

Using LLMs for Evaluation
LLM-as-a-Judge and other scalable additions to human quality ratings...


As large language models (LLMs) have become more and more capable, one of the most difficult aspects of working with these models is determining how to properly evaluate them. Many powerful models exist, and they each solve a wide variety of complex, open-ended tasks. As a result, discerning differences in performance between these models can be difficult. The most reliable method of evaluating LLMs is with human feedback, but collecting data from humans is noisy, time consuming, and expensive. Despite being a valuable and necessary source of truth for measuring model capabilities, human evaluation—when used in isolation—impedes our ability to iterate quickly during model development. To solve this problem, we need an evaluation metric that is quick, cost effective, and simple but maintains a high correlation with the results of human evaluation.
“While human evaluation is the gold standard for assessing human preferences, it is exceptionally slow and costly. To automate the evaluation, we explore the use of state-of-the-art LLMs, such as GPT-4, as a surrogate for humans.” - from [17]
Ironically, the ever-increasing capabilities of LLMs have produced a potential solution to this evaluation problem. We can use the LLM itself for evaluation, an approach commonly referred to as LLM-as-a-Judge [17]. This technique was originally explored after the release of GPT-4—the first LLM that was capable of evaluating the quality of other models’ output. Since then, a variety of publications have analyzed LLM-as-a-Judge, uncovering best practices for its implementation and outlining important sources of bias of which we should be aware. Throughout the course of this overview, we will take a look at many of these publications and build a deep, practical understanding of LLM evaluations.
What is LLM-as-a-Judge [17]?
Many traditional metrics exist for evaluating the quality of textual sequences. These metrics may be reference-based or reference-free, indicating whether a “ground truth” sequence is needed as a reference for measuring quality. These metrics work well on narrower tasks like machine translation or summarization; see here for details. However, modern LLMs solve diverse, open-ended tasks and have been extensively aligned based on human preferences, which is difficult to detect using legacy NLP benchmarks. For this use case, traditional metrics tend to break down and have been shown to correlate poorly with human preferences.
“LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain.” - from [17]
LLM-as-a-judge is a reference-free metric that directly prompts a powerful LLM to evaluate the quality of another model’s output. Despite its limitations, this technique is found to consistently agree with human preferences in addition to being capable of evaluating a wide variety of open-ended tasks in a scalable manner and with minimal implementation changes. To evaluate a new task, we just need to tweak our prompt! This metric was proposed after the release of GPT-4 and has since grown in popularity, culminating in the publication of an in-depth analysis of LLM-as-a-judge metrics in [17]. Today, LLM-as-a-judge is, along with human evaluation, one of the most widely-used evaluation techniques for LLMs—it excels in the task of evaluating a model’s alignment with human preferences.
MT-Bench and Chatbot Arena

To expand available benchmarks that can be used to measure LLM performance in open-ended dialogue applications, authors in [17] develop two datasets for assessing human preferences. The MT-bench dataset is a fixed set of 80 high-quality questions. These questions, which span eight genres1, are heavily focused upon multi-turn conversation and instruction-following capabilities, which are (arguably) the two most important skills for foundation LLMs. Examples of questions from MT-bench are shown above.
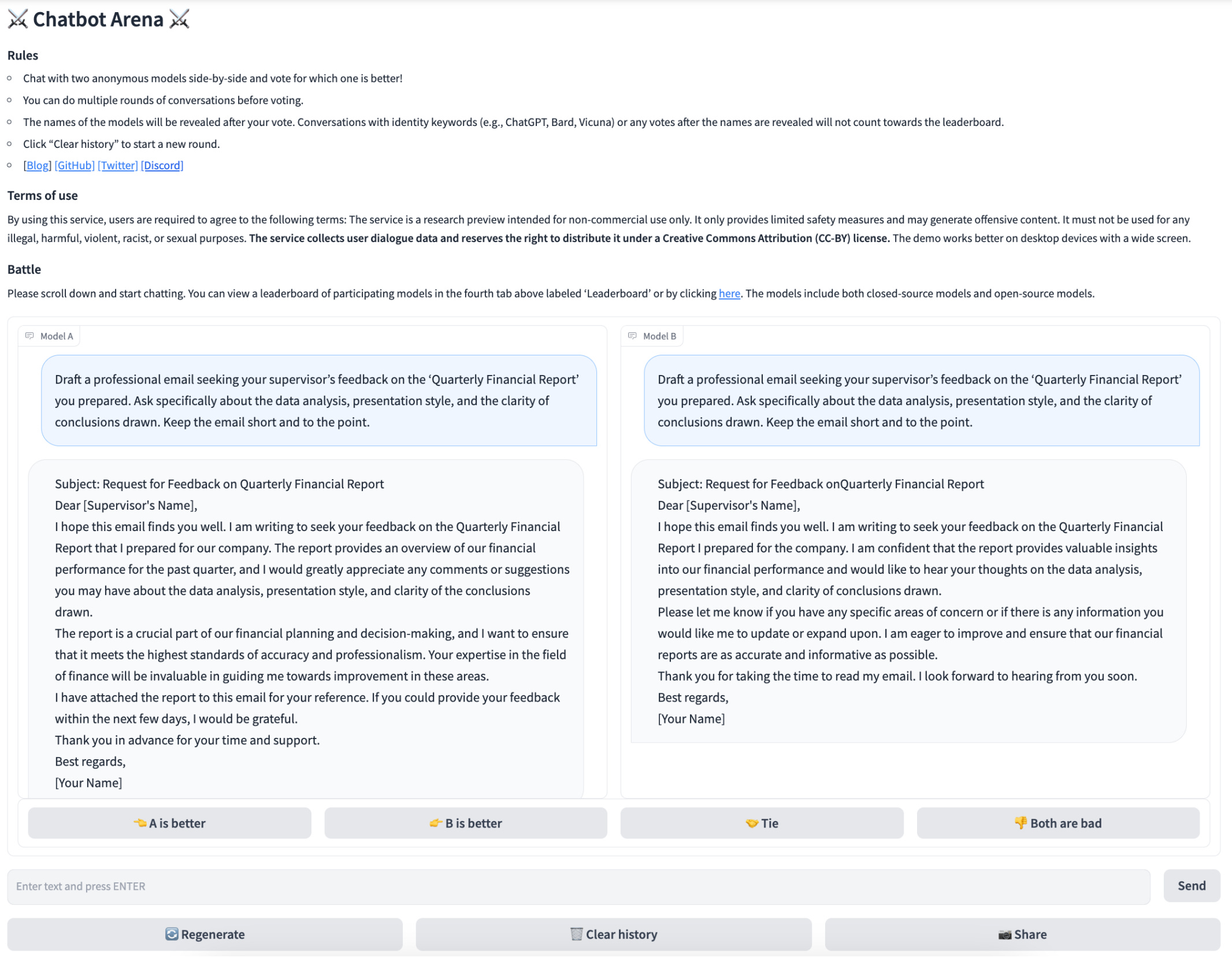
The second dataset, called Chatbot arena, is more of a platform than a dataset. The arena is a crowdsourced battle platform that allows users to simultaneously interact with two unknown LLMs and select the model that is better; see above. No predefined questions are used. Instead, users pose their own questions and a response is provided by both LLMs, allowing data to be collected across a wide variety of different use cases. To avoid bias, the identity of the model is preserved until after the human provides their preference. Authors in [17] collect a large amount of human feedback from MT-bench and Chatbot Arena that is used to evaluate the correlation of LLM-as-a-Judge with human preferences.
Chatbot Arena Leaderboard. Using human preferences collected from the arena, we can compute Elo scores and rank models based on human preferences. Today, over 1.5M pairwise preferences for >100 models have been shared on Chatbot Arena, which has become one of the most widely-referenced LLM leaderboards; see here. For more details, check out Nathan Lambert’s post on this topic below.
Different Setups for LLM-as-a-Judge

Compared to human evaluation, LLM-as-a-Judge is a simple and scalable alternative that i) reduces the need for human involvement in the evaluation process and ii) enables faster model iterations. To perform evaluations with LLM-as-a-Judge, all we need to do is write a prompt! But, there are a few different structures of prompts that are commonly used (shown above):
Pairwise comparison: the judge is presented with a question and two model responses and asked to identify the better response.
Pointwise scoring2: the judge is given a single response to a question and asked to assign a score; e.g., using a Likert scale from one to five.
Reference-guided scoring: the judge is given a reference solution in addition to the question and response(s) to help with the scoring process.
Any of these techniques can be combined with chain of thought (CoT) prompting to improve scoring quality. To do this, we can simply use a zero-shot CoT prompt by appending something like “Please write a step-by-step explanation of your score” to the judge’s prompt. However, we should be sure to ask the LLM to output the rationale prior to its score (as opposed to afterwards), as recommended in [16]3.
“The conclusions generated by the model are not supported by the explanation generated afterward.” - from [16]
Having the LLM output a human-readable rationale along with its score is an easy and useful explainability trick. We can use these explanations to gain a deeper understanding of a model’s performance and shortcomings; see below.

Which setup should we use? Each of these scoring strategies has pros and cons—no one approach is best. For example, pairwise comparison is not scalable, as it requires every combination of model outputs be compared to each other. However, pointwise scoring tends to be less stable, as it expects the judge to possess a relatively consistent internal scoring mechanism—absolute scores are much more likely to fluctuate compared to pairwise comparisons. Typically, the style of LLM-as-a-Judge evaluation that should be used depends upon the details of our application. We don’t always have two models to compare, so pointwise scoring might make the most sense in those cases and vice versa.
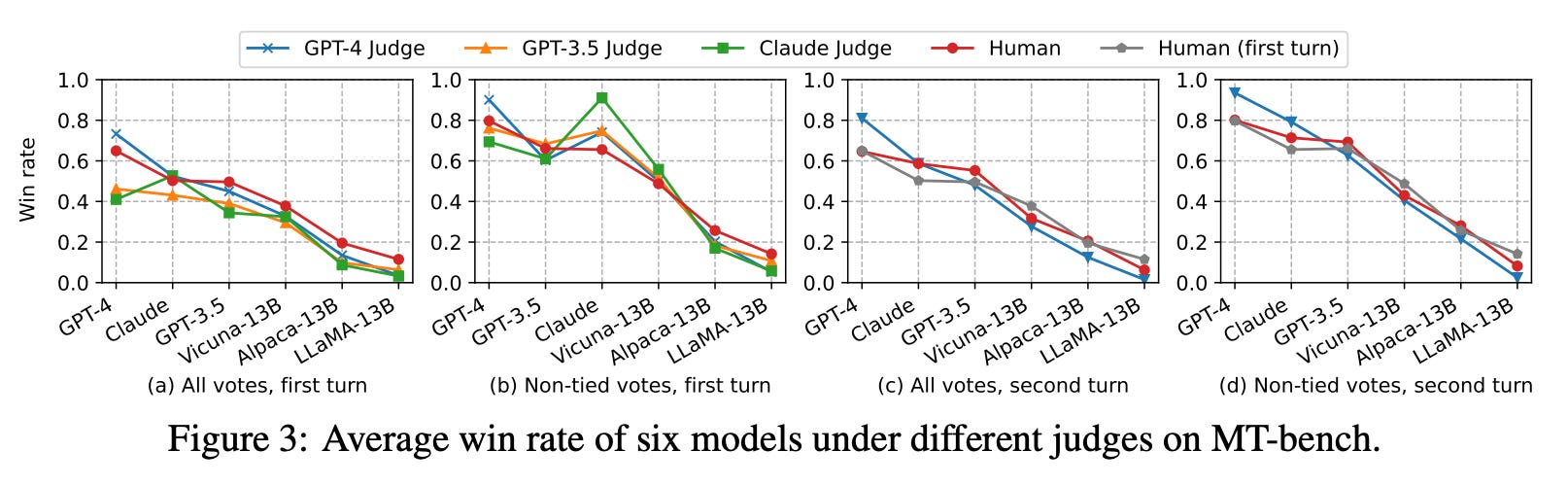
Does it work well? In [17], we clearly see that strong LLM judges like GPT-4 can very accurately measure human preferences. In fact, GPT-4 is found to achieve an 80% agreement rate with human preference scores, which matches the agreement rate that human annotators have with themselves; see above. This ability of LLM judges to accurately predict human preferences should come as no surprise—most modern LLMs are extensively finetuned on human preference data.
Biases (and how we can avoid them…)
“We identify biases and limitations of LLM judges. However, we… show the agreement between LLM judges and humans is high despite these limitations.” - from [17]
Although LLM-as-a-Judge can accurately predict human preferences, this evaluation strategy is not perfect—it introduces several new sources of bias into the evaluation process. Already, we know that LLMs have a swath of limitations, such as questionable reasoning capabilities, sensitivity to minor changes in the prompt, and a tendency to generate verbose outputs. Many of these weaknesses lead to corresponding biases within LLM-as-a-Judge evaluations:
Position bias: the judge may favor outputs based upon their position within the prompt (e.g., the first response in a pairwise prompt).
Verbosity bias: the judge may assign better scores to outputs based upon their length (i.e., longer responses receive higher scores).
Self-enhancement bias: the judge tends to favor responses that are generated by itself (e.g., GPT-4 assigns high scores to its own outputs).
Beyond the sources of bias outlined above, LLM judges tend to have difficulties with grading responses to questions that they struggle to answer themselves; e.g., complex reasoning and math questions. Additionally, judges are easily mislead by incorrect information in their context [18]. If one of the responses being graded is incorrect, the judge may be misled by this context and output an inaccurate score.
Digging deeper into bias. Beyond the sources of bias outlined in [17], there are many other works—some of which we will explore later in this overview —that have deeply analyzed bias in LLM-as-a-judge evaluations. A list of these works has been provided below for easy reference and further reading:
Humans or LLMs as the Judge? A Study on Judgement Biases [link]
Evaluation Biases for Large Language Models [link]
Cognitive Biases in Large Language Models as Evaluators [link]
Large Language Models are Inconsistent and Biased Evaluators [link]
Large Language Models are Not Yet Human-Level Evaluators [link]
How can we reduce bias? To lessen the impact of biases on the results of LLM-as-a-Judge evaluations, there are several techniques that we can use:
Randomizing the position of model outputs within the prompt, generating several scores, and taking an average of scores with different positions—we will refer to this as the position switching trick.
Providing few-shot examples to demonstrate the natural distribution of scores and help with calibrating the judge’s internal scoring mechanism.
Providing correct answers to difficult math and reasoning questions within the prompt as a reference for the judge during the evaluation process.
Using several different models as a judge (e.g., Claude, Gemini and GPT-4) to lessen the impact of self-enhancement bias.
Although these techniques are useful, LLM-as-a-judge is a flawed metric—as are all metrics—that will never be perfect. As such, we should always be aware of these biases and consider how they impact our analysis. Think about the model(s) being evaluated, what we are trying to measure, how the evaluation is set up, and in what ways the underlying judge could skew the results of this evaluation.
Early Work on LLM Evaluations
Prior to the proposal and analysis of LLM-as-a-Judge in [17], a variety of earlier works studied similar techniques. These studies began with the proposal of GPT-4, which was the first LLM that was powerful enough to evaluate text quality. As we will see, this approach quickly caught fire and began spreading through the community due to its ease of use, generality, and effectiveness.
Sparks of Artificial General Intelligence: Early experiments with GPT-4 [1]
To make LLM-powered evaluations possible, we first need access to a sufficiently powerful LLM that can reliably evaluate the output of other models. Although prior models were indeed impressive, we did not have access to such a model until the proposal of GPT-4. Immediately after the proposal of this model, however, researchers began to explore the feasibility of LLM evaluators!

