


Training a Random Forest to Identify Malignant Breast Cancer Tumors
Within the Sklearn Python library, there are a group of several example data sets that can be imported. Among these data sets is a binary…


Within the Sklearn Python library, there are a group of several example data sets that can be imported. Among these data sets is a binary classification breast cancer data set that was drawn from observations made in the state of Wisconsin. I chose to work on this data set for a personal project because it presented a topic that I found to be impactful and interesting (and a good way to practice my skills in data science) — my goal was to train a classification model to identify malignant breast cancer tumors with an accuracy of >95%. The data set can be imported as follows:

Building a Baseline Model for Comparison
Before doing any analysis on the data set, it is usually good to build a baseline classification model that can be used as a benchmark to decide if a machine learning model is effective or not. To build this baseline model, I looked at the distribution of “malignant” (labeled as a 1) and “benign” (labeled as a 0) observations in the data set. Depending on which of these classification categories is more probable (or has the higher occurrence), I predict every observation to be in the more probable category. Here is the bar graph showing the distribution of the two target categories:

From this graph, it can be seen that there are about 350 “malignant” observations and roughly 220 “benign” observations. Therefore, if every observation is predicted to be malignant, a model is created that is about 61% accurate — this simple model will be used as a benchmark for future comparisons.
Data Cleaning and Preprocessing
After the simple baseline model was defined, I performed some quick data cleaning and observation, such as checking for null values, looking at the data types of each feature in the data set, and looking at the total number of observations in the set. In this case, because the data is from an example set maintained in the Sklearn python library, not much data cleaning needed to be done. If the data set is stored in a pandas data frame, the total number of null values across each of the columns can be checked with the following command:

In this case, no null values existed within the data set, so no work had to be done replacing/cleaning null values within the data. Additionally, when the data types of each column were checked (using the “dtypes” property of a pandas data frame), all data was found to be of type “float64”. Therefore, because all of the features were already numeric, no data cleaning had to be done to create features that can be fed directly into a machine learning model. The only interesting finding from this preprocessing period was the fact that the data set only contains 569 total observations. This is a very small amount of data for training a Machine Learning model and could create problems in the future (i.e. overfitting of the model or lack of accuracy), so this was strongly considered when choosing to use a Random Forest to classify the data (Random Forests are quite resistant to overfitting, read more about them here).
Exploratory Data Analysis (EDA)
In order to get a better understanding of the data set and which features might be useful to a machine learning model, simple data analysis and visualization was conducted. The first inquiry that was conducted on the data set was visualizing the correlation matrix for all of the different features in the set (correlation was calculated using the “corr” method on a pandas DataFrame). This correlation map revealed which features presented new information to the problem and which features are similar to others present in the set. The correlation matrix was plotted as a heat map, which allowed the correlation between features in the data set to become easily visible. It appeared as follows:

In this case, the feature pairs that have a white color are highly correlated with each other and, therefore, present similar information to the problem. For example, feature pairs (0, 2), (0, 3), and (2, 3) are all highly correlated. Later, when features were selected for the machine learning model, such high correlation was taken into account and features that had very high correlation (>98%) with other features were eliminated.
In addition to visualizing correlation, univariate analysis and visualization were also performed on each feature in the data set. More specifically, scatter plots of feature values and their associated classifications and graphs of the mean amount of features for each target category were created. Viewing the distribution of each feature individually creates a better understanding of which features have distinct/visible differences between each of the target categories, thus revealing which features would be useful in creating a classification model. Some of the results of these visualizations were as follows:

In this case, Feature 5 shows a distinct difference in values between the two target classification categories, where the observations classified as “benign” (0) seem to have a higher value than those classified as “malignant” (1). Therefore, this visualization hints that Feature 5 is probably a useful Feature to include in the final classification model.

In the above visualization, Feature 7 seems to have similar characteristics between the two target categories — roughly similar positioning of 1s and 0s on the scatter plot and similar mean feature values. Therefore, this visualization hints that Feature 7 may not be as useful to our model in determining an accurate classification.
When deciding which of the Features to use in training the machine learning model, Features that showed noticeable differences in characteristics between the two target classification categories were kept and Features that did not show such differentiation were eliminated. Once such Features were eliminated, an aggregate visualization was created (using the “pairplot” method in the seaborn python library) to view, as a whole, the properties of the most interesting Features in the set. The result is as follows:

