
Vision Transformers: From Idea to Applications (Part Four)
How CLIP revolutionized visual-linguistic understanding...


This newsletter is sponsored by Rebuy, the Commerce AI company. Do you want to join a fast-growing startup? Do you like working at the intersection of engineering and AI? Then let me know! I’m in search of awesome engineers/scientists to learn and build with.
If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!
this post. This is part four of a six-part series (written by Sairam Sundaresan and myself) that explores the (vision) transformer deep learning architecture and its many, impactful applications. I will write parts two, four, and six as part of Deep (Learning) Focus, while Sairam will release the other parts on his Gradient Ascent newsletter. Read the previous posts here:
Part One: The Transformer Architecture [link]
Part Two: Vision Transformers [link]
Part Three: Object Detection with Transformers [link]
One of the most notable applications of the Vision Transformer (ViT) architecture in recent years was within the Contrastive Language-Image Pre-training (CLIP) model [1]. The main idea behind CLIP is to train a visual-linguistic (i.e., takes both images and text as input) deep learning model over pairs of images and textual descriptions. Notably, image-caption pairs are widely available on the internet. As a result, models like CLIP can be trained over data that’s already available online without depending upon labeled data for supervised training!
Underlying the effectiveness of CLIP is a simple pre-training task: identifying the correct caption for a given image. By teaching the underlying model to correctly identify valid image-caption pairs in this way, we can obtain an incredibly-effective model for deep learning on text and images. Notably, CLIP was popularized due to its use in DALLE-2 [2] and its ability to perform zero-shot (i.e., no training data is observed before making predictions) classification with 76.2% accuracy on ImageNet.
Given that CLIP makes heavy use of the ViT architecture, it is undoubtedly one of the more relevant applications of transformers for computer vision in recent years. Plus, separate transformer architectures are used to process both text and images in CLIP, making it an interesting method to overview within our series on ViTs. Within this post, we will overview the CLIP architecture and training pipeline, as well as explain how it can be practically used for tasks like image classification, search, and more.
How CLIP works…
We will now overview CLIP, including the architecture, the training process, and how the model is evaluated. The architecture and training approach adopted by CLIP can be used to train highly-accurate visual-linguistic models using pairs of images and text. We can leverage this model practically to obtain high-quality embeddings of image-caption pairs (i.e., joint embeddings that consider both image and textual data), or even to accurately classify images in a zero-shot manner.
The Architecture
CLIP takes both text and images as input. However, separate transformer architectures are used to process each of these inputs. These separate transformer architectures are (creatively) referred to as the image encoder and the text encoder. The image encoder takes an image as input and returns a vector, while the text encoder does the same with textual input.

image encoder. CLIP can either use a CNN or ViT-based image encoder, as shown in the figure above. Notably, the architecture of the ViT-based image encoder is identical to the ViT proposed in [3]. After both image-encoder variants are tested, authors in [1] conclude that the transformer-based encoder is more efficient and performs better. We can observe this improved efficiency of the ViT variant of CLIP within the figure below; see the difference in performance and efficiency between CLIP-ViT and CLIP-ResNet.

text encoder. For the text encoder, we can simply use a normal transformer architecture! In particular, authors in [1] adopt a decoder-only transformer architecture, meaning that the text encoder uses unidirectional (or masked) self-attention in each of its layers (same as a language model!). Using unidirectional attention (as opposed to bidirectional) is not strictly necessary for CLIP, as the model is never used for language modeling or generation applications. However, the authors claim that they adopt a decoder-only architecture to enable language generation in future variants of CLIP; see below.
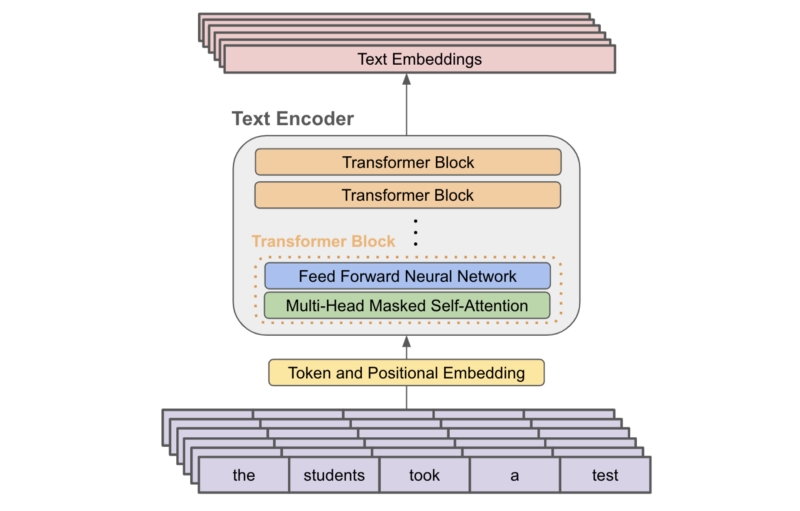
The full CLIP architecture is composed of both an image encoder, which uses the ViT architecture [3], and a text encoder, which uses a decoder-only transformer architecture. These separate modules take an image and a sequence of text as input, respectively, and produce vectors as output; see below.