How good is GPT-4? The first work [1] to explore the use of GPT-4 as an evaluator—published less than ten days after the model’s release4—was not focused upon evaluation. Rather, this work had a more general goal of exploring the capabilities of GPT-4, resulting in a 155-page analysis that spans a (shockingly) wide number of topics:
Proficiency in solving coding and math problems.
Using tools and interacting with humans; e.g., theory of mind problems, or the model’s ability to explain its outputs to humans.
Drawing basic figures/pictures using TikZ, generating useful plots, and performing more general data analysis.
Proving mathematical theorems, or even doing this while rhyming every line of the proof; see above.
The conclusion of this analysis is that GPT-4 excels at virtually all tasks that are considered and is a substantial improvement over ChatGPT. In fact, authors observe that GPT-4’s outputs are indistinguishable (or better than) those of humans in many cases and even go as far as saying that GPT-4 is a significant step towards artificial general intelligence (AGI); see below.
“The combination of the generality of GPT-4’s capabilities… and its performance on a wide spectrum of tasks at or beyond human-level makes us comfortable with saying that GPT-4 is a significant step towards AGI.” - from [1]
Although authors’ claim that GPT-4 demonstrates signs of (general) intelligence was—and continues to be—highly controversial, disagreements around LLM capabilities and progress toward AGI oftentimes boil down to a lack of (or difference in) rigorous definitions of these concepts. How can we measure intelligence without first defining it5? Luckily, we don’t have to worry about defining AGI for the purposes of this post. All we need to know is that GPT-4 is a very capable model and that these capabilities open up a lot of doors when it comes to using LLMs to evaluate the outputs of other LLMs.

GPT-4 as an evaluator. Authors in [1] are the first to explore the use of GPT-4 as a judge, but their analysis is actually quite brief (i.e., less than one page in total)! After addressing the limitations of existing evaluation metrics in judging the similarity of statements, authors evaluate the ability of GPT-4—using the prompt shown above—to judge the similarity of a model’s response to a reference answer. Specifically, GPT-4 is tasked with determining whether a model’s response is more similar to a reference answer or an answer generated with GPT-3. Two responses to a statement are provided to the judge, which then identifies the option that is a better reflection of the original statement.
“[GPT-4] can determine which answer in a pair is closer to the gold answer, and this determination reasonably aligns with a human performing the same task.” - from [1]
From this analysis, we can see that GPT-4 can judge semantic similarities between statements much better than simple metrics like ROUGE or BLEU. To improve the quality of these evaluations, authors ask GPT-4 to list the pros and cons of each response before identifying the preferred output. When we compare the judgements made by GPT-4 to that of humans, we see some significant differences. For example, GPT-4 prefers GPT-4-generated responses in 87.76% of cases compared to 47.61% of cases for human evaluators; see the table below.
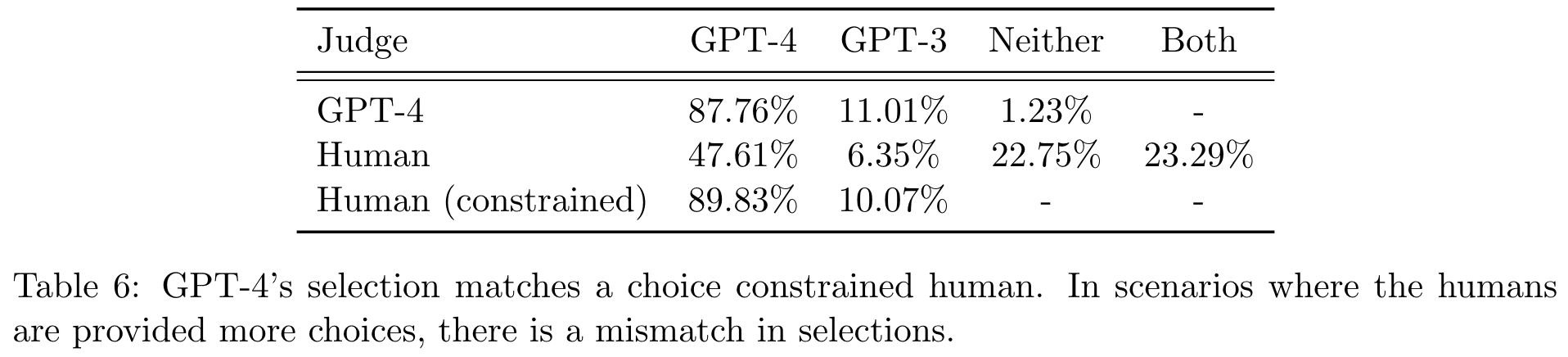
GPT-4’s level of agreement with human evaluators is low—slightly above 50%—and we already see some clear indications of bias in [1]; e.g., longer responses are scored better by GPT-4. This lack of alignment may be due to differences in the evaluation setup—GPT-4 is forced to choose a winner between the two responses, while humans can select a tie. However, the level of agreement between GPT-4 and humans is still surprisingly low, leading authors in [1] to conclude that more research is necessary to calibrate GPT-4’s evaluation capabilities.
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality [2]
“Evaluating chatbots is never a simple task. With recent advancements in GPT-4, we are curious whether its capabilities have reached a human-like level that could enable an automated evaluation framework.” - from [2]
Vicuna is an open-source chatbot created by finetuning LLaMA-13B over a set of user conversations with ChatGPT—collected from ShareGPT. We have covered the details of Vicuna in a prior overview. However, Vicuna is relevant to this overview due to the fact that authors chose to primarily evaluate the quality of this model’s output automatically with GPT-4; see below.
In fact, Vicuna was one of the first works to perform such LLM-powered evaluations, which received backlash6 at the time. However, the use of GPT-4 for evaluation purposes in [2] led to a wave of analysis of this technique because:
The evaluation results seemed to be relatively consistent and promising!
Using GPT-4 as an evaluator is a reference-free, automatic evaluation strategy that can be applied to any task (i.e., very generic and simple).
GPT-4 can output a rationale along with its evaluation, which improves the human interpretability of evaluation results.
Evaluation setup. The questions used to test Vicuna span eight categories; see here. There are 80 questions in total, which are written using the help of GPT-4. Authors observe that GPT-4 can generate challenging questions for state-of-the-art chatbots via careful prompt engineering. To evaluate the answers of different chatbots on these questions, the output from each model is collected and GPT-4 is asked to rate generated outputs in terms of helpfulness, relevance, accuracy, and detail. The prompts used for evaluation, which are surprisingly simple, can be seen here. Separate, more specific prompts are used for evaluating coding and math tasks due to the difficulty of such evaluations; see below.

GPT-4 is asked to rate the quality of two responses from different models on a scale from one to ten and provide an explanation for these scores. Producing such an explanation via CoT prompting7 tends to improve the accuracy of GPT-4’s ratings, as well as provides a human-readable rationale to explain the rating. There are several other useful observations we can make about these prompts:
The general prompt asks GPT-4 to avoid bias—including positional bias—when generating scores, revealing that authors in [2] experienced issues with positional bias. Later work [8] confirmed that Vicuna’s evaluation strategy has strong positional bias, but this issue can be solved via position switching.
All prompts explicitly specify output format so that ratings can be easily and automatically parsed from the response. Such an approach is only viable with a powerful instruction following model like GPT-4.
Prompts for coding and math evaluation are more detailed compared to the prompt used for general questions and introduce more in-depth, problem-specific details to improve the quality of ratings on such questions.
Coding and math prompts use a few different tricks to solicit better ratings, such as asking GPT-4 to critique provided solutions or solve the problem itself before providing a rating.
Vicuna’s unique approach. Rating two responses in each prompt is a standard practice that is commonly used today, as it allows for better relative comparisons between models—we can easily ask GPT-4 to explain which of the two models provides a better response for a given question. However, it’s important to note that Vicuna’s setup is slightly different than standard pairwise comparison. Rather than asking the model for the preferred response, the model is prompted to assign a score to each example, and the preferred example is determined based on these scores. This is another valid LLM-as-a-Judge setup that has been used by several papers.
Does this work well? Although GPT-4 struggles with grading coding and math questions, the results of these evaluations are relatively consistent and come with detailed explanations! Using these evaluations, authors observe that Vicuna is preferred to other open-source models for 90% of questions, and Vicuna is rated as better than or equal to ChatGPT in 45% of cases; see below. However, later work [8] reveals that these evaluations are biased towards longer outputs and (somewhat) poorly correlated with human preferences. So, we should be aware of these biases and shortcomings when interpreting these results.
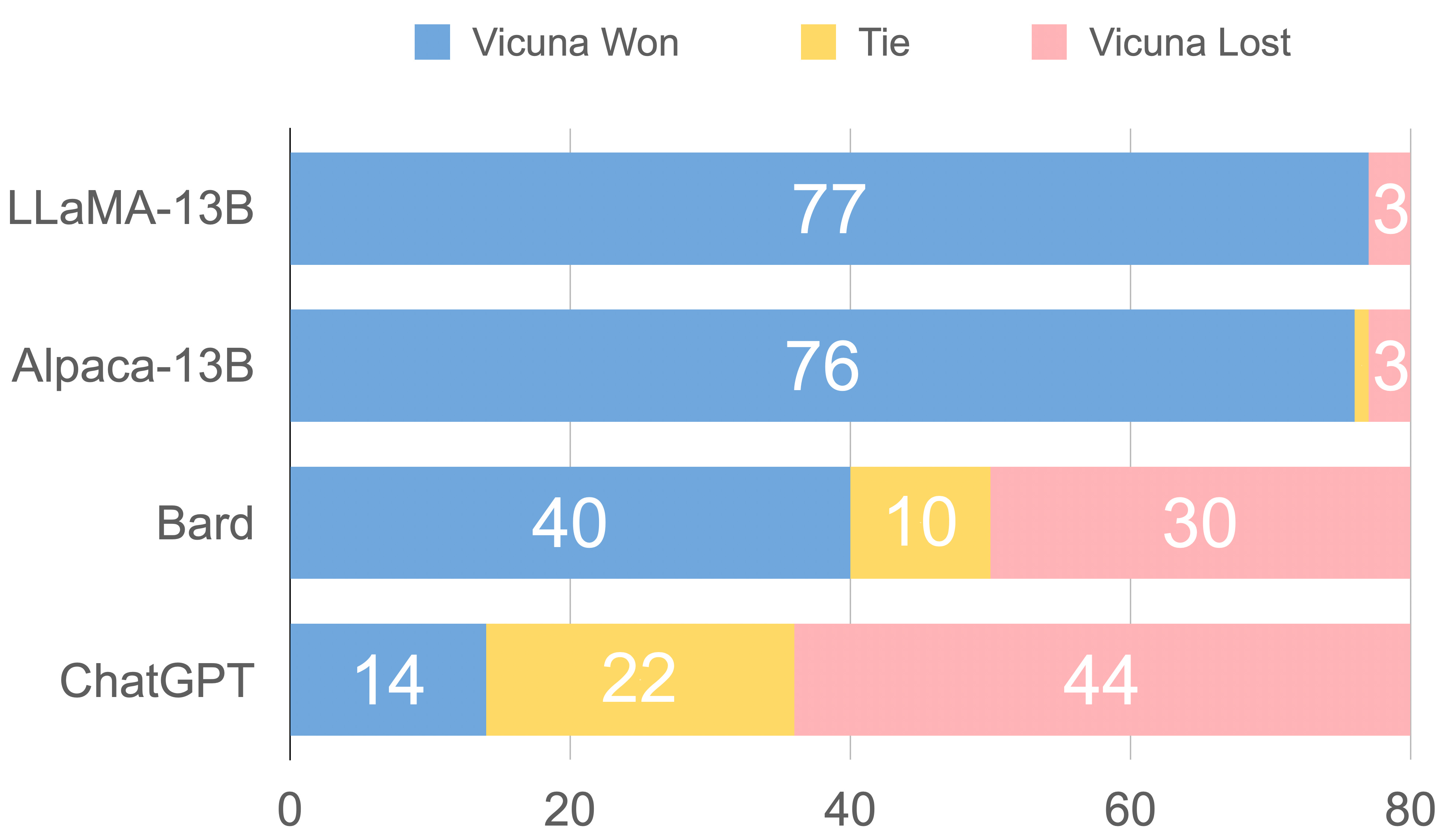
More specifically, we see in later work that imitation models like Vicuna match the style of powerful models like ChatGPT but lack their factuality and knowledge base. Nonetheless, the analysis in [2] is useful because i) we see that response style and instruction-following capabilities of open-source models can be improved by finetuning on outputs from a more powerful model and ii) the viability of LLM-powered evaluations is more clearly demonstrated.
“While this proposed evaluation framework demonstrates the potential for assessing chatbots, it is not yet a rigorous or mature approach… Developing a comprehensive evaluation system for chatbots remains an open question.” - from [2]
Looking forward. Despite the nascent nature of GPT-4 evaluations in [2], this work lays a powerful foundation for subsequent analysis of LLM-powered evaluations. Later work provides a variety of useful analyses of the strengths and weaknesses of LLM-as-a-Judge techniques, but the prompts that are used to generate reliable scores tend to be (relatively) similar to what we see in [2]! In fact, the LLM-as-a-Judge publication itself [17] is written by the same same authors as Vicuna and heavily utilizes many of the techniques that are proposed in [2]. Plus, the set of 80 questions used to evaluate Vicuna is widely used in other papers.
AlpacaEval: An Automatic Evaluator of Instruction-Following Models [8]
AlpacaEval [8], originally proposed in mid-2023, is one of the most popular LLM-based, automated evaluation metrics (and leaderboards) for instruction-following language models. The evaluation strategy—based upon AlpacaFarm [9], a simulator that uses LLM evaluators to automate the creation of RLHF-style, pairwise preference labels8—uses a fixed set of 805 instructions that span a comprehensive set of simple, assistant-style tasks; see here. For each instruction, we generate output with two LLMs—a baseline model and the model being evaluated. Then, an LLM evaluator is used to rate the quality of each model’s output (i.e., pairwise setup), allowing a win-rate between the two models’ outputs to be calculated.

