


Why 0.9? Towards Better Momentum Strategies in Deep Learning.
How more sophisticated momentum strategies can make deep learning less painful.

Thoughts and Theory
How more sophisticated momentum strategies can make deep learning less painful.

Introduction
Momentum is a widely-used strategy for accelerating the convergence of gradient-based optimization techniques. Momentum was designed to speed up learning in directions of low curvature, without becoming unstable in directions of high curvature. In deep learning, most practitioners set the value of momentum to 0.9 without attempting to further tune this hyperparameter (i.e., this is the default value for momentum in many popular deep learning packages). However, there is no indication that this choice for the value of momentum is universally well-behaved.
Within this post, we overview recent research indicating that decaying the value of momentum throughout training can aid the optimization process. In particular, we recommend a novel Demon strategy for momentum decay. To support this recommendation, we conduct a large-scale analysis of different strategies for momentum decay in comparison to other popular optimization strategies, proving that momentum decay with Demon is practically useful.
Overview
This post will begin with a summary of relevant background knowledge for optimization in deep learning, highlighting the current go-to techniques for training deep models. Following this introduction, the Demon momentum decay strategy will be introduced and motivated. Finally, we will conclude with an extensive empirical analysis of Demon in comparison to a wide scope of popular optimization strategies. Overall, we aim to demonstrate through this post that significant benefit can be gained by developing better strategies for handling the momentum parameter within deep learning.
Background
For any deep learning practitioner, it is no surprise that training a model can be computationally expensive. When the hyperparameter tuning process is taken into account, the computational expense of model training is even further exacerbated. For example, some state-of-the-art language models can cost millions of dollars to train on public cloud resources when hyperparameter tuning is considered (see here for more details). To avoid such massive training expenses, the deep learning community must discover optimization strategies that (i) facilitate quick convergence, (ii) generalize well, and (iii) are (relatively) robust to hyperparameter tuning.
Stochastic gradient descent with momentum (SGDM) is a widely-used tool for deep learning optimization. In the computer vision (CV) domain, SGDM is used to achieve state-of-the-art performance on several well-known benchmarks. However, the hyperparameters of SGDM are highly-tuned on well-known datasets (e.g., ImageNet) and, as a result, the performance of models trained with SGDM is often sensitive to hyperparameter settings.
To mitigate SGDM’s weaknesses, adaptive gradient-based optimization tools were developed, which adopt a different learning rate for every parameter within the model (i.e., based on the history of first-order gradient information). Although many such adaptive techniques have been proposed, Adam remains the most popular, while variants such as AdamW are common in domains like natural language processing (NLP). Despite their improved convergence speed, adaptive methodologies have historically struggled to achieve comparable generalization performance to SGDM and are still relatively sensitive to hyperparameter tuning. Therefore, even the best approaches for deep learning optimization are flawed — no single approach for training deep models is always optimal.
What can we do about this?
Although no single optimization strategy is always best, we demonstrate that decaying momentum strategies, which are largely unexplored within the deep learning community, offer improved model performance and hyperparameter robustness. In fact, the Demon momentum decay strategy is shown to yield significantly more consistent performance in comparison to popular learning rate strategies (e.g., cosine learning rate cycle) across numerous domains. Although some recent research has explored tuning momentum beyond the naive setting of 0.9, no large-scale empirical analysis has yet been conducted to determine best practices for the momentum parameter during training. Through this post, we hope to solve this issue and make momentum decay a well-known option for deep learning optimization.
Optimal Momentum Decay with Demon
Though several options for decaying momentum exist, we recommend the Demon strategy, proposed in this paper. Demon is extensively evaluated in practice and shown to outperform all other momentum decay schedules. Here, we take time to describe this momentum decay strategy, its motivation, and how it can be implemented in practice.
What is Demon?

Numerous, well-known decay strategies, including the Demon strategy, are depicted in the figure above, where the x-axis represents the progression of training from beginning to end. Most of these strategies were originally popularized as learning rate decay schedules. In this post, however, we also evaluate the effectiveness of each for momentum decay. In comparison to other decay schedules, Demon waits until the later training stages to significantly decrease the value of momentum. Therefore, for the majority of training, Demon keeps the value of momentum near 0.9, decaying swiftly to zero during later training stages. The Demon strategy is motivated by the idea of decaying the total contribution of a gradient to all future training updates. For a more rigorous description of the motivation for Demon, one can refer to the associated paper, which provides a more extensive theoretical and intuitive analysis. The exact form of the Demon decay schedule is given by the equation below.