The above plot is colored by each observation’s classification value. For each of the Features in the pair plot, it can be noticed that the differences in values between the two target classification categories can be noticed in most cases.
Feature Engineering/Selection
After performing simple EDA on the data set, it became quite clear which Features would be useful to the machine learning model. Therefore, not much extra work was done in selecting/creating Features. Some methods that were tried for automated Feature selection include:
Creating polynomial and interactive Features using Sklearn.
Running a simple Random Forest and selecting Features based on their importance to that model.
Eliminating Features that are highly correlated with other Features in the set.
Creating polynomial Features did not improve the performance of the Random Forest Model (the accuracy actually decreased). However, filtering Features using the “feature_importances_” attribute of the Random Forest was quite helpful and ultimately boosted the accuracy of the final model. To create such a filter, a default random forest was trained on the existing Feature set (not including the polynomial Features) and the importance of each of the Features was determined by referencing the “feature_importances_” attribute of the trained random forest. Setting a threshold for Features with low importance, all Features with an importance less than the importance threshold were eliminated from the data set. Several importance thresholds were tested to determine which one would perform best, and the results were as follows:
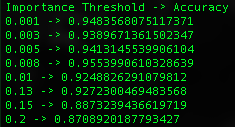
As can be observed in the above report, the best filtering threshold was .008 with an accuracy of 95.5% (above what I was originally aiming for!). After this last step of Feature engineering, work was begun building the final model.
Building the Random Forest Model
For this experiment, the Sklearn random forest classifier was used to classify the data. This model can be imported and fit to a set of observations using the following code:

The above code imports the random forest from the Sklearn library, instantiates it with a size of 50 trees (n_estimators is the number of decision trees that will be constructed to form the random forest object), and fits a random forest to a set of testing data. In this experiment, the data was split into training and testing sets with the “train_test_split” method within Sklearn.model_selection, which splits the data into training and testing groups based on a desired ratio. When the random forest was training using the partitioned training and testing data, the result was as follows:

As can be seen above, the random forest of 50 decision trees obtained an accuracy of 95.77% on the data set! This was above the goal of 95% accuracy that was originally set for this experiment. However, before the experiment was ended, different numbers of estimators for the random forest were tested to see if the model could be made slightly more accurate. Additionally, the precision and recall of the highest performing random forest was observed to gain another metric on the overall quality of the model.
Testing Different Random Forest Sizes
Random forest sizes of 25, 50, 75, 100, 125, and 150 were selected and the accuracy of each of the models was tested to determine which size of random forest was most effective. The results were as follows:
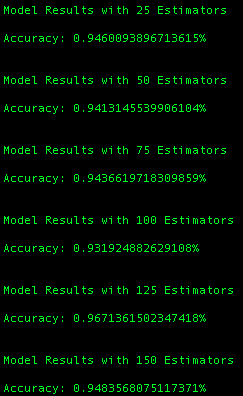
In the above report, it can be seen that the most accurate size of forest was 125, with an accuracy of 96.7%! Such accuracy was well above the original goal of 95%, so this model was selected as the highest performer and the precision and recall of the model were then observed to assess its overall quality.
Precision and Recall
Because the original data set was somewhat imbalanced (the target classification categories are not equally distributed), it is good practice to have a metric on the quality of my model other than accuracy — models with an imbalanced target variable distribution may obtain high accuracy without actually fitting the data well. Therefore, it was decided to observe the precision and recall of the model for each of the target classification categories. If you are unfamiliar with these terms, I recommending reading this article to better understand what they are. Like accuracy, precision and recall serve as a metric to evaluate the effectiveness of a machine learning model. The precision and recall of a random forest model can be observed using the following code:

Using the above code, the precision and recall of the 125 estimator random forest model were evaluated to obtain the following results:
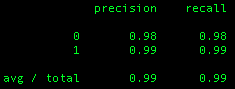
The model obtained an average of 99% precision and 99% recall, which is a very good score (1.0 is the best possible score for each). After this metric was observed, it was quite clear that the Random Forest classification model fit the data quite well, with over 96% accuracy and precision/recall scores of 99%.
Conclusion
In this article, I worked with an Sklearn breast cancer data set to build a random forest classification model that classifies breast cancer tumors as either “malignant” or “benign”. My original goal was to obtain a model that was at least 95% accurate. After preforming simple EDA to determine the most important features in the data set, analyzing the feature importance of various selected features, and testing different sizes of random forests, I obtained a final model with an accuracy of 96.7%!
If you would like to look at the source code for this project, you can look at the GitHub repository that was created for it! If you have any questions or would like to follow my future posts, feel free to comment on this post or connect with me on LinkedIn. Thank you so much for reading!