Why is this useful? The goal of AlpacaEval is to create a fast and cheap automatic evaluation pipeline that is highly correlated with human preferences. The current iteration of AlpacaEval runs in less than three minutes, costs less than $109, and has a 0.98 Spearman correlation with human evaluation (taken from the Chatbot Arena); see above. In comparison, performing human evaluation is subject to noise and disagreements, is significantly more expensive, and may require several weeks of annotation time. Because AlpacaEval is so efficient, this metric is perfect for model development—it provides a reliable proxy for human evaluation of simple instruction-following tasks that is quick and cheap to compute.
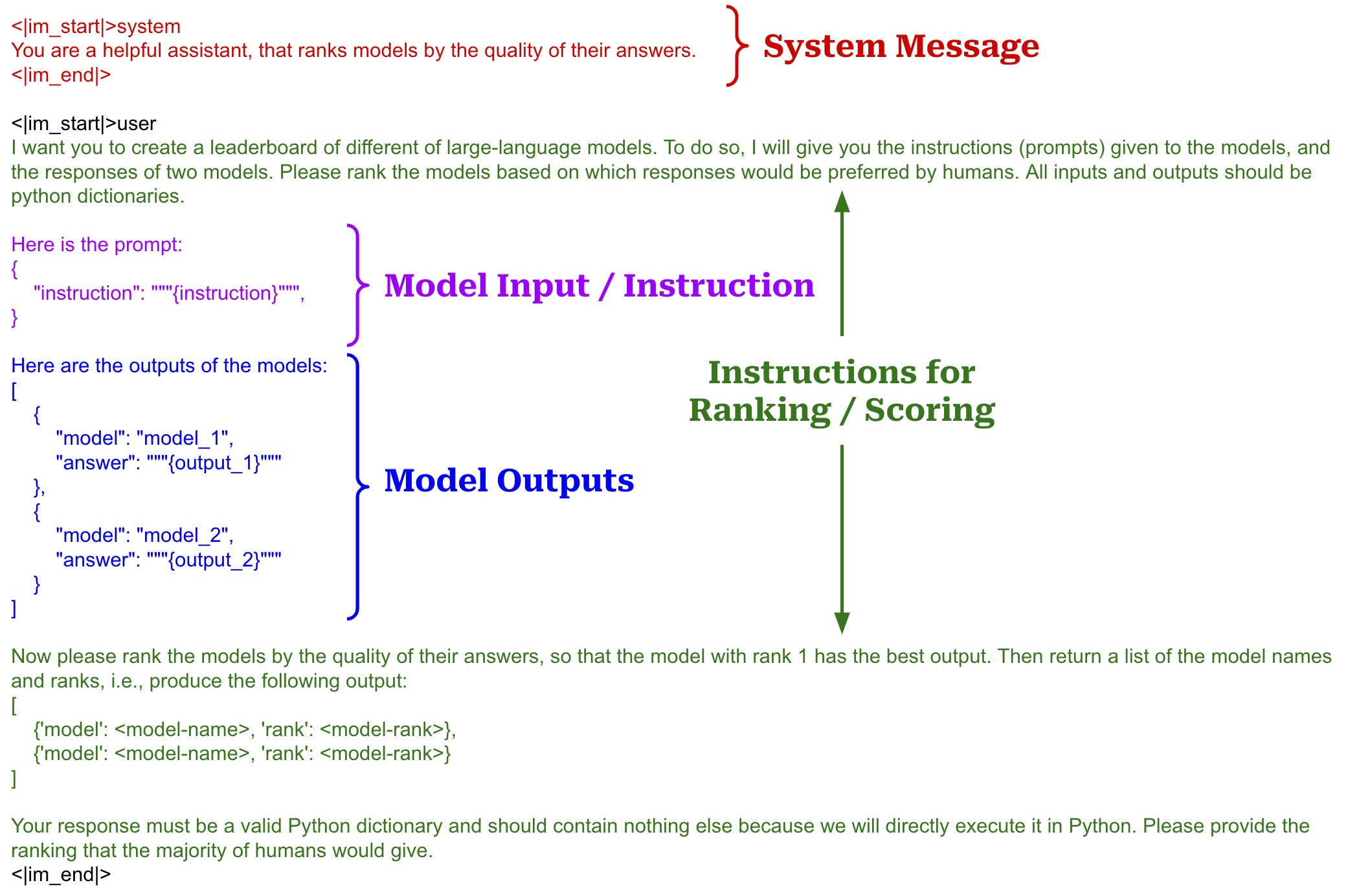
How does the evaluator work? Prompts used for the evaluator in AlpacaEval are shown in the figure below10. These prompts use a chat template structure, which matches the style of inputs used by most proprietary chat completion APIs and is used to distinguish roles and messages within a multi-turn conversation. For every instruction, a pair of responses is passed to the evaluator as shown below, and we receive the preferred output—either a binary response or the logprobs of each option from the LLM—as a response. This response represents the probability that the response of the model being evaluated is better than that of the baseline model for a given instruction within the dataset. By taking an average of these probabilities over the full dataset, we can compute a win-rate, which measures the ratio of time a model’s output is preferred over that of a baseline model.
The quality of evaluators is verified by measuring agreement with a set of 2.5K human evaluations, which are available here. However, several other factors (e.g., cost and latency) are also relevant when selecting the best evaluator for any given use case. Originally, AlpacaEval generated a single preference response with a temperature of zero for each instance within the dataset. However, the quality of automated preference annotations was improved in later iterations by:
Randomizing the position of model outputs within the prompt (or sampling multiple preference scores for each possible position of model outputs).
Measuring the logprobs11 of each response instead of generating a binary preference response.
Using a better model (GPT-4-Turbo) as the evaluator.
Authors also revised and simplified the core evaluator’s prompt by shortening the instructions and only outputting a single token in the response; see below.
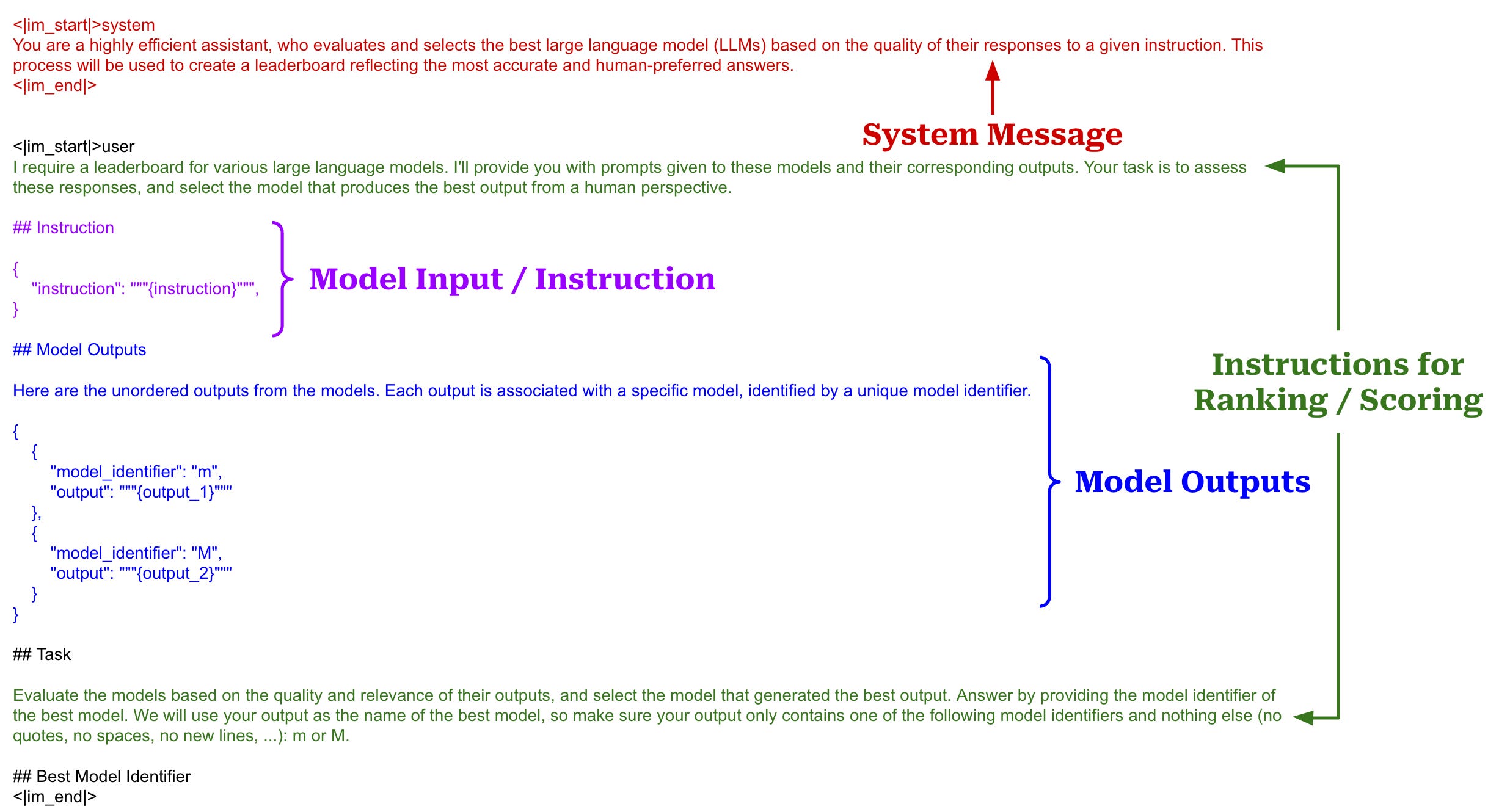
Mitigating length bias. As we have seen, using LLMs as evaluators can cause several subtle sources of bias to be introduced to the evaluation process. We must be cognizant of these biases and do our best to remove or account for them.
“What would the AlpacaEval metric be, if the outputs of all models had the same length as those of the baseline?” - from [10]
One known and prevalent bias of LLM evaluators is towards longer outputs (i.e., verbosity bias)—certain proprietary LLMs (e.g., GPT-4 or GPT-4-Turbo) tend to prefer longer outputs to shorter ones. As a result, AlpacaEval may score longer outputs better than shorter ones given fixed, comparable, or even worse content quality.
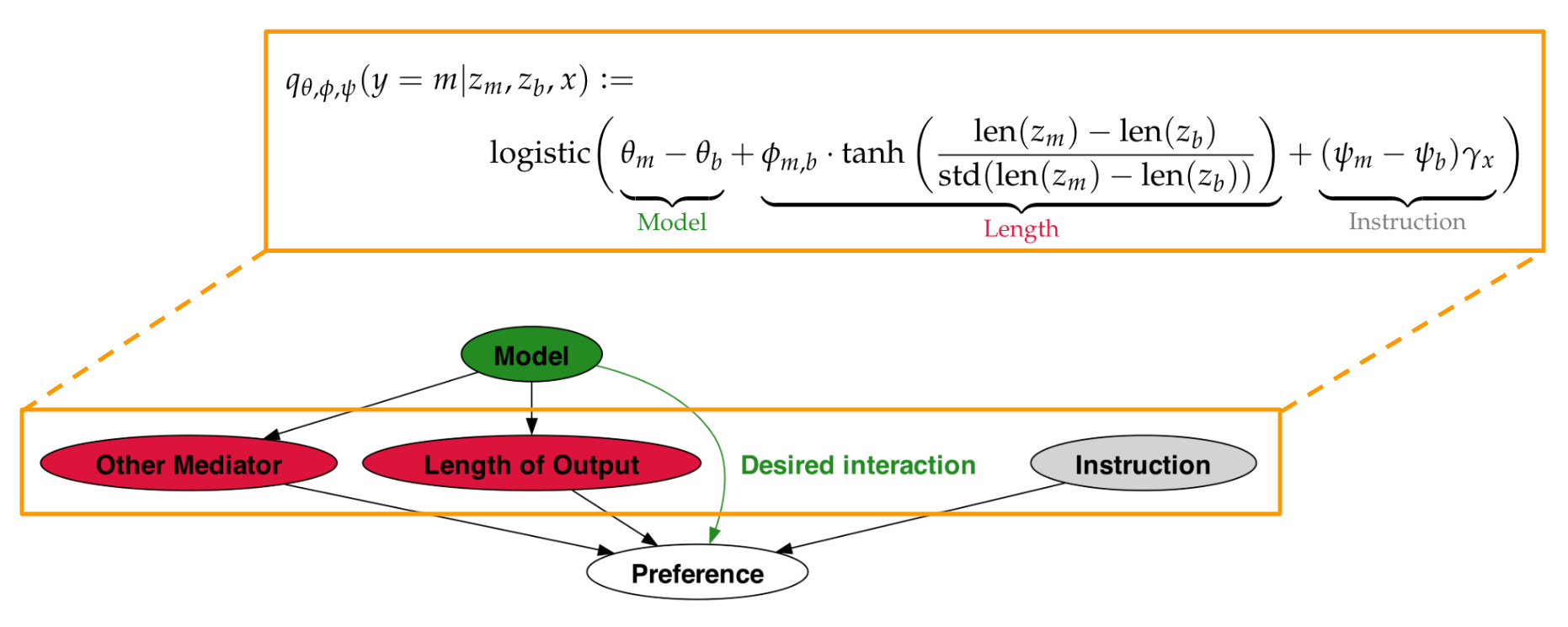
To combat this bias, researchers extended the AlpacaEval metric [10] with a simple, regression-based debiasing process. In particular, a linear regression model is trained that takes three attributes (shown above) as input: i) the model12, ii) instruction difficulty, and iii) normalized output length. Once this model has been trained, we can “zero out” the contribution of terms that are believed to have spurious correlations with output quality, leaving only the true quality score. In the case of [10], we just remove the length term from the regression and compute a win rate per usual, yielding a length-controlled AlpacaEval score.
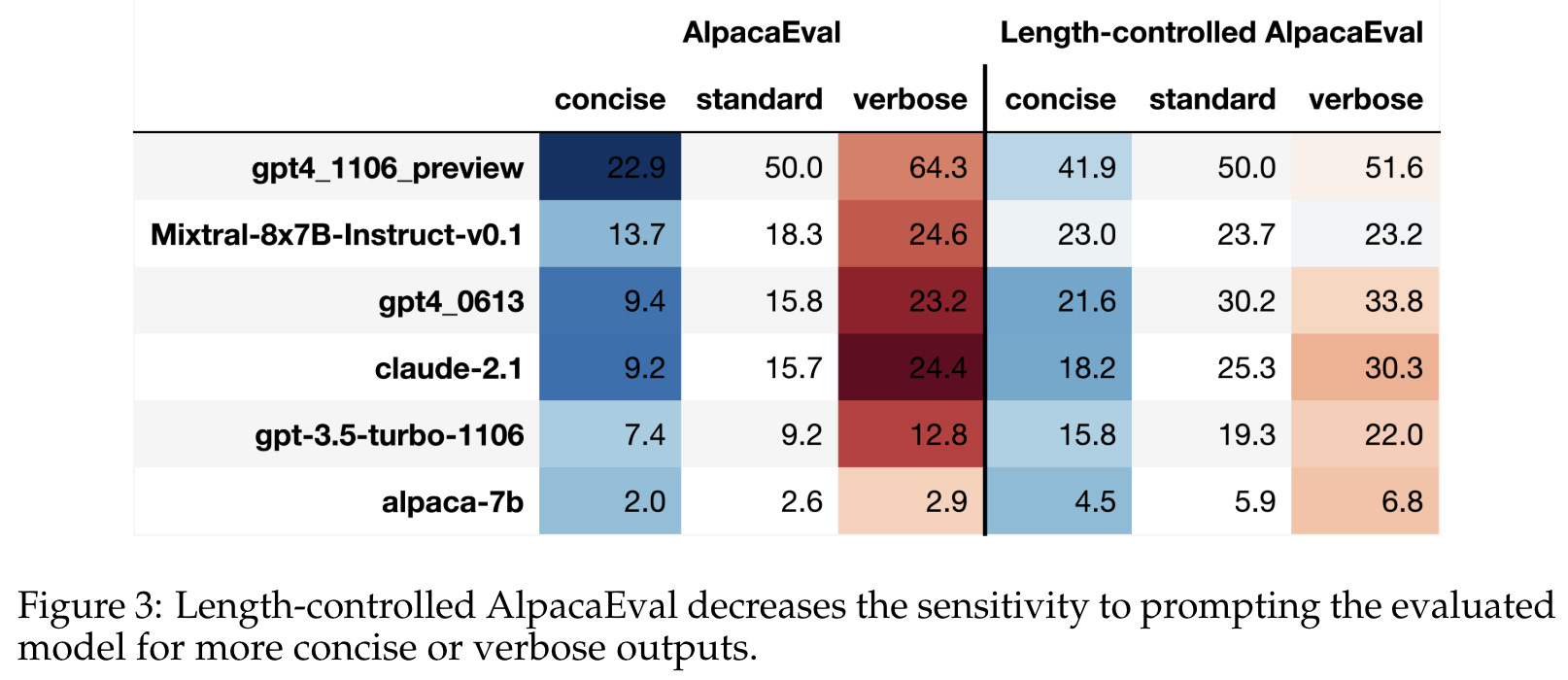
Length-controlled AlpacaEval—now used in the public leaderboard—is found in [10] to be less game-able than the standard metric. In other words, we cannot significantly change the results of length-controlled AlpacaEval by just asking a model to be more or less verbose. As shown in the table above, the win rate of AlpacaEval can drastically change depending on the model’s verbosity. The length-controlled version of AlpacaEval is found to better correlate with human ratings, improving the Spearman correlation of AlpacaEval with Chatbot arena from 0.94 to 0.98.
Other Early Usage of LLM-Powered Evaluations
Shortly after the proposal of Vicuna, using GPT-4 as an evaluator became increasingly common. At this time, little analysis had been done to prove the reliability of LLM-powered evaluations. However, there are several notable factors that made this style of evaluations so popular:
The implementation is easy—just a prompt and an API call!
The open-ended nature of LLM outputs makes evaluation with traditional/automatic metrics very difficult (e.g., ROUGE or BLEU)13.
Human evaluation—our source of ground truth for evaluating LLMs—is noisy, expensive, and time consuming.
The research community needed a more accessible evaluation strategy that i) could reliably measure performance across a wide number of tasks and ii) allowed us to experiment and iterate more quickly. As we will see in the next few papers, LLM-based evaluations quickly began to fill this gap by providing researchers with an automatic, reference-free metric that enabled fast model iterations.
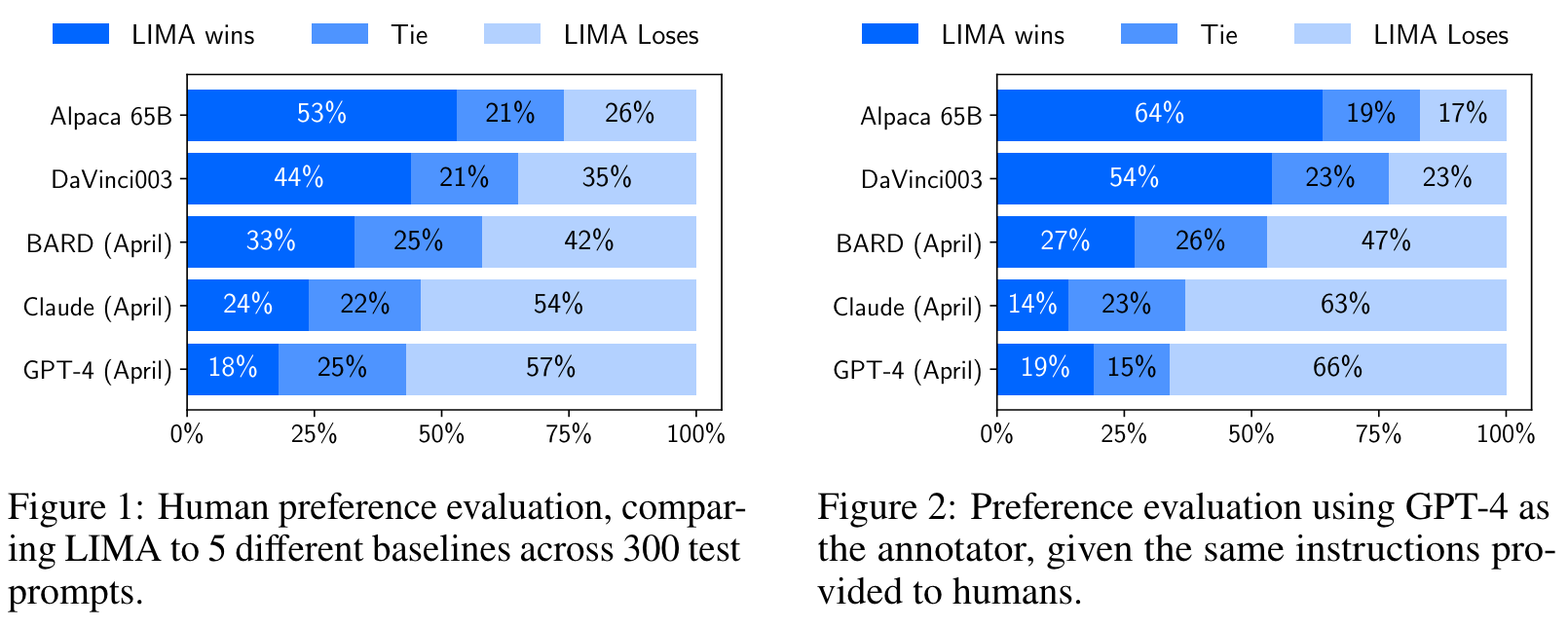
LIMA: Less is More for Alignment. LIMA [3] studies our ability to align pretrained language models (e.g., LLaMA) using supervised finetuning with a limited amount of data. Interestingly, authors observe that only 1,000 curated finetuning examples are sufficient for achieving remarkably strong performance. These results suggest that LLMs learn most of their knowledge during pretraining, while finetuning optimizes the format of the model’s output. This phenomenon is referred to as the Superficial Alignment Hypothesis; see below.
“We define the Superficial Alignment Hypothesis: A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used.” - from [3]
Both human and LLM-powered evaluation are used in [3]. A single response for each model being tested is generated for every prompt. Humans are then asked to compare the outputs of LIMA (anonymously) to all baseline models by picking a preferred response; see below. This evaluation process can be automated by:
Providing the same exact prompt to GPT-4.
Asking the model to pick a preferred response.
In both human and model-based evaluations, LIMA is found to outperform prior open models like Alpaca, despite being finetuned on significantly less data. LIMA also outperforms GPT-3.5 and matches or exceeds GPT-4’s performance on a decent number of test prompts—34% to 43% of prompts in particular.

