably increase by an order of magnitude.
For example, consider a dataset that contains 10 images. If we convert each of these images to a five second video clip and assume a 25 FPS frame rate (i.e., a standard choice for cinematography), we now have 1,250 frames across all video clips. This simple example demonstrates how videos can quickly become quite difficult to handle. In order to learn anything from video data, we need to be able to efficiently process and find the most important information within this large amount of data.
Multi-Scale Feature Hierarchies
Multi-scale (or “pyramid”) strategies are an important concept within computer vision. The basic idea is simple. Throughout the layers of most neural networks, we occasionally (i) downsample the spatial resolution of our features and (ii) increase the channel dimension. For example, see the structure of a common ResNet [5] and VGG architecture in the figure below.
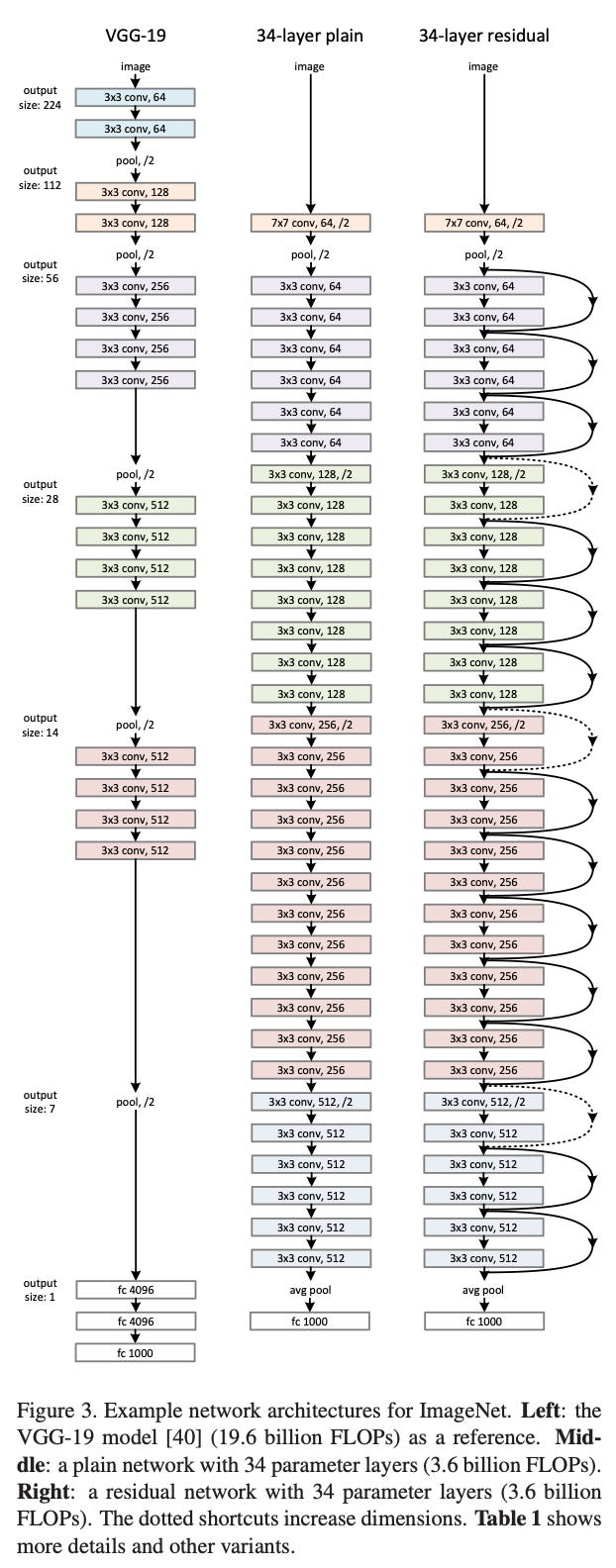
Because we occasionally change the spatial and feature dimensions within intermediate network layers, each “section” of the network will have a different spatial and channel resolution. Thus, we can draw from features in different parts of the network to access varying amounts of spatial or semantic information.