But, what should we do with these vectors, and how can we train CLIP to give us vectors that are useful? To answer these questions, we need to learn how the CLIP model is trained.
Training CLIP
We can probably think of several (reasonable) ways that deep learning models like CLIP could be trained over image-caption pairs. For example, should we try to generate the caption from the image? What about classifying the words that are present in the caption? Interestingly, prior work tried these approaches: they worked well, but not great [4, 5]. With the proposal of CLIP, we see that these tasks are actually too difficult to solve, which makes the training process really slow and inefficient. To get a better, more efficient model that can be trained over a ton of data to learn great representations, we need an easier objective!
training objective. In particular, CLIP draws upon related work in contrastive representation learning by proposing a simple training task: predicting the correct, associated caption for an image within a group of candidate captions; see below.
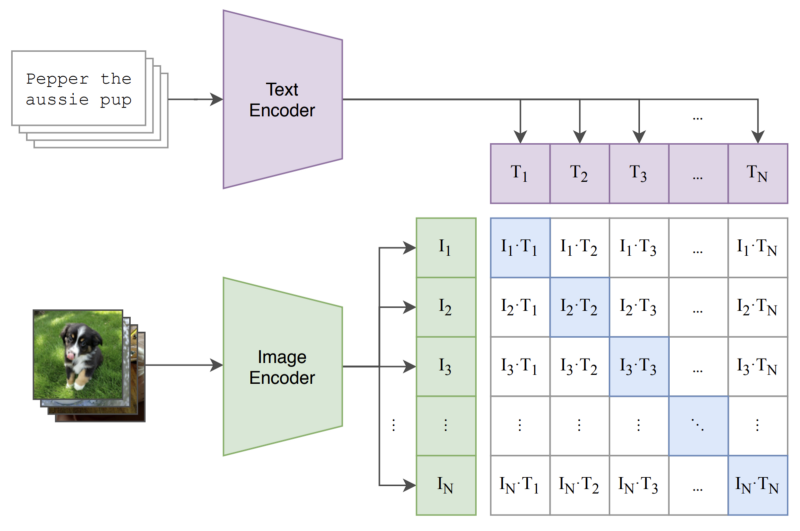
To practically implement such an objective, we just:
pass several images and captions through their encoders
maximize the cosine similarity between image and text embeddings of true image-caption pairs
minimize cosine similarity between embeddings of images and captions that aren’t paired together
In the deep learning literature, such an objective is called the multi-class N-pair (or InfoNCE) loss [6]. It is commonly used for contrastive learning (e.g., self-supervised learning).
why does this objective make sense? Upon learning about the InfoNCE loss, we might ask ourselves: why is this a good objective for CLIP? The training objective for CLIP encourages the formation of a joint embedding space for images and text. In other words, our training objective ensures that the image and text encoders output similar embeddings for images and textual captions that are related. Images and captions that correspond to similar concepts will have similar embeddings. As a result, the CLIP model can be used for a variety of applications that require a high-quality similarity metric between images and text, such as search, classification, recommendations, and more.
simple is better. Prior work on visual-linguistic understanding considered numerous alternative training tasks for models like CLIP, finding that natural language captions of images could be leveraged as a viable training target/signal. At the time, we weren’t sure whether training a computer vision model using just image captions as the training target was reasonable! The conclusion that this was possible was highly non-trivial, as most deep learning models for computer vision were trained using explicitly supervised datasets (e.g., classification datasets where each image has an associated class).
Although alternative training objectives worked reasonably well, they were inefficient. We had to observe a ton of data before the model performed well. Authors in [1] find that CLIP’s training objective is much more efficient in terms of the amount of training data needed to reach competitive performance; see below.