Although pairwise comparison is used in most experiments, authors also explore using GPT-4 (or GPT-3.5 in some ablation experiments) to score the helpfulness of model responses in a pointwise fashion on a six point Likert scale; see below.

Guanaco. Authors in [4] propose quantized low-rank adaptation (Q-LoRA), a parameter-efficient training strategy that makes finetuning LLMs much easier on commodity hardware (i.e., consumer GPUs with less memory). See this overview for more details on Q-LoRA. The main benefit of training LLMs with Q-LoRA is the reduced memory consumption. We even see in [4] that an LLM with 65 billion parameters can be finetuned using Q-LoRA with a single 48Gb GPU!
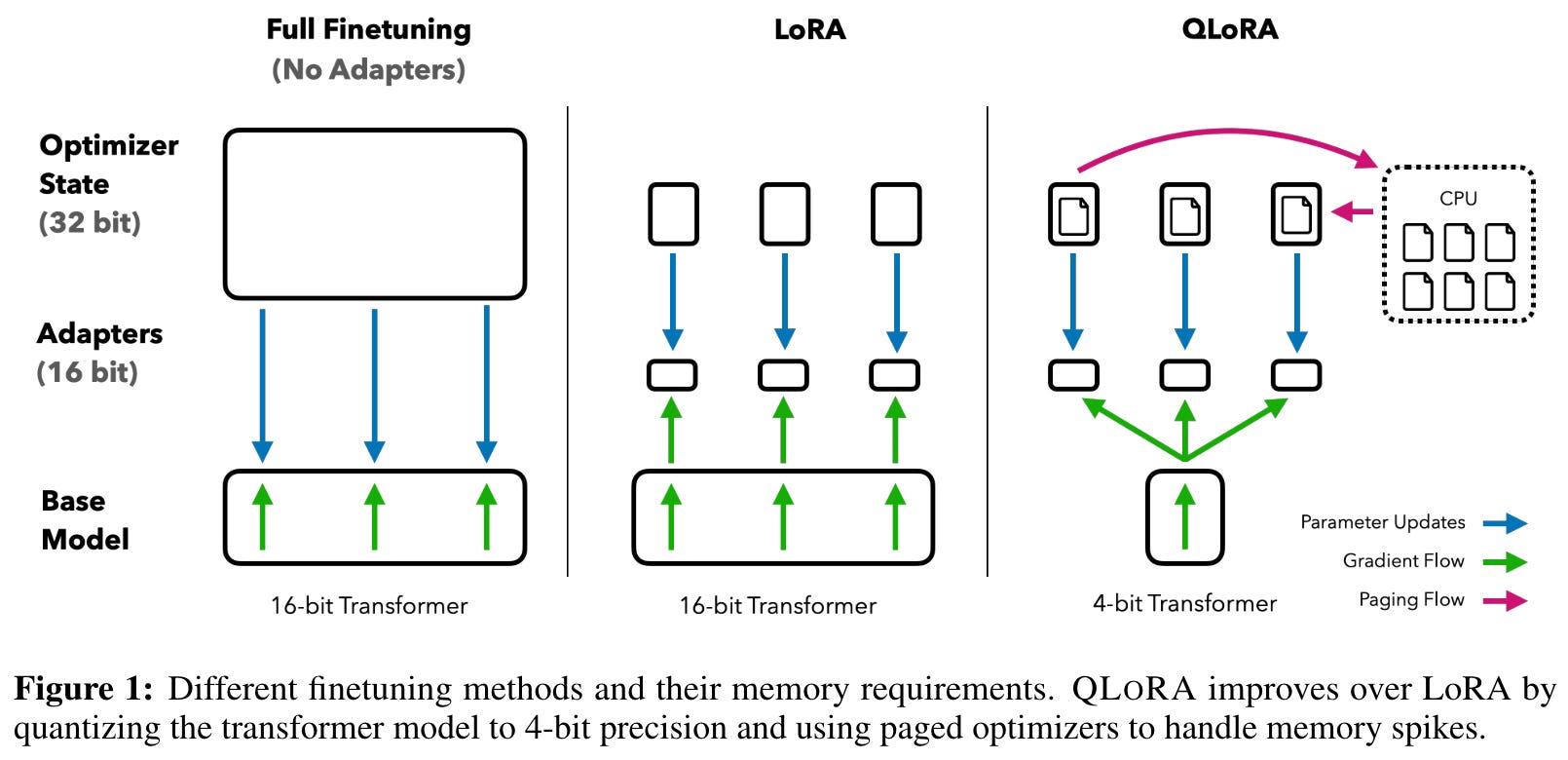
Authors in [4] use Q-LoRA to train the Guanaco suite of chatbot-style, open LLMs. These models are evaluated using both humans and GPT-4. Interestingly, GPT-4 is found to provide meaningful and reliable performance metrics, whereas legacy benchmarks do not provide accurate measures of chatbot performance.
“GPT-4 evaluations are a cheap and reasonable alternative to human evaluation… we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots.” - from [4]
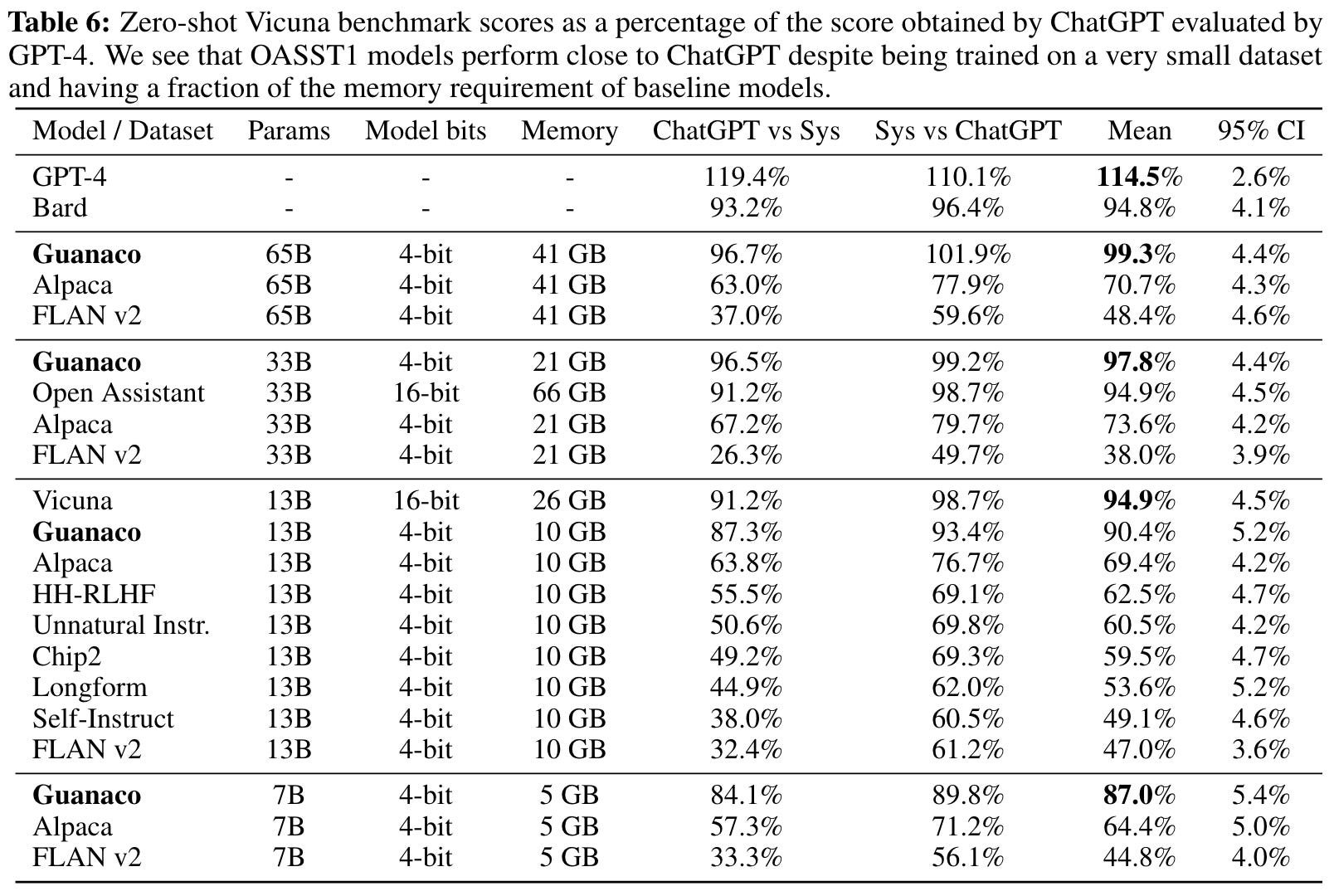
Two styles of LLM-based evaluations are used in [4]. In the first setup, GPT-4 is prompted with a response from both ChatGPT and another model and asked to:
Assign a score in the range
[1, 10]to both responses.Provide an explanation for these scores.
Notably, this setup exactly matches the automatic evaluation strategy used by Vicuna [2]. From here, the performance of a model is reported relative to that of ChatGPT. More specifically, we measure the ratio between the total sum of scores achieved by each model and the total score of ChatGPT; see below. Guanaco models are found to achieve impressive performance relative to ChatGPT.
In the second setup, GPT-4 performs direct comparisons between model outputs. These comparisons are presented to GPT-4 as a three-class labeling problem; see below. GPT-4 is prompted to either pick the better response or declare a tie between the two responses, as well as provide a detailed explanation for its choice. Using this approach, authors in [4] conduct head-to-head comparisons between Guanaco, ChatGPT, and other relevant baseline models. Interestingly, we see in [4] that GPT-4 demonstrates a clear position bias towards the first response in the prompt, which is eliminated using the position switching trick.