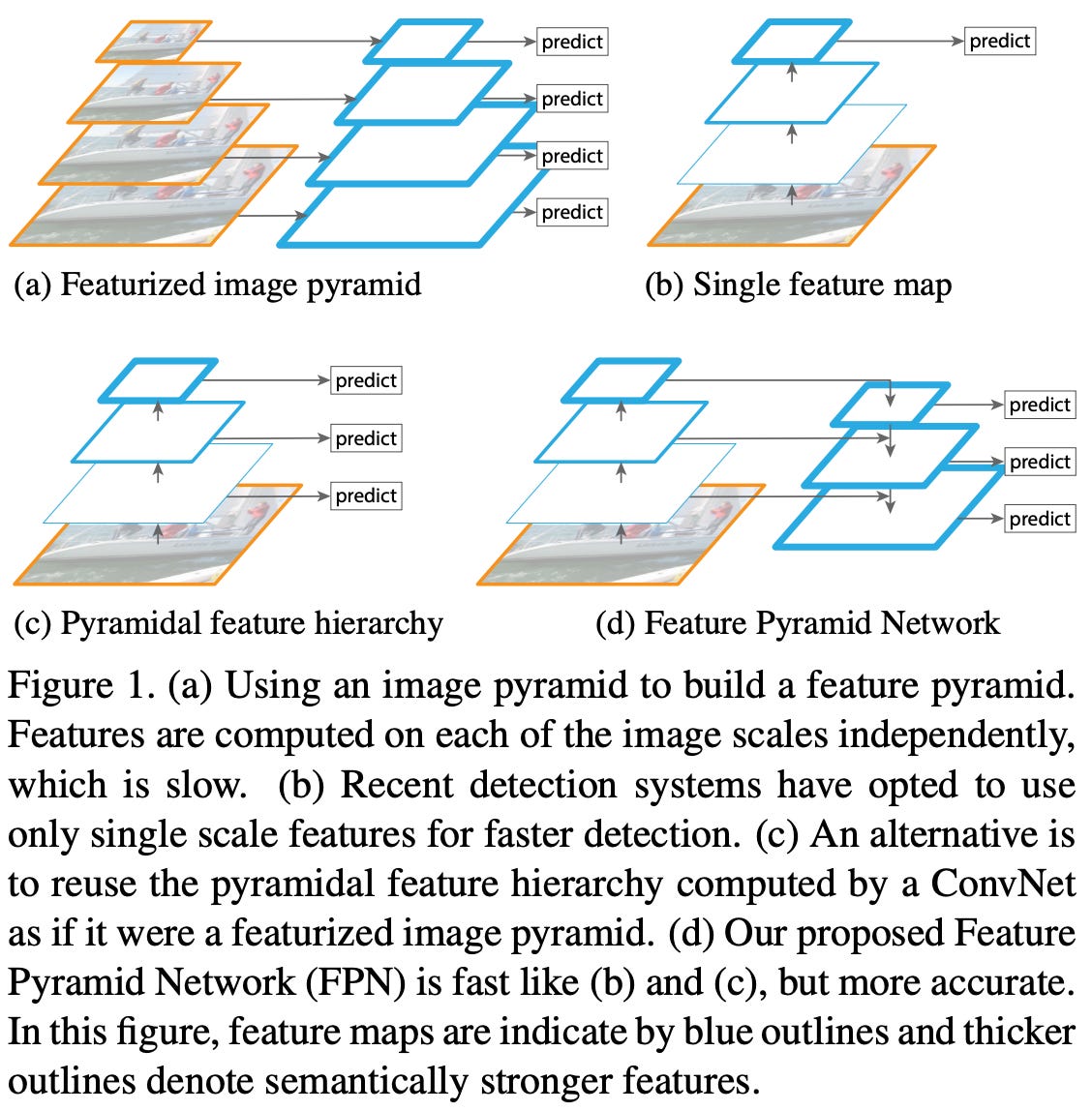
feature pyramid networks. One notable use of multi-scale feature hierarchies is within the Feature Pyramid Network (FPN) [4] for object detection in images. This model, illustrated above, uses a normal convolutional neural network. However, instead of making predictions based upon features in the network’s final layer, the FPN draws upon features from several different layers within the network. In particular, predictions are made using features with varying spatial and channel dimensions, allowing for both high-resolution spatial features and high-level semantic information to be taken into account in the network’s predictions.