In practice, this just means that, compared to baselines, CLIP performs better after observing significantly fewer image-caption pairs during training.
Zero-shot Classification with CLIP
Once we have trained a CLIP model using the objective explained above, we can use it in various ways. One of the main methods of using CLIP in [1], however, is for zero-shot classification. In other words, we take the CLIP model that is pre-trained over a large dataset of image-caption pairs, then directly use it to classify images from public benchmarks (e.g., ImageNet) without first performing any supervised training on these datasets.
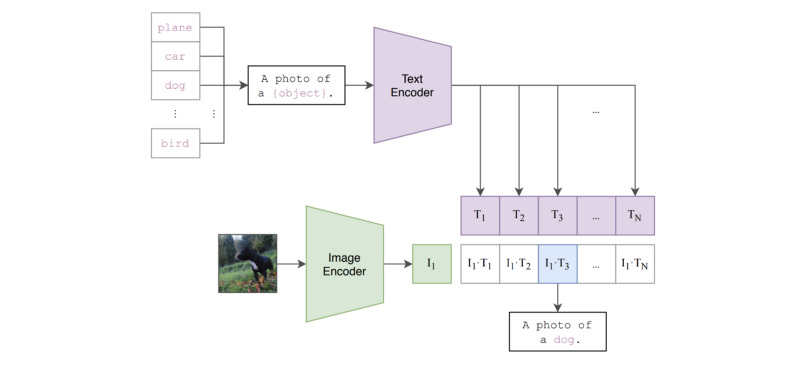
At this point, we might be thinking: how can we classify images from a dataset we have not trained on? However, we should recall that CLIP is trained to predict if an image and text snippet are an appropriate pair. This capability can be repurposed to perform zero-shot classification. By leveraging textual descriptions of unseen classes (e.g., class names), we can find the most appropriate class for an image by (i) using our text encoder to embed each potential class, (ii) using our image encoder to embed the image, and (iii) comparing these embeddings to find the image-text pair that is most fitting; see above for an illustration.
More specifically, we can perform zero-shot classification with the following steps:
Compute image feature embedding using the image encoder
Compute embeddings for the textual description of each class (e.g., class name) using the text encoder
Compute the cosine similarity between the image embedding and each class embedding
Normalize similarities to form a class probability distribution