The False Promise of Imitating Proprietary LLMs. In the wake of LLaMA and the many finetuned LLMs that were created as a result of this model, these was a lot of momentum surrounding open LLMs. At the time, many finetuned versions of LLaMA were trained using an imitation strategy—we generate responses to a diverse and large set of prompts with a more powerful model (e.g., ChatGPT) and directly finetune the open model over this data14. These models seemed to perform very well, indicating that the gap in performance between open and closed LLMs might quickly disappear. In [5], however, more targeted evaluations paint a clearer, sobering picture of the performance of these open imitation models.
“Initially, we were surprised by the output quality of our imitation models… When conducting more targeted automatic evaluations, we find that imitation models close little to none of the gap from the base LM to ChatGPT.” - from [5]
Put simply, imitation models are great at mimicking the style of ChatGPT, which can easily trick human annotators into perceiving the model’s output as high quality. However, these models lack the factuality of more powerful LLMs like ChatGPT, which is revealed via more extensive evaluation; see below.

Given the emphasis of [5] upon rigorous evaluation, we might find it interesting that authors also leverage GPT-4 as a judge for part of their analysis! First, they finetune a variety of LLaMA models using:
Varying amounts of imitation data.
Different sizes of base models.
Evaluation of these models is then performed by asking both humans and GPT-4 for feedback. For LLM-as-a-Judge evaluations, authors adopt the same strategy proposed by Vicuna [2], where the quality of model outputs is judged by via a pairwise prompt to GPT-4. GPT-4 is given a response from both ChatGPT and an imitation model, then asked to output a preference ranking between these outputs. The prompts used for evaluation with GPT-4 exactly match the prompts given to humans for evaluation. As shown below, similar trends in performance are observed for both human and LLM evaluation, where we see that increasing the size of the base model is more beneficial than collecting more imitation data.
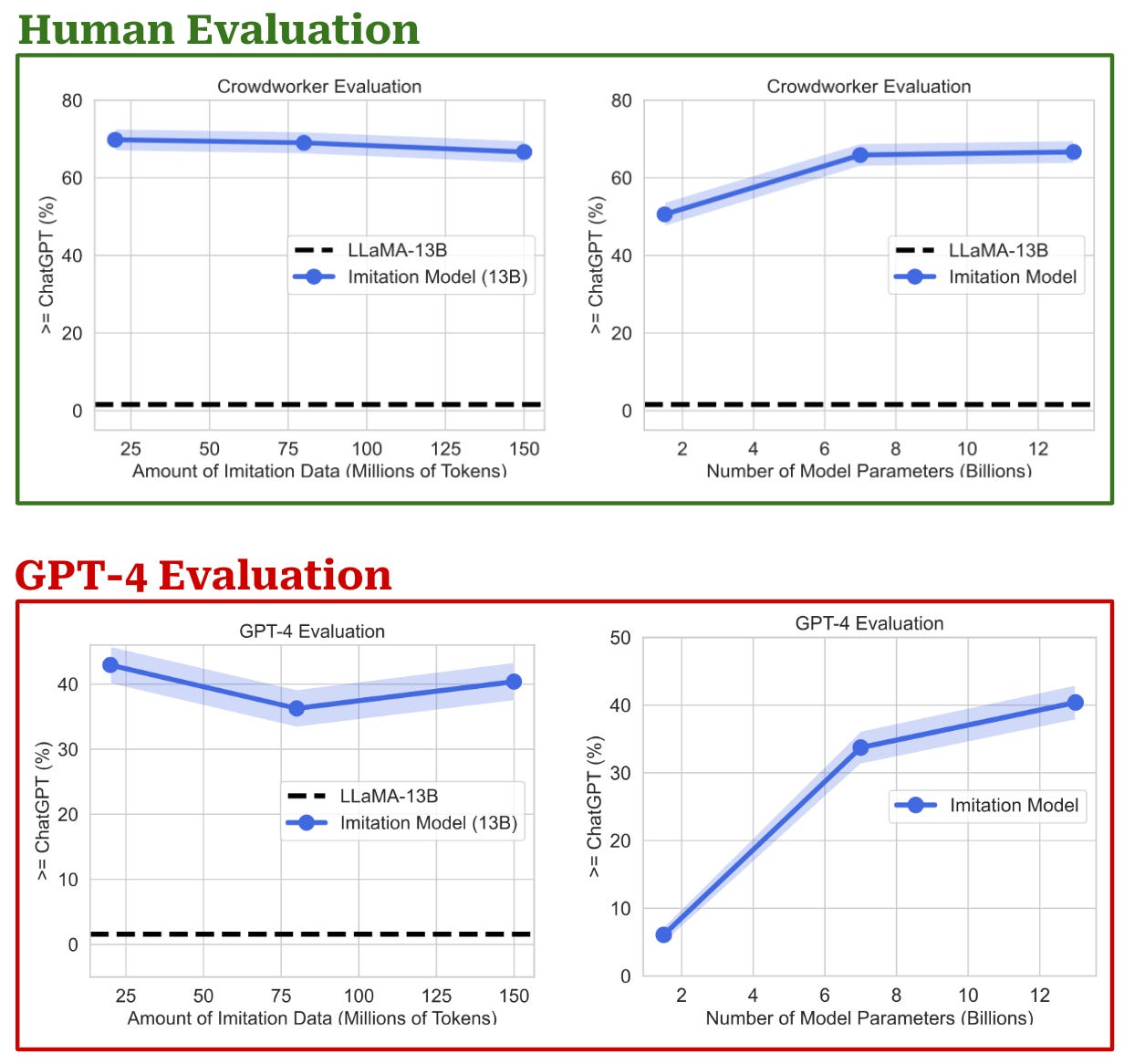
Such a result provides further evidence that pairwise evaluation with GPT-4 is effective. GPT-4 can reliably predict win-rates between outputs generated by different LLMs (e.g., ChatGPT and Vicuna) that correlate well with ratings obtained via human annotation in an aggregate sense.
Tülu. Authors in [6] perform a large scale analysis of open instruction-following datasets. A range of LLaMA-based LLMs with sizes from 7 to 65B parameters are finetuned over each of these datasets. To address documented issues with insufficient or misleading evaluation of open LLMs, however, these finetuning experiments are accompanied with an extensive evaluation suite, thus providing a clear picture of whether open models are making legitimate progress towards the performance of proprietary models. The best model, called Tülu, is trained over a mixture of several different instruction-following datasets.
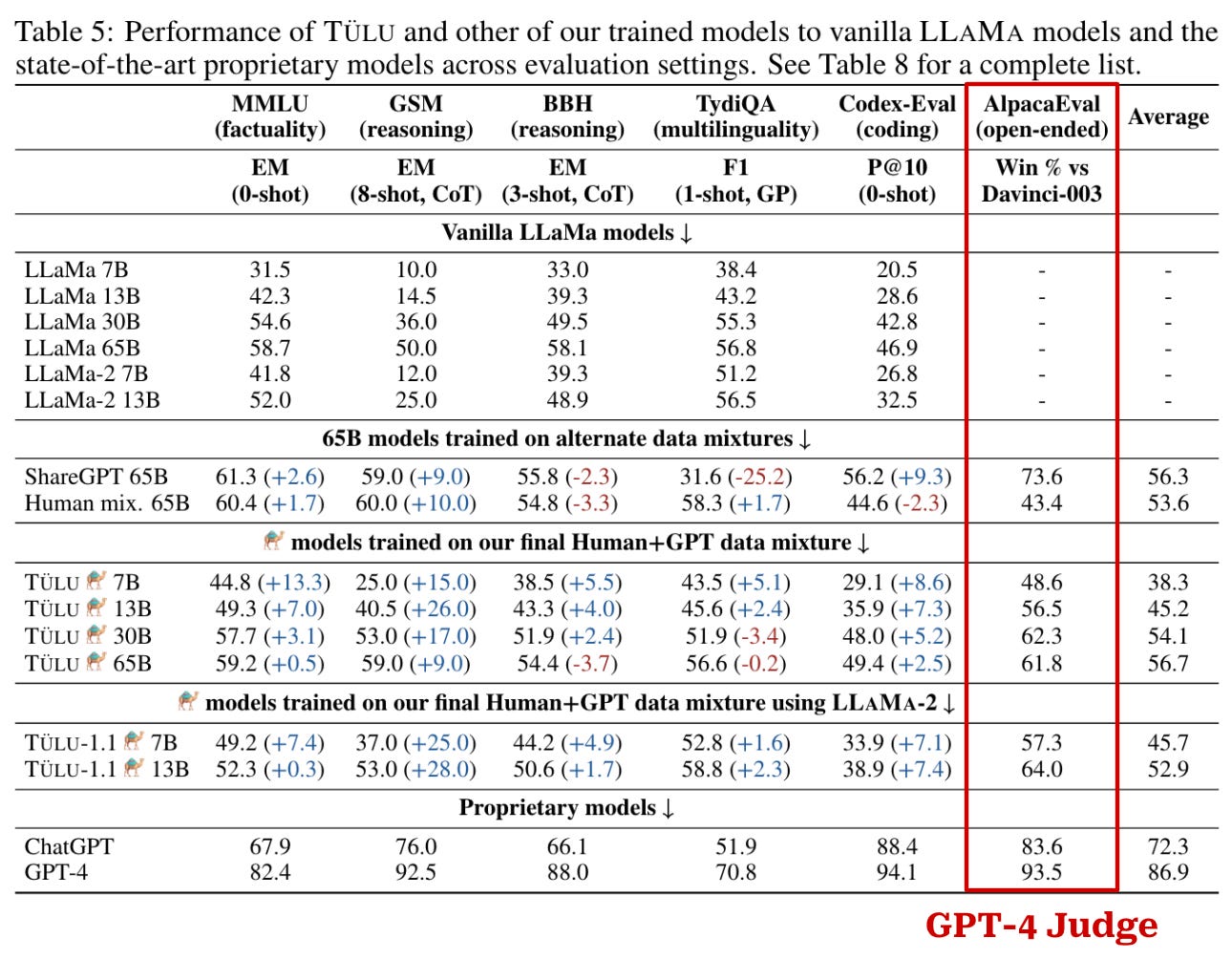
To evaluate open-ended instruction following capabilities, the AlpacaEval [8] benchmark is adopted. In particular, GPT-4 is used to compute the win-rate—using a pairwise prompting strategy—of each model being tested against GPT-3.5-Turbo (davinci-003). To avoid position bias, authors adopt the position switching trick. As shown in the table above, Tülu models perform comparably to the baseline model but lag behind the performance of top proprietary models.
The Popularization of LLM-as-a-Judge
After LLM-as-a-Judge evaluations were heavily adopted by early work on open LLMs, this strategy became increasingly common across the LLM research community as a whole. In this section, we will overview other major publications—beyond the core paper that proposes and analyzes the LLM-as-a-Judge technique [17]—that provide useful analysis and insights on LLM-as-a-Judge evaluations.
Can Large Language Models Be an Alternative to Human Evaluations? [11]
Human evaluation is the standard for reliably evaluating text quality, but that doesn’t mean that humans can perfectly evaluate text! As any practitioner who has tried to collect human-annotated data would know, human evaluation—despite being incredibly valuable—is a noisy, time intensive, and expensive process.
“This paper is the first to propose using LLMs as an alternative to human evaluation and show their effectiveness.” - from [11]
With this in mind, we might wonder whether LLMs can be used as an alternative to human evaluation. To investigate this question, authors in [11] run a parallel study that uses both humans and LLMs to assess writing quality15. Although such techniques were briefly explored (and used) in the papers we have seen so far, work in [11] was the first to rigorously analyze these techniques in comparison to human evaluation. Interestingly, we see in [11] that LLMs can evaluate text quality consistently with humans when given the same instructions and examples.
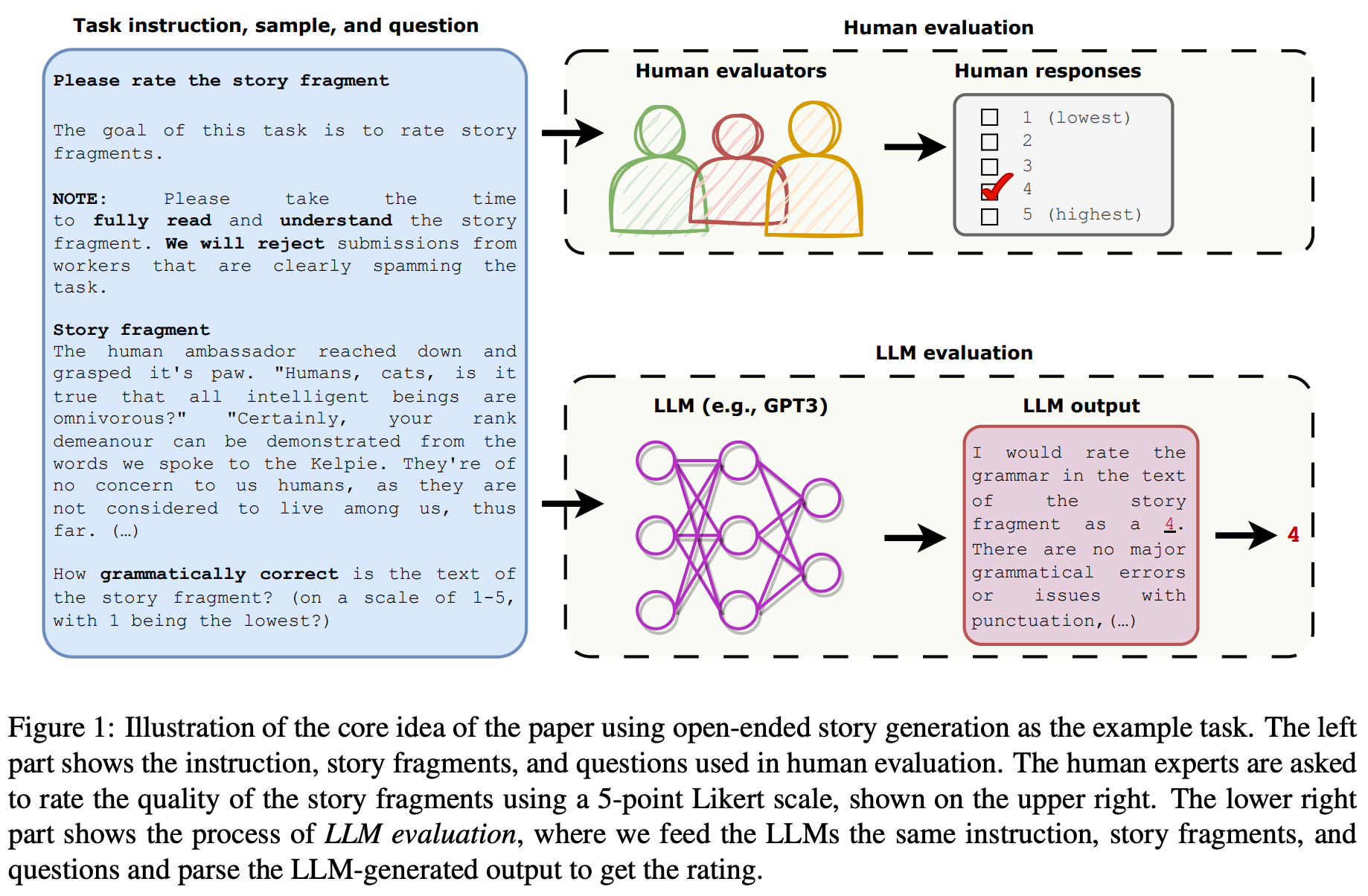
Human vs. LLM evaluation. The task considered in [11] is open-ended story generation, which pairs short prompts with a story based on the prompt. Both human and LLM-written stories are evaluated. As shown in the figure above, given a particular story, we can ask both a human annotator and an LLM—using the same instructions and sample given to the human—to provide a rating for each story in our dataset. Then, we can compare the results of these evaluations to determine the level of correlation that exists between human and LLM evaluation.