Here, t represents the current iteration index,T represents the total number of iterations during training, and beta represents the momentum parameter. Therefore, the above equation yields the value of the momentum parameter at iteration t of training for the Demon decay schedule. The initial value for beta represents the starting value of the momentum parameter. In general, beta can be initialized using a value of 0.9, but it is observed in practice that a slightly higher value yields improved performance (e.g., 0.95 instead of 0.9). In all cases, Demon is used to decay the momentum parameter from the initial value at the beginning of training to zero at the end of training.
Adding Demon to Existing Optimizers
Although the decay schedule for Demon is not complicated, determining how to incorporate this schedule into an existing deep learning optimizer is not immediately obvious. To aid in understanding how Demon can be used with popular optimizers like SGDM and Adam, we provide a pseudocode description of Demon variants for these optimizers below.

As can be seen in the algorithm descriptions above, the SGDM and Adam optimizers are not significantly modified by the addition of Demon. In particular, Demon is just used to modify the decay factor for the first moment estimate (i.e., the sliding average over the stochastic gradient during training) within both SGDM and Adam. Nothing else about the optimizers is changed, thus demonstrating that adopting Demon in practice is actually quite simple.
Demon in Code
The code for implementing the Demon schedule is also extremely simple. We provide it below in python syntax.

Experimental Analysis of Demon
We evaluate Demon extensively in practice. Experiments are provided on several datasets, such as MNIST, CIFAR-10/100, FMNIST, STL-10, Tiny ImageNet, PTB, and GLUE. Furthermore, Demon is tested with numerous popular model architectures, including ResNets and Wide ResNets, non-residual CNN architectures (i.e., VGG), LSTMs, transformers (i.e., BERT fine-tuning), VAEs, noise conditional score networks, and capsule networks. We conduct baseline experiments using both SGDM and Adam with 10 different variants of learning rate and momentum decay each. Furthmore, baseline experiments are provided for a wide scope of recent optimization strategies such as YellowFin, AMSGrad, AdamW, QHAdam, quasi-hyperbolic momentum, and aggregated momentum. We aim to summarize all of these experiments in the following section and demonstrate the benefit provided by momentum decay with Demon.
The Big Picture
Across all experiments that were performed (i.e., all datasets, models, and optimization strategy combinations), we record the number of times each optimization strategy yields top-1 or top-3 performance in comparison to all other optimization strategies. Intuitively, such a metric reflects the consistency of an optimization strategy’s performance across models and domains. These performance statistics are given below for the best-performing optimization strategies.

As can be seen above, Demon yields extremely consistent performance across domains. In particular, it yields the best performance of any optimization strategy in nearly 40% of all experiments — a >20% absolute improvement over the next-best cosine learning rate schedule. Furthermore, Demon obtains top-3 performance in comparison to other optimizers in more than 85% of total experiments, highlighting that Demon still performs well even when it is not the best.
Interestingly, in addition to yielding more consistent performance in comparison to many widely-used optimization strategies, Demon significantly outperforms other schedules for momentum decay. In fact, top-1 performance is never achieved by any other momentum decay strategy across all experimental settings. Such a finding highlights the fact that momentum decay is most effective when the proper decay strategy is chosen. Based on these results, Demon is clearly the best momentum decay strategy of those that were considered.
Detailed Experimental Results
Demon has been tested on numerous models and datasets within several different domains. Here, we provide detailed results for all experiments that were run with Demon. For each of these experiments, Demon is compared to numerous baseline optimization methods (i.e., outlined at the beginning of this section). It should be noted that the results from the experiments shown below were used to generate the summary statistics outlined above, thus revealing that Demon has by far the most consistent performance of any optimization method that was considered.
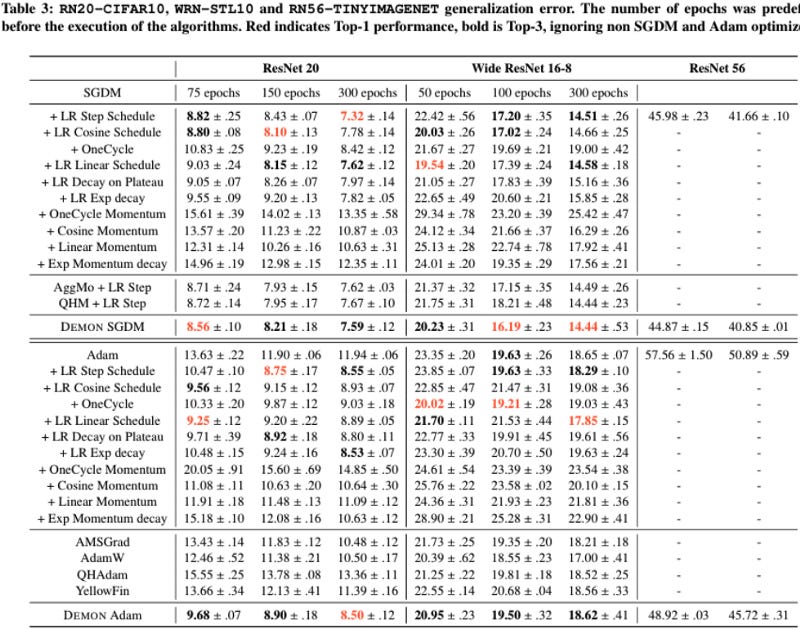