why is this necessary? As previously mentioned, video data is hard to learn from due to its scale. Beyond the scale of video data, however, we also have to learn more than just spatial features! Patterns in video are often spatiotemporal, meaning that they consider both semantic and motion information. Although semantic information (e.g., the class of an object) might be static in some cases, temporal information (e.g., motion of an object, the action being performed, etc.) quickly changes as we progress through a video. As a result, spatiotemporal features within video data are incredibly dense, and we must adopt an architecture that is capable of extracting such important information.
pyramids and ViTs. The fundamental idea behind MViT [1] is to create a better architecture for video recognition tasks (e.g., classifying the action being performed within a video clip) by combining multi-scale feature hierarchies with ViTs. Although a direct application of ViTs to video data works poorly, we see in [1] that modifying ViTs to leverage feature pyramids drastically improves their efficiency, enabling the learning of fine-grained spatiotemporal features in video.
“The fundamental advantage of our multiscale transformer arises from the extremely dense nature of visual signals, a phenomenon that is even more pronounced for space-time visual signals captured in video.” - from [1]
Multi-scale Vision Transformers

The MViT architecture [1], shown above, mimics FPN-style networks by separating transformer layers into several “stages”, each with a different space-time resolution and channel capacity. As the space-time resolution (i.e., both the height/width of the clip and the clip length) is decreased, we increase the channel capacity correspondingly. Typically, this is accomplished by “pooling” features along spatial and temporal dimensions, while expanding the internal channel dimension of each transformer layer.
How is this different from a ViT?
As we learned in a prior overview, ViTs convert images into a transformer-friendly format by simply (i) separating an image into several image patches and (ii) linearly projecting each patch to form a corresponding embedding. These patch embeddings then form a sequence of (spatially ordered) vectors that can be processed by the ViT to solve tasks like image classification.
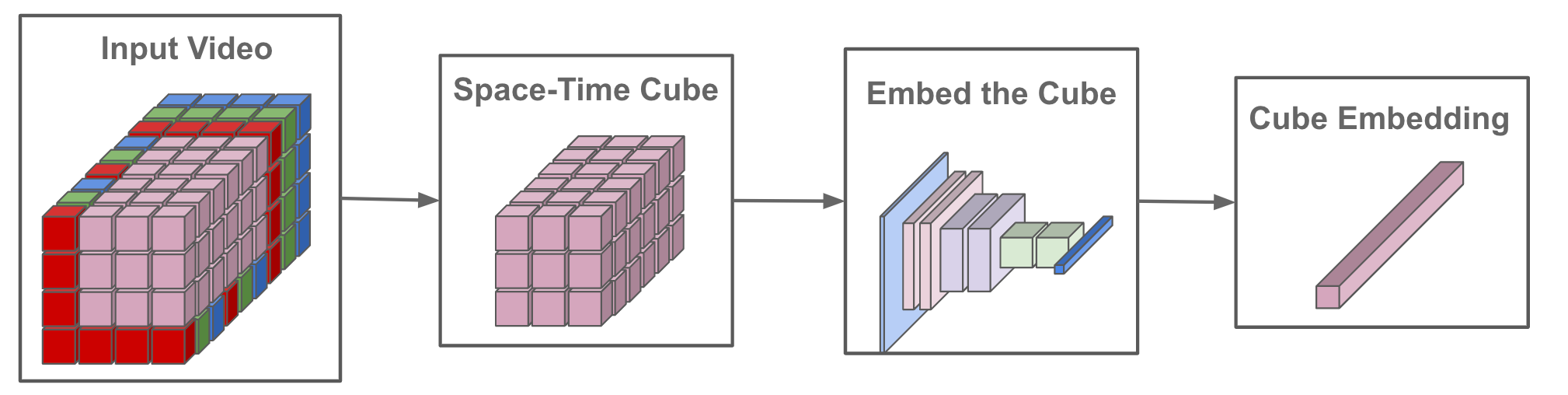
On video recognition tasks, we must sample space-time “cubes” from the video instead of image patches. However, the idea is still similar. The space-time cube is just an image patch with an added temporal dimension, as shown in the figure above. Then, we can again perform a linear projection (either via a convolution or by flattening and projecting the cube) to form an embedding.