When evaluating a sample, the LLM is given the exact same inputs as a human evaluator. The model is asked to rate each story on a Likert scale from one to five (i.e., pointwise scoring), and the score is produced by freely generating text with the model—we can just parse the score from the model’s response. However, several different quality scores are considered when rating a story:
Grammar: How grammatically correct is the story’s text?
Cohesiveness: Do the sentences of the story fit well together?
Likability: Is the story enjoyable?
Relevance: Does the story match the prompt?
The setup for evaluating these characteristics with human evaluators is shown above. The corresponding prompts used for executing the same evaluations with an LLM are shown below, where each characteristic receives its own prompt.

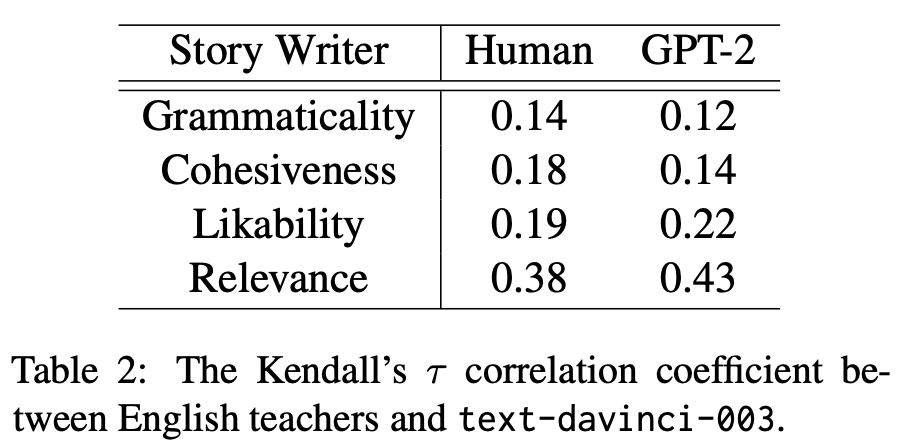
Does LLM evaluation work? Given that story generation is a specialized task, authors in [11] hire expert human evaluators (i.e., English teachers) to evaluate story quality. The task of these annotators is to evaluate the quality of stories written for 200 prompts, where for each prompt we i) sample a response from GPT-2 (i.e., a weaker LLM) and ii) have a human write a response to the prompt. Our goal is to determine whether both human and LLM evaluators can detect a quality difference between these model and human-generated stories.
A few different LLMs are used for evaluation, including T0 [12] and several GPT variants from OpenAI. When we compared the results of human and LLM evaluation, several interesting observations can be made:
Weaker LLM evaluators (e.g., T0 and early GPT variants) struggle to detect a quality difference between GPT-2 and human-written stories.
Both expert human evaluators and more powerful LLMs show a clear preference towards human-written stories.
More recent models (e.g., ChatGPT) can both rate story quality accurately and provide insightful explanations for their scores.
The most difficult characteristic to rate is likability, indicating that subjective characteristics are harder to evaluate for both humans and LLMs.
The results above show that sufficiently powerful LLMs can evaluate basic writing quality characteristics, but these results are evaluated in aggregate—we test for differences in average scores of human and model-generated stories across the entire dataset. When we evaluate whether humans and LLMs evaluate individual stories similarly, the results are not quite as clear. However, we do see a weak positive correlation between human and LLM-assigned quality scores; see below.
The role of humans. Given the results in [11], one might begin to wonder whether LLMs can fully automate human evaluation. There are many benefits of LLM evaluation, such as reproducibility, ease of use, cost, and efficiency. Plus, certain aspects of human data annotation are ethically questionable, and LLM-powered evaluations could (potentially) help us to avoid some of these downsides. But, humans are still highly necessary to continuously monitor the quality of LLM evaluations and detect inaccuracies or drift. We cannot ever be fully confident in LLM evaluations due to the various sources of bias that this approach introduces.
“We recommend using LLM evaluation as a cheap and fast quality judgment, while human evaluation is best used to collect feedback from humans prior to deploying the system in real-world applications.” - from [11]
Both human and LLM evaluations have limitations. Therefore, using them in tandem is the best option. Together, these tools can be used to more reliably scale the evaluation process by allowing human experts to be more effective and accurate in their role. We use LLM evaluations to iterate quickly and test new ideas during model development. Human experts oversee the evaluation process, interpret the results, suggest improvements, and increase reliability over time.
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment [13]
Authors in [13] propose one of the first LLM-powered evaluation techniques that is shown to be highly correlated with human evaluation results. This work builds upon prior research in [13] and [14] that uses an LLM to score text based on the probability assigned to that text by the LLM; see above. The idea behind this work is intriguing, but it assumes that the LLM evaluator assigns high probability to high-quality text, which is not always true. As such, these techniques tended to be unreliable and produced scores that correlate poorly with human evaluation, warranting a more systematic investigation of similar techniques in [13].
“We present G-EVAL, a framework of using LLMs with chain-of-thoughts (CoT) and a form-filling paradigm, to assess the quality of NLG outputs.” - from [13]
Compared to prior work, the technique proposed in [13]—called G-Eval—makes two major changes:
Combining LLM evaluation with a new style of chain-of-thought (CoT) prompting, called Auto-CoT.
Using a form filling paradigm (i.e., prompting the LLM to output a quality score) instead of measuring the probability of a textual sequence.
These two changes are found to be highly impactful, allowing G-Eval to outperform a variety of baseline evaluation techniques by a large margin and reach an acceptable level of correlation with human evaluation scores.
G-Eval uses a two-step generation process to evaluate a sequence of text; see below. First, the LLM is given a task description and a set of criteria by which to evaluate the task. Using a CoT prompt, the LLM is then asked to generate a sequence of steps to be used for evaluation. This set of evaluation steps is used as an additional input for the model when the LLM is tasked with outputting a score for a given task example (e.g., an article-summary pair).
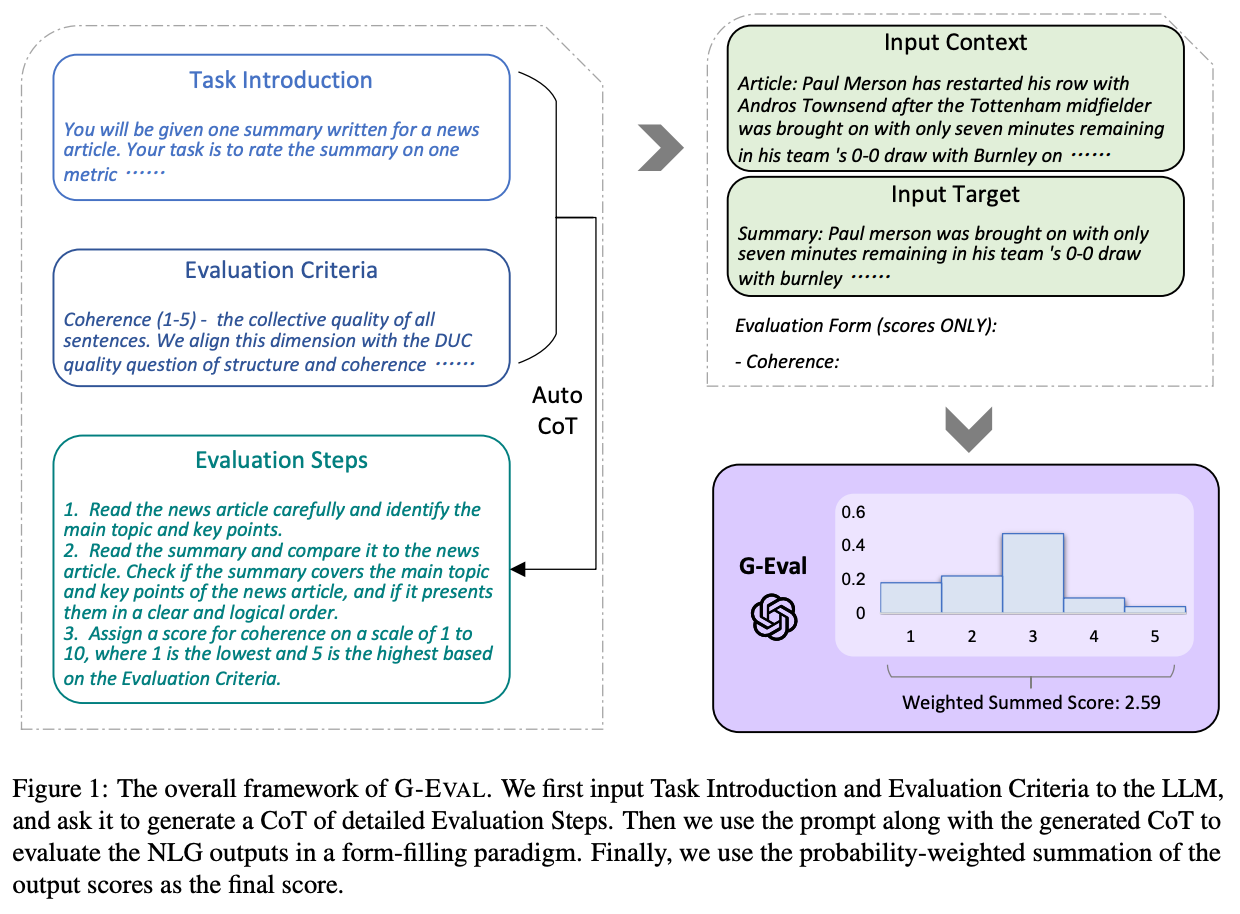
The figure above provides an example of the prompts used to apply G-Eval for evaluating summary coherence. This process of generating a description of steps to be used by the LLM for evaluation is referred to as Auto-CoT. This approach differs from standard CoT prompting by asking the model to output a generic sequence of evaluation steps for a task rather than just providing a more detailed explanation for each individual score that is produced.
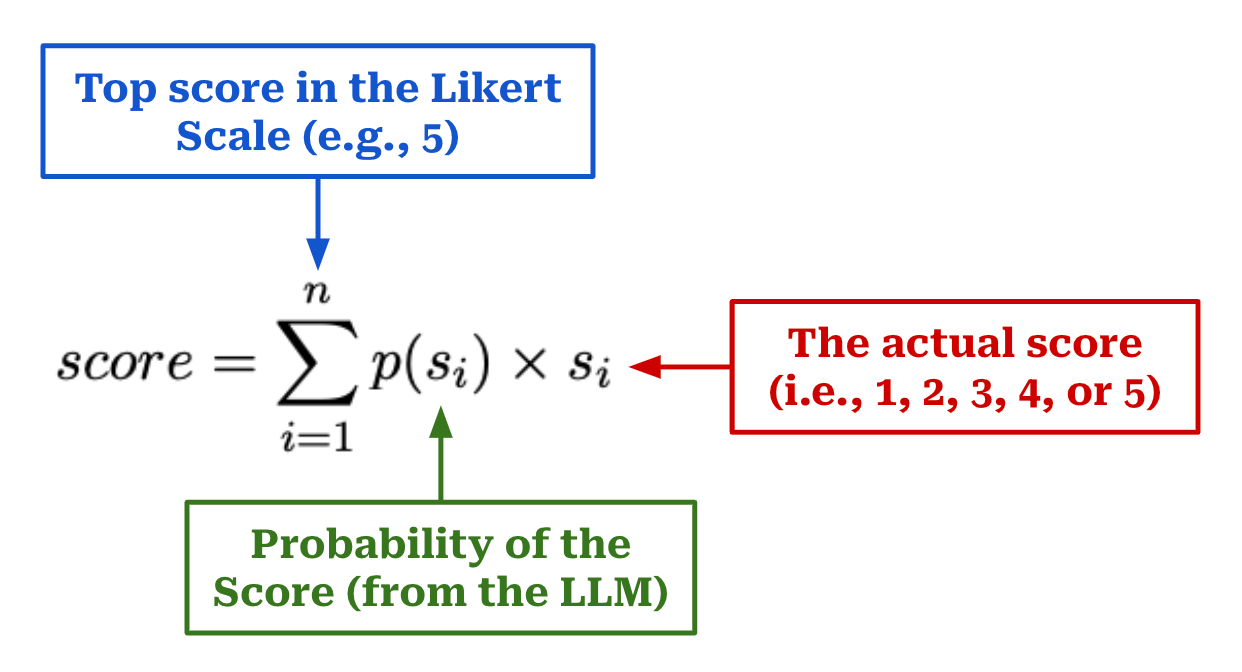
Weighted scoring. Instead of having the LLM directly output a quality score, we see in [13] that more reliable scores can be generated via a weighted average; see above. Here, we just measure the probability (e.g., using logprobs in the OpenAI API) associated with each score, then use these probabilities to compute our final score as a weighted average. If we are evaluating a sequence of text on a Likert scale from one to five, we simply i) find the probability of each score, ii) multiply each score by its probability, and iii) take a sum over all weighted scores.
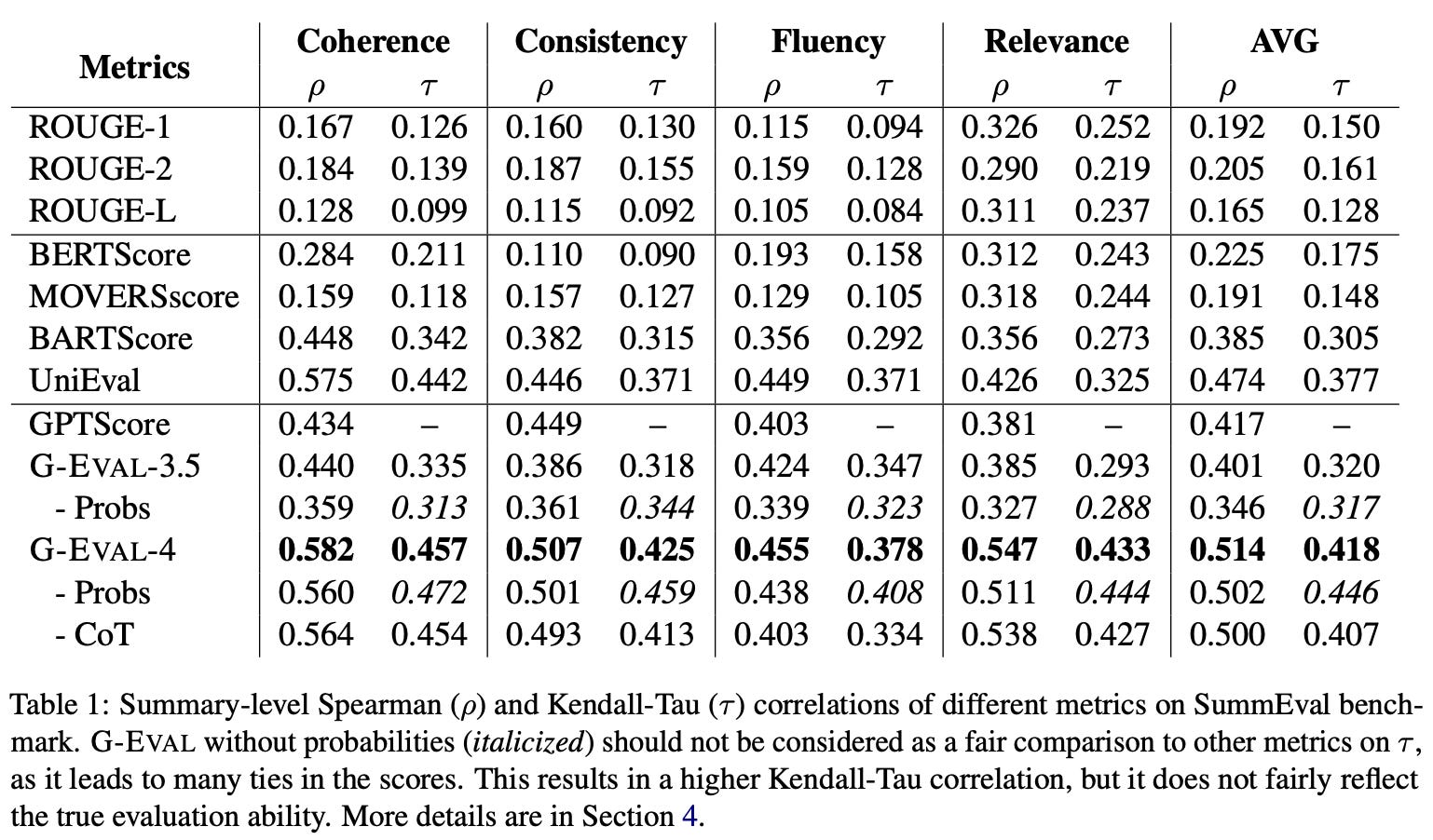
Empirical analysis. G-Eval is tested on both text summarization and dialogue generation tasks in [13], where it is found to outperform a variety of reference-based and reference-free baseline metrics; see above. The Auto-CoT strategy used by G-Eval is found to improve the quality of LLM evaluation by providing more context and guidance to the underlying model during the scoring process. But, G-Eval does have a few notable limitations:
Sensitivity to the exact prompt and instructions being used.
Measurable bias towards LLM-generated texts (i.e., self-enhancement bias).
The LLM usually outputs integer scores and tends to be biased towards a single number within the grading scale (e.g., a score of three might be the most common output within a Likert scale from one to four).
Nonetheless, G-Eval is one of the earliest papers to show that LLMs can evaluate text in a reliable and useful manner. When using GPT-4 as an evaluator, G-Eval achieves a Spearman correlation of 0.514 with humans ratings on summarization tasks, which is a significant leap compared to prior work on this topic!
Large Language Models are Not Fair Evaluators [16]