Hyperparameter Robustness
In addition to accelerating training and generalizing well, optimization strategies that decrease hyperparameter sensitivity are desirable because they can decrease the need for hyperparameter tuning, which is computationally expensive in practice. We evaluate the robustness of Demon to different hyperparameter settings in comparison to both SGDM and Adam optimizers (i.e., arguably the most widely-used optimizers in deep learning) by recording model performance (i.e., test accuracy) across a wide range of possible hyperparameters.

From left to right, the experiments depicted above are Wide ResNet on STL-10 with SGDM, VGG on CIFAR-100 with SGDM, and ResNet-20 on CIFAR10 with Adam. Demon performance is depicted in the top row, while the performance of vanilla optimizer counterparts (i.e., SGDM and Adam) are depicted in the bottom row. Lighter color indicates higher performance and a separate model was trained to generate the measurement within each of the above tiles. For all experimental settings that were tested, it can be seen that utilizing Demon during training yields a noticeably larger band of light color across different hyperparameter settings. For example, on the STL-10 dataset, Demon, in addition to achieving better top performance in comparison to SGDM, has an average of 5-6 light-colored tiles in each column, while vanilla SGDM has only 1–3 (roughly). These results demonstrate that Demon yields reasonable performance across a wide scope of hyperparameters, implying that it is more robust to hyperparameter tuning.
Other Notable Empirical Results
The experimental support for Demon is vast, and we recommend anyone who is interested in specific experimental metrics and results to refer to the paper. However, there are a few additional experimental results for Demon that are worth mentioning in particular.
Fine-Tuning with Demon on GLUE
Transformer models are one of the most computationally expensive models to train in deep learning. To test whether improved transformer performance can be achieved with Demon, we fine-tune BERT on several GLUE tasks using both Demon and Adam. The results are shown below.

As can be seen, Demon outperforms Adam for BERT fine-tuning on the GLUE dataset. Furthermore, to achieve these results, no extra fine-tuning was required for Demon. We simply employ the same hyperparameters used for other experiments and achieve better performance with minimal effort. This result is interesting, especially because Adam, which is one of the go-to optimizers in the NLP domain, has been tuned extensively on the GLUE dataset.
Better Qualitative Results for NCSN
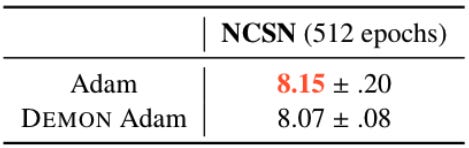
We find that Demon is quantitatively outperformed by Adam for Noise Conditional Score Networks (NCSN) trained on CIFAR-10, as shown in the table above. However, when the results of models trained with Adam and Demon are qualitatively examined, we notice an interesting pattern.

As can be seen above, the NCSN trained with Adam, despite achieving a slightly improved inception score, produces seemingly unnatural images (i.e., all images appear to have green backgrounds). In comparison, the images produced by the NCSN trained with Demon appear significantly more realistic.
Conclusion
Most practitioners in the deep learning community set the momentum hyperparameter to 0.9 and forget about it. We argue that this is not optimal, and that significant benefit can reaped by adopting more sophisticated momentum strategies. In particular, we introduce the Demon momentum decay schedule and demonstrate that is yields significantly improved empirical performance in comparison to numerous other widely-used optimizers. Demon is extremely easy to use, and we encourage the deep learning community to try it. For more details not included in this post, feel free to read the paper that was written for Demon.
Thanks so much for reading this post, any feedback is greatly appreciated. For anyone who is interested in learning more about similar research, the project presented in this post was conducted by the optimization lab at Rice University, Deparment of Computer Science. See here for more details on the lab, which is led by Dr. Anastasios Kyrillidis.