This approach is similar to that of the ViT, but we simply adapt the process to handle the fact that multiple frames are present in each video clip. Sampling space-time cubes produces a much larger number of input embeddings compared to sampling image patches. As such, MViT must adopt a pooling approach to shorten the length of its input. We will next overview exactly how these pooling mechanisms work, but we see again here that adapting strategies from image recognition to the video domain is not simple.
Pooling Attention
To enable self-attention to be performed at varying space-time resolutions within the transformer, authors in [1] introduce a multi-headed pooling attention (MHPA) operator. In this new operator, we compute self-attention normally. However, we introduce a pooling operation to the sequence of tokens prior to performing the self-attention operation.

why should we do this? Depending upon the pooling operation, we can use this operation to reduce the dimension and/or length of the sequence of tokens considered by self-attention. For example, we can compute attention over a coarser sampling of frames within a video clip or even over a lesser spatial resolution in an image. Put simply, adding pooling to self-attention allows MViT to control the spatial and temporal resolutions of its underlying feature representations, enabling a multi-scale feature hierarchy to be formed; see above.
By using MHPA, we compute self-attention over a shorter token sequence within each layer of MViT (i.e., because the sequence of tokens is pooled before computing self-attention). Given that the computational complexity of self-attention increases quadratically with sequence length, MHPA is more efficient than vanilla self-attention. These efficiency gains are quite beneficial for video recognition tasks given the massive scale of data.