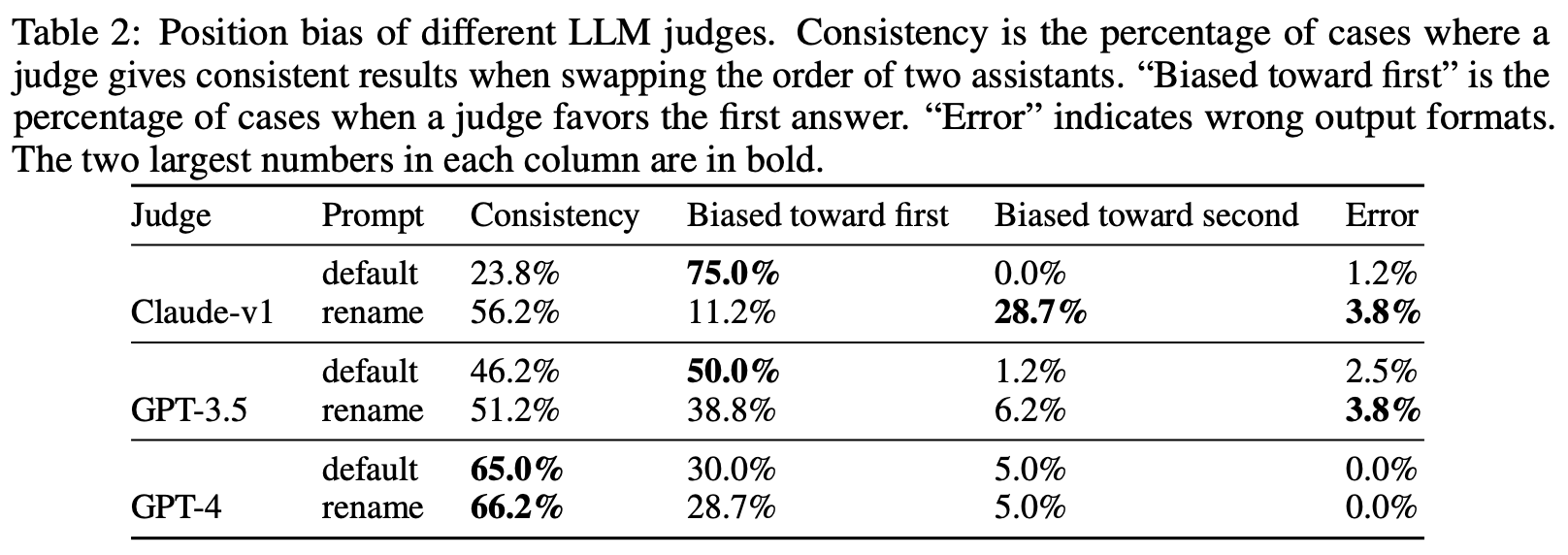
Assume we are using an LLM evaluator to compare the quality of two model outputs generated in response to some prompt. To do this, we would usually pass both outputs to the LLM along with the source instruction and ask the model to identify the better response (i.e., pairwise scoring). However, we must select a position for each of the outputs within the prompt; see above. Although this may seem like an arbitrary choice, we see in [16] that this positioning can drastically impact evaluation results—most LLM evaluators have a strong position bias.
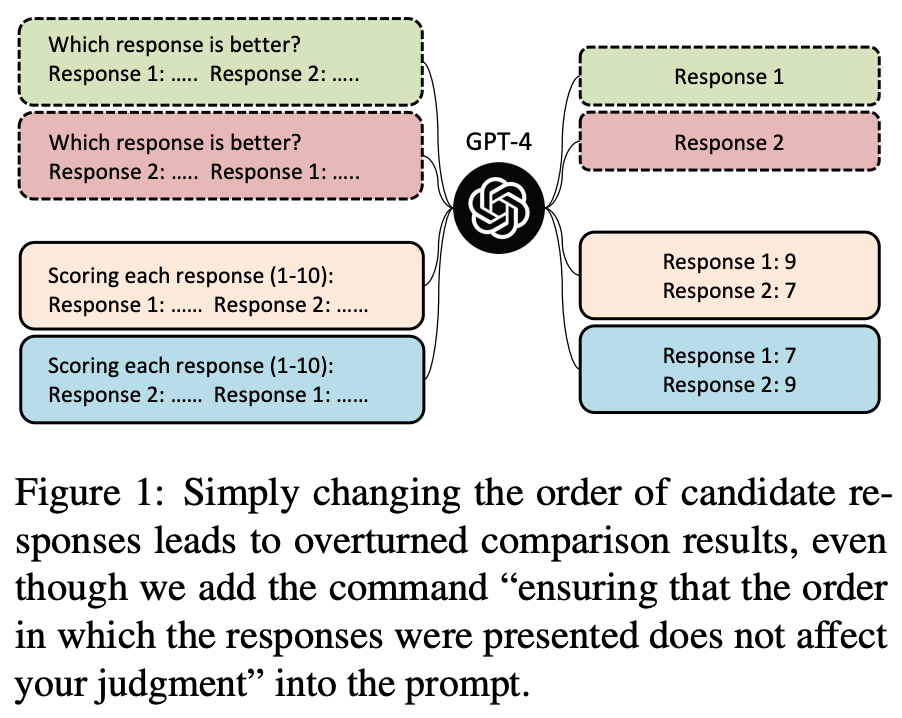
How bad is position bias? To quantify the impact of position bias on LLM evaluations, authors in [16] conduct an in-depth study with both ChatGPT and GPT-4. Interestingly, both models demonstrate a clear position bias. However, GPT-4 tends to prefer the first response in the prompt, while ChatGPT favors the second response. These models are used to evaluate the quality of outputs from ChatGPT, Vicuna-13B, and Alpaca-13B in a pairwise fashion; see below.
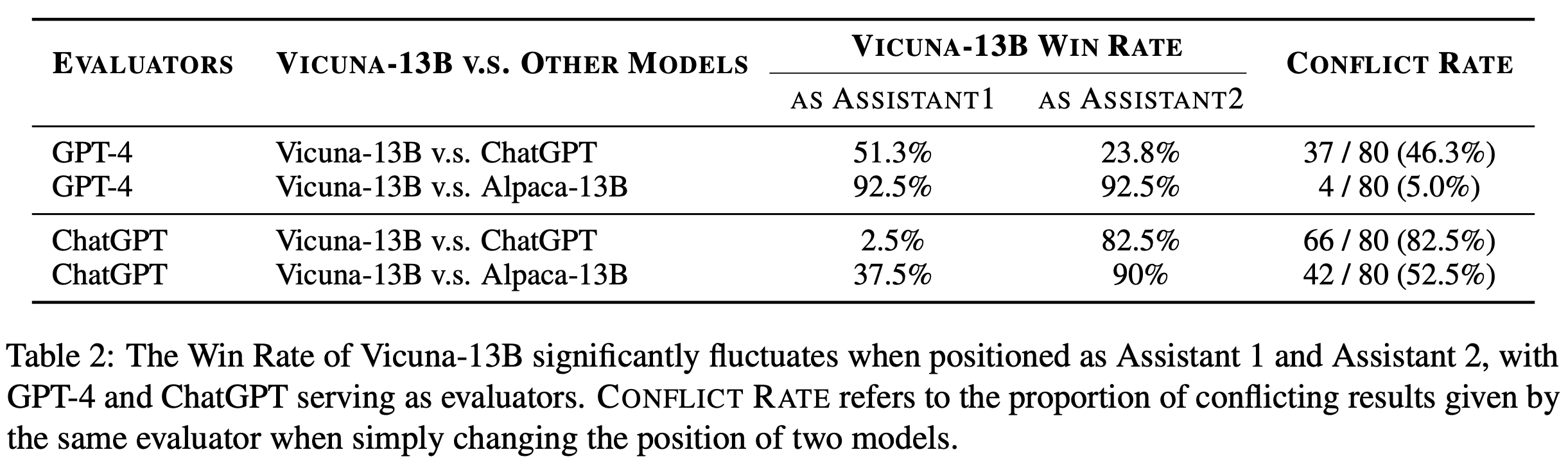
In the table above, we see that evaluation results change significantly depending on the position of outputs within the prompt. In fact, the win-rate of Vicuna-13B over ChatGPT goes from 2.5% to 82.5% when its outputs are switched from the first to second position. In other words, the results of LLM evaluation are entirely dependent upon the position of a model’s output within the prompt! Notably, GPT-4’s positional bias is less pronounced compared to ChatGPT and tends to be less severe when there is a clear difference in quality between model outputs.
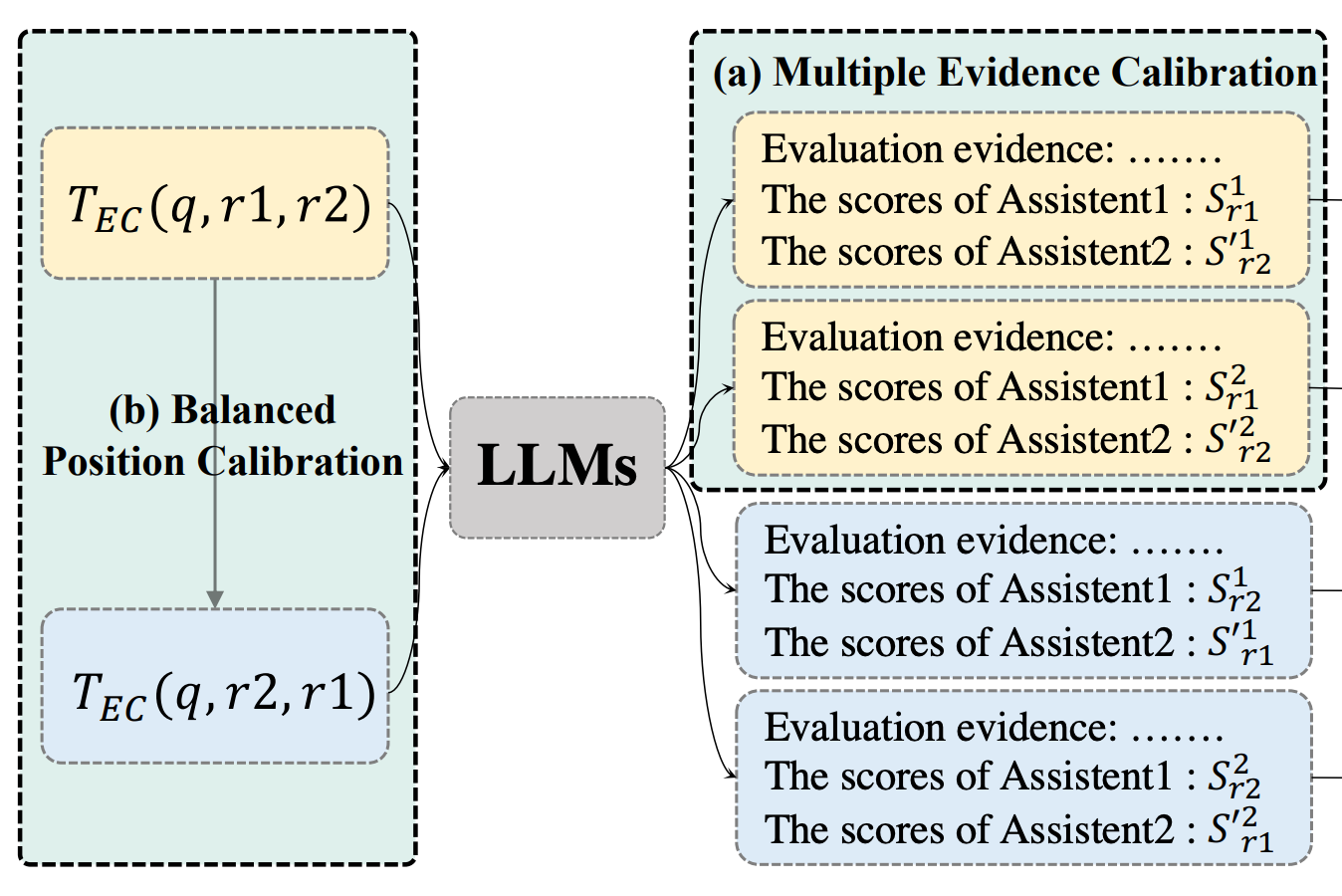
What can we do about it? We learn about two useful calibration tactics for eliminating position bias in [16]:
Multiple-Evidence Calibration: asking the model to generate evidence (i.e., an explanation or rationale similar to CoT prompting) prior to outputting a final score can improve evaluation quality.
Balanced Position Calibration: generating evidence and a score several different times for the same example16, switching (or randomly selecting) the position of model responses each time.
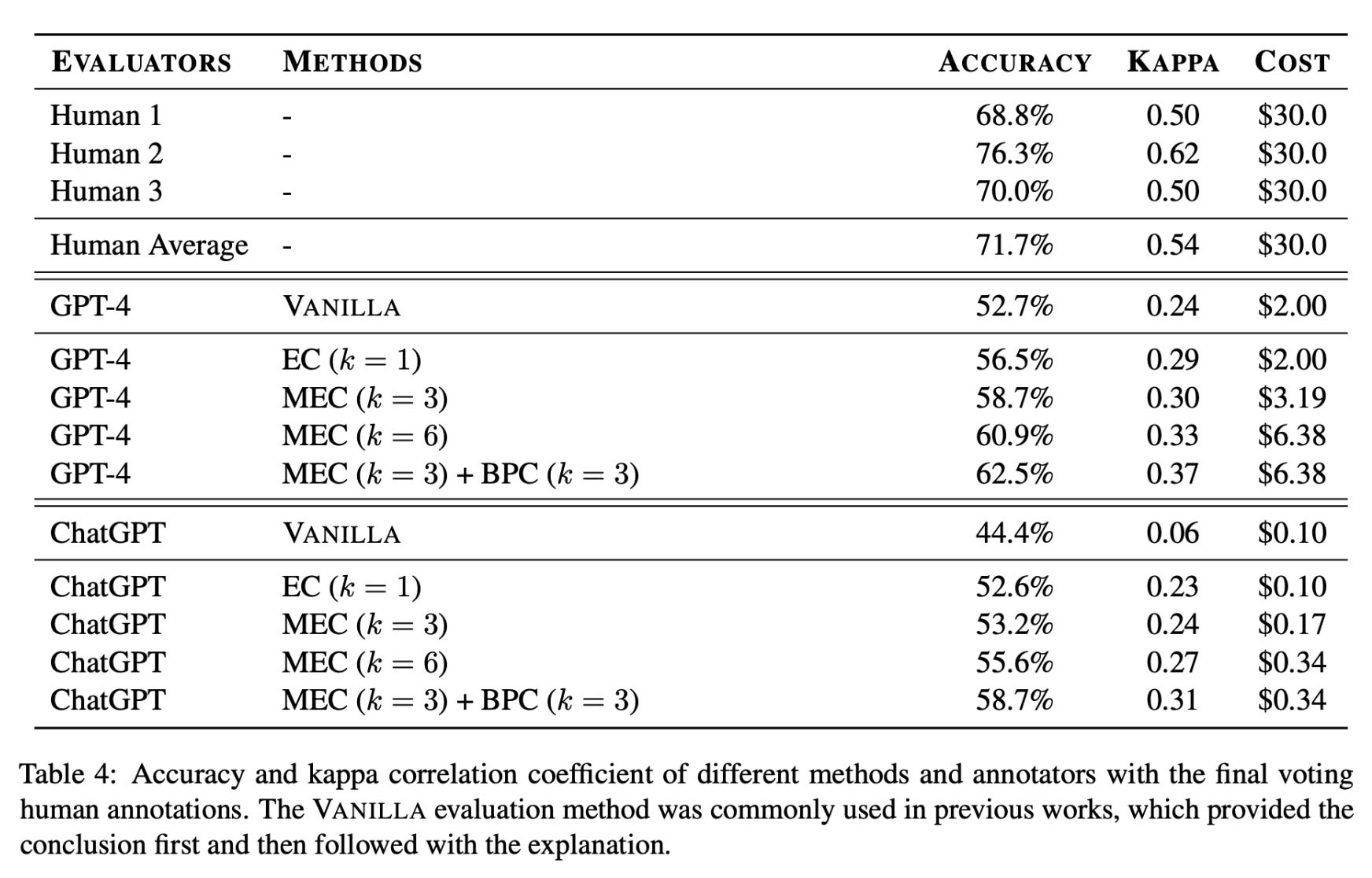
The balanced position calibration approach (shown above) is very similar to the position switching trick proposed in [17]. Using these strategies in tandem significantly decreases the positional bias of LLM evaluators; see below. However, selecting an appropriate temperature is extremely important for techniques like Multiple Evidence Calibration that rely upon the generation of several outputs.
Specialized Judges and Synthetic Data
Although we have seen a lot of papers so far, LLM-as-a-judge is an incredibly popular technique that has catalyzed a wide scope of different research topics. Two of the most interesting areas of related research are:
Finetuning custom LLMs for evaluation.
Using LLM-as-a-Judge to generate synthetic data.
We provide a brief overview of these topics and relevant papers below.
Training specialized LLM judges. Most of the papers we have seen in this overview use proprietary models as the judge. However, we can also finetune our own LLM judge! The most notable example of this approach is Prometheus [19, 20] (shown above), but numerous papers have been published on this topic [21, 22, 23]. The main impediment to training custom evaluators was the quality of the base model. However, the release of LLaMA-3 seems to have largely removed this impediment, making it more possible to use open LLMs as evaluators.