This approach enables accurate zero-shot classification, but it has notable limitations. Namely, class names may lack useful or relevant context that reveals their meaning (i.e., polysemy issue), some datasets may lack metadata like class names or descriptions, and single-word descriptions of images are uncommon within the image-text pairs used to train CLIP. Although we can’t do anything about datasets that have no metadata, authors in [1] show that we can mitigate the other problems by crafting “prompts” (see “zero/few-shot inference via prompting” here for more info) with class names/descriptions or using ensembles of zero-shot classifiers; see above.
fine-tuning CLIP. A lot of the evaluations performed in [1] are done in a zero-shot manner. However, recent research revealed that CLIP also has strong fine-tuning performance [7]; see below.
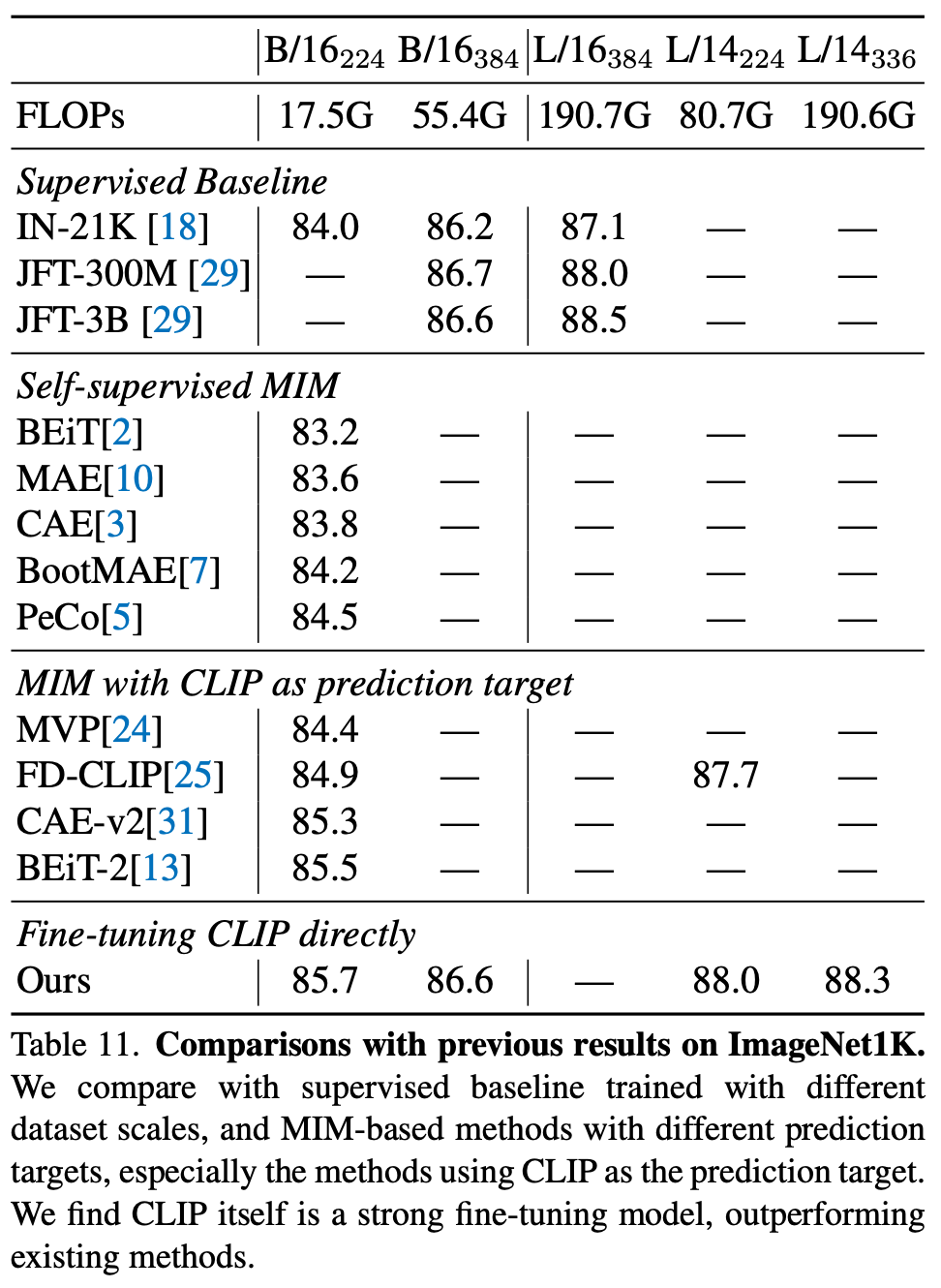
This finding was not a given. Most research after CLIP did not directly fine-tune the model, choosing instead to use its embeddings for training separate models (e.g., via distillation [8]). In fact, even results in [1] only fine-tune a linear probe on top of CLIP embeddings. The full CLIP model is never fine-tuned end-to-end. Due to recent research [7], however, we now know that CLIP can be fine-tuned to perform really well. We just need to use the correct hyperparameters and fine-tuning procedure!
CLIP at a glance

The full CLIP architecture, training procedure, and evaluation strategy is depicted above. As described before, CLIP has two architectural components (image and text encoder), both of which are transformer-based. The model is trained over image-caption pairs using a contrastive objective that pairs images with the appropriate caption in a mini-batch. Then, we can use the model for zero-shot classification by pairing images with the best class based on textual metadata associated with each class.
How does CLIP perform?
In [1], CLIP is evaluated in a zero-shot and few-shot manner, as well as with added fine-tuning. Here, I’ll overview the main findings from these experiments, which will provide a better understanding of the scenarios in which CLIP is most useful.
Zero-shot
CLIP’s zero-shot learning capabilities were revolutionary. The model improves zero-shot accuracy on ImageNet from 11.5% to 76.2%. Other datasets saw significant benefits as well; see below.