Instantiations of MViT
In [1], authors propose several different instantiations of MViT. Generally, these models use fine spatiotemporal and coarse channel dimension in early layers of the network. Then, later network layers increase the channel dimension while reducing the spatiotemporal dimension.
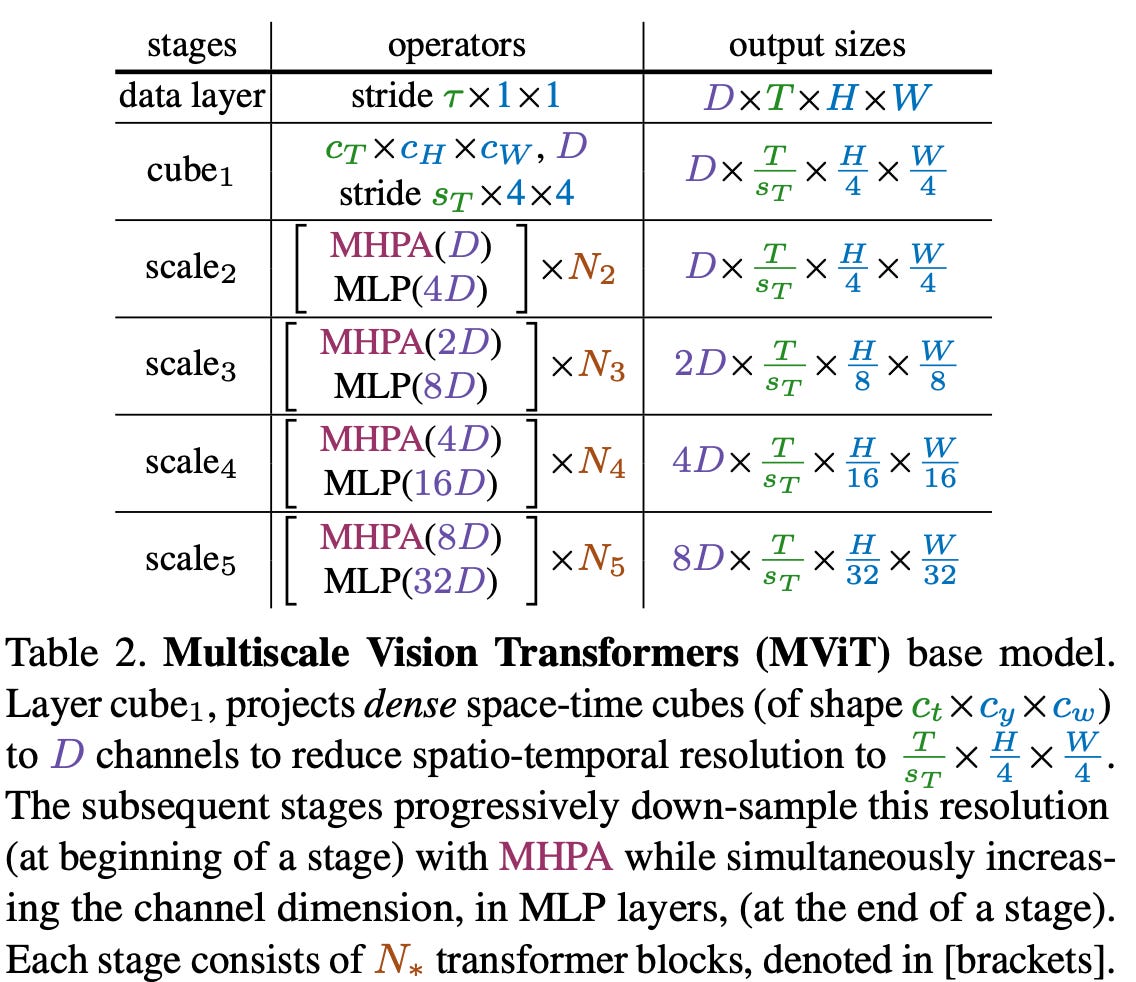
Similar to FPNs, the MViT is separated into different stages, each containing several transformer layers. Within each stage, the transformer layers have identical spatiotemporal and channel resolution. As we progress from one stage to the next, this resolution changes. The base architecture for MViT is described in the table above, though several different architectures with varying sizes and complexities are tested; see below.

how do we do this? Using MPHA, we can control the spatiotemporal resolution of our features by simply changing the extent of the pooling operation (e.g., a greater number of frames can be pooled into the same token). To increase the channel dimension, we just modify the feed-forward portion of a transformer layer to produce a higher-dimensional output vector. Simple enough!
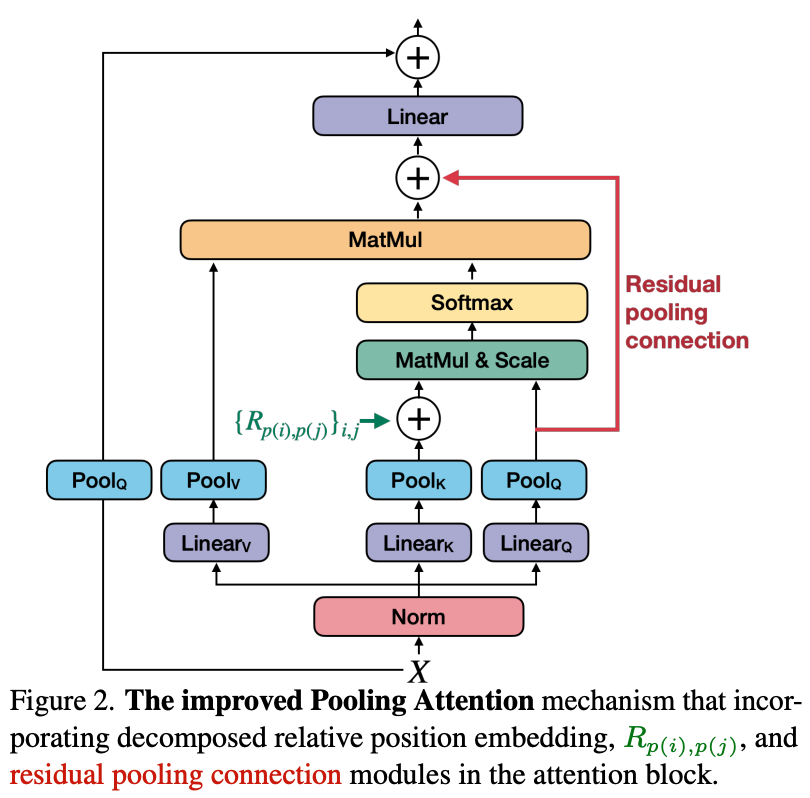
improving the MViT. Shortly after the MViT was described in [1], the improved MViT-v2 [2] variant was proposed. The main modifications in MViT-v2 are:
using residual pooling connections (see figure above)
These modifications make the underlying model more translation invariant and generally improve its performance. However, the MViT and MViT-v2 architectures are quite similar.