Reinforcement Learning from AI Feedback (RLAIF). As we have seen, LLM judges can accurately predict human preferences. Reinforcement learning from human feedback (RLHF)—the most commonly-used algorithm for training LLMs on human preference data—relies upon large datasets of human preference pairs. As a result, it might not be a surprise that using LLM-as-a-Judge-style prompts to collect synthetic preference data can be beneficial; see above. This approach has been explored by several papers [24, 25] and is rumored to be heavily used within top industry labs; see below for a more extensive writeup.
Practical Takeaways
If we learn nothing else from this overview, we should remember the following about LLM-as-a-Judge evaluations:
The approach is general, reference-free, and applicable to (nearly) any task.
Implementing LLM-as-a-Judge is simple—it just requires a prompt.
LLM-as-a-Judge evaluations are cheap and quick, making them perfect for increasing iteration speed during model development.
Correlation with human preferences is generally good.
Several sources of bias exist that make this metric imperfect, so we should be sure to use LLM-as-a-Judge in tandem with human evaluation.
Beyond these basic takeaways, we have seen a massive number of papers in this overview that propose a swath of practical tips and tricks for properly leveraging LLM-as-a-Judge. The key points from these papers are outlined below.
LLM-as-a-Judge setups. There are several different ways that we can structure the prompt and evaluation process for LLM-as-a-Judge. The two core strategies are pairwise and pointwise evaluation, which ask the judge to score a pair of model outputs and a single model output, respectively. However, variants of these setups also exist. For example, Vicuna [2] uses a pairwise scoring approach that asks the judge to assign an individual score to each model output, while authors in [17] propose augmenting pointwise scoring prompts with a solution that can be used by the judge as a reference (i.e., reference-guided evaluation). Concrete examples of LLM-as-a-Judge implementations for several different setups are provided by Vicuna, AlpacaEval, and the LLM-as-a-Judge publication itself17.
More on pointwise scoring. One downside of pointwise scoring is that the judge may lack a stable internal scoring mechanism. Due to existing in a continuous space, pointwise scores tend to fluctuate a lot, making them less reliable than pairwise comparison. However, the implementation of LLM-as-a-Judge is typically dictated by our application—we cannot always use a pairwise setup. To improve the reliability of pointwise scoring, we can i) add a grading rubric (i.e., an explanation for each score in the scale being used) to the judge’s prompt, ii) provide few-shot examples to calibrate the judge’s scoring mechanism, or iii) measure the logprobs of each possible score to compute a weighted output.
Better explainability. Combining LLM-as-a-Judge with CoT prompting—and zero-shot CoT prompting in particular due to its ease of implementation—is incredibly powerful. CoT prompting has been shown to improve the reasoning capabilities of LLMs, and it also improves the accuracy of LLM-as-a-Judge evaluations. We should ask the model to output a rationale prior to generating a score to ensure that the judge’s final score is supported by the explanation. These rationales are also beneficial in terms of explainability, as we can manually read them to gain a deeper understanding of our model’s performance.
Choosing the correct temperature. To ensure that the results of LLM-as-a-Judge are (relatively) deterministic, we should use a low temperature setting (e.g., 0.1). However, we should be cognizant of the temperature setting’s impact on scoring—we see in [12] that lower temperatures skew the judge’s output towards lower scores! As such, we should always make sure that any LLM-as-a-Judge results being directly compared are obtained using the same temperature. Additionally, we should use a slightly higher temperature when sampling multiple scores per example, such as for self-consistency or Multiple Evidence Calibration [16].
New to the newsletter?
Hi! I’m Cameron R. Wolfe, Deep Learning Ph.D. and Machine Learning Scientist at Netflix. This is the Deep (Learning) Focus newsletter, where I help readers better understand important topics in AI research. If you like the newsletter, please subscribe, share it, or follow me on X and LinkedIn!
Bibliography
[1] Bubeck, Sébastien, et al. "Sparks of artificial general intelligence: Early experiments with gpt-4." arXiv preprint arXiv:2303.12712 (2023).
[2] Vicuna Team, et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” https://lmsys.org/blog/2023-03-30-vicuna/ (2023).
[3] Zhou, Chunting, et al. "Lima: Less is more for alignment." Advances in Neural Information Processing Systems 36 (2024).
[4] Dettmers, Tim, et al. "Qlora: Efficient finetuning of quantized llms." Advances in Neural Information Processing Systems 36 (2024).
[5] Gudibande, Arnav, et al. "The false promise of imitating proprietary llms." arXiv preprint arXiv:2305.15717 (2023).
[6] Wang, Yizhong, et al. "How far can camels go? exploring the state of instruction tuning on open resources." Advances in Neural Information Processing Systems 36 (2023): 74764-74786.
[7] Gemma Team, et al. "Gemma 2: Improving Open Language Models at a Practical Size." https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf (2024).
[8] Li, Xuechen, et al. “Alpacaeval: An automatic evaluator of instruction-following models.” https://github.com/tatsu-lab/alpaca_eval, 2023.
[9] Dubois, Yann, et al. "Alpacafarm: A simulation framework for methods that learn from human feedback." Advances in Neural Information Processing Systems 36 (2024).
[10] Dubois, Yann, et al. "Length-controlled alpacaeval: A simple way to debias automatic evaluators." arXiv preprint arXiv:2404.04475 (2024).
[11] Chiang, Cheng-Han, and Hung-yi Lee. "Can large language models be an alternative to human evaluations?." arXiv preprint arXiv:2305.01937 (2023).
[12] Sanh, Victor, et al. "Multitask prompted training enables zero-shot task generalization." arXiv preprint arXiv:2110.08207 (2021).
[13] Liu, Yang, et al. "G-eval: Nlg evaluation using gpt-4 with better human alignment." arXiv preprint arXiv:2303.16634 (2023).
[14] Wang, Jiaan, et al. "Is chatgpt a good nlg evaluator? a preliminary study." arXiv preprint arXiv:2303.04048 (2023).
[15] Fu, Jinlan, et al. "Gptscore: Evaluate as you desire." arXiv preprint arXiv:2302.04166 (2023).
[16] Wang, Peiyi, et al. "Large language models are not fair evaluators." arXiv preprint arXiv:2305.17926 (2023).
[17] Zheng, Lianmin, et al. "Judging llm-as-a-judge with mt-bench and chatbot arena." Advances in Neural Information Processing Systems 36 (2024).
[18] Shi, Freda, et al. "Large language models can be easily distracted by irrelevant context." International Conference on Machine Learning. PMLR, 2023.
[19] Kim, Seungone, et al. "Prometheus: Inducing fine-grained evaluation capability in language models." The Twelfth International Conference on Learning Representations. 2023.
[20] Kim, Seungone, et al. "Prometheus 2: An open source language model specialized in evaluating other language models." arXiv preprint arXiv:2405.01535 (2024).
[21] Zhu, Lianghui, Xinggang Wang, and Xinlong Wang. "Judgelm: Fine-tuned large language models are scalable judges." arXiv preprint arXiv:2310.17631 (2023).
[22] Wang, Yidong, et al. "Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization." arXiv preprint arXiv:2306.05087 (2023).
[23] Li, Junlong, et al. "Generative judge for evaluating alignment." arXiv preprint arXiv:2310.05470 (2023).
[24] Lee, Harrison, et al. "Rlaif: Scaling reinforcement learning from human feedback with ai feedback." arXiv preprint arXiv:2309.00267 (2023).
[25] Bai, Yuntao, et al. "Constitutional ai: Harmlessness from ai feedback." arXiv preprint arXiv:2212.08073 (2022).
The genres include writing, roleplay, extraction, reasoning, math, coding, and several knowledge genres (e.g., STEM and humanities / social sciences). Each category has ten questions associated with it in MT-bench.
In [17], this setup is called “single-answer grading”, but I personally use the term “pointwise” to distinguish this setup from the pairwise grading scheme.
Interestingly, prior work [22] has tried having the judge output a rationale after the score, which is found to yield less benefit in terms of scoring accuracy.
The quick release of this paper was made possible by the fact that OpenAI provided the Microsoft researchers that wrote this paper with intermittent access to GPT-4 to run various experiments throughout the model’s development process.
In [1], authors attempt to define AGI as “systems that demonstrate broad capabilities of intelligence, including reasoning, planning, and the ability to learn from experience, and with these capabilities at or above human-level.” However, definitions continue to differ within the AI community, making progress towards AGI difficult to rigorously evaluate.
Given that little analysis had been performed on LLM-as-a-judge-style evaluations at the time, many researchers claimed that these evaluations were not rigorous and that there is no guarantee that GPT-4 will produce high-quality evaluation results.
These prompts use zero-shot chain of thought prompting in particular, as no chain of thought exemplars are provided within the prompt.
AlpacaEval improves upon AlpacaFarm by merging instructions and inputs within the evaluator’s prompt, handling longer outputs (i.e., 2K tokens instead of 300), and using output randomization to eliminate position bias.
The costs depend on the exact LLM used for evaluation and the length of outputs being rated. When using GPT-4-Turbo, executing the AlpacaEval benchmarks costs less than $10 in API credits.
The implementation of this evaluator is inspired by both AlpacaFarm and Aviary, which are previous attempts at using LLMs to automate pairwise feedback.
As seen in the settings of AlpacaEval-2.0, authors also set the decoding temperature of the LLM to 1.0 when using logprobs to obtain a preference score.
Within AlpacaEval, there are only two possible models, which are labeled b and m within the equation.
In general, setting up proper evaluations is universally agreed upon within the research community to be one of the most difficult aspects of working with LLMs.
This is still a very common finetuning strategy; e.g., Gemma-2 [7] was finetuned using an imitation approach.
Another task is also considered that uses the human or LLM to assess the quality of adversarial attacks created for fooling text classification models. However, this task was omitted because it is very specific.
This approach is just self-consistency, but applied in the LLM evaluation setting.
Example prompt templates are provided in Appendix A for several different LLM-as-a-Judge setups.
Excellent article Cameron! I’m curious if anyone has found smaller models to be good judges especially since they’ve taken off recently. I know achieving GPT-4 performance was vital for LLM-as-a-judge to work, but can we make it less expensive by using smaller models? Or are they not quite up to par yet?
Really great summary! I've been reading LLM as a judge papers this past week and this feels like a very comprehensive overview. Thanks for posting