To better understand the behavior of CLIP, authors in [1] compare its zero-shot performance to that of a pre-trained (on ImageNet) ResNet50. To use this model for evaluation, we remove its final classification layer so that the model outputs a vector of logits (rather than a class probability distribution) for each image passed as input. For evaluation, we embed all images (train and test set) using the pre-trained ResNet50, train a linear classifier in a supervised-fashion over the full training set to predict the correct class given an image embedding, then evaluate this classifier on the test set. The results from this evaluation are shown below relative to zero-shot CLIP performance.

CLIP outperforms this fully-supervised baseline on 16 of 27 total tasks. This result is quite impressive given that CLIP performs zero-shot classification and never observes a single training example from the dataset on which it is evaluated. When we itemize CLIP’s performance per dataset, we see that CLIP tends to perform worst on specialized/complex tasks (e.g., tumor detection and satellite image classification). Because of the wide and generic scope of CLIP’s training process, the model is most effective at generic object classification and action recognition tasks.
Few-shot
We can also evaluate the few-shot performance of CLIP by training a linear classifier to perform classification using CLIP embeddings as input (i.e., a similar strategy to that described above for ResNet50). Zero-shot CLIP matches the average performance of a few-shot linear classifier trained over four examples of each class. Furthermore, CLIP outperforms all few-shot linear classifiers when allowed to observe training examples itself; see below.

When a fully-supervised linear classifier is trained on top of CLIP features, it is found to outperform numerous baselines in terms of accuracy and compute cost; see below.

CLIP is not perfect. It struggles with specialized tasks and only works for datasets with good textual descriptions of each class. Nonetheless, the zero and few-shot performance of CLIP show that we can accomplish a lot with a model that creates a high-quality joint embedding space for images and text. CLIP is an initial proof of concept that will undoubtedly inspire future developments.
Takeaways
CLIP uses a simple architecture and a novel training objective to create a high-quality, visual-linguistic model that is trained over weakly-supervised image-caption pairs. From this model, we see that supervision from natural language provides a lot of useful information that can be used to train powerful deep learning models. The major takeaways from CLIP are outlined below.
finding the best training objective. Prior work indicated that we could use natural language (e.g., image captions) as a source of supervision for training a deep learning model. However, CLIP revealed that we must use the correct objective for this approach to work well. By implementing the contrastive objective that pairs images with descriptions via classification, we can train the underlying model more efficiently and to a much higher accuracy.
CLIP is the zero-shot queen/king. CLIP’s zero-shot performance on ImageNet is shocking. Have we ever seen a model that improves performance on a major dataset from 11.5% to 76.2%? This is fundamental breakthrough in deep learning, and CLIP became quite popular as a result (and from use in models like DALLE-2).
prompting is useful. Similar to work in large language models, prompting approaches are quite useful for CLIP. For example, if we are classifying an image that belongs to the class “dog”, it might help to use the textual description “A photo of a dog” instead of the single-word class description. These prompting approaches are a reoccurring and popular theme in the deep learning community. If we have some text that we are passing into a transformer for classification or generation purposes, we might get better performance by formulating this input as a prompt.
ViTs are great. Authors in [1] test both ResNet and ViT architectures for CLIP’s image encoder. The ViT-based encoder is shown to be better in terms of both efficiency and performance, revealing that vision transformers are an important component of the CLIP architecture. Yet another impactful application of ViTs!
New to the newsletter?
Hello! I am Cameron R. Wolfe, Director of AI at Rebuy and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I help readers build a deeper understanding of topics in deep learning research via understandable overviews of popular papers on that topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
This post is part two of a six-part letter series on Vision Transformers that I wrote with Sairam Sundaresan. Please subscribe to his Gradient Ascent newsletter as well!

Bibliography
[1] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
[2] Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 (2022).
[3] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[4] Li, Ang, et al. “Learning visual n-grams from web data.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
[5] Joulin, Armand, et al. “Learning visual features from large weakly supervised data.” European Conference on Computer Vision. Springer, Cham, 2016.
[6] Sohn, Kihyuk. “Improved deep metric learning with multi-class n-pair loss objective.” Advances in neural information processing systems 29 (2016).
[7] Dong, Xiaoyi, et al. "CLIP Itself is a Strong Fine-tuner: Achieving 85.7% and 88.0% Top-1 Accuracy with ViT-B and ViT-L on ImageNet." arXiv preprint arXiv:2212.06138 (2022).
[8] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 2.7 (2015).