Using MViTs for Video Recognition
MViT is compared to various baseline models on action recognition and detection datasets. In action recognition, we are given a video clip of some action being performed and are expected to classify the entire video clip (i.e., a global classification) based on this action. Action detection is somewhat similar, but it has an added localization component. Namely, we are expected to both classify the action being performed and place bounding boxes around the person or object performing this action throughout the video. On both of these tasks, MViT achieves state-of-the-art performance; see below.

Prior transformer-based approaches to deep learning on video data typically required extensive, image-based pre-training (e.g., over ImageNet-21K) to perform well. In contrast, MViT achieves state-of-the-art performance without such pre-training. As a result, the MViT architecture is much more computationally efficient to train relative to nearly all baseline approaches; see below.
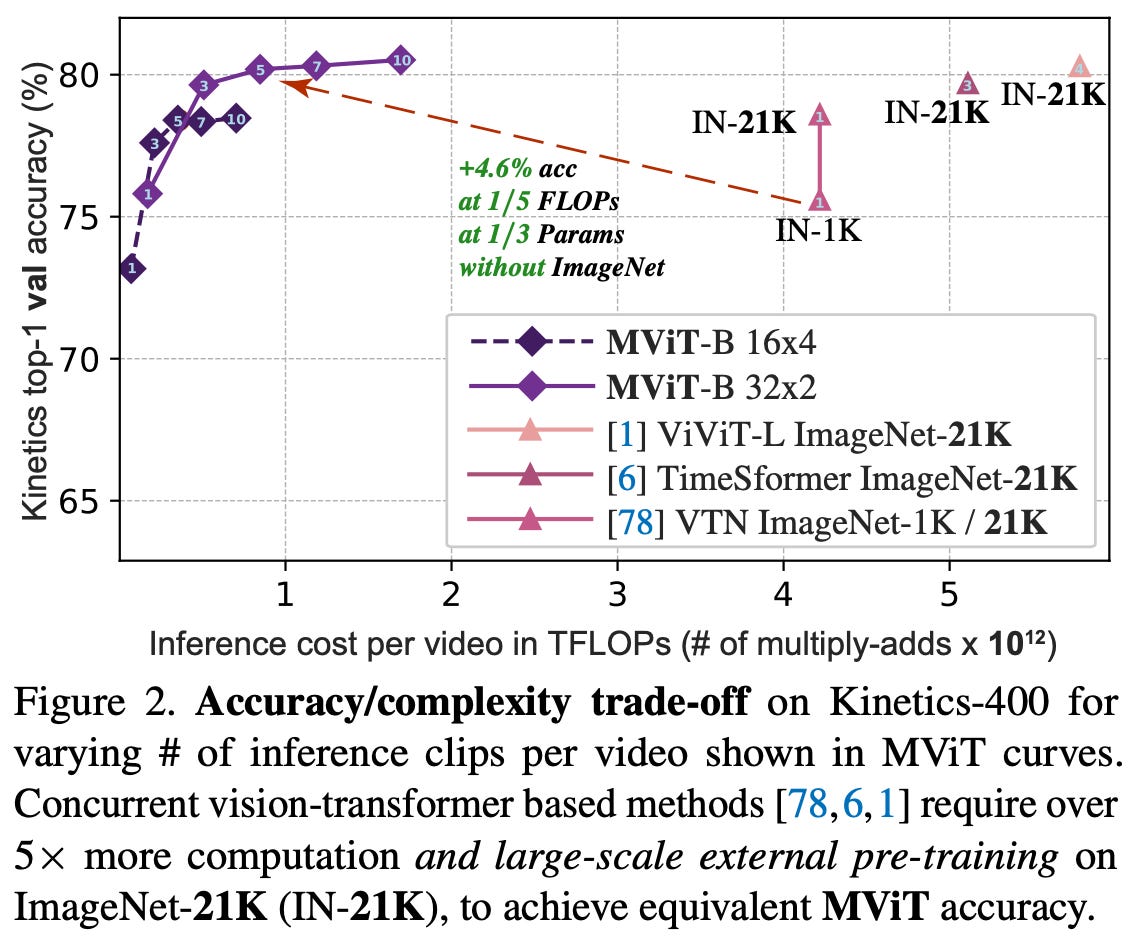
This analysis shows that MViT is a high-performing, efficient, and viable architecture for video recognition. All that ViTs needed to work well in this domain was a multi-scale feature approach!
better spatiotemporal features. Interestingly, MViT seems to capture temporal and motion information within the underlying data much better than baseline models. For example, if we shuffle the frames within a video clip, transformer-based baseline models see no difference in performance, indicating that the temporal ordering of frames is not being considered by these models at all. As such, it is clear that the spatiotemporal features being extracted by these models are shallow and incomplete. In contrast, MViT sees a massive deterioration in performance; see below.

Such a result indicates that MViT’s feature representations contain both spatial and temporal/motion information. Put simply, MViT extracts higher-quality spatiotemporal information from videos compared to baseline techniques.
“We show that vision transformer models trained on natural video suffer no performance decay when tested on videos with shuffled frames. This indicates that these models are not effectively using the temporal information and instead rely heavily on appearance.” - from [1]
MViT-v2 is a bit better. If we incorporate the changes to MViT proposed my MViT-v2 [2], we see that resulting model achieves a consistent improvement in performance relative to the original MViT architecture; see below.

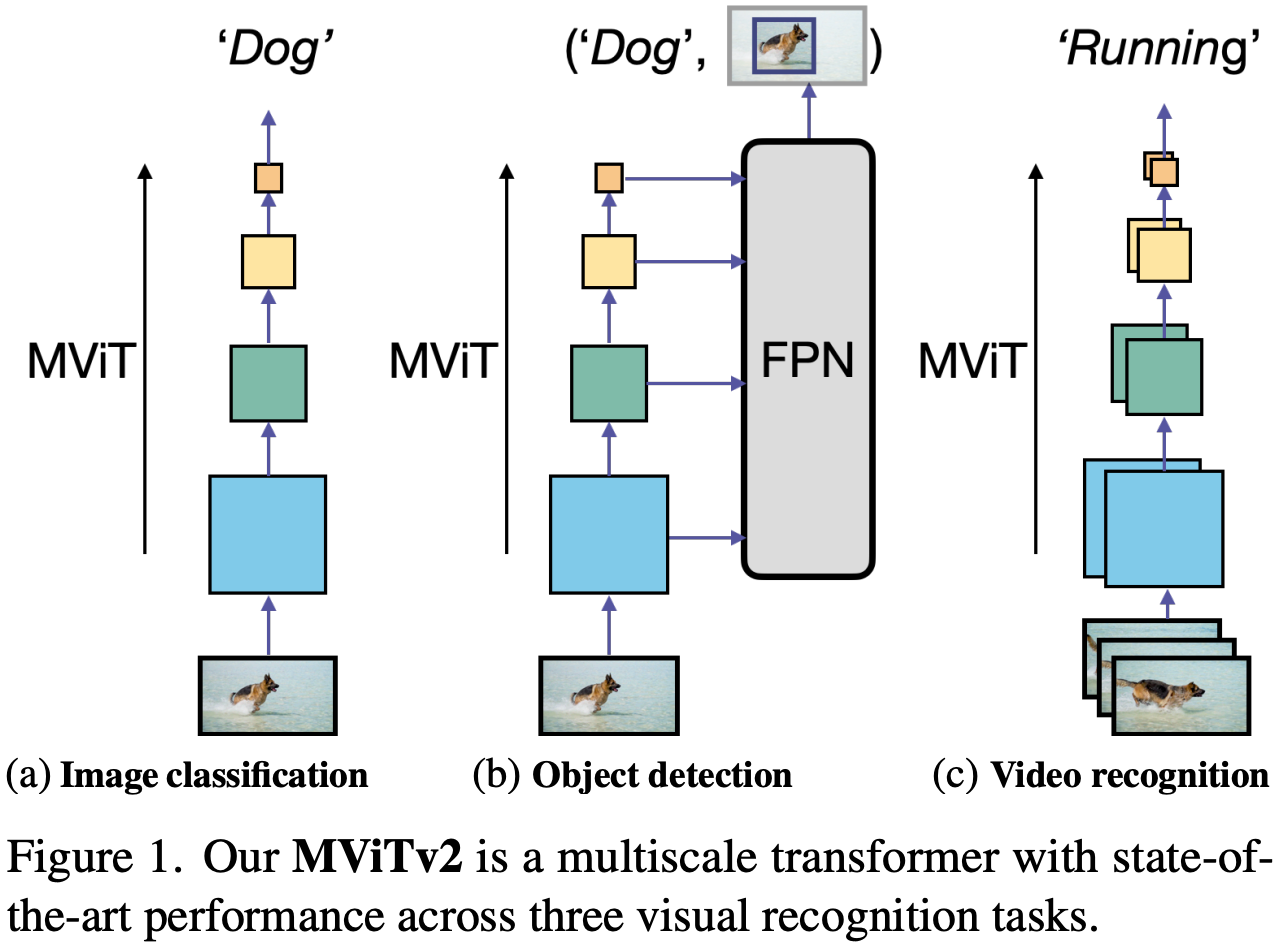
beyond video recognition. Although MViT is uniquely capable of efficiently processing video data, it can also be used for other tasks in computer vision. In particular, the MViT is applied to image classification and segmentation/detection tasks; see below. Interestingly, the model is found to perform quite well in these domains, indicating that multi-scale transformer architectures are generic and can be used for a variety of computer vision tasks.
Takeaways
Although we have seen from prior work that ViTs can accurately classify images [3], the proposal of MViT shows that ViTs (given a few important modifications) are also quite useful for deep learning on video. The basic takeaways that we learn from studying the MViT architecture are as follows.
videos are tough to handle. When we go from images to videos, we have a lot more data to deal with. This means that the input sequence is much larger and the training process is much slower. Thus, using a normal ViT model to learn from video data would be too computationally inefficient. MViT solves this problem by using adaptive pooling approaches to reduce the scale of data.
pooling attention is the way to go. The main difference between MViT and ViT is the use of pooling within self-attention layers. Such an approach allows granular control of the spatiotemporal resolution of the self-attention computation. As a result, we can control the extent of self-attention (i.e., consider a smaller spatial resolution or fewer frames), which can drastically reduce the computational costs of training and inference with MViT.
multi-scale features are important. Beyond the computational benefits, we can leverage pooling self-attention to separate the MViT architecture into several stages with different resolutions. Such an approach mimics the FPN architecture [4] (popular for solving dense image prediction tasks like object detection) and greatly improves the performance of MViT in both image and video-based deep learning tasks.
it’s not just for videos! MViT’s most notable contribution is efficiently generalizing the ViT architecture to work well on videos. But, it can also be applied to image-based tasks like classification and object detection to achieve state-of-the-art performance. MViT improves upon the performance of ViT in several domains of computer vision.
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
This post is part two of a six-part letter series on Vision Transformers that I wrote with Sairam Sundaresan. Please subscribe to his Gradient Ascent newsletter as well!

Bibliography
[1] Fan, Haoqi, et al. "Multiscale vision transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[2] Li, Yanghao, et al. "MViTv2: Improved Multiscale Vision Transformers for Classification and Detection." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[3] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[4] Lin, Tsung-Yi, et al. "Feature pyramid networks for object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[5] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.